-

Fototrend
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

P.H.
senior tag
válasz
 lezso6
#14196
üzenetére
lezso6
#14196
üzenetére
Neked és #14195 Abu-nak: A gyártástechnológiai fejlődés lassulásával egyre inkább jönnek elő az olyan "okos" dolgok, mint pl. ez. Az ilyesmit nehéz leírni, és nyilván az Intel és az ARM is kínál(ni fog) hasonló "okosságokat". Igen, eljött a kora az ilyesminek is; most sajnálhatjuk, hogy nem korábban.
-
P.H.
senior tag
válasz
lezso6
#14193
üzenetére
A microarch - hülyén megfogalmazva - egy nagyon oda-vissza dolog: a HSA pár tucat utasításával mindent meg lehet csinálni (még kevesebb utasítás is elég lenne, pl. a lebegőpontos számok kezelése leginkább bitbirizgálás, régen a 286-386-486 időkben a fordítóprogramok belefordították a programokba a sima integer utasításokkal való végrehajtást arra az esetre, ha nincs FPU), a többi (micro)architektúra 1000+ utasításai csak arra vannak, hogy egyes eseteket/helyzeteket gyorsabban lehessen megoldani (pl. SIMD esetén 2/4/8/16/32 számpárt ugyanannyi idő alatt mondjuk összeadni, mint egyetlen párt; vagy AES is volt eddig, csak most gyorsabb; az AVX is csak közel 2x gyorsabbá tenne bizonyos utasításfolyamokat, ha kihasználnák a programok).
Ezt viszont a leghatékonyabb kihasználni közvetlen kódban; fordított/köztes rétegeket felhasználó nyelvekben ez a hatékonyság csökken. Pl. Abu szerezi emlegeti a pJ/FLOP-ot mint mérőszámot alkalmazni, ami nyilvánvalóan nő, ha a futtatott kódot fordítani is kell előtte.
Ilyen szempontból az x86/x64-nek is csökkenni tűnik a hatékonysága, mivel ezt is úgymond fordítani kell chip-en belül, viszont azt is hozzá kell venni, hogy az x86/x64-nek így sokkal nagyobb a kódsűrűsége, mivel változó hosszúságú utasításokat használ; ezért pl. egy natív x64 programrésznek kb. harmadannyi az I-cache igénye, mint egy IA-64-é és kb. feleannyi, mint egy ARM-é; így kevésbé költséges pl. loop cache-t építeni bele. Ilyeneken is múlik az energiahatékonyság. -
P.H.
senior tag
Még ha el is fogadjuk, hogy a nanométer már nem megoldás minden problémára, azért azt semmiképp sem hagyható figyelmen kívül, hogy a nanométer-csökkentés gazdaságosabbá teszi a gyártást. De csakis a gyártást - azaz az 1 mm2 waferre eső költséget -, ami csak egy bizonyos része az egész "chip-készítési" folyamatnak, de az utóbbi években egyre markánsabban látható, hogy ez a "chip-készítési folyamat" egyre jobban szegmentálódik, úgy mint:
- ARM vagy MIPS mint ISA-tervező (a.k.a architektúra)
- Qualcomm, MediaTek, Apple, stb. mint "egyedi" elvárások készítője (a.k.a microarch)
- TSMC, GlobalFoundries mint gyártó cégek (a.k.a design implementation)Emlékeztetve erre: "An understanding of the terms architecture, microarchitecture, and design implementation is important when discussing processor design.
The architecture consists of the instruction set and those features of a processor that are visible to software programs running on the processor. The architecture determines what software the processor can run. [...]
The term microarchitecture refers to the design features used to reach the target cost, performance, and functionality goals of the processor. [...]
The design implementation refers to a particular combination of physical logic and circuit elements that comprise a processor that meets the microarchitecture specifications."Ebben a közegben a néhány nagy öregen (Samsung, IBM, Intel) kívül egyre kevésbé finanszírozható házon belül az összes lépés, legutóbb látványosan az AMD is elvesztette/kiszervezte a gyártást és a bele ölt költségeket, és az IBM is erre készül; tehát ez legalábbis nem a tehetségesség vagy a tehetségtelenség mutatója.
Ha viszont ilyen vertikális tekintetben nézzük az egyes fázisok költségeit (K+F, termelési eszközök, gyárak, ...), akkor úgy tűnik, először is a gyártás a legköltségesebb, nála lényegesen kevesebbe kerül a microarch-fejlesztés; új architektúra (ISA) kidolgozása pedig a legkevésbé költséges, lévén - nem lebecsülve a szükséges tudást, - inkább elméleti, mint gyakorlati dolog. A gyakorlat is ezt látszik igazolni, eddig legalábbis a leggyakoribb a "design implementation" váltás volt, kevésbé gyakori a microarch-újratervezés (bár az Intel - kissé érthetetlen, vagy piacilag nem teljesen magyarázható módon - a kettőt évente váltogatta), a legritkább az új ISA-k létrehozása. Ez igaz GPU-fronton is.
Mivel eddig a nanométer-csökkentés volt a legfőbb fegyver hatékonyság növelése érdekében, ha ennek lehetőségei elfogynak, ennek megfelelően egy-egy architektúrát "birtokló/felügyelő" cégnek még mindig kevésbé érdeke az ISA-ja felújítása, viszont igenis érdeke a legtöbbet kihozni microarchitecture-szinten belőle; ez pedig együtt jár - SZVSZ végre - a software-es oldalra helyezett nagyobb hangsúllyal is (gondolok itt arra, hogy az AMD se dobta volna be a pl. Mantle-t, ha számításai szerint úgy haladna a chip-hatékonység fejlesztése a következő 10 évben, mint az elmúlt 10 esztendőben).
A gyártó cégeknek viszont érdeke, hogy minél több eszköz legyen legyártva, hisz a csökkenő mm2-re eső gyártási költségek melletti növekvő egyéb költségek csak úgy behozhatók, ha minél több chip kerül legyártásra. Internet of Things, you know.
-
P.H.
senior tag
Szvsz a "nem szem elől tévesztés" egy másik, akár sikeresebb formája az is, ha - változtatva az régi Intel-stratégián - nem elnyomni szándékoznak a riválisokat, hanem azok eladott termékeiből is hasznot igyekeznek húzni (Android-Microsoft pl.).
Az már sokkal érdekesebb kérdés (és vita tárgya lehet), hogy ez a stratégiaváltozás annak köszönhető, hogy a régi Grove-Otellini tengelyű szemlélet változott az új CEO-val, vagy egyszerűen csak annak, hogy a gyártástechnológia adott legyártott mennyiséggel tudja visszahozni a befektetett dollármilliárdokat - a volumennek tehát legalább egyenes arányban kell nőnie kell a befektetett összeggel -, és az Intel eddig hagyományosan sikeres területei (szerver+asztal+notebook) már szerintük sem nem ígérnek akkora volument a következő 3-5 évre, hogy ezt vagy inkább következő gyártástechnológiai fejlesztéseket finanszírozza, és előnyét megőrizze. -
#12242
P.H.
senior tag
FireKeeper
#12238
P.H.
senior tag
válasz
 FireKeeper
#12238
üzenetére
FireKeeper
#12238
üzenetére
SZVSZ 2-nél több integer mag nem fog bekerülni egyetlen modulba belátható idő belül.
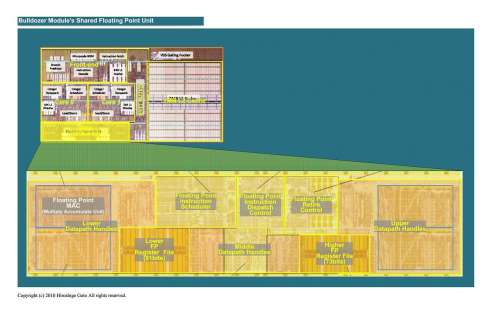
Ezen a képen jól látszik, nagyságrendileg mekkora egy Bulldozer-modulban a 2 integer core, nem kis része a modulnak ez. A Steamrollerben (legalábbis) a felső 'Instruction Decode' lesz megduplázva, így a 2 maghoz saját dekóder tartozik majd. Egy dekóder 4 utasítást tud 1 órajel alatt átkonvertálni belső RISC-műveletekre, ezért ha egyetlen van belőle, az órajelenként vált a két mag között: egyik órajelben az egyik magnak (programszálnak) ad legfeljebb 4 utasítást, a következő órajelben a másiknak legfeljebb 4-et. Így legjobb esetben 1-1 mag 2 órajelenként kap 4 utasítást, azaz 2.0 feletti IPC elméletileg sem hozható ki, ha egy modulon két szál fut. A két dekóder ezen segít, mivel maguk az integer-magok képesek max. 4 utasítást lefuttatni órajelenként, ha azok megfelelő sorrendben vannak és elég egyszerűek (azaz egy modul 8 db-ot).
-
P.H.
senior tag
A kérdés ott válik érdekessé, ha a kisebbekhez hozzávesszük a tervező+gyártó cégek közül mondjuk a Samsungot, az IBM-et: nem látjuk azt, hogy előre kimondanák, hogy (két)évente váltanak akár microarchitektúrát, akár gyártástechnológiát; és a TSMC is simán kihagyta a 32 nm-t pl. bizonyos okok miatt, ettől nem dőlt össze a(z ARM-)világ anno, sőt még a lendületét se törte meg.
-
P.H.
senior tag
Ezt, hogy "érdemi változás" elsősorban gyártástechnológiával érhető el, az Intel ültette el a tick-tock-kal (vajon mi lehet ennek az üzleti háttere/indoka? Minden (bér)gyártónak az az érdeke, hogy az adott gyártástechnológiát a lehető leghosszabb ideig futtassa, ezzel csak az Intel megy szembe a piaci igényeket figyelmen kívül hagyó, előre eldöntött 2 éves váltási stratégiájával).
A Bulldozer - Piledriver/Trinity - Richland azonos csíkszélességen bemutatott evolúció vagyis optimalizáció, ez, úgy vélem, elég sok fabless cégnél, pl. az ARM-nál is megszokott, és valószínűleg egyre többször fogunk találkozni ezzel a jövőben. -
P.H.
senior tag
"Az IGP lényegében sok kis vektormag, amiken külön szálak futnak... Csak (egyelőre) nem a hagyományos értelemben (nem az OS kezeli őket)."
HSA esetében nem is fogja az OS kezelni az IGP-re leosztott feladatokat

Sőt, az OS nem is fogja tudni, hogy mekkora GPU-kapacitás van a CPU mellett (akár tokban, akár buszon), továbbra is annyi magot fog mutatni, ahány CPU-mag van a gépben. Sőt, az CPU-ábrákon FPU-t fogunk látni, nem fog oda GCN bekerülni (Nem is lenne praktikus: miért korlátozná le magát az AMD, hogy egy FPU-t 1-2-4 (mennyi?) GCN-nel kiváltson, amikor mellé pakolhat akárhányat? Mondjuk 1 modul/2 mag mellé is akár 16-ot? )
)Elég okosan van a HSA-koncepció kitalálva, úgy látom.

-
P.H.
senior tag
Ebben csak az sántít, hogy az LLC a Last Level Cache rövidítése, ami az L3. Így meg szóhasználatban ferde a dolog.
És az IB slide-okon én (ami nekem hozzáférhető) L3$-t látok, pl.
L3$ lowers bandwidth needed from Ring Architecture
Media Applications benefits from infrastructure changes in EU/L3$/etcA média-alkalmazások hogy tudnak profitálni abból, hogyha az IGP L3-a teljesen különálló egység? (És mekkora ez amúgy?)
-
P.H.
senior tag
Ebből a "A procimagok nem tudnak majd belőle olvasni." nekem új. Ha ez így van, akkor miért hívják L3-nak, miért nem szimplán IGP L2-nek? A késleltetése miatt, vagy amiatt, hogy milyen CPU-cache-sel van egy szinten, vagy miért?
Az SB IGP-je azért volt újszerű, mert a CPU-k L3-ába írhatott, és onnan olvashatott is, Carmack ezért szerette, és emlegette más is, mint "tighter integration"-t, nem? A következő generációban miért lépnének ettől vissza?
-
-
P.H.
senior tag
Mire gondolsz, mi lenne így miért? A front-end sosem erőteljesebb a végrehajtási résznél, a back-end van mindig túlméretezve. Vagy láttál ellenkező példát valahol?
A blogom teli van PerfMonitoros tesztekkel, gondolom, csak figyelmetlenség miatt "ajánlod".
Az Intel HyperThreading-ével mostanában nincs baj, főleg nem a Sandy Bridge-ével. x86 CPU-fronton az a legjobb microarch, ami piacon van jelenleg, és nemigen lehet rajta (ki)fogást találni. Az Ivy Bridge még tovább csökkenti majd a fogyasztást és mobil performance processzor témában tarolni fog (pl. beérik a régi-új uop cache hatása). Hogy ez többet ér-e általánosságban rövid távon, mint az AMD GPU-ja, az majd kiderül.
"Természetesen reordering után értettem, és nem szám szerűen, hanem átlagban."
Ennek így nincs se füle, se farka. Az IPC szigorúan véve az órajelenként végrehajtott, befejezett utasítások száma, ami egyszerű esetben vagy 0 vagy a felépítés szélessége. Ezt árnyalja az AMD double decode (ahány uop-ra dekódolsz órajelenként, annyi fog majd órajelenként befejeződni, de utasításonként lehet 2 uop is) és a macro-fusion, az x86-utasítások összevonása.
Nem szigorúan véve pedig az órajelenként befejezett utasítások számának átlaga egy időszakban (pl. 50 ms) -
P.H.
senior tag
"Nagyon ritka, hogy 3 független utasítás jöjjön egymás után... Összetettebb számításoknál eleve 1.0 alatt szokott lenni az IPC. Többet számít a front-end, pl. elágazásbecslés."
Az eleje abszolút nem igaz és lényegtelen is, a vége csak részben igaz.
Kis, 10-15 utasításnál kisebb ciklusoknál (mert igazából ciklusokról beszélünk) irreleváns, hogy milyen függőségek vannak az utasítások között, nem in-order felépítésről beszélünk. A lényeg, hogy minél kevesebb felesleges és random memóriahivatkozás (L1- és L2-miss) legyen és hogy a front-end minél gyorsabban indíthassa a következő ciklust (itt számít OoO esetén is az utasítássorrend és az utasításválasztás, azaz hogy hány - fused - uop egy-egy utasítás).
15-20 utasításnál nagyobb, nem kiszámítható memóriahozzáféréstől mentes ciklusból bármikor mutatok neked olyat, ahol akár egymást követő 3 utasítás független, csak bírja a végrehajtás szusszal és a Reorder Buffer hellyel.A front-end és az elágazásbecslés a felépítés szélességének fele (1.5-2.0) felett kezd el csak számítani, de az már jó, ha egyáltalán eljutottál oda. Ezek nem apró lépésekben, hanem 0.25-0.5 IPC-közzel csökkentik a sebességet.
»Általában« az 1.0 tetőt a felesleges illetve az előre nem kiszámítható memóriahozzáférések okozzák, az pedig nem asm szinten dől el.
-
P.H.
senior tag
"Ki lehet, ki lehet, de az átlagos kód 1.0 körüli IPC-vel fut, ugyebár."
Azt vedd figyelembe, hogy az IPC-maximum nem a plafon meghúzását jelenti, hanem annyival vissza is skálázódnak a kódok. Tehát ha egy integer algoritmus 2.5 IPC-vel fut K10-en, ami 80%-os kihasználtságát jelenti az elméleti maximumnak, akkor 2 ALU+2 AGU-val ugyanez a kód nem fog 2.0 IPC-vel futni, mert ott a vége, hanem ugyanúgy kb. 80%-os kihasználtsággal, 1.5 körül. Ez visszaszámolható 1.0 IPC-s kódokra is.
(Hangsúlyozom, csak tiszta integer kódok esetén áll ez a "szabály", a valóság sokszor igazolta). -
P.H.
senior tag
válasz
 Zeratul
#9795
üzenetére
Zeratul
#9795
üzenetére
A programozók nagyon kicsi része, mivel a fordítókhoz a funkciókönyvárakat, library-ket, illetve az általánosan és gyakran használt algoritmusokat jellemzően kis csoportok vagy maguk a cégek készítik.
Azokban a programokban, amelyekben szükség van kézi fejlesztésekre, azokban ezek messze a leggyakrabban futó részek (pl. videokonvertálás, karakterfelismerés).
-
P.H.
senior tag
válasz
Zeratul
#9792
üzenetére
Mondjuk minden olyan programban, amelynek bizonyos részei kézzel optimalizáltak.
Pl. egyszerűbb, minden programban használt szubrutinok (memóriamásolás) vagy nagy időigényű algoritmusok. -
P.H.
senior tag
válasz
Zeratul
#9788
üzenetére
Lényegtelen, hogy csak az egyik ALU tud szorozni és egy másik tud csak 2 spec. műveletet végrehajtani, ha a további több, mint 50 utasítás végrehajtásában mindegyik részt vehet.
K10-en 3 ALU+3 AGU felállással egyszálas integer kódban ki lehet hozni folyamatos (több 10 perces) 2.5 IPC végrehajtást, ugyanaz a kód Bobcat-on 2 ALU+2 AGU-val 1.5 IPC-vel fut. Ezt a hátrányt kell órajellel kompenzálni.
-
P.H.
senior tag
válasz
 #95904256
#8736
üzenetére
#95904256
#8736
üzenetére
2 évvel ezelőtt is másról beszéltek az azóta sem implementált FMA megvalósításukkal kapcsolatban, mint ami most várható
Náluk attól függ még (jelen pillanatban is, és még pár hónapig), hogy mit lesz szükséges megvalósítani a konkurencia ellen: az utasításkódolás adott (VEX) és a fejlesztés mindenképp szükséges belül. Az FMA3-hoz ugyanúgy 3 bemenet kell, mint az FMA4-hez, és minden jel arra mutat, hogy jelenlegi generációban nem rendelkeznek az ehhez szükséges belső felépítéssel.
-
P.H.
senior tag
válasz
#95904256
#8731
üzenetére
A Haswell-lel kapcsolatban nem lennék biztos a dologban, annak a microarch-váltásnak arról kell szólnia, hogy a belső RISC uop-ok tudjanak kezelni 2-nél több bemeneti register-értéket (FP) illetve 1 EFLAGS-mezőt + legalább 2 register-értéket (INT) bemenetként.
A 2 register vagy 1 register + 1 EFLAGS bemenetre vonatkozó uop-megkötést úgy tűnik, még mindig hordozza a legújabb generációjuk is (eléggé régóta, talán P6 óta), belül: +1 közvetlen érték mint bement lehet emellett, kimenet lehet 3., átnevezett register.(Ennél többet ellenük nem nagyon lehet felhozni a Sandy Bridge ellen amúgy
)Ezt mindenképp meg kell lépniük a Haswell-nél, pont az FMA-jellegű dolgok miatt: a többi ilyen utasításnál a hátráltató hatást, azaz hogy 1-nél több uop-ra fordulnak, sikeresen elrejtették a kisebb (Nehalem) - nagyobb (Sandy Bridge) uop-cache-ekkel. Ezzel viszont egyidejűleg felgyorsítják az ADC/SBB, CMOVcc vagy akár a BLEND-utasításokat is.
-
-
P.H.
senior tag
válasz
 Remus389
#8583
üzenetére
Remus389
#8583
üzenetére
"nekik jön az Ivy Bridge és annak herélt változatai van még SSD project is, aztán slussz(legalábbis így hirtelen), és erre van 8x annyi ember és sokkal több zsé, meg gyárak meg minden"
Ha már ilyen olcsó összehasonlításokkal jössz "így hirtelen", hogy 1 milliárd tranzisztorhoz mennyi ember kell, akkor oda kellene számolni az Intel-nél a kb. 10 éves Itanium-ot (most épp 3 milliárd tranzisztornál tartanak) és a jó pár éve fejlesztett Larrabee-családot is. A cég SSD-i legalább kimutatható nyereséget termelnek már a megjelenésük óta...
nem is tudom valamikor olvastam hogy az egyik negyedévben(vagy évben) az Intel kábé 10.000.000.000, vagyis tiz milliárd profittal zárt, míg az AMD -300 millióval
ennek tükrében azért kisebbfajta csoda lenne ha a Bull technikailag megverné az InteltEnnek tükrében az is kisebbfajta csoda, hogy az Intel még nem áll a grafikai és a szerverpiac csúcsán...
-
P.H.
senior tag
válasz
Remus389
#8095
üzenetére
Kihagytad a számításból
- a platformosodást
- a jövőbeli AMD VGA-kal való továbbfejlesztett együttműködés lehetőségét
- azt a többséget, aki továbbfejlesztés helyett teljes gépet vesz/cserél pár éventeAz ár tekintetében a kompatibilitás sokaknak jó, de a nyújtott teljesítmény (esetleg ennek fölénye) pedig még többeknek. A gyártónak meg az, ha minél több(fajta) terméket értékesíthet ilyen címkékkel (lehetőleg minél többet ugyanabba a gépbe).
-
P.H.
senior tag
válasz
 Hakuoro
#7905
üzenetére
Hakuoro
#7905
üzenetére
Annyira nem meglepő, az FPU a nagy fogyasztó (pl. azt bővítik most több, mint 100 utasítással, az integer-egységeket 10-20-szal).
Illetve mindenhol arról beszélnek, hogy a Turbo megnöveli az (integer-)magok (Core) órajelét. Nem a modulokét, azaz az FPU-ét nem (ha már ez az AMD-s nevezéktan). Így megvan a dezz által emlegetett (double-pumped helyetti) eltérő órajel is modulon belül.
-
-
P.H.
senior tag
válasz
 atti_2010
#7693
üzenetére
atti_2010
#7693
üzenetére
Amit leírtál, törvényszerű.
Azt viszont érdemes hozzászámolni, hogy a AMD-k alapfesze (pár kivételtől eltekintve) 1.25-1.4 között mozog a 90 nm-es generációk óta, és ez úgy néz ki, a Bulldozer-rel sem fog változni.
Ez lehet akár SOI-sajátosság, akár kidolgozatlanság is, ki tudja.Viszont az Intel-nél az alap(mag)órajel közelében vagy felette tud dolgozni az L3 már régóta, AMD-nél viszont csak alatta, nyilván ez nem normális helyzet.
-
P.H.
senior tag
válasz
 Oliverda
#7680
üzenetére
Oliverda
#7680
üzenetére
Hát igen, ez a baj az AMD-féle L3-mal, a 65 nm-rel nagyjából azonos feszültség kell 32 nm-en is meghajtani őket. ([link])
A két AGU (AGLU?) viszont nagyjából ugyanolyan méretű, mint a két ALU. Ez jó előjel a 4 egyszerű ALU-op/cycle/thread várakozáshoz.
Igen kicsi integer végrehajtókat sikerült összehozniuk, ha a többi részegység jelölése (Immediate value storage, Register rename, ...) helyes
Bár a 2 azonos méretű, külön integer register file jelölése eléggé furcsa (első blikkre Netburst-szaga van, ahol a 32 bites műveletek két külön órajelen 16+16 bites műveletekként hajtódtak végre; nyilván itt legalábbis 32+32 bites műveletekről lehet szó).
-
P.H.
senior tag
válasz
Oliverda
#7655
üzenetére
"The integer scheduler can dispatch up to 4 micro-ops per cycle, one to each of the 4 pipelines. Almost all ALU operations are handled by the 2 EX pipelines, except some LEA instructions which also utilize AGU. Thus the integer core can execute only up to 2 x86 instructions per clock cycle, resulting in a maximum integer IPC of 2.0 (in units of x86 instructions). Note however this estimate does not include the computing throughput of the integer SIMD pipelines in the FPU."
vs
RWT nyitó hsz: "4 Integer ALU instructions/cycle for each core."Az, hogy ennyire eltérő következtetéseket lehet levonni ugyanabból a dokumentumból, nem lehet véletlen, inkább az író direkt szándéka; ezt anélkül mondom, hogy mit szeretnék jobban belelátni vagy igaznak vélni.
A PerfMonitort megpróbálom megint Intel-eken, korábbi próbálkozásaimkor el sem indult.
-
P.H.
senior tag
Nem a zavarás a kérdés, hanem az önállóan, egy szálon mutatott teljesítmény. (shared) FPU esetén ezt Te is annyira egyértelműnek látod, nem értem, miért nem kérdéses neked, hogy int-oldalon, 1 core esetén mi (felezett vagy akár teljes teljesítmény?) lesz.
Mert hogyne lehetne kihasználni a 3.0 vagy 4.0 IPC-t, pl. a blogomban nem egy 2.0 IPC feletti (csak integer), és általában 1.0 feletti (akár integer téren Brazos-on vagy pedig más AMD platformon floating-point-os) kódot írok le, és ezek nem benchmark kódok, ezek így mennek ki éles felhasználásra.
Intel-eken ugye nem megy a PerfMonitor, nem tudom egyszerűen mutatni a teljesítményt, de nagyjából visszaszámolható a mutatott teljesítmény alapján (pl. amit linkeltem, az is azonos IPC-n megy egy Core2 Celeronon, 1.35 IPC-n P3-mon és 0.65 IPC-n Prescott-on).Ha én tudok csinálni ilyen kódokat, akkor az OS-ek és fordítók library-készítői biztosan tudnak. Ehhez persze kellenek a (pontos) Opt. Manualok is, és az azokból levonható következtetések..
-
P.H.
senior tag
Mondom: "Sok helyen homályos vagy ellentmondásos, úgy tűnik, direkt"
Macro-opra gondolok, nyilván bizonyos megkötések mellett (pl. 2 csak reg,reg utasítás mellett 2 reg,mem - load+op - utasítás lehet, vagy csak 1 mem,reg - load+op+store-, vagy ki tudja).
Az IPC-t retirement-en szokás mérni, ez 4 macro-op lesz globálisan. 2 thread esetén 2.0 lesz a maximum (órajelenként váltva 4 utasítás más-más szálakról, azaz egy szálra vetítve 2.0 IPC), de kérdés, hogy 1 szál esetén lehetséges-e a 4.0 IPC maximum.
Illetve az, hogy az Intel-vonalon Core2 óta meglevő 3 (megosztott, egyszerű) ALU helyett 4/thread (2 komplex + 2 egyszerű) ALU lesz-e. -
P.H.
senior tag
Úgy tűnik, sok(kal több) érdemi információt nem lehet levonni belőle.
Az az ábra egy sima PR-slide ábra, nem Opt. Manualba való.
Én erősnek találtam elsőre leírni, hogy jó része (főleg a microarch utáni tételes optimalizálási leírások) sima másolás a K10-es verzióból, de most nézem, úgy tűnik, más nem:
"The SOG has looked that way for the last year. The original version that I got had even more mistakes."
"They clearly did a copy/paste from a previous version, but didn't get around to making all the necessary changes."Pl. ilyenek is benne maradtak, hogy:
"The processor is capable of performing three independent 64-bit additions each clock cycle and a 64-bit multiplication every other clock cycle."
"On each cycle, the in-order front-end engine selects up to three AMD x86-64 instructions to decode from the pick window."Továbbá a latency-táblázat sem akkurátus, több rossz vagy hiányzó érték mellett sehol nem szerepel benne, hogy az AGLU-k milyen integer-utasításokat tudnak/tudnának futtatni, amelyekkel kijönne a 4 integer op/cycle/thread ütem, ha a modul csak 1 szálat futtat, így a végrehajtás szinte semmilyen csorbát nem szenvedne a K10-het képest (tippem szerint azokat, amelyeket a Netburst double-pumped ALU-i is tudtak: MOV, ADD, SUB, CMP, AND, OR, XOR, NOT, NEG, TEST; esetleg kiegésztítve shift(1?)-tel, BT reg/mem,imm-mel és az új utasítások közül párral, de ugye sem derül ki konkrétan... az sem, hogy egyáltalán tudnak-e)
-
P.H.
senior tag
Sok helyen homályos vagy ellentmondásos, úgy tűnik, direkt, pl.:
- többször hivatkozik a 32. oldalon látható processzor-ábrára, amin igazából jelenleg semmi sem látszik
- az új integer utasítások típusa mindig FastPath Double, latency-értéke mindig NA
- There are four integer execution units per core. Two units which handle all arithmetic, logical and shift operations (EX). And two which handle address generation and simple ALU operations (AGLU). Ehhez képest az utasítástáblázatban csak a call és a lea mellett említik az AGLU-t mint végrehajtó egységet.
- "In addition, a particular integer pipe can execute two micro-ops from different macro-ops (one in the ALU and one in the AGLU) at the same time." Akkor 2 vagy 4 független execution unit vanA fentiek miatt fentartásokkal kezelve bármilyen kijelentést, a következő mondat azt jelezheti, hogy a 256 bites AVX-utasítások két 128 bites felének hatékony egyszerre indulnia/futnia, de nem kötelező: "Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together."
-
P.H.
senior tag
Úgy tűnik, a legtöbb integer-utasítás végrehajtási ideje marad 1 órajel, az L1-latency viszont nő, 3-ról 4 órajelre.
Új integer utasítások: T1MSCK, TZCNT, TZMSK, LSWPCB, LWPVAL.Move elimination, azaz FP-oldalon a 0 órajelű (register-file által lekezelt) register-to-register copy megvan, nem szükséges hozzá execution unit.
B.5 Amended Latency for Selected FMA Instructions
The following table shows amended latency time for selected FMA instructions, where special cases are applied in which additional latency is accumulated.
Ez a rész nem tiszta. -
P.H.
senior tag
"AMD Family 15 processors introduce a new feature where, in some cases, a comparison or test
instruction and its associated branch instruction can be "fused" into a single micro-operation."A Sandy Bridge az ADD / SUB + Jcc utasításokat is tudja egyesíteni, bizonyos megkötésekkel ("The first instruction can have an immediate operand or a memory source operand, but not both"), nem csak a CMP / TEST + Jcc eseteket. Vajon Bulldozer-nél is lesznek korlátok?
Uop-cache úgy tűnik, nem lesz a Bulldozerben.
-
P.H.
senior tag
Nincs könnyű helyzetben az AMD. Asztali piacon meg kell honosítania a modul fogalmat, mint értékmérőt, amit leginkább a két maghoz lehet kötni. A szerverpiacon meg ennek az ellenkezőjét kell állítania.
Mennyivel egyszerűbbek lennének az ilyen kérdések, ha a Rock is megjelent volna... -
P.H.
senior tag
Amikor az OS két szálat ütemez a magra, azokat párhuzamosan próbálja futtatni az Intel összes HT implementációja.
Netburst HT: "Both logical processors compete for the Trace cache access each clock. If their requests come in simultaneously, the Trace cache access is granted in turns to each of them every other clock. In other words, the first one accesses the Trace cache on the first clock, the second – on the second, then the first one access Trace cache again on the third clock, etc. If one of the threads is stalled (of there are no decoded micro-operations in the Trace cache for this thread), then the second thread has the Trace cache at its full disposal." ([link])
Core I7 HT: "The instruction fetcher and decoders are shared evenly between the two threads so that each thread gets every second clock cycle." [...] "There is no way to give one thread higher priority than the other in the CPU." ([link])
Az Atomban két decoder van: "The two instruction decoders are identical." [...] "It is impossible to assign different priorities to two threads running in the same core. Thus, a low priority thread may take resources from a high priority thread running in the same core, with the unfortunate result that the high priority thread runs at only half the maximum possible speed." ([link])
-
P.H.
senior tag
Igazából eddig az sem volt szokásos, hogy mondjuk két, önálló L1D-vel rendelkező képződményt egy egységnek kezeljünk, valószínűleg erőteljes újradefiniálásra szorul az eddigi bevált 'core' fogalom (decode, retirement - pl. FPU-kivételkezelés -, task-váltás, performance counters terén) és még nem derült ki, hogy ez a kifejezés mit és milyen teljesítményt jelent (pluszban a HT-hez képest) a fenti 'marketing süketelésekben' ("The Bulldozer module is a concept and part of an architectural design, it is not something that the user will come in contact with.")
-
P.H.
senior tag
Ugyan a következő számokból nem lehet közvetlenül érdemleges következtetést levonni, de egy tendencia kirajzolódhat: négy CPU-család hibalistájából ez derül ki:
- a Merom dokumentációja már lezárt, a hibák vagy Fixed vagy No Fix állapotban vannak, a 128 hibából 84-re nincs javítás, ez 65%
- a Penryn-ek 74 ismert hibájából 62-re nem terveznek javítást, ez 83%
- a Barcelona 3 stepping-jének eddigi 42 nyilvános hibájából 10-re egyáltalán nem volt javítás ütemezve, további 23 hiba érinti mindhárom verziót, azaz a hibák 78%-a nincs javítva. (Shanghai Revision Guide még nincs.)A Nehalem-ek 77 közzétett első revíziós hibáinak csak 57%-át nem tervezik javítani, 33 hiba mellett szerepel Plan Fix. Ennek egyik oka lehet, hogy kiemelkedően sok, összesen 12 hibának van köze az újradefiniált C6 power state-hez.
dezz #5868: az említett dologról csak ezt találtam: [link] "Even Intel's weird 6 core chip is no match to Shanghai. As for Intel's copycat chip Nahelem, it won't be available until later 2009, as Intel is still struggling with some cache coherence issues in 2P configurations."
-
P.H.
senior tag
válasz
Oliverda
#5667
üzenetére
Nézd meg ezt a tesztet és a konklúzióját: [link]
Remélhetőleg első része egy mély analízissorozatnak, ez most Core2-n és K8-on négy játék alatt.
A K10-es újítások elméletileg pontosan azokon a területeken történtek a K8-hoz képest, ahol az lemaradt ebben (L2 a Nehalem-mel más kérdés lett), mégsem látszottak a Barcelonán annyira. A legrosszabb az, hogy míg "The Core 2's IPC is about 5-10% higher than the K8 for our set of games", a K10 sem igazán tudja ezt a helyzetet megváltoztatni, pedig jó alapokról indul:
- The K8 has 20% fewer uops per instruction than the Core 2 for our set of games.
- The K8's L1D cache is more effective, with about 20% fewer misses per instruction retired for our set of games.Ebből nekem először is az szűrődik le, hogy a memória-alrendszerrel gondok vannak a Barcelonában, amelyet a Shanghai orvosol(hat, pl. a memvezérlő prefetch-e eddig be sem volt kapcsolva?).
-
P.H.
senior tag
válasz
Oliverda
#5656
üzenetére
Ezen mikroarchitekturális optimalizációkról sehol sem esett szó részletesebben eddig, pedig ezekkel dicsekedni szoktak a gyártók.
Attól félek, mintkettő igaz: die shot-on nincs lényeges változás (magban legalábbis), viszont a beharangozott funkciók egy része most, 45 nm-en fog (teljes egészében) életbe lépni, ahogy a DDR3-támogatás is a több, mint egy éves BKDG-k ellenére.
-
P.H.
senior tag
válasz
Oliverda
#5155
üzenetére
Kérsz szakmai önéletrajzot?
![;]](//cdn.rios.hu/dl/s/v1.gif)
A cache-tévesztések száma a méret, asszociativitás és line-size függvényében ([link]):

Ugyanez grafikusan, 32-byte line-size mellett:

A forrásból (18-20. oldal) kiderül, hogy ezek szimulált cache-eken tesztelt adatok, 5.6 MB adatot használó programmal, sebesség itt nem releváns. Viszont úgy gondolom, ha 45 nm-en nem tudják legalább 1x200 MHz-cel megnövelni az NB-órajelét, akkor nem az L3-latency lesz a legnagyobb gondjuk.
Itt lehet a kérdés nyitja:
In general, increasing the associativity of a cache above 8 seems to have little effects for a single-threaded workload. With the introduction of hyper-threaded processors where the first level cache is shared and multi-core processors which use a shared L2 cache the situation changes. Now you basically have two programs hitting on the same cache which causes the associativity in practice to be halved (or quartered for quad-core processors). So it can be expected that, with increasing numbers of cores, the associativity of the shared caches should grow. Once this is not possible anymore (16-way set associativity is already hard) processor designers have to start using shared L3 caches and beyond, while L2 caches are potentially shared by a subset of the cores.
(Mint azóta kiderült, nem lesz közös L2-megoldás a közeljövőben. Egy kisebb összeget felteszek arra is, hogy a VIA a kétmagos Isaiah-t FSB-n keresztül - PentiumD-hez hasonlóan - fogja megvalósítani, itt kiegyensúlyozott teljesítményt fog nyújtani a 16-way exclusive L1 és L2.)Az kérdéses, hogy kényszerű döntés volt-e a 6MB/48-way, vagyis jobb lenne-e a 8MB/32-way (ha elfért volna). Hajlok arra, hogy a (nagyrészt) exclusive cache-felépítés miatt nem kényszerű döntés; Nehalem-nél 16-utas lesz az L3, viszont teljesen más (MESIF) protocol-t használ (valamint "Nehalem’s 8MB and 16 way associative L3 cache is inclusive of all lower levels of the cache hierarchy and shared between all four cores.")
-
P.H.
senior tag
Az Intel Core optimalizálási gyorstalpalójának mintájára az AMD is kiadta a K10 software-fejlesztési irányelveket, videováltozatban: [link]
-
P.H.
senior tag
Van egy dolog, ami mellett nem tudok szó nélkül elmenni (megint
): az Itanium. A sok éves tervezés alatt gyakorlatilag »mindent« megoldottak program/fordító/utasítás szinten, amit az x86 vonalon rengeteg tranzisztorral spekulálnak.
Ha ránézek a Penryn-re, gyakorlatilag mindent megoldottak szilíciumon, amit az Itanium már a fordítóprogramok szintjén megkövetel az utasításkészlete és in-order felépítése miatt; SZVSZ innen nincs tovább.
- utasítás-átrendezés és függőségkezelés vs templates & (változó méretű) instuction groups
- memóriaművelet-átrendezés vs data és control speculation utasítások
- stack engine vs stacked register files + register stack engine
- Loop Stream Detection vs register rotation
- szinte minden utasítás valamely condition register-en alapuló feltételes végrehajtása vs conditional move(?)Illetve van tovább: a x86 fordítóknak fel kell nőniük ilyen szintre; és akkor rendesen működni fog az in-order Atom és a Larabee is. Az Itaniumnak ehhez nem kellett több, mint 32 általános integer (+ kommunikációs terület), 32 FPU és 32 condition (~flags) közvetlenül elérhető register (plusz az application register-ek).
-
P.H.
senior tag
Szépen hangzik, csak a megvalósítása nehéz (jelen pillanatban még), főképp az hiányzik belőle, hogy egyetlen szál mennyit profitálna ebből. Amit Hans felvázolt abban, amit #4924-ben linkeltem, pont ezt csinálná: a klasszikus decode- és környezetduplázás helyett az execution unit-okat többszörözi; viszont ezek között igen komoly kommunkációs megoldások kellenének, hogy felvegyék a versenyt a jelenlegi VE-k közti bypass network-ökkel, storeforward-dal, memóriaművelet-átrendezésekkel, stb.
Ez akkor lenne igazán ütős (és megvalósítható), ha pl. nem lehetne látni a Nehalem-ben azt a sok statically partitioned egységet.
-
-
P.H.
senior tag
válasz
#95904256
#4931
üzenetére
- SZVSZ a találati arány általában messze 80-90% felett van jó ideje, a prefetch-megoldások a döntőbbek inkább, adat-megközelítésben ezek sokkal kisebb találati aránnyal rendelkezhetnek.
- Nem értem pontosan, mire gondolsz itt, a függőségek esetén. (ok, INC nincs, ECX >= 8
). A VIA és az AMD esetén jól lehet látni, milyen módon oldják meg a portok közti elosztást (~FIFO, alap -> szabályok); az Intel-nek sincs sokkal több órajelbeli (= több lépcsőjű) ideje ezt a leosztást megoldani a közös ROB/RS-sel, tehát nagyon bonyolult nem lehet (csak nem utasítássorrendbeli egyszerű "balról jobbra"?)- VIA: "Pl. duplapontos szorzással 3 órajel alatt végez, viszont csak 2 órajelenként indítható. Az osztás viszont az első órajeltől kezdve átlapolt! Ilyet sem az AMD sem az Intel nem tud..." Pedig pont neki nem kellene tudnia ilyeneket, ismerve azt, hogy hova szánja...
Ígéretesen hangzik, de ezzel én megvárnám pl. a részletes latency/throughtput értékeket tartalmazó dokumentációt. -
P.H.
senior tag
válasz
#95904256
#4927
üzenetére
Feltételezve, hogy a "szerk:" részt nekem szántad:
Nem könnyű radikálisan új felépítést alkotni ("az aktuális K7-K8-K10 nagyon is jó"? volt erre egy hsz-em tavaly: "Az, hogy az AMD miért nem tudja járatni ezt az alapvető felépítést az annak „megfelelő” órajelen (szerintem egy olyan 4 GHz-ig kellene dual-core K10-nek skálázódni, hogy megoldódjanak rövidtávon az AMD problémái), ezt pontosan nem tudjuk, de lehetséges, hogy ennek okát nem a szűk értelemben vett magokon belül kell keresni." De jelen pillanatban én nem tudom, hol kellene keresni az okot.)
- branch-prediction eljárások (és amekkora megbízhatósággal rendelkeznek) nem hiszem, hogy manapság fontosabbak lennének a megfelelő prefetch-algoritmusoknál.
- OoO hatékonysága: ezen a téren SZVSZ az AMD teljesen jó úton jár, lásd pl. a VIA Isaiah-t, ahol ugyancsak egy-egy port-hoz külön ütemező (RS) járul. (Te írtad anno, hogy az Intel érzékenyebb az utasítássorrendre, mint az AMD.) De az AMD-féle egyszerű pack-stages átrendezésnek sincs tovább jövője, látszik, hogy a többiek kifinomultabb algorimusokat alkalmaznak.
- lebegőpontos végrehajtás: persze, minél gyorsabb, annál jobb. Jó kérdés, hogy min múlnak a tervezési szempontok: a VIA össze tudott hozni 2 clock-os összeadást, az Intel 3 clock-ost, az AMD 4-est. Abszolút nem tükrözik a számok az erőviszonyokat, a szükségleteket és az anyagi hátteret.
-
P.H.
senior tag
válasz
#95904256
#4923
üzenetére
Ezek csak találgatásoknak tűnnek megalapozott információk helyett, én azon gondolkodok inkább, hogy a találgatások között miért volt fontos kiemelni azt, hogy "- Not VLIW, still OoO superscalar architecture"
De ha meg akarnám magyarázni a dolgot, erre és erre indulnék el (amit eddig Hans de Vries legnagyobb tévedésének tartottam, máig nem tudom hova tenni).
-
P.H.
senior tag
válasz
#95904256
#4899
üzenetére
Ha valóban ekkora (órajelekben mérhető) hatása van a késleltetésre önmagában az asszociativitásnak (és most csak maradjunk a Merom-családon belül, ott igazán érdekes a kérdés, főleg visszafelé), akkor az E1xxx-es felvetés jogos is lehet - bár én nem hiszem.
De azt se feledjük, hogy itt (Barcelona-Shanghai esetén) cache-növekedésről is beszélünk, magasabb asszociativitás mellett (meg még esetleges órajel-változásról is).
-
-
P.H.
senior tag
válasz
#95904256
#4895
üzenetére
Azt hiszem, volt erről forrás is, de logikailag is szükségszerű: a fizikai címből eggyel több bitet használnak fel az L3 indexelésére, ekkor kijön 4 MB, és másfélszeresére növelik az asszociativitást, így jön ki a 6 MB.
A K8-as L2 esetén a fizikai címből jövő indexelő bitek számával játszottak (ennek a hibaleírásnak a 6. pontjában konkrétan le is írják ezt), az asszociativitás nem változott 256-512-1024 KB L2 esetén, a Core2-nél viszont fordítva van, azt hiszem: ahogy csökken a családok L2-mérete, annál kisebb az asszociativitás.
-
#4887
P.H.
senior tag
Balala2007
#4880
P.H.
senior tag
válasz
 Balala2007
#4880
üzenetére
Balala2007
#4880
üzenetére
Még nem néztem bele az AVX doksiba, de amit leírtál, arról ezek jutottak eszembe (csak a bekezdések elejét idézem, remélem, nem zavaró):
- ("SSE5 nem definiál uj architekturalis allapotot"...) a kérdés, az OS-gyártók (pl. a Microsoft) mennyire fog az AVX mellé állni, gondolok itt arra, mennyire fog visszamenni - Win98? WinME? Win2K? WinXP? Vista? - a patch-csel. Az SSE5 minddel használható lesz.
- ("SSE5 ortogonalis, azaz a regiszterek"...) az x86 egyre inkább arra haladt, hogy ortogonális megoldást adjon szinte minden korábbi register-specifikus megoldásra. Nem tudok indokot találni arra, miért jó visszatérni ehhez a szemlélethez.

- ("Az AVX a boviteseket a 2 vagy 3 byte-os VEX"...) az AMD elég korán elkezdte használni az 0F0Fh prefixet, az Intel a REP/REPNZ és az adatméretváltó byte-okat erőltette eddig. Szerintem ennek inkább decode-egyszerűsítési és valamilyen jövőbeli kiterjeszthetőségi okai vannak. Logikus, bár áldozattal jár.
- ("Az AVX onmagaban csak az alap float és"...) érdekes. Az általános, hétköznapi CPU-orientált média(/image)-alkalmazások inkább felszorzott integer adatokon dolgoznak, ahogy eddig láttam (bár mondjuk én jobban szeretem az fp-megközelítést). Talán az Intel minőségi okok miatt nem erőlteti az integer-t (DCT/IDCT, átméretezés, stb) a nagyobb adatmennyiségen dolgozó algoritmusoknál; kb. ott lehet sebességben így (jobb minőség mellett), mint a kisebb méretű integer-utasításokkal.
- ("Az SSE5 tartalmaz egy olyan FMA supportot, aminek az a hátránya"...) 16-os register-készletre nem hiszem, hogy célszerű alkalmazni valódi négyoperandusos műveleteket (több memóriaoperandus pedig kényszerűen megnöveli pl. az utasítás méretét).
-
P.H.
senior tag
Sokadszor újragondolva a dolgot, most úgy vélem, hogy nem kellene hájp-nak nevezni azt, ami itt történt, és az AMD 'csinálta'. Mindvégig szem előtt volt a hiba leírásában, mégsem kapott elég nagy hangsúlyt:
"In this case, the MC4 status register (MSR 0000_0410) will be equal to B2000000_000B0C0F or BA000000_000B0C0F. The MC4 address register (MSR 0000_0412) will be equal to 26h."
Bár magának a hibának sok gyakorlati jelentőséget a mai napig nem tulajdonítok (»nagyon« szerencsétlen helyzet kell ahhoz, hogy a hiba hatása kézzelfogható problémát okozzon), az Opteron-ok célterületén a Machine Check Architecture nem csak egy pipa az Everest-ben a CPUID-fülön, hanem nagyon komolyan vett dolog, a Machine Check Exception-ön túl is: "Machine check errors are either recoverable or irrecoverable. Recoverable errors are those that the processor can correct and, thus, do not raise the machine check exception (#MC). However, the error is still logged in the machine check MSRs and it is the responsibility of the system software to periodically poll the machine check MSRs to determine if recoverable errors have occurred. If a recoverable error has been logged in the machine check MSRs, a second recoverable error can overwrite it." (K8 BKDG)
Úgy eladhatatlan egy server-processor, hogy (vélt vagy valós) L3-hibát jelez, le is álltak velük (pl. "Now the L2 and L3 cache have the same data, which shouldn't happen given AMD's exclusive cache hierarchy. If the line in L2 gets evicted once more, it'll be sent off to the L3 and there will be a conflict creating a L3 protocol error." [link])
Azt pedig nehéz lett volna megmagyarázni, hogy az Opteron-ok hibája egyáltalán nem jelentkezik az Phenom-okban. Még akkor is, ha a desktop OS-ek nem figyelik és loggolják folyamatosan az MCA-státuszt, csak a kivételre 'ugranak'. -
P.H.
senior tag
válasz
 Raymond
#4663
üzenetére
Raymond
#4663
üzenetére
Értem. Nagyon eltérőt mást ebben a felbontásban sem lehet találni a magokon belül, csak két másik dolgot:
- megfordították az L2 cache-eket
- a Northbridge látható része némileg eltér a korábbitólfLeSs #4664: Ezt hogy érted?
A képen csak azt akartam mutatni, hogy láthatóan a 128-bit SSE-t úgy érték el, hogy a korábbi 64 bites végrehajtókat megduplázták fizikailag (a K8-as képet innen fordítottam be 90 fokkal, és kicsinyítettem. -
P.H.
senior tag
válasz
#95904256
#4657
üzenetére
Az FPU-részek méretét benéztem, a keret letakarja a mag egy részét. Viszont épp készítettem ezt a képet (kicsit jobban látható invertált és kissé kiemelt képen a Shanghai mag, 10%-kal kicsinyítve a Barcelona -maghoz), amikor feltűnt valami:

A L1D - Load/Store - Data TLB és az FPU határán bal oldalon, az eredeti képen vörösen, az invertált képen kéken derengő vékony vízszintes sáv nem volt Barcelonában. Valami hasonló sejlik az invertált képen (de nem bírom kinézni, a felirat takarja) L1C - Decode- Instruction TLB és az integer egység között is ugyanúgy bal oldalon. Vajon mik lehetnek azok?
-
P.H.
senior tag
válasz
#95904256
#4653
üzenetére
Olyan sok különbséget nem látok a kettő között, sőt, semmit, így ránézésre (a Core0-on jobban látszanak az L1 cache-ek és buffer-ek, talán Core1-en a mag funkcionális egységek jobban kivehetőbbek).
Hacsak nem arra gondolsz, hogy a 2x64-bit FPU két része (ha jól tévedek, a négyosztatú magon - a K8-as FPU - Data & Load/Store - Integer - Instruction/Decoding felépítésből kiindulva - a legfelső rész az) inkább 1:2, mint 1.5:2 osztást mutat.
-
P.H.
senior tag
Mindhárom lehetőség forrása ez a 2006-os prezentáció lehet (a 22. teljes oldal). A HT Retry a BKDG szerint már támogatott, a memory mirroring lehetősége adott az unganged mode miatt/mellett (bár nem látom nyomát sem a BKDG-ben, pedig ott kellene lennie), a data poisoning meg lehetséges, hogy nem is oda, a BIOS-hoz tartozik.
-
P.H.
senior tag
Amik a K8-ban is voltak:
- Machine Check Architecture
- Chipkill ECC
- egy-egy scrubber az ECC-védett L1D-hez, L2-höz és DRAM-hoz
- a memória-scrubber támogatja a DRAM Scrub Redirect-etA K10-zel kapcsolatban több helyen lehet olvasni a
- HT Retry Protocol-ról
- memóriatükrözésről
- data poisoning-ról
de hiteles forrást nem találtam eddig ezek támogatásáról. -
P.H.
senior tag
Mivel még mindíg tart a K10-uborkaszezon, erre visszatérek még egyszer.
A tavaly nyári hírek szerint a kétmagos megoldások 2008 elejére (Q1) jöttek volna - akkor még szó nem volt X3-ról -, alig pár héttel a Phenom-ok után, emiatt feltételezem, hogy a négymagos és a kétmagos tervek külön-külön, egyszerre futottak egy ideig, más felépítéssel. Most ott tartunk, hogy a négymagos és a hárommagos megoldásokról szinte mindent tudunk pro és kontra, a kétmagosról szinte semmit, olyannyira, hogy nem alaptalan a feltételezés, hogy az első dual-core CPU-k a négymagosok nagyon hibás verziói lesznek (íme az AMD elrontott marketing-je). Pedig nem hiszem, hogy úgy gondolták, hogy a 'féltenyérnyi' Phenom-magmérettel majd 'leigázzák' a desktop-világot.
Ezek fényében lesz kétmagos Q1 helyett Q2: abban a stádiumban, hogy pár hónapon belül indulnak a kétmagosok piacra, hol tart a folyamat? Mennyit is kellene mostanság tudni róluk? Szétnéztem, lehet, hogy átsiklottam valami felett, most szinte semmi információ.Elsősorban az sem világos, hogy miért csúsznak vele. (Gyártási problémák? Áttervezés? Nagyobb figyelem a szerver-vonalra? TLB-hiba? Pedig utóbbi lehet a leggyengébb érv, mert ebből nem lesz(?) többutas megoldás; kevesebb mag is van, és feltételezve, hogy a hiba tényleg nem függ közvetlenül az órajeltől; bár csak az alacsonyabb órajelű Phenom-ok kaphatók.) Mindenhol szinte ugyanazt találom (amit a PH!-hír is közölt).
Továbbá pl. sem a méret, sem a tranzisztorszám, sem a tervezett fogyasztás nem ismert eddig, a cache-méret sem biztos (és igen, lehetséges, hogy tényleg 2x1MB L2-t terveznek), sem az induló órajel.4 GHz: Ennyire nem hatott komikusnak még nyáron, és most sem adtam megvalósíthatósági tanulmányt mellé, csak spekuláció. A kétmagos K10-eket muszáj az akkorra megmaradó (és azt gondolom, a jelenlegi) K8-vonal teljesítménye fölé pozicionálni. Lehet ebben a kérdésben óvatosan fogalmazni ("Thus far, all of AMD's guidance has pointed towards a 3GHz Phenom late in the second quarter. If AMD can launch a Kuma CPU in the 3.2-3.4GHz range around the same time, it'll improve the company's competitive standing during the critical back-to-school period.", de minek? Úgy néz ki jelenleg, hogy ha a kétmagosok induló órajele 2.6-2.8 GHz-en fog tetőzni (ha az év végéig ez - 65 nm-en - emelkedik is, az sem lesz gyógyír), akkor már most el lehet kezdeni a róluk szóló teszt konklúziójának írását. Vagy 'rágjam végig a körmöm' nyáron a tesztjük olvasása alatt, hogy jobb lesz-e, mint egy mostani 6400+?
Szerintem.
-
P.H.
senior tag
Nagyjából úgy nézett ki a képlet a Core 2 TLB-bugnál, hogy az OpenBSD részéről De Raadt a sárba gyalázta a processzort, Linus Torvalds kifejentette, hogy jelentéktelen a hiba, az MS kiadott egy javítást. (Az Intel meg kiadott később egy kiegészítést a System Programming Guide-hoz a TLB-ről...)
Most az AMD-bugnál az OpenBDS csendben van, az AMD kiadott egy Linux-kernel patch-t ("Linux users may have another option in the form of a patch for that operating system's kernel. Sources estimate this patch's performance hit at less than one percent, but it comes with several caveats") és egy BIOS-patch-t is, (mert) az MS nem tervez részt venni a hiba javításában. ("At present, Microsoft doesn't offer a Windows hotfix to address the problem, and our sources were doubtful about the prospects for such a patch.").
Mindegy, a lényeg, hogy minél hamarabb kellene lennie kétmagos K10-nek is.
-
P.H.
senior tag
"Ha arra gondolsz, hogy a K10 mellett párhuzamos folynia kellett volna egy kétmagos K10 fejlesztésnek is, akkor igen, így lett volna az igazi, de ha belegondolsz, hogy a K10 milyen kínszenvedés közepette látta meg a napvilágot, akkor gondolhatod, hogy miért nem így történt."
Igen, az akkori piaci környezetben, amikor elkezdődött a tervezése (és még ma is) ez lett volna az igazi (mert nem sok plusz-munkát igényelt volna; vagy semennyit sem, mert: )
"Nyilván arra appelláltak, hogy a hibás K10-eket fogják eladni letiltott magokkal."
Ehhez hozzáteszem, amit Raymond írt valamely topikban, hogy a jelenlegi kapacitással legyártott négymagos K10-ekre sincs igazán felvevőpiac. Erre értem, hogy nincs az AMD-nél kidolgozott üzletpoilitika jelenleg (miért nincs?) a letiltott magos változatok propagálására és eladására sem.
#3907: nyilván a hiba is szerepet játszik (főleg az, hogy az MS nem adott ki javítást, mint a Core 2 bug-ra), az árat meg szerintem gyorsan mérlegelni fogják (gondolom, hozzáértők irányítják az AMD piaci stratégiáját is).
Bár nem jött össze az nekik, mint az X2-nél. -
P.H.
senior tag
#3895: Nagyjából erre gondoltam, amit az első bekezdésben írsz.
#3896: Tudom, mikorra tervezik, azt nem értem igazán, csak miért akkorra.
#3897: Ha le is lehetett szűrni régóta, hogy a elsősorban a szerver-piacra tervezik a K10 első verzióit, amellett azért nem tudok elmenni szó nélkül, hogy mindezt egy 'béta-terv' (~ mainstream megoldás) nélkül tették, és úgy néz ki, ilyen egészen a közelmúltig nem volt náluk (hozzátéve, hogy egy quad->dual megoldás tervezése sokkal könnyebb, mint egy single->dual-é. Főleg, hogy single megoldás a K8 tervezése óta nincs is igazán az AMD fegyvertárában.)
#3899: egyetértek
+ ennek a magletiltogatós játékhoz is kellett volna lennie mára üzleti alapnak.
-
P.H.
senior tag
Nem akarok nagyon belefolyni az üzleti politikába, de van arra valami magyarázat, hogy az AMD miért nem fektet nagyobb hangsúlyt jelenleg a K10-alapú dual-core megoldásokra?
Mindenhol a négy- vagy hárommagos megoldásuk folyik a csapból is (illetve nem is folyik, csak csepeg), de a nagy többség akkor is egy kétmagos megoldással elégedett lenne, tekintve az Intel dual-core és quad-core topikok látogatottságát (és továbbra is fenntartom, amit korábban említettem, hogy SZVSZ egy kétmagos, 4 GHz-ig skálázódó, K10-alapú termékvonaluk kihúzná őket a jelenlegi mocsárból rövid távon).
-
P.H.
senior tag
SZVSZ mindkettőtök érvelése tartalmaz egy-egy apró hibás következtetést.
akosf: Mint a fentiekből kiderül, az K10 tervezésekor megtartották maguknak azt a lehetőséget, hogy a CPU kisebb feszültség- és órajelértékekkel induljon, mint a névleges (emellett induláskor a teljes rendszerben egyetlen mag indul (Boot Strap Processor), a többi reset-jele egy ideig még él, amíg az indító mag el nem végez bizonyos tevékenységeket ~ el nem jut a BIOS bizonyos részéig). A folyamat úgy folytatódik, hogy először is megnézi a mag, hogy single-plane vagy dual-plane lapon van-e a rendszer, majd a további megismert információk alapján a végleges órajeltől kezdve, visszafelé haladva kiszámolja, hogy egy-egy P(erformance)-state-hez milyen elméleti Amper-mennyiség szükséges, és ha azokat a lap nem tudja szolgáltatni, egyszerűen letiltja azok későbbi beállítási lehetőségét (2.4.2.7 Processor-Systemboard Power Delivery Compatibility Check bekezdés a K10 BKDG-ben). Majd később kapcsol a megmaradt állapotok közül a legmagasabbra; előfordulhat, hogy a névlegesnél alacsonyabb órajelre. Ez a sima AM2-lapoktól is igényel(het) bizonyos kooperációs képességet. Tehát ez nem jelenti plusz teljesítmény elérését (hacsak úgy nem, hogy a folyamat 200 MHz-es external clock-ot vesz alapul a szorzókhoz, ha ezt emeled, akkor sem tilt le bizonyos állapotokat).
dezz: SZVSZ a helyzet fordított. Az AMD az AM2-specifikációk átadásakor érzékeltette, hogy egyes későbbi Phenom processzorai komolyabb elvárásokat támasztanak e téren (vagy nem futnak a névleges órajelükön), ezért az definíciók feletti 'biztonsági tartalékokat' a gyártók komolyabban vették, ezért rendelkeznek jelentősebb tuningpotenciállal az AM2-be tervezett legnagyobb K8-ak is.
-
P.H.
senior tag
Elképzelhető, hogy az új procik pl. alacsonyabb órajelen (magszorzóval) indulnak, és ha minden rendben, akkor kapcsolnak normál üzemmódba. (Tehát egyfajta forced C'n'Q-val indítanak.) Vagy akármi. Nyilván az AMD is gondolt erre.
Gondolt.
Power Control Miscellaneous Register CofVidProg (bit 31): COF and VID of P-states programmed. Read-only.
1 = Out of cold reset, the VID and FID values of the P-state register specified by MSRC001_0071[StartupPstate] have been applied to the processor.
0 = Out of cold reset, the boot VID is applied to all processor power planes, the NB clock plane is set to 800 MHz (with a FID of 00h=800 MHz and a DID of 0b) and core CPU clock planes are set to 800 MHz (with a FID of 00h=1.6 GHz and a DID of 1h).
MSRC001_0071 COFVID Status Register StartupPstate (bit 34:32): startup P-state number. Read-only. Specifies the cold reset VID, FID and DID for the NB and core based on the P-state number selected.
Vagy minden 800/1600 MHz-en indul K10-ben, vagy előre beégetett (akár a végleges órajeleknél kisebb) értékeken és feszültségen.
-
#3680
P.H.
senior tag
VaniliásRönk
#3678
P.H.
senior tag
válasz
 VaniliásRönk
#3678
üzenetére
VaniliásRönk
#3678
üzenetére
Lehetséges, hogy félreértelmezem, de:
""Processor" shall mean any Integrated Circuit or combination of Integrated Circuits capable of processing digital data, such as a microprocessor or coprocessor (including, without limitation, a math coprocessor, graphics coprocessor, or digital signal processor) that is capable of executing a substantial portion of the instruction set of an AMD Processor or an Intel Processor."
Ebben nincs benne, hogy pl. a teljes AMD64 utasításkészletet ismernie kell az Intelnek.
"For purposes of this Section 3.9, "Indirect Infringement" means a claim for infringement where the accused infringer is not directly infringing the subject patent rights(s), but is in some manner contributing to a third party's direct infringement of the subject Patent Rights(s) by, for example, supplying parts or instructions to the third party that as a result of such parts or instructions enable such third party to infringe directly the subject patent rights(s). Indirect Infringement includes without limitation contributory infringement and inducing infringement."
Így, az Intel lenne vagy nem lenne ...-ben, ha az AMD-t megvenné valamely 'harmadik fél'. Avagy jogi kérdések tömkelege jönne itt, pl. az "infringe directly the subject patent rights" az utasítások mekkora részét engedi ilyen esetben használni, az eladott, a vevő és a 'sértett fél oldalán?
-
P.H.
senior tag
válasz
Raymond
#3408
üzenetére
Igazad van, a Revision Guide-ok nem egészen naprakészek, a legfrissebb K8-as (2007 október) sem.
Ez az egész kezd hasonlítani egy szappanoperára. Kezdve ott, hogy:
"Saucier clarified the exact nature of the workaround for the erratum that AMD has provided to motherboard makers and PC manufacturers. The fix comes in the form of a BIOS update, and this BIOS patch includes an update to the CPU microcode."És
"Because the hardware bug—known as an erratum—affects all revisions and clock speeds of AMD's quad-core processors, it affects the newly introduced Phenom 9500 and 9600 processors, as well. And although AMD is no longer shipping quad-core Opterons to major server vendors and general customers, it is shipping Phenoms to large PC builders and distributors."
Az Opteronok alacsonyabb órajelen mennek, mint a Phenom-ok, de náluk több a magasabb terhelés esete, mint asztalon. És "Saucier flatly denied any relationship between the TLB erratum and chip clock frequencies."No most szétnéztem a Tyan server-oldalán: a Thunder h2000M S3992(-E) november 19-én kapott új BIOS-t (a szeptember 12-ei BIOS-ok óta támogatják a Quad-Core Opteronokat), a szeptember 14-én útjára indított (Thunder/Tomcat) h1000E sorozat november 13-án kapta az újat. A (nekem sokat sejtető; az Asus gyakorlatilag 'dobta' az összes nV3600 lapját a négy socketes megoldása kivételével, az nV2200-as Socket F-es lapok támogatják a K10-et) 'nVidia 3600 NPF' alatti Thunder n3600R (S2912)-nél ez olvasható BIOS-update alatt:
2007/08/14 S2912_v300 v3.00
TYAN Thunder n3600R (S2912) BIOS V3.00
New features and Fixes:
* Updated AGESA code to v3.1.1.0
* Added AMD Quad Core CPU Support*
*Note: Must use AMD Barcelona B3 stepping CPU's (or later) for Quad Core Support
[/I]
Akár ebből is gondolhatom, hogy a B3 stepping-en (és a hibán) nem november 19-én kezdett el gondolkodni az AMD...Az Asus részéről (esküszöm, az elmúlt két-három héten a Quad-Opteron logo-k ezen az oldalon kiszúrták az ember szemét, a felsoroltak mind szerepeltek ott, quad-támogatással):
- KFN4-D16(/1U): legutóbbi BIOS 2007/05/24
- KFN4-D16/SAS: legutóbbi BIOS 2007/07/03
- KFN4-DRE: legutóbbi BIOS 2007/11/07 (1.Fix Barcelona BA cpu revision is unknow. 2.Fix Barcelona B2 cpu revision is unknow.)
- a 4x4 kukába került
Ez vagy azt tükrözi, hogy vagy az Asus-lapok fél éves BIOS-szal (tökéletesen) támogatják a K10-családot, vagy az Asus 'szívózását', vagyis inkább komolytalanságát szemlélteti.
Mindenesetre a Newegg (tárolt oldal persze) kora ősszel még árult kombó Asus KFN5-D SLI-t + Barcelona-t. -
P.H.
senior tag
válasz
Raymond
#3405
üzenetére
Nem hiszem, hogy újabb lenne a probléma, ezt a .PDF-et majdnem egy hónapja mentettem le (a korai K8-as MOVS hibára kerestem forrásokat), most csak azt néztem meg, hogy nincs újabb az AMD oldalán, tehát a B2-vel alig változott az errata-lista.
(Hogy 'most derült rá fény'? Mese vég nélkül, ahogy korábban említettem.
) -
P.H.
senior tag
válasz
Raymond
#3399
üzenetére
Ez lehet: 254: Internal Resource Livelock Involving Cached TLB Reload
Description: Under a highly specific and detailed set of conditions, an internal resource livelock may occur between a TLB reload and other cached operations.
Potential Effect on System: The system may hang.Bár a virtualizációs hibát (INVLPGA of A Guest Page May Not Invalidate Splintered Pages) a B2-re elméletileg kiküszöbölték, több más, hétköznapokat is érintő hiba is lehet még (244: A DIV Instruction Followed Closely By Other Divide Instructions May Yield Incorrect Results, 260: REP MOVS Instruction May Corrupt Source Address, 278: Incorrect Memory Controller Operation In Ganged Mode)
280: Time Stamp Counter May Yield An Incorrect Value - ezen akár is mosolyogni lehet
-
P.H.
senior tag
Létezik egy Anandtech-es, számomra meglepő módon márciusi keltezésű cikk a Barcelonáról (nem tudom, volt-e ebben a topikban korábban linkelve). Még leglepőbb számomra, hogy az AMD Developer Central több cikke is hivatkozik rá, de végigköveti elég jól és érthetően a 10h Family-ben debütáló fejlesztéseket.
(nagyonOFF: - pl. az említett AMD-s hivatkozások miatt, vagy az Introduction fejezetben leírt erőviszony-fejlegetések miatt is - nem vagyok biztos benne, hogy teljesen objektív a cikk, de saját szubjektív véleményem szerint azt elég jól vázolja, hogy a fejlesztések milyen viszonyban vannak az akkori piaci Intel-termékekkel.)
-
P.H.
senior tag
válasz
Raymond
#2961
üzenetére
A Northbridge FID-váltások warm reset után lépnek életbe, ez biztos. Így a folyamat sokkal bonyolultabbá válik, mint a K8-as váltások, lásd a K8-as 9.5.6.2.2 Changing the FID alatt leírt utasításfolyamot (itt van kiemelve a BIOS-ból).
Cold reset után természetesen mindenképp kell DRAM-Training, de a warm reset is említésre kerül a témakörében - nekem egyelőre homályos, hogy mi okból. Mindenesetre a KFSN4-DRE BIOS-át letöltöttem és a fent használt IDA disassembler-t (trial version-t) is. Delphi-ben belenéztem ebbe a BIOS-ba, meg is találtam az AGESA-kódblokkot - és mivel tényleg C-ben íródott, átláthatónak is tűnik -, de a Delphi 32 bites kódként fejt vissza, a BIOS viszont 16 bites alapból, utasításonkénti mode-váltásokkal a 32 bites esetekre; gépi kódból látszik, hogy hol rossz a mnemonik és utasításhossz-megfeleltetés, és mi lenne valójában, de az x86 szépségei miatt egyelőre azt mondom, hogy szinte mindenhol rossz - az RDMSR-eket és WRMSR-eket használtam eddig viszonyítási alapul -. De megpróbálok egy kis időt szakítani az IDA kiismerésére.
Az viszont bántja a szemem, hogy a Barceloná-kat támogató Asus lapokra nincs letölthető friss CPU-driver (a KFSN4-sorozatra sem, pedig ezt a három lapot szeptember 10 után dobták piacra). Vagy lehetséges, hogy a 'POWERNOW For CPU' utility-nek köze van az órajelekhez? Mondjuk az AGESA-blokk fordító-szerepe elméletileg pont erre szolgálna, hogy nem kell teljesen új magasszintű támogatás.
-
P.H.
senior tag
válasz
Raymond
#2752
üzenetére
Eddig jutottam pár nap alatt, tovább nem látom az utat, ezen leírás alapján*:
- K8 esetén ezt az egy FIFO-buffer-t találtam (NB -> HT?) :
3.6.18 HyperTransport™ FIFO Read Pointer Optimization Register
This register allows the separation of read/write pointers in the HyperTransport technology receive/transmit FIFOs to be changed from their default settings. The pointer separation written to this register takes effect after a warm reset. The value of this register is maintained through a warm reset and is initialized to 0 on a cold reset.Change Read Pointer For HyperTransport Link 2 Receiver (RcvRdPtrLdt2)—Bits 18–16.
Moves the read pointer for the HyperTransport receive FIFO closer to the write pointer thereby reducing latency through the receiver.
000b = RdPtr assigned by hardware
001b = Move RdPtr closer to WrPtr by 1 HyperTransport clock period
010b = Move RdPtr closer to WrPtr by 2 HyperTransport clock periods
011b = Move RdPtr closer to WrPtr by 3 HyperTransport clock periods
100b = Move RdPtr closer to WrPtr by 4 HyperTransport clock periods
101b = Move RdPtr closer to WrPtr by 5 HyperTransport clock periods
110b = Move RdPtr closer to WrPtr by 6 HyperTransport clock periods
111b = Move RdPtr closer to WrPtr by 7 HyperTransport clock periods
AMD recommends setting this field to 5 for all coherent HyperTransport links and noncoherent HyperTransport links to AMD chipsets. Optimal value for noncoherent
HyperTransport links to other chipsets needs to be determined by the developer and tested to ensure stability.Change Read Pointer For HyperTransport Link 2 Transmitter (XmtRdPtrLdt2)—Bits 21–20.
Moves the read pointer for the HyperTransport technology transmit FIFO closer to the write pointer thereby reducing latency through the transmitter.
00b = RdPtr assigned by hardware
01b = Move RdPtr closer to WrPtr by 1 HyperTransport clock period
10b = Move RdPtr closer to WrPtr by 2 HyperTransport clock periods
11b = Move RdPtr closer to WrPtr by 3 HyperTransport clock periods
AMD recommends setting this field to 2 for all coherent HyperTransport links and noncoherent HyperTransport links to AMD chipsets. Optimal value for noncoherent
HyperTransport links to other chipsets needs to be determined by the developer and tested to ensure stability.- az AMD által kiadott NPT Guide-ot kihagytam.
- K10 esetén viszont van több is:
[1]. F2x[1, 0]78 DRAM Control Register (169. oldal, NB -> MCT vagy NC -> DCTs?)
RdPtrInit: read pointer initial value. Read-write. There is a synchronization FIFO between the NB clock domain and memory clock domain. Each increment of this field positions the read pointer one half clock cycle closer to the write pointer thereby reducing the latency through the FIFO. This field should be written prior to DRAM initialization. It is recommended that these bits remain in the default state.
Bits Read to Write Pointer Separation
0000b - 0010b Reserved
0011b 2.5 MEMCLKs (For DDR3, this encoding is reserved.)
0100b 2 MEMCLKs
0101b 1.5 MEMCLKs
0110b Reserved
0111b - 1111b Reserved[2].F3xDC Clock Power/Timing Control 2 Register (242. oldal, NB -> core(s)?)
[bit 14:12] NbsynPtrAdj: NB/core synchronization FIFO pointer adjust. Read-write. Cold reset: 000b. There is a synchronization FIFO between the NB clock domain and CPU core clock domains. At cold reset, the read pointer and write pointer for each of these FIFOs is positioned conservatively, such that FIFO latency may be greater than is necessary. This field may be used to position the read pointer and write pointer of each FIFO closer to each other such that latency is reduced. Each increment of this field
represents one clock cycle of whichever is the slower clock (longer period) between the NB clock and the CPU core clock. After writing to this field, the new values are applied after a warm reset. BIOS should program this field to 5h for optimal performance.
0h Position the read pointer 0 clock cycles closer to the write pointer.
1h Position the read pointer 1 clock cycles closer to the write pointer.
... ...
7h Position the read pointer 7 clock cycles closer to the write pointer.[3]. F4x1[9C, 94, 8C, 84]_x[DF, CF] Link FIFO Read Pointer Optimization Registers (264. oldal, NB -> HT?)
There is a synchronization FIFO between the NB clock domain and each of the link clock domains. At cold reset, the read pointer and write pointer for each of these FIFOs is positioned conservatively (30 bit-times apart), such that FIFO latency may be greater than is necessary. This register may be used to position the read
pointer and write pointer of each FIFO closer to each other such that latency is reduced. Each of the fields of this register specify the number of positions to move read pointer closer to the write pointer. After writing to this register, the new values are applied to the FIFOs each time the link disconnects and reconnects, including
warm resets and LDTSTOP_L assertions. Reads from the register after a write but before the link disconnects and reconnects, returns the current value, not the pending value from the last write. Async clocking mode does not move the pointers closer than programmed, it only allows them to keep the programmed separation when the received clock is faster or slower than the transmit clock. (mindegyik link-re külön-külön: )
0h Position the read pointer 0 bit times closer to the write pointer.
1h Position the read pointer 2 bit times closer to the write pointer.
... ...
Fh Position the read pointer 30 bit times closer to the write pointer.(*) lehet, hogy a fentiekben teljesen rossz nyomok járok (csak ne lenne a "memory clock domain" kifejezés...)
Valamiért azonban a (50. oldal) 2.5 Processor State Transition Sequences és a 2.5.1 ACPI Power State Transitions bekezdés teljesen üres (jelenleg). Pedig a legutolsó K8-as guide-okban nagyon részletes folyamatábrák és leírások és táblázatok (9.5 Processor Performance States alatt 9.5.4 BIOS Support for Operating System/CPU Driver-Initiated P-State Transitions, 9.5.5 Processor Driver Requirements, 9.5.6.2 P-state Transition Algorithm) voltak a témában. CPU driver-ből egyelőre nem találtam nyár utánit (vagy valamit, amit érdemes lenne visszafejteni; bár csak az ASUS oldalán kerestem).Ami még feltűnőbb (lehet, hogy csak nekem): első ránézésre - számadatok nélkül - erre a felépítésre azt mondanám, hogy a Northbidge-rész magasabb órajelen jár, mint a magok - mégiscsak (1-)2-3-4 magot szolgál ki, továbbá több-processzoros rendszerekben a többi node-tól érkező kéréreket is ki kell szolgálnia (pl. HT->DCT routing, vagy ami a talán a legfontosabb: [...]"MCT maintains cache coherency"[...]), és a #2732 negyedik pontban idézett egyenletrendszer is ezt sugallja valahol (az NB a legalább leggyorsabb mag felén, és legfeljebb a leglassabb mag 32x-esén üzemel órajelben - leállított magokat nem figyelembevéve).
-
P.H.
senior tag
Sok feltűnt, szeptember 10-én. Mivelhogy:
"A témához kapcsolódik, hogy a gyártó ismertetői eddig a maximális fogyasztási értékeket tartalmazták (az AMD-nél ezt jelöli az ún. TDP), és a részletes specifikációk természetesen ezentúl is közlik ezt az adatot, azonban a végfelhasználók felé egy újabb mutatót, az Average CPU Powert (ACP) fogják inkább kommunikálni. Ez az Intel gyakorlatához hasonlóan nem csúcsfogyasztást jelöl, hanem nagy terhelést okozó, de tipikusnak tekinthető alkalmazások alatt mért disszipációt – az AMD persze hangsúlyozza, hogy ebben már benne van a magok és a HyperTransport-vezérlők mellett a memóriavezérlő fogyasztása is. Így lehetséges, hogy ugyanazok a Barcelona magos processzorok, melyeknél korábban 68, illetve 95 wattos TDP értéket jelöltek meg a hírek, most 55, illetve 75 wattos ACP értékekkel futnak." (forrás)
-
P.H.
senior tag
válasz
#95904256
#2868
üzenetére
Gondolom, talán itt a '98 első kiadására gondolsz, vagy CPUID teszt nélküli korai programokra (a Guide-ok szerint az egy-egy instruction set utasítást is tesztelni kell, hogy ne dobjon kivételt, de ezt nem használom, és nem is bízom ezekben a kódokban). Én nem ütköztem az általad említett SSE-hibába Win '98 alatt sosem (bár nem térképezem, felhasználóink közül milyen arányban futtatják a programjainkat a két kiadás közül).
Mindenesetre ellenkeztél, amikor anno felmerült a kernel-beli FPU-kódok tiltása.
Természetesen nem kötözködni akarok, én meg x87-hibára emlékszem. (GlobalAlloc vagy GlobalRealloc vázolta át az x87 stack-et valamelyik Windows alatt?)
Új regiszterek: a CISC-szemlélet x86-on még mindig nagyon erős, a gépi kód határoló tényezői miatt (és szerintem pont emiatt is igyekszik mindenki a lehető legkevesebb register-rel megoldani a fejlesztéseit). A következő lépés valamikor bizonyosan 'felhasználói' szinten 64+ vagy 128+ (256-512 architekturális, átnevezési) register lesz; 16+16-ot még éppen lehet kezelni kézi assembly-ben (az igazán emberbaráti elnevezések nélkül is - R8-R15 -), tovább nem lehet ipari körülmények között, csak fordítóprogramok által. Szerintem ezzel az x86/x64 assembly szint halálát előjelezed meg, pedig ez az assembly-szint (talán) az egyik erőssége az x86-nak (jelenleg is; bár már rég nem olyan erős, mint volt anno 1-2 évtizede. Lásd pl. RISC - vagy GPU-kódok -, majdnem lehetetlen kézzel kódolni rájuk).
De ne legyen igazam, ez csak az én (megrögzötten konzervatív voltomból fakadó) véleményem (= én így szeretném
) -
P.H.
senior tag
válasz
#95904256
#2852
üzenetére
"El is felejtettem megemlíteni hogy míg a POPCNT az Intelnél az SSE4 része, addig az AMD-nél nem része az SSE4a-nak, viszont tartalmazni fogja a K10-es...
Hogy egész pontosak legyünk: az Intel-nél az SSE4.2 témakörében kerül említésre a bevezetése, de Intel és AMD esetében is külön, azonos (EAX=01, bit 23) bitje van a CPUID-ben. Érdekes módon az LZCNT-nek nincs, az Intel nem is tervezi használni.
#2857: én annak sem örülök, hogy egy-egy utasításnak - de még 10-20 elem alatti utasításcsoportnak - is külön bitje van CPUID-ben, kezdve pl. a CMOVcc-vel. Ahol MMX+SSE-t nem lehet használni, ott csak ezek miatt nem fogok külön, P1-től eltérő kódot írni.
Még annyi, hogy az MS-nek tudtommal kb. annyi köze van az utasításkészletekhez, hogy task-váltásnál le tudja menteni és vissza tudja állítani korrekt módon a teljes register-képet (3DNow!/MMX-nél nem volt gond az x87-mapping miatt, SSEx és x64 esetén igen). Az, hogy a kernel nem használ ki bizonyos utasításkészleteket, innentől nem érinti a felhasználói programokat
-
-
P.H.
senior tag
válasz
#95904256
#2842
üzenetére
20-30%-ot írtál (elég 'diplomatikus' megfogalmazás volt
)AMD esetében 4 utasításhoz miatt kell a CPUID result-ban tesztelni az SSE4A bitet: EXTRQ, INSERTQ, MOVNTSD, MOVNTSS.
Intel-nél ezen mnemonikok egyikét sem látom.
Ezek szerint az AMD SSE4A-jának semmi köze nincs az Intel SSE4(.1)-éhez. (POPCNT lesz Intel-nél is, SSE4.2-ben).
-
P.H.
senior tag
-
P.H.
senior tag
válasz
Raymond
#2737
üzenetére
Nem olyan 'olvasmányos', mint a legutóbbi K8-Guide-ok, az biztos
De engem zavar az még mindig, hogy nem találom benne egyértelműen, hogy OS-initated core vagy NB P-state (ha utóbbit egyáltalán tudja az OS befolyásolni) váltások esetén is kell-e újra RAM-training és -felprogramozás, vagy nem. Mert (javíts ki, ha tévedek)
- ha kell, akkor a North Bridge órajelétől nem függ a DRAM-órajel
- ha nem kell, akkor viszont függ.Dezz #2245: Ez nem egyértelmű (számomra) most sem, hogy a 10h-k tartják, vagy nem. (És ha tartják, milyen módon)
-
P.H.
senior tag
A BIOS and Kernel Developer's Guide-ot böngészem pár napja, nem tudok egyértelmű álláspontra jutni a memória kérdésében, de a lényeg talán a következő:
1.: 185. oldal: F2x[1,0]94 DRAM Configuration High Register (a MEMCLK a szabványhoz igazodik, akárhonnan is származzon?)
[bit 3] MemClkFreqVal: memory clock frequency valid. Read-write. System BIOS should set this bit after setting up F2x[1, 0]94[MemClkFreq] to the proper value. This indicates to the DRAM controller that it may start driving MEMCLK at the proper frequency. BIOS should poll FreqChgInProg to determine when the DRAM-interface clocks are stable. Note: this bit should not be set if the DCT is disabled. BIOS must change each DCT’s operating frequency in order. See section 2.8.7.5.
[bit 2:0] MemClkFreq: memory clock frequency. Read-write. This field specifies the frequency of the DRAM interface (MEMCLK). The definiton varies with the DDR type, F2x[1, 0]94[Ddr3Mode].
Bits - DDR2 Definition - DDR3 Definition
000b - 200 MHz - Reserved
001b - 266 MHz - Reserved
010b - 333 MHz - Reserved
011b - 400 MHz - 400 MHz
100b - 533 MHz - 533 MHz
101b - Reserved - 667 MHz
110b - Reserved - 800 MHz
111b - Reserved - Reserved2.: 98. oldal: 2.8.7.8.4 Calculating MaxRdLatency (a memória a North Bridge clock-hoz (egész pontosan az MTC-éhez) »igazodik«? Így lenne logikus, lásd köv. bekezdés)
The MaxRdLatency value determines when the node's memory controller can receive incoming data from the DCTs. Calculating MaxRdLatency consists of summing all the synchronous and asynchronous delays in the path from the processor to the DRAM and back at a given MEMCLK frequency. BIOS incrementally calculates the MaxRdLatency and then finally programs the value into F2x[1, 0]78[MaxRdLatency].
The following steps describe the algorithm used to compute F2x[1, 0]78[MaxRdLatency] used for DRAM training. K is used as a temporary placeholder for the incrementally summed value.
1. Multiply the CAS Latency (in MEMCLKs) by 2 to get the number of 1/2 MEMCLKs units for Tcl and store into K.
• K = 2 * CL; See F2x[1, 0]88[Tcl].
2. If registered DIMMs are used then add 2 to the incremental sub-total K.
• If F2x[1, 0]90[UnbuffDimm]=0 then K = K + 2
3. If the all coarse prelaunch setup delays are 1/2 MEMCLK then add 1, else add 2 to the sub-total K.
• If (F2x[1, 0]9C_x04[AddrCmdSetup] and F2x[1, 0]9C_x04[CsOdtSetup] and F2x[1,0]9C_x04[CkeSetup] = 0) then K = K + 1
• If (F2x[1, 0]9C_x04[AddrCmdSetup] or F2x[1, 0]9C_x04[CsOdtSetup] or F2x[1, 0]9C_x04[CkeSetup] = 1) then K = K + 2
4. If the F2x[1, 0]78[RdPtrInit] field is 4, 5, or 6, then add 4, 3, or 2, respectively, to the sub-total K.
• K = K + (8 - F2x[1, 0]78[RdPtrInit])
5. Add the maximum (worst case) delay value of F2x[1, 0]9C_x[2B:10][DqsRcvEnGrossDelay] that exists across all DIMMs and byte lanes.
• K = K + (Maximum F2x[1, 0]9C_x[2B:10][DqsRcvEnGrossDelay])
6. Add 5.5 to the sub-total K. 5.5 represents part of the processor specific constant delay value in the DRAM clock domain.
• K = K + 5.5
7. Convert the sub-total value K (in 1/2 MEMCLKs) to Northbridge clocks (NCLKs) normalized to 200 MHz clk (multiplying before dividing avoids rounding errors):
• K = K * 200 * (F3xD4[NbFid] + 4); see F3xD4[NbFid] for more information on the state of NbFid.
• K = K /(current memory clock frequency); see F2x[1, 0]88[MemClkFreq]
• K = K / 2; removes the 1/2 MEMCLK component
8. Add 5 NCLKs to the sub-total. 5 represents part of the processor specific constant delay value in the Northbridge clock domain.
• K = K + 5
9. Program the final MaxRdLatency with the total delay value (in NCLKs):
• F2x[1, 0]78[MaxRdLatency] = RoundUp(K)Note: if F2x110[DctGangEn] = 1, BIOS sets both DCT’s F2x[1,0]78[MaxRdLatency] to the maximum of either channel's computed MaxRdLatency value.
3. 50. oldal: 2.6.1 Northbridge (NB) Architecture
Major NB blocks are: System Request Interface (SRI), Memory Controller (MCT), DRAM Controllers (DCTs), L3 cache, and Cross Bar (XBAR). SRI interfaces with the CPU core(s). MCT maintains cache coherency and interfaces with the DCTs; MCT maintains a queue of incoming requests called MCQ. XBAR is a switch that routes packets between SRI, MCT, and the links.
A fentiek a magoktól független, de azonos órajelen és feszülségen működnek - ez az ötödik frequency és a második voltage plain, betartva a következőket (hozzátéve, hogy
COF = Current Operational Frequency
P-state = operational performance states (states in which the processor is executing instructions, running software) characterized by a unique frequency and voltage)4. 33. oldal: 2.4.2.3 P-state Bandwidth Requirements
• The frequency relationship of (core COF / NB COF) <= 2 must be maintained for all supported P-state combinations. E.g., a core P0 COF of 2.4 GHz could not be combined with a NB P0 COF of 1.0 GHz; the NB P0 COF would have to be 1.2 GHz or greater; if the NB P0 COF is 1.2 GHz, then the NB P1 COF of 0.6 GHz may only be supported if the corresponding core P-state specify a COF of 1.2 GHz or less.
• All core P-states are required to be defined such that (NB COF/core COF) <= 32, for all NB/core P-state combinations. E.g., if the NB COF is 4.8 GHz then the core COF must be no less than 150 MHz.
• All core P-states must be defined such that:
• CPU COF >= 400Mhz.(Azt nem találom sehol, hogy eddig C'n'Q által levett magórajel mellett K8 esetében a memória órajele is leesett-e, de itt 'DRAM clock domain'-t említenek, saját 'clock domain'-nel rendelkezik az összes mag és az NB is.)
-
P.H.
senior tag
válasz
Raymond
#2555
üzenetére
Ahogy a Socket F-es (vékony) réteget szívatja az Asus, úgy bárki megteheti. Eddig két Opteron-os lapról tudok részükről (11 Socket F lapjuk van), ami biztosan támogatja a Barcelonákat:
- KFSN4-DRE official released BIOS Rev1001 (2007/09/13 update)
- KFN5-Q/SAS BIOS v1005 (2007/10/11 update):
Updated AGESA 3.1.2.0 for AMD Barcelona CPU.És a korona:
Dear xxxxxx xxxxxxxx
Sorry, KFN5-D SLI won’t support Barcelona core Opteron CPUs.
If anything need my help please let me know.
Ivan
Server Technical Support Dept.
AsusTek Computer Inc. -
P.H.
senior tag
válasz
#95904256
#2122
üzenetére
Kis deja vu: Pentium Pro (16 vs 32 bit). Végülis az is szerver CPU-nak készült.
Érdekesek a 64 bites eredmények. Valahol egyszer korábban írtam, hogy szerintem jelenleg a 64 bites felépítés megvalósítása ott tarthat, mint a 32 bites a 386/486 idején. Spekuláció és kérdés: vajon az AMD megtette az első lépést előre ebből az állapotból? (Hisz az x64 saját fejlesztésük.)
[Szerkesztve] -
P.H.
senior tag
válasz
 robyeger
#1495
üzenetére
robyeger
#1495
üzenetére
Ha kiörömködted magad, akkor nézzük, mit ábrázol a kép az AMD szerint:
![[kép]](http://kepfeltoltes.hu/070827/345264234AMDcores_www.kepfeltoltes.hu_.jpg "[kép]")
innen: [link]
AMD Eighth-Generation Processor Architecture (White Paper), October 16, 2001
A nem létező rajongásomnál sokkal érdekesebb, hogy ha egy kétmagos AMD CPU felépítésével teljesen tisztában vagy, akkor miért nem ismered fel a szerkezetét képen, ránézésre.
''-Az hogy a processzor milyen mikrokódokra bontja szét a komplex x86 utasításokat lényegében szoftveres, ezt szokták hiba esetén patch-elni alaplapi BIOS frissítésekben és esetenként változtatni egy új stepping megalkotásakor.''
Csak ennek semmi köze a MOESI-hez, és úgy általában a cache protocol-okhoz. Bár a fentiből is kiderül, hogy fogalmad sincs, hogy a pl. a cache probe kifejezés mit takar.
[Szerkesztve] -
P.H.
senior tag
A gondolattal eljátszva, ha a megjegyzést le kellene fordítani magyarra, akkor az hogyan nézne ki? Tehát hogyan kell érteni?
Legegyszerűbben, mik a nyilvánvaló tévedések a következőkben?
A processzorok összes HyperTransport linkje szinkron módban működik, a HyperTransport I/O Link Specification-ban leírt módon (ez feltételezi, hogy aszinkron módot is tudnak, bár nem ismerem az adott specifikációt). Ezen leírt szinkron mód elengedhetetlen feltétele, hogy az összes link esetén mind az adó, mind a vevő vonalak azonos óraegységeken alapuljanak. (Mivel a korábbiak - pl. ''Processors can be configured with link frequencies from up to two link frequency groups.'' - alapján feltételezhetően a koherens és a nemkoherens linkek eltérő frekvencián működhetnek egy CPU-n belül). Ha egy link két végén lévő eszközöknél két különböző órajelgenerátor állítja elő a közös frekvenciát, akkor a következő követelményeknek kell eleget tenniük:
1. Mindkét órajelgenerátor azonos forráson alapul -> azonos frekvencia feltétel? (Ez itt a sejtésem szerint a fenti bináris értékekre utal, amelyek szabványosak, bármilyen alapból legyenek előállítva. Vagy emellett egyben az egyetlen közös alapórajelre meglétére is utal, mely mindkét eszköznek egyik adott bemeneti jele kell legyen? Utóbbi léte leegyszerűsíti a helyzetet.)
2. Spread spectrum (erre mi a helyes magyar kifejezés? Kiszélesített? Vagy nem szigorú határú?) órajelezés már csak akkor engedélyezhető, miután (ha egyáltalán) a két órajelgenerátor esetleges eltérő üteme már összehangolttá válik. -> azonos fázis feltétel? (Ettől válik kérdőjelessé bennem az előző kritériumban említett system-wide egyetlen közös alapórajel. Vagy ez csak 8 CPU-s, kiegészítő alaplapos rendszerekben lenne boot-kor eltérő ütemű?)
[Szerkesztve] -
P.H.
senior tag
Most vettem észre, hogy nekem lementve a linkelt .PDF 2005 októberi verziója (rev. 3.28) van, viszont a link egy 2003-asra mutat, amiben még nincs benne az említett záró megjegyzés:
''Note: The processor’s HyperTransport links operate in Synchronous (Sync) mode as described in the HyperTransport I/O Link Specification. Sync mode operation requires the transmit and receive clocks for all links to be derived from the same time base. If different clock generators are used to drive the reference clock to the devices on both sides of the link, then the following requirements must be satisfied to ensure proper link operation:
1. All clock generators must use the same reference clock source.
2. Spread spectrum clocking must not be enabled in any of the clock generators unless the frequency deviations are synchronized between the outputs of all clock generators.''
És nincs benne a 12.4 szakasz sem:
''The BIOS should determine the set of frequencies that a processor is capable of for every HyperTransport™ link connected to the processor. Each frequency in the set must be defined by the corresponding link frequency capability bit in the LnkFreqCap field, Function 0, Offsets 88h, A8h, C8h, and it must be equal to or less than the maximum frequency values specified in the processor data sheets.
If a HyperTransport™ link is non-coherent, then the BIOS should initialize the HyperTransport™ link frequency (Link field, Function 0, Offsets 88h, A8h, C8h) with the highest value from the set of frequencies of which the processor is capable and which is less than or equal to the maximum frequency values specified in the chipset data sheets, and the maximum frequency supported by the platform.
If a HyperTransport™ link is coherent, then the BIOS should initialize the HyperTransport™ link frequencies (Link field, Function 0, Offsets 88h, A8h, C8h) of both processors with the highest common frequency value from the sets of frequencies of which each processor is capable that is less than or equal to the maximum frequency supported by the platform.'' -
P.H.
senior tag
válasz
#95904256
#1482
üzenetére
Ezen a területen sokkal jártasabb vagy nálam, szerintem ezáltal [link] (BIOS and Kernel Developer's Guide for AMD Athlon 64 and AMD Opteron Processors) lehet legjobban rálátni.
Ebből is a következő rövid szakaszok érdekesek:
3.3.13 LDTi Frequency/Revision Registers
12.4 HyperTransport™ Link Frequency Selection
Az első alatt felsorolt bitértékek nem tűnnek sem osztónak, sem szorzónak (bár attól még lehetnek):
''Processors with multiple HyperTransport™ links are capable of operating the links at different frequencies. There are three supported link frequency groups:
800 MHz, 400 MHz, 200 MHz
1000 MHz
600 MHz
Processors can be configured with link frequencies from up to two link frequency groups.
0000b = 200 MHz
0001b = reserved
0010b = 400 MHz
0011b = reserved
0100b = 600 MHz
0101b = 800 MHz
0110b = 1000 MHz
0111b = reserved
1000–1110b = reserved
1111b = 100 MHz''
És a 3.3.13. záró megjegyzése sejtetni engedi, hogy az összekötött eszközöknek lehet saját órajelgenerátoruk.
[Szerkesztve] -
P.H.
senior tag
#1467: ''Én nem hiszem, hogy csak szoftveres akadálya lenne, hogy a magok gyorsítótárai közvetlenül kommunikáljanak, mondjuk a MOESI protokoll lenne a hibás.''
Ebben mi a szoftveres?!
#1468: ''viszont feltételezésem szerint az L1 és a TLB az SRQ-hoz már szintén magórajelen kapcsolódik,''
És megint egy olyan mondat, amely teljesen komolytalanná teszi a megelőző és következő mondandódat. Persze a TLB szép rövídítés, nagyon szakmaian hangzik megemlíteni, és jól illik a többi 2-3-4 betűs közé; csakhogy tartalma a mag magánügye, nem kapcsolódik sehogyan a külvilághoz.
#1470: ''A Hammer-nél 1mag van!!! (2001-es prezentáció)''
Ezt így felejtd el. A Clawhammer pl. 1 magos CPU, de a Hammer (rendszer)architektúra, ahogy ez a [link] prezentáció is így kezdődik. Ugyan 2001-es, de azért nem nehéz belátni, hogy az IMC, az XBAR és SRQ tervezésekor már több magot feltételeztek. Te is használod, korábban is már belinkelted azt a képet:![[kép]](http://kepfeltoltes.hu/070825/AMD0_www.kepfeltoltes.hu_.jpg "[kép]")
Ezen [link] hsz-ed óta nem bírtam megérteni, hogy miért nem lapozol a következő két oldalra, de most már látom: mert nem érted, hogy ez egy darab kétmagos CPU ábrája.
#1475: ''én ilyen fajta ábrából szeretnék egy 2magost látni''
Tehát ott van, továbbá még kettő, amely részletesen megbontva ábrázolja a parancs- és adatáramlásokat:![[kép]](http://kepfeltoltes.hu/070825/AMD1_www.kepfeltoltes.hu_.jpg "[kép]")
![[kép]](http://kepfeltoltes.hu/070825/AMD2_www.kepfeltoltes.hu_.jpg "[kép]")
És hangsúlyozom, a ''to CPU'', a ''CPU0'' és a szürke ''CPU1'' kifejezések magokat jelentenek, a további processzorok még mindig a HyperTransport-linkek másik, nem ábrázolt végein vannak. Továbbá igazából nincs is közvetlen adatcserére utaló útvonal ábrázolva, mint amilyen parancsút viszont van.
[Szerkesztve] -
P.H.
senior tag
válasz
#95904256
#1461
üzenetére
Azt kell ilyenkor nagyon mérlegelni, hogy egy-egy, a közös adatterülethez való hozzáférésre mennyi, azt nem érintő önálló számítási művelet jut, mert ha sok, akkor hatékony lesz az az eset is, amit írsz (pl. ismert előre, hogy egy-egy tartományra jutó számítási feladat hossza órajelekben vagy percekben/órákban mérhető).
''Honnan tudja egyik-másik CPU hogy a másik CPU mely memóriacímeket birtokolja?''
Ez a cikk [link], amit korábban linkeltem, egy elég jó kezdeti betekintést ad ebbe a világba. (Amit a link mellett írtam, ''Az alján látható, hogy többek között az Intel által használt MESI cache-protocol és az AMD által használt MOESI eltér skálázhatóságban, utóbbi mellett több magot lehet összerakni, mint előbbinél, ezért használja ezt az AMD.'' esetében ''magot'' helyett talán inkább ''CPU-t'' kellett volna írnom, bár ez sem igaz, a node kifejezés az igazi, mert Kentsfield esetén a 2x2 mag 2 node, a négymagos K10 pedig 1 node. A two vs three hop jelentéstartalma és -eltérése, és sok egyéb dolog pedig pl. innen [link] kiolvasható konkrét teljesítményadatok találhatók benne, de nem a riválisokkal összehasonlítva, hanem arra vonatkozólag, hogyan viselkedik egy többmagos-többprocesszoros Opteron-rendszer különböző körülmények között).
De amit felvetettél, jogos (pl. a cikkből, a legegyszerűbb megközelítésben):
''When a processor reads or writes a cache line, it must broadcast a snoop request to all other processors in the system to ensure that it gets the most recent valid cache line. When a processor wishes to write to a cache line, it must first broadcast an invalidate snoop, which tells other processors to evict that cache line. In both cases, the processor must wait to receive responses from all other processors before proceeding.''
[Szerkesztve]









 )
)












![;]](http://cdn.rios.hu/dl/s/v1.gif)




Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Kész rémálom lesz Linuxot használni jövőre az USA egyes államaiban
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- AMD Navi Radeon™ RX 9xxx sorozat
- Napelem
- Fogyjunk le!
- Energiaital topic
- OLED monitor topic
- Samsung Galaxy Buds3 Pro - szárat eresztettek a babok
- Lexus, Toyota topik
- Samsung Galaxy Felhasználók OFF topicja
- További aktív témák...
- BESZÁMÍTÁS! Asrock B450M R5 5500 8GB DDR4 256GB SSD GTX 1050 Ti 4GB Zalman T3 Plus DeepCool 400W
- HIBÁTLAN iPhone 12 Pro 256GB Graphite - 1 ÉV GARANCIA - Kártyafüggetlen, MS3283
- Telefon felvásárlás!! Samsung Galaxy A20e/Samsung Galaxy A40/Samsung Galaxy A04s/Samsung Galaxy A03s
- Lenovo ThinkPad E15 Gen 2 15,6" - i7 1165G7, 16GB RAM, 512GB SSD, jó akku, számla, 6 hó gar
- Poco F4 GT 12/256GB - Független, Fekete - 1 Év Garanciával
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest