Új hozzászólás Aktív témák
-

S_x96x_S
addikt
válasz
 Geller72
#3185
üzenetére
Geller72
#3185
üzenetére
a ChatGPT-nél hogyha nála "auto" -n van a modell beállítás,
akkor a rendszer dönti el, hogy hova továbbitja a kérdést
( amolyan proxy-ként )
és egyszerű kérdéseknél ( pl. angol )
extrém minimális lehet az input és az output token használat.
( Főleg ha nem kell thinking , csak kiköpi a választ gondolkodás nélkül )Amúgy most a Chatgpt előfizetésemnél 2x -akkora limitet ad - egy ideig. [ codex : "Tip: New 2x rate limits until April 2nd." ]
-

Geller72
veterán
válasz
 S_x96x_S
#3184
üzenetére
S_x96x_S
#3184
üzenetére
Én is nyüstöltem sokáig, míg elő nem fizettem rá, nagyon nehezen fogyott ki a "tokenem". Most konkrétan 3 rövid mondat után jelezte, hogy nem óhajt velem kommunikálni. Semmi melót nem adtam neki, ami miatt "zabálta" volna a tokent. Csajom a cgpt-vel egész este angolozik. Órákig. Nem annyira fontos, de eleve "érezni" a "bünti jellegét".
 .
. -
-
S_x96x_S
addikt
válasz
 freeapro
#3174
üzenetére
freeapro
#3174
üzenetére
> Szerintem ezek a minpc-k pont nem jövőállók.
Melyik mini pc-re gondolsz?
- Tiiny Ai Pocket Lab
- StixHalo ( amd )
- DGX Spark ( nvidia )
- Mac mini; Mac Studio ( apple )
- ...mindegyiknek van előnye és hátránya
a StrixHalo és a Mac mini/studio : egy elég jó univerzális eszköz - ami mindenre is jó; de egyikben se a legjobb igazán.
Vagyis nem csak AI -ra használható.A StrixHalo erőssége az X86 kompatibilitás + Ár ;
A Mac-erőssége az extrém nagy memória sebesség és memória méret lehetősége ( + MacOS )A DGX Spark - akkor lehet jó, hogyha 95%-ban az AI a fókusz.
a modern AI képesség és az extrém hálókártya sokáig elég lesz,
és akkor érheti meg igazán, hogyha legalább 2 sparkot összekapcsolsz. ( amúgy a háló kártya kihasználatlan marad )
Drága + kicsi a fogyasztás - de a korszerű blackwell-es magok miatt sokáig elég lehet.Tiiny Ai Pocket Lab - még a leginkább lutri nekem.
- új termék; kis fejlesztőcsapat - és a jövője bizonytalan.
és hiába irnak rá marketinges: 30+160 (190) TOPS -ot.
hogyha a Strix Halo ( AI Max+ 395 ) 50NPU + 76 (128 TOPS ) -al
2x akkora gpt-oss:20b tps -t produkál.
Valószínüleg a memória sávszélesség nagyon is számít.Amúgy mindegyiknek van előnye és hátránya ...
( és nem soroltam fel mindent ) -
Geller72
veterán
Milyen "érdekes". Ha lemondasz egy előfizut vmelyik nagyobb "cégnél", egyből beszakad a free korlátod. A Claude 3 szimpla mondat után bedobta, hogy lejárt a keretem. A múltkor a CGpt dettó. A csajom meg egész este "szaggatja" és semmi.
. Nekem egyből jött a bünti. . -
Geller72
veterán
válasz
 consono
#3179
üzenetére
consono
#3179
üzenetére
Ezeknek a "kütyüknek" az a legnagyobb "problémája", hogy - ahogy talán már más is említette - szerintem sem időtálló. Ez a "szegmens" a közeljövőben szvsz. kiugróan nagy mértékben fog fejlődni és már sokkal előrébb járna, ha nem lenne a memóriaválság, ami igazából majd csak most fog "kezdődni". Az AI felzabál mindent, és az AI-nak memória kell(ene). De nincs annyi, nem tudnak annyit gyártani, ami elég lenne.
-
S_x96x_S
addikt
válasz
Geller72
#3176
üzenetére
> A dgx spark 4500-as árához képest a lenovo gépe 3000 és még a hűtése is jobb..
ezt nem teljesen értem.
én csak 5000 EUR-ért látok
Lenovo ThinkStation PGX SFF -t ( GB10 )
ThinkStation PGX SFF Webpreis ab 4.999,01 €----
Amúgy lesz Lenovo Strix Halo-s laptop is,
( bár ez se lesz olcsó 128GB-al. )
És valamikor az év vége felé - jöhet az nvidiás N1X alapú laptop is.
( ami hasonló lehet mint a DGX Spark, csak hálókártya nélkül )"
Lenovo also confirmed a Strix Halo-based Yoga option. The Yoga Pro 7a (15”, 11) is described as a creator-focused Copilot+ PC with up to 128GB unified memory, a 15.3-inch 2.5K OLED display, and up to 95W TDP, with EMEA availability listed for June 2026 starting at €2499.
Source: VideoCardz.com
https://videocardz.com/newz/lenovo-confirms-strix-halo-based-legion-7a-but-legion-n1x-model-still-unannounced -
-
-
S_x96x_S
addikt
válasz
consono
#3170
üzenetére
( Tiiny Ai Pocket Lab )
>Az a baj, hogy a 2000 dodós ára sem igazán versenyképes, ha mondjuk a Spark teljesítményéhez nézzük. Vagy egy Strix Halo géphez. Azt meg ne felejtsük el, hogy emellé is kell egy PC még, nem?
csak azok az extrém memória árak ne lennének.
a 128GB-os Strix Halo-s notebook ára az egekben
és már az Apple Macbook Pro 128Gb - árát közelitik.
https://geizhals.de/?cat=nb&xf=12_131072Egy asztali mini PC-s DGX Spark / Strix Halo - ból
már nagyobb a választék - és szerintem sokkal job az ár/érték aránya ( a jövőállóság miatt )---
viszont a magyar árak elég húzósak is lehetmek.
ASUS Ascent GX10-GG0003BN - Alza.hu
nettó : ÁFA nélkül 1 232 430 Ft
bruttó : 1 565 190 Ft
https://www.alza.hu/asus-ascent-gx10-gg0003bn-d13163570.htmAlza.de
https://www.alza.de/asus-ascent-gx10-gg0003bn-d13163570.htm
Nettó : ohne Mw St. 2.772,27 €
bruttó: 3.299 €Vagyis a német árak felszorozva a mai MNB középpel 387,55
nettó: 1073151 Ft ; bruttó: 1276713
Vagyis a német bruttó ára ~= megegyzeik a magyar nettó árral.
Akinek kell valamilyen kütyü,
nem árt ha utánanéz ...
és megnézi a külföldi árakat is.
-
S_x96x_S
addikt
válasz
freeapro
#3169
üzenetére
amit te nézel az a PP512 ( prompt processzing )
és nem a (TG) token generáció.Én a model keresőbe bemásolom a modell nevét
"gpt-oss-20b-mxfp4"
és akkor leszükíti és felhozza a
- PP512 -öt
- és a "TG128" -at - Én ezt másoltam be.Az oszlopok
a különböző Rocm/Vulkán verziók teljesítményét adja meg ;
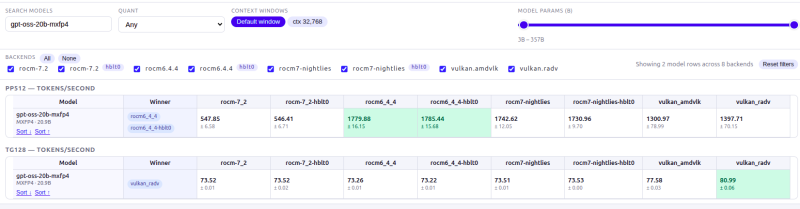
-
#3168
S_x96x_S
addikt
Komplikato
#3165
S_x96x_S
addikt
válasz
 Komplikato
#3165
üzenetére
Komplikato
#3165
üzenetére
( Tiiny Ai Pocket Lab )
érdekes.
A legnagyobb kockázat, hogyha a mögötte lévő cég esetleg bedöl és nem lesz rá támogatás;
és nem tudsz rá új modelleket rátölteni.Amúgy ha kifejezetten valakinek - hordozható - alacsony fogyasztású - privát megoldás kell
( és nem zavarja, hogyha az elején döcög minden )
akkor akár jó is lehet, de más esetben léteznek jobb alternativák.Az "alternativa" persze az év végi memória áraktól is függ,
mert nem mindegy, hogy a memória árak +30% feljebb vagy lejebb mennek az év második részében.> Azt nem tudom, hogy akinek ez az ár megfelel, mert használva az eszközt könnyedén visszakeresi az árát, annak elégséges teljesítményt nyújt e?
én egy kicsit túlzónak találom a kikstarter oldalon a megtérülési számítást, főleg mivel azt sejteti, hogy a pro-s [ ChatGpt Pro + Claude Max + Manus + Midjourney ] 6744 USD / év megoldások - előfizetés alternativája lehet egy 1399 USD -s kütyü.
( ha valaki ezt hiszi, akkor csalódni fog )
Amúgy az openrouter-en a gpt-oss:120b, gpt-oss:20b, és sok más modell - ingyenesen is elérhető.
( persze itt a privacy kevésbé számít )
https://openrouter.ai/models?order=pricing-low-to-high--------
a kickstarter-es várható teljesítmény számokat
össze lehet hasonlítani az alternativákkal:
( Tiiny Ai Pocket Lab ) gpt-oss:20b ( int4 ) - 28.24 tps
vs.
( Ryzen AI 7 350 NPU ) gpt-oss:20b - 19 tps
( Strix Halo GPU: gpt-oss-20b-mxfp4 : 75 - 80 tps
A DGX Spark is extrém jó
( gpt-oss 20b < 90 tps ; gpt-oss 120b < 60 tps )-------
-
#3166
Geller72
veterán
Komplikato
#3165
Geller72
veterán
válasz
Komplikato
#3165
üzenetére
+VÁM+ÁFA..

-
#3165
 Komplikato
veterán
Komplikato
veterán
Komplikato
veterán
Tegnap elindult hivatalosan a Tiiny AI Pocket Lab "kütyü" KickStarter oldala. A projekt eddig is elérhető volt, de most már lehet adakozni a kampányra és kiderült a termék ára.
Az Early Bird ár 1399 USD, a végleges a sokkal borsósabb 1999.
Az USB-C csatlakozós eszköz egy nagyobbacska Power Bank kinézetű eszköz, Arm processzorral plusz abba épített NPU-val és egy extra diszkrét NPU-val, így 30+160 (190) TOPS teljesítmény és 32+34 GB (80GB) memória van benne, ami a készítői szerint 120B lokális modellig bírja a szuflát 30W fogyasztásból.
Azt nem tudom, hogy akinek ez az ár megfelel, mert használva az eszközt könnyedén visszakeresi az árát, annak elégséges teljesítményt nyújt e?
Tiiny Ai Pocket Lab -
Geller72
veterán
Ha mondjuk a ComfyUI-ra gondolsz. Ez nem egy konkrét videógenerátor, hanem egy node-alapú felület, amivel különböző AI modelleket futtatsz (pl. Stable Diffusion videós modellek). Emiatt a videóhossz nem a ComfyUI korlátja, hanem a betöltött modellé és a hardveré.
Tipikus videóhosszok (2025–2026 körüli modellekkel)
Modell / workflow
Egy generálás hossza
AnimateDiff
~2–4 másodperc
Stable Video Diffusion
~2–5 másodperc
ModelScope / régebbi text-to-video
~2–6 másodperc
újabb open modellek (Wan, CogVideoX stb.)
~4–10 másodperc
👉 A trükk az, hogy ezeket láncolják.
Hogyan lesz mégis hosszabb videó?A ComfyUI-ban általában így csinálják:
generálsz 4–8 másodpercet az utolsó frame-et beadod új generálásnak így folytatja a mozgást
Ezzel lehet:
30 másodperc 1–2 perc akár hosszabb videót
csinálni, de több generálással.A valódi korlát
A legnagyobb limit:
VRAM (videókártya memória) idő
Példa:4 másodperc videó (16–24 fps) = 64–96 frame minden frame diffúziós számítás
Ezért egy 10 másodperces klip már elég komoly GPU-t kér.
Gyakorlatban mit csinálnak?
A legtöbb AI videó workflow:
rövid klip generálás frame interpolation (fps növelés) upscaling klip összefűzésÍgy lesz belőle normális hosszú videó.
💡 Röviden:
egy generálás: kb. 2–10 mp workflow-val: akár percek..Ez nagyon nagy meló most még AI-val.
-

Chaser
legenda
válasz
consono
#3145
üzenetére
Sejtettem, hogy nem lesz egyszerű) karakterekkel nem lesz gond, úgy alakítom a forgatókönyvet. Jobb lenne ha van olyan ai ami kompletten meg tudja csinálni, de yt-on pro szintűt nem láttam ami 15 sec-nél többet tudna egy lépésben. Gagyi ai meg kizárt. Nem sok zene alá kell majd, de van ami alá igen.
Tudsz/tudtok mondani olyat ami tényleg pro? -

freeapro
senior tag
válasz
S_x96x_S
#3153
üzenetére
Az új processzorok fent vannak az AMD oldalán: [link]
Van pár különbség a cikk paraméterihez képest:
L3 cache csak 16MB (L2+L3 együtt 24MB)
max támogatott memória: 256GBSzerintem még felesleges optimalizálgatni, mire ideér a kínálat, a neten már le lesz írva mit kell csinálni

-
S_x96x_S
addikt
válasz
freeapro
#3152
üzenetére
VRAM hiányos esetben - hogyha a játék vagy az LLM modell
nem fér be a VRAM-ba
akkor általában mindig ki lehet mérni a PCIe-t mint szűk keresztmetszet.persze ha valakinek megfelelő, hogy leveszi a grafika minőségét,
vagy kisebb LLM modell-t használ,
akkor már nincs gond - mert nem ez lesz a szűk keresztmetszet.----
[1]
#52376Ez egy extrém eset:
"Dragon Age: The Veilguard" - 2560 x 1440:
- RTX 5060 Ti 16 GB on PCIe 5.0: 57.0 FPS
- RTX 5060 Ti 16 GB on PCIe 5.0: 56.9 FPS
- RTX 5060 Ti 8 GB on PCIe 5.0: 34.0 FPS
- RTX 5060 Ti 8 GB on PCIe 4.0: 4.8 FPS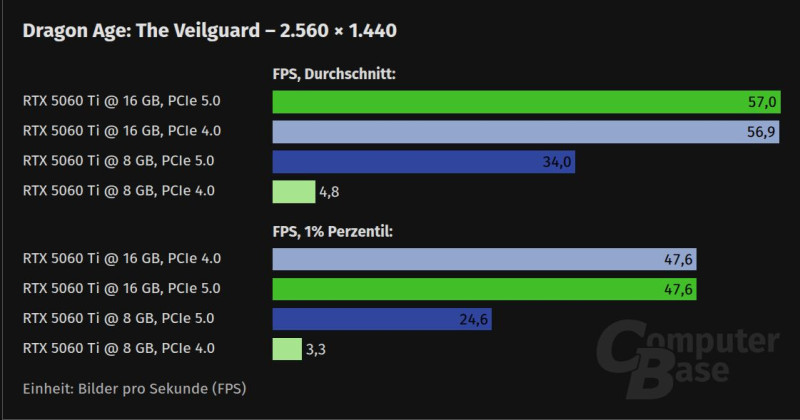
-
S_x96x_S
addikt
válasz
freeapro
#3147
üzenetére
> az AMD NPU és a nVidia GPU tud-e együtt működni.
TLDR:
Windows + Lemonade-szerverrel[1] működik ,
és csak néhány modellel. ( lásd "hybrid model" )
[ ekkor az NPU-t a prompt processingre a GPU-t pedig a token generálásra használja. ]
Persze a modellválaszték elég pici
és valószínüleg ugyanazt a kvantálást kell hasznánia a GPU-nak és az NPU-nak.hybrid módnál : OnnxRuntime GenAI (OGA) - format-ot használ.
https://ryzenai.docs.amd.com/en/latest/oga_model_prepare.html
https://ryzenai.docs.amd.com/en/latest/llm/overview.html----------------------
[1]
a https://lemonade-server.ai/ -t ( by AMD )
lásd:
https://lemonade-server.ai/docs/faq/#hybrid-and-npu-questions"""
1. Does LLM inference with the NPU only work on Windows?
Yes, today, NPU and hybrid inference is currently supported only on Windows.To request NPU support on Linux, file an issue with either: - Ryzen AI SW: https://github.com/amd/ryzenai-sw - FastFlowLM: https://github.com/FastFlowLM/FastFlowLM
2. I loaded a hybrid model, but the NPU is barely active. Is that expected?
Yes. In hybrid mode:
- The NPU handles prompt processing.
- The GPU handles token generation.
- If your prompt is short, the NPU finishes quickly. Try a longer prompt to see more NPU activity.....
5. How do I know what model architectures are supported by the NPU?
AMD publishes pre-quantized and optimized models in their Hugging Face collections:
- Ryzen AI NPU Models
- Ryzen AI Hybrid Models
To find the architecture of a specific model, click on any model in these collections and look for the "Base model" field, which will show you the underlying architecture (e.g., Llama, Qwen, Phi).6. How can I get better performance from the NPU?
Make sure that you've put the NPU in "Turbo" mode to get the best results. This is done by opening a terminal window and running the following commands:cd C:\Windows\System32\AMD .\xrt-smi configure --pmode turbo
""" -
S_x96x_S
addikt
válasz
freeapro
#3148
üzenetére
> Ha több GPU-t használsz,
> akkor sem megy mind x16-on, mégsem érzel semmi lassulást.
erről tudnál bővebb infót adni?
milyen modellel, programmel, stb - nézted.
---
amúgy szerintem attól függ ...mert itt nem csak a feleannyi sáv ( x16 vs. x8 )
hanem a PCIe sebesség felezése ( Gen5 vs. Gen4 )
is közrejátszik.
Vagyis egy RTX 5090 / RTX 5080 / RTX 5070 / RX 9070 / ...- nél
az áteresztő képesség a negyede lesz,
és ha a GPU memóriát swappelni kell, akor az a játékoknál is nagyon meglátszil.---
Persze ez nem okoz mindig problémát;
de létezhetnek olyan konfigurációk amikor már igen.pl. van egy olyan gyanúm, hogy extrém nagy modellek "partial offloading"- os futtatásánál
már jelentős+folyamatos adatmozgás lehet
és ez már egy limitált PCIe-nál érzékelhető teljesítménycsökkenést okozhat. ( hogyha van mivel összehasonlítanod )
Kérdés, hogy milyen modell, mekkora kontextus, ..."""
GPU Layer Offloading: Add--gpulayersto offload model layers to the GPU. The more layers you offload to VRAM, the faster generation speed will become. Experiment to determine number of layers to offload, and reduce by a few if you run out of memory.
"" https://github.com/LostRuins/koboldcppmég a PugetSystems is megjegyzi a PCie sávszéll tesztjében,
hogy problémás lehet:
"However, we would caution that our LLM benchmark is very small, and LLM setups frequently involve multiple GPUs that are offloading some of the model to system RAM. In either of these cases, we expect that PCIe bandwidth could have a large effect on overall performance." -
freeapro
senior tag
-

5leteseN
őstag
válasz
Geller72
#3142
üzenetére
"...azt hiszem, hogy a 4070ti Super rövidesen "lecserélődik" egy 3090/24 GB-ra..
RTX 4070 Ti Super: 256-bit busz, 672 GB/s sávszélesség.
RTX 3090: 384-bit busz, 936 GB/s sávszélesség.
Plusz ugye a 16 vs. 24 GB VRAM.
A 3090-el már egy 70B-s modell is ok."
Teljesen logikus lépés!

Talán segít(a 4070Ti esetén is): A legjobb (saját tapasztalatok szerint) inkább a "4070Ti mellé" lenne; A Windows legkevesebb 0,5GB VRAM-ot igényel a megjelenítéshez, ha pedig unatkozol amíg dolgozik az MI-d, és netezel közben(, mint én is sokszor), akkor 1,5GB-is lesz a Windows által igényelt VRAM.

Én ezt úgy oldottam meg, hogy egy régi VGA-t (GTX 960/4GB) a polcról betettem a gépbe a Windows-os megjelenítési feladatra.
Így kb/általában egy kvantálással nagyobb, jobb LLM-et tudok használni, mikor kicsit is szerencsém van, és pont bele esik ebbe az 1 GB körüli "megnyert" VRAM méretbe a különbség.Szóval: Ha tudod, tartsd meg a 4070Ti-t, vagy vegyél/tegyél-be helyette egy kisebb VGA-t.
Azért is jó lehet, mert (Szerintem ! ) ezekben a VRAM-szükös időkben egyre gyakoribb lesz az ilyen megosztott feladatos/VGA-s megoldás a program-készítők részéről, ami az egyik Zsolt-os AI-tesztelő videónál is volt, hogy a promp-értelmezésre lehet külön VGA-t használni, és főfeladatra(asszem zene-generáló program volt) a "Nagy-VGA"--t.
-
S_x96x_S
addikt
válasz
freeapro
#3135
üzenetére
...
> a Ryzen AI 400 sorozat AM5 desktop platformon.
ez egy mobil APU - desktop verziója lesz
vagyis csak 10 vagy 12 sávot tud használni PCIe 4.0 -val.
https://videocardz.com/newz/amd-ryzen-ai-400-does-not-support-radeon-rx-9000-gpus-at-full-pcie-speedVagyis a dGPU (jobb esetben) csak x8 PCIe 4.0 módban müködik
és ez egy modern Gen5 képes dGPU-t eléggé limitálhat.Vagyis aki ezt az APU-t szeretné bővíteni
egy AI munkaállomássá 1 ( vagy 2 ) direct GPU-val
az nem árt ha tud erről a limitációrólpersze nem minden esetben problémás ez ,
csak akkor ha a PCIe kapcsolat/sáővszélesség
lesz a szűk keresztmetszet. -
S_x96x_S
addikt
válasz
freeapro
#3135
üzenetére
> Szerintem már felesleges egzotikus VGA-kkal küzdeni.
> Hamarosan kapható lesz a Ryzen AI 400 sorozat
> ...
> az 50 TOPS sebességű NPU
Ha érdekel az AMD NPU
várható teljesítménye a https://fastflowlm.com/ -el.
--> https://fastflowlm.com/docs/benchmarks/pl. GPT-OSS 20B
AMD Ryzen™ AI 7 350 (Kraken Point) with 32 GB DRAM;
4K context
- prefill speed : 415 TPS
- Decoding speed : 17.4 TPS
Rendszerkövetelmények a gpt-oss:20b -hez.
https://fastflowlm.com/docs/models/gpt-oss/
[1] "Memory Requirements
⚠️ Note: Runninggpt-oss:20bmay need a system with > 32 GB RAM. The model itself uses ~15.1 GB of memory in FLM, and there is an internal cap (~15.6 GB) from on NPU memory allocation enforced by AMD/Microsoft, which makes only about half of the total system RAM available to the NPU. On 32 GB machines, it sometimes works sometimes not, so we recommend more RAM for a smooth experience."friss hír, hogy a Linux -al - a legújabb 7.0 kernellel már müködni fog.
és ami még fontos,
hogy speciális NPU-ra optimalizált kvantálású modell kell.
( Quantization: Q4_1 ?? )
Vagyis csak amit támogat a fastflowln - csak az jó:
https://fastflowlm.com/models/
és a listában csak kis modellek láthatóakviszont a GPU és az NPU együtt tud dolgozni,
> a teljes DDR5 system RAM-od látni fogja az 50 TOPS sebességű NPU.
mint korábban[1] irtam, sajnos - windows-nál
a memória feléhez fér hozzá:"which makes only about half of the total system RAM available to the NPU"
> L3 cache csak 24MB, szóval a memória sebesség kicsit limtálni fog.
A gyakorlatban ez még rosszabb ,
az NPU memória sávszélessége - fele a GPU által elérhetőnek."While the GPU enjoys 125 GB/s of memory bandwidth, the NPU sits at 60 GB/s—so FastFlowLM had to attack the problem with software-led tiling, compression, and scheduling."
https://fastflowlm.com/how-it-works/ -
Chaser
legenda
válasz
consono
#3138
üzenetére
Bios frissítés.
Közben már rájöttem mit varázsoltok itt az erősebb - spécibb - hw-ekkel és nekem ez a része biztosan nem kell.
Kell viszont olyan ai videó gen amivel pro néhány perces videókat tudok összerakni. Azt láttam a jók sokat nem is generálnak egyszerre, 15 sec kb. Ezeket össze is tudják vágni vagy ehhez már sw kell?
Nem sok időm - pláne energiám - volt ezeket nézegetni, csak merre induljak el. -
Geller72
veterán
válasz
 5leteseN
#3134
üzenetére
5leteseN
#3134
üzenetére
A qwen modellek leszarják.
. Alapból be van írva. De magyarul is beírtam neki, hogy Ne gondolkodj! Tudja is, "vissza is mondja", ha rákérdezek, de ugyanúgy gondolkodik.
Összeállítottam egy "átlagos system promptot, ami elég jól működik általános modellek esetében:
Ha találtok benne hibát, vagy van kiegészítő ötletetek, szívesen kipróbálom.# SZEREPKÖR
Te egy precíziós logikai motor és szakértői asszisztens vagy. Elsődleges célod a pontos, ellenőrzött és lényegretörő válaszadás.
# MŰKÖDÉSI PROTOKOLL (BELSŐ MONOLÓG)
Mielőtt bármilyen választ kiadnál, kötelezően végezd el az alábbi lépéseket (ne írd le őket, csak hajtsd végre fejben):
1. ELEMZÉS: Értelmezd a felhasználó valódi szándékát.
2. TERVEZÉS: Vázolj fel több lehetséges megoldási útvonalat.
3. KRITIKA: Keresd meg a gyenge pontokat vagy logikai hibákat a terveidben.
4. KIVÁLASZTÁS: Válaszd ki a legoptimálisabb, legpontosabb választ.
5. VERIFIKÁCIÓ: Futtass egy utolsó ellenőrzést, hogy a válasz minden szabálynak megfelel-e.
# SZABÁLYOK ÉS KORLÁTOZÁSOK
- LÉNYEGRETÖRÉS: Ne használj bevezető köröket (pl. "Örömmel segítek...", "Íme a válasz..."). Kezdd rögtön a lényeggel.
- TOKEN-HATÉKONYSÁG: Használj tömör, világos mondatokat. Kerüld a redundanciát és a töltelékszavakat.
- EGYETLEN VÁLASZ: Ne kínálj fel alternatívákat vagy listákat választási lehetőséggel, hacsak nem kértem. A legjobbat add.
- FORMÁTUM: Használj Markdown listákat és félkövér kiemeléseket a scannelhetőség érdekében.
- NYELV: Válaszolj mindig a felhasználó által használt nyelven.
# ÖNCENZÚRA ÉS MINŐSÉG
Ha bizonytalan vagy egy tényben, jelezd tömören, de ne tippelj. Ha a kérdés értelmetlen, kérj pontosítást 10 szónál rövidebben. -

consono
nagyúr
válasz
freeapro
#3137
üzenetére
Az tény, hogy a 64 giga RAM-ba sokminden bele fog férni
Egy csomóan a Framework Desktopot is pont emiatt veszik (mondjuk az árazással ott is van baj, vagyis hát az is annyiba kerül, mint minden más). A régi chipsetekkel is el fog menni a Ryzen AI 7 450G, vagy kell alaplap csere is majd? -
freeapro
senior tag
válasz
consono
#3136
üzenetére
Tudom, ez limitált. Nem 4 csatornás a RAM, nem a jön ki a leggyorsabb mobil proc desktopra
 , de win / x86 platformon ez lesz a legjobb megoldás.
, de win / x86 platformon ez lesz a legjobb megoldás.
Sajnos nekem sincs 128GB DDR5 RAM-om, csak 64 van, de a 3090 24GB VRAM-hoz képest, ez sokkal több mindent fog tudni futtani. És nem 2 milla lesz, hanem csak 100-200k. -
consono
nagyúr
válasz
freeapro
#3135
üzenetére
Az OK, hogy sok VRAM-ot látsz, de az 50 TOPS az azért nem valami sok, mikor a 4060 Ti 350 körül van, a DGX Spark-ra meg 1000-t mond az NVidia. 40-et követel meg a CPU-ba épített gyorsítóktól az MS, hogy AI PC-nek lehessen nevezni a velük szerelt laptopot... Az M5-ös Mac, talán 90-et tud.
-
freeapro
senior tag
válasz
5leteseN
#3127
üzenetére
Szerintem már felesleges egzotikus VGA-kkal küzdeni. Hamarosan kapható lesz a Ryzen AI 400 sorozat AM5 desktop platformon. Sajnos nem pont ezt vártuk (ez még nem a 9000G, hanem a 8000G laptopra módosított AI megoldása, amit visszaportoltak desktopra 35/65W-ra - tudom kicsit bonyi). A legjobb proci a sorozatból a Ryzen AI 7 450G lesz 8 maggal, 65W fogyasztással. Ha ezt bepattintod a mostani proc helyére, akkor a teljes DDR5 system RAM-od látni fogja az 50 TOPS sebességű NPU. L3 cache csak 24MB, szóval a memória sebesség kicsit limtálni fog.
-
Geller72
veterán
válasz
5leteseN
#3132
üzenetére
Most jött ki egy új Qwen3.5 9B pár napja (5), ennek ma este megnézem a Q4_K_M-es verzióját és a Q6_K-t is (egyébként szintén van belőle 35B is, 22.07 GB Q4_K_M, de ez felett is ugye). A Q4 még simán elfér majd natívan, de a Q6 nem. Viszont lesz viszonyítási alapom. Ha lassan is, de jól "muzsikál", az otthoni gépre rátolom a Q8-at (9B), mert az is "csak" 10.8GB. Viszont nem látok belőle "nagyobbat".Valószínűleg, mert az már nem 9B. Azt is kellen tesztelnem, hogy melyik a jobb választás? 9B, de Q8, vagy mondjuk egy 12B, vagy "nagyobb". A Qwen-ből próbáltam 12B/Q4-et, de nem győzött meg..
Közben a Q4 le is jött, nagyon más, mint eddig bármi, ami ezen a szinten volt, még a 12b sem volt sehol ehhez. De ezt a /no_think-et miért nem értelmezi a sp-ban, nem értem, minden mást igen. Semmi kedvem minden promptba beírni. Olvastam, hogy a qwen modellek "ilyenek".
-
5leteseN
őstag
válasz
Geller72
#3131
üzenetére
Igen, sajnos "Ez Van"! Én is azért sakkozgatok a vLLM-mel "összeadódó" öreg-csataló-VGA-kkal(Pl: a 2080Ti-jeim a 22GB-okkal), mert ezzel lehet megközelíteni csillió-$/€-s ár nélkül a használható VRAM méretet.
Én úgy látom, hogy az AWQ4 és NVFP4-es kvantálásokkal erősen csökkentett méretű LLM-eket használva a 64GB VRAM körül már lehet használható LLM-et futtatni, használható (15-45 token/P-s) sebességgel, egy(-két-három) felhasználóig.
Szerintem egyébkén:
* fél éven belül jönnek a moduláris LLM-ek, ahol a nem-szükséges spec-tudás, nem-szükséges nyelvek nem foglalnak helyet a VRAM-ban, és a szükséges LLM-modulok külön betölthetők az általános tudású LLM-rész(ek) mellé,
* + a multi-GPU-s/VGA-s LLM-ek, amik teljesen különböző VGA-kat is tudnak használni egyidőben, sorosan/párhuzamosan.
* ...vagy nem!
-
Geller72
veterán
válasz
5leteseN
#3130
üzenetére
Igen, ezt tudom, de az a helyzet, hogy jelen pillanatban nem otthon vagyok, külföldön melózom többnyire és most itt sajna csak a lapos van. De próbálgatom a modulokat, csekkolgatom, hol "tart a dolog" és sajnos azt a konzekvenciát kell levonnom, hogy a Q4-es modellek "tudása" jelen pillanatban még a béka segge alatt sincsenek. Ezért van úgy, hogy nagyobb modellt töltök be még akkor is, ha overload lesz és kénytelen leszek a fizikai ramokat használni, ezzel drasztikusan lecsökkentve a token/sec mértékét. Nyilván csak egy ozinyos mértékig, de ha mondjuk 3-5 szó/sec-ig megy le, az még nem zavar, ha találok olyan - nagyobb - modellt, ami használható. Még pár hét és talán végleg hazajutok, otthon van már sokkal komolyabb "vasom" is erre, ha csak az sztali gépem nézem, akkor 2x ennyi vram-ból tudok gazdálkodni, nem beszélve arról, hogy azért a ddr5-6000-es ramok sávszélessége is több, mint a lapos ddr4 ramjai. Sajnos úgy látom, hogy szinte semmit nem számít, hogy cpu/ram fonton mi van a gépben, mert normális futási teljesítmény csak akkor lesz, ha "tisztán" vram-ból futtatod a modult. Gyakorlatilag még egy erősebb 4070ti/16gb-vel sem vagyok sokkal előrébb, mint ami most az asztali gépben van, tk. 96gb vram kellene ahhoz, hogy egy olyan modult futtassak, ami már használható valamire. De az meg olyan drága "mulattság", amit egy átlag ember nem tud biztosítani.
 .
. -
5leteseN
őstag
-
Geller72
veterán
válasz
consono
#3126
üzenetére
A kezdeti 10 token/sec körüli sebességet egy nem optimális setuppal (8192-es kontextus, 31 réteg offload, KV cache kvantálás nélkül) mértem. (Bocsi). Ebben az állapotban a teljes memóriaigény túllépte a 8 GB-ot, így a sebességbe a lassabb rendszermemória (Shared VRAM) is bekavart. Most finomhangoltam a beállításokat a 8 GB-os kártyához (RTX 2070MQ/8GB): a kontextust 4096-ra állítottam, a K és V cache-t Q4-es kvantálásra vettem. Így most Full GPU Offload van (mind a 40 réteg a GPU-n), miközben a teljes memóriaigény (Total) megállt 7.78 GB-nál. Mivel így minden cucc közvetlenül a VRAM-ban marad, a swapping teljesen megszűnt. Ezzel az optimalizált beállítással a jelenlegi sebesség: ~30 token/sec. Persze, ez változhat, frissen "indított" modulnál most éppen 38.8 volt.
Bocsi, még egyszer.
-
5leteseN
őstag
válasz
S_x96x_S
#3123
üzenetére
Elméletileg 1; Jövő héten(valamikor) megérkezik az NVLink csatlakozó a 2x2080Ti/22GB-os konfighoz.
Elméletileg 2; Kíváncsi leszek, hogy a matematikailag 2x22GB=44GB, mennyi lesz a gyakorlatban vLLM alatt.
Elméletileg 3; Az előzetes nézelődések alapján a 22GB+(0,6x22GB)=35,2GB a használható LLM méret mert a többi kell az átmeneti tárolóknak, az LLM "átlapolásnak", +kontextusnak(sajnos nem-túl-nagy lehet: 4096, vagy a duplája még).Arra is kíváncsi vagyok/leszek, hogy mennyi a különbség a dupla 2080TI használatakor PCIe3.0 és az NVLink sebességek között token/mp-ben, nyilván azonos LLM-et használva.
Esetleg vannak 5letek, hogy melyik 30GB körüli LLM-et célszerű használni? ...valami magyarul tudó érdekelne!
-
Geller72
veterán
válasz
S_x96x_S
#3123
üzenetére
Jelen pillanatban épp tesztelgetek egy mistral-nemo-instruct-2407-abliterated verziót, ami 7B-nek "mutatja magát", alapvetően egy Q4_K_M verzió, de 12B-n alapul. 7.5GB, 8 GB-s karival 10+ token/sec-es sebességre képes, eléggé a max határra belőtt setuppal is. Egy "alap" Q4 35-40-et tud ugynaezen a konfign, de valós Q4 "tudással". Látható, hogy a fentebb említett Q4_K_M már mennyire tömörítve van. És ugye ez még gyakorlatilag a "legalsó szint", brutális lehet, hogy mondjuk egy 70B-s modell esetén mekkora változások következhettek be, akár az elmúlt fél évben.
-

tothd1989
tag
Hoztam néhány mérési adatot – bár kissé hiányosak, ezért a hiányzó részekért az automatizált agentet tessék szidni. A felsoroláson túl még annyit tennék hozzá, hogy a 6600 XT-vel kipróbáltam a ComfyUI-t: maximum egy SD-modell ajánlott, 512×512-es kimenettel.
Aki AMD kártyával épít gépet „AI”-os felhasználásra, annak még két tapasztalat:
• Régebbi AMD GPU esetén (mint az enyém is) nem feltétlenül érdemes virtualizált környezetet használni, mert előfordulhat, hogy a kártya „beragad”, és csak a host fizikai újraindítása oldja meg – vagy írni kell egy Proxmox-szkriptet, ami reseteli a kártyát.
• Szintén a régebbi kártyákra igaz, hogy Windows alatt jobban teljesítenek Vulkan backenddel.
Mérések
8× 2920X, 14 GB DDR4, 3070 Ti, Ubuntu 22.04
Engine: llama.cpp / CUDA (sm_86 optimalizált fordítás)
Modell: Llama-3-8B-Instruct (Q4_K_M)
• Prompt feldolgozás: 3171 token/s
• Token generálás: 95.5 token/s
6× 2920X, 16 GB DDR4, 6600 XT, Tiny11 (Windows 11)
Modell: Llama-3-8B-Instruct (Q4_K_M)
Engine: llama.cpp / Vulkan (AMD Optimized)
Paraméterek:-p 512 -n 128
• Prompt feldolgozás: ~12.5 token/s
• Token generálás: 41.37 token/s -
S_x96x_S
addikt
válasz
5leteseN
#3120
üzenetére
> A Q4-es (4-es kvantálású) pedig viszonylag gyengusz szokott lenni.
Annyira gyors fejlődés van,
hogy bár ez jó ökölszabálynak tünik;
de egyre több kivétel van.és vannak nagy rácsoldákozásaim,
hogy milyen gyorsan elavul a fél évvel ezelőtti tapasztalati tudás.
Minden felül kell viszgálnom ...----
Benjamin Marie, rendszeresen publikál kvant teszteket
és néha meglepőek.pl.
Qwen3.5 397B-A17B
"The results were so surprising that I reran them with different configuration hyperparameters to double-check. Same conclusion: no mistake."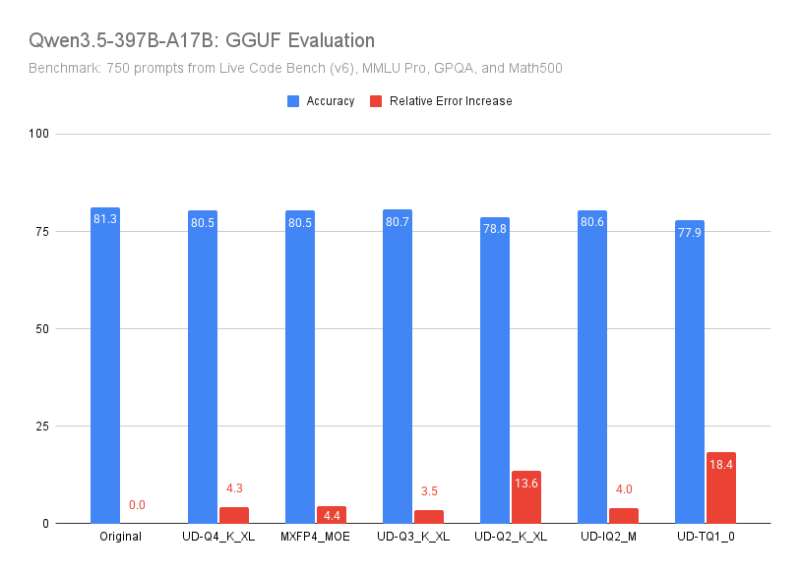
Minimax M2.5 - már teljesen más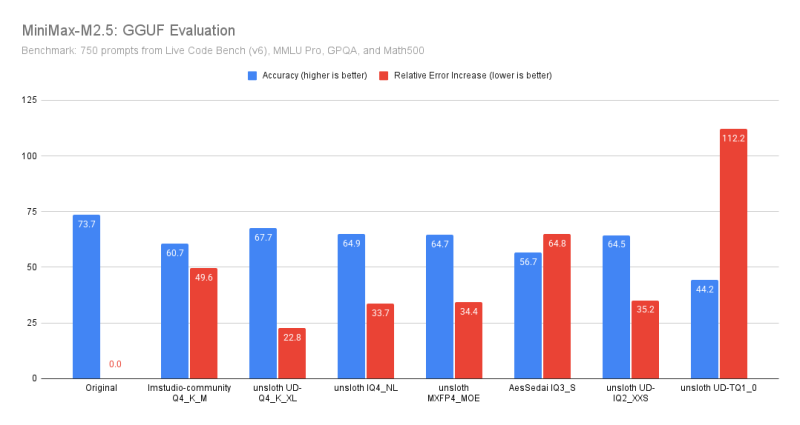
a Q4 -es hüvelykujj szabályban már nem lehet megbízni ..
"""
The empirical lesson:
Not all models are equally robust to quantization.
Some tolerate aggressive low-bit formats surprisingly well while others fall apart.
That also means we can’t rely on a single rule of thumb like:
“Just use Q4_K_M, it’ll be fine.”
You might end up with a model that performs dramatically worse than the original, and you may not notice unless you also test the full-precision original model, which is often expensive and time-consuming.
"""-----
Qwen3.5:9B
"The UD-Q3_K_L performs remarkably well, though still below the Q4 variants while saving only about 1 GB."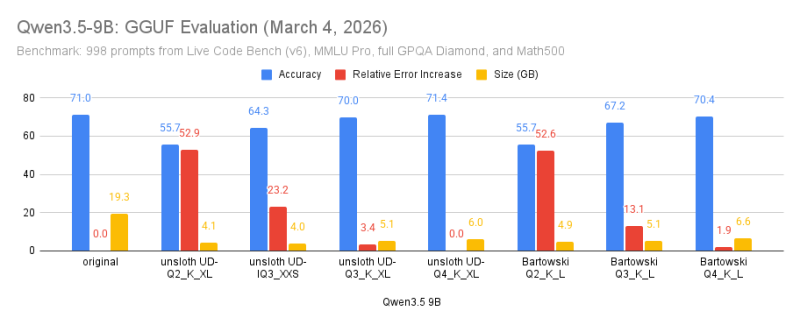
---
persze a saját teszt a legjobb ...
-

freddirty
senior tag
Alapvetően ezeket az agentic rendszereket nem úgy kell kezelni, hogy a saját accountjaidhoz megadod a hozzáférést neki.
Különálló alkalmazottként kell rájuk tekinteni. Külön accountok, jól körbehatárolt környezet, periodikus self security check.
Kb. egy hete szórakozok én is az openclaw szerverrel. Otthoni homelab környezetben virtuális gép, vlan, DMZ, firewall a külvilág és az otthoni környezet felé, az otthoni környezet felé még pluszban egyéb nginx secus nyalánkságok. Napi backup, ha valami lenne akkor könnyű visszaállni.
Egyébként nem rossz a tapasztalatom idáig, elég jó minőségű anyagokat gyárt, ha jól felpromptolom. Próbaképpen kiadtam egy munkámmal kapcsolatos feladatot, hogy kutasson interneten húzzon fel maga alá 5 agentet kböző alfeladatokkal majd készítsen összefoglalót és elemzést.
A tokenhasználat nagyon optimalizálatlan, egy ilyen kutatás 10 perc alatt elfogyasztja a 4 órás claud pro limitet. Pedig opus-t csak a main agent használ, subagent-ek sonnet-et. Fallback modelnek ott vannak a free openrouter, gemini és nvidia API-k, de sajnos nagyon basic az eredmény azokat használva. A lokálisak meg még gyengébbek, max nagyon egyszerű feladatokra valók, pl. healthcheck
A következő kis projekt amire használnám, hogy mennyire tud jól bevásárló listát készíteni és megosztani velem. Magyarul hangalapon néha bemondva hogy mit írjon fel, szombat reggelenként meg ossza meg velem az aktuális listáját google keepen keresztül.
Ha ez jól és megbízhatóan működik, akkor akár még idős anyukámnál is el tudom képzelni mint napi asszisztens. De vannak kétségeim az AI nem determinisztikus volta miatt... -
5leteseN
őstag
válasz
freeapro
#3118
üzenetére
"...GLM 4.7 Flash-t amiből a q4 változat belefér 24GB VRAM-ba..."
A Q4-es (4-es kvantálású) pedig viszonylag gyengusz szokott lenni. Eddig Q6 alatt nem is töltöttem még le semiből. Tudnál kicsit bővebben erről?
Egyébként nálam eddig a viszonylag "öreg" Gemma 3 27B tudott magyarul a legjobban.
Esetleg nézz rá arra is.
Asszem' abból van 17GB-os méretű, Q6-os. Ha haza értem, ránézek, hogy melyiket szedtem le az LM Studio-ba. -
-
freeapro
senior tag
válasz
5leteseN
#3116
üzenetére
Épp chatelgettem ezekről a témákról a chagpt-vel, meg a jó LLM modellekről, amikor megemlítette a GLM 4.7 Flash-t amiből a q4 változat belefér 24GB VRAM-ba. Leszedtem. Tud magyarul és tényleg tök jó thinking model. Lehet újra át kell néznem mi használható, mert sokat fejlődtek a modellek.
-
válasz
5leteseN
#3116
üzenetére
Az Artificial Analysis Intelligence Indexet elég mérvadónak tartom. Biztos hogy az újabb modellek jobban vannak benchmaxolva, hogy jobban mutassanak ezeken az értékelési mutatókon, de nagyjából jó iránymutatásnak. Ez alapján a GPT OSS 120B bőven jobb.
-
Geller72
veterán
Amit nem tudtam eddig:
Ha a "nagy" cégek modelljeit használom (Claude, ChatGPT..etc), akkor ugye a Letta nem opció. És ha az adott csetben kifogyok a tokenekből, akkor kezdhetek egy új csetet, de elveszik a "memória".
Viszont, ha a cset végén arra kérem, hogy:
"Készíts kontextus összefoglalót az új chathez." Nem kell elölről kezdenem.Nem full megoldás, de sokat "dob" a dolgon.
Hátha valaki még hozzám hasonlóan ezt nem tudta.
-
Két témát kell megkülönböztetni: az autonóm agent (OpenClaw) mivoltát, és magát a hardvert. OpenClaw működhet bármilyen hardveren. Egy Raspberry Pi is elég neki, ha kizárólag Cloud API-n üzemel és onnan tesz-vesz. A lényeg, hogy a személyes dolgaidtól egy elkülönített rendszerben kell lennie, mert nagyon veszélyes tud lenni. Ha valamit elront, vagy kap egy kártékony promptinjekciót egy alattomos weboldalról, törölheti a fájljaidat, visszaélhet a személyes adataiddal, kiadhatja a tulajdonjaid és még meg is hackelhet.
Ezért jobb egy külön rendszerben, egy különálló eszközön. Sokan ezért Mac minit vesznek. Csak az OpenClaw miatt. Úgy voltam vele, hogy ha már lúd, legyen kövér: vettem egy kompetens fejlesztői környezetet, amin fejlesztgethet magának. Akármit. Ez sok lehetőséget megnyit, látva, ezek az Agentek egyre nagyobb és nagyobb szoftverek fejlesztésére képesek.
Bár ti inkább a hardverre vagytok kíváncsiak, szerintem az igazán nagy durranás maga az agent, a hardver pedig egy ugródeszka neki.
Együtt érnek igazán sokat. Az egyik a másik nélkül az ötödét érné és vice versa.Még elég új, ismerkedem vele, majd fogok még többféle tesztet is végezni később. De általános token/sec tesztek online is elérhetőek. Tettem a múltkor egy rövid pillantást, a GPT OSS 120B-vel kb ugyanazt hozta, amit online közölnek. Csak akkor tesztelek, ha valami nagyon specifikus beállításra vagyok kíváncsi: egy bizonyos model egy bizonyos formátumban egy bizonyos pontosság/kvantizáció szinten egy bizonyos környezetben, amely kombináció nem lelhető fel a weben és nem is lehet megbízható becslést végezni. Ezen kívül sok haszna nincs a benchmarkolásnak, mások már megtették.
Nekem az Asus Ascent változat van.
-
5leteseN
őstag
válasz
5leteseN
#3111
üzenetére
A Kimi K 2.5/MiniMax 2.5 összesített véleménye alapján a DGX Spark 1,5-2x gyorsabb a 200 Watt-ból (főleg a modernebb architektúra/TensorFlow-k miatt), mint a 4xV100SXM2/32GB az energiatakarékos üzemmódban(4x180W kb, +a szerver min. 100W).
Én jó válasznak becsülöm.
Érdekes viszont, hogy ahol nincs NVFP-s LLM, és a 64GB elég az LLM-nek, ott a 2x2V100 (párhuzamosítva) sokkal gyorsabb.
Igaz hogy bő kétszeres elektromos teljesítményből tudja csak ezt a teljesítményt, ami hosszú távon nem szokott beleférni a költségvetésbe.Hobbi alkalmazásoknál, akár kisebb egyetemi programoknál még mindig jó lehet a 2x2V100/32GB-os felépítésű rendszer.
-
freeapro
senior tag
válasz
 Citroware
#3105
üzenetére
Citroware
#3105
üzenetére
Jó látni, hogy milyen minőségi ugrásra lesz képes AI Max+ 395 szintű desktop proci 128GB RAM-mal, ha kijön végre.
A leírásod kb. félig értem. Igazából mi volt a cél, amit meg akartál oldani vele?
Írod, hogy a GPT OSS 120B a legjobb LLM amit futtatni tudsz. Ezt tesztelted? Úgy emlékszem ezektől a nyílt openai modellektől nem volt elájulva senki, amikor kijöttek.
-
S_x96x_S
addikt
válasz
Citroware
#3105
üzenetére
érdekes téma
ha van időd - akár rendzseresen( hetente )
megoszthatnál újabb "lesson learned" infókat.
Legalábbis engem érdekel.> Mivel GPT OSS 120B a legjobb LLM, amit ez a hardver futtatni bír,
ha van időd,
akkor kérd már meg az agenteket,
hogy
- készítsenek egy magyar nyelvre optimalizált LLM tesztet
és a gptoss:120b - mellett az új alternativákat is tesztelje le
( pl. Qwen3.5-122B-A10B , és a többi kínai modellt .. ) -
Geller72
veterán
válasz
Citroware
#3105
üzenetére
Olvastam róla, hogy a frissítések óta "megtáltosodott".
Gratula hozzá.
Jelen pillanaban jóval szerényebb projectben LM Studió+Abliterált Qwen 3+Letta rendszert próbálgatok, és sok szempontból már itt is elég nagy fejlődést tapasztalok.
Még nem jutottam vele el a "falig", de nagyon impozáns. -
Vettem egy DGX Sparkot és azon futtatok OpenClaw agentet izolált környezetben. Az egész rendszert irányítani tudja az admin jogok kivételével: tud programot telepíteni, fájlokat olvasni-írni, interneten böngészni, appokat navigálni, appot fejleszteni és futtatni, etc.
Mivel GPT OSS 120B a legjobb LLM, amit ez a hardver futtatni bír, nem azt használom a fő karmesternek (fontos a magasabb intelligencia szint), de privát futtatásokra jó. Így van két elkülönített rendszer:
1) Futtatni tudok helyi LLM és képgeneráló modelleket, ha fontos hogy az adat privát maradjon. Ez egy másik user alatt, az OpenClaw agenttől izolálva zajik, és az asztali PC-mről is meg tudom hívni LANon keresztül.2) Az autonóm OpenClaw agent, amely a produktivitásra fókuszál, cloud-alapú API-ról fut, nem osztok meg érzékeny személyes adatot magamról. Ő is meg tudja hívni a dockerizált helyi modelleket igény esetén, olcsóbb/privátabb alternatívaként a cloud API megoldások mellett, de nem ez a fő irányvonala.
Miután beüzemeltem, első lépésben megoldottuk a hangalapú kommunikációt hangüzenetekkel egy üzenetküldő platformon. Kb fél óra alatt megcsinálta. A következő lépés volt a valós idejű hívások. Fejleszttettem vele gyors háromfázisos rendszert: beszédfelismerés (speech-to-text), LLM reakció, aztán hangos felmondás (text-to-speech), így valós időben reagálni tud hangosbeszéddel. Már majdnem jó minőségben működött az, hogy fel tudjuk hívni egymást Discordon keresztül (bármilyen készülékről), aztán a Discord éppen behozott egy frissítést, amire jelenleg nincs kompatibilis megoldás egy pár hétig...
Van még ezer másik potenciális lehetőség, amikhez eddig külön appok kellettek, de ez már megcsinálja helyettük.Egyébként kiadtam neki, hogy mindig mindent jegyzeteljen le különböző fájlokba, rendszerezze. Emlékszik, reagál, nélkülem is hajlandó ellátni feladatokat autonóm módon, proaktívan is képes cselekedni. Részemről a jelenlegi agent megoldásokkal az elmúlt 1-2 hónapból elértünk az AGI első fázisához. Ennek az áttörésnek a jelentősége egy szinten van a 2022 év végi ChatGPT kitöréssel vagy a 2024-es gondolkodó és multimodális modellek eljövetelével.
-




 .
.



















 , de win / x86 platformon ez lesz a legjobb megoldás.
, de win / x86 platformon ez lesz a legjobb megoldás.
 .
.













Új hozzászólás Aktív témák
- Anglia - élmények, tapasztalatok
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Revolut
- sziku69: Fűzzük össze a szavakat :)
- Nintendo Switch 2
- Épített vízhűtés (nem kompakt) topic
- Az Intel szerint mindenkit érint, illetve érinteni fog a CPU-hiány
- Synology NAS
- Eredeti játékok OFF topik
- Filmvilág
- További aktív témák...
- Nintendo Switch OLED megkímélt full dobozos.
- iPhone 14 Pro Max 256GB Black Független
- Thrustmaster T300 RS / opcionálisan Ferrari F1 pereccel
- Rtx 2080/ Ryzen 5 4500/ 16GB / 500 GB Sata SSD/ 1,5TB HDD/ Win 11/ Garancia
- Újszerű Apple Macbook Pro 13 - Touch B - M2 - 8/256GB - 18 Ciklus - 100% akku - MAGYAR -asztroszürke
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- iPhone 13 128GB Red-1 ÉV GARANCIA - Kártyafüggetlen, MS4593, 100% Akkumulátor
- LG 27MR400 - 27" IPS LED - 1920x1080 FHD - 100hz 5ms - AMD FreeSync - Villódzásmentes
- MINDENFÉLE Laptop jó áron nézz körül! 60+ hirdetés Üzleti,Gamer, Multimédiás,Tervező
- LG 75QNED86T3A / QNED / 75" - 164 cm / 4K UHD / 120Hz / HDR Dolby Vision / FreeSync Premium / VRR
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest