- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 martonx
veterán
martonx
veterán
Köszönöm szépen a választ.
Oda írtam a példát. Az id pont úgy van ahogy írtad.
És azt is tudom hogy constraint és /vagy foreign key -t kell használom, de nem tudom hogyan.
Azért írtam le a kódot, hogy lehessen látni, hogy mit szeretnék.
Természetesen azid FROM usres(id)sort kellene javítani,
constraint és /vagy foreign használataval,
Csak nem tudom hogy.
Bárhogy próbáltam, sehogy se volt jó.Sqlite pdo php -val használom.
Google legelső találatát javaslom megnézni a nagyon meglepő: sqlite foreign key keresésre.
Ha ez alapján még mindig nem megy, és nem világos, akkor ugyan nem használok sqlite-ot, de gyere vissza kérdezni, és segítünk. -
martonx
veterán
Hello,
Hogy kell létrehozni táblát úgy, hogy az id-je egy másik tábla id-je legyen? (Utolsó előtti sor.)CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id FROM users(id),
address TEXT)Szerintem foreign Key-re gondolsz. Egyáltalán milyen SQL-ről beszélünk?
Az Order tábládba legyen id (int autoincrement mondjuk), userId, ami legyen Foreign Key a User táblára és az address mező.
-
martonx
veterán
Jelenleg van kb. 200 tábla, ez talán felmehet max. 500-ra, tehát nem olyan sok tábláról beszélünk.
Negyed óránként történik a szenzorokbol kiolvasás, ez lehet gáz fogyasztás számláló, vagy villamos energia számláló állás, tehát rekord sem lesz olyan sok.
Van még egy olyan gond is hogy nem ugyanabban az időben olvasnak ki minden szenzort, tehát nem 00/15/30/45 a datetime-ban a min értéke. Ez olyan gondot okoz hogy simán nem lehet join-al kapcsolni az adatokat ha pl. számolni akarok velük, hanem külön külön át kell előbb konvertálni a fent említett 15 perces osztásra és utána mehet a Join.
A fentebb javasolt View megoldás jó lehetne olyan szempontból is, hogy abban ezt az átalakítást már meg lehetne tenni, így a View-ből indított Query-k már egyszerűbbek lehetnek. Ezt úgy tenném meg hogy a legközelebbi 15 perces egész értékre tenném át a View-ban az adatot, de ügyelni kellene arra is hogy ha több olvasás is történt akkor is csak egyet használjon fel. Az új mérési pont belépésekor pedig elég lenne azt csak a View-be felvenni.
Értem azt hogy egy táblában kellene lenni az összes szenzor adatnak és minden adatnak legyen egy szenzor azonosítója pl. "MP001". De azt hogyan javasoljátok megtenni? Tehát lineárisan, azaz Union-al egymáshoz fűzni őket, vagy mátrix szerűen, egy rekordba összefűzni az összes adatot ami egy időponthoz tartozik? Ez utóbbi esetben Join-al az átkonvertált negyed órás adatokat lehetne felhasználni. Ez utóbbi a felhasználás szempontjából (műveletek végzése, Grafana diagramban megjelenítés) talán jobb lenne, de mivel a szenzor azonosítók lennének a mezőnevek, előre kellene definiálni az összes lehetséges MP mezőt hogy egy új MP esetén ne kelljen adatstruktúrát változtatni. Ez nem túl elegáns megoldás.
A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?
Egyedi ID mezőt hogyan tudok ez esetben mellé tenni?Az említett Triggeres módszert nem ismerem, az mennyiben lenne más/jobb?
500 tábla nem sok pont ugyanarra??? Elmebeteg mennyiség. Sürgősen tervezzétek át, fejlesszétek újra.
-
martonx
veterán
Hogy ez mekkora butaság volt, de már mindegy.

-
martonx
veterán
Jaja, csak ötleteltem, ha már ennyire gyorsan változó adatokról van szó. Az egész rendszer ismerete nélkül, nekem látatlanban ez az egész inkább architekturális hibának tűnik, mintsem megoldandó problémának.
-
martonx
veterán
Sziasztok!
Egy PostgreSQL-es kérdésem lenne, amin már régóta agyalok, mi lenne a megfelelő megoldás.
- Adott egy - nem túl bonyolult - függvény, ami egy táblából dolgozik a lekérdezéshez és nagyon gyakran, 0,5 másodpercenként meg van hívva, tehát nagyon fontos, hogy igen gyors legyen (ez meg is valósul, tényleg nagyon gyors).
- Ennek a táblának a tartalma dinamikusan változik, 20 másodpercenként frissül és alapvetően elég kevés rekordot tartalmaz pont azért, hogy gyors legyen.
- A kérdés az, hogy milyen megoldással frissüljön ennek a táblának a tartalma úgy, hogy ne akadályozza a függvény futását, amely ezt a táblát használja.
- 1. megoldás: a frissítés abból áll, hogy először TRUNCATE-elem a táblátTRUNCATE TABLE tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
- 2. megoldás:DELETE FROM tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;Ezt a két lépést úgy akarom megoldani, hogy egy blokkban fusson le, tehát egy függvénybe teszem bele.
Fontos kérdés, hogy mi van, ha éppen akkor hívódik meg a függvényem, ami a táblát használja, amikor éppen a frissítő függvény (truncate/delete, majd insert) fut?
Előállhat olyan helyzet, hogy épp üres táblát használ a függvényem?inmemory tábla esetleg? Egyébként biztos SQL szinten kellene ezeket a gyorsan változó adatokat kezelni?
-
martonx
veterán
-
martonx
veterán
-
martonx
veterán
Hello,
Gépemen fent van a PHP és az Apache server. A mysql-t szeretném feltenni, de ha felteszem hogy állítom be hogy az Apache server lássa? Tehát hogy futtatni tudjam a mysql -t, és használni.
Mindenki a wamp -ot pakolja. Én azt nem teszem fel.
Nekem így külön kell, de erről sehol se találok videót, hogy hogyan.
Angol tutorial is jó lenne.Ó, megint előkerültél :) Úgy látszik egy életen át tanulsz...
Én innen indulnék neki: https://www.sitepoint.com/how-to-install-php-on-windows/ -
martonx
veterán
Ilyenkor jön a dinamikusan összerakott pivot, némi string mágiával, vagy ahogy nyunyu mutatja.
-
martonx
veterán
A többi alternatíva, amit ajánlottam sem fizetős. Más kérdés, hogy azoknak a hosztolását meg kell oldanod valahogy, ami végülis pénzbe kerül. Nekem pl. MeiliSearch lakik egy 1 magos Azure linux VM-en, kemény havi 15 EUR-ért (plusz áfa).
Hidd el, ezek a kereső cuccok sokkal jobbak, mint amit magadnak raksz össze, pl. typo tűréstől kezdve csomó mindent tudnak. -
martonx
veterán
Sziasztok !
Nem igazán ismerem ezt a fulltext keresési módot, de találtam egy lekérdezést, amivel kísérletezek és én is írtam egyet saját kútfőből.
Egy webshop keresést szeretnék megvalósítani, úgy hogy a találatokat relevancia szerint csökkenő sorrendben adja vissza.
Van egy products nevű tábla mindenféle lényegtelen mező mellett a lényegesek:
product_model
product_name
product_description
Ezekből egyedül a product_model-en van btree index. /van id mező is, de azt most nem vettem bele ebbe/
Ezekben szeretnék keresni.Amit találtam fulltext lekérdezés, annál azt talapasztalom, hogy bárhogy próbáltam a * karakterrel feljavítani az illesztést, nem tudok vele úgy keresni, hogy pl.
a keresőszó: "fúró", akkor a "fémfúró"-t tartalmazó sort nem adja vissza, de a "fúrókészlet"-t igen, csak a szavak kezdetére tudok illeszteni.Fulltext keresés, nem saját munka: Lehet ezt módosítani, hogy a szavak végére is illesszen? Hiába raktam az elejére (is) csillagot.
SELECT
product_name,
(
(
1.3 *(
MATCH(product_name) AGAINST(
'lyukfúró*' IN BOOLEAN MODE
)
)
) +(
0.6 *(
MATCH(product_description) AGAINST(
'lyukfúró*' IN BOOLEAN MODE
)
)
)
) AS relevance
FROM
products
WHERE
status = 1
AND
(
(MATCH(product_name, product_description) AGAINST('lyukfúró*' IN BOOLEAN MODE))
OR
LCASE(product_model) LIKE '%lyukfúró%'
)
ORDER BY
relevance DESC,
LCASE(product_name) ASCErre találtam ki az alábbi megoldást: Mi erről a véleményetek, nagy baromság ?
Itt a példa keresőszó a "bmw vezérlés benzin", mindegyik szóra csinálok egy ilyen kis csoportot (3 case when) és az where-ben az AND-al kapcsolt részek.select*,(case when product_model like '%vezérlés%' then 10 else 0 end) +(case when product_name like '%vezérlés%' then 5 else 0 end) +(case when product_description like '%vezérlés%' then 2 else 0 end) +
(case when product_model like '%bmw%' then 10 else 0 end) +(case when product_name like '%bmw%' then 5 else 0 end) +(case when product_description like '%bmw%' then 2 else 0 end) +
(case when product_model like '%benzin%' then 10 else 0 end) +(case when product_name like '%benzin%' then 5 else 0 end) +(case when product_description like '%benzin%' then 2 else 0 end)as priorityfromproductswhere(product_model like '%vezérlés%'orproduct_name like '%vezérlés%'orproduct_description like '%vezérlés%')AND(product_model like '%BMW%'orproduct_name like '%BMW%'orproduct_description like '%BMW%')AND(product_model like '%benzin%'orproduct_name like '%benzin%'orproduct_description like '%benzin%')order bypriority desc,LCASE(product_name) ASCInkább javaslom erre beüzemelni egy ElasticSearch-öt / MeiliSearch-öt, vagy legfapadosabb megoldásnak a Google Custom Search Engine-t behúzni az oldaladra, és azzal keresni. De majd mindjárt jönnek az SQL szakik, és jól ledorongolnak, hogy nem SQL-ben oldanám ezt meg.
-
martonx
veterán
Külön programmal. A DB csak tegye ki egy külön táblába, hogy kiknek kell emailt küldeni.
Aztán majd egy külön program ez alapján kiküldi a saját workflowja alapján.
Így a DB is csak azt teszi, amihez ért, és majd a programozó is azt teszi amihez ért (rem,élhetőleg). Ráadásul az email küldés egészen bonyolult is lehet retry policy-vel, fogadottság ellenőrzéssel stb....
A mindent DB-vel megoldatásban óhatatlanul ott van a deadlockok, bármilyen más okból db lockok okozása, amivel vicces módon mondjuk egy sima email küldéssel akár a komplett DB-det is bedöntheted, pedig de jó ötletnek tűnt emailt küldeni a DB-ből (mondom ezt úgy, hogy bármikor elismerem nem vagyok DB szakértő, de régebben láttam már MS SQL-t megállni, valami ilyen huszadrangú jó ötletnek tűnt feature megakadása miatt).
De nyilván mindenki akinek kalpácsa van, az utána mindent azzal akar megoldani, klasszikus probléma. Rám is igaz lehet az előbbi, hogy minél több mindent inkább külön programmal oldanék meg, simán lehetnek esetek, amikor nem ez a jó megközelítés pl. irdatlan adatmennyiségek esetén. -
martonx
veterán
Sziasztok!
EGy kicsit speciálisabb kérdéssel jönnék. Adott sql server 2019. Csomagot kellene készítenem SSDT segítségével. Visual studioban a send mail nem opció, mert ahhoz su jog kellene. Így marad a Script task, ahol a system.net.mail segítségével tudnék levelet küldeni.
Ami a gondom, hogy igyekeznék hatékony kódot írni. A feladat annyi lenne, hogy van egy leválogatás. Egy hibalista az érintetteknek. Egy felhasználó egy rekordon szerepel és neki kellene levelet küldeni. Erre kurzort gondolnám a leghatékonyabbnak. De nem tudom miképp rakjam össze. Execute SQL task-ban a kurzort meg tudnám írni, de miképp "hívom meg" a script task-ban található emailküldést?
Remélem sikerült röviden összefoglalni a dilemmám
De miért az SQL szerver küld emailt könyörgöm? Annyira nem az SQL szerver feladata. Noha nyilván lehet a kereket kézben vinni, a szögleteset meg gurítani, de miért jó ez nekünk?
-
martonx
veterán
Üdv, lehet a kérdésem nem teljesen idevaló, de hátha tudtok segíteni.
MS SQL 2019 expresst telepítettem egy kis fogyasztású gépre, amin Win10 pro van
Alig használjuk, ezért alvási idő 1 órára van állítva.
A gép elalszik de az első SQL csatlakozás vagy lekérdezés felébreszti, minden ok.
Újra elalszik és 10-ből 8x nem ébred újra ugyanazon lekérdezéstől.
Mi lehet az oka? Hogy lehet beállítani, hogy mindig felébredjen?Szvsz ennek semmi köze ehhez a topikhoz.
-
martonx
veterán
Igazából az lenne a feladat, hogy egy webcímben GET kérés paramétereként adom meg a kezdő és a záró dátumot. Valahogy így:
http://weboldal.hu?id1=2022-07-10&id2=2022-07-20
De a lényege az lenne, hogy akinek megadom ezt a linket, az ne tudjon másik dátumra lekérdezni. Én a weboldalon legenerálok egy md5-ben lévő dátumot. Esetleg teszek még más karaktereket is mellé, hogy véletlenül se tudjon legenerálni másik dátumra kódot. (ha esetleg rájönne, hogy csak egy dátum van az md5-ben) Ezt elküldöm a felhasználónak. Ezért kellene valahogy így kódolni a paramétereket:http://weboldal.hu?id1=ea88fe6807b44f248329a85debee3c58
Ez így egy dátumra való lekérdezéssel működik is, mert ott az adatbázisban minden sor dátumát át tudom alakítani md5-re és utána csak össze kell hasonlítani a webcímben kapott md5 értékkel. De nekem két dátum között található összes sort kellene lekérdeznem, amit így nem lehet.
Vagy esetleg van másmilyen bevált megoldás arra, hogy a GET kérés paraméterében lévő értékek manipulálásával ne tudjon mást lekérdezni a felhasználó?Szvsz, ennek semmi köze nincs az SQL-hez. Webszerver oldalon illene megoldani.
Webszerver generál egy MD5-ös hash-t, és ugyanígy a webszerver fogadja, és alakítja vissza értelmes adattá a kapott MD5-ös hash-t. -
martonx
veterán
Attól függ, mi van a DB-ben. Szerintem többnyire igen a válasz.
-
martonx
veterán
Sziasztok,
van egy táblám, amiben van kb 1000 adat
Van egy selectem, amibe ezt az 1000 adatot egyesével szeretném beillesztve lefuttatni, és az 1000 adattal lefutott eredményt szeretném kiexportálni.
Merre induljak el, mi lehet ilyenkor a megoldás? (Ja, oracle-t használnék )
)
Köszönöm előre isKonkrétabban?
-
martonx
veterán
Selectnél működik:
SET @row_number = 1;
SELECT
(@row_number:=@row_number + 1) AS num,`cust_partnerkod`
FROM cikktorzs_customer WHERE `cust_partnerkod`= 200000De update-nál nem, ugyanarra az értékre updateli az összes érintett sort:
SET @row_number = 1
UPDATE cikktorzs_customer c_c, (SELECT (@row_number:=@row_number + 1) AS num, cust_partnerkod AS i_c_p FROM cikktorzs_customer LIMIT 1 ) i_c_c SET `cust_partnerkod` = cust_partnerkod + @row_number WHERE cust_partnerkod = 200000Akkor csináld kurzorral.
-
martonx
veterán
"mentőövnek Oracle alatt ott a rowid, nem tudom többi DB alatt van-e ilyen rendszer szinten mindig egyedi sorazonosító" - mssql-nél nincs ilyen automatikusan, de bármikor tud generáltatni, ha kell.
-
martonx
veterán
Sziasztok, újra.
Szóval...
Van egy tanár, egy tantárgy és 1 megtartott tábla.
Miután az admin feltöltötte az adatokat a tanár és a tantárgy táblákba, azt kellene elérni, hogy a megtartott táblába hozzá tudjon rendelni 1 tanárhoz tartozó órákat... De pl. 1 matek és fizika órát adó tanárhoz ne lehessen hozzárendelni magyar órát... Csak azokat az órákat, amiket ő tarthat.
Ehhez elég ez a 3 tábla, vagy szükség van még plusz táblára, és hogy lehetne ezt megoldani?Én csinálnék egy plusz táblát, amiben összerendelném, hogy egy tanárhoz milyen órák tartozhatnak.
-
martonx
veterán
-
martonx
veterán
Felejtsd el az Asp.Net Webformst! Vedd úgy, hogy nincs olyan, hogy gridview.
A tutorial videókat rühellem, de itt van a hivatalos doksi: Tutorial: Get started with EF Core in an ASP.NET MVC web app | Microsoft Docs -
martonx
veterán
-
martonx
veterán
Sziasztok!
Mivel sql lekérdezés (bár c# is egyben), ide jöttem első körben...
Van egy update parancs... Videó alapján próbáltam megcsnálni. De most elakadtam...
Itt a videó linkje, ha lenne valakinek 3 perce:
https://www.youtube.com/watch?v=pH7E-GM8HjE&t=1474sPl 24:14 perctől is látszódik a kód...
Engem csak az update sor érdekelne... És a where záradék... Vajon mi lehet ott?Találtam 1 ilyet...
String updatedata = "Update lecturedetail set attendance='" + markstatus + "' where rollno=" + rollno;
Ez nem jó, nyilván átírva sem...
Bocsánat, nem értek hozzá és szeretném megérteni.Szép délutánt!
Ez mégis mi a f....sz?
Ez a youtube videó annyi sebből vérzik. Asp.Net Webforms 2022-ben???
Kézzel megírt SQL parancsok 2022-ben????
És mindehhez a zseniális indiai akcentus. Régi szép emlékeket idéz, amikor együtt dolgoztunk indiaiakkal, és nap, mint nap a röhögéstől sírva meséltük a programozós horror sztorikat egymásnak a cégnél a kollégákkal. Bár akkor ezt megélni inkább tragikus volt, mára szép és kitörölhetetlen emlékké halványult
-
martonx
veterán
Üdv!
Az alábbit kellene megoldanom, de nem jövök rá a nyitjára..
Van egy tábla benne a számla alap adatok (nevezzük T1, mezők: szamla_is, vevo_id, kelte, tejlesites, esedekes, brutto)
Van további két táblakapcsolat. Mindkettő ugyanaz így egyet írok le:
(fejléc legyen T2, mezők: id, datum törzs legyen T3, mezők: id, fej_id, szamla_id, osszeg)
Értelemszerűen a másik tábla is ugyanez:
(fejléc legyen T4, mezők: id, datum törzs legyen T5, mezők: id, fej_id, szamla_id, osszeg)Mivel a két utóbbi táblába szerepelHET a számla_id így union-al összefűzve (ha kézzel beírom az id-t le tudom kérni a legnagyobb dátumot:
SELECT max(datum) as fizetve FROM (
(SELECT T2.datum FROM T2, T3 WHERE T2.id=T3.fej_id AND szamla_id='keresett számla')
UNION
(SELECT T4.datum FROM T4, T5 WHERE T4.id=T5.fej_id AND szamla_id='keresett számla')
)
Így kapok egy fizetve dátumot ami ugye megegyezik azzal amit keresek.
Viszont amit szeretnék, hogy ez a fizetve dátum szerepeljen a számla lekérdezés eredményébe.Azaz
SELECT T1.szamla_id,T1.vevo_id,T1.esedekes,T1.brutto (ide jönne a fizetve lekérés ami a keresett számla szöveg helyett a T1.szamla_id-t kellene tartalmaznia )
FROM T1 WHERE T1.vevo_id='vevőazonosító'Remélem érthetően fogalmaztam...
Szóval az összes UNION módot és SELECT módot már megpróbáltam...
Van rá lehetőség? Mert ugye php alatt foreach-ba árgyazott lekéréssel meg lehet kerülni, de ugye az ahány számla annyi adatkapocslat lenne a fizetve dátum miatt. Ami nem jó..Köszönöm!
dbfiddle példát csinálsz nekünk?
-
martonx
veterán
Sziasztok!
Adott egy SQL adatbazisban egy tabla, ahol az elso oszlop az ID (INT), illetve van meg 10 masik oszlop varos nevekkel, a cella ertekek itt 1-100ig terjedo random szamok (km).
1. Hogyan tudok egy bizonyos ID-ra ugy raszurni, hogy az 5 legnagyobb erteku oszlop (legtobb km) ASC sorrendben legyen. (Horizontal sorting?)
2.Kivalasztani azt a recordot a tablabol, amelyik a legtobb cellat tartalmazza, aminel >= 50 az ertek?Huh, remelem ertheto, ahogy megfogalmaztam ezt.
Koszi a segitseget elore is!
Dbfiddle példát kérek
-
martonx
veterán
Köszönöm, hogy rászántad az időt és ezt ilyen részletesen leírtad, de valószínűleg akkor rosszul (túlbonyolítva) tettem fel a kérdést, mert (bár pár új részletet megtudtam, köszönet érte, de) nem erre irányult a kérdésem, ez a része tiszta.
Ezt írta bambano: az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Én pedig azt szeretném megérteni, hogy miért jobb egy ilyen módszert kifejleszteni (ennél a példánál maradva: rd aldomain, átirányítás saját aldomain-ről a külső linkre) ahelyett, ahogy pl. tegnap a tesztszerveren megcsináltam, hogy simán csak megnyitja a külső linket (href), mellé meg fut egy szkript (onclick), ami szerver oldalon realizálódik és tárolja az összes adatot ami szükséges. Miért kell hogy saját szerverre mutasson a link, és onnan legyen az átirányítás a külső linkre?
@martonx: Köszönöm.
A jelenlegi megoldasod így jó
-
martonx
veterán
Annyira szeretném érteni, amit írtok, de csak
 fejek jönnek elő belőlem (meg rengeteg kérdés).
fejek jönnek elő belőlem (meg rengeteg kérdés).Google Analytics erre a megoldás, saját kókányolás helyett.
Szeretnék egy menüpontot, hogy pl. "Legolvasottabb cikkek". De az nem világos, hogy hogyan lehet jobb az Analytics-es adat, mint a saját szerveren tárolt. Vagy van rá mód, hogy direktben elérjem ezt az adatot (Google), és be tudja építeni egy query részeként? Tehát hogy pl. rendezze sorba a cikkeket aszerint, hányszor voltak megnyitva (aka. Legolvasottabb cikkek). Mert csak erre kellene.az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Ezt elmagyaráznád, kérlek, hogy miért jó? Szeretném megérteni, hogy aztán implementálni tudjam. (Ez offtopic ide, ezért rakom off-ba, de nagyon szeretném érteni.)
Így hirtelen ami eszembe jutott, hogy külső linkekkel operál az a hírkereső. Meg is néztem gyorsan, ott ez hogyan van megoldva.Egy példa (direkt nem alakítom linkké):
https://rd.hirkereso.hu/rd/39891270?place=6544&partner=hirkereso&url=https%3A%2F%2Fprohardver.hu%2Fhir%2Fjon_lg_elso_hibrid_projektora.htmlEz ide dob tovább:
https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlMegköszönném, ha lenne annyi türelmed, hogy pár szóban elmagyarázod, hogy ez a link miért így épül fel. Pl. itt miért kell az "rd" aldomain? redirect, gondolom, de ez miért kell?
https://rd.hirkereso.hu/rd/39891270
Ez is ugyanoda továbbít, már a többi rész nélkül is. (és minden más cikkhez is van egy ilyen "redirect-id") Akkor miért kell a többi rész? Nem is igazán értem, bár ez gondolom a saját kódjához kell valamiért.És ennek a headerjében van a
Status Code: 301 (from disk cache)
location: https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlViszont semmilyen forrásadatot nem látok, nem tudom, hogy továbbít.
Szóval talán az aldomain azért kellhet, mert ezekhez a külsős linkekhez csinált 1-1 saját linket a redirect aldomain-ban, és ezek a linkek 301-el továbbítják a valós cikkhez?
Ez plusz forgalmat generál neki? Vagy miért jó?Milyen rendszert kell építeni mögé? Mit kell hogy tudjon?
És miért jobb, ha így nyílik meg a link, mintsem a direkt link? Mi a célja, szerepe?
A startlap pl. a külsős linkeket simán csak belinkeli, nincs redirect. Akkor ők rosszul csinálják?Vagy ha nincs türelmed, kedved, természetesen azt is megértem, csak kérlek, ez esetben legalább a megfelelő keresőszavakkal segíts, hogy a megfelelő cikkeket találjam meg.
Egy általános "url redirect" sajnos nem mondja meg, hogy hogyan (és miért) kell saját weblapról saját weblapra átirányítva átirányítani. (Se másik jó pár keresés az utóbbi majd' 1 órában.)
Köszönöm.
Áhá így már értem. Bocs az elején félreértettelek. Mivel SQL-t használsz, jobb módja nincs. Más módok is vannak persze, pl. beüzemelsz egy külön NoSql-t ehhez, inmemory SQL táblát használsz, felhőben valami Queue-ba dobod be az eventeket, és majd onnan egy microservice a maga nyugijában updatelgeti a DB-t, stb...
-
martonx
veterán
Nem saját link egyik sem, mind kifelé mutat, és 5 percenként jön pár 20-50-100 új.
Pl.:<a href="https://mobilarena.hu/tema/sql-kerdes/friss.html"target="_blank" rel="noopener noreferrer">SQL kérdések</a>Azt, hogy melyikre hányszor kattintanak, csak saját kódon belül tudom mérni. (Vagy nem tudom jól használni a Google toolját.
 )
)De akárhogy is, ott is ugyanaz lenne a helyzet a végén (Google adatbázisa), ott is van egy számláló egy rekordhoz, amit emelni kell.
Simán csak egy update?UPDATE clicks SET clicks_counter = clicks_counter + 1 WHERE link_id = 123Vagy van ennek jobb módja is? Mert nem tudom, mennyire "jó" ha folyamatosan update van a táblán (még ha erre is van kitalálva).
Tök mindegy hova mutat a link, ha a te kódodban van
Google Analytics erre a megoldás, saját kókányolás helyett. -
martonx
veterán
Sziasztok!
Szeretném mérni, hogy egy-egy linkre az oldalamon mennyien kattintanak (és erre építve új menüpontokat létrehozni, tehát ezek a számok új query-khez kellenek majd).
Elsőre azt gondoltam ki, hogy minden linkhez
<a hrefteszek egyonclickeseményt, ami minden rákattintásnál (ellenőrzés után) beír majd egy ehhez létrehozott táblába: a link id-jához tartozó számlálót megemeli eggyel.
Tehát lenne egy clicks tábla, abban egy id, egy link_id és egy clicks_counter mező.
Kattintás, link_id = xyz, megnézi, ez benne van-e a clicks táblában, ha igen, akkorclicks_counter = clicks_counter + 1.Van ennél egyszerűbb, szebb, jobb megoldás?
Csak azért kérdezem, mert az is eszembe jutott, mi van akkor, ha mondjuk 2 user pont ugyanakkor kattint ugyanarra a linkre. Mondjuk eddig 0 volt az értéke a counterének, megy egyszerre a 2 query, mindkettőnek azt mondja, hogy clicks_counter = 0, így mind a kettő 1-re fogja állítani. Vagy ezt okosan lekezeli az SQL?
Vagy máshogy kell ezt lekezelnem?Köszi a tippeket előre is.
Erre való a Google Analytics.
-
martonx
veterán
Ez a 2 példa jó, köszönöm.
Viszont ugye ha esetleg programhiba rontotta el az adatokat, az nem jelenti, hogy csökkenni fog az adatbázis mérete. Tehát a vizsgálatom nem helyes (a régi fájlok törlésére vonatkozólag), legalábbis nem elég. Bár ezt az esetet (programhiba) úgyis csak utólag lehet észrevenni.Nem felhőben vagyok, és 5 percenként pár 100 rekord van mentve, így muszáj vagyok sűrűn backupolni. Legalább egy 2-3 órás periódusban gondolkodom. Aztán azért lenne fontos a megfelelő vizsgálat (arról, hogy nem-e egy sérült adatbázis-állaptot mentek le), mert arra gondoltam (és úgy csináltam meg), hogy másnap a legelső backupnál törli az előző napi backupokat, kivéve a legutolsót. Így a végén minden napról lesz egy valid mentésem.
De ez még sok kérdőjeles koncepció, bár minden eleme készen van már és működik, csak ahogy írtam is, arra alapoztam, hogy ha nagyobb a lementett adatbázis az előzőnél, akkor valid is. És ez így nem biztos.
Szerintem egy kicsit kevered a dolgokat. A backup nem erre való. Backupolni elég naponta egyszer (gondolj bele, amikor X TB-os DB-ket 2 óránként próbálna meg bárki menteni
) . Amire te gondolsz az inkább egyfajta tükrözés, amikor két DB-d van, és időnként a másikba átszinkronizálod az adatokat.
Illetve még olyat szoktak, hogy inkrementálisan backupolnak, így nem foglal annyi helyet. -
martonx
veterán
Kérlek, segítsetek irányba állni a témában:
Úgy csináltam meg az adatbázis biztonsági mentését, hogy mivel nem tarthatok meg minden backupot, ezért a már feleseges(nek vélt) fájlokat egy idő (fájl darabszám) után nem tárolom tovább.
Mivel alapból abból indultam ki, hogy ha baj van az adatbázissal, akkor az elsősorban adatvesztést jelent, így akkor az előző mentéshez képest kisebb lesz a mentett (.sql) fájl. Ezért ha kisebb, nem menti, ha pedig nagyobb, akkor mentheti, tárolhatja, hisz' került bele új adat, ergo rendben az adatbázis. Ehhez mindig az előző mentés (tömörítés nélküli) fájlméretét veszi alapul.De most az ötlött belém, mi van, ha az adatbázis mérete nem csökken? Nem tudom, milyen eset lehet ez, de tegyük fel (extrém példa), az én oldalamat akarják a legtöbben feltörni, sikerül is, és teledobálják saját reklámokkal. Az adatbázis mérete így nőni fog. A szkriptem viszont jelenleg csak a méretnövekedésből veszi, hogy rendben van minden az új mentéssel, ami ebben az esetben hibás következtetés lenne, így a régi (még nem "meghekkelt") mentések potenciális automatikus törlés célpontjai lesznek, és a végén használható backup nélkül maradok.
Pontosan milyen esetekre kellene felkészítenem a biztonsái mentés mechanizmusát?
Mert úgy érzem, ha csak a fájlméretet nézem, már a fenti (oké, nem túl reális) példa alapján sem jó a vizsgálatom.Ott van ugye, ha a szolgáltatót támadják, vagy esetleg hardverhiba miatt ugrik minden adat. Erre ugye megoldás, ha felhőbe is mentek folyamatosan.
Milyen (akár reális, akár 1:1M-hoz esélyű) esetek vannak még, ahol a biztonsági mentés megléte "életet menthet"? Mert akkor úgy módosítom, mit vizsgáljon.
Köszi!
Mondok egy nem is annyira extrém példát:
Amikor kézzel mókolsz a DB-ben, és te magad hibázol. Vagy ami még rosszabb, kiderül, hogy volt egy programhiba, ami elrontotta az adatokat.
Nem igazán értem, miért neked magadnak kell a backuppal bajlódnod. Jó mondjuk 8 éve csak felhőben dolgozok... -
martonx
veterán
-
martonx
veterán
Furcsa ez a fórum, elvileg segítőkészséget ígértek, de ahogy visszaolvastam, a nekem írt "tanácsok" nagy része nem a témához tartozik, vagy félrevezető.
![;]](//cdn.rios.hu/dl/s/v1.gif)
Utána néztem, az acces is sql alapú, ami 1992-es megegyzés (szabvány?) alapján jött létre, majd 1999-ben volt egy újabb verzió, de azt már nem mindenki fogadta el. Akkor most nem mindegy, hogy a program 2007-es vagy frissebb, ha évtizeddel korábbi kódot használ?
Legyen lényeges téma is:
Agyalok egy ideje a megoldáson, szerintem táblák közötti kapcsolat mindennek a kulcsa, azt kellene valahogy összehozni, ebben lenne szükségem segítségre, az pedig még a programtól független megoldásnak tűnik.Amin elakadtam:
A project minta adatbázisban van egy jónak látszó megoldás, hogy a projekt-hez lehet feladatokat csatolni, amihez felelőst lehet kinevezni, de ha jól értem, ez csak úgy működik, hogy a projektnek is van felelőse (tulajdonosa?).Az én megoldásomban a projekt az eseményekből áll, amihez sok résztvevő tartozik - azaz ellentétes a példával, ahol csak egy felelős van - és az eseményekhez kellene feladatokat csatolni, amiknek lenne felelőse.
DE: a feladat megvalósításával az is eseménnyé válik.(Példa:
esemény: telefonhívásos megbeszélés 2 személy között, megegyeznek, hogy az egyik megvesz valamit, majd elviszi a másiknak, aki azt majd később visszaadja neki.Erre két megoldást látok:
1.séma
Az egyik megoldásnál van egy esemény 2 fővel, telefonos megbeszélés, majd lesz egy újabb esemény 2 fővel a találkozóról, ahol a lényeg az, hogy az egyik átad valamit a másiknak.Az első eseményhez kapcsolódik két feladat, az első feladatnak az egyik személy a felelőse, és a téma a bevásárlás.
A másik feladatnak mindkét személy a felelőse és a téma adott helyen és időben találkozni.A második esemény már a megvalósult találkozó lesz, ahol adott helyen és időben a két személy találkozik és megtörténik az átadás.
Ehhez rögtön kapcsolódik egy újabb feladat, a második személy a felelőse, és adott határidőre vissza kell adnia a dolgot az első személynek.Ekkor kell két külön tábla, az egyik az esemény, amikhez feladatok kapcsolódhatnak, a másik a feladat, ahol csak az a lényeg, hogy megvalósult, vagy sem.
A hátránya, hogy néha ugyan az a dolog feladat és esemény is lesz, lekérdezésnél esemény és feladat sorrendet kell választani.2.séma
A fenti folyamat azzal a különbséggel, hogy a feladatok a sikeres teljesüléskor eseménnyé válnak.
Ekkor a lekérdezés (megjelenítés) egyszerűbb lesz és nem lesz párhuzamos adat, de fogalmam sincs, hogyan lehet ezt megvalósítani - talán kell egy "kód" mező, hogy ez feladat vagy esemény?A másik problémám az, hogy a feladathoz egy felelős kell, ami a ms projekt mintában látszik, hogy csak egy személy kapcsolódik hozzá, DE! amint eseménnyé válik, akkor már ellenkező irányú kapcsolat kell, mert akkor már több résztvevője lehet az eseménynek.
Tehát, ha az ms projekt sémáját követem, akkor a második feladatot, amikor két személynek kell találkoznia, mindkét személynek ki kell osztani, személyenként lehet egy feladat, és mindkettőnek teljesülnie kell, hogy létrejöjjön a két feladatból az egy esemény.Ez önellentmondásnak tűnik számomra, ti ezt hogyan oldanátok meg? (vagy fel, ha az ellentmondást fel kell oldani.)

Az 1-es sémára szavazok. Viszont tényleg van ezt értelme ennyire mikroszkopikus felbontásban, ultra részletesen adatbázisban ábrázolni?
Feladat és eseményenként? Ennyi erővel akkor már az is feladat és persze esemény lehetne, hogy a találkozóra menet kimész az utcára, felülsz a villamosra, veszel egy menetjegyet stb...Szóval szerintem továbbra is túlbonyolítod.
-
martonx
veterán
Taci:
nem hiszem, hogy "kattintgatással" végig lehet vinni egy projektet.
Nem is, projektet csak ésszel lehet végigvinni.Talán próbálj meg kisebb területeket lefedni a kérdéseiddel, mert ezek talán túl általánosak, megfoghatatlanok, vagy nehezen megválaszolhatóak.
Vagyis nem értettétek meg, hogy egyetlen részletkérdés volt a probléma, és nem jeleztetek vissza, hogy nem értitek.Számomra a te javaslatod volt érthetetlen, értelmetlen nekiállnom sql programozási példáknak, amikor csak egyetlen részprogramra keresem a választ:
Hogyan lehet adatot bevinni az eset táblába jövőbeli feladatként, hogy az rögtön ugyan annak a táblának egy még nem létező rekordjára hivatkozzon?És azt kérlek, ne feledd,
Kérlek, ne feledd, hogy a fórum korlátoltsága miatt csak egyetlen beírás lehetséges, ha hetekig nincs válasz, vagy újabb beírás, hetekig kell várnom, hogy esetleg rákérdezzek, miért nincs válasz, mert még a beírást se tudom utólag módosítani.Próbáld ki, milyen érzés naponta többször ránézni a fórumra csak azért. hátha végre valaki írt valamit, hogy lehessen folytatni a munkát.
Kínzótábornak is elmegy ez a fórum.
martonx:
Ez egy SQL fórum, nem pedig MS Access fórum.SQL kérdésem volt, nem access - amúgy az acces is sql alapú, csak vizuális megoldású, de van sql nézet nézete is.
Hogy táblák között milyen kapcsolatok vannak, SQL query-kben mit-hogy érdemes megcsinálni, abban tudunk segíteni, de szerintem itt senki nem használ MS Access-t (többek között ezért is próbáltalak volna lebeszélni róla).
Pontosan ez volt a kérdésem, az általad javasolt megoldásra irányult, hogyan lehet vele adatot bevinni, mert nem értem és nem találtam rá sehol példát, pedig végignéztem az acces helpjének a részeit és letöltöttem és végignéztem az access2007 videókat yt-ról, még az angol nyelvűeket is.Sőt, letöltottem az elmúlt tíz év access érettségi feladatait is, de azok nem foglalkoznak adatbevitellel, csak lekérdezésekkel és jelentésekkel.
Mindenhol csak 1-sok, sok-1 vagy sok-sok kapcsolat van, de az utóbbinál is két különböző tábla között, te viszont ugyan abba a táblába tetted vissza a kapcsolatot, amire sehol sincs példa.
Ezért kérdeztem, hogy adatbevitelt hogyan oldod meg ott?
Nem értem, ha egyszer egy táblában egy rekordot kezdek bevinni, hogyan tudok ugyan abba a táblába egy vagy több újabb rekordot úgy beszúrni, hogy még nem zárom le a rekordot, ráadásul rögtön kapcsolat lesz az újonnan bevitt rekordokkal?A mi szemszögünkből nézve az MS Access form készítés mizériája egy szinten van az MS word-ös példámmal.
Igen, a könyvben is pár oldalon vannak az adatokkal kapcsolatos dolgok, majd sok-sok oldalon, hogy milyen betűtípus, szín, meg sok minden lehet és hogyan lehet logot használni képként, stb. amik nem érdekelnek.
Remélem így már érthető, hogy miért állt itt meg a segítségünk. Olvass MS Access doksikat, nézz MS Access form gyártó youtube videókat, ha létezik olyan, akkor írj direktben MS Access fórumokra, és biztos meg lesz a kérdésedre a megoldás.
Lásd a fentieket, úgy tűnik, egy sql megoldást javasoltál, amit az access könyvek nem ismernek, erre kérdeztem rá.
A könyvek, help és videok alapján arra tippeltem, hogy az adatbevitelnél talán egy lekérdezést kell meghívni, ami létrehoz egy új rekordot, és utána lehet az adatot bevinni, de nem értem, hogyan, ha egyszer még a tábla korábbi rekordját nem zártam le. (Sőt, több jövőbeli feladat lehet, úgyhogy sok új feladatot kell beszúrni a táblába.)Lehet, hogy jelentkezhetnél a megoldással a ms-nél is, hogy nem csak különböző táblák között lehet sok-sok kapcsolatot létrehozni.

Kérlek nézd el nekem, hogy utoljára valamikor 2010 táján Access-eztem, és nem is hiányzik.
A gépemen is csak azért van, mert múltkor a kedvedért feltelepítettem, hogy bebizonyítsam hogy lehet Accessben egy táblát önmagához kötni."Ezért kérdeztem, hogy adatbevitelt hogyan oldod meg ott?
Nem értem, ha egyszer egy táblában egy rekordot kezdek bevinni, hogyan tudok ugyan abba a táblába egy vagy több újabb rekordot úgy beszúrni, hogy még nem zárom le a rekordot, ráadásul rögtön kapcsolat lesz az újonnan bevitt rekordokkal?"Fingom sincs (régen is VBA-t programoztam Access mögött, nem az adatbeviteli formokkal tökölődtem), hogy kell az adatbeviteli formokat összenyomkodni varázslóban.
VISZONT: háttal ülsz a lovon logikailag. Adatbevitelnél lényegtelen a kapcsolat az esemény, és a jövőbeli esemény között, mert nyilván ekkor még nincs is kapcsolat. Felviszed az eseményt, és kész. Ez az esemény lesz a szülő eseményed.
Egy dolgot kell megoldanod, hogy amikor egy újabb eseményt felviszel a formon, akkor ki tudj (de ne legyen muszáj) választani egy szülő eseményt, pl. az előzőleg felvittet. Így tudod logikailag megoldani, hogy a jövőbeli események kapcsolódnak az őket kiváltó eseményhez, azaz a tábla önmagához kapcsolódik.
Fogalmam sincs, ezt hogy kell csinálni a formon, de biztos, hogy elég csak a form varázslójában kattintgatni.Sok sikert, részemről téma lezárva.
-
martonx
veterán
Ez egy SQL fórum, nem pedig MS Access fórum. Hogy táblák között milyen kapcsolatok vannak, SQL query-kben mit-hogy érdemes megcsinálni, abban tudunk segíteni, de szerintem itt senki nem használ MS Access-t (többek között ezért is próbáltalak volna lebeszélni róla).
Azaz a formok gyártásában, mi itt nem fogunk tudni segíteni neked.
Ahogy azt is hiába kérdezed meg itt, hogy MS Wordben, hogyan formázzuk hupililára egy bekezdés hátterét, miközben felhőcskés szegélye legyen. A mi szemszögünkből nézve az MS Access form készítés mizériája egy szinten van az MS word-ös példámmal.Remélem így már érthető, hogy miért állt itt meg a segítségünk. Olvass MS Access doksikat, nézz MS Access form gyártó youtube videókat, ha létezik olyan, akkor írj direktben MS Access fórumokra, és biztos meg lesz a kérdésedre a megoldás.
-
martonx
veterán
Na nagy nehezen csak tudtam lockolni a táblát (phpMyAdminból nem volt olyan egyszerű), adtam hozzá egy 30 másodperces sleep-et.
Abban a 30 mp-ben valóban nem volt hozzáférés a táblához, ez viszont a weboldal felőli oldalon abban mutatkozott meg, hogy új adatot nem tudott behúzni. De ami cache-elve volt, azt szépen hozta újra, mintha semmi se történt volna.Viszont így bár lehet, hogy maga az UPDATE processz hamar lefutna (sőt, igazából folyamatosan azt nézem, hogy futtatom, és közben privát böngészésben nézem, hogy ne cache-ből szedjen adatokat, de így is gond nélkül betölt mindent) inkább napi 1x futtatom csak (az UPDATE-et használó karbantartó szkriptet), azt is valami hajnali órában, így biztosan nem fog "bad user experience"-t okozni.
Köszönöm ismételten a segítséget!
Amúgy jó lenne, ha valahogy ezt a rengeteg segítséget meg tudnám hálálni. Nem szeretek csak kérni, úgy vagyok rendben magammal, ha viszonozni is tudom.
Úgy hálád meg, hogy ugyanitt majd segítesz másoknak
-
martonx
veterán
Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem.
Próbáltam direktben lockolni is a táblát (LOCK TABLE cikkek WRITE), de egyrészt ez alatt is ment minden, másrészt a SHOW OPEN TABLES által visszaadott adatokban azt láttam, hogy nincs is lockolva. (Szóval lehet, ez nem is volt jó teszt ehhez.)
Úgy csináltam anno meg amúgy (a kategóriás karbantartó szkriptet), hogy 100 rekordonként tol egy commit-ot. Nem tudom, ebben a kontextusban ennek köze van-e bármihez.
Annyit találtam még (SQL oldalon), hogy talán lehet csak az érintett mezőket lockolni:
SELECT ... FROM your_table WHERE domainname = ... FOR UPDATE
Ezzel van tapasztalatotok? Jó lehet ide?Az indexeket létrehoztam az érintett mezőkre. Viszont ott észre vettem egy "érdekességet":
Azt mondta az egyik mezőnél (utf8mb4), hogy Warning: #1071 Specified key was too long; max key length is 767 bytes. Ennek utána olvastam, és értem is az okát.A kérdésem az lenne ezzel kapcsolatban, hogy amikor ránézek az indexre, ezt látom:
varchar(255)-ből varchar(191) lett. (ugye 767 / 4).
Ez azt jelenti, ha az eredeti sztring 255 karakter hosszú, indexelve ebből csak az első 191 lesz? Vagy ez pontosan hogyan "manifesztálódik"?"bár szemlátomást, ő magával is ezt teszi
"
Ott a pont. Bár hidd el, nem szánt szándékkal teszem.
Bár hidd el, nem szánt szándékkal teszem. "Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem."
Erről beszéltem, hogy igen, ezek a problémák, amik itt felvetődnek jogosak, és léteznek, de a te rendszered mire ide elér, hogy DB szinten lock stratégiákon kell gondolkoznod, és erre optimalizálnod lehet, hogy:
1. sose fog megtörténni
2. ha mégis akkor meg te leszel a következő magyar bank / telko ez esetben zokszó nélkül fel fogsz tudni venni egy komplett fejlesztő csapatot Szóval elvileg nem haszontalan ezeken itt pörögni, gyakorlatilag viszont az
-
martonx
veterán
csomó lehetőséged van tehermentesítened az adatbázist, anélkül, hogy belegörcsölnél az SQL minden mélységébe. Pl. cachelés
Hibernate cachelésétől ments meg Uram minket.
Olyan szinten telibeszarja a DBk többfelhasználós jellegét, hogy öröm nézni.
Addig konzisztens csak önmagával, amíg rajta kívül nincs senki más, aki módosíthatja ugyanazt az adatbázist!Ha a háttérben megupdatelsz egy rekordot, azt a Hibernate nem szokta észrevenni, és a felette lévő alkalmazásban módosul a becachelt verzió, akkor szemrebbenés nélkül hülyeséggel írja felül a már megváltozott rekordot.
Nesze neked tranzakciók függetlensége.
Nem csak Hibernate létezik ORM-ként, és nem csak ORM szinten lehet cachelni
Maximális respect a DB tudásodnak, de nem kell mindig mindent DB szinten megoldani.Ez itt nagyon off topic, de minek görcsöltetitek, és csuklóztatjátok szegény kezdő kollégát (bár szemlátomást, ő magával is ezt teszi
) olyan problémák, olyan technológiai szintű mélységében, amikkel egyrészt jó eséllyel a való életben találkozni se fog (vagy végül elég lesz egy hiányzó indexet feltennie), másrészt, ha nem is DB szinten, hanem kód szinten de, tök simán kezelni lehet. -
martonx
veterán
Ez nagyon hasznos információ, köszönöm!
Tehát ilyenkor sorbanállás van? Tehát egy sima Select is sorban áll, és a (honlapot használó) user nem kap vissza addig adatot, amíg az update nem végez?
Akkor csak lenne még kérdésem:
Melyik a jobb megoldás ezt a helyzetet kezelni?
- Egy index a cikk_id-ra (ezt kapja vissza a kategóriakarbantartó szkript),
- vagy mégiscsak egy külön tábla ennek a mezőnek?Nem fér bele semennyi várakozás, sorbanállás, hogy a user megkapja a tartalmat (a honlap a kért adatokkal betöltődjön). Most oké, még pár 10ezer rekordnál a karbantartó szrkipt hamar végez, de később ez csak lassulni fog.
Tényleg nagyon köszönöm ezt az információt!
"Egy index a cikk_id-ra" - itt alapból is kellene indexnek lennie, mivel ez Foreign key. Probléma megoldva
Egyébként meg ez ugyan SQL fórum, de mivel egy web alkalmazásról beszélünk, csomó lehetőséged van tehermentesítened az adatbázist, anélkül, hogy belegörcsölnél az SQL minden mélységébe. Pl. cachelés
-
martonx
veterán
Lehet, ez buta kérdés, de ma valahogy eszembe jutott, hogy van a MySQL-felhasználó, amit az adatbázishoz "kapok" a szolgáltatótól.
Van értelme annak, hogy a weblappal kapcsolatos műveletekhez (rekordok felvétele, lekérdezése és frissítése) létrehozzak egy másik felhasználót, aminek csak a valóban elengedhetetlen jogokat adom meg?
Mert most a tesztkörnyezetben a "fő felhasználót" állítottam be, de szerintem az úgy nem lesz az igazi (főleg biztonsági szempontból talán).Pl. nem kell, hogy tudjon rekordot/táblát/mezőt/bármit törölni, így nem kap Delete-jogosultságot. Csak mondjuk Select, Insert, Update. (Data)
A Structure-nál kell gondolom a táblákkal kapcsolatos funkciókat beállítani, szóval ott pl. nem kellene semmi.
Az Administration rész még nem tiszta, annak utána olvasok.
Ti használtok külön felhasználót ezekre a feladatokra?
Ha igen, milyen jogosultságokkal bír, milyen feladatokhoz?Köszi.
Nem használunk külön felhasználót. De nyilván lehet, ha úgy nyugodtabb vagy.
-
martonx
veterán
-
martonx
veterán
-
martonx
veterán
Pedig csak egy mondat volt.
1. Csak éppen értelmezhetetlen, mert az Acces nem enged két kapcsolatot két tábla között, lásd lentebb.
2. Nekem már papírom van róla, hogy nem vagyok aktív, felesleges emlékeztetned rá.
A tények:
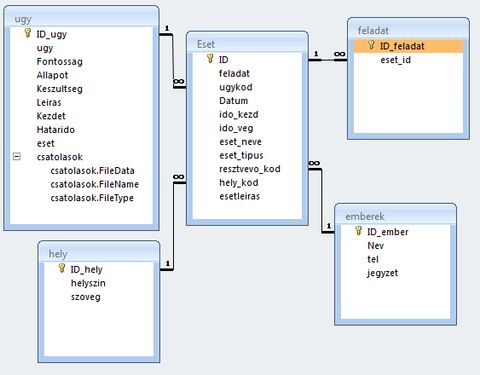
Láthatod, hogy ott van az új feladat tábla, de vagy ezt a kapcsolatot hozom létre, ami a képen látható, vagy a másikat, az Eset táblából a feladat-ot kötöm össze a Feladat tábla ID_feladat-tal.A kettő egyszerre nem megy, ezért nem értem, amit írtál.
Akkor fuss neki még egyszer, mert az Access igenis tud több kapcsolatot két tábla között

-
martonx
veterán
Pedig csak egy mondat volt.
Csinálsz egy új táblát, amit mondjuk hívj Feladat-nak. Eddig meg van ugye?
A táblának két mezője lesz:
SzülőEsetID
FeladatEsetIDEz a tábla fogja megmondani, hogy egy Esethez milyen más esetek, a te értelmezésedben ekkor már Feladatok tartoznak.
-
martonx
veterán
Na tessék, itt van, eddig jutottam:
Egy ügy elindul, annak sok eseménye (eset) lehet, vannak résztvevők és esetleg van helyszíne, van típusa, amit listával meg lehet oldani.
Ez eddig szép és jó.Az ügy táblát az access sablonbol vettem át, érdekes, hogy csak egy csatolás volt, itt pedig három sor jelenik meg, a "fontosság-állapot-készültség" sorokra talán nem lesz szükség, egyenlőre benne hagytam.
Ott vagyok elakadva, hogy bizonyos eseteknél feladatokat kell meghatározni, amelyek újabb eseményeket várnak el, vagyis szükség lenne egy újabb eset táblára.
Az a kérdés, hogy ezt hogyan lehet megoldani?
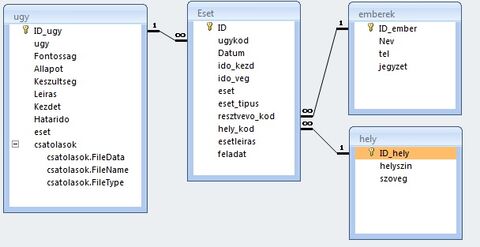
Csinálsz egy feladatok táblát, ami tartalmaz egy szülő Eset ID-t, és ehhez több eset ID-t.
-
martonx
veterán
OK,megpróbálok gyorsan áttekintést adni, de most estem vissza, megint ezernyi dolgot varrtak a nyakamba, hogy "neked úgyis mindenre van időd."

Nos, a táblákkal elakadtam, igen, amiket írtam, az megvan, és talán első lépésben annál nem kell több adat, ha igen, talán egyszerű lesz hozzáírni.
Elolvastam pár leírást, és volt egy nagyon jó javaslat, hogy mindent a legvégső lekérdezés alapján kell megtervezni, de itt elakadtam, mert többféle módon kell majd látni az adatokat.
Tehát az alapsor adott, dátum és idő, ha egyszeri dologról van szó (levél, telefon) és idősáv, ha esemény (pl. hosszú beszélgetés) kell.
Azaz itt már bejön egy kódmező, ahova az esemény formáját lehet kiválasztani.
Azután az adott esemény valamilyen ügyhöz tartozik, valamint vannak résztvevő személyek (aki levelet írt, vagy aki(kk)el beszéltem, utóbbi esetben van helyszín is.Azután jön a nagy dilemmám, hogy a kapcsolatokat hogyan tegyem bele, mert a fentiekből következik, hogy egy ügyhöz sok esemény kapcsolódik, de az egyszer dátum szerinti sorrendben van, másodszor van bizonyos események között logikai kapcsolat van (pl. megbeszélés után van több feladat, levelet írni, telefonálni, vagy következő megbeszélésre iratot beszerezni), és emellett bejön még a határidő és feltétel, hogy a következő megbeszélés csak akkor lehetséges, ha azok teljesültek.
Ezért talán az "ügy" és az "események" között kell egy újabb kódmező, ami azt jelzi, hogy teljesültek a feltételek, és tovább lehet lépni.
A végső megjelenítés történhet az adott ügy szerint, hogy mikor és mi történt, kik vettek rész és hol voltak az események - itt megint bejön a dilemma, hogy időbeli vagy logikai sorrend legyen.
Valamint kell olyan megjelenítés is, hogy adott személlyel milyen ügyeim voltak, ami sokkal bonyolultabb lesz, hiszen az adott személyről van szó, de az ügy listájában ott lesz, hogy az adott személy az ügynek csak bizonyos eseményeiben vett részt.
Nost így ennyi van a fejemben, két napja nem voltam pc előtt, majd talán holnap tudok egy képernyőképet feltenni, hogy a három táblával eddig mire jutottam.
https://crm.org/crmland/free-crm
No, így hogy már jobban összeszedted, hogy mit is szeretnél, én a helyedben itt néznék szét.
Ezek közül konkrétan a Monday.com-ot használtuk az egészen korrekt volt. -
martonx
veterán
Értelemszerűen csak az adatbevitelre vonatkozott.
sztanozs
Dehogynem, a lekérdezéseknél az adatokat csak megjeleníti, átírásuk nem lehetséges, vagy csak előre tervezetten.Még mindig várom a választ a kérdésemre, hogy hogyan lehetséges-e a táblák átmásolása különböző adatbázisok között, mert láttam, hogy a sokféle különböző minta adatbáziban lényegében ugyan azok a táblák voltak alapként.
(furcsa, hogy csak egy választ engedélyez a fórum, akkor így írom, hátha így elfogadja.)
Ez esetben hogy segítsünk, ha az adatbevitelen kívül semmit se tudunk arról, hogy mit is szeretnél :D
Az adatbevitel alapján erre egy Excel tábla untig elég. -
martonx
veterán
"Az egyik program az legyen, ahova minden este beírom, hogy aznap mi történt, dátum és óra szerint, hogy mi volt az ügy, mi történt, levél vagy telefon, vagy cselekedet, és ki hívott vagy írt levelet. Esetleg legyen megjegyzés, vagy figyelmeztetés, hogy ott valamire várni kell, vagy határidő van"
Ezt írtad, és igen, ezt egy excel sorba elég felvinned
-
martonx
veterán
Helyes,akkor ez nekem való, a bíróságot meg nem akarom többet látni.
Sejtettem, amint a Northwin-det megnyitottam, hogy amit akarok, az jóval egyszerűbb, majd átnéztem a többit is, azt hiszem, a task és projekt ami részben kell nekem, de sok velük a gond.
Az első kérdésem:
Azt látom, hogy kis különbséggel azonos táblák vannak különböző fájlokban.Hogyan lehet a táblákat átmásolni másik access fájlba, vagy több access fájlból egyet csinálni, és a fölösleges táblákat törölni?
Tényleg Access kell neked? Nem kevered az Excel-el? Mert amit leírtál, ahhoz az Access csak önszopatás.
-
martonx
veterán
Nem, angollal hadilábon vagyok, csak az írott szöveget értem valamennyire. Igaz, németet még annyira se, a francia és spanyol és más nyelvek pedig hottentotta kategóriák nekem.
Nem akarom megtanulni a programozást, meg akarok csinálni azokat, amikre szükségem van.
Elegem van abból, hogy azt mondják, hogy ahhoz fizetnem kell milliókat, amikor látom, hogy access-ben csak kattintgatnak és máris működik.Nemrég egy szélhámos megalázott a bíróságon, hogy összekevertem dátumokat és nem emlékeztem pontosan az adatokra, így még nekem kellett fizetnem azért, hogy átvert.
Két programra van szükségem, amiket meg akarok csinálni, ha már senki se akar segíteni nekem, akkor "magad uram" elv alapján, és amikor elakadok, akkor kérek majd továbblépéshez segítséget.
Az egyik program az legyen, ahova minden este beírom, hogy aznap mi történt, dátum és óra szerint, hogy mi volt az ügy, mi történt, levél vagy telefon, vagy cselekedet, és ki hívott vagy írt levelet. Esetleg legyen megjegyzés, vagy figyelmeztetés, hogy ott valamire várni kell, vagy határidő van, így ne legyen az, hogy valamiért nem kapom meg a levelet, vagy nem hívnak, és utána azt mondják, hogy de, hívtak és volt megállapodás.
Ha kell, akkor ott legyen, akár a bíróság számára is bizonyíthatóan, hogy pontosan mikor mi történt, és akkor már az adott ügy összes történését lehessen csak látni.
Bár már nem akarok többször bíróságra menni az életemben, csak meg akarom mutatni, hogy van egy lista a történésekről, így a szélhámosok már ne is próbálkozzanak többet.A másik program az idézeteknek legyen, nagyon pontosan emlékszem mondatokra, de nem tudom, hogy melyik filmből, vagy könyvből valók.
Ezek szerintem egyszerűen megvalósíthatóak, vagy legalábbis annyira, hogy segítséggel még én is össze tudom ezeket kattintgatni.
Szia!
Ezekhez nem kell access. Amire te gondolsz az az Excel, aminek van még számtalan más ingyenes alternatívája.
Viszont semmi ilyet nem fog a bíróság bizonyító erejűnek elfogadni, de ettől még saját szórakoztatásodra / önmagad megnyugtatására miért ne vezethetnéd ezeket az adatokat. -
martonx
veterán
Az indexekkel kapcsolatban annyit hadd kérdezzek már még, hogy kell-e őket valahogy "kezelni, karbantartani"? Van nekem bármi dolgom velük a létrehozásukon kívül? Mert elsőre azt gondolnám, hogy minden más már a rendszer dolga lenne, de azért inkább rákérdezek, hátha figyelnem kell (majd idővel) valamire, bármire.
Első körben ezt találtam: [link]
Ezt úgy tudom elképzelni, hogy (maintenance módban) az indexeket újraépítem majd, ha szükség lesz rá (törlés, és újra létrehozás), ahogy írja is.
1. Ember csináld már meg amit akarsz, ne tökölődj a mi lesz majd 50 év múlva ha nyerek a lottón szintű problémákon.
2. amit linkeltél MS SQL-re vonatkozik, tudtommal te valami játszós DB-t használsz (MariaDB vagy MySQL vagy valami ilyesmit).
3. Egyébként igen, van amikor karban kell tartani az indexeket, nyugodj meg, te sose futsz ilyen esetbe bele, vagy ha igen, addigra már rég milliárdos leszel, és lesz DB admin embered, aki majd elszórakozik az ilyen problémával. -
martonx
veterán
ElasticSearchtől azóta kapok sikítófrászt, mióta kedvenc adóhatóságunk olyat szeretett volna az adószámla egyenlegek tárolására + napi újraszámolására, mert az menő, passzol a mikroszerviz architektúrába, és jól skálázható. (meg ingyenes(?) a licensze, tehát többet lehetett volna a projektből khm. megtartani)
Szerencsére főnökömnek sikerült megértetnie velük, hogy nagy mennyiségű, jól struktúrált adat kezelésére rendes RDBMS való, meg arra találnak hozzáértő szakembereket is, sok tapasztalattal.
Aztán a projekt végén, amikor csak a mi modulunk készült el határidőre (emiatt nem kellett meneszteni a projektért felelős álomtitkárt, meg az illetékes vezérőrnagyokat a sóhivatalból), akkor jól le lettünk szúrva, hogy de hát az architektúra szerint semmi SQL nem lehet a kódban, hol van az ElasticSearch, így nem veszik át.
Közben a projektmenedzseri divatlapokban olvasott menő három-négybetűs buzzwordökből összeollózott szent architektúrát szolgaian követő többi fejlesztőcsapat 2 év alatt 2 év késést hozott össze
"az adószámla egyenlegek tárolására + napi újraszámolására" - attól még, hogy valakik hülyék, szöveges keresésre igenis kiváló (sőt erre lett kitalálva) az ElasticSearch.
Az állami projekteket meg inkább nem kommentelném -
martonx
veterán
Lenne egy egyelőre csak elméleti kérdésem.
Ha jól tudom, valahogy összefüggésben van az indexelt mezők száma, illetve az adatbázisba való írás sebessége: minél több mező van indexelve, talán annál több idő a rekordok adatbázisba való írása. Ezt jól tudom?
Azt szeretném kideríteni, van-e olyan "váltópont", ahonnan már annyira belassulna az adatbázisba való írás, hogy nem érné meg az indexelés használata.
A kérdés háttere:
5 percenkénti kb. 100-400 új rekorddal számolva (még ezt nem tudom, mennyi lehet valósan, de itt körül, szóval legyen ennyi a példa kedvéért) megéri-e full text search-re átállnom a gyorsabb keresés kedvéért?
Ehhez ugye be kell állítanom full text indexet azokra a mezőkre, amiben keresni akarok. Pl.:
ALTER TABLE feed ADD FULLTEXT(title)
ALTER TABLE feed ADD FULLTEXT(description)Viszont mivel elég sok rekord kerül a táblába folyamatosan, azt szeretném kideríteni, hogy emiatt (és a többi) indexelés miatt lehet-e gond később (bármikor, akármikor) a teljesítménnyel, esetleg belassulhat-e annyira az adatbázisba való írás, hogy az 5 percenkénti cron job "túl sűrű" lesz, mert ennyi idő alatt nem végez az új rekordok tárolásával?
Lehet, hogy teljesen alaptalan a "félelmem", de ez a kérdés bennem van már egy ideje, de még csak most jutottam a keresés rendbe tételéhez.
Jelenleg jobb híján a LIKE %%-os keresést használom, kb. 1 mp a lekérdezési ideje egy 300e-res táblánál, szóval nem vészes, úgyhogy az sem tragédia, ha ez marad egy ideig. Plusz a full text search-keresés amúgy sem olyan egyszerű, mint jó lenne.
Szerintem megválaszoltad magadnak. A hídon majd ráérsz akkor átmenni, amikor odaértél.
Egyébként is van sok lehetőséged, én a helyedben, amikor a mostani megoldás elkezd kevés lenni (ha lesz ilyen), akkor első körben megpróbálnám a felvázolt full text search-öt SQL oldalon megvalósítani.
De ennél is jobb tud lenni, ha beüzemelsz egy ElasticSearch szervert az SQL-ed fölé, és ez szolgálja ki a szöveges kereséseket. Bár ez elég overkill. -
martonx
veterán
Sziasztok!
A MsAccess fórum elég kihaltnak tűnik, ezért itt tenném fel a kérdésem:
Van egy gyermektábor, amiben 3 tábla adja az adatbázist.
Az első tábla, a gyerekek neve, szülők kapcsolattartó elérhetősége, extra adatai vannak.
A második tábla, a gyerekek egyedi táboros igényeit taglalja (vega, hány napot van, melyik foglalkozás érdekli, stb).
A 3. táblába szeretném a gyerekek információs táblájából kinyerni CSAK a nevüket, és mellé a második tábla opciós mátrixát dinamikusan hozzáilleszteni. (táborba érkezés regisztrációkor név: mit kér enni, mire jött, stb)
A problémám az, hogy míg az adatok lookup table szerű dinamikus változói szépen létrejönnek, addig a gyerekeket egyesével kell a rekordok közé felvenni, és rohadt fárasztó 100 gyereknél. Van rá valami mód, hogy a recordokat autofill módon feltöltse az első táblából?
Később jöhet még 1-1 gyerek, azokat már manuálisan hozzáadnám a 3. táblához, de a tömeget nem szeretném egyesével.
Ha ez túl Microsoft-os téma (szintaktika acces szinten), akkor kérlek ne haragudjatok, viszont ha szemantikailag (lehetetlen teljes adattáblákból oszlopok "copy"-ja másik táblában adatbáziskezelő programokban) vagyok lemaradva, kérlek világosítsatok fel, miként oldanátok meg a problémám.
A válaszokat előre is köszi.Szvsz egy access makró programozás probléma, aminek a nyelve a VBA, nem pedig SQL probléma. Vagy pedig még a kérdés felvetést sem sikerült megértenem.
Ezer éve volt, hogy access-t VBA-val programoztam, egy porickám se kívánja feleleveníteni. -
martonx
veterán
Adott ugyanaz a témakör, ami korábban is.
A kérdésem a következő lenne:Adott példának okáért ez a lekérdezés: DB Fiddle
Itt ami fontos lenne nekem, hogy ha egy kategóriára azt mondom, hogy nem érdekel (
category_id not in (27)), akkor azokat az elemeket ne jelenítse meg, amikhez ez a kategória hozzá van rendelve. (Pl. ha azt mondom, allergiás vagyok a mogyoróra, akkor ne mutasson olyan recepteket, amiben mogyoró van)Ezzel az adott lekérdezéssel viszont nem így működik.
Direkt úgy módosítottam a példát, hogy könnyen látni lehessen:INSERT INTO `items_categories` (`id`, `item_id`, `category_id`) VALUES(349, 117, 27),(350, 117, 26),(351, 117, 29)Tehát 117-es elem benne van a 27-es, 26-os és a 29-es kategóriában.
Ha én azt kérem, hogy azokat az elemeket ne jelenítse meg, amik a 27-es kategóriába tartoznak (
category_id not in (27)), azt várnám, hogy a 117-es elemet nem jeleníti meg egyáltalán.Viszont ebben a formájában ez nem így működik, mert ezzel csak azt érem el, hogy eredménybe visszaadja a 117-est is, mert a 3 rekordból kizárja azt az egyet, ami a 27-es kategóriás, viszont a maradék kettő miatt a találati listában marad.
Hogyan lehet megoldani ezt?
Köszönöm.
Szerintem hibás a feltétel vizsgálatod.
Tippre ez adja az elvárt adatokat:WHERE
item_id not IN (select item_id from items_categories where
category_id in (27))ah, és rögtön válaszoltam, nem görgettem le, látom nyunyu is ugyanerre jutott

-
martonx
veterán
-
martonx
veterán
Ultimate megoldásom, hogy kidobod a vicc MySql-t (ha mariadb-nek is hívják) és átállsz valami normálisra. Értem ezalatt az Mssql-t, Oracle-t, PostgreSQL-t.
-
martonx
veterán
Értem a logikát mögötte, és amúgy tök jó ötlet, köszönöm a tippet - de sajnos kb. 0,2 mp-cel lassabb, mint az előző.
Csak kíváncsiságként:
Itt az ORDER BY 2 ugye a második mezőt jelenti, ami jelen példában a MAX(item_date)? Ha sok mezőm lenne a SELECT-ben, és nem akarnám számolgatni, ide írhatnám azt is az ORDER BY 2 helyére, hogy ORDER BY MAX(item_date)? (Most így lefut a lekérdezés, az eredmény ugyanaz, csak nem tudom, az ORDER BY-os résznél is műveletnek veszi-e a MAX-ot, vagy már a fenti SELECT-ben elvégzettre hivatkozik?)Igen, és ekvivalens a kettő szintaktika.
-
martonx
veterán
Sajnos semmin nem változtatott, ~300e rekordnál a lekérdezésed ~13 mp alatt dob csak eredményt.
Viszont a Profiling szerint a legtöbb időt a "Copying To Tmp Table On Disk" viszi el.
És amit korábban linkeltem magyarázat szerint rendesen indexelt tábláknál ez a lépés nem is kellene, hogy ott legyen:
"But generally speaking, the indexed sort would probably be chosen, if for no other reason, because it does not need to accumulate the entire result set in temporary storage before sorting and thus uses much less temporary storage."Szóval ebből gondolom, hogy talán az indexeléssel lehet baja. Csak azt nem találom, mi. Egy (a lekérdezésnél használatlan) mezőn kívül mind indexelve van. A rajzolást már elkezdtem, hátha a végére jutok valahol.
És ha a * helyett, csak 1-2 mezőt kérdezel le? Akkor is lassú?
-
martonx
veterán
-
martonx
veterán
Köszönöm, hogy ránéztél.
Nem Select *-ot fogok használni, viszont itt nincs annyi mező, hogy a query-t bonyolítsam vele, így az olvashatóság kedvéért ehhez a példához elégnek találtam.
A Group By-nak tényleg nem jártam alaposabban utána még - főleg azért nem, mert ahogy írtad is az okát, működött, így nem gondoltam, hogy baj van vele. Mindenképp alaposan utána járok most már, már amikor tegnap a hibát láttam, akkor felírtam a teendők közé.
Megfogadom a tábla- és mezőneves tanácsodat.
Nem item a tábla neve ("rendes" neve van), de a fenti (egyszerűsítő) törekvés miatt ebbe a példába elégnek találtam.
Sajnos igen, ez a db fiddle-teszt nem elég arra, hogy itt és ennyi adattal kiütközzön a hiba úgy, mint sok adattal nálam.
De köszönöm szépen az ötletet is, és hogy ránéztél.
Még annyi, hogy ha nézted, a where-ből az egyik feltételt átemeltem a join-ba, ami elvileg nem kellene, hogy számítson, de na, láttunk már fűben nyulat...
-
martonx
veterán
Sikerült feltöltenem, bár nem túl sok adattal: db-fiddle
(Fel akartam tölteni ~300e rekorddal, de nem hagyta, így nem akartam az időt húzni, hogy megtaláljam, hol a határ.)Eredetileg ezt a lekérdezést írtam bele (Group By-jal és Distinct nélkül):
SELECT *FROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Viszont erre ezt a hibát dobta:
Query Error: Error: ER_WRONG_FIELD_WITH_GROUP: Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.ic.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_byÉszrevételeim:
1. Select *-ot el kellene felejteni, és ki kellene írni azokat mezőket amiket ki szeretnél listázni.
2. Group By-nál szépen leírja, hogy mi a baja: bele kell venni a többi listázandó mezőt is (érdemes utána járnod, hogy mi is az a group by, mysql, mariadb specialitás, hogy a példádban szereplő szintaktikailag helytelen group by egyáltalán futni tud bizonyos helyezetekben).
3. Önszopatás a táblák mezőit a táblanévvel kezdődően elnevezni. Ha van egy táblád, aminek categories a neve, akkor annak id, és name mezői legyenek, ne pedig category_id, category_name.
4. Nekem ez 4 ms alatt lefut, bár nyilván több szemszögből sem lehet összehasonlítani a te adataiddal (eltérő adat mennyiség, és MySql vs MariaDB, localhostos erős géped, vs. valami ingyenes osztott hosting a dbfiddle alatt).
SELECT DISTINCT *
FROM items AS i
JOIN items_categories AS ic
ON i.item_id = ic.item_id
JOIN categories AS c
ON c.category_id = ic.category_id
AND c.category_id NOT IN (1,3,13,7,20)
WHERE i.item_id NOT IN (117,132,145,209,211)
ORDER BY i.item_date DESC5. Az Item nevű tábláktól idegrángást kapok. Légyszi nevezzük már el normálisan a táblákat. Jó, hogy nem fiszfasz, meg izé nevű tábláid vannak fiszfasz_izé nevű kapcsolótáblákkal. Aztán amikor 2 év múlva ránézel, te se fogod érteni, hogy mit is akartál az egyes táblákkal leképezni.
-
martonx
veterán
-
martonx
veterán
-
martonx
veterán
Korábban írta, hogy MariaDBt használ, azt meg nem támogatja az SQLFiddle.
Múltkor próbáltam felrakni a gépemre a MariaDBt, de már az is gondot okozott, hogy találjak Win7 x64-en elinduló verziót, asszem a 10.3.30-ig kellett visszamennem.
Utána meg szívtam a mellécsomagolt HeidiSQL IDEvel *, aminek a működése eléggé az agyamra ment, meg az Oracle hibaüzeneteinél is semmitmondóbb hibaüzenetektől ** is a falra másztam, amikor valami szintaktikai hiba volt, vagy éppen Oracle kompatibilis módban lévő MariaDBnek nem tetszett a kód.
Kb. fél nap google után inkább feladtam, hogy az Oracle alatt hibátlanul működő példámat átírjam MariaDBre.*: Rég dolgoztam ennyire használhatatlan IDEvel, szerintem még az SQL Server 2000-ét is alulmúlja. (2005-től jött helyette a Visual Studio stílusú SQL Server Management Studio)
**: pl. a lemaradt egy vessző hibaüzenet végére odamásol sortörések nélkül 5 sor kódot, amiből minden látszik, kivéve az, hogy melyik sor végéről maradt le.

Ennyire hülye még az Oracle SQL Developer se szokott lenni, pedig az sem a szívem csücske.Szvsz az majdnem MySql :)
-
martonx
veterán
A category_id-ra szükségem van, nem szedhetem ki. (De amúgy a teszt kedvéért kivettem, és semmi sem változott, se a sebesség, se a distinct nem hozta a kívánt eredményt.)
Annyit találtam, hogy ha használom a GROUP BY-t is, akkor a megfelelő eredményeket kapom, és valamelyest gyorsul a lekérdezés is. (És DISTINCT-tel vagy anélkül is ugyanazt a (jó) eredményt adja, szóval így a DISTINCT talán nem is kell.)
select p.*from product pjoin product_category pc1on pc1.product_id = p.idjoin category c1on c1.id = pc1.category_idwhere c1.name in ('sárga', 'piros', 'kék')group by p.idorder by p.date desc;Így a korábbi ~20 mp helyett már megvan ~9 mp alatt.
És az explain-je is sokkal jobban néz ki:

De a 9 mp még mindig szörnyű.
Merre tovább?
Vagy ez nem is a jó út?
Az adatbázis szerkezete a hibás?
Vagy a lekérdezés?Jelenleg nyitott vagyok a teljes adatbázisszerkezet átalakítására is. Egyszer már megcsináltam a javaslatotokra, megcsinálom megint, ha kell. Csak működjön végre.
Mindenesetre keresgélek még, hátha találok ilyen hasznos dolgot, mint a group by. Bár néztem már annyi mindent, millió stackoverflow-bejegyzést...
Nem tennél fel ide DB sémát, és adatokat? DB Fiddle - SQL Database Playground (db-fiddle.com)
Mert így leginkább csak magaddal tudsz társalogni. -
martonx
veterán
Sajnos kb. pont ugyanez a kód (illetve a saját kiegészítéseddel ugyanez), amit írtál (és ami sztanozs tanácsára ki lett egészítve DISTINCT-tel), ez fut le eszméletlen lassan.
Bemásolom, hogy ne kelljen visszakeresni, és kiegészítem a DISTINCT-tel:
select distinct p.*from product pjoin product_category pc1on pc1.product_id = p.idjoin category c1on c1.id = pc1.category_idwhere c1.name in ('sárga', 'piros', 'kék')order by p.date desc;Ha benne van együtt a DISTINCT és az ORDER BY is, akkor ~20 mp, ha csak az egyik, akkor 0,05 mp a futási idő.
Plusz a DISTINCT nem is működik (úgy, ahogy elvárnánk), mert ha a product_category táblában egy id-hoz több category_id is van (és van, mert ezért lett ez a tábla létrehozva), akkor annyiszor listázza a product-ból az id-t. (Pedig pont ezért lenne használva, hogy egy id-t csak egyszer listázzon.)
A profiling opciót bekapcsolva ezt látom, ami "fura":
- Copying To Tmp Table On Disk: 18.9 s
- Sorting Result: 1 s
Tehát csak ez a 2 lépés 19.9 másodpercbe kerül, ha van DISTINCT és ORDER BY is.Ha csak az ORDER BY van, akkor:
- nincs Copying To Tmp Table On Disk lépés
- Sorting Result: 6 µsHa csak a DISTINCT van, akkor:
- Copying To Tmp Table: 2.8 ms
- nincs Sorting Result lépésAhogy utána olvastam, azt írják, hogy a DISTINCT és az ORDER BY is sorba rendez, és nem szeretik egymást. Azt is írják, hogy ha az egyiket használom, akkor a másikat valószínűleg nem kell. De hát ez itt nem igaz, mert a DISTINCT azért kell, hogy 1 id csak egyszer jelenjen meg (ami amúgy most sajnos nem igaz, ahogy feljebb írtam is), az ORDER BY meg azért, mert időrendi sorrendben van szükségem a találatokra.
Nagyon nem tudom, merre tovább. Követtem a tanácsaitokat, megcsináltam és átírtam mindent, ahogy javasoltátok, (amit köszönök ez úton is), de sajnos valami még nem kerek, és magamtól nem találok megoldást rá.
Higgyétek el, ég az arcom, hogy ennyiszer kell írnom, és segítségért kuncsorognom - nem jókedvemből teszem. Felajánlottam, hogy fizetek is a szaktanácsadásért és a segítségért, csak végre haladhassak, mert már 1 hónapja egy helyben veszteglek - de sehonnan nem kapok segítséget, sehol egy szakember.
Lehet, hogy nagyon kellene egy index a p.Date-re...
-
martonx
veterán
Sziasztok!
Van egy pivotolt lekérdezésem ami érdekes módon rossz, hiányos eredményt ad, az összegek sem "nagyösszesenben" sem az egyes részösszegekben nem stimmelnek. A kereszttábla fejei teljeskörűek, minden lehetséges értéket megadtam a
FOR-nál:SELECT * FROM
(
(
SELECT
VALTOZO1,
VALTOZO2,
OSSZEG
FROM
TABLA_A
)
UNION
(
SELECT
VALTOZO1,
VALTOZO2,
OSSZEG
FROM
TABLA_B
)
)
PIVOT
(
SUM(OSSZEG)
FOR VALTOZO1 IN ('V_X','V_Y','V_Z','V_Q','V_W')
) PV1Ha ugyanezt lekérem
SELECT * FROM
(
(
SELECT
VALTOZO1,
VALTOZO2,
OSSZEG
FROM
TABLA_A
)
UNION
(
SELECT
VALTOZO1,
VALTOZO2,
OSSZEG
FROM
TABLA_B
)
)kóddal és magam összesítem, az eredmény helyes, pivottal nem.
Mi lehet a hiba, hol kezdenétek keresni?
Csakis itt lehet a hiba:
FOR VALTOZO1 IN ('V_X','V_Y','V_Z','V_Q','V_W')
De ezt nyilván te is tudod
Konkrét példa adatok nélkül elég nehéz megmondani, hogy mi megy félre, pl. nem jó pivot oszlop nevek. -
martonx
veterán
Megcsináltam mindent, amit javasoltatok, pont úgy, ahogy javasoltátok. Készen és beállítva az új táblák, rendben a kapcsolatok az indexek, és a rekordszám is feltornázva 500e fölé (a kategória-elem kapcsolatok száma 800e körül).
És így a javasolt a JOIN-os lekérdezés ideje: 25 másodperc...
A régi, pazarló LIKE-os lekérdezés ideje: 0.3 másodperc (egy picit javítva a LIKE-os módon már csak 0.01 másodperc)...Nem értem.
Csak "érdekességként" írtam ide (bár nekem bosszúság), már találtam valakit, aki remote-ban tud segíteni - bár ő is pont ugyanezt a JOIN-os módszert mondta, miután átnézne a tábláimat.
25 másodperc...
Ott valami nagyon-nagyon félrement... -
martonx
veterán
(Mivel egyelőre még nem tudom kipróbálni a megoldást, így csak agyban tudok a témán "dolgozni", és az jutott eszembe, hogy) mi lenne, ha a ~30 kategóriának csinálnék egyszerűen mezőket a jelenlegi táblában? Lenne category1, category2 stb. nevű mező, értékként 0, ha a rekordhoz nem tartozik, 1, ha igen.
Így nem kellene LIKE-ot sem használni már, az eredeti lekérdezésSELECT * FROM tableWHERE channel_idIN ('id1','id2','id3','id4')AND(category LIKE '%category1%'OR category LIKE '%category2%'OR category LIKE '%category3%'OR category LIKE '%category4%'OR category LIKE '%category5%'OR category LIKE '%category6%')AND(category NOT LIKE '%category7%'AND category NOT LIKE '%category8%'AND category NOT LIKE '%category9%')ORDER BY date DESC LIMIT 4nézhetne ki így is:
SELECT * FROM tableWHERE channel_idIN ('id1','id2','id3','id4')AND(category7 = 0AND category8 = 0AND category9 = 0)ORDER BY date DESC LIMIT 4(Mert most látom csak, hogy feleslegesen szűrtem arra is, hogy milyen kategóriákat listázzon, ha egyszer már ott van az is, hogy miket NE, és csak 2 állása van (vagy benne van, vagy nincs)).
Ez lenne olyan hatékony, mint a 3 táblás JOIN-olás? Vagy még hatékonyabb, esetleg kevésbé?
(Most kíváncsi lennék, az EXPLAIN erre mit mondana.)Felejtsd el
-
martonx
veterán
Most (utazás után, de még pár hétig nem otthon) volt egy kis időm jobban átolvasni és értelmezni, amit a 3 tábláról írtál. Teljesen jól érthető, köszönöm. Pár részlet még nem világos benne, de azoknak utánajárok.
Illetve 1 dolgot mégis kérdeznék a kódoddal kapcsolatban:
where c.name like '%akármi%'
Ha úgy csinálom, ahogy mondod, és ha 1 terméknek 3 kategória, és így 3 külön rekord a product_category-ban, akkor itt nem kellene már LIKE-ot használnom sem, hiszen rekordonként csak 1 kategória lenne. Szóval ez akkor lehetne inkább:where c.name = 'akármi', nem?
(Több kategóriára szűrésnél meg valami ilyemi:where c.name = 'akármi'or c.name = 'akármi1'or c.name = 'akármi2'
Javítsatok ki, ha tévedek, kérlek.)És ha jól értem, ugye azt írod, hogy csináljak egy product_category táblát, amibe úgy kerülnének bele a rekordok, hogy ha a fő táblámban (product) mondjuk van 2 millió rekord, és mindegyikhez tartozik 2-4 (átlagban 3) kategória (category). Akkor e szerint a product_category táblában jelen állás szerint 6 millió rekord lenne.
Ez tényleg gyorsabb, mint a 2 milliós? Bár gondolom, erre is írta tm5 a redundanciát (ha nem, kérlek írd meg, mire).
Meg hát ugye azt is írtátok, hogy LIKE-nál az egész adatbázist átnézi, nem számít az indexelés és semmi, szóval az mindenképp lassú.Na ezt nem kis idő lesz így átírnom. Mielőtt nekikezdek: ezt az utat javasoljátok akkor?
- Külön tábla a kategóriáknak.
- Külön tábla a termékek és kategóriák kapcsolatának.
- Lekérdezés előtt (már ahol aktív a kategóriára való szűrés) JOIN.Köszönöm.
"És ha jól értem, ugye azt írod, hogy csináljak egy product_category táblát, amibe úgy kerülnének bele a rekordok, hogy ha a fő táblámban (product) mondjuk van 2 millió rekord, és mindegyikhez tartozik 2-4 (átlagban 3) kategória (category). Akkor e szerint a product_category táblában jelen állás szerint 6 millió rekord lenne."
Ez azért tud gyors lenni, mert ezek mind Foreign Key-ek, azaz indexeltek. Itt tenném még hozzá, hogy sokkal tisztább érzés lenne Kategória ID-re szűrni Name helyett.
-
martonx
veterán
És meg is van az eredmény... 2 millióig tudtam felvinni a duplikálást. Most pedig az apache logban ezeket találom:
Nincs elegendő memória-erőforrás a parancs feldolgozásához.
Érvénytelen cím hozzáférésére tett kísérlet.
Fatal error: Out of memory (allocated 467664896) (tried to allocate 16384 bytes)És nem is tölt be semmit az adatbázisból.
Jelenleg ez csak egy desktop server, csak tesztelni.
De előfordulhat ilyen hiba a szolgáltatónál is?
Az én kódomban van a hiba?Amúgy nem egy nagy lekérdezés volt, csupán ennyi:
SELECT * FROM table ORDER BY date DESC LIMIT 4És erre dobta a fenti hibákat.
Nekem kell javítani/változtatni valamit, vagy ez a DesktopServer korlátjai miatt van, és a normál szerveren (szolgáltató) ezzel nem lesz gond?
Köszi.
Upd.: 1 milliónál is ugyanez a baja. De 500ezernél már lassan, de végzi a dolgát.
A szolgáltatón múlik, simán lehet, hogy a desktop géped által kibírt 2 milliónak a töredékét se fogja elbírni.
De lehet, hogy a többszörösét
Minden csak pénz kérdése... -
martonx
veterán
Egyébként meg lehet, hogy a tákolt eljárás ezredmásodpercekre kireszelése helyett inkább a folyamatot kéne átnyálazni, hogy az mennyire optimális, azzal valószínűleg SOKKAL többet nyernél.
Egy korábbi combos adatmigrációs projekten anyáztak velem állandóan a nagy adatmennyiségen lefutó sok adatellenőrző szkript "lassúsága" miatt.
(Én reszelgettem a szkripteket azon a projekten)Aztán következő projekten újrahasznosítottuk az egész adatellenőrző keretrendszert, csak annak a gazdája már nem volt a csapatunk része, így elmélyedhettem a kolléga kódjában, és tele volt kurzorokkal, meg dinamikusan összerakott SQL hívásokkal
Egészben az volt a legszebb, hogy az összes rekordra egyesével hívta meg az ellenőrző szkripteket.Azt meg tudni kell, hogy Oracle alatt egy exec 'select 1 from dual;' akkor is másfél másodpercig tart, ha fejreállsz közben...
Végeredmény az lett, hogy az egyesével futtatott szkripteket összefűztem egy clobba, aztán az lett dinamikusan futtatva.
Plusz kivettem a kurzort az egész elől, mert az ellenőrző szkriptek eleve úgy voltak megírva, hogy egész táblára futottak, így egy százezres táblán elég volt őket egyszer meghívni, nem kellett rekordonként külön-külön...Eredmény? 20 perc helyett lefutott az egész 15 másodperc alatt.
Tanulság?
Ne engedj Java/C/C# programozót SQLt "kódolni", mert az teljesen más műfaj.
(Pláne, ha natív SQL helyett Hibernate-tel vagy LinQ-el súlyosbítja)Kiváncsi lettem volna, hogy a keretrendszer 2.0-át visszaportolva a légycsapó projektbe, mennyi ideig tartott volna a 3 betűs nagybank összes telefonvonalának adathelyesség ellenőrzése az eredeti 12 óra helyett
Én mint C# fejlesztő, aki mellette sokat SQL-ezett is régen, ezzel nem értek egyet.
Csak szimplán nem kell hülyének lenni, és el kell mélyedni az egyes nyelvekben.
Az SQL totálisan más logikai megközelítést igényel, mint egy normális programnyelv. De mindkettő megérthető, megtanulható.
Több olyan kollégáról is tudok, akiknél nagyon szépen megfér egymás mellett a két világ ismerete, harmonikus használata. -
martonx
veterán
Sziasztok!
Ismét egy PostgreSQL-es kérdés, ezúttal már függvényt írok, PL/PgSQL nyelven: A függvényemben több select-et is futtatok, de előtte "be akarom cache"-elni egy lekérdezés eredményét, hogy később már sokkal gyorsabb legyen a többi select (leszűkíteni a sorok számát nagyon jelentősen).
Tehát kvázi ideiglenes táblát szeretnék létrehozni, amit csak az adott függvényen belül használok. CTE-vel sajnos nem megy, mert egy CTE-t csak egy select tud felhasználni, én pedig konkrétan 9 select-et fogok használni.
Próbáltam TEMPORARY TABLE-lel, de az lassúnak tűnik. A ROWTPYE vagy RECORD típus tökéletes lenne, de sajnos csak egy sort tud tárolni, így az nem jó. Tábla típus pedig sajnos nincs.
Van esetleg valami tippetek hogyan lehetne ezt a leghatákonyabban megcsinálni? Itt most nagyon fotnos lenne a jó teljesítmény, hiszen rendkívül időkritikus a dolog.A temp tábla nem szabadna, hogy lassú legyen. Hacsak nem felejtkeztél el arról, hogy a temp táblára is ugyanúgy rá kell pakolni az indexeket.
-
martonx
veterán
Amúgy azért őket választottam, mert habár saját HTML (és CSS, JS, PHP, SQL) kódot írtam, nem tudom, hogyan "védhetném" meg az oldalamat a különböző féle (általános) támadások ellen. Ezért eleve abból indultam ki, hogy WordPress-re van millió kiegészítő, van pár (elvileg) nagyon jó, ami a biztonságért felel (pl. Wordfence), így némi kompromisszummal, de tudom a 2 világot (saját kódok szabadsága + WordPress biztonsága) kombinálni.
Régebben amikor WP-t tanultam, akkor ajánlották és használtam a Wordfence plugint, azokból a reportokból láttam, hogy mennyi mindent megfogott. Fogalmam sincs, hogyan kell/lehet egy weblapot/tárhelyet másképp megvédeni, és védeni pedig sajnos van mitől, nem a backup-ok visszaállításával szeretném az időmet majd tölteni.
Na de ez teljesen más téma (security), amihez még annyira sem értek, mint az SQL-hez (és az sem sok... ), szóval muszáj vagyok már kész megoldásokat és rendszereket használni, mert erre tényleg nincs már időm/energiám 0-ról megtanulni (mert elég nagy témakör, ha jól sejtem.)Nem is azt mondom, hogy magad hostolj bármit, hanem fisfos hosting cégek himihumi mysql-jei helyett, normál felhőben (Azure, AWS, Google) kellene bármit futtatnod. De ez már nagyon off topik itt.
-
martonx
veterán
300 és 500 karakter között
Akkor bőven jó lesz a Like is még nagyon sokáig (már ha a fisfos hosting vicc mysql szervere is úgy akarja).
De a fulltextsearch-öt ráérsz majd akkor bekapcsolni (vélhetően hosting váltással együtt), amikor elkezd köhögni az oldal. -
martonx
veterán
Úgy látom, a PHP-oldali résszel készen vagyok (nagy meglepetésemre).
Viszont a kereséshez (és szűréshez) kapcsolódó lekérdezések még mindig a "régi csúnyák":
Így néz ki jelenleg, ha keresést indítok 3 különböző szóra:
SELECT * FROM the_only_one_tableWHERE((title LIKE '%kereso_szo_1%'ANDtitle LIKE '%kereso_szo_2%'ANDtitle LIKE '%kereso_szo_3%')OR(description LIKE '%kereso_szo_1%'ANDdescription LIKE '%kereso_szo_2%'ANDdescription LIKE '%kereso_szo_3%'))ANDid NOT IN (672,467,439,395,325,143,10,156)ORDER BY date DESCLIMIT 4(az id NOT IN részt csak azért hagytam benne, hogy megmutassam, hogy megfogadtam a tanácsaitokat, és így valóban kulturáltabb az egész
)A kereséshez (és ugyanilyen elven (LIKE %%-kal) működik a szűrés is):
Az ajánlás alapján rákerestem a full text search-re. Ott elsőnek a CONTAINS-t találtam. De kézzel (phpMyAdmin-ban a konzolban) sem adott vissza találatot:WHERE CONTAINS ((title, description),'"kereso_szo_1" AND "kereso_szo_2" AND "kereso_szo_3"')Láttam keresési találatokat
MATCH-re,MATCH AGAINST-re, de a leírásuk sem győzött meg, hogy ezeket kellene használnom.Szóval martonx tanácsát megfogadva inkább rákérdezek, hogy hogyan lehetne megoldani a keresést/szűrést a a
LIKE %%használata nélkül?
Engem -tapasztalatlant- persze nem zavar, csak ugye írtátok, hogy rém pazarló. A LIKE-nál keresés miatt pedig muszáj vagyok a %%-ot használni, mert a szöveg bármelyik pontján lehetnek a keresett szavak.Köszi!
Full Text search-öt előbb a DB-ben be kell kapcsolni fel kell paraméterezni (az általad linkelt fisfos hosting cégeknél pláne erősen kérdéses, hogy be tudsz-e ilyet kapcsolni). Bevallom én még sose használtam, mert nem kellett. Igaziból, ha nem sok millió, egészen nagy méretű szövegben kell keresned, akkor szerintem a Like is simán megteszi.
Full text search helyett én pl. hehe a Google-t használom a weboldalaimon, amiket a Google egyébként is indexel
Programmable Search Engine | Google Developers
Így nem az én DB-mnek kell belegebednie az oldalon keresések kiszolgálásába, hanem a Gugliénak, ráadásul ingyen. -
martonx
veterán
Jelenleg egy lokál gépen futó DesktopServer nevű környeztet használok a fejlesztésre. Itt MariaDB van használatban.
Ha van valakinek egy szabad 5 perce, csak akkor olvasson tovább.
Ez egy "itthoni tanulós projekt", semmi több. Érdekelt a téma, így elkezdtem egy weblapot készíteni 6 hónappal ezelőtt. De ekkor kezdtem el csak az alap dolgokon felül használni mindent, ami kell hozzá: HTML, CSS, JS, PHP, SQL.
Nagyon szépen haladtam mindennel, 6 hónapja minden szabadidőmet beleöltem, és most már úgy láttam, 2 héten belül készen vagyok, és költözhetek a kis projektemmel a szolgáltatóhoz: Versanus, velük van pozitív tapasztalatom korábbról. Nem tudom, hogy ott milyen adatbáziskezelő van.
Na szóval örültem, hogy végre a kis projektemet a "nagyvilág elé tárhatom" (értsd: rokonok és kollégák
), és a todo-listám egyik utolsó eleme volt, hogy utánakérdezzek, hogy a lekérdezéseim nem pazarólak-e.És mint kiderült, sajnos rossz logika mentén építettem fel az egész adatbázist. És az a baj, hogy 6 hónapja amióta csinálom, erre a logikára épül minden de minden. Tegnap átnéztem a kódjaimat, nyilván az új típusú (1 db) táblát könnyen létrehoztam, a tartalomfeltöltő php kódot is könnyen átírtam az ajánlás alapján, hogy a több tábla helyett egybe írjon csak, külön oszlopba pedig, hogy melyik forrásból származó bejegyzéseket tárolja.
De aztán jöttek a JS-ek, plusz a lekérdezésért felelős PHP, és ott sajnos csak nagy nehézségek és időveszteséggel tudnám csak átírni az egy táblás módszerre, hogy szépen működjön. Sajnos nem erre a logikára építettem fel, így kvázi kezdhetném előröl, mert másképp csak a régi módszer kódjait tudom "megerőszakolni", és mivel arra építettem fel mindet, sosem lesz szép tiszta igazán, csak ha előröl kezdem.
És őszintén, ez most nagyon elvette a kedvem. Tökre örültem, hogy végre 6 hónap fáradozása a számomra tök ismeretlen területen végre manifesztálódik, erre kiderült, hogy nagyjából kezdhetem előröl.
Mielőtt tényleg így döntenék, kérlek, írjátok meg, tényleg akkora gond-e, ha külön táblákban vannak az adatok.
Források szerint készítettem el őket, 1 forrás - 1 tábla. Nagyon max 15-20 forrásból fogok dolgozni. Forrásonként naponta kb. 100 bejegyzéssel.
1 bejegyzéshez tartozik egy id, egy link, egy rövidebb és egy hosszabb szöveg (300 karakter max), illetve 2 kép linkje (csak link), plusz még 2 rövidebb tartalmú szöveg (50 karakter max). Ennyi.Most már én is látom, hogy sokkal jobb lett volna az 1 tábla, mert minden bejegyzés pontosan ugyan olyan felépítési, ugyanolyan oszlopok vannak minden táblában.
Viszont a kódjaim most tökéletesen működnek, millió ellenőrzést és vizsgálatot tettem beléjük, próbáltam minden eshetőségre felkészíteni. És sajnos a sok táblás megvalósítás egyáltalán nem kompatibilis az 1 táblással, tényleg át kellene írnom mindent, JS-től kezdve PHP-kig mindent, még HTML-eket is.
És ha nem szörnyen rossz, tarthatatlan, pocsék lassú a mostani felépítés (max 15-20 tábla, napi 100 bejegyzés / tábla, tehát 2000 bejegyzés / nap, 14e bejegyzés / hét, 728e bejegyzés / év), akkor nem kezdeném előröl.
Az nagyon visszavetne, már így is elszállt a kedvem.Bocs, hogy hosszan taglaltam ezt, de kérlek, írjátok meg, valóban elengedhetetlenül szükséges-e előröl kezdenem az új szerkezettel. A rokoni/kollegális elérésekhez biztosan nem.
De később, ha a fél ország ezt olvassa majd (best case scenario ), lehet valami hátulütője a több táblás felállásnak? Ha egyszerre 5 millióan nézik az oldalt, lapoznak, futnak a lekérdezések (LIMIT 4, szóval 1 lekérdezés csak max 4 találatot ad vissza mindig), milyen negatív következményei lehetnek, ha a több táblásnál maradok? Lelassul minden mindenkinek? Vagy a szolgáltató szól rám?Ezt összefoglalnátok nekem pár gondolatban, kérlek?
Eléggé elkeseredtem most, de persze ha ez a több táblás módszer a fenti számolásokat alapul véve is tarthatatlan, és később csak problémám lenne belőle (belassulna az oldal a felhasználóknak), akkor egyelőre hagyom az egészet, és majd ha megint találok rá ennyi időt egyszer, átírom.
De ha csak a tábla karbantartása miatt lenne jobb, ha egy lenne a több helyett, akkor az nem gond, mert mindent eleve a több táblásra készítettem el.Köszönöm, és elnézést az eszméletlen hosszú posztért, de 2 sorban ezt nem lehet (vagy csak én nem tudtam) rendesen elmagyarázni.
Ezt fogd fel tanulópénznek, és igen, mindenképp írd át normálisra a táblastruktúrát. Legalább ezzel is tanulsz.
Illetve máskor lehet nem árt kérdezni, mielőtt magadtól kitalálsz valami butaságot, és 6 hónapig rossz irányba mész (jó persze sokszor a kérdezéshez is már kell egy alap tudás...).Egyúttal szólok előre, hogy az ilyen vicc tárhelyeknél, majd még csak ezután fog kezdődni a kálváriád, amikor ki fog derülni, hogy MariaDB-t nem támogatnak
A helyedben egyből a felhőt céloznám meg (ok, ott meg nem évi 10K HUF lesz a hosting, bááár lehet, lusta vagyok utána nézni a DB áraknak). -
martonx
veterán
mondjuk az is relatív, hogy kinek mi a nagy adatbázis. a postgesql párszázmillió rekorddal még szépen elgurul
8 éve próbálkoztam az egyik mobilszolgáltató adattárházán dolgozni, aztán a DB műveletek query planjét logoló táblából (~napi 10 millió rekord?) kellett volna adatokat kinyernem egy adatvizualizációs projekthez.
Próbaképpen lekértem negyedórányi adatot, erre 10 perccel később jött a teradata üzemeltető leordítani a hajamat, hogy ilyet ne merjek még egyszer lekérdezni, mert letérdelt tőle a 24 node-os DWH, alig bírták kilőni a querymet.
Pedig előtte direkt megnéztem, milyen indexek vannak a táblán, meg mekkora a várható eredményhalmaz mérete, nehogy egyszerre túl sokat akarjak lekérdezni...
Előző munkahelyemen a legnagyobb táblában 6 milliárd sor volt, és naponta pár tíz millióval bővült. Ebben csak az volt a pláne, hogy tök sima MSSQL vitte a DB-t egy 32 magos 256Gigabyte memóriás szerveren AWS-ben.
Mondjuk nyilván még ez se volt semmi a telkok DB-ihez képest. -
martonx
veterán
-
martonx
veterán
-
martonx
veterán
Sziasztok!
Bár ritkán adom fel, de ez most kifogott rajtam és a Google se segített.
Alap: SQL Server
Minta:CREATE TABLE t1 AS (id int,name varchar,dependency int);INSERT INTO t1 VALUES (1,'n1',0);INSERT INTO t1 VALUES (2,'n2',1);INSERT INTO t1 VALUES (3,'n3',1);INSERT INTO t1 VALUES (4,'n4',2);INSERT INTO t1 VALUES (5,'n5',3);INSERT INTO t1 VALUES (6,'n6',3);SELECT DISTINCT ca.idFROM t1LEFT JOIN t1 AS t2 ON t2.ID = t1.dependencyLEFT JOIN t1 AS t3 ON t3.ID = t2.dependencyCROSS APPLY (SELECT t1.ID UNION ALLSELECT t2.ID UNION ALLSELECT t3.ID ) AS c (id);A nagy kérdés, hogy én komfortosabb vagyok a JOIN-okkal, mint az APPLY-okkal. Ezt bevallom értelmezni se tudom. Az megvan, hogy egy hierarchiát épít, de a CROSS APPLY esetén a (id) kicsit fura, mert melyik ID-val köti össze a CROSS APPLY-ban lévő ID-t? Vagy duplikálna? A kód szerzője ismeretlen
Valami ilyesmi lenne?
SELECT DISTINCT ca.idFROM t1LEFT JOIN t1 AS t2 ON t2.ID = t1.dependencyLEFT JOIN t1 AS t3 ON t3.ID = t2.dependencyLEFT JOIN (SELECT t1.ID UNION ALLSELECT t2.ID UNION ALLSELECT t3.ID ) AS c ON t1.ID = c.ID OR t2.ID = c.ID OR t3.ID;A Cross Apply-t nem tudod Joinra fordítani, talán leginkább a FULL OUTER JOIN hasonlít hozzá. Ebben az esetben duplikálni fog.
-
martonx
veterán
Még annyit érdemes tudni a többiek által leírtakon túl, hogy van egy TRUNCATE TABLE parancs, ami ugyanúgy kitöröl mindent egy táblából mint a DELETE parancs, csak DDL utasításként viselkedik, tehát azonnal végrehajtódik és nem is lehet rollback-elni. A DELETE-et a tranzakción belül még igen. Cserébe villámgyors. A DELETE az sok rekordra nagyon lassú tud lenni.
Illetve a truncate alapállapotba hozza a táblához tartozó indexeket, incrementeket is. Delete meg tényleg csak az adatot törli.
-
martonx
veterán
Opre szerver + 2 klienses és szolgáltatásos beadandó ami páros munka lett volna egyedül toltam le mert beleszart a társam, tanárt nem láttam a félévben mindent demonstrátor tart van olyan tárgyunk (digitális rendszerek, ALU és alap tervezési feladatok) 2x tartottak konzit amúgy egy fél hiányos fél katyvasz pdf halmazból OMB módszerrel tanulj.
Nem véletlen kértem segítséget és hagytam a végére dolgot nem épp lustaságból. Szeptember 1 óta ~200 km-ert mentem motorral, mikor ügyintézni kellett beszaladnom a TO-ra vagy a városba, egy út oda és vissza ~40km.
Nem jött be...!
Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
Ez esetben mea cupla, és gratula a szorgalmadhoz!
-
martonx
veterán
-
martonx
veterán
Mitől függ, hogy miképp hivatkozok egy subquerryre?
Kicsit kavarodás van fejben mert két esetet nem igazán ismerek fel a típus feladatokban:
Mikor mint tábla kezeljük a subquerryt és INNER vagy NATURAl JOIN-al fűzzük hozzá a lekérdezéshez és mikor elnevezzük a keresett értékeket pl dolgozok és a subquerry megy a FROM mögé mint dolgozok d, (subquerry) kereset majd WHERE segítségével helyezzük kontextusba az értékeket.
(próbáltam formázni de a PPT-ben is istentelenül tördelve és szóközölve volt... )Egyik: részlegenként listázva a minimális béreket
SELECT e.department_id, last_name, legkisebbFROM employees e, (SELECT department_id, MIN(salary) legkisebbFROM employees GROUP BY department_id) minWHERE e.salary=min.legkisebb AND e.department_id=min.department_id;A másik meg:
Listázzuk azon dolgozók vezetéknevét, fizetését és részlegük nevét, akik többet keresnek, mint amennyi a részlegük átlagfizetése.
SELECT last_name, salary, department_nameFROM employees INNER JOIN departments USING (department_id) NATURAL JOIN(SELECT department_id, ROUND(AVG(salary)) részlegátlag FROM employeesGROUP BY department_id) WHERE salary > részlegátlag;edit.: Ennél azt használom ki, hogy minden adatom megvan az eredeti táblában és a keresés által visszakapott "adat halmazban" is ezáltal mint táblát tudom kapcsolni és soronként kezeli az adatokat? Ilyen elven az első is mehetne így nem?
Nem tudom mennyire érthető a gondom.
De előre is nagyon köszi, hatalmas segítség lenne ha letisztulna melyik kapcsolatot honnan ismerem fel szöveg alapján!Használj légyszi dbfiddle-t, azon keresztül minden sokkal jobban látszik, és rögtön futtatni, próbálgatni is lehet.
A problémádat nem értem, hogy mit nem értesz. Mi a kérdésed? Vagy csak panaszkodsz? -
martonx
veterán
Hello! Nagyon ovi és dedo kérdés de egyszerűen nem akaródzik működni (Centos OS + Oracle 12c virtuális gépen, gyakran produkál érdekeseket), de
SELECT allapot AS "Állapot", ROUND(AVG(ar),2) AS "Átlag ár"FROM motorok GROUP BY allapot HAVING ar < 5000000;Nem az az ökölszabály, hogy a csoportostás alanyát kell SELECT után és azon kívül COUNT, Min, Max etc mehet? Akkor mégis miért kapok:
Köszi előre is!
Itt is motorok? :D
Tippre havinghez ugyanaz a round avg... kell, mint a selectbe -
martonx
veterán
Bármely programnyelvbe beletartoznak a deklaratív nyelvek is, ahova az SQL is tartozik.
Deklaratív programozási paradigmánál az elemi adatokat/tényeket és a köztük lévő kapcsolatokat definiálod, majd ezek elemeire kérdezel rá ("szűrsz"), gép meg majd valahogyan megoldja.
Programozási nyelvek másik, nagyobb csoportja az imperatív nyelvek csoportja, ahol az egymás után következő elemi utasításokat/lépéseket rágod a gép szájába.Programozó részéről ezek két különböző megközelítést, gondolkozásmódot igényelnek.
(Ezért nem értem, mi a francnak erőltetik pl. a lambda-függvényeket a modern imperatív programnyelvekben. Hacsak nem az a cél, hogy elméleti matematikusok svájci bicskaként tudják használni a Java 8-at?)Bocs, pontatlan voltam. Az SQL-t nem számítom a programnyelvek közé. De igazad van végülis ez is programnyelv, csak épp nem imperatív. Ugyanígy nem tekintem programnyelvnek a CSS-t sem
Legalábbis a magam pongyola megfogalmazásában.A Java lambdát ne keverd ide, az csak egy syntetic sugar, nem attól lesz deklaratív nyelv a Java. De kezdünk nagyon eltérni az eredeti problémától
-
martonx
veterán
Meg lehet csinálni SQLben is, csak kell hozzá egy tárolt eljárás, amiben :
- csinálsz egy kurzort a negatív raktárkészletekből csökkenő sorrendben (hova = id, mennyi = -val)
- CTASsal lemásolod az eredeti raktár táblát egy újba (hogy ne az eredetit updatelgesd)
- végigiterálsz a kurzoron
-- kiveszed az aktuális maximum értéket, és az id-ját a raktár_másolatból, és ha az nagyobb, mint a az aktuálisan kezelendő hiány, akkor
--- update raktár_másolat set val=val-mennyi where id=honnan;
--- update raktár_másolat set val=val+mennyi where id=hova;
--- insert into mozgások values (honnan, hova, mennyi);Végén megvan a raktár_másolatban a művelet utáni új raktárkészlet, mozgásokban meg a teendők listája.
Ettől még fenntartom azt, hogy Javaban egyszerűbb lenne lekódolni+gyorsabban is futna.
De pár bolt esetén nem biztos, hogy olyan nagy lenne SQLben sem a futási idő."Ettől még fenntartom azt, hogy Javaban egyszerűbb lenne lekódolni+gyorsabban is futna."
Mármint bármilyen programnyelven (javascript, php, c#, python, java, stb...) és nem csak egyszerűbb lenne lekódolni, és nem csak gyorsabban is futna, de könnyedén debuggolható, logolható, verzió kezelhető is lenne.
Noha mindezt SQL-el is meg lehet oldani, de elképesztően nyögve nyelősen. -
martonx
veterán
Én is valami hasonlóra jutottam, mint nyunyu, hogy ehhez minimum egy tárolt eljárás szükséges, ezt 1 sql paranccsal nagyon nem lenne egyszerű megoldani.
Valami olyasmit csinálnék, hogy generálnék 2 listát (plusz(i): pozitívok csökkenő sorrendben, minusz(j): negatívok növekvő sorrendben) és mennék végig a minusz listán úgy, hogy a plusz-os lista aktuális elemével megpróbálnám kiegyenlíteni a negatív értéket. ha nem tudom, akkor nézem a következőt a minuszból. Addig megy a ciklus, amíg a végére nem érsz valamelyik listának. + eköré még kellene még egy loop ami az elején újraszámolja a plusz, minusz listákat és addig megy amíg vannak update-ek. Valami ilyesmi lenne...És szerintem ezzel el is értünk oda, amikor a feladatot már tipikusan nem SQL-ben kellene megoldani, és a végén egy manuális jóváhagyás sem ártana, azaz mindez csak javaslat lenne a humán kezelőnek.
-
martonx
veterán
Sziasztok!
MSSQL környezetben a következő problémára keresem a választ:
adott egy tábla ahol az id mellett van egy érték oszlop is. Az érték lehet pozitív és negatív szám is. Ahol az érték negatív oda kellene át tenni onnan ahol ez pozitív. Az eredménynek az kellene, hogy honnan hova tegyünk át és mennyit, hogy a negatív eltűnjön.
Megvalósítható ez és hogyan szerintetek?
Konkrétabban nem lehetne? dbfiddle példa esetleg?
-
martonx
veterán
A belső selected jó (leválogattad a kérdéses ID-jű sorokat), de ehhez újra hozzá kell joinolnod az items táblát, hogy vizsgálni tudd a type és status-t.
Ilyenkor mennyire elegáns lenne db fiddle példa...














 )
)







 fejek jönnek elő belőlem (meg rengeteg kérdés).
fejek jönnek elő belőlem (meg rengeteg kérdés). )
)
![;]](http://cdn.rios.hu/dl/s/v1.gif)




 Bár hidd el, nem szánt szándékkal teszem.
Bár hidd el, nem szánt szándékkal teszem. 

















Új hozzászólás Aktív témák
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
- Nvidia Quadro FX570
- Apple MacBook Pro 14 M4 2024 24GB/512GB SSD újszerű állapotú 100% akku 40 ciklus
- Thrustmaster TMX Force Feedback Kormány szett 3 hónap Garancia Beszámítás Házhozszállítás
- HIBÁTLAN iPhone 12 Pro 256GB Gold -2 ÉV GARANCIA - Kártyafüggetlen, MS5550, 100% AKKSI
- Dobozos ÚJ! HP ZBOOK Firefly 16 G10 /i7-1355U/16GB/1 TB SSD/FHD+/IPS/NVIDIA 4 GB Magyar bill
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest