-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Busterftw
nagyúr
-
#52832
 gV
őstag
VoltanIgor
#52831
gV
őstag
VoltanIgor
#52831
gV
őstag
válasz
 VoltanIgor
#52831
üzenetére
VoltanIgor
#52831
üzenetére
J, K a régi TM presetek.
L, M az új TM2-esek. az L preset UltraP-nál, az M a többire +DLAA.______
na közben jött új nv inspector, megy a dioval is az M. -

PuMbA
titán
Hú, 4000-res és 5000-res szérián kegyetlen gyors az M és L preset, (mondjuk nem csoda, mert ezek a kártyák a target) illetve még csúcs 3000-res szérián is. 2000-res és alsó, közép 3000-reseken már jelentős frametime időt vesz el és sokkal több memóriát is eszik (4K-ban 200MB-tal, azaz 1,5x annyit). 4060 és 5060 kártyákat azért jó lenne ha odatették volna, ha már 3060 van.
Hasonló a helyzet, mintha az AMD kiadná előző genre az FSR4-et. Futna, de lassabban

-
gV
őstag
NVIDIA DLSS 4.5 Delivers Major Upgrade With 2nd Gen Transformer Model For Super Resolution & 6X Dynamic Multi Frame Generation | GeForce News | NVIDIA
NVIDIA RTX Remix Update Introduces New Logic System For Dynamic Graphics Effects | GeForce News | NVIDIA
NVIDIA App Update Adds DLSS 4.5 Super Resolution & New GeForce Game Ready Driver | GeForce News | NVIDIA -

X2N
őstag
válasz
 M@trixfan
#52822
üzenetére
M@trixfan
#52822
üzenetére
Az érdekes lehet, a pluszban generált frame-ek adott esetben lehet fel se tűnnének, ha nem minden második/harmadik frame lenne generálva. Egy ilyet megnéznék. 120fps-ről mondjuk felhúzná a monitor képfrissítésére 144-re hogy meglegyen a szinkron. Viszont a jobb kijelzők már így is tudnak VRR-t.
PuMbA-Így már drogok se kellenek, fake frame-ket vízionál a kártya.

-
PuMbA
titán
válasz
M@trixfan
#52822
üzenetére
Jelenleg arra se. DigitalFoundry jól mutatja videón, hogy a baj az, hogy a mesterséges képkockák nem tökéletesek és amíg a 2x-esnél jól elfedik a hibákat a valós képkockák, 4x-esnél már a képkockák jó része generált, azaz képhibákkal teli és az agyad már észreveszi ezeket a hibákat. Minél több a generált képkocka, annál jobban feltűnőek a képhibák. Nézd meg, hogy a DLSS4 2x-es frame gen is hogy hajlítja az utat az autó mögött:
6x-es framegennél már olyan lesz ez mintha LSD-n lennél
-
Busterftw
nagyúr
NVIDIA will officially announce DLSS 4.5 tomorrow.
2nd Gen Transformer model
Dynamic Multi Frame Generation (3x to 6x)
NVIDIA confirms DLSS 4.5 will be supported by all RTX GPUs (20, 30, 40, and 50 series). However, Dynamic 6x Frame Generation will launch in spring 2026 as an RTX 50 exclusive feature. -

S_x96x_S
addikt
válasz
 Busterftw
#52817
üzenetére
Busterftw
#52817
üzenetére
ha lenne ilyenje, az nvidiának ( gyors és olcsó inference )
akkor nem kellene a Groq.
és nem tartana a TPU-tól se.Bank America: "... a megállapodás azért fontos, mert az Nvidia ezzel implicit módon elismeri, hogy miközben a GPU-k továbbra is dominánsak az AI-tanításban, a piac gyorsan az inferencia felé tolódik, ahol a Groq LPU-hoz hasonló, ASIC-szerű célhardverei komoly előnyt jelenthetnek; ezek az LPU-k kiszámíthatóan és rendkívül gyorsan generálnak tokeneket, így kiegészíthetik az Nvidia általános célú, nagy HBM-memóriára és széles skálázhatóságra épülő GPU-platformját, amely továbbra is erős marad tanításban és sokféle modell, ügyfél és felhasználási eset kiszolgálásában. "
-
Busterftw
nagyúr
-
S_x96x_S
addikt
válasz
 Raymond
#52815
üzenetére
Raymond
#52815
üzenetére
olvasd el újból amit irtam,
megadtam a linket, hogy hol találod.---
Nehéz ezt félre érteni:
Jensen Huang: “We plan to integrate Groq’s low-latency processors into the NVIDIA AI factory architecture, extending the platform to serve an even broader range of AI inference and real-time workloads,”Ha meg összeesküvés elméletek felé akarod vinni a témát,
abban biztos nem vagyok partner.
Majd valaki más megvédi Jensen Huang-ot és az nvidiát.
-
S_x96x_S
addikt
(Groq + Nvidia) - Bank of America optimista véleménye :
"... a megállapodás azért fontos, mert az Nvidia ezzel implicit módon elismeri, hogy miközben a GPU-k továbbra is dominánsak az AI-tanításban, a piac gyorsan az inferencia felé tolódik, ahol a Groq LPU-hoz hasonló, ASIC-szerű célhardverei komoly előnyt jelenthetnek; ezek az LPU-k kiszámíthatóan és rendkívül gyorsan generálnak tokeneket, így kiegészíthetik az Nvidia általános célú, nagy HBM-memóriára és széles skálázhatóságra épülő GPU-platformját, amely továbbra is erős marad tanításban és sokféle modell, ügyfél és felhasználási eset kiszolgálásában. Bár a GPU- és LPU-architektúrák együttélése bonyolítja a termékútitervet és az árazást, egyben növeli az ügyfélválasztékot és erősíti az NVIDIA versenyhelyzetét a specializált inferenciachipekkel szemben, különösen ha a jövőben GPU és LPU egy rackben, NVLinken összekapcsolva működik. Ugyanakkor több kérdés is nyitott marad, például mit jelent pontosan a nem kizárólagos licenc az IP-tulajdon és az esetleges versenytársi licencelés szempontjából, képes lett volna-e az Nvidia ezt a technológiát önállóan is kifejleszteni (például a Rubin CPX irány mentén), illetve a Groq Cloud tud-e árversennyel fellépni az Nvidia-alapú LPU-megoldásokkal szemben. Összességében azonban, a részletek hiánya ellenére, az ügylet hosszú távon stratégiailag pozitív lehet, és a 2020-as Mellanox-felvásárláshoz hasonlóan tovább erősítheti az Nvidia AI- és hálózati skálázásra épülő versenyelőnyét, ... "
"Huang az idei év egyik legfontosabb bejelentésén hosszasan érvelt amellett, hogy az Nvidia képes lesz megőrizni vezető pozícióját, miközben az AI-piac súlypontja a betanításról fokozatosan az inferenciára tolódik át."
( portfolio.hu )
-
S_x96x_S
addikt
válasz
Raymond
#52812
üzenetére
> Ha ez a fo argumentumod akkor valamit csak latsz mogotte.
Nem hiszem, hogy nekem kellene
megvédeni Jensen és az nvidia döntését.Ha, konkrét számok kellenek, akkor azokat te is képes vagy megtalálni.
A Groq low-latency képességet nagyon könnyű szemléltetni - egy voice-chat -es demóval, amikor a késleltetésnek elég természetellenes hatása van.
---
A többi fórum olvasó kedvéért - megkértem az egyik AI-t,
hogy magyarázza el átlagos "gamer" szinten mi a Groq LPU lényege:"Groq LPU: Ez az AMD 3D cache ötletét viszi abszurd szintre, de AI-hoz. A chip tele van pakolva óriási on-chip SRAM-mel (230 MB/chip, ami primary storage, nem csak cache!), ami villámgyors (80 TB/s bandwidth), szemben a GPU-k off-chip HBM-jével (8 TB/s körül). Nem kell külső memóriához "szaladgálni" – minden súly (model weights) bent van a chipen, azonnali hozzáférés. Plusz: determinisztikus, mint egy futószalag egy autógyárban (Henry Ford stílus). A compiler előre megtervezi minden egyes műveletet clock cycle-nyire pontosan – nincs várakozás, nincs random késés, nincs dinamikus scheduling. Ez olyan, mintha a játékodban minden frame előre scriptelve lenne, zero stutter, perfect predictability.
...
Specifikusan inference-re építve, nem univerzális mint a GPU:
Az NVIDIA GPU-ja olyan, mint egy svájci bicska – jó mindenre (gaming, training, ray tracing), de inference-ben sok core unatkozik, memória bottleneck van (off-chip HBM lassabb), és random késések (non-deterministic). A Groq LPU-ja meg egy single-purpose fegyver: óriási on-chip SRAM (230MB/chip, villámgyors, mint infinite cache), determinisztikus futószalag (minden clock cycle előre tervezve, zero stutter).
...
Olcsó gyártás régi node-on (GlobalFoundries 14nm):
Az NVIDIA-nak vadászni kell a legújabb TSMC 4nm kapacitásra, ami brutál drága és mindig hiány van (mint a legújabb GPU-k scalpolása release-kor). A Groq meg egy "régi" 14nm-es node-ot használ GloFo-nál – ez érett, olcsón gyártató, mindig van kapacitás, nincs várólista. Mint ha te egy régi Ryzen 5000-es CPU-t vennél 3D V-Cache-sel olcsón, miközben mások az új Zen5-ért ölnek – és mégis gyorsabb bizonyos játékokban.
...
Olcsóbb üzemeltetés: Kevesebb energia (akár 10x jobb performance/watt inference-ben), alacsonyabb cost per token (millió válasz olcsóbban). Mint ha a villanyszámlád fele lenne ugyanazért a frame rate-ért, de itt AI-chatért. Nagy cégeknek (cloud providerek) ez milliárdos spórolás – miért fizetnének NVIDIA premiumot, ha Groq olcsóbban adja ugyanazt a "pinget"?
"""
-

Raymond
titán
válasz
 S_x96x_S
#52811
üzenetére
S_x96x_S
#52811
üzenetére
Attol hogy leirod meg parszor ugyanaz atool meg nem lesz ertelme. De OK, legyen meg a lehetoseged:
"Az Nvidiának jelenleg nincs olyan alacsony késleltetésű inference megoldása, amely összemérhető lenne a Groq LPU-val."
Ez mit jelent szamokban es mi az amit igy nyertek? Nem prozara vagyok kivancsi hanem szamokra. Ha ez a fo argumentumod akkor valamit csak latsz mogotte.
-
S_x96x_S
addikt
válasz
Raymond
#52810
üzenetére
ugyanazt tudom ismételni - egy picit másképpen,
Az Nvidiának jelenleg nincs olyan alacsony késleltetésű inference megoldása, amely összemérhető lenne a Groq LPU-val.
NINCS - pedig lenne rá igény.
Ráadásul a Groq LPU energiahatékonysága is jelentősen jobb a hagyományos Nvidia GPU-alapú inference-nél.
(ami kisebb költséget jelent az adatközpontoknak)
Persze egy inference célú ASIC - mindig optimálisabb egy általános GPU-nál, főleg ha olyan jó mérnökök tervezik, mint Jonathan Ross és csapata - akik mögött ott a TPU.
A politikai szál (1789 Capital,Trump Jr.) érdekes; de ha még lenne is politikai szándék, attól ez még nem cáfolja az üzlet technológiai értékét és azt, hogy az nvidiának nincs ilyen technológiája.Amúgy ha a Groq LPU nem lenne valós fenyegetés,
akkor miért fektetnének bele - és miért fizetne érte bárki is?Az IBM + Groq együtmüködést "Oct 20, 2025" - én kötötték, valószínüleg azután, hogy az nvidiát és az amd-t is megversenyeztették - és a groq 5x gyorsabb eredményt produkált:
IBM: "Powered by its custom LPU, GroqCloud delivers over 5X faster and more cost-efficient inference than traditional GPU systems. The result is consistently low latency and dependable performance, even as workloads scale globally. This is especially powerful for agentic AI in regulated industries."
Ezen kivül a Groq már építi az adatközpontjait Szaud-Arábiában
és Finnországban is.És ne felejtsük el az nvidia másik problémáját,
hogyha az OpenAI+Broadcom -os chipnek és a Goole TPU -nak
nem ad jó Nvidiás ASIC-os alternativát,
akkor nagyon gyorsan kiszorulhat az inference piacról. -
Raymond
titán
válasz
S_x96x_S
#52809
üzenetére
"Ian Cutress is meglepődött"
Meg, ugyanugy ahogy mindenki mas is mivel ennek ezen az aron nulla ertelme van technikailag. A fantazmagoriakra amiket itt gyartasz nem reagalok mert sok ertelme nincs amikor azzal kezdesz hogy "az nvidiának lesz egy elég jó inference megoldása, ami hiányzott az eddigi portfóliájából"

A megoldas egyszeru, ez megint egy ujabb resz a Trump csaszar lepenzelese sorozatban, semmi mas. A szeptemberi Series E egyik befektetoje az 1789 Capital ahol Don jr. csucsul. A masik jomadar pedig a Disrupt, ezek voltak a volannal ebben a korben. Biztos egyik se tudta hogy harom honap mulva, meg az iden, jon a telapo teli zsakkal...
-
S_x96x_S
addikt
A Groq (ASIC) tökéletesen illik az
Nvidia AI factory architecture -jába, vagyis gyorsan integrálható
( és ez is a terv az nvidia részéről. )
És mivel a Samsung készíti 4nm-en a Groq -ot,
az "NVLINK Fusion" támogatás is megoldhatóA low-latency képesség, pedig -
az AI gyakorlati alkalmazhatóságához kell - mint következő lépés,
amire valós igény van.
Persze az egészet másképpen is lehet keretezni.
"NVIDIA spent $20B admitting GPUs aren't fast enough for inference."Amúgy még - Ian Cutress is meglepődött
-
S_x96x_S
addikt
válasz
S_x96x_S
#52801
üzenetére
ha már felkérést kaptam a kifejtésre,
a Groq LPU integrálásával az nvidiának lesz egy elég jó inference megoldása, ami hiányzott az eddigi portfóliájából.
https://archive.ph/dd5s9 ( FT )
Jensen Huang -email: “We plan to integrate Groq’s low-latency processors into the Nvidia AI factory architecture, extending the platform to serve an even broader range of AI inference and real-time workloads,”(az AI területén a növekedés az inference lesz, és ehhez cél csipek kellenek )
Az Inference alatt a ChatGPT és társait kell érteni,
és ez most drága és lassú.FT: 'Groq has focused on developing chips that can accelerate AI “inference”, the process of returning responses to users’ queries via chatbots such as OpenAI’s ChatGPT or Google’s Gemini.'
A Groq így fogalmazta meg, hogy drága és lassú az nvidia technológiája - és segít nekik, hogy "high-performance, low cost inference" -megoldásuk is legyen:
"Today, Groq announced that it has entered into a non-exclusive licensing agreement with Nvidia for Groq’s inference technology. The agreement reflects a shared focus on expanding access to high-performance, low cost inference."Az ár tükrözi a stratégiai fontosságát a területnek.
mert ha nem lenne fontos, akkor nem is fizetnének ennyit.
bár a végső ár és a részletek még homályosak.Jensen szerint olcsóbb most - mintha a Groq a fejükre nőne, vagy ha egy rivális megszerezné.
A licenc + top talent poach - egy proaktiv megoldás,
hogy a Groq további erősödését függetlenként megakadályozza,
( vagy hogy egy konkurens cég felvásárolja )
És mivel a Groq alapítója tervezte a TPU-t is, ami teljesen más paradigma,
egyszerűbb, hogyha erre az emberre bízzák az nvidia technológiájának átalakítását. -
S_x96x_S
addikt
válasz
Raymond
#52805
üzenetére
szájbarágosabb verzió:
hogy mi a szenzációs a Groq chip-ben - és miért ideális inference -re
- Anastasia:"Is This the Fastest AI Chip Ever?" ( 2024mar )
https://www.youtube.com/watch?v=NzYpoPhckCkés hogy miért fenyegetés a Groq az nvidia jövőjére:
https://x.com/The_AI_Investor/status/2003979714130858031 -
S_x96x_S
addikt
a Groq LPU integrálásával az nvidiának lesz egy elég jó inference megoldása, ami hiányzott az eddigi portfóliájából.
(az AI területén a növekedés az inference lesz, és ehhez cél csipek kellenek )Az ár tükrözi a stratégiai fontosságát a területnek.
Jensen szerint olcsóbb most - mintha a Groq a fejükre nőne, vagy ha egy rivális megszerezné.What is a Language Processing Unit?
https://groq.com/blog/the-groq-lpu-explained -
#52799
 b.
félisten
TESCO-Zsömle
#52798
b.
félisten
TESCO-Zsömle
#52798
válasz
 TESCO-Zsömle
#52798
üzenetére
TESCO-Zsömle
#52798
üzenetére
A másik cégnek viszont kell, ha csak valóban nem kerül bizonyos tulajdonrész át az Nvidiához.
-
#52797
b.
félisten
TESCO-Zsömle
#52796
válasz
TESCO-Zsömle
#52796
üzenetére
20 Mrd,durva. Nem volt még nekik ekkora befektetés.
-
[Nvidia to license AI chip challenger Groq’s tech and hire its CEO]
"CNBC reported that Nvidia is acquiring assets from Groq for $20 billion; Nvidia told TechCrunch that this is not an acquisition of the company and did not comment on the scope of the deal. But if CNBC’s numbers are accurate, this purchase is expected to be Nvidia’s largest ever, and with Groq on its side, Nvidia is poised to become even more dominant in chip manufacturing."
-
Busterftw
nagyúr
RedGamingTech a forrás, szóval...
-
S_x96x_S
addikt
a 100M IOPS -ot - 512B -os egységben kell érteni,
( és valószínüleg PCIe Gen7 duplázza - a Gen6-os 50M IOPS-t )"The AIN P drive is envisaged as a PCIe Gen6 drive capable of 50 million IOPS with a 512B data access chunk, which compares to the 4KB block used currently for random read and write IOPS, which run at the 7 million IOPS level for PCIe gen 6 SSDs, according to an SK hynix slide. Our files record Micron’s 9650 Pro and Max PCIe Gen 6 drive operating at 5.5 million random red IOPS. SK hynix must know faster PCIe gen 6 drives are coming. Its AIN P drive will be 7x faster than them and, SK hynix says, a 100 million IOPS model could be available in 2027. This is far beyond any performance level put out by its competitors."
https://blocksandfiles.com/2025/10/28/sk-hynix-aims-for-ai-flash-glory-with-ain-trifecta/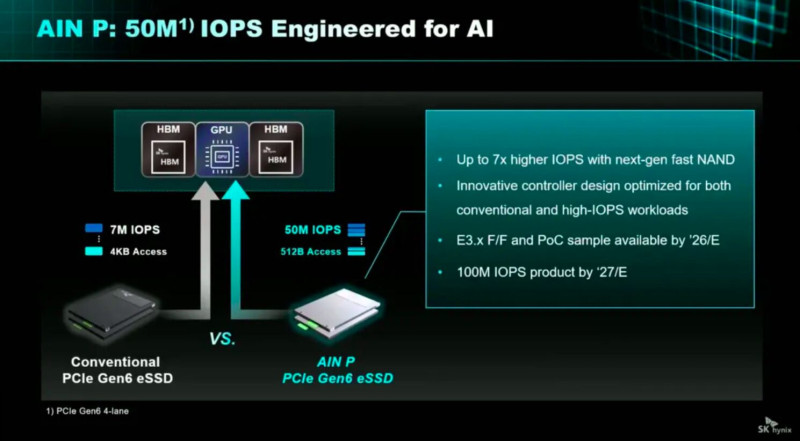
-
[link]
"Nvidia is working with SK Hynix on a brand-new AI solid-state drive (SSD) with 10x the performance of current AI server SSDs, a project code-named “Storage Next”, media report. A prototype is expected in 2026. It's being designed as a memory layer between an AI server’s memory and storage, while also preparing for the future needs of data centers in Space. The performance target of the new AI SSD is 100 million Input/Output operations per second (Wow!). Taiwan’s Phison is a co-developer." -
-
S_x96x_S
addikt
válasz
 Beaumont
#52785
üzenetére
Beaumont
#52785
üzenetére
most a memória lett a szűk keresztmetszet,
és ahhoz kell igazitani mindent. ( a gombhoz a kabátot )- Hiába gyártanának ugyanannyi GPU chip-et, hogyha csak a fele mennyiséghez van elég "jó áras" memória, amit elfogad a piac is.
- Ezen kivül a memória áremelkedés tovább gyűrűzik, megnöveli a notebook-ok és a pc-k árát --> visszaesik a kereslet ---> és kevesebb cpu, gpu, kell.
---
A frame.work az áremelkedést már így szemlélteti.
"A single rack of NVIDIA’s GB300 solution uses 20TB of HBM3E and 17TB of LPDDR5X. That’s enough LPDDR5x for a thousand laptops, and an AI-focused datacenter is loaded with thousands of these racks! " -
#52788
 Heroes fan
őstag
Heroes fan
őstag
Heroes fan
őstag
Megszünt a 3060 végleg, már nem gyártják tovább.
-
S_x96x_S
addikt
válasz
Beaumont
#52781
üzenetére
szerintem az NVIDIA titokban készülhet a Blackwell refresh-re,
és ez a csökkentés csak az átállás része ;
hamarosan sokkal jobb GPU-k érkeznek!
( 1 year cadence )
Emelett a csökkentés lehetővé teszi, hogy az NVIDIA még több erőforrást fordíthasson az AI-fejlesztésekre, ami végül jobb gaming élményt eredményez. Vagyis ezzel a játékosok jól járnak!![;]](//cdn.rios.hu/dl/s/v1.gif)
-

Beaumont
aktív tag
[Nvidia plans heavy cuts to GPU supply in early 2026]
Ahogy varhato volt a RAM mizeria utan...
-
-
#52779
Heroes fan
őstag
Quadgame94
#52778
Heroes fan
őstag
válasz
 Quadgame94
#52778
üzenetére
Quadgame94
#52778
üzenetére
 ez jó volt.
ez jó volt. -
#52778
 Quadgame94
őstag
Heroes fan
#52777
Quadgame94
őstag
Heroes fan
#52777
Quadgame94
őstag
válasz
 Heroes fan
#52777
üzenetére
Heroes fan
#52777
üzenetére
Gondolom a sarokban ültél a sötétben magzatpózban két hónapig és vártad ezt a frissítést. Most már kijöhetsz a fényre. Minden rendben! Mitulát báti hotta neted a frittitét
-
#52777
Heroes fan
őstag
Heroes fan
őstag
Így is késtek vele 2 hónapot.
-
#52776
b.
félisten
huskydog17
#52774
válasz
 huskydog17
#52774
üzenetére
huskydog17
#52774
üzenetére
Jó hír

-
#52775
 FLATRONW
őstag
huskydog17
#52774
FLATRONW
őstag
huskydog17
#52774
FLATRONW
őstag
válasz
huskydog17
#52774
üzenetére
Ez fantasztikus hír, imádom a PhysX-et.
-
#52774
 huskydog17
addikt
huskydog17
addikt
huskydog17
addikt
Megjelent az első 590-es branch driver (591.44).
Ezzel megszűnt a Maxwell és Pascal architektúrák mainline támogatása, ahogy azt az NV már fél éve kikommunikálta, így ebben nincs semmi váratlan.
Ezzel egyetemben a 32 bites GPU PhysX gyorsítást visszahozták 9 játékhoz és egy 10. játékhoz később érkezik a támogatás.:"We heard the feedback from the community, and with the launch of our new driver today, we are adding custom support for GeForce gamers’ most played PhysX-accelerated games, enabling full performance on GeForce RTX 50 Series GPUs, in line with our existing PhysX support on prior-generation GPUs.
By installing our new GeForce Game Ready Driver, the full GPU-accelerated PhysX experience can now be enjoyed in:Alice: Madness Returns
Assassin’s Creed IV: Black Flag
Batman: Arkham City
Batman: Arkham Origins
Borderlands 2
Mafia II
Metro 2033
Metro: Last Light
Mirror’s Edge" -
S_x96x_S
addikt
válasz
Busterftw
#52769
üzenetére
Nem ertem ez hogy jon ide. ... es StrixHalot ... nem hasznal jatekra,
--> pedig már legalább 3 db Strix Halo gaming handheld is létezik.
( bár nagyrészt jövőre jönnek )de amúgy ha másképp értetted,
akkor jelzem, hogy az RTX 5090 -t SE kifejezetten játékra veszik.
És a rövid úpgrade ciklust úgy kell érteni, hogy
a consumer nvidia GPU-k többsége ( ~80% -a ) 8-12GB VRAM-os -
#52771
Busterftw
nagyúr
Heroes fan
#52770
Busterftw
nagyúr
válasz
Heroes fan
#52770
üzenetére
Aham.
-
Busterftw
nagyúr
-
#52768
Busterftw
nagyúr
Heroes fan
#52767
Busterftw
nagyúr
válasz
Heroes fan
#52767
üzenetére
Errol johet teszt, mert kontextus nelkul ez igy nem jelent semmit.
-
S_x96x_S
addikt
válasz
Busterftw
#52763
üzenetére
> Amig a tobbsegnel Nvidia vga van, nem fognak kifogyni a VRAMbol.
Ahogy Jensen mondaná:
"More VRAM you buy - More you save"
és az NVIDIA-nak a rövid upgrade-ciklus = végtelen cashflow!Hogyha 2026–27-ben megérkeznek az új konzolokra
(PS5 Pro / Xbox Next) optimalizált
next-gen gamek >=16 GB-os VRAM igénnyel ;
akkor Jensen megint csak mosolyog,
és elkezdi forgalmazni az új nagyobb VRAM-os GPU-kat.Jelenleg a konzolgyártók döntik el a minimumot
és az NVIDIA pedig boldogan eladja a "megfelelőt".
win-win.
és még a GDP is növekszik ;
habár a mi pénztárcánknak nem tesz jót.De milyen erdekes hogy ez jegyzed meg, amikor epp csak az Nvidia kinal consumer vonalon 32GB-at, senki mas....
consumer vonalon ott
- az Apple M chip - a nagy egyesített memóriával
- valamint az AMD-től a StrixHalo ( 32,64,128GB ) -al.
- és jönnek a next-gen konzolok.A "dgx spark" -os GB10 -es még nem jelent meg
consumer vonalon, de talán jövőre olyan is lesz. -
válasz
Busterftw
#52764
üzenetére
Ez nem olcsójánoskodás, ha a GDDR6 sávszélességge elég a kártyához, akkor minek tegyenek rá 7-et? Az RTX (vagy legalábbis "RTX") 5050-en is GDDR6 van.
Az NVIDIA-nak azért kellett a GDDR7 szinte az egész vonalon, hogy alacsonyan tudják tartani a memóriabusz szélességét. Gondolom, ez most így érte meg, de ha tartósan magasan maradnak a memóriaárak, akkor ez változhat. -
Busterftw
nagyúr
Epp ezt akartam linkelni, senki nem gondolkozik lassabb memoriaban, ennel a gennel is csak az AMD szivatta meg a vasarloit es olcsojanoskodott.
Az emlitett gyorsabb memoriakat a Samsung listazza mar:
Az SK Hynix mar 48 Gbps sebessegrol beszel (24Gb (3GB).
-
#52763
Busterftw
nagyúr
Heroes fan
#52743
Busterftw
nagyúr
válasz
Heroes fan
#52743
üzenetére
Amig a tobbsegnel Nvidia vga van, nem fognak kifogyni a VRAMbol.
Az ujabb UE5 jatekoknal van eppen az, hogy 4K-n boven eleg a 16GB, az a minimum.De milyen erdekes hogy ez jegyzed meg, amikor epp csak az Nvidia kinal consumer vonalon 32GB-at, senki mas....
"20-on gigát azért betud kajálni 1-2"
Na most akkor mar csak a foglalt es a hasznalt vram kozotti kulonbseget kellene megerteni... -
S_x96x_S
addikt
Az LPDDR sem lesz korlátlan, laptopok kellenek és a telefonpiac brutálisan nagy..
- létezik kínai fejlesztésű LPDDR5X ,
( de kínai - GDDR6/GDDR7-ről nem tudok )
vagyis a memória hiány eltérően érinti a memória típusokat.- az LPDDR -es verzió low-end -es megoldás lenne
most egy Ryzen Z2 -es kézikonzol - az abszolute low-end
egy strix halo - a középkategória leges leg-alja
és a StrixH -hoz képest egy 384-bit LPDDR6 2.2x memória sávszélességet ad.- Az Apple az M modelljeivel már hozza a 400 - 550 - 800 [GB/s] -os memória sebességet - LPDDR5 -re építve.
-
válasz
S_x96x_S
#52759
üzenetére
RDNAA5/ MLID/LPDDR. feljebb.
A memória hiány mindenkire hatással lesz és van.
Az LPDDR sem lesz korlátlan, laptopok kellenek és a telefonpiac brutálisan nagy..És nem lehet 3-4-5 év múlva lassabb memóriákban gondolkodni mint most ,mert azt el lehet adni egyszer hogy most visszalépett az AMD a 20 -as számrendszerbből az RDNA4 gyel vagy most GDDR6 van 7 helyett,,de jelenleg a mai hír szerint a Samsung igen is gyárt 28 Gbps 3 GB memóriákat a Geforce vonal számára és 32-36 Gbps memóriákat az AI / pro szegmensnek 3 GB verzióban. [link]
És ez nagy előnye lehet az Nvidiának, mert 3-4-8 GB modulok is licenszelve vannak a szabványban a GDDR7 re.
Előfordulhat hogy a 3-4-8 GB modulok némileg hatékonyabban gyárthatók lehetnek mint az 1- 2 és csökkenthetik a gyártási kapacitás hiányt majd idővel.( nem az árat) Pl 4 darab 4 GB -os vagy 2 darab 8 GB modul pont felbiggyeszthető lenne a mostani 8x2 helyett.
AMD nek Intelnek Nvidiának együtt kell kezelnie a helyzetet mert memória nélkül ugyan úgy nincs se AI se gaming se semmi mint CPU és GPU nélkül.
ráadásul az AMD nek ott a PS5 Pro is mint bevétel, ami most még több ramot tartalmaz és jön a PS6 nem sokára ,ami meg necces lenne, ha visszalépne ebben, mikor épp előre akarnak lépni állítólag memória kapacitásban az új konzolgenerációban..csak ki fogja azt megfizetni... -
S_x96x_S
addikt
itt a fórumban
az nvidia nézőpontjából vizsgáljuk a témát
És ha kifejezetten az Intel vagy az AMD nézőpontjára , reagálására
vagy kiváncsi, akkor másik forumot javasolnék.Persze az nvidiának azt is végig kell gondolnia,
hogy a versenytársak ( AMD, Intel ) , hogyan reagálnak
a memória drágulásra. ( ~ competitive response analysis )
és erre mi a legjobb válasz.amúgy korábban emlitettem is az AMD -t.
// + MLID szerint az RDNA5 AT3 -as
384-bit LPDDR6 / 256-bit LPDDR5X - memória kontrollerrel jöhet ;
-
S_x96x_S
addikt
-
S_x96x_S
addikt
> OK, de a példa a jelenből van, az 5070 alterntívája.
bár nem kizárt;
de nem hiszem, hogy gazdaságos lenne
egy back-to-future GDDR6-os Blackwell -t kiadni
( chip át-tervezés, tesztelés, gyártás, partnerek felkészítése , stb. )
amikor nem lehet tudni, hogy meddig tart ez a memória mizéria;
és mit igértek a memória gyártók Jensennek.Rövid távra sokkal egyszerűbb előszedni
az RTX 4060, 4070 -es GDDR6 -os verziókat ;
+ a TSMC-nél legyártatni
de ez is 3-4 hónap míg a piacra kerül.A várható Low-end gpu hiányra
más helyettesítő termékek is várhatóak
( >=2026 -ban )
- INTEL+RTX
- vagy az ARM+Nvidia consumer chip ( N1, N1X )vagyis az nvidia menedzsmentnek több alternativája is van
a probléma kezelésére. -
S_x96x_S
addikt
> és akkor lehet olcsóbb típust tenni a kártyákra - ie. mondjuk az 5070-en lehetne 256-bit mellett 16 GB GDDR6.
A GDDR6 -ot nem hiszem, hogy fel akarná támasztani az nvidia
Sőt - minden memória partnert noszogathat, hogy GDDR7 -re állítsák át az eddigi GDDR6 termelést is, mert kell neki az AI-hoz.
( ráadásul ezzel az RDNA4 ellátási láncát is meg tudja neheziteni )A jövőben ( >=2026 ) az x050/x060 -nél
simán lehet LPDDR6/5X - desktopon is ;
így olcsóbban lehet akár 24GB/32GB/64GB-ot is adni
az alsó kategóriákban.
// + MLID szerint az RDNA5 AT3 -as
384-bit LPDDR6 / 256-bit LPDDR5X - memória kontrollerrel jöhet ; -
#52752
 Jacek
veterán
Heroes fan
#52751
Jacek
veterán
Heroes fan
#52751
Jacek
veterán
válasz
Heroes fan
#52751
üzenetére
Befoglalt memoria egy ket jateknal. Persze minnel tobb annal jobb.
-
#52751
Heroes fan
őstag
VoltanIgor
#52747
Heroes fan
őstag
válasz
VoltanIgor
#52747
üzenetére
20-on gigát azért betud kajálni 1-2
-
Az 50-es kártyára szerintem teljesen jó a 8GB, még a következő szériában is. A 60-asra azért már gázos lenne, most is nagyon durván határeset a 8.
Mondjuk ha ennyire drága marad a memória, akkor vszleg el kell majd gondlkodniuk azon, hogy más buszméretet használnak az adott tiereken, és akkor lehet olcsóbb típust tenni a kártyákra - ie. mondjuk az 5070-en lehetne 256-bit mellett 16 GB GDDR6. -
#52748
Raymond
titán
Heroes fan
#52743
Raymond
titán
válasz
Heroes fan
#52743
üzenetére
Meanwhile, in the real world...
-
#52747
 VoltanIgor
aktív tag
Heroes fan
#52743
VoltanIgor
aktív tag
Heroes fan
#52743
VoltanIgor
aktív tag
válasz
Heroes fan
#52743
üzenetére
"Jaja 4k-ra a 32 lesz lassan az ajánlott."
Azért ne vicceljünk már -
#52746
Jacek
veterán
Heroes fan
#52745
Jacek
veterán
válasz
Heroes fan
#52745
üzenetére
Szerintem örüljünk ha 12-16--24--32 marad, ugy hogy 12 a 60-as
Szerintem lesz 8Gb -
#52744
Jacek
veterán
Heroes fan
#52743
Jacek
veterán
válasz
Heroes fan
#52743
üzenetére
Mivel patika mérlegen méri az NV ezért néhány kivételtől eltekinve ugy van belőve hogy az életben nem fut ki 16-ból, mostanában foglalttban sem látok maxra töltött memoriat.
Diablo4 televág bármit
Namost mivel minden gyártósot szerver(AI)-hoz való memora allítottak át, gondolom a GPU-hoz is begyűrüzik a memoria para -
#52742
 M@trixfan
addikt
Heroes fan
#52738
M@trixfan
addikt
Heroes fan
#52738
M@trixfan
addikt
válasz
Heroes fan
#52738
üzenetére
Merőben más volt a chip binning a 3000-és széria idején és nem voltak LLM modellek így elterjedve mint most. Az új Unreal Engine, az “AI”, a rekonstrukciós technológiák, VR, 4K felbontás merőben átrendezte a memóriaigényt is a teljesítményigény mellett. Nagyon tudatosan belőtte az NVIDIA, hogy az 5000-es szériában a 80-as mindenből fele a 90-esnek. 16GB MOST éppen ajánlott, de már vannak aggodalmak. Tudatosan terelve vannak az emberek a 90-es felé, value szempontból sajnos “jobb” mint a 80-as széria, eddig nem így volt.
-
#52741
b.
félisten
Heroes fan
#52738
válasz
Heroes fan
#52738
üzenetére
Maximum a bányászláz idején volt az másfél millió,de akkor egy 3080 is 500 K volt.
Üdv a való világban, ezt hívják úgy hogy fejlődés.2020 szeptemberében jelent meg a 3090. -
#52740
Quadgame94
őstag
Heroes fan
#52738
Quadgame94
őstag
válasz
Heroes fan
#52738
üzenetére
Ennyi erőből egyik kártya sem éri meg, mert 4 év múlva harmadáért veszed majd meg.
-
#52739
Jacek
veterán
Heroes fan
#52738
Jacek
veterán
válasz
Heroes fan
#52738
üzenetére
Hat meg a TNT2-ot
-
#52737
S_x96x_S
addikt
Quadgame94
#52736
S_x96x_S
addikt
válasz
Quadgame94
#52736
üzenetére
> Én azért gondolok MCM-re mert a technológia simán tart majd ott.
A döntés
a versenytől [ 1] és a meglévő technológia lehetőségektől[2] is függ.[1] ~ mennyire sikerül jól az AMD megoldása ; vagyis a piaci nyomás;
[2] a raszteres teljesítményt hogyan tudja az nvidia gyakorlatban skálázni - mert erre még nem nagyon tudok példát. -
#52735
S_x96x_S
addikt
Quadgame94
#52729
S_x96x_S
addikt
válasz
Quadgame94
#52729
üzenetére
> GR102 - MCM lesz szerintem.
> Két darap Grafikus lapkával, amelyek egyenként 16 384 Shadert tartalmaznak.
(szubjektív vélemény)
Monolitikus sokkal valószínűbb (a költségek miatt is) .
amúgy a "RUBIN CPX" is single-die ;> "36 Gbps memóriát" kap
A RUBIN CPX -re "30 Gbps GDDR7" -et irnak ,
Ha 2027H1 -ben lesz is elegendő 36 Gbps -es memória,
azt nem a consumer vonalra fogják allokálni.
( a kis volumen és az ár miatt se )Vagyis én
- monolitikus RTX 6090 -et ( CPX-alapon )
- és +40% teljesítményt várok ( az RTX 5090-hez képest )
ami még mindig erős fejlődés.És nagy valószínűséggel ez már PCIe 6.0 -ás lesz.
-
#52733
X2N
őstag
Heroes fan
#52731
X2N
őstag
válasz
Heroes fan
#52731
üzenetére
Lesz még itt sírás, szerintem alacsonyra lőttem be a 6090-árát
Az MCM nem lesz olcsó úgy készüljetek. -
#52730
Quadgame94
őstag
Quadgame94
#52729
Quadgame94
őstag
válasz
Quadgame94
#52729
üzenetére
GR103 pedig csak az egyik lapka felét kapná meg. Összesen 16 384 magot. Ez nagyon rávallana az NV-re. RTX 6080: 1200 USD
- 360-380 mm2 Monolitikus
- 16 384 Shader
- 512 TMUs / 128 ROPs
- 3.2 GHz Boost
- 256-bit GDDR7 32-36 Gbps
Teljesítmény:
- Raszter: RTX 4090 és RTX 5090 között.
- AI/RT: RTX 5090 közelébenRTX 6070 Ti: 800 USD
- 360-380 mm2 Monolitikus
- 12 288 Shader
- 384 TMUs / 128 ROPs
- 3.2 GHz Boost
- 256-bit GDDR7 32 Gbps
Teljesítmény:
- Raszter: RTX 4090 -10%
- AI/RT: RTX 4090 -
#52729
Quadgame94
őstag
Quadgame94
őstag
Nagyon messze van még az RTX 60 széria, de a Rubin-ról már eléggé sokat lehet tudni. Összeszedtem sok adatot és a 3 nm előnyeit összevetve az RTX 60 széria brutális lehet, persze szép árazással is egyben.
GR102 - MCM lesz szerintem. Két darap Grafikus lapkával, amelyek egyenként 16 384 Shadert tartalmaznak. Ez soknak tűnik, de a lapkákon csak a legfontosabbak lesznek:
GPC: 8
- 8 Raster Engine
- 64 TPC / 128 SM / 16 384 Shader
- 128 ROPsA GPC szerintem teljesen más lesz. Kap majd egy AI/RT Cluster-t, és így külön lesznek az RT és Tensor magok a TPC-n belül. Ez a cluster kap külön L1/Tex cache-t is. Nyílván nem tudom hogyan lesz felépítve, de logikus lenne az eddigi L1 Tex-et L0-nak hívni, és L1-et pedig ketté bontani: L1A az SM-eket táplálja, az L1B pedig a AI/RT Clustert. És ezek osztoznak egy nagyobb L2 gyorsító táron. 4 MB elég ide, hiszen úgy is jönnie kell egy nagyobb méretű Last level cache-nek.
GR102
o 2x 220-240 mm2 Grafikus lapka
o 1x I/O lapka + NVLINK
o 16 GPC / 128 TPC / 256 SM / 32 768 Shaders
o 1024 TMUs / 256 ROPs
o 8 MB L0D
o 65 MB L1A + 32 MB L1B
o 64 MB L2
o 160 MB LLC vagy L3
o 1024 Tensor Cores
o 256 RT Cores
o 512-bit GDDR7 – 36 GbpsVégső méret valahol 600-650 mm2 körül lenne. I/O lapka mehetne akár 6 nm-en is.
RTX 6090:
GeForce RTX 6090
Általános:
- Q1/Q2, 2027
- 3 nm N3P + 6 nm
- 500W TDP
- $2499-2999
Lapka:
- MCM - 600-650 mm2 s
GPU
- 16 GPC / 120 TPC
- 240 SMs / 30 720 Shaders
- 240 RT Cores
- 960 Tensor Cores
- 960 TMUs & 256 ROPs
- 3000+ MHz Boost Clock
Memória:
- 32 GB GDDR7 VRAM
- 512-bit 36 Gbps (2304 GB/s)
Cache: 64 MB L2 + 160 MB L3
Teljesítmény:
- Raszter: RTX 5090 + 60%
- AI/RT: RTX 5090 + 80% -
#52728
 deathcrow42
addikt
X2N
#52727
deathcrow42
addikt
X2N
#52727
-
Busterftw
nagyúr
NVIDIA Announces Financial Results for Third Quarter Fiscal 2026
- Data Center revenue was a record $51.2 billion, up 25% from the previous quarter and up 66% from a year ago.
- Gaming revenue was $4.3 billion, down 1% from the previous quarter and up 30% from a year ago. -
S_x96x_S
addikt
"NVIDIA Reportedly Planning a Major Shift in Its AI Business Model, Moving to Control More of the AI Server Stack to Boost Margins"
https://wccftech.com/nvidia-reportedly-planning-a-major-shift-in-its-ai-business-model/ -
Busterftw
nagyúr
válasz
S_x96x_S
#52722
üzenetére
Itt inkabb az eppen elerheto volumen szamit az Nvidianak, az AMD-nek nem kell annyi foglalas, a kereslet sokkal kisebb vs Nvidia, utobbinal igy is bottleneck van.
Illetve az AMD peldaul eddig is jobb node-n volt, ami nem jelentett vegul jelentos piaci elonyt:
RX 5000 7 nm vs RTX 2000 12nm
RX 6000 7nm vs RTX 3000 N8De irhatnank a N3 Blackwell vs N3 MI350-et, egal node-n visszafogja oket a volumen es a teljesitmeny.
Valoszinuleg az Nvida itt valami custom N3P(?)-t kap, csokkentve a kulonbseget az elso generacios N2 kozott. -
S_x96x_S
addikt
válasz
Busterftw
#52721
üzenetére
> TSMC 3nm
> large share of this capacity is expected to be allocated to NVIDIA 'exclusively'."
az amd- 2026-ban a TSMC 2nm -rel tervez gyártatni,
ami kockázatosabb;
mig az nvidia eddig sokkal konzervativabb/kockázatkerülőbb volt,
de ez a jövőben ( >= 2027 ) változhat
( pl. a rubin ultra / feynman esetén )"NVIDIA is claimed to be TSMC's first A16 node customer, and this move marks a unique shift in the firm's approach, since it had tended to rely on older processes from the Taiwan giant."
( wccftech, 2025-sep-15 ) -
Busterftw
nagyúr
"The report claims that TSMC plans to expand the 3nm capacity of its fab located in Southern Taiwan Science Park from 100,000 wafers per month to 160,000 wafers, which is around a 50% increase, and interestingly, a large share of this capacity is expected to be allocated to NVIDIA 'exclusively'."
Rubinra mar most megvannak a vasarlok. -
Úgy gondolod? Több, mint fél éve startolt a 9070 XT, akkor az MSRP-k között 25% volt (5070Ti-hez képest). Most (legalábbis itthon) a piaci árak között kb. ugyanannyi a különbség. Nem érzékelem, hogy az NVIDIA-t annyira meghatotta volna a 9070 XT-től érkező verseny
Ill. ha 6070Ti-t Blackwell chipből csinálnak, akkor az nyilván nem a 102-es lesz, szóval a vágott 103 helyére bejön a vágatlan 103. Az biz' elég siralmas lenne.
Mondjuk a 6060-asokat végső soron meg lehet oldani a 104-es chipből is, kicsit visszafogják az 5070 órajeleit meg a voltokat, akkor tűrhető 6060Ti lehet belőle... -
S_x96x_S
addikt
válasz
S_x96x_S
#52710
üzenetére
"5060 Ti 16G will be in short supply very soon."
https://x.com/Zed__Wang/status/1986837551332925732"NVIDIA GeForce RTX 5060 Ti 16GB Expected to Face Short Supply Soon"
https://wccftech.com/nvidia-geforce-rtx-5060-ti-16gb-expected-to-face-short-supply-soon/ -
S_x96x_S
addikt
válasz
S_x96x_S
#52698
üzenetére
RTX 50 Super - pletyka frissités: 2026 Q3 !
"No cancellation yet, just delayed. Now planned to launch in 26Q3, previously set to launch in 26Q1."
https://x.com/Zed__Wang/status/1986837279831433277NVIDIA GeForce RTX 50 SUPER GPUs Reportedly Postponed To Q3 2026
https://wccftech.com/nvidia-geforce-rtx-50-super-gpus-postponed-to-q3-2026/ -
S_x96x_S
addikt
válasz
S_x96x_S
#52698
üzenetére
2026 se lesz annyira egyszerű,
mivel az nvidia elkezdte a high-end AI rackekben is használni a "cost-efficient" GDDR7 -et.
és emiatt sok memóriagyártó rögtön a 4GB -os modulokra
fog ráállni ( a 3GB helyett )"NVIDIA's Rubin CPX may reshape AI memory demand, boosting GDDR7 over HBM"
https://www.digitimes.com/news/a20250912PD210/nvidia-hbm-rubin-demand-market.html--
"Rubin CPX delivers up to 30 petaflops of compute with NVFP4 precision for the highest performance and accuracy. It features 128GB of cost-efficient GDDR7 memory to accelerate the most demanding context-based workloads. " (nvidia) -
#52704
deathcrow42
addikt
gbors
#52703



































![;]](http://cdn.rios.hu/dl/s/v1.gif)















Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- BestBuy topik
- Máris limitálja egy európai disztribútor a GeForce-ok szállítását
- Autós topik
- Samsung kuponkunyeráló
- Android programozás, Android alkalmazások készítése
- CES 2026: Látható gyűrődés nélküli hajlítható kijelzőt hozott a Samsung
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Jövedelem
- Linux felhasználók OFF topikja
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- További aktív témák...
- Telefon felvásárlás!! Samsung Galaxy A14/Samsung Galaxy A34/Samsung Galaxy A54
- GYÖNYÖRŰ iPhone 13 Mini 128GB Green- 1 ÉV GARANCIA -Kártyafüggetlen, MS4200
- Seagate Desktop SSHD 2TB 3,5" - ST2000DX001 45-80%
- REFURBISHED - DELL Performance Dock WD19DCS (210-AZBN)
- Beszámítás! Apple Macbook Air 15 M2 2023 8GB 256GB notebook garanciával hibátlan működéssel
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest