Új hozzászólás Aktív témák
-
#7812
 Abu85
HÁZIGAZDA
Petykemano
#7810
Abu85
HÁZIGAZDA
Petykemano
#7810
Abu85
HÁZIGAZDA
válasz
 Petykemano
#7810
üzenetére
Petykemano
#7810
üzenetére
A 14 nm-es váltás nem jelenti azt, hogy a lapka magasabb órajelre kapcsolható, illetve alacsonyabb lesz a fogyasztása. A konzolok tervezésénél nem tipikus igények játszanak főszerepet. Itt az MS és a Sony is fix órajeleket kér, ha a program elindul. Ilyen körülmények között a váltás nem hoz majd olyan előrelépést, mint amit PC-n tapasztalhatunk majd. Nagyrészt nem a kisebb csíkszélesség miatt csökken egy lapka fogyasztása, hanem a tervezés következtében, hogy egyre jobbak legyenek a turbók stb. De ilyenek a konzolban nincsenek.
A konzoloknál a sematikus dizájnt nem szokott változni, tehát az sem kizárt, hogy fogyasztásnövekedést hozna a kisebb csíkszélességre való átállás, emellett a 28 nm-es node még mindig a legolcsóbb, tehát másra áttérni ma nem éri meg. -
Abu85
HÁZIGAZDA
Még annyit tennék hozzá, hogy ma sokkal nehezebb elnyerni egy konzoldizájnt, mint 2004-ben. Az X360 és a PS3 gyakorlatilag meglévő, némileg átírt API-kkal kezdtek. A Sony viszont hozott egy teljesen nulláról írt libGCM-et a PS3-ra, és ezt az MS is lekövette az X360 életciklusának vége felé. A PS4 már eleve egy libGNM-mel kezdett, és a libGNMX, mint wrapper opció. Az X1 picit lemaradt, de sokaknak elérhető már a D3D mono. Amiatt, hogy a konzol megjelenésekor kvázi rögtön van low-level API, az elsődleges rosta az GPU-architektúra dokumentációja lett, tehát eleve olyan rendszert kér a Sony és az MS, amelyhez a gyártója nyíltan áll hozzá, értsd elmondják hogyan működik. Ezért ma konzoldizájnra gyakorlatilag két cég esélyes: AMD és Imagination.
-
Abu85
HÁZIGAZDA
Bizonyosan meg lesz a mostani konzoloknál a 8-10 éves életciklus. Ez a piac csak így működőképes. A Microsoft és a Sony a fejlesztők felé ezekre garanciákat vállal, mert minden egyes konzolgeneráció leváltásánál gyakorlatilag azt mondják, hogy az előzővel nem kompatibilis, újra kell írni mindent, ha jól akarod használni, de ez jó üzlet lesz, mert 8-10 évig itt lesz az alap. És a fejlesztők számára ez az életciklus garantálja, hogy a befektetésük biztosan megtérül.
Azok a fejlesztések, amelyek ténylegesen erre a konzolgenerációra jönnek, nagyjából 2016-2017-ben érnek be. Ezek nagyrészt szoftverek, és ha az MS és a Sony 2017-ben már új konzolt hoz, akkor a fejlesztőknek az egész egy marha nagy pénzkidobás volt. Még akkor is, ha az esetleges új konzolok is AMD64 és GCN párosítások. -
#7784
Abu85
HÁZIGAZDA
huskydog17
#7782
Abu85
HÁZIGAZDA
válasz
 huskydog17
#7782
üzenetére
huskydog17
#7782
üzenetére
Az 1.0 is így néz ki. Ezen is látszik a rossz élsimítás és átlátszóság. De nem ez az igazi gond, hanem a zártság. Ez egy izolált környezet. Úgy van megírva alá a motor, hogy a Hairworks összes eleme aktív lehessen. Mi van, ha a játék motorja valamit nem támogat? Például az önárnyékot, ahogy a Wither 3 esetében. Nem tudod módosítani, így le kell kapcsolni az effekt önárnyékát. Mi van, ha az MSAA-t nem támogatja a motor? Ezen működik az AA, ha nincs meg az alap hozzá, akkor le kell kapcsolni a teljes AA-t, ahogy Monster Hunter Online esetében. [link]
Ezek teljesen behatárolják a Hairworks minőségét, mert nem tudod rászabni a rendszert a motorra. -
Abu85
HÁZIGAZDA
Inkább a képminőség romlása nélkül. Az x16 beállítás után már nincs előnye a további tesszellálási szinteknek. Teljesen felesleges egy haj-/szőrszálat 350-380 szakaszból felépíteni. Nem ezen múlik az effekt minősége, mert a szőr esetében egy pixelen belül lesz körülbelül 30 szakasz, amelyből egy az, ami számít. De viszont rossz vagy nincs önárnyékolás, élsimítás és átlátszóság. A HairWorks legnagyobb problémája az, hogy annyi erőforrást elpazarol a tök felesleges számításokra, hogy a végeredményben meglátszó számításokra már nem marad elég idő. Ezért néz ki olyan spagettiszerűen a HairWorks-féle haj. Nincsenek minőséget adó számítások rajta. Maga az alap nem tűnik rossznak. Akár jobb is lehetne, mint a TressFX, ha hozzáadnák a minőséget és a sebességet.
-
Abu85
HÁZIGAZDA
A Hitman esetében mint mondtam nem tudni, hogy mit döntenek a fejlesztők. A Glacier 2 jelen pillanatban csak az AMD saját API-ját támogatja a low-level megoldások közül. Nem valószínű, hogy a két szabványos megoldás közül mindkettőt beépítik. Szóval vagy DX12 lesz belőle vagy Vulkan. Decemberre mindkettő elérhető. Azt tudom, hogy az Eidos a Dawn esetében azért választott DX12-t, mert rendszer része lesz a PureHair és PureMaterial, ami a TressFX 3.0-ra épít és ez egy HLSL-ben írt technológia. Az I/O Interactive ezt nem tervezi alkalmazni a Hitmanben. Ez nekik szabadabb választási lehetőséget ad.
Az EA Vulkan API-ra lő. Ők a HLSL-t el akarják hagyni. Vagy csinálnak saját nyelvet, vagy OpenCL-t használnak.
-
Abu85
HÁZIGAZDA
Ezért írtam low-levelt, ha elolvasod. Ez jelenthet három különböző API-t jelenleg. Például az EA a DX12 elé helyezi a Vulkan API-t, mert nekik az az átállás könnyebb. Főleg source-2-source fordítóval. Gyakorlatilag lefuttatják az AMD API-jára írt kódjukon és van lesz egy szabványos kódjuk hozzávetőleg két óra munkával. A DX12-re való átállás valószínűleg eltartana egy hétig, mert azt a kódot az Xbox One-ból kellene venni, és pár effektet bele kellene még műteni.
-
Abu85
HÁZIGAZDA
(#7684) rocket - erre akart válasz lenni csak félrenyomtam.

És csináltak belőle egy Windows 10 exkluzív címet. Hol a probléma? Lesz Windows 10 PC-re és Xbox One-ra is. Az övék az IP.
Az indie és az AAA nem zárja ki egymást. Mint írtam a Star Citizen AAA és egyben indie is.

-
Abu85
HÁZIGAZDA
válasz
 Televan74
#7730
üzenetére
Televan74
#7730
üzenetére
A következő évben a HBM1/2 termelése ténylegesen felfut. De nem valószínű, hogy az NV elsőre vállalja. Azért elég kockázatos egyszerre architektúrát, csíkszélességet váltani a nagy teljesítményű interposerekhez való kötelező igazodással. Ezek önmagukban is problémásak, egyben pedig...
A Pascal gaming szempontból igazából azért fontos, hogy az NV-nek is legyen egy VR-re tervezett hardvere, mert az AMD-nek már ott a Fiji. Ahogy látod mindegyik VR játékot fejlesztő cég AMD-n demózott az E3-on, mert nem tudnak mást tenni. Lényegesen jobb az AMD VR csomagja, és ez megvásárolható az Oculus startra. Az NV ezt lekési, de a lényeg, hogy minél hamarabb hozzák a finomszemcsés preempciót és a GPGPU compute fejlesztéseket a Pascallal, mert ez kell a VR-nek.
-
Abu85
HÁZIGAZDA
Nem. Azt mondtam, hogy low-level API-t fog támogatni, és a Glacier 2 Mantle-t támogat is. Innen pedig lehet dolgozni másra is. Ez már az I/O Interactive döntése. Azt nem tudom, hogy a DX12-t választják-e vagy a Vulkan API-t. Csak annyit, hogy a motorba már be van építve a Mantle és a TrueAudio. Még akár az is lehet, hogy DX11 és Mantle lesz csak, bár ezt nem tartom valószínűnek, amikor az AMD-nek lesz Mantle->Vulkan source-2-source fordítója.
-
Abu85
HÁZIGAZDA
Mivel kezdettől fogva crossmultira van tervezve a Fable Legends, így nehezen képzelhető el, hogy csak Xbox One-ra jön. Főleg úgy, hogy be van jelentve, hogy itt lesz PC-n is, persze csak Windows 10-hez. De nem ez lesz az egyetlen Windows 10 only játék idén. Jön egy másik Unreal Engine-es DX12 cucc ősszel.
Én is számoltam több indie címet. A Star Citizen is az például. Még mindig nem tudom, hogy az MS-nek honnan van a száma, de mint mondtam ők biztosan jobban informáltak.
(#7676) Laja333: Pláne úgy, hogy a Vulkan binding modellje egyedül GCN-en nincs emulálva. Persze ettől a shaderben kell megadni a memóriaelérést, de a CPU fogja betölteni és nem a GPU maga. Majd a Valve megköszöni a PC Worldnek, hogy aknázzák alá az üzletüket.
-
Abu85
HÁZIGAZDA
A Fable Legends egy crossplatform multis játék lesz. Az MS az év elején jelentette be, hogy egyszerre jön PC-re és Xbox One-ra, és két platformon lehet majd egymás ellen játszani.
A saját számaim nem slide-ból vannak. Egyszerűen megkérdeztem, hogy ki támogatja a low-levelt az érkező játékokban. Aki visszaírt annak behúztam magamnál egy strigulát. Sokan nem írtam vissza egyébként. Lehet, hogy ezért van az MS-től jóval nagyobb számot. Ők biztosan sokkal jobban informáltak nálam.
(#7664) gbors: Az is lehet. Én mindenesetre inkább irkálok külön a fejlesztőknek, az a biztos. Lassan válaszolgatnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Inkább 20-30 ms közötti értékekről volt szó. Tartósan 60 ms feletti érték az már konkrét akadás. De értem. Az SLI így jó.

Megjegyzem nem véletlenül álltak le a frame-pacing tesztek. Úgy nem éri meg pénzelni a tesztlaborokat az FCAT-hoz szükséges (igen drága) kütyükkel, hogy az SLI ebben a tekintetben rosszabb lett az elmúlt időszakban, mint a Crossfire. -
Abu85
HÁZIGAZDA
Igen, sajnos ez történik, amikor a várt adat nem érkezik meg. Ilyenkor a GPU nem tud mit csinálni, mint vár rá. Ezért lett lecserélve a hidas megközelítés, mert már 2560x1600-ban is látszott a probléma, csak még nem volt olyan jelentős, mint 4K-ban.
Maga a jelenség nem az SLI sajátja. Ugyanúgy felfedezhető a hidas CF-en is. Egyedül az XDMA CF immúnis rá. -
Abu85
HÁZIGAZDA
Annak nem sok köze van hozzá. Az a gond, hogy az XDMA a teljes PCI Express sávszélt felhasználhatja interframe kommunikációra, míg az SLI hídja csak 500 MB/s. Egyszerűen ez kevés. Nem lehet vele mit csinálni. Ugyanúgy kevés lenne az AMD CF hídja is. Azon is látszik, hogy egyszerűen olyan limites lesz 4K-ban, mint az SLI. Még akkor is, ha 900 MB/s-ot tud. Sajna ez van.
-
Abu85
HÁZIGAZDA
Annyira azért nem érdekes. Korábban is kiderült, hogy 4K-hoz a hidas technológia korlátozó. Megfogja a skálázódást és rontja az egyenletességet. Radeonnál szimplán az XDMA előnye látszik. Jobb lesz tőle a skálázódás és kevesebb lesz az akadás. Majd a DX12-nél a híd úgyis elveszik.

-
Abu85
HÁZIGAZDA
A dedikált GPU-k jövője egyértelműen az Inteltől függ. Nekik lejár az FTC-vel kényszerítése idén szeptemberben, amely arra kötelezte őket, hogy a dedikált GPU-knak x16-os PCI Express csatolót kell biztosítani. Nyilván ez nem kedvezett az Intel terveinek, de a hatóság szava döntött. Ez 2010 augusztusa óta ismert volt. A piac szereplői 5 évet kaptak a saját lábra állásra. Szeptembertől kezdve az Intel jóakaratától függ, hogy létezhetnek-e vagy sem.
-
Abu85
HÁZIGAZDA
Azt nincs értelme kivásárolni, mert akkor csak dedikált GPU-ként használható. A dedikált GPU-k eladásai éves szinten folyamatosan esnek, és ez már öngerjesztő, mert azért emelkednek az árak és lassul a generációváltás, hogy a visszaesést kompenzálják, ami újabb visszaeséshez vezet, ami újabb áremelést von maga után kompenzálás céljából, és így megy majd tovább addig, amikor már nem éri meg fejleszteni sem erre a piacra. Senki sem fog egy olyan piacra vásárolni, amelyiknek a jövője gyakorlatilag borítékolhatóan borús.
-
Abu85
HÁZIGAZDA
válasz
 Joczeek
#7588
üzenetére
Joczeek
#7588
üzenetére
Ha fel akarják vásárolni az AMD-t, akkor az ellen az Intel kardoskodni fog, mert gyakorlatilag az arra irányulna, hogy a Microsoft kitegyen mindenkit a platformjából, és saját hardvert tervezzenek. Akkor az Intelnek tényleg a bérgyártás marad. Nyilván ez nem túl kedvező számukra, így egy tényleges ajánlat esetén ahol lehet megtámadják a lehetséges akvizíciót.
-
Abu85
HÁZIGAZDA
Ha ilyen megtörténik, akkor az MS konkrétan egy második Apple lenne. Itt nem csak a konzolról lenne szó, mert az Xbox One-ért tök felesleges vásárolni, ha megveheted magát a kész hardvert, ráadásul kiszámíthatóan, hiszen előre rögzítve vannak a feltételek, és így a kockázat alacsony.
Csak úgy van értelme kiadni egy csomó pénzt, ha utána minden Windows platform alá saját hardvert raknak, de ez nagyobb váltás lenne, mint amennyit önmagában megér. Jórészt azért, mert lapkákat most is tudnak vásárolni, illetve a Qualcomm a jövőben sem fogja nekik azt mondani, hogy nem szállítanak WP-be platformot, és az AMD is bármikor készít nekik újabb egyedi megrendelésre egyedi lapkát.A Sony MIPS+Imaginationre építene a jövőben, ha megtörténik. De az aktuális szerződést nem lehet felbontani.
-
Abu85
HÁZIGAZDA
válasz
 #35434496
#7386
üzenetére
#35434496
#7386
üzenetére
A Microsoft SDK-jából származik. Van benne számos sample, hogy hogyan lehet a DX12 képességeit használni, és ezekre programok is vannak. Az async shader nevű program tartalmazza az aszinkron compute kihasználhatóságát, és azt már lehet mérni, akinek van SDK-ja. Persze még a mostani driverekkel, és mint mondtam az Intel tiltani fogja, mert nekik ez a képesség lassít.
Az aszinkron compute implementálása egyébként sokat számít. A grafikus vezérlők ma pipeline-okat futtatnak egymás után. Ezért van alacsony kihasználtságuk, mert a pipeline-ok sorban érkeznek és egyszerre csak egy fut. Ha kész, akkor jön a következő, és a következő, és a következő, és egyszer elfogynak, amikor kész lesz a képkocka. Persze akkor meg lesznek újak. Az async shader annyit tesz, hogy a queuing modellt a mai soros formáról megváltoztatja párhuzamosra. A mai modernebb GPU-knak van pár compute parancslistája, és azokon fogadhatnak compute pipeline-okat. Ezeket úgy be lehet tölteni, hogy bizonyos compute pipeline-ok párhuzamosan lefussanak grafikus pipeline-ok mellett, vagyis ne soros legyen a feladat végrehajtás a grafikus vezérlőkön belül. Ehhez a DX12 azt követeli meg, hogy a hardver képes legyen egyszerre fogadni legalább egy grafikai és egy compute parancsot. Persze lehet többet is. Ezek futtatásának ütemezése a fejlesztők feladat. Itt azt kell figyelembe venni, hogy a különböző architektúrák milyen hardverállapotban képesek compute shadert futtatni. A GCN például stateless, vagyis akármi lehet a hardverállapot mindig tud mellette compute shadert futtatni. A Maxwell 2 már a pixel/ROP state-hez köti ezt, ami kedvezőtlenebb dizájn. Például, ha egy program mondjuk tesszellálás mellett akar compute pipeline-t futtatni, akkor azt a GCN-en megteheti, de a Maxwell 2 állapotváltásra kényszerül, vagyis a hardveren belül egyszerre úgy sem futhat a hull/domain shader és a compute. Erre egyébként vannak optimalizálási javaslatok, mint az, hogy a legjobb a compute feladatokat a shadow mapok generálásakor futtatni, mert akkor a Maxwell 2-n a pixel/ROP state van betöltve. Az Intel problémája pedig speciális. Ők azzal vesztenek, hogy async shaderrel az IGP órajele alacsony lesz. Egyszerűen olyan magasra fut a terhelés, hogy nem tud turbózni, így 1200 MHz helyett 300 MHz-e történő számításra kényszerül. Nyilván ez okozza a lassulást, és ezért lesz letiltva a funkció. A GCN1 hatékonysága pedig azért van a GCN2/3 mögött, mert vannak hátrányosabb tényezői, mint a lassabb kontextusváltás. Persze ez relatíve még így is nagyon gyors, csak nem annyira jó, mint amit a GCN2/3 tud. -
Abu85
HÁZIGAZDA
válasz
mcwolf79
#7378
üzenetére
Nem láttam az üveggömbben, hanem kaptam eredményeket. Ma csak egyetlen program van, ami aszinkron compute-ot használ, ami a Thief, de csak az 1.8-as patch után. Ebben látható valamennyire az aszinkron compute, igaz, hogy lightos a terhelés, de látható a változás.

Itt a GCN2 és GCN3 az aszinkron compute miatt nagyon elhúz a minimum fps-ben mindentől. Még a 280-től is elhúz a 380, de utóbbi ugye egy átnevezett 285. És ez látszik egyébként a GCN2/3 kártyák fogyaszátásán és megelegédésén is, hogy azt az extra teljesítményt nem egy párhuzamos dimenzióból szedik elő. Itt az is látszik, amit korábban írtunk, hogy a GCN1 aszinkron compute mellett nem annyira hatékony, de még így is a második leghatékonyabb csomag a GCN2/3 után. A GCN2/3 hatékonysága nagyjából azonos.
Vannak egyébként erről DX12-es tesztek már, mert az AMD készített rá az SDK-ba egy példaprogramot. Ott a GCN1 nagyjából +15-25%-ot hoz. A GCN2/3 +35-45%-ot. A Maxwell 2 +5-15%-ot. A Broadwell IGP-je -45-60%-ot, de mivel ez negatív skálázódás, így ezt a képességet az Intel le fogja tiltani a driverben, hogy ne lassítsa a félretervezett hardverdizájn a kódot. -
Abu85
HÁZIGAZDA
Lehet, hogy kockázatos volt, sőt, biztos is, de átnyomták a változást. Tehát innentől kezdve elkönyvelhetik, hogy jól döntöttek. Egyébként nyilván semmi garancia nem volt arra, hogy a Microsoft és a Khronos elkezd építeni API-kat az AMD ötleteire és konkrét kutatásira építve, de megtörtént, ez ma már tény.
(#7275) rumkola: A kernel driver eltűnik. Ez már ismert. A user mode driver marad meg. Bizonyos allokációs funkciók és a shader fordító lesz benne. A memóriavezérlés, az allokációs stratégia, a hazárdok kezelése, stb., mind átkerül az alkalmazásba egy univerzális driverbe, ha úgy tetszik.
-
Abu85
HÁZIGAZDA
Low-level API-nál, jelen esetben Mantle-nél ugyanaz van, mint a Tonga cGPU-val. Amelyik programra nincs memóriaoptimalizálás ott az újabb architektúrára épülő GPU lassabb. A Battlefield 4-hez nem készült ilyen patch. A többi játékot már patch-ekkel felkészítették a Tongára (vagy eleve jól adták ki), és ebből az optimalizálásból a Fiji is profitál, bár nem feltétlenül ugyanúgy, ahogy a Tonga.
Ez a low-level API átka. Ha jön egy zsír új architektúra, akkor simán lehet, hogy a felét sem tudja az előző generációnak, csak azért, mert a programban van az, ami régen a kernel driverben volt, és az a programban nyilván nem cserélhető egy új driverrel.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#6760
üzenetére
Itt programozástechnikai dolgok is beleszólnak. A Maxwell egy dologban nagyon különbözik a Keplertől. Nem kell speciálisan etetni egyetlen SIMD-jét sem, mert mindegyikhez van elég szál. A Kepler esetében a hatból csak négy SIMD kaphatott szálakat, és a maradék két SIMD esetében független feladatokat kellett speciálisan leprogramozni, amit aztán a shader fordító megpróbált befűzni, hogy ki legyen használva a multiprocesszor maradék 33%-a is. Ez eléggé melós dolog, és sokszor nem lehet jól megoldani. Ma valószínűleg ez nem fókusz, és efféle optimalizálás nélkül a Kepler elveszti a shader processzorainak 33%-át. De erre továbbra is lehet optimalizálni, csak az NV nem fog.
A GTA5-nél kísérleteznek a mikrokóddal. Továbbra is gond, hogy a hiba alaplap- és nem kártyafüggő.
-
Abu85
HÁZIGAZDA
Szerintem a Kepler annyira nagy probléma elé nem néz. A gondok leginkább az újabb TWIMTBP játékokra vonatkoznak, de más játékokban nincsenek ilyen problémák. Gaming Evolved játékokban például szinte sehol. Nyilván az nem jó, hogy az NVIDIA elkezdte az amortizációt a Keplernél, de úgy gondolom, hogy maximum pár TWIMTBP játék esetben lehet teljesítményprobléma a Keplerrel. Nyilván ez üzlet. Egy elégedetlen tulaj hamarabb vált, mint egy elégedett. Valszeg az NV kiszámolta, hogy a keménymagot ugyan elvesztik, mert ők utánajárnak, hogy a Kepler csak vissza van fogva, de amíg a felméréseik azt mutatják, hogy 10-ből 9 felhasználó nem tud felbontást váltani, addig megéri szétszopatni a vásárlóidat. Az az egy hozzáértő vesz mást, de a maradék kilenc ~fele talán rávehető, hogy évente cseréljen.
-
Abu85
HÁZIGAZDA
Hát elég jó élményt adhat. De nem kell itt egymillióra gondolni, elég a 200 ember. És a szinkronizáció mindenre kiterjed, vagyis mindenki ugyanazt látja.
Vannak számításigényes megvilágítási technikák. Abban én sem vagyok biztos, hogy jó irány, de gondolkodni kell a Grid költségeire. A felhő átka az üzemköltség melletti alacsony kihasználatlanság. Akkor lehet hasznot termelni belőle, ha van sok előfizető, és ha valaki esetleg nem akar előfizetni teljes játék streamre, majd előfizet a megvilágítás streamelésére. Ha akarod, ha nem ez szükséges ahhoz, hogy a kiépített gépeket fenntartsák. Az NVIDIA keresni fog minden lehetőséget, hogy a felhasználóbázisából előfizetői bázist csináljon, különben le kell bontani a Grid központokat.
-
Abu85
HÁZIGAZDA
Abból a szempontból innovatív, hogy valószínűleg felhő nélkül nem tudnál egymillió játékost bevágni egy nagy és interaktív MMO-ba, mert meghalna a rendszer a szinkronizálásnál.
Ugyanúgy vannak olyan grafikai problémák, amelyekre a kliens oldalán nem létezik megoldás.
A felhőben csak az a nehéz, hogy milyen legyen az előfizetés. Nyilván nem fog ingyenesen üzemelni, mert a gépeket fenn kell tartani. Most is csak azért érhető el ingyen a Shieldről, mert tesztelgetik. Amint ki lesz alakítva a tartalom, számos exkluzív rendszerrel pénzt fognak érte kérni. Valószínűleg annak függvényében, hogy a mai tesztelgetésen milyen költségeket mérnek. -
Abu85
HÁZIGAZDA
Teljesen mindegy, hogy mi alakítja a cégek jövőképét. Egy innovatív gondolat, vagy az a probléma, hogy a piac a termék alatt idővel megszűnik. Mindkettőre ugyanúgy kell reagálni. Vinni előre a gondolatot.
X86 licenc nem szükséges már. A Windows 10-et is felrakod ARM-ra, és működik, ezen belül ott van az univerzális áruház, ami pont azért létezik, hogy hardverfüggetlenül legyen kezelve a rendszer. Ha Windows 10-es a cucc, akkor eléred az áruházban a programokat.Az NV gondolata a Griddel nem egyedi. A Microsoft is felhőből irányítja a Forza AI autóit az Xbox One-on. Az NV-nek az ötlete csak annyiban különbözik, hogy ők grafikát számoltatnának inkább a felhőben.
-
Abu85
HÁZIGAZDA
AZ NV-nek a Gridje egy eléggé életképes dolog lehet a jövőben. Vannak olyan tervek, hogy MMO-kat terveznek a felhőbe és ténylegesen ott lesz szimulálva az egész, vagyis nem kell a gépek között szinkronizáció. Mindenki pontosan ugyanazt fogja látni. Vagy az effektek felhőbe ültetése egy nagyon érdekes projekt, amely évekkel korábban kezdődött, és a Grid már megadja rá az alapot. Ezzel a koncepcióval a felhő kiszámolhatja a megvilágítást a játékba és a képkockát befejezi a kliens. Ami ezekben még kérdéses az a fenntarthatóság, mert egyelőre nehéz látni, hogy miért mennyi előfizetési díjat szedjen be az NV. Illetve az is kérdés, hogy mi legyen azzal, aki nem akar előfizetni, vagy elmegy a net, tehát alap megvilágítás a kliens oldalon is kell.
-
Abu85
HÁZIGAZDA
válasz
 MiklosSaS
#6711
üzenetére
MiklosSaS
#6711
üzenetére
Mivel bénázott? Tényleg nem értem. Az Intel is mutatott Xeon rendszereket FirePro S-sel, pedig nekik ott a Xeon Phi. Ők sem bíznak a Xeon Phi-ben? Mindenki rajtuk röhög?
Az általános számítás nem olyan egyszerű, mint a grafikai, mert ott számos hátráltató tényező van. Az Intel architektúrájával az egyik, hogy kapásból elveszti a számítási teljesítményének a felét, ha függőség van a kódban, ami azért elég jellemző GPGPU-ban. Nem véletlen, hogy az AMD és az NVIDIA inkább birtokláslimites architektúrákat tervez, mert nem előnyös a függőséglimit. Erre majd az Intel is áttér, csak nem olyan egyszerű megtervezni.
-
Abu85
HÁZIGAZDA
Ez még a jövő, nem a történelem. Be is mutogatták a Builden az Unreal Engine 4-gyel, illetve a Stardock is elmondta, hogy nekik is olyan a rendszerük, hogy az IGP-t is beszámítja a feldolgozásba, ha van. Erről már volt is szó, hogy a 290X-szel egy A10-7850K +20%-ot ad, ha az IGP-je aktív. Ez egy nagyon fontos lépés, amit a Microsoft letett a WDDM 2.0-val és az IOMMU módjával, mert alapvetően erre épül számos Xbox One játék, csak ott statikus particionálással dolgoznak a fejlesztők. PC-n ez nem kell, mert eleve ott az IGP, de a funkciót lehetővé kell tenni. Valószínű egyébként, hogy a pathfinding innen szivárgott le a PC-s kutatásnak is.
A váltásnak az elsődleges előnye, hogy az IGP kihasználása a CPU-s SIMD-ekkel szemben olcsóbb és egyszerűbb. -
Abu85
HÁZIGAZDA
válasz
#85552128
#6702
üzenetére
Nem azt mondtam, hogy elég bele, hanem azt, hogy nem egyértelmű a piac iránya a gyártók számára. Még az Intel számára sem, és ezért csinálnak két processzort ugyanabba a kategóriába. A Skylake verzió a processzorrészre, míg a Broadwell-K opció az IGP-re gyúr. Az a baj, hogy annyira kiszámíthatatlanok most a fejlesztések, hogy nem tudják eldönteni melyik lesz a jobb.
Ami az egészet teljesen kiszámíthatatlanná teszi, hogy a fejlesztők olyan dolgokban is gondolkodnak, amelyet egyik érintett sem tartott lehetségesnek. A pathfinding offload kutatási irány lett, és az IGP-k is rendelkeznek minimum 200-1000 szál futtatásának lehetőségével, tehát baromira jó ötletnek tartják a stúdiók ezekre átnyomni az NPC-k AI-ját.
-
Abu85
HÁZIGAZDA
Ez teljesen válasz a kérdésre. Az E3-ra építettek rendszereket, arról van videó. Az a rendszer kereskedelmi forgalomba nem kerül.
Nem kell benne hinni vagy nem hinni. Lesz egy új lehetőség, ami nyilván ki lesz használva. A gyártók előtt ott a lehetőség, hogy ezt lefedjék a megfelelő termékekkel a Quantum projektben is, ha az alaplap Mini-ITX-es és nem fogyaszt többet a proci 95 wattnál.
-
Abu85
HÁZIGAZDA
Ezek tesztrendszerek, amelyeket az E3-ra raktak össze. Mint mondtam a gyártók nem ilyet fognak összerakni maguknak. Egy LGA1151-esben és egy Socket FM2+-osban opcióban gondolkodnak. Nyilván egyébként lehetne Broadwell-K is, ami az Intelnek a DX12-höz tervezett Gaming rendszere nagy IGP-vel, de ez drágább marad, mint a Skylake, mert jóval erősebb az IGP-je és jóval jobb lesz az IGP offloadot használó játékokban. De lehet, hogy lesz olyan cég, amely Broadwell-K-t rak bele, és azzal egyik helyen sem lesz a leggyorsabb a procirésze a rendszernek, de alapvetően mindkét irányt tisztességesen kiszolgálja. Mint írtam a Mini-ITX alaplap az egyetlen követelmény, maximum 95 wattos procival.
-
Abu85
HÁZIGAZDA
A DirectX 12 (és később a Vulkan is) kínál nagyon jó lehetőségeket az IGP használatára, és sokkal többet ér az így nyerhető gyorsulás, mint amit a processzorból ki lehet sajtolni. Ráadásul azzal, hogy az IGP számol komoly vektormatematikai problémákat, a processzormagok teljesen felszabadulnak. A WDDM 2.0 az IOMMU móddal egy nagyon jó alap lesz arra, hogy az IGP teljes egészében átvegyen olyan feladatokat, mint a tartalomkikódolás, a rendezés, vagy a kivágás view frustum cullinggal. Mindegyiket sokat alkalmazzák ma a játékokban és a processzor csinálja. De mivel egyre komplexebb jelenetre van szükség, így jól jön, ha a processzormagok helyett az IGP, azaz egy teljesen szabad erőforrás meg tudja oldani ezeket az extrém módon párhuzamosítható problémákat.
-
Abu85
HÁZIGAZDA
válasz
 Locutus
#6686
üzenetére
Locutus
#6686
üzenetére
Amit hallok az érdeklődő gyártóktól, hogy ők két opcióban gondolkodnak. Az egyik az LGA1151, míg a másik a Socket FM2+. Ezzel a két opcióval le lehet fedni a következő érát, így lehet dönteni aszerint hogy az adott játékhoz erős procirész kell, vagy erős IGP. Egyelőre nem lehet eldönteni, hogy melyik a jó út, mert nagyon vegyes a H2 játékfelhozatal. Némelyik játék egyáltalán nem használ majd IGP-t, míg némelyik játék sokat gyorsul tőle, ha a számításokat nem kell elvinni a dGPU-ig vagy nem a CPU-n kell futtatni.
-
Abu85
HÁZIGAZDA
Ez normális. A Maxwell úgy van tervezve, mint egy ultramobil GPU-architektúra, tehát nem egy nagy széles buszra van felfűzve az összes multiprocesszor, hanem a pici buszok a multiprocesszoron belül futnak át a lapkán. Ennek az előnye, hogy rengeteg tranzisztort lehet megspórolni, de hátránya, hogy ha letiltasz egy multiprocesszort, akkor a buszok egy része is eltűnik, vagyis ez negatív hatással lesz a lapka más részeire, függetlenül attól, hogy azok teljesek-e.
A memória 970-szerű particionálása attól függ, hogy le van-e tiltva az L2 cache egy szelete. Mivel itt nincs, így a teljes memória ugyanolyan sebességgel érhető el.
-
Abu85
HÁZIGAZDA
Annyit hozzátennék, hogy az UE4 támogatni fog multi-GPU-t, csak nem olyan formában, ahogy eddig megszoktátok. A DX12-be egy olyan rendszer kerül ahol az IGP megcsinálhatja a post-process munkát, tehát dGPU+IGP multi-GPU-ra befogható lesz mindegyik DX12-es UE4-es játék. Ez a mód minden olyan IGP-vel működik, amely támogatja a DX12-t, és az IGP-hez bármilyen DX12-t támogató dGPU társítható. Persze az IGP ereje alapvetően meghatározza majd a nyerhető sebességet, de ez már hardveres kérdés.
-
#6392
Abu85
HÁZIGAZDA
Malibutomi
#6391
Abu85
HÁZIGAZDA
válasz
 Malibutomi
#6391
üzenetére
Malibutomi
#6391
üzenetére
Nehéz megmondani, mert ilyet PC-n még senki sem csinált. Csak konzolon volt bevett szokás újraírni a szoftverinfrastruktúrát a hosszú életciklus miatt. De a konzolokból kiindulva reális lehet a +5-30% konfigurációtól és programtól függően.
Kérdezd meg Laja333-at, neki úgy néz ki, hogy van valami előzetes tapasztalata.
Egyébként ez is szerintem egy egyszeri alkalom. Általában a PC-kben hiába van 70-80%-nyi kihasználatlan teljesítmény, akkor is mire abból valamennyit befognak a driverben már rég itt az új architektúra, tehát meg sem próbálják azt, amit a konzolokkal csinálnak a nagyobb frissítésekkor. Az AMD is csak azért tette, mert tudták, hogy legalább 5 generációt építenek GCN-re. Megéri az életciklus közepére újraírni a szoftvereket, immáron tapasztalattal.
-
#6388
Abu85
HÁZIGAZDA
Malibutomi
#6387
Abu85
HÁZIGAZDA
válasz
Malibutomi
#6387
üzenetére
Ja. Meg új shader fordító. Majd a Windows 10-zel lesz itt a teljes csomag a nyár folyamán. A bátrak a Windows 10 drivert felhackelhetik Windows 8.1-re.
-
Abu85
HÁZIGAZDA
válasz
 tom_tol
#6373
üzenetére
tom_tol
#6373
üzenetére
Professzionális területen. Az AMD pár negyedéve folyamatosan rekordbevételt ér el a HPC és a munkaállomás piacáról. Nyilván ehhez hozzájárul az, hogy a GCN létezik, és több területen nincs rá alternatíva. Ha te olyan gépet akarsz, ami DP-ben a csúcs, akkor FirePro S9150-et kell venned. Nyilván az is segít ezen, hogy több szabványos rackbe egy Tesla K80-at be sem lehet építeni, mert jóval többet fogyaszt és a rack hűtése miatt a teljesítménye 30%-kal esik.
A Xeon Phi az nem téma manapság. Azért volt felkapott, mert az Intel azt mondta, hogy a meglévő OpenMP kódokat újra lehet fordítani és futnak. Na most ezt elfelejtették azzal kiegészíteni, hogy így viszont nem lesz gyorsulás.
A HPC piacon az NV a Maxwellt érthető okokból nem vezette be, így a Kepler a GCN ellenfele még mindig. -
-
Abu85
HÁZIGAZDA
A FirePro S9150 eléggé nagy siker. Többek között ez a rendszer van a világ leghatékonyabb szuperszámítógépében. Ez az L-CSC, ami 5,27 GFLOPS/wattot tud. A hozzá legközelebbi, hasonló fogyasztási karakterisztikával (~50 kW) rendelkező GPGPU-s szuperszámítógép 3,63 GFLOPS/wattra képes, szóval az előnye a GCN-nek ezen a piacon elég nagy. Nem hiszem, hogy az USA szeretné, ha ez a technológia kínai kézbe kerülne.
(#6368) NetTom: A Tianhe-2 nem számít. Az Xeon Phit használ, pontosabban nem használ, mert csak be van építve. Tehát tud izmozni Kína, de valójában a gép 85%-a kihasználatlan.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#6362
üzenetére
Nem teljesen. Erre rákérdeztem és elvileg senki sem nyilatkozott így, legalábbis senki sem tud róla, de ezt majd kivizsgálják, mert a Northland máskor is írt már meg olyat, hogy xy nyilatkozott és közben nem is.
A Xilinxszel kapcsolatban nem mondtak semmit, de innen tudom, hogy az FPGA-kat rossz ötletnek tartják. Egyébként ez érthető. Minden cég az előrelépés lehetőségét nézi egy új irányzattal. Az Intelnek az FPGA előrelépés, mert minden GPGPU-s koncepciójuk működésképtelen. Az AMD-nek egy FPGA nem előrelépés, mert a GCN működőképes. Itt nem csak a teljesítmény/fogyasztást vizsgálják, hanem azt, hogy az FPGA-k programozására a legbarátságosabb lehetőség az OpenCL, míg egy GPGPU programozására ott a Java9 is, ami azért jóval magasabb szintű nyelv és a hatékonyság így is magas. -
Abu85
HÁZIGAZDA
válasz
Locutus
#6359
üzenetére
Nyilván Kína közeledését nem szívesen veszik. Azért ha ráteszik a kezüket a GCN-re, akkor az nagy baj, mert építhetik a szuperszámítógépeket, amikkel lealázzák az USA-t. Nyilván nagyobb az esélye annak, hogy megkérik az IBM-et, hogy adjanak jobb ajánlatot és akkor kiírnak nekik valami zsíros kormányzati tendert cserébe.
De az amcsik is tudják, hogy az AMD nagyon sok pénzt kér, mert nem cél az eladás, annyit pedig senki sem fog adni, mert ami kell az AMD-ből xy cégnek azt elérik a semi-custommel. Ez sem tetszik az amcsiknak, de ez ellen nem tudnak tenni.
A Xilinxnek nagyobb szüksége van az AMD-re, mint az AMD-nek a Xilinxre. Eleve az AMD az OpenCL-es FPGA-kat a szerverlapkákban rossz ötletnek tartja. Nyilván egy GCN-nel a zsebükben ezt nem nehéz így látni. -
Abu85
HÁZIGAZDA
válasz
Televan74
#6354
üzenetére
A Samsung is mindig ugyanarra jut. Nekik az AMD-ből a GCN és a Mantle kell. Ezeket pedig elérhetik jóval olcsóbban úgy, hogy rendelnek egy semi-custom lapkát a saját technológiájukkal összerakva. A Xilinxnek a Zen kell, ezt pedig szintén elérhetik semi-custom üzletágon keresztül. Megvizsgálható a felvásárlás, de a semi-custom lehetőségével nagyságrendekkel kisebb kockázat megrendelni a terméket, és az a nyereség oldalán ugyanazt fogja hozni az adott cégnek. Még a 3rd party IP is része a semi-custom üzletágnak, tehát semmi hátránya nincs összerakatni a lapkát, mint összerakni.
-
Abu85
HÁZIGAZDA
Nem a kínaiakkal van a baj, hanem, hogy mi értelme lenne nagy felárral vásárolni. A Samsung mindig megvizsgálja az AMD felvásárlásának lehetőségét, de mindig ugyanarra jutnak, hogy IP portfólió ide vagy oda, akkor is jelentős ráfizetéssel mehetne végbe a felvásárlás.
És itt jön elő az, hogy szükséges-e nagyjából 8-10 milliárd dollár kiadása, amikor az AMD teljes IP portfóliója elérhető a Semi-Custom üzletágon keresztül. Tehát ha bárki elgondolkodik ezen, akkor arra fog jutni, hogy ha szüksége van egy olyan lapkára, ami tartalmaz valamit az AMD IP portfóliójából, akkor egyszerűbb azt a Semi-Custom üzletágon keresztül megrendelni, mint egy kockázatos üzletbe belevágni. Nyilván a Xilinxnek erre szüksége van, így ők rendelni fognak. És ilyen formában nagyságrendekkel olcsóbb a buli. -
Abu85
HÁZIGAZDA
Az FP16-ot láttam. Azt nem tudom mennyire fogják használni, de bizonyos pufferek esetében felesleges FP32-ben dolgozni, mert nem hoz minőségelőnyt, viszont az FP16 eddig sok hardveren nem volt elérhető. Az Intel már megmutatta, hogy sokszor lényegesen előnyösebb az FP16, mert kétszeresére növeli az adott eljárásra levetített teljesítményt és csökkenti a fogyasztást.
A legnagyobb DX12-e fícsőrök egyébként nem ezek, hanem az async DMA/shader, a typed UAV loads, a resource heap lehetőségek, illetve ez a szép nevű:
VPAndRTArrayIndexFromAnyShaderFeedingRasterizerSupportedWithoutGSEmulation
-
Abu85
HÁZIGAZDA
Ezek közül minden csak a Mantle-ön érhető el. De a fontosabb dolgok ott vannak a DX12-ben és a Vulkan API-ban. Az FP16 biztosan. A stateless compute igazából egy automatikus hardveres fícsőr, ehhez nem kell külön támogatás. A fine-grained preemption egyelőre valóban nincs ott egyik szabvány API-ban sem, de a WDDM 2.0 fel van rá készítve, szóval bevethető. Sub-dword addressing és cross-lane ops az érkező OpenCL-en keresztül a Vulkan API-n át használható.
-
Abu85
HÁZIGAZDA
Ezt hogyan képzeled? Az NV odamegy az EA-hez és a Square Enix/Eidoshoz, hogy nekünk van xy% részesedésünk, és ezért használjatok GameWorksöt? Ez nem fog megtörténni, mert ezek a kiadók nem akarják lekorlátozni a kiadott játékaik grafikáját. Sokkal célszerűbb saját maguknak megírni a biztosan működő rendszereket.
(#6285) rocket: A Pascal elmondom miket vezet be: FP16, stateless compute, fine-grained preemption, sub-dword addressing, cross-lane ops. Mindegyik újítás már most! ott van a GCN3-ban (Tonga, Iceland, Wani, Fiji). API oldali támogatás is van rájuk.
-
Abu85
HÁZIGAZDA
válasz
 Yllgrim
#6278
üzenetére
Yllgrim
#6278
üzenetére
Nem arra írtam az 1000 eurót, csak úgy általánosan írtam le. De ha visszaolvasol a Radeon találgatós topikban, akkor írtam, hogy nem lesz olcsó.
(#6277) imi123: De mivel? Hogy megőrzi a PC-n az innovációt? Ennek örülni kellene. Jelenleg ezt az Intel és az AMD kutatásai képviselik.
(#6265) huskydog17: Ez nem olyan egyszerű. Az EA, Square Enix/EIDOS, a SEGA, a Capcom, még a Crytek is főleg azért partnere az AMD-nek, mert nekik vannak olyan hozzáértő mérnökeik, akik még egy nagy tudású programozónál is jobban megértik a GeForce hardverek működését. Egyszerűen csak azért, mert maguk is ilyen rendszereket terveznek. Nagyon fontos a PC-ben érdekelt cégeknek, hogy ha az NVIDIA nem mondja meg, hogy mit-hogyan-merre, akkor legalább valaki más tegye meg. Nyilván egy csomó cégnek teljesen jelentéktelen az a modell, amit az NV kínál a zárt middleware-ekkel. Ők kiszámíthatóságot akarnak, és azt csak saját kódokkal lehet elérni. Nagyrészt ennek köszönhető, hogy a downgrade-ek szempontjából az EA és a Square Enix jellemzően nem szokott hírbe kerülni. Képesek maguk irányítani a sorsukat.
Azért meg lehet nézni, mondjuk a Rebelliont. Ők totál független fejlesztők, nincsenek semmilyen kiadó pénzcsapján. Mégis olyan optimalizált játékokat tesznek le az asztalra, hogy azokat sok nagy kiadó is megirigyelné, és azt sem lehet mondani, hogy nem csinálnak semmi különöset, mert például az Asura az első olyan PC-s motor, amely obscurance fields effektet használ. Ez a saját fejlesztésű implementációjuk, és ez egy pici kis angol stúdió, és több grafikára vonatkozó technikai újítást raknak le, mint több nagyobb kiadó, nem beszélve a példás optimalizálásról. Azt akarom ezzel mondani, hogy nem a szaktudás hiányzik azokból a stúdiókból, akik rossz optimalizációval állnak elő. Egyszerűen sok esetben nincs is lehetőségük az optimalizálásra, mert egy vagy két vízfejű a vezetőségben, különböző értelmetlen szerződések megkötése után nem engedi meg, hogy a technikai csoport célirányosan dolgozzon, vagy esetleg nem adnak rá pénzt.
-
Abu85
HÁZIGAZDA
A GameWorks minden hardveren hátrány. Kérdezz meg bárkit, hogy a HairWorks vagy a TressFX minősége a jobb. Még számos NV tulajdonos is azt mondja, hogy a TressFX. Le is írtam egy cikkben, hogy mi hiányzik a GameWorksből, hogy elérjék a TressFX szintjét. Csak ezt nem lesz egyszerű megtenni, mert rengeteg erőforrást elpazarol az algoritmus, lényegében a semmire.
Amit nem értek, hogy ezen miért kell siránkozni? Igen a PC átalakul. A jövőben nem lesz olyan, hogy egy márkán belül mindent elérhetsz. Lesznek GeForce és Radeon exkluzív dolgok. Nem mondom, hogy ez jó, de ez van. Viszont a döntés a tietek, hogy milyen hardvert vásároltok a PC-be. Vagy akár az is, hogy mentek konzolra, teljesen mindegy. De azért siránkozni, hogy az AMD stratégiailag még mindig értékesebbnek tartja az optimalizált játékot, mint a mesterségesen magas gépigényt egyszerűen blődség. Ők ezt az utat választották és kész. Az NVIDIA az ellentétes irányt választotta, fogadjátok el azt is. Ott is ki lehet fizetni 1000 eurót évente az új csúcsért. De alapvetően egyetlen piaci szereplő sem kényszeríti rátok, hogy megvegyétek az új VGA-kat.
A kritizáló fejlesztőkkel mégis mit kezdjen az NVIDIA? Ők választottak, és nem kérnek a GameWorksből. Ennyi. Nekik sem kötelező elfogadni egy olyan szerződést, hogy nem optimalizálhatják a kiadásra váró játékot. Szép is lenne, ha ez kötelező lenne.
(#6275) rocket: Félreérted a fejlesztőket. Johan Anderssont nem érdekli, hogy a GameWorks létezik-e vagy sem. Magasról tesz rá, hogy az NVIDIA éves szinten mennyi pénzt éget el különböző fejlesztésekre, amiket nem lehet végül beépíteni sehova, mert ha megmozdul valami, akkor képi hiba van (lásd GI Works). Ez totál hidegen hagy mindenkit, aki ezt a csomagot kritizálja. Ami nem hagyja hidegen őket, hogy az NV nem dokumentálja a hardvereit, eléggé leépítették a fejlesztőeszközeiket, és nem kínálnak ISA disassemblert. Még ha akarnak sem tudnak jelen formában GeForce-ra optimalizálni. Nem mondja meg az NV, hogy miképp kell. Erről is írt már Matías N. Goldberg, hogy ez miért baj számára, meg azt is, hogy ez régen nem volt így az NV-nél. [link]
Itt alapvetően azt akarják a fejlesztők, hogy az NV ne legyen ilyen elzárkózó. Az, hogy a GameWorksöt nem nyitják meg őszintén szólva senkit sem érdekel, mert nem akarják használni, de az már érdekli őket, hogy amit írnak az mennyire optimalizáltan fut GeForce-on. Az az érdekük, hogy jó legyen, főleg a low-level irány mellett, ahol a fejlesztőkön elég sok múlik a kernel driver eltűnése következtében, és az NV a problémák esetén simán rájuk mutat, hogy ők a hülyék és nem a driver a probléma, mert driver már hagyományos értelemben nincs is.Sajnos a GCN és a Maxwell még mindig lényegesen gyorsabb Witcher 3-ban, mint a Kepler, Fermi, TeraScale 2, stb. Az R9 285 és a GTX 960 még mindig a GTX Titan szintjét képes hozni, mert annyit ezek is gyorsultak, amennyit a Kepler. Mondjuk ez nem baj, de ettől függetlenül nem történt felzárkózás.
-
Abu85
HÁZIGAZDA
Valószínűtlen, hogy az AMD egy akkora rage-et akar a felhasználóktól a fórumon látni, mint amit most az NV kap. Emellett tényleg meg kell érteni, hogy tök logikátlan húzás lenne az AMD-től zárt middleware-ekt fejleszteni. Van a PC-n egy vezető iparági igény arra, hogy szabaduljunk meg a feketedobozoktól. Elsődlegesen az API szintjén és ebben az AMD vezető szerepet vállalat. Kidolgozták a lehetőségeket, hogy hogyan lehetne ezt megtenni, és a Microsoft és a Khronos ezt kisebb nagyobb mértékben átemelte, illetve még átemeli szabványba. Az AMD a PC iránt tényleg érdeklődő nagy stúdióktól folyamatosan azt hallja nem akarnak feketedobozt, de akarnak ISA dokumentációt, használható fejlesztőeszközöket, esetleg ISA disassemblert. Az NVIDIA is tudja ezt, azért annyira még nem távolodtak el ezektől a stúdióktól, hogy Johan Andersson, Daniel Baker, Joshua Barczak, John Kloetzli, Kevin Floyer-Lea, Emil Persson, Tiago Sousa, Masaru Ijuin, stb, lényegében az iparág keménymagjának a véleményét ne ismerjék arról, hogy mennyire nem akarnak feketedobozokat, ettől függetlenül az feketedobozt elimináló igényeikre újjabb feketedobozzal válaszoltak. Twitteren erről olvashatsz is tényleges PC-s fejlesztőktől véleményt: [link] Van köztük Timothy Lottes és Bart Wronski, anno az NVIDIA/Epic Games és az Ubisoftnál dolgoztak. Timothy már az AMD-nél van, míg Brat elment a Sony-hoz. Az Ubisoft esetében például fontos, hogy a technikai csapat magja Michal Drobottal az élen az elmúlt év végén kilépett, és ebben nagy szerepe volt ahhoz, hogy nevüket adták olyan projektekhez, amelyeket valójában nem tudta optimalizálni a sok-sok feketedoboz miatt, illetve alapvetően olyan irányokra kényszerítette őket az Ubisoft, amiről már helyből tudták, hogy nem fog működni, de azt kellett csinálniuk, mert a "hozzáértő" szakemberek a vezetőségben azt mondták, hogy jó lesz. Az NVIDIA is azt mondta nekik. Annyira jó lett, hogy még a GeometryWorksöt sem tudták integrálni, mert képtelenek voltak működésre bírni az egészet, tehát, amire felépült a projekt, hogy majd rajzolási parancsokat spórolnak a tesszellálással teljesen tévút volt. Ezért néz ki az AC: Unityben sok felület sokkal rosszabbul, mint az AC: Black Flagben. Főleg a tetők. Úgy volt tervezve, hogy lesz tesszellálás, de nem működött a zárt middleware-en keresztül. Ezért éri meg a vezetőségnek a döntéseit a technikai csoport véleményére hagyatkozva meghozni, mert ők ismerik a motort, míg például egy külső cég nem. Aztán persze ígérni sok dolgot lehet, majd azok 90%-a a játék kiadásáig nem fog teljesülni. Ezért is volt az Ubisoftnál az elmúlt évben ez a sok downgrade botrány, mert hiába akarsz egy grafikai szintet, ha az zárt effekteket nem tudod működésre bírni. Egy dolog, hogy mit akarsz és mi valósítható meg. CD Projekt is ezzel küzdött. Elgondolták, hogy majd beimplementáljuk a middleware-eket, aztán, ahogy jöttek a middleware-ek sorban derült ki, hogy hát ez ezzel nem kompatibilis, akkor ezt jó lenne átírni a motorban, akkor ezt az effektet így bukjuk, stb. A végére elfogyott az idő, még a megjelenés csúszásával is, és jött a downgrade, mert hiába terveztek dolgokat feketedobozokkal valójában mindig nagyon nehéz dolgozni. Nem a fejlesztőn múlik, hogy valami megvalósítható-e. Ezért látod 2015-ben azt a vezető irányt, hogy egyre több middleware-t nyitnak meg. Annyira komplex lett az egész, hogy sok esetben másképp nem lehet biztosítani a működést, downgrade-et pedig senki sem akar.
Még, ha az AMD-nek ugyanaz meg is fordul a fejében, hogy valahogy mesterségesen érdemes lenne visszafogni az előző generációt, hogy az új jobbnak tűnjön, alapvetően az egyetlen lehetőség erre tényleg egy GameWorks-féle stratégia. De az a hátrány, amit ez ad a fejlesztőknek a sok beláthatatlan downgrade-del a megjelent játékokon, sokkal jobban árt a PC-nek hosszútávon, mint amekkora előnyt jelent az adott időszakban az eladásokban. A konzolok ilyen irány mellett előnybe kerülnek, mert hiába van bennük egy csúcs-PC-hez képest korlátozott teljesítmény, akkor is az előny, hogy amit elgondol a fejlesztő azt képes megcsinálni, míg feketedobozok mellett ez sok esetben nem sikerül. Mindegy, hogy hogyan kommunikálód le a downgrade-et, elmondod nekik, hogy használhatatlan zárt effekteket kaptál, vagy kitalálsz valami kíméletes hazugságot, maga a grafika leépítése megtörtént, és a PC-s játékos szomorú lesz.
És alapvetően az a gond, hogy nem a valós problémáról beszél az ipar. Mert a GameWorks esetében az, hogy xy hardveren rosszul fut, nem valós probléma, kapcsold ki és kész, vagy iktasd ki driverben a teljesítményzabáló részeit. Az a gond, hogy teljesen értelmetlen fejlesztési modellt kényszerít ki, és a végére rengeteg terv nem fog megvalósulni. Egyszerűen egy építésznek is baromira nehéz lesz a munkája, ha azt várják el tőle, hogy egy kész tető alá építsen egy házat. Kvázi ezt várja el a GameWorks a fejlesztőktől. És akkor csodálkozunk, hogy a megjelenés előtti bemutatókon a játék sokkal szebb volt, mint ami végül megjelent? Ez a valódi problémája a feketedobozoknak. Minden formájuknak. Mindenki döntse el magában, hogy ez jó-e a PC-nek vagy sem.
Ez a valódi problémája a feketedobozoknak. Minden formájuknak. Mindenki döntse el magában, hogy ez jó-e a PC-nek vagy sem.Nem tudom pontosan, hogy mik lesznek az extrák. Vagy több sebesség, vagy több effekt. Két dolgot tudok a fejlesztőktől, hogy a DX12-ből két számukra fontos dolog hiányzik, ami megvan a Mantle-ben. Az LDS tartalmának korlát nélküli olvasása, és a GDS korlát nélküli használata. Ezeket használni fogják konzolon, sőt, már használják is, így az erre épített effektek átmenthetők. Például az Ubisoft HRAA élsimítása az LDS korlát nélküli olvasására épül. Gyakorlatilag PC-re a konzolon alkalmazott AEAA konstrukcióval csak Mantle-re menthető át.
A DX12-ből négy vezető kihasználású funkció lesz, amelyet gyakorlatilag mindenki bevet. A Typed UAV loads, az aszinkron DMA, az aszinkron compute és a multiadapter valamilyen formája. Az első hármat azért alkalmazzák a fejlesztők, mert összességében konzolon 40-70%-os extra sebességet is hozhat, és a kód gyakorlatilag módosítás nélkül átmenthető PC-re, ahol ugyanennyi előnyt fog kínálni. A multiadapter PC-s dolog, de annyira egyszerű használni, hogy legalább az IGP+dGPU rendszerekre lesz valamilyen implementáció. Azok annyira elterjedtek a világban, hogy megéri velük foglalkozni.
A tesszelláció kapcsán ha megnézed a vezető irány a fixfunckiós blokk elhagyása. Ez hardverben megmarad, de például a LORE motor már compute shadert használ a háromszögek felbontására. Az eredmény az, hogy jobb lesz a minőség és gyorsul tőle a program. Több motor is átvált a jövőben szoftveres tesszellálásra, mert a fejlesztők jobb minőséget akarnak nagyobb sebességgel, és erre a fixfunkciós blokk korlátozottan alkalmas.
(#6258) Szaby59: Kettő, de nem a szám lényeges, hanem az, hogy megtörténik.
Többször mondtam, hogy a Dragon Age: Inquisition DX11 kódja nem stabil. Az EA support hivatalosan a Mantle kódot ajánlja. Ezért van beépítve. A DX11 kód sosem lesz teljesen stabil a mutex zárolásaival. Nagyon nem véletlen, hogy a Microsoft ezeket a technikákat nem ajánlja implementálni, függetlenül attól, hogy lehetséges. Sajnálom, de ez van. A következő körben már mindenki kap low-level támogatást.
(#6259) huskydog17: A Capcom a Panta Rhei motort fogja később használni mindenre. Ma még nem létezik PC-s portja, mert DX11-re kvázi portolhatatlan, de később meg lesz oldva.
-
#6257
Abu85
HÁZIGAZDA
Malibutomi
#6253
Abu85
HÁZIGAZDA
válasz
Malibutomi
#6253
üzenetére
Olvasd a GeForce fórumot, hogy milyen felháborodás van a GameWorksből. Abból, hogy a Radeonok egy szimpla driverbeállítással minőségvesztés nélkül nagyon gyorsan tudják futtatni a HairWorksöt, és abból, hogy a Kepler a TWIMTBP játékokban, miért van ennyire leszakadva a Maxwelltől. Ezt baromira el akarja kerülni az AMD, mert ez nem üzlet. Az NV-nek az, mert átállítja az embereket a felhőbe.
Kínálják majd a GRID-et előfizetéssel, és mehetsz oda játszani. Sőt, alapvetően vannak olyan GameWorks effektek fejlesztés alatt, amelyek nem is a kliensgépen futnak, hanem a felhő kiszámolja az aktuális részinformációkat, és visszaküldi az adatot a kliensgépnek, ami összerakja a képkockát az adatok alapján. Ez a jövőkép az AMD szerint nem jó, mert nagyon kevés hely van a világon megfelelő internetinfrastruktúra az effekteket a felhőben számoltatni.(#6255) wjbhbdux: A Frostbite a PC számára fontos, mert az EA akkora lépésekben halad előre, hogy a többieknek mérföldes lemaradásuk lesz sebességben és minőségben a Frostbite új verzióihoz képest. Csupán abból származik majd a Frostbite előnye, hogy az EA-nek van egy valag pénze kutatni, fenntartanak egy teljes stúdiót csak motorfejlesztésre, és mindent saját maguk írnak meg. Ezzel gyakorlatilag lekövetik azt a modellt, amit a Sony felvázolt még pár éve, hogy grafikai áttörés nagyrészt ebből lesz. Ezért kampányolt az EA elsőként a low-level irány mellett, mert szükségük van a nagy kontrollra a hardver felett, hogy kiépítsék az előnyöket. Valószínűleg nem sok kiadó lesz, aki képes majd követni őket. A Squate Enix EIDOS divízió már elindult utánuk, illetve a Capcom is, de az, hogy ők csak később fedezték fel a 100%-ban saját kód jelentőségét időhátrányt jelent az EA-vel szemben. Az Ubisoft még esélyes lenne erre, ha figyelmet fordítanának a PC-re, de annyira ezt a platformot nem tartják fontosnak.
-
#6251
Abu85
HÁZIGAZDA
huskydog17
#6247
Abu85
HÁZIGAZDA
válasz
huskydog17
#6247
üzenetére
Nézd az NV szabadon eldöntheti, hogy milyen optimalizáláshoz adják a nevüket. Korábban is láttuk, hogy nagyon rossz optimalizálással is jó az NV-nek egy játék. Tekintve, hogy sok szabad kapacitásuk van nem valószínű, hogy válogatnak a potenciális címek között.
rocket: Vannak az AMD-nek effektjei. Rengeteg. Radeon SDK a gyűjtőneve. Az valóban igaz, hogy ez nem zárt, hanem nyílt forráskódú. Ez azért van, mert a zárt forráskód sokszor megakadályozhatja az effekt beépítését. Nem véletlen az az irány 2015-ben, hogy nyitják meg sorra az eredetileg middleware-eket. Nagyon sok potenciális licencelőnél ez kritérium lett.
A másik dolog amiért az AMD nem csinál GameWorks alternatívát stratégiai jelleggel, mert nem tartják jó ötletnek az egy éve kiadott hardverek teljesítményét mesterségesen limitálni csak azért, hogy az új generáció jobbnak tűnjön. Ennek nem örülne a felhasználó.
Felsoroltam párat fentebb, hogy az AMD milyen játékokon dolgozik jelenleg. Több cím nem szerepel a doksikban. Annyit tudok még mondani, hogy némelyik játékban vannak olyan funkciók, amelyeket csak Radeonokkal érhetsz majd el. Elsődlegesen azért mert a Mantle-höz kötődnek.
-
Abu85
HÁZIGAZDA
Akkor elmondom az igazi okát. A cél az effekt sebességének meghatározása, és a fejlesztők lehetőségeinek a korlátozása. Az NV meg szeretné határozni a játék gépigényét és az új illetve az előző generáció közötti teljesítménykülönbség nagyságát.
Én PC-s portok minőségével törődő kiadót még nem látok mögötte. Nyilván a fejlesztők tudják, hogy ha licencelik, akkor letámadják a fórumokat a felhasználók, hogy a játék szarul van optimalizálva.
Egyébként nem kell ezt olyan szélsőségesen felfogni. Az NV az Ubisoft és a Warner igényeihez fejleszt, míg az AMD az EA, Square Enix, SEGA, Capcom igényeihez.
-
Abu85
HÁZIGAZDA
Szerinted mire szolgál egy zárt MiddleWare? Miben segíti a fejlesztők munkáját?
Fejtsd ki kérlek miért lenne jó azoknak a fejlesztőknek fekete dobozt adni, akik évek óta ezek megszüntetését követelik.Szerk.: Egyrészt még nincs eldöntve, hogy lesz-e limit és ha lesz, akkor mennyi. Másrészt az AMD-nek ezzel kötelessége foglalkozni, mert az EA hardverpartnerei. Azért kapják az EA-től a támogatást, hogy segítsenek optimalizálni a Frostbite-ot, és írjanak hozzá olyan funkciókat a Mantle-be, amit Johan akar, de szabványosan nincs rá megoldás. A partneri viszony kétirányú az EA és az AMD között.
-
#6245
Abu85
HÁZIGAZDA
huskydog17
#6243
Abu85
HÁZIGAZDA
válasz
huskydog17
#6243
üzenetére
Nem a Frostbite 3-at használja a játék. Az EA egy nagyon durva fejlesztési tempót diktál, amióta különvált a Frostbite Team és a DICE. Mostantól évente lép egy hagyott a Frostbite és nem két évente.
A Ghost Games döntése attól függ, hogy mi az ideális a játékhoz.
-
Abu85
HÁZIGAZDA
Valaki akar innovációt, valaki pedig nem. Ez a kiadó anyagi lehetőségein múlik.
Ez említett kiadók és fejlesztők döntése nem függ az AMD-től. Ők csak nagyobb kontrollt akarnak és ezt a feketefobozok mindenféle formája akadályozza. Volt a Sony-nak egy előadása korábban. Azt hiszem három éve beszélt róla a Santa Monica Studio, hogy totális hiba a middleware-ekre hagyatkozni, mert elveszik a lehetőség összehangolni az egyes pipeline-okat. És akkor mondták, hogy a következő motorjukhoz nem hasznalnak majd middleware-t és mindent saját maguk írnak meg. Ebből született a The Order 1886. Most a nagyobb kiadók ezt akarják követni, hogy el tudjak érni az Order szintű grafikát. Ha képesek finanszírozni ennek a költségeit, akkor joguk van erre menni.
-
#6239
Abu85
HÁZIGAZDA
huskydog17
#6238
Abu85
HÁZIGAZDA
válasz
huskydog17
#6238
üzenetére
Attól függ, hogy a Ghost Games hogyan dönt. Ez nem az AMD és a Frostbite Team döntése.
-
Abu85
HÁZIGAZDA
válasz
 Laja333
#6231
üzenetére
Laja333
#6231
üzenetére
Vagy rossz branchet választottak. Az Unreal Engine 4 csak egy alap. Ahhoz meg számos komponens választható. A middleware-ek megkönnyítik a fejlesztő munkáját, de ennek az ára a gépigény növekedése. Függetlenül attól, hogy mennyire gagyi a grafika. Az Epicnek is inkább a lehetőségek kiszélesítése, és az egyszerűbb használhatóság fontosabb az optimalizálásnál. Ezt mindkét megjelent UE4 játéknál láttuk.
-
Abu85
HÁZIGAZDA
A GW felé egy EA, egy Square Enix EIDOS divízió, egy Codemasters, egy SEGA nem tud váltani mert megakadályozza az optimalizálást. Nekik van erre anyagi keretük. Elég csak azt látni, hogy egyre több middleware-t cserélnek saját technológiára. Nekik nem n+1-ik zárt middleware kell, hanem kontroll. Többen rájöttek, hogy ha mindent házon belül írnak, akkor abból nem csak jobb sebességet, hanem jobb grafikát is ki lehet hozni.
-
Abu85
HÁZIGAZDA
Nem tudok most többről. Lehet, hogy van és még nem írták fel. Igazából a jövőben egyszerűbb lesz ez belőni. Amelyik kiadó és fejlesztő saját lábra áll, saját technológiákat fejleszt az AMD-t fogja választani. Amelyik kiadónak és fejlesztőnek ilyen kutatásokat nincs lehetősége finanszírozni azoknak az AMD nem tud mit nyújtani.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#6207
üzenetére
Ezek az AMD címei a következő időszakra: Star Wars: Battlefront, Need for Speed, XCOM 2, Deus EX: Mankind Divided, Ashes of the Singularity, Star Citizen, Mirror's Edge, Mass Effect 4, Hitman, Star Control, EVE Valkyrie. Többet nem soroltak fel. Azt nem tudni mi melyik API-t támogatja, de valamelyik low-levelt, esetleg többet is. Némelyik játék kap TrueAudio támogatást.
-
#6203
Abu85
HÁZIGAZDA
Firestormhun
#6202
Abu85
HÁZIGAZDA
válasz
 Firestormhun
#6202
üzenetére
Firestormhun
#6202
üzenetére
Ez még egy márciusi specifikációra épül, azóta már sok dolog változott. Például megoldották, hogy a Kepler TIER_2 szintre kerüljön a bekötési modell szempontjából, illetve az UAV sincs 8 slotra korlátozva, mert bevezetésre került a virtuális UAV. Igaz, az nem cache-selhető, de működni fog a kód. Emellett a Kepler shader fázisonként támogat 8 UAV-t, ezzel a modellel. Tehát amíg ebből nem fut ki, addig nem kell virtuálishoz nyúlni.
A GCN sem stimmel, mert az TIER_3-as bekötési szintű, és végtelen mennyiségű UAV-t támogat. -
Abu85
HÁZIGAZDA
Nem. A bekötési modellnél a TIER_3 ki lett emelve a feature level szintekből, ahogy a PS-specifikus stencil referencia is, illetve a CR TIER_2 szint.
A Tiled Resources is ki lett ezekből emelve.Valójában ez elég bonyolult lett, de lesz egy cikk, ami táblázatokba foglalja a végleges, és még ámenre váró specifikációt.
Az a lényeg, hogy a TIER az nem egy általános dolog. Vannak funkciók és azoknak belsőleg vannak TIER szintjeik. És ezekből a funkciókból a kötelezőek vannak hozzákötve a feature level szintekhez, ezen belül is egy kötelező minimum TIER szinttel. De ezt majd egyszerűbb lesz a táblázatokból látni.
-
Abu85
HÁZIGAZDA
Mondjuk ez érdekes cikk így. Elmondja, hogy mit támogat a rendszer és berakja a Caps Viewer képet, amiben "No" van odapörkölve két funkció mellé is.
Szerintem le kellett volna írnia, hogy a WHQL driverekben a Microsoft megtiltja a nem véglegesített funkciók támogatását, mert így a user csak azt látja, hogy nem támogatja. -
Abu85
HÁZIGAZDA
Nem lesz kupakja.
(#6153) gbors: Ezt mondom egy ideje. Ezzel csak a saját felhasználóikat szívatják, mert az AMD-seknek csak annyit kell tenni, hogy x16-ra állítják a maximum faktort és jobban megy a HairWorks, mint GeForce-on valaha is fog. Ezért nettó hülyeség, amit csinálnak, hiszen a GeForce tulajdonosoknak az egyetlen lehetőség inaktiválni az effektet. Nekem a HairWorks aktiválása 45-ről 30 fps-re csökkenti a sebességet, de ha beállítom a 16x korlátot, akkor csak -2-4 fps-be kerül, és ugyanazt kapom. Nem velem szúrtak ki, hanem a saját felhasználóikkal. Én boldogan bekapcsolom és élvezem, mindenféle komoly teljesítményveszteség nélkül.
Bár én az Intel terveit nem tudom, de emlékszel az Ionra? Az Intel tudja, hogy nem számít ha valami jobb, ha nem tudod megvenni.
-
Abu85
HÁZIGAZDA
válasz
 cyberkind
#6060
üzenetére
cyberkind
#6060
üzenetére
Én ezt sem látom annyira reálisnak. Úgy néznek ki a Kepler VGA-sok, mint akik Maxwellre akarnak váltani? Inkább GCN-t nézik, mert nem tetszik nekik, hogy az anno ezer dolláros Titánt már a középkategóriás Maxwellek és GCN-ek ütik.
(#6064) Szaby59: De milyen igény? Fizetünk ennyit és ennyit, ha használod? Ez nem igény, csak vannak olyan fejlesztők, akik pechesek, hogy az Intel és az AMD partnerprogramjába már nem férnek be. Az NV-nek meg erre bőven van kapacitása, mert a tehetős kiadók már elmentek tőlük.
-
Abu85
HÁZIGAZDA
Abszolút nem vagyok arról meggyőződve, hogy a PC-piacnak jót tesz, ha mesterségesen magas egy játék gépigénye a beépített zárt effektekkel. Nem tudom, hogy ezt az NVIDIA miért látja úgy, hogy ez a PC érdeke. Szerintem, ha megkérdeznénk őket, valószínűleg ők sem tudnák elmondani.
-
Abu85
HÁZIGAZDA
Módját vagy hiányát? Mert ez az, amit a fejlesztők a legjobban kritizálnak, hogy nem tudják optimalizálni a zárt middleware-eket. Mi sem láthatjuk azt, hogy ezek jól optimalizált, jó minőséget kínáló rendszerek lennének. Ha azt látnánk semmi gond nem lenne, de helyette azt látjuk, hogy szimpla felhasználói hack minőségvesztés nélkül a kétszeresére gyorsítja a HairWorksöt. Milyen optimalizáció ez, amikor ilyet meg lehet tenni? Miért kellene ezt titkolni? Az iskolában kellene oktatni, hogy ezt ne csináld.
A másik dolog, hogy ezt mennyire célszerű megcsinálni, hogy közben tudod, hogy az iparág nagyágyúit elveszted ezzel a stratégiával? Ők nem akarnak feketedobozokat. Évek óta ezek ellen küzdenek, mert csak megakadályozzák őket abban, hogy jó minőségű programot szállítsanak.
-
Abu85
HÁZIGAZDA
Tehetős fejlesztő még nem is használta, szóval természetesen senkinek a fejéhez nincs pisztoly nyomva. Maximum nem kapnak pénzt, ha nem használják.
Szerintem 2015-ben, amikor sorra nyitják meg a middleware-eket a zártság melletti indokok okafogyottak. Főleg egy hardvergyártónak, ahol nem is ebből élnek. Mert egy Havokot még megértenék, de ők is nyitnak, miután az EA és az Ubisoft belengette, hogy váltanak nyílt forráskódú motorra, ha nem kapnak teljes kontrollt a Havoktól. Nyilván innen nem volt kérdés, hogy nyitni kell.
-
Abu85
HÁZIGAZDA
Sok más oka nincs annak, amiért megéri szívatni a fejlesztőket. Az innováció a PC-n nem szolgálja az NV érdekeit. Ezért minden olyan effekt, amit átadnak a fejlesztőknek zárt, hogy bármennyire okos és tehetős egy partner ne tudja úgy módosítani, hogy szebb és gyorsabb legyen az adott effekt, mint ahogy azt az NV elgondolta.
Cégen belül tök jó példa az AndroidWorks. Nemrég mutatták be. Abban a GameWorks for OpenGL nyílt forráskódú és szabadon módosítható, annak érdekében, hogy a fejlesztő lehetősége meglegyen az innovációra, ami Androidon már érdeke az NV-nek. -
Abu85
HÁZIGAZDA
válasz
#85552128
#6033
üzenetére
Ez a következménye annak, hogy az API-k felnőttek a hardverek tudásához. Az ipar ezzel a lehetőséggel szabadon fejlődhet.
A bekötési modell fejlesztése alapvető lehetőséget ad, hogy egy effekt minősége jó legyen. A TressFX előnye ma, hogy messze ez kínálja a legjobb leképzési minőséget a hajra és a szőrre, mert tartalmaz OIT-t, ami ennek a koncepciónak az alapja, hiszen mindenképp abból a hajtincsből kell a színminta, amely legfelül van. Viszont a TressFX 2 UAV-t igényel a működéshez, vagyis ahhoz, hogy ez minden karakteren működjön korlát nélküli bekötés kell.
A HairWorks a másik véglet, mivel nem igényel UAV-t. Meg is látszik a minőségén, hogy ki van hagyva a legfontosabb eljárás a leképzéséből, amivel nincs garantálva, hogy jó hajtincsből lesz meg a pixel színmintája. -
Abu85
HÁZIGAZDA
válasz
#85552128
#6030
üzenetére
Mások a célok itt. Az új API-knak a korlát nélküli bekötési módjai azt teszik lehetővé, hogy a programozók a hardver használatánál és az algoritmusok kialakításánál szabad kezet kapjanak. Nyilván korlátozza a lehetőségeket, ha hardveres vagy szoftveres szempontok miatt nem tudják létrehozni a szükséges erőforrást a hardveren belül. Ez megakadályozza az innovációt.
A GameWorks egy más céllal született. Azzal, hogy az NVIDIA kontrollálhassa az adott játék igényeit, és teljesen elfojtsák az innováció lehetőségének a csíráját is.
Nagyon érdekes az AndroidWorks. Az NV-nek Androidon érdeke az innováció, és nyílt forráskódú, szabadon módosítható GameWorks effekteket adnak a GitHubra feltöltve, ellentétben a PC-s rendszerrel. -
Abu85
HÁZIGAZDA
válasz
#85552128
#6030
üzenetére
A TIER3-as bekötési szint alapvetően egy skalár processzort igényel a multiprocesszorba, hogy a bekötés ne a mintavételezőbe, hanem magába a multiprocesszorba történjen. Egy ilyen rendszer már eleve garantálja azt, hogy a bekötés korlát nélküli, mert nem egy fixfunkciós egység gondoskodik a meglévő erőforrásokról, hanem egy teljesen programozható. Alapvetően a GCN minden bekötést egységesként kezel. A hardver belül nem különbözteti meg ezeket, így mindegyik létrehozott erőforrás írható, olvasható, akár egyszerre is, és gyorsítótárazható. Az API-kkal kapcsolatos különbségeket majd a meghajtó lekezeli.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#6027
üzenetére
Ahogy írtam korábban, alapvetően a bekötési modell messze a legfontosabb. Mivel ez határozza meg, hogy mennyi erőforrás áll rendelkezésre a fejlesztőknek, vagy másképp fogalmazva mennyi effektet képesek engedélyezni egy játékon belül. Például az idén érkező DX játékban a TressFX mindenkinek a haján rajta lesz, de ezt a módot csak akkor aktiválja, ha TIER3 a bekötési szint. Alacsonyabb szinten csak a főszereplő hajára lesz korlátozva.
Azért tervezte ennyi ideig a bekötési modellt a Microsoft, hogy az mindenkinek jó legyen. Szépen lehessen használni az Xbox One képességeit, miközben ez a PC-s portolást ne nehezítse. Egyszerűen az effekteket alacsonyabb szinten le lehet tiltani, és mindenki boldog. -
Abu85
HÁZIGAZDA
válasz
#85552128
#5992
üzenetére
Nem. A DirectX 12 az DirectX 12. A feature level innentől kezdve nem komoly dolog, mert nagyrészt csak opcionális funkciókat tartalmaz, zömében nem véglegesítetteket.
A DX12-ben a legfontosabb újítás szoftveres, vagyis az overhead csökkentése. Ez a kulcstényező és nem más. A másik fontos újítása az asszinkron compute, ami a GPU-limit ellen küzd. Ezzel lehetőség van ezeket a masszívan párhuzamos lapkákat tényleg párhuzamosan dolgoztatni, mert nem csak sorban kerülhetnek rá feladatok.A bekötési modell az azért nagyon fontos és azért van folyamatosan kiemelve a fejlesztők és a Microsoft által, mert ez határozza meg az API-nak azokat a képességeit, ahogy a hardvert elérheti. A GPU-k nem olyanok, mint a CPU-k, hogy írsz rá programokat és azok futnak. Itt amellett, hogy van memóriájuk, még masszív limitációkkal írhatók programok rá. Ezért került bevezetésre a DX12-ben ez az új bekötési modell, hogy a fejlesztők ahogy egyre komplexebb programokat írnak, ne fussanak ki az erőforrásokból. A hosszabb távú cél igazából az, hogy a fejlesztőnek csak arra kelljen figyelni, hogy a GPU-nak van x GB memóriája és azon belül annyi erőforrást hoznak létre amennyit abba belefér. Ma ez óriási limit, mert az API nem enged meg akármit, még akkor sem, ha a hardverek jók lennének. Ez pedig akadályozza azt, hogy végeredményben hány effektet írhatsz bele az adott játékba. Hosszabb távon ezt az állandó kompromisszumkényszert akarja leküzdeni a Microsoft ezzel az átdolgozott DX12-es bekötési modellel. Egyszerűen, ha a fejlesztő megálmodik valamit, akkor csinálja meg, ne azért legyenek kidobva dolgok a programból, mert kifutott az API által megengedett erőforrásokból.
A véglegesített specifikációk tekintetében a GCN egyes verziói egységesek. A nem véglegesített opcionális specifikációk esetében meg kell várni a véglegesítést.
Az overhead biztosan csökken, az független a feature level szinttől. Ezt két dolog határozza meg. Az egyik a parancsok párhuzamos beírása a parancspufferekbe, ami egy szoftveres funkció, vagyis igazából nem igényel semmilyen komolyabb dolgot a GPU-n. Jó persze kér egy modernebb hardvert, de az elmúlt hét évben megjelent GPU-k elméletben tuti jók. Amelyik cucc kap DX12 drivert ott ez a funkció megy. A másik a bekötési modell, ami szintén meghatározza az overheadet. Ebból a szempontból a TIER1 jár a legnagyobbal, mert az emuláció. Nem rossz így sem, de érezhető lesz. A TIER2 már bindless, tehát eléggé alacsony a többletterhelése. A TIER3 pedig explicit bindless, vagyis nincs többletterhelése.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#5990
üzenetére
A Vulkanról még felesleges beszélni, mert a base specifikációk sincsenek véglegesítve. Ettől függetlenül egy hasonló bekötési modellt használ, mint a DX12, csak más paraméterezéssel, és több emulációs lehetőséggel. De a véglegesítésig ezek változhatnak. Láthatod, hogy a DX12 modelljét négyszer módosítottak, mire végleges lett.
A DX12 végleges bekötési modelljével (amire még mindig rá kell mondani az áment, de szinte ki van zárva, hogy változik) a TIER1 egy emuláció lett. Azt támogatja az Intel Gen7.5, Gen8 és az NV Fermi. A TIER2-t a Kepler és Maxwell, míg a TIER3-at a GCN.
Az opcionális funkciók nincsenek véglegesítve, mert kevés volt rá az idő. A fejlesztők használhatják, de a Microsoft kiadta nekik, hogy vigyázzanak vele, mert ha év végén jön egy végleges verzió és változik, akkor a kiadott program nem fog működni.
Egyébként igazából a ROVs egy mutex zárolás a rendszerben. Olyan mint az Intel PixelSync, a GCN ezt tudja támogatni, mert a GDS-re írható egy olyan implementáció, amely zárolja a folyamatokat a megfelelő megérkezéséig. Ezt OpenGL-ben már támogatják. A Conservative Rasterization igazából eltérő interpolációt igényel a hardverben. De mivel a GCN szoftveres interpolációt használ már évek óta, így az egész támogatás csupán a fordítón múlik és nem a hardveren. Eleve az interpoláció a GCN-en annyi, hogy a CU-nkénti 64 kB-os LDS-ből 32 kB-ban ott vannak az interpolált háromszögadatok. Annyi interpolációs rendszert írsz rá a shadereken keresztül, amennyit akarsz. Most csak egy van, de például a Mantle új verziójában maga a fejlesztő is megírhatja a saját interpolációs rendszerét.A Wikipédiás táblázat teljesen téves. Nincs olyan, hogy hUMA a DX12-ben, az egy HSA specifikáció
. IOMMU-van a WDDM 2.0-ban. És azt sem tudja támogatni egyetlen dedikált GPU. Emellett azt hiszik, hogy a TIER szinten az egyes eljárásokon a bekötésre vonatkoznak. Hát nem.A DX12-ben és a WDDM 2.0-ban nincs minden opcionális rendszer véglegesítve.
Ami véglegesítve van arra a támogatás ilyen:
Bekötési modell fentebb, nem írom le újból.
WDDM MMU modell: emulált: Intel Gen7.5, NV Fermi, dedikált: Intel Gen8, NV Kepler és Maxwell, AMD GCN
WDDM GPUMMU: minden dedikált GPU
WDDM IOMMU: csak APU: AMD Kaveri, Carrizo vagy Intel Broadwell, Skylake
Aszinkron Compute: AMD GCN, NV Maxwell (kivéve a GM107). Az Intel Gen8 támogatja, de az Intel mondta, hogy náluk ez lassulást okoz, így nem fogják engedélyezni.
SAD4: mindenen emulált, kivéve a GCN, ott ez dedikált utasítás
Aszinkron DMA: AMD GCN, NV Maxwell (kivéve a GM107). Emellett számos korábbi Quadro VGA-n ez működni fog, mert a Kepler óta van két DMA az NV GPU-ban, de abból a GeForce-okban egy mindig le lett tiltva.
Atomi számláló: mindenen emulált, kivéve a GCN, ott ez dedikált utasításVéglegesítésre vár még a maradék opcionális funkciók és a WDDM hard preempció. Ezeket az elkövetkező egy évben tervezik befrissíteni a Windows 10-be. Lehet, hogy apránként, lehet, hogy egyszerre.
A bekötési modell gyakorlati haszna csupán az, hogy mennyire limitálja az adott modell az erőforrás-használatot. Kvázi ennek a jelentősége az lesz, hogy mennyi effekt kerülhet egy játékba egyszerre. Itt főleg compute effektre kell gondolni, mert leginkább az UAV-k száma lesz a limit. Ma nagyjából 4-7 compute effekt van egy játékban, de a jövőben ez a szám növekedni fog, tehát végeredményben az a cél, hogy a limitáció tulajdonképpen csak a memória legyen, és ne más.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#5982
üzenetére
Én Witchert az első rész után csak így veszek. Az Enhanced patch mellett kiszedik a bugokat, és jó lesz. Az első részt egy nagy bug miatt be se tudtam fejezni az Enhanced patchig, akkor is újra kellett kezdenem. Szóval a W2-nél már tanultam ebből és csak később vettem meg. Most is ugyanígy teszek. Mire lesz Enhanced verzió, addigra az ára is a fele lesz.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#5979
üzenetére
A gépigényre gyúrni az EA-nek megint egyszerűbb. A Dragon Age: Inquisition a Frostbite aktuális verziójának utolsó nagyobb címe. Ez azt jelenti, hogy a 3-as főverzió már eléggé optimalizált, hiszen az első játék óta másfél évet lehetett polírozni. A Red Engine új, szinte polírozás nélküli rendszer.
Majd az EA is át fog állni a következő nagyobb Frostbite frissítésre. Talán nem 4 lesz a neve, de az NFS és a SW: Battlefront már ezzel jön. -
Abu85
HÁZIGAZDA
válasz
#85552128
#5964
üzenetére
És most hasonlítsd össze az EA és a CDPR készpénzállományát és fejlesztői lehetőségeit.
De amúgy ja egyetértek, a Dragon Age: Inquisition-t grafikailag nem sikerült lenyomni, csak ez pénzkérdés inkább, mintsem technikai.Egyébként nem vagyok benne biztos, hogy az elkövetkező két évben bárkinek is esélye lehet a PC-n az EA által követett újszerű fejlesztési modell mellett. Egyszerűen a váltásokra marha sok pénzt mozgósítottak, és marha jó a szakemberi gárda a Frostbite mögött. Leghamarabb a Square Enix tudja őket befogni, de ők is lassabban kapcsoltak, és alapvetően több erőforrást kell majd mozgósítaniuk.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#5926
üzenetére
Azóta csúnyán eltelt 7 év. 7 éve jó volt, ma semennyire nem az. Valószínűleg 7 év múlva a DX12-re is azt mondjuk, hogy limitál, és jön a következő lépcső. Biztosan megmondom most, hogy a DX12 sem tart örökké. De az elkövetkező fél évtizedre jó lesz. Addig pedig van idő újat fejleszteni.
-
Abu85
HÁZIGAZDA
Nem is kell, hogy összekapcsolva legyenek, bár szinkronizáció azért van. De elég, ha egy rosszul kialakított API és a kernel driver nem engedi a programszálakat hozzáférni az amúgy szabad erőforrásokhoz.
Ez tudom, hogy nagyon mellbevágó dolog, hogy a PC ennyire pazarló platform lett, de ez van. Viszont nem véletlenül alakult úgy, hogy két év alatt egy komplett reformot végigvittek az érintettek a teljes rendszeren.Amikor arról beszélünk, hogy a DX12 micsoda előrelépés a DX11-hez képest, akkor az jön elő, hogy milyen jó ez a DX12. Valójában ezt úgy kellene felfogni, hogy milyen rossz a DX11. A DX12 csak rendbe hozza, amit már rég rendbe kellett volna hozni.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Szándékosan belinkeltem azt a részt, ahol erről beszél.
Ez egyszerű. Attól, hogy nincs kernel driver még a feladatokat el kell végezni. Az alkalmazásnak explicit elérése van a GPU felé, de ez csak azt jelenti, hogy meghatározhatják, hogy mit csináljon a hardver, de a parancskiadáshoz már szükséges egy driver, ami például lefordítja a szoftver queue-t a hardver nyelvére, stb. Ez a user driverben fog látszódni, még akkor is, ha az alkalmazásban van rá a kód.












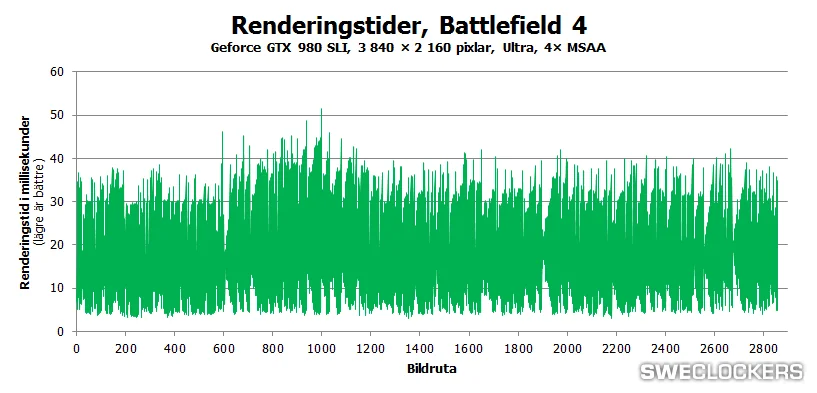
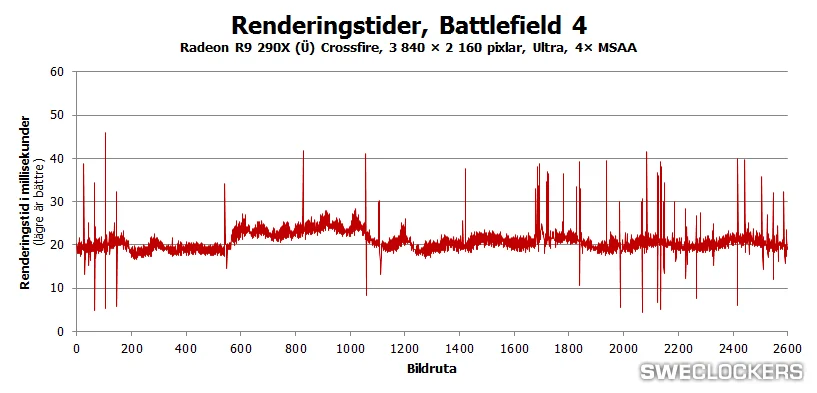


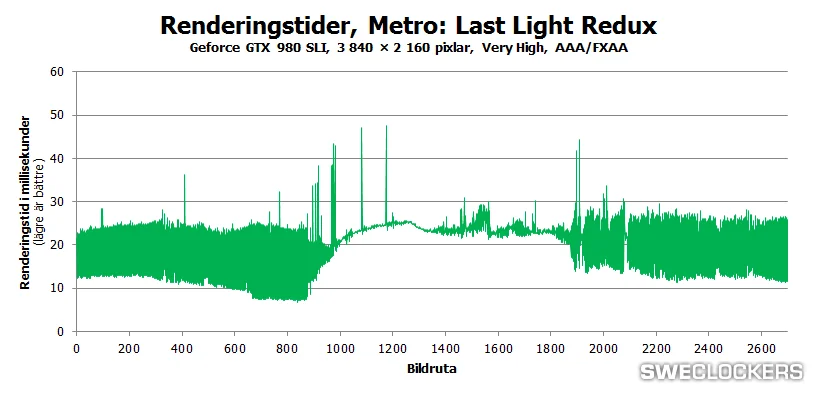
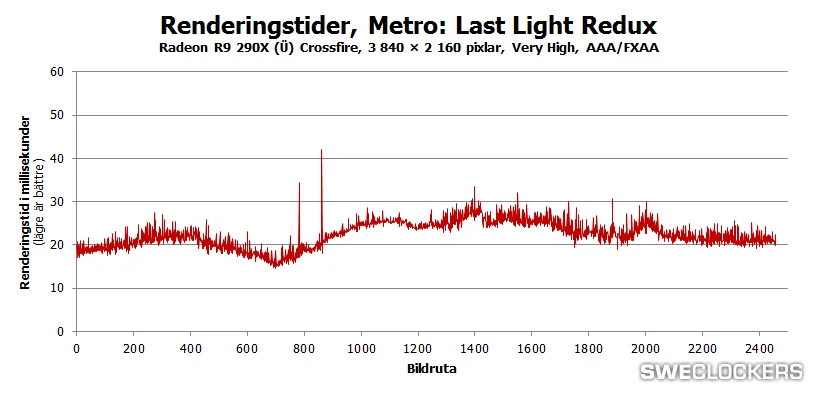


















 Ez a valódi problémája a feketedobozoknak. Minden formájuknak. Mindenki döntse el magában, hogy ez jó-e a PC-nek vagy sem.
Ez a valódi problémája a feketedobozoknak. Minden formájuknak. Mindenki döntse el magában, hogy ez jó-e a PC-nek vagy sem.



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Linux Mint
- Hobby elektronika
- Bemutatkozott a Fairphone 6
- Pánik a memóriapiacon
- Eredeti játékok OFF topik
- Energiaital topic
- Soundbar, soundplate, hangprojektor
- Samsung Galaxy Watch (Tizen és Wear OS) ingyenes számlapok, kupon kódok
- MWC 2026: Kezünkben a minden tekintetben európai okostelefon
- Napelem
- További aktív témák...
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7700X 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- SONY PS4 PRO
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7700X 32/64GB RAM RTX 5070 Ti 16GB GAMER PC termékbeszámítással
- Bomba ár! Dell Latitude 7290 - i5-7GEN I 8GB I 256GB SSD I 12,5" HD I HDMI I Cam I W11 I Gari!
- GYÖNYÖRŰ iPhone 13 Pro 128GB Sierra Blue -1 ÉV GARANCIA -Kártyafüggetlen, MS3965
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest