-

Fototrend
AMD FX processzorok topikja
- AM3+ tokozás
- Nyolc, hat, vagy négy mag
- DDR3-1866 RAM támogatás
- Szorzózármentes modellek

Új hozzászólás Aktív témák
-

dezz
nagyúr
A SuperPI lényegi kódja még valamikor a '90-es években készült, x87 alapon, ami az x86 procik korai FPU-ja volt, ma már kvázi semmi sem használja, mert kevésbé hatékony, mint akár a scalar SSE2 kód (nem beszélve arról, hogy az utóbbi vektor [SIMD] módban is használható, sokszor kevert scalar+vektor módban használják). A mai FPU-k leginkább csak kompatibilitási okokból támogatják. Mellesleg a SuperPI-t már anno Intelre optimalizálták.
[ Szerkesztve ]
-
dezz
nagyúr
Az mikor fog kiderülni, hogy valóban csak ennyit tud az egész mikroarchitektúra, vagy valamit nagyon elb...énáztak ezzel a verzióval? Mert most vagy hazudtak kezdettől fogva, vagy ők sem erre számítottak. Illetve az is lehet, hogy cégen belül is ment a félrevezetés.
(Csak most ne jöjjön senki azzal, hogy persze, hogy ennyit tud a 2x2-way scalar INT + shared FPU, mert az nem normális, hogy szinte(?) még a Bobcat is jobban teljesít, per thread...)
Az árazás is elég "érdekes". Úgy tűnik, több hullámban éri el az AMD illetékeseit a teljes szembesülés a valósággal... Még nem jöttek rá, hogy ilyen árakon nem fognak tolongani érte?
Egy biztos, totál hülyeség volt az integer clusterek alapján elnevezni x-magosnak és másfélszer erősebbnek beharangozni, mint amilyen valójában... Közepes 4-magos/8-szálas prociként mennyivel szimpatikusabb lett volna... Egész más lenne a megvilágítása a dolognak. Akkor persze az árakat is másképp kellett volna szabni, de előbb-utóbb az is bekövetkezik.
-
#415
dezz
nagyúr
Cybertrone
#401
dezz
nagyúr
válasz
 Cybertrone
#401
üzenetére
Cybertrone
#401
üzenetére
A másik topikban korábban már linkeltem, mi volt a gond a B0/B1 steppingekkel (az NB-ben lévő komoly hiba miatt mégjobban leült a sokszálas teljesítmény). Tehát, ez tudott dolog.
Azt is tudjuk már, hogy a B2-ben is van egy számottevő hiba (L1I kezelés), bár elvileg ez csak 3% lassulást okoz MT-ben.
Az a kérdés, van-e még valamilyen komoly hiba, amit később javíthatnak?
(#404) Klikodesh: És? Elvileg annyiból is ki lehet hozni többet.
(#407) siriq: Nem a kérdésemre válaszoltál...
(#410) Raymond:
1. Fiery még sokkal rosszabbnak állította be a most megjelenő verziót, mint amilyen.
2. És nem csak ezeket, hanem a teljes mikroarchitektúrát mondta kvázi szemétrevalónak. Azért ez így egy kicsit durva...[ Szerkesztve ]
-
dezz
nagyúr
"itt van benne miert."
Hol?
"Nem kell a tereles."

"Mondtam akkor is, hogy nem kell itt a bios revekre varni."
Utólag(?) könnyű okosnak lenni... De honnan tudhattad volna vagy tudhatnád ezt ilyen biztosan? Pl. egyesek (lásd pl. OBR) korábban a B0 és B1 alapján mondott ítéletet, aztán jól kiderült, hogy azokban milyen hibák voltak. Mi van, ha a B2-ben is van valamilyen komoly hiba, csak már úgy gondolták, így már nem olyan rossz, hogy még hónapokat csúsztassák a megjelenést? Ha egyre kevésbé is valószínű, teljesen nem lehet kizárni. Szóval, ezt az "én megmondtam, ti hülyék" attitűdöt hanyagolhatnád.
Különben sem állítottam semmit, hanem azt kérdeztem, hogy ez mikor derülhet ki pontosan? Mert hogy Fiery is arról beszélt, hogy egy bizonyos ponton a leggyengébb a Bulldozer. Nos, most már el lehet mondani, hol van az a pont?
(#423) Jack@l: "Aza shared fpu egy kamu, azt a gyakorlatban perpill nyugodtan lehet 1-nek venni..."
Butaság. Akkor elég nehezen lenne egy szinten sima, nem AVX/FMA-s kóddal is az X6-ossal a 8150, a maga 4db FlexFP-jével.
-
dezz
nagyúr
"A többi megintcsak a jó öreg marketing bullshit."
Ez meg a tipikus flame-bait... Mintha nem tudnád, hogy az AMD féle CMT teljesen más, mint az Intel féle SMT (HT)... Valamelyik tesztben van erről egy rész, hogy hány %-ot nyerhetne a BD a megfelelő ütemezéssel.
(#440): Épp most volt szó róla, hogy nem sokat számít, hogy 1600 vagy 2000+. A több cache hatását egy erősen szintetikus teszttel lehetne kiküszöbölni. Van ilyen valahol, X6-tal összemérve?
(#441) siriq: Erre gondolsz?:
"Csak a memo vezerlot kellene javitani."Mi a baj vele? Így is sokkal jobb, mint a PhII-é. Az kit érdekel, hogy szintetikus tesztekben alulteljesít az SB-hez képest? Nem ezen múlik itt a dolog...
"Meg egy kicsi ipc noveles."
Na és azt hogyan, ha 'szar az egész úgy, ahogy van'?
[ Szerkesztve ]
-
dezz
nagyúr
válasz
 #95904256
#447
üzenetére
#95904256
#447
üzenetére
A HT-nál sokkal jobban zavarják egymást a szálak egy magon belül, amit az a kis turbó még kompenzálni sem nagyon tud, nem hogy többet számítana. A BD-nél kicsit más a helyzet.
(#448): Ezért:
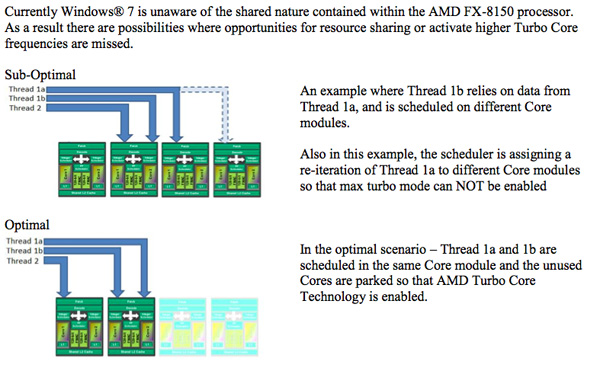
Itt (+ köv. oldal) pedig azt elemzik, mennyit számít az ütemezés.
(#451) Abu85: "Ha mindegyik erőforrás aktívan használatban van, akkor mindegy, mert a turbó nem létezik."
Akkor sem teljesen mindegy, hogy az azonos adatokon (már ami a L2-be fér) dolgozó szál-párok egy modulra kerülnek-e.
(A BD-n all-cores-on-nál is van turbó, a TDP határain belül. Nem tudom, ezt mennyire hagyták érvényesülni a teszteknél.)
[ Szerkesztve ]
-
dezz
nagyúr
"Az elozo generacio leveri clock-for-clock"
Ez ki a fenét érdekelne, ha bőven ellensúlyozni lehetne órajellel, megfelelő fogyasztás mellett? Ha pl. egy újabb steppinggel/revízióval javítani tudnak az utóbbiakon, jobban fog kinézni a dolog. Később az IPC-n is javíthatnak, teljes átalakítás nélkül.
"az aktualis csucs _mainstream_ desktop konkurens procit (2600K) nem tudja megverni"
1. Lehet hangsúlyozni, hogy mainstream, de az a 2600K a korábbi csúcskategóriát is igencsak megszorongatja.
2. Sok számításigényes alkalmazásban vagy előtte, vagy legalább is a sarkában van. (Több esetben, ahol lemarad, Intelre optimalizálásról beszélhetünk.)"de me'g az eggyel kisebb teljesitmeny lepcsojut (2500K) sem egyertelmuen veri."
A fenti esetek többségében előtte jár. Játékoknál valóban lemarad, bár itt is vannak kivételek, ráadásul GPU bottlenecknél, azaz hétköznapi esetben nem igazán számít a dolog.
"Anno a Willamette-rol is hasonlo volt a velemenyem, az az architektura is megbukott. SZVSZ ez is meg fog, majd lesz helyette megint valami teljesen mas, 5 ev mulva...
Ha 5 évig húzza vele az AMD, akkor nem nagyon lehet bukásnak nevezni...
Egyébként akkor elárulod most már, hogy hol van az a bizonyos nagyon gyenge pont?
(#471) akosf: Az általam betett képen a turbónak is van szerepe.
-
-
dezz
nagyúr
válasz
#95904256
#509
üzenetére
Néha nem árt pár másodpercnyi gondolkodás.

(#511) Jim-Y: Nem sokkal egyszerűbb megnézni a teszteket, mint olyan bugyuta válaszokat indukálni, mint pl. (#514) Jack@l? Egyébként feladatfüggő, néhol az X4 980-nál is jobb, néhol meg jóval lassabb.
(#523) TheChos3nOne "Előtte se tudtak cpu szinten sokat felmutatni
 "
"Ezzel csak kinyilvánítottad a tudatlanságodat... K8 vs. P4? K8 X2 vs. P-D? x86-64? (Az AMD dolgozta ki.) Első IMC x86 vonalon? Koherens HyperTransport alapú multiprocessing (aminek az Intel féle QPI szinte 1:1 másolata), ami sokkal jobban skálázódott, mint az Intel FSB alapú megoldásai?
-
dezz
nagyúr
Tulajdonképpen annyi, hogy ez a proci nem kimondottan egy gamer-proci... Ahol persze nem a CPU-n múlik a dolog, ott kvázi mindegy, sőt talán éppen ott hoz pár fps-t (korábban is volt hasonlóra példa). Sokszálas, nagy integer (scalar és SIMD) teljesítményt igénylő feladatokban viszont ott van a 2600K mellett, néha előtt.
(#577) akosf: Szerintem tök egyértelmű az ütemezés és a turbó kapcsolata. Ki tehet róla, hogy nem jutott az eszedbe?
(#578) siriq: Kicsit talán mérsékeld a hallucinogén anyagok fogyasztását...
(#591) cowboy_bebop: Szerintem is, és alapvetően az is.
[ Szerkesztve ]
-
dezz
nagyúr
Hát, azoknak sokmindenről szolni kellene...

Úgy tűnik, éppen ki is vagyok tiltva egy időre az xtremesystemsről, mert "szóltam", vagy másnak is csak annyi jön be, hogy message: 1 hour? Mondjuk már de. óta.
(#607) Jack@l: Mi abban a személyeskedés, hogy sorra szándékosan butaságokat írkálsz?
(#611) akosf: Na, akkor meg nem értem, mi a probléma.
[ Szerkesztve ]
-
dezz
nagyúr
Megjegyzem, nem azt írták, hogy best for gaming, csak azt, hogy alkalmas több-képernyős játékra, és végülis azt nem lehet mondani, hogy egy gyenge proci, amin nem lehet játszani. Azt sem zárnám ki, hogy a sok szál miatt bizonyos esetekben jobban is megy vele az Eyefinity.
(#615) akosf: Akkor még érdekesebb, hogy az egyik percben még világos előtted az ütemezés és a turbó kapcsolata, a másikban meg már nem.
[ Szerkesztve ]
-
dezz
nagyúr
Mások meg, akik szintén tesztelték, azt írták, hogy nagyon is jó. (Most persze hallgatnak, de az más kérdés.) Másrészt az sem igaz, hogy a B2 semmivel sem jobb, mint a B1. Mellesleg még a B2 is tartalmaz egy hibát, ami az AMD szerint csak 3%-ot jelent, de ki tudja, valóban így van-e? (Kicsit nehezen hihető, hogy 3% miatt buherálják meg alaposan a Linux kernelt és várnak a MS-tól is egy javítást erre is.) Aztán ott van még az ütemezés kérdése is. Emellett Fiery a Piledrivert is leírja, de még a Steamrollert is.
(#619) Jack@l: Eleve feladatfüggő a dolog, így értelmetlen egy ilyen általános képlet. Itt pl. egész jól szerepel a 4-magos is.
[ Szerkesztve ]
-
dezz
nagyúr
A Fritz miért is releváns? A renderelők között is szép különbségek vannak, a CineBench mellesleg Intelre optimalizált. A szintetikus tesztek eredményei meg inkább csak érdekességek, legalábbis ami a sávszéleket illeti, de az aritmetikai eredmények is eléggé elviek.
Amúgy, ha már szintetikus, akkor mit szólsz a SPEC-ekhez? De a WinRAR is érdekes. [link]
[ Szerkesztve ]
-
dezz
nagyúr
válasz
#95904256
#623
üzenetére
A HT és az CMT közötti különbség leginkább a turbó miatt fontos, az ütemezés szempontjából. Eléggé nyilvánvaló, nem? (A megfelelő párosítás HT-nál sem mellékes.) Senki sem akar hülyének beállítani, de ha netalántán magadból csinálnál azt, arról nem tehetek. Mellesleg szerintem senki sem hiszi azt, hogy emiatt hülye vagy.
[ Szerkesztve ]
-
dezz
nagyúr
Oli szerintem cikket ír vagy ilyesmi, mert nem sok értelme itt vitatkozni.
Tesztelték, és ki is jött egy up to 10%-os különbség. (A CPU-terhelési grafikonokat elnézve pár játéknál lehet ez több is.) Emellett ott van a L1I trashing, amit kiküszöbölve szintén jön még pár %. Az is különös, hogy elvileg a B2 javított egy fontos hibát, ami betett a B0/B1 MT teljesítményének, de ennek nem sok látszatja van...És akkor most mi baja az IMC-nek? És a cache-nek? A write-through jellegre gondolsz?
szerk: hű, de beindult hirtelen a topik, éjjel 1-kor.

(#632): Na ja, JF-et szerintem sem látjuk többet...
(#630) bozont: A Piledriver alapú, AM3+-os Wishera jön jövőre 28nm-en.
[ Szerkesztve ]
-
-
dezz
nagyúr
Mondtam már, hogy mérsékeld a hallucinogének fogyasztását, mert már kezded összemosni a valóságot a lázálmaiddal. Lincselés akkor van, ha egy bizonyos másik, általad nyilván felmagasztalt oldalon mond ellent valaki egyes házigazdiknak. Ő erre megüti a kellő hangnemet, ami egy jól betanított vezényszó a hordának, ami aztán azt tesz, amit akar. A Ph! ehhez képest nőegylet.

-
dezz
nagyúr
Nem hiszem, hogy az a kifejezés ebben a formában elhangzott volna. Meg lett kérdezve, miért csak az Intel szerepel a támogatók között, lett kapva rá egy válasz, és elnézést lett kérve a magam részéről, hogy ezt felhoztam. Mellesleg, az Intel praktikáit jól ismerjük, még ha te talán semmi áron sem ismernéd el. Aztán volt, aki nem hitt a szintetikus tesztek relevanciájában, joga van hozzá. (Mellesleg régebben maga Fiery is kinyilvánította, hogy nem lehet rájuk igazán alapozni.)
Hozzátenném, nem kevés érzéketlenség kell ahhoz, hogy csak úgy belehányjuk az AMD tulajok képébe, hogy a rég várt új proci egy hatalmas nagy szarkupac és minden leszármazottja is az lesz. Mindezt szinte felvillanyozva, mintha valami jó hír lenne. Ha ezek után valaki csodálkozik (mint pl. te), hogy ezt nem kitörő öröm fogadja, az beteg.
És éppen akkoriban volt szó arról is, hogy a B0/B1 hibás és ezért kell várni a B2-re vagy éppen C0-ra. Hibás chip alapján jönni a fenti kijelentésekkel nagy sebbel-lobbal, elég érdekes. Az máig kérdéses, hogy hogy fértek hozzá már akkor B2-höz, amikor elvileg még senki más.
ps. a "lincshangulat"-ról inkább az jut eszembe, amikor egyszer-kétszer Abu próbálta néhány nyilvánvaló dologról (dark silicon, GPGPU, stb.) győzködni a HWSW Inteles hordáit...
-
dezz
nagyúr
válasz
#95904256
#646
üzenetére
Nézd csak ezt a részt: "Valamelyik tesztben van erről egy rész, hogy hány %-ot nyerhetne a BD a megfelelő ütemezéssel." No és mivel is nyerhetne a legtöbbet? Hát a turbóval... Nem én tehetek róla, hogy számodra nem egyértelmű, ami más számára az.
"Másfelől, mint ahogy írtad a megfelelő párosítás még akár HT-nak is kedvezhet."
Kötve hiszem, hogy annyit, mint 6-800 MHz órajelmelekedés.
(#650) Hakuoro: Nocsak, nocsak... Ennyit nem szabadna javulnia a single threadnek per module... Valaki azt vetette fel, hogy a nemrég felfedezett L1I trashing kiiktatása miatt lehet... És/vagy nem kapcsolta ki az illető a turbót, így minden 2. int xluster kiiktatása miatt feljebb mehetett az all-cores turbó.
(#652) sasa134: Még kiderülhet, hogy csak ezzel a verzióval (Zambezi) van valami komoly probléma, nem a teljes mikroarchitektrával. Illetve, hogy részben a gyártástechnológián múlik a dolog. Egyesek szerint sokat fog csökkenni a fogyasztás, ahogy javul a gyártástechnológia. Ezzel együtt az órajel is növekedhet.
(#658): Mainstreamre ott van a Llano.
(#657) subaruwrc: Elmagyaráznád, mi a fene értelme van SuperPI alapján hasonlítgatni, amikor az egy totál elavult és eleve Intelre optimalizált "teszt"? A 3D11 is gyanús az utóbbit illetően.
(#668) subaruwrc: Mikor volt IMC limitált?
(#680): Nem mondom, hogy nem egy érdekesség a geekeknek a C2C, de hogy csak amiatt lenne érdemes elolvasni...
[ Szerkesztve ]
-
dezz
nagyúr
válasz
#95904256
#695
üzenetére
Részben a turbó, részben az azonos adatokon dolgozó threadek párosítása. Az előbbi akár 16+%-ot is hozhat, utóbbi előnye (nem kimondottan erre optimalizált kód esetén) ennek töredéke. Így nyilvánvalóan mindkettőről szó van, de a turbó a fontosabb.
Nem tudom, meddig fogunk még lamentálni ilyen magától értetődő dolgokon?
(#704) darky@: Aki sokat warezol, transzkodólgat és nem 1024x768-ban játszik, annak nem lesz rossz az FX...
-
-
dezz
nagyúr
Felmerült a kérdés, vajon mennyit lehet nyerni azzal, ha kevésszálas esetben modulonként csak egy szálat futtatunk (fixen az egyik magon), így annak nem kell osztozni a másikkal. Korábban az AMD azt állította, hogy ez kevesebb, mint amit a max. turbóval nyerni lehet (tehát, hogy jobb kevés, magasabb turbóra kapcsolt modulra zsúfolni a szálakat és a többi modult kikapcsolni). Nos, az eredmények nem igazán ezt mutatják...
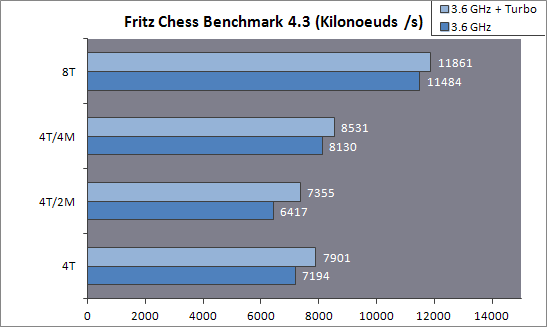
(Innen.)Turbó nélkül itt 26% a gyorsulás, de turbóval is 15%! (4T/4M: 4 modul működik, modulonként 1 mag aktív; 4T/2M: 2 modul működik, mindkét magjuk aktív; 4T: 4 modul, minden maggal, a 4 szálat az OS pakolgathatja.)
Úgy tűnik, hogy az AMD számára a fogyasztás volt a fő szempont a fenti ajánlásban:
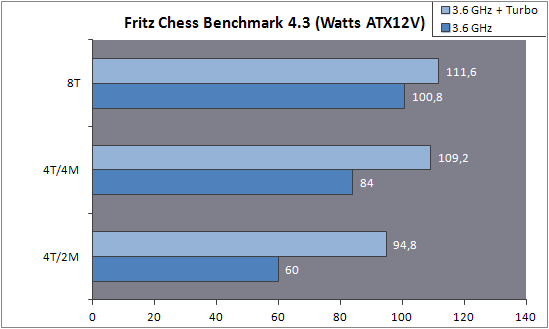
Pedig a turbót is beleszámolva alig van különbség a telj./fogy. között:
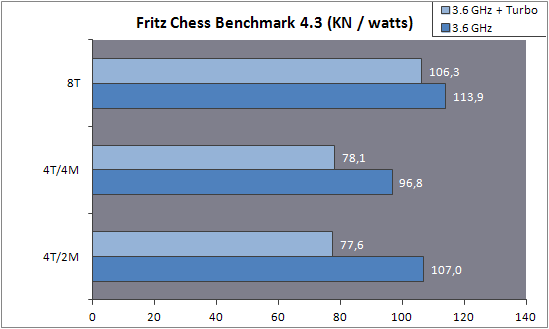
itt van még egy sor hasonló eredmény.
Úgy néz ki, kevésszálas esetben (pl. legtöbb játék) mégis csak jobb, ha az SMT-hez passzoló rendben látjuk el munkával a magokat... 1. modul 1. mag, 2. modul 1. mag, 3. modul 1. mag, 4. modul 1. mag, 1. modul 2. mag, 2. modul 2. mag, stb. (A Win8 ezt is fogja tudni. Nem is értem, hogy a Win7 miért nem tudja. Vagy nincs erre valami boot opció?)
Másik kérdés, hogy vajon miért van ez? Tehát, hogy elég távol vagyunk az AMD által ígért 1,8x szorzótól 2 szál/modul tekintetében. (Néhány kivételtől eltekintve, mint pl. rar/zip, ahol közelíti a 2x-t.) Egyesek szerint ez a nemrég kiderült L1D trashing miatt van (amire állítólag készül az OS patch), bár azt az AMD csak -3%-ra taksálja.
-
-
dezz
nagyúr
Ne keverd a "szálakat"...
Ami az INT teljesítményt illeti, külön kell választani a "nem számolós" és a "számolós" esetet, mert az első az INT clustereket használja, a másik pedig az FPU-ban lévő SIMD INT egységeket!
Az első esetre egy példa pl. a DhryStone CPU test, amiben szinte pontosan a 2500K és a 2600K között van.
A másodikra meg pl. a videokonvertálás, amiben több esetben még a 2600K-t is megelőzi: [link] (És akkor még nincs is XOP/FMA4-re optimalizálva.)
(#845) Jester01: Később előkerítem. Vagy keress "cache invalidation modul bulldozer"-re, vagy ilyesmi.
[ Szerkesztve ]
-
dezz
nagyúr
Tessék, itt van még egy példa: [link] (Bár nem tudom, hogy maga a codec, mint binary ugyanaz-e.)
Mellesleg több 3D-renderelő is jobban fut vele, most nincs időm keresni.
(#860): Onnan, hogy jópár tesztet végignéztem, és többször is feltűnt a dolog. De a kötekedésed eleve logikátlan (ha egy példa van - első linkem -, abból már látható, hogy nem lehetetlen a dolog).
[ Szerkesztve ]
-
dezz
nagyúr
válasz
 Oliverda
#895
üzenetére
Oliverda
#895
üzenetére
"A Cinebench nem igazán fekszik neki"
Azért nem, mert ez egy bevallottan az Intel közreműködésével készült, az ICC-vel (az Intel fordítója, ami csak Intelre fordít jó kódot) fordított holmi...
Néhány más 3D-rendererrel "érdekes módon" jobb eredmények születnek, néhánnyal meg is előzi a 2600K-t!
Amúgy ehhez mit szólsz?
ps. ment privi.
[ Szerkesztve ]
-
#1013
dezz
nagyúr
->Raizen<-
#988
dezz
nagyúr
válasz
 ->Raizen<-
#988
üzenetére
->Raizen<-
#988
üzenetére
"Ha 3 szál terhelésnél fog 5 ghz turbót kapni 2 modul még az kevés lesz."
Játékokban önmagában talán kevés lenne, de sokszálas alkalmazásokban most is ott van a 2600K nyomában, sőt esetenként meg is előzi. +500 MHz alapórajel be is biztosítja az utóbbit.
(#995) kop8: Már miért ne lehetne jobb. Jelenleg jópár tényező hat erősen negatívan.
(#1000) Ueda: Vagy már van egy AM3+ vagy AM3+-t támogató AM3-as lapja, és olyan alkalmazásokat futtat, amikben jobb, mint az X6 (ill. esetenként a 41xx is jobb, mint az X4), plusz bízik abban, hogy a patchek és az új utasításkészletek bevetésével még javul a helyzet.
(#1003) darky@: Nem olyan nagyon gyenge, más tényezők is vannak itt.
[ Szerkesztve ]
-
dezz
nagyúr
válasz
 subaruwrc
#1056
üzenetére
subaruwrc
#1056
üzenetére
"7.2-n egy alap sb-t nem fog meg mondjuk superpibe .. ami azért igencsak felveti a WTF ?
kérdést hatékonyság terén .."Bazz, ki a fenét érdekel a SuperPI?

Az alap kódja a '90-es évekből származik, az akkori x87 FPU-hoz készült, amikor még az SSEx sehol sem volt. A mai procik leginkább kompatibilitási okokból támogatják, de mivel kicsi a jelentősége, az AMD procikon durván 2x lassabbak ezek az utasítások, mint a modernebbek, amiket a mai programok használnak. Emiatt nagyjából 2x lassabb a SuperPI egy AMD procin, azonos órajelen, mint egy Intelen. De ennek kb. semmi jelentősége, egyátalán nem reprezentálja a két proci közötti teljesítménykülönbséget. Főleg, hogy ráadásul egyszálas.Egyébként most valami tűzfal mögött vagy és nem jönnek be a külföldi oldalak, vagy mi van?
[ Szerkesztve ]
-
#1083
dezz
nagyúr
KIRA\/NOVA
#1082
dezz
nagyúr
válasz
 KIRA\/NOVA
#1082
üzenetére
KIRA\/NOVA
#1082
üzenetére
Viccnek elmegy.
-
dezz
nagyúr
Mutassak még vagy egy tucatot? Szét kellene talán nézni, mint hogy itt "tépitek a szátokat" néhány ilyen-olyan eredményen... Az a helyzet, hogy sokszálas alkalmazásoknál eléggé "ott van" a Bulldozer. A gond a kevésszálasakkal van... Bár ott is jobb a helyzet, ha ilyenkor modulonként csak egy szál fut (Win8). A legproblémásabb az egyszálas teljesítmény!
(#1087) Ren Hoek: Érdemesebb a 8120-ast venni és némileg feljebb húzni (akkor még nem fogyaszt túl sokat).
8-szálas i7-ből viszont a 2600 a legkisebb, ugye (desktopon)...
Az x264 talán a létező legjobb H.264 enkóder... (A Handbrake is azt használja.)
Hacsak nincsenek valami nagyon extra igényeid, akkor a játékokkal sincs különösebb gond...
[ Szerkesztve ]
-
dezz
nagyúr
válasz
subaruwrc
#1091
üzenetére
Nem a lelkivilágomat zavarja, hanem a józan észt! De komolyan. Leírtam, úgy tűnik, ehhez is korán volt: az avítt x87-ben valóban kb. 2x lassabb az AMD, de ma már desktopon semmi sem használja az x87-et (mondjuk minden 10000. utasítás x87 egy FPU-intenzív kódban). Ezek után a SuperPI alapján megítélni a dolgokat nem a legokosabb dolog a világegyetemben. Hacsak el nem osztod kb. kettővel az időeredményt AMD oldalon, hogy valamivel közelebbi mutatót kapj az általános teljesítményre vonatkozóan. És akkor még csak egyetlen mag kihasználásáról beszélünk egy 8-magos procinál. (Vagy vehetjük szálnak, de olyan szál, ami az Inteles HT-nál sokkal jobban skálázódik. FPU erő szempontjából amúgy is 2x a mutató egy X4-hez képest, megfelelő kóddal.)
A tűzfalas dolgot úgy értettem, hogy ha már annyira de annyira kíváncsi vagy az eredményekre, nos akkor miért nem keresel rá? A google sem jön be? Már megbocsáss a poénkodásért... Remélem, nem gázol nagyon a lelkedbe!
[ Szerkesztve ]
-
dezz
nagyúr
válasz
subaruwrc
#1100
üzenetére
Kibúvó, hogy a SuperPI eredmény totálisan mást mutat, mint amit más alkalmazásban látni fogsz, ezért talán nem kellene arra alapozni?
(#1101) akosf: "Ugye tudod, hogy lebegőpontos számításokra az x87, SSEx, AVX utasítások ugyanazt az FPU-t használják?"
Tudom, csakhogy más az utasítások latencyje és máshogy aránylanak ezek egymáshoz a különféle uarchoknál. Különösen ami az AVX-et illeti.
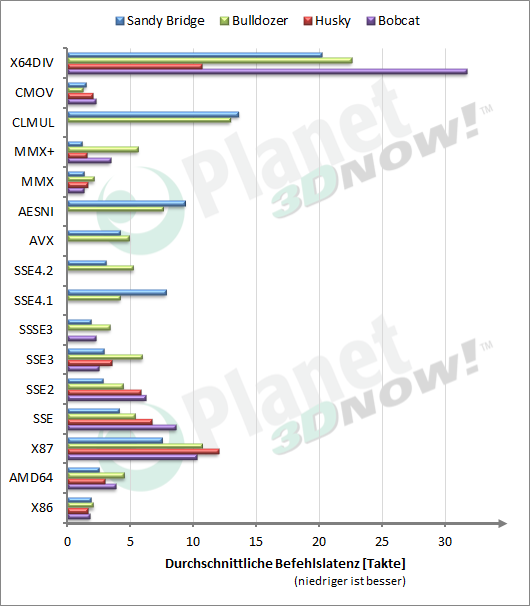
"Ha x87-ben X % az eltérés AMD és Intel közt, akkor SSE és AVX kódban is annyi..."
Nos, erre már Oliverda válaszolt. Mellesleg, a SuperPI még lassabb AMD-n, mint a fentiekből következne. Lehet, nem is csak annyiban kedvez az Intelnek, hogy x87 alapú...?
(#1103) Jack@l: 1db BD FPU 2x teljesítményre képes (megfelelő kóddal), mint 1db K10 FPU, C2C.
[ Szerkesztve ]
-
#1274
dezz
nagyúr
Ricsiii1992
#1247
dezz
nagyúr
válasz
 Ricsiii1992
#1247
üzenetére
Ricsiii1992
#1247
üzenetére
Az Bulldozer FPU-jában a korábbi FADD és FMUL egységeket FMAC egységek váltották fel, amik FMA-s kóddal mutatják meg igazán, mit tudnak, azzal viszont hasít! (Ez a program az új utasítások nélkül is jól optimalizált BD-re [ezért gyorsabb jóval alapból is a 8150, mint az X6 1100T]. Plusz itt látható AVX-es eredmény is, amit már csak az SB miatt is előbb-utóbb minden renderer támogatni fog.)
Játékokban persze így sem lesz világ csodája a cucc. (Már amikor a procin műlik a dolog.)
-
dezz
nagyúr
válasz
 Jester01
#1275
üzenetére
Jester01
#1275
üzenetére
Ha megnézed, sehol sincsenek tizedesek. Lehet, hogy az 100.9%.
Ezt leszámítva van még, amit nem értesz rajta?A 61xx-ben 6 MB L2 + 8MB L3 van.
(#1276) Jack@l: Pfff, hol látsz te itt kampánygépezetet? Olyan az Intelnek van.
Itt van egyébként a C-ray oldala. Ez tisztán a CPU mag erejét méri, benne az FPU-val. Bulldozer eredmény ide még nincs feltéve, de X6 és i5 2400 már van, és mint látható, az utóbbi alacsonyabb órajelen veri az X6-ost. Azt meg a korábban linkelt videókonvert és rendering tesztekből lehet látni, hogy a 81xx képes verni a 2600K-t. (Külön optimalizálás nélkül is.)
(#1288) leonel: Nem sikerült leszűrni a topikból (akár csak az utóbbi 100 hsz-ből), hogy alapvetően attól függ, mire akarod használni a gépet?
[ Szerkesztve ]
-
dezz
nagyúr
"mindig ezzel az egy kiszemelt agyonverem a 2600-at de még a 980-as procit is ábrával jössz, ami ráadásul gyanus hogy meg is van hekkelve"
Mindig csak ezzel jövök? És ezek mik? Ezek is mind meg vannak hekkelve? Azért odáig ne süllyedjél már, hogy hazudozol is. Ja, bocs, már lesüllyedél.
Kampányt itt te és még 2-3 ember folytat itt: lejáratókampányt, úgy beállítva a dolgokat, hogy a BD mindenre rossz, holott közel sem ez a helyzet.
"Elhiszem hogy jó a bull, de azé maradjunk már a földön..."
A fenti eredmények a Marsról származnak, vagy mi? Azokban az alkalmazásokban FMA nélkül is egálban van a 2600K-val. Akkor szerinted mi lesz FMA-s kóddal, amire ki van hegyezve? Szerined miért ezt választotta a Cray az új világelső szuperszámítógépéhez?
"FMA-t meg már kitárgyaltuk mért jó és mért szutyok ahol nincs nagyrészt fma instrukció.(vagyis nagyjából a programok 98%-nál)"
Na, ha annyira képben vagy, amennyire hiszed, akkor magyarázd csak el... Kíváncsian várom.
(#1292) leonel: "Tudtommal ez egy fórum..."
...aminek az az egyik íratlan(?) szabálya, hogy mielőtt kérdezünk, olvasunk, mert egyrészt így elkerülhetjük, hogy újrageneráljuk a vitát, másrészt tiszteletlenség semmibe venni a többiek által befektetett időt és energiát. A "kérem" és a "köszönömöt" nagyon kedves gesztus, de semmiből sem áll beírni...
Maximalista játékra valóban nem a 41xx a legjobb választás.
(#1295) Jester01: És mi van, ha 5%-ra van felkerekítve? Örvendetes, hogy találtál egy apróságot, amibe beleköthetsz, miközben egyrészt a gyakorlat is azt mutatja, hogy lehetséges a dolog (lásd fenti tesztek), másrészt elvi szinten is helytállóak a számok... Ugyanis, képzeld csak el, peak FLOPS-ban C2C 1,5x erősebb a BD, mint az X6, és ebből architektúrális okokból többet tud kihasználni a BD, mint a K10, így nem lehetetlenség a 2x szorzó, megfelelő kóddal.
-
dezz
nagyúr
-
dezz
nagyúr
Akkor a #1288-asban miért is csak így általánosságban tetted fel a kérdésedet, tehát anélkül, hogy leírtad volna, mire akarod használni a gépet? Költői kérdés volt, nem kell válaszolni. Azt esetleg elmondhatod, én mit nem értelmezek...
(#1301) Jester01: Ha az elvi és gyakorlati alapjai a helyén vannak, akkor értelmetlen hiteltelenségről beszélni egy apróság miatt. Lehet, hogy azért van néhány pixellel kijjebb tolódva, mert ott bolddal van szedve a 100%.
[ Szerkesztve ]
-
dezz
nagyúr
Már többször leírtam, hogy bizonyos dolgokra jó, más dolgokra meg nem ez a legjobb választás. Hogy ennek ellenére mégis egész mást próbálsz a számba adni, az egy újabb nagy egyes a bizonyítványodban. (Miközben te minden igyekezeteddel úgy próbálod beállítani, hogy semmire sem jó.)
Nos, a kérdésem kicsit beugratós volt. Elsősorban nem az FMA-n múlik ugyanis, hogy bizonyos esetekben jó a BD, más esetekben meg nem. Ennek okát meg tudnád fogalmazni?
Hát persze, a Crayos dolognak bizonyára semmi köze ehhez, és hogy az Intel Haswellében szintén ott lesz az FMA, majd 2013-ban.
Ha esetleg nem tudnál róla, a Titan a Jaguar upgrade-elésével születik meg. Nos, igen, bizonyára csak reklámcélból cserélik le annak 37300 6-magos Opteronját (ami lényegében ugyanaz a chip, mint az X6) Bulldozer alapú Interlagosra...
ps. meddig dől még itt belőled a hülyeség?
[ Szerkesztve ]
-
dezz
nagyúr
"Az xtremesystems.org sem ugy neznek rad ahogy kellene, ahogy latom a valaszokat a sok kommentedre."
Ha ez így lenne, akkor is * alak volnál, de még *, vagy nem érted, amit olvasol... 2 ember nem értett 1-2 dolgot, ezért alaposabban el kellett nekik magyarázni. Még csak vita sem volt. Ennyi történt. (Vagy csak nem arra a múlt heti "esetre" gondolsz, amikor egy %-os adatot félreértettem, és utána gyorsan korrigáltam is magam? Nem, ennyire nem lehetsz szánalmas.) Az angolul tudóknak, erről a topikról van szó.
"FMA elony de nem most es meg desktoppon nem is lesz egy ideig."
Ez azért tévedés, mert hétköznapi számításokban is jobban teljesít a BD FPU-ja FMA-s kóddal, mint simával. (Hogy miért, azt épp tegnap írtam le az általad emlegetett topikban, de látom, mennyire figyelted/értetted a tartalmakat...)
"Ahogy a Llano sem fogja megvaltani a jovot egyik naprol a masikra."
Csak miatta az Intel is kénytelen jobban rágyúrni az IGP-re... Plusz újra beszállhatott az AMD a játékba mainstream mobil vonalon.
"Lesz majd ugy C0 addig felesleges vitatkozni ezt mar leirtam. (engem nem fog zavarni ha az amd erosodik, nekem csak jo de nem fog a fanatizmus alttal).
Nem felesleges, amíg egyesek úgy próbálják beállítani, hogy sehol sem szerepel jól.
(#1309) Jack@l: Többnek nézegettem már a forráskódját. (És igen, értettem is, mivel programozó vagyok.) Term. futtattam is őket, többféle módon.
Ha már egyszer adottak az FMAC egységek a BD-ben, az FMA használata nem hátrány, hanem előny. A hátrány ott jelentkezik, ha nem használjuk. "Kár", hogy sokszálas számolós feladatokban így is egy szinten van a BD a 2600K-val.Abu: Itt nem csak a pontosságról van szó. Ajánlom figyelmedbe ezt: ezt.
[ Módosította: philoxenia ]








 "
"







 (1 szál/modul vs. 2 szál/modul)
(1 szál/modul vs. 2 szál/modul)












Új hozzászólás Aktív témák
A nem témába vágó beszélgetésekhez keressétek fel a (nemcsak) FX-tulajdonosok bazi nagy OFFolós topicját, vagy az AMD offtopikot!
- Rövid teaser trailert kapott a Dragon Age: Dreadwolf
- Fotók, videók mobillal
- Kertészet, mezőgazdaság topik
- 3 évig még biztosan nem rendelhetünk Xiaomi EV-t
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- Vírusirtó topic
- Rossz üzlet az EV-kölcsönzés
- MIUI / HyperOS topik
- A személyre szabott reklám lehet a streaming következő slágere
- További aktív témák...