-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

bjasq99
tag
válasz
 Busterftw
#71010
üzenetére
Busterftw
#71010
üzenetére
Úgyanazon a node -on a Maxwell és az RDNA 2 tudtak jelentőset előrelépni (Mondjuk volt is hova) Az rdna 4 pedig raytracingben, de meg kell jegyezni, hogy ott azért enxhén szólva sem volt optimális az architektúra korábban. Annyi, hogy most is lehetett volna érdemi előrelépés nvidián, ha nem sajnálnának minden dollárt és csak egy 15% al nagyobb gput adnának úgyanezen áron. (Ha lenne egyáltalán) Szóval megértem teljesen az Nvidia kritikákat, nyilván nekik az Ai ra építeni hardvert nagyobb biznisz, de akkor vállalják a userek negatív kritikáját és igen is legyen kritika. Valamit valamiért. Nem kaphatsz meg mindent. Ha az Ai -t választod akkor kapd a userek elégedetlenségét vagy ha a usereket akkor keress kevesebbet. De az, hogy az egyik terület prefelálása a másik árán ne váltson ki negatív visszhangot az irracionálisnak kellene legyen.
-
bjasq99
tag
válasz
 Quadgame94
#71007
üzenetére
Quadgame94
#71007
üzenetére
Az nvidia pont hogy nagyon hasonló Streaming Multiprocessorokat használ minden generáción, csak órajel magszám és memória skálázás történik. (meg persze új tensor tipusok támogatása). A regiszterek egységnyi feldolgozóra vetitett aránya a Maxwell!!! óta nem változott. Akkor volt számotvető az előrelépés amikor jött egy node váltás pl Maxwell 28nm -> Pascal 16 nm Turing 12 nm -> Ampere 8 nm -> Ada 5 nm. És az is jól látszik hogy a legnagyobb teljesítménybeli előrelépés a legnagyobb nodváltásnál jött Samsung 8nm -> Tsmc 5 nm
-
bjasq99
tag
válasz
 S_x96x_S
#71006
üzenetére
S_x96x_S
#71006
üzenetére
Megint megelőztél!🙂 Végig mindenben igazam volt, nagyon sok a limitáció, nagyon komplex lenne olyan hardvert készíteni amely limitációk nélkül tudna dinamikus regisztert foglalni.
És figyelem, ha a fejlesztők nem tartanak be pár szabályt akkor a programvégrehajtás teljesen meg is állhat! -
bjasq99
tag
válasz
S_x96x_S
#70967
üzenetére
Pont akartam is írni, nagyon jó cikk.
Jól gondoltam, ez az "out of order memory" az rdna 4 -en nem nagy szám, és csak hiányosságokat pótól, szóval nem egy csoda fegyver.
Röviden leírva: a wavek (egy wave amd esetén 32/64 szál amit a simd egység lockstepben végez) a programozási modell szerint teljesen függetlenek egymástól, szóval a hardver olyan sorrendben ütemezi őket ahogy akarja. Nyilván a memória elérések is függetlenek. Ebből adódóan ha egy wave cache hitbe ütközik akkor a többi wave, töle függetlenül érhetik el a memóriát, nem kell megvárni az elöző misses wave adatelérését, hisz a wavek függetlenek.
Ennek elméletben így kellene müködnie, de az eddigi amd hardverek kötöttebbek voltak, és a másik wavek -nek is meg kellett az elötte ütemezett cache misses wavet várnia.
Ennek semmi logikai alapja nincs, csak egy hardveres limitáció volt. (Kicsit bonyolultabb a helyzet de nem akarom részletezni arra ott a cikk)
Ami a lényeg hogy az amd most már tudja amit az nvidia hardverek eddig is tudtak. -
bjasq99
tag
Azért azt nem szabad elfelejteni hogy az mcd die -ok a 7900 xtx -en 6 nm -s ek. A tranzisztor mennyiségre nincs bagy különbség a 9070 xt és a 7900 xtx között 53.9 vs 57.7.
Vagyis ha az egész 7900 xtx -t 4 nm en gyártanák (elméletben) akkor 9070 xt méretű lehetne, főleg ha számoljuk, a 256 bites memória buszhoz kevesebb hely kell és mêg csak die to die vezérlő sem kell. (Persze ez csak elmélet, valószínűleg a 7900 xtx nem skálázodott volna jól 256 bites buszon, és ezért kellett 24 gb, ezzel megválaszolom BerserkGuts #70812 kommentjét is) -
bjasq99
tag
válasz
 bjasq99
#70755
üzenetére
bjasq99
#70755
üzenetére
Szóval ahogy ígértem egy szerintem lehetséges helyzet amikor a dinamikus allokáció elhasal és végtelen ciklusba kerül.
Alap helyzet: Több wave is nagy regiszter mennyiséget akarna foglalni, de az egyiknek már nem jut elég.
Következmény: A wave leáll addig ameddig nem szabadul fel számára elég regiszter.
2. Feltétel a végtelen ciklushoz: Képzeljük el hogy a megállított wave ben fel kellene oldani egy lockot (vagyis egy memória címet visszaadni a közösbe, hogy ne csak az az egy wave használhassa), miközben a futó wavekben fut egy ciklus ami azt ellenőrzi hogy fel van e oldva már a lock. Az ilyen esetben a nem futó wavenek kellene feloldania a lockot, de mivel nem fut így nem tudja, ezért a másik wavek nem tudnak előre haladni a végrehajtással és így regisztert sem tudnak visszaadni, ami miatt nem fog tudni futni a nem futó wave... és így tovább, létrehozva a végtelen ciklust. -
bjasq99
tag
válasz
bjasq99
#70754
üzenetére
Szóval az általam már boncolgatott helyzetben amikor a szálak max regiszter terhelése egybe esik és együtt több regisztert foglalnának mint amennyi hardveresen van, akkor ez deadlockhoz is vezethet. Én elöször azt írtam hogy ilyen esetben nyilván meg kell állitani egy wavet, de a deadlock is logikus leírom miért. Azt azonban nem tudom hogy ilyen helyzetben mindig deadlock lesz a vége mert túl sok az allokálni kívánt regiszter vagy csak bizonyos helyzetekben mint pl amit a következő hozzászolásomban leírok.
-
bjasq99
tag
válasz
 bitblueduck
#70751
üzenetére
bitblueduck
#70751
üzenetére
Sok kérdőjel van még bennem, de az biztos hogy sok a megszorítás, sok mindent nagyon költséges lenne hardver szinten implementálni.
Itt van ez is amin a legtöbbet gondolkodom és amit már felvetettem elötte:
3.3.3.2. Deadlock Avoidance
Dynamically allocating VGPRs can lead to deadlock when all VGPRs have been allocated but every wave needs
to allocate more VGPRs to make progress. Hardware mitigates this with a mode that reserves just enough
VGPRs that at least one wave can reach the maximum VGPR allocation at all times. This does not prevent deadlock
when multiple waves require the maximum allocation to progress -
bjasq99
tag
válasz
bjasq99
#70745
üzenetére
Vagyis összefoglalva: csak compute shaderekben, egy workgroupban nem lehet mixelni a dinamikusan nem dinamikusan allokáló threadeket, nem mehet le 0 nagyságúra egy thread regisztere, és nem is terjeszkedhet a teljes regiszter állományra, és csak wave 32 ben működik. Szóval vannak azért megkötések a használatára.
-
bjasq99
tag
Ha valaki elmerülne kicsit az rdna 4 részleteiben, az rdna 4 instruction set manualból:
A dinamikus regiszter foglalás egy két részlete:
3.3.3. Dynamic VGPR Allocation & Deallocation Compute Shaders may be launched in a mode where they can dynamically allocate and deallocate VGPRs; dynamic VGPRs is not supported for graphics-shaders. Waves must be launched in "dynamic VGPR" mode to be granted this ability; without it instructions requesting to alter the VGPR allocation size are ignored. Dynamic VGPRs are supported only for wave32, not wave64. Dynamic-VGPR workgroups take over a WGP (no mixing of dynamic and non-dynamic VGPR waves on a WGP): if any workgroup is using dynamic VGPRs, only dynamic VGPR enabled workgroups or waves may be running on that WGP. DVGPR workgroups take over a WGP when the workgroup is launched in WGP-mode, and take over a CU when launched in CU-mode. VGPRs are allocated/deallocated in blocks of 16 or 32 VGPRs (configurable) and are added to or removed from the highest numbered VGPRs, keeping the range of available logical VGPRs contiguous starting from VGPR0.
Waves may allocate up to a maximum of 8 blocks of VGPRs and have a minimum of one block. Block Size The VGPR block size is configurable to be 16-VGPRs with a maximum allocation of 128 VGPRs per wave, or 32-VGPRs with a maximum allocation of 256 VGPRs per wave. This block-size is a chip-wide config; it cannot be modified per draw or dispatch. "Blocks" are also called "segments" in some contexts. Waves using block-size of 16-VGPRs must not access VGPRs above 127 - results are unpredictable. Waves in dynamic VGPR mode are initialized with one VGPR-block allocated. -
bjasq99
tag
"Navi 48 nagy átlagban egál a Navi 31-gyel, miközben az erőforrások tekintetében kétharmada csak."
Ahogy a 70261 ben is elemzem, sokkal több tranzisztort igényel az rdna 4, ha esetleg tudsz nagyjából valamit arról, hogy nagyságrendileg egyes hardveres újításoknak mik a tranzisztor igénye, mi dobta meg így a tranzisztor számot akkor azt leírhatnád, köszönöm!
Valamint még egy olyan kérdés, hogy akkor most van koherencia engine a gpuban (ami biztosítja a memória koherensebb elérését) -
bjasq99
tag
Vegyük csak a tranzisztor mennyiséget és vizsgáljuk meg az rx 7800 xt die -t és a 9070 xt die-t : Elöször is a 7800 xt tranzisztor mennyisége mindenhol rosszul van feltüntetve mert csak 28.1 mrd tranzisztort írnak ami, csak a gcd a valóságban (Igen még a prohardver tesztben is rosszul van írva!) (Ha valaki kiváncsi, hogyan jön ki hogy a 28.1 mrd tranzisztor csak a gcd annak le tudom vezetni a matekot!) Na a 4 mcd ami az rx 7800 xt -n van az kb 8 miilliárd tranzisztor teheát a totál kb 36 milliárd tranzisztor és összeségében. A 7800 xt n van 60 CU míg a 9070 xt -n 64 ami a 60 nak a 1.0667 szerese. Amely változás egyenes arányú változása esetén csak kb 38-39 milliárd tranzisztort venne igénybe,(ha még a nagyobb órajel miatt extra tranzisztorokat is bele vesszük akkor is sok tranzisztor hinyzik)
Míg az 53.9 Milliárd tranzisztor, amivel a 9070 xt rendelkezik lényegesebben több, vgayis sok tranzisztorba kerültek az extra feature ők mint a ray tracing, matrix unit, dinamikus allokáció stb. -
bjasq99
tag
válasz
 paprobert
#70248
üzenetére
paprobert
#70248
üzenetére
"A fejlesztők kényelmét (is) szolgálja, indirekten a szoftver-kompatibilitást növelheti, és az AMD driver költségeiből faraghat. Ebből a szempontból nyerő fejlesztés, de valóban, ettől még nem a farok fogja a kutyát csóválni."
Szerintem pont, hogy drágább a driver frissités, mert egyre több hintet használnak szofveresn ők is, akár az nvidia. Valamint igaz, hogy jelenthet elönyt ez az implementáció, de szerintem rendesen igényel tranzisztort, mindjárt le is írom azt is, ami helyett több CU lehetne. -
bjasq99
tag
válasz
paprobert
#70248
üzenetére
Nem értem teljesen, vagy valamiben lemaradtam a hardverek terén.
Nem tudom, hogy fogalmazzam meg jól, szemléltetem egy leegyszerűsített példával:
Legyenek a szoftveres regiszterek nevei a, b, c, d a fizikai regisztereké x, y, w, z és 2 futtatott szál.
Az 1. szál a végrehajtása során használja a-t és b-t is de legtönször csak a-t míg a 2. szál szintén így csak c, d vel. Most úgye statikus allokáció esetén lefoglalunk 2-2 szoftveres és jelen esetben fizikai regisztert is mindkét szállnak.
Nézzük a dinamikus allokációt: A compiler megcsinálja a regiszter allokációt szofveres szinten 3 szálra: az 1 szál hazsnál egy "rendes" a -t és egy dinamikusan allokált d-t, A 2. egy b-t és d-t a 3. egy c-t és d-t. Na amikor fut a shader és első szál észleli hogy nek kell egy d regiszter akkor ellenörzi, hogy van e szabad fizikai neki és ha van akkor allokál, majd befejezi a d vel a munkát és felszabadítja, majd jön a 2. szál szintén így majd a 3. is. A gond akkor keltkezik ha jön mondjuk a második szál hogy használja a d regisztert (amihez a z fizikai regiszter van hozzá rnedetlve), de nem tudja mert a z fizikai regiszter le van foglalva az 1. vagy a 3. szál által. (Nyilván a 2. szálnak regisztert kell használni, nem változtathaja meg dinamikusan a kódot hogy valamit kiír a memóriába és a helyére betölti a szükséges adatot.) És ilyenkor nincs más mint hogy felfüggeszti a hardver ezen szál futását hisz nincs regiszter. Továbbá az implementáció része hogy csekkolni kell hogy van e szabad fizikai regiszter -
bjasq99
tag
válasz
paprobert
#70235
üzenetére
Kifejtenéd ezt jobban! Szerintem nem lehet rendesen kiegyensúlyozni, mert nem dönthető előre el, hogy egy adott szál mikor jut el egy bizonyos állapothoz, szerintem statisztikai alapon lehet a használatát megfontolni, vagy esetleg a wave ütemezőt megspékelni, hogy a peakeket eltolni egymáwtól, de csak a parancsamotorokkal szerintem nem lehet megoldani. Igen én is egyetértek, hogy ez nem egy olyan megváltó fejlesztés (mindenesetre az utóbbi 15 év legizgalmasabb hardveres fejlesztése), hisz szerintem azért bőven bőven igényel tranzisztort hisz kell valami tag szerű tároló ami a foglalt regisztereket tárolja, az is kérdéses, hogy hány százaléka a regiszter állománynak dinamikusan foglalható és hogy milyen asszociatívitással rendelkeznek az egyes szálak foglalás szempontjából, a full asszociativ nehez kivitelezhető nem releváns szerintem, míg a minél kisebb asszociatívitás esetén csökken foglalható regiszter több szál foglalása esetén. Annak fényében különöden nem értem, hogy az amd miért ilyeneket csinál, hisz a regiszter területük így is sokkal nagyobb mint a geforcoké és nyilván azért a fejlesztők nem hagyják megdögölni a geforce implementációját, (hisz övék a piac), így az amd ilyen tipusú elönyei csökkennek, míg több az elköltött tranzisztor és fogyasztás.
-
bjasq99
tag
Abu85 technikai kérdésem lenne, a dinamikus regiszter allokációhoz:
Mi történik abban az esetben ha a futtatott szálak peak regiszter használatai egyszerre is bekövetkeznek, ilyenkor tullépve az allokálható fizikai regiszterterületet (túllépi ilyenkor mindenképp hisz pont az a lényeg hogy nem minden thread lefoglalja a saját maximum regiszter igényét.) Gondolom ilyen esetekben néhány szál aki nem tud már regisztert foglalni, fel lesz függesztve, hisz nincs számukra fizikai regiszter, a kevesebb regiszter használatra meg nem lehet real timeba újra fordítani. Ezért gondolom, hogy a compiler csak jól megfontolt esetekben választja a dinamikus regiszter allokációt, statisztikai alapon amikor kicsi az esélye a peak regiszternyomások összeérésenek, azaz ha ezen peakek relative kicsik a teljes végrehajtás szempontjából. Úgyanakkor ezekből következik, hogy nem minden program fog jelentősen gyorsulni, főleg ray tracing esetén lesz hatásos ez a feature. Más esetekben meg lehet használni a statikus allokációt, amely más esetekben szerintem jobb hatásfokot is elérhet, és szerintem kisebb fogyasztást is, hisz a dinamikus regiszter allokációhoz kell szerintem egy cache tag szerű tároló, ami nyilvántartja, hogy melyik cache üres, és aminek a müködése nyilván árammal jár. Erősitsd meg esetleg ezt is ha tudod, kiváncsi vagyok, hogy müködik az üres regiszterk nyilvántartása, szerintem ez csakis hardveres lehet. -
bjasq99
tag
válasz
bjasq99
#67545
üzenetére
Akár a cpuk úgy a gpuk regiszter területeik több portot szolgálnak ki. A tensor core egy ilyen port része ami a regiszter területből kapja az adatokat feldolgozásra. Másik portokon helyezkednek el "cuda" magok amik ugyanazt a portot érik el. Egy órajel ciklusban elméletben több különböző portra adható ki munka ( ha van elég operandus) , de egy porton belül lévő egységeknek nem lehet egyszerre munkát kiadni ( ez a port konfliktus ). Más kérdés hogy úgy tudom hogy egy ilyen sm negyednek ( az sm negyedének külön ütemezői vannak ) csak egy dispatch unitja van szóval nem tud két utasítást elkezdeni 1 órajelben egy ilyen negyed, szóval az nvidia nem dual issue hardver. A tensor core így tud párhuzamosan futni: a dispatch unit az első órajel ciklusba kiadja a munkát a az egyik cuda mag portnak ami egy 16 széles simd -t tartalmaz , de egy warp 32 elemből áll szóval a comit hoz 2 órajel ciklus kell. És itt jön az hogy a masodik órajelciklusban a dispatch unit már szabad, így ő már ki tud egy másik végrehajtandó utasítást adni egy másik portnak egy másik warpból , pl egy tensor portnak vagy egy másik cuda portnak.
És akkor így a két operáció párhuzamosan fut.
Ezért fölösleges dual issue nak és co issue nak nevezni az Nvidia hardverét mert különböző warpokból egymás után kerülnek ki a párhuzamosan futó micro op -k. -
bjasq99
tag
Én is elöször erre emlékeztem, de matrix unit forrásaim szerint csak a cdnak ban vannak:
"While RDNA 3 doesn't include dedicated execution units for AI acceleration like the Matrix Cores found in AMD's compute-focused CDNA architectures, the efficiency of running inference tasks on FP16 execution resources is improved with Wave MMA (matrix multiply–accumulate) instructions" -
bjasq99
tag
válasz
 Yutani
#67524
üzenetére
Yutani
#67524
üzenetére
Igen ebbe a részletbe szándékosan nem mentem bele, nézzük is:
1. a számadatok alapján a 7900 xtx "mátrix" teljesitménye 10 tlops -al még jobb is mint a 2080 ti nak.
2. ha jól emlékszem, de mindjárt megkeresem akkor az rtx 20 -s széria tensor műveletek mellett nem tudott shadereket futtatni.
3. ha tud is futtatni párhuzamosan shadereket akkor azok nem fognak natív sebességen futni a regiszter és cache nyomás miatt
4. a párhuzamos a futtatás sebesség töblete csak abban az intervallumban van jelen amíg megy a felskálázás.
Ezekből megítélve semmivel sem futna egy nvidia dlss féle eljárás rosszabbul egy rx 7900 xtx -en mint a 2080 ti -on. -
bjasq99
tag
Abu85: Ha esetleg te is megerősítenéd nekem hogy 100 tflops = 100 tflops. (Jó ez lehetne félrevezető is, de látod miről beszélek, pontosan tudom hogy 100 tflops != 100 tlops ha a memória subsystem nem olyan jó, de azt egyértelműen ki lehet mondani, hogy az amd nek van olyan jó cache rendszere mint az nv nek. )
-
bjasq99
tag
válasz
 Raymond
#67514
üzenetére
Raymond
#67514
üzenetére
Igen tudom. És pont ezért az amd is ki tud préselni ugyanannyi tflopst. Mindegy hogy melyiken megy a mátrix szorzás, ugyan akkora lesz a teljesítmény. Az általános fpu -n ugyan úgy fut a mátrix szorzás csak a program más és a futás a hardveren, de ha a teljesítményük megegyezik akkor megegyezik. Hidd el ha valamihez akkor a hardverekhez értek.

-
bjasq99
tag
"Az új DLSS és famegen FP4 alapú ezt a támogatást kapta meg az 5000 széria." Úgy mondani hogy ezt a támogatást kapta meg, kicsit félrevezető, mert ami fp4 -t igényel, az fp8 -on is elfut. És eddig is támogatva volt az fp8. Most a Blackwell tensor core -k 2x akkora sebességgel tudnak futtatni fp4 -t mint fp8 -t, de az adában is bőségesen elég fp8 teljesítmény volt.
-
bjasq99
tag
válasz
Raymond
#67504
üzenetére
Pontosan ismerem az architektúrákat, ezért probálok edukálni. Leírtam, hogy mennyi az rtx 2080 ti és mennyi az rx 7900 xtx fp16 teljesítménye. Lehet hogy a hardver alatta más ( az Nvidia tensor core egy systolic array https://en.wikipedia.org/wiki/Systolic_array míg az rdna 3 ezt a teljesítményt packed dual issued utasításokkal éri el )
-
bjasq99
tag
válasz
 Micsurin
#67502
üzenetére
Micsurin
#67502
üzenetére
Nem tudom mit akarsz érteni az univerzális végrehajtó egységen. A cpu ban vannak integer alu -k és fpu alu -k. Teljesítmény szempontjából csak a teljesítmény számít
Ha teszem azt hogy egy processzornak 128 bit-es simd egysége van a másiknak meg 256 bites és mégis úgyanakkora gflops-t biztositanak akkor ugyanakkora a teljesítményük. Valószínűleg a 128 bites változat fog kevesebbet fogyasztani. Az nvidia amd esetében is mátrix szorzás esetén, ha ugyanakkora is a teljesítmény akkor is az nvdia dedikált tensor corejai kevesebbet fognak fogyasztani mint az amd fpuja -
bjasq99
tag
válasz
Micsurin
#67497
üzenetére
Mindegy minek hívjuk, leírtam, hogy mennyi az rtx 2080 ti tensor magjainak és az rx 7900 xtx teljesítménye ugyanazon fp16 formátum esetén. Az lényegtelen hogy az amd esetében ezt a teljesítményt nem egy tensor/ml core nak nevezett fpun éri el hanem a sima fpu -k dual 16 bittes issue -val
-
bjasq99
tag
Nem tudom, hogy az RDNA 3 -on miért nem tudna egy dlss szintű felskálázó futni, ugyanis mint írod még a Turing széria is képes az új dlss -t is futtatni.
A számok pedig:
2080 ti tensor tflops (in fp16) : 113.8
rx 7900 xtx tflops (in fp16) : 123
Szóval ha a 20 -as széria bírja akkor az rdna 3 nak is kellene. -
bjasq99
tag
válasz
 hokuszpk
#67466
üzenetére
hokuszpk
#67466
üzenetére
Köszönöm! Szerintem lehetetlen middle gaming piacra ilyen cache systemet gyártani, úgy hogy megérje. Az az ellenvetésem, hogyha az Amd egy ilyen rendszert normális árak mellett meg tudna csinálni, akkor simán tudnának egy rtx 5090 nél is jelentősen!!! gyorsabb kártyát hozni és ekkor nem hagynák el a felsőházat. Ott még kevésbé is kellene spórolni a magasabb ár miatt
-
bjasq99
tag
válasz
 Petykemano
#67457
üzenetére
Petykemano
#67457
üzenetére
Nem tudom hol említett abu cache lapkát, én csak cache koherencia hardverről olvastam tőle, mások vizionáltak óriás cacheeket.
-
bjasq99
tag
válasz
bjasq99
#67427
üzenetére
Igaz a 7xxx szériában az io die -ok -ra került a cache, de az sem x3d cache. És egyáltalán nem olcsó megoldás az ilyen nagy szávsélességet biztositó tokozás megoldása. Valamint az IO die -okat sem lenne gazdaságos megduplázni, lásd ezt a képet az rx 7900 xtx ről és gondolj bele hogy nézne ki ha 2x akkora lenne az a hat io die.
.jpg)
-
bjasq99
tag
válasz
hokuszpk
#67380
üzenetére
Bevezető: mia a cache line: A memóriát program oldalról nézve byteonként olvashatod. A valóságban viszont, az olvasás legkisebb egysége az a cache line. Ha egy byte -ot is kérsz le, akkor is be kell olvass egy teljes cache linet, és abból fogja neked kivenni az általad kért byteot.
És akkor a teljesítmény:
Nem csak a miss/hit arány számít. Nézzük: amd-n egy Simd egység 128 byte széles, és a cache line is 128 byte széles. (nem véletlen) Most nézzük mi történik aha a simd adat olvas a cache ből: Ha a simd lanel folyamatos elérést produkálnak ( egy lane az 32 bit azaz 4 byte) azaz a következő a memória elérés: lane0: base + 0byte, lane1: base + 1 * 4byte, ... lane31: base+ 31* 4byte (úgye a 31 lane a simdben, a base az olvasás kezdő címe) ha ez fent állés még az is hogy a base igazitott azaz 128- al osztható (128 mert ekkora egy cache line) akkor ez esetben gondold át az olvasásod 1 cache lineból fog kijönni. Más esetekben pl ha nem igazitott a base vagy random a simd lanek memória elérése akkor egy olvasás már nem egy cachelineból hajtodik végre. Valójában ez azt jelenti, annyi olvasás műveletet kell elvégezni ahány cachelinet érint az olvasás. Ha a simd összes lane -e különböző cache lineból kér adatot, akkor 32x kisebb lesz a sávszélesség. Remélem segíthettem és már jobban érted a cache szerkezetét. -
bjasq99
tag
válasz
hokuszpk
#67346
üzenetére
Azért ennél komplexebb egy cache, számítás modell. Elöször is nem csak az számít, hogy mennyi a hit/miss arány, hanem a cache teljesítménye, ha ugyanis egy olvasás több cachelineból kér adatot akkor drámaian csökken a sávszélesség. Másodszor a cache hit/missre rátérve, nem igaz az, hogy csak a cache méretétől függ. Oké az last level cache az shared, de a többi privát. Ha két eltérő compute uniton futó szál is, ugyanahhoz a memória területhez nyúl, akkor duplikálva lesznek az adatok( mindkét privát cacheben benne lesz) Míg ha koherensebb lett volna az adat elérés akkor a két szál egy CU alatt futhatott volna cache duplikálás nélkül. És igen fontos tényező a privát cache -ek teljesítménye. Az 500 mb -os cache meg teljesen irreális, szóval mindent kicsit okosabban kell csinálni, nem erőből. Persze egyet értek, hogy a legjobb dolgokhoz a fejlesztők explicit támogatása is kell.
-
-
bjasq99
tag
Egy kérdés Abu a frame genhez: Olyat nem lehet csinálni, hogy nem a két véglegesen elkészült kép alapján interpolálni, hanem a még el nem készült kép nem végleges állapotából generáltatni a köztes képet. Teszem azt a példa kedvéért, hogy a készülő valós képkocka már majdnem kész, de mondjuk a poszt processing nem fut le még rajta, amikor is elkezdjük a köztes képet generálni, és azon lesz előbb kész a poszt processing is, kirajzoljuk a köztes képet, majd elvégezzük a poszt processinget a valós képen is és végül azt is kirajzoljuk. Nyilván még többre gondolok, nem csak a poszt processing későbbre tolása, hanem más számítások eltolására is. Ezzel lehetne a késleltetést csökkenteni FG esetén, mig a teljesitményt úgy gondolom, számotvetően nem érintené. Nyilván az ilyen játékoknak explicite támogatnia kellene, az ilyen megoldást. Esetleg erre pedig megoldás lehetne ha egységesitenék az apiban a FG -t, persze jól megírva szabadságot biztositva a kreatív megoldásokhoz. Bocs, hogy ide írom tudom ez egy AMD-s topik, és az én kérdésem általánosabb, estleg lehetne egy pure architektuális topikot csinálni.
-
bjasq99
tag
Na akkor kifejtem mert úgy látom elég nagy még a zavar, szóval olvassátok el következő írásaim, s talán akkor világosabb lesz.
1. #60341 HSM, és mindenki aki nem érti, hogy hogyan lehet összhangban a Chips and Cheese mérése az Amd slide -jával ami az Infinity Cache hitrate -t elemzi. Látszólag nagy az ellentmondás mert a néhány 10 Mb -os cachre az Amd prezije kis hitrate -t mutat, míg chips and cheese mérései arról tanúskodnak, hogy a kisebb L2 cache -nek is milyen jó a hitrateje. Ebben azonban NINCS!!! semmilyen ellentmondás, mert a hitrate a hit/request aránya. Nos az infinity cache -be csak olyan requestek érkeznek amelyek nem voltak benne az L2 cache be. Magyarán ezek azok a requestek amelyek már rosszabb hatásfokkal cachelhetők. Tehát nem szabad az L2 Cache -be és az Infinitiy Cache be érkező requesteket összekeverni, nyilván ha nem lenne L2 akkor a 10 Mb -os Infinity cache is baromi jó hitrate -el rendelkezne.
De ha nekem nem is hisztek akkor chips and cheese mérés:
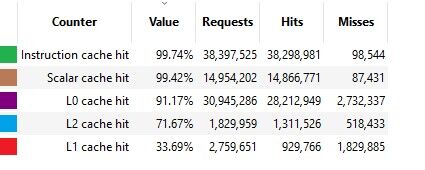
Azt kell figyelni, hogy a kisebb (igaz nem osztott) L0 cache mennyivel jobb hitrate -t generál mint a nagyobb L1, de ez nincs ellentmondásban, hisz nyilván L1 ből már csak az jön ami L0 nincs benne. Nézzétek a request számot is. -
bjasq99
tag
Bocs úgy emlékszem, hogy abban a cikkben amit linkeltél nincsenek játék tesztek, csak egyéb mérések, amik nem feltétlen reprezentatívak játékok során mért hitrate -re. Ami reprezentatív az a cikk amit legutóbb hoztam és valós játékokban mért hitrate. És, Abu szerintem nem jó az érvelésed,, hogy pár kb os shaderek hitratejeként emlegeted, de ez nem számit, az számít, hogy az adott shader milyen arányban fordul elő a feldolgozásban. Mint vizsgálták azok a shaderek a feldolgozás döntő részét képviselték, hiába, hogy kicsikék. Igen és vannak olyan feladatok amelyek sokkal nagyobb memória téren garázdálkodnak, de még sem ők a döntő többségük. Pl a raytracinges CP mérés: 21 ms frametime ból 7 ms vett el a vizsgált shader 82 % -os L2 hitrate -el. A 7 harmada a 21 nek tehát ha feltételezük, hogy a fame generálás többi folyamatában 0% os a cache hitrate (ami örületesen nagy túlzás csak a szemléltetés miatt) akkor is marad 82/3 = 27.3 % hitrate a teljes frame esetében, remélem lehet követni.
-
bjasq99
tag
Azt akarom leszögezni, hogy az Abu által felvázolt driveres Nv működésből fakadó hátrány igaz (lsd HUB). És mindenki figyelmébe ajánlom aki elolvasta chips and cheesen a Nv hardver elönyeit, hogy olvassa el a scalar datapath -ról való értekezést amiben egyértelműen Jensen bácsiék használnak sokkal primitívebb megoldást.
És nyilván tudnak Cpu limites feladatokban is gyorsulni, (amint előző hozzászólásomban leírtam, de ennek meg van a felső korlátja, az igazi a driveres "nem issue" kigyomlálása lenne. -
bjasq99
tag
válasz
 GeryFlash
#60324
üzenetére
GeryFlash
#60324
üzenetére
Bocsi csak lehetséges magyarázatok miért gyorsul Nv kisebb felbontáson:
1. ami le volt írva chips and cheeseben is, hogy javították kis terheltség esetén a hardver kihasználtságát.
2. szerintem nem lehet semmit sem úgy elképzelni, hogy valami homogén cpu limites. Egy Cpu limites folyamatról azt tudjuk, hogy nagyobb részben a Cpu határozza meg a teljesítményt, de nem tudjuk, hogy milyen arányban. Lehet pl 60% ban vagy 90% ban, mindegy is csak azt akarom mondani, hogy ettől a fentmaradó rész egy gyorsabb gpu -tól fog gyorsulni, s így a "pure cpu limites" résznek is több ideje marad.
Nyilván az nagyon nem mindegy milyen arányban vannak ezek. -
bjasq99
tag
Abu egy kérdés:
Idézet tőled: "És GPU-król lévén szó az L2 cache hit eléggé fos. Jellemzően 5% alatti, és ha mondjuk sokszorosára növeled az L2-t, akkor is 10-15% alatt marad"
Ezzel szemben Chips and Cheese mérési eredményei RDNA 2 esetében, valós játékokat tesztelve:
Cyberpunk 2077, RT On:
DispatchRays call: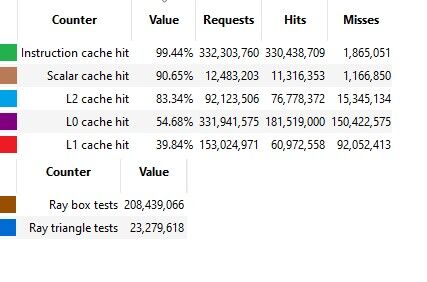
Vagy pl:
The longest duration compute call (number 4473):
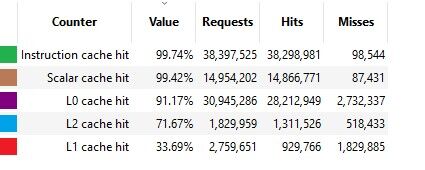
És egy csomó más esetben is a mérési eredmény az, hogy sokkal sokkal magasabb a shared cache hit rate az általad felvázalthoz képest.
Akit érdekel a cikk: https://chipsandcheese.com/2023/02/19/amds-rdna-2-shooting-for-the-top/
Szóval, hogy is van ez?
Szerintem egyik gyártó sem olyan amatőr, hogy olyan rossz cache policyt tervez aminek csupán 5% alatti lenne a hit rate -je.
-
bjasq99
tag
Abu, akkor azzal te is egyetértesz, hogy a metszés vizsgálatért felelős alukat (legyen az doboz vagy háromszög) meg kell hagyni mert emulálásuk jelentős overhead lenne, csak ezen alukat be kell egy normális ütemezővel és memória eléréssel rendelkező hardveregységbe tenni?
-
bjasq99
tag
Igen pontosan ezt írom #60184 -ben, hogy két különböző dologra gondolunk jó feature alatt.
Bocsánat én szimplán tisztán elméleti szinten gondolkodok ilyenkor, hogy mi lehet a maximális potenciál, de azt is tudom, hogy ez nem reális csak engem az elméleti határok érdekelnek.
Abban viszont te is bele mentél az elméleti határokba, amikor kijelentetted, hogy 100 évig is trainelhették volna akkor sem lett volna jobb. -
bjasq99
tag
válasz
bjasq99
#60182
üzenetére
Az egész onnan indult, hogy mitől jó egy feature, kell hozzá e a támogatottság.
Na ez attól függ, hogy hogyan definiáljuk a feature jóságát.
Én úgy definiálom, hogy ha elméletben mindent megtesznek a feature kihasználása érdekében, akkor az sokat ad a felhasználónak.
Ezért mondom, hogy az Fsr újítása is csak innovatív mert lehet nem fogják soha kihasználni a tudását. Ezért írtam, hogy a feltételes időben a dlss 1 jóságát is, ott sem támogatták elággé.
Te szávaidból kivéve pedig valahogy úgy definiálod a feature jóságát, hogy számításba veszed a fejlesztési költséget, és a terjeszthetőséget.
Ezen definíció esetében nyilván a támogatottság nem a jó feature feltétele, hanem következménye. -
bjasq99
tag
Az első dlss nem általánosan az Nv által trainelt neurális hálót használt, hanem minden játékgyártónak saját magának kellett volna játékspecifikusan trainelni a hálóját.
A vulkan -os példára pedig akkor én is rávághatnék egy olyan választ mint te tetted az Amd Fsr -jára. Lehet, hogy elhanyagolható összességében mindkettőnek a felkapottsága, de még tartalmazhatnak innovatívabb fejlesztéseket. -
bjasq99
tag
válasz
Petykemano
#60170
üzenetére
Szerintem egyáltalán nem ez az út, szerintem a legjobb út a felskálázó programok programozhatóvá tétele amit talán nem lehet megoldani fixfunkciós hardverekkel.
A jelenlegi, helyzetben egyedül az Nvidiát nem? értem.Mint jól látjuk, az Fsr jól fut az aluk -on felesleges bármiféle fixfuunciós megoldásba kirakni, nem is beszélve, hogy ezek szerint némileg ad lehetőséget egyéb adatokkal táplálni.
Az Nv dlss -t régebbi kiadásban láttuk, hogy jól futott a cuda magokon.
Tehát az a sok tranya amit a tensorokra költenek valamilyen szinten pazarlás. -
bjasq99
tag
Most attól, hogy összességében jobb a Dlss mint az Fsr az miért zárná ki a lehetőséget, hogy egyes részeiben innovatívabb. Korántsem írom, hogy jobb vagy rosszabb, mert most attól függ, hogy jó vagy rossz egy feature, hogy menyire is támogatott. Ha a gyártok normálisan foglalkoztak volna a Dlss 1-el talán most az lenne a legnagyobb feature.
-
bjasq99
tag
válasz
Petykemano
#60161
üzenetére
Mindenkihez szólok megvan mindenkinek az amikor egy időre az egész dlss nem a tensor core-k on hanem az általános feldolgozó egységeken futott?
-
bjasq99
tag
válasz
bjasq99
#60163
üzenetére
Az Nvdiára is értve az előzőket. Mert az, hogy egy ennyire gyártóspecifikus algoritmust megoldjuk a compute unitokba integrált tensor core -okkal az szerinem sokkal pazarlóbb mintha a gpu ban lenne egy külön részegység amely a mostani tansor core -k feladatát látják el.
-
bjasq99
tag
válasz
Petykemano
#60161
üzenetére
Én csak olyat olvastam hogy a felskálázás részét áttennék az Igpu -ra.
Engem is foglalkoztat ez a kérdés, hogy mivel a gyártói felskálázás egy sokkal "gyártóibb" megoldás mint a ray tracing hatékony kezelése, akkor miért nem húznak köré egy egész pipeline-t így spórolni a tranzisztorokkal. -
bjasq99
tag
Szerintem szoftveresen nagyon nagyot lehetne dobni, csak nem válalják a plusz munkát. Nézd a Dlss 1 is olyan volt, hogy minden játékgyártónak egyedileg kellett volna trainelnie a neurális hálót, de erre sem vették a fáradtságot, pénzt. Nem azt mondom, hogy a mostani rendszer nem nyereségesebb, hanem azt, hogy technikai oldalról iszonyat potenciál marad így ki.
-
bjasq99
tag
Szerintem meg az a legnagyobb vicc a felskálázás terén (bármelyikről legyen szó), hogy az egész olyan információkat számol amelyek ott lehetnének, de az egész rendszer egy félszemű óriás.
Magyarán a felskálázó eljárások, csak néhány információt lát a frame elkészültéből (a pixel színét, motion vektort stb), de ezek elenyészők.
Gondoljuk el, hogy mire lehetnének képesek a felskálázó algoritmusok ha a game engine fejlesztők saját maguk implementálnák le, és kihasználnák szofverük minden apró részletét.
Szerintem ez lenne az igazi, és a Microsoft, Nv, Amd, Intel nem skálázó eljárásokat adnának ki, hanem keretrendszereket, amelyekkel könnyebb lenne az engine gyártóknak felskálázási szoftvereket készíteni. -
bjasq99
tag
Nem is ez volt a téma tárgya hogy Amd nél nincs RayTracing, csak ebben az Nv volt a mindent vivő első,
aki az alkalmat megragadva megkovácsolta az Rtx hívó-szavát.
Egy Brand mind felett
Rtx az egyetlenElpusztítani is valószínűleg olyan nehéz, mint a végzet-hegyébe egy Gyűrűt dobni.
-
bjasq99
tag
Először is Abu add el ezeket a feature -ket olyanoknak akik Om gépeket vásárolnak, de egyáltalán nem Nv volumenű fejlesztések.
Míg a kisebb terhelés driver oldaláról nem releváns. Aki 4090 -t vesz az nem fog 1080p ben játszani míg aki 1080p ben játszik az nemfog olyan kártyát venni akinek ne Gpu limitje lenne a fő gond.
Ez az előző driveres érvem csak józan észből szólt, de igazából nagyon nem számít, csak az hogy nem eladható az Amd újításai. -
bjasq99
tag
"Az AMD a legtöbb újkori feature-jét az NV után dobta be" igen #60118
pontosan ezt írtam le.
Szóval kifejtettem, hogy leárazással nem megy semmire az Amd mert nem tudja megfogni akkor sem a Nv vásárlókat csak a price/performance bajnokokat, akik igy is a piros oldalon vannak.
Nyilván ha jobban leáraznak akkor talán nagyobb lesz a market share, de valószínűleg olyan kicsi mértékben, hogy nem érné meg. Nézd 20% plusz ár Nv nél kb ugyanolyan drága gyártású gpu nál -
bjasq99
tag
válasz
Petykemano
#60107
üzenetére
Igen az Oem vásárlók nagy része valószínűleg valamilyen mértékben fanatikus, csak ezt nem fejtettem ki a tényezők között. Nekik elég vagy elég a Brand neve vagy ha a nem ennyire fanatikus akkor elég megemlíteni nagy vonalakban pár featurot. Elég, hogy tudja ha bekapcsoljuk a Dlss3 -t akkor 2x olyan erős lesz a kártyád (mert igen találkoztam fórumókban, hogy fogalmuk sem volt arról, hogy ez azért mégse olyan mintha nativan 2x annyi fps -d lenne), (sima Dlss: az is AI, az Ai jó, Fsr az nem Ai, tehát nem jó tehát helló NvidiAi) (nem azért tényleg zseniális amit az Ai-al elért az Nv)
-
bjasq99
tag
válasz
Petykemano
#60114
üzenetére
Igen ameddig az Amd nem tud mást is előhúzni a kalapból addig a price/performace marad az egyetlen ige.
Mert nem elég a temérdek feature, túl kell Nv - t licitálni.
Mert dolgozik ám nagyon az Amd, de nem tudja a hátrányát behozni. (egyenlőre) Látjuk, hogy dolgozik mert lett Fsr lesz abból 2 is és lesz Fsr 3 is, de mindig másodhegedűsek. (Szerintem video felskálázó is lesz csak kérdés mikor)
Mert mindenki emlékszik az elsőre, míg a második a ködbe vész.(Elég megnézni a sportokat) -
bjasq99
tag
Megpróbálnék én is bekapcsolódni ebbe kartell témakörbe és kifejteném gondolataim, hogy milyen magyarázatok lehetnek amelyek nem feltételezik a kartellt a két cég között, de mégis magyarázná részben az előállt furcsa helyzetet.
1.Kérdés: Ha a hardverek tudják amit tudnak akkor a jelenleginél az Amd miért nem áraz le jobban?
1. Válasz:
1. tényező: ha az Amd lejjebb ad minimálisan az árakból akkor nem változik jelentősen semmi, szerintem az Nvidia vásárlók nagy része el van köteleződve cégük mellett, (részben featurok, marketing stb) számukra nem jelentene semmit ha a konkurencia minimálisan még jobban alávágna az áraknak.(És ne írjátok, hogy nektek fontosabb lenne a price/performance mert akkor nem tartoztok ebbe az elkötelezett vevőtáborba) Lássuk be most is ez a helyzet, hogy Amd -nek jobb a price/performance (Raytrcinget leszámítva) de a vásárlók elkötelezettek Nv mellett a jól ismert dolgok miatt.
Igazából úgy modellezhető talán a piac, hogy mindkét gyártónak megvan a saját fanatikusan elkötelezettei akik bármi áron kitartanak a cégük mellett, semmi esetben sem vennének a másik márkától. Ebbe a rétegbe szerintem kevesebben tartoznak, de az Nv nél jóval többen mint Amd -nél. A második rétegbe azon elkötelezettek tartoznak akik nem szimpla hívők, nekik kell valami kézzel fogható ami visszaigazolást ad döntésük helyességéről. Melyik ember miben találja meg az igét azon múlik, hogy ki hova tartozik. Aki a price/performance -ban találta meg az élet értelmét az Amd -re szavaz, aki pedig a feautorok, megbízhatóság, konzisztencia, kényelem valamelyikében azoknak az Nvidia felé húz a szíve. Itt szerintem hatalmas a különbség, és ide tartozik a legtöbb vásárló.
A harmadik csoport a résen lévők akik az általuk legjobbnak megítélt kártyát veszik, cégtől függetlenül. Szerintem belőlük kevesebb van, (Magyarországon több), de itt is Nv vezet (szerintem).
2. tényező: Nézzük meg 7900 xtx és rtx 4080 kb egy ár gyártani kb egy teljesítmény Msrp 1000 vs 1200 Usd az 20 % +. Tehát ha Amd brutális leárazásba kezdene és 0 bevétellel adná Gpuit akkor is követhetné őket Nv úgy hogy van még 20% nyereségük, de inkább több mert az 1. tényező miatt sokan maradnának Nv nél mert csak azon emberek pártolnának át akik nem elkötelezettek.
Az Amd -nek elég a mostani ár is, hogy megadja vásárlói számára a lelki nyugalmat a price/performance körében.
A 2. kérdést majd később vetem fel így is túl hosszú lett.
Állitásaim nem puszta tényként vagy szigorúan vett mérési eredményként kell kezelni, csupán meglátásaim amelyekre szívesen várok megjegyzéseket. -
bjasq99
tag
Egy amolyan konyha matek mint amiket te szoktál végezni:
Ad102 alu száma: 18432 , tranya: 76.3 Mrd
Ga102 alu: 10752 , tranya: 28.3 Mrd
Az Ada nak 18432/10752=1.71 szer annyi tranyát kellene tartalmazzon ha lineárisan skálázodna minden (tudom Abu nem).
Tehát 1.71*28.3 = 48.5 Mrd tranzisztor kellene.
Na most vegyük bele az L2 cache tranzisztor igényét :
Mint máshol írtam 128 Mb cachet meg lehetne csinálni 6 Mrd tranyából, de mivel ez L2 cache és nagy buszokat tartanak neki fent így számoljunk a duplájával 12 Mrd tranzisztorral.
Igy is csupán 60.5 Mrd tranzisztor van meg a 76.3 -ból, pedig a cache-t illetően úgy érzem inkább felül becsültem tranya számban. -
































Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Call of Duty: Black Ops 7
- Milyen NAS-t vegyek?
- Battlefield 6
- Mibe tegyem a megtakarításaimat?
- Automata kávégépek
- TCL LCD és LED TV-k
- Chieftec-Prohardver nyereményjáték
- Gigabyte alaplap topik
- One otthoni szolgáltatások (TV, internet, telefon)
- Amit látnod kell 80’ – 90’ évek, egész estét betöltő mozi filmjei.
- További aktív témák...
- ELADÓ: Sapphire PULSE Radeon RX 7800XT Gaming 16G - Garanciával
- Gigabyte GTX1660 TI OC 6GB
- ASRock Radeon RX 6700 XT Phantom Gaming D OC 12GB számlával és garanciával eladó!
- Sapphire Pulse RX 6700 XT 12GB használt videókártya számlával és garanciával eladó!
- BONTATLAN ASUS Prime Radeon RX 9070 XT 16GB GDDR6 OC Edition
- 5G Lenovo ThinkPad P14s Gen 3 Intel Core i7-1280P Nvidia T550 32GB 1000GB 1 év teljeskörű garancia
- Targus DOCK423A - USB-C Dual HDMI 4K HUB - 2 x HDMI (120Hz)
- Panasonic CF-XZ6 AIO all-in-one laptop tablet 2k touch i5-7300u speciális ütésálló rugged
- Apple iPhone 14 128GB,Használt,Adatkabelel,12 hónap garanciával
- iPhone 13 128GB 88% (1év Garancia)
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi