Új hozzászólás Aktív témák
-

Simid
senior tag
Nem tegnap jutottak hozzá, hanem hónapokkal ezelött. Nem tudom mennyi pontosan egy gyártósor átállítás, de gondolom nem 3-4 hónap ha már van bejáratott termékük az adott node-on és csak a volument növelnék az új gyártókapacitással. Szóval elképzelhető, hogy lesz hatása a Q3-ra is.
-
Simid
senior tag
Ha 1Mrd nem is, de a saját prognózisuk szerint egy fél biztosan. Viszont lehet, hogy ennél is jobb lesz a bevételük, mert azóta hozzájutottak plusz gyártókapacitáshoz (Huawei, MediaTek) amikkel korábban nem számolhattak. Úgy néz ki az AMD mostanság mindent elad amit legyárt, kapacitás szűkében vannak és ezért csapnak le minden felszabaduló gyártósorra.
-
Simid
senior tag
Felejtsd el az előző két választ!

Ha kicsit belegondolsz, ezt egy cég sem tudja megtenni. Ha mondjuk egy 10Mrd$-os cég fel akarja vásárolni az összes saját részvényét, ahhoz kellen hogy legyen 10 milliárd dollárnyi vagyona (cash vagy egyéb pénzzé tehető eszköz). Viszont ha egy cégnek van ennyi vagyona, akkor biztos, hogy ennél sokkal többet ér, tehát nem tudja felvásárolni magát. Ha egy cég mégis csupán csak annyit ér mint az eszközei összesen (tehát nincs 'cégértéke') és ezt mind arra költi, hogy felvásárolja a saját részvényeit, akkor azzal felszámolja saját magát. Ez történik lényegében a vagyonfelosztással járó megszűnés esetén. -
#3887
Simid
senior tag
Petykemano
#3886
Simid
senior tag
válasz
 Petykemano
#3886
üzenetére
Petykemano
#3886
üzenetére
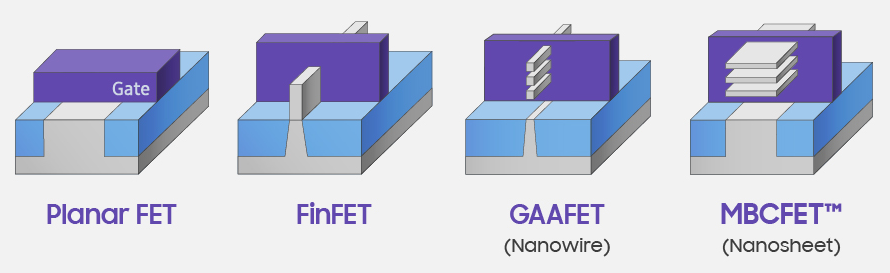
Ha jól értem ez a GAA egyik fajtája és először a Samsung fog előállni vele. Lehet csak arról van szó, hogy a TSMC-nek is sikerült olyan áttörést elérnie ami miatt ebbe az irányba megy.
-
#3842
Simid
senior tag
Petykemano
#3840
Simid
senior tag
válasz
Petykemano
#3840
üzenetére
Szerintem engedd el ezt az 'early 5nm' elképzelést, nem fog az jönni 2021H2 előtt. Az apple elviszi mind egyelőre, a high power verzió pedig nincs még tömeggyártásban úgy tudom.
A Warholról csak egy kétes eredetű kiszivárgott diáról tudunk, azon pedig 7nm szerepelt. Szóval ha úgy gondolod lesz Warhol, akkor fogadd el azt is, hogy 7nm-en jön. Az úgy nem működik, hogy egy adott leakből csak azt hisszük el ami tetszik.solfilo: Azóta már cáfolta a Sony.
-
Simid
senior tag
Pontosan! Ez a lényeg.
Folyamatosan ez a felvetés, hogy a monolitikus dizájnnal jobb lenne a késleltetés. De a rosszabb késleltetés a IF működéséből adódik. Az elektron ugyan olyan gyorsan fog haladni chipen kívül mint belül, a késleltetést az fabric controller fogja meghatározni, ami nagyon hasonló monolitikus felépítés esetén is. -
Simid
senior tag
Szerintem nem is az korlátozza most őket, hogy óvatosak voltak, hanem egyszerűen nem volt elég gyártókapacitás. Gyakorlatilag mindent eladnak amit legyártanak. A 3. negyedévben ugye jelentős gyártókapacitás bővülés volt a TSMC-nél (+Huawei kiesése), így júliustól az AMD a legnagyobb megrendelőjük. A negyedéves jelentésükben is komoly ugrást várnak árbevételben Q3-ra és Lisa Su még így is panaszkodott a szűkös gyártókapacitásra.
Szerintem ez az oka, annak is, hogy viszonylag hamar jönni fog az 5nm-es Zen4 meg RDNA3. Minél több gyártósort akarnak párhuzamosan kihasználni.Más:
Nagy a hurráoptimzmus: Bank of America believes AMD will be the next $100 billion chip company
Néhány perce ez be is következett. 100 milliárd USD felett járt a tőzsdei értékük. -
Simid
senior tag
válasz
 Cathulhu
#3626
üzenetére
Cathulhu
#3626
üzenetére
Értem, hogy miért írod azt amit, de ez maximum egy vérszegény B-tervnek jó.
A példádnál maradva, egyrészt még mindig annyi a kereslet a gumikacsákra, hogy egyáltalán nem fáj nekik, hogy diófa asztal az viszont nincs, mindent eladnak, sőt még kevés is a kapacitás. Persze ez hosszú távon nagyon megbosszulhalja magát, de szerintem nincs nagyon választásuk. Gondolj bele, hogy mi lett volna, ha azt csinálják amit írsz és 2 éve kiszervezik. Akkor az elmúlt 2 évben a kiszervezett gyártósorok 100%-kát le is foglalták volna, szóval nem bérgyártóként működtek volna. Vagy nem foglalják le mind, akkor viszont nincsen ekkora bevétel. Speciel ebben egyetértek Abuval, hogy rekord bevétel ide vagy oda, a háttérben már komoly probléma nekik, hogy melyik kezükbe harapjanak.
Az Intel évente több tízmillió CPUt ad el és nincs az a bérgyártó jelenleg aminek kapacitása lenne legyártani ekkora mennyiséget (versenyképes, 5-7-8nm-re gondolok most persze). Vagy kifejlesztik és kiépítik maguknak a gyártósorokat és akkor hülyék lesznek bérgyártásba kiadni vagy gumikacsát árulnak és akkor hosszútávon megszűnnek annak lenni, amik az elmúlt évtizedekben voltak."Az intel 10 es 7 nanoja se lenne rossz, ha nem az egyetlen megrendelojuk az intel lenne, lehetetlen elvarasokkal (10+ magos hatalmas monolitikus designok, 5+ GHz-ekkel)."
Ez csak feltételezés! Mi itt a fórumon sehogy sem fogjuk megfejteni, hogy egy több évtizedes múlttal, komoly szakmai tapasztalattal megáldott és bőséges anyagi forrással rendelkező cég miért nem tudja tartani a lépést. Az hogy mi csak annyit látunk, hogy szar a kihozatal és alacsony az órjel, az lehet hogy csak a jéghegy csúcsa. De igazából ez mindegy is! Ha tényleg diófa asztalt akarnak, akkor ahhoz az kell amiket felsoroltál. Gumikacsát azt tudnak sokan gyártani. -
Simid
senior tag
válasz
Cathulhu
#3622
üzenetére
Dehát most sem az a problémájuk, hogy nincs mit gyártani. A gyárkiszervezésnek szerintem két oka lehet. Vagy nincs elég pénz a fejlesztésre, vagy a kiépített gyártósorokkal nem tudják visszatermelni a költségeket. Az AMD-nél mindkettő fennállt annak idején, Intelnél egyik sem. Az a problémájuk, hogy nincs megfelelő technológiájuk és ezen a kiszervezés/bérgyártás nem fog segíteni.
Olvastam egy összehasonlítást múltkor a különböző félvezetőgyártókról. Az Intel kb 800.000wafer/hó kapacitással rendelkezik (ez szerintem 200mm equivalent). Nem tudom ebből mennyi lehet a 14nm és 10nm együtt, de gondolom több mint a fele és ezen még bővítettek idén. A TSMC teljes 7nm gyártókapacitása 140000wpm, most hogy duplázták 2020 H2-ben. Szóval ha az intel ekkora szereplő akar maradni akkor kell nekik a saját gyár, mert brutális mennyiségben gyártanak most. Ha nem lesz versenyképes technológiájuk, akkor hiába a rekord nyereségek, nem fogják tudni fenntartani a jelenlegi pocíciójukat. -
#3514
Simid
senior tag
Petykemano
#3513
Simid
senior tag
válasz
Petykemano
#3513
üzenetére
Ennek a gúnyos megjegyzésnek mi az előzménye?

Mondta korábban valaki, hogy értelmetlen az SMT4? IBM elég rég használ már 8 szálas SMT-t is. -
#3447
Simid
senior tag
Petykemano
#3446
Simid
senior tag
válasz
Petykemano
#3446
üzenetére
Mint laikus kérdem. Itt most mi a lényeg? A Bfloat16 támogatása? A100 is tud ilyet, AMD-nél gondolom a CDNA is fog tudni.
Abu két napja írt cikket az új Intel server procikról, abban is benne volt ez a dia. A kommentekben arra is válaszolt, hogy miért lehet ez jobb mint gyorsítót használni:"A memória a kulcs. Abból nagyon sok van a CPU mellett, és némelyik AI algoritmus sok memóriát igényel. De ha a munkafolyamatod befér egy gyorsító memóriájába, akkor arra kell menni."
-
#3441
Simid
senior tag
Petykemano
#3437
Simid
senior tag
válasz
Petykemano
#3437
üzenetére
Az alsó link pont arról szól, hogy konkrétan a Vermeer is idén jön.
-
Simid
senior tag
válasz
 solfilo
#3128
üzenetére
solfilo
#3128
üzenetére
Végülis igazuk van! Az intel már évek óra nem szivatja azzal a vásárlóit, hogy az újabb generációkkal elértéktelenítik a korábbi procikat...
Azért jó nagy idióták dolgozhatnak ott, ha szerintük az, hogy kiadnak alsóbb kategóriás termékeket kevesebb maggal az elismerése annak, hogy nem kell a több mag. Mintha azt mondanák az Nvidia az GTX1650 kiadásával elismerte, hogy az RTX tévút volt. -
-
#2518
Simid
senior tag
Petykemano
#2516
Simid
senior tag
válasz
Petykemano
#2516
üzenetére
Ez elég furcsa. A következtetést nem igazán értem. Idén biztos elstartolnak a konzolok és akkor már év közepétől gyártani kell a chippeket. Hiába jön előtte a ZEN3, akkor sem értem, hogy miért lenne kevesebb a semi-custom bevétel mint most. Esetleg az lehet, hogy a kifizetések elcsúsznak időben és csak jóval a szállítás és értékesítés után kapja meg az AMD a jussát. A ZEN 3 meg biztos nem jön Q4 előtt, ha már az AMD is ekkora jelzi a roadmapen.
-
Simid
senior tag
válasz
 S_x96x_S
#2217
üzenetére
S_x96x_S
#2217
üzenetére
"a várakozás mérő most 15%-nál tart ...
AMD: ZEN3 architecture finished – expects 15% faster IPC"Az idézett szöveg alapján nem azt mondta Norrod, hogy a ZEN3 ennyit hoz majd, hanem hogy a ZEN2 többet - az AMD szerint 15% - hozott mint amit várni lehetett volna egy továbbfejlesztéstől. A ZEN3 viszont annyit fog hozni, amennyit egy teljesen új archtól várnánk.
Persze ez még akár több is lehet mint amit a cikk sugall, de a lényeg, hogy a ZEN3 IPCről ennél konkrétabbat nem mondtak, a 15% egy félreértelmezés szerintem a guru3d-től. -
#2014
Simid
senior tag
Petykemano
#2010
Simid
senior tag
válasz
Petykemano
#2010
üzenetére
Sajnos sok szempontból elnagyolt a számolás (pl a tsmc-nek nyilván nem csak waffer eladásból van bevétele, a fejlesztési költségek is részben náluk csapódnak le). Viszont van egy tévedés benne, ami miatt amúgy is borul az egész számolgatás. A 29% HPC részarány nem a 7nm-re vonatkozik, hanem a TSMC összes bevételére. Annak csak egy töredéke az AMD.
-
Simid
senior tag
válasz
S_x96x_S
#1515
üzenetére
A közelgő újdonságokról árulkodnak az AMD kiszivárgott útitervei
"- Az az AMD dia, amire hivatkozol szintén leak volt. ( és belsős dia )"
Mindenbe bele lehet kötni ha nagyon akarsz. Szerintem hatalmas különbség van egy hivatalos AMD rendezvényről kiszivárgott (igen nagy valószínűséggel hiteles) dia és egy Jim szupertitkos forrása alapján összedobott álomtáblázat között.
Amúgy igazad van, leak volt. Itt már csak az a kérdés, hogy mi a francért adott valaki nagyobb valószínűséget az Adored leaknek mint az akkora már biztosra vehető AMD-s terveknek??-"- semmi sincs kőbe vésve. prioritások változhatnak, valamint nem várt problémák is sűrűn adódhatnak..."
Itt miről beszélsz pontosan? Nem várt problémaként kiadnak egy chipet amit nem is kezdtek el tervezni vagy mi? Nincs olyan, hogy változnak a prioritások meg újratervezgetünk és hirtelen lesz a semmiből egy új dizájn ami addig nem volt. Ha 2019-ben az AMD 7nm-es APU-t akart volna kiadni akkor az tuti, hogy rajta van a 2018 márciusi roadmapen. Ha előtte törölték az utitervből vagy csúsztatták, akkor meg tuti nincs ott egy 2018 végi leakben (már ha a leak valós terveket közöl ugye...). Szerintem ennyi!
Szerk.: Még annyit tennék hozzá, hogy ezt nem ilyen utólag okoskodásnak szánom. Egyrészt inkább már hanyagolnám a témát. Másrészt ugyanezt többen is elmondtuk még a CES előtt. Csak ugye az ilyen véleményeken csúnyán átgázolt a hypetrain....
-
Simid
senior tag
Jajj hagyjuk pls ezt az Adored leaket (már megint)!
Miről beszéltek egyáltalán? Hogy lehetett ez bármikor is valós terv?? Az APU SKU-k feltüntek nektek? Tényleg elhisszük, hogy 2018-ben (vagy akár 2017-ben) az AMD nem tudta, hogy milyen lapka tervezésében nem fogott bele?
Már lassan másfél éve tudjuk hivatalos AMD diákról, hogy nem lesz asztali 7nm-es APU 2020 előtt (talán ha minden jól megy mobil széria lesz év végén).
Világos, hogy minden leaket valószínűség alapon kell kezelni, csak nem mindegy hogy a leak közlője hogyan áll hozzá a dologhoz. Jimünk már az elején hangoztatta, hogy mennyire bízik a forrásában, aztán az első besülés (CES) után is erősködött, hogy jó az csak kicsit változott és tovább nyomatta a hülyeségeit. Ki az az idióta aki ezek után nem kérdőjelezi meg a forrást? Teljesen hiteltelen a srác.
A legnyagyobb baj, hogy elindított egy nagyon rossz trendet. Minden jöttment leakelget összevissza már. A Moore's Law is dead, Creoteks és társaik egymásra licitálva vlogolgatnak a fantazmagóriákról. -
Simid
senior tag
válasz
S_x96x_S
#1073
üzenetére
Azért adjunk már arra is némi esélyt, hogy az az álláspont igaz, ami Abu írt. Lehet tényleg a megnövekedett Rome kereslet miatt csúszik.
Szerintem sem nyírja ki a TR-t egy 16 magos Ryzen 3000. Kevésbé lesz kelendő a mostani a széria az biztos, de a TR esetleges előnyei nem csak a magszámból adódnak.
-
Simid
senior tag
válasz
joysefke
#1056
üzenetére
A pozitív megvilágítást én itt csak arra értettem, hogy a chiplet nyújtotta nagyobb mozgástér a külső szemlélő számára bizonytalanságot vagy kapkodást sugallhat. Lisa Su szerintem az év elején még azért nem mondta ki, hogy lesz 16 magos Ryzen mert élni akartak azzal a lehetőséggel, hogy erről csak később döntsenek és nem azért, mert ez volt a B terv ha gyászosak az órajelek.
Persze ez csak tippelgetés részemről is. Nem azt zárom ki, hogy rosszabbak lehetnek az órajelek mint várták, hanem azt kétlem, hogy ezen múlna részükről a 16 magos verzió.
A GloFo-val kapcsolatban nem mondanám tökölésnek, akkor sem ha tényleg ők a szűk keresztmetszet. Egyszerűen csak lehet, hogy nem megoldható részükről, hogy gyorsan átállítsák a gyártósorokat más termékekről IO die gyártásra.
Egy teljesen légből kapott példa:
Korábban teljesen logikusnak tűnhetett, hogy minden fullos 8 magos chiplet menjen EPYC-be meg TR-be mert ott hoz a legtöbb profitot, a desktopot meg elindítják 6-12 magos darabbokkal a hibás, de még használható chipletekből összerakva.
De ha a Rome esetében olyan megrendelések jöttek be az utóbbi időben, amik elsősorban az olcsóbb kevesebb magos, de körítés szempontjából verhetetlen (PCIE4.0, brutál cache, 8 csatornás mem., CCIX stb.) SKU-kra mutattak igényt, akkor pont az lenne a logikus lépés amit most látunk. Csúsztatják a TR-t így az I/O die mehet EPYC-be, a jobban sikerült 8 magos chipleteket pedig bevetik mainstream vonalon és jöhet a 16 mag. Cserébe a 6-8 magos verziókat (már azokat amik 2+1 die-ból épültek volna fel) szintén csúsztatják és a CPU chipletek mehetnek EPYC-be, a Matisse I/O meg ugyanúgy fel lesz használva csak 16 magos kiszerelésben, nagyobb profittal.
Most persze nem állítom, hogy ennek bármi köze lenne a valósághoz. Csak azt szeretném érzékeltetni, hogy pont az ilyen legózás és utolsó pillanatos variálás lehetősége az egyik nagy előnye a chiplet felépítésnek. -
Simid
senior tag
válasz
joysefke
#1053
üzenetére
Szerintem egyszerűen a chipletes sakkozásból adódik ez a bizonytalanság. Ezt most pozitív értelembe írom (AMD szemszögből), mert a megjelenés előtt sokkal tovább várhatnak ki és variálhatnak még akkor is, amikor egy monolitikus felépítés esetében már erre nem lenne lehetőség.
-
Simid
senior tag
válasz
joysefke
#999
üzenetére
"Pont ennek nincsen szerintem értelme.
Miért adnának egy 250$-ért -ennyi most a 2600X- egy nyolc magos ZEN2-t, ami a 9900K-val van pariban."Valahogy ez az érvelés nekem nagyon ismerős az elmúlt két évből.
Az első széria megjelenésénél is sokan jöttek azzal, hogy ha 6800K teljesítményt tud, akkor nem fogják lényegesen olcsóbban adni. Aztán kevesebb mint fele volt az ára még a 1800X-nek is.
De a 2700X esetében is ez volt mikor jöttek az első pletykák a $300-os árról.Persze a dolog itt most annyit változik, hogy ez lehet az első AMD proci széria tizenpár év után, ami minden szempontból jobb lehet(!) az Intel ajánlatánál. Illetve az sem mellékes, hogy mostanra a Ryzen mint márkanév is jelent valamit.
Ezzel együtt is úgy gondolom, hogy az AMD-nek csak akkor érdemes emelni az árat (magszámra vetítve), ha kapacitás korlát miatt így is el tudják adni azt amit legyártanak (vagy mert annyira drága gyártani, hogy csak így éri meg...). Ha van elég kapacitás, akkor alacsony árakkal kell küzdeniük mostmár nem csak az Intel mindshare-rel, hanem saját korábbi kiváló ár/érték arányú ajánlataikkal is.
-
Simid
senior tag
Válasz ERRE a hozzászólásra.
"Ez a kiskapu neked is adott: ha nem pont annyi a frekvencia és nem pont annyi az ár, akkor máris mondhatod, hogy mekkora hazugság volt az egész, miközben egészen addig azzal érveltél, hogy cégek az utolsó pillanatig nem tudják maguk sem, hogy mivel fognak piacra lépni."
Na akkor el is jutottunk a lényeghez! Ilyen esetben számomra egy több mint fél évvel a megjelenés előtt kiszivárgott AMDs tervezet pont annyit ér mint egy okosan megszerkesztett fake leak. Pont azért mert utólag nem igazán lehet küldönbséget tenni a kettő között. Ha egy belsős info is annyit változhat fél év alatt, hogy kb semmi nem pont úgy lesz, akkor engem nem érdekel, hogy amúgy igaz-e vagy sem. Hangsúlyozom, hogy ez az ilyen esetekre vonatkozik, amikor pontos árakat meg spect közölnek ennyivel előre.Korrekt, hogy leírtad amiket kértem!
 A kiegészítésekkel is egyet tudok érteni. Most már csak az a kérdés, hogy ebből mi nem volt ismert tavaly amikor az ominózus Adored videó megjelent? Kb csak a megjelenési dátum, de azt is belehetett volna lőni, hogy legkorábban tavasz. Ezért érthetetlen számomra, hogy az amúgy elég precíz, részletes és AMDs nyilatkozatokat rendszeresen idéző/elemző Jim miért nem említette meg a videójában, hogy amúgy a leak számos ponton ellentmond mindannak amit az AMD kommunikált vagy a korábbi gyakorlatnak. Szerinted miért nem tette? (tudom, később a magyarázkodós videóben már előjöttek ezek is...)
A kiegészítésekkel is egyet tudok érteni. Most már csak az a kérdés, hogy ebből mi nem volt ismert tavaly amikor az ominózus Adored videó megjelent? Kb csak a megjelenési dátum, de azt is belehetett volna lőni, hogy legkorábban tavasz. Ezért érthetetlen számomra, hogy az amúgy elég precíz, részletes és AMDs nyilatkozatokat rendszeresen idéző/elemző Jim miért nem említette meg a videójában, hogy amúgy a leak számos ponton ellentmond mindannak amit az AMD kommunikált vagy a korábbi gyakorlatnak. Szerinted miért nem tette? (tudom, később a magyarázkodós videóben már előjöttek ezek is...)Még annyit, hogy szerintem jelenleg több okból is okos húzás lenne az AMD szemszögéből ha kezdetben csak 12 magig mennének el. Persze ezt kizárólag a cég szempontjából gondolom, nem felhasználói szempontból.
-
#788
Simid
senior tag
Petykemano
#787
Simid
senior tag
válasz
Petykemano
#787
üzenetére
Nagyon szeretnéd látom ha menthető lenne a csatorna renoméja, de ez a hajó már elment (legalábbis a decemberi leak kapcsán).
Ez egyértelműen az adored leak másolata. Hozzáadták a 10%-os árrésüket és átváltották saját valutára.
Alsó hangon is 3 hónapra vagyunk a megjelenéstől. Tényleg elhiszi valaki, hogy egy szingapúri kisker teljes árlistát kap ennyivel előre?Legalább vették volna ki a listából leginkább hiteltelenítő Navi IGPs APUkat.... Azokról kb biztosan lehet tudni, hogy ebben a formában idén nem lesznek.
-
Simid
senior tag
Miért ennyire egyértelmű mindenki számára, hogy a külön I/O die érezhetően nagyobb késleltetést okoz? Próbáltam nemrégiben utánanézni az IF működésének és az elég világosan kiderült, hogy ha ZEN magokról van szó, akkor a a CCX-ek mindig IF-en keresztül csatlakoznak a többi részegységhez. legyen az IMC, PCIE vagy egy másik CCX. Így van ez a Zeppelin, a Raven Ridge, a Naples és a Rome esetében is. Miért nem mindegy, hogy a dieon belül van-e vezetékezve, vagy azon kívül, ha a sávszél ugyanaz? Az elektronok tudtommal fénysebességgel haladnak, szóval az a pár centi pikosecundumokban mérhető különbséget jelent csak.
A TR esete azért nem jó példa itt, mert ott sem a távolság a gond, hanem az, hogy darabokban van az I/O és az azt kezelő fabric is. Tehát a fabric részeknek (SDF/SCF plane) kommunikálni kell egymással majd a hozzájuk tartozó CCX-szel. Becsapós, ha a fizikai kiépítést nézzük, mert abból valóban úgy tűnik, hogy az egyik lapka közvetlenül csatlakozik a másikhoz, de - az ábrák alapján amik az IF működését magyarázzák - a magok szintjén nem ez a helyzet.
A Rome esetében nem tudni, hogy van, de elég valószínű, hogy azért van külön I/O die, hogy az egész egyben lehessen és azt azt összekötő fabric is egységes legyen. Gondolom ha a Ryzen esetében is külön lesz az I/O, akkor ugyan ez lesz a lényeg ott is.
Mit gondolok rosszul?
-
#621
Simid
senior tag
Petykemano
#620
Simid
senior tag
válasz
Petykemano
#620
üzenetére
Fogalmam sincs, hogyan működik a gyártósorok átállítása egy másik dizájnra, de gondolom nem 2 hét. Arról sincs semmi infonk, hogy egyáltalán a yield, a gyártókapacitás vagy maga a termék véglegesítése (nem tape outra gondolok, hanem sorozatgyártásba kerülő steppingre) a szűk keresztmetszet. Lehet ha a világ összes gyártókapacitása a rendelkezésükre állna akkor sem tudnák előbb kiadni. Na meg ott van a kérdés, hogy egyáltalán ugyanazon a gyártósorokon készülnek-e a mobil lapkák mint a ZEN2.
-
Simid
senior tag
válasz
S_x96x_S
#618
üzenetére
Pedig ez is csak felesleges hypekeltés. Miért nem hiszünk inkább az AMDnek? Olyan szerintem még sosem volt, hogy direkt negítív irányba kamuztak volna. Már pedig azt elég világosan közölték, hogy a megjelenési sorrend EPYC-RYZEN-NAVI és még a Romera is csak annyit közöltek, hogy valamikor 2019. Akkor miért várunk itt januárban (meg mostmár decemberre...) bejelentést?
Én legkorábban májusra várnék 7nm-es Ryzent. Ezt arra alapozom, hogy a 2000-s széria szerintem akár jöhetett volna hamarabb is, azért lett így időzítve, hogy fél úton legyen a ZEN1 és a ZEN2 között. Tehát 13 hónap legyen a generációk között. Akkor is max pár high-end SKU.
-
Simid
senior tag
"...meg lehet spórolni egy IF utat a másik processzorlapkához, feleződik a késleltetés... Ugye az eddigivel ellentétben az I/O lapkás megoldás annyiból fájó, hogy 2x kell átmenni az IF-en a másik oldalra."
Na erre írtam azt korábban, hogy nem tudom honnan jön a feltételezés, hogy így működik. Kiindulva a korábban linkelt NVSwitch működéséből (ahol 16(!) GPU tud kommunikálni egymással, úgy hogy bármely kettő esetében elérhető a max sávszél és a min a késleltetés) itt sem tűnik lehetetlennek egy olyan összeköttetés kialakítása amiben két CCX (most feltételezem, hogy egy 8 magos die az egy CCX) ugyan olyan gyorsan éri el egymást mint bármi mást az I/O dieon belül, még úgyis, hogy egymással nincsenek közvetlenül összekötve. Fizikailag persze ez az ember benyomása, hogy ez két lépcsős folyamat, de az adat a vezetékben fénysebességgel megy szóval az a pár centi nem fog számítani, hogy die-on belül vagy kívül.

Innentől meg csak topológia kérdése, hogy hogyan működik.
(Mondjuk tényleg borítja az egész okoskodást, ha a lapkák még egymással is direkt összeköttetésben vannak.)"Mivel elvileg 64 MB L3 lenne egyenként mind a 8 lapkában, ezért legalább 512 MB-os L4 kell, hogy ez működhessen."
Nekem az utolsó infóm (pletykák) az, hogy 256MB L3 van összesen tehát 32MB van egy lapkában.
De még ez is brutál nagy lenne és kell hozzá ugye egy nem kicsi vezérlő. Ez a legfőbb kételyem a nagyméretű L4 cache-sel kapcsolatban. 8 DDR4 vezérlő, 128 PCI4.0 lane, fullos SB és egy felhizlalt IF van abba az I/O dieban, ha emellé még beraktak több száz MB L4 cachet akkor minden elismerésem nekik. -
#537
Simid
senior tag
Petykemano
#535
Simid
senior tag
válasz
Petykemano
#535
üzenetére
"zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés"Igen, ismerem ezt a grafikont. Pont ez az a rész amit nem értek. Ugye van egy 8MB-os rész ami gyorsan elérhető az adott CCX számára. Aztán van egy kevésbé gyorsan elérhető 8MB L3 (kvázi L4). És TR vagy EPYC esetében további 16/48MB L3 (kvázi L5) ami még ennél is lassabban elérhető.
Az Intel esetében az eDRAM a die-on volt, így gyorsan elérhető volt. Ilyen a Rome esetében úgy néz ki nem lesz.Továbbra sem kétlem, hogy egy L4 cache nagyon hasznos lehet szerver környezetben, főleg így, hogy a RAM elérés már minden esetben IF-el összekötött I/O die-on történik. De ez semmit nem fog javítani azon a problémán amit ez a lépcsős grafikon mutat nekünk. Egyszerűen megnövelik annak a cachenek a méretét ami lassan (de a rendszer memóriánál még mindig sokkal gyorsabban) elérhető.
Hogy röviden összefoglaljam, a közeli és gyorsan elérhető L3 hiányát nem lehet pótolni egy távoli és lassan elérhető L4-gyel. Gondolom ezért döntöttek a megnövelt L3 mellett.
"Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency."
Ez is megvan, de én úgy értelmeztem az előadásból, hogy ez nem fog változni a IF 2.0 esetében sem, csak szélesebb a link. Laikusként nézegetve az IF működését pl ezen leírás alapján nekem az jött le, hogy az SDF bár a mem órajelen üzemel a szinkronizáció miatt, de máskülönben független tőle. Ha ez nem így van és ténylegesen a rendszer memórián keresztül történik a kommunikáció, akkor máris értelmet nyer egy esetleges L4 cache.
-
Simid
senior tag
válasz
Cathulhu
#533
üzenetére
"egyrészt a nagy L4-be prefetcher sokkal nagyobb szeleteket tud betölteni mint L3ba"
Erről fogalmam sincs, szóval elhiszem.
"másrészt így mind a 64 mag között lesz egy nagy közös cache, nem csak CCX páronként."
Úgy tudom az első gennél is megosztott az L3. Fizikailag persze szét van szórva, de legalább az adott CCX gyorsan hozzáfér a saját szeletéhez.Hogy kicsit magam ellen is beszéljek. A több cache nyilván mindig jó, csak nem mindenhol éri meg. Az I/O die cachenek meg van az az előnye, hogy szabadon variálható a különböző termékkategóriákra. Desktopra/HEDT-re úgyis más I/O kell majd valószínűleg. Ha a CCX-ek mellé rakják nincs meg ez a rugalmasság.
-
Simid
senior tag
válasz
Cathulhu
#530
üzenetére
Oké, értem én, hogy úgy általában mi a gyorstárazás előnye. Akkor pontosítok kicsit: Mi értelme egy IF-en keresztül elérhető L4 cachenek ebben az esetben?
Itt most lehet én értem félre az IF működését (illetve erről az új fajtáról nem sokat tudunk), de a probléma eddig az volt, hogy vagy a CCX saját cache-ben volt az adat vagy az IF-en keresztül kellett azt bekérnie, ahol viszont a többi CCX L3$ adataihoz is hozzáfér. Most ez annyit változott, hogy már a RAM hozzáférés is minden esetben IF-en keresztül történik, cserébe nagyobb a cache és szélesebb lett egy-egy IF link.
Ebből nekem az jön le, hogy bármit is csinál az I/O die, azt IF-en érkező utasítások alapján csinálja. Egy itt elhelyezett nagyméretű cache is csak az IF-en keresztül lesz hozzáférhető és semmivel nem lesz gyorsabb mint egy másik CCX L3$-éhez való hozzáférés. Akkor viszont felmerül a kérdés, hogy ha már több cachet szeretnének, akkor miért nem a CCX mellé rakják azt? Így legalább az adott CCX gyorsan érné el, de a többinek is gyorsabb lenne mint a RAM. Persze, értem én, hogy 7nm vs 14nm és SRAM vs eDRAM, szóval rohadt drága lenne. De az sem mellékes, hogy így legalább több die-on lenne elosztva egy hatalmas tömb helyett és ez viszont költség csökkentő tényező.
Lehet pont ezért duplázták meg a magonkénti L3 mennyiségét, mert hasonló módon gondolkodtak.Ha jól értem, ti azt feltételezitek, hogy az I/O die-on keresztül elérni egy másik lapkát nem olyan közvetlen elérés mint most a zeppelin esetében, hanem valami két lépcsős folyamat (CCX-I/O majd I/O-CCX). Így valóban lenne értelme a két lépcső közé cachet rakni. Én viszont úgy képzeltem ezt (megintcsak laikusként, lehet teljesen hibásan), hogy az I/O die egy IF switch, hasonlóan mint az NVSwitch. Ebben az esetben az IF-en keresztül bármi elérhető közvetlenül és így késleltetés szempontjából az hogy I/O die-on lévő L4 vagy egy másik CCX L3-a, az tök mindegy.
-
#528
Simid
senior tag
Petykemano
#527
Simid
senior tag
válasz
Petykemano
#527
üzenetére
Ennek az eDRAM-nak mi lenne a funkciója amúgy? Értem én, hogy L4 cache, de miért érné meg ez egy CPU-nál? (Laikusként kérdezem, tényleg nem tudom)
A zeppelinhez képest nem csak a redundanciát kell szerintem figyelembe venni, hanem azt is, hogy ez egy jóval bonyolultabb IF, ami már 8 chipet képes összekötni. Gondolom ez nem kis különbség a korábbihoz képest.
-
Simid
senior tag
Ha már témánál vagytok.
-
Simid
senior tag
Az árához képest elég jól teljesít.
-
Simid
senior tag
Érdemes elolvasni a hozzászólásokat, látszik, hogy a srác hozzáköltött dolgokat ("It is only my assumption based on what has been said about Kaby Lake clock levels.") Azt sem tudja, hogy tényleges tesztpéldányok alapján csiripelt-e a 'kismadár'.
Gondolom amit ő hallott az csak a KL szintű órajelekre és az annál 2-3%-kal nagyobb IPC-re vonatkozik (ami mellesleg szerintem teljesen hihető és elfogadható adat lenne). Az utolsó sor a konkrét adatokkal csak az ő tippje ezen infok alapján, legalábbis a kérdőjel erre utal.
A 7nm node várható javulásairól meg annyit, hogy ezek az adatok amik a diákon szerepelnek csak speciális feltételek mellett valósulnak meg. Például a 2X power efficiency gondolom csak a feszültség/órajel görbe egy optimális pontján lesz igaz és mondjuk csak SRAM cellák esetében. A szerver CPU-kat próbálják erre a pontra belőni; kiindulva a 64 magos EPYC pletykából ez akár meg is lehet.
Az IPC javulást meg úgyis architektúrából kell hozni, itt szerintem teljesen reális, hogy az első nagyobb fejlesztés hoz 8-10% pluszt. -
#344
Simid
senior tag
Petykemano
#343
Simid
senior tag
válasz
Petykemano
#343
üzenetére
"Please note that actual wafer starts per month (WSPM) output of a fab depends on multiple factors, including process technologies used. As a result, all the WSPM capacity numbers are relative and may not reflect actual performance. Keep in mind, that as foundries and IDMs increase usage of multi-patterning techniques, their effective WSPM output drops as wafers spend more time in the cleanroom. Hence, to keep the wafer starts per month capacity, chipmakers need to add equipment (which may, or may not, involve physical expansion of the cleanroom space)." by Anandtech
Gondolom ez lehet az oka.
-
Simid
senior tag
Szerintem asztali RR csak a felsőkategóriás Ryzen 2000-ek megjelenése után lesz. Mivel a 2000 szériába tartoznak (legalábbis a mobil verziók elnevezése alapján), így nem hiszem, hogy az alsóbb szegmenssel indítanának. Meg amúgy is úgy tűnik, hogy a gyártókapacitás szűkös. Amíg nem tudnak eleget gyártani mobil fronton addig nincs okuk sietni vele.
-
Simid
senior tag
Ha csak nincs architektúrális akadálya akkor elég furcsa lenne ha nem lenne tiltott verzió. De szerintem később még natív két magos lapka is lesz. Különben elég nehezen fogják felvenni a versenyt mobil fronton. Ott még intel sem ad 15W-on négy magot. Nem tudom AMDnek erősebb IGP-vel és feltehetőleg kevésbé jó processel miért menne.
-
Simid
senior tag
A Raven ridge alapú APUkból tuti lesz i3 ellen valami, tekintve hogy a legerősebb a legjobb esetben is a skylake i7 ellen mehet (de inkább i5 lesz az). Persze ez még valószínűleg több mint egy év mire vágott RR APUt kapunk desktopra. Addig nyilván próbálják elszórni a Bristolt.
-
-
Simid
senior tag
Azt vedd bele, hogy ezek átlag eredmények, tehát benne vannak gondolom olyan programok amik 1-2 szálat terhelnek csak és ilyenkor pl a 6900K 4Ghz-ig tud turbózni. Szóval ennyit illene a Summit ridgenek is elérni, különben az összegző grafikonokon (ami alapján a legtöbben besorolják) nem fog olyan jól mutatni, hiába lesz hasonlóan erős munkára.
Illetve az erősebb APUknál is kulcsfontosságú lesz az órajel. -
Simid
senior tag
Nem nagyon értem ezt a számolást.
Tudjuk hány magos ES ez? Azt lehet tudni Aots hány magig skálázódik?
Ha 4c/8t akkor 22%-kal alacsonyabb órajelen kb 13%-kal lassabb mint a Haswell -> Elég jó!
Ha 8c/16t akkor meg kérdés a skálázódás, de akár az is lehet, hogy -> Nagyon gyenge! -
Simid
senior tag
Érthető és jogos is amit írsz, csak valahogy itt is más az elmélet és a gyakorlat. Jól hangzik, hogy hozzáértő emberek szakmai keretek közt megvitatják a dolgokat, de a valóság az, hogy a szakik egymásközt sosem elemezgettek ott. A topik amióta csak követem arról szólt, hogy kevésbé hozzáértők találgatásait, számolagatásait, félreértelmezéseit javítják ki vagy véleményezik. Ha megnézed például az említett AIDA fejlesztők hozzászólásait, az igazán értékesek szinte mind reakciók az ilyen kevésbé kompetens megnyilvánulásokra vagy szimpla válaszok az olyan laikus érdeklődők kérdéseire mint amilyen én is vagyok. Ezért is kedvelem nagyon az olyan emberek hozzászólásait, mint Fiery. Mert tudom hogy nem vaktába beszél mégis veszi a fáradságot, hogy magyarázzon olyan dolgokat is amiről esetleg már többször volt szó korábban és az ő szemszögéből talán triviális.
Ezzel szembe a topicgazda mit tett hozzá a fórumhoz? Gúnyos, fenyegetőzős, kioktató hozzászólások között nagyritkán belinkel valamit....A vadhajtások és eltévelygések kezelésére meg bőven elég lett volna az is, amit pl te is csináltál párszor: röviden rámutatni miért értelmetlen a felvetés vagy miért nem oda való a téma. Számomra ezek a hozzászólások is érdekesek voltak sokszor.
letepem: Teljesen egyetértek!
-
Simid
senior tag
Pont ezért gondolom, hogy polaris nehezen lesz az NXben ha az idén jelenik meg. Nem vagyok ebben járatos, de tudtommal egy konzolhoz jóval a megjelenés előtt már kész fejlesztői kitek kellenek. Amihez meg a véglegeshez nagyon hasonló hardver.
Mindegy is, kár ezen rugózni, szerintem kamu a hír.(#40) Petykemano: Erről van szó! Ebből az AMD jelenlegi helyzetét nézve 1. és 5. ami reális. Egy XV+Poláris(szerű) megoldás esetében meg devkithez lehetne nagyon hasonló 28nanos Carizzo szerű hardvert adni, a megjelenésre meg jönne a 14nanos alacsonyabb fogyasztással magasabb órajel stb. (ez lehet hülyeség így, nem tudom).
-
Simid
senior tag
Azért egy meglévő architektúrát nem olyan egyszerű átdobni más processre. 28-14nm elég nagy ugrás, visszafele meg aztán pláne nem fog menni. Ha polaris-t 14nanora lett tervezve akkor az még részleteiben sem fog jönni 28nm-en.
Szóval vagy nem APU és tényleg ilyen PC szerű lesz (ami jó nagy fail egy konzolnál...) vagy nem 14nano vagy nem idén jön.Valdez: Azt még el tudnám képzeli, hogy ha amúgy is kellett egy Nintendos megrendeléshez akkor átrakták XV 14nanóra és Bristol is ezen jön. Erre viszont Abu azt írta nem jöhet azon, mert nincs kész a HDL 14nm FinFetre. Na de a Polaris akkor, hogy készül? Ha annak jó a HPL akkor egy kisebb APUnak miért ne lenne jó?
-
#32
Simid
senior tag
Petykemano
#30
Simid
senior tag
válasz
Petykemano
#30
üzenetére
Ezért nem tudom hova tenni, mert jövő tavaszig nem igen lesz Zen APU. Viszont nem gondolnám, hogy APUn kívül más szoba jöhetne manapság egy konzolban. De ha már polaris és 14nm akkor XV vagy cats sem nagyon jöhet szóba.
Furcsa, hogy még találgatásokat sem láttam mi lehet a polaris mellett. -
#29
Simid
senior tag
Petykemano
#28
Simid
senior tag
válasz
Petykemano
#28
üzenetére
Ezt nem igazán tudom hova tenni. Mikor fog megjelenni ez az NX? Nem lehet hogy Zen alapú lesz a CPU rész? Ha 14 nanon készül akkor mi értelme lenne korábbi uarchot átvinni erre a processre ha már van újabb?
Szerk.: Most nézem graphics cardot írnak. Létezik, hogy nem APU lesz?












 A kiegészítésekkel is egyet tudok érteni. Most már csak az a kérdés, hogy ebből mi nem volt ismert tavaly amikor az ominózus Adored videó megjelent? Kb csak a megjelenési dátum, de azt is belehetett volna lőni, hogy legkorábban tavasz. Ezért érthetetlen számomra, hogy az amúgy elég precíz, részletes és AMDs nyilatkozatokat rendszeresen idéző/elemző Jim miért nem említette meg a videójában, hogy amúgy a leak számos ponton ellentmond mindannak amit az AMD kommunikált vagy a korábbi gyakorlatnak. Szerinted miért nem tette? (tudom, később a magyarázkodós videóben már előjöttek ezek is...)
A kiegészítésekkel is egyet tudok érteni. Most már csak az a kérdés, hogy ebből mi nem volt ismert tavaly amikor az ominózus Adored videó megjelent? Kb csak a megjelenési dátum, de azt is belehetett volna lőni, hogy legkorábban tavasz. Ezért érthetetlen számomra, hogy az amúgy elég precíz, részletes és AMDs nyilatkozatokat rendszeresen idéző/elemző Jim miért nem említette meg a videójában, hogy amúgy a leak számos ponton ellentmond mindannak amit az AMD kommunikált vagy a korábbi gyakorlatnak. Szerinted miért nem tette? (tudom, később a magyarázkodós videóben már előjöttek ezek is...)




Új hozzászólás Aktív témák
- G.SKILL Trident Z5 RGB 32GB (2x16GB) DDR5 6000MHz CL36 - XMP - 99 hó garancia
- G.SKILL Trident Z RGB 32GB (2x16GB) DDR5 6600MHz CL34 - XMP - 99 hó garancia
- G.SKILL Ripjaws M5 RGB 32GB (2x16GB) DDR5 6000MHz CL30 WHITE - XMP - 120 hó garancia
- CRUCIAL 32GB (2x16GB) Pro OC DDR5 6400MHz CL32 WHITE - XMP/EXPO - 120 hó garancia
- Kingston FURY Beast 32GB (1x32GB) DDR5 6000MHz CL36 - WHITE - XMP/EXPO - 120 hó garancia
- Honor 400 Lite / 8/256GB / Kártyafüggetlen / 12Hó Garancia
- Eladó szép Nokia 7 Plus 64GB / 12 hó jótállás
- Akciós kisWorkstation! Dell Precision 3570 i7-1255U 4.7GHz / 16GB / 512GB / Quadro T550 4GB FHD 15"
- KÉSZLETKISÖPRÉSI ULTRA GIGA AKCIÓ! CTO 0perces SKY MacBook Air 15" M4 10C/10G 16GB 1000GB 1 év gar
- Vadiúj VGA-k!! Kamatmentes részletre is! Érdeklődj!!!
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest