Új hozzászólás Aktív témák
-

S_x96x_S
addikt
> Az a kérdés, hogy saját Apple processzort meddig fogják (tudni) skálázni.
> Mert ez mégiscsak egy ARM. A mostani 10-15 wattos TDP-szint az elvileg
> már eléggé teteje az ARM-nak, tudják vajon ezt tovább tolni?
> Mert akkor lehet igazán veszélyes.
> De jelenleg "csak" az ultramobil piacon tűnik úgy, hogy tarolnak (perf / watt arányban).az arm már rég átlépett a veszélyes kategórián,
az ARM- ISA ( utasításkészlet szabadon licenszelhető ) - bárki bármilyen architektúrát mögé tud tenni.
#1. nyár óta a TOP500 HPC ( szuperkomp"ly"uterek)
listáját egy ARM alapú gép vezeti ( A64FX )
https://www.top500.org/lists/top500/2020/11/
SUPERCOMPUTER FUGAKU - SUPERCOMPUTER FUGAKU, A64FX 48C 2.2GHZ, TOFU INTERCONNECT D https://www.top500.org/system/179807/"Az ARM-alapú Fugaku fejlesztése 2014-ben vette kezdetét, a K computert idővel lecserélendő. A Fujitsu óriása 150 000 darab, 48-magos A64FX processzort állít csatasorba, melyek az Arm v8.2-A utasításarchitektúrára és 512 bites vektormotorokkal dolgozó SVE (Scalable Vector Extension) utasításkészletre építve 7 nanométeres node-on készülnek, 2 GHz felett ketyegő órajelekkel. A 8,786 milliárd tranzisztort tartalmazó lapkák HBM2 memóriát használnak a szokásos DDR interfész helyett, és a köztük való kapcsolat a Tofu interconnect nevű, háromdimenziós hálózati topológia révén jön létre."
https://prohardver.hu/hir/fujitsu_leszallitotta_fugaku_utolso_moduljait.html
A legrosszabb, hogyha az AMD alábecsüli az ARM felől érkező fenyegetést.
inkább becsülje túl - mint alul ... ( alá - Ballmer effect )amúgy most éppen a Patrick Moorhead-et ekézik - az M1-es review-ja miatt..
https://daringfireball.net/2020/12/m1_macs_truth_and_truthiness
"Moorhead’s review bears little relation to the reality of the M1 Macs, but plays right into expectations of the status quo. ARM chips are efficient and Apple’s ARM chips are the best, but none of them are a threat to Intel and AMD’s x86 chips for high-end performance."és gonosz módon felemlegetik, hogy mit irt, az A7 ( első 64 bites chipről )
“Adding 64-bit processor capabilities adds nothing to the user experience today, as it would requires over four gigabytes of memory,” Patrick Moorhead of Moor Insights and Strategy, and a former executive at AMD, told AllThingsD. “Most phones today only have one to two gigabytes of memory, and it will be years before the norm is four.”megj:
Patrick Moorhead - 2011-ben hagyta ott az AMD-t, (a stratégiáért felelt, de ő se láthatja a jövőt)
"Patrick departed AMD in 2011 where he served as Corporate Vice President and Corporate Fellow in the strategy group. There, he developed long-term strategies for mobile computing devices and personal computers. Moorhead also served in his 11 years at AMD leading product management, business planning, product marketing, regional marketing, channel marketing, and corporate marketing. Moorhead also worked at Compaq Computer Corp. during their run-up to the #1 market share leader position in personal computers. Patrick also served as an executive at AltaVista E-commerce during their search leadership reign, pioneering cost per click e-commerce models." https://moorinsightsstrategy.com/patrick-moorhead-3/ -
#4433
 Petykemano
veterán
lezso6
#4431
Petykemano
veterán
lezso6
#4431
Petykemano
veterán
Én nem úgy gondoltam az almás gép vásárlását, hogy arra felbarkácsolsz egy windows.
Hanem arra, hogy létezhet-e az a jelenség, hogy average joe dönt úgy, hogy a következő notebookja nem windows-os, hanem almás lesz. Főleg, ha ilyeneket hall, hogy gyorsabb is az almás, meg 2x annyu akkuidőt biztosít.Átmenet nyilván nem egyik napról a másikra történne meg. De az Apple példáját követhetik mások is, pl Qualcomm. Bár minden jel arra mutat, hogy az x86 limitáció nem könnyen átléphető kérdés, azért az Apple magjaiban is van munka.
Én egyébként azt gondolom, hogy 25W-nál tovább nem tudják tovább tolni a 4+4-es TDP-jét. Viszont az M1X 8+4-es simán lehet 35, vagy akár 45W-os is.
A rosetta2-re azt mondják egész jó. Én nem tudom.
#4432 solfilo
Ugyanilyen történeteket telefon témában hallottam évekkel ezelőtt Vett vki egy 60e Ftos Android készüléket: lassú, szar, fos
Aztán bement a boltba és vett egy - akkor még - 250eFt-os Iphone-t és elégedett volt. -
#3727
Petykemano
veterán
lezso6
#3726
Petykemano
veterán
Senki nem gondolta, hogy a CTR az AVFS-t váltaná ki.
A korrekt válasz az, hogy az AVFS olyan feszültség-frevencia páros beállítását lehetővé tevő algoritmus, ami figyelembe veszi a környezeti hőmérséklet és egyéb szempontokat. De nem feladata és célja az adott kröülmények között beállított frekvenciához a legalacsonyabb stabil feszültség megtalálása.
Anno innen olvastam: [link]
Ha az AVFS levágja, hogy mennyire jó minőségű a chip, akkor azt gondoltam valahogy ezt az alapján teszi, hogy a frekvencia stabilitását figyeli adott feszültség mellett és ha instabil, akkor emeli a feszültséget.
Ha erre képes, arra is képesnek kéne lennie, hogy csökkentse a legalacsonyabb stabil feszültségig. Ezt teszi a CTR is, nem?
És ha jól emlékszem végülis az AMD-nek is van valami Auto UnderVolt megoldása, bár az lehet, hogy csak a GPUknál.
Na de mindegy, ez egy régi vita.
-

Cathulhu
addikt
Az jo, hogy AVX2, de abbol nem a 256 bites utasitasok, az is zicher. Mondom, akkor a Zen2-nek a Zen/Zen+ duplajat kellene hoznia.
"The floating-point unit underwent major modifications in Zen 2. In Zen, AVX2 256 bit single and double precision vector floating-point data types were supported through the use of two 128 bit micro-ops per instruction. Likewise, the floating-point load and store operations were 128 bits wide. In Zen 2, the datapath and the execution units were widened to 256 bits, doubling the vector throughput of the core."
-
-
#2175
Petykemano
veterán
lezso6
#2173
Petykemano
veterán
Technológiai szempontból igazad van, de szeritnem ez árfüggő is.
Ha a Cascade lake X árban nem a 24-32 magos Threadripperrel versenyez, hanem az $500-$750 áras AM4-ekkel, akkor nyilván azokkal kell hasonlítani.
De ha ár alapján mondjuk a 18 magos intel egy szinten van a 24 magos TR-rel, akkor az összehasonlítás szerintem valós igényből fakad.Valós igény - mindkét megközelítés valós és lehetséges:
- azonos áron melyik jobb?
- Egy bizonyos teljesítményszintet hol kapom meg olcsóbban -
S_x96x_S
addikt
> habár a memória-csatornák száma ugye eltér,
> de pont ez lenne az érdekesmeg még ott van az AVX-512 ; ami érdekes lehet.
Ha AVX-512 -vel 4x akkora teljesítményt lehet elérni egyes ritka cél feladatoknál, akkor az AMD 2x CPU core-ja még mindig nem elég.persze ez spéci célterület.. és az árral is súlyozni kell az eredményt.
de ahogy látom az AT - hozzárakta az INTEL és az AMD HEDT vonalát is.pl-
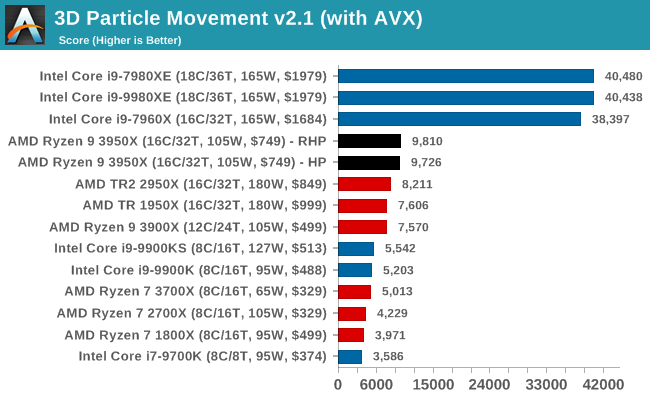
-
#1772
Petykemano
veterán
lezso6
#1770
Petykemano
veterán
aktív interposer, ami egyben IO lapka is.
rajta:
- 10 CPU die
- 4 HBM
?és jut-e ebből az AM4-re ?
Szerintem nem. Szerintem az AM4-re zen3 már nem jön. Meg fogjuk kapni a Ryzen 4K-t, ami egy zen2 refresh lesz.Ugyanakkor érdekes, hogy azt hiszem Papermaster azt mondta, hogy a Milan DDR4-et fog használni...
Egyébként most őszintén, ha a Vega56-ot megéri még $300-ért árulni, akkor ilyen árban már cpu mellé is kéne tudni pakolni HBM-t.
-
szerintem már pusztán a memóriavezérlő összevonásával kap egy UP-ot a TR platform, a magszám duplázás meg a másik UP... De az IPC is ilyen magszám esetén "megdobja" a teljesítményt (így akár a magszám duplázás is elhagyható lenne, akkor is hoznának egyes esetekben 50% teljesítmény többletet a 3. generációs TR cpuk, de leginkább sokkal kiegyensúlyozottabb lenne a teljesítményük)...
Szerintem memóriavezérlő duplázás nem lesz, csak magszám 48 és 64 magig.. TR4 be meg a zen3 magok miatti száll duplázás "vár".. asztali ryzen meg marad zen2 egy új steppingjén ami már a "második generációs TSMC DUV"-ján készülne, látszólag elegendő maradna a jelenlegi intel ellen de egy 10 magos CL refresh ellen is (max kicsit nagyobb órajeleket engednek majd ha felszabadul némi Epyc kapacitás a zen3 modellek miatt)...
Szépen "lassan" nagyobbra nyitják az ollót a HEDT és asztali cpuk között (szerintem).
5nm bevezetésével se kell rohanni amdnél ... pedig már jövőre is lehetne gyártani rajta, valószínű 1 évre rá már eleve a 2. generációs változatra épít majd belőle...
Intel erősen elbénázta látszólag a dolgokat, most érik be a pár évvel ezelőtti "tunyaság" ... bár ez átmeneti 2 nehéz év (lesz), azt meglátjuk majd az utódból náluk mi sül ki.
Ha az AMD a mostani kis "megszusszanással" nem "akad be" akkor izgalmas időszakok jöhetnek majd a következő "TIKK"-re (kb. egy időben jön elvileg mindkét vállalatnál) -

Devid_81
félisten
Max meg annyi, hogy HEDT 32 magig, UHEDT 64
Aztan ki tudja, meg a vegen ez is lehet, bar az Intelnek mar a mostani TR-re sincs valasza, szoval ezek utan 2x-esen nem lesz valaszuk
Ezzel csak az lesz a baj mint a VGA piacon ami kialakult, hogy az egyetlen versenyzo kedvere arazhat, es az altalaban nem szokot jol sikerulni
Aztan meglatjuk, lehet az lesz, hogy az X570-es kap egy price cut-ot es felere csokken, es X590 lesz az ami arban atveszi a helyet...nah szerintem innom kell egy kavet mert meg almodok
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Devid_81
félisten
Nem tudom mi a zsak lehet ez oszinten

Valoszinuleg az egyik AM4 (de minek?!) a masik TR platformos chipset lesz.
Tudom ezzel sokat nem segitettem, de en is elegge sotetben tapogatozok
Nehogy kitalaljak, hogy majd a 3950X-hez kell valami speci cucc mert akkor idesirok kb
Mindenesetre szerintem a Szeptember/Oktober eleg jo lesz megint uj hardwareben...csak kerdes kinek van ennyi penze elegetni ezekre

-
#1024
Petykemano
veterán
lezso6
#1023
Petykemano
veterán
Persze, ez ez supercomputer. De hát a jelenlegiek 200-400 petaflops körül vannak. Az még elképesztően messze van, hogy egy eszköz tudjon exaflopot.
"Frontier will feature more than 100 Cray Shasta cabinets, with densities of up to 300kW per cabinet, and a 4:1 GPU to CPU ratio."
4GPU+1CPU az nagyjából 1000-1200W lehet
Ha egy ilyen cabinet 300kW-os, akkor kb 250-300 node jönne ki egyi llyen cabinetre (nem számolva más hálózati eszközök fogyasztásával), ami öszesen 25000-30000 node-ot jelent, ennyi CPU-val és 4x ennyi GPU-val?
(Ennél valószínűleg valamivel kevesebb) -
#1022
Petykemano
veterán
lezso6
#1021
Petykemano
veterán
A "Key Features" résznél INT8 TOPS
A "GPU Specifications" résznél INT8 TFLOPS mértékegységDe ezzel sajnos nem vagyunk közelebb, hogy vajon az 1.5exaflops FP32 (15tflops), FP16 (30tflops), INT8 (60tops) vagy INT4 (120tops) számításával jött-e ki.
1.5exaflops = 1500petaflops = 1500000tflops
1500000÷120 = 12500Szerinted lesz dedikált feldolgozó?
-
#1020
Petykemano
veterán
lezso6
#1019
Petykemano
veterán
nem számolva a CPU-k teljesítményével, ha INT4-ben mérnénk az 1.5exa(fl)ops-t, akkor 12500 Vega20 kellene.
De itt két helyen is exaflops-t írnak. Csak nem tévesztik el? az INT4, meg INT8 számítási kapacitást tops-ban, vagy teraops-ban szokták megadni. nem?
FP16-tal számolva 50000 Vega 20-at kellene beépíteni, FP
a 2018-as toplistás supercomputerben 27,648 NVIDIA Volta V100s van, tehát ez az 50000 annyira nem hangzik soknak akkorra.
Kicsit azért olcsó lenne INT4-es vagy INT8-as számmal dobálózni, még akkor is, ha a célterület az AI.
De még ha úgy is van, és ez lesz a leggyorsabb supercomputer, akkor is érdekes és izgalmas lehet majd élőben látni, hogy hogy teljesít a ROCm. Azt gondolnám, hogy ha beválik, akkor az sok hasonló PR megrendelést hozhat. -
#673
Petykemano
veterán
lezso6
#672
Petykemano
veterán
Világos, hogy az Apple és a MS is saját magának fog arm szoftvert készíteni , vagy támogatni, nem egy OEM arm minipc vagy notebook számára. (Ebben inkább a Google lehet érdekelt.) De ha macekre es a surfacekre is armon jön szoftver (tegyükhozzá a ms nyilván mimdemt metresz azért, h ne legyen winrt), akkor előbb utóbb összeérhet az az arm gravitáció a szoftvereknél és az olcsón kínált hosszú üzemidejű notebook. Nem?
-
#614
Petykemano
veterán
lezso6
#613
Petykemano
veterán
Igen, ez igaz.
De nem az a nagy kükönbség, hogy anno... volt ez az FSB, Front Side Bus frekvencia, ami ilyen 100-133MHz volt (és akkor 3-4-5MHZ-cel ezt is lehetett húzni.) És akkor a CPU frekvencia az FSB-nek valamilyen szorzata volt. A nagy találmány az integrálás során Gondolom az volt, hogy rövidebb utak mellett magasabb frekvencián tudott menni a belső bus. Ha jól tudom, az Intel ring busa például a magok frekvenciáján megy (ami mondjuk így fura, mert az nem fix)
Ha az AMD megoldotta, hogy az IF, vagyis az IO frekvencia nagy távolságra is tudjon magas frekvencián üzemelni, például a RAM frekvenciáján, ami 1200-1800MHz most, akkor máris 10-15x gyorsabb, mint régen a northbridge. Ha esetleg az IF2-vel megoldották, hogy a RAM névleges frekvenciájával (2400-3600) szaladjon akkor azzal a késleltetéseken is jelentős mértékben javíthatnak, hiszen azonnal el tudják kapni a felszálló és leszállóági adatcsomagot. (Esetleg hasonló trükkel)Mindenesetre érdekes.
-
#612
Petykemano
veterán
lezso6
#611
Petykemano
veterán
Az jövő évi amd lineup olyan, hogy tök könnyen lehet rá hihető elképzeléseket felvázolni.
Számomra ennek megfelelően hihető, nagyjából ilyesmire számítanék én is.
Lesz új apu, a Picasso, de arról Fiery eddig végig azt mondta, 14nm.
Ahol szerepel még IGP, zen2 magok mellett, az nyilvánvalóan nem apu, de egy chiplet felépítés mellett ráköthetnek az IO mellé egy Vega 20 (Vega12) lapkát.Más kérdés, hogy az a 14/20CU mire lenne alkalmas 2ch DDR4 sávszél mellett, de ettől függetlenül nem.kivitelezhetetetlen. ebben egyedül az hihetetlen, hogy ezért csupán $20-al kérnének többet.
Máskülönben a frekvenciák hihetők - minden spekuláció arra megy, hogy a kis lapkaméret és az egységes gyártás komoly válogatási lehetőséget biztosít, ami lehetővé teszi a 20-25%-kal jobb frekvenciát elérő lapkák termékké tételez.
Az árak is nagyjából, de csak nagyjából. Talán 10-15%-kal tényleg nyomottabbak, mint amire egy új termék megjelenésekor szokásos. De a 2700X most is $300 körül megy, az 1800X $499-ért debütált. Talán abban igazad van, hogy ha sikerül egyszálon is lenyomni az intelt, akkor azért akár kérhetne többet is - ez szokott lenni a Céges magatartás.Az 5GHz base utolsó sorokat én se hiszem el.
-
Cathulhu
addikt
-
#593
Petykemano
veterán
lezso6
#592
Petykemano
veterán
Az szerintem nem lesz, amíg az ARm ökoszisztéma nem gyorsulja le az x86-ot (nem feltétlenül sebességben, hanem lendületben)
AZ AMD legalábbis pontosan tudja, hogy X86 piacon csak az intellel kell versenyeznie, ha teret kap az ARM, ott legalább féltucat, de inkább tucat versenyző szállhat be a ringbe nem is beszélve arról, hogy a legnagyobb ügyfelek (Amazon, Google, Microsoft, Baidu, stb) meg is tehetik, hogy fejlesztenek maguknak valamit, ami lehet, hogy nem olyan jó, mint az Apple évek alatt összepakolt chipje, de van olyan jó, mint bárki másé a piacon és biztosan olcsóbb összeollózni a kész IP-ket, mint fejleszteni.
Az Arm licencdíja darabszámra megy (nem?), márpedig biztos nem fognak annyi szervercpumagot eladni, mint a mobil piacon. Tehát erre az Armnak még szerintem ki kell találnuia valamit. Talán az interconnect drága? -

HSM
félisten
Na igen, de a program oldaláról meg elég necces lehet ennyi szálat etetni, egy 8 magos processzornál ez 32 szál.... Pfff... Sok sikert ennyire jól skálázódó kódot írni....
Szerverekbe persze van/lehet értelme, de asztali CPU-knál szvsz a legtöbbször a 2 szál/mag sincs kihasználva.
-
Mondjuk igen, elég jó a 2200U, ismerősnek vettem egyet Acershopból, bele +4GB RAM (összes Aspire 3-at 4GB-tal szerelik
 ), szépen muzsikál.
), szépen muzsikál.
Én az olcsóbb HP gépeket hiányolom, meg hogy Dellnél egyáltalán nincs Raven, ASUS-nál is csak mutatóban, legalább is nálunk. De tényleg jobb valamivel a helyzet, mint előző APU szériáknál. -
Hiába jó, ha alig lehet kapni. Olcsóbb modellje csak Acernek és Lenovonak van (azok is jellemzően 2 magos Ryzen 3 2200U-val szerelve), elég gyér a kínálat sajnos.
Bár az is igaz, hogy mintha jobb lenne kicsit a kínálat, mint anno Carrizo vagy Bristol start után egy évvel volt. -
#555
Petykemano
veterán
lezso6
#551
Petykemano
veterán
ITT egy elemzés az Intel i gen1-gen8 "ipc" eredményei és a memória sávszélesség közötti összefüggésről.
A HT eléggé rontja a grafikont... vagyis értelemszerűen egy kezelt szálra kevesebb sávszélesség jut; a HT magok több sávszélességet igényelhetnek.
A videó csak érinti, hogy a CPU magok feldolgozóképességének fejlődésétől elmaradó memóriasávszélesség bővülést a processzorok többszintű cache bevetésével kezelik. Ez kell, hogy adattal tudják elég gyorsan etetni a feldolgozókat. (Ez nem újdonság.Ez az SMT4 érdekes dolog, mert ha megvan a backend 4 szál kiszolgálásához ... de ugye az is hogy? kb 2-3 ILP elérése egyszerű. Most ha jól tudom, 4 integer és 4 128bites fp feldolgozó van. (Bevallom itt már rezeg a léc, hogy fejből mit tudok) tehát mondjuk az SMT4 hatékony kihasználáshoz a zen backendjét meg kéne másfélszerezni? Vagy lehetséges, hogy a 256 bitesre bővítést már eleve úgy hajtották végre, hogy 8 128 hites, amiből 2-2 összeáll 256bites utasítás egy órajel alatti végrehajtására, mint a bulldozerben? Mert mondjuk így elfér az SMT4...
Nade oda akartam kilyukadni, hogy ezt etetni is kell. Akkor itt még durvább cache méretekre és. Sávszélességre lehet számítani.
Illetve ami még segíthet az a tömörítés.
-
Cathulhu
addikt
AVX-re programot irni marha egyszeru, es a latency is kicsi, mig GPU-ra nem olyan trivialis. Amugy mindketto SIMD, szoval attol meg lehet, hogy a backend az a GCN-lesz, de a kod az AVX. Ha van egy kodod, ahol erzed hogy van ertelme a SIMD-nek, azt par perc alatt megirod es lemered, mig GPU-nal szorakozni kell a hosttal, bufferekkel, kernelekkel, stb. Raadasul mig az egyik folyamatosan etetni kell adattal, hogy a latencyt elfedd, addig a masiknal eleg 128/256 vagy 512 bites reszeket kiragadni, azon azonnal lefut, visszairod es mar vissza is kapod a vezerlest.
-
#541
Petykemano
veterán
lezso6
#540
Petykemano
veterán
Annak esetleg látnám létjogosultságát, hogy az egymás melletti chipletek közvetlen módon kommunikáljanak egymással ezzel megtartva valamiféle strukturális visszafelé kompatibilitást az EPYC1-gyel, ahol szintén volt olyan, hogy lapkán belüli magok a lapkán kívüli magokhoz viszonyítva gyorsabb eléréssel rendelkeztek. Így minden optimalizálást, amit az EPYC 1 megkap, áthozható a ROME-hoz is és vica versa, minden ROME optimalizálás értelmet nyer az EPYC1-nél is.
Amúgy looncraz is rajzolt egyet:
![[link]](http://files.looncraz.net/Zen_2_AMD_Rome_IOLayoutTheory.jpg "[link]")
"Decided to throw together a roughly scaled (probably should have been wider and slightly shorter) version of the IO chip using the Zepplin die shot.
This includes everything we know (ahem.. or believe) to exist on the IO die (8 IFOPs, 128 PCI-e lanes, 8 DDR4 channels, etc...) and all of the strange unknown blocks from the Zepplin die. And there was enough room to add 128MiB of L4.. using the L3 from the CCXes directly.
I estimated ~26ns nominal latency to any IFOP from the L4, which is half the latency as to main memory - and with potentially more than double the bandwidth reaching a chiplet (400GB/s). Latency to the L4 from a core would be hard to estimate, but it would be 20~30ns faster than going to main memory, so it's a big win."
-

Simid
senior tag
"...meg lehet spórolni egy IF utat a másik processzorlapkához, feleződik a késleltetés... Ugye az eddigivel ellentétben az I/O lapkás megoldás annyiból fájó, hogy 2x kell átmenni az IF-en a másik oldalra."
Na erre írtam azt korábban, hogy nem tudom honnan jön a feltételezés, hogy így működik. Kiindulva a korábban linkelt NVSwitch működéséből (ahol 16(!) GPU tud kommunikálni egymással, úgy hogy bármely kettő esetében elérhető a max sávszél és a min a késleltetés) itt sem tűnik lehetetlennek egy olyan összeköttetés kialakítása amiben két CCX (most feltételezem, hogy egy 8 magos die az egy CCX) ugyan olyan gyorsan éri el egymást mint bármi mást az I/O dieon belül, még úgyis, hogy egymással nincsenek közvetlenül összekötve. Fizikailag persze ez az ember benyomása, hogy ez két lépcsős folyamat, de az adat a vezetékben fénysebességgel megy szóval az a pár centi nem fog számítani, hogy die-on belül vagy kívül.
Innentől meg csak topológia kérdése, hogy hogyan működik.
(Mondjuk tényleg borítja az egész okoskodást, ha a lapkák még egymással is direkt összeköttetésben vannak.)"Mivel elvileg 64 MB L3 lenne egyenként mind a 8 lapkában, ezért legalább 512 MB-os L4 kell, hogy ez működhessen."
Nekem az utolsó infóm (pletykák) az, hogy 256MB L3 van összesen tehát 32MB van egy lapkában.
De még ez is brutál nagy lenne és kell hozzá ugye egy nem kicsi vezérlő. Ez a legfőbb kételyem a nagyméretű L4 cache-sel kapcsolatban. 8 DDR4 vezérlő, 128 PCI4.0 lane, fullos SB és egy felhizlalt IF van abba az I/O dieban, ha emellé még beraktak több száz MB L4 cachet akkor minden elismerésem nekik. -
#527
Petykemano
veterán
lezso6
#526
Petykemano
veterán
1000 az egész
65-80 között becsülgetik a chiplet méretét, ahhoz képest szemre ~5x nagyobb az IO chip.
75x8=600
75x5=375Ezek nem az én méréseim, becsléseim, csak amik szembejöttek.
Volt egy számítás, ami szerint a zen1ben a CCX 44mm2, kettő együtt mondjuk 90mm2 a maradék ~100 az uncore. Ebből 4 volt a naplesben. A kérdés az, hogy mennyi lehetett a redundancia az önállóan is működőképes zeppelin chipek miatt, amit ki lehetett vágni (usb, northbridge, huzalozás), aminek a helyére esetleg elfér eDRAM.
Ennek persze csak akkor van létjogosultsága, ha a zen2 chiplet mérete inkább nagy. Ha kisebb, az uncore is kicsi -
HSM
félisten
Mint írtam, akkor látom ennek értelmét, ha marad a több CCX-es felépítés, és azt is írtam, hogy akkor ez jó lenne gyorsabb adatcserés opciónak az új IF-on a CCX-ek között.
Illetve ezzel már a Threadripper is sokkal életképesebb lehetne, mint HEDT platform, lényegesen javulhatna a NUMA felépítés miatti egyenetlen (és sokszor magas) késleltetés, akár a magok, akár a memóriaterületek között. -
#507
Petykemano
veterán
lezso6
#506
Petykemano
veterán
L4$ két okból lenne hasznos.
Egyrészt úgy tűnik, hogy a zeppelin esetén a 2 egy lapkán levő CCX között is nagy késleltetés volt. Az IF ugyan kezelte, hogy 2db L3 tömb van, de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors.UGyanez igaz most az epyc2-re is. Lehet, hogy egy CPU-nak egy másik CCX-ből kellő adat pont ott van a másik CCX L$-ban és a lokalizációt az IF lekezeli, de mégiscsak gyorsabb lehet, ha a IO lapka vissza adja, mintha át kell nyúlni a másik CCX L3-ába, és onnan vissza az IO-hoz és onnan az eredeti adatkérő cpu maghoz.
Másrészt segíthet önmagában a memóriaelérés gyorsítótárazásában is.
Ha jól emlékszem a broadwell használta L4.-ként a eDRAM-ot és némileg hasznára vált
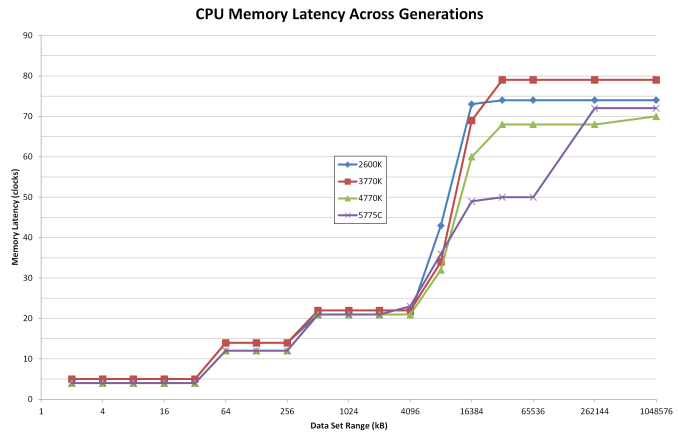
AT -
Cathulhu
addikt
WSA a titok nyitja szerintem ahogy irtak feljebb is. Illetve adok azokra a feltetelezesekre is, hogy azon belul azert 14 es nem 12, mert igy tudnak eDRAMot is beletenni. Ami amugy az AMD szamara egy remek differencialo eszkoz lehet olcsobb es dragabb termekek kozott (kicsit mint pentium 2-nel a cache). Az meg nem akkroa gond, hogy az eDRAM nagy selejtarannyal gyarthato csak, hiszen a 14 nano mar tobb mint kiforrott, illetve lehet letiltogatni abbol is es a legangyobb opciokat aranyaron adni.
Ha mindez igaz lenne (nekem tetszik az otlet) akkor Lisa hatalmas dobasa, gyakorlatilag ket legyet egy csapasra, olcso IO vezerlo a GloFotol, WSA teljesitve, mehet a fontosabb chiplet gyartas a fejlettebb TSMC-hez.
-
#501
Petykemano
veterán
lezso6
#500
Petykemano
veterán
Ott készül a Subor+ chipje, és a vega12 is (az apple-nek) 14nm-en. És a raven ridge is.
12-n a polaris30, a pinnacle ridge még fél-háromnegyed évig (bár szerintem ez ugyanaz a gyártósor, csak újabb maszk vagy ilyesmi)
Ezzel együtt a GF 14 még mindig olcsóbb lehet egy ilyen amúgylóbaszónagy méretű chipnél, mint a TSMC 16. Ez az IO lapka nagyobb, mint a vega10!















![;]](http://cdn.rios.hu/dl/s/v1.gif)







 ), szépen muzsikál.
), szépen muzsikál. 
Új hozzászólás Aktív témák
- 2014 Opel Adam 1.4Benzin GLAM White 87Le 175.000km Megkímélt Eladó-Cserélhető
- 2008 Fiat 500 1.2 8V 69Le Sport 139.000Km Hibakódmentes Eladó-Cserélhető
- AMD Ryzen 5 5600H 8Mag 16/512 4GB FHD 120Hz
- Asus ROG FLOW X13 x360 Érintős MINI Gamer laptop -50% Ryzen 9 6900HS 16GB/1TB RTX 3050Ti 4GB FHD+
- DJI FPV Fly More Combo drón szett - CARBON
- Gamer PC-Számítógép! Csere-Beszámítás! R5 3600 / GTX 1080 8GB / 32GB DDR4 / 512 SSD!
- GYÖNYÖRŰ iPhone 13 mini 128GB Green -1 ÉV GARANCIA - Kártyafüggetlen, MS3338
- Törött Apple iMac 19.2 i5-8500 Radeon Pro 560X 4GB 16GB 256GB SSD 21.5" 4K Retina
- ÁRGARANCIA!Épített KomPhone i5 14400F 32/64GB RAM RX 9060 XT 16GB GAMER PC termékbeszámítással
- HIBÁTLAN iPhone 13 128GB Green -1 ÉV GARANCIA - Kártyafüggetlen, MS3665, 100% Akkumulátor
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: NetGo.hu Kft.
Város: Gödöllő