-

Fototrend
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

Oliverda
félisten
válasz
 Oliverda
#6594
üzenetére
Oliverda
#6594
üzenetére
Ha már szóba került az SMT pontosabban a HT akkor itt egy teszt amibe na Netburst és a Nehalem HT hatékonyságát próbálják összemérni:
Pentium XE vs Core i3 Hyper-Threading review
Itt meg egy kis találgatás:
Llano core: potentially superior to Nehalem - clearly!... yes i believe so!.. 32B fetches with (if the announcement about improved fetch materializes) similar branch/loop handling as Nehalem, much better execution with cluster design and 6 ports for execution units with an augmented (84 to 72 entries meaning an augment of ~15% in the instruction window(ROB) along with many tweaks allover, how difficult would be to push that to +20% performance over Deneb ?) instruction window on par with Nehalem, improved(much?) memory fill with forwarding schemes and disambiguation close or on par with nehalem.. yet clearly bottlenecked at decode with only 3 decode slots( it doesn't but only if it could borrow the o-o-o decode slots of BD ! )... but its "balanced" and clustered nature should make it much more clock friendly than Nehalem... I wouldn't be surprised if the gain is close to 20% comparing core to core at the same clock with K10... also considering "turbo" and power management... It should mark the end of the narrower(3 wide) and faster single thread core processors... yet i hope we will see an improved Llano2...
Bulldozer: truly advanced. Yet IMHO, bottlenecked at decode with only 4 decode slots( yet advanced o-o-o design) for the potential of 2 threads. "IF" with only 2 ALU per core/cluster if should also be bottlenecked at execution, considering that the 2 core clusters are independent and never work together.
This processor with 2 L1-$I cache blocks interleaving accesses consecutively, it seems that is the rumor now, should be a fetch monster, and if it provides "value prediction" with superb re-execution mechanisms upon a much better memory fill and all the other techs to speed up the back end, it should really be a "throughput" monster... yet that decode bottleneck and narrow execution upon each thread should help nothing. BD screams for Macro-ops and uOPs fusion as it is( has identical problems of core2 and Nehalem) .
Clock to clock it should be in league with Llano core at single thread execution ( perhaps a "startegic" decision... for not trashing Llano sales ?)... perhaps a tiny little better, yet clearly inferior to SB at single thread execution with 3 ALUs and 6 ports for 2 threads ( "IF" there is only 2 ALUs per core/clusters in BD). But OTOH it "could" be a speed monster, compensating that way its inferior fixed point(INT) narrowness. If only 1 more decode slots at the front end, and 1 more ALU at each core/cluster, and this processor would completely burier SB, if not at single thread then at multithreading when the 2 cores are actives; that is, firing 2 threads in the same module would not hurt fixed point(INT) execution in any of the core/clusters, as it seems it might happen now...
Ugyanez a Sandy Bridge-ről:
An evolution of Nehalem, a more elaborated tick not a tock. Yet it addresses one of the more fundamental bottlenecks of Nehalem at execution with 6 ports for the execution units. The rest should be more tweaked accounting for Hyperthreading. "IF" the front-end has separated L1-$i cache blocks for the 2 simultaneous threads it should also improve this fetch 16B bottleneck upon single thread code, it remains to be seen if it can achieve 20% over Nehalem which i doubt... nevertheless it should provide a good boost over Nehalem. ZeroingIdioms should give the entrance into FMAC execution with compiler oriented "code transformations" and in here there is a serious advantage, if for nothing else, at benchmarketing with Intel code.
-
Oliverda
félisten
Igen, hogy a P4-ről már ne is beszéljünk.

Mondjuk a Bulldozer egy kicsit radikálisabb újításokat fog hozni a K10-hez képest mint a K10 hozott a K8-hoz képest. Nyilván ez önmagában semmire sem garancia. Még kissé homályos az architektúra.
#6592:
Két dolog van. Egyrészt az az interjú majdnem kereken 5 éves, 2005 márciusából való. Gondolom fel tudod idézni hogy akkor mi volt a helyzet. Másrészt az én értelmezésem szerint sehol sem állította Fred hogy nincs semmi értelme.
...he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources."
Ez szvsz messze nem azt jelenti hogy nincs semmi vagy 0 értelme lenne.
"However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree."
Ezt pedig már nem Fred barátunk mondta hanem a drágalátos jómadár Anand Lal Shimpi rittyentette oda.
Már 2005-ben is arról beszéltek, hogy majd inkább a CMT-t fogják alkalmazni a jövőben ha odakerülnek. Ez egy 2005-ös slide. A CMT (elvileg) hatékonyabb mint az SMT, valamint nincsenek olyan mellékhatásai, hogy bizonyos alkalmazásoknál még inkább hendikepet jelent a bekapcsolása nem pedig előnyt. Nyilván nem az ilyen alkalmazások vannak többségben de azért pár helyen kifejezetten javasolják a HT kikapcsolását:
* A consultant who deals with Cognos, a leading BI software by IBM, recommend disabling HyperThreading because it “frequently degrades performance and proves unstable.”
* Microsoft recommends turning off HyperThreading when running PeopleSoft applications because “our lab testing has shown little or no improvement.”
* A Microsoft TechNet article recommends disabling Hyper-threading for production Exchange servers and “only enabled if absolutely necessary as a temporary measure to increase CPU capacity until additional hardware can be obtained.”
* Advanced Clustering found when running High Performance Linpack (HPL) that “Using HT on the other hand causes a ~10% drop in performance compared to HT not being used.”
Itt az iXBT-s tesztben lévő felső két táblázat eredményei sem éppen rózsásak ebben ez ügyben.

Hogy miért nem implementálták azt sosem fogjuk biztosan megtudni de én erősen kétlem, hogy megengedhették volna maguknak a "csakazértsem" hozzáállást. Pár fórumon lelkes tagok azzal foglalatoskodnak hogy az AMD elmúlt bő 1 évtizedben bejegyzett patentjeit túrják, és ha jól emlékszek találtak olyan patentet amit még valamikor 2000 körül jegyeztek be és már a CMT-vel állt kapcsolatban. Ergo én azt sem tartom kizártnak, hogy az évek során előre megfontoltan úgy alakították ki a fejlesztési stratégiájukat, hogy abba semmilyen módon nem fért volna bele az SMT.
-
Oliverda
félisten
válasz
 #95904256
#6586
üzenetére
#95904256
#6586
üzenetére
Nincsmit.
Amúgy az SMT (állítólag) sosem volt téma:
When Intel announced Hyper Threading, AMD wasn't (publicly) paying any attention at all to TLP as a means to increase overall performance. But now that AMD is much more interested and more public about their TLP direction, we wondered if there was any room for SMT a la Hyper Threading in future AMD processors, potentially working within multi-core designs.
Fred's response to this question was thankfully straightforward; he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources." However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree.
A megvalósításhoz szükséges plusz szilíciumról meg ezt állítják:
"If you were to pull one core from each module, you would remove ~5% of silicon from the total die."
Valamint optimális esetben állítólag 80%-ot is hozhat a megoldás. Még mielőtt valaki megkérdezi hogy ez hogyan jött ki, nem tudom mert nem én számoltam. A HT esetében ugyanez 20%.
-
Oliverda
félisten
válasz
#95904256
#6584
üzenetére
Egyelőre kb ennyi a hivatalos belőle:


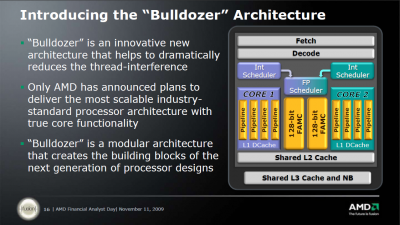
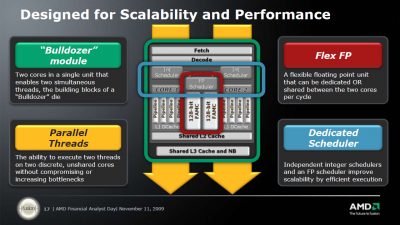
Ami nem hivatalos:
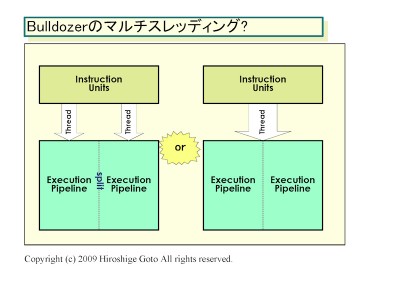


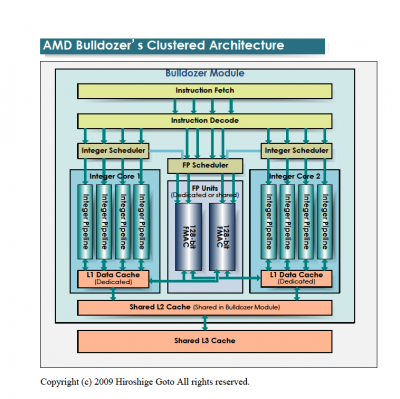
A CMT-ről:
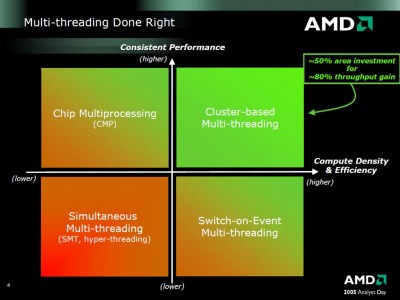

(ez nagyítható)
Tehát itt épp arról van szó hogy a CMT hatékonyabb, azaz jobb terület/teljesítmény mutatója, valamint nincs meg az a hátránya mint a HT-nek, hogy bizonyos alkalmazások nem hogy gyorsulnának de még inkább belassulnak a hatására. [link]
A Bulldozer-nél a "core" részegység mint olyan megszűnik létezni és "module" lesz helyette. Amit feljebb látsz az egy darab modul. Egy ilyet két magnak fog látni az OS. Az L1 I-Cache, az L2 és az FPU megosztott lesz a modulon belül, de terheléstől függően dinamikusan használhatóak lesznek ezen részegységek erőforrásai. Tehát pl. egy egy szálat terhelő alkalmazásnál a teljes FPU sávszélesség használható lesz. A modulok egy nagyobb megosztott L3-mal lesznek összekötve. A legnagyobb egy lapkás verzió elvileg 4 modult fog tartalmazni (32nm-en).
Ez sem hivatalos:

-
Oliverda
félisten
Próbáld ki. Indíts el mondjuk egy Super PI-t és látni fogod, hogy egy négymagos procinál ha nem állítasz affinity-t akkor minden magot 25%-on terhelni a win és nem egyet 100%on. Kétmagosnál 50-50%.
Tud normálisan működni mert (már) párhuzamosan mozognak a magok órajelei. Nem tudom hogy az Intel-nél ez hogy működik de gyanítom hogy ott is hasonló módon mivel a windows ezen tulajdonsági minden CPU-ra ugyanúgy vonatkozik. Nem hiszem higy driver-rel kiküszöbölhető. Ez a kernel sajátossága.
akosf
2011-ben de ennek az Intel HyperThreading-jéhez nem sok köze lesz. Az AMD CMT-ben (Cluster-based Multi-threading) gondolkozik és nem SMT-ben. Tekerj kicsit visszább és már találni fogsz róla itt infókat.
-
Oliverda
félisten
-
-
Oliverda
félisten
XP alatt működik az eltérő órajeles C'n'Q az összes Phenom-mal csak éppen az windócok elcseszett szálkezelése nem igazán ideális hozzá. Alapértelmezetten ("set affinity" nélkül) win folyamatosan dobálgatja a magok/szálak között a folyamatokat, így a magok nem tudnak lekapcsolni huzamosabb időre, mert amire éppen lejjebb váltanának egy-két p-state-et addigra már kapcsolhatnak is feljebb. Ennek köszönhetően be is lassul az egész hóbelebanc. Vista és 7 alatt már csak párhuzamosan mozognak a magok órajelei ezzel kiküszöbölve a fenti problémát. Amúgy ez a turbo-nak is keresztbe tesz/tehet.
"C'n'Q in Phenoms is slow compared to how Intel Turbo can switch speeds.The biggest problem with dynamic core clocking - delay between states. AMD's new Thuban and Lisbon core supposedly address that problem by moving all power controlling logic into CPU. This should ensure faster p-state switching and less delay. In return we should get less hit from retarded Windows task scheduler when doing light workloads."
-
-
-
Oliverda
félisten
válasz
 Bluegene
#6539
üzenetére
Bluegene
#6539
üzenetére
Ez nem hit kérdése.
Amúgy elég sok alkalmazás van ami kihasználja. A legtöbb videóvágó és -kódoló, renderelő valamint tömörítő képes rá. Nem csak 12-t hanem akár 48-at is. Nézz utána ennek is ha nem hiszed.
Ne legyen már itt is idióta vita abból hogy semmi sem használja ki a kettőnél több magot.
-
Oliverda
félisten
"Az, hogy server foronton jon ez meg az... meg majd jon a 6 magos Phenom asztalira meg mindig keves lesz."
Mihez lesz kevés? ...és miből gondolod hogy "kevés" lesz?
Vegyél két hatmagos Opteron-t ha annyira kevés lenne neked leggyorsabb X4. Azt kb annyiból ki lehet hozni mint az i7-980-at.

-
Oliverda
félisten
válasz
Bluegene
#6525
üzenetére
Szerintem ennek fuss neki még egyszer mert ott a 32nm-es gyártástechnológiáról volt szó, és nem az első 32nm-es Intel CPU és a Bulldozer megjelenése közötti időről. Másrészt mivel az AMD már nem gyárt csak tervez, ezért ez az összehasonlítás már annyira nem állja meg a helyét.

Valószínűleg már akár az év második felében is lehetne 32nm-es AMD CPU a piacon, a gyártástechnológia rendelkezésre fog állni, csak éppen maga a Lliano nem lesz még abban a fázisban hogy kereskedelmi forgalomba lehessen hozni.
"a bulldozer megjelenése 2011 közepe(ha nincs csúszás)"
Ez honnan jött? Valami forrás esetleg?
"ha a bulldozer csúszik őszre közel két év is lehet"
Ha öreganyámnak kereke lett volna, nyilván omnibusz lett volna. Ha öregapámnak áramszedője lett volna, akkor pedig ő lett volna a villamos.

"egyébként az intel addigra már majdnem 22nm-en fog tartani(2012-ben)"
Az AMD is, pontosabban a GF.

Globalfoundries Starts on 22nm Fab
Áldásos lenne ha a saját kútfőből hirtelen kiszaladt forrás nélküli vad kitalációkat inkább nem erőltetnénk itt túlzottan. Esetleg kicsit alaposabban utána lehetne nézni a dolgok hátterének és akkor kevesebb lenne a hülyeség.
-
Oliverda
félisten
"Az AMD legnagyobb baja, hogy konkrétan egy egész gyártástechnológiai lépcsővel vannak lemaradva az Intelhez képest."
Jelenleg az összes i7 proci 45nm-en készül. Ezt a csíkszélességet használja az AMD is már majd 1.5 éve. Tehát messze nem ez a legnagyobb baj.
dezz:
Valahogy kétlem hogy itt az ebben az írásban is említett power gating-re gondolnak de jó lenne ha tévednék.
-
Oliverda
félisten
-
Oliverda
félisten
-
Oliverda
félisten
-
Oliverda
félisten
-
Oliverda
félisten
Ahh...tehát szerinted attól függ, hogy éppen van-e értelme a clock 2 clock összehasonlításnak, hogy aktuálisan kb. hány százalék különbség van két architektúra között azonos órajelen. Ez eszembe nem jutott volna.
"És ha megnézed a teszteket akár itt a PH-n is, a legtöbb esetben vizsgálat tárgyát képezi az azonos órajelen elért teljesítmény."
Már amikor:[link]
"(A családomban is van olyan, aki irtózik az AMD-től és az ATI-tól.)"
Én is ismerek olyat aki az Intel-től meg az nV-től irtózik de nem hiszem hogy ezeknek bármi jelentőségük lenne. A nagy PC gyártókat kellene rávenniük arra, hogy minél több AMD-s gépet adjanak ki és akkor van esély a részesedés növelésére. Most jó esetben 10 modellből 2 AMD-s.
Bluegene: [link]
-
Oliverda
félisten
Nincs abban semmi irónia, kérem szépen.
Akkor viszont nem teljesen értem, mert te úgy írtad mintha a C2D megjelenése előtt nem számított volna a c2c összehasonlítás:
"Szerintem a C2D megjelenése óta újra számít a két vetélytárs órajele és c2c összehasonlítása."
...ha a megjelenése előtt nem számított akkor azóta miért számít?
Ugye a Netburst és K8 architektúrát egymásnak eresztve láttuk, hogy nagyon messze van a P4 az A64-től c2c összehasonlításban, ezért azt el is felejtettük egy jó időre.
Ettől anno még mindig többen vettek P4-et mint Athlon-t, c2c összehasonlítás meg fogyasztás ide vagy oda.
Szvsz a P4-nek is leginkább az elszabadult fogyasztás és a gyártástechnológia határok miatt fellegzett be végül. Persze a kettő valahol összefügg. Mondjuk ha a 3.2GHz-es Northwood ugyanannyit fogyasztott volna mint az Athlon 64 3200+ akkor már kicsit más lett volna a kép. Na meg ha nem rekedtek volna meg 3.8GHz környékén az órajelekkel, mert ugye eredetileg magasabbra szerettek volna menni, csak az a feljebb említett akkori gyártástechnológia korlátok miatt ez nem jött össze.
Tehát lehet hogy pár embernek köztük Neked is érdekes a c2c összehasonlítás de valójában ez egy mellékes információ. Nem arról van szó, engem is érdekel de ha ugyanazzal a fogyasztással magasabb órajelen kapnám meg ugyanazt a számítási teljesítményt mint amit egy alacsonyabb órajelű variáns nyújtana, és netán még egy kicsit olcsóbban is akkor már nem igazán izgatna a c2c.
Na meg amúgy is a 10 gigahercc a menőbb.

-
Oliverda
félisten
"Szerintem a C2D megjelenése óta újra számít a két vetélytárs órajele és c2c összehasonlítása."
Ebben most éreznem kellett volna némi iróniát vagy sem?
"Én mindenesetre nagyon fogok örülni, ha az AMD előhúz valamit a kalapjából, és c2c összehasonlításban azonos vagy jobb teljesítményt lesz képes felmutatni. Ez azért is fontos, mert az órajeleket nem lehet az egekig emelni, így viszont muszáj lesz a műveleti sebességet növelni."
Úgy fest hogy ilyet nem fog előhúzni mert sokadrangú kérdés, hogy c2c összehasonlításban hogyan szerepel. Az órajeleket valóban nem lehet az egekig húzni de megfelelő megtervezett architektúrával és gyártástechnológiával talán elérhető az amit feljebb pedzegettem.
Bluegene:
Az a gond hogy még azt sem lehet tudni, hogy a Sandy Bridge meg a Bulldozer mikor jön pontosan nem hogy az Ivy Bridge. Arról nem is beszélve hogy a Sandy Bridge is csúszik mert az eredeti terv szerint még az év utolsó negyedévében meg kellett volna jelennie. Tehát ilyen meglehetősen pontatlan időpontokhoz kötött találgatásokba szerintem meg végképp nem éri meg belemenni.
-
Oliverda
félisten
A legelső kérdést nem igazán értem. Pontosabban azt hogy most ez hogy jött fel pont arra a hsz-re.
"Vajon mikor jut el az AMD oda, ahol most a már kifutó C2D/C2Q proci vannak?"
Mondjuk talán a Bulldozer-rel. Azzal egy ugrással az i7 is mögéjük kerülhet ha nem baltáznak el valamit nagyon.
Amúgy a C2D/C2Q procikat még a LIano is befoghatja clock 2 clock ha ezeknek a változtatásoknak valóban van alapjuk, bár a LIano nem az egetrengető CPU pówerről fog szólni.
Amúgy ennek a clock 2 clock méricskélésnek egyre kisebb jelentősége van a vásárló szempontjából. Sőt szerintem lassan a magok száma is hasonló sorsra fog jutni. Ár/teljesítmény arány valamint a fogyasztás. A legtöbb vásárlót elsősorban ezek érdeklik.
Valszeg a Bulldozer sem lesz olyan gyors clock 2 clock mint a Sandy Bridge, de ha magasabb órajelen ugyanannyit vagy netán még kicsivel kevesebbet fog fogyasztani és emellett hozni fogja azt számítási teljesítményt is akkor ez sokakat nem fog érdekelni.
-
Oliverda
félisten
-
Oliverda
félisten
A négymagoshoz képest biztos alacsony lesz. Szerintem 3GHz-nél magasabb órajelű nem lesz belőle. Gondolom ha max egy vagy két magot használó alkalmazás fog futni akkor majd feltekerheti ideiglenesen a magok órajelét mondjuk 300-400MHz-vel magasabbra. Így ilyen alkalmazásokban sem fog lemaradni a legmagasabb órajelű X4 mellett.
-
-
Oliverda
félisten
válasz
 leviske
#6456
üzenetére
leviske
#6456
üzenetére
Persze, semmi sem biztos csak a halál meg az adók.
A 2.8GHz-es hatmagos Istanbul 1.325V-on megy ami máris jóval kevesebb mint az említett 140W TDP-s 3.2GHz-es 955 alapfeszültsége. Ez a CPU tavaly júliusban jelent meg azóta már eltelt durván fél év. Ennyi idő alatt általában lejjebb szoktak csúszni egy fogyasztási osztállyal. Van erre már számtalan példa.
-
Oliverda
félisten
Én első körben 3GHz-es max órajelet tippelek 140 wattos TDP mellett. Aztán később ez még mehet fel a fogyasztás meg le. Persze nem nagy mértékben mert mégiscsak 6 magról van itt már szó.
Amúgy pletyka szinten olyat is lehet olvasni hogy ezen lapkák gyártásánál már a jól megszokott SOI mellett a HKMG-t is bevetik.
-
Oliverda
félisten
válasz
leviske
#6449
üzenetére
Perszem, nem esélytelen. Csinálok én neked megfelelő feszültséggel kétmagosból is 140W-os procit nem arról van szó.
Akkor inkább úgy mondom hogy eléggé valószínűtlen. Azt a táblázatot meg bárki csinálhatta. Hasraütésszerű az egész.
"Ez alapján egyáltalán nem tűnik esélytelennek, hogy 140W-os lesz a 2,8GHz-es változat."
Ebben én megint nem látom a logikát. 3.1GHz-en kb. plusz 16 wattot fogyaszt egy plusz mag. Ezzel számolva még a 125 wattot sem érné el a proci fogyasztása 3.1GHz(!)-en.
-
-
Oliverda
félisten
Jól csalódsz de a Fusion-nak külön foglalata lesz. Desktop-on Socket FM1 a mobil vonalon pedig Socket FS1. Tehát jönnek új alaplapok új foglalattal és új chipkészlettel, pontosabban csak új déli híddal mivel az NB mint olyan már teljesen benne lesz a CPU-ban IGP-stől és PCI-E vezérlőstől együtt. A jelenlegi AM3-as foglalattal elég nehéz lenne kivitelezni a dolgot.
Ráadásul az első Fusion-nak nem sok köze lesz a Bulldozer-hez egészen pontosan semmi köze nem lesz hozzá.
A jelenlegi Propus lapka kissé finomított verziója fogja képezni a CPU részt. Ami szinte biztos az az hogy 512-ről 1MB-ra fog nőni a magonkénti L2 cache. L3 nem lesz.A dedikált memória pedig szerintem majd magára a CPU nyákjára kerülhet rá valami hasonló módon:

Ez amúgy egy GPU. Radeon E4690 a neve.
-
Oliverda
félisten
"Ahol kell a dedikált 128 bites memória busz egy 1400-1800 Mhz-es GDDR3 memóriával (és ez ma már inkább az alsó kategória magasabb szintje), ott már nem versenyképes a CPU-ba integrált GPU, egyszerűen elvérzik a szűk memória sávszélesség miatt."
...ha nagyon akarnák akkor éppen erre lenne egy egyszerű megoldás. Mondjuk szerintem kap egy dedikált ~256 megás VRAM-ot GDDR5-tel 64biten, valamint lesz egy állítható UMA-s rész ami a rendszermemóriából jön le. Hasonló módon mint a jelenlegi IGP-s megoldásaiknál.
-
Oliverda
félisten
AMD Constrained on 40 nm GPUs From TSMC
The AMD executives said the company will begin shipping its Fusion line of integrated CPU-GPU products late in 2010. The integrated Fusion products will compete for market share with the discrete graphics processors, Meyer said. AMD is expected to ship Fusion first on a silicon-on-insulator (SOI) technology, and follow that with a bulk Fusion product.
-
Oliverda
félisten
válasz
leviske
#6433
üzenetére
Nem linkelek. Erre nem szeretnék már több időt pocsékolni. Így is többet szántam rá mint kellett volna.
"Emiatt maximum azt fogom kétszer meggondolni, hogy veled kommunikációs sávot nyitok, de elvégre ez is valami. Semelyikőnk nem veszít semmit."
Na, de legalább valahol csak megérte...
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Oliverda
félisten
Egy kis esélylatolgatás... (nem hivatalos!
)"L3 of T-RAM, dependency prediction, store to load forwarding, "collapsing buffer", "ESP look ahead" and better overall branch prediction would make a hell of a family 10h "tic", with perhaps 20-30% better performance at the same clock speed and with a substancial smaller size... and all those are described in AMD patents back in 1998...
... keeping XMM register pack but augmenting the FPUs to do FMAC on 128 wide instructions would make this CPUs to the next level and promote family 10H ahead of anything that Intel has now in the SSE* war...
BD could be prepared then to be a x86-128 "kryptonit"..."
-
Oliverda
félisten
válasz
 zsolt320i
#6430
üzenetére
zsolt320i
#6430
üzenetére
Egyrészt nem hülyéztem le itt senkit. Másrészt nem probléma az ha valaki egyszer-kétszer nagy ritkán rossz következtetést von le, de ha szinte minden alkalommal ez van az már "kissé" fárasztó tud lenni. Mondjuk nem is ezzel van a probléma hanem azzal ha valaki szinte tényként kezeli ezeket a rossz következtetéseket. Elhiszem hogy ez téged nem zavar de ettől még engem zavarhat.
Amúgy ha emiatt legközelebb már kétszer meggondolja hogy mit ír akkor már van/volt értelme.
-
Oliverda
félisten
válasz
leviske
#6427
üzenetére
"Tisztázzuk, mikor először reagáltam rá, annyit néztem a képen, hogy mi a neve és 941 tűt ír."
Ez itt a baj. Először talán el kellene mindent olvasni, kicsit gondolkozni és majd csak utána írni.
"Később vettem észre a többit és kb magamnak csodálkoztam rá"
Remek. Már csak az a kérdés hogy akkor ezt mégis minek kellett itt megosztani.
"Arról viszont spec tőled hallok először, hogy SSE5 végül nem lesz..."
Pedig ez már hónapokkal ezelőtt kiderült és szerintem erről is van itt visszább infó, csak néha nem ártana olvasgatni is egy kicsit és nem csak write only módban üzemelni.
"Megjegyzem, te is csak azt írtad, hogy erősen fake _gyanús_."
Megjegyzem hogy te ennek ellenére elsőre kapásból úgy értelmezted mintha azt írtam volna hogy 100%osan valódi és eredeti.
-
Oliverda
félisten
válasz
leviske
#6422
üzenetére
Jó, akkor lefordítom. A gyengébbek kedvéért. Az a kép egy fake. Ezt írtam is alatta, erre rácsodálkozol és szinte tényként kezeled sőt még meg is lepődsz rajta hogy már 941 és nem 939. Na ettől tudok hülyét kapni.
1. Phenom III márkanév mint olyan nem létezik és nem is biztos hogy létezni fog.
2. Olyan logo nem létezik
3. SSE5 mint olyan már nem létezikLegalább annyi esze lehetett volna a készítőnek, hogy ezeket nem rakja bele de az a logo mindent visz.
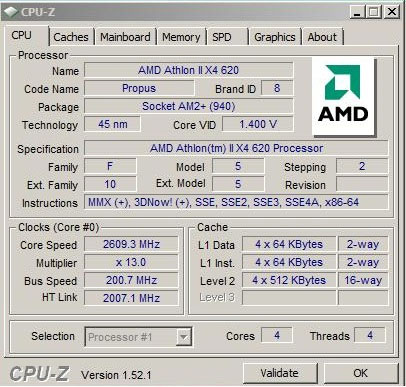
Az összes még friss AMD-re (ES is) ilyen logot mutat a CPU-Z.
Belátom hogy elqrtam amikor naivan belinkeltem azt a képet. Tanultam belőle.
Jared: A 2MB L2/modul még talán igaz is lesz.
-
#6408
Oliverda
félisten
Balala2007
#6405
Oliverda
félisten
válasz
 Balala2007
#6405
üzenetére
Balala2007
#6405
üzenetére
Nem tudom hogy ez mennyire igaz, de:
AMD have released some cache details for Orochi (Bulldozer uarch) via a patch to Open64:
L1D is 16KB, 4-way and uses 64B cache lines, with a 18 clock miss penalty. Barcelona's 64KB, 2-way with a 3 clock access latency and 11 clocks for a miss. Any clues as to whether that's good or bad, or what it could mean for L2 (since L2's shared), since it's quite a big change from K10?
-
#6393
Oliverda
félisten
csatahajós
#6392
Oliverda
félisten
válasz
 csatahajós
#6392
üzenetére
csatahajós
#6392
üzenetére
Az első már elég régen kiderült (visszább van is róla infó), a második pedig nem nagy meglepetés. Talán valamikor tavasszal már több infó lesz.
-
Oliverda
félisten
válasz
Bluegene
#6341
üzenetére
"A korábbi hírek szerint az első Bulldozer architektúrára épülő chip a Zambezi kódnevet viseli és az Orochi processzorok családjában kap helyet. A termék nyolc darab x86-os processzormaggal, két darab 128 bites FMAC egységgel, megosztott másod- és harmadszintű gyorsítótárakkal, valamint beépített memóriavezérlővel rendelkezik majd."
Ekkora ökörséget....
Az egy dolog hogy nem értenek hozzá de legalább fordítani tudnának normálisan vagy válasszanak olyan forrást ami megbízható.
ufff...véletlenül beleolvastam a hozzászólásokba

-
Oliverda
félisten
válasz
leviske
#6336
üzenetére
"Kétlem, hogy ezt az álláspontot képviselnék akkor is, ha Ők lennének teljesítményben a második gyártó, kevesebb haszonnal a termékeken. Jelenleg megengedhetik maguknak, hogy ilyenekkel ne szórakozzanak, be tudják nyelni az elmaradt hasznot."
Ez csak találgatás, és szerintem egyáltalán nem biztos hogy ebben az esetben változna a véleményük. Főleg az alábbiakat figyelembe véve.
"During a question-and-answer session following his keynote speech, Otellini was asked his thoughts on including three cores on a processor die, as AMD indicated it would on Monday. AMD’s solution turns off one core, which may or may not have met its rated speed. “We see a distinct advantage in having all the cores on our die work,” Otellini replied."
Kétmagos Nehalem Xeon készült letiltósdival tehát ez az egész nem azon múlik hogy melyik gyártó hányadik helyen áll a teljesítmény versenyben.
"Azonos teljesítmény esetén pont az AMD-től mernék drágább processzort várni, miután nekik van teljes platform és így rá tudnak segíteni, plusz ott a Stream."
A piac nagy része még akkor is az Intel termékeit vásárolja ha a konkurencia olcsóbban jobbat, gyorsabbat kínál. Ennek fényében elég rossz húzás lenne drágábban adni a nagyjából megegyező teljesítményű terméket.
-
Oliverda
félisten
válasz
leviske
#6334
üzenetére
Tehát az 500-asok fogyasztása inkább a 65W TDP felé közelít, csak valamennyivel túllépték? Akkor nem szóltam.
"Levezettem többször is.
Ha az Intel taktikáját vesszük alapul, akkor egyszerűen nem illik a képbe a 6magos változat."Az egy dolog. Az AMD nem az Intel így nem értem hogy miért kellene az Intel taktikáját alapul venni.
 Az Intel-nek hárommagos CPU-ja sincs az AMD-nek mégis van. Mik vannak.
Az Intel-nek hárommagos CPU-ja sincs az AMD-nek mégis van. Mik vannak. "Ellenben az AMD most áll egy nagyobb ugrás előtt, ahol illene minimum c2c egy szintre ugrani az Intellel."
...ha csak egy szintre ugranak akkor nem lesz 1000 dolláros procijuk.
"Itt is az Intelből indultam ki. Semmibe nem telne az Intelnek is kiadni egy 3magos i7-est, meg i5-öst, mégsem teszi, pedig kétlem, hogy annyival jobb volna a kihozatal."
Már elmondták párszor hogy ők nem fognak magokat letiltogatni (legalábbis desktop vonalon). Ezért sem értem hogy miért kell mindenben az Intel-ből kiindulni. Két külön cégről van szó, ne keverjük a kettőt.
A GPU vonalon történteket sem kellene idekeverni mert egyelőre messze áll egymástól a két terület. Meg ott az nVidia a fő konkurens.
-
Oliverda
félisten
válasz
leviske
#6330
üzenetére
"...bár ez lehet, hogy már veszélyes üzem, mert egyelőre úgy tűnik, hogy a fogyasztásra kihatással vannak a letiltott részek és mondjuk extrém esetben egy X2-es Thuban már nem feltétlen lenne 80W-os TDP alatt 3,1GHz-en"
Biztos hogy 80W alatt lenne még így is. Az a "kihatás" pedig elég minimális.
"Visszatérve a Bulldozerekre, mint írtam, pont a Llano miatt kétlem, hogy lenne X6-os változat desktopon."
Mivel négymagos biztosan lesz akkor nem értem hogy miért ne lenne hatmagos is...
Ez az ár spekuláció meg finoman szólva elég meredek. Főleg úgy hogy még lövése sincs senkinek, hogy mit fog tudni a CPU és mit fog tudni a Sandy Bridge alapú konkurens. Kb. olyan mintha a jövő heti lottószámokat elemezgetnéd.
"Az persze tényleg kérdés, hogy lesz-e akkora az OEM piac, hogy betudja fogadni a hibás darabokat..."
Milyen OEM piac?
Mintha eddig csak az OEM piacnak szánták volna a hibás darabokat. -
Oliverda
félisten
Szerintem a négymagos C32-es még ugyanaz a lapka lesz mint amit a Shanghai-nál használnak.
Amúgy eddig még arra sosem volt példa hogy olyan Opteron CPU kerüljön forgalomba amiben le lett volna tiltva cache vagy mag. Ergo kivétel nélkül az összes ilyen proci teljes értékű lapkából készült eddig. Ez alól max. a HT linkek képezhetnek kivételt, bár szerintem az sincs vagy nem volt letiltva, inkább csak nem vezették ki ezeket a lábakhoz. Pl. az AMD Overdrive a Phenom II X4-nél látja mind a négy HT linket de persze csak egyet ír aktívnak.
...de ezen nem veszünk össze.

-
Oliverda
félisten
Itt a legfrissebb.
A kódnév a tokozással együtt változik általában még akkor is ha tök ugyanaz marad a lapka.
Deneb - Socket AM2+/AM3
Shanghai - Socket F
Lisbon - Socket C32Szerintem a six-core C32-es procinak már más kódneve lesz ami nincs a táblázatban.
Például a Phenom X2-n is Deneb van csak letiltottak 2 magot és ezzel a kódneve is megváltozott Callisto-ra.
-
Oliverda
félisten
"Apropó észbejutás, az jutott az eszembe, hogy az AM3r2/AM3+ újdonsága esetleg a magonkénti eltérő fesz lehet, ami még hatékonyabbá teheti a magonkénti dinamikus órajel-szabályzást."
Ez korábban itt már nekem is megfordult a fejemben. Szép és jó is lenne egész ha pl. a Windows nem dobálgatná folyamatosan a különböző process-eket a magok között. Négy mag esetben emiatt gyakorlatilag elég nehezen kivitelezhető a terhelés függvényében változó magórajel. A végeredmény ugyanis egy baromira belassuló rendszer lesz. Legalábbis a K10/K10.5 esetében biztosan. Aztán lehet hogyha töredékére tudnák redukálni a különböző órajel váltásokhoz szükséges időt akkor már jobban működne.
-
Oliverda
félisten
válasz
leviske
#6299
üzenetére
"Tehát a Zambezitől nem 8 mag/16szálat érdemes várni?"
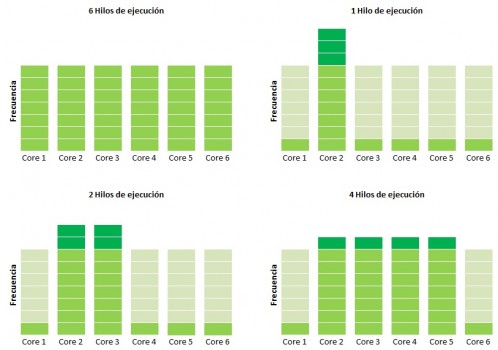
Nem. Egy modulban két integer egység lesz és egy megosztott FPU, megosztott L2 cache, stb (ott az ábra). Az OS-ek majd egy integer egységet ismernek fel egy magnak és a köznapi értelemben vett 8 magos verzióban 4 modul lesz ergo 8 integer egység. Tehát az OS 8 magot fog látni egy ilyen CPU esetében nem többet és nem is kevesebbet. Olyan hogy 16 szál nem lesz ennél.
-
Oliverda
félisten
Senki sem mondta de a laikusok közül ezt sokan nem tudták/tudják. Még mindig szoktam látni olyan apróhirdetéseket ahol nem 3200+-t írnak hanem 3200MHz-et annak ellenére hogy "köztudottan" arányszám volt.
Ez is pont azért került bevezetésre mert ha az egyszeri júzer bemegy a bótba' és ránéz az árlistára akkor ne gondolja azt reflexből hogy a Pentium 4 3.2GHz biztosan jobb és gyorsabb mint az Athlon 64 2000MHz. Viszont ha a Pentium 4 3.2GHz mellett/alatt már Athlon 64 3200+ volt akkor talán már meggondolta a dolgot.






![[/IMG (IMG:http://blogs.amd.com/work/wp-content/uploads/2010/03/image0021.jpg)(/IMG)]](http://blogs.amd.com/work/wp-content/uploads/2010/03/image0011.jpg "[/IMG (IMG:http://blogs.amd.com/work/wp-content/uploads/2010/03/image0021.jpg)(/IMG)]")







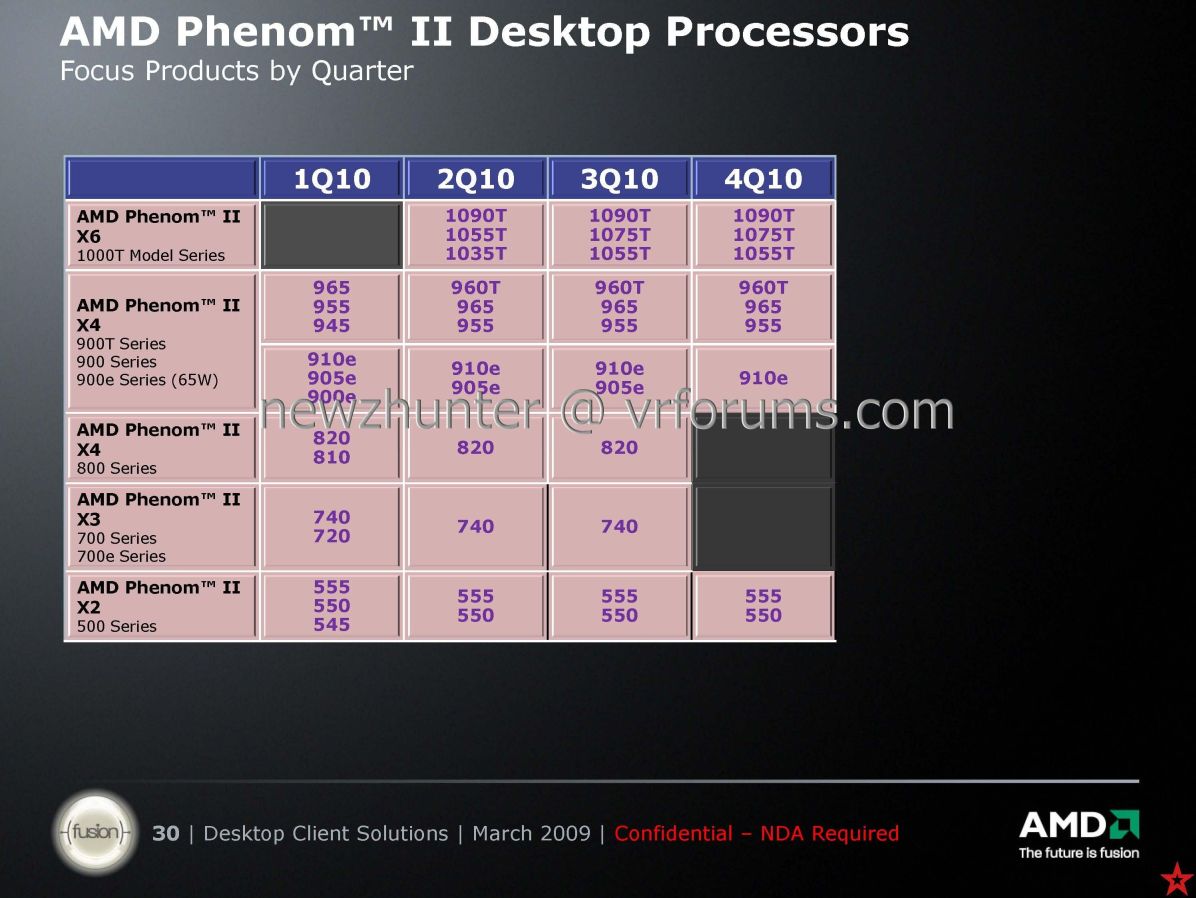






 A HT pedig messze nem ér annyit mint 6 valódi mag. Sok esetben még ront is nem hogy javít.
A HT pedig messze nem ér annyit mint 6 valódi mag. Sok esetben még ront is nem hogy javít.
















![;]](http://cdn.rios.hu/dl/s/v1.gif)












 Az Intel-nek hárommagos CPU-ja sincs az AMD-nek mégis van. Mik vannak.
Az Intel-nek hárommagos CPU-ja sincs az AMD-nek mégis van. Mik vannak. 
Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- AKCIÓ! Apple Watch SE 2024 44mm Cellular okosóra garanciával hibátlan működéssel
- Ventilátor bazár /NZXT/CORSAIR/LIAN LI/DEEPCOOL/ZALMAN/120MM/140MM/VEZÉRLŐK/LED KIT-ek/
- BESZÁMÍTÁS! MSI B460M i5 10400F 16GB DDR4 512GB SSD RTX 2060 6GB Zalman S2 TG FSP 600W
- S21 Dobozában 128/8
- HIBÁTLAN iPhone 12 Pro 128GB Gold-1 ÉV GARANCIA - Kártyafüggetlen, MS4441, 100% Akksi
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest