Új hozzászólás Aktív témák
-
szerintem sem ott, nyugodtan folytassátok itt. ugyanakkor kócos asm ismereteim alapján én is azt mondhatom, h nem olyan "szarvashiba" ez, mint egy egyetemi doga alapján gondolnád. persze, h az egyidejűséggel számolni kell, de 4 mag, háromféle cache, egyéb gyorsítók és ooe mellett ez nagyon nem egyszerű. és igen, valóban nem megoldás, h mindent lockolunk, mert akkor ugye rendre kiszórunk 3 magot, a cache-eket stb.
mennyivel is egyszerűbb volt a 386-ost programozni, igen
 (pedig már az is egy komplex chip volt)
(pedig már az is egy komplex chip volt) -

Supra
tag
Köszi Fless és grat, frankó a cikk!

Most akkor a TLB hiba még javitás alatt van, vagy a B3 steppingben már javitva lett? Nekem úgy rémlik már igen, de korántsem vagyok biztos benne...

(Végigolvastam a Topicot, remélem nem mentem el a válasz felett)Egyébként tényleg fogalmuk sincs az embereknek a valóságról, a marketing szinte mindig legyűri azt - csak tudnám, miért hisz az emberek 99% vakon benne... Egyszer majd megértem... Talán...

-

fLeSs
nagyúr
"Ezt kompenzálta az AMD-nél jóval magasabb órajele, vagy nem? "
Helyesbítek: próbálta kompenzálni.
 De a P4 eleve úgy jött ki, hogy majd az SSE2... Az FPU gyenge volt.
De a P4 eleve úgy jött ki, hogy majd az SSE2... Az FPU gyenge volt."Nocsak, ez elég jó hír.
 (Korábban ugye megszeppenve nézegettük a L3 latencyjét, hogy ez majd jól hozzáadódik a memóriáéhoz.)"
(Korábban ugye megszeppenve nézegettük a L3 latencyjét, hogy ez majd jól hozzáadódik a memóriáéhoz.)"Pedig a K10-zel foglalkozó cikkeimben erről szó is esik.
"Hát, nem tudom, de ahogy néztem, pl. a h.264 több képkocka között is keresgéli a módosulásokat."
Utána kéne néznem.
-

dezz
nagyúr
Ezt kompenzálta az AMD-nél jóval magasabb órajele, vagy nem? (Monjduk annyira nem foglalkoztam vele, jól elvoltam az Athlonjaimmal.
)"A K10-nél a memből közvetlenül az L1-be kerülnek az adatok, ugyanez igaz az L3-ra is (az L2-t megkerülve), szóval az L3 latency-je nem adódik hozzá semmihez."
Nocsak, ez elég jó hír.
(Korábban ugye megszeppenve nézegettük a L3 latencyjét, hogy ez majd jól hozzáadódik a memóriáéhoz.)"Nem ismerek olyan kódoló algoritmust, aminek az L1+L2-nél nagyobb tárterületre lenne szüksége."
Hát, nem tudom, de ahogy néztem, pl. a h.264 több képkocka között is keresgéli a módosulásokat. -
fLeSs
nagyúr
A P4 x87-ben egy rakás sz@r volt (kicsit emlékezz vissza). Csak ALU-ban volt versenyben az AMD-kkel a duplagyors ALU-k miatt.
Az elméleti max memsávszél nem mond semmit a "sustained"-hez képest. A P4 elméleti max memsávszélben jó volt, de valósban nagyon-nagyon gyenge volt, mondhatni egy rakás szar (magas memory latency + chipset latency + multi-drop busz). Ez a Core-ra is igaz azzal a különbséggel, hogy komoly prefetcherek vannak benne, ezért kicsit más a téma.
A P4 játékok alatti gyenge teljesítményéhez nyilván van köze a hosszú pipeline-nak is, amit rossz elágazásbecslésnél újra feltölteni (+a trace cache-t) nem túl mókás dolog (gondolom erre utaltál), de a branch predictorok hatékonyságét 95% fölöttire jósolta az intel pont emiatt, tehát a a fő gond az volt, hogy a P4 alapvetően nem volt jó FPU-ban sem és memben sem."Akkor miért nem gyorsul szinte semennyit sem itt a Phenom mag, miközben a memória-tesztekben 15%-kal jobb?"
A K8 memelérése az órajel növelésével növekszik, mert az L1 túl szűkös.
A K10-nél nincs jelen ez a "bottleneck". Szóval elképzelhető, hogy a tomshw tesztben éppen olyan órajelen mértek, aminél a kettő együtt áll úgymond. Utólag én is rájöttem, hogy a szintetikus architectúrás tesztünkben a memelérési adatok nem sokat érnek, mert a procikat 2 GHz-en teszteltem, és ott a K8 még nagyon gyenge. 3,2 GHz-en már jóval magasabb értéket ér el, és a 12,8 GB/s-es max sávszélnek sokkal nagyobb %-át használja ki. A K10-nél nincs ilyen, bár vmilyen szinten van, mert a K10-et írásban meg az L3 fogja vissza, de erről később a tesztben. Olvasásban unganged módban asszem 95%-os a mem kihasználtsága.
Naszal ami nekem lejött az az, hogy sávszélben az L3 ponthogy nem ér semmit, csak az alacsony latency miatt jó.
Elképzehető, hogy a tomshw tesztben egy olyan szerencsés együttállás következett be, hogy a K8 órajeléből fakadó L1 sávszél + nagy (1MB) L2 éppen úgy szolgálta ki a WinRAR-t, mint a K10-est a kicsi L2-vel (512 KB) és a lassú L3-mal."Sok véletlenszerű hozzáférésnél nem lehet pufferelni, és a prefetch sem tud vele mit kezdeni - így folyamatosan csak hozzáadódik a memóriaelérési időhöz a L3 latencyje."
A K10-nél a memből közvetlenül az L1-be kerülnek az adatok, ugyanez igaz az L3-ra is (az L2-t megkerülve), szóval az L3 latency-je nem adódik hozzá semmihez.
"Ez leginkább a jpeg-ről és mjpeg-ről mondható el, de a modern video codecekben eléggé ott van a mozgásfelismerés is, ami már nagyobb mennyiségű adaton végzett munkát igényel."
Nem ismerek olyan kódoló algoritmust, aminek az L1+L2-nél nagyobb tárterületre lenne szüksége.
-
dezz
nagyúr
"A játékok általában FP intenzívek, az FP műveletek pedig sávszéléhesek -> a nagy cache és a gyors memhozzáférés döntő."
Bizonyára igaz ez a műveletek valamekkora részére. De a game-logikának vannak olyan elemei is, amik sok véletlenszerű hozzáférést igényelnek (láncolt listákon való végiglépkedés, nagy egymástól függő feltételrendszer kiértékelése, útkeresés, stb.).Úgy vélem, az FP-ben és memória-sávszélben sem rossz P4-ek ezért voltak mégis gyengébbek játékokban az Athlon64-eseknél korábban.
"WinRAR: szintén a memelérés a döntő a könyvtár miatt"
Akkor miért nem gyorsul szinte semennyit sem itt a Phenom mag, miközben a memória-tesztekben 15%-kal jobb?"ezt kifejtenéd bővebben?"
Sok véletlenszerű hozzáférésnél nem lehet pufferelni, és a prefetch sem tud vele mit kezdeni - így folyamatosan csak hozzáadódik a memóriaelérési időhöz a L3 latencyje."Így van, a gyorsabb SSE döntő. De a 128 bit széles műveletek miatt ugyanennyire döntő az L1 (és talán az L2) sebessége. Az L1 2x64bit load/1x64 bit store-ról 2x128bit/2x64 bitre bővült."
Persze, de a L1 a szokásos besorolás szerint a mag része, azaz ennyivel is jobb az új mag. A L3, amiről szó volt, viszont már úgymond kívülről van hozzácsatolva."Az L3 már nem játszik szerepet, mert a videókódolás kis mennyiségű szekvenciális, ismétlődés nélküli adatfolyamon dolgozik."
Ez leginkább a jpeg-ről és mjpeg-ről mondható el, de a modern video codecekben eléggé ott van a mozgásfelismerés is, ami már nagyobb mennyiségű adaton végzett munkát igényel. -
fLeSs
nagyúr
A játékok általában FP intenzívek, az FP műveletek pedig sávszéléhesek -> a nagy cache és a gyors memhozzáférés döntő.
WinRAR: szintén a memelérés a döntő a könyvtár miatt"viszont ahol meg a latency (sok kicsi hozzáférés a memóriához), ott inkább csak hátráltató tényező."
ezt kifejtenéd bővebben?
"Videotömörítésnál is inkább előny a L3, de legalább annyira a kétszeres szélességű SIMD (SSEx) feldolgozás."
Így van, a gyorsabb SSE döntő. De a 128 bit széles műveletek miatt ugyanennyire döntő az L1 (és talán az L2) sebessége. Az L1 2x64bit load/1x64 bit store-ról 2x128bit/2x64 bitre bővült. Az L3 már nem játszik szerepet, mert a videókódolás kis mennyiségű szekvenciális, ismétlődés nélküli adatfolyamon dolgozik.
-
dezz
nagyúr
Hát azért a játékoknál mutatott 10-20%-os gyorsulás sem elhanyagolható. (Kivétel persze van lefelé is és fölfelé is - mármint van, ahol csak néhány % a gyorsulás [lassulás eddig nincs], máshol meg elképesztő 43%.)
Jó kérdés, hogy a L3 mennyit számít. Ahol a sávszél számít, ott előny (bár pl. a WinRAR szinte semmit sem gyorsul - ott talán a vinyó a szűk keresztmetszet, nem tudom), viszont ahol meg a latency (sok kicsi hozzáférés a memóriához), ott inkább csak hátráltató tényező.
Videotömörítésnál is inkább előny a L3, de legalább annyira a kétszeres szélességű SIMD (SSEx) feldolgozás.
Jó lenne, ha kikapcsolható lenne a L3, de ennek egyelőre semmi jele.
-

azbest
félisten
Hmm, nemrég olvastam én is ezt a tesztet. A teszt alapján valóban lényeges gyorsulást mutat bizonyos alkalmazásoknál, például videótömörítésnél. Azért volt egy olyan gondolatom olvasás közben, hogy vajon milyen eredmény jönne ki L3 nélkül. Tudom az is a proci része, de sokkal tekintélyt parancsolóbb számomra a különbség, ha nem csak a cache méretén múlik.
Ahogy nézem a k8 1MB l2vel garázdálkodik (nem közös a 2*1), míg a phenom 512k l2 + 2MB L3.
De nem is kritikának szánom ezt a hozzászólást, csak kíváncsi vagyok, vajon a cache méret mennyire szól bele.939-et úgy hallottam tényleg leállították egy időre, és meglepő is volt olvasni róla hogy újra nagyobb mennyiségben elérhető (talán HerrZ a blogjában írta). Az ára is akkor csökkent az x2-knek, előtte elég horror volt az am2-höz képest.
-
-
-
dezz
nagyúr
"A lassúságért kiabálóknak annyiból lehet igaza, hogy úgy tűnik nem nagyobb teljesítményű egy magja mint a k8asoknak."
De, azért gyorsabb, egyes dolgokban jelentősen: [link]----------------------------------------
Más. Szó volt róla, mit lassít a workaround, stb.
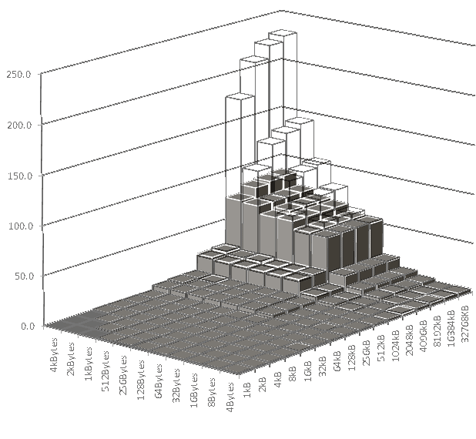
(Az átlátszó rész a workarounddal mért latency.)
Nos, a L3-at nem, csak a memóriahozzáférést, de azt nagyon. Talán az egész TLB-t letiltották, úgy, ahogy van. (Érdekes, hogy ezt így meg lehet tenni.) innen -
#31
 Raymond
titán
FehérHolló
#30
Raymond
titán
FehérHolló
#30
Raymond
titán
válasz
 FehérHolló
#30
üzenetére
FehérHolló
#30
üzenetére
Pedig pont ez nem volt az off
Lehetett volna public. -
-
#28
 P.H.
senior tag
FehérHolló
#27
P.H.
senior tag
FehérHolló
#27
P.H.
senior tag
válasz
FehérHolló
#27
üzenetére
A gondok ott jelentkeznek, amikor több egyszerűbb műveletre bontott eljárás verseng ugyanazért az adatért egy-egy lépésében, vagy pl. itt, ahol párhuzamosan működik az utasításvégrehajtás és a TLB részéről elkövetett L2-hozzáférés.
Persze le lehet zárni a teljes rendszer elől a cache-ek vagy a memória egy részét egy adott művelet teljes lefutásának idejére, de ez nagy általánosságban erőteljes teljesítményvesztéssel jár (pl.utasításszinten a LOCK prefix, amit amúgy a test-and-set bitműveletek elé a programozónak magának kell kitennie, vagy a XCHG reg,mem - tartalomcsere register és memória között -, ahol ez automatikus), csakhogy maga az Intel írja, hogy:
Locked operations are atomic with respect to all other memory operations and all externally visible events. Only instruction fetch and page table accesses can pass locked instructions.
(Persze tisztán elméletileg, mert az ilyen eseteket természetesen illik megoldani, csak fel kell készülni rájuk. Illetve arra, hogy nem a Halley-üstökös megjelenésének gyakoriságával fordul elő ilyen helyzet egy (többször) négymagos rendszerben
) -
#27
 FehérHolló
veterán
P.H.
#24
FehérHolló
veterán
P.H.
#24
FehérHolló
veterán
Attól még lehet egy műveletsor oszthatatlan, hogy több egymással párhuzamosítható egyszerűbb műveletből áll. Például testandset-típusú műveletsorok.
Persze vannak olyan esetek, amikor olyan ritkán következik be a rákfene, hogy nem is foglalkoznak a kivédésvel, mert egyszerűen nem éri meg.
Most vagy nem gondoltak rá, vagy rosszul értékelték a helyzetet, de melléfogtak. -

vati
senior tag
Az AMD akkor elásta magát nálam pár évtizedre, amikor 2006 nyarán váratlanul kidobta a s939-es foglalatot, minden ésszerű magyarázat nélkül.
2006 tavaszán még úgy tűnt, az s939 teljesen okés, tele voltak a boltok ilyen lapokkal és procikkal, hallani lehetett hogy hamarosan jön a K10, és az AMD jövője általában biztató.
Be is vásároltam alaposan egy s939-es konfigba, gondolva hogy pár évig még elél a foglalat és DDR1 ramok is, majd később fejlesztek CPU-t is, memóriát is.
Aztán pár hét leforgása alatt jövőtlen ócskavas lett a gépem
Nem a C2D megjelenése miatt, hanem amit az AMD lépett rá. Ez így kiszámíthatatlan, komoly cég ilyet nem csinál. Nem vagyok hajlandó évente alaplapot cserélni, azt min 3-4 évre veszem.
Nekem ámokfutásnak tűnik az AMD 2006 nyara utáni üzletpolitikája, előtte edig a tökvakarás rá a legjobb kifejezés. Durrantottak egyet a K8-al, aztán ültek a babérjaikon.
A K10-nek kb. pont egy éve kellett volna kijönnie, hogy labdába rúgjon. Szerverben talán jobb lenne, de csak tavaszig, és sajna pont azt nem tudják szállítani. Desktopban állva hagyja őket a C2D, lassan minden árkategóriában. (tudom, most álltam át Intelre 8 év AMDzés után..) Bukás.Nem jobb marketing kéne az AMDnek, inkább csináljanak jó procikat, és kiszámítható üzletpolitikát az előre menekülésnek álcázott kapkodás helyett.
Hosszú távon nem lehet a pár % fanatikus gépépítő AMD-fanból megélni. -
#24
P.H.
senior tag
FehérHolló
#14
P.H.
senior tag
válasz
FehérHolló
#14
üzenetére
A 'szarvashiba' szvsz túlzás, kifejezetten meg lennék lepve, ha ezt egy elemi műveletnek tervezték volna meg. Ez az egész inkább annak a művészete, hogy hogyan lehet több kisebb, párhuzamosan végrehajtható egységre bontani a műveleteket úgy, hogy a hatásuk legyen olyan, mintha egyetlen atom lenne, felkészülve minden olyan helyzet lekezelésére tervezéskor, amik bezavarhatnak. Ha ezzel nyernek pár százalékos gyorsulást, már megérte.
Amúgy van valami kísérteties hasonlósága a hibának ezzel:
107 Possible Multiprocessor Coherency Problem with Setting Page Table A/D Bits
Description
In a multiprocessor system, a coherency failure may occur in a situation involving a TLB refill, an L1 fill, an L1 victim write, and an external probe, when all four addresses match as described in the following sequence:1. A TLB miss occurs which requires the state of the page A (accessed) or D (Dirty) bit in one of the associated page map entries.
2. The cache line containing the page map entry must hit in the L2.
3. A younger load or store misses both in the data cache (DC) and L2 causing a DC line fill.
4. The DC fill generates an L1 victim.
5. The L1 victim is in the modified state.
6. The L1 fill matches the L1 index (11:6) of the TLB reload but not the L2 index [15:6, 14:6, or 13:6 for 1M, 512K, 256K] of the cache line containing the above page map entry.
7. The LRU bit for the L2 index points to the way (1 of 16) containing the page map entry.
8. The L1 victim arrives at the L2 in a small window after the TLB reload read, but before the write of the A/D bit(s).
9. An external probe arrives for the same address as the page map entry.Potential Effect on System
In the unlikely event that the above conditions occur, multiprocessor memory coherency issues may occur leading to unpredictable system failure. This erratum has not been observed outside of a highly randomized synthetic stress test.Suggested Workaround
BIOS should set BUCFG.ThrL2IdxCmpDis (bit 43) to one.Csak akkor még nem volt L3. (Az L2-ből akkor is és most is többek között úgy kerülhet ki adat, ha helyet kell csinálni valaminek az L1-ben.) Ez minden Ex stepping-ek előtti K8-at érintett (Clawhammer, Newcastle, Winchester, ...)
-
fLeSs
nagyúr
Az a helyzet, hogy annak az írásnak igaza van, ezt én is leírtam már egy korábbi írásomban, igaz nemtom a Core 2-nek mi köze a Barcelonához.
Egy kicsit ferdítesz.A K10 architektúrális előnyei csak a szerverekben lennének kézzel foghatók, ott is csak addig, amíg a Nehalem meg nem jelenik. Mivel az AMD a hiba miatt éppen nem szállítja a K10 alapú Opteront, ezért egyelőre még ott sem.
Desktopon a Phenom lassabb a jelenlegi (65 nm-es) Core 2-nél, a 45 nm-es pedig nagyon elveri (főleg a nagyobb cache és az SSE4 miatt). Itt akkor következhet be vmi változás, ha átállnak a 45 nm-re, és órajelben felküzdik a Phenomot bőven 3 GHz fölé, erre nincs túl sok esély legalább 1 évig.
Mobilban az AMD sajna nem konkurencia.
Ha tehát a fejlettségi szintet vesszük alapul, akkor az AMD tényleg le van maradva. De az ár/teljesítmény mutató alapján veszünk procit, és abban még lehetnek jók a Phenomok, csak ehhez az AMD-nek óriási áldozatokat kell majd hoznia: drágán legyártható procikat kell majd olcsón adnia ->kevés profit->kevesebb fejlesztés->még nehezebben zárkózik fel az Intel mellé->ördögi kör. A 45 nm-es gyártástechre való átállás elég nagy megkönnyebbülést jelent majd nekik.
Amúgy semmilyen kapcsolatban nem állok az Index-szel.
-

Narancs
őstag
Nagyon jó az írás!
Nem tudom milyen konkrét kapcsolatban álltok az Index-szel, de az ottani Tech rovat rendszeresen negatív színben tünteti fel az AMD-t. Legutóbb például ezt írják az Intelről:"Jövőre érkezik például az új Intel-processzor, a Nehalem...igazi vadállatról beszélhetünk, sőt, szakértők szerint az új csip jelenti az 1995-ös Pentium Pro óta a legjelentősebb változást. A processzorba integrált memóriavezérlő kerül, készülhet belőle nyolcmagos verzió is, és lesz olyan modell, amibe grafikus gyorsítót raknak. A brutális teljesítmény ellenére a csipek fogyasztása várhatóan nem lesz nagyobb, mint az aktuális generációé."
Pár sorral alatta ezt az AMD-ről:
"Az AMD ehhez képest nem sokat tud felmutatni, az első félévben valószínűleg leköti a gyártót a Barcelonával kapcsolatos problémák orvoslása, meg a világ első hárommagos processzorának a piacra dobása. A Core 2-esekkel is csak alig versenyképes Barcelona mindenesetre nehezen állja majd a sarat a Nehalemekkel szemben."Tehát az Intel még meg sem jelent processzora "vadállat" lesz, és "brutális ererjű", amit az integrált memóriavezérlő és az akár 8 magos felépítés biztosít majd. Ezzel szemben az AMD csak valami szarral próbálkozik, ami alapból lassabb mint az Intelé, és ráadásul még csak most fejlesztik a három magot, mikor az Intel már a 8 magosat dobja ki. Amiben integrált memóriavezérlő is lesz, amiről ugyan az átlag olvasó nyilván nem tudja micsoda, de ha az lesz benne akkor biztos sokkal jobb lesz mint a ratyi AMD.
A sok baromság helyett leírhatták volna, hogy egyelőre gyártási nehézségek miatt az egyébként architektúrálisan fejlettebb Phenom procik még nem nyújtják az elvárt teljesítményt, de jövőre igazi ellenfelet kaphatnak a Core procik a K10 személyében, ha az említett kezdeti nehézségeken túlesik a gyártó. Vagy vmi hasonlót. Mert aki nem keni annyira témát, vagy nem olvassa például a PH!-t, annak teljesen más jön le szerintem, mint a valóság.
Az idézetek innen
származnak. -
#21
 TheVeryGuest
senior tag
TheVeryGuest
senior tag
TheVeryGuest
senior tag
"...Ez egy egyszerű cache-koherencia probléma..."
Többprocesszoros rendszerekben nagyjából szerintem ez a legnagyobb létező probléma, amit meg kell oldani. -
#20
fLeSs
nagyúr
FehérHolló
#19
fLeSs
nagyúr
válasz
FehérHolló
#19
üzenetére
Ebben az írásban az érthetőség lenne a lényeg.

-
#19
FehérHolló
veterán
fLeSs
#18
-
#18
fLeSs
nagyúr
FehérHolló
#14
fLeSs
nagyúr
válasz
FehérHolló
#14
üzenetére
Asszem a szöveg eredeti formájában jobban érthető, de most átjavítottam a kedvedért.
-
#15
 twollah
nagyúr
FehérHolló
#14
twollah
nagyúr
FehérHolló
#14
twollah
nagyúr
válasz
FehérHolló
#14
üzenetére
Nahat csak nem Inteles geped van...
-
#14
FehérHolló
veterán
FehérHolló
veterán
Elképzelhető, hogy az egyik mag másodszintű gyorsítótárjának (L2 cache) TLB-jében az accessedd vagy dirty* bit átállítása 0-ról 1-re nem zajlik le elég gyorsan.
Nem az a baj, hogy nem zajlik le elég gyorsan, hanem az, hogy az írás és a dirty állítás nem egy oszthatatlan utasítást képez, hanem két külön utasításban valósítható csak meg. Így közbeszólhat más. Szarvashiba.
-
#11
 Winner_hun
félisten
Winner_hun
félisten
Winner_hun
félisten
Hát hogynepersze
Örülök neki hogy nem érdekel a számítástechnika, ezt megérteni
Bár lehet nem teljesen fáradtan és nem egyszeri olvasás után a megértési hányados kicsit magasabb indexet mutatna
-
fLeSs
nagyúr
Ez inkább a kihozatallal függ össze.
Négy mag + L3 = Phenom X4
Ha a 4 mag ép, de az L3 sérült, akkor nemtom mivan, egyelőre nem úgy tűnik, mintha ki akarnának adni ilyen procit.
Három mag + L3 = Phenom X3
Három mag L3 nélkül = csonka Phenom X3
Két mag + L3 = Athlon 6xxx
Két mag L3 nélkül = ...
és így tovább. -

ody42
senior tag
Igazad lehet az L3 cache kikapcsolásával kapcsolatban, az AMD mérnökeinek gondolom jobb ötlete is van, nekem mint laikusnak jutott ez eszembe, nem értek a témához, csak a dailytech-en olvastam a következőt:
"AMD's latest roadmap hints that its tri-core processors are merely quad-core processors with one core disabled. The company also indicated that it will introduce some of these tri-core processors with the L3 cache disabled. Removing the shared-L3 cache from the chip design eliminates the TLB bug."[link]
Ebből gondoltam, hogy mindennapos felhasználásban annyira nem lehet nagy vérveszteség kikapcsolni, ha az AMD is fog kiadni L3 nélküli 3 magos procikat. Nyilván nem ez az elegáns megoldás
mindenesetre kár lenne az AMD-ért, mindig a kicsiknek szurkolok, remélem azért lesz még nagy dobásuk a jövőben
-
azbest
félisten
Vajon a tlb patch vagy az l3 letiltása (ha lehetséges a biosban) okoz nagyobb teljesítmény csökkentést? (bár valószínűleg alkalmazástól függ... pl több független program futásakor kevésbé fontos az l3 mint egy többszálúnál, ahol azon át érik el egymás műveleteinek eredményét a magok)
Egyébként értem már a felháborodásodat: hibának hiba, de közelsem olyan súlyú (nehéz előidézni), hogy ilyen nagy hőbörgés legyen körülötte.AMD marketing gépezetét kiáshatnák már a homokból ("homokszem a gépezetben"
)...A lassúságért kiabálóknak annyiból lehet igaza, hogy úgy tűnik nem nagyobb teljesítményű egy magja mint a k8asoknak. Persze azt tudom már a cikkekből, hogy sok programszál egyidejű futásakor hatékonyabb, mint a core architektúrája - kevésbé akadályozzák egymást a magok a k10ben.
Nekem mindenképp tetszik a phenom, mert remek bővítési lehetőség az am2 rendszerhez (majd amikor kevés lesz az igényeimhez a mostani 2 magos) és már most sem olyan vészes az ára (hiába a verszeny a vásárlóknak jó dolog).
-
#2
 venember83
nagyúr
venember83
nagyúr
venember83
nagyúr
Kosz, igy kell ezt!


 (pedig már az is egy komplex chip volt)
(pedig már az is egy komplex chip volt)





 Izé, valahogy elsiklottam felette. (Olvastam már róla eleget korábban, így már kicsit lankadt a figyelmem.
Izé, valahogy elsiklottam felette. (Olvastam már róla eleget korábban, így már kicsit lankadt a figyelmem. 

 De a P4 eleve úgy jött ki, hogy majd az SSE2... Az FPU gyenge volt.
De a P4 eleve úgy jött ki, hogy majd az SSE2... Az FPU gyenge volt. (Korábban ugye megszeppenve nézegettük a L3 latencyjét, hogy ez majd jól hozzáadódik a memóriáéhoz.)"
(Korábban ugye megszeppenve nézegettük a L3 latencyjét, hogy ez majd jól hozzáadódik a memóriáéhoz.)"


























Új hozzászólás Aktív témák
- eBay-es kütyük kis pénzért
- Az Intel szerint mindenkit érint, illetve érinteni fog a CPU-hiány
- MacBook Neo vs MacBook Air – Megéri a félár?
- Katasztrofális PC-piacra figyelmeztet az IDC
- Autós topik
- WoW avagy World of Warcraft -=MMORPG=-
- Vége a dalnak: nincs több Samsung harmonikamobil
- Milyen széket vegyek?
- Apple Watch
- Xiaomi 17 Ultra - jó az optikája
- További aktív témák...
- Sage BES 875 BSS darálóval egybeépített karos kávégép
- AOC Q27G4XF 27 2560x1440 QHD Monitor 2026.10.27-ig Garancia Házhozszállítás
- Xbox Wireless Headset 3 hó garancia, számlával!
- Honor 200 8/256GB Újszerű,Kártyafüggetlen,Tartozékaival. 1 Év Garanciával!
- Honor 200 8/256GB Újszerű,Kártyafüggetlen,Dobozos,Tartozékaival. 1 Év Garanciával!
- Beszámítás! VALVE INDEX virtuális valóság szemüveg garanciával hibátlan működéssel
- HIBÁTLAN iPhone 13 Pro 128GB Gold -1 ÉV GARANCIA -Kártyafüggetlen- MS4674, 100% AKKSI
- Minden szoftver mellé teljesen audit és NIS2 biztos, jogilag hiteles licencigazolást adunk át!
- Beszámítás! Sony PlayStation 5 825GB SSD lemezes konzol garanciával hibátlan működéssel
- Dell és HP szerver HDD caddy keretek, adapterek. Több száz darab készleten, szállítás akár másnapra
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest