Új hozzászólás Aktív témák
-
#355
 -=MrLF=-
senior tag
Petykemano
#354
-=MrLF=-
senior tag
Petykemano
#354
-=MrLF=-
senior tag
válasz
 Petykemano
#354
üzenetére
Petykemano
#354
üzenetére
Szerintem ebből nem jön komplett gép, de remélem jön valami egyszerűbb lap azzal hozhatnának ki Barabone csomagot. Négy DP++ kimenettel, meg ECC RAM támogatással ez a fenti lap aranyárban lesz.
protonmail.com Secure Email Based in Switzerland . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . startpage.com The world's most private search engine from Netherland
-
#356
 S_x96x_S
őstag
Petykemano
#352
S_x96x_S
őstag
Petykemano
#352
S_x96x_S
őstag
válasz
Petykemano
#352
üzenetére
>Ez biztos drága,
Nem olcsó , $325 - $450 között lesznek - akár már agusztusban.
""
The Sapphire FS-FP5V will be available later this month. Consumers interested in grabbing one can order it directly through Sapphire's website. Pricing is as follows:
FS-FP5V1807B V1807B 35-54W 52093-00-40G - $450
FS-FP5V1756B V1756B 35-54W 52093-01-40G - $390
FS-FP5V1605B V1605B 12-25W 52093-02-40G - $340
FS-FP5V1202B V1202B 12-25W 52093-03-40G - $325
""
https://www.tomshardware.com/news/sapphire-amd-ryzen-v1000-apu,37408.htmlAz UDO Bolt - 229$ -tól indul - Látja valaki, ami miatt a közel $100 -os felár indokolt?
https://www.kickstarter.com/projects/udoo/udoo-bolt-raising-the-maker-world-to-the-next-leve
Mottó: "A verseny jó!"
-
#373
 Cathulhu
addikt
Petykemano
#372
Cathulhu
addikt
Petykemano
#372
Cathulhu
addikt
válasz
Petykemano
#372
üzenetére
Mennyire megbizhato az urge? Mert ez inkabb tunik egy Zen++-nak, mint egy Zen2-nek.
"95W 8C/16T 4.2 base/4.5-4.6 Boost?"
mindezt 7 nanon? mondjuk ugy, hogy elegge buzlikAshy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#375
Cathulhu
addikt
Petykemano
#374
Cathulhu
addikt
válasz
Petykemano
#374
üzenetére
Se a 2x energiahatekonysagba se az 1.35x-os performance-ba nem illik bele, meg ugy a ketto kozti atmenetbe sem igazan, szerintem. Mindenesetre ha ez lenne a Zen2, az (nem)kicsit csalodast kelto lenne, szerintem
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#380
S_x96x_S
őstag
Petykemano
#378
S_x96x_S
őstag
válasz
Petykemano
#378
üzenetére
>A legújabb GF hírek szerint....
>A matisse vagy nem 7nm, vagy nem a GF gyártja.vegyes stratégia is lehetséges. az AM4-es ZEN2 magú procik ( ár) alsó szegmensét a GF - a felső ( drágább; > 8 core ) szegmensét a TSMC gyártja.
persze ez felboritja a tisztán 7nm-es next gen roadmap-et.Az Anandtech-es cikkben ezt már így fogalmazták meg:
"Furthermore should AMD decide to start on any new chips that don’t require a bleeding-edge manufacturing process (e.g. a chipset), then GlobalFoundries is still an option."hivatalos AMD reagálás ( befektetőknek )
Anandtech elemzések:
AMD's 7nm CPUs & GPUs To Be Fabbed by TSMC, on Track for 2018 - 2019
https://www.anandtech.com/show/13279/amd-to-fab-7nm-cpus-gpus-at-tsmcGlobalFoundries Stops All 7nm Development: Opts To Focus on Specialized Processes
https://www.anandtech.com/print/13277/globalfoundries-stops-all-7nm-development
" The company will keep working with AMD for many years to come in fabbing current-generation CPUs and GPUs, and then switching exclusively to wafers with embedded APUs/GPUs as well as with first-gen EPYC dies, as these products have very long lifecycles. However, the number of wafers GlobalFoundries processes for AMD will be dropping rapidly starting from 2019. Whether GF will be able to substitute AMD’s orders with orders from enough smaller players to Fab 8 full utilized is something only time will tell."Mottó: "A verseny jó!"
-
#382
S_x96x_S
őstag
Petykemano
#379
S_x96x_S
őstag
válasz
Petykemano
#379
üzenetére
>Állítólag a Threadripper 2 miatt kell mennie, merthogy papíron jól mutat, de szűkös a pálya,
>ahol tényleg skálázódik.Szerintem ezt az Intel Fan-ok terjesztik .. A 16 magos - 2950-es elég jó !
de végiggondolva:
Az már az EPYC piaca ... nem hiszem, hogy a saját EPYC piacuk kannibalizálását akarnák.
Meg a mostani Threadripper2 -tőt az X399-es alaplap korlátai fogják vissza. ( pl. memóriacsatorna ) nem sajnálták a magokat.De majd a piac eldönti.
Úgyis jönnek a Gamer EPYC lapok
Mottó: "A verseny jó!"
-
#384
S_x96x_S
őstag
Petykemano
#383
S_x96x_S
őstag
válasz
Petykemano
#383
üzenetére
>A 32 magos TR2-re gondoltak, nem az egyébként jó frissítésnek számító 16 magosra.
Szept4 -el kezd Jim Anderson az új helyén, és szerintem az ő döntése, hogy megvárta a TR2 launch-ot.
Valószínüleg aug1-verl értesítette Su-t és az új cégével ( Lattice Semiconductor ) már tavasszal elkezdődtek a puhatolozzó megbeszélések.
Tehát én nem hiszem, hogy a 32magos threadripper miatt kellett mennie.Mivel Jim Anderson CEO - szeretett volna lenni és Lisa Su szénája egyre erősödött - nem sok lehetőséget látott a cégen belül.
Legalábbis ez a hivatalos álláspont.
"An AMD spokesman said that it was always Anderson's career ambition to eventually become a chief executive."A 32magos Threadripper kb +30%-os cpu freq -on üzemel a 32magos Epyc-hez képest
és a tesztek nagy többségénél ez bőven elegendő, hogy leverje az EPYC-et is a tesztekben.
Ezen kivül még olcsóbb is.
Valamit a 32 magos TR az a chip, ami elvette az Inteltől a koronát. A 28magos Inteél demó után nem volt más választása az AMD-nek.
Szóval én inkább azt hiszem ez pozitiv lap lesz az AMD történetében.Sikeresség II.
Az árazás lineáris a magok számával. A 16magos fele annyi mint a 32 magos.
És ha nem kell a piacnak, akkor még mindig csökkenthetnek árat.
Vagyis nincs rossz processzor - csak rosszul árazott proceszor
persze ha kijönnek a 7nm-es EPYC-procik, akkor már más lesz a felállás, de jó árazással akkor sincs gond.Mottó: "A verseny jó!"
-
#420
 HSM
félisten
Petykemano
#419
HSM
félisten
Petykemano
#419
HSM
félisten
válasz
Petykemano
#419
üzenetére
A négy lapkás Threadrippereknél van két lapka, aminek nuku memóriája sincs.
A sima kétlapkás Threadrippereknél mindkét lapkának van memóriája, a probléma ugyanakkor ott is jelen van, hiszen ha az adott magnak olyan adat kell, ami a szomszéd csip tárában van, akkor megint a lassú távoli elérés esete fog befigyelni. Ezért találták ki a game módot, ami ha jól emlékszem, komplett lekapcsolja az egyik magot, praktikusan kreálva egy sima AM4-es procit.
"Second, Game Mode disables the cores in one of the silicon dies. This isn’t a full shutdown of the 8-core Zeppelin die, just the cores. The PCIe lanes, the DRAM channels and the various IO are still active, but the cores themselves are power gated such that the system does not use them or migrate threads to them."
Forrás: [link]
Itt szépen le is mérték, gyors DDR4-3200-as memóriákkal: 65ns near memory and 108ns far memory (87ns average). Szóval, a far memory 65ns egész jó (most nem trollkodom, hogy a 8 éves X58 rendszerem vígan befigyel gyors DDR3 ramokkal 50ns alá, vagy mégis?![;]](//cdn.rios.hu/dl/s/v1.gif) ), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
A késleltetés a system agent órajelén múlik, ha minden igaz, ami emlékeim szerint a ram frekvencia felén megy, ezért is fontos Ryzen alá a magas órajelű ram, mert szuperül csökken tőle a rendszer késleltetése.
Szóval ez egy jó megoldás, lekapcsolva a fél TR-t megoldani, hogy csak lokális memória elérés legyen, ami gyors, csaképpen ugyanezt olcsóbban is lehet produkálni egy sima AM4-es Ryzennel.
[ Szerkesztve ]
-
#422
HSM
félisten
Petykemano
#421
HSM
félisten
válasz
Petykemano
#421
üzenetére
Szerintem logikus döntés, hogy a memóriasebességgel skálázódik a rendszer. Minél gyorsabb a memória, annál több adatot kell elszállítani. Így szerintem egy fix aránnyal összeszinkronizálni is egyszerűbb lehetett a dolgokat. Ettől függetlenül én is fontosnak látnám még javítani ezen interconnectek sebességén.
"Kicsit olyan, mintha a két CCX a memórián keresztül kommunikálna."
Hát, nem lépődnék meg, ha így lenne.
"csak nem világos, hogy miért a memóriaelérés késleltetése alacsonyabb a szomszédos L3$-nél?"
Gondolom, a szomszédos L3 tartalmát először ki kell írni memóriába, majd onnan betölteni a másik L3, tehát nyilván ez egy memória írással lassabb lesz, mint ha csak egyből a memóriából kéne beolvasni.Vigyázat, nem tudom (ha valaki ismeri az architektúrát javítson ki), ez csak feltételezés.
-
#425
Cathulhu
addikt
Petykemano
#421
Cathulhu
addikt
válasz
Petykemano
#421
üzenetére
Nem igazan a memoriak orajeletol fugg, pontosabban az I/O bus sebessegen megy, ami viszont egyenesen aranyos a memoriak sebessegevel. Ha igy kozelited meg, akkor viszont teljesen ertheto miert van ez. Azt nem tudom egyaltalan meg lehetne-e valositani ertelmes kereteken belul, hogy ettol elterhessen, talan amihez nem kellene nagy varazslat, hogy annak valami egesz szamu tobbszorosen uzemeljen, de azt az orajelet meg lehet siman nem birna.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#427
HSM
félisten
Petykemano
#423
HSM
félisten
válasz
Petykemano
#423
üzenetére
"Akárhogy is, felvetődhet a kérdés, miért hagytak ki egy csak CCX-ek közötti megosztást célzó L4-et a lapkából?"
Ha engem kérdezel, logikus döntés, hiszen az egész dizájn azon nyer nagyon sokat, hogy gyakorlatilag két független CPU-komplexként működik a két CCX. Ugye, ezen nyernek, hogy nem kell állandóan adatot szinkronizálni 8 mag cache-ei között, ami lényegesen komolyabb meló lenne, mint 4-et szinkronban tartani, hanem minden CCX megteszi magán belül, ha pedig adatot kell cserélni, megoldják a memórián keresztül.(#424) S_x96x_S: Tény. Mondjuk ennek a benchnek a hitelességét nálam erősen megkérdőjelezi, hogy a 2600X 6 maggal hozza ugyanazt, mint a 2700X 8-al. Itt nekem valami nem kerek.

-
#433
 Fiery
veterán
Petykemano
#432
Fiery
veterán
Petykemano
#432
Fiery
veterán
válasz
Petykemano
#432
üzenetére
Bulldozer? Mit kommentaljak egy halott allatorvosi lovon?
-
#436
Cathulhu
addikt
Petykemano
#435
Cathulhu
addikt
válasz
Petykemano
#435
üzenetére
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#440
 Petykemano
veterán
Petykemano
#439
Petykemano
veterán
Petykemano
#439
Petykemano
veterán
válasz
Petykemano
#439
üzenetére
Úgy tűnik, egy CCX 8 mag lesz. 32MB L3$
Kicsit tartok attól, hogy innentől minden cpu lapka mellé kell IO lapka is és innentől minden lapkaközi kommunikáció lapkán kívül történik (core-core, core-ram)es az is igaz, hogy így contol chipből is többet kell majd tervezni.
De az így biztosra vehető, hogy a mainstream LEHET 16 magos. És az is valószínű, hogy a control chiphez fog csatlakozni az igp is nagymértékű flexibilitást biztosítva.ZenX - ezmiez?
Találgatunk, aztán majd úgyis kiderül..
-
#441
S_x96x_S
őstag
Petykemano
#439
S_x96x_S
őstag
válasz
Petykemano
#439
üzenetére
>Talán így fog mutatni az epyc2 és ryzen3
rengeteg ábrát fabrikált, de ezek csak spekulációk.
"Reminder: These aren't leaks, just my idle speculation. Do what you want with them."
https://twitter.com/chiakokhua/status/1057166488627380224Mottó: "A verseny jó!"
-
#444
 solfilo
veterán
Petykemano
#443
solfilo
veterán
Petykemano
#443
válasz
Petykemano
#443
üzenetére
Az is lehet, hogy csak utólag magyarázzák a bizonyítványt.
Athlon 200GE hozza az A10-9800 teljesítményét, miközben 35W vs 65W TDP.
Itt mértek pár játékkal, hol egyik, hol másik a gyorsabb: [link]
Hogy lesz ebből azonos teljesítmény azonos thermal limitnél, ha ekkora fogyasztásdifi mellett is kb egyformán teljesítenek?
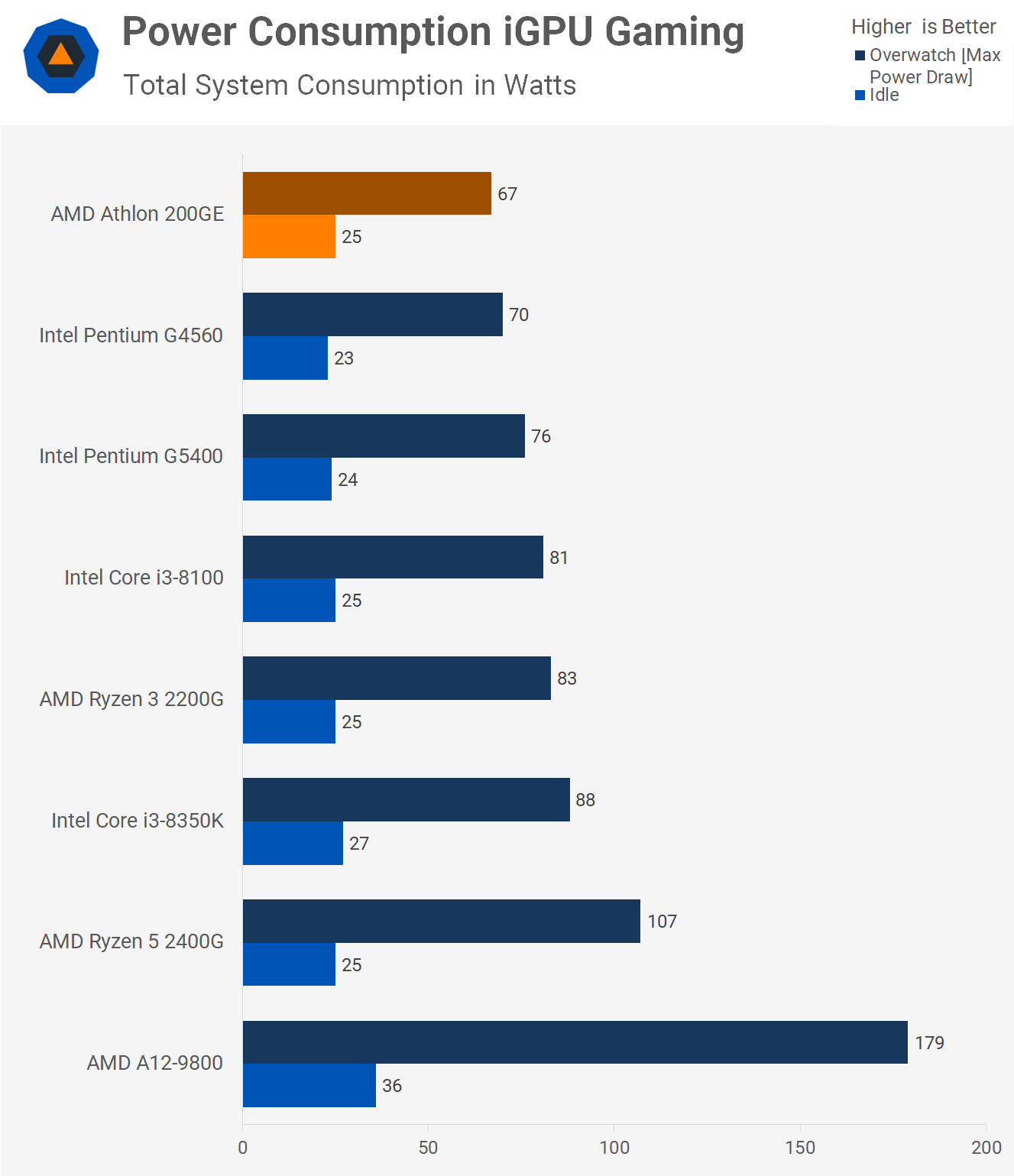
mondjuk ez alapján, hogy "We will continue to maximize the thermals to allow the Bristol Ridge APU to run at maximum speed", elég spórolósra vehették a hűtést.
[ Szerkesztve ]
solfilo
-
#449
S_x96x_S
őstag
Petykemano
#447
S_x96x_S
őstag
válasz
Petykemano
#447
üzenetére
>Már nem büdös a technocol.
ez már presztizsharc ... mindenáron a leggyorsabbnak kell lenni:
“It is our intent and design to deliver performance leadership throughout 2019,” Lisa Spelman , INTEL
itt már a tecnocol is megengedett.de a gazdaságosság már más tészta :
"Intel could meet or beat AMD on performance, slash prices like crazy (with this 48-core Cascade Lake AP part not costing much more than a monolithic top-bin 28-core Skylake part), and still lose out bigtime on performance/watt and cost/performance/watt."
https://twitter.com/NicoleHemsoth/status/1059438873804193793bővebb : "INTEL TO CHALLENGE AMD WITH 48 CORE “CASCADE LAKE” XEON AP"
https://www.nextplatform.com/2018/11/05/intel-to-challenge-amd-with-48-core-cascade-lake-xeon-ap/"We will see what AMD has to say this week out in San Francisco, and then take stab at trying to figure out how it will map to what Intel is doing. We have heard on the rumor mill that Rome Epycs will have 48 cores (as we expected) and only eight memory channels (we were hoping for more, but Rome has to be socket compatible with Naples); others are expecting AMD to crank Rome up to 64 cores in a socket, and still others say Rome is 48 cores and the kicker “Milan” processors will reach up to 64 cores. Intel just forced AMD’s hand into disclosure"
Engem a 12 memóriacsatorna egy kicsit meglepett, de ha nem számítanak a költségek - akkor mindent lehet
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#451
Cathulhu
addikt
Petykemano
#450
Cathulhu
addikt
válasz
Petykemano
#450
üzenetére
Dehogynem, threadripper 2 előtt chiller? Pont ilyen kétségbeesett volt, csak sajnos működik.
Bízom benne, hogy az Zen2 ezt a borzalmat is alázza.
Azt meg nem is minősíteném, hogyha a xeonhoz képest 20% mindössze az előrelépés, akkor hogy jött ki az Epychez képest 240... Nagy nehezen találtak valószínűleg egyet AVX512 tesztet, innentől kezdve nem támadható a kijelentés...Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#453
Cathulhu
addikt
Petykemano
#452
Cathulhu
addikt
válasz
Petykemano
#452
üzenetére
Ez arra jo, hogyha valakit holnap meggyozne mondjuk az Zen2-es Epyc es elgondolkodna a valtason mondvan az intelnek semmije sincs ez ellen, mehessen a marketinges es lebeszelhesse az ingadozot. Aztan az mar kit erdekel, hogy ehhez ugyanugy foglalatvaltas kell mintha epycre allna az ember, vagy hogy ennek a foglalata sem lesz hosszabb eletu mint az SP3.
Arra van barmi esely, hogy AVX512 support jojjon a Zen2-ben? Tudom nagyon retegigeny, de az intel egyetlen megmaradt fegyvere benchmarkokban.Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#454
S_x96x_S
őstag
Petykemano
#450
S_x96x_S
őstag
válasz
Petykemano
#450
üzenetére
>Az intel nem szokott ilyen megelőző csapásokat intézni.
Az AnandTech -esek szerint is szokatlan
"Food for thought... at 11pm PT on a Sunday. Kind of an odd time for this announcement."
https://twitter.com/IanCutress/status/1059340497569832960Az AMD Horizont eventjének nem látom az időpontját. de szerintem késő este / szerda hajnalban lesz valami infó. ( SanFrancisco időzóna )
"AMD's next horizon event is scheduled for Tuesday, November 6, 2018, where we will discuss innovation of AMD products and technology, specifically designed with the datacenter on industry leading 7-nanometer process technology."Várhatóan az AnandTech -en lesz valami ...
https://twitter.com/IanCutress/status/1059186720497852416Mottó: "A verseny jó!"
-
#461
Petykemano
veterán
Petykemano
#450
Petykemano
veterán
-
#462
Cathulhu
addikt
Petykemano
#461
Cathulhu
addikt
válasz
Petykemano
#461
üzenetére
Ugy nez ki lesz live blog
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#463
S_x96x_S
őstag
Petykemano
#461
S_x96x_S
őstag
válasz
Petykemano
#461
üzenetére
mostani infó
Magyar idő szerint este 6óra. ( 18:00 )
AMD Next Horizon Live Blog: Starts 9am PT / 5pm UTC
https://www.anandtech.com/show/13547/amd-next-horizon-live-blog-starts-9am-pt-5pm-utcMottó: "A verseny jó!"
-
#484
Cathulhu
addikt
Petykemano
#450
Cathulhu
addikt
válasz
Petykemano
#450
üzenetére
Kicsit visszatekintve tegnapra:
"Linpack up to 1.21x versus Intel Xeon Scalable 8180 processor and 3.4x versus AMD EPYC 7601
Stream Triad up to 1.83x versus Intel Scalable 8180 processor and 1.3x versus AMD EPYC 7601"Na ma az derult ki, hogy az uj Epyc64C128T elmeleti lebegopontos teljesitmenye 4x-esere nott, illetve hogy c-rayben (szinten elvileg erosen lebegopontos) elveri a dual 8180-at. Ha ez igaz, akkor itt kerem buciraveres esete fog fennallni.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#487
 TRitON
aktív tag
Petykemano
#486
TRitON
aktív tag
Petykemano
#486
TRitON
aktív tag
válasz
Petykemano
#486
üzenetére
Én úgy értettem, hogy a tegnap bemutatott CCX chiplet-ekben lévő, az EPYC-ben amúgy letiltott DRAM és I/O vezérlő lesz aktív, így nem kell sehova külön chipet tervezni.
Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
#494
Cathulhu
addikt
Petykemano
#493
Cathulhu
addikt
válasz
Petykemano
#493
üzenetére
Valoszinuleg a gigantikus (Zen1-hez kepest legalabbis) L3 a kulonallo IO-t probalja kompenzalni.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#497
Cathulhu
addikt
Petykemano
#495
Cathulhu
addikt
válasz
Petykemano
#495
üzenetére
Ez bennem is felvetődött, hatalmas lett az IO chip, sok minden elfér benne, egy L4 meg kifejezetten hasznos lenne.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#500
 lezso6
HÁZIGAZDA
Petykemano
#499
lezso6
HÁZIGAZDA
Petykemano
#499
válasz
Petykemano
#499
üzenetére
Szerintem szimplán csak olcsóbb a GloFo. Meg ugye ha az AMD nem gyárt semmit a GloFo-nál, akkor utóbbinak kb lőttek.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#503
lezso6
HÁZIGAZDA
Petykemano
#501
válasz
Petykemano
#501
üzenetére
Jó, ez jogos, ott az OEM. De azért ha nem gyárt a procikhoz ott semmit, az jelentős kiesés a GloFo-nak szerintem.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#509
lezso6
HÁZIGAZDA
Petykemano
#507
válasz
Petykemano
#507
üzenetére
Egyelőre az Infinity Fabric 2-t kéne látni akcióban. Az eDRAM meglehetősen bruteforce megoldás.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#510
HSM
félisten
Petykemano
#507
HSM
félisten
válasz
Petykemano
#507
üzenetére
"de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors"
Vélhetőleg az nem a másik L3-ból olvasott, viszont ha ott volt a szükséges adat aktuális állapota, akkor azt előbb vissza kellett menteni a rendszermemóriába, hogy utána onnan a másik CCX kiolvashassa.Ez nem nem volt gyors, és lassulást okozhatott, hanem keményen okozott is az erre fel nem készített alkalmazásoknak, lásd pl. az Nv drivert mikor megjelent a Ryzen.
Így viszont egy L4-el lehet csinálni egy viszonylag gyors köztes lépcsőt, amin keresztül a memória kihagyása nélkül, lényegesen gyorsabban lehet adatot cserélgetni a CPU csoportok között.
Amúgy vannak alkalmazások, amik nagyon szerették az L4-et, lásd pl. a PH tesztet: [link], egy esetben még az 5960X-et is odakente!
 [link]
[link](#509) lezso6: Bruteforce avagy sem, én AM4-en is szívesen látnék egy 32-64MB-ot belőle L4-ként, ha marad a több CCX-es felépítés.
[ Szerkesztve ]
-
#520
lezso6
HÁZIGAZDA
Petykemano
#515
válasz
Petykemano
#515
üzenetére
Igen, most már világos. Én úgy értettem, hogy külön chip, stb. IF-fel így logikus meg az is, hogy miért ekkora az I/O (~300 mm2).

Számolgattam...
Az Intel 22 nm-en készülő 128 MB eDRAM-ja 84 mm2. Wikichip alapján csak cellákkal számolva 31 mm2 jön ki, ami ugye kevés.
De ha csak az Intel 22 nm és a GloFo 14 nm eDRAM cella méretéből arányosan szorzok, akkor az jön ki, hogy 202 mm2 512 MB eDRAM. Tehát az I/O chip kétharmadát vinné.Azonban nem hiszem, hogy 100 mm2-re ráfér minden I/O. TriTon számai alapján legalább 40 mm2 lenne egy alap uncore kiszerelés a Zeppelinből. Így 160 mm2-re jön ki a tiszta I/O. Emellé 256 MB eDRAM fér a fenti számolás szerint. Hacsaknem a tömbösítések miatt valahogy "megtrükközhető" kisebbre.
SRAM biztos nincs az I/O-ban. Az sokat fogyaszt és 3x akkora.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#522
S_x96x_S
őstag
Petykemano
#519
S_x96x_S
őstag
válasz
Petykemano
#519
üzenetére
>Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot,
> ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat
>és a lapkán 12 chiplet kapna helyet?jó kérdés - spekulálásra tökéletes.
biztos elemzik az AMD-nél, de óvatosak - kicsi az erőforrásuk és egy ilyennek a bevezetése nem olyan rövid idő. Ha valamelyik partnernek lesz egy ilyen igénye - akkor lesz.
imho: A 12ch DDR4 akkor lesz fontos, hogyha memória sávszél limites lesz az EPYC(2;3;4) - és a DDR5 extrém drága lesz.
Vagyis ez lesz a szűk keresztmetszet.De talán a memória compresszálás valamit segíthet a sávszélességnél is
- és nem véletlenül van ott a Chiphell-es ábrán, ha már titkosítják a memóriát(AES), akor lehet előtte tömöríteni is. ha GPU-knál bejött miért ne lehetne a CPU-knál is ?
https://arxiv.org/pdf/1807.07685.pdfDe az EPYC CPU-nál a HBM bevetése is (elméleti) alternativa.
- "HBM is a new type of CPU/GPU memory (“RAM”) that vertically stacks memory chips, like floors in a skyscraper." https://www.amd.com/en/technologies/hbmnem tudom igazából,
de nem is zárom ki mint elméleti lehetőséget.Én a Deep learning miatt a hibrid HBM+DDR4/5 irányt forsziroznám inkább mnt a 12ch -t:
de 1 év múlva okosabbak leszünk.Mottó: "A verseny jó!"
-
#525
S_x96x_S
őstag
Petykemano
#524
S_x96x_S
őstag
válasz
Petykemano
#524
üzenetére
> Arra gondolsz ..
akár,
de fontos megjegyezni, hoy a memória probémákkat fókuszban tartja az AMD.
és tényleg nem mindegy, hogy egy szállra mekkora memória sávszélesség esik."Over the last decade, we have actually lost major grounds. In other words, the GPU and CPU are increasing in performance at a much faster rate than the memory bandwidth. The inability to feed the processors with data fast enough continues to increase and as the gap widens, memory bandwidth will exceed in severity the other barriers in the future."
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/3/"Full 3D Stacking" - van hosszú távon megcélozva, de rövid távon akár lehet tényleg egy 12/16 csatornás megoldás.
"Su’s ambitious vision didn’t stop with 3D stacking. She proceeded to explain a concept she called “full 3D stacking” whereby AMD would be able to stack the GPU on top of the CPU along with the HBM and NVRAM all together to form a “superchip” of a sort with incredibly high bandwidth and I/O communication between the data, the CPU, and the GPU."
...
"AMD believes that in the future workloads will become increasingly diverse and no one type of design would be able to attack every problem. “In the legacy world, the CPU was the center of everything.” Su said. But in the future heterogeneous architectures will take on a much more prominent role.
Su believes that there is a lot of opportunity in not only maintaining the rate of performance and efficiency but also accelerating the performance curve over the next ten years. “What I would like to say is that there is an opportunity to really bring in all of the conversation around 2.5D integration, 3D integration, multi-chip architectures, memory integration, and different types of memory so that we re-architect the system in a way that each of the components are able to get as efficient as possible.”"
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/4/
persze ettől nem lettünk okosabbak, de majd megátjuk milyen lesz a végleges Epyc ROME és az utódja.
szóval nem tudok semmit se ..
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#526
lezso6
HÁZIGAZDA
Petykemano
#523
válasz
Petykemano
#523
üzenetére
1000 mm2? Wat, mi annyi?
Ha csak cellát számolok, akkor ~75 mm2 512 MB eDRAM GloFo 14 nm-en, ami eléggé apró, a HD SRAM ugyanígy számolva ~350 mm2-re jön ki. De ezt persze valamivel vezérelni is kell meg kérdéses a buszszélesség is.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#528
 Simid
senior tag
Petykemano
#527
Simid
senior tag
Petykemano
#527
Simid
senior tag
válasz
Petykemano
#527
üzenetére
Ennek az eDRAM-nak mi lenne a funkciója amúgy? Értem én, hogy L4 cache, de miért érné meg ez egy CPU-nál? (Laikusként kérdezem, tényleg nem tudom)
A zeppelinhez képest nem csak a redundanciát kell szerintem figyelembe venni, hanem azt is, hogy ez egy jóval bonyolultabb IF, ami már 8 chipet képes összekötni. Gondolom ez nem kis különbség a korábbihoz képest.
-
#531
lezso6
HÁZIGAZDA
Petykemano
#527
válasz
Petykemano
#527
üzenetére
Kiegyenesítettem a perspektívából a legjobban sikerült Rome fotót simára. A nyáklap 58.5 mm × 75.4 mm, szóval pixel-arányból kiszámolható melyik lapka mekkora. Zeppelinre így 220 mm2 jön ki, szóval egész pontos.
Eredmény: egy Zen2 lapka ~75 mm2, az I/O lapka meg ~430 mm2.
Hely szintjén meg lehet spórolni gyakorlatilag elég sok mindent. Csak az Infinity Fabric, PCIE, DDR4 vezérlő szentháromságra van szükség. Előbbi kettő új, így nem tudni mekkora, utóbbi ismert csak, kb 60 mm2 + körítés lenne legalább.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#537
Simid
senior tag
Petykemano
#535
Simid
senior tag
válasz
Petykemano
#535
üzenetére
"zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés"Igen, ismerem ezt a grafikont. Pont ez az a rész amit nem értek. Ugye van egy 8MB-os rész ami gyorsan elérhető az adott CCX számára. Aztán van egy kevésbé gyorsan elérhető 8MB L3 (kvázi L4). És TR vagy EPYC esetében további 16/48MB L3 (kvázi L5) ami még ennél is lassabban elérhető.
Az Intel esetében az eDRAM a die-on volt, így gyorsan elérhető volt. Ilyen a Rome esetében úgy néz ki nem lesz.Továbbra sem kétlem, hogy egy L4 cache nagyon hasznos lehet szerver környezetben, főleg így, hogy a RAM elérés már minden esetben IF-el összekötött I/O die-on történik. De ez semmit nem fog javítani azon a problémán amit ez a lépcsős grafikon mutat nekünk. Egyszerűen megnövelik annak a cachenek a méretét ami lassan (de a rendszer memóriánál még mindig sokkal gyorsabban) elérhető.
Hogy röviden összefoglaljam, a közeli és gyorsan elérhető L3 hiányát nem lehet pótolni egy távoli és lassan elérhető L4-gyel. Gondolom ezért döntöttek a megnövelt L3 mellett.
"Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency."
Ez is megvan, de én úgy értelmeztem az előadásból, hogy ez nem fog változni a IF 2.0 esetében sem, csak szélesebb a link. Laikusként nézegetve az IF működését pl ezen leírás alapján nekem az jött le, hogy az SDF bár a mem órajelen üzemel a szinkronizáció miatt, de máskülönben független tőle. Ha ez nem így van és ténylegesen a rendszer memórián keresztül történik a kommunikáció, akkor máris értelmet nyer egy esetleges L4 cache.
-
#542
lezso6
HÁZIGAZDA
Petykemano
#541
válasz
Petykemano
#541
üzenetére
Szerintem semmilyen strukturális kompaTIBILÁTÁS nem kell, a lényeg a socket. Oprendszer felé úgyis egy processzorként látszik az egész, aztán úgyis kap másik drivert.
Érdekes a rajz, nagyon megy a spekuláció. Ha azt a 128 MB SRAM-ot rá tudta zsúfolni, akkor 512 eDRAM simán elfér, wikichip alapján egy eDRAM cella negyede sincs egy SRAM-énak a Glofo 14 nm-én.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#550
Petykemano
veterán
Petykemano
#549
Petykemano
veterán
válasz
Petykemano
#549
üzenetére
Ugyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
(A gput folytassuk a radeon találgatósban)[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#552
Cathulhu
addikt
Petykemano
#549
Cathulhu
addikt
válasz
Petykemano
#549
üzenetére
Az való igaz, hogy azt mondták az IF órajele azért szinkron a RAMmal, mert egyébként mindenféle cacheket kellene bevetni és ez megbonyolítaná a designt, de ha most lesz egy nagy L4, akkor az IF gyakorlatilag olyan órajelen üzemelhet amilyet csak fizikálisan elbír, a feladata az L3-L4 szinkronizáció lesz, ha jól sejtem. A nagy késleltetés meg részemről csak egy rossz előérzet.
#551 igen emlékszem, jól meg is mosolyogtam, de egyre inkább úgy érzem, hogy nem vicc. Még a végén eljön az Abu által évek óta mondogatott szoftver rendering korszak
[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#557
Cathulhu
addikt
Petykemano
#556
Cathulhu
addikt
válasz
Petykemano
#556
üzenetére
De nem úgy volt, hogy a PCI express marad a chipleteknél?
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#568
lezso6
HÁZIGAZDA
Petykemano
#567
válasz
Petykemano
#567
üzenetére
A Picasso csak egy ráncfelvarrt Raven Ridge lesz. A változás mindössze az energiamenedzsmentet érinti. Ez valamikor jövő év első felében fog érkezni, nagy eséllyel 12 nm-en, Zen+ alapon.
Lásd Raven Ridge, ami sima 14 nm Zen, de a Zen+ energiamenedzsmentjét kapta meg, és az idén februárban jött, pár hónappal a Zen+ magos processzorok előtt. Ez alapján a Picasso is ilyesmi hibrid lesz. Szerintem az IGP 1500 MHz körül fog ketyegni + natív DDR4-3200 támogatás.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#572
Cathulhu
addikt
Petykemano
#571
Cathulhu
addikt
válasz
Petykemano
#571
üzenetére
Furcsa amugy, pont az APU piac lenne ami fekszik az AMD-nek, megis ezerrel hanyagolja.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#590
lezso6
HÁZIGAZDA
Petykemano
#588
válasz
Petykemano
#588
üzenetére
Hát, ez van, akkor mégis 4+4. Bár igazából mindegy, a késleltetés a millió dolláros kérdés.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#594
S_x96x_S
őstag
Petykemano
#593
S_x96x_S
őstag
válasz
Petykemano
#593
üzenetére
>Az szerintem nem lesz, amíg az ARm ökoszisztéma nem gyorsulja le az x86-ot
Eddig a szoftveres támogatás volt a legnagyobb probléma, de ezek egyre inkább megoldódnak.
Hiába volt az ARMv8 -ha nem tudott optimalizált kódot generálni az a fordító. ( llvm, go, gcc )
Az opensource-os package-ket nem tudták kitesztelni, optimalizálni
- de most már egyre több Cloud-ban elérhető ARMv8-as gép
Ennek ellenére még most is előfordul, hogy 1-2 éves stabil linux rendszereket ( ubuntu 18.04 LTS) nem tudsz használni alapból - mert csak az ubuntu 18.10 -esen van lefordítva az adott package. ( ARMv8-ra !!! )
szóval konzervativ cégeknél ez már eleve probléma.
Persze ott vannak a pici málnás gépek, meg a klónjaik - vagyis egyre több fejlesztő tudja elérniMindenesetre ha a Windows-nak elterjed az ARM-es verziója, és lesz Windows server ARM-re is, akkor
az megint egy újabb lendületet ad.Az ARM lassan de biztosan erodálja az AMD64(X86) -os piacot.
megj: A ZEN-1 es szoftveres támogatás se ment olyan könyen, és a laptopokon még mindig kiforratlan.
Az AMD64(X86) - nem tökéletes de legalább kiforott, kevesebb meglepetés éri ott a felhasználót/fejlesztőt.
és ha az AMD olcsón tud ZEN -es csipeket adni, akkor az ARM-es erjeszkedés is lelassul.Mert az AMD versenytársa igazából a feltörekvő ARM (és az IBM-es Power) velük kell árban versenyeznie.
Ha olcsón tud hatékony teljesítményt adni az AMD a ZEN-es architektúrával, akkor ezzel le tudja lassítani az ARM-es szerverpiacot. ( de megállítani nem tudja )[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#596
lezso6
HÁZIGAZDA
Petykemano
#593
válasz
Petykemano
#593
üzenetére
Közvetlenül nem biztos, hogy nyomnák az ARM-ot, viszont customként eléggé rizikómentes, folyamatosan tejelő, Lisa Su kompatibilis biznisz lehetne. Ami tapasztalatot összeszednek IF skálázhatóság terén a Zennel, azt a K12-nél is tudják hasznosítani, ami igencsak ütőképes.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#605
Cathulhu
addikt
Petykemano
#604
Cathulhu
addikt
válasz
Petykemano
#604
üzenetére
Ezek ujabb vagy regebbi ARM szerverek?
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#607
S_x96x_S
őstag
Petykemano
#604
S_x96x_S
őstag
válasz
Petykemano
#604
üzenetére
>"The con: it's too damn slow. It does well on the Phoronix Test Suite.
>It does poorly benchmarking our website fully deployed on it (nginx + php + MediaWikiAzért találtam olyan teszt - amikor a legjobb ár teljesítményt nyújtja az ARM.
( Még az Intel és az AMD ellen is - AWS árakon )Persze a Rust"parallel Mandelbrot" - inkább kivétel, de egy jó fordítóval tényleg ki lehet hozni a maximumot az ARM-ből.
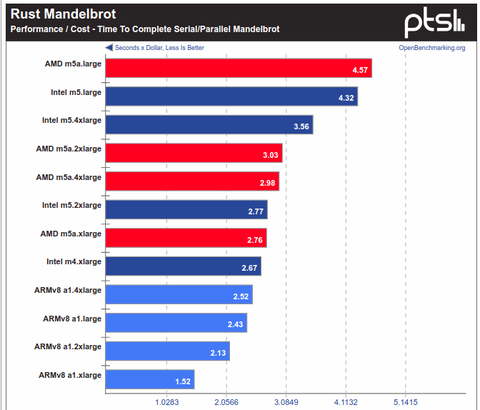
A Rodina v.2.4("OpenMP LavaMD") - tesztben meg az Intel-lel van (ár-teljesítmény) pariban az ARMv8 ,
nem véletlen, hogy az AMD-nak erősítenie kell az AVX2-ön.A PHP/Python -on teszteket meg bukta az ARM.
"The performance of the Graviton processors powering the A1 instances came up well short of the comparable M5 general instance types with either AMD EPYC or Intel Xeon processors. Even with the cheaper pricing, the performance-per-dollar was still generally just on-par with the equivalent or slightly better than the Intel/AMD offerings."
https://www.phoronix.com/scan.php?page=article&item=ec2-graviton-performance&num=5A mostani AWS-es ARM chipek tesztelésre jók - ez lesz a fő piac. A többi területen pedig csak kivételesen rughat labdába ( Mandelbrot
)visszatérve az AMD-re ; azért én látok egy erős fenyegetést az ARM-es vonalról.
jövőre jön ki az ARM Neoverse (Ares 7nm) -en
és
"The Neoverse war plan calls for server processors that will eventually scale up to 128 cores. Our guess is that Arm will use a multichip module approach that leverages the Cortex-A72 blocks to get 48 cores on a die at first, and then puts eight cores on a chiplet or chip block at first with “Ares” in 2019, then twelve cores per chunk with “Zeus” in 2020, and then sixteen with “Poseidon” in 2021, which also switches to 5 nanometer chip etching. Variants used in dataplane applications that have up to 256 cores eventually, which is interesting indeed."szóval nem lesz könnyű éve az AMD-nek jövőre.
Az ARM jön fel mint a talajvíz - és szintén a TSMC-vel gyártat.
https://www.arm.com/company/news/2018/10/announcing-arm-neoverseÉs kis szerencsébel még az Intel is kijöhet 2019 végén a saját 7nm-es termékeivel
"Intel is facilitating a 7-nm fab with EUV in Chandler, Arizona, now, but no production is expected until at least late next year. Even Intel’s current 14-nm yields are “above threshold but vary widely by product,” said Jim McGregor, principal of Tirias Research." (via)szóval nem fogunk unatkozni.
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#609
S_x96x_S
őstag
Petykemano
#608
S_x96x_S
őstag
válasz
Petykemano
#608
üzenetére
> ryzen3, pcie4 @ computex
Az új pcie4.0 -ás GPU-s kártyákhoz kell AM4-es alaplap is. Váható volt.
De ez valószínüleg megnöveli az alaplapok árát is.
Szerintem kb 30% -al drágább lesz az X570 -es alaplap a hasonló X470-es hez képest.Vajon a B550 -re lesz-e pice 4.0 támogatás?
------
Egyéb érdekesség:
- német Mindfactory Novemberi stat: ( 69% AMD - 31% Intel ( darabszámra ))
- AMD Athlon 200GE -et unlockolni lehet az új MSI biossal.
- AMD EPYC CPUs Grab 2 Percent Of 2018 Server Market, 7nm Zen 2 Rome Could Top 5 Percent In 2019
- Gigabyte H261-Z60 Server Review 2U4N AMD EPYC for Dense Compute - vagyis kezd beindulni a szerver támogatás ..
--- itt érdekesség: a CPU0-ra kötött majdnem összes háttértár lehetővé teszi az 1 CPU-s módot is."When it comes down to it, this is the dense platform you want to use. Using today’s AMD EPYC “Naples” gen1 parts, one can handle 256 cores, 512 threads, 8TB of RAM, 24x SATA SSDs, 8x M.2 NVMe SSDs, OCP networking, and still have room for 16x PCIe x16 half-length low profile cards. Intel platforms simply cannot match this. Indeed, we know the next-generation AMD EPYC 2 “Rome” will double this maximum core count so we will be looking at 512 cores and 1024 threads in a single 2U box. The current and next-generation of comparable Intel Xeon Scalable servers will be limited to 224 cores/ 448 threads and cost a lot more to get to that number. If you are looking for cost-effective compute density, the Gigabyte H261-Z60 is available today and has a bright roadmap.
Our biggest points of improvement would be that that the Central Management Controller continues to gain features. This would be an enormous benefit to the unit but it is an option we would love to see as it would be nice to login via a single management interface per chassis. This is still a great feature simply for reducing cabling. The other point of improvement is we want to see NVMe. Gigabyte launched the H261-Z61 variant of this server, which has that functionality built-in. Now the action would simply be to pick that SKU if you want more NVMe.
Overall, these high-density plays are awesome for virtualization clusters. There is a bigger implication though. Since all but one M.2 slot is accessible via CPU0, one can retain virtually all of the functionality using a single AMD EPYC processor. That means a 4x CPU, 128 core/ 256 thread 2U system is extremely affordable and offers a surprising amount of expandability in such a compact form factor."
Mottó: "A verseny jó!"








![;]](http://cdn.rios.hu/dl/s/v1.gif) ), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.











Új hozzászólás Aktív témák
- MacSzerez.com - iPad Pro 11" M2 / 4.Generáció / 128GB / Wifi / Asztro / Garancia!
- Eladó Philips TAB8505/10 soundbar, tökéletes állapot!
- ZOTAC Geforce RTX 3080ti Trinity OC
- LENOVO LEGION IDEAPAD Y520-15IKBN , i7 7700HQ , 1050 Ti , 12GB DDR4 , 128GB m.2 , 1TB HDD
- MSI STEALTH 16 Studio A1VGG. i9-185h - 64GB - 2TB SSD - 4070 8GB - közel 3 év gari - Win11Pro
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Ozeki Kft.
Város: Debrecen