Új hozzászólás Aktív témák
-

hapakj
őstag
Honnan van az infó, hogy csak inline ray tracinggel megy? S akkor mit jelentek a következő kijelentések ebben a blogpostban?
we will introduce DXR tier 1.1 with the following new additions on top of tier 1.0.
DXR tier 1.1 is a superset of tier 1.0.
Ezek számomra egyértelműen azt jelentik, hogy az 1.1 mindent tud, amit az 1.0. Épp ez a minor verziós lényege is. Ott nagyon nem jellemző, hogy funkcionalitást vennének el. Ha mondjuk DXR 2.0 lenne, akkor már felmerűlne a gyanú, hogy esetleg kivettek valamit, de még akkor sem feltétlen.
16 textúra az marhasok textúra per material. Igazából nem is érdemes textúra számban számolni, hanem bit/texelben, s jól megválasztott tömörítésekkel azt is szét lehet dobni 5-6 textúrába általában. Szóval a tömörítés hatékonysága mellett én nem látom, hogy annyira megugrana a cache terhelés, s részemről még arra sem találtam megerősítést, hogy per textúra mellett kéne 1.5Mb adatszerkezet. Per texture group mellett elhiszem, mert azt írják, hogy együtt tömörítik a textúrákat, úgy meg már abszolút jók vagyunk.
-

Abu85
HÁZIGAZDA
Egy alkalmazáson belül több pipeline van, és úgy már lehet vegyíteni a kettőt.
DXR 1.1-gyel megy, tehát csak az inline raytracinggel. A DXR 1.0 a dynamic shader based raytracing. A DXR 1.1 erre nem tartalmaz semmilyen specifikációt, mert nem kompatibilis vele.
#27 hapakj : Például azért hátrányos, mert 24 MB-tal maximum 16 textúrán tudsz vele egyszerre dolgozni. Azért az nem sok. És eközben még minden egyéb grafikai feladat belassul, mert a cache másra van használva.
Ezért csalóka a példaprogram, ami csak azt csinálja, ami a célfeladat. Na de képzeld el ezt egy játékban, ahol azért jóval több texútára van, azok adatszerkezetei telítik az L2 gyorsítóárat, tehát innentől kezdve minden adatért a VRAM-ig kell mennie a GPU-nak, így nem lesz elég konkurens wave, hogy átlapolható legyen a memóriaelérés késleltetése. Tehát egy ponton túl a GPU nem fog semmit sem csinálni, mert arra vár a munkafolyamat, hogy megérkezzen a memóriából az adat.
De nem gond ez, ezt az NVIDIA is a következő vagy az az utáni generációnak szánja. Most csak arra kíváncsiak, hogy érdekli-e ez a fejlesztőket. Ha igen, akkor majd később bedobnak 500 MB cache-t. Ha meg nem, akkor semmi gond, másfelé fejlesztik a hardvereket és megölik ezt az irányt, ahogy csont nélkül megölték nemrég a DMM-et is, amit az előző generációban az évszázad innovációjaként harangoztak be. Élt két évet.
-
hapakj
őstag
Az természetesen világos, hogy egy pipeline nem lehet egyszerre dynamic shader based vagy inline raytrace pipeline, hiszen előbbiben a RT shadereket kell bekötni utóbbikban meg a compute vagy pixel shaderekben van az inline raytracing. De ez nem jelenti azt hogy egy alkalmazásban ne lehetne a kettőt használni különböző feladatokra. S továbbra sem értem hogy a DXR 1.1 követelményből honnan jött a cikkben említett következtetés, hogy csak inline raytracinggel menne az RTXMG.
csak közben generálnak textúránként 1,5 MB-os adatszerkezetet, ami viszont a cache-nek hatalmas hátrány.
- erre mondjuk utalást a Sampleban egyelőre nem találtam, s ha még igaz is. Nem látom miért lenne hatalmas hátrány, ha még a legkisebb Ada GPU-ban is 24 MB cache van.Amúgy ezt az 1000x lassulást, még 1080 Ti-on sem tapasztalom

-
Abu85
HÁZIGAZDA
Azért hivatkoznak rá additionként, mert nem tudod használni a DXR 1.0-val együtt. Tehát a pipeline vagy 1.0-s vagy 1.1-es. És az inline raytracing a dynamic shader based raytracinget egészíti ki, de nem úgy, ahogy felfogod, hanem úgy, hogy konkrétan neked kell eldönteni, hogy melyik pipeline-ban melyiket használod. A kettőt egyszerre nem tudod, mert nem kompatibilis a két módszer egymással. Már ha a működését nézed, akkor látod, hogy mennyire eltérő az egész. Nem tudod egy pipeline-on belül használni a kettőt, mert másképp működnek, másképp működik a bekötés, stb.
Ez a pontos megfogalmazás. Ha egy pipeline DXR 1.1, akkor az a pipeline inline raytracinggel fog működni. Mással nem tud, mert a specifikáció ezt határozza meg. Ha egy pipeline DXR 1.0, akkor az csak dynamic shader based raytracinggel fog működni. Mással ez sem tud, mert a specifikáció ezt határozza meg.
Igen, ez hatalmas előny a VRAM-on belül, csak közben generálnak textúránként 1,5 MB-os adatszerkezetet, ami viszont a cache-nek hatalmas hátrány. De úgy gondolom, hogy ezzel az NVIDIA nem is az aktuális generációra dolgozik, hanem majd a következő vagy a későbbi generációra, amibe már tudnak rakni 500 MB-os cache-t. Ha ez az irány tetszik a fejlesztőknek, akkor van egy fejleszthetőségi irány a hardverekre nézve. Ha meg nem tetszik, akkor nem lesz 500 MB-os cache a hardverekben, és akkor NTC kuka. Általában a technikák egy része a kukában végzi, nem most lenne az első alkalom, de látniuk kell, hogy a fejlesztőket érdekli-e, mert erre hardvert kell tervezniük. A mostani hardverek nem jók rá. Ha lesz érdeklődés, akkor tervezhetnek rá olyan hardvert, amivel jó lesz.
-
hapakj
őstag
nem nem igaz.
DXR 1.0 = dynamic shader based raytracing
DXR 1.1 = inline raytracing + DXR 1.0 (dynamic shader based raytracing)Az inline raytracing-re mindenütt additionként hivatkoznak a DXR 1.1-es blogpostokban
Szóval azt állítani, hogy ha valami DXR 1.1-et követel az azt jelenti, hogy csak inline raytracinggel fog működni az határozottan pontatlan megfogalmazás.
S persze az is nyilvánvaló, hogy a különböző cachek hatékony kihasználása változhat különböző usecase-ek esetén, s ha a gyártó (nvidia) úgy ítéli meg, hogy mondjuk az új NTC hatékony működéséhez bizonyos adatoknak érdemes perzisztensen bennmaradni, akkor meg tudja oldani. S továbbra is az, hogy a BCn tömörítés 10Mb-jéről 1.52Mb-re tolták le a material texture pack helyigényét hatalmas előny. -
Abu85
HÁZIGAZDA
Mint írtam maga a specifikáció fundamentálisan eltér.
DXR 1.0 = dynamic shader based raytracing
DXR 1.1 = inline raytracingLe is írtam, hogy mennyire jelentős az eltérés. És emiatt a kettő olyannyira nem kompatibilis egymással, hogy egy adott pipeline-ban ez a kettő nem is vegyíthető. Vagy így működik, vagy úgy, de egyszerre egy pipeline-on belül együtt nem.
A buszt használják csak, de nem maradnak ott. Ha ottmaradnának, akkor a GPU-k sokkal lassabban dolgoznának. Nyilván ez egy nagyon okos döntés a gyártók részéről, hogy egy ennyire specifikus munkafolyamat esetében nem hagynak teleszemetelni egy fontos gyorsítótárat. És ez teljesen tudatos. Az NV és az AMD GPU-knak is kell az L2 és az IC+L2. És nem, nem a hagyományos texture mappinghez tartozó adatoknak. Azoknak van külön gyorsítótár mindegyik dizájnban. Ez teszi gyorssá a működést. Semmit nem nyernének vele, ha például az L2-t csak a textúrázás miatt read-only-vá kellene tenni, hogy illeszkedjen a textúrázási munkafolyamatokhoz. Csak egy nagyon masszívat lassulna a hardver. Nyilván megtehetnék, de nincs mögötte logika, mert a munkafolyamathoz van beépítve dedikált erőforrás, és emiatt azt használják.
-
Abu85
HÁZIGAZDA
DXR 1.1=inline raytracing
Ez nagyon leegyszerűsített ábra. És általánosan ez a gond némelyik ábrával, hogy nagyon egyszerűsítik azt, a hardver valós működéséhez viszonyítva.
Ez sokkal jobban mutatja, hogy mi történik:
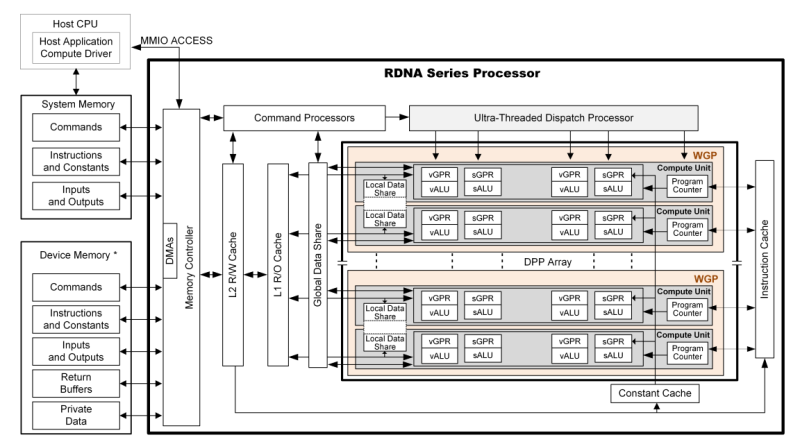
Itt látható, hogy nem pont úgy van bekötve, minden, mint a fenti egyszerűsített ábrán.
Az AMD dizájnja az L1-ből eteti a texútrázókat, ami read-only, és ezen belül használ egy L0-t, ahova bejuthatnak még a textúraadatok a hagyományos textúrázással. Plusz van egy GDS is, ami például teljesen egyedi, és oda már textúraadat nem juthat be.
A parancsprocesszor van összeköttetésben az L2-vel és a GDS-sel, nem véletlenül, ez vezérli ezt a folyamatot, és textúraadat közvetlenül az L1-be jut, és onnan lépdelhet fel.Az AMD multiprocesszora a felépítését tekintve sokkal CPU-szerűbb. Ezért ennyire bonyolult a cache-szervezése. Az NV multiprocesszora sokkal egyszerűbb és maradibb dizájn ilyen szempontból.
Ha nagyon össze akarjuk hasonlítani, akkor az AMD-nél az Infinity Cache látja el azt a feladatot, amit az NV-nél az L2, és az AMD-féle L2 és L0 látja el azt a feladatot, amit az NV-nél az L1. És az AMD-nek ezen túl még van L1, GDS, plusz még pár specifikus gyorsítótára. Nagyon más dizájn. De a hagyományos textúrázást tekintve alapvető fundamentumként ott van, hogy a texture mappinghez szükséges adatok read-only gyorsítótárba jutnak, csak az AMD-nél ez a teljes GPU-n belül megosztott L1, míg az NV-nél ez a multiprocesszoronkénti L1 egy szelete.
-
hapakj
őstag
Értem én hogy a DXR 1.1 kötelező, ezzel nincs is baj, csak a cikk ezen mondata, azt sugallja, hogy csak inline raytracinggel használható az RTXMG:
nyilván szem előtt tartandó limit, hogy kötelezővé teszi a DXR 1.1-et. Utóbbi nem baj, de nem mindenhova jó az inline raytracing.
Ami úgy látom, nem igaz mert RT pipelineokkal is használható.
Hja az L1 vagy alacsonyabb szintű gyorsítótára particionálása usecase-ekre világos és logikus. De én pl nem igazán láttam olyan cache hiearchiát, ami bármelyik levelt skippelni, pl itt sem jelölnek ilyet:
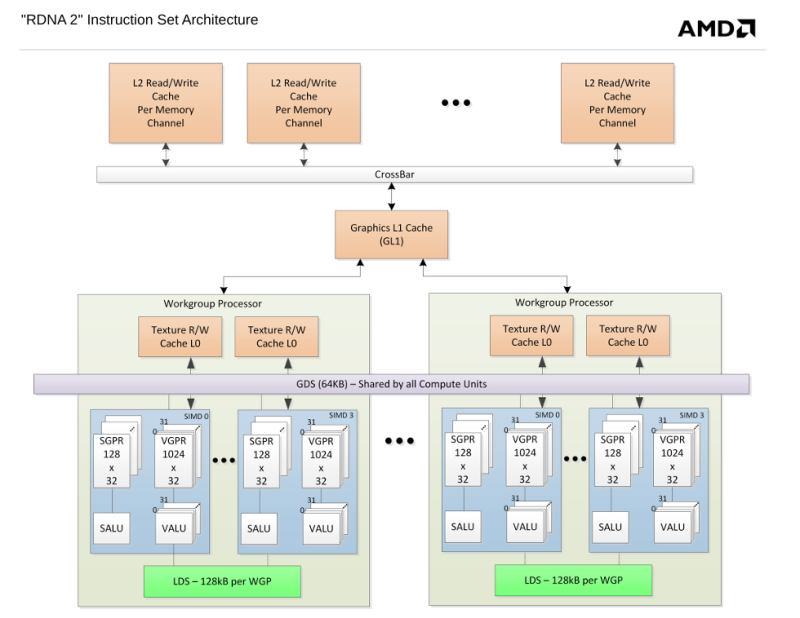
-
Abu85
HÁZIGAZDA
A Requirements szó az követelményt jelent. Akkor ajánlás lenne írva ide, ha ez nem követelmény lenne.
Az újrahasznosítással kapcsolatos tényező csak egy nehézség, de bőven kezelhető. Nem ez jelenti a nagy gondot, hanem a texútrákhoz tartozó 1,5 MB-os adatszerkezet. És ez független attól, hogy a tömörítés mekkora, az adatszerkezet hozzá szükséges, hogy kezelni tudja a hardver.
#19 hapakj : Nem teljesen. Az hardverfüggő, hogy ezt hogyan implementálják. Általában dedikáltan. Kb. 8 kB-os tárról van szó egy textúrázóblokkra. Az NV ezt úgy implementálja, hogy ha a program használ textúrákat, akkor az L1 gyorsítótárból kötelező leválasztani egy 8 kB-os részt, és azt a hardver csak olvashatóvá teszi. Ide kerülnek direkten a hagyományos textúrázáshoz szükséges adatok. Ezt azért választja le így a hardver, hogy ezek az adatok ne is kerüljenek máshova. Ez a működés teljesen megakadályozza, hogy az L2 gyorsítótárban texture mappinghez való adat legyen. És ez nem bug, hanem feature, mert így a leggyorsabb. Erre még anno az Ampere-nél többen rákérdeztek, és az NV hangsúlyozta pont, hogy ez szándékosan ilyen. Ezzel a működéssel a leggyorsabb a hardver, az L2 másra van, oda ilyen textúra színadatok nem kerülnek. És még egyszer hangsúlyozom, hogy ez nem bug, hanem feature. Azt próbálják elkerülni, hogy a textúraadatok összeszemeteljék a cache-t.
-
hapakj
őstag
-
hapakj
őstag
Hát nyilván más az erőforrás bekötés, meg egyik esetben konkrét Ray Trace pipeline van, a másikban meg compute és pixel shaderekben van a inline raytrace.
"Requirements: DirectX Raytracing 1.1 API or higher"
- ezt nem vitattam, de ez nem mondja, hogy a DXR 1.0-ban bevezetett Ray Trace pipelineokkal ne működne, s ahogy nézem az SDK-ban lévő Sample is azt használja.
Hát pedig pont az újrahasznosítás miatt lenne drága. Pont az az egyszerűbb, ha mindenhez saját textúra van, s nem kell az artistoknak problémázni, ha bármibe belenyúlnak az másra is hatással lesz.
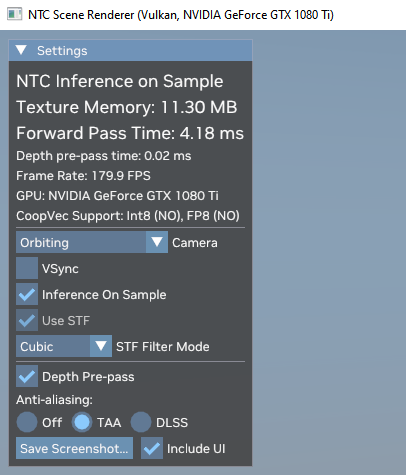
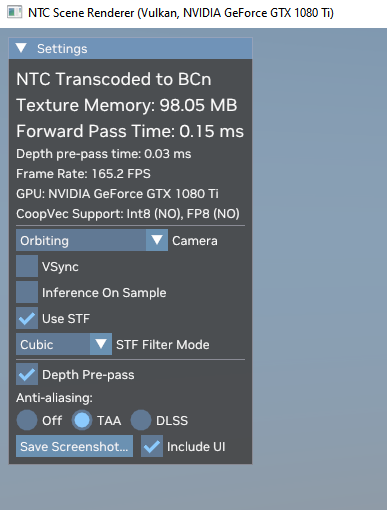
Hát az SDK-ban lévő példa azt írja, hogy egy 6 textúrából álló material csomagot 1.52MB-re tömörítettek be a 10MB BC tömörítés helyett. Ez nagyon jó eredmény. -
Abu85
HÁZIGAZDA
Ez nem igaz. A DXR 1.0 és 1.1 nagyon különbözik. Konkrétan két különböző elven működő specifikáció.
A DXR 1.0 a dynamic shader based raytracing, ami úgy működik, hogy a rendszer alapvetően kilő a sugarakat, a hardver pedig a gyorsítóstruktúra segítségével megkeresi, hogy hol lesz eltalálva egy háromszög, ha egyáltalán lesz találat, és ennek megfelelően jöhet egy hit vagy miss shader. Bármelyiket is hívja meg a program, az be lesz linkelve az erre vonatkozó bekötési táblába, és ez alapján tudja a rendszer megosztani a hit vagy miss shaderrel a szükséges adatokat, vagyis ilyen formában lesz lekövetve egy sugár útja, ameddig tart. Ez akkor előnyös, ha komplex shadereket futtat a program több virtuális anyag használata mellett, és ezt azért kezeli jól a DXR 1.0, mert az árnyalással kapcsolatos munka ütemezését a rendszer kezeli. Viszont vannak limitációk: a gyorsítóstruktúra nem köthető be minden shader lépcsőn, API szintjén kezelt állapotobjektumot és shaderekre vonatkozó bekötési táblát igényel, illetve nem teszi lehetővé a rendszer a relatíve alacsony szintű sugárbejárás kezelését.
Ezekre a limitációkra jött a DXR 1.1, ami egy más elvű módszer, mivel inline raytracinget vezet be. Ez a korábbi módszerhez képest megszünteti a bekötési táblát, illetve nem lesz több elszeparált dinamikus shader. Ehelyett már az eredeti shader tartalmazza a kontextus struktúráját, és utasítja a hardvert, hogy kezdje meg a bejárási lépcsőt. Ha egy sugárnak lesz találata, akkor a függvény visszatér, viszont már ott van a kontextus struktúrája a shaderben, amivel rögtön megkezdődhet a munka, nem kell már semmiféle adatmozgás, illetve elszeparált dinamikus shader indítása ehhez. Ezzel az árnyalással kapcsolatos munka ütemezése is kikerült a rendszer alól, és ez ugyan az esetek jó részében kedvező, de ritkább esetekben nem az. Emiatt a DXR 1.1 nem továbbfejlesztése a DXR 1.0-nak, hanem egy kiegészítése, de úgy, hogy bizonyos esetekben a DXR 1.0 a gyorsabb, bizonyos esetekben pedig a DXR 1.1. Emiatt a Microsoft mindkettőt megtartotta, mert jelenleg nem tudnak egyetlen megoldással minden problémát lefedni.
Ott van a GitHub-on: "Requirements: DirectX Raytracing 1.1 API or higher" - de az NV is mondta, hogy a Mega Geometry nagyon specifikus, nem működik minden környezetben, egyszerűen nem tud. Megvannak a maga limitjei az API limitjein túl.
Program válogatja, hogy mennyi az újrahasznosítás, de azért manapság jellemző. Ezek komplex játékok, ahol van lehetőség jól megtervezett módon újrahasznosítani. Nemcsak olcsóbb lesz a tervezés, de gyorsabban készül el a játék, és összességében a hardvernek is jobb, ha újra van hasznosítva egy textúra, csak nem az NTC-s formában. Ott ez rosszabb, de eddig erre nem kellett figyelni.
Benne van a GitHub linken minden. Minden textúrához 1,5 MB-os adatszerkezet tartozik. Tehát ha egy textúrán feldolgozás történik a GPU-n belül, akkor ez az 1,5 MB-os adatszerkezet határozza meg, hogy miképpen kell kezelni azt a textúrát. Ha 16 textúra van egy kötegben, akkor 24 MB-nyi adatszerkezetet kell valahogy betölteni a cache-be, mert enélkül az NTC nem üzemképes.Használják az utolsó szintű gyorsítótárat a GPU-k, de a hagyományos textúrázásra van saját cache a textúrázók mellett. Ez ráadásul szándékosan csak olvasható gyorsítótár, mert nem lenne jó, ha felül lenne írva benne az adat az ALU-k által. Egyszerűen azért ilyenek a GPU-k, mert egy dedikált gyorsítótárral a leghatékonyabb a hagyományos textúrázás, és emiatt nem is kerülnek bele a hagyományos textúra mappinghez szükséges adatok máshova. Ha ez megtörténnek, akkor csak lassulna minden munkafolyamat. Tehát a mai GPU-knál az, hogy bizonyos adatok nem kerülnek az utolsó szintű gyorsítótárba nem bug, hanem feature.

-
hapakj
őstag
De nem értem? A DXR 1.1 és DXR1.0 nem különböző dolgok, hanem az 1.1 a 1.0 kiterjesztése inline ray tracinggel. Én nem találtam arról forrást hogy az RTXMG ne működne a DXR 1.0-ban bevezetett Ray Trace pipelineokkal.
Nem, nem annyira tipikus az textúrák újrahasználata. S azzal, hogy csökkenteni a VRAM terhelést, csökkenti a cache terhelést. Erről az 1000x-es cache terhelésről forrás?
Hát azzal is elég szkeptikus vagyok, hogy egy GPU ne használná az utolsó szintű gyorsítótárát kb bármire. Szóval ezzel kapcsolatban is néznék egy techpapert

-
Abu85
HÁZIGAZDA
Attól függ, hogy kinek nem az. Azért a DXR 1.0-nak előnyei is vannak. Nem véletlen, hogy egy játék használja egyszerre az 1.0-t és az 1.1-et is. Mert valamire nem jó az 1.1.
Pedig nagyon tipikus, hogy bizonyos textúrákat újra felhasználnak. Ettől még kötegelhetők, csak ilyen formában nem hozza már azt a tömörítési arányt, amit egy példaprogram, ami mindössze 7 textúra. De ennél sokkal nagyobb gond jelenleg, hogy az utolsó szintű cache-t gyakorlatilag teljesen lefoglalja. Tehát ez a fajta megoldás ugyan csökkenti a VRAM kapacitására vonatkozó terhelést, de drasztikus mértékben rontja a grafikai feladatok feldolgozásának hatékonyságát, mert kb. ezerszer nagyobb lesz a cache terhelése. Viszont, ha elkezdenek a gyártók 500-700 MB-os cache-eket alkalmazni, akkor már jó lehet a dolog.
#4 Duck663 : Jó, de senki se mondta, hogy ez gyorsít. Ez a módszer csak a VRAM-mal spórol, de drasztikus mértékben lassítja a grafikai számításokat. Meg ez igazából nem erre a generációra lett kitalálva. Ha lesz rá érdeklődés, akkor megéri majd 500 MB-os cache-eket rakni a GPU-ba, és onnan már kedvezőbb lesz a működése.
#7 hapakj : Az mindegy, hogy a textúra mérete csökkent, mert azt amúgy sem cache-eli be egyetlen GPU sem az utolsó szintű gyorsítótárba. Annak van saját gyorsítótára a multiprocesszorokon belül, ami pici és csak olvasható. Máshova a textúraadatok nem kerülnek be, mert nem lenne hasznos, ha tele lenne szemetelve a grafikai számításokhoz használt gyorsítótárstruktúra. Az NTC-vel viszont feldolgozandó textúránként van 1,5 MB-nyi adatszerkezet, ami mindig csak az utolsó szintű gyorsítótárba fér be. Ez meghatározza majd azt is, hogy egy GPU egyszerre mennyi textúrán dolgozhat, mert szükséges az adatszerkezet megléte az adott textúrához. Tehát ezt csomagolni is úgy kell majd, hogy a minimum célzott hardver utolsó szintű gyorsítótárának mérete meghatározza majd, hogy maximum mennyi textúra helyezhető egy kötegbe, mert ha mondjuk több van benne, akkor az nagyon szar lesz, hiszen nem lesz elég cache az összes adatszerkezet betöltéséhez, és ez úgy kb. 1000x lassabb felfolgozást fog eredményezni.
Ezek mind manuális döntések, amelyeket a fejlesztőknek kell meghozni. Sőt, igazából az lenne az optimális, ha nem az utolsó szintű gyorstótár határozná meg a köteg nagyságát, mert tényleg nem túl jó dolog a többi számításra nézve, ha nem lesz cache-elhető a munkafolyamat. Tehát a jelenlegi hardverek mellett ez a rendszer nagyon extrém limitekkel működik csak.
-
#14
hapakj
őstag
Dragon3000
#13
hapakj
őstag
válasz
 Dragon3000
#13
üzenetére
Dragon3000
#13
üzenetére
Hja, szerintem is nem elhanyagolható mennyiség van még. A Mesh Shading támogatásának elterjedtségéből, jött fel s arra reagáltam, hogy 16xx széria támogatja azt.
-
#13
 Dragon3000
nagyúr
hapakj
#12
Dragon3000
nagyúr
hapakj
#12
Dragon3000
nagyúr
Ha csak a 10x0 szériát nézzük, az is kiteszi a 7,85%-ot, így téves ez a megállapítás, hogy "Ma már a userek kevesebb mint 8%%-a használ 10-es vagy régebbi szériás kártyát", mert ezt a százalékot szinte csak a 10x0 széria összehozza. Azért bőven van még régebbi nvidia is a statisztikában.
-
#12
hapakj
őstag
Dragon3000
#10
hapakj
őstag
válasz
Dragon3000
#10
üzenetére
16x0 szerintem már tud Mesh Shading-et, csak RT magok nincsenek benne, így csak szoftveres DXR 1.0-t tud. Amúgy vicces, mert a CUDA magok fejlettsége miatt a software-s raytrace-ben eléggé lenyomják a 10xx szériát.
-
#10
Dragon3000
nagyúr
X2N
#8
Dragon3000
nagyúr
Steam statisztika szerint a 10x0 és 16x0 megoldások kiteszik a 15,18%-ot, ezek mellé még jönnek a régebbi megoldások is, így jóval több az, mint az általad írt 8%. Nem szabad elfelejteni, hogy nagyon sok olyan játék is meg szokott jelenni, aminek nincs nagy gépigénye és ezentúl ezekhez sem jönnek profilok a régi kártyákra.
-
hapakj
őstag
Igen, épp ezt akartam mondani, hogy mostanra esett be annyira az elterjedése, hogy elkezdik mellőzni a támogatásukat. (Azért a 8% is több mint sok így 7 év után és egy 1080/1080 Ti még ma is erős). Alan Wake 2 már használ Mesh Shadinget, és gyanítom hogy a The Dark Ages, meg az Indiana is.
-

X2N
őstag
Ma már a userek kevesebb mint 8%%-a használ 10-es vagy régebbi szériás kártyát, nem lehet probléma, 10-es kártyát már nem is lehet kapni, szinte mindenki váltani fog a következő 1-2évben, ha DOOM The Dark Ages-re gondolsz igen ott már 20-as széria lesz a minimum követelmény.
-
hapakj
őstag
Azért vegyünk hozzá, azzal hogy memória igényt növelsz, azzal sávszélesség igényt is, a sávszélességet nem olyan egyszerű növelni, hogy nagyobb kapacitású chipeket raksz a VGA-ra. A memória buszt kellene szélesíteni, ami komplexebb PCB, nagyobb tokozás a chipnek, több hibalehetőség.
A számítási kapacitás meg sokkal jobban növekszik, s valszeg extra cache-t betenni is egyszerűbb.Jelen esetben a cache-t valszeg a kicsomagoláshoz használt neuron háló foglal helyet, de mivel magának a textúrának a mérete csökkent, ezért annak cachelése is kevesebb cache-t igényel.
-
#5
X2N
őstag
Cyberboy42
#3
X2N
őstag
válasz
 Cyberboy42
#3
üzenetére
Cyberboy42
#3
üzenetére
Minden azon múlik hogy használják-e a fejlesztők, a Mesh Shadinget(2018) is csak 1-2 játék használta eddig, pedig amikor be lett mutatva mennyire ígéretes technológia volt.
-

Duck663
őstag
Én egyáltalán nem vagyok elájulva a dologtól. Mi a jobb vagy rosszabb? Ha megnövekszik a memóriaigény, vagy ha a utolsó gyorsítótárat kinyírjuk tulajdonképpen egyetlen dologgal?! Amitől lehet hogy szebb lesz egy játék, de semmiképpen sem gyorsabb. Hát nem tudom, engem egyáltalán nem nyűgözött le a dolog. De másképp is felteszem a kérdést, mi az olcsóbb vagy a drágább? Megnövelni a memória mennyiségét, vagy megnövelni a gyorsítótár méretét?
-
hapakj
őstag
a technika jelenleg csak DirectX Raytracing mellett alkalmazható, ezen belül is kötelező a DXR 1.1-es verziója, az eredeti 1.0-s nem jó hozzá.
- ez abszolút nem gond. Ugye minden RTX kártya támogatja a DXR 1.1-t. Csak a GTX kártyák ragadtak meg 1.0 implementációnál.A textúrák csoportokban tömörítése sem hátrány. Soha nem láttam még olyat, hogy különböző Materialokhoz együtt használt textúrákat bárhol újrahasználnának. Ezeket az artistok és az általuk használt toolok együtt kezelik. Abszolút logikus batchekben együtt tömöríteni.
Hát hajrá a többi gyártónak, hogy felzárkózzon ezekhez a techekhez




















Új hozzászólás Aktív témák

- OTP Bank topic
- Diablo IV
- Kormányok / autós szimulátorok topikja
- Melyik tápegységet vegyem?
- Küszöbön az androidos PC-k
- Gyúrósok ide!
- Milyen TV-t vegyek?
- hcl: Philips M120D/10 kamera hackelés és parajelenségek
- Kerékpárosok, bringások ide!
- Mégis marad a Windows 10 ingyenes frissítése
- További aktív témák...
- Bomba ár! Dell XPS 15 9550 - i7-HQ I 16GB I 512SSD I 15,6" FHD I GTX960M I Cam I W10 I Gari!
- Bomba ár! Dell Latitude 5400 - i7-8GEN I 8GB I 256SSD I 14" FHD I HDMI I Cam I W11 I Gari!
- DELL Precision 5560 i7-11850H 32GB 1000GB T1200 FHD+ 1 év garancia
- Lenovo ThinkPad 40AF docking station (DisplayLink)
- AKCIÓ! ASUS ROG STRIX Z270G Gaming WiFi alaplap garanciával hibátlan működéssel
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest