Új hozzászólás Aktív témák
-
válasz
 S_x96x_S
#4547
üzenetére
S_x96x_S
#4547
üzenetére
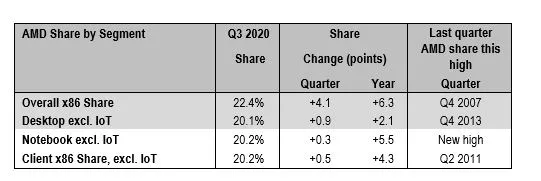
Passmark, techspotnál is elmentek otthonról

Néhány ezer bench futtatás eredményét látjuk.
PassMark notes that its data is made up of thousands of PerformanceTest benchmark (download here) results and, as its software only runs on Windows OS, the charts do not reflect non-Windows usersKb semmire sem lehet ebből következtetni, csak arra, hogy a desktop AMD userek aktívabban indítják el a benchet, mint a notis AMD-sek, desktopon Intel verés, notiban meg kikapnak Passmark szerint, miközben a notis piaci részesedés a nagyobb az eladások alapján.
Amúgy az overall hogy lehet nagyobb, mint a részek összege, egyedül az IoT részesedést nem látjuk? Ebben lenne nagy részesedése az AMD-nek? Van egyáltalán bármilyük is ebben a szegmensben?
via -
#4536
 Petykemano
veterán
S_x96x_S
#4533
Petykemano
veterán
S_x96x_S
#4533
Petykemano
veterán
válasz
S_x96x_S
#4533
üzenetére
Bármilyen chipgyártónak akkor lenne érdeke pc szintű arm chipet készíteni, ha készen állna a szoftveres környezet, ami nem teszi használhatatlanná a nulladik kilóméterkőnél.
A MS-Nak akkor érné meg az arm irányába lépéseket tenni, ha kapható lenne olyan arm lapka, ami úgy veri agyon az x86 konkurenciát, mint az M1.1-eshez: Vagy ha valaki külön megfizeti. Pl Google, MS
2-eshez: Vagy akár saját magának is elkészítheti. Pl Google, MS -

Busterftw
nagyúr
válasz
S_x96x_S
#4533
üzenetére
Érdekes cikk, pl meglepett a cikk alapján, hogy az Intel nem áll rosszul a Lakefield/AlderLake miatt.
X86 de big.Little, szerintem ez egy jó köztes megoldás.A legnagyobb gondot a Microsoft okozza szerintem, a Windows fejlesztése ebbe az irányba nem halad elég gyorsan.
Ez is érdekes: (AMD)
"We're not going to do it just to have a bigger number."
Ryzen 8-12-16 mag desktopra akkor mi volt?
-

S_x96x_S
addikt
válasz
S_x96x_S
#4523
üzenetére
> A legnagyobb valószínűsége szerintem annak van,
> hogy valamelyik Kínai gyártó lép be 3.-ként a piacra valamilyen agresszív fejlesztésselSMIC:
persze - nagy célok (5nm! 3nm!) és konfliktusok ( + vezetőváltás ) ott is megvan.
SMIC & Chinese Pursuit of Latest 5nm Chip Process Will Be Gutted By C.E.O.’s Sudden Departure"I originally came to mainland China not to seek high-ranking officials, but simply to contribute to the mainland's high-end integrated circuits. At present, 28nm, 14nm, 12nm, and n+1 technologies have all entered mass production, and the development of 7nm technology has also been completed. Risk mass production will be available in April next year. The 8 most critical and most difficult technologies of 5nm and 3nm have also been carried out in an orderly manner [EMPHASIS ADDED]. Only when the EUV lithography machine arrives, we can enter the full development stage."
-

HSM
félisten
válasz
S_x96x_S
#4518
üzenetére
Annyiból nem vagyok meglepve, Apple-nek nagyon kell a kapacitás, ők vélhetőleg sokat nyernek a saját SoC-on, így a liciten akár jó magas árat is kínálhattak érte. Míg mondjuk az AMD-nek most még talán annyira nem égető, lehet még faragni a 7nm-en, és amúgy is X86-on és GPU fronton is látszólag előnyben vannak azzal is.
#4519 Petykemano : "azzal küzdenek, hogy a fejlesztéseket gyártástechnológia (sűrűség és fogyasztás) - független módon tudják implementálni"
Itt pont az a gond, hogy sok mindent nem lehet gyártástechnológia függetlenül implementálni. A gyártástechnológia erősen beleszól a szükséges kompromisszumokba, optimumokba, ami sok mindent boríthat az összefüggéseken keresztül. Emiatt igen kíváncsi leszek, a Cypress Cove esetén hogyan fog sikerülni a mutatvány, pl. a szükségszerűen megnyirbált gyorsítótár méretekkel. -
#4519
Petykemano
veterán
S_x96x_S
#4518
Petykemano
veterán
válasz
S_x96x_S
#4518
üzenetére
Az kemény...
Sejtettem, hogy valami ilyesmi áll a háttérben.
a zen4-ben nyilván vannak olyan fejlesztések, amelyek feltételezik az 5nm adta alacsonyabb fogyasztást és sűrűséget. Ez nem meglepő, a (gyári) ARM lólépéses fejlődése is nagyrészt ennek köszönhető. És az intel megállása is azért történt, mert nagyon megcsúsztak a következő gyártástechnológiával. Ott is azzal küzdenek, hogy a fejlesztéseket gyártástechnológia (sűrűség és fogyasztás) - független módon tudják implementálni (vagy legalábbis ugye dönteni róla, hogy vállalható-e vagy sem) Ennek a küzdelemnek a gyümölcsse lesz a cypress cove a Rocket lake-ben.Pár dolgot nyilván lehoznak zen3+ néven. Erre is volt már példa, a zen2-nél emlegették, hogy az új TAGE branch predictor eredetileg a zen3-hoz készült volna, de mivel előbb elkészült, a zen2-be emelték be.
Ám ha az elnevezésből indulunk ki - zen3->zen3+ - akkor ugye nagy IPC emelkedést nem lehet várni.
Korábban ABU azt mondta, a zen4 hamarabb jön a szerverekbe. Ez alapján azt gondolnám, a Genoa el fog rajtolni jövőre, csak kevés SKU-val és selejt nélkül.
-
#4514
Petykemano
veterán
S_x96x_S
#4511
Petykemano
veterán
válasz
S_x96x_S
#4511
üzenetére
Még az előzőhöz:
Nem tudom mennyire lehet cpu tervezési tudást egyik és másik ISA-val működő cpu-nál is felhasználni. Vajon bármi ami a zen, az egyértelműen és azonnal ugyanolyan jó, vagy jobb Arm cpu-vá válna ugyanazon csapat keze között?
vagy miközben persze figyelni kell fél szemmel, hogy mi van a konkurenciánál, meg hogy működik az Arm mag, összeszedni a jó ötleteket, stb, azért profi x86 és profi Arm mag készítéséhez két külön, gyakorlott csapat kell?A roadmaphoz:
Elég érdekes. Ezt már többször mondtam, tudom, az unalomig ismételgetem. Itt az M1 az AMD nyakán. Jó, desktop CPU-k terén még csak gyülekeznek a felhők és persze M1-et nem lehet Az apple-től függetlenül vásárolni. De ez a roadmap eléggé ráérős ezzel a zen3+-szal, nem?Az Arm irányából érkező fenyegetés ellenére lazítana az AMD a feszített fejlesztési tempón? Milking? Vagy ennyire nincs hozzáférése az 5nm-es gyártósorokhoz?
-
#4513
Petykemano
veterán
S_x96x_S
#4506
Petykemano
veterán
válasz
S_x96x_S
#4506
üzenetére
- mi lesz a következő lépés ?????
FPGA
Az AMD és a MS is híve a programozhatóságnak.Mivel az MS konzol gyártó is ( XBOX ) ,
- és lesz az ARM-el saját tapasztalata
- és ha 70%-on tudja emulálni az X86-ot ( vagyis a jövőben nem látszik teljesítményvesztés)
akkor az MS is az Apple útjára léphet konzolok terén.Az AMD fegyverténye itt szerintem nem az x86, hanem a mélyintegráció.
az M1-nél azt emelték ki, hogy a cpu és a gpu közös címteret lát. Mások azon kuncogtak: az Apple elérte az a cpu-gpu integrációnak azt a szintjét, amit az AMD már a Kaverivel hozott.És a GPU sem piskóta. Mármint nem elég csak x86 helyett arm cput leemelni a polcról, a gpu-t is helyettesíteni kell. Az Apple egy kb 5 éves úton halad, amire ha a MS csak most lép rá, akkor abból azért nem lesz azonnal eredmény. (Itt merül föl az AMD felvásárlása a MS által)
De a kérdés attól még szerintem jogos, ha ma még nem is aktuális: miért terveztetne a MS konzol lapkát az AMD-vel.
A következő 3 évben azt látom valószínűbbnek, hogy a MS saját tervezésű ARM szerver procikat helyez üzembe és "ehhez" a következő konzol generációt az AMD-vel (AMD-vel?) már ARM alapon tervezteti meg.
Ott lesz még az nVidia is, akinél ott az ARM fejlesztés + meglévő GPU fejlesztés.
nagyot csodálkoznék, hogyha az nVidia 2 év múlva nem próbálkozna a betámadással ..
( de a Sony és az MS is meg fogják keresni, csak azért - hogy jobb alkupozíciót nyerjenek az AMD-nél )Az Nvidiának van már arm alapú konzolja: shield.
Mindazonáltal elég érdekes vita ez, miközben arról is szó van, hogy minden megy felhőbe.Egy olyan nagy cégnek mint az MS - mindig kell "B" terv.
Nem függhet más cégektől ..
És azt már mindenki megtanulta, milyen függeni az Inteltől ...
( emlékeztető Apple már lépett is ---> M1 )Ezt mondtam, hogy volt egy időszak, amikor épphogy az volt a policy, hogy szervezzünk ki mindent, ami nem core-kompetencia. => ez egyben függést is jelent. Nyilván persze ha a beszállítói piacon sok a lehetőség, nagy a verseny, akkor lehet válogatni. Az x86, sőt az egész CPU piac pont nem ilyen volt.
Az AMD-nek egy esélye van .. a rugalmasság és a flexibilitás ...
ha eljő az az idő, akkor neki is ARM-es design-al kell a piacra lépni ...
és ez szerintem 1-2 éven belül bekövetkezik.
Vagyis a változást nem lehet megállítani ...
azon kell elgondolkodnia az AMD-nek, hogy mikor álljon a változás élére!
( szerencsére jobb menedzsmentje van, mint az Intelnek, de ki tudja mennyit tudnak profitálni a következő 10 évből ... )Ebben a kérdésben szerintem tökre a szoftveres cégek diktálnak. És nekik szerintem most az lehet az érdekük, hogy ne vegye át az intel helyét az AMD, hanem virágozzék ezer virág.
-
#4504
Petykemano
veterán
S_x96x_S
#4503
Petykemano
veterán
válasz
S_x96x_S
#4503
üzenetére
Érdekesek a trendek.
Volt egy időszak az elmúlt 50 évben,.amikor az outsourcing volt a buzzword. A cégek igyekeztek megszabadulni minden olyan tevékenység cégen belül tartásától, ami nem képezte a cég primer kompetenciájának részét. A benzinkutaknál az üzemeltetés, nagy cégeknél az irodaház takarítása. Őrzés-védés-portás.Világos, hogy nem csupán arról volt szó, hogy a takarítást végezze a takarításra szakosodott alvállalkozó, mert így mindenki a kaptafájánál marad. Hanem sokkal inkább a cégméret csökkentése, szakszervezetbe tömörülés lehetőségének elvágása: a takarítás attól lett olcsóbb outsourcingolva, hogy a takarítást végző személyzet munkajogi értelemben kiszolgáltatottabb helyzetbe került.
De sok esetben nem csak a melléktevékenység kiszervezése volt jellemző,.hanem a főtevékenység bizonyos részei is. Például a chipeknél a chiptervezés benn maradt, a gyártás kiszervezésre került. Ennek meg nyilván méretgazdaságossági okai voltak.
Érdekes, hogy most minden nagyobb cég rájön, hogy a vertikális integráció előnyös. Ez nem az az x86-ról szól. Ha a MS csupán elégedetlen lett volna az x86-tal, akkor a Qualcommtól is tudott volna megrendelni Valamit. Az arm csak lehetőseget teremt arra, hogy ezt viszonylag magas szintű építőkockákból bárki megtegye. De azért mégiscsak foglalkozni kell a tervezéssel. Vélhetően nem csupán az a cél, hogy ne külsős csinálja, hanem valami egyedi alkotása. És foglalkozni kell a gyártással is.
Én továbbra is úgy látom, hogy erre a vertikális integrációra a HP és. Dell nem lesz képes,.mert bármilyen remek ötletük is lenne, nincs a kezükben a szoftver irányítása, amivel a remek hardver ötletet ki Lehetne használni.
Vajon ha az Apple, a MS és a Google saját szerver és kliens processzorok és eszközök gyártásába kezd, amiben nyilván valamilyen heterogén előny lesz kihasználható, vajon a processzorgyártóknak (qualcomm, AMD, Intel, mediatek) és gépgyártóknak (HP, Dell, lenovo) leáldozott?
Vagy Linux alapon lehet majd olyan vertikálisan nem integrált közösségi szoftverkörnyezet, amely versenyképesen életben tartja ezeket?
-

hokuszpk
nagyúr
-
HSM
félisten
válasz
S_x96x_S
#4463
üzenetére
Ami szerintem érdekes és számomra új infó, hogy 2008-ban a tranzisztor keret 10%-a ment el a dekóderre, ami azért kiélezett versenyben nem tűnik kevésnek, bár tény, hogy nem is vállalhatatlanul sok. Ez ha nem tévedek K8-K10 architektúra, és 3 dekóder esete magonként, ahol ráadásul erősen dekóder limites volt a rendszer. Érdekes lenne mai környezetben egy hasonló adat.

#4467 Petykemano : Az Arm A5x magok valóban lényegesen jobb perf/watt-ot tudnak, csak éppen meglehetősen alacsony abszolút teljesítmény mellett. Hiszen arra tervezték őket.
 Lásd: [link] [link]
Lásd: [link] [link] -
HSM
félisten
válasz
S_x96x_S
#4459
üzenetére
"vagyis a komplexitáson többet veszít az X86-64-ISA - mint amennyit nyer a "tömörségével"
Ehhez azért komolyabb analízis lenne szerintem szükséges. Csupán arra akartam ráirányítani a figyelmet, hogy óriási előnynek tűnhet, hogy több a dekóder, de többre is van szükség, mert ugyanazt a munkát egy RISC architektúra több utasításból végzi el, tehát nem megalapozott az órajelenként dekódolt utasításokból és órajelből kiindulni, mert más az utasítás architektúra."making designing decoders that are able to deal with aspect of the architecture more difficult"
Itt azért a tranzisztorköltségre vetített extra teljesítményt is érdemes számba venni. Lehet érdemesebb pl. két egyszerűbb magot beépíteni, mint egy túlzottan komplexet, ha egyébként az egy szálon elért teljesítmény megfelelő.#4460 hokuszpk : Ez kinek és miért lenne jó?
 Viszont abban látok fantáziát, ami az eredeti koncepció volt, hogy minden chiplet K12, ugyanazzal az IOD-vel, tehát csak CPU-t kell cserélni a szerverben, és át is álltál egyikről a másikra. Ez azért elég egyedi és rugalmas is lenne.
Viszont abban látok fantáziát, ami az eredeti koncepció volt, hogy minden chiplet K12, ugyanazzal az IOD-vel, tehát csak CPU-t kell cserélni a szerverben, és át is álltál egyikről a másikra. Ez azért elég egyedi és rugalmas is lenne. -
#4458
Petykemano
veterán
S_x96x_S
#4454
-
HSM
félisten
válasz
S_x96x_S
#4439
üzenetére
Közben jobban megnézve látom, írják ők is, pl. 3DPMavx: "On the power side, we can see why SMT Off mode is warmer – the cores are drawing more power. Looking at the data, SMT Off mode is running ~4350 MHz, compared to SMT On which is running closer to 4000 MHz."
Mikor írtam, nem volt időm alaposan végigolvasni, ebből a részből csak az ábrákat néztem át.
#4442 S_x96x_S : "az csak a programkód méretére van kihatással, de a végrehajtás már más"
Miért lenne más? Ha egy X86 utasítás-sor "tömörebb", akkor adott számú utasítást dekódolva órajelenként, azonos órajelen mégiscsak több hasznos "munka" lesz elvégezve, mint egy RISC architektúrán. Az, hogy belül a dekóder hány belső utasításra bontja, már más részegységek baja lesz."persze lehet vitatkozni, de szerintem az X86-64-ISA elég komplex az AArch64 -hez képest."
Nem fogok veled vitatkozni, ez így van. És ez az előnye és hátránya is. Előnye, mert toldozgatják foltozgatják évtizedek óta, alapvetően a kompatibilitás megtartása mellett. Hátránya, hogy többnyire nem optimális egy ennyire komplex, toldozgatott foltozgatott architektúra egy alapokról bizonyos célokra kifejlesztetthez képest."izgalmas évtized jön"
Efelől semmi kétségem.#4446 Petykemano : "Azt mondod, hogy az AT tesztjében nem a backend fogyott el, hanem a TDP?"
Pontosan. Főleg a 12-16 magosok igen könnyen limitessé válnak, sok a mag, valamint a maximális BOOST órajelek is magasak."Vagy megfordítva. a kikapcsolt SMT-t a TDP kereten belül kompenzálja valamivel magasabb frekvenciával."
Pontosan. Az SMT OFF alacsonyabb magszintű kihasználtsága alacsonyabb fogyasztással jár azonos feszen/órajelen (kevesebb a "hasznos" órajelciklus, több a várakozás), amit némileg magasabb órajellel tud orvosolni a boost, ha van még elérhető, nyilván így azért rosszabb hatékonyságot felmutatva. Ezt erősíti meg, amit idéztem az AT méréséből az első bekezdésben.#4449 S_x96x_S : " Ha 4 erős lenne, akkor multi core-ban is verné a zen3-at."
Azért azt ne felejtsük el, hogy akkor a fogyasztás sem ennyi lenne... Valamint a laptopokba szánt Zen APU-k is lényegesen magasabb perf/watt aránnyal üzemelnek, nem olyan nagyon sokkal lassabban, mint asztali társaik. Asztali Zen-nél komoly kompromisszum, hogy csipletekre szedték a hatékonyabb gyárthatóság kedvéért, de ennek fogyasztás és memória késleltetés terén bőven van ára. -

-vitya-
őstag
válasz
S_x96x_S
#4449
üzenetére
gondoltam, hogy ki kellene fejteni pontosabban...
 nincs bárhol bevethető szerver konfigurációja ARM-nek, semelyik gyártótól. Mivel létezik a kis fogyasztású meg létezik a szerverfarmos, kettő között kb semmi. Ráadásul ezek sem terjednek, annyira sem, mint az EPYC, pedig az is lassan terjed. Ha minden részen létezne valódi, megfontolható alternatíva, akkor igenis az ARM veszélyessé válna azonnal, mert nagyon erősek az alapok (ahogy írtad is, a tesztek alapján, amit mindketten néztünk ;-) )
nincs bárhol bevethető szerver konfigurációja ARM-nek, semelyik gyártótól. Mivel létezik a kis fogyasztású meg létezik a szerverfarmos, kettő között kb semmi. Ráadásul ezek sem terjednek, annyira sem, mint az EPYC, pedig az is lassan terjed. Ha minden részen létezne valódi, megfontolható alternatíva, akkor igenis az ARM veszélyessé válna azonnal, mert nagyon erősek az alapok (ahogy írtad is, a tesztek alapján, amit mindketten néztünk ;-) ) -
#4450
Petykemano
veterán
S_x96x_S
#4449
Petykemano
veterán
válasz
S_x96x_S
#4449
üzenetére
Itt van egy specint2006-os táblázat: [link]
Az A77 nagyjából a zen2-zen3 ipc-jével rendelkezik.Ehhez képest tud +70-80%-ot az Apple chipje, A14. Ez persze elképesztő mérnöki teljesítmény.
A bárki által elérhető X1 elvileg az A77-re kb 30% IPC-t rak. Tehát elmondható, hogy már az X1 is meghaladja IPC-ben a zen3-at és az AMD, ha valóban a továbbiakban is csak 15% IPC növekedést hoz generácónként, akkor a zen4 lesz pariban az X1-gyel.Ez persze desktop környezetben nem annyira jön ki, mert ahogy írtad, frekvenciával kompenzál. De szervereknél 3-3.5Ghz az általánosan elérhető frekvencia, ahol energiahatékony a mag, tehát nem lehet frekvencia-előnnyel kalkulálni.
Ez azt jelenti, hogy ha valaki jövőre csinál ez X1 magokból álló szerver cpu-t, annak komoly esélyei vannak lehagyni a Milant. Nyilván ez se pofonegyszerű, mert ugye azt mondják, hogy a jó mag még kevés, sok mag esetén az interconnect is számít.
Lehet, hogy ez nem a Marvelltől fog érkezni. DE szerintem elég valószínű, hogy az AWS hoz egy graviton3-at.
-
-vitya-
őstag
válasz
S_x96x_S
#4447
üzenetére
Én ezt úgy látom, hogy ez egy HA ... AKKOR feltétel rendszer
ha az AMD továbbra is ilyen erős EPYC procikat tud csinálni, amihez az ARM alig/nehezen tud felnőni, meg az intel sehogy, AKKOR nem kell annyira aggódnia, egyszerűen csak mindig a legjobbat kell tudni szállítani - de mondjuk most meg még aggódhat is, hiszen bár rég lelépte az intelt, de ez annyira nem látszik a szervereknélha az intel visszajön, akkor aggódhat, főleg, ha kifullad a nagy menetelés az AMD-nél
ha az ARM nagyon hosszú távon elkezd erős és versenyképes procikat felmutatni a szerverekhez is, akkor hosszú távon igenis komolyan nyerhetnek cégek arm alapon... De szerintem az egy távolabbi jövőkép (lehet) -
-
#4426
Petykemano
veterán
S_x96x_S
#4415
Petykemano
veterán
válasz
S_x96x_S
#4415
üzenetére
> https://erik-engheim.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2
A cikk első részével nem teljesen értek egyet. Mármint azzal persze igen, hogy a hardveres gyorsítók számítanak. Azzal nem, hogy a Dell-nek vagy a HP-nek abban bármiféle szerepe tudna lenni, hogy milyen hardveres gyorsítók épülnek be a termékeikbe. Jó, hozzáteszem, ez úgy igaz, hogy nem tudom, ezek a cégek mekkora tényleges befolyással tudnak lenni a szoftveres környezetre. Merthogy a hardveres gyorsítók kihasználhatósága sokkal inkább ezen múlik, mint azon, hogy a gép összerakója mit álmodik meg. Ha a Dell vagy a HP megálmodik valamilyen hardveres gyorsítót, akkor nem elegendő ARM IP-ből összedobálnia, megterveznie, VAGY megrendelni az AMD-től vagy inteltől. Vagy saját magának kell a szükséges szoftvert is hozzátenni, vagy megkörnyékezni az MS-ot, Google-t, hogy nézzétek, milyen jó lenne, ha.
Az idézetedhez pedig hozzátenném:
- Az ILP növelésében segít az Out of Order execution.
- Minél nagyobb a ROB (Re-order buffer), annál nagyobb a soron kívül, párhuzamosan végrehajtható utasítások száma
- A ROB-ot a decoder eteti "micro-op" utasításokkal.
Így összességében az M1-ben a lényegesen 3x nagyobb ROB-ot egy 2x akkora teljesítményű decoder eteti.És a magyarázatban ez a lényeg:
"This is where we finally see the revenge of RISC, and where the fact that the M1 Firestorm core has an ARM RISC architecture begins to matter.
You see, for x86 an instruction can be anywhere from 1–15 bytes long. On a RISC chip instructions are fixed size. Why is that relevant in this case?
Because splitting up a stream of bytes into instructions to feed into 8 different decoders in parallel becomes trivial if every instruction has the same length.
However on an x86 CPU the decoders have no clue where the next instruction starts. It has to actually analyze each instruction in order to see how long it is.Namost két dolgot nem értek.
Úgy tudom, hogy a az x86 processzorokban belsőleg már valóban nem CISC hanem RISC architektúrák, van egy belső fordító. A legújabb atom magban épp az pláne, hogy valódi CISC x86 végrehajtást csinál és így tud energiahatékony lenni alacsony teljesítmény mellett.
A másik dolog: nem tudom, hogy vajon micro-op cache nem pont ezért van-e?És miért ne lehetne valamikortól olyan x86 processzort csinálni, aminek van fix utasítás hossza. Nyilván egy úgy forgatott program nem futna régi processzorokon. De ez kb egy olyan átállást jelente, mint a 32bit vs 64bit. Egy új processzor nyilván tudna visszafelé kompatibilis lenni.
De vajon az Apple-nél nem kell minden programot újraforgatni? Vagy ha A MS úgy dönt, hogy akkor Arm, akkor nem kell mindent újraforgani?De azzal persze egyet kell értsek, hogy az Apple-nek beépíteni 8-16 magot valószínűleg könnyebb, mint az AMD-nek és az intelnek levezényelni az x86-ban egy ilyen változást.
Ugyanakkor ha ez ennyire triviális, hogyhogy csak az apple-nek jutott eszébe?
Egy választ a másik linked tartalmaz (ez nem az x86 utasítás hossz limitációval magyarázza)
"The answer of wide decode and deep reorder buffer gets much closer than the “tricks” mentioned in tweets. That still doesn’t explain how Apple built an 8-wide CPU with such deep OOO that operates on 10-15 watts.
The limit that keeps you from arbitrarily scaling up these numbers isn’t transistor count. It’s delay—how long it takes for complex circuits to settle, which drives the top clock speed. And it’s also power usage."Ahogy írtad is, az intel már most 5 decodernél jár 10nm-en.
A kommentben a hangsúly a késleltetésen, a tranzisztorok gyorsaságán van. Az 5nm ugye eleve sűrűbb és az Apple mindig is a legsűrűbb libraryt használta. Vajon elképzelhető-e, hogy a 8 decoder beépíte azért lehetséges, mert a sűrű 5nm-en elképesztően rövidek a késleltetések, kicsi a delay.
Ha ez igaz, akkor elképzelhető, hogy az intel és az AMD is képes lesz 5nm illetve 7nm-en előrelépni 5 vagy akár 6 decoder irányába.Az urak is jól elvitatkoztak azon, hogy az M1-gyel az Apple az elmúlt 10-20 év ILP növelhetőségének tudományos kutatását tette zárójelbe.
-
válasz
S_x96x_S
#4418
üzenetére
vs 2019 július, amikor a Ryzen 3000 széria nyitott. Akkor közel dupla annyi 3000-est adtak el, mint most 5000-est, miközben jóval alacsonyabb volt az összeladás (összkereslet). Eléggé látszik, hogy nincs készlet.
Az mondjuk elég megdöbbentő a 2020 novemberi ábrán, hogy közel annyi Ryzen 5000 fogyott (shortage ellenére), mint Intel proci összesen.

-
#4413
Petykemano
veterán
S_x96x_S
#4411
Petykemano
veterán
válasz
S_x96x_S
#4411
üzenetére
"és az M1 után a Nuvia célja már nem is annyira valószínűtlen .."
Igen, természetesen. Főleg, hogy a Nuvia asszem 2022-re ígért terméket.
Ide is bedobom, hogy mennyire lehet játszani a zen3 magok energiahatékonyságával:
[link]
komment itt: [link]tl;dr
A zen3 mag teljesítménye és fogyasztása optimalizálható olyan szintre, amikor már csak ~30% választja el a M1 magjaitól. A zen3 lényegesen nagyobb package powerhez nyilván hozzájárul a 14nm-es IO és az MCM. Majd meglátjuk Cezanne-nal mit tud.az AT fórumon valaki spekulál, hogy mit hozhat a zen4, milyen cache bővítés fér bele, mi az ami már inkább ront a késleltetésen, stb. Felmerül annak lehetősége, hogy az L3$ mérete visszacsökken 16MB-re, és cserébe az 512KB-os L2$ bővül 1MB-ra.
-
-vitya-
őstag
válasz
S_x96x_S
#4404
üzenetére
Hát ez ugye nem meglepő fordulat
Ha valahogy, valamiben első tud lenni, akkor marketing szempontból ki KELL azt domborítani.
Most majd láthatjuk: amelyik oldal átveszi, hasonló komment nélkül, mint amit az ET tett, az részrehajló oldal. Nem néztek mögé, és nem vizsgálták meg a dolgot jobbanDe ja, teszteljenek csak ACvel ÉS DCvel is. Láthatjuk ETnél, hogy nem olyan rossz a helyzet Ryzennél
-

Cathulhu
addikt
válasz
S_x96x_S
#4251
üzenetére
elvileg a one API lenyege pont az lenne, hogy ugymond sebessegvesztes nelkul kapsz egy absztrakciot az osszes ilyen vektor kod felett, mint AVX, OpenCl, etc, vagy nem jol ertem? Mert akkor meg pont az intel dolgozik ezen.
Amugy ez csak most ugrott be, de mi van ha mondjuk Zen5-os Epycekben lesz egy programozhato FPGA resz, ahova a vevo olyan vektorgyorsitot tolt fel amilyet csak akar. Pl kijott egy uj AVX utasitaskeszlet? Vagy egy uj AI utasitas? Nopara, frissitsuk anelkul, hogy ki kellene dobni. Vagy ezt a reszt mar erosen tulgondolom? -
#4254
Petykemano
veterán
S_x96x_S
#4251
Petykemano
veterán
válasz
S_x96x_S
#4251
üzenetére
Hmm
Smart.Access ide vagy oda, a fusion lényege az volna, hogy nem csak közös címtérben dolgoznak, hanem tényleg közös memóriát használnak és se pcie-n keresztül, ad absurdum se memóriában nem kell másolgatni a feldolgozandó adatot."Full Access to gpu memory"
Arra utal, hogy a CPU úgy fogja látni a gpu memóriáját, mintha egy másik memory pool lenne.A sebességnövekedés.ott érhető tetten, hogy a gpunak alacsonyabb késleltetéssel fognak rendelkezésére állni az adatok, amiket a CPU feldolgozás/előkészítés után máskülönben a rendszermemóriában tárolna.
Szóval ez arra jó, hogy ha valami alapvetően a gpun fut, akkor annak alá tud dolgozni a CPU. Ez a CDNA esetében is szerintem kifejezetten hasznos lesz
Sőt, bármihez jó, ami valami gyorsítón.fut, akár gpu, akár fpga.De azt nem látom.ebbe bele, hogy ezzel megvalósítható lenne az AVX512 utasítások offloadolása.
De az irány persze mindenképp a heterogén feldolgozás, és azt értem, hogy ezzel egy programban meg lehet majd mondani, hogy egy parancs egy adathalmazon min fusson (vagy akár adattípustól függően automatizálni is lehet) csak én még azt nem értem, hogy egy-egy utasítást kiszervezése lehetséges-e egyáltalán.
-
S_x96x_S
addikt
válasz
S_x96x_S
#4251
üzenetére
igazából a PCIe5.0 - el minden megváltozik ..
dupla sebesség + CXL támogatás lehetősége,
de addig is .. erősödhet az AMD ...STH: https://www.servethehome.com/amd-radeon-rx-6900-xt-6800-xt-6800-rdna-2/
"It will be interesting to dive more into what this is. We know AMD needs a cache coherent interconnect for its exascale efforts and effectively had to swap CCIX for CXL. It would be very interesting if this is an early derivative of this effort." -
#4241
Petykemano
veterán
S_x96x_S
#4240
Petykemano
veterán
válasz
S_x96x_S
#4240
üzenetére
"Revenue was $2.80 billion, up 56 percent year-over-year and 45 percent quarter-over-quarter driven by higher revenue in both the Enterprise, Embedded and Semi-Custom and Computing and Graphics segments."
Tényleg megjelent náluk az inteltől hiányzó $1mrd.
"Computing and Graphics segment revenue was $1.67 billion, up 31 percent year-over-year and 22 percent quarter-over-quarter."
"Enterprise, Embedded and Semi-Custom segment revenue was $1.13 billion, up 116 percent year-over-year and 101 percent quarter-over-quarter." => EPYC v konzol?
"For the fourth quarter of 2020, AMD expects revenue to be approximately $3.0 billion, plus or minus $100 million, an increase of approximately 41 percent year-over-year and 7 percent sequentially."
-
S_x96x_S
addikt
válasz
S_x96x_S
#4226
üzenetére
> (#piac-versenytárs-figyelés) Intel ..
Az STH is az Intel-es dilemmáról ír
maradni Intelen(1,2) ; kockáztatni az ARM-el (4) , vagy AMD (3.)?https://www.servethehome.com/the-2021-intel-ice-pickle-how-2021-will-be-crunch-time/
"A great example of this is with the NVIDIA A100 GPU and specifically the NVIDIA DGX A100 platform. NVIDIA has historically used Intel Xeon CPUs in its high-end systems even through the V100 generation ecosystem followed. Now, if you want to run the top-end GPU you use AMD EPYC 7002 Rome, not Intel Xeon. As another benefit, you get faster networking and storage as well. The ecosystem is validating and releasing reference platforms for PCIe Gen4 on AMD not Intel at this point which is monumental, yet underappreciated. When Ice Lake does launch, it will now be the Xeon chips that are subject to re-validation efforts. That means while AMD platforms will have had many quarters of bug fixes and deployments, Intel systems will get the resourcing to bring them online, but that will be compressed if Ice Lake Xeons have too short of a time on the market before Sapphire Rapids in 2021 (realistically 2022.)"
"3. Deploy AMD EPYC Rome now, Milan later in 2021/ 2022, then make a decision on PCIe Gen5. Outside of Intel, the rest of the industry is validating on AMD EPYC Rome now. If they were waiting for Ice Lake in Q1 2020, by now they have swapped to Rome. Even NVIDIA, a sworn enemy of AMD, could not take the risk of sticking with Intel for its Ampere GPUs."
"At this point, most industry observers have figured out the above. That is not to say PCIe generation is everything. We are going to deploy another Cascade Lake Xeon node or two this year simply to get access to Intel Optane DCPMM or now PMem 100. Still, AMD has a bigger platform, it is getting better with Milan and the ecosystem is building around its platforms in the PCIe Gen4 generation. Remember, if you have a PCIe Gen4 connected device that you need to ship for revenue to customers, AMD is now the enabler of your technology."
"These delays now have some OEM partners disappointed. Investors are questioning Intel’s execution. The big questions now are how can you navigate uncertain schedules if you are a customer or partner, especially since the concept of a “launch” has become nuanced to where Intel will claim it has launched a processor, but they are not generally available."
-

awexco
őstag
válasz
S_x96x_S
#4209
üzenetére
AMD 1-2 céggel elkeztek haverkodni , hogy közös temékeket hozzanak tető alá hozni . (ethernet,wifi )
Lehet ők is termékkapcsolást akarnak mint intel .
Lenne fantázia mert glo12+ on gyártható cuccok szal kapacitás lenne .
Azt nemtudom , hogy infinity fabrik kompatibilis cuccokra is rágyurnak e mert ha van fantázia benne és jó az ár akkor az is egy piac . Lehet , nem túl nagy de ha egyszemélyben mindennel ki tudják szolgálni a vevőket akkor pl nem kell intel hálókari amd-s proci mellé . -
#4206
Petykemano
veterán
S_x96x_S
#4205
Petykemano
veterán
válasz
S_x96x_S
#4205
üzenetére
Itt két lazán kapcsolódó dologról beszélünk.
Az egyik a 7nm-es wafer ellátás
A másik pedig Charlie féle TCO, költségGondolataim:
1) chiplet IO
Ha jól emlékszem, a Rome IO die egyik jellegzetessége és hiányossága volt, hogy egy core nem tudja egyszerre minda 8 DDR4 csatornát használni, csak 2-t, azt, amelyik az IO lapka hozzá legközelebbi kvadránsában helyezkedik el. Ha ezt nem oldották fel, akkor nagy IO lapka helyett MCM módon raknak le IO lapkákat. A spórolás ott jön, hogy mindegyik sku-ra annyit raknak, amennyi ott szükséges.
Ennek persze akkor szerintem kevés jelentősége van, ha továbbra is 12/14nm-es IO lapkákat használnak. Bár annak is van egy ára ($20-100), de az így megspórolható összeg eladott EPYC chipenként pont ez a $50 körül van és nem is igazán segítene az ellátáson, csakis akkor , ha egyébként a Milan 7nm-es IO lapkával jönne.
A 7nm-es IO lapka egyébként indokolt - a fogyasztás miatt és esetleg a magas IF clock végett.
Namármost a chiplet IO azért nem hülyeség, merthogy ugye valójában a X570 chipset egy pont ugyanolyan IO lapka volt, mint a procik melletti, tehát tudnak kommunikálni egymással.2) kicsi EPYC
Forrest Norrod az egyik interjúban valami ilyesmit mondott, a TCO-ban nem a CPU ára a legmeghatározóbb, hanem a CPU teljesítménye. CPU-d hibahatáron túl, mondjuk 20%-kal erősebb a konkurenciánál, akkor a TE CPU-dból a vásárlónak kevesebb pont azzal a 20%-kal kell kevesebb szervert kell építenie, ami annyival kevesebb alaplapot, házat, memóriát, háttértárat, és helyet, hűtést igényel.
Ez alapján a kicsi EPYC ereje (mármint TCO szempontjából) nem abban fog megmutatkozni, hogy az IO lapka kisebb és ezért olcsóbban adható, hanem leginkább abban, hogy az egész platform lényegesen olcsóbb lesz - mintha ugyanazt olyan platformon adnák kevesebb maggal, ami a legütösebb sku-t is ki tudja szolgálni.Ha a kettőt összeteszem, akkor az jön ki belőle, hogy tudnak úgy kicsi EPYC platformot építeni, hogy nem kell egy köztes IO lapkát tervezni, mert össze lehet rakni két olyan IO lapkát, ami amúgy az AM4 platformra megy.
-
#4133
Petykemano
veterán
S_x96x_S
#4132
Petykemano
veterán
válasz
S_x96x_S
#4132
üzenetére
Az új celeronokba és pentiumokba nyomja bele, amik fél éven belül megjelennek.
De az nem fog fél éven belül akkora penetrációt elérni, hogy a fejlesztők - maguktól - foglalkozzanak vele.De ha elérhető a hardver és elkezdik benyomni a játékokba meg más szoftverekbe is, akkor arra jó öszönző lehet, hogy újítsál és persze intelt vegyél, mert az AMD elavult.
Kicsit sajnálom, hogy AVX-512-re épít az intel, ahelyett hogy megcsinálta volna rendesen úgy, mint a SVE, hogy bármilyen proci jó, de az erős procikba vastag feldolgozót teszünk, az atomokba vékonyat.
-

.Ishi.
aktív tag
válasz
S_x96x_S
#4069
üzenetére
Akkor lehet, hogy januárban mutatják be az alsóbb szegmens tagjait? Egy sima 4300G-re fáj a fogam, nem lenne rossz, ha már lehetne kapni.
(És tudtommal a 4350G-t nem lehet csak úgy megrendelni...de javítsatok ki, ha tévedek.)A kékek részéről már simán összejöhetne egy jó kis belépőszintű ITX alapú masina, viszont a pirosaknál sokkal erősebb az iGPU, így várnék arra.
-
#4073
Petykemano
veterán
S_x96x_S
#4072
Petykemano
veterán
válasz
S_x96x_S
#4072
üzenetére
Bár a cpukat válogatják, de azt nem tudom, hogy a minősítés aktív tesztelés alapján történik-e, vagy csak ilyen mintavétel alapján, hogy hát az ostya közepén általában ilyen, a szélén meg olyan. Azt feltételezem, hogy azért valamilyen aktív tesztelésnek kell lennie, hogy legalább a működésképtelen példányokat kiválogassák, vagy megállapítsák, hogy hol hibás. De valószínűleg itt cél a gyorsaság. A CTR finomhangolása viszont ha jól tudom, több tízpercen keresztül is tarthat. Emiatt elég valószínűtlen, hogy ilyet csináljanak. Pedig amúgy mekkora jó lenne már - az AMD-nek - ha minden a cpu-kat ennyire finomhangolva tudná legörgetni a gyártósorról.
De azt igazán megtehetné az AMD, hogy megveszik ezt a programot és beemelik a Ryzen Masterbe. Viszont az meg abból a szempontból nem érdekük, hogy jobb terméket kapj, mint amit megfizettettek veled.
Az a 67% kemény!
-
#4021
Petykemano
veterán
S_x96x_S
#4013
Petykemano
veterán
válasz
S_x96x_S
#4013
üzenetére
De miért gondolod, hogy ellátási gondokkal küzdenének?
Chiplet. Nem új nodeon készül, kiváló a kihozatal, apró a chiplet és látszólag nem is nagyobb. Eközben a matisse gyártása leállhat/csökkenhet.
Persze ha másra is kell a wafer, lehet szűkös.A szűkösség magyarázná azt is, miért a legnagyobb volumenben fogyó sku drágult legnagyobb mértékben.
Akkor is bunkóság! Álomgyilkosok!

Nem is arra gondoltam, hogy aki 3600X-ről váltana, hanem valami régebbi prociról. Eddig dédelgetted az elképzeléséidet, hogy $200-250-ért kapható 3600/X, számolgatod, mivel nyernél többet, de majd milyen jó lesz, hogy már mindjárt itt van az új széria és juhúúú. Erre kiderül, hogy a perf/$ nem javul.
Ha így nézed, akkor az történt, hogy betoltak egy új szintet, pont úgy, mint at XT példányokkal
-

gereii
csendes tag
válasz
S_x96x_S
#3967
üzenetére
még nincs minden kőbe vésve, de:
- valami olyan lap, amin van 2x PCIE 4.0-ás csati - most egy Strix B550-E Gaming van kinézve
- ramból ami biztos, hogy 64GB-nyi minimum 3200-asok - talán hyperx furyk, de ha változik az alaplap, akkor QVL alapján nézek mást
- tárhelynek egy 500-as nvme windowsnak, appoknak, állandó használatban lévő 3D asseteknek, 2tb sata SSD éppen futó projekteknek és 2tb HDD archivált, vagy ritkábban használt cuccoknak
- valamilyen brutáljól szellőző, csicsamentes ház - Gamersnexus ajánlata alapján Lian Li Lancool 2 Mesh
- a procira egy DRP 4, de lehet AIO lesz - a két GPU valszeg egy kazánházat csinál majd odabent, szóval lehet a levegő helyett jobb lesz a viz
- tápnak egy 1300 wattos G2 EVGA - ez az egyetlen alkatrész, ami már megvande aztán lehet mire normális áron procihoz + videokártyákhoz jutok, annyi tesztet és fórumot olvasok, hogy mindent felforgatok

+ persze ha van valami jótanács itt, azt is szivesen fogadom (bár az már heavy offtopic lesz)
-

Devid_81
félisten
-
#3950
Petykemano
veterán
S_x96x_S
#3948
Petykemano
veterán
válasz
S_x96x_S
#3948
üzenetére
Kezdetben biztos drága lesz a DDR5. Tehát ha most nem is ruházol be DDR4-es rendszerre, akkor sem biztos, hogy jövő ilyenkor már értelmes, mai DDR4-gyel versenyképes áron lehet majd hozzájutni. Ha persze a pénz nem annyira számít, akkor érdemes várni.
Pont emiatt én azt gondolom, hogy lesznek már jövőre DDR5-ös alaplapok az AMD-től is.Mármint ha már most tudná a DDR5-öt a Vermeer, akkor végképp nem érteném, hogy mi a cél a Warhol generációval. Úgy adná magát, hogy jövő nyár felé jöhetne egy félgeneráció, ami olyan, mint a Matisse 2 volt, apró bütykölés, kicsit magasabb all-core frekvencia, de DDR5-ös IOD és AM5 foglalat X670 alaplappal.
Abban, hogy már most be van építve, azért nem hiszek, mert biztos több láb is kéne hozzá, ha meg már úgyis más cpu package kell ahhoz, hogy ddr5-öt használhass, akkor már rákerülhet egy másik IOD is.
De abban teljesen igazad van, hogy a DDR5-ös 16 magos zen3 interferálhat a TR-rel, ha azt nem eleve DDR5-tel adják ki.
-
awexco
őstag
válasz
S_x96x_S
#3941
üzenetére
Amd részéről nem biztos , h mobil fronton szükség lesz a pcie5 re Sok vizet nem zavar mobil és desktop fronton csak a fogyasztást növeli meg .
Gyanítom , h mobil fronton az inkább zen 3.5 lesz inkább . Mint ahogy tette most is a kiadott 4xxx szériás mobil procik a zen2 és széria módosított, feltuningolt verziója . Uez igaz a VGA-ra is . Továbbá lehetnek addig még meglepetések . Pozitív irányba az AMD részéről .
-
Cathulhu
addikt
válasz
S_x96x_S
#3879
üzenetére
Ezt ugy tudom elkepzelni kb, ahogy az ilyenkor lenni szokott, sok sok aprobetuvel
+40-50% IPC increases over Zen2 for only a third of the power.* ** *** **** *****
* specialis reszfeladatokban
** node: 5nm
*** 1 GHz rogzitett frekvencian
**** fele annyi maggal, mert egy-egy mag dupla akkora
***** jovobeli fordito optimalizaciokat belegondolvaNem azt mondom, hogy itt mind feltetlenul igaz, csak az ilyen nagyot mondo cegeknel ezek azert ott szoktak lenni. Az ARM veszelyes (marmint kire-mire? ram mint felhasznalora nem...), de jobban hiszek olyan cegeknek, akik mar letettek valamit az asztalra. Szoval ha a Qualcomm, az intel, az apple allit ilyet mondjuk, akkor meghintem egy kis soval es jo, de ha a nuvia, akkor kirohogom.
-
#3877
Petykemano
veterán
S_x96x_S
#3875
Petykemano
veterán
válasz
S_x96x_S
#3875
üzenetére
"+40-50% IPC increases over Zen2 for only a third of the power."
Nagyon impozáns.
MLiD is arról beszélgetett az egyik vendégével - kicsit messziről indítva -, hogy a szoftverek haladnak a konténerizált-virtualizált futás irányába, aminek megvan az az előnye, hogy ilyen virtuális csomagokat lehet futásidőben migrálni egyik eszközről a másikra és hogy ez felhasználói élmény szempontjából milyen cool lenne. És hogy az apple is errefelé igyekszik nyilvánvalóan az Armmal, mert intel alapon nem tudták (rendesen) megoldani.És hogy az új kulcsszó az edge computing, vagyis cégek arrafelé haladnak, mármint ilyen google, MS, Amazon, stb, hogy a végfelhasználóhoz közel biztosítsanak relatív nagy számtási teljesítményt. Abban az értelemben, hogy lehet, hogy pár év múlva nem lehet majd Threadripper workstationt kapni, hanem lesz majd minden nagyobb városban valami adatközpont és onnan lehet bérelni a hardvert és fogod és odamozgatod a notebookodról a VM-et/konténert, amiben a photoshopod fut és használod a kapacitást.
Na és most jön a lényeg, hogy azt mondta MLiD, hogy jó, de hát látjuk, hogy mekkora fejlődés van az alacsony fogyasztású processzorok között, most 8 mag befér 15W-ba, 5nm-en lehet, hogy már 16 magos U szériás procik is jöhetnek. (Nem feltétlen jövőre)
Hogy ez milyen viszonyban áll az edge computinggal, és hogy mi mit vált le vagy ki, azt most hagyjuk, mert nem erre akarnám rátekerni, hanem a 16magos 15W-os cumókra.
A nuvia terméke vajon mikor lesz elérhető? 2021-2022?
Ezek az összehasonlítások azért félrevezetők picit, mert addigra feltehetően az AMD-nek is lesznek már fejlettebb termékei. 2022-ben az intel Alder Lake is kijöhet, ami a jelenlegi Cometh Late-nél 40-50%-kal magasabb IPC-t ígér. És a feltehetően akkortájt érkező zen4 is 30%-kal magasabb IPC-vel rendelkezhet, mint a zen2 (és akkor ez egy olyan konzervatív alacsony szám, amit ha nem sikerül meglépni, akkor az lemaradást eredményez az AMD számára)És gondolom nem is ugyanazon a gyártástechológián fog készülni.
Azért érdekes lesz.
Annál is inkább érdekes a hír, hogy az Nvidia felvásárlás után történt.
-
#3866
Petykemano
veterán
S_x96x_S
#3865
Petykemano
veterán
válasz
S_x96x_S
#3865
üzenetére
"A DPU is essentially PCIe on one side and Ethernet on the other. "
Én a Mellanox-szal látok hasonlóságot.
[link]Azt gondolom valami ilyesmire az AMD-nek is biztos szüksége lehet.
Ha nem abban a világban élnénk, hogy a cégek elképesztő vagyonokkal rendelkeznek, a versenyhatóságon meg pár yachtozásért kábé minden átmegy, akkor azt is mondanám, hogy lehetne partnerségben is gondolkodni. De úgy tűnik, hogy erős a "piacról való kiszorítás" igénye és ennek nyilván a fentiek miatt egy ellenséges felvásárlás remek eszköze lehet.















 Lásd:
Lásd:  Viszont abban látok fantáziát, ami az eredeti koncepció volt, hogy minden chiplet K12, ugyanazzal az IOD-vel, tehát csak CPU-t kell cserélni a szerverben, és át is álltál egyikről a másikra. Ez azért elég egyedi és rugalmas is lenne.
Viszont abban látok fantáziát, ami az eredeti koncepció volt, hogy minden chiplet K12, ugyanazzal az IOD-vel, tehát csak CPU-t kell cserélni a szerverben, és át is álltál egyikről a másikra. Ez azért elég egyedi és rugalmas is lenne. 





















Új hozzászólás Aktív témák
- Samsung Galaxy S22 és S22+ - a kis vagány meg a bátyja
- Formula-1
- Több évig húzódó per várhat az Apple-re az iPhone-ok uralma miatt
- Windows 11
- Építő/felújító topik
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Amlogic S905, S912 processzoros készülékek
- Diablo IV
- Windows 10
- Azonnali VGA-s kérdések órája
- További aktív témák...
- Bomba ár! HP 255 G7 - AMD A4 I 4GB I 128SSD I HDMI I 15,6" FHD I Radeon I HDMI I W11 I Cam I Gari!
- ÁRGARANCIA!Épített KomPhone i5 13400F 16/32/64GB RAM RTX 5060 Ti 16GB GAMER PC termékbeszámítással
- LG 34GS95UE - 34" Ívelt OLED / QHD 2K / 240Hz & 0.03ms / 1300 Nits / NVIDIA G-Sync / AMD FreeSync
- ALIENWARE Area-51 R6 Threadripper Edition 1920X
- ÁRCSÖKKENTÉS Lenovo ThinkPad T570, T580, P51s, P52s eredeti Lenovo, belső akkumulátor eladó
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest