-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Dyingsoul
veterán
válasz
 core i7
#27201
üzenetére
core i7
#27201
üzenetére
Az egyik könyvben ami nyitva volt meg talán Pascal arcának rajza volt. Nem tudom mire vélni ezt a rengeteg utalást a Pascal sorozatra.
- Szakmai kérdésekre privátban nem válaszolok, mivel másoknak is hasznos lehet. Erre való a szakmai fórum! -- YT: youtube.com/dyingsoulgaming -- FB: facebook.com/DyingsoulGaming/ Stream: http://twitch.tv/dyingsoul
-
#27203
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Abu, mesélj már picit arról a 40MB L2$-ről. Ami 10x több, mint a Vega20 és navi10 és 7x több, mint a GV100 és a TU102 esetén
Találgatunk, aztán majd úgyis kiderül..
-
#27204
 Abu85
HÁZIGAZDA
Petykemano
#27203
Abu85
HÁZIGAZDA
Petykemano
#27203
Abu85
HÁZIGAZDA
válasz
 Petykemano
#27203
üzenetére
Petykemano
#27203
üzenetére
A gépi tanuláshoz kő a cache, mint az állat.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#27205
 FollowTheORI
nagyúr
FollowTheORI
nagyúr
Brutális lett ez az új GPU...


Steam/Origin/Uplay/PSN/Xbox: FollowTheORI / BF Discord server: https://discord.gg/9ezkK3m
-

Freddy S
tag
válasz
 FollowTheORI
#27205
üzenetére
FollowTheORI
#27205
üzenetére
Hello, bejelentettek valamit? RTX3060 mikor lesz? A mostani RTX2000 szériák ára megy lejjebb?
LGB - Lets go Brandon ugyanazt jelenti mint FJB csak takartabban. FJB pedig F - Csúnya szó, J - Joe, B - kitalálhatod!
-
[RTX3080 TI engineering sample specs leaked]
GA102 GPU based on TSMC N77
5376 Cuda Cores at 2.,2GHz - +21 TFLOP
18 Gbps memory with 864 Gbps Bandwidth
Displayport 2.0
PCIe 4.0x16
Expected to be 50% faster than the RTX2080TI
4x faster Ray Tracing performance
Double the number of Tensor Cores
Can do both Global illumination, shadows and reflections at the same time with no performance loss
DLSS 3.0
Double L2 cache
NVCache for SSD and SSD performance boost
Can switch between using the bandwidth for SSD, VRAM and DDR dynamically at the same time
The official reveal is expected to be in September.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27208
 - = Zk = -
félisten
b.
#27207
- = Zk = -
félisten
b.
#27207
- = Zk = -
félisten
Expected to be 50% faster than the RTX2080TI
kiv leszek, mire kell ezt érteni.. .gondolom RT nélküli, DX11/12-es "alkalmazásban".. esetleg "géming"" Persze, ha elég ideig torzítasz egy "nézőpontot" akkor előbb-utóbb találsz hozzá igazságot. " , "A minőséget meg kell fizetni,minden másra ott az AMD!!! " " Pontosan. Különben is, akkor jó, ha nekünk jó. Ha mindenkinek jó, abban mi a jó" by Zebra
-

Jack@l
veterán
jó-jó, de hbm lesz e rajta? Me anélkül labdába se fog rúgni raytracingben... (sírás lesz ha kijön a nagy navi és kettéh* )
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
#27210
FollowTheORI
nagyúr
b.
#27207
Nekem ez a saját józanságmérce excel táblám, ami a múlt alapján próbál kb tippelni mi a várható spec.
 Ami nagyon eltér azt elvetem... de ez az engineering sample pletyka, főleg a TFLOP és a most bejelentett Ampere 100 TFLOP alapján kicsit túl optimista.
Ami nagyon eltér azt elvetem... de ez az engineering sample pletyka, főleg a TFLOP és a most bejelentett Ampere 100 TFLOP alapján kicsit túl optimista. 
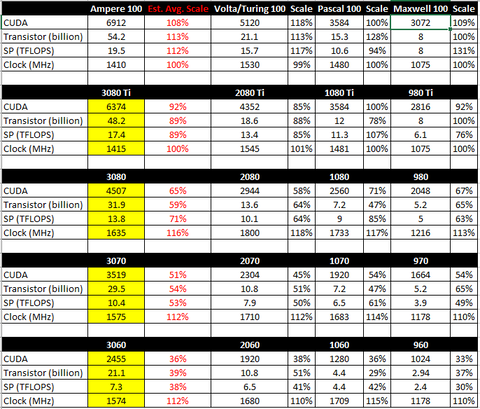
A táblázathoz magyarázat: az Est. Avg. Scale az elmúlt három generáció GPU-inak csúcshoz való viszonyításának (Scale) átlaga... a sárga prognózis spec pedig a most bejelentett Ampere 100 alapján a "levetítése", vagyis beszorozva a várható százalékkal minden kategóriára. Szóval szuper tudományos.
![;]](//cdn.rios.hu/dl/s/v1.gif)
[ Szerkesztve ]
Steam/Origin/Uplay/PSN/Xbox: FollowTheORI / BF Discord server: https://discord.gg/9ezkK3m
-
#27211
FollowTheORI
nagyúr
Freddy S
#27206
-
#27213
 b.
félisten
FollowTheORI
#27210
b.
félisten
FollowTheORI
#27210
válasz
FollowTheORI
#27210
üzenetére
A most bejelentett Amperenek semmi köze nem lesz se a Geforce, se a Quadro vonalhoz ezért nem jó a táblázatod , illetve a belőle levonatkoztatott adatok
Tensor magok töltik ki a 850mm2 legnagyobb részét és nem tartalmaz RT gyorsító struktúrát. Az A100 egy teljesen különálló Ampere kártya AI szegmensre, mátrix szorzásra kifejlesztve ezért lépett előre a Voltához képest csak 30 % általános feldogozókból de 20x gyorsabb lett tensor számításban+ nincs benne RT gyorsító struktúra, míg a geforce/ quadro vonalban lesz. Tehát nagyjából az A100 ból semmire nem érdemes következtetni, még a a memória is eltérő rajt.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27215
FollowTheORI
nagyúr
b.
#27213
-
#27216
FollowTheORI
nagyúr
FollowTheORI
#27215
válasz
FollowTheORI
#27215
üzenetére
Na jó nem trollkodok, hamár így a PH is lehalt tőle.
Szóval nem az a lényeg hogy van e RT mag vagy sincs benne, hanem az hogy a méretek és a releváns paraméterek kb mindig ugyanúgy skálázódnak, és hiába lesz a "sima" FP fejlődés kisebb, az RT meg mondjuk 10x-es, ami valójában most számítani fog az még mindig a hagyományos grafika.
Ez lesz a mérce ezt fogják bencsmárkolni és a táblázat számomra azért releváns, mert kb egymáshogy képest belövi a képességeket és a méreteket/tudást...
Ahogy a keynote-ból is kiderül maga az NV is úgy látja a rációt az RT-ben, hogy meg van támogatva DLSS-el, mert egyszerűen túl "sokba" kerül, és ezen nem változtat sokat, ha még többet raknak bele, lényegileg szükség lesz a trükkökre.
Másrészt látható az új Cryengine és az UE5-ből is, hogy az RT nem lesz annyira kulcsszerep ebben a formában ahogy az NV csinálja.Ha megnézed a Volta - Turing - Ampere arányokat, szerintem elég jól kiadja majd a matek.
A Voltában sem volt RTX, összegészében a "nagyszámok törvényei" alapján kb ezek az arányok maradni fognak következő körre is. Ezen belül meg amennyire nőtt a tenzor, stb, és a hagyományos, kb ugyanolyan arányban várható az RTX vonalon is ez.No de majd meglátjuk mi jön. Igazából ezis csak egy találgatás.
[ Szerkesztve ]
Steam/Origin/Uplay/PSN/Xbox: FollowTheORI / BF Discord server: https://discord.gg/9ezkK3m
-
#27217
b.
félisten
FollowTheORI
#27215
válasz
FollowTheORI
#27215
üzenetére
Nem néztem be semmit. Azt írtam Nincs benne dedikált RT gyorsító nem pedig azt, hogy nem alkalmas RT de az A100 teljesen elter minden eddigi gyorsító kartyatol mert celspecifikus hardver, szinte mindent a mátrix szorzasnak vetették alá.,a méretet is... Elég megneznef, hogy a Voltaban 21 milliárd tranzisztorok hány CUDA mag tartozik és az A100 bán az 54 milliardhoz képest mennyit nőtt a CUDA mag szám... A geforcokban és Quadroban lesz dedikált hardver...Ahogy a Voltaban sem volt.. Az utána érkező geforce vonal neve nem véletlenül lett Turing, nem pedig Volta mert csak alapjaiban épült rá.
Az hogy valamiről ami még sem jelent kijelento módban beszélsz az a te dolgod nekem nem feltétlenül kell egyetértenem vele, megindokoltam miért. Az A100 az első igazán celspecifikus gyorsitojuk...
UE5 hardveresen támogatott RT t fog kapni ahogy a 4 is kapott. Nem Nv csinálja "úgy" hanem Microsoft és a dx 12 ultimate, Ampere RDNA 2 és az új konzolok pont azt mondják, hogy nagy elirelepes lesz ebben.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27218
b.
félisten
FollowTheORI
#27216
válasz
FollowTheORI
#27216
üzenetére
De természetesen ettől lehet igazad, meg fogjuk látni. Abban egyetértek veled, hogy az 50 % optimista.
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27219
FollowTheORI
nagyúr
b.
#27217
Nekem nagyon úgy tűnik az új motorokból, hogy a hw RT továbbra sem lesz igazán rentábilis, főleg a mainstream vonalon, lehet hogy a csúcs Titan-al lehet majd ezzel villogni érdemben (a mostanihoz képest) és nem az lesz az első hogy azonnal kikapcsolja mindenki, de nem ez lesz a fókusz várhatóan továbbrasem.
Ezért mondom az NV sem véletlen, hogy a DLSS-re feküdt rá és azt emelte ki, és az UE5 se véletlen, hogy a komplexitás problémákat "komplexitás-egyszerűsítési" oldalról próbálja megoldani/oldotta meg.
Az új konzolok, tuti nem lesznek elég erősek ehhez szintén. Nyilván lehetnek majd ízelítők, mint ahogy most is vannak, de a lényeg a compute rész lesz még mindig, és hogy abban mit virítanak.
Engem az sem fog meglepni, ha az RT core rész alig nő (arányaiban), és lentebb is (RTX vonalon) a tenzor magok és képességek nőnek majd inkább, mint az Ampere esetén. Szerintem a különböző AI és machine learning algoritmusokon alapuló rekonstrukciókon és "egyszerűsítéseken" lesz a hangsúly, nem a hardver RT-n. Csak ezért sejtem elég erősen, hogy nem ez lesz a hangsúly, mint ahogy sokan várják. Illetve az Abu által is gyakran emlegetett sávszélesség problémák miatt sem, főleg GDDR6-al, hiába lenne itt 10x annyi RT mag.
Konzol szinten már most is elég erősen a rekonstrukciós technikákon múlt a látvány, szinte mindig az van/volt, hogy valami kisebb felbontáson kell dolgozni, és utána abból kihozni a legjobbat/mégjobbat. Ez így fog maradni a jövőben is, és szerintem a PC-re is ez fog átszivárogni a motorokban és megoldásokban is. UE5 demó is erősen erre alapult.Érdemes azt is figyelni a szoftver oldalon a motorok merre mennek és mit csinálnak, az lesz a fontos. Szerintem.
[ Szerkesztve ]
Steam/Origin/Uplay/PSN/Xbox: FollowTheORI / BF Discord server: https://discord.gg/9ezkK3m
-
#27220
 szmörlock007
aktív tag
b.
#27217
szmörlock007
aktív tag
b.
#27217
szmörlock007
aktív tag
B., tekintve a pletykát, hogy ugye nvidiának is érkezik az nvcache, ami az amd hbcc-hez lesz hasonlítható (már a célját tekintve, működését még nem tudjuk), elég valószínűnek tartom hogy a quadro szériába az Nvidia is a csúcskártyára ssd-t pakol, mint azt tette az amd még a vegánál (meg valószínűleg az rdna2-uarchoz is lesz ilyen pro kártyájuk).
Te mennyire látsz erre esélyt?
Azért ssd-vel megpakolva, rt-vel felszerelve nagyon durva professzionális kártyák lehetnek ezek mindkét oldalon.[ Szerkesztve ]
-
#27222
b.
félisten
szmörlock007
#27220
válasz
 szmörlock007
#27220
üzenetére
szmörlock007
#27220
üzenetére
Simán elkepzelheto megoldás, de az érdekesebb a geforce vonal/x86-64/windows /dx12mert elméletileg licensz nélkül ezt nem tudnak megoldani. Lehet, hogy vettek/kaptak? Ki tudja?
Professzionális szegmensben ez megoldhato."A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27224
b.
félisten
szmörlock007
#27223
válasz
szmörlock007
#27223
üzenetére
Az NVcache HBC szerű megoldásához kell licensz amit rebesgetnek, arra értettem. Ha az SSD-t eléri az Ampere akkor már rátehetik akár arra is. Ehhez egyébként Nvidiának ez is a lehetséges megoldás. [GPUDirect Storage: A Direct Path Between Storage and GPU Memory]
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#27225
 core i7
addikt
FollowTheORI
#27219
core i7
addikt
FollowTheORI
#27219
core i7
addikt
válasz
FollowTheORI
#27219
üzenetére
Szerintem is csiszolgatják ottvan benne ,de addig nem nagyon fognak mindent erre összpontosítani míg nem lesz minden AAA címben az. Talán 2 gen múlva jön a HBM3 erősebb RTX kártyákkal
[ Szerkesztve ]
-
#27226
Abu85
HÁZIGAZDA
FollowTheORI
#27219
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#27219
üzenetére
Nem hát. Nagyon sok dolgot meg lehet jó minőségben oldani RT nélkül. Az RT pedig félkarú óriás addig, amíg nem tudod kellő távolságra lőni a sugarakat. Mert ugye minél távolabb számolsz, annál több secondary ray jön a képbe, ahol már nincs koherencia, tehát ott már a sávszél a limit. Ahol igazi előnye van, az a 3D audio, a reflection és a translucency. Minden másra van gyorsabb, és nagyon is jó minőségű alternatíva RT nélkül is.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
core i7
#27227
üzenetére
A secondary ray-ekre nyilván. Azok össze-vissza mennek. Ha sok van belőle, akkor minden sugárra külön memória-hozzáférés kell. Alternatív megoldás a hardverbe építeni egy olyan koherenciadetektort, ami megpróbálja a sugarakat csoportosítani, és akkor alkalmazható lesz a lokalitási elv.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Jack@l
veterán
Csak érdekességképp. Elég gyorsan őrölnek az nvidia malmai, meg a piac is.
https://www.techpowerup.com/267171/atos-launches-first-supercomputer-equipped-with-nvidia-a100-tensor-core-gpuA hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
Abu85
HÁZIGAZDA
Nézőpont kérdése. Te mint végfelhasználó valószínűleg nem jutnál hozzá még hónapokig, de egy nagy megrendelő, már hozzájuthat az első példányokhoz a nyáron.
A TF64 se 64 bit float.

De ezt egyébként a gyártók megengedhetik maguknak, ha nem iparágilag definiált formátumot használnak. Pontosan ezért létezik az IEEE 754. És ez ugyanúgy követelhető az API-ból is, vagy akár az alkalmazásból, tehát mondhatja egy tendernél a megrendelő, hogy neki aztán nem kellene "dzsunkaformátumok", és IEEE 754-es specifikációkat nézzenek csak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Raymond
félisten
Ad TF32 - Nem tudom, nekem nem ugy tunt hogy itt is titkolodznanak vagy sumakolnanak. Az Anadtech-en olvasva vilagosan le volt irva hogy ez nem FP32 es a sajat blogban sincs egyelonek beallitva hanem csak mint jol hasznalhato formatum bizonyos feladatokra: [link]
Privat velemeny - keretik nem megkovezni...
-

lenox
veterán
Mondjuk en pont meg szoktam kapni az ilyeneket honapokkal a kiadas elott, mert eleg sok bugot talaltam mar amit mas nem.
A TF64 se 64 bit float.
Mi a TF64 szerinted? Mert amit a cikkben irtal, hogy 19,5 TFLOPS, az valojaban nem TF64, hanem FP64 Tensor Core, es az nv szerint az rendes FP64.#27233: Nekem a neve a felrevezetes, meg rogton az abra, ami a linkeden van. Persze, a magyarazat az oke, meg a feature is oke.
-
Abu85
HÁZIGAZDA
Kérdés, hogy van-e SXM4-et fogadó rendszered. Enélkül nem mennél sokra a hardverrel.
Egyik tensor formátum se felel meg az IEEE 754 specifikációknak. Némileg különböznek a megszokottnál. Sokszor nagyok, például TF32.
Az a lényeg, hogy amilyik FP nem a Tensoron fut, az mind IEEE 754-nek megfelelő formátum, míg minden más nem. Legalábbis így egyszerűsítették le nekem. [ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem részletezték, hogy miben nem felelnek meg. Azt írták, hogy ha az IEEE 754 követelmény, akkor a tensor műveleteket hagyjam figyelmen kívül, és a normál számítási kapacitást nézzem.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ha az, akkor miért mondták azt a különbségeket firtató kérdésemre, hogy a tensor formátumok nem felelnek meg az IEEE 754-es speckóknak?
Nem mellesleg, ha full FP64 precision van tensorból, akkor minek építenek be egy rakás DP feldolgozót, amivel csak a tranyókat foglalják?
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Raymond
félisten
A megoldas egyszeru.
"miért mondták azt a különbségeket firtató kérdésemre, hogy a tensor formátumok nem felelnek meg az IEEE 754-es speckóknak?"
Mert igy is van, ha megfelelnenek akkor nem "TF" jelolesuk lenne hanem standard "FP".Olyan hogy TF64 nincs. Van TF32 mint formatum (ami nem IEEE754) es van FP64 Tensor Operations ahol rendes conform FP64 formaturol van szo.
Privat velemeny - keretik nem megkovezni...
-
lenox
veterán
Ezt biztos, hogy tolem akartad kerdezni? En csak szembesitelek a valosaggal, nevezetesen, hogy nem ir az nv oldal olyan formatumot, amit te irtal a cikkedben, de aminek a sebesseget megadtad arra viszont azt irja, hogy full fp64. Hogy mi alapjan talalgattal azt gondolom azzal kene tisztaznod akitol kaptad az infot.
-

gV
őstag
NVIDIA Ampere Architecture In-Depth itt is leírják majdnem ugyanezt:
For HPC, the A100 Tensor Core includes new IEEE-compliant FP64 processing that delivers 2.5x the FP64 performance of V100.
és van egy ilyen rész is:
Third-generation Tensor Cores:
Acceleration for all data types, including FP16, BF16, TF32, FP64, INT8, INT4, and Binary.
FP64 Tensor Core operations deliver unprecedented double-precision processing power for HPC, running 2.5x faster than V100 FP64 DFMA operations. -
Jack@l
veterán
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
Jack@l
veterán
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
Dyingsoul
veterán
Annyi fizikai és fénnyel kapcsolatos demot láttunk már gyurmával, krómmal, textillel, tükrökkel, folyadékkal stb... komolyan csodálkozom azon, hogy ezt még mindig kajálják az emberek.
- Szakmai kérdésekre privátban nem válaszolok, mivel másoknak is hasznos lehet. Erre való a szakmai fórum! -- YT: youtube.com/dyingsoulgaming -- FB: facebook.com/DyingsoulGaming/ Stream: http://twitch.tv/dyingsoul















 Ami nagyon eltér azt elvetem... de ez az engineering sample pletyka, főleg a TFLOP és a most bejelentett Ampere 100 TFLOP alapján kicsit túl optimista.
Ami nagyon eltér azt elvetem... de ez az engineering sample pletyka, főleg a TFLOP és a most bejelentett Ampere 100 TFLOP alapján kicsit túl optimista. 

![;]](http://cdn.rios.hu/dl/s/v1.gif)
















Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- ASUS GTX 770 DirectCU II 2GB GDDR5 256bit OC videokártya
- Dobozos ASUS GeForce GTX 1050 Ti OC 4GB GDDR5 128bit (ROG STRIX-GTX1050TI-O4G-GAMING) Videokártya
- Gainward Geforce GTX 750 ti 2Gb
- MSI RTX 4080 VENTUS 3X 16GB OC
- Gigabyte Aorus 3060 Ti 8 GB DDR6 eladó(nem garis,nem dobozos) játékra volt használva .
Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: Ozeki Kft
Város: Debrecen