Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 rumkola
#39451
üzenetére
rumkola
#39451
üzenetére
Shader fordító kell, és a subgroup pont egy shader nyelvre vonatkozó fícsör. PC-n ugye nem tudsz binárist szállítani, mint konzolon. Muszáj IR-t használni, és azt még le kell fordítani gépi kódra.
Ezekkel nehéz bánni, mert maga a shader intrinsics egy nagy fícsőr a DX12 és a Vulkan API-ban is, és nyilván tudták a cégek, hogy eljön az első játék, ami ezeket szabványos formában használja, csak közben van egy fix anyagi kereted, amit megpróbálsz a lehető legjobban elkölteni, például nem dobod el az erőforrást subgroupra, ha annak nincs hatása semmilyen játékban. Aztán persze amikor van, akkor majd gőzerővel odarendeled az erőforrást, hogy hozd a sebességet.
-
Abu85
HÁZIGAZDA
A World War Z esetében még a driverekkel lehet gond. [link] - tegnap írtam róla.
Alapvetően ez az első játék, ami használja a Vulkan 1.1 nagy újítását a subgroup (gyakorlatilag wave) terminológiát, amit a GLSL KHR_shader_subgroup kiterjesztésén (a Vulkan shader modell 6.0-ja) keresztül ér el. Ezt az SSR és shading fázisoknál alkalmazza, ami azért elég nagy részét teszi ki a leképezésnek.
Az async compute is eléggé agresszív, gyakorlatilag három compute futószalag is átfedi egymást a grafikai munkák mellett, amit például az Intel és az NVIDIA nem nagyon ajánl, mert nagyon tudnia kell a hardvernek ezzel bánni. Ez itt a Vulkan teljes futószalagja: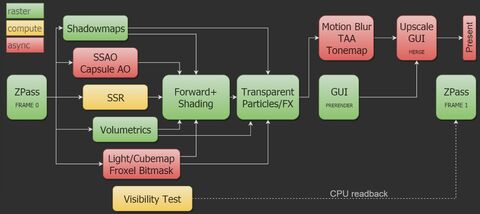
És a modernebb hardvereken használ még kevert pontosságot is a szabványos KHR kiterjesztéseken keresztül.
Emellett agresszívra van megírva a memóriamenedzsment, hogy Vulkan alatt kevesebb VRAM is elég legyen. Ez se feltétlenül kedvez mindegyik aktuális driverimplementációnak, mivel a gyártók nem szoktak hozzá ezekhez az agresszív megoldásokhoz, a legtöbb fejlesztő inkább több VRAM-ot használt explicit API-val, mert úgy nagyobb a mozgástér. HBCC-vel ez mindegy, az ugye eleve hardveres menedzsment.Ezekhez egyesével sem nagyon nyúltak korábban a fejlesztők, hát még egyszerre. Emiatt a Saber külön elmondta a kérdéseimre, hogy a Vulkan implementációknál lehetnek még fennakadások, mert hiába építik általában bele az új képességeket a gyártók a meghajtókba, addig nem igazán optimalizálnak rájuk, amíg production ready szinten el nem kezdik őket használni a játékok. Az AMD például még a kiadás előtti héten átlagban +10-15%-ot talált a legújabb shader fordítójukkal, illetve a kicsit általakított queuinggel.
Szóval, ha valamelyik játék hozza a nagy újításokat, akkor általában az lesz, hogy az aktuális driverek limitációiba beleütközik, de ez idővel javulni fog, amit a hardvergyártók is elkezdik optimalizálni az implementációt az API újításaira.
Azért nem nehéz visszaemlékezni, hogy amikor bejött a Vulkan 1.0, akkor is voltak drivergondok az első alkalmazással (Doom), de eltelt kb. fél-háromnegyed év, és nagyjából ezek megszűntek. Most itt az első játék, ami Vulkan 1.1-et használ, és menetrendszerűen jönnek a gondok, majd eltelik megint x hónap és megjönnek az optimalizált meghajtók a Vulkan 1.1-re. Itt most azért akkora probléma nincs, lényegében a shader fordítón kell optimalizálni, jól kell, hogy kezelje a subgroupokat.
(#39442) huskydog17: Szerencsére a Vulkan leképezőnek nincs baja. A probléma minden érintett szerint a driver. Még az AMD is azt mondja, hogy bőven maradt teljesítmény benne, de a játék megjelenésére akartak egy értékelhető állapotot a 19.4.2-höz (ha jól működik a meghajtó, sose hozol az utolsó héten +10-15%-ot). Az Intel és az NV nem is adott még ki semmit (nekik ugye nincs még rétegezve az explicit API-k támogatása, tehát sokkal lassabban tudnak reagálni az egyes problémákra, mint az AMD). Tényleg az a baj, hogy hirtelen jött egy játék, ami egy rakás olyan új dologhoz hozzányúl a Vulkan alatt, amit korábban egy játék sem használt. Aztán a gyártók felszisszenve tapasztalták, hogy "baszki a driverek nem működnek annyira jól" a Vulkan modern kiterjesztéseivel.
-
Abu85
HÁZIGAZDA
Az AMD AGESA-t kínál az alaplapgyártóknak erre vonatkozóan. A legújabb támogatja a Zen2-t, most ez nem végleges támogatás, annyira jó, hogy amint jön a végleges AGESA, azt egy Zen2-vel is be lehessen frissíteni, ne kelljen venni egy olcsó régebbi procit, csak a BIOS frissítésére. Ezt az AGESA-t az alaplapgyártók használhatják a BIOS-okban. A Zen2-höz az AGESA 0.0.7.1 vagy 0.0.7.2 verziókat kell keresni a BIOS-oknál. A végleges verziószám 1.0.0.7 lesz. Az ASRock több 300-as alaplapnál támogatja. [link] , [link] , [link]
Igazából még az MSI sem foglalt állást. Nem akarom a cég működését elemezni, de furán vannak felépítve, mert például az NVIDIA GPP-nél is írogattak a dolgozók dolgokat, aztán az MSI kiadott egy közleményt a médiának, hogy azok nem hivatalos információk, és ezeket csak ők biztosíthatják a "xyz" e-mailekről. Most is csak írogatnak dolgokat az embereik, de ha most szigorúan vesszük az MSI korábbi állítását, akkor ezek nem számítanak hivatalosnak az ő értelmezésükben. Értem, szarul működik így, de most mit csináljak velük, ha nem tudják pórázon tartani a dolgozóikat, akkor azt kell mondani róluk, hogy nem képviselik a cég álláspontját.
 Megkérdeztem már őket, hogy most akkor mi van, csak a hivatalos csatorna lassú.
Megkérdeztem már őket, hogy most akkor mi van, csak a hivatalos csatorna lassú.Az AMD egyébként valószínűtlen, hogy állást foglal az ügyben. Ők az AGESA-ig törődnek ezzel.
-
Abu85
HÁZIGAZDA
Egyáltalán nem ez a tapasztalatunk. Kb. ott tartunk, hogy az ASRock nem véletlenül van ott. Mi azért rengeteg megjelenés előtti hardvert kapunk, és az ASRock lapjával ezek manapság pöcre mennek, míg a többiekével nem igazán. Emiatt voltak bizonyos procik ASRock lappal tesztelve, mert a többiek cuccában meg se moccantak. Ebben persze valószínűleg nagy szerepe van annak, hogy rengeteg neves mérnököt elvittek a konkurenciától, és a kiadásoknál sem az RGB világítás a kulcstényező, hanem a működés. Persze RGB-ben nem annyira jók, itt tényleg a többiek viszik a prímet.
 Viszont nagyon jók a hűtés tervezésében. Meglepő, de még az egyszerű bordák ellenére is az ASRock lapjainak a VRM-jei a leghűvösebbek.
Viszont nagyon jók a hűtés tervezésében. Meglepő, de még az egyszerű bordák ellenére is az ASRock lapjainak a VRM-jei a leghűvösebbek.Az AMD például ma helyből ASRock lappal szállítja a tesztprocijait, de az Intel is kezdi átvenni ezt. Egyszerűen nekik is számít, hogy a tesztcucc pöcre megy, vagy sem. Persze kapunk külön ASUS lapot is, így sokszor lehet választanunk, de az AMD és az Intel választása manapság az ASRock, és egyre többször érezzük, hogy nem véletlenül.
Szerk.: Egyszerűen arról van szó, hogy az ASRock kockáztatott az elmúlt időszakban. Megtömték a marketinget, szerváltak egy rakás neves mérnököt, és emelték az alaplapoknál a gyártási mennyiséget. Ez nagy kockázat egyenként is, együtt pedig öngyilkosság, ha nem jön be, de bejött. Persze valószínűleg számított, hogy az Intelnek voltak ellátási gondjai, jó időben kezdtek az AMD-hez dörgölőzni, meg persze az se volt mindegy, hogy a Biostar máshol ette az MSI piacát, de végeredményben az ASRock jókor hozott jó döntéseket az alaplapok piaca szempontjából.
-
Abu85
HÁZIGAZDA
válasz
 Devid_81
#39396
üzenetére
Devid_81
#39396
üzenetére
Semmit. A Gigabyte és az MSI hozott pár hibás döntést, ami miatt az ASRock elkezdte enni a piacukat. Most pedig kénytelenek alacsonyabb fokozatban lapátolni a pénzt a kemencébe. Az is számít egyébként, hogy az AMD mekkora támogatást fizet a gyártók felé. Jelenleg az ASUS és az ASRock van nekik az első két helyen, vagyis több marketinglóvét kapnak, mint a Gigabyte és az MSI. Ez persze nem szimpla döntés kérdése, ehhez bizonyos feltételeket kell teljesíteni, amit a Gigabyte és az MSI nem tudott megütni, míg az ASUS és az ASRock megfelelt. A Gigabyte és az MSI inkább az Intelre koncentrált, csak pechük, hogy pont ők vannak leszállóágban, és így elkezdtek problémákkal küzdeni az alaplappiacon. Az Intel viszont nekik fizet több marketingtámogatást, csak ez nem kompenzálja a kieső DIY eladásokat.
Külön pech egyébként, hogy a Biostar nagyon rácuppantontta magát az irodai szegmensre, ahol az MSI hagyományosan erős volt, tehát már a Biostar is eszi az ottani eladásukat. Az MSI nem tud vele mit tenni, mert az Intelnek nincs elég processzora, amit el lehetne adni ide, míg a Biostar csinált pár nagyon régi procis AMD alaplapot, amit két kézzel szór az ügyfelek felé.
Tényleg nagyon kicsi döntéseken múlik, hogy vesztesz-e a konkurenciához képest, de ha vesztesz, akkor az sokat számít.
-
Abu85
HÁZIGAZDA
válasz
Devid_81
#39394
üzenetére
Meg is tartják. A Zen2-t támogató AGESA már ki van adva. Ez akármelyik Socket AM4-es alaplaphoz jó. Az ASUS és az ASRock már be is rakta több 300-as sorozatú lap BIOS-ába. De egyébként lesz még egy új AGESA. A mostani igazából arra kell, hogy ha veszel egy Zen2-t, akkor az alaplap ne csak pislogjon rá, hanem tudjon is BIOS-t frissíteni. Emiatt adják ki most a gyártók a BIOS-okat az új AGESA-val.
(#39392) b. : Nem mindenki küzd problémával. Az ASRock például elég jól elvan. Persze ehhez az MSI és a Gigabyte piacát eszik, de ez egy ilyen küzdelem. Ha nincs elég vásárlóerő, akkor a többiektől kell valahogy elvenni. Ugyanúgy az MSI és a Gigabyte is kockáztathatott volna a marketing erősítésével.
-
Abu85
HÁZIGAZDA
[link] - vótmácikk, csak még nincs konkrétum. Az, hogy összeraksz egy rakás RISC magot, nem nagy cucc, gyakorlatilag mindenki megcsinálta már. A lényeg, amikor végleges termék szintjén csinálod. Az a nehéz.
(#39349) Petykemano: Készül egy cikk a Gen11-ről (nagyjából a 2/3-ada kész is). Annak megvan a whitepaperje, csak vannak kérdéseim, amelyekről előbb megkérdezem az Intelt. A GPU-s részleg válaszolni is szokott, így szeretem túráztatni a cégeket.

-
#39336
Abu85
HÁZIGAZDA
szmörlock007
#39335
Abu85
HÁZIGAZDA
válasz
 szmörlock007
#39335
üzenetére
szmörlock007
#39335
üzenetére
Akkor olvasták el sokan az április elsejei híreket, és mentek vásárolni.

-
Abu85
HÁZIGAZDA
Az alapötlet Sweeney-é. Ő vetette fel legelőször, hogy meg lehetne ezt csinálni. Csinált is egy tesztalkalmazást PC-re, illetve a Sony PS4 bemutatójára. Ez volt az Elemental demó. Aztán lelőtte az egészet, mert nem működött normálisan. De közben egy rakás cég elkezdte kutatni az SVOGI-t, nem csak az NVIDIA, viszont egyedül a Crytek jutott el addig, hogy PC-n ezt ténylegesen megvalósítsa. Az első működő SVOGI implementáció egyébként a Sony-é volt, de ők csak PS4-re csinálták meg azt.
Amit a gyártók csináltak, hogy elkezdték vizsgálni az SVOGI-t a feladatok GPU-ra helyezése szempontjából. Még az Intel és az AMD is dolgozott rajta, csak nagyon gyorsan lelőtték az egészet, mert úgy látták, hogy megvalósíthatatlan. Ezután az Intel a VPL-re, míg az AMD az LPV-re tért át a kutatás szempontjából. Egyedül az NV maradt meg az SVOGI kutatása mellett.
A vezető technológia egyébként az LPV lett, azt alkalmazza a legtöbb motor, mert volumetrikus megoldás, és nem igényel előfeldolgozást.Legelső SVOGI bemutató egyébként az Elemental demó volt, ugye Sweeney ezzel már az előző évtizedben szemezhetett, így sikerült összeraknia egy programot 2012-re. Csak hát nem elég demonstrálni valamit kísérleti szinten, meg is kell azt valósítani ténylegesen. Az egyébként jó, hogy erre az egyes cégek rácuppannak a kutatás szempontjából. Ez viszi előre az ipart, ebben vitathatatlan érdemei vannak az NV-nek is, de rajtuk kívül még egy rakás ember dolgozott ezeken. A legnagyobb érdemei egyébként a Sony-nak vannak, egészen pontosan James McLarennek, ő talált olyan megoldásokat a problémákra, amelyek elvezettek a működő megvalósításokhoz. Nem véletlen, hogy a Sony alkalmazta ezt először egy játékban.
Ha pedig mindenképpen az NV-től keresel embert, aki tényleg sokat tett a működő, és nem csak mutatóba csinált SVOGI-ért, akkor Alexey Pantaleev az.
-
Abu85
HÁZIGAZDA
Nekik azért működik, mert előttük senki sem találta ki azt az ötletet, ami miatt működik.
Amit linkeltél az például eléggé mutatja, hogy mennyire más, amit a Crytek csinál, ugyanis köztudott a CryEngine-ről, hogy a voxelizációt a CPU-n hajtják végre. Az Epic és az NVIDIA is GPU-n voxelizált, amit a Crytek már az elején kizárt, mert az előbbi két cégnek nem működött. Publikálhatod, hogy dolgoztál egy ilyenen, csak végeredményben, a Crytek megoldása működik, míg a te publikált cuccod nem.
-
Abu85
HÁZIGAZDA
Sweeney megoldása soha az életben nem működött. Az egy dolog, hogy bejelentesz először valamit, hogy megcsinálod, de azt meg is kellene csinálni. Sweeney pedig nem csinálta meg, inkább hagyta az egészet.
Jelenleg az Unreal Engine main branch ezeket a megoldásokat támogatja:
- Lightmass (ez teljesen baked opció)
- DFAO (ez csak AO és nem GI)
- DFGI (ez már GI, de kísérleti fázisban van jó ideje, az újabb verziók szétfagynak, ha bekapcsolod)
- LPV (na ez működik valamennyire, de "ezer éve" kapott frissítést, szóval kb. halott)Szóval jelenleg az UE4-ben a main branch-ben nincs implementálva semmilyen SVOGI megoldás, de még olyan sem, ami minőségileg megközelítőleg hasonlót tud adni. Kb. a Lightmass az egyetlen, ami out-of-box használható, és az EPIC támogatja, vagy lehet licencelni az Enlightent.
A VXAO nem működik main branch-csel, vagyis ha ezt választod, akkor az EPIC nem ad terméktámogatást, ami elég baj, mert bug van bőven a motorban, aztán ezeket javíthatod kézileg. Ez olyan költség, amit egyszerűen senki sem vállal be, ezért nem látsz egyetlen VXAO-s játékot sem az UE4-re.
A CryEngine hatalmas előnye, hogy úgy kínál SVOGI-t, hogy egyrészt a megvalósításuk gyors, másrészt, ha bekapcsolod, akkor marad a terméktámogatás. Ez azért óriási különbség.
A Crytek az SVOTI működését nem részletezi pontosan, de amikor még bemutatták, akkor mondták, hogy nem is indultak el azokon az utakon, amelyeken az Epic és az NVIDIA elhasalt. Egy teljesen újszerű megközelítést alkalmaztak, ami a saját szabadalmazott technológiájuk lett.
-
Abu85
HÁZIGAZDA
Leírtam neked korábban, hogy ez nem igaz. Se az octree, se a globális illumináció nem az NV-től jött. Ezeket már nagyon-nagyon régóta ismerjük.
Az SVOGI-t valójában az UE4 kezdte nyomatni, legelőször Sweeney, de hiába erőltette egyszerűen nem működött nyílt területeken, aztán az NV csinált egy másik implementációt, aminek VXGI volt a neve. A VXGI már sokkal jobb volt nyílt terepen, viszont nem szerette, ha megmozdult valami a jelenetben. Ezért nem mozgot semmi az NV-nek a holdra szállós demójában. Azóta ezt megoldották, de óriási a VXGI teljesítményigénye, tehát a production ready szinttől nagyon messze vannak még.
A Crytek az alapok tekintetében ugyanazokat elemezhette, amit az Epic és az NV, de tanulva a két cég hibáiból, egy új implementációt csináltak, amit SVOTI-nak neveznek. Ez volt az első SVOGI megoldást PC-re, amit egy játékban is bevetettek, és máig az egyetlen. Ez egyébként nagy előny a Cryteknek, mert amíg az SVOTI megoldásuk igen kevés erőforrást igényel, maximum 10%-ot vesz le a sebességből, addig a middleware-es UE4 VXGI, vagy a Unity SEGI inkább 60-90%-os mínusszal működik. És ez egyáltalán nem mindegy, mert hiába műtöd bele a motorokba ezt, a CryEngine integráltan tartalmazza a technikát, míg az UE és a Unity motorokat nem ezekre tervezték. Ezért rakott ebbe egy rakás pénzt a Crytek, mert egy integrált megoldás fényévekkel gyorsabban működik, mint a 3rd party cuccok, de rohadtul nem egyszerű ezt beépíteni tényleg működőre. -
#39250
Abu85
HÁZIGAZDA
huskydog17
#39249
Abu85
HÁZIGAZDA
válasz
 huskydog17
#39249
üzenetére
huskydog17
#39249
üzenetére
Ubisoft pre-briefing. A GDC-n lesz róla előadás.
A Far Cry 5-ben sincs a 8 GB-os kártyákhoz képest. Nem itt mutatkozik meg a több memória előnye, hanem az akadások számában, ahogy Scott Wasson itt meg is mutatta: [link]
Fontos megérteni, hogy a mai motorok streaming vezérlése miatt az átlagra csak akkor van igazán befolyással a VRAM mennyisége, ha az nagyon kevés. Ha némileg kevés, akkor az átlag sebesség meglesz, de a mérés intervalluma alapján lehet számolni az 50 ms felett elkészült frame-ek mennyiségét.
-
#39248
Abu85
HÁZIGAZDA
huskydog17
#39247
Abu85
HÁZIGAZDA
válasz
huskydog17
#39247
üzenetére
14 GB-ot igényel. Egészen pontosan 13,7 GB-ot, ez az Ubisoft hivatalos mérése. 8 és 11 GB-ot is fut a 4K Ultra, csak ha nincs legalább 13,7 GB-od, akkor a streaming rendszer akadásokat eredményezhet. Az átlag egyébként itt elég jó lesz, csak a minimum nem, ezért nem mér a gyári benchmark minimumot, mert nagyon memóriafüggő.
Ezeket elvileg majd részletezik a GDC-n, egyelőre csak előzetes press briefinget tartottak. DX11-ben egyébként elég a ~10-11 GB is, csak a motort nem erre tervezték.
Annyi a lényeg azt korábban már leírtam. [link] Annyi extra infó még, hogy a Microsoft dolgozik az UAV overlap szabványos megvalósításán, de a Division 2-re már nem ígérték meg, hogy megírják a szabványos optimalizálást, mert nem tudni, hogy ezt mikor kapja meg a Windows. Barycentric állítólag lesz Intelre, míg GeForce-ra nem, ott inkább lassít. Hiába optimalizálás, nem erre tervezték a Fermi alapjait, így nem hasznosak rá a barycentrik optimalizálások. Intelen is csak azért működnek, mert gyakorlatilag ott a co-issue lehetőség az EU-kban.Amire érdemes figyelni az a parancsgenerálás, és a GPU etetése. Ez sokkal hatékonyabb lett az új Snowdroppal.
-
Abu85
HÁZIGAZDA
Ez csak HPC-only dolog. Nem tudnak otthoni szinten mit kezdeni. Otthon nem tényező az, hogy sok PC-t összekötsz tízezer dolláros komponensek használatával.
A CCIX ISA-tól független, tehát ha azt támogatják, akkor igazából van memóriakoherencia akármilyen ISA-val rendelkező processzorral. Azt nem tudom, hogy az Intel CXL-je hogyan van specifikálva. Ahhoz képes, hogy nyílt szabvány, olyan nagy titok, hogy még az NVLinkről is sokkal többet lehet tudni.
-
#39235
Abu85
HÁZIGAZDA
Petykemano
#39233
Abu85
HÁZIGAZDA
válasz
 Petykemano
#39233
üzenetére
Petykemano
#39233
üzenetére
Ez nem DirectX Raytracinget használ. Arról van szó, hogy a Crytek írt a saját motorjába egy olyan rendszert, amely lényegében megcsinálja a DirectX Raytracing feladatait, csak nem ezt a kiegészítést használja, hanem compute shaderekkel fut Vulkan és DirectX 12 API-kon.
Nagyon sok függ attól, hogy a Crytek mit akart. Azért nem mindenki elégedett a DXR-rel, rendkívül sok a korlátozás benne, de a Microsoft se mondta, hogy nem fogja fejleszteni, tehát nem feltétlenül biztos, hogy érdemes saját rendszert írni, és a korlátokat megkerülni, akár az is opció, hogy megvárják a DXR 2.0-t vagy 3.0-t. Gondolom a Crytek inkább a saját rendszert választotta. Ez is megoldás, de nem egyértelmű, hogy mi a legjobb.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#39217
üzenetére
Yutani
#39217
üzenetére
Lefordítható valós növekedésre, csak kell hozzá elég draw call. De igazából nem ez a lényeg, hanem ez: [link] - jó ez még a Mantle API volt, de dettó ugyanez a haszna a DX12-nek és a Vulkánnak is. Itt az Oxide elég jól felvázolja a problémát, tényleg jó mérésekkel szemléltetve.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Átlag szinten ~61 vs ~68 fps van. Minimumban ~31 vs ~50 fps. Azért nem kicsi ez a különbség a DX12 javára.
(#39202) sylex1: Szerintem ne hajszold a 144 Hz-et, a legtöbb multis játék eleve nem frissít a hálózaton keresztül ekkora frekvencián. Vegyél valami nagy frissítésű Freesync monitort, és akkor variálható a frissítési frekvencia, aztán nem gond, ha nincs meg a 144 Hz. Az NV oldalán van hitelesítési lista a FreeSync cuccok G-Sync kompatibilitásáról. A felbontás a kijelző méretétől függ. Azért 27 colon már ajánlott az 1440p. 4K leginkább 32 coltól optimális.
-
Abu85
HÁZIGAZDA
Azt, hogy a kilengések nem túl nagyok, így érzésre jellemzően nem számítottak, de alacsony sebességnél eléggé észrevehetőek voltak.
A másik bejegyzés, hogy a játék 4K-ban 13 GB-ot kér max textúrák mellett, de nincs érezhető hátránya a 11 GB-os kártyáknak. 8 GB-ot kér WQHD-ben és 6 GB-ot Full HD-ben.
(#39188) huskydog17: A streaming rendszerű textúrázás miatt ugye pont az a lényeg, hogy a memória igazából sosem fogy ki amolyan hard jelleggel, hanem állandó töltögetés lesz. A TechReportos Scott Wasson nemrég csinált egy mérést a korábbi tesztrendszerével, hogy hol számít igazán, ha nincs elég memória: [link] ... lényegében a memóriatöltéseknél mindig 50 ms fölé csúszik a frame-time. Igaz ez itt a Far Cry 5, ahol ugye még a DX11-es meghajtó él, így még a driver menedzselte a memóriát, de az látszik, hogy ha átdobod a hagyományos VRAM modellt HBCC-re, vagy raksz még egy csomó memóriát a GPU mellé, mennyivel csökken a kilengések száma. Az átlag fps tekintetében viszont ez nem igazán látszik.
Ezért nem túl szerencsés egy normál menedzsmentet használó VGA-t a Division 2-ben a HBCC-s Vegákkal összemérni, mert a Vegán nem azt látod, hogy a GPU ennyivel jobb, hanem azt, hogy a HBCC kikapcsolhatatlan. A driver az ECM-mel csak az ICM-et váltja. Ha mondjuk rá lehetne kényszeríteni a Vegát, hogy működjön szimplán VRAM-ként az a 8 GB-nyi memória, akkor ugyanolyan kilengései lennének, mint a GeForce-oknak.
-
#39187
Abu85
HÁZIGAZDA
huskydog17
#39186
Abu85
HÁZIGAZDA
válasz
huskydog17
#39186
üzenetére
Eléggé unfair összemérni a Vega 64, a 2070 és az 1080 frame time-ját. Hiába 8 GB-os mindhárom kártya, a Vega 64 kikapcsolhatatlanul ICM-ben működik, tehát nyilván nem fut ki a 8 GB-ból, míg a másik kettőnél látszódnak a 8 GB okozta spike-ok. Az ICM-et egyedül a driveres ECM tudja felülírni, de az is lényegében ugyanaz.
Erre mostantól figyelni kell, mert hiába van ugyanannyi memória a VGA-n, mostantól jönnek az alkalmazásszintű ICM HBCC-t támogató programok.
-
Abu85
HÁZIGAZDA
Egyrészt ők eléggé jól tartják a finanszírozhatóságot, tehát valószínűleg megcsinálják, ahogy eddig lényegében minden váltást a FinFET bevezetése óta, másrészt a Krzanich által kirúgott mérnökök a Samsunghoz és a TSMC-hez mentek. Nem annyira közismert, de francia nyomtatott Canard PC korábbi írásából valószínűsíthető, hogy az Intel problémái ahhoz köthetők, hogy Krzanich a kinevezése után jól leépítette a gyártástechnológiák fejlesztéséért felelős mérnöki csapatokat, mert sokallta a fizetésüket, és egyetemekről éppen kikerült fiatalokkal töltötte fel az állományt. Feltételezhetően ez lehet az oka annak, hogy az Intelnek a 14 nm is zűrös volt, míg a 10 nm nem jött össze. Ezzel szemben a Samsung és a TSMC terveknek megfelelően fejleszt.
Egy gyártástechnológiai váltást el lehet rontani. Az benne van a pakliba, bár manapság egyre inkább csak pénzkérdés az egész, mert a problémákat igazából a szükséges berendezések ára adja, és nem az átállás nehézsége (lásd GlobalFoundries, ahol ott volt az IBM technológiája, de extrém beruházások nélkül nem finanszírozható az egész). Két váltást egymás után rontani már inkább menedzsmenti probléma.
-
Abu85
HÁZIGAZDA
Az mindegy igazából. A gyártósorok átalakítása is ugyanolyan jó, csak mivel az EUV itt nem kizárható, így olyan gyárak kellenek, amelyek az EUV-s berendezések hőtermelésére készülnek. Ezért csinált a TSMC két 7 nm-es verziót. Mert az EUV-s opcióhoz nem jó mindegyik üzem, míg az EUV nélküli alapvetően a meglévő üzemeken belül is biztonsággal kiépíthető.
Trump bácsi támogatása csak annyit jelent, hogy nem lesz akkora veszteségük a 7 nm-es átálláson, de valójában sokkal többre mennének, ha 2022-ig lenne versenyképes node-juk. Marha sok idő van még a 7 nm-ig, mire azt normálisan beindítják simán 2023 végét fogunk írni. Addigra a TSMC és a Samsung GAAFET node-on lesz. Az Intel CEO-ja sajnos pénzügyes, így nem látja a hosszabb távú következményeket, de ha mondjuk lenne egy mérnök CEO, akkor most valószínűleg azon dolgozna, hogy licenceljék a Samsungtól az 5 vagy 3 nm-es node-ot. Azzal gyakorlatilag legalább arra a szintre hozhatják magukat, ahol az ipar áll, és akkor nem kellene a saját 7 nm-ükbe pénzt ölni, hanem mehetne a befektetés olyan területre, ahol vissza tudják szerezni a gyártástechnológiai előnyt. Azért érdemes már számolni azzal, hogy a 14 nm-t az Intel nagyon jóra ígérte, és alig indult be, a 10 nm-nél kevesebb problémát ígértek, és nem működött. A 7 nm most megint nagyon durva lesz, és... Amikor zsinórban elrontanak két node-ot általában érdemes elgondolkodni rajta, hogy nem-e érdemes lenne némi strukturális átalakítás. Csak ehhez tényleg egy vérbeli mérnök CEO kellene végre. Renduchintala ott volt most alternatívának, csak hát indiai születésű.
 Pedig amióta ott van az Intelnél igen sok jó döntést hozott. Ha anno Perlmuttert választják CEO-nak, már rég előrébb lennének, csak ő meg izraeli volt.
Pedig amióta ott van az Intelnél igen sok jó döntést hozott. Ha anno Perlmuttert választják CEO-nak, már rég előrébb lennének, csak ő meg izraeli volt. -
Abu85
HÁZIGAZDA
válasz
 Puma K
#39152
üzenetére
Puma K
#39152
üzenetére
Ennyit nem lassít!
Igen a Denuvonak valóban van teljesítményevő hatása, de egyrészt leginkább DirectX 11-ben érződik, mert ott ugye nincs explicit többszálúsítás, illetve még az is kell, hogy alacsony felbontást és grafikai minőséget állíts be, és akkor kb. ki tudsz mérni maximum 10% mínuszt, átlagban számolva (persze kereshetsz egy olyan jelenetet, ahol van egy extrém különbség, viszont az a teljes futtatás 0,0000001%-os része). Ugyanakkor ez például Full HD-ben már hibahatáron belülre csökken, DX12-ben pedig teljesen eltűnik, mert explicit többszálú lett a parancsgenerálás. -
Abu85
HÁZIGAZDA
válasz
 imi123
#39151
üzenetére
imi123
#39151
üzenetére
Érdemes tudni róla, hogy DirectX 12-ben shader modell 6.2-t is tud használni, ha megvan a megfelelő Windows 10 frissítés.
Eléggé megkavarták egyébként a shadereket:
DirectX 11-ben kétféle shader van szállítva... AGS 5.3 az AMD-nek és szabványos a többieknek.
DirectX 12-ben az AMD mindig AGS 5.3-at kap, míg a többiek szabványos SM 5.1-et Windows 10 októberi frissítés alatt, de felette az Intel Gen9+ és a Turing bizonyos shaderekre szabványos SM6.2 kódot kap. Így működik ezeken is az FP16, nem csak a Vegákon.
Sajnos ennél több nem lett szabványosan portolva, így az UAV Overlap, illetve a barycentric optimalizálás csak AMD-n megy. Utóbbi viszont állítólag később át lesz dobva SM6.2-re, csak a kód mostani állapota inkább lassít, így ezzel nem akarták visszafogni a GeForce-okat és az Intel IGP-it. -
Abu85
HÁZIGAZDA
A jövőben ezek a gyártók nem tudnak mit kezdeni egymás hardvereivel. Megmarad ugyan a PCI Express, de ki lesz egészítve. Az AMD-nél PCI Express with CCIX lesz. A Rome platform már támogatja, és innen nyilván hozhatod asztaliba is, viszont marhára nem lehet mit kezdeni a CCIX képességével, ha nem CCIX hardvert raksz bele. Az Intel azért nem lépett be a CCIX-be, mert zárt kiegészítést hoznak a PCI Express-hez. Tehát amit veszel majd hardvert az Inteltől GPU-ban, az sokkal többet fog tudni, ha az Intel CPU-ja mellé rakod, mintha egy AMD GPU-t raknál a gépbe. Ezzel szemben az AMD GPU-ja sokkal többet fog tudni, ha AMD CPU mellé rakod, mert működni fog a CCIX képesség, szemben az Intel GPU-jával, ami saját UPI kiegészítést használ a memóriakoherencia problémájára.
Ha tehát egy cég vásárolni akart, az már nem tud, mert az AMD az IF és CCIX, az Intel a UPI, míg az NVIDIA az NVLINK protokollt dolgozta ki a memóriakoherencia kezelésére. És persze a PCI Express mint alap csatoló meglesz, de ha például egy CCIX-es hardvert nem CCIX-es PCI Express vezérlőhöz raksz, akkor a CCIX képesség nem fog működni. És ugyanez van más protokollokkal is. A hardver működni fog gyártói keveréssel, de a tudás egy részét bukod.
Annyira előrehaladottak már ezek a fejlesztések a gyártóknál, hogy ha hirtelen megvennék a másik divízióját, akkor négy évet buknának, mert át kellene tervezni a hardvereket. Vagy a CPU-kat vagy a GPU-kat.Egyébként a CCIX ugyan szabvány, tehát mindenki mehetne erre, de az Intel és az NVIDIA különcködik. Ők úgy érzik, hogy elég erősek ahhoz, hogy saját zárt rendszerrel arra kényszerítsék a vásárlóikat, hogy az Intelnél a CPU-khoz Intel GPU-t vegyél, míg az NVIDIA-nál a GPU-khoz, NVLINK-et támogató CPU-t vegyél.
-
#39134
Abu85
HÁZIGAZDA
Petykemano
#39133
Abu85
HÁZIGAZDA
válasz
Petykemano
#39133
üzenetére
Az Intelnél az eDRAM leginkább sehogy sem működik. Nagyon régi leképezőknél ad előnyt, de az újabb GPGPU-s cullingot alkalmazóknál már semmi haszna. Annyira sok a modern leképezőknél a feldolgozandó adatmennyiség, hogy gyakorlatilag nem tudsz építeni a nagyon aprócska tárkapacitásra. Nem véletlen, hogy az Intel is Counter Strike-kal demonstrálta és nem Battlefielddel.
Az Xbox One-ban az ESRAM azért működhet, mert közvetlen elérése van rá a fejlesztőknek, tehát például tudnak olyannal trükközni, hogy a back buffer color és depth targetjeit használod az egyes effektek számításánál. Viszont ha nem trükköznek, akkor ugyanúgy nem ér semmit. PC-n meg erre nincs semmi, az Intel eDRAM egy mezei L4 cache, így a hatásfoka fényévekkel van a közvetlen elérhetőséget biztosító Xbox One ESRAM mögött, már ha utóbbit használod ugye. Szimpla cache-ként ez sem valami hasznos. Az Xbox One X-ből ügye ezt ki is vették, illetve a rendszermemóriából emulálják ha szükség van rá. Egyszerűen ezek a kicsi, de gyors memóriás konfigurációk a Counter Strike-hoz jók ugyan, de a mai motorok nem így működnek.A Samsung mondta a Low Cost HBM-re, hogy mindenképpen olcsóbb a JEDEC HBM-jüknél. Bár azt nem írták, hogy mennyivel. 0.X-et írtak.
-
Abu85
HÁZIGAZDA
válasz
Yutani
#39130
üzenetére
2-3 watt körül van. Órajeltől függően.
(#39131) Petykemano: Csak az eDRAM az Intelnél sem volt több dísznél. Xbox One-ba jó. Oda rátervezik a játékot. PC-be nem az, maximum csak dísznek jó.
A Low Cost HBM elsődlegesen azoknak jó, akiket a HBM bonyolultsága tartott vissza az implementációtól. Azért 1024 bites TSV-t stackenként tervezni nem egyszerű ám. 512 bitet sokkal könnyebb.
Az AMD-nek a tervezés szempontjából valószínűleg mindegy, mert nekik azért elég nagy itt a tapasztalatuk, viszont egy APU-nál a hely azért korlátozott, így más tényezőket is meg kell vizsgálni. Például a Si-less interposert opcióként.
-
Abu85
HÁZIGAZDA
Samsung Low Cost HBM. Az 200 GB/s-ot tud nagyjából, per stack ugye. Ez nem szabványos, sokban különbözik a JEDEC HBM-től, például csak 512 bites a busz, nincs pufferlapka, nincs ECC, más a struktúra, illetve sokkal kellemesebbek az interposerre vonatkozó igények. A Samsung-féle Low Cost HBM előnye, hogy érezhetően olcsóbb a JEDEC HBM-nél, viszont hátrány, hogy többet fogyaszt. Persze a HBM szintjén mérve, tehát ha még 50%-kal nő is a fogyasztás, az is eléggé lófütyi kategória.
-
Abu85
HÁZIGAZDA
válasz
 atok666
#39106
üzenetére
atok666
#39106
üzenetére
A mai rendszereknél a magszám növelésével nem igazán kell hozzányúlni az órajelhez. Maga a hardver elintézi ezt, ha nem tudja tartani az adott fogyasztási kereten belül. Egyszerűen fel van rá készítve, hogy a megfelelő szintre vegye vissza, ha az adott munkafolyamat ezt megkívánja. Például bizonyos AVX módoknál még a közölt alapórajel alá is visszamehetnek a procik. Nem probléma, mert stabilitási gondokat nem okoz, tehát nyugodtan meg lehet adni a specifikációra a magas órajeleket, a hardver majd eldönti, hogy mit állít be magának.
Simán meg tud verni egy 12-magos egy hatmagost egy NUMA-aware motorban, amely nem tartalmaz legacy pathot az öreg API-kra. Ilyen motorok készülnek most. Nyilván a fejlesztők is tudják, hogy az órajelben már nem bízhatnak. Ezt az Intel is folyamatosan kommunikálja nekik. Már csak azért is, mert a 10 nm-es Ice Lake mintája 3 GHz fölött nem stabil. Ezen persze még lehet növelni, de a 10 nm-es node-ot nem a magas órajelre tervezték, hanem egy rendkívül low-power optimalizált megoldás annak érdekében, hogy annyi magot lehessen a lapkába rakni, amennyi van a dinnyében. Ezért sem lesz Ice Lake asztali szinten egy jó darabig, de egyébként készül oda egy 20-magos verzió, csak egyelőre jobb a Comet Lake, viszont 2020-ban már jöhet a sok mag, mert bőven skálázódnak majd az új játékok.
-
Abu85
HÁZIGAZDA
válasz
 pengwin
#39096
üzenetére
pengwin
#39096
üzenetére
Nem olyan nehéz ez. Kínálnak valamit x pénzért, de ami kellene a partnereknek azt nem kínálják fel kevesebb pénzért. Antikompetitív? Az hát. Hogyan tudsz védekezni ellene? Maximum nem veszed meg a terméket, de az sem megoldás, mert valamit árulni kell, tehát belekényszerítenek és kész.
El tudják látni a piacot. Ha az eladás garantált, már csak amiatt is, mert az OEM bele van kényszerítve a megvásárlásába, akkor nyilván nem gond többet gyártani.
A második foglalat az nem jó. Azzal az a gond, hogy drága lenne. Senki sem akar drága megoldást, mert azon kevés lenne a haszon. Sokkal célszerűbb oda berakni a CPU mellé a tokozásba. Ehhez már minden technológia adott. Régen nyilván nehézkes volt, mert maga a tervezés nem chipletek szintjén zajlott, de ma már átálltak. Az AMD mindenképpen, és az Intel is át fog, mert sokkal hatékonyabb ez a megközelítés.
(#39098) atok666: Nézd meg azokat a motorokat, amelyek erre vannak kitalálva. Például a Nitrous. Ott nagyon szépen skálázódik a sok mag. Ezért is lépdel az AMD és az Intel is inkább a magok növelésének az irányába. Idén az AMD-nél 12 mag lesz a mainstream maximum, bár nyilván csinálhatnának 16 magot is, de nem fognak, mert a 12 mag is túl sok lesz a 10-magos Comet Lake-nek. Az viszont tisztán látszik, hogy merre mennek. Nem az órajelet hajkurásszák, hanem a magokat öntik bele a lapkákba, mert összességében sokkal hatékonyabb, és természetesen tudják azt, hogy az új motorverziók már úgy vannak megírva, hogy ezeket a magokat ki is használják. Ha nem így lenne, akkor nem ilyen hardverek jönnének, de magát az alapproblémát a Microsoft és a Khronos kezelte egy-egy új API-val.
(#39102) Zsébernardo: Azt számítsd bele, hogy se az Intel, se az AMD nem az aktuális játékokra készíti az idei csúcsprocesszorát. A 10-magos Comet Lake, illetve a 12-magos Matisse a 2019-es címekre jön. Azokra a címekre, ahol egyébként nem egy el fogja hagyni a DX11-et, így meg lehet válni a legacy feldolgozási modellektől. De egyébként lehet, hogy lesz 16-magos, mert az id tech 7 azt mutatja, hogy skálázódna rá, csak az AMD nem annyira rajong az ötletért, mert a Threadripperek piacát enné a cucc, és az Intelnek úgy sincs a 12-magosra sem válasza. De persze a Bethesda nagy partner, nyilván van némi beleszólásuk, hogy csinálnak-e nekik egy külön szupererős mainstream procit. Ha nagyon nyalnak, akkor talán megteszik.
-
Abu85
HÁZIGAZDA
válasz
 korcsi
#39093
üzenetére
korcsi
#39093
üzenetére
Attól függ, hogy milyen dedikált. Egy GeForce MX200 sorozat igen olcsó, miközben gyorsabb az Intel IGP-jénél. De érdekes lesz majd látni a Ryzen Mobile 3000-et. Ott már az AMD rárakja a pénzt azt a 30-50 dollárt IGP-re, és így például a Lenovo nem rak mellé dedikált GPU-t, mert most már fizetni kell az IGP után is.
Nagyban meghatározza az OEM-ek döntéseit, ha az IGP-s prociknál az ár úgy van szabva, hogy az IGP ajándék legyen, vagy úgy, hogy azt a cég felszámítja. Utóbbi esetben nem igazán van lehetőség dedikált GPU-ra, még akkor sem ha befér, mert a Ryzen Mobile 3000 alaplapja kb. akkora, mint az Intel Coffee Lake U-s modelleké. És az is lényeges, hogy az AMD szokott csomagot kínálni, alig 20 dollár a legkisebb Radeon, ha valaki vesz egy mobil Ryzent, tehát még ez a 20 dollár sem éri már meg a gyártóknak, ha az IGP-ért az AMD azt mondja, hogy most már fizetni kell. Képzeld mennyire sikítva tenyerelnek a NEIN gombra, ha nem 20, hanem 200-300 dolláros extra kiadásról lesz szó. -
Abu85
HÁZIGAZDA
válasz
 #00137984
#39088
üzenetére
#00137984
#39088
üzenetére
Az órajel önmagában ma már nem sokat ér. A mai motorok az explicit API-kkal explicit párhuzamosan generálják a parancsokat. Tehát az órajel és a magok száma együtt számít.
A Raytracing árnyékok lényegében csak a memória-sávszélességtől függnek. Ugye itt az a buktató, hogy a raszterizációval ellentétben a memóriaelérések sugárkövetésnél eléggé véletlenszerűek, vagyis nem lehet rá optimálisan építeni a gyorsítótárakkal, miközben azért a raszerizálásnál azért viszonylag jellemző, hogy a lokalitási elv érvényesül. A Raytracing árnyékoknál különösen a sávszélesség a döntő fontosságú, hiszen nincs árnyalási munka, ami a többi effektnél inkább meghatározza a teljesítményt.
A játékok sebessége nagyban függ a leképezőtől. A motorok régóta olyan megoldások felé mennek, amelyek jelentősen javítják az árnyalás hatékonyságát. A tiled light tree, illetve a texel shading lesz a vezető irányzat a következő generációban, amelyek lényegesen gyorsabbak a mai, sokszor light culling nélkül deferred shadinghez képest.
Az API csak egy interfész, amivel elérhetsz a hardverhez. De maga az API nem igazán határozza meg a leképeződ munkáját.
A mai motorok egészen extrém szinteken skálázódnak. A mag igazából már nem probléma. Ez addig volt gond, amik a legacy API-k feldolgozási modellje egy száltól tette függővé a leképezést. De pont emiatt hoztuk az explicit API-kat. Dobáljuk is a magokat a procikba, mert innentől kezdve ez többet fog írni, mint az órajel.
-
Abu85
HÁZIGAZDA
válasz
#00137984
#39086
üzenetére
A TDP azért nem igazán kritikus gond, mert korlátozott a hardver teljesítményének kihasználhatósága. A következő lépésben az új generációs EPYC 64 magot fog kínálni 180 watton belül. Ebből ugye nyilván nem csak a mag fogyaszt, hanem a körítés is, de jelenleg ott tart a dolog, hogy a Zen 2 lazán működik 2-5 wattos magszintű fogyasztással, függően az órajeltől. Egy PC-be pedig eléggé felesleges 16-nál többet építeni, tehát egy 3,5 GHz hozható vele 65 watton belül. Egy 8-magos verzió 35 watton is játszva megoldható, és akkor a következő generációs GPU-k sem olyanok, mint régebben, egyre több dolgot átvesznek az ultramobil szintről, és ezeket igen erősen fejlesztik is. Jó persze az AMD, az NV és az Intel azért annyi ideje ezzel nem foglalkozik, mint egy Imagination mondjuk, tehát hatékonyságban le vannak maradva, de ez csak azt jelenti, hogy sok tartalék van még, amit ki lehet használni. És akkor ott a memória, amiből lehet menni HBM-re, ami mérföldekkel takarékosabb, mint a hagyományos megoldás. Az Intel és az NV előtt még ott az AVFS. Az AMD ezt már használja, de nyilván ez is fejleszthető. Szóval a TDP most jelenleg az egyik legkisebb gond. A legnagyobb probléma aktuálisan a költség, ugyanis ahhoz, hogy az új gyártástechnológiák alapjait a gyártók ki tudják fejleszteni, gyárakat kell építeniük. Egyre többet, ez viszont egyre nagyobb költség, a szükséges berendezések sem olcsók, főleg az EUV, aminél a hatékonyság elég rossz, emiatt hatalmas hőt termel, ami miatt a gyár hűtésigénye egészen extrém pénzmennyiségbe kerül. Mindezt úgy biztosítják a bérgyártók, hogy az új node-okon a waferek nem csak drágák, hanem kurva drágák, vagyis hiába mész egyre kisebb csíkszélre, hiába csökken a lapkaméret, a gyártási költség egyre csak növekszik. Ilyen anyagi feltételek mellett nem biztosítható a Moore-törvény hagyományos módszerekkel történő alkalmazása, vagyis új lehetőségeket kell találni az előrelépésre.
Az Intelnél a Sunny Cove is 2-3 wattos szinten működik. 4-5 watt azért nincs, mert nem igazán stabil a mostani stepping 3 GHz felett, de ha ezt megoldják, akkor valószínűleg 4-5 watton belül a 4 GHz elérhető itt is.
-
Abu85
HÁZIGAZDA
válasz
 tom_tol
#39083
üzenetére
tom_tol
#39083
üzenetére
Most nem igazán fizettetik ki az IGP-t. Nézd meg a Ryzen 5 2400G-t. Annak az ára lényegében a processzor teljesítményéhez van szabva. Az IGP gyakorlatilag grátisz, jó nyilván nem, de effektíve nem kerül semmibe, mert hasonló teljesítményű négymagos csak Ryzen CPU-t is hasonló áron vehetsz.
Na most a dGPU proci mellé tokozásával már kifizettetik majd a dGPU-t. Az OEM vagy kéri a csomagot, vagy nem tud venni semmit. És akkor ha a dGPU ~200-300 dolláros árát felszámolják, akkor egészen más kérdés már az OEM részéről is, hogy vegyen-e mellé még ~200-300 dollárért egy hasonló teljesítményű VGA-t. Ez valóban nem a csúcskategória lesz, hanem a középszint, de ha Jon Peddie jelentése alapján a piac ~96%-a 300 dollár alatti GPU-t vásárol. Ha innen kirakod a VGA-kat, akkor azok luxusszintre esnek, hiszen annyira kiszeded alóluk a piacot, hogy nem lesz értelme középkategóriás VGA-kat csinálni, vagyis a generációváltások költségeit a high-endben kell kitermelni. Ezt csak úgy lehet, ha annyira megdrágítod a VGA-kat, hogy az a ~3-4%-nyi extrém igényekkel rendelkező user ki tudja fizetni a fejlesztéseket. Ezért is olyan magabiztos az Intel, hogy nagy részesedésre fognak majd szert tenni. Hát persze, ha nem hagynak az OEM-eknek választási lehetőséget, akkor ez nyilván nem nehéz. Persze lehet jönni azzal, hogy így is rendelhetnek VGA-t az OEM-ek, mert nem tart pisztolyt az Intel a fejükhöz, de valójában igen, árazópisztollyal segítik nekik a "jó" döntések meghozatalát. -
Abu85
HÁZIGAZDA
válasz
atok666
#39080
üzenetére
Az Intelnek ~70% a GPU-piaci részesedése, és ez nagyrészt abból van, mert az OEM-ek ezt rakják a gépekbe. Szerinted most érdekli őket, hogy ez a felhasználóknak jó-e? Másrészt a felhasználókat érdekli, hogy van jobb? Az a helyzet, hogy a piacnak a jelentős része nem igazán tudja, hogy az Intelt, az NV-t és az AMD-t eszik vagy isszák-e.
-
Abu85
HÁZIGAZDA
válasz
tom_tol
#39075
üzenetére
Csak úgy tudnak részesedést szerezni, ha árút kapcsolnak. Ennyi az egész. Vagy így csinálják, vagy nem éri meg ebbe invesztálni.
(#39076) Zsébernardo: Nem a TDP a gond. Azzal, hogy a VGA-piac elvesztette a bányát, kapásból egy iszonyatosan durvát drágult. Ahogy elvesztik az OEM-eket, az egész luxusszintre fog kényszerülni. Innentől kezdve a TDP mindegy lesz, mert a VGA-k vételára egészen új szintekre megy majd fel. Oda az Intel is tervezni fog VGA-t, mert naná, hogy megéri 1000-2000 dolláros szintet kiszolgálni, de ettől a tömegpiac nem fogja tudni megfizetni.
Láthatod most is, hogy az AMD sem akar itt versenyezni. Szépen beárazták a Radeon VII-et a 2080-ra. Nekik ez így nagyon jó, és az új generáció sem lesz ám olcsóbb, sőt. A 7 nm-es node az drágább, szóval felfelé fognak menni az árak. Egy területen tudod ezt megfogni, ha a tokozásba rakod a CPU mellé a GPU-t. Ilyenkor a CPU-n meglévő, egyébként jellemzően bődületesen nagy profit elég, és a GPU-t adhatod előállítási költségen.
-
Abu85
HÁZIGAZDA
válasz
 xEon1337
#39072
üzenetére
xEon1337
#39072
üzenetére
Nekik a kezükre játszik a Microsoft, tehát ARM-mal is mehetnek a piacért, ahogy a Qualcomm teszi. Csak azt kell megvárni, hogy a Microsoft kilője a Win32-t teljesen, vagy átköltöztessék a futtatást az Azure-ba.
(#39073) Petykemano: Nem nagyon érdekli az ARM a szerverpiac szereplőit. Lehet, hogy később érdekelni fogja, de egyelőre nem sok jel mutatkozik erre.
-
#39071
Abu85
HÁZIGAZDA
zovifapp111
#39069
Abu85
HÁZIGAZDA
válasz
 zovifapp111
#39069
üzenetére
zovifapp111
#39069
üzenetére
Az AMD tud ugyanúgy platformot kínálni, mint az Intel. Az IEDM-en felvázolták már ezt, hogy miképp fog kinézni az egész: [link]
Az, hogy most kié lesz jobb? Ezek hosszabb távú tervek, leginkább 2021-2022 környéki. Nem tudja senki, hogy a következő generációs gyártási eljárásokra hogyan állnak át a cégek. Rövidtávon biztos előnyben vannak a 7 nm-rel, de ez maximum 2021-ig dönti el a versenyt. Az Intelnek is lesz 7 nm-je, már arra koncentrálják az erőforrást, az AMD-nek is át kell majd állnia 5 nm-re, de vannak olyan pletykák, hogy ki akarják hagyni, és rögtön 3 nm-re ugranának, az meg nem veszélytelen, mert ott már GAAFET van, szóval sok a kérdés.
Az biztos, hogy az Ice Lake a jelenlegi adatok alapján nem túl veszélyes. Az AMD 3 TFLOPS-os rendszerchipet csinál, míg az Ice Lake az 1 TFLOPS-ot lép csak át. A Gen11-nél az a kérdés, hogy az 1 TFLOPS hogy jön össze, mert az Intel IGP-k dizájnban beragadtak egy igen régi szintre, vagyis 4+4 co-issue kell a kihasználásukhoz. Erre tudsz jól fordítani egy elavult leképezőt használó programnál, de egy újnál szinte lehetetlen, és akkor az 1 TFLOPS-ból rögtön 0,5 TFLOPS lesz.
A Gen12-es architektúra már érdekesebb, de az ellen a Navi jön. Hosszabb távon pedig a GPU-k nem így fognak ám kinézni, mert szükség lesz a dinamikus regiszterallokálásra, vagyis nagy áttervezések jönnek hamarosan. A jó ég tudja, hogy azt ki csinálja meg a legjobban. Az Intelnek és az AMD-nek a CPU-s üzletágból biztos sok tapasztalata van ebben, de CPU-t tervezni azért más. -
#39068
Abu85
HÁZIGAZDA
Petykemano
#39067
Abu85
HÁZIGAZDA
válasz
Petykemano
#39067
üzenetére
Persze. Nem azért adják ki ezeket, mert annyira jó, hanem mert így el tudják adni azt a pár százaléknyi selejtet is, amit máskor kidobnak, mert a normál gyártási folyamatokkal is ki tudják elégíteni a keresletet.
Az Intelnek elég, ha meggyőzi az OEM-eket, hogy ne vegyenek több VGA-t, jó az amit ők raknak majd a tokozásra a CPU mellé. Ha ezt megteszik, akkor a VGA-piac magától átmegy egy olyan áremelkedésen, hogy beesik a luxusszintre. A DIY nem kicsi, de nem lényeges piac, így ami jó az OEM-eknek, az jó a DIY-re is. Attól, hogy neked nem tetszenek az elérhető hardverek, még nem tudsz mást választani.
Az AMD sem fog csak CPU-val foglalkozni egy idő után. Egyszerűen nekik is lényegesen kedvezőbb, ha az OEM-eket nem kell győzködni a Radeonok megvásárlásáról, hanem megy a holmi csomagban a procin. Az Intel se véletlenül kezdett el erre fejleszteni, az ilyen megoldások nagyon veszélyesek ám rájuk is, viszont ha kínálnak ők is alternatívát, akkor simán jól kijönnek belőle.Teljesen mindegy, hogy mit játszol a memóriával. Az egészhez két komponens kell, egy memóriakoherens interfész a CPU és a GPU közé, illetve egy hardveres memóriamenedzsment. Az AMD-nek már megvan mindkettő, IF és HBCC ugye. Az Intelnek is megvan az első, ez az UPI, míg egy HBCC-hez hasonló megoldást nekik nem nehéz összehozni.
-
#39066
Abu85
HÁZIGAZDA
Petykemano
#39053
Abu85
HÁZIGAZDA
válasz
Petykemano
#39053
üzenetére
Nem. A Radeon Software az Sasa Marinkovic érdeme. Ő az aki levezényelte az egész váltást, az ötletek nagy része is tőle származott. A ROCm Gregory Stoner érdeme volt, most már James Edwards viszi.
Raja leginkább az SSG-t, illetve a professzionális vonalat (hardver/szoftver) futtatta fel. Az SSG kétségtelenül egy pokolian nagy húzás volt.(#39058) Devid_81: Az Intel visszabutított 10 nm-es node-ja most már látszólag működik. Azzal nem lesz gond. Ahol problémás ezzel az eljárással, az a magas órajelek elérése, de egy GPU-nál ez amúgy sem kritikus, mert nem nagyon járnak 2 GHz fölött.
(#39061) pengwin: Az a peche az Intelnek, hogy az AMD is átdolgozta a Vega 20-ra a parancsprocesszort. Aláz is a Forza Horizon 4-ben, ahol a többi hardvernél ez a limit: [link]
Az NV is át fogja dolgozni, hiszen ehhez már évek óta nem nyúltak, tehát pont időszerű. -
#39065
Abu85
HÁZIGAZDA
zovifapp111
#39048
Abu85
HÁZIGAZDA
válasz
zovifapp111
#39048
üzenetére
Egyáltalán nincs szükségük arra, hogy az NV-nél és az AMD-nél jobbat csináljanak. Az Intel a processzoraira fog építkezni. Ezzel kiszolgálják a teljes PC-s piac 70-80%-át, és azt fogják mondani az OEM-eknek, hogy a CPU-k mellé jár majd a tokozáson a dGPU. Az OEM kérdezheti, hogy nincs-e csak CPU, de az Intel majd mondja, hogy nincs. Fizesd ki a dGPU-jukat, és kapcsold ki, ha akarod, de ez ugye akkora extra költség, hogy épeszű OEM úgy sem kapcsolja ki, tehát meg is nyerték a piacot. Rohadt nehéz ám vásárlóként választani hardvert, ha közben nincs választék.
A következő időszak csodafegyvere az árukapcsolás lesz. Hiába törvénytelen, az Intel és az AMD már aktívan alkalmazza. Nézd meg a cloud gaming területét. Az NV taposta ki az egészet, mégis az AMD és az Intel platformjaira kötik a nagyok (Microsoft, Google, Tencent) a szerződéseket, mert az NV nem tud csomagot kínálni processzor hiányában. És az Intel most lényegében úgy nyeri meg a Tencentet, hogy gyakorlatilag nincs is jelenleg hardvere, amit tudnak szállítani nekik, de annyira jó a csomagajánlat, hogy az NV versenyképtelen, hiába tudják azt mondani, hogy gyerekek nekünk működik is, ők meg csak papírokat mutogatnak. Még az AMD sem kínált az Intel alá a Tencentért, amiben persze az is lehet, hogy nekik ott a Google, illetve az Amazonra koncentrálnak inkább, de a komplett platform kínálata borzalmasan nagy fegyvertény, mert olyat tudsz ajánlani a partnereknek, amivel képtelenség platformszintű megoldás nélkül versenyezni.
-
Abu85
HÁZIGAZDA
válasz
 TTomax
#39047
üzenetére
TTomax
#39047
üzenetére
Az Intel nem úgy képzeli ezt el, hogy majd te választasz a proci mellé VGA-t, hanem odarakják a dedikált GPU-t a tokozásra, és kifizettetik veled, akkor is, ha neked nem kell. Ilyen szempontból az OEM-eket már megnyerték, mert ők aztán tuti nem raknak majd VGA-t a gépekbe, ha közben az Intelnek muszáj fizetni ezért +200-400 dollárt.
Az AMD is ugyanezt fogja csinálni. Látod, hogy már felkészültek rá az I/O lapkával, ami mellé nem csak CPU chipletet rakhatsz, hanem ugyanúgy beköthetsz IF-en keresztül egy dedikált GPU-t is. És onnantól kezdve az OEM-ek döntésének megint harangoztak, mert nyilván nem éri meg az extra VGA-val jelentős többletköltségbe verni magukat.
Szóval nem, nem abból lesz piaci előny, hogy leraknak valami "dulva" cuccot az asztalra, hanem abból, hogy eldöntik, hogy ezt veheted meg és kész. Aztán verheted az asztalt, hogy neked kurvára nem kell, de ez a kínálat, szóval vagy fizetsz érte, vagy veszel konzolt.Azt veszi amúgy itt az Intel számításba, hogy ha az OEM-eket kiüti a VGA-piacról, akkor olyan szinten megdrágul a VGA-k gyártása, hogy luxuskategória lesz az egész szegmens, és ezzel gyakorlatilag mesterségesen kihúzzák a piac alól a jelenlegi vásárlóbázis 80%-át. Így nagyon könnyű ám piacot nyerni.
-
-
#38971
Abu85
HÁZIGAZDA
Petykemano
#38970
Abu85
HÁZIGAZDA
válasz
Petykemano
#38970
üzenetére
De ez miért érdekes a Windows szempontjából? Ezer éve benne van a driverben. A Linuxon azért történnek ilyenek, mert a Windows erőforrások huszadából készül a támogatás. Nem mellesleg a GPGPU culling a motorba építve sokkal hatékonyabb, nem véletlen, hogy oda rakják be.
-
#38969
Abu85
HÁZIGAZDA
Petykemano
#38968
Abu85
HÁZIGAZDA
válasz
Petykemano
#38968
üzenetére
Milyen culling sztorinak?
-
Abu85
HÁZIGAZDA
válasz
TTomax
#38960
üzenetére
A compute culling compute shadert követel, nem muszáj hozzá DX12.
(#38961) Szaby59: A PBR bármibe bele lehet rakni. A forráskódot ismerik szóval nem nagy kunszt. Ennek a nehézsége nem igazán a programkód megírása.
Nem tudom igazából, hogy milyen stabilitási dologról van szó. A compute culling kikapcsolhatatlan. Nincs szállítva mellette a legacy culling path. Túl körülményes lenne megoldani ezt egy végtermék szintjén.
Senki sem beszélt a DX12-ről. Ez egy API, de az eljárások alatta API-tól függetlenek. A leképező az egyetlen különbség, de az kb. kétezer kódsor, ami a teljes motorhoz képest igazán elhanyagolható. Funkcionális szempontból viszont a DX11 és a DX12 ugyanarra képes, csak utóbbival van explicit párhuzamos parancsgenerálás.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#38956
üzenetére
A Bioware a Mass Effecthez igényelt motort még 2013-ban. Azt fejlesztik azóta is. Eléggé külön haladnak a Frostbite Teamtől, hiszen teljesen más fejlesztőeszközöket használnak.
A Frostbite Team esetében az a probléma, hogy nagyon gyorsan fejlesztenek, mert nekik lényegében csak ez a koncepció. Emiatt annyira töredezett a Frostbite használata az EA-n belül, mert amíg a Frostbite Team lényegében a kompatibilitást is megvágja a sebességért, ez azért egy játékon éppen dolgozó stúdiónál nem realitás. A legtöbben egyszerűen csinálnak maguknak mellékágakat abból a verzióból, amelyet még régen elkaptak, de újakra csak ritkán állnak át. A Bioware pedig ennek a legextrémebb példája, ők egyszerűen minimálisan sem hajlandók megvágni a kompatibilitást, így ők azok, akik a legtöbb limitációt szenvedik el ettől.
Lényegtelen, hogy valami open world vagy nem. Előbbi inkább a tesztelést bonyolítja, de a mai motorok már alapvetően streaming rendszerek, tehát a működés szintjén édesmindegy, hogy a játéktér mekkora, mert ugyanúgy nem tölti be a teljes pályát, hanem csak a játékos közelében lévő részeket, és ugyanez igaz a nem open world játékokra is. Nem ez számít igazán, hanem az, hogy a leképező hogyan vágja ki a fényeket, a nem látható háromszögeket, stb. Ebben több a 2016-os Frostbite verzió, amit a Frostbite Team tervezett meg, és nyilván a GPGPU culling nagyon sokat segít, hiszen ennek a hatékonysága egésze extrém szintet üt meg. A fények jobb kivágása még várat magára, mert maradt még a deferred+, illetve a 2018-as verzióban a clustered deferred, de 2019-ben jön a Tiled Light Trees. [link] - ezen a videón látható, hogy látványosan hatékonyabb. Ebből is simán nyernek +20-30%-ot.
(#38957) TTomax: Bezony. A GPGPU culling célja az volt, hogy hatékonyabb legyen a nem látható háromszögek kivágása. Mivel a Frostbite rendszere az eredeti cullinghoz képest sokkal több nem látható háromszöget is képes eltávolítani még a leképezés megkezdése előtt, így sokkal kevesebb munka hárul a GPU-ra. Nyilán az eredeti megoldással is ugyanaz lesz a képkocka, csak ott akkor dobod el a nem szükséges adatokat, amikor már a hardver mindent kiszámolt rájuk. Ezért vezették be ezt az újdonságot, hogy még a számítások előtt váljanak meg a nem szükséges adatoktól.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#38953
üzenetére
A release szám csak akkor ér velemit, ha a Frostbite Teamhez kapcsolódik, de mivel a Frostbite-ot az EA-n belül több stúdió is megkapja, így némely leányvállalat külön fejleszti a Frostbite Teamtől. Ezért nincs benne DX12, hiszen maga a motorverzió még az MEA közvetlen továbbfejlesztése, de nem emelték át bele a Frostbite Team újabb leképezőit, amelyek azért sokkal gyorsabbak, mint amit anno kapott a Mass Effect.
A Bioware elkérheti a legújabb leképezőt is a Frostbite Teamtől, de ez csak a 2016-os parancsgenerálással kompatibilis, vagyis a Frostbite Team 2015-ös alapjaira építő motorba nem építhető bele, így nem kompatibilis az Anthem által használt rendszerrel. Hiába írod a release mögé a 2017-et, az már a te mellékágad, és nem a Frostbite Teamé. Át kell állni legalább a 2016-ös főverzióra!, hogy működjön. Onnantól kezdve viszont nagyon könnyen beépíthető akár a Battlefield V DX12-es leképezője is, hiszen a kompatibilis alapok megvannak hozzá. Viszont az Anthemhez ez nem jó, így oda egy különálló DX12 leképező készült, csak nem igazán működik. Még...A motorverzió a DX12 szempontjából mindegy. Az alapvető követelmény a 2016-os Frostbite főverziójának parancsgenerálása, és ahhoz használható a 2016-ös, 2017-es, vagy 2018-as DX12 leképező is. Ezek között nincs olyan hatalmas különbség egyébként. Majd a 2019-es változik inkább, ott jön a régóta ígért Tiled Light Trees: [link]
(#38954) Puma K: Semmi baja nincs magának a DX12 API-nak, de akkor működik igazán, ha a parancsgenerálás is ehhez van szabva. Ez a váltópont a Frostbite-nál a 2016-os verzió volt. Abban egy csomó dolgot bevezettek még, shader intrinsics, compute culling, egy rakás GPGPU-s trükk. Ez mind hiányzik a Bioware motorverziójából, tehát az ezek által nyerhető +70-80% teljesítmény sincs ott. Persze a Bioware eléggé különc az EA-n belül, nekik fontosabb a fejlesztőeszközeikkel való kompatibilitás megőrzése, míg a DICE azért sokkal gyorsabban lépked előre. Az is igaz persze, hogy sokkal több erőforrásból.
-
Abu85
HÁZIGAZDA
válasz
 GodGamer5
#38946
üzenetére
GodGamer5
#38946
üzenetére
Az Anthem az DX11. Mint írtam egy nagyon régi, nagyjából három+ éves Frostbite verziót használ. Még az első Star Wars Battlefront is újabb Frostbite-tal ment. Ebbe amúgy bele lehet műteni a DX12-t, de az nem lesz igazán jó, mert nagyon-nagyon régi a parancsgenerálásra vonatkozó kód. Legalább a Battlefield 1 Frostbite verziójára át kellene állni a normális DX12-höz, de az meg eléggé nehézkes, mert pont olyan területeken történt változás, ami nem teszi kompatibilissé a régi motorverziókkal a megfelelő működést.
Ezért sem fut igazán jól a hardvereken, mert hiába kevésbé komplex a grafikai szint, mint például a Battlefield V esetében, akkor is évekkel régebbi a motor, és ez a sebességén látszik.
-
Abu85
HÁZIGAZDA
Az early access a kísérleti funkciókat jelöli az UE4-ben. Ezek általában egy verzióval később lesznek véglegesek. Mondjuk az igaz, hogy ennél a motornál ez mindegy, sokszor a végleges funkciók sem működnek.
(#38815) b. : Érdekes, hogy a PhysX-hez kapcsoló van rendelve. Végül csak a PhysX cloth maradt a játékban, annak is van DirectCompute back-endje, és alig terhel. Akkor lenne értelme a kapcsolónak, ha nem vették volna ki a particles és a destruction effekteket.
(#38817) Raymond: A Vulkan még mindig Early Access, pedig már ott volt a 4.20 Previewben. Még a 4.22-ben is marad Early Access egyébként. Ezért is tértem át Unity-re, mert fájdalmasan lassan kap végleges státuszt valami. Egy, de inkább két verzió mire az összes engine komponenssel kompatibilis lesz. Persze az igaz, hogy a Vulkan is használható a 4.20 óta, de csak limitációkkal.
-
Abu85
HÁZIGAZDA
Igazából lehetne értelmet találni, csak annyira nem költenek rá erőforrást, hogy kvázi használják az NV kidolgozott cuccait, amelyek talán nem is illeszkednek jól az adott motorba, stb.
Most lehet, hogy megköveztek, de én simán használnám fizikailag korrekt hangleképzésre.
![;]](//cdn.rios.hu/dl/s/v1.gif) Ez független a grafikától, tehát a motornál a raszterizációhoz meghozott döntésekkel nem kellene megküzdeni (amivel jelenleg eleve nem küzdenek, hagyják úgy ahogy van, aztán olyan lesz amilyen a DXR, a lényeg, hogy az NV fizessen).
Ez független a grafikától, tehát a motornál a raszterizációhoz meghozott döntésekkel nem kellene megküzdeni (amivel jelenleg eleve nem küzdenek, hagyják úgy ahogy van, aztán olyan lesz amilyen a DXR, a lényeg, hogy az NV fizessen).Amire amúgy simán jó lenne az a valós idejű lightmap. Oké, piték még a mai hardverek erre, de három év múlva már elég gyorsak lesznek.
Szerk.: A különbség látszik, csak a képek felén az RTX off tetszik, a másik felén az RTX on.
Jó lenne ez egyébként, csak az a baj, hogy igazából mindent a motorban a raszterizációhoz szabtak, és arra csak úgy ráengedni az RT-t, hát nem túl okos dolog. Érdemes lenne ehhez külön is dizájnolni, de én úgy gondolom, hogy kb. úgy megy ez az adott stúdiónál, hogy építsük szimplán be, karoljuk fel a pénzt, aztán viszlát. -
Abu85
HÁZIGAZDA
Nem a shading rate miatt más a Guru3D, hanem a benchmark miatt. Annak a terhelése worst case. Azért van úgy megcsinálva, mert ha ott megvan a 60 fps, akkor a játék összes részén meglesz, míg ha csak sima gameplay-t nézel, akkor azt is be tudod lőni mondjuk 60-ra, de lehet, hogy a megterhelő részeken abból lesz 40-50 is. Direkt vannak így csinálva a benchmark részek a játékoknál, hogy reális legyen a legrosszabb eshetőségre.
-
Abu85
HÁZIGAZDA
Régen tudtál. Valószínűleg a Softbank sokat vett ennél olcsóbban is. Most jött el az a pont, amikor megéri kiszállni, és átülni egy másik részvényre. Majd visszaszállnak, ha újra olcsón tudnak NV részvényt venni. Általában egy befektető a gyengén árazott részvényt keresi a jövőképpel, mert azon lehet sokat nyerni. Ha a völgyben vagy, akkor onnan csak felfelé van út, de ha a hegyen, akkor csak lefelé. Ilyen ez a részvénypiac, rosszul hangzik, hogy kiszállnak, de túl nagy jelentősége azért nincs.
-
Abu85
HÁZIGAZDA
Nem sok köze lehet ezekhez. Az NV részvényei a jövőképért voltak felárazva. Az automotive és cloud gaming vitte előre, mert ebbe raktak egy csomó pénzt. De a cloud gamingből a nagyok nem igazán az NV megoldásait választják, míg az automotive esetében is lassan jönnek a konkrét sikerek. Ezzel együtt most kezdődött visszacsúszni a felülárazás a kriptodöglés hatására, így most érdemes kiszállni. Valószínűleg pozitívban vannak. Ha lemegy újra a részvény 30-40 dollárra, akkor újra vásárolnak egy csomót. Ez üzlet számukra, nem kell sokat belelátni. A pénzt befektetik olyan cégekbe, ahol a részvényár a hegyre felfelé megy, és nem lefelé jön onnan.
-
Abu85
HÁZIGAZDA
válasz
 hokuszpk
#38580
üzenetére
hokuszpk
#38580
üzenetére
DLSS és DXR külön jön. Valószínűleg két cikkben, de ezt még nem tudom megmondani.
(#38583) Petykemano: Nem. Mi ezt a tesztplatformot október első felében raktuk össze. Azóta nem változtattunk rajta.
(#38584) b. : Nem eldöntöttük. Vannak mérések a mérnöki mintáról. Ezeket ugyan nem árulhatjuk el, de az AMD például nyilvánosságra hozta a CES-en, hogy az új EPYC-ből egyetlen CPU fog annyit tudni teljesítményben, mint az Intelből két csúcs-Xeon (és ez egyébként egy low power modell lesz, tehát jön nála gyorsabb). Ez most egy Athlon 64-es sztori lesz megint. Két gyártástechnológiai lépcső előnye már meglátszik.
-
Abu85
HÁZIGAZDA
válasz
atok666
#38439
üzenetére
Az allokációk lehetnek eltérő méretűek, de nem célszerű mondjuk nagyon kicsi allokációkat csinálni, mert eléggé eltérő az, ahogy az AMD, az Intel és az NV drivere kezeli a memóriát.
DX12-ben (és Vulkan API-ban is) nem a nyers mennyiség határozza meg igazán a működést, hanem a memória strukturális felbontása:
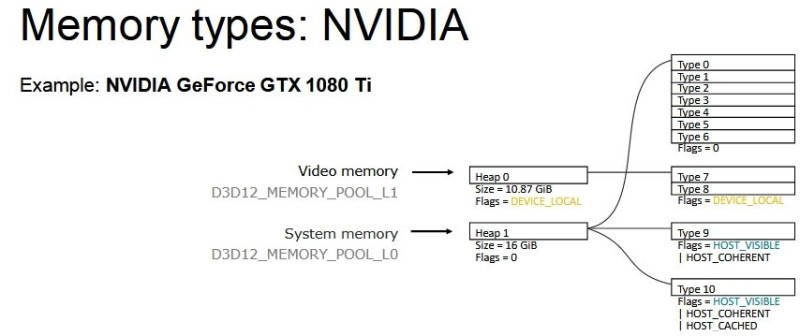
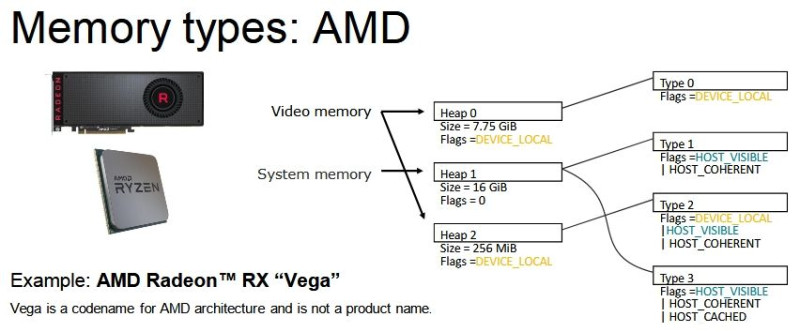

Na most egy olyan megoldás kell, ami jól működik a fenti három struktúrán belül. Tehát az nem elég jó, hogy működik AMD-vel, mert akkor az Intel és az NV szopni fog. Egy közös többszöröst kell keresni.Ha ez megvan, akkor ott a töredezettség problémája, vagyis vagy ugyanolyan méretű lesz minden allokáció, ami nem túl szerencsés, vagy végül a sok allokáció cseréje miatt fragmentált lesz a VRAM egy idő után. Tehát előfordulhat, hogy van szétszórtan 200 MB szabad hely, de nincs egybefüggően, tehát mindenképpen törölni kell egy allokációt, hogy egy új 200 MB-os beférjen.
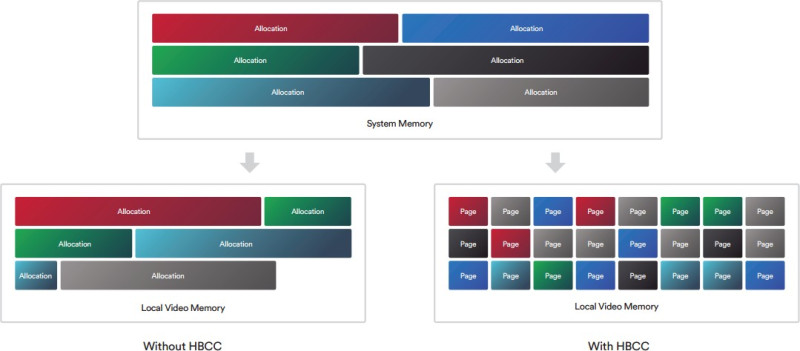
Itt láthatod, hogy ha azt a fekete allokációt a rendszermemóriából be akarod másolni a VRAM-ba, akkor egyszerűen nem tudod megtenni, mert nincs annyi egybefüggő szabad hely. Ki kell törölni mondjuk a pirosat és a zöldet. Ugye itt a HBCC is látható, ami lényegében azt valósítja meg, amit kvázi elgondolsz. Ne is másold az allokációt, hanem csak a szükséges lapjait. Mindegyik lap ugyanakkora, tehát a töredezettség kizárva, illetve mindig az van a memóriában, ami kell. De a jelenlegi API és WDDM kombinációja ezt a megoldást nem támogatja. Nem erre tervezték a rendszert. Meg lehetne oldani, viszont akkor nulláról kell kezdeni az egészet, vagyis új API, új display model, új meghajtók, új hardverek, új OS.(#38440) mormota79: Nem annyit használ, hanem jóval kevesebbet, de mivel a WDDM-et nem tervezték ilyenre, ezért az AMD meghajtója egy trükköt alkalmaz. Amikor bekapcsolod a HBCC-t, akkor keletkezik egy olyan erőforrás, aminek a fedélzeti memóriája megegyezik a beállított HBCC szegmenssel. Legyen az mondjuk 24 GB.
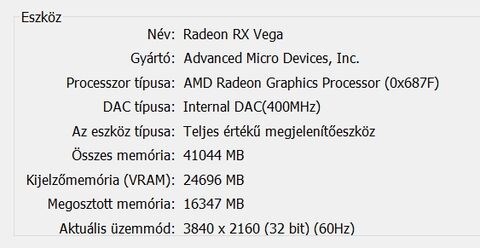
Ilyenkor az OS felé és a programok felé az egész VGA úgy néz ki, mintha egy 24 GB VRAM-mal rendelkező hardver lenne. Ez alapvetően befolyásolja a programok által kiolvasott adatokat, hiszen a meghajtónak el kell rejtenie mindent, ami a háttérben történik ahhoz, hogy az OS felé gyakorlatilag tudjon hazudni a valós hardverről, amin fizikailag nincs 24 GB-nyi memória. Na most ezt még az AMD saját eszközei sem tudják mérni, mert nyilván hazudnia kell az adatokról a meghajtónak, hogy a háttérben a HBCC működhessen, és az AMD profilozói is ezeket a hazugságokat látják csak, ahogy például egy 3rd party program is csak ennyit tud elérni, plusz a Windows is csak ennyit lát. Egyébként létezik egy külön hardver, amit a fejlesztők igényelhetnek. Ez lehetővé teszi, hogy a HBCC mód valós működését kiolvashassák, de ehhez nem lehet hozzájutni átlagemberként. Szóval mi csak azt láthatjuk, amit a driver hazudik. -
Abu85
HÁZIGAZDA
válasz
TTomax
#38436
üzenetére
Csak API szinten nem lehet. Nem a lapalapú menedzsmentre találták ki a rendszert. Új WDDM-mel és egy ahhoz írt teljesen új API-val megoldható lehetne, de annyira nagy változás szükséges hozzá, hogy megint dobni kell a kompatibilitást. A legegyszerűbb módja ennek a hardveres megoldás, vagy hardveresen asszisztált, amivel a Microsoft az OS szintjén kezelné azokat a hardvereket, amelyeknél az x86/AMD64 licenc hiánya probléma. De nem biztos, hogy mondjuk az NV nem nyomná kapásból a nagy piros NEIN gombot, mert az AMD és az Intel teljesen hardveres tud lenni, ők pedig egy szoftveres rétegre lennének utalva. Nekik sokkal inkább az lenne a jó, ha a Microsoft beemelné az ARM-ot az ökoszisztémába, és kivégeznék a picsába a Win32-t, aztán mehet minden a Store-ról.
(#38437) HSM: Azok az adatok picik méretileg. Ezért nincs igazából ebből probléma, feltéve, ha nincs nagyon elbaszva a motor streaming rendszere.
-
Abu85
HÁZIGAZDA
válasz
atok666
#38434
üzenetére
Úgy kell elképzelni, hogy a VRAM-ba allokációk kerülnek. Mondjuk van egy adat, ami kell, de az nincs benne a VRAM-ban, akkor az API-n keresztül megkereshető, és az az allokáció, amiben van az adat a rendszermemóriából átmásolható a VRAM-ba. De mindegy, hogy mennyi adatra van belőle szükséged. Ha csak 4 kB-ra, akkor is másolni kell a teljes allokációt, ami lehet akár 100-400 MB is. Tehát 4 kB-ért elpazarolsz akár 400 MB-ot. Ez egy extrém eset, de lényegében erről van szó. Nyilván egyébként az adott allokációkból nem csak 4 kB fog kelleni, de eléggé tipikus, hogy nem kell majd az összes, sokszor még az 50%-a sem, de muszáj másolni, mert másképp nem nem működik a mostani rendszer.
Az AMD pont ennek a gyökerébe nyúlt bele a HBCC-vel. Ez a rendszer lapalapú. Azt mondja, hogy ha csak az a 4 kB kell, akkor másold csak azt, ne rakjál emiatt 400 MB-ot a VRAM-ba, ami aztán úgyse kell. -
Abu85
HÁZIGAZDA
válasz
Raymond
#38420
üzenetére
Egyik játéknál sem az igazi. Amíg konzolon sokkal hatékonyabban bánnak a memóriával a programok, addig PC-n nincs közvetlen hozzáférés az erőforrásokhoz. Az más kérdés, hogy nem is lehet, mert sokféle konfiguráció van, de ettől még nem volt jó az a modell, ami a rendelkezésre állt. Ezért jöttek az explicit API-k, amiknél a jó hír, hogy megoldottuk az allokációk törlésének a problémáját, ezért jár a pacsi, viszont eközben átestünk a ló túloldalára, ami már túl bonyolulttá teszi a fejlesztőknek a memória hatékony kezelését. Tehát effektíve megoldottunk egy problémát, de közben teremtettünk egy újat. Elméletben kezelhetőt, de egy pénz mozgatta világban a gyakorlat mást fog mutatni.
A HBCC teljesen más tészta. Ez nem szoftveresen akarja kezelni az egyes problémákat, hanem gyökerestül új megoldást kínál, aminél a jelenlegi problémák már a működésből eredően nem is létezhetnek.
Az persze igaz, hogy az ok ugyanúgy az volt, hogy a mai programok elpazarolják minimum a memória felét:
De a megoldás tekintetében hardveresen alakította át az egész rendszert az AMD. -
Abu85
HÁZIGAZDA
válasz
TTomax
#38416
üzenetére
Az egész VRAM kezelése nem normális PC-n, ez tökre látszik a HBCC-n, ami akár negyedannyi fizikai memóriával is működik, mint a játék követelménye. Egyszerűen nagyon magas a pazarlás, tipikusan kétszeres-háromszoros. Szóval a probléma igazából nem a valós igénye a játéknak, hanem a WDDM-en belüli, rendkívül rossz hatásfokú erőforrás-kezelés. Ezt nem lehet megoldani szoftveresen. Hardveresen kell fellépni a allokációk kezelésénél keletkező probléma ellen.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#38413
üzenetére
Nem kell ezt ennyire mellre szívni gyerekek. Ha az AMD nem fizet azokért a textúrákért, akkor be se kerülnek a játékba. Szóval, akinek ez nem tetszik kiválasztja az Ultra helyett a High részletességet, és menni fog. Aki pedig nagyon érzékeny a legapróbb részletekre is, vesz olyan VGA-t, amin van elég VRAM.
-
Abu85
HÁZIGAZDA
válasz
 PeTeR_33
#38404
üzenetére
PeTeR_33
#38404
üzenetére
Igen. Az AMD most azt csinálja, hogy az eredetileg tervezett részletesség fölé rendel egy még nagyobb részletességet. Ezért kapott például a Far Cry 5 is egy textúracsomagot a megjelenés után, csak mostanában már a megjelenésre, vagy kicsivel utána hozzák a textúracsomagot a partnereik. Nagyon egyszerű az oka annak, amiért ezt csinálják. Az NV-nek nincs HBCC-je. Valójában az a részletesség, amit adnak az extra textúracsomag leginkább 4K-ban számítanak. Full HD-ben elég az egyel kisebb beállítás, amivel eleve érkezett volna a játék, ha az AMD nem rendelné a nagyobb részletességet.
-
Abu85
HÁZIGAZDA
Az NV soha nem cáfol vagy erősít pletykát. Ez alapvetően egy protokoll. Ebből még nem következik semmi. A Micron azért érdekes feltételezés, mert akkor az azt jelentené, hogy a legyártott RTX-ek fele rossz, mert kb. ilyen arányban látja el a Micron és a Samsung a rendeléseket. Ezért nem valószínű a Micron. Sokkal valószínűbb egy másik komponens, ugyanis vannak pletykák, hogy egy kínai gyár egy rakás rosszul specifikált VRM-et adott el a VGA-gyártóknak. De ez is pletykaszintű dolog, viszont itt annyi háttér van, hogy nem a Redditen írta Pista, hanem a TUL manapság külön kiemeli az OEM-ek felé, hogy ők nem vesznek bizonyos gyáraktól. Ugye mi értelme ezt kiemelni, ha nem lenne valami para bizonyos komponensekkel, amiket valószínűleg már sokan nem vesznek. De biztosat itt sem lehet tudni. Én elhiszem, hogy a Micron egy könnyű célpont, csak ma is tömegével gyártják vele a VGA-kat.
A hivatalos egyébként az a szöveg, hogy nincs semmi gond, minden a legnagyobb rendben a meghibásodási aránnyal. [link]
Ki kellett venni két fogamat, mert nekimentek volna a jobb alsó hatos gyökerének. Ez viszont nekem kell, így beáldoztuk a 7-8-ast. Viszont ezek be voltak nőve a csontba, legalábbis nagyrészt, így nem volt őket egyszerű kivenni. A műtét után influenzás lettem, ami nem jó kombináció, így be is gyulladt a seb, amit most kezelnek, de már annyira van bennem élet, hogy átaludjam az éjszakákat, és ne kelljen ehhez túladagolnom magam Diclofenacból.
-
#38371
Abu85
HÁZIGAZDA
Petykemano
#38370
Abu85
HÁZIGAZDA
válasz
Petykemano
#38370
üzenetére
Igen. Lassan megmaradok.
-
Abu85
HÁZIGAZDA
Valójában fingunk sincs, hogy mi a hiba, akkora a hírzárlat erre vonatkozóan. Ha van hiba egyáltalán, és nem csak arról van szó, hogy túl sok a komponens, ami a megszokotthoz képest megnövelte a bedöglő hardverek számát.
(#38337) .Z. : Nem a Frostbite motor a lényeg, hanem a verziószám. A BFV-nél a legújabb verzió dolgozik, míg az Anthemben még a BF1-nél is régebbi. Most ettől ne várjatok BFV sebességet.
-
#38032
Abu85
HÁZIGAZDA
->Raizen<-
#38031
Abu85
HÁZIGAZDA
válasz
->Raizen<-
#38031
üzenetére
jólmegszívattak
-
Abu85
HÁZIGAZDA
válasz
Raymond
#37963
üzenetére
Minden egyes képtömörítésnél (lényegében a textúráknál is erről van szó) az a kérdés, hogy a tömörítéssel vesztett minőséget megéri-e elbukni a tömörítésből származó előnyért cserébe. És itt azért nincs egzakt érték, mert projektfüggő, hogy ez konkrétan mit jelent a gyakorlatban. Minden esetben, minden projekt igényeit felmérve lehet találni egy olyan köztes pontot, ami a minőség és a tömörítés szintje szempontjából még éppen megfelelő az adott felbontásokra vonatkozóan.
-
-
Abu85
HÁZIGAZDA
válasz
hokuszpk
#37954
üzenetére
Nagyon röviden arról van szó, hogy a textúrákat bizonyos formátumban szállítják a játékokban. Ezek például a DXT-k (BC, azaz Block Compression néven is futnak). Sokféle van, különböző textúratípusokra. A lényeg az, hogy ezek veszteséges tömörítési formátumok, amelyek formátumtól függően valami:1 arányú tömörítést kínálnak. Leginkább 4:1, de vannak eltérők is.
Tehát amikor tömörítetlen formátumról beszélünk, akkor ott a nyers textúráról van szó, ami készül, és utána lehet gondolkodni, hogy milyen formátumban érdemes a komponenseket szállítani az adott motorban. Ez leginkább attól függ, hogy milyen minőséget akarsz látni. Magának a tömörítésnek a hátránya a veszteség, ami esetenként eléggé látható, tehát ezekre a problémákra lehet valami kerülőutat keresni, stb.A lényeg igazából az, hogy ha PBR pipeline-ról van szó, akkor fémhez mondjuk szükséged elég sok komponensre. Más felületekre, mondjuk kőnél nem igazán fontos a fémes hatás, tehát ott egy komponens mínusz, és ez itt a lényeg. A felület függvényében változó, hogy a PBR mennyi komponenst igényel. Viszont még ha tömörítesz is, és általában tömörítesz, akkor is ott van az a probléma, hogy már nem csak egy diffúz textúra kerül a felületre, hanem esetleg AO, normal, specular, height, edge, metallic, stb. Tehát a PBR rendkívül memóriazabáló, mert sokkal több textúrából kell megoldani azt, amihez régen relatíve kevés textúra is elég volt. Persze sokkal jobban is néz ki a program. Tipikus módszer, hogy a fontosabb modellek kapnak nagyobb részletességű textúrát, míg a nem túl fontos felületekre marad a kisebb részletességű, hiszen a hardveren nincs végtelen memória.
Jelenleg úgy 4K a maximum textúrafelbontás, ameddig elmegy egy játék, mert nincs igazán szükséged a 8K-ra, ha nincs ehhez optimális felbontása a kijelzőknek. Ez egyelőre ilyen úri hóbort, kipróbálni ki lehet, de sok haszna még nincs, viszont borzalmasan zabálja a memóriát. Az, hogy mennyire függ a tömörítés minőségétől. Egy hétkomponenses 8K-s fémpadlót le lehet húzni kb. 300 MB-ra, de kérdés, hogy megéri-e bukni annyi minőséget vele. Itt olyanra kell gondolni, mint amikor az ATI behozta a 3Dc-t. Az például sokkal jobban bánt a normal mapokkal, mint az S3TC. Több minőséget adott vissza. A DirectX-nél is készül egyfajta reform, hiszen már nagyon időszerű az ASTC megjelenése, ami veszettül jó megoldásokat kínál ám egy rakás aktuális problémára. A hardverek is kezdik támogatni (AMD Vega, Intel Gen9), csak a Microsoft vár még.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#37904
üzenetére
Nem úgy van felhasználva. Valószínűleg valamilyen más formátumban. Én például 670 MB-ra tömörítettem le.
A lényege ennek inkább az, hogy ma már a textúrázás nem olyan, mint régen, amikor volt egy diffúz textúra, aztán kész is. Ma már számos komponens van mellé, amelyek a PBR pipeline-hoz kellenek. Persze felületenként változó, hogy mennyi. De, hogy brutálisan zabálják a VRAM-ot a PBR előtti időkhöz képest, az biztos. Ez egyszerűen látszik a mai programok memóriahasználatán, illetve az egyes programokban, amelyek a grafikai beállításokhoz javasolnak egy megfelelő VRAM mennyiséget. A mai világban ez így működik. Egyszerűen sok memória kell a magas részletességhez.
Az egy másik kérdés, hogy a problémát hogyan kezeled. Akár az is megoldás, hogy a karakterek részletessége nagyobb, aztán spórolsz az egyéb, kevésbé fontos modellek, vagy éppen a felületek textúráján. Ilyen trükkökkel kordában lehet tartani a PBR memóriaéhségét. Tipikus példa a BFV, ahol a karaktereken látszik, hogy eléggé jók a textúrák, míg a környezeten már kevésbé. De hát basszus, nincs elég memória.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#37899
üzenetére
Tessék: [link] - a nap végéig meghagyom a linket, aztán törlöm.
Ez egy 8K-s PBR fémpadló (7 komponens és ~1,1 GB), amivel dolgoztam a hétvégén. Sikerült betömörítenem elfogadható minőséggel 670 MB-ra az összes komponenssel, de ez még így is egyetlen egy textúra.
A PBR-es világ nem olyan, mint régen, hogy olcsón megvan minden. Kétpofára zabálja a memóriát. Igen jó optimalizálás csak a fontos részletekre alkalmazni komoly felbontást, míg a kevésbé lényeges objektumok mehetnek 1K-s textúrákkal. -
Abu85
HÁZIGAZDA
válasz
TTomax
#37897
üzenetére
Akkor megfogalmazom egyszerűbben. Ezt úgy képzeld el, hogy amíg régen egy 2K-s textúra mondjuk foglalt úgy 7 MB-ot tömörített formátumon, addig ma ugyanez egy PBR pipelinnal 70-80 MB közötti. 4K textúránál ~30 vs ~300 MB-ról van szó. 8K-nál egy fémfelület tömörítetlen PBR textúrázása ~1 GB, és ez egyetlen egy textúra. A tömörítés szempontjából egy jó minőségű, de jobb formátummal is ott lesz a memóriaigény fél GB/fémfelületere való textúra (ennél még mehetsz lejjebb, csak ugye a minőség...). Az RE2-nél ugye sok a fémfelület, tehát ahhoz azért kell a hét BPR komponens. Szóval ma már nem olyan egyszerű ez a dolog, hogy ez csak egy textúra.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#37894
üzenetére
Nem játék típusától függ ez, mert attól, hogy csőben mész, még lehetnek részletesen az objektumok, amik megjelennek. Leginkább ma a PBR pipeline-ok zabálják a memóriát, mert ma már nem csak egy szimpla textúrával tapétázod a felületeken, hanem az ezekhez tartozó textúrakomponensekkel is (akár 5-7-tel). Hiába hordoznak ezek csak "kiegészítőinformációkat" az alaptextúrához, a tömörítetlen méretük ugyanakkora. Az RE Engine új verziója már továbbfejlesztett PBR, az előző motorhoz képest.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#37886
üzenetére
keIdor
#37886
üzenetére
Készül még a DXR patch a Tomb Raiderhez, csak azzal a dizájnnal, amit alkalmaznak még 2080 Ti-n se igazán fut. Emiatt elég sok munka van vele a háttérben. Az a lényeg, hogy a BFV-be igazából ezt már az év elején elkezdték tervezni, míg a SotTR-be csak a nyáron merült fel, hogy bele kellene rakni. Egyszerűen csak "turn on the light". Na most amíg a BFV-nél erre konkrétan rátervezték a geometriát, csináltak egy minimum LOD-nál is egyszerűbb szintet mindenre, addig a SotTR-nél ezt kihagyták, mert nem volt rá idő. Szimpla "turn on the light" módszerrel viszont nagyon rossz a teljesítmény. Helyenként még Full HD-ben sem volt meg a 25 fps egy 2080 Ti-vel. Ergo a tervekhez képest sokkal több időt vesz igénybe beépíteni. Jelenleg úgy áll a helyzet, hogy valamikor a Q1-ben kiadják. Legutóbb januárra mondták, de az a helyzet, hogy mondták már novemberre és decemberre is. Szóval mindig a következő hónapban érkezik.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#37884
üzenetére
A késleltetéselőny nincs ingyen. Ha megnézed mondjuk a Radeon Chillt, akkor a kikapcsolt állapot default 1 pre-renderjéhez képest az aktív Chill 0-s pre-renderje már önmagában -10%-ot eredményez a teljesítmény tekintetében a legtöbb programon. Most elképzelheted ennél a motornál a 7 és az 1 közötti eltérést. Persze ez motorfüggő nyilván, de számít, hogy mennyire tudod etetni a GPU-t, ha úgy döntesz, hogy a magas késleltetést mint tényezőt nem számolod problémának.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#37876
üzenetére
Nem is a sebesség csökkentése volt a cél DX12-nél, hanem a késleltetés csökkentése. Ebben a DX11-es leképező az átalakításokkal eléggé rosszul működik. Annyira, hogy az már káros lehet a játékélményre. Azért 7 pre-render frame-et használni egyáltalán nem egészséges. Sokkal kedvezőbb a DX12-es módnak az 1-es beállítása. Emiatt törték annyira magukat, hogy legyen egy normálisan működő memóriamenedzsment, amit tényleg minden VGA-n jól lehet beállítani, és nem azt írja ki, hogy kevés a VRAM-od, szóval dobd vissza a textúrabeállítást. Végeredményben a választást adják meg feléd. Ha nem érdekel a késleltetés, akkor használhatod a DX11-et is.
Az a baj manapság, hogy minél jobban tolsz egy motort a DX12 felé, annál több kompromisszumra kényszerülsz DX11-ben. Muszáj hozni a leképezőt, mert sok a Win7-es user, de borzalmasan nehéz minden egyes szempontból jó minőséget biztosítani alatta. Emiatt csinálta például azt a Rebellion, hogy írtak egy Vulkan leképezőt is a DX12-es mellé, és így megszabadultak a DX11-től, miközben a Win7-es userek is futtathatják a programot. Csak ez se könnyű út ám, hiszen bármennyire is ott a spiregg projekt, az mégse gyári támogatású, tehát nem feltétlenül úszod meg, hogy a HLSL shadereket ne írd át. A Capcomnak még az is problémát jelent, hogy az AMD-re külön shadereket is szállítanak, és azokat nem tudja ám fordítani a SPIR-V codegen. Például a Rebellion az új motorverziónál már nem foglalkozik ezzel, mindenki szabványos shadert futtat, nincs olyan, hogy az AMD nagy puszipajtás, aztán rájuk külön optimalizálnak.
-
Abu85
HÁZIGAZDA
Ja a jobb textúra. Az igen. De az valójában nem része a játéknak, hanem amolyan ingyenes DLC-ben tölthető majd le. Tipikusan, amiket a partnerek kérnek, azokat nem feltétlenül csinálják meg a megjelenésre, mert így is szoros az időbeosztás.
Az RE7-hez képest nagyon átírták a motort. Az RE7-et eredetileg DX11-re tervezték, míg ezt már alapból DX12-re. Ezzel elég sokat csökkentettek a késleltetésen, mert a DX11-es verzió még eléggé fos 7 pre-render frame-mel megy, és driverrel ez nem bírálható felül. A DX12-es módban már csak 1 a pre-render frame. Alapvetően ezért vezették be ezt a leképezőt. Ezért kellett egy csomó DX12-es problémát megoldani, például a normális memóriamenedzsmentet.
-
Abu85
HÁZIGAZDA
Ez már benne van a Resident Evil 2-ben. Ha kifogy a memória, akkor elkezdi a kisebb textúrákat betöleni.
A HBCC inkluzív címzés módja várat magára. Arról nincs sok adat. Igazából szerintem kicsi az előnye ezen a szinten a szimplán driverből engedélyezhető exkluzív címzés módhoz képest, tehát nagy dolgokat szerintem nem érdemes attól várni. Az inkluzív címzés inkább ott durva nagyon, amikor a hardveren a fizikailag elérhető memória 8 GB, és eközben a VRAM-igény 30 GB-hoz közelít.
-
Abu85
HÁZIGAZDA
Annyi szerepe van, hogy ha beállítod a HBCC-t mondjuk 16 GB-ra a driverben egy 8 GB-os Vega 56/64-en, akkor gyakorlatilag az a program felé valóban 16 GB-nak fog látszódni, és nyilván a blokkalapú menedzsment miatt bőven megoldható, hogy minden textúra magas részletességű legyen, hiszen HBCC mellett nem igazán beszélünk allokációkról, lévén a menedzsment hardveres. Kvázi működik, ahogy egy L3 cache.
-
Abu85
HÁZIGAZDA
A legtöbb játék 1 GB-os vagy 256 MB-os allokációkkal dolgozik. Leginkább azért, mert az AMD, az Intel és az NV ezeket ajánlotta régebben (AMD/Intel a 256 MB-ot, míg az NV az 1 GB-ot). Ma az AMD már inkább azt mondja, hogy a legjobb a konfigurálható allokáció, mert azt driver és hardver párosokra lehet szabni. Csak ezt könnyű ám mondani, meg ugye ez sokaknak leesett már az elején. A kérdés mindig is az volt, hogy miképpen lehetne egy olyan memóriamenedzsmentet írni, ami tényleg jól működik kicsi és nagy allokációkkal is. Ezért nem láttunk még olyat, amit a Resident Evil 2 hoz.
Nézd a fejlesztő szemével. Nekik az lett volna a legegyszerűbb, ha írnak a kódba egy sor ellenőrzést, ami ha detektálja a 8 GB vagy kevesebb VRAM-ot, akkor kiszürkíti a High beállítást. Ha mondjuk olvassák most ezt a topikot, akkor valószínűleg elgondolkodnak rajta, hogy felesleges volt azt a kb. 5000 sort beírni, annak érdekében, hogy a 8 GB-os VGA-kat ne kelljen kötelezően medium szintre rakni, mert láthatóan nem nagyon értékelitek a munkájuk jelentőségét.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#37834
üzenetére
Az nem jelent igazán problémát. A gond inkább az allokációk kezelése. Az az optimális, ha a textúrákra egy nagy allokációt használsz, mert azon belül az adatokat igen hatékonyan lehet kezelni, defragmentálni, stb. De ugyanakkor a nagy allokáció gond is, mert gyakorlatilag egyet létrehozhatsz a VRAM-ban, és abban kell megoldani mindent. Emiatt terjedt inkább az a nézet, hogy a kis allokációk a jók, és abból legyen sok. Így viszont a memória szemetelése harapta meg a fejlesztőket. Az igazság valahol a kettő között van, de nem tudsz mondjuk alkalmazni egy optimális 2 GB-os allokációt, mert azzal nehezen kezeled a kevés VRAM-mal rendelkező kártyákat. Emiatt dolgozta ki a Capcom ezt a megoldást, mert így gyakorlatilag a felhasználó dönti el az allokációk nagyságát. Csak ezt a program oldalán nem nem könnyű ám megírni, hogy ez a rendszer működjön is mindhárom gyártó driverének, amúgy teljesen eltérő memóriavezérlésével.
Az előnyei viszont egészen egyértelműek. Ha nem ez lenne, akkor egy nem HBCC-s 8 GB VRAM-os kártyán csak benyomnád szimplán a High beállítást és kiírná, hogy nincs elég memóriád hozzá. Így viszont egyrészt kiválaszthatod a High 8 GB-ot, amivel azt jelzed, hogy a maximum lehetséges VRAM-ot akarod adni a programnak, amit az alkalmazás ki fog számolni, kb. 6,5 GB lehet, és arra létrehoz egy 6,5 GB-os egybefüggő allokációt, amit könnyű menedzselni. De akár azt is mondhatod, hogy kérsz 4 GB-os allokációt, és akkor lesz neked egy 4 és mellé egy nagyjából 2,5 GB-os allokációd. Az hardver- és driverfüggő, hogy melyik működik jobban, a lényeg az, hogy kapsz egy rakás választási lehetőséget, aminél nem biztos, hogy tényleg megkapod a maximális részletességet, mert a memória fizikailag hiányzik a kártyádról, de jóval jobban jársz, mint a medium opcióval, ami minden textúrát visszavenne közepesre, így viszont csak a textúrák egy részének a minősége csökken, attól függően, hogy a hardvered mit enged.
Azt tudni kell, hogy a fejlesztők képtelenek a hardveren pótolni a hiányzó memóriát, de arra van befolyásuk, hogy ha már van mondjuk 8 GB-os VGA-d, de a medium igazából 6 GB VRAM-ot igényel, akkor azzal a maradék 2 GB-tal kezdjenek valamit. Mert ha szimplán visszavetetnék veled mediumra, akkor buknád ezt az erőforrást.
(#37833) b. : Ebben semmi görénység nincs. Ezzel jól jártok. Megkapjátok a lehetőséget, hogy ha kevés a VRAM, akkor ne kelljen szükségszerűen a közepes részletességet választani, hanem valamelyik magas részletességű opció tud biztosítani bizonyos felületekre magas részletességű textúrákat. Hardverenként eltérő, hogy melyik működik igazán jól, de ki lehet próbálni. Full részletességet amúgy sem kapnának a kevés VRAM-mal rendelkezők, de nem mindegy, hogy minden textúra közepes részletességű lesz, vagy csak egy részük. Ennél jobban ezt nehéz megoldani, mert nem tudod úgy kiszolgálni a 11-16 GB-os hardvereket, meg a HBCC-t, hogy az ne jelentsen hátrányt a 8 GB-os hardvereknek. De a hátrány mértéke csökkenthető. Megcsinálhatták volna azt is, hogy 8 GB VRAM mellett kiválaszthatatlanra rakják a High beállítást. Nekik ez sokkal egyszerűbb lett volna hidd el.
-
Abu85
HÁZIGAZDA
válasz
#34576640
#37807
üzenetére
A HDMI-s FreeSync az AMD zárt rendszere. Azt nem tudja támogatni az NVIDIA. De amelyik monitor DisplayPorton keresztül is támogatja a FreeSync-et, az valahogy működni fog GeForce-szal is. Nem biztos, hogy olyan limitekkel, amit a kézikönyv ér, mert azokat Radeonhoz szabták, de valamilyen szinten menni fog.




 Megkérdeztem már őket, hogy most akkor mi van, csak a hivatalos csatorna lassú.
Megkérdeztem már őket, hogy most akkor mi van, csak a hivatalos csatorna lassú.
 Viszont nagyon jók a hűtés tervezésében. Meglepő, de még az egyszerű bordák ellenére is az ASRock lapjainak a VRM-jei a leghűvösebbek.
Viszont nagyon jók a hűtés tervezésében. Meglepő, de még az egyszerű bordák ellenére is az ASRock lapjainak a VRM-jei a leghűvösebbek.

![;]](http://cdn.rios.hu/dl/s/v1.gif)








 Pedig amióta ott van az Intelnél igen sok jó döntést hozott. Ha anno Perlmuttert választják CEO-nak, már rég előrébb lennének, csak ő meg izraeli volt.
Pedig amióta ott van az Intelnél igen sok jó döntést hozott. Ha anno Perlmuttert választják CEO-nak, már rég előrébb lennének, csak ő meg izraeli volt. 



















Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Őskoczka
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- Formula-1
- Anime filmek és sorozatok
- TCL LCD és LED TV-k
- Kerékpárosok, bringások ide!
- Itt a Galaxy S26 széria: az Ultra fejlődött, a másik kettő alig
- Brogyi: CTEK akkumulátor töltő és másolatai
- BestBuy topik
- Apple MacBook
- További aktív témák...
- HIBÁTLAN iPhone 13 Pro Max 256GB Sierra Blue -1 ÉV GARANCIA - Kártyafüggetlen, MS4302
- AZONNALI SZÁLLÍTÁSSAL Eladó Windows 8 / 8.1 Pro
- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max/
- HIBÁTLAN iPhone 13 Pro Max 256GB Sierra Blue-1 ÉV GARANCIA - Kártyafüggetlen, MS4224
- BESZÁMÍTÁS! Asus B250M i3 6100T 8GB DDR4 240GB SSD GTX 1050 Ti 4GB Zalman T3 Plus DeepCool 400W
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest