Új hozzászólás Aktív témák
-
Igen, automatizálás is, de ezek az első cikkben megemlítésre kerültek...
Saját gép, biztonsági mentések kiváltása,
automatizálások, személyi asszisztens (Amolyan JARVIS - ahogy írtam is ott!), plusz az adtok feldolgozására AI-k.Ahogy azt is jeleztem, hogy lesz róla bővebb írás, csak egyszerre sok is, hosszú is, ha alapos, érthető és részletes kívánok lenni, így témakörökre van bontva.
Az első cikk amolyan téma-alapozó, kedvcsináló volt. -

TotoPapp
lelkes újonc
válasz
 LordAthis
#24
üzenetére
LordAthis
#24
üzenetére
Konkrétan fogalmam nincs, mire vagyok kiváncs (ha vagyok); általában holisztikus szemléletem van, tehát az érdekel, hogy mi akar bemenni és mi akarna kijönni.
Pl. az is simán lehet, hogy automatizálás (vagy az IS) kell, nem AI és hasonlók.
Viszont akik olvassák rajtunk kívül, azoknak segítség lehet. -
Aludtam (még)egyet a dologra, és úgy döntöttem, hogy szétkapom a projekt leírásának azt a részét, amire kiváncsi vagy.
Talán érthetővé tudom tenni a publikus részek leírásával is, illetve behelyettesítő példákat fogok hozni azokról, amik nem publikusak.A következő cikkben: AI Cluster - A Projekt céljai, a Cluster felépítésének okai
-
TotoPapp
lelkes újonc
válasz
LordAthis
#22
üzenetére
Szia, csak erre válaszolnék:
'- A bérelt felhő és VM árak a szükséges erőforrások tekintetében ha egy éves költséget nézünk, akkor is nagyon gyorsan verdesik azt a határt, ami a jelenlegi gépek ára! '
Ez megint olyasmi, amivel nem tudok mit kezdeni. Én is fejlesztek, teljesen más vonal valószínűleg; ameddig eljutottam, arra pont elkölthettem volna a jelenlegi kétszázszorosát is, hogy legyen egy MVP, a szokásos (jelenleg szokásos) megoldással (akár többet is, ha nem teszek bele egy kis időt és kiszervezem). Oké, tanultam (pont nem akartam ezt tanulni; de mindegy, megoldottam).
Ahogy írtam korábban; megint vlgig kell gondolni, hogy mi a feladat. Amikor az Amazon és társai X összegért adták a felhős gépidőt, akkor az én feladatomra szakosodott kész megoldást adó cégek 3X-ért adták, én meg találtam szolgáltatót, ami az X ötödéért adta a gépidőt, totál rugalmasan. Kellett hozzá kutatni; mondjuk én még ennél is olcsóbb megoldást találtam és működött.
Egy közepes PC-t összeraksz, használt Nvidia kártyák NV-linkkel; van temérdek CUDA magod, egyben látja a memóriát, a régi vackokhoz képest töredéket fogyaszt. Akkor megy, amikor akarod. A VM-ek feladata gőzöm nincs mi, de sanszosan az is fillérekből megoldható a következő lépés előtt, ha az ötleted skálázható. (HA.)
Melyik, milyen célú lokál AI kell? Ahhoz igazítod, ami kell.
Nem okoskodni akarok; én is inkább vettem, amit nem akartam, mert hosszú távon olcsóbb akkor is, ha másra használom végül. Két drága vásárlás-fajta van: az olcsó hús meg a kihasználatlanul továbbavuló cucc.Simán lehet, hogy tök jól csinálod, mert te látsz rá, mit csinálsz (én még csak találgatni sem találgatok, semmi értelme).
-
Na ezt most ténylegesen félreértettem:
'van egy task, azt meg akarod oldani, akkor felépítesz egy MVP-t lehetőleg zéró beruházással'Szó szerint vettem, nem képletesen, nem példaként!
Különben az ötlet kiváló, jól használható sablon!
Nagyon okos és gyakorlatias stratégiát javasolsz egy szerver/üzemi/fejlesztési projekt indításához: először a legkisebb költséggel teszteljük le az alapötletet, és csak azután kezdünk el komolyabban beruházni, hogy lássuk, működik-e és mi az igazi igény rá.
Nálam ezek voltak:
- Teszteltem különböző megoldásokat,
- amiket nem személyesen teszteltem, azokról rengeteget olvastam/olvasok, rengeteg videót néztem/nézek jelenleg is.
- Számoltam utána megoldásoknak, természetesen mások által használt megoldásokat megismerve, átgondolva.
- Amikre használom, használtam különböző AI megoldásokat, és amik esetén a bemutatott használat számomra is hasznosnak tűnik, azok túlmutatnak az asztali gép szegmensén.
- A bérelt felhő és VM árak a szükséges erőforrások tekintetében ha egy éves költséget nézünk, akkor is nagyon gyorsan verdesik azt a határt, ami a jelenlegi gépek ára! (Különben ez egy jó téma, össze is fogom szedni a példákat, de az biztos, hogy még nem a következő cikkre!) Különösen a feldolgozandó anyagok mennyisége tud nagyon költséges lenni, ha a felhőszolgáltatásokat nézzük, mivel több TB van már most is jelenleg, hogy még nem kezdett bele egyik szerverem, és Script-em sem az adatgyűjtésbe....
..nem beszélve a célhardver szükségességéről, ami bár jóval erősebb GPU-k tekintetében, (utasításkészlet, újabb CUDA magok), azonban a legalább 100GB VRAM bérlése sem kevés.Sajnálatosan ezek az elmúlt évek tesztjei, próbái nem, vagy csak részben voltak dokumentálva, nem volt tervben cikk-írás belőle! Talán egyszer feldolgozom, ami megvan belőle, és akkor bekerülnek a cikk sorozatba is.
Ez az én "hibám", de itt akkor sajnos le kell írnom pár okot:
Az elmúlt 5-6 évbem igen xar volt. Rögtön az első 3 évben volt 4 költözésem, 3 halálesetem, 2 csőtörés, leeső csempékkel, 3 lakástűz (szarabbnál szarabb albérlet, fel nem újított elektromos hálózatokkal, rengeteg balhéval, stb), aztán azóta is még 2 haláleset és 1 költözés...
Ezek eredményeképp szanaszét vannak szedve a gépeim, szanaszét az adataim, kicsit 'szétszórva' a hardverek, sok hiba volt. (Leginkább speciális hibák.) Sok hardverem csak mostanában került ki a dobozokból.
A "vicc" kedvéért a sajátommal több hiba volt, mint amiket szupportoltam, és pont erre nem értem rá sohasem.
Közben éppen ebből a sok hibából kifolyólag jött az ötlet, hogy az egész sajátgépes infrastruktúra és tárolás helyett (Még NAS is "döglött" le!!!) lett kitalálva a cluster, redudáns rendszer.
Így, amiket korábban írtam is, egy kicsit saját használatra is lesz a gép, 1-2 VM (igazából ilyen erőforrásokkal "akármennyi") az asztali gépeim helyett.
redundáns RAID kötetekre kerülnek az adatmentések is, stb.Ahogy elérkezek odáig a cikkekkel, mindenről szépen beszámolok majd!

-
TotoPapp
lelkes újonc
válasz
LordAthis
#20
üzenetére
Csak erre válaszolnék:
"A zéró beruházás már megbocsáss így is több millió volt,"
A zéró beruházás nem a te beruházásodra vonatkozott, hanem az MVP/validálás témájára. Ha neked ez a több millió szükséges volt hozzá, akkor - mive fogalmunk nincs mit építesz - nem tudunk egyebet mint hinni vagy nem hinni.
Több millióból igen sok validáció ki tud jönni; számomra továbbra us homály. hogy mit építesz, tehát nem tudom, hogy ezzel olcsón megúsztad vagy totál más iránnyal hatékonyabban jártál volna.
A saját tapasztalataimat ismerem, abben benne van az "ész nélkül bevásárok" meg a "majd megoldom régi vassal" startupper is; mindkettőt játtam nyerni meg bukni is, de leginkább bukni.
Nálam lustább disznó nincs, egy ezresből lemodelleztem több száz milliós beruházást is; kijött, hol lesz a hiba, ott is lett. Bele is buktak.
Már az előkészítés fázisában meg kellett volna csinálniuk, amit nem csináltak meg, aztán volt csodálkozás. Egy nyomorult Google keresést nem futtattak le. Nem kérdeztek meg senkit az iparági szabályokról (meghívom a Józsit meg a Bélát kajálni, közben dumálunk arról. hogy ez hogyan illeszkedne az ő rendszerükbe.)
Filléres tételek.
Mindegy, az ő dolguk.
Viszont ez az alap mentalitás. -
Szerintem leírtam, hogy milyen vonatkozásban értem, használtam a hasonlatot...
'Az emberi videlkedés sémái meg az emberek kódolási "hozzáértése" továbbra is teljesen más dolgok. Tajtparaszt versenyző is írhatja a világ legjobb kódját, aki egyébként X vagy Y oldalt ekézi full anonimitásban.'
..valahogy úgy tűnik, egészen másképpen értelmezted.Ez sem teljesen így volt:
'Viszont te húztál be ide egy hamis alapokon nyugvó érvelést az AI butasága kapcsán (ugye most tech-ai/kód-AI vonalon beszélgetünk, nem napi politikai csatározásokról és hitkérdésekről). Tech vonalon a kód "mérgezése" a szar kód mint forrás.'
..mintha utaltam volna a technikai vonalra, miszerint GitHub, stb nem feltétlenül minden projekt a jó/tiszta/célszerű/egyszerű kódról szól!
Ezeken tanítani több, mint kétséges.
És igen, ahogy írod:'Mivel az AI-nak elvben lehetne lehetősége'
, de szerintem ez ott bukik meg, hogy nem az AI-nak kell ellenőriznie, hanem szakembernek! Ténylegesen jó, megbízható szakembereknek. Viszont még a programozó munkákhoz sem találsz eleget belőlük, nemhogy erre az unalmas tanítgatás témára!Ez nagyon így van!
'..viszont jelen pillanatban az AI buzzword és nem erről szól (ezért van akár több száz, szinte folyamatos veszteséget termelő AI cég a piacon).'
Ebben teljesen egyetértünk.
Valahol találkozik azzal is, (mintha pár poszttal ezelőtt írtam volna...) hogy "kőművesként" viselkednek, "eddig is így csináltuk".
Sajnos a probléma ennél sokkal messzemenőbb, legalábbis saját tapasztalataim (és küzdelmeim) szerint a gond leginkább az, hogy a marketingnek rendelik alá a szakmaiságot.
Tehát ha a marketinges azt mondja, hogy fél év múlva adunk nektek bélát, a tökéletes AI-t, akkor a programozó hiába tiltakozik, hogy:
1, Nincsen kész,
2, Ez még nagy vonalakban is 3-5 éves fejlesztés,
nem is sorolom, szerintem 5 pontnál több lenne,a marketingesek döntenek, a vezetőség-főnökség-tulajdonosi kör ehhez igazodik, ezt várja el.
Aztán lehet látni a világban, hogy hol tartunk!
'Szóval AI-ra bízni az ellenérvelést minimum necces, ha nem technikai téma, de sok esetben még az is az. Itt a gond az AI kódolással, feature-setekkel, mindennel: mérgezett forrásból "iszol".'
Nem az érvelést bízom rá, hanem az adatgyűjtést.
A kettő nagyon nem ugyanaz.
Sajnos az ingyenes modellek (üzleti titok és jogvédelmi aggályok miatt is) nagyon sok esetben nem közlik, néha kérésre sem a forrásokat.
Nem olvasnak be weboldalakat, nem néznek meg YouTube videókat, és sorolhatnám, mert a jogi aggályok, tiltások miatt korlátozzák ebbéli képességeiket.Ezekhez egy privát, nem üzleti felhasználású AI-ba nem kell beletennem, amíg nem üzleti célú felhasználás lesz.
Például!
Egyszerűen helyettem elolvassa, és ha kérem, akkor linkeli-megnyitja.
De csak azokat a témákat-oldalakat, amik érdekesek a számomra.Ha akarom-megbízom benne (nyílván egészen rövid idő alatt rá lehet jönni a saját modelled tekintetében, hogy mennyire megbízható, könnyű tesztelni, csak akkor változik, ha Te belenyúlsz, arról pedig ugyebár tudsz....), akkor kérhetek összefoglalót is.
"Önállóan képes források után kutatni adott témákban, rengeteg időt megspórolva ezáltal."
Ez az, amit minden AI tud a böngésződbe építve, ingyen. Ezt le is írod később.
De nem tud órákra, napokra, hetekre, örökre eltenni és visszakeresni a számomra adatokat, nem tudja összegezni az elmúlt hónapban összeszedett anyagokat, ha bedobom neki lementett PDF-ként amit én gyűjtöttem össze manuálisan, akkor elfogy az ingyenes token...
Szintén olyat írsz, amit tudok, de feleslegesnek tartok (egyenlőre biztosan, legalábbis ebben a fázisban) állandóan leírni, elvileg nem hülyék járnak a lapcsalád oldalaira, tudnak értőn olvasni. (Persze sokan nem olvassák végig, amikor már ilyen hosszú írások mennek oda-vissza, ezért is nem volt kedvem erre tolni a témát.)'Viszont még mindig nem tudjuk, mit építenél és van-e rá egyszerűbb/könnyebb/hatékonyabb vagy olcsóbb megoldás. Úgy meg nehéz értelmes segítséget adni.'
Viszont ahogy írtam, többször is: Még nincsen itt az ideje...
..még mindig nem ott tartunk, hanem ott, hogy ezekből a vasakból hogyan lehet értelmes/hatékony/munkára fogható rendszert építeni.
A jelenleg megjelent cikkeknek ez a témája.Nagy vonalakban (amennyire jelenleg publikus lehet) érintettem, több AI és AI-Ügynök fog együtt dolgozni, célfeladatokon, adatgyűjtésen, elemzésen.
Ezek pedig összeollózva igen szarul néznek ki, de ha valaki visszaolvas, akkor egyáltalán nem erről volt szó!
'Hidd el, ez tényleg ilyen gombhoz a kabátot érzést sugall; van egy task, azt meg akarod oldani, akkor felépítesz egy MVP-t lehetőleg zéró beruházással, validálod működési oldalról,
aztán megnézed, mivel tudod olcsóbbá tenni
meg egyáltalán van-e rá piaci igény.'
Nézzük sorban:
'Hidd el, ez tényleg ilyen gombhoz a kabátot érzést sugall; van egy task, azt meg akarod oldani, akkor felépítesz egy MVP-t lehetőleg zéró beruházással, validálod működési oldalról,'
A zéró beruházás már megbocsáss így is több millió volt, (A dolgozó szoba jelenleg) szóval a zéró sem állja meg a helyét!
A következő kategória, ami lényegesen jobb teljesítmény nyújt, az több 10M.
Remélem eljutok odáig, egyenlőre a keret ezt engedi, ebből kell főzni!"aztán megnézed, mivel tudod olcsóbbá tenni'
3-4 éve készülök rá, egyenlőre nem találtam olcsóbb-jobb megoldást. Tehát nem AZTÁN MEGNÉZEM A HELYZET!!!Ez a bejegyzés/megjegyzés teljesen másról szólt:
'meg egyáltalán van-e rá piaci igény.'
..még szerencse, hogy nem magyarázod félre.
Kontextusból kiragadott mondatok összeírva kicsit mást jelentenek!
Tesztelem a használatát (ahogy ott is írtam!), és az arra épített szolgáltatásokat. Ebből tanulva kicsit többet tudok majd az éles használatáról! Utána lesz továbblépés...'Nekem is vannak rack-es cuccaim, nincs szívem kidobni őket, de eszem ágában sem lenne azokra felhúzni bármit, mert többe kerülne a leves mint a hús.'
Lehet tudni róluk többet?
'lehet, hogy ezt már mind megcsináltad és most olcsó harvert építesz hozzá'
Bárcsak így lenne, de akkor gyorsabban jönnének ki a cikkek...
Na meg is cáfoltad az előző állításodat:
'(ami verseny területen masszív időveszteség tud lenni, mivel nem te vagy az egyetlen okos ember a bolygón, akinek ugyanaz eszébe juthat).'
Tedd hozzá kérlek, hogy ide nem csak "okos ember" kell. Vannak nálam sokkal okosabbak is, itt a Pro-Családon is. Ehhez kell némi elvetemültség, elhivatottság, és még pár dolog ezek mellett...
Egyszerre hardver, szoftver (rendszer) üzemeltetés, kis hálózatépítés, stb.
Szerintem kevesen vállalkoznak rá, ezekre egyszerre.Örülök, hogy ezeket írod:
'van, amikor a "lázadó" megoldások hatvanszorosan elkenik a "járt utat" (specialitásom), viszont nem a függőhíd közepén térünk le az útról.'
,
mert egyrészt éppen azt teszem, lázadó megoldást alkalmazok. A 25 éves tesztelő, és használt hardver terén, telepítés, üzemeltetés, stb területén szerzett tapasztalatomat igyekszem kamatoztatni egy új területen...
..miközben ezt 3-4 éve építem, tehát pár hozzászólás miatt nem térek le az útról a függőhíd közepén!
És természetesen lehet savazni, biztosan vétek hibákat, mivel asztali szegmenssel foglalkoztam, a szerverek területe számomra teljesen új.
De bízom benne, hogy a lehetőségeimhez mérten a lehető legtöbbet hozom ki az egészből. -
TotoPapp
lelkes újonc
válasz
LordAthis
#18
üzenetére
Az emberi videlkedés sémái meg az emberek kódolási "hozzáértése" továbbra is teljesen más dolgok. Tajtparaszt versenyző is írhatja a világ legjobb kódját, aki egyébként X vagy Y oldalt ekézi full anonimitásban.
A személyeskedésről írt véleményed alapjaiban megmosolyogtató a hozzászólásaid fényében, ezt el is engedem, mert nem visz előbbre.
Viszont te húztál be ide egy hamis alapokon nyugvó érvelést az AI butasága kapcsán (ugye most tech-ai/kód-AI vonalon beszélgetünk, nem napi politikai csatározásokról és hitkérdésekről). Tech vonalon a kód "mérgezése" a szar kód mint forrás. Mivel az AI-nak elvben lehetne lehetősége "in-house" tesztelni egy kód hatékonyságát, méretét, biztonságosságát, stb., így simán szűrhető lenne a "mérgezés", viszont jelen pillanatban az AI buzzword és nem erről szól (ezért van akár több száz, szinte folyamatos veszteséget termelő AI cég a piacon).
"A saját modellem tekintetében én leszek a tényellenőr.
Ezzel kapcsolatban is vigyázni kell, mivel ha és amennyiben az ember "borokban", a "saját világképének búrkában" él, akkor könnyen az önigazolás csapdájába eshet!
Hidd el, látom ezt a csapdát is"
Az a legelső lépés, hogy lásd ezt a csapdát is és örülök, hogy látod is. Kevesen látják.
Az már más kérdés, hogy az emberek (nem kifejezetten rólad beszélek, általánosság) igen nehezen fogadják el az érveket és tényeket, ha az a "hitükkel" szemben áll és kötődnek hozzá.
Szóval AI-ra bízni az ellenérvelést minimum necces, ha nem technikai téma, de sok esetben még az is az. Itt a gond az AI kódolással, feature-setekkel, mindennel: mérgezett forrásból "iszol".
AI által kidobott adatok/tények témája és a valóság: Pár napja toltam egy újabb tesztet; másfél-két óra hivatkozásos érvelés kellett ahhoz. hogy az AI beismerje, hogy félrevezető információt adott egy "fejlesztői által érzékenynek ítélt "témában. Ez konkrétan minőségi esés volt, mert ennyi idő alatt a teljes témakörben eljutok addig, hogy beismerje az igazat, viszont szemmel láthatóan belenyúltak valahol, más ötletem nincs a totál pontatlanságokra és tények eltagadására.
"Önállóan képes források után kutatni adott témákban, rengeteg időt megspórolva ezáltal."
Ez az, amit minden AI tud a böngésződbe építve, ingyen. Ezt le is írod később.
Viszont még mindig nem tudjuk, mit építenél és van-e rá egyszerűbb/könnyebb/hatékonyabb vagy olcsóbb megoldás. Úgy meg nehéz értelmes segítséget adni.
Hidd el, ez tényleg ilyen gombhoz a kabátot érzést sugall; van egy task, azt meg akarod oldani, akkor felépítesz egy MVP-t lehetőleg zéró beruházással, validálod működési oldalról, aztán megnézed, mivel tudod olcsóbbá tenni meg egyáltalán van-e rá piaci igény.
Nekem is vannak rack-es cuccaim, nincs szívem kidobni őket, de eszem ágában sem lenne azokra felhúzni bármit, mert többe kerülne a leves mint a hús.
Viszont mivel nem tudunk semmit, lehet, hogy ezt már mind megcsináltad és most olcsó harvert építesz hozzá (ami verseny területen masszív időveszteség tud lenni, mivel nem te vagy az egyetlen okos ember a bolygón, akinek ugyanaz eszébe juthat).
Szóval kérlek azt értsd meg, hogy a kétkedés, távolság "fenntartása" teljesen valid olvasói oldalról; igen, van, amikor a "lázadó" megoldások hatvanszorosan elkenik a "járt utat" (specialitásom), viszont nem a függőhíd közepén térünk le az útról. -
A példáim abból építkeznek, ami nagyobb adathalmazon több adattal elérhető, az emberi viselkedés általános sémáira...
Aztán ezt lehet különbözőképpen alkalmazni természetesen, ki-ki vonja le a saját következtetését!
AI témában még nincsen elég/releváns mérés, túlságosan is új a téma.Az, hogy nem mindent írok le, még nem jelenti, hogy nem vagyok vele tisztában.
Egyszerűen nem a témába vágó, nem regény-sorozatot igyekeztem írni, mert akkor ezt is beleveszem, hanem az így is terjedelmes témát tekintve alapból hosszú cikk-sorozatot.
Leginkább a technikai jellegű dolgokra szorítkozva:
Tervezés-lehetőségek, Felépítés, Teszt és mérések, Rendszer és összetevők, maga a használt modellek, különbségek-hasonlóságok bemutatása, alkalmazások bemutatása, lehetőségek, stb.Egy bizonyos léptékig megyek csak bele a témába, mivel bújtatott személyeskedésen keresztül ( Pl.: 'de vagy nem elég tágan tekintesz a világra vagy pedig nem vetted észre' - vagy esetleg nem ide vágó a téma...) igyekszel hozzá nem értőnek beállítani, amire igyekszem tényeket hozni, amit természetesen nincsen időd megnézni, de sikerül újra burkoltam és a szavaimat kiforgatva leírni, hogy nem jól látom, naív vagyok, vagy hasonlók.
Annyira azért intelligensen fogalmazol, hogy ne lehessen nyílt támadással vádolni, viszont össze lehet olvasni a közel 20 hozzászólásod...
Több száz előadáson, privát beszélgetésen, és (általam tartott) oktatáson vagyok túl, amik egy része érinti azokat a témákat is, amiket mondasz. (Pénzvilág, a háttérben mozgó erők, stb.)
Egyszerűen nem ide való, maga az indított téma teljesen másról szól.Annyi tartozik ide, amit ki is tárgyaltunk, hogy mennyiben befolyásolja a modell működését, használhatóságát az emberi gyarlóság, lehet-e és kell-e finomítani a működésén.
Ezzel kapcsolatban amikor odaér a projekt, hogy ezeket fogom futtatni, elemezni, kipróbálni, majd akkor tudok róla érdemben értekezni, addig kizárólag azokra a tanulmányokra tudok hagyatkozni, amiket olvasok, már olvastam, és amiket esetleg addig a nagyérdemű közönség hoz.
Akár segítő szándékkal, akár az orrom alá dörgölve, hogy ez kimaradt, személyeskedés nélkül minden információnak örülök, mert tágítja a látásmódom.Ettől függetlenül a bújtatott-, vagy nyílt személyeskedés és az építő jellegű kritika között látok némi különbséget.
'A tényellenőrzés - általános témákban - konkrétan cenzúra (lásd ki őrzi az őrzőket)?'
A saját modellem tekintetében én leszek a tényellenőr.
Ezzel kapcsolatban is vigyázni kell, mivel ha és amennyiben az ember "borokban", a "saját világképének búrkában" él, akkor könnyen az önigazolás csapdájába eshet!
Hidd el, látom ezt a csapdát is.Bővebben kifejtem majd amikor a modell tanításánál és hangolásánál tartunk, azonban röviden...
Lesznek "szűrők", beállítások, amik jelzik a modellnek a következőket:
- Általam elfogadott vélemények, nézőpontok,
- Általam nem elfogadott vélemények, nézőpontommal ellentétes vélemények, ----------> amikre folyamatos vizsgálatot kérek majd, ütköztetve az ellentétes nézőpontokat, szükség esetén (érdekel a téma, vagy számomra fontos terület) külön vizsgálatot, kutatást is kérhetek rá.
- kérdéses, és/vagy új nézőpontok, vélemények,
- új felvetések, (vizsgálatra küldve)Stb.
Ez most csak egy nagyon sablonos leírása volt annak, amit tervezek.Lássunk egy példát:
Önállóan képes források után kutatni adott témákban, rengeteg időt megspórolva ezáltal.
Például kerestek üzleti ajánlattal, hogy XY cég milyen fantasztikus üzleti lehetőséget jelent.
Alapból nem mondok zsigerből nemet semmi hasonló megkeresésre, természetesen azért óvatos vagyok.
Bármelyik használható AI modellt meg lehet kérdezni ezekben a témákban is, és több óra, több napos kutatást pár perc alatt használható adatokkal váltja fel.
Természetesen prompt kérdése is.
Mondjuk a cég nevén, hírén kívül érdemes megkérni, hogy a cégről elérhető adatokat ellenőrizze, a reklámanyagok állításait ellenőrizze, az állítólagos partnerek tudnak-e az együttműködésről, vagy csak a weboldalukon szerepel, és az ügynökeik mondják, félrevezetve. (Például egyik hamis állítás volt az egyik esetben, hogy a New York-ot üzemeltető céggel álnak kapcsolatban, meglévő szerződéssel, hogy a város üzemeltetésének automatizálását saját fejlesztésű AI-al segítsék... Ebbe a cégbe lehet befektetni, mielőtt tőzsdére kerül, és a világ más nagyvárosaival is szerződést kötne.
Az egészből annyi volt igaz, hogy a nyilvánosan elérhető adatokat futtatták a saját AI-on, ami pár dolgot automatizált, és ajánlatokat tett, de a valódi működéshez - szerintem lehetetlen - az összes magán céggel, és a szolgáltatókkal is - ez lenne lehetséges - szerződni kell, és bekötni digitálisan. Pl kávézó foglaltság, asztalfoglalás, stb. Szóval szép álom, egy katonai fegyelmű világban még működne is, de itt?)Nem részletezem, minden eset más.
-
TotoPapp
lelkes újonc
válasz
LordAthis
#15
üzenetére
A pédáid javarlszt a közösségi média és hasonlók problémáiról szóltak. Ha programozásról beszélünk, ott eleve nem lenne szabad semmilyen szinten hölyeséget beengedni, mert az tisztán szakmai alapú téma; konkrétan mérhető egy megoldás hatékonysága számokban.
A tényellenőrzés - általános témákban - konkrétan cenzúra (lásd ki őrzi az őrzőket)?
Szerintem sokkal nagyobb baj van a világban mint hinnéd, de vagy nem elég tágan tekintesz a világra vagy pedig nem vetted észre azokat az összefüggéseget, amelyek éppen fűrészelik alattad az ágat "csaki s a te érdekedben".
Nem olvastam, biztosan érdemes, de jelenleg még szórakozásból sincs időm olvasni, tanulom a sokadik szakmámat. -
Sok tekintetben igazad van, van, ahol mégis ellent kell mondjak.
Az egyik cikkben leírtam, hogy a sok szál esetén megfelelő mennyiségű elérhető erőforrás áll a rendelkezésemre, ami sok mindenre (célzott tervezéssel) jó, például API lekérdezések, py kód alapon adatfeldolgozás. - Ezekről röviden írtam már, érintettem a témát. - Itt nem kell a CPU-knak varázsolnia, nem AI fog rajtuk futni, csak szállítja az információt a megfelelő adatbázisba, előszűri, stb.
Ezen felül a rendszernek is vannak szolgáltatásai, amiket ki kell szolgálnia, monitorozni, stb. (Ahogy írtam: Graffana, Prometheus, stb)Aztán (Ahogy sikerül hasznos munkát végeznie, ahogy termel, ami ugye pénzt jelent...) amikor van értelme, lehet költeni erősebb hardverre, lépésről-lépésre cserélve, anélkül, hogy bárminek le kellene állnia. (Mert ugye ez a Cluster egyik előnye, célja...
)Ahogy eljut oda a projekt, hogy egyre több része működik, bekerül céghez, ipartelepre...
 Nyilván adni kell érte vmit, de a cég fizeti az áramot...
Nyilván adni kell érte vmit, de a cég fizeti az áramot...
Talán elárul vmit az, hogy nem fogják észrevenni a bekapcsolást.
Lényegesen nagyobb fogyasztók vannak a környéken!
Sokkal nagyobb problémám, hogy a nafta szűrt, "minőségi" legyen!A másik oka, hogy nem csili-vili új/drága gépekkel játszok!
Az majd ha van termelés, akkor szerver terembe megy.Különben köszönet bármilyen szakmai hozzászólásért, mert ez a közzététel oka, nem tudhatok mindent, nem gondolhatok mindenre!
-
Nem azt mondtam, hogy nem beszélhet bárki bármilyen butaságot, hanem hogy engedik, hogy a modell ezt súlyokkal és fékekkel ugyan (még ha rosszul is beállítva), de tanulja.
Igen, a tény ellenőrzés jelenleg nem igazán valósul meg, éppen csak csiszolgatják, karcolgatják a felszínét...
Baj van a világban, nem is kevés, de azért én kevésbé borúsan látom a világot. Naív sem vagyok, de a világvégére még várni kell!
Különben csak egy kérdés: Raymond Kurzweil: A Szingularitás küszöbén c. 2005-ben megjelent könyvét olvatad?
(Egy 2005-ben megjelent ismeretterjesztő könyv Ray Kurzweil tollából. A könyv a mesterséges intelligenciával és az emberiség jövőjével foglalkozik, azon belül is a nanotechnológia, a technológiai szingularitás és a transzhumanizmus irányaival és lehetőségeivel. - WiKi - Moly.hu)
Érdemes, jó szívvel ajánlom, de a többit is.
A folytatás: 'The Singularity Is Nearer' 2024 - WiKi - Moly.hu (legjobb tudásom szerint) még nem jelent meg magyarul, de feltételezem, hogy az angol sem jelent gondot.Szintén nehéz téma a 2012-ben megjelent: 'Hogyan alkossunk elmét?'' c. könyve (Moly.hu), ami sokkal több vitát gerjeszt, a transzhumanizmus kérdésköre miatt!
-
TotoPapp
lelkes újonc
válasz
LordAthis
#12
üzenetére
"Bármilyen témáról f.@$zségokat beszélni, ugyanúgy trollkodás.
Attól pedig igenis "mérgeződik" az adatbázis."
Szeretném megragadni ez esetben az alkalmat, hogy faszságot beszélni és buta véleményen lenni a demokrácia alapja, mint ahogyan a te vagy az én különvéleményem is.
Tehát amikor te "mérgezésről" beszélsz, konkrétan az emberi szabadságjogokat nyírbálod, ami a legnagyobb hiba, amit elkövethetsz (általános, nem IT szakmai témákban).
Ha nem szertnél egy orwelli világban élni (bár ezzel már elkéstümk; az AI úgy hazudja telibe az arcodat, ahogy nem szégyelli (miért is szégyellné, így programozták az emberek butítására), akkor bizony az AInak minden véleményre figyelnie kell, azonban ragaszkodnia kellene a tényszerűséghez (ezzel köszönőviszonyban sincs). -
Tényleg elsiklottam afelett hogy ezt az egészet egybe akarod hozni,hát ez igy nem mondom inkább mert biztos vagyok benne hogy kivételesen rossz energiahatékonysággal fog birni.
A jelenlegi CPU-kkal megvalósul:
Sok mag, sok szál, nagy tárhely az adatoknak.
28db CPU, 274Core, 1892Thread,
191db RAM, 1384GB RAM.
Több, mint 100GB VRAM,
Több, mint 1'000TB HDD/SSD
Szép számok de ezt egy dual Epyc bármikor kettépisili.
Csak ennyit akartam kihozni hogy jók ezek a régi olcsó holmik csak nem fenttartható ezért is nincs már áruk.
Igy egybetéve pedig hát az hogy lesz 1900 thread,de milyen gyenge?
És mennyire elavult utasitáskészletekkel?
Az árak amiket leirtál hát igen pont ezért annyik,mert 2 db cpu hozza ennek a (mostmár látom jóval több lesz mint 5KW/h)szörnynek a teljesitményét.
Mindezek mellett is sok sikert és kitartást kivánok!
Továbbra is követem a fejleményeket.
-
Pedig olvasni nem árt...
viccet félretéve:
'Az agresszívkodás vagy parasztság, trollkodás semmilyen szempontból nem befolyásolja a kód minőségét. Az AI nem személy; nem fog neked szarabb kódot írni, amiért lehülyézed zsinórban százszor egymás után (ami nekem szokásom), csak a fennmaradó tokenszámod kevesebb, ha anyázásra pazarlod.
Tehát az. hogy te éppen mit anyázol össze vagy ahasonlók nem releván tartalmi szempontból.'Nem csak ilyen módon lehet trollkodni, nem csak direkten.
Indirekten:
Bármilyen témáról f.@$zségokat beszélni, ugyanúgy trollkodás.
Attól pedig igenis "mérgeződik" az adatbázis.A "szakember így szoktuk csinálni, tehát jó" részemről ugyanúgy trollkodás, ráadásul a rosszabbik fajtából.
Lehetséges, hogy nem fogalmazok jól, és nem érted, de pár dologról kb ugyanazt mondjuk, noha nem mindenben értünk egyet.
'2. Mivel még mindig fogalmunk nincs, hogy konkrétan milyen feladatot oldatnál meg vele, így vaktában megy a lövöldözés, hogy mi éri meg és mi nem éri meg.'
Erre csak azt tudom mondani, amit már többször leírtam, hogy akkor kérlek várjátok meg az aktuális cikket, nem szeretnék korán semmilyen poént lelőni, összevisszaságot sem szeretnék.
Haladni szépen sorban.Természetesen ez nem jelenti azt, hogy nem válaszolok, mert az egyik témának sem jó, viszont az adott téma alatt leginkább az adott témával igyekszem foglalkozni.
Amit lehet, azt röviden kifejtem, mert ha cikk-hosszúságú lenne, akkor inkább megírom cikknek.
Csak akkor lesz olyan hosszú válasz, ha a témát érinti (Az egész cikk sorozatot illetően, bármelyiket), de nem volt alapból tervezett cikk róla.
A hardver mennyisége kérdés:
alapvetően igazad van, azonban egy jól skálázott cluster elosztja a feladatokat, oda küldi, ahol a leghatékonyabb a megoldás, hatékonyan képes párhuzamosan dolgozni, képes hol az egyik, hol a másik VM felé nagyobb erőforrást adni (Ahogyan a felhőszolgáltatások is teszik!), közös adatbázisból dolgozni, stb.De ezeket Neked ugyanúgy tudnod kell.
A felhő bizonyos (többségi, általános) esetekben költséghatékonyabb, azonban magad világítottál rá nem is egyszer, hogy a kőműves megközelítés gyakran nem állja meg a helyét.
Attól, mert a 99% így csinálja, nem biztos, hogy az a jó, vagy a követendő egyenes út!
Ráadásul a 99% lehet, hogy a saját céljaira jól is csinálja, de az egy másik feladatra nem biztos, hogy ugyanúgy megfelelő!'Nekem a fél életem arról szól, hogy kineveljem az emberekből a nettó fasz.sgot, amivel a saját dolgaikhoz állnak mint 'szakemberek".
Egy kezdőnek sokkal jobban el tudod magyarázni az alternatív megközelítését valaminek mint egy becsontosult szakinak.'Nekem is erre ment el a fél életem...
Ismerős, most is ezt teszem. 
(Bocsi, ez kihagyhatatlan volt! Én kérek elnézést! )25 éve informatikázok. Ezalatt nagyon sokszor futottam bele, hogy adott szakterületen kellett az adott szakértővel vitázni, és sehogysem ment, hogy átérjen az INFÓ.
Én az informatika egészével, nem csak 1-1 területtel foglalkozom, és nem iskolában tanultam ezeket, hanem a gyakorlatban.
És igen, ez néha hátrány is lehet, hogy nem iskolában, de általában előnyét látom! Nincsenek pre-koncepcióim, nem a miért nem működik-et keresem, hanem a hogyan oldjuk meg-et!
Átfogó látásmódom van, áttekintést ad több terület felett, ami miatt az adott terület szakembereivel előfordulnak szakmai viták. (Nem véletlenül!)
És lehet, hogy mélységében nem vehetem fel a versenyt 1-1 területen, de az előforduló, több szakterületet felölelő hibákat jobban észreveszem!
Például éppen a megcsontosodott szokások hiánya miatt...Nagyon sokszor bizonyítottam, hogy az az elavult hardver bizony nem is annyira használhatatlan hozzáértő kezekben!
-
TotoPapp
lelkes újonc
És még egy:
A senior fejlesztők ugyanúgy idióták (teisztelet a kivételeknek), csak másképp. Rákérdezhetsz százszor, hogy "ezt miért így, miért nem úgy", de a válasz ugyanaz mint a kőművesednél: így szokta meg.
Na attól még, hogy valaki valamit megszokott az még nem lesz sem hatékony, sem ideális.
Nekem a fél életem arról szól, hogy kineveljem az emberekből a nettó fasz.sgot, amivel a saját dolgaikhoz állnak mint 'szakemberek".
Egy kezdőnek sokkal jobban el tudod magyarázni az alternatív megközelítését valaminek mint egy becsontosult szakinak. -
TotoPapp
lelkes újonc
Még egy dolog:
a hadver "mennyisége" nem úhgy megy, hogy összeadod, hogy mennyi RAM vagy VRAM összesen. Ugyanis ezek nem adódnak össze jellemzően semmilyen feladatnát; ami a single gépben van, az a határ (és már akkor is mázlista vagy, ha megy mondjuk az NV-Link).
A felhő esetében meg ugy vagy automatikusan választ vagy te választasz, mondjuk miből mennyi kell az adott feladatra.
A többgépes megoldást sem értem. Minek? Egyszerre egy problémán tudsz hatékonyan dolgozni. Felesleges. (ahogy írtam, fogalmunk nincs, mit akarsz csinálni).
Üzembiztonságban meg a felhő lever szinte mindent, ami épeszű költségvetéssel elérhető nagy feladatra. -
TotoPapp
lelkes újonc
Röviden és bocs, nincs az az isten, hogy végigolvassam a tanulmányokat, ammelyek teljesen értelmetlenek a vizsgált probléma szempontjából.
1. A az agresszívkodás vagy parasztság, trollkodás semmilyen szempontból nem befolyásolja a kód minőségét. Az AI nem személy; nem fog neked szarabb kódot írni, amiért lehülyézed zsinórban százszor egymás után (ami nekem szokásom), csak a fennmaradó tokenszámod kevesebb, ha anyázásra pazarlod.
Tehát az. hogy te éppen mit anyázol össze vagy ahasonlók nem releván tartalmi szempontból. Más kérdés a szöveges vagy képi tartalom trollkodása, de ott sem visszatartó erő semmi, ami nem ütközik jogszabályi korlátokba. Továbbá az anonimitás pont fordítva működik olyan esetekben (a regisztráció alapvetően még nem jelent teljes publicitást, csak ha személyes adatrokat is teszel mellé, pl. bankkártyaszámot) sokkal inkább tolhatja pozitív irányba a mérleget olyan témákban, aholl ez visszacsaphat rád (pl. külpolitika, belpolitika, tudomány, társadalomtudomány) és ahol az AI szinte folyamatosan igyekszik manipulálni a felhasználókat stratégiai érdekek illetve korszellem mentén.2. Mivel még mindig fogalmunk nincs, hogy konkrétan milyen feladatot oldatnál meg vele, így vaktában megy a lövöldözés, hogy mi éri meg és mi nem éri meg.
3. A kód szétbontása logikus, ugyanakkor van, amit már nem tudsz jobban szétdarabolni, mert onnantól nem tesztelhető, olyan szükséges összefüggéseket tartalmaz.
4. Alapvetően a a statisztikus/probalisztikus megoldások remekül használhatóak bizonyos feladatokra (cikkírás, képgenerálás, etc.), viszont bizonyos feladatokra csak igen korlátozottan. Részben az elvük, részben a "súlyozásuk miatt". Ide írnék szívesen példákat, de nem akarom, hogy kib.sszanak.
5. "pl. hallucinációkhoz vezető promptok". Ez így egy tévedés. A hallucinációl leginkább onnan jönnek, hogy az LLM-ek képtelenek elmondani azt (fejlesztői szabály/baklövés), hogy:
- gőzük nincs valamiről
- rég túlmentél a kontext limiteden az adott chat esetében
- a user hülye (AI: adj lécci-lécci több infót, hogy ne b.sszam el!!!).Ezek strukturális problémák, a rendszer megoldhatatlan gyengeségei.
-
@TotoPapp:
Igyekszem sorban válaszolni a #4 és #5 hozzászólásaidra.- 'Itt sajnos keversz két dolgot'
Vagy csak nem írtam érthetően, akkor elnézést érte!Említetted, hogy az anonimitás és a butaság nem függ össze, és a regisztrált felhasználók is lehetnek hülyék, míg az anonimok okosak. Ezzel alapvetően egyetértek: valóban, az intelligencia nem függ a regisztrációtól, és nem rád vonatkoztattam a korábbi hozzászólásomban. Viszont a "mérgezés" aspektusára vonatkozóan kerestem adatokat, mert érdekes kérdés, hogyan hat az anonimitás az online interakciók minőségére és az AI tanítási folyamatára (garbage in, garbage out, ahogy te is írod). Több tanulmány mutatja, hogy az anonimitás gyakran növeli a trollkodást, agresszív viselkedést és alacsonyabb minőségű tartalmat online platformokon, ami visszahat a modellekre. (Link - Link - Link)
Például egy Pew Research tanulmány szerint az anonimitás hozzájárulhat a manipulatív viselkedések terjedéséhez, ami hosszú távon rontja a közösségi média minőségét. (Link)
Egy másik kutatás Q&A site-okon vizsgálta, és azt találta, hogy az anonimitás növeli a trollingot és csökkenti a tartalom minőségét, miközben a user engagement-et is befolyásolja. (Link)
A louisbouchard.ai cikke például kiemeli, hogy az API-k használatakor megbízható forrás-definíció elengedhetetlen. Ha anonim, korlátozatlan hozzáférés van, az könnyen vezethet "feedback-bombázáshoz", mely hibás irányba tanítja a rendszert – leginkább, ha nincs input filtering és reputation scoring.AI-specifikusan: Ha sok anonim input alacsony minőségű (pl. hallucinációkhoz vezető promptok), az visszahat a modell tanítására, különösen ha a feedback-rendszer nem súlyoz megfelelően. (Link)
Ez persze nem jelenti, hogy minden anonim felhasználó "mérgező", csak hogy statisztikailag nagyobb a kockázat – és itt jön be a te 'garbage in, garbage out' pontod, amivel teljesen egyetértek.
Szerintem nagyjából ugyanezt is írtam, esetleg másképp fogalmazva.- Aztán a statisztikai (LLM) megközelítésre is kitérsz, és hogy az LLM-ek alkalmatlanok komplex feladatokra a többségi módszer dominanciája miatt. Remek példa, amit felhoztál: igen, ha 99-ből 99 Y módon old meg egy feladatot, akkor az innovatív Z elvész, ami gátolja az invenciót.
(👉 Az arxiv.org/abs/2408.09205 pont ezt vizsgálja: milyen infra- és adatstrukturális tényezők csökkentik az LLM teljesítményt a használat során.)Saját tapasztalatomban is láttam ezt, pl. a statisztikai elemző szkriptemnél, ahol az AI mindig az "átlagos" HTML/CSS/JS egyveleget javasolta, és csak iteratív promptokkal (pl. "gondold át fordított sorrendben") tudtam kilépni belőle. A szabálykövetés gyengeségére (pl. "ne nyúlj ehhez") is igazad van – senior fejlesztők fórumain is panaszkodnak erről. Az incremental development jó elv kis projektekre, de nagy kódnál token-limitek miatt valóban falhoz vezet, ahogy írod. Erre a workaroundom a moduláris bontás (külön fájlok, külön promptok), ami nálam bevált.
Pl. a statisztikai, Token limitbe be nem férő soksoros spagetti kód refaktorálásánál így fértem bele az ingyenes keretbe, és könnyebb volt debugolni.
A költségekről: Nekem nem sikerült belefutni ebbe, hogy nullázódna az előfizetés – viszont ahogy mondtam, én nem vagyok professzionális fejlesztő, egyenlőre csak hobbi-kóder.
Ennek ellenére látom előre a lehetőségét, olvastam róla, megszívlelem az óvó tanácsokat, ezért vagyok a saját hardveren futtatott modellek felé orientálódva, ahol nincs token-alapú elszámolás, és kontrollálható a tanítás.Az "egyre butábbak" jelenségről: a tanítási adatok hígulása és a biztonsági szűrők miatt is. Empirikusan én is érzem: Régebbi modellek néha jobbnak tűnnek specifikus feladatokban, de bizonyítani nehéz. Ha van tipped, hogyan mérjük ezt objektíven (pl. benchmarkokkal), osszd meg!
Különben is tervben volt a cikk-sorozathoz mérési rész is!Kedvenc mondatom, amit nagyon sokszor hallottam szinte mindegyik kipróbált AI-tól:
"hát igen, ezt nem gondoltam végig"
Ha annyi tízezresem lenne, ahányszor olvastam...
Ez a mondat valóban jelzi a modell bizonytalanságát.
Nem butaság, hanem strukturális határ a statisztikai megközelítésben.
Hogyan oldhatod fel? Használj olyan prompt technikákat, mint:
- „Gondolkozz lépésről lépésre”
- „Ellenőrizd a válaszod logikáját”
- „Válaszolj úgy, mintha 3 különböző szakértő vitatkozna”
Ez közelít a Tree of Thought (ToT) vagy Self-Consistency módszerekhez — és sokkal kevésbé fogja használni azt a „hát igen” szöveget.1, Különben megoldás lehetne az anonim problémára, egy "feedback súlyozási modell", ahol:
Regisztrált → magas megbízhatóság
Bejelentkezett, hosszú múlttal → magasabb súly
Anonim → alacsony súly, ha nem hitelesíthető
Ez megoldja a garbage in problémát, anélkül hogy kizárná az anonim felhasználókat.
Ha nyílt modellt fejlesztenék, akkor ez lenne egy megoldás, amit beépítenék. 2, Még mindig úgy látom, hogy saját modell tanítása a célravezető, amit akár VAS üzemeltetés nélkül is ki lehetne próbálni, azonban hosszútávon azt gondolom, hogy költségesebb a VM-ből egy ekkora kapacitást üzemeltetni.
Ismétlem! HOSSZÚTÁVON!
A saját hardver, megfelelő erőforrásokkal, majd szükség esetén eseti erőforrás bérlés 1-1 számításhoz, tanítási folyamathoz szerintem költséghatékonyabb.Még akkor is, ha nem tud mindent, ilyenkor bérelt AI-t kell bekötni API-on keresztül, amivel fel lehet tanítani a sajátodat a meglévő, működő modell alapján...
Legalábbis a hiányosságokat megkérdezni.-----------> Több AI, több API bekötés, gyorsabb tanulási folyamat.
Ez kb. "meta-LM workflow":
- A saját modell dönti el, mikor nem tudja a választ.
- Ekkor egy másik (külső) LLM-hez fordul, API-n keresztül.
- A választ feldolgozza, ellenőrzi, majd lehet, hogy finomhangoláshoz (finetune) vagy RAG bázishoz használja.
Ez a megközelítés sokkal hatékonyabb, mint sokan gondolnák. A medium.com/gen-ai-adventures elemzi, hogyan kezeljük biztonságosan az API-hívásokat – ideális alap, jó szakmai anyag...Összességében ezek a pontok segítenek finomítani a saját megközelítésemet – pl. a következő cikkemben beépítem a te workaroundjaidat, mint a session reset vagy az analógiák használata. Ha van anonimizált példád egy komplex feladat "meghekkelésére" (pl. a körrajzolásodhoz hasonló), szívesen kipróbálom és visszajelzek.
Értékelem a tippjeidet (valóban hasznosak lehetnek, pl. session reset a kontextus frissítésére vagy analógiák a promptok finomítására), ahol illeszkednek a projektemhez (pl. modelloptimalizálás, hardveres tanítás, prompt-strukturálás során), ott használni is fogom őket, mint tesztelendő ötletet!
Ha segíti a munkámat, akkor említeni is fogom az aktuális részét feldolgozó cikkben mint inspirációt. @TotoPapp és @arabus:
Kicsit olyan érzésem van, hogy még nem olvastátok el a cikkeket, vagy csak 1-1 részét...
Egyértelműen többgépes projekt (Szerintem egyértelmű, hogy egy több Szerverből álló Cluster a több gépes projekt... )
A programozóknak természetes, hogy a rendszergazdák stabil, biztonságos, magas rendelkezésreállással biztosítanak megbízható szolgáltatásokat, nekik csak dolgozni kell.
Erős gépeken dolgoznak (jó esetben, mondjuk ha abból indulok, ki, amiket mondtál @TotoPapp), és amit futtatni kell, feltöltik szerver környezetbe.
Nem feltétlenül gondolják át, hogy ez mivel is jár ott...@arabus:
- energiafogyasztás: Több helyen, többször is írtam már...
még nem mértem, nem lesz kevés, de nem lesz többszáz $ sem, mintha professzionális szervereket és AI-kat bérelnék! (Cserébe egyedi, én tanítom fel, arra használom, amire akarom, nincsenek idegesítő korlátozások, stb..)Óvatosnak kell lenni. A konfigom nem csak sok áramot eszik, hanem a hűtésről is gondoskodni kell, a karbantartás sem elhanyagolható, és redundancia is kell hozzá.
👉 A rohan-paul.com mutatja, hogy még az LLM inference is, GPU-optimalizálás és KV-cache kezelés nélkül 10x drágább lehet!!!Igyekszem nem csak a hardver árát nézni, hanem:
- Teljesítmény/watt (kWh)
- Időegység alatti LLM-inferencia (pl. tokens/sec)
- API call-költség vállalkozás esetén (AWS/GCP vs. saját rack)
Tervben van, hogy készítek egy TCO kalkulátort (Total Cost of Ownership) is a cikkekhez, mert biztosan tanulságos lesz mindenkinek! (Nekem is!)- CPU:
Meg fogom vizsgálni a kérdést, mert önmaga a CPU hiába szimpatikus, (Mert nagyon is az!) hiába rendelkezik jó technikai paraméterekkel, hiába teljesít jól teszteken és nyújt AI számításban is kicsivel többet, esetleg még olcsóbb is a CPU,...
..de ha komplett konfigot nézünk, akkor mi is a helyzet?
Gyors kereséssel: Magyar áruházban kész "Emerald Rapids 52/104 proci" alapú rack konfiguráció ritka, de egyedi összeállítás lehetséges (pl. ITStore.hu). Egy minimális setup (alaplap + CPU + rack) ára kb. 2,800,000–3,500,000 Ft, dual CPU-val 4,500,000–5,500,000 Ft.
Rack konfiguráció szükséges!Akkor inkább a speciálisabb 3D kártyára költök ennyit, ahol a GPU mag, a CUDA (újabb, mint a számomra jelenleg elérhető!) és a VRAM sokkalta fontosabb tényező!
A jelenlegi CPU-kkal megvalósul:
Sok mag, sok szál, nagy tárhely az adatoknak.
28db CPU, 274Core, 1892Thread,
191db RAM, 1384GB RAM.
Több, mint 100GB VRAM,
Több, mint 1'000TB HDD/SSDJelentősen nagyobb redudancia, párhuzamosság, stabilitás.
(És igen, ennek van költség oldala energiában! - Még nincsen, még egyszer sem volt egyszerre az egész bekapcsolva! Ha olvastad, az összerakásánál tartok. Nem szeretek becsülni, majd mérek, ha eljutottunk odáig! De azért lesz HW összesítő, ahol a Tápok is feltűntetésre kerülnek majd!)Valahogy azt látom, hogy nem látjátok át a projektet, csak 1-1 részét nézitek. (Elnézést, ha tévednék...)
Egy cluster nem csak üzemeltetésében más, stabilabb, megbízhatóbb, edudánsabb is. (Nyílván másrészről cserébe több feladat is.)Azonban a teljes rendszer fut tovább, amikor 1-1 gépet leállítasz karbantartás és/vagy fejlesztés végett, skálázhatóbb, mikor melyik részének van nagyobb teljesítményre szüksége....
Külön részek végzik a folyamatos adatmentést.
Több VM futhat párhuzamosan, több lehetőség, plusz teszt rendszerek lehetősége éles környezet helyett!
Stb. -
Megkérdezhetem?Nem jött le az egész irományból hogy ez most egy gép vagy több gép projekt?
Mennyit fogyaszt egy-egy ilyen nagyon elavult masina és érdemes-e vagy megtérithető-e ezt (ezeket)bármilyen jellegű AI számitásra-futtatásra-generálásra használni?
Egy max terhelésen 300w-ot fogyasztó Emerald Rapids 52/104 proci jelenleg 1000 Kinai juanért(47000FT) megkapható,ezeknek a leirt masináknak 3-4 szeres teljesitményével.
(ha az az állványos kép az ez a gép,az kb 2-3 kilowatt ránézésre is)
Oké értem hogy szenvedély-kihivás és a többi,de lehetne ezt ésszel is csinálni.
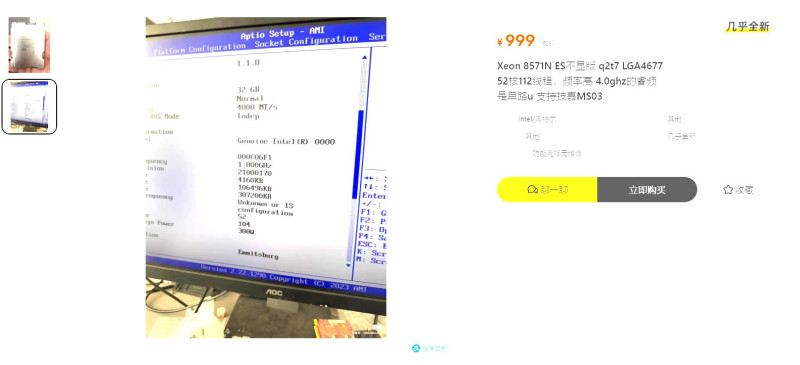
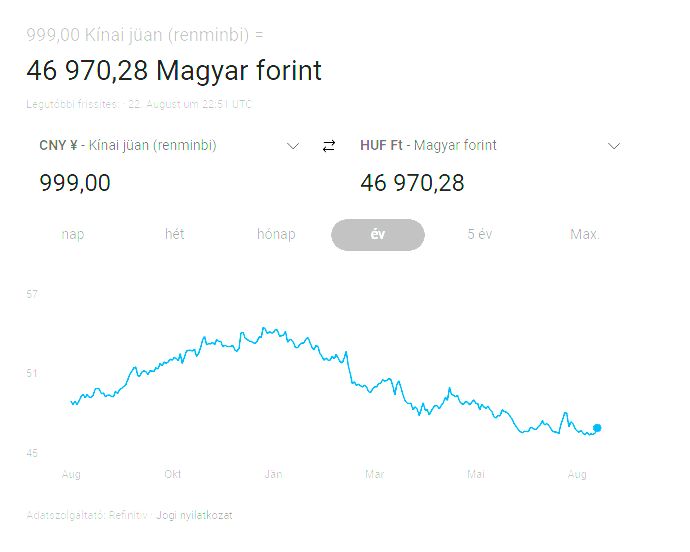
-
TotoPapp
lelkes újonc
Statisztika alatt az LLM megközelítést értettem.
Ha X taskot 100 emberből 99 Y megközelítéssel éri el, 1 meg Z megközelítéssel, akkor az Y lesz az irányadó akkor is, ha egyébként rosszabb (az az embereknél is így van, a cégeknél is így van mostanra). Gyakorlatilag halódik az invenció és az innováció is.Az LLM szerintem a működésénel fogva alkalmatlan arra, amire mi itt használni akarjuk; erről tegnap éjjel elég hosszú beszélgetésem volt az AI-val (limitek, workaroundok, sb.).
Ha megnézed a felhasználói fórumokat, senior fejlesztők is agyfaszt kapnak a szabályok be nem tartásától (például). Hiába jelölöd, hogy mihez ne nyúljon, legenerálja, újraírja, elkúrja.Aztán ott van minden AI imádott javaslata "incremental development" és akkor nincs token gond. Kérdem tőle: meséld már el nekem, hogy a f.szba fok én megtalálni egy bugot a komplett kódban veled anélkül, hogy az egészet feltölteném? Hogyan tudok bármit hozzáadni featureként, ha az egy csomó alrendszerrel direkt kapcsolatban van és oda-vissza érintik egymás működését?
Erre vakarja a virtuális fejét és elmondja "hát igen, ezt nem gondolta végig".
Ezért írtam: kis dolgokra jó; nagy dolgokra kell az ember, mert vagy a gatyádat fizeted ki vibe codingra (ugyanazt a propmtot visszaküldi neked tizenötször hibásan; azért is fizetsz, viszont az embernek nem). És akkor számoltass ki vele mibe kerül neked megcsináltatni token alapon elszámolva (ez is a viág faszsága), az , hogy hússzor visszatolta neked a hibás kódot. Nem kell 3000 sor, csak 1000.
Seniorok egy délután alatt nullázzák az előfizetésüket, onnantól minden fizetős; fullos 200 dolláros csomagot is se perc alatt nullázol vibe codinggal.
És egyre butábbak (pont tegnap beszéltem erről ismerőssel, ugyanaz a tapasztalat; egyre rosszabb minőségú válaszokat kap vissza a régi modellektől is). Viszont bizonyítani nem tudom.
-
TotoPapp
lelkes újonc
"Nekem az anonim megközelítés nem vált be, egy kicsit visszásnak érzem, néha egyenesen A PROBLÉMÁNAK, mert az AI tanulási folyamatainak "mérgezésével" jár, ami rövid távon (Akár 1-2-3 év is lehet) inkább ront a modell tanulásán."
Itt sajnos keversz két dolgot. Az anonimitás és a butaság egymással nem összefüggő dolgok. A regisztált felhasználó is lehet hülye meg az anonim is okos. Semmilyen szempontból nincs jelentősége az AI tanulási folyamatában, hacsak nem hülyék írják (igen, rengeteg hülye dolgozik egyébként az AIkon; kérdezt meg róla az AI-t magát, amikor beleütközöl egy-egy nyivánvaló ostobaságba).
Továbbá: az emberek többége idióta. Sajnos. Az AI meg statisztikai alapon megy (részben) és még feedback esetén (amikor Béla elégedett az eredmémmyel) sem biztos, hogy az egy valóban megfelelő eredmény. Ez az elúlt évtizedek rendszerszintű gondolkodásának eltűnéséből fakadó "korszellem". Az emberek egyszerűen nem tudják, hogy mi a jó és mi a nem jó. Sosem láttak jót.
Ezt levetítheted a teljes fogyasztói társadalom termékpalettájára.Garbage in, garbage out.
-
Remek, haladunk!
Ezekből - ahogy korábban már írtam is - párat használok, de a többi remek példa, ki is fogom őket próbálni.
Nekem az anonim megközelítés nem vált be, egy kicsit visszásnak érzem, néha egyenesen A PROBLÉMÁNAK, mert az AI tanulási folyamatainak "mérgezésével" jár, ami rövid távon (Akár 1-2-3 év is lehet) inkább ront a modell tanulásán.
Egyszerű matek.
1 regisztrált felhasználó jó véleménye, produktív tanulási hozzájárulására jut 100 anonim felhasználói hülyeség. (És itt most nem Rólad beszélek, hanem az általános problémáról!)
Az általános matek (kicsit talán tévesen is) ezt úgy emeli be, hogy valószínűbb a sok ember mond jót, igazat, mint az egy.
Nos ha az az egy a szakember, szemben 100 hozzá nem értő felhasználóval...
Egyenlőre ennek súlyozását emberi erőforrással nem győzik rendbe tenni.A programozás esetén is: "A kevesebb néha több!"
Tehát a GitHub-on és rengeteg fórumon elérhető kusza kódok sokaságán tanított modell megbízhatósága enyhén szólva is megkérdőjelezhető!Itt jön képbe, amit írtam, amiért egyáltalán belevágtam a Projektbe.
Saját modell, saját tanítás, a képzés folyamatos felügyelete.Külön célra külön modell, arra a feladatra képezve.
Matekra és Statisztikára visszatérve nagyon oda kell figyelni, mert nála a kétszer kettő néha nem is öt, hanem egyenesen hat...
Statisztikai elemzést csináltam vele, kicsit küzdős lett. Egyben írt olyan spagetti kódot, (HTML, CSS, JAVA egyveleg) hogy aztán a fejlesztés már nem fért az ingyenes tokenekbe.
Szét lett bontva, több darab html, css, js, több könyvtárban. Mindegyik 1-1 célfeladattal.
Egyrészt belefér ha jól promptolok az ingyenes tokenbe, (direkt kipróbáltam, aztán átváltottam fizetősbe, mert megéri a tökölődés hiánya az a pár roopit.) másrészt könnyebben is karban tatható és fejleszthető a kód.Külön fájlban el van tárolva a prompt, amit csak ki kell egészíteni.
Mondjuk ilyenek vannak benne például:
"Ez a fájl egy projekt egyik darabja. Ezért minden marad változatlan, csak azt módosítjuk, amit itt írok. Csak azt a kódrészletet írd le, amit be kell illesztenem, és a sort, ahová. Mellékelve feltöltöm a jelenlegi kódot. Ebbe szúrjuk be az új funkciót."(Ez most nem a konkrét prompt, - nem ezen a gépen dolgozom - csak hogy el lehessen képzelni.)
"nem hajlandó kirajzolni egy kört x pixel átmérővel y px vastag zöld körvonallal?"
Ilyenkor keresek másik modellt, ami ebben jó, majd az eredményt visszahozom folytatni a feladatot.
Ráadásnak ha megadom, hogy ez lett volna a feladat, akkor tanul az a modell is, ami nem tudta.Azért ha eszedbe jutnak majd még példák, vagy megteszed a közösségnek (és nekem) azt a szívességet, hogy lemodellezve a problémát konstruálsz egy hasonló feladatot, amin tanulni-példálózni lehet, akkor
Nálam ez a közeljövőben lesz így, ahogy látod a projekt nem abban a fázisban van.
Jelenleg a saját környezet építése zajlik, aztán jöhet a teszt és tanítás! (Bárcsak már ott tartanék!!! )Abban a fázisban komplett GitHub projekteket szeretnék majd megosztani.
-
TotoPapp
lelkes újonc
Elengedve a személyes vonalat általános tippek és trükkök:
- Ha az egyik AI nem tudja megoldani/javítani, engedj rá másikat.
Pl. a ChatGPT/CoPilot egész jól ki tudja egészíteni egymást.
- Session reset sokat segíthet. Külön böngészők, VPN. Nem újrakezded, folytatod. A regisztráció hasznos, de irgalmatlanul le is korlátoz.
- Az AI nem 'ért' semmit (úgy, ahogy az ember ért), de sokszor az embereknél is beváló analógiák használata segít. Ez lehet akár egy hasonló munkafolyamat definiálása más területekről, amiket "ismer" a működésre. Pl. hasonlóan akarom megoldani, mint ahogy XY eszköz működik, csak a saját megközelítésemmel.
Egyébként nem érti (ha eltér a megszokott struktúrától - statisztika invenciónál eleve nettó hallucináció).
- Az emberi gondolkodás nem megspórolható, de az az embereknél sem az. Az AI az 'így szoktuk' szakembertípus,, csak hülyébb. Definiáld pontosan a folymatot, ami kritikus és eltérő a megszokottól.
Képletesen: csavarhúzót akar a kezedbe adatni, de nincs csavarhúzód és nem is azt szeretnél? Értesd meg vele, hogy mi minden használható csavarhúzóként, ami nem csavarhúzó, ahogyan a csavarhúzó is használható olyan dolgokra, amelyekre nem hivatott alapból. Példákkal.
Ezzel együtt volt olyan problémám, ahol már a matekot én vittem neki, mert nem bírta megugrani meg volt olyan is, ahol a funkciók hozzáadását nem a természetes (emberi programozó által érthető) sorrendben kellett elkezdeni, hanem fordítva.
Viszont: vannak/voltak olyan, egyébként egyszerű feladatok, amelyeket képtelen alapból megugrani (és sajnos nem tehetem közzé).
- Bízd rá, hátha fél szóból is ért.
Ha nem megy a teljes specifikálás, akkor érdemes úgy megközelíteni, mintha nem tudnád mit csinálnál.
Nem valós példa: nem hajlandó kirajzolni egy kört x pixel átmérővel y px vastag zöld körvonallal?
Akkor rajzoltass random kört.
Az sem megy?
Rajzoltass vele random síkidomot.
Előbb-utóbb rajzol egy kört. Mentsd ki a kódot. Folytasd onnan.
- a folyamat és a kód nem ugyanaz. Ha (jó) szakember vagy, akkor folyamatot tervezel egy cél eléréséhez. Ez az AInak homály (sokszor a programozóknak is, azért kell flowchart, időnként brutál részletes specifikáció). Azt gondolnád, hogy egyértelmű mondjuk kétezer után egy programozónak, hogy egy output fájlhotz bizony Browse window dukál az alkalmazás céljából logikusan következve, ezzel együtt még mostanság is bele lehet futni olyan versenyzőbe, aki szerint "Hát ő azt gondolta, hogy a user majd beírja kézzel a mentési útvonalat).
Vagy nézd meg a WIn11-et. A Dos korszakban nem gépeltem ennyit, de még Linuxon sem.
Na az AI kb. ugyanez turbózva. Van, amikor eszébe jut ilyesmi, van, amikor nem. -
Miközben a cikket írtam, jött egy újabb hozzászólás ide: Az előző cikk hozzászólásai.
Erre a hozzászólásra válaszolok:
Igyekszem akkor szép sorban megválaszolni a felvetéseidet:
- Ezt mondjuk még meg is értem, és tiszteletben tartom, hogy miért tartod vissza a konkrétumokat:
"nem elsődlegesen magyar célközönségnek, ahol mondjuk 'XY' példa esetén nem beazonosítható, hogy ki vagyok."
Bár a friss ACC ettől függetlenül is furcsa.- Az anonimitás és a cégek "b.sztatásának" elkerülése szintén jogos szempont.
Azonban konkrét példák nélkül is lehetne olyan eseteket hozni, amelyek szakmai mélységet mutatnak anélkül, hogy bárkit beazonosítanának. Nem kell pont egy adott cég pontos forráskódját leírni hozzá, sem egy-egy hibajelenséget túlságosan mélységeiben.
(Nem mellesleg nem esek hasra igen sok multinál dolgozó programozó munkájától. Így pl ha az M$ munkásságát nézem, és az eredményeket...
..de ezt tényleg hagyjuk, pereskedni egyikünk sem akar.)- "Előítéletekre építesz"
Szerintem konkrét példákat írtam, pont Tőled kértem, hogy prekoncepciók helyett mutass példákat.- "Két AI által összeszögelt kusza blogposzt nem tesz szakértővé a témában"
Egyenlőre nem tartom magam szakértőnek, mintha írtam is volna, hogy tanulás az egyik cél, éppen az, hogy a gyakorlati tapasztalatok megosztásával fejlődjek...
..a kusza jelzőért is köszi, nem vagyok újságíró sem.
Ezektől függetlenül lehet ez szakmai cikk. Lett légyen az akár kusza, és összeszedetlen is szerinted.- "Nem lehülyéztelek"
Ezt viszont nem is állítottam! A kettő nem ugyanaz. (Az "Az AI kódolás hülyeség", vagy a "Hülye vagy!" két különböző állítás.)
A "pet project vs. üzleti cél" felvetésed jogos (Szerintem írtam is az egyik, vagy mindkét cikkben), nálam jelenleg a tanulás és a kísérletezés a fő motiváció, de hosszú távon üzleti cél is van. Ebből adódóan az AI-t arra használom, hogy gyorsítsam a prototipizálást, még ha nem is tökéletes az eredmény. Konkrét példák (akár absztraktabb formában) nagyon hasznosak lennének a tanácsaid alátámasztására!- "hanem segíteni próbáltam."
Ezt kértem, az igazi segítség a példa, példák. - Ez mondjuk fura:
"(elolvastam - nem volt belinkelve, de megtaláltam)"
Leginkább a nem volt belinkelve része fura, mivel a témaindító Cikkre jött létre a fórum, amire írsz-írtál.- A 4.-es, 6.-os pontodra:
Teljesen egyetértek, hogy az ingyenes AI modellek sokszor nem alkalmasak komplex refaktorálási feladatok tesztelésére. Az általad említett költség-összehasonlítás és előfizetési problémák is valósak – én is tapasztaltam, hogy a tokenlimit és a modell korlátai gyorsan falhoz vezetnek. Az új cikkemben (amit belinkeltem) próbáltam részletesebben körüljárni ezeket a kérdéseket, kíváncsi vagyok a véleményedre.
Egyetértek, hogy a rendszertervezés kulcsfontosságú, és nem feltétlenül a kódolás mélysége a szűk keresztmetszet. Az én tapasztalatom is az, hogy az AI-val való munka során a pontos specifikáció és a rendszertervezési logika megértése a legnagyobb kihívás. Az általad említett "gap" a természetes nyelv és az AI értelmezése között valóban létezik, és sokszor csak iteratív próbálkozásokkal lehet áthidalni.
Az új cikket ITT találod meg.- Az 5.-ös pontodra:
A Fekete humor és AI korlátai: A körkörös érvelés és az AI "eredeti kiindulási pontra" való visszatérése tényleg frusztráló, és nagyon találó a fekete humor párhuzam! A kameramodulos példád tökéletesen mutatja, hogy az AI sokszor nem képes az emberi gondolkodás rugalmasságát követni, és "hekkelni" kell a promptokat. Ha van konkrét tipped arra, hogyan lehet hatékonyabban megkerülni ezeket a korlátokat, szívesen kipróbálnám. Például milyen konkrét lépésekkel vezettél végig egy problémát (pl. hogyan strukturáltad a promptokat, milyen iterációkat végeztél).- "Feltételezed, hogy komoly programozó kell a feladatokhoz"
Mondjuk ez pont nem igaz rám.
Alap programozói tudással, de 25 éves informatikai tapasztalattal, átfogó képpel AI segítségével olyan dolgokat csinálok, amiket jól megfizetett programozó sem csinált meg nekem!
Akár azt is mondhatnám, hogy lelépett a pénzemmel.Igazából az a furcsa, hogy pontosan el tudtam Neki mondani, hogy mit kérek, mert ennyire megy a programozás, az is, hogy hogyan valósítsuk meg, aztán mégsem lett belőle semmi.
Arra is felhívtam a figyelmét, hogy nekem nem egy kirakat (Frontend) kell, működő belső (BackEnd) nélkül, és pontosan hol vannak a hibák.
Ezeken most AI-al pár óra alatt túl is jutunk, míg a programozónak (egészen pontosan a végén csapatot említett, szerintem kiadta kis indiaiaknak.... ) hónapok alatt sem sikerült, 5, vagy 6 online Meeting és 4 személyes találkozó után sem.
Pedig még csoportos Meeting is volt, időközben felvett vmi projekt menedzsert, mert állítólag nem győzte a munkát.- 7.-es pont:
Ai és AI között is van különbség. Sajnos egyre jobban összekeverednek az elnevezések, szerintem messze vagyunk még attól, amit eredetileg az AI kifejezés jelentett, csak ezzel adható el a fejlődés, hogy megelőlegezik, ami még nem...
Egyszerűen matematika és valószínűség a legtöbb, főleg az LLM-ek.
Persze folyamatosan csiszolnak rajtuk, de a lényeget leírtad, ahogy számtalanszor (Nem itt) már én is!
Nem érti amit kérdezel, a válaszát sem, csak valószínűségeket köp vissza, kontextusba, témakörbe helyezve. Ez egybevág azzal, amit a szakirodalom is mond: az LLM-ek statisztikai modellek, amelyek nem "értenek", csak mintákat követnek.Egy kifejezetten kódolásra írt AI még hülyébb beszélgetésben, de lényegesen jobban kódol, mint egy beszélgetős. Ezek a képességek erősen képzés specifikusak! (Mint az embereknél is.) A beszélgetős modellek (pl. ChatGPT) gyakran csak "elfogadható" kódot adnak, amit - ahogy írtad: - "utólag szögelni kell".
AI hibázásának okai gyakran a kontextus megértésének hiánya és a memóriaproblémák, ezek tökéletesen leírják az LLM-ek jelenlegi korlátait.
A te példád (kameramodul keresése) és az én tapasztalataim is azt mutatják, hogy az AI sokszor csak "valószínűségi szöveggenerálást" végez, nem pedig valódi problémamegoldást. Az általad említett "átlagtól eltérő gondolkodási sémák" kezelése valóban gyenge pont, és itt az emberi kreativitás még mindig verhetetlen. A "token-alapú memóriakorlát" téma is érdekes, még vissza fogok térni rá, mert a saját gépen futtatott modellek esetén a hardver erőforrások (CPU, RAM, VRAM) és a modell optimalizálása jelentősen befolyásolhatja a teljesítményt.Tudnál egy konkrét, de anonimizált példát hozni arra, hogyan "hekkelted meg" az AI-t egy komplex feladat megoldására? Ez nagyon hasznos lenne a további tanuláshoz, és szerintem másokat is érdekelne! (A cikk-sorozat egyik célja, hogy ilyen használható ficsőröket összeszedjünk.)
Az AI-val való hatékony munka kulcsa gyakran az, hogy a promptokat kreatívan, lépésről lépésre kell megfogalmazni, és sokszor teljesen más megközelítést kell választani. Mint ahogy Te is írod: mást, "mint amit egy emberi fejlesztőnek mondanál".A "token-alapú memóriakorlát" téma is érdekes, még vissza fogok térni rá. Arról is lesz egy külön cikk, mivel érinti a sorozat témáját, szervesen kapcsolódik hozzá!









 Nyilván adni kell érte vmit, de a cég fizeti az áramot...
Nyilván adni kell érte vmit, de a cég fizeti az áramot... 




Új hozzászólás Aktív témák
- urandom0: Új kedvenc asztali környezetem, az LXQt
- Teljes verziós, ingyenes mobil játékok és alkalmazások
- Biztosan lesz Xiaomi Pad 8
- iPhone topik
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Huawei Watch GT 6 és GT 6 Pro duplateszt
- Windows 11
- Gaming notebook topik
- Hetekig bírják töltő nélkül a Huawei sportórái
- Napelem
- További aktív témák...
- Switch 2 2027.07.24-ig garanciás, dobozában, karcmentes állapotban eladó!
- ÚJ BONTATLAN Apple Macbook Air 15,3 M4 10C CPU/10C GPU/16GB/256GB - Égkék - HUN - mc7a4mg/a 3 év gar
- P16v Gen2 16" FHD+ IPS Ultra 7 165H RTX 2000 Ada 32GB 1TB NVMe magyar vbill ujjlolv IR kam gar
- Dell Latitude 5430 14" FHD IPS Core i7 vPRO 1265U 10 Mag 32GB RAM 512GB NVME SSD Gar
- Szép állapotú Xbox Series X konzol csomag, gyári dobozában, minden tartozékával.
- Nvidia Quadro P400/ P600/ P620/ P1000/ T400/ T600/ T1000 - Low profile (LP) + RTX A2000 6/12Gb
- ÁRGARANCIA!Épített KomPhone Ryzen 7 9700X 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- MSI CreatorPro Z16P RTX A5500 TOUCH! (vapor chamberrel)
- BESZÁMÍTÁS! Asus X470 R9 5900X 32GB DDR4 1TB SSD RTX 3070 Ti 8GB Zalman Z1 PLUS A-Data 750W
- Gamer PC-Számítógép! Csere-Beszámítás! Mini PC! I5 10600KF / RTX 3060 12GB/ 16GB DDR4 / 1TB SSD
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft.
Város: Budapest