Új hozzászólás Aktív témák
-

S_x96x_S
őstag
>Ezekhez mikor jon ki az uj chipset?
Az új alaplapokkal (+PCIe gen 4.0 ) ?
Talán 2019.Q3 Képek már vannak róla, és addig még sok minden változhat.
A 2019-es CES-en lesz várhatóan bővebb infó.De addig is a mostani EPYC alaplapokba be lehet tenni, hogyha a proci korábban kijönne.
AMD Rome Motherboard Pictured, Arrives In Q3 2019
". According to a motherboard vendor that displayed a new motherboard designed to support the Rome processors and PCIe 4.0, the first wave of fully-compatible Rome motherboards will arrive in Q3 2019, likely signalling the beginning of shipments for the Rome chips."
https://www.tomshardware.com/news/amd-rome-motherboard-epyc-cpu,38071.htmlMottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
 paprobert
#21
üzenetére
paprobert
#21
üzenetére
>256 MB L3 cache.
>Csak ennyi?Már ez is dupla annyi (magonként) mint az EPYC 1-nél.
Ott a 32magosnál volt 64Mb
AMD EPYC™ 7601 : # of CPU Cores 32 : Total L3 Cache 64MB ( 8x 8MB )most meg a 64 magosnál 256
mostani gen:
AMD EPYC 7601 32-Core Processor (4N 32C 64T 2.7GHz/3.2GHz, 1.33GHz IMC, 32x 512kB L2, 8x 8MB L3)következő gen:
AMD Eng Sample: 2S1404E2VJUG5_20/14_N (64C 1.4GHz, 800MHz IMC, 64x 512kB L2, 16x 16MB L3)Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Szerintem te még a Monolitikus chipeket szeretnél látni ( közös cache-el ) - de már nem ez a trend az AMD-nél.
>Első körben szvsz a nagy gyengeségek befoltozásának kellett volna prioritást adni,
Szerintem ez történt.
- Infinity Fabric-ot csiszolgatták ( second generation IF )
- AVX2 -öt duplázták
- "Optimized IO die improves latency and power"
- Security"
Zen 2
- World's first 7nm High Perf x86 CPU
- CPU Core Execution Enhancements
- 2nd Gen IF
- More Security Elements
- Modular Design
- Improved pipeline, DOuble loading point and load store
- Doubled core density
- Half energy per operation
- Improved branch predictor
- Better instruction pre-fetching
- Re-optimized instruction cache
- Larger op-cache
- FP with to 256-bit
- Doubled load/store bandwidth
- Increased dispatch/retire
- Maintained high throughput modes
- Security
- Memory Encryption with Increased Flexibility
- Hardware enhanced spectre mitigations
- Zen introduced a multi-chip approach
- Enabled configurability, increased peak compute
- Zen 2 Each IP is its optimal technology
- 14nm IO die
- 7nm CPU chiplets
- Optimized IO die improves latency and power
- Revolutionary new approach
">oda pedig jól jött volna a 8 magos CCX közös L3-mal.
Szerintem nem az volt az igazi szűk keresztmetszet, ami visszafogta a teljesítményt,
hanem az első generációs Infinity Fabric - és ezt most jelentősen átdolgozták.
Persze a ZEN2-eseknek máshol lesz már a szűk keresztmetszete.Az igazi teszteknél majd megtudjuk a valóságot - de szerintem igéretes lesz a ZEN2
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
>Az, hogy 4x mag / CCX az szerintem egy masszív szűk keresztmetszetet teremt
> ami érezhető mind asztali mind szerver fronton.mivel nincsenek még független ZEN2-es tesztek,
vagy ami infó van - az jelentős IPC növekedésről szól
emiatt az "érezhető szűk keresztmetszet" egészen máshol lesz mint ahol bárki várná - főleg az ZEN1 alapján spekulálva.Ha az I/O die-ban valóban lesz egy böszme nagy L4-es cache, akkor csak picit fogod érezni a különbséget.
Valamint az L3 cache is a duplája lesz.Szerver és HPC fronton a szűk keresztmetszet az Infinity Fabric volt.
Valamint valószínüleg 8 magos ccx-et tervezni most nem fért bele az időbe.egy 4 magos CCX-nek megvan az az előnye, hogy
- ZEN2-es(7nm) Athlon procikat (max 4 mag )
- olcsó notebook APU-kat
- olcsó konzol chipeket ( semi custom )
lehet belőle összelegózni.Ha igazán jól (skálázhatóak ) az Infinity Fabrik(v2) -
akkor oly mindegy , hogy 4core-os ccx -ből vagy 8core-os ccx-ből van összelegózva.az Infinity Fabrik(v1) -nek a skálázhatóság volt a fő baja, a ccx-ek keresztbe-kasul kommunikáltak.
Hiába cseréled led a 4 magos ccx-et -> 8magos ccx-re , a skálázhatósági probléma ugyanúgy fenmarad.Nézd meg dupla annyi magot javasolsz - ugyanakkora adatkapcsolatra ?
Nekem úgy tünik - hogy még rosszabb lesz az eredmény.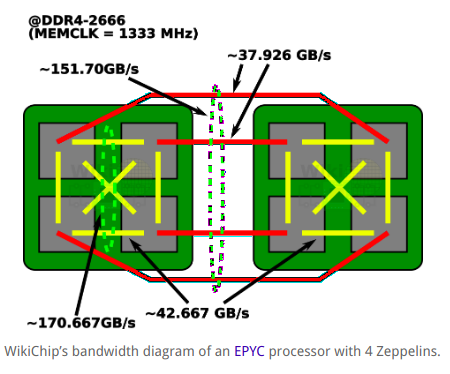

Nem a ccx-ekkel van a gond, hanem az összeköttetésekkel. A masszív szűk keresztmetszet - a kapcsolatokban van.
bővebben:
https://fuse.wikichip.org/news/1064/isscc-2018-amds-zeppelin-multi-chip-routing-and-packaging/Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Januárban megtudjuk - az biztos, hogy más elképzeléseink vannak a szűk keresztmetszetről.
Ez nem baj.összefoglalva az álláspontom:
---------------------
A 4magos ccx -> 8magos ccx-re való cseréből csak a programok egy része profitál, ott is akkor ha belefér az L3 cache-be, ha nem fér bele, akkor gáz .. és azt se növelheted a végtelenségig.
viszont abból, hogy az I/O die segítségével jobb latency-t és bandwidth -et igérnek, abból minden program profitál és mellette még skálázható is.
Valamint a ccx-ek mostani felépítésének megtartását az egyre jobb (szoftveres) ZEN1-es optimalizáció is elősegiti. Mind a windows mind a linux egyre jobban tudja kezelni a ZEN1 architektúriát.
A ZEN1 -nek a " latency + bandwidth." volt a szűk keresztmetszete. és ezen javítottak rengeteget!
persze ez csak az igéret. majd meglátjuk a tesztekben.""
C: With all the memory controllers on the IO die we now have a unified memory design such that the latency from all cores to memory is more consistent?MP: That’s a nice design – I commented on improved latency and bandwidth. Our chiplet architecture is a key enablement of those improvements.
"The architecture with the central IO chip provides a more uniform latency and it is more predictable."
------
persze nem biztos, hogy jól látom.
De szerintem ezt a témát az AMD mérnökei eléggé kielemezték. és nem véletlen, hogy ezt az arhitektúrát alakították ki.
Nem hiszem, hogy azért választották ezt az architektúrát, hogy lassabb legyen a ZEN2.------
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
>Nekem nem a CCX- koncepcióval magával van gondom, ...
> hanem azzal, hogy ezek _mellett_ a 4mag/CCX dologhoz nem nyúltak
> és nem bővítették. (6 vagy 8 mag per CCX)Ha én elkezdem analizálni a problémát ( Root cause analysis ) akkor rákérdezek
Q: miért is gyorsabb a monolitikus design ( több mag összedrótózava ) mint a ccx/chipletes?
A: " latency + bandwidth."
Q: Hogyan lehet ( " latency + bandwidth.") -en javítani ?
A: Több féleképp.
A1: picivel több magszám: (6vagy8) - de ez nem skálázható - csak részben oldja meg a problémát
A2: picivel több programszál (thread) hasonló mint az A1.
A3: I/O Die , Áttervezett Infinity Fabric ( skálázható megoldás ) Főleg mivel a GPU kapcsolatot is megoldja.Szóval akkor az A3 -re kell tenni most a fókuszt mert az a szűk keresztmetszet. Ha ezt áttervezzük, akkor mindenhol érzékelhető teljesítménynövekedést kapunk.
Megoldja az APU ( " latency + bandwidth.") ( CPU - GPU kapcsolódási ) problémát.De mi legyen majd a ZEN3 -ban és a ZEN4 -ben?
Ha a ChipHell -es legújabb infó igaz, akkor
Zen 3: SMT4
Zen 4: AVX512az SMT4 - 4 szállat jelent. Az IBM Power most SMT8-nál tart.
( "POWER8 provides eight SMT hardware threads/core (or SMT8)" )Vagyis ha igazak a pletykák, akkor az AMD a több szállas utat ( is ) választotta
Persze ettől még lehet másik ccx-e is az AMD-nek. ( volt erről pletyka , hogy kétféle ccx-lesz )
mindenesetre valami ok miatt az EPYC2 -ben ilyen várható.De az is lehet, hogy a program rosszul olvasta ki az L3-as cache-t , volt ilyen tipp is.
Vagyis nem lehet tudni semmi biztosat.
A teljesítményre meg végképp nem lehet következtetni azon kivül, amit az AMD eddig is megadott IPC ügyben.[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
>Azt mondtam, hogy a 4mag/CCX egyértelműen visszafogja az architektúrát.
32, 48 és 64 (128 !?) magnál extrém minimális az a visszafogás amitől te tartasz.
és itt már a most javított I/O die (Lattency+bandwith) számít.
egy 8 magos AM4-es procinál persze ez is fontos lehet,
de egy erre optimalizált AM4-es I/O die -al itt is lehet (Lattency+bandwith) hasonlóan emelni a sebességet.durva példa:
- I/O die (L4?) cache - hozzáad mindenhez +12% sebességet.
- Az L3 cache szintén hozzáad +3 %-ot
- A 2x 4ccx -es kivitel - meg néhány esetben levesz 5% sebességet.Ha jól csinálják, akkor a pozitiv fejlesztések ellensúlyozzák a néha megjelenő hátrányt a 4magos ccx -es kiviteltből eredendően.
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
>Honnan veszed, hogy "extrém minimális" lesz sok mag mellett?
>ezek pedig jelenleg a CCX<-IF->CCX kommunikációra vezethetőek vissza.64 magnál ugyanúgy megmaradnak a CCX-ek - nem lesz monolitikus design.
úgyanúgy kell kommunkálni.
A te javaslatoddal csak részben lett megoldva a probléma.
Viszont a többi fejlesztéssel ezt a problmát minimalizálni lehetett.A ZEN1 érzékeny volt a memórisebességére és a késleltésre. Ha ezt lecserélik és duplázzák az L3-at,
akkor a te általad jelzett ZEN1-es problémát minimalizálták.A mostani konkurenciával meg hiába hasnlítod össze. extrém magszám felett ők is ragasztóznak.
>Deszktopon ez úgy tűnik semennyire nem fog változni,
>ugyanúgy megmarad a <4-mag> <=IF=> <4-mag> rendszer
>mint potenciálisan szűk keresztmetszet kicsit javított késleltetésekkel.Az Intel monolitikus designjával ne hassonlítsd össze, főleg mert
az új Intel desing (dual-ring?) meg lehet, hogy másolja az AMD-t.
"
There is also some suggestion Intel might utilise a dual ring bus design for this Comet Lake chip, instead of the single ring bus used for the i9 9900K, or the mesh design picked up by the similarly ten-core i7 7900X and upcoming i9 9900X. That’s an intriguing thought and could possible suggest a move to something more akin to AMD’s CCX design.With this Comet Lake rumour that would potentially suggest a pair of either five- or six-core chips (with one core disabled) arrayed in a similar way to the quad-core CCX of Ryzen. And that sort of setup will need a whole lot of space.
"
https://www.pcgamesn.com/intel-comet-lake-cpu-10-core-14nmHa az Intel össze tud rendesen ragasztózni 2 chipletet - akkor az AMD-nek is képesnek kell lennie rá.
>Játékokban ez továbbra is vissza fog ütni.
meglátjuk mivel kompenzálja ezt az AMD. Ha lesz egy böszme nagy L4-es cache, akkor kevésbé lesz érzékeny a DDR4 memória sebességére , jobb lesz a játékoknál is.
és nem lehet annyira észrevenni mint most.Mottó: "A verseny jó!"






Új hozzászólás Aktív témák

ph Gyorsítótárral brutálisan ki van tömve a Zen 2, 64 maggal majdnem 300 MB-ról beszélünk.
- Milyen hagyományos (nem okos-) telefont vegyek?
- A fociról könnyedén, egy baráti társaságban
- Napokon belül indul a testkamerás Bodycam című FPS korai kiadása PC-n
- Computex 2024: extravagáns üveg-alumínium házköltemény az In Wintől
- Facebook és Messenger
- Otthoni hálózat és internet megosztás
- Xiaomi 13 Ultra - can't touch this
- Politika
- Filmvilág
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- További aktív témák...
Állásajánlatok

Cég: Alpha Laptopszerviz Kft.
Város: Pécs

Cég: Ozeki Kft.
Város: Debrecen