Új hozzászólás Aktív témák
-

snowdog
veterán
Így sem jó.
Korábban képekkel illusztrálva részletesen leírtam hogyan kell létrehozni saját oszlopokat, azokat hogyan kell definiálni, és hogyan kell használni a képeken látható sablon tesztelőt.
Köszönöm a munkádat! Most tartok egy kis szünetet. Találtam egy regex tesztelő, oktató programot, eljátszogatok vele egy kicsit.

-
snowdog
veterán
válasz
 snowdog
#1670
üzenetére
snowdog
#1670
üzenetére
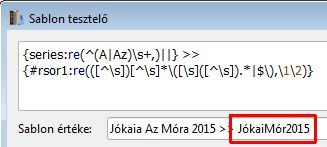
Megszületett a jó megoldás. Igaz hogy még eggyel több "vak" oszlop kellett hozzá, de ez már lényegtelen, úgy sem látszik. A részleteket olyan sokszor kitárgyaltuk már, hogy azokba most nem megyek bele, csak a végeredményt teszem ide. A sorozat nevet átalakítja csupa nagybetűssé, kiszedi az "a, az, és, :, - betűket, és a számokat, majd veszi a szavak első betűjét, ebből jelenítem meg az első kettőt. Ezen lehet változtatni, ha valaki kevesebbet, vagy többet szeretne (utolsó sor).
Ha csak egy szóból áll a sorozatnév, akkor annak csak az első betűje jelenik meg. Még gondolkodom rajta, hogy ilyenkor ennek az egy szónak sz első két betűjét vegye. De ez már a jövő.

{series:uppercase()}
{#rsor1:re((A|AZ|ÉS|:|-|[0-9].*)\s+|[0-9]|[-], )||}
{#rsor2:re(([^\s])[^\s]+(\s|$), \1)}
{#rsor3:re((\s),)}
{#rsor4:shorten(2,,0)}{series_index:0>2}
[ Szerkesztve ]
-
snowdog
veterán
zseko itt szépen leírta hogyan kell a saját oszlopokat beállítani. [link]
Annyi saját oszlopot kell definiálni, ahány sort az előbb betettem. Minden saját oszlophoz a sablon részbe kell ezeket bemásolni (legalsó mező). Minden saját oszlopba egy sort, másképpen nem is lehet. Láthatóvá csak a legutolsót kell tenni, hiszen abban van az eredmény. Ezért neveztem a többit "vak" oszlopnak. Ha igény lesz rá, akkor a saját fórumomba készítek egy lépésről-lépésre útmutatót, képekkel. Ezt a fórumot ezzel nem terhelném.
A sablon tesztelővel nem kell foglalkozni, azt csak azért tettem be, hogy akit érdekel nyomon tudja követni hogyan alakult ki a végeredmény.
[ Szerkesztve ]
-
snowdog
veterán
Annyit még hozzátennék, hogy ezzel még csak a Calibre egyik oszlopában tettük láthatóvá a rövidített sorozatnevet. Ahhoz hogy ez a Kindle olvasón is megjelenjen, ki kell tölteni a "Metadat kapcsolatok" megfelelő mezőit (úgy emlékszem korábban erről már volt szó). A programsorok közül az utolsó sort kell beírni a "Forrássablon" mezőbe.
u.i. megkerestem, szintén zseko írt róla. [link]
[ Szerkesztve ]
-
snowdog
veterán
Kicsit csiszoltam rajta, most már az egyszavas sorozatnevekből is egy kétbetűs rövidítést állít elő. És ismét eggyel kevesebb saját oszlop kell hozzá, vagyis összesen négy (szemben az előző öttel). Így a saját oszlopnevek sorrendben: rsor1, rsor2, rsor3, rsor
Ebből megjeleníteni csak az utolsót, az "rsor"-t kell (a többi elől ki kell, vagy ki lehet venni a pipát. Ezt kell a "Metadat kapcsolatok"-nál megadni.Ez most annyiban más mint az előző, hogy nem a szavak első két betűjét veszi, hanem a szavak első és utolsó betűjét. De ez szerintem lényegtelen, mert csak arra van szükség, hogy a sorozatokat megtudjuk egymástól különböztetni. Nekem legalábbis mindegy, hogy ezt melyik két betű jeleníti meg. Akinek így nem jó, az természetesen csiszolgathatja tovább.
{series:uppercase()}
{#rsor1:re((A|AZ|ÉS|:|-|[0-9].*)\s+|[0-9]|[-], )||}
{#rsor2:re((\s),)}
{#rsor3:shorten(1,,1)}{series_index:0>2}
A kép csak a feldolgozás menetét illusztrálja, a tartalma másra nem jó!
G.F.
Az oszlop típus minden oszlopnál ugyan az mint eddig (Más oszlopból előállított oszlop), de figyelj az oszlopnevekre! Ha továbbra is problémád van vele, akkor javasolom a képen látható "Sablon tesztelő" használatát, ami könnyen rávezethet a hibára.[ Szerkesztve ]
-
-
snowdog
veterán
Mert a regex-el így tudtam egyszerűen megoldani. Mint írtam, ha valaki mást szeretne, az csiszolgassa tovább a regex-et.
Az utolsó előtti változat azt teszi amit szeretnél (JM). [link] Csak ott az egyszavas sorozatnévnél van egy kis bibi.
Elég sok időt eltöltöttem vele, egyenlőre nem kívánok vele többet foglalkozni.
[ Szerkesztve ]
-
snowdog
veterán
Nekem ebből az útmutatóból az jön le, hogy ki kell csomagolni. A te hibaüzeneted meg a csomagolt fájlra hivatkozik. Csak tippelek, mert én nem telepítettem.
Installing the DeDRM plugin for calibre
Download the latest tools package, and unzip it.
(On Windows, right-click and “Extract All…”; After extracting all, rename the tools_vX.X.X.zip file to tools_zipped_vX.X.X.zip to prevent later confusion)
Run calibre. From the Preferences menu select “Change calibre behavior”.
(Do not click “Get plugins to enhance calibre”, that option is reserved for ‘official’ calibre plugins.)
Click on Plugins (under “Advanced”) — it looks like a jigsaw puzzle piece.
Click on the large “Load plugin from file” button
Navigate to the tools folder unzipped in step 2
Open the “DeDRM_calibre_plugin” folder
Select the DeDRM_plugin.zip file in that folder
Click on the “Add” (sometimes “Open”) button.
Click on the “Yes” button in the “Are you sure?” warning dialog that appears. A “Success” dialog will appear, saying that the plug-in has been installed. Click on “OK”.Megvan, itt található amire szükséged van:
DeDRM_tools_6.5.5 plugin.zip\DeDRM_calibre_plugin\DeDRM_plugin.zip[ Szerkesztve ]
-
snowdog
veterán
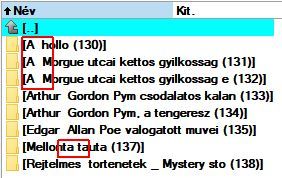
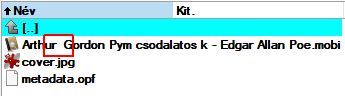
Ma egy érdekes dolgot vettem észre. A Calibre könyvtárakban ahol a könyv címe több szóból áll, az első és a második szó között mindenhol két space karakter van. Mind a könyvtár, mind a fájl nevében. A mellékelt képen látni, hogy azért kivételek is vannak.
Nem hiszem hogy felhasználói beavatkozás okozná, hiszen ebbe a felhasználó nem tud beleszólni. A metaadatoknál természetesen mindenhol csak egy szóköz van.
-
snowdog
veterán
válasz
snowdog
#1693
üzenetére
Próba képen kimentettem egy ilyen könyvet a HDD-re, és a mentett fájlnévben is dupla szóköz van az első két szó között. Tehát a Calibre nem csak a saját belső használatakor alkalmazza a dupla szóközt. Ha úgy lett volna, akkor már nem is izgatna a dolog. Így viszont zavaró.
[ Szerkesztve ]
-
#1697
snowdog
veterán
hampidampi
#1695
snowdog
veterán
válasz
 hampidampi
#1695
üzenetére
hampidampi
#1695
üzenetére
Igazad van, csak első ránézésre a metaadatoknál nem vettem észre, ott egynek látszott. Ha kitörlöm a láthatatlan szóközt, akkor rendben van.
Van arra valamilyen bevált módszer, hogy ne egyesével kelljen javítgatnom a címeket? Vagy kezdjek el kísérletezgetni vele?
-
#1699
snowdog
veterán
hampidampi
#1698
snowdog
veterán
válasz
hampidampi
#1698
üzenetére
Köszönöm az iránymutatást, ezzel is sokat segítettél. Akkor kezdődik a kísérletezés.
Ha megvan a megoldás, közzé teszem.
-
#1700
snowdog
veterán
hampidampi
#1698
snowdog
veterán
válasz
hampidampi
#1698
üzenetére
Elsőnek reguláris kifejezéssel próbálkoztam. Így ki tudom szűrni a nem karakter jelet.
A példában a "A francia nő" címben az f betű előtt van a ZWJ, és csak azt cserélem csillag karakterre, hogy lássam hol bújt meg. Innentől kezdve már csak egy csere metódust kell alkalmaznom.

-
snowdog
veterán
válasz
snowdog
#1701
üzenetére
Kipróbáltam működik!

Találtam olyan könyvcímet amiben per jel is volt, ezért a regex ismét módosult (lehet hogy később még más is előjön).
[^ a-zöüóőúéáűí-]A végén a per jel (/) az hibás megközelítés volt. Az a probléma, hogy a regx nem fogadja el a -()/ stb. karaktereket, pedig ezek is szerepelnek könyvcímekben, és ezeket nem kellene kiszűrni. Még rá kell jönnöm a regex hogyan fogadja el ezeket a karaktereket.
[ Szerkesztve ]
-
snowdog
veterán
Azt hiszem megtaláltam a megoldást. Minden ami nem ASCI karakter, és nem az ékezetesek. Így már megmarad az összes olyan karakter, amit kerestem (pl. ! ? ( ) / [ ] stb.)
[^\x20-\x7eöüóőúéáűí]Persze jobb lenne azt az egyetlen ZWJ karaktert kiszűrni, de annak megoldására még nem jöttem rá.
-
snowdog
veterán
Ebben a témában lehet hogy elbeszéltetek egymás mellett.
Arra nincs lehetőség, hogy a Calibre-nek megszabd, hogy milyen fájlneveket használjon (a saját mappáiban). Tehát abban a mappában, ahol maga a könyv van, ott olyan fájlnév lesz, amilyent a Calibre meghatároz. Erre írták, hogy ezzel ne foglalkozz.
Ha az olvasóra küldöd, vagy kimásolod a HDD-re, akkor már megszabhatod, hogy hogy nézzen ki a fájlnév. Akkor már lehet elöl a szerző, vagy lehet elöl a cím, stb.
Azt is megszabhatod, hogy a Calibre kezelőfelületén hogy jelenjenek meg a szerzők nevei. Ha akarod elöl van a vezetéknén, ha akarod hátul. Ha akarod van közöttük vessző, ha akarod nincs. Csak akkor ennek megfelelően kell a Calibre-t beállítanod.
De akárhogyan is állítod be, maga a fájlnév mindig ugyan olyan lesz.
[ Szerkesztve ]
-
snowdog
veterán
Annyit segítsetek még, a Drive-ra hogy a bánatba tudom feltenni a könyvtáramat anélkül, hogy még a Drive mappába be kelljen másolni (duplikálni gyakorlatilag) ? Mert ezzel az öreg masinával rámenne a hétvége a másolásra/feltöltésre.
Elolvastam párszor ezt a kérdést, de még mindig nem értem.
Tehát másolás nélkül akarod felmásolni a fájlokat? Hát az nem fog menni. De ha azt kérdezted volna, hogyan lehet automatizálni a másolást, hogy ne egyenként kelljen, akkor arra már lehetett volna válaszolni. Azért nem írok róla többet, mert nem vagyok benne biztos mit is szeretnél.
-
snowdog
veterán
Egyet értek veled, én is ezt a formátumot részesítem előnyben, az én könyvtáraim is így vannak rendezve.
De azért meg kell említeni, hogy nem minden komoly hely (a M.E.K.-et annak tartom) alkalmazza ezt a módszert.

Azt gondolom mindenki maga döntse el milyen formátumot választ. Ha tudunk, akkor segítünk beállítani.
[ Szerkesztve ]
-
snowdog
veterán
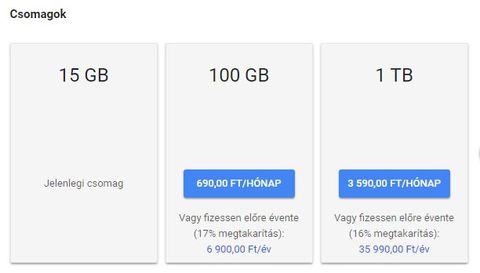
A Google drive nem csak 25 gigáig működik? Mert azt nem nehéz kinőni.
Alapesetben 15 GB, aztán idővel lassan növekszik. És hogy ezt nehéz kinőni, ezzel vitatkoznék. Amit készítettem közös Drive-ot abból kettőt kell használnom, bár van egy kis rátartás, de a könyvek egyen már nem fértek el.
Mondjuk a gépemen kitörlök egy formátumot, mert nem kell, vagy rossz minőségű, attól még a másik gép könyvtárában ott marad.
Ezért célszerű a másolatot pl. a Drive-ra tenni, mert akkor egy jó szinkronizáló programmal ez is kiküszöbölhető. Én ezt használom (nálam a honlapjuk valamiért nem jelenik meg). [link]
[ Szerkesztve ]
-
snowdog
veterán
válasz
 Bosco01
#1730
üzenetére
Bosco01
#1730
üzenetére
Ha egy új Google fiókot regisztrálsz, akkor alapból a Drive mérete 15 GB. Aztán idővel minél több mindent helyezel el rajta, a Drive mérete folyamatosan növekszik. Ennek ütemét a Google szabja meg. A saját Drive-om jelenleg 17 GB.
Persze vásárolhatsz nagyobb tárhelyet is.
[ Szerkesztve ]
-
#1759
snowdog
veterán
hampidampi
#1757
snowdog
veterán
válasz
hampidampi
#1757
üzenetére
Köszönöm. Korábban én is ezt a verziót használtam, aztán egyszer valaki írta, hogy van újabb verzió, akkor telepítettem ezt a hibásat. Most visszatettem a régit.
-
snowdog
veterán
Egy ilyen könyvtár rendbetétele borzasztóan macerás. Én az enyémet már hónapok óta takarítom.
A több formátumból egy formátum megtartása nagyon egyszerű lenne, ha eldöntenéd melyiket akarod megtartani. a többi egy művelettel törölhető. Csakhogy az én gyűjteményemben az egy könyvhöz tartozó különböző formátumú könyvek minősége nem mindig azonos. Ahhoz hogy a legjobbat tudjam megtartani, bizony egyenként mindet meg kell nézni.A különböző könyvtárak - különösen ha nem egy forrásból származnak - esetén a duplikált könyvek eltávolításánál ugyan ez a probléma. Honnan tudod, hogy a két két könyvtár közül melyikben van a jobb minőségű könyv? Hát onnan, hogy egyenként megnézed őket. Én így csinálom.
-
snowdog
veterán
Egy jó ideje rendezgetem a könyvtáraimat (én szerzők kezdőbetűje alapján csoportosítottam őket, így 26 könyvtáram van), és azt vettem észre, hogy többnyire az epub könyvek a legjobban szerkesztettek. A többit többnyire ebből a formátumból konvertálták, hol jobban, hol rosszabbul. Ezért nem biztos hogy azzal jól jártál, hogy első körben a duplák közül az epub formátumúakat törölted. Én inkább azokat hagytam volna meg.
Ráadásul ha valamiért bele kell nyúlni a könyvbe, akkor a Calibre szerkesztője sokkal gyorsabban dolgozik egy epub könyvvel, mint mondjuk az AZW3-al (a mobi-t meg meg sem nyitja).
A Metaadatok moly.hu dőlt betűs kihagyásába én is belefutottam, de még nem találtam rá megoldást, olyankor a moly.hu-ról copy-paste módszerrel szedem le a szöveget.
A Megjegyzés(ek)-ben a bekezdések közötti nagy sorközt HTML módban manuálisan írom át. Itt feltehetően magát a Calibre-t kellene átírni. Hátha valakinek erre is lesz ötlete, engem is érdekel.
Csak halkan jegyzem meg, hogy párhuzamosan ugyan azt a nagy munkát csináljuk. Egyébként ezért hoztam létre a már többször belinkelt fórumomat (itt a lábjegyzetben is látható), hogy a hozzám hasonló lelkesekkel próbáljak közösen dolgozni, kialakítani egy olyan módszert, ahol összehangoltan végeznénk a munkát. Eddig nem jött össze, nem érdekelt senkit. Pedig így mindannyian sokat dolgozunk feleslegesen.
[ Szerkesztve ]
-
#1780
snowdog
veterán
hampidampi
#1779
snowdog
veterán
válasz
hampidampi
#1779
üzenetére
Ha Molyról töltesz le pluginnel, vigyázz a címbeli dupla szóközökkel. Tud tréfás dolgokat művelni.
Annyival egészíteném ki, hogy a második szóköz "láthatatlan"!
-
snowdog
veterán
válasz
snowdog
#1796
üzenetére
Úgy látom a keresést csak az első új sor jelig hajtja végre, abban meg nincs benne a keresendő szöveg.
Nem jól láttam. Viszont a szövegben elhelyezett html kódokat a kereső nem látja. Csak a szöveg elején és a végén találhatókat. A lényeg hogy a bemutatott módszer nem működik.
-
snowdog
veterán
Mutatok egy példát.
Így néz ki a comment szöveg nézetben:

Így néz ki html nézetben:
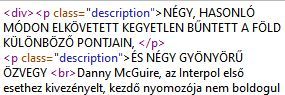
És így néz ki a keresőmezőben (a pirossal bekeretezett helyen lenne a html kód, de nem látható, ezért nem működik a csere funkció):

Az "ÖZVEGY" után levő <br> sem látható csere mezőben.
[ Szerkesztve ]
-
snowdog
veterán
Ez a nagy kérdés. Egyébként próba képpen csináltam egy rövidített comment bejegyzést, és abban nekem is megjelent a html kód. De a comment-ek 99%-ánál nem látható (bár nem néztem át az összes comment-et, az arányt a megnézettekből következtettem). Nem tudom mi lehet az oka.
Kíváncsi lennék rá, nálad milyen lehet ez az arány.
[ Szerkesztve ]
-
snowdog
veterán
válasz
snowdog
#1802
üzenetére
A problémát a következő képpen oldottam meg. Megnéztem hol van a szövegben olyan hely, ahol html kód van. Bár a kereső mezőben nem volt látható, de azt a helyet ahol a html kódnak lenni kellett (ez többnyire mint egy space volt látható) felmásoltam clipboard-ra, mint keresendő mintát. Ezt a mintát cseréltettem a <br> html kódra.
És láss csodát, működik!
-
snowdog
veterán
válasz
Bosco01
#1814
üzenetére
Szia!
A Calibre-ben a konvertálás beállításainál a "Kinézet és megjelenés" pontban a "Kinézet" fülön a "Bekezdések közötti térköz eltávolítása" előtti check-box-ot jelöld be, és a "Behúzás mérete" értéket állítsd be a neked megfelelőre. Ezt a műveletet automatizálni is lehet, és egyszerre bármennyi könyvön el lehet végzi. Remélem ezzel módszerrel működni fog.



































Új hozzászólás Aktív témák
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Alpha Laptopszerviz Kft.
Város: Pécs