Új hozzászólás Aktív témák
-
#3468
 Petykemano
veterán
Petykemano
#3368
Petykemano
veterán
Petykemano
#3368
Petykemano
veterán
válasz
 Petykemano
#3368
üzenetére
Petykemano
#3368
üzenetére
Tévedtem.
Az AMD a 4800HS-re kihozta, hogy ez már most 31x energiahatékonyabb.
Van egy remek Anandtech elemzés.
De a lényeg, hogy nem úgy számolják a 25x efficiency értéket, hogy a bázishoz képest 25x nagyobb teljesítmény azonos fogyasztás mellett. Hanem ez a 25x a teljesítmény - lényegében bármilyen (legkedvezőbb) TDP mellett és az ehhez a TDP-hez tartozó idle fogyasztás együttes szorzatának optimuma."Overall AMD has achieved a 5.02x performance gain with a 6.33x idle efficiency, which the company is wrapping up into a combined 31.77x performance efficiency metric."
Találgatunk, aztán majd úgyis kiderül..
-
#3469
 solfilo
veterán
Petykemano
#3468
solfilo
veterán
Petykemano
#3468
válasz
Petykemano
#3468
üzenetére
Hú ez így eléggé mellbevágó elsőre, meg talán másodikra is.

Az elemézést köszi!solfilo
-
#3472
solfilo
veterán
Petykemano
#3471
válasz
Petykemano
#3471
üzenetére
Arra tippelnék, hogy kitalálták ezt a hatékonyságnövekedést, mint reklámfogást, s hogy jó megdöbbentő legyen már az igéret is, ezt az utat választották, de szerintem is szimpibb és érthetőbb lett volna az az irány, amit írtál.
[ Szerkesztve ]
solfilo
-
#3487
 olymind1
senior tag
Petykemano
#3486
olymind1
senior tag
Petykemano
#3486
olymind1
senior tag
válasz
Petykemano
#3486
üzenetére
Végülis ha átállnak erre a gyártásra, akkor a processzorjaikban a SoC-ot és a chipkészleteiket is alacsonyabb fogyasztásúvá és hőtermelésűvé tehetik, mégjobban odavágva a konkurenciának

-
#3488
 S_x96x_S
őstag
Petykemano
#3486
S_x96x_S
őstag
Petykemano
#3486
S_x96x_S
őstag
válasz
Petykemano
#3486
üzenetére
> GF 12LP+ ; AMD vajon fogja használni valamire?
- 1600AFFFFFF

- ZEN3 I/O Die ???
( A Matisse I/O die 12nm "likely GlobalFoundries 12LP" )[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#3490
S_x96x_S
őstag
Petykemano
#3489
S_x96x_S
őstag
válasz
Petykemano
#3489
üzenetére
> És akkor gondolod a Vermeer erre várt?
nem tudom ...
ez már túl erős kijelentés lenne ..- még az se biztos, hogy a Vermeer ezt használja
- vajon a GF részéről ez egy paper launch -e
- mi volt az eredeti GF roadmap-en, amit az AMD-vel kommunikáltak.de nem is zárom ki
... annyira nem lennék meglepve, hogyha kiderülne, hogy mégis 12LP+de most még nincs elég infó.
nem tudom.

Mottó: "A verseny jó!"
-
#3514
 Simid
senior tag
Petykemano
#3513
Simid
senior tag
Petykemano
#3513
Simid
senior tag
válasz
Petykemano
#3513
üzenetére
Ennek a gúnyos megjegyzésnek mi az előzménye?

Mondta korábban valaki, hogy értelmetlen az SMT4? IBM elég rég használ már 8 szálas SMT-t is. -
#3516
joysefke
veterán
Petykemano
#3515
válasz
Petykemano
#3515
üzenetére
Különös, hogy senki sem őrjöng, hogy az SMT4-nek SHEMMMI értelme!!!
Hát például azért mert a kutyát nem érdekli az ARM és kb senki sem gondolja, hogy belátható időn belül egy két speciális területtől eltekintve alternatívája lehet az x86-nak.Én pld az sem értem, hogy "Az AMD CPU-k jövője, amit tudni vélünk" topikban miért az ARM a fő téma, vagy hogy egyáltalán hogyan kerül ide az ARM.
-
#3519
S_x96x_S
őstag
Petykemano
#3515
S_x96x_S
őstag
válasz
Petykemano
#3515
üzenetére
> Ezzel együtt persze érdekelne is, hogy milyen architekturális különbség
> állhat a háttérbenszoftveres oldalról - hogy a 128 thread .. mögött SMT2 vagy SMT4 van annyira nagy különbség nincs ..
- vannak jól párhuzamosítható feladatok ..
- és vannak rosszul párhuzamosítható feladatok,
- és vannak régi - párhuzamosságra nem felkészített - szoftverkódok ..Az új programozási nyelvek - pl. GO - egész új szemléletmódott hozott be - viszonylag egyszerűen implementálva az alkalmazásfejlesztésnél ..
https://divan.dev/posts/go_concurrency_visualize/
ha jól megírom .. ami nem nehéz a csatornákkal ... akkor akár >4096 mag-ig is automatikusan skálázza magát ..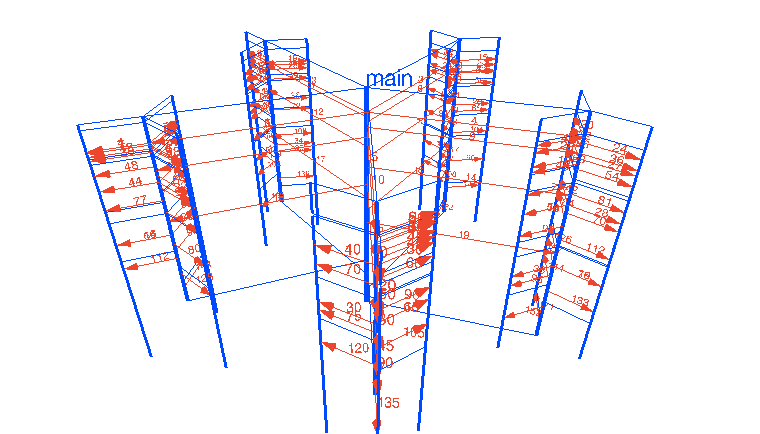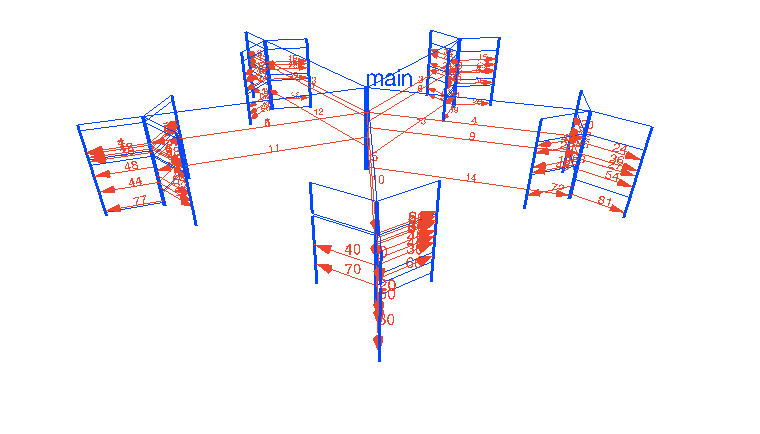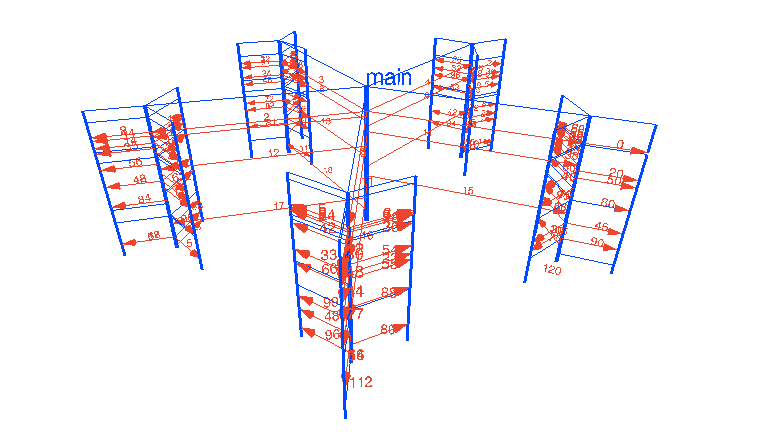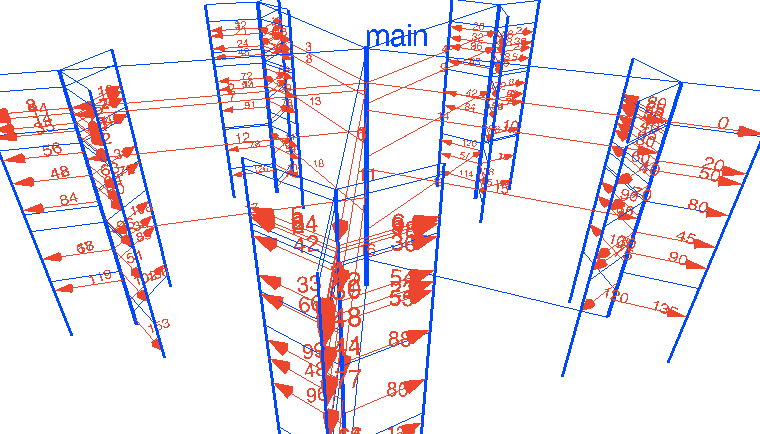
a webes feladok nagyrészt jól párhuzamosíthatóak ..
Mottó: "A verseny jó!"
-
#3527
 Devid_81
nagyúr
Petykemano
#3526
Devid_81
nagyúr
Petykemano
#3526
Devid_81
nagyúr
válasz
Petykemano
#3526
üzenetére
Ez nagyon erdekes, foleg ha nem csak egyetlen tudja 1000db-bol
Az a kerdes mennyire lesz ez elmaradva a cache kulonbsegek miatt a "nagytesoktol"?
Ha jol ertem a 4X00G procikban egyetlen cpu die van van es nincs I/O, avagy a latency is maskeppen alakulhat a tobbitol.
Mindenesetre varjuk sok szeretettel ezeket, meg a mai teszteket az XT-krol...
-
#3530
Devid_81
nagyúr
Petykemano
#3529
Devid_81
nagyúr
válasz
Petykemano
#3529
üzenetére
Minden tech review-ban lehuzzak, de igazuk is van.
Teljesen felesleges volt az egesz.
Az aruk is borzalmas, mar ugyis mindenki a regi X-esekhez fogja viszonyitani.
Angliaban pl: 3600XT £249, 3800X £279, 3800XT £399...
Ebbol nem adnak el sokat, mindenki a regieket fogja vinni, azokhoz legalabb jar huto is.
...
-
#3536
 Busterftw
veterán
Petykemano
#3535
Busterftw
veterán
Petykemano
#3535
Busterftw
veterán
válasz
Petykemano
#3535
üzenetére
Szerintem egymast kannibalizaljak a piacon.
Az desktopon/HEDT/szerver szegmensben elerheto sok mag es hasonlosag miatt osszefolyik a paletta. -
#3537
 Cathulhu
addikt
Petykemano
#3535
Cathulhu
addikt
Petykemano
#3535
Cathulhu
addikt
válasz
Petykemano
#3535
üzenetére
mindenki intelt vesz
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#3543
S_x96x_S
őstag
Petykemano
#3541
S_x96x_S
őstag
válasz
Petykemano
#3541
üzenetére
> Mit gondolsz, a Ryzen 4000 PRO és a hagyományos asztali verzió együtt rajtol?
nem tudom ... még a Threadripperes WS -t emésztem

... vagy kamu ... vagy sikerült a szivárgást kiküszöbölnie az AMD-nek ..és ha nincs szivárgás ... minden váratlan és meglepő ...
amúgy örülnék neki, ha minél több mindent piacra nyomnának ..
Mottó: "A verseny jó!"
-
#3546
S_x96x_S
őstag
Petykemano
#3545
S_x96x_S
őstag
válasz
Petykemano
#3545
üzenetére
> A józan ész persze azt mondatja az emberrel,
> .... a 8chTR most kerül a piacra, akkor a zen3 még biztos jó messze van.kivéve, hogyha Lenovo exclusive - mint ahogy pletykálják pár napja ..
( kisebb legelő == kisebb piac ; de a tehenek száma ( Lenovo ) is kevesebb == 1 )
és ha kisszámú is ... azért vannak olyan ügyfelek, akiknek ez megéri már most ..."This is also a major hint as to the availability of the 3995WX. It won't surprise us if the processor will be an OEM-exclusive (if not a Lenovo-exclusive). The Threadripper PRO 3995WX, in addition to the Ryzen PRO feature-set, reportedly features an 8-channel DDR4 memory interface, doubling the memory bandwidth over that of the current retail-channel flagship 3990X."
https://www.techpowerup.com/269665/amd-ryzen-threadripper-pro-3995wx-to-debut-with-a-lenovo-workstationszerintem ez tipikusan az a "prémium" terület,
ahol akár már az új N7/LP12+ -on gyártott kis számú még ZEN-es Rome chipletes procikat ki lehetne nyomni a piacra ...de amúgy nem kell sok ..
- csak re-brandelnek egy High Freq -es 64 magos Epyc chipet ..
egy minden jóval ( hangchip; ) feltunningolt Epyc alaplappal ..most leggyorsabb EPYC: az EPYC 7H12 64c/128t
- Base FREQ 2.6 GHZ
- Max Boost Clock Up to 3.3GHzde a Threadripper™ 3990X ennél is többet tud , csak sajnos 4 csatornás.
- Base Clock 2.9GHz
- Max Boost Clock Up to 4.3GHzvan rá piac ..
Anandtech: " However, there are still markets that want high frequency components, and quite often users will look at consumer hardware, which doesn’t offer the trimmings of the enterprise world, such as ECC memory, RAS features, management, and high-speed IO. We’ve seen OEMs build servers on super rare ‘consumer-grade’ processors, like the auction-only 5 GHz 14-core parts that offer the peak of performance, but fall down on basic enterprise features, such as ECC memory."Mottó: "A verseny jó!"
-
#3548
 awexco
őstag
Petykemano
#3545
awexco
őstag
Petykemano
#3545
awexco
őstag
válasz
Petykemano
#3545
üzenetére
Lehet TR magas GHz-re Epyc meg alacsony fogyastásra van válogatva ?
Igy fura számomra a két kategória összemosása .I5-6600K + rx5700xt + LG 24GM77
-
#3552
 hokuszpk
nagyúr
Petykemano
#3544
hokuszpk
nagyúr
Petykemano
#3544
hokuszpk
nagyúr
-
#3553
awexco
őstag
Petykemano
#3550
awexco
őstag
válasz
Petykemano
#3550
üzenetére
Gondolom Amd úgy viselkedik mint egy kúrva .... felméri a terepet és a kuncsaftnak azt csinálja amiért fizetnek ...
I5-6600K + rx5700xt + LG 24GM77
-
#3556
S_x96x_S
őstag
Petykemano
#3555
S_x96x_S
őstag
válasz
Petykemano
#3555
üzenetére
> Egy pár mondatban összefoglalható, hogy mi az ellenszenv oka?
az én értelmezésem szerint a fragmentáció a legnagyobb problémája
.... a rengeteg AVX-512 variáció
https://en.wikichip.org/wiki/x86/avx-512#Implementation
... aminek nehéz a támogatása ...
meg összehasonlítva az ARM SVE2 -vel .. az AVX-512 .. gányolás...Az ARM-es SV2 bár késői szülés ... de alaposabban átgondolt mint az Inteles rögtönzés - és jobban skálázódik .. mobiltelefontól --- az ARM-es HPC -ig .. egy utasításrendszer ... amit bárhol lehet használni ...
későbbi e-mail -ben jobban kifejtette ...
-------------------------------
"Now, that said, do I hate MMX/SSE/AVX/AVX2 with the same burning passion as AVX512? No. Because there's a big difference between them.MMX/SSE was a first-attempt (plus fixes). The i387 was a particularly nasty thing to be compatible with anyway, it's entirely understandable why it was done the way it was done. In hindsight, maybe it could have been done better, but a "in hindsight" argument is always complete BS. So that's not a valid argument. MMX/SSE was fine.
AVX/AVX2 were reasonable cleanups and honestly, I don't think 256 bits is a huge pain even as a baseline. And Intel has been good about keeping AVX always there. Afaik, new CPU's really have gotten AVX reliably. So it hasn't been a fragmentation issue, and while I think it has the same state dirtying issue ("helper function using MMX instructions and saves/restores the instructions it modifies will be clearing upper bits in AVX registers and trashing state"), I think it was a fairly reasonable extension.
So again, AVX/AVX2 was fine. Was it "lovely"? No. But I think it's a reasonable baseline.
So what's different with AVX512?
One fundamental difference is that fragmentation issue. It came up before AVX512 was even out, with the failed multi-core Knights atoms having a completely different versions. But it's really been obvious lately, with even today, in CPU's being sold, it being a "marketing feature".
But the other - and to me really annoying - fundamental issue is "by now, you should have damn well have learnt from your mistakes".
Here, look at the real competition for Intel and x86 long-term: ARM. They had an equally disgusting and horrendously bad FPU situation originally. Yes, their FPU situation was differently bad from the i387, but the whole soft-FP vs VFP vs random other implementations was arguably worse than Intel ever had, even if at the time, you would find the usual ARM fanbois that made excuses for just how horrendous the situation was.
But then ARM got their act together, and NEON happened. I'd say that was roughly the equivalent to SSE, because I'll call the original mess of nasty shit comparable to the nofp/i387/IBM-mis-wiring-the-exception-pin/MMX era. The timing may not line up, but with NEON, ARM at least had gotten rid of their messy lack of standards, and I think it's fair to compare it to Intel and SSE conceptually.
So ARM did SVE, and I'll call that their AVX/AVX2. But now you see signs of differences. Part of it is just the name. "S" for "Scalable". ARM is starting to do something interesting and fundamentally different from what AVX was for Intel.
And then ARM designed SVE2, and again, let's see how it actually plays out in real life, but I think it has the potential to be their "AVX512 done right". And they designed it to have a reasonable downgrade/upgrade path, to be extensible, to do that masking and memory accesses etc that is so important for compilers to auto-parallelize.
Honestly, if I were into HPC and vectorization, I'd be all in on the ARM bandwagon.
As it happens, I'm not into HPC and vectorization, and it's possible that exactly because I'm not into it, I'm missing why SVE2 has some horrible problems. And I realize that AVX512 does some things that a very very very small minority of people care deeply about (I don't know why, but some people really love the shuffle instructions and will put up with absolutely anything if they get them).
So just as a bystander, I'm looking at AVX512, and I'm looking at SVE2, and I'm going "AVX512 really is nasty, isn't it"?
And by now it's the third big generation, and the "it wasn't clear what the right answer was" is no longer an excuse for doing things wrong. People knew that scaling up and down the CPU stack was an issue. This wasn't something where Intel couldn't have seen it coming - when Intel was designing AVX512, Intel was still trying to also enter the smartphone and IoT area.
Have I sufficiently explained why I absolutely despise AVX512?
And yes, maybe in five years, AVX512 is there everywhere and my fragmentation argument goes away.
Buy maybe in five years, SVE2 is everywhere too, and is happily working in cellphones and in supercomputers, and I think I won't be the only person in the room that says "AVX512 is a butt-ugly disgrace".
We'll see, even if it might take years. I'm happy to be proven wrong.
And I'm here for the heated technical discussion anyway. Tell me why I'm a pinhead and a nincompoop, and why SVE2 is so bad, and why AVX512 is clearly better.
Because this forum is about architecture design and implementation, isn't it? So I think it's very fair to put down that gauntlet: AVX512 vs SVE2. "Gong plays" - FIGHT!
Linus"
https://www.realworldtech.com/forum/?threadid=193189&curpostid=193248[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#3557
S_x96x_S
őstag
Petykemano
#3555
S_x96x_S
őstag
válasz
Petykemano
#3555
üzenetére
> Mármint az ARMos SVE - túl azon, hogy ott dinamikus/változtatható
> a bithossz - mennyiben jobb?
> az SVE-t az armos oldalon istenítik.
ARM-es oldalon nem kell újrafordítani a szoftvert ..
ha 2048 bitesre megírod .. mögötte a hardver lehet 128 vagy akár 2048 bites ..vagyis a következő öt évre a szoftvereket a hardver automatikusan skálázza ... nem lesz olyan mint az X86 -oldalon, hogy mindig újra kell fordítani az AVX-512 ... majd az AVX-1024 .. vagy az AVX-2048 -ra ...
és ez az Apple oldalon nagy előny ...
mert támogatni fogja az SVE2 -öt.lesz egy gyenge mag ... ami 128 bites hardverre fordítja a 2028 bites utasításokat ..
és lesz egy erős mag ... ami 1024 bites hardver ...
és ARM-es oldalon a kettő között egyszerű az átjárás .. szoftveres kompatibilitás megvan ... könnyű hibrid CPU -t összerakni.------------------------------------------
mig most az Inteles oldalon a Hibrid cpu-knál erős és a gyenge mag két külön implementáció hardveresen és szoftveresen .. a gyenge nem tudja az AVX-512 -öt .. emiatt az erősön is le kell tiltani
mivel fontos a homogenitás az utasításkészletben ...
... szívás és hajtépés ....
Ahogy az AT -irta
https://www.anandtech.com/show/15877/intel-hybrid-cpu-lakefield-all-you-need-to-know/5"
The hair-pulling out moment occurs when a processor has two different types of CPU core involved, and there is the potential for each of them to support different instructions or commands. Typically the scheduler makes no guarantee that software will run on any given core, so for example if you had some code written for AVX-512, it would happily run on an AVX-512 enabled core, but cause a critical fault on a core that doesn’t have AVX-512. The core won’t even know it’s an AVX-512 instruction until it comes time to decode it, and just throw an error when that happens. Not only this, but the scheduler has the right to move a thread when it needs to – if it moves a thread in the middle of an instruction stream, that can cause errors too. The processor could also move a thread to prevent thermal hotspots occurring, which will then cause a fault.There could be a situation where the programmer can flag that their code has specific instructions. In a program with unique instructions, there’s very often a check that tries to detect support, in order to say to itself something like ‘AVX512 will work here!’. However, all modern software assumes a homogeneous processor – that all cores will support all of the same instructions.
It becomes a very chicken and egg problem, to a certain degree.
The only way out of this is that both processors in a hybrid CPU have to support the same instructions completely. This means that we end up with the worst of both worlds – only instructions supported by both can be enabled. This is the lowest common denominator of the two, and means that in Lakefield we lose support for AVX-512 on Sunny Cove, but also things like GFNI, ENCLV, and CLDEMOTE in Tremont (Tremont is actually rather progressive in its instruction support)."
Mottó: "A verseny jó!"
-
#3560
S_x96x_S
őstag
Petykemano
#3559
S_x96x_S
őstag
válasz
Petykemano
#3559
üzenetére
> De miért ne lehetne az AVX512-t, vagy későbbieket olyanná "tenni"
majd valamit az AMD kitalál ...
de amúgy nincs könnyű helyzetben ...
ha meg teljesen új dolgot csinál .. akkor csak a fragmentációt növeli ..én amúgy az AMD helyében az APU-s dolgot erőltetném ...
vagyis az AVX-512 -es utasításokat valami belső fordító áttolja a GPU részre .. és ott hajtódnak végre. persze ez a gyakorlatban nem biztos, hogy optimális ...ami érdekes az Raja - OneApi -ja ... ami automatikusan osztja el a feladatot a cpu és a gpu között ... szerintem ez lehet az Intel "B" terve ... az AVX-512 mellett ...
és ne felejtsük el a fejlesztés alatt álló Centaur Technology -s CNS -core ... ami szintén az AVX-512 -es piacra pályázik ...
> hiszen az SVE2-ben ha jól értem az utasításkészlet megegyezik,
> és a hardver vektorhossz-képességével lehet szegmentálni.
> Az intel meg ezt összekötötteigen .. az én megértésem is hasonló ..
Az ARM kód binárisan ugyanaz ..
mig az X86( Intelnél) ... nem lehet tudni, hogy az 1024 bites utasításoknak mi lesz a kódja ..
a 2048-asokat meg végképp nem .lehet tudni ..
míg az új ARM-es hardvereket rögtön ki tudják használni a szoftverek ..
az új Inteles AVX-1024 -es kódnál ez nem igaz .. . hasonló mint most az AVX-512 ... kevés program használja ki .. kell új fordító támogatás ... stb ...
nehezebb a hibakeresés és a debuggolás is ...--------------------
amúgy ha valaki nem érti az avx-512 fragmentációt annak itt egy ábra ..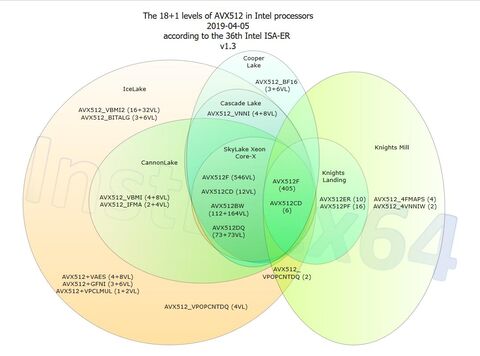
[ Szerkesztve ]
Mottó: "A verseny jó!"
-

Balala2007
tag
válasz
Petykemano
#3559
üzenetére
Van az AVX, AVX2, AVX256 és AVX512 között más különbség is, mint a vektorhossz?
Marmint
- a plusz 16 regiszter (4x regiszterter)
- a +8 kreg es maszkolhatosag
- a szinte teljes adatortogonalitas es konvertalhatosag
- a disp8 tomorites
- az implicit blending/zeroing
- az implicit broadcasting
- a ternlog
- a rotalas/v rotalas
- a 2-source crosslane permutaciok
- a compress/expand
- a full popcnt
- az 8x8bit affin transzformacio
- scatter/gather-en kivul?Egy rakas FP cucc, de azt most nem mondom el.
AIDA64.com
-
#3583
S_x96x_S
őstag
Petykemano
#3582
S_x96x_S
őstag
válasz
Petykemano
#3582
üzenetére
Amúgy az STH keresztelte el WEPYC-nek
https://www.servethehome.com/amd-threadripper-pro-is-a-workstation-epyc-or-wepyc/Mottó: "A verseny jó!"
-
#3594
S_x96x_S
őstag
Petykemano
#3593
S_x96x_S
őstag
válasz
Petykemano
#3593
üzenetére
nem tudom ... én is találgatok magamban ...
viszont találtam már rendelhető APU-kat .. árral ...
és valamiből 2 verzió is van ( MPK =?= dobozos )
https://prohardver.hu/tema/re_teritette_az_amd_az_asztali_ryzen_soc_apu-kat/hsz_29-29.htmlremélem ez alapján csak valami OEM-es szivesség .. és 1 hónapon belül mindenkinek elérhető.
Mottó: "A verseny jó!"
-
#3600
S_x96x_S
őstag
Petykemano
#3599
S_x96x_S
őstag
válasz
Petykemano
#3599
üzenetére
> Vajon miért most akar pénzt látni ebből a softbank?
Talán mert kompenzálni akarja a WeWork, Uber veszteségeket ..
https://www.bloomberg.com/news/articles/2020-05-18/softbank-vision-fund-books-17-7-billion-loss-on-wework-uberMottó: "A verseny jó!"
-
#3604
hokuszpk
nagyúr
Petykemano
#3599
hokuszpk
nagyúr
válasz
Petykemano
#3599
üzenetére
mert mar egy ideje valahog nem jonnek be a befekteteseik.
https://index.hu/gazdasag/2019/11/19/softbank_vision_fund_szon_maszajosi_masayoshi_son_kockazati_tokealap_startup_befektetesi_buborek/
Első AMD-m - a 65-ös - a seregben volt...
-
#3611
joysefke
veterán
Petykemano
#3599
válasz
Petykemano
#3599
üzenetére
Esetleg azért mert most még érthetetlenül magasan szárnyalnak a jövőbemutató techcégek a tőzsdéken (Apple, Ms, nv, Amazon) és ki akarják használni a hullámot?
-
#3622
Cathulhu
addikt
Petykemano
#3621
Cathulhu
addikt
válasz
Petykemano
#3621
üzenetére
en viszont azt mondom inkabb valasszak le (ahogy kellett volna mar 2 eve), mintsem adjak el a gyartosorokat (igy kinai vagy egyeb azsiai kezbe keritve) vagy szimplan par ev mulva leselejtezve. Mukodhetne a gyartas, ha nem csak az intel igenyeit kellene szem elott tartani
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#3646
Devid_81
nagyúr
Petykemano
#3645
Devid_81
nagyúr
válasz
Petykemano
#3645
üzenetére
Szvsz a Zen3 nem azert "kesik" mert nincs kesz.

Nincs nyomas alatt az AMD, hogy kiadja es raernek vele, plusz honaponta dobnak valami ujat a piacra, csoda, hogy gyozik amugy.
Viszont ha mar az 5nm-est tesztelgetik az nagyon jo jel, es innen is latszik akarmit ad ki az Intel az elkovetkezendo par evben arra lesz azonnal AMD valasz.
Nagyon ugy nez ki, hogy teljesen behoztak az egykori lemaradasukat, es mar egy ill. lassan ket lepessel a konkurencia elott jarnak...
-
#3647
S_x96x_S
őstag
Petykemano
#3645
S_x96x_S
őstag
válasz
Petykemano
#3645
üzenetére
töpreng ...
Az új APU 7nm-en 156 mm2 ( 8 core + GPU )
Ez alapján nem biztos, hogy APU ..A ZEN2 chiplet viszont az AT -szerint 74-80 mm2
"The Zen 2 design paradigm, compared to the first generation of Zen, has changed significantly. The new platform and core implementation is designed around small 8-core chiplets built on TSMC’s 7nm manufacturing process, and measure around 74-80 square millimeters."Viszont az AVX-512 -nek kell a hely
.. és amit megnyerünk a méret csökkentéssel - elveszítjük a fejlesztésekkel.Mottó: "A verseny jó!"
-
#3654
awexco
őstag
Petykemano
#3652
awexco
őstag
-
#3689
S_x96x_S
őstag
Petykemano
#3686
S_x96x_S
őstag
válasz
Petykemano
#3686
üzenetére
(ha lesz) akkor szerintem elsőként a monolitikus 5nm/3nm-es APU-kban lehet ilyen big-little felépítés.
Az ARM-es konstrukciók most kb >24h rendelkezésre állást tudnak,
az x86 ( AMD /Intel ) ennek a fele ...
És ki tudja, hogy a jelenlegi laptopok jövője mennyire van megszámolva .. lassan a telefonhoz elég egy kihajtható képernyő és egy kihajtható billentyűzet. a felhasználók nagy részének nem kell igazából laptop .. vagyis valamit lépni kell .. mert az X86 piac egyre zsugorodik ..és a szerver fronton is várható hasonló trend ..
Mottó: "A verseny jó!"
-
#3690
S_x96x_S
őstag
Petykemano
#3686
S_x96x_S
őstag
válasz
Petykemano
#3686
üzenetére
> De azt nem értem, hogy az AMD miért bontaná meg az egész jó,
> kompakt zen magokat, ...
> L2$ két különböző feldolgozó egységet tápláljon?
furcsa, .. az Intel -nél is valamifajta osztott L2 lehet ??
( lásd "1.5M L2" az ábrán )
( via )Mottó: "A verseny jó!"
-
#3696
awexco
őstag
Petykemano
#3695
awexco
őstag
-
#3702
solfilo
veterán
Petykemano
#3701
-
#3705
S_x96x_S
őstag
Petykemano
#3704
S_x96x_S
őstag
válasz
Petykemano
#3704
üzenetére
 Most van a "Hot Chips 32 held Sunday-Tuesday, August 16-18, 2020."
Most van a "Hot Chips 32 held Sunday-Tuesday, August 16-18, 2020."
Ma lesznek még érdekes előadások: https://www.hotchips.org/program/
- "AMD Next Generation 7nm RyzenTM 4000 APU"
( persze sajnos csak 1 AMD-s előadás .. )-----
> IBM Power10:
https://www.hardwareluxx.de/index.php/galerie/komponenten/prozessoren/ibm-power10-press-conference-deck.html
- PCIe 5 x64![;]](//cdn.rios.hu/dl/s/v1.gif)
Azért kíváncsi leszek, hogy az AMD-nek lesz-e PCIe5.0 -ja jövőre ..
( az IBM és az Intel is 2021 -re tervezi )Mottó: "A verseny jó!"
-
#3712
Petykemano
veterán
Petykemano
#3708
Petykemano
veterán
válasz
Petykemano
#3708
üzenetére
Alibaba azt állítja, a 12nm-es RISC-V procijuk gyorsabb, mint a 2017-es ARM A73
[link]Találgatunk, aztán majd úgyis kiderül..
-
#3714
S_x96x_S
őstag
Petykemano
#3712
S_x96x_S
őstag
válasz
Petykemano
#3712
üzenetére
Izgalmas időszak jön
> Alibaba azt állítja,
Hot Chips 2020 Live Blog: Alibaba Xuantie-910 RISC-V CPU (3:00pm PT)
https://www.anandtech.com/show/15991/hot-chips-2020-live-blog-alibaba-xuantie910-riscv-cpu-300pm-pt--------------
Viszont az XBOX chipje érdekes ... (főleg mivel AMD tervezés )
- N7 Enhanced-re irják .. lehet,, hogy a ZEN3-asok is ilyenek lesznek?
Hot Chips 2020 Live Blog: Microsoft Xbox Series X System Architecture"
Q:Coherency CPU and GPU?
A: GPU can snoop CPU, reverse requires softwareQ: TSMC 7nm enhanced, is it N7P, N7+, or something else?
A: It's not base 7nm, it's progressed over time. Lots of work between AMD and TSMC to hit our targets and what we neededQ: Says Zen 2 is server class, but you use L3 mobile class?
A: Yeah our caches are different, but I won't say any more, that's more AMD.Q: With 20 channels GDDR6, is that really cheaper than 2 stacks HBM?
A: We're not religious about which DRAM tech to use. We needed the GPU to have a ton of bandwidth. Lots of channels allows for low latency requests to be serviced. HBM did have an MLC model thought about, but people voted with their feet and JEDEC decided not to go with it."Mottó: "A verseny jó!"
-
#3720
Cathulhu
addikt
Petykemano
#3719
Cathulhu
addikt
válasz
Petykemano
#3719
üzenetére
Van Gogh is labeled with ‘CVML’ which probably means ‘Computer Vision and Machine Learning’. Thus, the series is likely to focus on an entirely different market than Cezanne.
Azert ez nekem fura. Ugyebar a Van Gogh az RDNA-s es a Cezanne a Vegas, viszont a ket architektura kozul a Vega van inkabb compute-ra kihegyezve. (nem is tudom RDNA-ra van-e egyaltalan ROCm, mivel nekem szemelyesen nem az van, igy csak a phoronix forumokrol remlik az allando nyafogas.
szerk: quick chek, igen az utobbi ROCm hirnel is a postok jo resze errol szolt, AMD reply:
"As with Navi we are already implementing, testing and upstreaming support in the lower level components - what is not being supported officially yet is the upper level components, primarily HIP and the libraries that run over HIP. OpenCL should be in pretty good shape already, and we are testing the lower level ROCm components in the AMDGPU-PRO packaged stack as a prelude to using them for OpenCL as well"
viszont a kovetkezo kerdes/valasz:
- What's really missing for me is ROCm support for Ryzen APUs (e.g. to be able to do development and testing with it on my notebook… even if I later use bigger machines with discrete GPUs to do the actual number crunching)
- Agreed, and I think it's fair to say that view is gaining broader acceptance internally.
Szoval osszegezve, se Navi support egyelore, se APU support (es ezekszerint hivatalosan tervben sincs), es igy akarnal 2021-ben egy ML APU-t kiadni? Good luck...[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#3721
hokuszpk
nagyúr
Petykemano
#3719
hokuszpk
nagyúr
válasz
Petykemano
#3719
üzenetére
egy jo Munkacsyt azert meg varnek toluk
Első AMD-m - a 65-ös - a seregben volt...
-
#3723
 Yutani
nagyúr
Petykemano
#3722
Yutani
nagyúr
Petykemano
#3722
Yutani
nagyúr
válasz
Petykemano
#3722
üzenetére
Úgy tűnik, hogy az AVFS csak egy bizonyos szintig képes finomhangolni a CPU-t. A CTR pedig kihozza még azt a kis pluszt, amit az AVFS benne hagy. Tehát az AVFS ilyen formán a "jó" szintet hozza, de nem a "legjobb"-at.
#tarcsad
-
#3726
 lezso6
HÁZIGAZDA
Petykemano
#3722
lezso6
HÁZIGAZDA
Petykemano
#3722
válasz
Petykemano
#3722
üzenetére
Wat?
Nem, nagyon nem...Gyorsan átfutva ez a CTR undervolting tuningprogram, míg az AVFS az órajelváltozásért felelős "algoritmus", ami figyelembeveszi a fogyasztást, környezeti hőmérsékletet, stb-t. A CTR nem az AVFS-t váltja ki, hanem csak megkeresi a legalacsonyabb feszültséget, s a nagy trükk az, hogy erre CCX-enként képes. Az undervoltinggal meg ugye javul a perf/watt arány, így pont az AVFS miatt gyorsul.
S ilyen eddig is volt, a lényeg, hogy ahol van AVFS (vagy hasonló rendszer), ott undervoltinggal tudsz gyorsítani a rendszeren, miközben a fogyasztás nem emelkedik. A CTR annyit változtat, hogy CCX-enként van undervolting, azaz finomabban be lehet hangolni az undervoltingot, azaz még több teljesítményt tud kivenni, mint egy sima unvervolting.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#3728
lezso6
HÁZIGAZDA
Petykemano
#3727
válasz
Petykemano
#3727
üzenetére
"Ha az AVFS levágja, hogy mennyire jó minőségű a chip, akkor azt gondoltam valahogy ezt az alapján teszi, hogy a frekvencia stabilitását figyeli adott feszültség mellett és ha instabil, akkor emeli a feszültséget."
Itt a keveredés, ilyen nincs, legalábbis nem abban a formában, mint egy kézi undervoltnál, amikor is rendesen stressz tesztelsz, s nem 1 percig, hanem órákig, vagy inkább napokig. Ráadásul ezek se feltétlenül biztos értékek, hanem mondjuk csak 99.99%, ami otthoni környezetbe oké, de új CPU-ként eladni nem. Meg ugye egyik CPU gyártónak sincs kapacitása ennyire rommáreszelni minden egyes legyártott CPU-ját, hogy mi a lehető legalacsonyabb feszültség, ahol még nem hibázik. Ezért marad benne tartalék, ezt tudod a CTR-rel kihasználni. Lásd még feloldható magos procik, csak ott durvább a nyereség.
Az AFVS lényege, hogy a konkrét környezeti változókat is figyelembeveszi, amire a DVFS nem képes. Ennyi, nem több. S akkor ebből következik az, hogy pl hűvösebb környezet (jobb hűtés) esetén gyorsabb a processzor.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#3730
S_x96x_S
őstag
Petykemano
#3729
S_x96x_S
őstag
válasz
Petykemano
#3729
üzenetére
érdekes .. köszi ..
----
Azon gondolkodtam,
( vagy csak most tudatosítottam )
hogy az L3 egységesítés ( 1x32Mb a 2x16Mb helyett )
az egyszálas teljesítménynek igencsak jó tesz ...
----
Míg a ZEN2-nél a csak 1-2 szálas programok max 16MB L3 cache-t tudtak kihasználni, a másik 16MB-L3 kihasználatlan volt.
A ZEN3-nál ez már duplázódik!
----
Ez alapján az egyszálas teljesítmény növekedés ~ nagyobb lehet mint a többszálas. ( A ZEN2-höz képest )
ami a játékoknál igencsak jól jön - az Intel ellen.
----
Remélem szeptember végén már lesz valami ZEN3-as "hivatalos" infó is az AMD-től.
( vagy hátha lesz valami bejelentés szeptember 7 -én ? )Mottó: "A verseny jó!"
-
#3732
Cathulhu
addikt
Petykemano
#3729
Cathulhu
addikt
válasz
Petykemano
#3729
üzenetére
Mindig ezzel az ARMhoz kepest kevesnek tunikkel jottok, mintha az ARM tempoja hosszu tavon tarthato lenne... Nagyon alolrol indultak, onnan konnyu 50%-okat hozni. Az ARM a 2010-es evek ota fejlodik ugy, mint az x86 a '90-es evekben. Lassan az is el fogja erni a hatarait, es a 10%-oknak is tapsolni fognak. Es van egy olyan sanda gyanum, hogy ez egybe fog esni azzal az idoszakkal, amikor vegre beerik az x86 teljesitmenyet. A fizikat nem lehet megeroszakolni.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#3733
S_x96x_S
őstag
Petykemano
#3731
S_x96x_S
őstag
válasz
Petykemano
#3731
üzenetére
> mit szólsz a Genoa listájába felkerülő NVDIMM-P-hez?
mivel az AMD a CCIX tagja is
és annak a spec-nek is része a perzisztens memória ..
szerintem akár már most is támogathatná - PCIe4.0 alatt.de amúgy jobb későn mint soha ..
@Pinky Demon:
> Mindig ezzel az ARMhoz kepest kevesnek tunikkel jottok,
mert tényleg kevés ..
.. az ARM-en a CCIX-es perzisztens memóriával nyomulnak. [1]
.. az Intelnek meg van egy 3DXP-je , ráér a szabványossal ;
.. Az AMD -nél meg nagy csend .. pedig igény lenne rá, és CCIX-esen már ő is támogathatná.
[1]
https://www.ccixconsortium.com/wp-content/uploads/2020/02/Lenovo-Arm-CCIX-MemExpan-ArmTecCon19.pdfMottó: "A verseny jó!"
-
#3735
Cathulhu
addikt
Petykemano
#3734
Cathulhu
addikt
válasz
Petykemano
#3734
üzenetére
Nem azt mondom, hogy sose lesz versenykepes, hanem azt, hogy kb ugyanoda fog eljutni mindketto. Raadasul nem egy teljesen mas szemleletu, vilagot esetlegesen a sarkabol kiforgato uj CPU elvekrol beszelunk, hanem a good old ARM, ami pont annyira hagyomanyos, mint az x86 (ott meg lattuk mire ment vele aki nagyot akart ujitani), szoval csodat nem varok. Ugyanott fogja vegezni mindketto elobb utobb. Lehet egyik oldaon neha szerencsetlenkedes, vagy epp nagyobb elorelepes, de hosszu tavon atlagban nem varok kulonbseget koztuk.
Az Apple azert rossz pelda itt, mert ok egyertelmuen a single core teljesitmenyre mentek ra. Egy 8 magos Zen2 3.9 mrd tranzisztorbol gazdalkodik, egy A13 pedig 8.5 mrd-bol. Ennek mondjuk tobb mint a fele a GPU es egyebek, de a CPU budzse hasonlo lehet (arra most pontos szamot nem talaltam), viszont annak meg joresze mindossze 2 magra oszlik, mig a Zen2-nel 8-ra. Igaza van az applenek amugy, mert kb ezek az igenyek azon a piacon es ahogy mondtad az nem a szerver piac. Szoval lehet az egymagos teljesitmenyt kigyurni, hogy bucira verje a jelenlegi desktopokat (1 magon) de ennek ara van, tranzisztorban es energiaban is, es itt megint csak azt tudom mondani, hogy a fizikat nem lehet megeroszakolni.
Szoval amig nem jon elo valaki egy radikalisan uj architekturaval (amit en nem varok ARM alapon) es mindenki a TSMC-nel gyartat, addig mindenki ugyanazt a keretet tudja majd felosztani. Az egyetlen elonye az ARMnak, hogy szabadon customizalhato, ha valaki szerver procit akar, ujat legozik ossze, ha valaki mobil procit, akkor olyat. Nem veletlen hogy a felhos cegek ugranak ra erre.Nuvia meg nagyon lutri. A szkeptikus enem azt mondja, lufi az egesz, kelti a hypeot, behuzza par eladhato nevvel a befektetok millioit, aztan elcsuszik a halalba es vegul emlekezni se fog rajuk senki. Annyi ilyet lattunk mar. Aztan lehet bejon az az 1% esely, hogy tenyleg valami nagyot alkotnak.
Egy szo mint szaz, amig az AMD tudja reszelgetni a Zent ciklusonkent 10-15%-al (ami ha sokaig ragaszkodik a Zenhez, lesz majd 5% is) addig jopar evig nem lesz felni valoja az ARMtol, mert mire azoknak is beernek az igeretei, addigra o is elorebb kerul. Az intel meg ennyi toketlenkedessel a hata mogott sincs igazan veszelyben egy x86 konkurenciatol, hatmeg egy teljesen gyerekcipoben jaro, alig ismert, validalatlan ARMtol (szerver piac). Itt az Amazon es tsai sajat procijai az egyeduli kihivasok, de azok nem az ARM mivoltuk miatt, hanem egyszeruen azert, mert akarmi is az, az Amazon inkabb azt fogja nyomatni (lehetne RISCV is)
apropo, ha egyszer vegre beindulna a RISCV biznisz, ott is jonnenek evrol evre az 50-100%-ok.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#3737
 paprobert
senior tag
Petykemano
#3736
paprobert
senior tag
Petykemano
#3736
paprobert
senior tag
válasz
Petykemano
#3736
üzenetére
"Feltételezem, hogy ha egy. Matisse ccd nem kéne 5ghz körüli értéket elérjen, kisebb is lehetne."
Ez egy érdekes felvetés, de szerintem pont hogy a szerver felhasználású frekvencia tartomány volt a target, és csak a piszok jó hardveres energia-mendzsmentnek és a boost algoritmusnak köszönhetően tudtak 4.5 környékére jutni.
Ezeket elhagyva valószínűleg lehetne kisebb, de többet ér így a termék, mivel a magas órajelre szükség van, és nem csak desktop környezetben.Az én olvasatomban a Zen nagyon sok szempontból a nagymacska mag családba tartozik, annak minden jó tulajdonságával, csak már nem ragad le 2.5 GHz-en.
640 KB mindenre elég. - Steve Jobs
-
#3741
Petykemano
veterán
Petykemano
#3734
Petykemano
veterán
válasz
Petykemano
#3734
üzenetére
A Marvell elkaszálta a ThunderX3-at, mint általános célú bolti terméket. Semi -custom módban viszik tovább.
Ennek szerintem kell köze legyen a konkurenciához, vagyis például a Milanhoz.
Találgatunk, aztán majd úgyis kiderül..
-
#3742
S_x96x_S
őstag
Petykemano
#3741
S_x96x_S
őstag
válasz
Petykemano
#3741
üzenetére
> ThunderX3
TLDR: nem mennek még át teljes pályás letámadásba ... fókuszálnak.
Amúgy tényleg nem könnyű ...
ráadásul a COVID miatt az OEM-ek átálltak kockázatkerülő módba,
és most nem annyira lelkesek egy ilyen pénzbe kerülő kalandhoz ;
ami vagy bejön vagy nem ...
de ha be is jön, akkor is a saját piacukat szegmentálják vele ..
Pár éve még elég volt az Intelt támogatni .. ami kényelmes volt.
Most bejött a képbe az AMD ...
És ez bekavar a cégen belüli méretgazdaságosságnak is, mert a piac annyira nem duplázódik.
És akkor most itt egy nem X86 alapú platform is ..."Although Arm and vendors have discussed cost benefits, it seems as though putting together a general-purpose Arm alternative to Intel Xeon/ AMD EPYC is not viable at this point. Arm vendors are effectively competing on cost with much lower volumes. That is the simple answer. The more interesting answer is that Arm is clearly winning in the data center, just in the less obvious segments." ( az STH-h linkből )
Fókuszálnak:
"Marvell .... effectively means they are still doing development where the customer is helping to fund the chip development. "De ami késik, az nem múlik ...
Mottó: "A verseny jó!"
























 Most van a "Hot Chips 32 held Sunday-Tuesday, August 16-18, 2020."
Most van a "Hot Chips 32 held Sunday-Tuesday, August 16-18, 2020."![;]](http://cdn.rios.hu/dl/s/v1.gif)



Új hozzászólás Aktív témák
- Vodafone otthoni szolgáltatások (TV, internet, telefon)
- nVidia tulajok OFF topikja
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- Vicces képek
- VR topik (Oculus Rift, stb.)
- ThinkPad (NEM IdeaPad)
- Fortnite - Battle Royale & Save the World (PC, XO, PS4, Switch, Mobil)
- Ukrajnai háború
- Milyen légkondit a lakásba?
- Visszavonta az Intel és a Qualcomm Huawei-hez kiadott exportlicencét az USA
- További aktív témák...
- MECHANIC PCB repair PAD - 2. generációs kialakítás
- DC csatlakozós ventilátor kábel - 1 utas vagy 3 utas változat
- ÚJ, bontatlan iPad PRO 13 (2024) M4 CHIP! 256GB WIFI asztrofekete, 1 év Apple garancia!
- Samsung Galaxy S22 Ultra 5G 256GB, Kártyafüggetlen, 1 Év Garanciával
- HP Victus 16-r1019nt - ÚJ 16" FullHD IPS GAMER notebook - i7-14700HX, 32GB, RTX 4070
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest