-

Fototrend
A Microsoft Excel topic célja segítséget kérni és nyújtani Excellel kapcsolatos problémákra.
Kérdés felvetése előtt olvasd el, ha még nem tetted.

Új hozzászólás Aktív témák
-

cousin333
addikt
Sziasztok!
Némi segítséget/infót kérnék egy Excel 2016-os problémához.
Van egy táblázatom adatokkal, ahol az első oszlop egy dátum, a többiben meg összegek szerepelnek. Készítettem 3 kimutatás-diagramot (3 különböző fülön) és beállítottam úgy, ahogy szeretném. Mindhárom esetben az említett dátum mező került a "sorok" közé. Ezt a mezőt szeretném az Elemzés > Mező csoportosítása paranccsal összerendezni.
Bár elvileg 3 különböző kimutatásom van, ez a csoportosítás mindhárom esetben érvényre jut. Például szeretném, ha az első táblában havi bontás szerepelne (csak a hónapok, évek nélkül), a másikban viszont csak az évek, de ha az egyiket beállítom, megy vele a másik is.
Nem lehetne őket függetleníteni?
-
#28998
cousin333
addikt
King Unique
#28997
cousin333
addikt
válasz
 King Unique
#28997
üzenetére
King Unique
#28997
üzenetére
A harmadik sort jelöld ki, és úgy mehet az Ablaktábla rögzítése...
-
#28995
cousin333
addikt
King Unique
#28994
cousin333
addikt
válasz
King Unique
#28994
üzenetére
Ha csak az első sort akarod rögzíteni, akkor Nézet fül, Panelek rögzítése és itt a Felső sor rögzítése. Ha több sort is szeretnél fixálni, akkor kijelölöd az első sort, amit már görgetni akarsz, majd ugyanitt Ablaktábla rögzítése.
-
cousin333
addikt
Azért lesz nulla az eredmény, mert a SZUMHATÖBB függvény egy tartomány elemeit összegzi, de csak akkor, ha minden kritérium teljesül. Te pedig a jelek szerint azt szeretnéd, ha vagy-vagy teljesülés esetén is összegezne, de ezek szerint a te esetedben nincs olyan sor, ahol minden feltétel egyszerre igaz lesz, tehát a metszet nulla.
"A függvény az összegtartomány argumentum egyes celláit csak akkor adja össze, ha az adott cellára az összes meghatározott feltétel igaz." (Office súgó)
-
cousin333
addikt
válasz
 joe86t
#19668
üzenetére
joe86t
#19668
üzenetére
Most akkor csak a "lefedett" oszlopok száma érdekel, vagy írni kell a soronkénti nullákat is? Mondjuk az alábbi megoldás némi módosítással erre is képes.
Tehát, a példádnál maradva a B:X oszlopok 1001-es sorába az alábbi képlet jöjjön (mindegyikbe az értelemszerű az oszlop betűjelekkel):
=DARAB(HOL.VAN($A$1:$A$50;B1:B1000;0))
Fontos! A képletet tömbképletként kell bevinni, tehát Ctrl + Shift + Enter -rel kell nyugtázni. Ez megadja, hogy az adott oszlopban hány elemet talált meg az A1:A50 tartományból.
Ezt a B1001:X1001 sort aztán kiértékelheted egy cellában, ami így a keresett értéket adja:
=DARABTELI(B1001:X1001;">0")
A megoldás működik, de nem biztos, hogy nincs ennél egyszerűbb. Most ennyire futja tőlem...
-
#18801
cousin333
addikt
kőbaltazár
#18796
cousin333
addikt
válasz
 kőbaltazár
#18796
üzenetére
kőbaltazár
#18796
üzenetére
Az FKERES függvény súgójában benne van

=FKERES(B22;$I$41:$J$45;2;0)
Ez a B22 cella tartalmát keresi a $I$41:$J$45 tartomány első oszlopában. Eredményül a találattal azonos sorbeli cella tartalmát adja a második oszlopból (innen a "2"). Az első oszlopban pontos egyezést keres (ez a "0"), tehát ha az I41:I45 tartományban nem szerepel pontosan a B22 tartalma, akkor hibát jelez.
-
cousin333
addikt
Ilyenre gondolsz? (nagyítható)
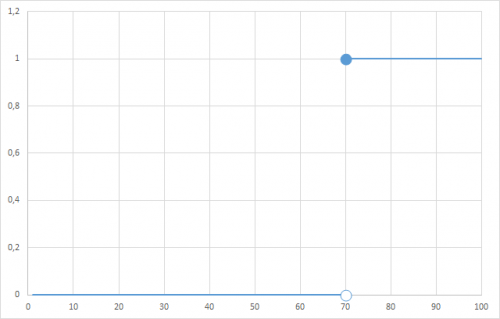
Ezt úgy tudod megoldani, ha a 70-es szám 2x szerepel a listádban (egymás után), egyszer 0, egyszer pedig 1 értékkel. Ábrázold X,Y függvényként, adatpontok nélkül, egyenes összekötő vonalakkal. A lényeg, hogy a kész grafikonon ki kell jelölnöd a második 70-hez tartozó értéket, de csak azt (tehát nem az egész görbét)! És itt megmondod neki, hogy neked nem kell vonal, ellenben jelölő igen. Aztán kijelölöd a 0 értékű 70-est, és szintén jelölőt raksz oda, fehér középpel.
Amúgy ha csak simán egy matematikai tartományt akarsz ábrázolni, tehát nem fontos, hogy mondjuk mi van a 32-es értéknél (illetve ott mindig 0 van), akkor felesleges ez az 1-től 100-ig történet. Egyszerűen hozz létre egy üres X,Y grafikont és adj hozzá 2 görbét. Az egyiknél az X értéke legyen {1;70}, az Y meg {0;0}. A másiknál az X legyen {70;100} az Y meg {1;1} (a kapcsos záójel mindkét esetben fontos!). Egyenes vonalú összekötéseket használj, jelölők nélkül, majd egyenként jelöld ki a két végpontot a 70-es értéknél, és adj hozzá jelölőt is.
-
cousin333
addikt
válasz
 pirit28
#14303
üzenetére
pirit28
#14303
üzenetére
Lehet, hogy rosszul értelmezem a leírtakat, de szerintem a megoldás a Rendezés és szűrés. Ez a 2010-es verzióban a Kezdőlap fülön van, a jobb szélén levő Szerkesztés csoportban.
Előtte kijelöld a táblázatot a nevekkel és adatokkal, amiket sorba szeretnél rendezni, majd itt kiválasztod az Egyéni sorrend...-et.
Ha ez megvan, akkor meg tudod mondani, hogy sorokba vagy oszlopokba rendezzen, illetve, hogy mely sorok/oszlopok alapján.
Próbálkozáshoz azért javaslom a biztonsági másolatot.

-
-
cousin333
addikt
válasz
 hallgat
#14105
üzenetére
hallgat
#14105
üzenetére
Igen, a kódomat írva nekem is az volt a legfőbb gondom, hogy hogyan lehetne gyorsan törölni, Szerencsére rátaláltam arra az utasításra, ami képes kijelölni az üres cellákat. Innen már csak üressé kellett tennem a megcélzott elemeket, az meg ment gyorsan.
De egyébként a fenti problémára van jobb megoldás is, nem tudom, a 2003-ban megy-e:
- jelöld ki a teljes táblázatot: Ctrl + Shift + Space (ez is jó trükk amúgy)
- Adatok fül, Adateszközök, Ismétlődések eltávolítása
- kiválasztod az oszlopo(ka)t, amik alapján az ismétlődést megállapítodennyi...
-
cousin333
addikt
válasz
hallgat
#14107
üzenetére
Tulajdonképpen a kódja nem egyenként töröl, legalábbis nem soronként, hanem kihasználja azt az adottságot, hogy az ismétlődések egymás után szerepelnek. Megkeresi a teljes ismétlődő blokkot és egy lépéssel törli. A sebesség tehát inkább a blokkok számától függ, mintsem a benne lévő ismétlődő sorok számától.
-
cousin333
addikt
válasz
 zz76zz
#14100
üzenetére
zz76zz
#14100
üzenetére
Még annyit, hogy a
sorok = ""
sort kiveheted, mert (már) nem csinál semmit.
emonitor megoldása is jó, és egész gyors.
"Már csak annyi gondom van, hogy a scrip futtatása köznem a dátumokat átformázza és katyavaszos lesz."
Ezt kicsit jobban is definiálhatnád. Eleve dátumok vannak benne, vagy ez Excel hiszi azt? Milyen formátumban? Mit jelent pontosan, hogy összekutyulja?
-
cousin333
addikt
válasz
hallgat
#14093
üzenetére
Na, megalkottam a gyilkos VBA kódot
Nyilván lehetne még rajta reszelni, de úgy tűnik, működik, méghozzá elég gyorsan. A kód feltételezi, hogy a kérdéses számok az A1:A20000-es tartományban vannak. Akkor is így kell megadni, ha a számok csak a 2. sorban kezdődnek! Ha nem az első sorból indítasz, akkor módosítgatni kell a kódot, mert nálam a tartomány indexe és a sor száma ugyanaz (lásd a For ciklust).Gyakorlatilag megnézem a teljes listát, és ha azonosat találok, megjelölöm azzal, hogy törlöm a mellette(!) lévő cella tartalmát (különben csak minden 2. egyezést találna meg). A törlést nem a munkafüzeten végzem, mert az ennyi adatnál lassú lenne, hanem "belsőleg".
Ezután fogom a teljes tartományt, és kijelölöm illetve törlöm azokat a sorokat, amiben a B cella üres. A kód:
Sub duplikatum()
Dim szamok As Variant
szamok = Range("A1:B20000").Value
sorok = ""
For i = 2 To UBound(szamok)
If szamok(i, 1) = szamok(i - 1, 1) Then
szamok(i, 2) = ""
End If
Next i
Range("A1:B20000").Value = szamok
Range("B1:B20000").SpecialCells(xlCellTypeBlanks).EntireRow.Delete
End Sub -
cousin333
addikt
válasz
hallgat
#14093
üzenetére
Mindenképpen az egész sor törlése kell, nem csak egy adott mennyiségű oszlopé?
A sebesség azért lassú, mert sokszor nyúlsz a cellákhoz. Ilyen adatmennyiségnél ez már komoly problémát jelent.
Azt írtad, hogy az ismétlődések csak egymás után fordulnak elő. Akkor egyszerűen menj végig az oszlopon, és ha az aktuális cella megegyezik az előző cellával, akkor töröld ki az adott sort. Csak arra figyelj, hogy legközelebb is ugyanezt a sort vizsgáld, mert a törlés miatt eggyel kevesebb lett. Vagy alulról indulj el felfelé.
-
cousin333
addikt
válasz
zz76zz
#14092
üzenetére
Javaslom, hogy ilyenkor próbálj ki két dolgot: a képletkiértékelőt, ahol lépésről lépésre láthatod, hogy hogyan számol, illetve az egyes függvények súgóját.
Azért nem működik, mert "Ha a keres_szöveg értéke nem található, a függvény az #ÉRTÉK! hibaértéket adja eredményül."
A megoldást pl. a HAHIBA függvény jelentheti.
A másik, hogy ilyen logikai vizsgálatnál az egymásba ágyazott HA függvényekkel csak a saját életedet bonyolítod. Mi van, ha még egy feltételt teljesíteni kellene? Javaslom a VAGY függvény használatát, amivel a képleted így nézne ki:
=--VAGY(A1="n"; A1="item";HAHIBA(1=SZÖVEG.KERES("2012*"; A1;1); 0))
A két mínuszjel azért van az elején, mert a VAGY függvény kimenete IGAZ vagy HAMIS, ezzel a művelettel viszont 1 ill. 0 lesz belőle. Egyébként írhatnád úgy is, hogy
=(A1="n")+(A1="item")+HAHIBA(1=SZÖVEG.KERES("2012*";A1;1);0)
-
cousin333
addikt
válasz
detroitrw
#14032
üzenetére
A sokféle lehetséges variáció miatt nem elhanyagolható a kézi módszer.
Én készítettem egy gépi változatot, ami a Solver funkcióra alapoz, és brute-force módszert használ: [link].
Persze igyekeztem minimalizálni a lehetőségeket számos korlátozás bevezetésével. Mindenesetre nálam gond nélkül futott egy órát, és még nem adott végleges eredményt. Igazából nem tudom, meddig futna...
Az egyes cellákat kicsit nehéz kibogarászni, mert a lehető legtöbb konkrét számot és a legkevesebb képletet szerettem volna felhasználni, így remélve azt, hogy gyorsul a számolgatás.
A lényeg, hogy az egyes sorokban látod a különböző elosztási típusokat (max. 5-öt), ahogy te is csináltad a kézi módszernél. A rendszer azt számítja, hogy melyik hosszból mennyit használjon, illetve az adott osztást hány lécen alkalmazza.
A Solver a maradék hosszok négyzetösszegét igyekszik minimalizálni, ami nem feltétlenül a legoptimálisabb cél, de talán nem okoz olyan nagy hibát.
-
cousin333
addikt
válasz
 #90999040
#14027
üzenetére
#90999040
#14027
üzenetére
Szerintem meg ismétléses permutáció lenne, mert az egyforma hosszú léceket nem lehet megkülönböztetni. Akkor pedig 72! / (12! * 6! * 6! * 12! * 24! * 12!), ami persze még mindig nem kevés.
De a megoldás nem ilyen bonyolult, mert nem kell ennyi esetet végigvenni éppen azért, mert a szálak hossza fix, tehát a lécek nem jöhetnek akármilyen sorrendben.
-
-
cousin333
addikt
válasz
 buherton
#14005
üzenetére
buherton
#14005
üzenetére
"Az már csak hab a tortán, hogy két gépen dolgozok. Egyiken magyar office 2010 van, a másikon angol office 2003."
Részvétem...
"Hogyan lehet olyan function készíteni, hogy ne legyen bemenő változó, és ne térjen vissza semmivel? Egyáltalán lehet ilyen?"
Tudtommal nem lehet. A function azért function, mert értékkel tér vissza. Cellát formázni meg pláne nem lehet vele, még azt sem, amelyikbe beleírod.
Szubrutinnal viszont tudsz formázni, nem kell, hogy bemenete vagy kimenete legyen. Csak a hívását kell megoldanod valahogy. Vagy egy másik függvény triggereli (szubrutin, nem function!), vagy mondjuk egy gombra kötöd.
-
-
#13849
cousin333
addikt
terencehill
#13847
cousin333
addikt
válasz
 terencehill
#13847
üzenetére
terencehill
#13847
üzenetére
Azt kérdezted, hogy az E oszlopbeli listát hogyan tudod legenerálni. Megírtam. Azt nem mondtam, hogy piszkáld az A-B oszlop táblázatát.
Tehát tulajdonképpen létrehozod az E oszlopos listát a fenti módszerrel, majd használod a függvényt az F oszlophoz, amint már korábban megírtam (a SZUMHA-t). Ez nem veszi figyelembe a szövegeket, tehát ha két azonos kódhoz egy szám és egy szöveg tartozik, akkor értelemszerűen csak a számot "adja össze".
-
#13846
cousin333
addikt
terencehill
#13845
cousin333
addikt
válasz
terencehill
#13845
üzenetére
Ha nem változik túl gyakran a lista, akkor szerintem nem kell erőltetni a képleteket, mert eléggé lassúak is lehetnek, és, mint a mellékelt ábra mutatja, csak a gond van velük. A képeid alapján 2007-et vagy 2010-et használsz.
Egyszerűen másold ki a lista elemeit a "Sorszám" részből (a példádban A2:A4) mondjuk az E oszlopba.
Jelöld ki őket, majd az Adatok fülön az Adateszközök csoportban használd az Ismétlődések eltávolítása funkciót.
Ha kell, akkor megfejelheted egy sorba rendezéssel is.
-
#13840
cousin333
addikt
terencehill
#13839
cousin333
addikt
válasz
terencehill
#13839
üzenetére
A képen lévő példával élve kell egy listát csinálnod az előforduló sorszámokról (mint nálad az E4 és E5 cellákban). Ekkor az F4 cellába ez kerüljön:
=SZUMHA($A$2:$A$4;E5;$B$2:$B$4)
Az első és a harmadik elem fixen a listád, a középső elem ("E5") meg az aktuálisan hivatkozott sorszám. Ezt a függvényt aztán kiterjesztheted a következő sorokra is.
-
cousin333
addikt
válasz
 VásRló
#13221
üzenetére
VásRló
#13221
üzenetére
Szerintem így direktbe sehogy. Én a következőt csinálnám:
- A DÁTUM és IDŐ, valamint a KÖZÉP függvények segítségével meghatároznám az időt emészthető formában. A képlet, feltéve, hogy a kérdéses dátumod az A1-es cellában van:
=DÁTUM(KÖZÉP(A1;7;4);KÖZÉP(A1;4;2);KÖZÉP(A1;1;2))+IDŐ(KÖZÉP(A1;12;2);KÖZÉP(A1;15;2);0)
- Ezt beírnám a mellette lévő oszlop minden sorába, ahol ilyen dátum szerepel
Ez így már sorbarendezhető. Ha mindenképpen az eredeti felállás kell, akkor:
- Fognám ezt az új oszlopot, és másolás, irányított beillesztéssel (csak az értéket) bemásolnám az eredeti dátumoszlopba.
- Majd kijelölve ezt a régi-új oszlopot, a cellaformázásnál egyéni formátumot adnék meg a következő formátumkóddal:
nn.hh.éééé óó:pp
Ekkor elvileg ugyanúgy fog kinézni az eredeti és az új oszlop, de már sorba is lehet rendezni. Tesztelve, nálam működött (Excel 2010).
-
cousin333
addikt
válasz
 asuspc96
#13180
üzenetére
asuspc96
#13180
üzenetére
Akkor most tisztázzuk még egyszer, amolyan kérdezz-felelek formában:
- van 3000 sorod és 5 oszlopod (ez fix? kb. mindig ennyi?)
- a számok 1 és 100 között vannak (van egy behatárolható tartomány?)
- kell az X leggyakoribb szám kilistázva
- kell az Y leggyakoribb egymás utáni kombináció (egymás utáni számok? egymás alattiak? egy sorban lévő kombinációk?Mennyire változnak a számok? Függvényként kell, vagy csak néha-néha kéne kiszámolni (gondolom igen)?
-
cousin333
addikt
válasz
 poffsoft
#13150
üzenetére
poffsoft
#13150
üzenetére
Ma is tanultam valami újat...
"kérdéseim: egy adattömbben a módusz a leggyakoribb értéket adja meg"
Úgy látom, hogy Excel 2010-ben a MÓDUSZ már mint kompatibilitási függvény szerepel, és az új változatban kettéosztották:
1. Van a MÓDUSZ.EGY, ami megfeleltethető a régi MÓDUSZ-nak
2. Van a MÓDUSZ.TÖBB, ami tömböt ad eredményül, és pontosan gyakoriság alapján rendezi sorba az elemeket. Ezt tömbképletként kell bevinni, különben az 1. pontbeli eredményt kapjuk.asuspc96: Több tízezer szám esetén a tömbképlet felejtősebb... bár elnézve a konfigodat még az is működhet...
Amúgy melyik Excel verzióról beszélünk? A kombinációra vonatkozó kitételt továbbra sem értem 
-
#13136
cousin333
addikt
Vizes Tomi
#13127
cousin333
addikt
válasz
Vizes Tomi
#13127
üzenetére
Üdv!
Esetleg részleteiben vagy egészében nem tudnád elérhetővé tenni a fájlt? Csak mert akkor mindenki ki tudná próbálni a saját megoldását, és nem telne el olyan sok idő két javaslat között...
ui: az eredeti csv fájl, vagy annak részlete lenne a legjobb.
-
cousin333
addikt
Bocs, hogy nem válaszoltam, nem voltam gépközelben. De látom, sikerült megoldanod a problémát. Igen, azt az oldalt én is ismerem, sőt, tulajdonképpen én is onnan néztem ki anno.
Az a helyzet, hogy ennek a képletnek a legnagyobb rákfenéje, amivel te is találkoztál: alapvetően nem mindegy, hogy a forrásadatok (X és Y) függőlegesen, vagy vízszintesen vannak-e, az eredményt (az együtthatókat) függőlegesen, vagy vízszintesen várod-e illetve, hogy a tizedes elválasztód pont, vagy vessző...
-
#12956
cousin333
addikt
Gabriel_86
#12934
cousin333
addikt
válasz
 Gabriel_86
#12934
üzenetére
Gabriel_86
#12934
üzenetére
Üdv!
Neked is mondanám, hogy szerintem rosszul közelíted meg a kérdést. Nem a grafikonból kellene kibogarászni a függvényt, hanem az eredeti adatokból, amin a grafikon is alapszik.
Ennek megfelelően az alábbi képletet kell egymás melletti 3 cellába, egyszerre(!) beírni, majd Ctrl + Shift + Enter:
=LIN.ILL(Y; X^{1\2})
ahol X és Y az értékpárok megfelelő (és egyenlő elemszámú) függőleges tömbjei.
Ha csak az egyik együttható kell, akkor az mehet így is egy tetszőleges cellába, sima Enterrel nyugtázva. (ez a négyzetes tagé):
=INDEX(LIN.ILL(Y; X^{1\2});1)
Ez meg a sima, első hatványhoz tartozó:
=INDEX(LIN.ILL(Y; X^{1\2});2)
-
cousin333
addikt
Mindenképpen makróban kellene, vagy jó lesz függvénnyel is? Utóbbi esetben jelölj ki 6 egymás melletti cellát (ahova az értékeket akarod), majd írd be ezt a függvényt:
=LIN.ILL(Y;X^{1\2\3\4\5})
ahol X és Y értelemszerűen a függvény X és Y adatai, mindkettő függőlegesen, oszlopba rendezve. Ha beírtad, akkor Ctrl+Shift+Enter (tömbképletet hoz létre), és egymás mellett láthatod az ötödik, negyedik... nulladik hatvány együtthatóját.
-
cousin333
addikt
válasz
 fgordon
#12378
üzenetére
fgordon
#12378
üzenetére
Üdv!
Nekem is előjött az általad jelzett hiba, aminek az oka, hogy a függvényt tömbképletként kell bevinni, tehát nem Enterrel, hanem Ctrl+Shift+Enterrel! Nézd meg, hogy a cellában a függvény kapcsos zárójelek között van-e. Egy bug az általam használt LibreOffice-ban, hogy ha nincs, és kijelölöm a függvényt, majd Ctrl+Shift+Entert nyomok, akkor sem csinál belőle tömbképletet, hanem előtte a függvényt "módosítanom" kell, pl. úgy, hogy felülírom a függvénybeli C1 hivatkozást C1-re...
Minkét megoldást (Office 2003 és LibreOffice 3.4.4) átküldtem e.mailben az adataidnál megadott címre.
mod: A levél nem ment át, mondván nincs ilyen cím. Akkor viszont innen érheted el.
"első találat egy 2007-es doc, amiben a hol.van angolul = LOOKUP"
Ez kellemetlen, de attól még hibás állítás. A német változat ("Vergleich") valószínűleg jó, bár még sosem próbáltam.
-
-
cousin333
addikt
Egy másik lehetséges megoldás:
Feltételezve, hogy a felső értéksor (0 6 8 10 12) az A1:E1 tartományban van, az alsó (0 0,049... stb.) a B2:E2-ben, és az általad megadott érték (8,54) pedig A4-ben, úgy az eredmény - egy lépésben - az alábbi képlet szerint adódik:
=TREND(ELTOLÁS(A1;1;HOL.VAN(A4;A1:E1)-1;1;2);ELTOLÁS(A1;0;HOL.VAN(A4;A1:E1)-1;1;2);A4)
Átírva a te cellahivatkozásaidra:
=TREND(ELTOLÁS(G7;1;HOL.VAN(B21;G7:AD7)-1;1;2);ELTOLÁS(G7;0;HOL.VAN(B21;G7:AD7)-1;1;2);B21)
Ez az Excel 2010-re igaz, régebbi verzióknál az ELTOLÁS helyett az OFSZET alkalmazandó.
-
cousin333
addikt
válasz
Regirck
#12312
üzenetére
A GYAKORIBB függvényt én hoztam létre, nincs angol neve (ergo ugyanúgy kell megadni elvileg). De ha megkeresed a hozzá tartozó kódot, és átírod a gyakoribb előfordulásait (elvileg kettő van belőle, az egyik magának a funkciónak a neve) egy más kifejezésre, onnantól az lesz a függvény neve. Magyarul is, angolul is, németül is meg szuahéliül is.
-
cousin333
addikt
válasz
 Delila_1
#12313
üzenetére
Delila_1
#12313
üzenetére
"A tömb rendezésére én sem ismerek rövid megoldást, marad pl. a buborék módszer."
Vagy azt csinálod, amit én: kiírtam a teljes tömböt egy ideiglenes oszlopba, majd rendeztettem (makróból) az Excellel, és visszaolvastam a rendezett tömböt. De ez sem túl elegáns (és gyaníthatóan nem is a leggyorsabb), jobb ötletem viszont nem volt.
-
cousin333
addikt
válasz
Regirck
#12307
üzenetére
"Viszont egy dolog zavar, belépésnél folyamat csipog a vírus irtóm! A makrók miatt vagy mi miatt?"
Igen, valószínűleg a makrókkal van gondja. Ez elég bénán van megoldva szerintem, nem tudom, hogy a sajátfüggvények miért lettek egy kalap alá véve a makrókkal, amikor sokkal korlátozottabbak a képességeik (emiatt nem is tehetnek kárt a gépedben). Viszont így csak xlsm-ként engedni menteni.
Igaz, a fájl tartalmaz egy tesztmakrót is (nem én írtam), amivel függvények, utasítások futási idejét lehet mérni (így össze lehet hasonlítani két megoldást, hogy melyik a gyorsabb).
"Ha hozzájön még néhány sor akkor simán átírjuk az E2857-et annyival amennyivel nőtt nem kell túl bonyolítani makrókkal szerintem!"
Maga a GYAKORIBB függvény egy sajátfüggvény azaz "herélt makró". De jobban jársz, ha az adattartományodat - fejlécekkel együtt - kijelölöd, majd táblázattá alakítod (Beszúrás fül > Táblázatok csoport > Táblázat), és a függvényt erre a táblázattartományra alkalmazod. Ekkor, ha új sort vagy oszlopot adsz hozzá, azt automatikusan beveszi a táblázatba, és így az általa mutatott tartomány is bővül, ergo nem kell semmit átírni.
De a függvény módosítható lenne úgy is, hogy nem a tartományt kell megadni, hanem annak csak egy celláját, ő meg automatikusan kiválasztaná az egész - összefüggő - tartományt.
-
#12311
cousin333
addikt
m.zmrzlina
#12303
cousin333
addikt
válasz
 m.zmrzlina
#12303
üzenetére
m.zmrzlina
#12303
üzenetére
"Ezt nem értem."
Excel 2010-ben van olyan parancs, hogy Adatok > Ismétlődések eltávolítása. Ezzel kaphatsz egy listát, amiben minden elem csak egyszer szerepel. Ha viszont több oszlopot adsz meg neki, akkor csak azt tekinti ismétlésnek, ha két megadott sorban minden elem ugyanaz. Tehát mondjuk A2=A10, B2=B10 és C2=C10, akkor a második és tizedik sor egymás duplikáltjai.
"Valóban nem. 3-4 kattintás."
Erről beszélek. Nem bonyolult, de meló, főleg, ha sokszor kell.
"???"
A megoldásod lényege, hogy egy oszlopban szerepel minden egyedi érték, és mellette egy másik oszlopban minden darabszám. 1000 különböző értéknél ez 2000 cellányi információ, miközben a felhasználónak mondjuk 1-2-re van szüksége.
"Túlértékelsz"
Pedig kinéztem belőled.
-
cousin333
addikt
válasz
Delila_1
#12308
üzenetére
Köszönöm a választ. De szerintem félreértettük egymást, vagy nem elég pontosan fogalmaztam. Ezekkel a rendezési lehetőségekkel tisztában vagyok (bár a sorrend megfordítós megoldás ötletes), a kérdésem a makrókra vonatkozott. Tudom, hogy a VBA tud rendezni (Array.sort), meg sorrendet fordítani, de nekem úgy tűnik, ezek Excelben nem elérhetőek. Vagy mégis?
Ergo a különbség tartomány és tömb között (legalábbis az én értelmezésemben):
tartomány: pl. "A1:B20"
tömb: Dim lista(1 to 20, 1 to 2) as Double -
#12302
cousin333
addikt
m.zmrzlina
#12301
cousin333
addikt
válasz
m.zmrzlina
#12301
üzenetére
Ha új elemet adsz hozzá, azt be kell tenned a Q-beli listádba is. A "minden elem egyszer" elv is nehézkes, ha több oszlopod is van. Tudtommal a rendezés sem megy magától. Ráadásul lesz egy csomó cellád tele sosem használt értékekkel. Vagy azokat is mindig törölheted le.
Ne érts félre, amit írtál az jól működik, számításigény szempontjából talán a lehető leggyorsabb is, csak "nem megy magától".
Tényleg, ha már itt tartunk: nem tudsz valami gyors módszert tömbök (nem tartományok!) gyors rendezéséhez? Esetleg két dimenziós tömböt egy adott oszlop szerint rendezni? Vagy a tömb tartalmát invertálni (az első elem legyen az utolsó... stb.)?
-
-
cousin333
addikt
válasz
Regirck
#12293
üzenetére
A lottós relatíve egyszerű: létrehozol egy 90 elemű tömböt, majd végigmész a számokon és az annyiadik tömbelemet növeled eggyel, amennyi a szám (pl ha a szám 15, akkor a tömb 15. eleméhez hozzáadsz egyet).
Így megszámolod mindet, a sorrend innen már viszonylag könnyű. Ugyanakkor mindezt nagy számokra (pl. vonalkód) vagy szövegekre nem lehet alkalmazni, szóval nehezen tudnád ezekre átemelni a lottós megoldást.
Mindenesetre érdekel a dolog, lehet, hogy holnap megnézem.
-
cousin333
addikt
válasz
Regirck
#12289
üzenetére
Milyen számok ezek? Van bennük rendszer? Pl. csak 0 és 100 közöttiek... stb.
A nagy számmennyiség miatt "látatlanban" azt mondanám, hogy makróval kellene megoldani. Függvényből leginkább valami tömbképlet tűnik járható útnak (bár szerintem ahhoz kevésbé általános feladat kellene), viszont az sok adatnál eléggé lassú tud lenni....
-
cousin333
addikt
válasz
 alexnowan
#12259
üzenetére
alexnowan
#12259
üzenetére
Kicsit konkrétabb példa? Mondjuk pár sor (akár kamu) adattal? Mit szeretnél hol látni? Egyáltalán, mit akarsz megvalósítani, biztos, hogy a pivot a jó megoldás?
Ha a 4 oszlopodat a pivotban is akként akarod látni, akkor a mezőket a szumma értékek területre kell húzni. Vagy másképpen a leír1-2-t az szmma értékek területre, az azonosítót meg a Sorcímkék részre.
De a kérdés továbbra is inkább az, hogy pontosan mit akarsz megvalósítani?
-
cousin333
addikt
válasz
fgordon
#12258
üzenetére
Szerintem megértettem, hogy mit akartál írni. Az általam linkelt képletek teljesen jól működnek Excel 2010 alatt. Mint az előző hozzászólásomban kifejtettem, a LibreOffice nem úgy kezeli a tömbképlet másolását, mint az Excel (szerintem hibásan, mert a tömbképlet eljárás a lényegét veszti el ezáltal, lásd a te példádat).
Nem csoda, hogy mindig az A1-es értéket kapod meg, mert ez a szerencsétlen minden D-beli cellában ugyanazt számolja. Gondolom másoltad a képletet, miután beírtad a D1 cellába, amit írtam. Na, akkor nézd meg, hogy a D2, D3... stb. cellában mi van. A válasz: ugyanaz, mint a D1-ben.
A második példámmal szemléltetve a dolgot: Excel 2010-ben ez van az egyes cellákban:
D1
=HA(C1;INDEX($A$1:$A$3;HOL.VAN(1;(B1=$B$1:$B$3)*(SOR(B1)<>SOR($A$1:$A$3));0));"")D2
=HA(C2;INDEX($A$1:$A$3;HOL.VAN(1;(B2=$B$1:$B$3)*(SOR(B2)<>SOR($A$1:$A$3));0));"")D3
=HA(C3;INDEX($A$1:$A$3;HOL.VAN(1;(B3=$B$1:$B$3)*(SOR(B3)<>SOR($A$1:$A$3));0));"")Remélhetőleg látszik a minta: a D1-ben látható "C1" ill. "B1" hivatkozások "C2", "B2" ill. "C3", "B3" hivatkozásokká frissülnek a függvény másolásakor. Namost az LibreOffice mindhárom D cellába azt írja be, amit az Excel csak a D1-be. Nem csoda, hogy az eredmény is mindig ugyanaz lesz.
Remélem, elég érthető voltam, ennél jobban már nem tudom magyarázni. Szóval szerintem de, az LibreOffice-ban van a hiba. Vagy csak máshogy működik, amit nem ismerek. De ha valamit félreértettem volna, javíts ki.
-
#12243
cousin333
addikt
soldierboy
#12242
cousin333
addikt
válasz
 soldierboy
#12242
üzenetére
soldierboy
#12242
üzenetére
Úgy látom, hogy a 2007-ben ugyanott van, mint a 2010-ben, tehát lásd az előző hozzászólásomat, kivéve, hogy az elején nem a Fájl-ra kell kattintani (mert olyan ott nincs), hanem az Office gombra (vagy mi az).
Ugyanez angolul: [link]
-
#12241
cousin333
addikt
soldierboy
#12240
cousin333
addikt
válasz
soldierboy
#12240
üzenetére
Melyik verziót használod? Excel 2010-ben Fájl, Beállítások, Képletek, S1O1 hivatkozási stílus, pipát kivesz. Ha régebbi verzió, akkor is azt keresd meg (beállítások között, vagy a súgóban), hogy hol lehet ezt átkapcsolni.
-
cousin333
addikt
válasz
fgordon
#12236
üzenetére
Libre Office nem támogatja a HAHIBA (IFERROR) függvényt, tehát a második mód lép életbe, ami támaszkodik a C oszlopra is:
=IF(C1;INDEX($A$1:$A$3;MATCH(1;(B1=$B$1:$B$3)*(ROW(B1)<>ROW($A$1:$A$3));0));"")
Ezt kell beírnod a D1 cellába, majd Ctrl+Shift+Enter! Sajnos a képlet további cellákba másolásával van egy kis gond, nevezetesen az LibreOffice elég "érdekesen" kezeli ezt, ugyanis a hivatkozások nem futnak együtt úgy, hogy pl. Excelben. Tehát a fenti képlet a második sorban is csont ugyanígy néz ki, míg Excelben a C1-ből C2, a B1-ből B2 lesz.
Ergo jelenleg működik a fenti képlet, de minden sorba egyenként kell bemásolni, és aktualizálni őket...
A megoldást momentán nem tudom, mint ahogy a képletkiértékelőt sem találom, ami lépésenként hajtja végre a függvényt, mutatva a köztes állapotokat, hogy látni lehessen, hol nem csinálja azt amit várnék tőle. Tudsz erről valamit?
-
cousin333
addikt
válasz
fgordon
#12220
üzenetére
Excel 2010 alatt így nézne ki a megoldásom (a példádban a D1 cellába kell beírni):
=HAHIBA(INDEX($A$1:$A$3;HOL.VAN(1;(B1=$B$1:$B$3)*(SOR(B1)<>SOR($A$1:$A$3));0));"")
A függvényt tömbképletként kell bevinni (Ctrl+Shift+Enter-rel)! A rögzített tartományokat értelemszerűen kell beállítani, a B1 paraméterél szám az aktuális sort jelölje.
-
cousin333
addikt
válasz
 bozsozso
#10912
üzenetére
bozsozso
#10912
üzenetére
Még egy javítás eszembe jutott. Ehelyett:
=HA(ÜRES(A1);"";SZUM(--($A$1:$A$10<=A1)-(ÜRES($A$1:$A$10))))
a C1 mezőbe kéne írni, hogy
=SZUM(--($A$1:$A$11=0)) vagy
=DARABÜRES($A$1:$A$11) ez volna a jobb, ha van ilyenedés akkor a B1-be mehet, hogy
=HA(A1=0;"";SZUM(--($A$1:$A$11<A1))-C$1)
majd értelemszerűen "lehúzni" függvényt a B oszlopban, ameddig kell.
Így a második $A$1:$A$11 tartományt nem kell minden egyes B-beli cellában kiszámolni.
-
cousin333
addikt
válasz
 föccer
#10918
üzenetére
föccer
#10918
üzenetére
Azért sem értettem először, hogy hogyan hoztatok ki az enyémnél ennyivel egyszerűbb függvényeket, aztán néztem, hogy mit is csinálnak...
Mindenesetre abban is van kihívás, hogy a ti értelmezésetek alapján hogyan lehetne beépített függvények használatával minél kisebb gépigénnyel végrehajtani a műveletet.Ez is egy megoldás, de ha megvan a képlet, akkor szerintem egyszerűbbnek nem egyszerűbb. Pláne, ha új elemeket is szeretne néha felvenni a listára.
A megoldásom alapvetően jó, akkor van baj, ha hosszú (vagy hosszú lesz) a lista - mondjuk pár ezer sor -, mert így eléggé számításigényessé válik (amikor felfedeztem őket, tisztára "beleszerelmesedtem" a tömbképletekbe, de mostanra rájöttem, hogy sok mindenre, amire használható, van sokkal gyorsabb gyári függvény (pl. SZUMHATÖBB(), vagy elegáns, de nem jól bővíthető, ugyanakkor jelentősen növelheti a számításigényt. Erre a feladatra azért jól jönnek, legalábbis kisebb adatmennyiségnél...). Ilyenkor már inkább szóba jöhet a szűrő, vagy valami makró.
bozsozso: Egy kicsit még lehet tovább egyszerűsíteni:
=HA(A2=0;"";SZUM(($A$2:$A$11<=A2)-($A$2:$A$11=0)))
-
cousin333
addikt
Igen, valóban Ctrl+Shift+Enter, sorry...
De ezek szerint nem volt egyértelmű a feladat. Legalábbis a többiek megoldása nem azt csinálja, amit az enyém, hiszen a B oszlopbeli számok mindig emelkedő számsorban jönnek. Én a feladatot úgy értelmeztem, hogy a B oszlopbeli szám mutatja, hogy az A oszlopban lévő dátum hányadik az időrendi sorban. Ezt az aprócska félreértést azért jó lenne tisztázni

A tesztfájlom pl. így nézett ki (a Vissza az egyik, az Előre a másik időbeli irány:
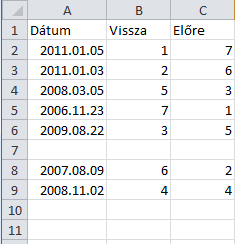
-
cousin333
addikt
válasz
bozsozso
#10904
üzenetére
Előrebocsátom, hogy létezhet ennél jobb megoldás, de most ez jutott eszembe. B1-be ezt kell írni:
=HA(ÜRES(A1);"";SZUM(--($A$1:$A$10>=A1)))
A képletet tömbképletként kell megadni,tehát nem Enterrel nyugtázandó, hanem Ctrl+Alt+Enterrel! Ezt a függvényt aztán le lehet húzni egészen B10-ig.
Itt azt kell látni, hogy az $A$1:$A$10 tartomány nem akkora, amennyi dátum jelenleg be van írva, hanem nagyobb, hogy a jövőbeli elemek is beférjenek (vagy valami ofszetes számolgatós függvény is kell bele, ami utánaállítja, de ez szerintem már nem túl gazdaságos).
A fenti függvény a legfrissebb dátumnak adja a legkisebb sorszámot. Ha fordítva kell, akkor arra is van megoldás, ami nálam még rondábbra sikerült:
=HA(ÜRES(A1);"";SZUM(--($A$1:$A$10<=A1))-SZUM(--(ÜRES($A$1:$A$10))))
B változat összevonva a két szummát:
=HA(ÜRES(A1);"";SZUM(--($A$1:$A$10<=A1)-(ÜRES($A$1:$A$10))))
C változat (2010-ben van ilyen függvény, a többit nem tudom):
=HA(ÜRES(A1);"";SZUM(--($A$1:$A$10<=A1))-DARABÜRES($A$1:$A$10))
föccer: Az úgy natúrban kevés lesz...
-
#10899
cousin333
addikt
m.zmrzlina
#10891
cousin333
addikt
válasz
m.zmrzlina
#10891
üzenetére
Ez a sor:
kilistahossz = Application.WorksheetFunction.CountA(Range(Cells(1, 1), Cells(belistahossz, 1)))
véletlenül nem ez akart lenni?
kilistahossz = belistahossz - Application.WorksheetFunction.CountA(Range(Cells(1, 8), Cells(belistahossz, 8)))
Legalábbis a feladat alapján: azon sorokat másolja, ahol a H oszlopbeli cella nincs kitöltve.
-
#10898
cousin333
addikt
m.zmrzlina
#10897
cousin333
addikt
válasz
m.zmrzlina
#10897
üzenetére
Értem én, hogy elvileg gyorsabb, azért is lepett meg, hogy nálam lassabban futott, mint az "alap" megoldás. Persze lehet, hogy csak az én implementációm volt rossz (most sajnos nem tudom beírni a kódot).
Nálam 3 x 20 ezer celláról van szó, a műveleteket 4 ezerszer hajtom végre ezen a bemeneti tartományon, tehát nem lehet panasz a terhelésre. Először tömbképlettel csináltam, kb. leölte a gépet...
-
#10896
cousin333
addikt
m.zmrzlina
#10891
cousin333
addikt
válasz
m.zmrzlina
#10891
üzenetére
Amennyire én értek hozzá, jónak tűnik a megoldás. Nem mellesleg éppen ma szembesültem én is ezzel a módszerrel...
Viszont például az én problémámra (amivel jelenleg foglalkozom), úgy tűnik, gyorsabb a "sima" megoldás, nevezetesen, hogy a bemenő változókkal egyesével feltöltök egy-egy tömböt, az eredményeket kiszámolom egy másik tömbbe, majd egyesével kiírogatom őket a megfelelő helyekre. Nem biztos, hogy tuti módszerrel csinálom, mindenesetre a "sima" módszer futása kb. 6,3 mp, míg az egyszerre olvasósé 10,6 mp (persze számolni is kell, nem csak egyik helyről a másikra pakolászni). Szóval érdemes lehet több megoldást megvizsgálni és Timer funkcióval megmérni egy nagyobb adattömegen, hogy mi a gyorsabb (esetleg különböző adatmennyiségek esetén is nézni, hogy hogyan skálázódnak a különböző módszerek).
Mindenesetre már összeállt a fejemben egy másik megközelítés, ami reményeim szerint sokkal gyorsabb lesz majd. Ennél a problémánál is gyorsabb megoldásnak tűnik, ha végigmész a 8. oszlopon, és ha az adott sorban nincs értéke, akkor a komplett sort (akár a
Sheets("újhely").Range("A11:H11").Value = Range("A23:H23").Value
módszerrel) átmásolod az új helyre.
-
cousin333
addikt
válasz
DjSteve85
#10656
üzenetére
Üdv!
Célszerűen rendezd az 1. lapfül elemeit az irányítószám szerint sorrendbe, majd cseréld fel az A és B oszlopokat (hogy a településnév legyen elöl).
Feltételezem, hogy az 1. lapon A1:A100-ig vannak a nevek, és B1:B100-ig az irányítószámok.
Ekkor a 2. lapfülön az A oszlop első sorába írd ezt a függvényt:
=FKERES(A1; Fül1neve!$A$1:$B$100; 2; HAMIS)
A Fül1neve helyett nyilván az első fül neve kell (de ha kijelölöd, automatikusan beírja neked). Ha nincs olyan nevű település (mert pl. elgépelted), akkor #HIÁNYZIK hibát dob.
-
cousin333
addikt
válasz
cousin333
#3879
üzenetére
No, akkor egy vizuális példa:

Az Y értékek az első sorban, az X értékek az első oszlopban vannak, a Z-k meg közöttük. Ebből csináltam egy szép felület diagramot. Amint az látható, az X értékeket címkeként kezelte a program, nem értékekként. Ennek eredményeképpen az X tengelyen teljes összevisszaság van (2, 4, 5, 6, 3). Ha úgy jelenítené meg, ahogyan én gondolom, akkor előbb jönne a 2-es, és hozzá a neki megfelelő Z pont, aztán a 3-as, és hozzá a neki megfelelő Z pont... stb.
Ez működik is, ha XY-ként ábrázolom, de az csak két adatsorral működik (X és Y)

Szóval a fentieket kellene kombinálni. Bár már gyanítom, hogy nem fog menni...

-
cousin333
addikt
válasz
Delila_1
#3876
üzenetére
Természetesen ez nem okozna problémát, nem is erre gondoltam. A képedet alapul véve képzeld el a következőket:
- nincs első sor
- A2 üres
- hogy az X értékek az A3 : A10 tartományban vannak
- az Y értékek az B2 : C2 tartományban vannak
- a Z értékek a B3 : C10 tartományban vannakEzt szeretném 3D-ben ábrázolni úgy, hogy az X, Y, Z értékek a hasonló nevű tengelyeken szerepeljenek. Ezt csinálja a "felület" grafikon. De azzal az a problémám, hogy az (1) X=4, Y=2, Z=1 pont az YX síkon pontosan fele olyan messze van a (2) X=7, Y=2, Z=4 ponttól, mint a (3) X=6.5, Y=2, Z=3.5 ponttól. Tehát az X tengely mentén haladva az origóból kiindulva, előbb következik az (1), aztán a (2), végül a (3). De ha megnézed az X értékeit, akkor előbb kellene lennie (1)-nek, aztán a (3)-nak (mert 6.5<7), majd a (2)-nek. A példaként írt értékekből az is látszik, hogy az XY síkon az (1)-nek ötször olyan messze kellene lennie a (3)-tól, mint a (2)-nek a (3)-tól....
Megkísérlek én is összeütni egy példa-képet, mert ez így nehezen emészhető...
-
cousin333
addikt
Üdv mindenkinek!
Az volna a kérdésem, hogy hogyan lenne lehetséges - ha egyáltalán az - Office 2002 alatt kombinálni az XY és a felület ábrázolást egy diagramnál. Tehát:
- van egy "adatmátrixom", két változóval (X és Y)
- minden X-Y kombinációra van egy konkrét Z értékem
- az X és Y változók is paraméterek (konkrét értékek), nem csupán címkék
- szeretnék egy olyan felületet ábrázolni (mint a felület diagramnál), ahol az egyes XY pontok nem egy négyzetháló kereszteződéseiben helyezkednek el, hanem az X ill. Y értékekkel arányosan (mint az XY ábrázolásnál, csak nem két változóm van, hanem 3: a Z az X és az Y függvényében)Remélem, érthető voltam, várom szíves válaszaitokat











































Új hozzászólás Aktív témák
- Vezetékes FEJhallgatók
- 200 megapixeles kamerával lép szintet a Moto G87
- Lassan küszöbön a NTE: Neverness to Everness premierje
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Kertészet, mezőgazdaság topik
- Azonnali fotós kérdések órája
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- Kerékpárosok, bringások ide!
- Fogyjunk le!
- OLED TV topic
- További aktív témák...
- Lenovo T495 Ryzen 5 pro 3500U, 16GB RAM, 512GB SSD, jó akku, újszerű állapot, számla, garancia
- BESZÁMÍTÁS! ASUS B450M R7 5700 32GB DDR4 512GB SSD RTX 3060 12GB Rampage SHIVA Cooler Master 650W
- Xiaomi Redmi Note 13 / 8/256GB / Kártyafüggetlen / 12Hó Garancia
- BESZÁMÍTÁS! Intel Core i9 11900K 8 mag 16 szál processzor garanciával hibátlan működéssel
- HIBÁTLAN iPhone 12 Pro 128GB Graphite -1 ÉV GARANCIA - Kártyafüggetlen, MS4644
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest