Új hozzászólás Aktív témák
-

cousin333
addikt
válasz
 Siriusb
#2032
üzenetére
Siriusb
#2032
üzenetére
Először is: a ClassC feleslegesen örököl a ClassA-tól, hiszen a ClassB már megörökölt tőle mindent.
"Szeretném ClassC-ben végrehajtatni a ClassB.f1()-et anélkül, hogy bármi mást örökölne ClassB-ből"
Erről már lekéstél, tekintve, hogy a ClassC a ClassB-ből örököl...

Feltételezve, hogy a ClassC-t úgyis példányosítod, a
super()lesz a megoldásclass A:
def f1(self):
print('f1 in Class A')
class B(A):
def f1(self):
print('f1 in Class B')
class C(B):
def f1(self):
print('f1 in Class C')
def f2(self):
super().f1()
c = C()
c.f2()f1 in Class B
Ha pedig konkrétan a ClassA
f1()függvényét akarod elérni, akkor:class A:
def f1(self):
print('f1 in Class A')
class B(A):
def f1(self):
print('f1 in Class B')
class C(B):
def f1(self):
print('f1 in Class C')
def f2(self):
super(B, self).f1()
c = C()
c.f2()f1 in Class A
A
classmethodis mehet, de akkor nem kell a ClassC-nek a ClassB-ből örökölnie. -
cousin333
addikt
válasz
Siriusb
#1889
üzenetére
Tudtommal Amerikában már a Python az első számú tanulónyelv az egyetemeken.
1. Nem szoktam GUI-t készíteni. Általában Jupyter Notebook-ot használok. Ha mégis kellene (egyszer már kellett), akkor én a Qt-re szavaznék, a Qt Designer használatával. De igazából a többit nem nagyon ismerem. Ami szerintem lényeges kérdés: programozott GUI, vagy sima drag&drop (lásd a már említett Qt Designer). Nekem mindenképpen az utóbbi.
2. Anaconda + PyCharm Community Edition. Szerintem mindent tudnak, amit kell, még azt is, amit nem. Csomagok frissítése (magát a Python verziót is beleértve!), ill. tesztelés, modul készítés, integrált verziókövetés, scratch... stb.
-
cousin333
addikt
válasz
 s1999xx
#1876
üzenetére
s1999xx
#1876
üzenetére
A fájlból azért nem szerencsés az import-tal beolvasni, mert a fájl tartalma kell, hogy a mezőben szerepeljen (legalábbis az én elképzelésem szerint). Ennek az az értelme, hogy a felhasználó is látja a szkriptet, sőt, apróbb módosításokat is tud rajta végezni. Persze ehhez az sem árt, ha már előzetesen beimportáltunk mindenféle segédfüggvényeket, hogy ez a szkript már rövid és lényegre törő lehessen.
Működését tekintve hasonlítana mondjuk a Robot Framework megoldásához, csak itt nem kell teljesen feleslegesen egy külön leírónyelvet elsajátítani, mehet minden Pythonban.
Ez az ötlet mérés-adatgyűjtés területén merült fel bennem. A "rendes" GUI-s programok ugyanis általában jól működnek, amíg pontosan úgy használják őket, ahogy a fejlesztők megálmodták. De ha már nem pont azt és nem pont úgy kell, akkor jönnek a problémák, míg a fenti exec-es megoldás sokkal rugalmasabb lehet.
-
cousin333
addikt
válasz
s1999xx
#1869
üzenetére
Egy ötlet: készítesz egy általános jellegű GUI-t. Mondjuk van benne egy nagyobb szövegmező egy vászon, amire grafikont lehet rajzolni, néhány gomb, tekerő, csúszka... stb.
A lényeg, hogy a szövegmezőbe lehet Python kódot beírni (vagy fájlból betölteni), amit aztán futtatni tudsz. Ehhez kell az
eval(), így a kód használhatja GUI elemeket is, például függvényt rajzolhat, vagy feldolgozhat egy másik mezővel, gombbal betöltött adatfájlt.A lényeg, hogy a Python egy szkriptnyelv, aminek egyik előnye, hogy nem kell előre megírni a teljes kódot, hanem dinamikusan futtathatod. A fenti példa tulajdonképpen egy tuningolt parancssornak is tekinthető.
UI: a Robot Framework nem tudom, mennyire jó példa. Annak pont az a lényege, hogy a tesztet nem Pythonban írod meg, hanem egy - szerintük - egyszerűbb leíró nyelvvel amit a framework aztán értelmez.
-
cousin333
addikt
válasz
 pigster
#1824
üzenetére
pigster
#1824
üzenetére
"There's been a number of complaints about the choice of the name 'decorator' for this feature. The major one is that the name is not consistent with its use in the GoF book [11]. The name 'decorator' probably owes more to its use in the compiler area -- a syntax tree is walked and annotated. It's quite possible that a better name may turn up." [link]
Ilyen az élet...
-
cousin333
addikt
válasz
pigster
#1822
üzenetére
Alapvetően jól látod.
"A @decorator_func a decorated_func = decorator_func(func_needs_decorator) -val egyenértékű (állítólag)"
Nem egészen. A
@decorator_funcaz tudtommal afunc_needs_decorator = decorator_func(func_needs_decorator)
sorral egyenértékű, tehát nem véletlen, hogy "felülírja" az eredeti függvényedet (legalábbis az aktuális alkalmazásban), de ez az írásmód eleve csak egy "syntactic sugar" a fent említett lépésre. Különösen akkor jön jól, ha mondjuk több dekorátort is használni kéne egyszerre.A dekorátorokról, működésükről, használatukról itt van egy alapos cikk: [link]. Azért linkeltem, mert a hozzászólások között konkrétan felteszik ugyanazt a kérdést, amit te. A választ idézve:
"The whole point of decorators is to modify the behavior of the function through a wrapper so we don't have to actually modify the function. The function is not permanently modified; the behavior changes only when it's decorated."
Gyakorlatilag egy mások által készített függvényt ki tudsz egészíteni anélkül, hogy hozzá kéne nyúlnod. Vagy az alap függvényedet általánosabban írhatod meg, és az aktuális felhasználás során dekorátorokkal specifikálhatod. Mindezt egy átlátható szintaxissal. Ha meg mindkettő funkcionalitására szükséged van, még mindig ott az első módszer.
-
cousin333
addikt
A Python egy nagyon magas szintű szkriptnyelv, bár azok közül talán a legjobb, ha minden szempontot figyelembe veszünk (elterjedtség, kiforrottság, fejlesztőeszközök, közösség, licensz, tanulhatóság, bővítőmodulok száma, minősége.... stb.).
Ennek megfelelően az előnyei is ugyanazok a klasszikus "kompilált" nyelvekkel (pl. C/C++) összehasonlítva: míg utóbbiak elsősorban a futtatási sebességükkel tűnnek ki, addig a Python a fejlesztési tempójával. Egy szkriptnyelv nagyobb teretz enged például a kísérletezgetésnek, az iteratív fejlesztésnek. Ez a pénzügyi területen is jól jöhet, hiszen egy frissebb, fejlettebb algoritmus többet érhet, mint egy gyors(abb). Például az egyik népszerű Python modul, a pandas fejlesztőjei is pénzügyi területen dolgozik.
Ráadásul a Python parancsértelmezője C nyelven íródott, így a C/C++ kód viszonylag egyszerűen integrálható. Általában úgy megy ez, hogy a tipikus, teljesítményigényes feladatokat megírják C-ben és a Python kód ezeket az algoritmusokat használja a háttérben. Így a Python előnyei mellett a sebesség is megmarad.
A nyelv pozitívumai miatt a Pythont elég széles körben használják, főleg webes, tudományos és műszaki közegben, de említhetném a mostanában sláger gépi tanulást és MI-t is. Meg kb. mindenhol, ahol jobban számít a rugalmas, elegáns, kompakt kód, mint a nyers sebesség vagy a hardverigény. Elsősorban PC-n vagy nagyobb rendszereken, mobil eszközökön kicsit még esetlen.
-
cousin333
addikt
válasz
 GreenIT
#1779
üzenetére
GreenIT
#1779
üzenetére
Nem, egy ideje már én is gondolkodtam arról, hogy el kéne kezdeni...
Ebből a célból létrehoztam egy Google dokumentumot, amit mindenki elér és szerkeszteni tud, aki érez magában erőt, tudást. Ha összejön valami használható, akkor bejelentkezünk vele a modiknál.
-
#1777
cousin333
addikt
Victor Súgó
#1763
cousin333
addikt
válasz
 Victor Súgó
#1763
üzenetére
Victor Súgó
#1763
üzenetére
Az absztrakt osztályt valóban benéztem, de egyébként nem értettem félre.
Én is láttam, hogy nincs saját doksi, de pont ez a lényeg: minek? A PyQt csak egy wrapper a C++ implementációhoz. Ugyanazokat az osztályokat, metódusokat, paramétereket használja, csak éppen "pythonosan". Teljesen felesleges mindent duplán leírni, a dokumentáció használatához meg nem kell C++ tudás. Te egy random példát hoztál, én meg annak alapján leírtam, hogyan kell használni. Amúgy - mint írtam - a QtDesigner sok terhet levesz az ember válláról.
Az absztrakt osztályoktól nem tudom, mit remélsz, de a Python is támogatja őket a gyári abc modullal.
Szokjon C++-ra, akinek két anyja van...
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
-
#1762
cousin333
addikt
Victor Súgó
#1761
cousin333
addikt
válasz
Victor Súgó
#1761
üzenetére
Elsőre szokatlan lehet, de igazából nem bonyolult, hála pl. a PyQt-nek. Nem is kell érteni a C++-hoz. Egyszerűen példányosítod a QAbstractSlider-t a PyQt5.QtWidgets modulból, ahogy bármelyik Python osztállyal is tennéd. A C++-os súgó pedig felsorolja a hozzá tartozó metódusokat (Public Functions) és tulajdonságokat (Public Slots), amiket setter/getter-ként kell használni, ugyanazzal az elnevezéssel, ami a dokumentációban szerepel. Valamint leírja a signal-okat, amikkel más függvényeket lehet rendelni bizonyos eseményekhez (pl. a gomb meg lett nyomva).
-
#1760
cousin333
addikt
Victor Súgó
#1754
cousin333
addikt
válasz
Victor Súgó
#1754
üzenetére
PyQt: mit nem találtál a dokumentációban? Szerintem csak arra kell figyelni, hogy a verziószám megegyezzen, amúgy nem volt gondom vele, csak a logikájára kell ráérezni. Igaz, nem használtam olyan intenzíven/sokat.
Nem triviális elkezdeni - ahogy szerintem a többit sem - de pl. az Anaconda disztribúció tartalmazza a QtDesigner-t, amivel fogd és vidd technikával lehet GUI ablakokat létrehozni és elmenteni. Innen már csak pár sor Python kód, és be is töltötted, csak a mögöttes logikát kell hozzátenni a slot-okkal meg az érték kiolvasásokkal, ami már egyszerűbb.
Egy másik - mások által sem említett - alternatíva, amit én még nem használtam, csak olvastam róla, de érdekesnek tűnik, az a Kivy.
-
cousin333
addikt
válasz
 t72killer
#1752
üzenetére
t72killer
#1752
üzenetére
Ha eddig Matlaboztál, akkor a Spyder - meg általában az (I)Python - valóban ismerős lesz. Ugyanakkor tudom javasolni kipróbálásra a Jupyter Notebook-ot. Az Anacondával együtt már fel is telepítetted. Ez egy webszervert indít, amit a böngészőn keresztül érhetsz el. Itt cellákba írhatsz kódot, formázott szöveget és cellánként, tetszőleges sorrendben tudod futtatni őket, akár többször egymás után. Értelemszerűen elérheted a feltelepített modulokat és IntelliSense-szerű javaslatokat, valamint súgót is kaphatsz. Szerintem remek eszköz kísérletezni, majd - a notebookot letisztázva - új bemenetekkel végigfuttatni a kifejlesztett feldolgozási folyamatot.
Az egyes cellákba lehet markdown formázott szöveget, képeket, képleteket, videókat ágyazni, de vannak interaktív widgetek is (pl csúszka, progress bar). Az eredmény elmenthető többek közt HTML fájlként (a képekkel együtt).
Itt találsz egy rakás példát, hogy hogyan is néz ez ki:
- basic intro
- Matplotlib bemutató
- numpy bemutató
- audio szűrés
- kvantálási hibák
- térképészet
- egy kis Big Data meg mégegy DatashaderrelItt online ki is tudod próbálni, bár tulajdonképpen felesleges, ha úgyis fel van már telepítve...
-
cousin333
addikt
válasz
t72killer
#1750
üzenetére
Az Anaconda gyakorlatilag egy Python disztribúció (olyasmi, mint mondjuk egy Linux). Tartalmazza magát a Python-t, egy rakat 3rd party modult, csomagkezelőt, meg pár külsős eszközt, mint például az Anaconda Navigator. A Spyder és a Jupyter is ezek közé tartozik, de értelemszerűen külön is telepíthetők, nem kell hozzájuk Anaconda. Például egy sima Python telepítővel a hivatalos oldalról, ami alapból felteszi a pip nevű csomagkezelőt. Azzal parancssorból kb. ennyi a telepítés:
pip install spyder jupyter
Mindazonáltal, - noha a Navigátort nem használom - az Anaconda jó cucc, integrálva tartalmaz egy csomó mindent, és képes egy lépésben frissíteni a csomagokat, vagy akár magát a Python verziót is.
Egyébként nem tudom, miről váltanál Spyder-re. Egy időben én is azt használtam, aztán váltottam PyCharm-ra. Ez nincs benne az Anacondában, külön kell feltenni: [link]
Ha viszont csak kattintgatni, kísérletezgetni akarsz, nem komplett programot fejleszteni, akkor arra ott a Jupyter Notebook

-
-
cousin333
addikt
válasz
GreenIT
#1705
üzenetére
Az általános Python könyvek nem szoktak ezzel foglalkozni, mint ahogy millió más specifikus funkcióval, modullal sem. Magyarul pedig még egy könyvet is nehéz találni, nemhogy válogatni. Szóval az opciók:
- internetes keresés (lelkes Python blogok)
- specifikus netes oktatóanyag: pl. [link]
- specifikus könyvek: [link]Általában az ilyen "big data", "adatfeldolgozás Pythonnal" típusú könyvek érintőlegesen foglalkozhatnak a témával, bemutatva a szerző kedvenc adatbázis alkalmazását.
-
cousin333
addikt
válasz
 Regirck
#1600
üzenetére
Regirck
#1600
üzenetére
Amint már mások is írták akad itt még pár eldöntendő kérdés.
A legegyszerűbb megoldás szerintem néhány függvény: a beolvas, hozzaad és a torol.
fajl = 'd:\\szovegfajl.txt'
def beolvas():
with open(fajl, 'r') as file:
lista = [line.strip('\n') for line in file]
return lista
def hozzaad(elem):
lista.append(elem)
with open(fajl, 'w') as file:
for i in lista:
file.write(i + '\n')
def torol(sorszam):
_ = lista.pop(sorszam)
with open(fajl, 'w') as file:
for i in lista:
file.write(i + '\n')Vagy valami ilyesmi...
-
cousin333
addikt
válasz
 alec.cs
#1595
üzenetére
alec.cs
#1595
üzenetére
A program pontosan azt írja ki, amit a leírtak - a
return- alapján ki kell írnia. Úgy gondolom, hogy az mo fájlban a msgid szövegeket cseréli le a hozzá tartozó msgstr részre akkor, ha a sztringben egy "_" szerepel, ha azt zárójelben az id követi. Ez a behelyettesítés hiányzik a kódodból.Tudnál olyan részletet bemásolni, ahol működik a csere?
-
cousin333
addikt
Nagy fájlok esetében nem is nagyon erőltetném a
print-et, főleg, ha sok az egyezés. Érdemesebb inkább kiírni egy eredmény fájlba.A másik: a
set()konstruktor egy iterálható objektumot vár, és a nyitott fájl objektum ilyen, szóval a kis fájll beolvasást tovább lehet egyszerűsíteni.# a kis fájl beolvasása
with open("kis-a.txt") as kf:
words = set(kf)
with open("nagy-b.txt") as nf, open("eredmeny.txt") as ef:
count = 0
for line in nf:
if line in words:
ef.write(line)
count += 1
print count, "egyezést találtam!" -
cousin333
addikt
válasz
 fpeter84
#1557
üzenetére
fpeter84
#1557
üzenetére
Így már más. Én ezt találtam: [link]. De persze kérdéses, hogy ezen a rendszeren hogyan működik.
Esetleg nincs benne valami timer, sysclock ilyesmi, szóval Python nélkül? Mikrokontrollerrel megoldható lenne, de ez komplexebb rendszer.
A másodpercenkénti kiértékelés működhet, de az meg kis szélsebességnél lesz pontatlan, szóval kombinálni kell a két megoldást.
-
cousin333
addikt
válasz
alec.cs
#1545
üzenetére
Szerintem ez egy kézenfekvő megoldás, de nyilván lehet cifrázni:
def fugg(percek):
ora, perc = percek // 60, percek % 60
if ora and perc:
print('{0} óra {1} perc'.format(ora, perc))
elif ora and not perc:
print('{0} óra'.format(ora))
else:
print('{0} perc'.format(perc))ui: Használd te is a Programkód kapcsolót. Különösen Pythonnál...
Ugyanez a legújabb, 3.6-os Pythonban még szebb:
def fugg(percek):
ora, perc = percek // 60, percek % 60
if ora and perc:
print(f'{ora} óra {perc} perc')
elif ora and not perc:
print(f'{ora} óra')
else:
print(f'{perc} perc') -
cousin333
addikt
-
cousin333
addikt
válasz
 xAttilax
#1532
üzenetére
xAttilax
#1532
üzenetére
Már írtak egy megoldást és neked is sikerült, de az én receptem erre a gyári glob modul, ami pontosan erre (is) jó:
import glob
file_lista = glob.glob("C:/ana/*.xlsx")A file_lista az adott mappában lévő xlsx kiterjesztésű fájlok neveinek a listája lesz, az egyes elemek mindjárt mehetnek az open_workbook metódusnak.
A másik lehetőség a
glob.iglob(), ami hasonlóan működik, de komplett lista helyett egy generátor függvénnyel tér vissza. Ez akkor jó, ha sok fájlod van (százas, ezres nagyságrend). -
cousin333
addikt
Mit akarsz gyorstalpalni? Youtube videók: [link]
Aztán persze van könyv is: Python for Data Analysis.
Szerintem nem száraz a hivatalos dokumentáció sem, különösen a 10 perces bemutató. Kifejezetten jól dokumentált modul, sok rövid példával. Én is itt kezdtem az alapokkal:
Series,DataFrame,Panel(utóbbi már nincs).Az alap koncepciókat kell megérteni - az meg azért nem egy machine learning -, a többit meg a dokumentációból kikeresed, ahogy a szükség megkívánja. Például hogyan tudok két DataFrame-et egyesíteni oszlopok mentén [link]... stb.
Van már cheat sheet is: [link]
Ha mindenáron oktatást akarsz, akkor itt egy akció: [link]
A Jupyter Notebook használata persze alap az ismerkedéshez...
ui: én már ezt várom: [link]
-
cousin333
addikt
válasz
 K1nG HuNp
#1479
üzenetére
K1nG HuNp
#1479
üzenetére
Akkor írhatod így is:
for index, kod in enumerate(adatok, 1):
szamok = set(kod)
if len(kod) != len(szamok):
ismetlodo = index
break
else:
ismetlodo = NoneA második példád elég célravezetőnek tűnik, momentán én sem tudnék egyszerűbb megoldást írni. Esetleg a
random.randrange()függvényt használhatod, akkor nincs a második "-1", de sokkal egyszerűbb nem lesz. Ha minden igaz:n = 6
kodszam = random.randrange(10**(n-1), 10**n) -
cousin333
addikt
válasz
K1nG HuNp
#1477
üzenetére
Az
if-et nem tudja megszakítani, nincs is értelme. Szóval a külsőfor-ból lép ki.Ha jól látom ez a kód a listákból álló adatok nevű lista annyiadik elemét adja meg (1-essel kezdve a számozást), ahol a listában van legalább egy ismétlődő elem.
Lehetett volna egyszerűbben is:
for index, kod in enumerate(adatok, 1):
szamok = set(kod)
if len(kod) != len(szamok):
breakEkkor az index értéke eleve a keresett ismetlodo lesz. Valószínűleg létezik szebb megoldás is.
-
cousin333
addikt
válasz
K1nG HuNp
#1422
üzenetére
Az eredményt tekintve megegyeznek. A technikai hátteret nem ismerem, de a list comprehension (az első megoldás) nem csak szebb és kompaktabb, hanem valamivel gyorsabb is. A disassembly jelentősen különbözik, de az első esetben van egy függvényhívás, aminek a hossza nem ismert.
ui: Nyilván a második példád helyesen:
lista = []
for nev, sorszam, valami in adatok:
if sorszam == 2:
lista.append((nev, sorszam, valami))Szerintem a fentiek igazak a második esetben is, a
lambdajavára. -
#1403
cousin333
addikt
AeSDé Team
#1402
cousin333
addikt
válasz
 AeSDé Team
#1402
üzenetére
AeSDé Team
#1402
üzenetére
A Pycharm tudja mindazt, amit hiányolsz, de persze nem Netbeans-nek hívják, ezért máshogy működik.
16/17. sor: amint kiteszem a nyitó zárójelet (na jó, némi késéssel), kiírja a lehetséges paraméterek listáját, akárcsak a függvényhívás. Vagy Ctrl + P.
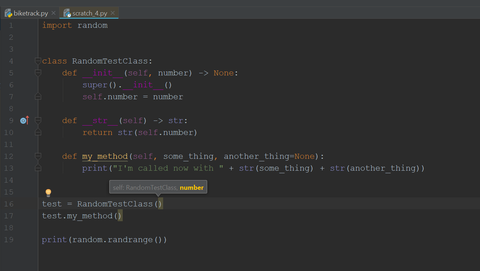
Mindkettőnél bekapcsolható, hogy a lista folyamatosan látszódjon. Ctrl + Shift + A után:
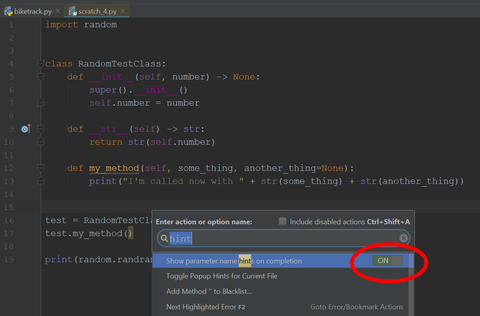
19 sor ugyanezt használhatja, de ha nem vagy biztos magadban, akkor Ctrl + Q és megkapod a hozzá tartozó dokumentációt, amit ki is tűzhetsz magadnak:
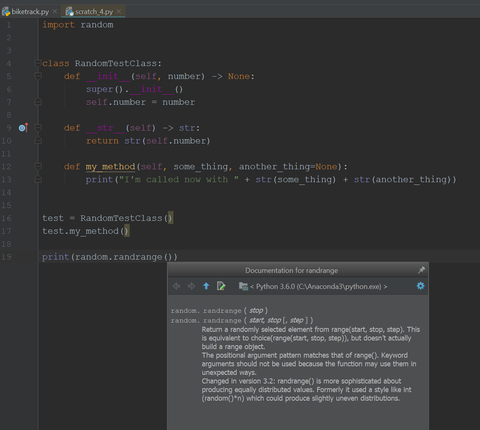
Remélem segítettem.
-
#1399
cousin333
addikt
AeSDé Team
#1398
cousin333
addikt
válasz
AeSDé Team
#1398
üzenetére
Nem tudom pontosan mit hiányolsz, de a PyCharm mindegyiket támogatja. A billentyűzet-kombinációkat is át lehet programozni.
Visual Studio-hoz elvileg van pythonos kiegészítő.
-
cousin333
addikt
válasz
K1nG HuNp
#1389
üzenetére
Igen, úgy van, ahogy leírtad. Az #1387-ban lévő megoldás is helyes, de nem szerencsés. Azzal keverted meg magad, hogy mindent
hossz-nak hívsz.Az eredeti
hosszegy lista, tehát iterálható. Amax()pedig pont ilyet vár, hogy végiglépdeljen (iteráljon) az elemeken. Akeyparaméter egy függvényt vár, ami egyenként végrehajtódik minden egyes listaelemen. A max aztán ennek a függvénynek a kimeneteire vonatkozik. Az alapverzió valahogy így néz ki:hossz = [[1, 230], [2, 324], [3, 69], [4, 5], [5, 240], [6, 248]]
def masodik(lista):
return lista[1]
max_hossz = max(hossz, key=masodik)Namost ehhez a feladathoz teljesen felesleges egy külön függvényt definiálni. Erre találták ki a
lambdafüggényt, ami tulajdonképpen egy rövid, névtelen, "eldobható" megoldás:hossz = [[1, 230], [2, 324], [3, 69], [4, 5], [5, 240], [6, 248]]
max_hossz = max(hossz, key=lambda x: x[1])A fenti esetben az x a hossz lista elemeit jelenti (egyenként):
x=[1, 230]majdx=[2, 324], aztánx=[3, 69]... stb. A visszatérési érték pedig ezen elemek 2. tagja, amikre aztán a max kiszámítja a maximumot. Az eredmény viszont nem ez a szám lesz, hanem az az eredeti listaelem, ami ezt a számot adta:[2, 324]. -
-
cousin333
addikt
Szia!
Nincs ilyen eszközöm, se tapasztalatom az Adafruit driverekkel.
A Python 3 egyik komoly újítása a teljes körű Unicode támogatás volt, emiatt sokkal jobban kezeli az ékezetes karaktereket, nyilván ezért megy jobban.
Ha a 3-as kikapcsolja a kijelzőt, és nincs hibaüzenet, akkor szerintem ez valami konfigurációs beállítás lehet, amit máshogy paramétereztek a 3-as verzióban (pl. energiatakarékosság miatt). Nincs a driverben valami ilyen beállítás? Mérd meg pontosan a kikapcsolási időt, többször is. Ha nagyon egyforma az idő, akkor szerintem ez lesz az ok.
-
cousin333
addikt
válasz
 #73749248
#1320
üzenetére
#73749248
#1320
üzenetére
Milyen modulokról van szó? Lehet, hogy van alternatívájuk.
Nyilván ennél kicsit árnyaltabb a kép, de a Python 3 elég régóta elérhető, deklaráltan csak ezt fejlesztik a továbbiakban, szóval szerintem amelyik modul nem támogatja a 3-ast, azt lehet, hogy nem kéne már erőltetni...
-
cousin333
addikt
válasz
 Atomixx
#1305
üzenetére
Atomixx
#1305
üzenetére
Akkor nem az importálás a hiba (ami meglepő is lenne), hanem rossz az adott sor behúzása. A Pythonban a blokkokat nem
{}vagybegin ... endjelöli, hanem a behúzás mértéke. Emiatt nagyon érzékeny az ilyesmire. Egy adott blokkban lévő kódsorokat pontosan ugyanúgy kell behúzni: ez érvényes a "fő" kódra is. Másold ide az első pár sorodat "programkód" formázással, pontosan úgy, ahogy a fájlban szerepel. Gyaníthatóan az import time sor máshogy van behúzva, mint az alatta/fölötte levő. Az sem jó, ha az egyik sornál tabulátort használsz, a másiknál szóközöket. A tipikus - és javasolt - behúzás 4 szóköz. -
#1297
cousin333
addikt
DrojDtroll
#1296
cousin333
addikt
válasz
 DrojDtroll
#1296
üzenetére
DrojDtroll
#1296
üzenetére
Hogy néz ki most a kód? És ha simán a
cam.location-tappend-eled? Tehát egyben, nem elemenként?Ha már Python, az utolsó két sor meg legyen:
for loc in locs:
print(loc)A jelenlegi megoldástól feláll a szőr a hátamon. Ez nem C...

ui: Ide is simán beszúrhatod a példakódokat, nem kell hozzá külön szolgáltatás. Persze ne az egészet, csak a lényeget.
-
cousin333
addikt
válasz
 Victoryus
#1288
üzenetére
Victoryus
#1288
üzenetére
Mielőtt válasz érkezne: használd a "programkód" kódot ha Python szkriptet szúrsz be, különben ömleszti a PH motor (pl. törli a szóközöket). Ennél a nyelvnél meg nagyon nem mindegy, hogy mit menyire húztál be, a programod működőképessége múlhat rajta.
"Úgy néz ki, hogy egyik sorban van az alkatrész neve, másik sorban a darabszám és az azonosító száma."
Gondolom az a sor az valójában oszlop akart lenni.
Ilyen feladat megoldható az alap Pythonnal, de én inkább a Pandas modult javasolnám, sokat egyszerűsödik vele a feladat. Elvileg ennyit kell a parancssorba (nem a Python promptba!) írni:
pip install pandasEgy pár soros fájlminta - "monospace" kóddal - valóban nem lenne rossz.
-
#1287
cousin333
addikt
concret_hp
#1286
cousin333
addikt
válasz
 concret_hp
#1286
üzenetére
concret_hp
#1286
üzenetére
Szerintem akkor is a
groupbya megoldás... csak nyilván nem magában.Béta verziós megoldás. Íme az "eredeti" táblázat:
>>> df.head()
Datum Ugyfel Termek Ar
0 dátum1 ügyfél1 termék1 ár1
1 dátum1 ügyfél1 termék2 ár2
2 dátum1 ügyfél1 termék3 ár3
3 dátum2 ügyfél1 termék1 ár1
4 dátum2 ügyfél1 termék2 ár2A
groupbyobjektum szétbontja egyedi csoportokra a dátum és az ügyfél neve alapján:gr = df.groupby(['Ugyfel', 'Datum'])Ezután már az
applymetódussal tudunk az egyes részeken tetszőleges függvényeket futtatni (lehet akársumis), majd az eredményt összefűzni. A kissé favágó megoldás az összeadásra:def func(group, cucc1, cucc2):
x = group[group.Termek == cucc1].Ar.squeeze()
y = group[group.Termek == cucc2].Ar.squeeze()
return x+y
gr.apply(func, 'termék1', 'termék2')Az eredmény:
Ugyfel Datum
ügyfél1 dátum1 ár1ár2
dátum2 ár1ár2
ügyfél2 dátum1 ár1ár2
ügyfél6 dátum2 ár1ár2
dtype: objectA
functartalmán még lehet finomítani... -
#1283
cousin333
addikt
concret_hp
#1282
cousin333
addikt
válasz
concret_hp
#1282
üzenetére
Pedig azt hittem, értem. Szerintem fuss neki a magyarázatnak mégegyszer
 . Esetleg konkrét példát is írhatnál.
. Esetleg konkrét példát is írhatnál. 
-
#1280
cousin333
addikt
concret_hp
#1279
cousin333
addikt
válasz
concret_hp
#1279
üzenetére
Hát, nem lett valami érthető...
Ha jól értem, akkor végeredményként fele annyi sort szeretnél és összegezni a 3. oszlopban azokat az értékeket, ahol az 1. és 2. oszlopok azonosak. Vagy valami ilyesmi.
Tehát a példád alapján az új táblázat ez lenne:
a-x-A+B
b-x-A+B
a-y-A+B
b-w-A+BKonkrét példa jobb lenne, nekem két fogalom ugrik be: multi-index és a
groupby. -
#1274
cousin333
addikt
Capricornus
#1273
cousin333
addikt
válasz
Capricornus
#1273
üzenetére
-
-
cousin333
addikt
válasz
#82595328
#1262
üzenetére
"Azt gondoltam, hogy ha példányosítom a származtatott osztályt, akkor abban benne lesz a szülőosztály is."
Jól gondolod, ez a példában is így van. Nem látom az ellentmondást, amit nem értesz. Ha a származtatott osztálynak van egy init függvénye, akkor az felülírja a szülő osztály init-jét, hacsak külön nem hívod meg. Ez nem a szülő osztály példányosítása!
A példádban az egyik és a másik példányváltozók, így nem s léteznek, amíg nem adsz nekik értéket a példányosítással. Az osztályváltozó "tud olyat", hogy példányosítás nélkül is létezik. Csinálhatsz például ilyet:
class Egy():
egyik = 1
masik = 2
def szorzat(self):
return self.egyik * self.masik
class Ketto(Egy):
def __init__(self, egyik):
self.egyik = egyik
a = int(input('Adj egy számot!'))
b = int(input('Adj még egy számot'))
egyke = Ketto(a)
print ('Egyik = %s' % egyke.egyik)
print ('Masik = %s' % egyke.masik)
print ('Szorzat = %s' % egyke.szorzat())Ekkor az egyik és a masik osztályváltozók, és az Egy osztálynak nem is kell
__init__(), azt a Ketto tartalmazza. Amikor példányosítod a Ketto-t, akkor már lesz egyself.egyikésself.masiknevű változója 1 illetve 2 értékkel. A fenti példában mi kötelezően felülírjuk az egyik értékét, a masik marad 2. -
cousin333
addikt
válasz
#82595328
#1255
üzenetére
Amikor a példádban példányosítod a Ketto osztályt (ez lenne az egyke - lehetnének konzekvensebbek is az elnevezéseid), akkor a következőt kapod: lefut a
Ketto.__init__()függvény, benne értéket kap az egyik példányváltozó. Lesz egyszorzat()nevű metódusod, ami összeszorozza az egyik-et a masik-kal. Vagyis csak szorozná, de az masik nem létezik!A hibát azért kapod, mert a
Ketto._init__()csak két paramétert vár, a self-et (ezt implicit) és az egyik-et, te viszont hármat adtál meg: a self-et, az egyik-et és a masik-at.Amúgy pontosan az történt, amit szerettél volna: a Ketto init-je felülírta az Egy init-jét. A probléma ott van, hogy előbbiben nem hívod meg a szülő osztály (az Egy)
__init__()metódusát. Írták, hogyEgy.__init__(), de ez nem szerencsés, mert név szerint hivatkozik a szülőosztályra, helyette többnyire a super() az alkalmazandó. A kódod helyesen:class Egy():
def __init__(self, egyik=1, masik=2):
self.egyik = egyik
self.masik = masik
def szorzat(self):
return self.egyik * self.masik
class Ketto(Egy):
def __init__(self, egyik):
super().__init__(egyik=egyik)
a = int(input('Adj egy számot!'))
b = int(input('Adj még egy számot'))
egyke = Ketto(a)
print ('Egyik = %s' % egyke.egyik)
print ('Masik = %s' % egyke.masik)
print ('Szorzat = %s' % egyke.szorzat())A példányosításnál csak az a paramétert írtam oda. A Ketto init függvénye meghívja az Egy init függvényét, de csak egy értékkel (egyik), a masik értéke az
Egy.__init__()-ben megadott alapértelmezett 2-es, emiatt a végén kiírt szorzat 2*a lesz, a b-től függetlenül. -
cousin333
addikt
válasz
#82595328
#1250
üzenetére
Most ez lesz belőle, ha lefuttatod:
Traceback (most recent call last):
File "C:\Users\cousi\.spyder-py3\temp.py", line 25, in <module>
print ('Egyik = %s' % egyke.egyik)
AttributeError: 'Ketto' object has no attribute 'egyik'Több probléma is van itt. Az egyik probléma - ami a futtatáskor is látszik -, hogy az egyik nem kap értéket. A másik, hogy a szorzat függvény, ahogy megírtad, két paramétert vár, de nem kapja meg őket (utolsó kódsor). Igaz, nincs is értelmük, mert nem használnád egyiket sem (a self.akármi az mindenhonnan látható, hiszen már átadtad a self-el). A harmadik, hogy csak a Ketto inicializáló függvénye fut le, bár ez így nem feltétlenül hiba, és az egyes probléma megszüntetésével orvosolható.
Két lehetőség közül az első az 1-es és 2-es problémát javítja:
class Egy():
def __init__(self, egyik=1, masik=2):
self.egyik = egyik
self.masik = masik
def szorzat(self, egyik, masik):
return self.egyik * self.masik
class Ketto(Egy):
def __init__(self, egyik, masik):
self.egyik = egyik
self.masik = masik
def szorzat(self):
return self.egyik * self.masik
a = int(input('Adj egy számot!'))
b = int(input('Adj még egy számot'))
egyke = Ketto(b, a)
print ('Egyik = %s' % egyke.egyik)
print ('Masik = %s' % egyke.masik)
print ('Szorzat = %s' % egyke.szorzat())A második pedig - némi módosítással - a 2-es és 3-as problémákat orvosolja, amivel az 1-es lesz idejétmúlt:
class Egy():
def __init__(self, egyik=1, masik=2):
self.egyik = egyik
self.masik = masik
def szorzat(self, egyik, masik):
return self.egyik * self.masik
class Ketto(Egy):
def __init__(self, egyik, masik):
super().__init__(egyik, masik)
def szorzat(self):
return self.egyik * self.masik
a = int(input('Adj egy számot!'))
b = int(input('Adj még egy számot'))
egyke = Ketto(b, a)
print ('Egyik = %s' % egyke.egyik)
print ('Masik = %s' % egyke.masik)
print ('Szorzat = %s' % egyke.szorzat())A második megoldás inkriminált sorát így is írhatod, hogy legyen értelme is az örökléses példádnak. Ekkor az egyik az mindenképpen 1 lesz.
super().__init__(masik=masik)ui: Nem tiszta, hogy tulajdonképpen mit akartál felülírni mivel...
Tipp: a függvényparaméterek felsorolásánál használj szóközöket, úgy áttekinthetőbb lesz a kód.
-
cousin333
addikt
válasz
 EQMontoya
#1198
üzenetére
EQMontoya
#1198
üzenetére
"Akkor látszik, hogy a relációsjel precedenciája nagyobb az összeadásénál."
A helyzet az, hogy fordítva kell olvasni a listát, tehát pont az összeadás prioritása nagyobb.
"The following table summarizes the operator precedences in Python, from lowest precedence (least binding) to highest precedence (most binding)"A Pythonban lehet olyan feltételt írni, amitől a C egy hátast dobna, pl:
if 5 < x <= 14:
print('Közötte van')A fenti példában:
a < b+c == TrueEz így értékelődik ki:
(a < (b + c)) and ((b + c) == True)Ebből a második tag
Falselesz, aminek az oka:
"The default behavior for equality comparison (== and !=) is based on the identity of the objects. Hence, equality comparison of instances with the same identity results in equality, and equality comparison of instances with different identities results in inequality."Az
a+begy számot ad eredményül, ami nem azonos aTrue-val. De ac< a+beredménye már egy boolean, ami lehetTruemeg lehetFalse. -
cousin333
addikt
válasz
 cadtamas
#1189
üzenetére
cadtamas
#1189
üzenetére
Gondoltam, hogy nincs korábbi munka, azért furcsállottam, hogy két környezetet használsz (gondolom az egyik 2.7, a másik 3.x).
A PyCharm-ban a projekt beállításainál ki tudod választani az interpretert. De ha rám hallgatsz, törlöd a "normál" Pythont és meghagyod az Anacondát.
Már írtam párszor: a Gerard Swinnen könyv jó és magyar de elég régi. Ha megy az angol, inkább olyan könyvet keress.
-
cousin333
addikt
válasz
cadtamas
#1187
üzenetére
Nem, a pip egy külön csomagkezelő modul, ami eleve része az Anaconda telepítésnek...
Igazából az a kérdés, hogy miért használsz 2 különböző környezetet. Ha pedig mégis kell, akkor az Anaconda támogatja ezek létrehozását. Ráadásul a csomagkezelője (conda) a Pythont is csomagként kezeli, ezért lehetőséged van arra is, hogy egyidejűleg használj egy 64-bites Python 3.6-t a legfrissebb csomagokkal az újabb munkáidhoz és mondjuk egy 32 bites 2.7-et adott verziójú csomagokkal a régebbi kódjaidhoz.
-
cousin333
addikt
válasz
 kezdosql
#1178
üzenetére
kezdosql
#1178
üzenetére
A list comprehension-re találtam egy jónak tűnő fordítást: listaképző
Ez a funkció tulajdonképpen egy tipikus for ciklus alkalmazásnak a tömörebb megfogalmazására szolgál: amikor egy meglévő listán (pontosabban iterálható elemen) kell végigmenni, hogy elemről-elemre haladva az egyes elemeken végrehajtott műveletek segítségével egy új listát hozzunk létre.
Például ha minden elemhez hozzá akarunk adni 2-t, és ebből lesz az y.
x = [1, 2, 3, 4, 5]
y = []
for elem in x:
y.append(elem+2)Ezt leegyszerűsíthetjük egy (két) sorra, így nincs a felesleges értékadás az elején és nem kell egyesével hozzáadogatni az új elemeket sem.
x = [1, 2, 3, 4, 5]
y = [elem + 2 for elem in x]Ráadásul lehet megadni feltételt is, mindezt szintén egy sorban:
x = [1, 2, 3, 4, 5]
y = [elem+2 for elem in x if elem % 2 == 0]Ennek a "hagyományos" megfelelője:
x = [1, 2, 3, 4, 5]
y = []
for elem in x:
if elem % 2 == 0:
y.append(elem+2)Az első esetekben az eredményül kapott y hossza megegyezik az x-ével, az utóbbinál meg rövidebb, vagy egyenlő.
-
cousin333
addikt
válasz
 s3toraph
#1042
üzenetére
s3toraph
#1042
üzenetére
A Spyder egy ingyenes, nyílt forrású fejlesztőkörnyezet, egy időben én is azt használtam. Tulajdonképpen semmi rosszat nem tudok felhozni ellene, az IDLE-nél nyilván klasszisokkal jobb. Keresztplatform, tehát minimális eltéréssel tudod használni Linuxon és Windowson egyaránt.
Linuxon szerintem helyből, a Windowson a 3.4-től kezdődően az alaptelepítés része a pip nevű csomagkezelő: [link]. Egyszerűen a parancssorba írd be:
pip install spyder
Ez elvileg felteszi neked a megfelelő verziójú programot, és mindent, ami kell hozzá, Windowson és Linuxon egyaránt. Azért írtam, hogy elvileg, mert mostanában nem a "mezei" Pythont használom, hanem az Anaconda nevű disztribúciót, amiben a Python, meg a Spyder mellett milliónyi más modul is benne van, előre telepítve. Ez viszont neked talán feleslegesen nagy, Raspberry-re mindenképpen.
Amúgy meg ott a dokumentáció: [link]
A Spyder alternatíváit már felsorolták a többiek, nagyon mellényúlni szerintem egyikkel sem tudsz, innentől ízlés kérdése. Személy szerint én mindenképpen IDE-t használnék, és nem "szövegszerkesztőt", mint a Notepad++, VIM és társaik.
A megírt progamjaid valószínűleg futnak majd mindenhol, feltéve hogy a gyári modulokat használod. Ha nem, akkor sincs minden veszve, csak esetenként problémásabb lehet a dolog.
-
-
cousin333
addikt
válasz
EQMontoya
#1034
üzenetére
Ez melyik sshtunnel verzió? Csak mert a hivatalos dokumentációban is szerepel a
with-es megoldás, ráadásul szinténstart()nélkül.A hivatalos oldalon fenn van a fájl a kérdéses sorral: sshtunnel.py
Az
__enter__()metódus - awithnem az__init__()-et használja - pedig tartalmazza aself.start()függvényhívást.Vagy akkor valamit rosszul értek...

-
cousin333
addikt
válasz
s3toraph
#1009
üzenetére
Újabb, mint a Swinnen könyv, ráadásul a Python 3-al foglalkozik, de frissnek azért nem mondanám. Ahogy látom, ők is kb. antikváriumból hoznák, ha megrendeled
. Az oldalszám alapján elég alapos, de ennyiért nekem nem kéne.Szerintem a neten találsz elég sok segédanyagot, videót vagy éppen oktató appot. Ezek jó része persze angol, de talán itt az ideje kicsit fejleszteni a nyelvtudást. Hosszútávon mindenképp jól jársz vele.
Ha minden kötél szakad, az alapokhoz jó a Swinnen könyv is, akár "háttér olvasmányként". Sok minden változott azóta, de az alapok maradtak.
-
cousin333
addikt
válasz
xAttilax
#1001
üzenetére
Az enumerate egy beépített függvény, ami "végiglépdel" egy lista vagy sztring elemein (karakterein) és minden lépésben két értékkel tér vissza: az elem sorszámával és magával az elemmel. Illusztráció:
>>> for i, char in enumerate("012abc34567de89f"):
... print(f'Az {i}. elem a "{char}".')
...
Az 0. elem a "0".
Az 1. elem a "1".
Az 2. elem a "2".
Az 3. elem a "a".
Az 4. elem a "b".
Az 5. elem a "c".
Az 6. elem a "3".
Az 7. elem a "4".
Az 8. elem a "5".
Az 9. elem a "6".
Az 10. elem a "7".
Az 11. elem a "d".
Az 12. elem a "e".
Az 13. elem a "8".
Az 14. elem a "9".
Az 15. elem a "f".Mondjuk én nem erőltetném a kettős for ciklust, inkább így csinálnám:
lista = input('Írd be a karakterláncot: ')
osszeg = 0
for char in lista:
if char in ("0123456789"):
osszeg = osszeg + int(char)
print('A szamjegyek osszege: ', osszeg)Ugyanez két sorba összevonva:
lista = input('Írd be a karakterláncot: ')
osszeg = sum([int(char) for char in lista if char in ("0123456789")]) -
cousin333
addikt
válasz
EQMontoya
#986
üzenetére
Tudom, ismerem, de azért köszönöm a kiegészítést. Az már mondjuk inkább Python level 2 szintű megoldás...
. Plusz kell hozzá még egy sor:from collection import defaultdictÖsszességében az eredeti 9 sor kódból lett 7. A level 3 megoldás meg már csak 3 soros:
import pandas as pd
data = pd.read_table('myfile.txt', sep=';', names=['Film', 'Rendezo'])
data.Rendezo.value_counts() -
cousin333
addikt
Én kezdőként így csinálnám:
megnyitom a fájlt olvasásra (kulcsszó: open, with)
soronként beolvasom a fájlt egy listába (pl. list comprehension, strip)
készítek egy üres szótárat (dictionary)
soronként végigmegyek a listán (for)
szétválasztom a címet és a rendezőt (split, ahogy már előttem írták)
ha a rendező még nem szerepel a szótárban,
akkor hozzáadom a nevét a szótárhoz egy 1-es számmal, vagy a film címével (listában)
ha a rendező szerepel a szótárban,
akkor hozzáadok a név melletti számhoz 1-et, vagy a név melletti listához a filmcímetEz kb. annyi kód, amennyivel fentebb leírtam, minden sorhoz egy kódsor tartozik. Az első módszerrel (a vagy előtt) a rendező által rendezett filmek számát kapod, az alternatív megoldással meg azt, amit most írtál, hogy ki szeretnéd hozni.
SPOILER! A kód kb. így nézne ki az első módszerrel (filmszámolás):
with open('myfile.txt', 'r') as f:
filmlista= [line.strip('\n ') for line in f if line != '\n']
osszesites = {}
for alkotas in filmlista:
cim, rendezo = alkotas.split(';')
if rendezo in osszesites:
osszesites[rendezo] += 1
else:
osszesites[rendezo] = 1És a for ciklus így nézne ki a másodikkal:
for alkotas in filmlista:
cim, rendezo = alkotas.split(';')
if rendezo in osszesites:
osszesites[rendezo].append(film)
else:
osszesites[rendezo] = [film]Remélem működnek, nem teszteltem le.
-
cousin333
addikt
A NumPy egy sokkal alapvetőbb funkcionalitást nyújtó és szélesebb körben használható modul. Az ML-re léteznek sokkal specifikusabb kiegészítők. A legismertebb talán a scikit-learn. Ezt találtam a Youtube-on: [link], ha esetleg érdekel.
-
cousin333
addikt
Hogyan képzelted a Machine Learning-et? Kézzel lekódolod az alapoktól és futtatod? Mert léteznek modulok külön erre a célra. Nem tudom, hogy azok belsőleg milyen pontosságot használnak, vagy egyáltalán milyen adattípusokat, de csak jól működnek, ha erre lettek kitalálva...
-
cousin333
addikt
válasz
EQMontoya
#968
üzenetére
Én is erre gondoltam először, de a #966-ban egyértelműen ott van, hogy
prec = 28(ez az alapértelmezés). Amit én írtam, az meg nem fog működni, mert hibásan adtam meg. De ha jó lenne, akkor sem menne, mert egy másik config esetében sincs semmi a flags-nél, mégis jó. Aclamp = 1-re gondoltam még, mint lehetséges ok, de az sem az. Szóval most már nem tudom, mi van... -
cousin333
addikt
Mert csak a Decimal-t importáltad a decimal modulból. Írd ezt és akkor lesz:
In [1]: import decimal
In [2]: decimal.Decimal(19/155)
Out[2]: Decimal('0.12258064516129031640279123394066118635237216949462890625')
In [3]: decimal.getcontext()
Out[3]: Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, ca
pitals=1, clamp=0, flags=[FloatOperation], traps=[InvalidOperation, DivisionByZe
ro, Overflow]) -
cousin333
addikt
Nálam a 3.6 van telepítve és jól működik.
Nálad mit ad vissza a decimal.getcontext() függvény? Nálam:
Out[6]: Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, ca
pitals=1, clamp=0, flags=[FloatOperation], traps=[InvalidOperation, DivisionByZe
ro, Overflow]) -
cousin333
addikt
A már említett PyPi oldalon rákeresve, vagy a modul honlapján le van írva, hogy éppen mivel kompatibilis. Nem biztos, hogy ki van írva az összes jó változat, legtöbbször pl. 2.7+ és 3.3+ jelölés szerepel. A legfontosabb, hogy a 2-es és 3-as verziókat kell külön kezelni. Sok modul ráadásul csak gyári függvényeket használ, avagy "pure Python", az ilyeneknél nem szokott gond lenni a kompatibilitással. A Githubon szoktak lenni readme fájlok, de a kisebb projektek általában gyengébben dokumentáltak, beleértve a kompatibilitást is. Általában ami támogatja a Python 3-at az fut a legfrissebb változattal is, legfeljebb nem használja ki az újdonságokat.
Szerintem egy kicsit túlpörgöd ezt a témát, ami neked kell, az benne van az alaptelepítésben is. Ahogy írtam, a pip remekül használható külsős modulok telepítésére, automatikusan a kívánt verziót teszi fel (pl. 32 vs 64 bit), a függőségekkel együtt. A githubos Home asistant könyvtárad is fel tudod így tenni:
C:\> pip install pyhs100
-
cousin333
addikt
Szerintem nyugodtan töröld a mostani Pythont, és tedd fel helyette a legfrissebbet: Python 3.6.0. A gyári könyvtárak nyilvánvalóan támogatottak (lásd urllib), ahogy a kérdéses külső modulok is:
- Requests
- Beautiful SoupHa feltetted a friss Pythont, akkor elvileg lesz parancssorból működő pip-ed is, amivel a fent említett modulokat is telepítheted, az esetleges függőségeikkel együtt:
C:\> pip install requests beautifulsoup4
A PyPi-t nem tudod feltenni, mert az csak a hivatalos honlap a külsős Python modulok számára. Azért említettem, mert a pip elvileg minden csomagot fel tud tenni, amit itt megtalálsz, de ez inkább a későbbiekre szól.
-
cousin333
addikt
válasz
 pbalintka
#945
üzenetére
pbalintka
#945
üzenetére
Ez valóban félreérthető volt, a zárójeles rész csak magyarázat akart lenni. Azt szerettem volna kifejezni, hogy az urllib2 (hangsúly a "2"-n!) a Python 2 gyári modulja, és mint ilyen, nincs keresnivalója a Python 3-ban. Utóbbiban gyárilag nincs is benne (ezzel a névvel), ha megnézed a dokumentációt, és a lap tetején kiválasztod valamelyik 3-as verziót, akkor a főoldalra dob, pont emiatt.
Ő Python 3-at használ, tehát ne erőltesse az urllib2 telepítését (ő írta, hogy külön megpróbálta feltenni), használja a gyárilag meglévő "sima" urllib-et. Ha nem írja konkrétan a "2"-est, nem is akadok fenn rajta.
Magyarán nincs szó arról, hogy ne használjuk a gyári modulokat, sőt! De ne próbáljunk a 3-as Pythonba "kiselejtezett 2-es modulokat" beledrótozni.
Amúgy az utóbbi időben talán a time volt az egyetlen gyári modul, amit direktben használtam, szinte mindig külsős fejlesztéseket importáltam (amik persze építenek a gyári modulokra is, de ez legyen az ő problémájuk). Mellesleg pont azért, mert kényelmesebbek, mint a "lower level" gyáriak.
Na, jó sokat írtam kb. a semmiről, de remélem már érthetőbb voltam.
-
cousin333
addikt
Természetesen Windowsra is elérhető a pip. Tulajdonképpen van valamilyen jelentősége annak, hogy a 3.3-at használod, vagy csak ezt találtad meg? A 3.4-től kezdve ugyanis a pip a gyári Python telepítő része.
Ha pedig nincs fenn, akkor így tudod feltenni: [link]. Mindenképpen érdemes, mert a segítségével sokkal egyszerűbben és kényelmesebben tudsz új modulokat telepíteni. Kezeli a pontos verziót és az esetleges függőségeket is.
Ahogy nézem az urllib2 a Python 2 telepítés része (gyári modul), így használata semmiképpen sem javasolt. A Python 3-ban ehelyett van a már linkelt urllib, illetve annak almoduljai. Ezen kívül javasolják még a Request modult, mint az életedet megkönnyítő kiegészítőt, ami gondolom az urllib fölé épül.
A Request-et - csakúgy, mint a linkelt Home Assistant könyvtárat (pyHS100) -, könnyen felteheted a pip-pel, mivel mindkettő része a PyPi-nek (Python Package Index):
c:\> pip install request pyhs100
-
cousin333
addikt
Leírhattad volna a Python kódodat is. Milyen könyvtárat akartál feltenni és hogyan? Én a pip-et javaslom erre a célra (csomagtelepítésre), sokkal egyszerűbb és a megfelelő verzió megy fel. Pl. a parancssorba írva:
C:\>pip install numpy pandas matplotlib
A webes felhasználásban nem vagyok otthon, de szerintem a gyári urllib amit te keresel, pontosabban annak a request és parse moduljai.
-
cousin333
addikt
Van egy sztringem (pl. "X1") és abból szeretnék egy 1 elemű listát (pontosabban iterable-t). Azaz keresem a magic nevű metódust/megoldást, ami tudja az alábbit:
>>> input = "X1"
>>> magic(input)
["X1"]Eddig nem vészes. Ugyanakkor azt is szeretném, ha a magic akkor is működne, ha az input már eleve egy lista, ilyenkor viszont ne variáljon rajta semmit:
>>> input = ["X1", "X2", "X3"]
>>> magic(input)
["X1", "X2", "X3"]Nyers erővel nyilván megoldható lenne, de nekem az volna a kérdésem, hogy mi erre a "legpythonikusabb" (legelegánsabb, legegyszerűbb) megoldás? Egyáltalán létezik ilyen? Vagy éppen ellenkezőleg, túlságosan triviálisat kérdeztem?
-
cousin333
addikt
"Sosem szerettem a for ciklust kombinálva a range függvénnyel"
Semmi gond, a Python sem szereti annyira.
Inkább a listaelemeken való iterálást preferálja. Pl.:lista = ['egy', 'ketto', 'harom']
for elem in lista:
print(elem)Ez szükség esetén megfejelhető az enumerate és a zip használatával, valamint a lista "szeletésével":
for elem in lista[1:]:
print(elem)Az persze megint egy más kérdés, hogy akkor hogyan lehetne "pythonikusan" leimplementálni a fenti példát...
-
cousin333
addikt
Nekem ehhez már késő van, de első ránézésre 2 dolgon úszhatott el a kódod:
- indexelés: ha jól látom a példában az a[1] a legelső elemet jelenti, Pythonban viszont ez az a[0] Nem mondom, hogy emiatt rossz, csak erre oda kell figyelni
- Python ismeret hiánya: a pszeudo-kódban a ciklus egyértelműen 2-től m-ig megy, viszont a használtrangefüggvény 2-től (m-1)-ig fut csak!Erre utal az is, hogy a te eredményed látszólag eggyel elcsúszott a helyes megoldáshoz képest. Talán inkább range(1, m) kellene, de persze ez nem feltétlenül oldja meg a problémádat.
-
cousin333
addikt
válasz
EQMontoya
#904
üzenetére
Ez egy nem triviális kérdés, hiszen mindenkinek mások az előismeretei, képességei és gondolkodásmenete, de szerintem a Think Python (PDF) egy ilyen kezdő-barát könyv, mert érhetően, egyszerű szavakkal, tömören elmagyarázza a programozás alapjait is. Egyébként ebből a szempontból a Swinnen könyv is ajánlható, sőt, összehasonlítva meglepően sok az egyezés a két forrás között...
Ami nekem a Swinnen könyvben nem tetszik - és amit már többször is jeleztem -, hogy elavult: 2005-ben adták ki, ami a Python 2.4 ideje... a 3-ast nem említi, hiszen az akkor még nem is létezett. Sok minden most is érvényes, más dolgok viszont megváltoztak, kibővültek azóta, akár az alap dolgokat tekintve is. Csak néhány példa:
- print: statement vs függvény
- egész osztás
- xrange vs range (izip vs zip... stb)
- sztring vs byteSzerintem ha valaki most ismerkedik vele, az egyből a 3-assal kezdjen és ne tanulja meg feleslegesen (es adott esetben hibásan) a 2-est, csak majd jóval később, ha szüksége lesz rá (ha szüksége lesz rá).
Hozzáteszem: magyar nyelven még mindig nem nagyon van alternatívája a Swinner könyvnek.
-
cousin333
addikt
válasz
szucstom
#898
üzenetére
Könyv szempontjából elsősorban az a kérdés, hogy 2-es vagy 3-as verzió, az alverziók kevésbé számítanak. Ez azért is jó, mert pl. a 3.6 vadonat új, könyv aligha van hozzá, de szerencsére a korábbiak is jók: [link]
Értelemszerűen a mindenkori legfrissebb, de inkább referenciának mintsem tanulásra való oldal a hivatalos Python dokumentáció: [link]
-
cousin333
addikt
válasz
szucstom
#896
üzenetére
Használd a Programkód kapcsolót.
Az a problémád, hogy a könyv, amit használsz, a Python 2.7-ről (vagy még régebbiről) szól, te viszont valamelyik 3-as változatot használod. Abban a
printmár függvény, ezért kell a zárójel. Tehát helyesen:a = 150
if a > 100:
print("a meghaladja a szazat") -
cousin333
addikt
válasz
cadtamas
#893
üzenetére
A fájlbeli coding sor tudtommal a forrásfájl karakterkódolását definiálja.
Kezdjük azzal a kérdéssel, hogy hogyan írod/olvasod a fájlt? Ha a klasszikus
openfüggvénnyel, akkor annak van egy encoding paramétere, amit célszerű megadni. A lehetséges kódolások listája (bár kicsit régi): [link]. Innen az UTF-8 vagy a cp1250 ajánlott.ui: Mindez a Python 3.x szériára vonatkozik, de remélhetőleg azt használod...
-
cousin333
addikt
válasz
cadtamas
#889
üzenetére
Hát, lehet, hogy rosszul látom, de az
xt,yt=x,ysor hatására szerintem annyi történik, hogy az xt nem olyan lesz, mint az x, hanem maga lesz az x csak másik elnevezéssel. Magyarul amint módosítod az egyiket, módosul a másik is. Így azifmáshogy elnevezettelseága (a másodikif) az első elemmel másolja felül az összes többit.Nem teljesen világos nekem a program működése, de ha a listában egy elem kimegy, egy másik meg be, de a többi marad, akkor azt másolgatnám, hanem csak az utolsó elemet törölném, az elsőt meg hozzácsapnám. Erre a legmegfelelőbb típus mondjuk nem a list, hanem a deque, mondjuk ez azért elég speciális és tudtommal inkább teljesítmény okokból létezik. A te kígyód meg sosem lesz olyan hosszú, hogy ez problémát jelentsen...

Listával valahogy így tudsz elé beszúrni egy új elemet:
x = uj_x0 + x[:-1] -
cousin333
addikt
válasz
EQMontoya
#883
üzenetére
Ha már optimalizálás, tud valaki javasolni egyszerűen használható grafikus könyvtárat, amivel mindenféle interaktív grafikonok készíthetők és könnyen elboldogul több millió adatponttal?
Amiket néztem: matplotlib (jó, de nem túl gyors), Seaborn (kb. ugyanaz), Plot.ly (netes, fizetős is, nem érdekel), Bokeh (ezt még nem ismerem eléggé), Vispy (ez lenne a favoritom, de még mindig félkésznek tűnik). Jó lenne valami, ahol a
data.plot()-nél nem sokkal bonyolultabb szerkezetekkel célt lehet érni. -
cousin333
addikt
Félreértés ne essék, a te megoldásod is teljesen jó, sőt, rövid tesztem alapján valamivel gyorsabb is. Csak nekem meg valahogy a list comprehension rögzült, talán azért, mert a Java nem fertőzött meg
.A tuple meg azért az, mert elvégre tuple unpacking-ről van szó
. Egyébként teljesen jó a lista is.










![;]](http://cdn.rios.hu/dl/s/v1.gif)
























 . Esetleg konkrét példát is írhatnál.
. Esetleg konkrét példát is írhatnál. 












Új hozzászólás Aktív témák
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Lítium-ion/Li-ion akkumulátorok
- Milyen belső merevlemezt vegyek?
- Vicces képek
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Lexus, Toyota topik
- E-roller topik
- gban: Ingyen kellene, de tegnapra
- One mobilszolgáltatások
- További aktív témák...
- Gtx 1080/ Intel I7 8700K/ 16GB Ram/ 256GB M2 SSD/ 1TB HDD/ Win11
- Gtx 1050Ti/ Intel I5 7500/ 16GB Ram/ 256GB Sata SSD/ 1.5TB HDD/ Win11
- Gtx 1050Ti/ Intel I5 7500/ 16GB Ram/ 128GB M2 SSD/ 1.5TB HDD/ Win11
- Acer Aspire 3 A317-53-76NV. Intel 11.gen I7 / 16Gb ram / 512Gb ssd / 17,3"
- Intel 545S 512GB M2 Sata SSD
- Lenovo ThinkPad T14s Gen 3 i5-1245U 14" FHD+ 16GB 512GB 1 év teljeskörű garancia
- Keresünk iPhone 16/16e/16 Plus/16 Pro/16 Pro Max
- ÁRGARANCIA!Épített KomPhone i5 14400F 16/32/64GB RAM RX 9060 XT 16GB GAMER PC termékbeszámítással
- Kingston FURY Impact 32GB DDR5 4800MHz KF548S38IB-32
- Dell Wyse 5470,14",FHD, N4100 CPU,8GB DDR4,128GB SSD,WIN11
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest