-

Fototrend
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
-

Fiery
veterán
válasz
 leviske
#14059
üzenetére
leviske
#14059
üzenetére
Az AVX-512 tobbek kozt azt jelenti, hogy 512 bites vektor adatokkal tud dolgozni az FPU. Kerdes, hogy egy adott muveletet (pl. osszeadas, szorzas, osszeadas+szorzas egyszerre, stb) milyen sebesseggel hajt vegre egy processzor. Ha mondjuk feltesszuk, hogy hasonlokepp implementaljak az AVX-512-t a Kaveriban es a Haswellben is, akkor sajnos a megosztott FPU miatt mindenkepp a Kaveri fog kikapni, eleg csunyan. Kerdes persze, hogy mire az AVX-512 bekerulhet egy AMD processzorba, addigra melyik architektura marad meg vegul az AMD-nel: a mostani Bulldozer, vagy a Kabini alapjat ado Jaguar. Ez utobbinal ugyanis nincs megosztott FPU, viszont az AVX utasitasok vegrehajtasa sem tul gyors. Nem a teljesitmenyre van a Kabini/Jaguar, hanem az alacsony fogyasztasra ugyebar.
A GPU-nak az AVX-512-hoz nem sok koze van. Hacsak nem egy x86 GPU-t (MIC) veszunk, ami AVX-512 alapokon mukodik, de azt leghamarabb 2015 kozepen (Skylake) kapjuk csak meg, ha megkapjuk egyaltalan.
-
#14058
Fiery
veterán
Armagedown
#14057
Fiery
veterán
válasz
 Armagedown
#14057
üzenetére
Armagedown
#14057
üzenetére
Akkor jo esellyel a Kaveri nyerne. De egyelore nincs egyik oldalrol sem minden kihasznalva "rendesen", ugyhogy ezek csak elmeleti kerdesek
 Aztan azt sem tudni pl., hogy a Turbo pontosan hogyan viselkedne a gyakorlatban, ha szokatlan modon az x86 CPU-magok es az iGPU is egyszerre le lenne terhelve maximalisan.
Aztan azt sem tudni pl., hogy a Turbo pontosan hogyan viselkedne a gyakorlatban, ha szokatlan modon az x86 CPU-magok es az iGPU is egyszerre le lenne terhelve maximalisan. -
Fiery
veterán
"Mikor is jön az AVX-512? 2015 elején, közepén, végén?"
Attol fugg, hova, melyik platformra. De 2016 lesz az inkabb. Kiveve, ha az Intel meglep minket azzal, hogy mar a Skylake-ben is ott lesz az AVX-512 (ennek en 1% eselyt adok). Csak ugye azt azert nem szabad elfelejteni, hogy ha most optimalizalsz egy kodot AVX/AVX2-re, akkor pikkpakk at tudod majd dobni AVX-512-re, ha megjelenik. Ergo nem egyfajta igeret az AVX-512, hanem inkabb egy utiterv. Azt uzeni a fejlesztoknek, hogy az AVX ki lesz terjesztve 512 bitre (a kesobbiekben 1024 bitre), ergo erdemes foglalkozni a temaval, mert amit most megirsz AVX/AVX2-re, az utana kis meloval ugrasszeruen fog gyorsulni az ujabb architekturakon.
"Mennyien veszik a fáradtságot AVX assembly programozásra manapság?"
Akik veszik ra a faradsagot, azok specifikus kodot fejlesztenek altalaban, es igy nincsenek a CPU-gyarto altal korbehordozva a mediaban (mint amit most az AMD a HSA-val csinal).
-
Fiery
veterán
válasz
leviske
#14041
üzenetére
Az AVX-512 nem kulonbozik olyan sokban az SSE-tol, csak szelesebbek a regiszterek es tobbfele utasitas van, sok mindent nagyon "kenyelmesen" meg lehet vele oldani. Ha valaki veszi ra a faradsagot, akkor nagyon szep teljesitmenyu kodot lehet AVX-512-re irni. Ha mondjuk a Haswellt (4770K) vesszuk alapul, csak a CPU reszt nezzuk, es mondjuk ebbe pakolunk AVX-512-t, akkor kapasbol magasabb elmeleti lebegopontos teljesitmennyel (866 GFLOPS) gazdalkodhatunk, mint a Kaveri iGPU-janal. Arrol ne is beszeljunk, hogy ha a Skylake-nel -- tegyuk fel -- a CPU es az iGPU is megkapja az AVX-512-t, es az iGPU-t is tudod direktben programozni, akkor az aggregalt lebegopontos teljesitmeny egeszen jopofa mereteket (pl. 1.5 TFLOPS) olthet
Persze inkabb az az eselyes, hogy a Skylake utan, a Goldmont kornyeken konvergal majd csak az AVX-512-vel a CPU es az iGPU, es vegre megszabadulunk a GPU-tol -- ami eddig is csak egy kenyszer szulte nyakatekert megoldas volt. -
Fiery
veterán
válasz
leviske
#14039
üzenetére
A HSA annyibol lehet jo dolog az atjarhatosag/portolas szempontjabol, hogy ha egy adott szoftver adott reszfeladatat HSA-ra fejlesztik (es pl. konkretan OpenCL-ben vagy Javaban irjak meg), akkor az az adott resz remekul portolhato lesz barmilyen HSA-compliant rendszerre. Ez azonban me'g baromi keves, es valojaban nem sokat segit egy komplett szoftver portolasanal.
Hogy egy konkret peldat is mondjak. Pl. vegyuk az AIDA64-et. Egy bazinagy szoftver (cca. 1 millio kodsor mindennel egyutt), amit nagyon nagy melo lenne x86 Windowsrol barmi masra portolni. Ha az AIDA64 OpenCL benchmarkjait atdobod HSA-ra (nem nagy melo), akkor az OpenCL benchmarkokat szabadon tudod onnantol portolni barmilyen mas HSA-s platformra -- ami egyelore nem letezik, hiszen az x86 Windows Kaverival az egyetlen letezo HSA-s platform ugyebar
De ha lenne mondjuk HSA-s OSX vagy iOS vagy Android vagy barmi mas, akkor oda az OpenCL benchmarkokat egyszeruen lehetne portolni. A gond az, hogy magukat a benchmark metodusokat tudod csak igy portolni, minden mast is at kell vinni az uj platformra. Ha pl. csak az OpenCL benchmarkokat nezzuk (es nem az egesz AIDA64-et), akkor a GPGPU Benchmark panelt kellene mint felhasznaloi interfeszt lekodolni az uj platformon, es az ala "betolni" a HSA-s benchmark metodusokat. Nyilvan ez nem egy oriasi feladat, de egy komplett szoftvernel maga a HSA-s resz altalaban marha kicsi/rovid.Azt sem szabad elfelejteni, hogy egy komplett szoftver portolasanal altalaban a felhasznaloi felulet a legnehezebben portolhato, azzal van a legnagyobb gond, ha at kell vinni valahova. Kiveve persze az olyan specialis eseteket, mint az OSX <--> iOS, ahol kicsit konnyebb ezt megoldani. A felhasznaloi felulet ujrairasa/portolasa utan az "engine" portolasa mar altalaban kisebb melo szokott lenni, azzal sokkal konnyebb megbirkozni.
-
Fiery
veterán
válasz
 Thrawn
#14031
üzenetére
Thrawn
#14031
üzenetére
Ahogy Abu is emlitette, a Windows felhasznaloi feluletenek egyes elemeinel jol johet a HSA. De a melyebb szinteken felesleges ilyesmivel kinlodni, nem hoz annyit teljesitmenyben. Raadasul, a HSA-nak pont az a lenyege, hogy az oprendszertol amennyire csak lehet, fuggetlenitse a GPGPU-s szamitasok menedzseleset, kikerulve a hagyomanyos layereket. Ha az oprendszer melyerol felnyulsz a HSA-hoz, akkor az egyreszt baromi rizikos, masreszt meg a HSA alapveto celkituzeseivel elegge szembemenne
-
Fiery
veterán
válasz
leviske
#14029
üzenetére
Az ARM-mal nem az a problema, hogy hogyan torsz be, hanem az a platform ami az ARM alapu cuccokon fut (legyen szo Android, iOS vagy WP8/RT-rol), hogyan teszi lehetove a munkad penzre valtasat. Epp a napokban volt hir rola, hogy egyre kevesbe fizetnek az emberek az app-okert. 1 dollart sem, 1 eurot sem adnak ertuk. Ez a problema, nem az, hogy hogyan torsz be a piacra

A HSA-t (sot az OpenCL-t sem) pedig jelenleg egyik tabletes/mobiltelefonos platform sem tamogatja _altalanosan_. Az asztali Windows lesz az elso, ami ezt tamogatja, azon kell a fejlesztoknek eloszor megbaratkozni a HSA-val.
-
Fiery
veterán
válasz
 stratova
#14015
üzenetére
stratova
#14015
üzenetére
Nem, ez egy nagy semmi. Az AMD utitervein nem szerepel semmilyen hasonlo CPU/APU. A 2, 4 es 8 processzoros szerverek, valamint a nagyteljesitmenyu desktop PC-k (HEDT) piacarol mar kiszallt az AMD. A Warsaw csak egy gyenge faceliftnek tekintheto, lenyegeben egy ujracsomagolt Vishera. A Warsaw utanra viszont nincsenek tervei az AMD-nek, kulonosen nem Steamroller alapokon, amire a linkelt hir utal.
-
Fiery
veterán
-
-
Fiery
veterán
válasz
leviske
#13982
üzenetére
Az alapveto problema az volt, hogy a HP, Lenovo, Dell, Acer kozul egyik gyarto sem vallalta volna be a GDDR5-os PC-t (legyen az alaplap, desktop, notebook, tablet, 2-in-1, 3-in-1, all-in-one, stb). Tul draga a memoria, nem bovitheto, es nem hoz eleget teljesitmenyben. Egy high-end Intel alapu cuccban talan elfert volna egy ilyen megoldas, mint ahogy a Crystal Well-re is van egy igen vekony piac. De amig az Intel reszesedese ezekben a felso regiokban mondjuk 99%, addig az AMD-e legjobb esetben is 1%. Az utobbira nem erdemes epitenie a gyartoknak. Ez van, ilyen az elet...
Mas kerdes, hogy az Asus (ami hires arrol, hogy mindent epit, amit csak el lehet kepzelni) epitett volna-e alaplapot GDDR5 memoriaval. Talan egyet csinaltak volna, ha maskepp nem, koncepcio/prototipus szinten. De egyetlen ilyen potencialis alaplap miatt az AMD-nek nem eri meg levalidalni a GDDR5 tamogatast.
-------
Carrizo leghamarabb jovo ev tavasszal erkezik, de inkabb a szeptember az eselyes. Addig nem hiszem, hogy erdemes varni, ha a Kaveri amugy szimpatikus a potencialis vasarlonak.
-
-
Fiery
veterán
válasz
Thrawn
#13976
üzenetére
A fo ok az volt, hogy nem talalt olyan PC gyartot az AMD, aki bevallalta volna a GDDR5-os alaplapokat vagy notebookokat. Ergo hiaba is validaltak volna le, hiaba lett volna ra referencia konfig, ha csak mondjuk egy szem Asus alaplap keszult volna ily modon el. Arrol meg aztan ne is beszeljunk, hogy manapsag mar sokkal tobb mobil PC fogy, mint desktop, ergo inkabb a mobil vonalon lathato trendek a meghatarozoak.
-
Fiery
veterán
válasz
leviske
#13975
üzenetére
No offense, de nem sokan adnanak 500 dollart egy Kaveri alaplapert...

Sokkal jobban megdobná a koltsegeket a GDDR5, mint amennyit hozna teljesitmenyben. Az sem veletlen, hogy a Crystal Well nem terjed(t) el jobban: az is sokkal dragabb egy alig lassabb Core i5/i7-hez kepest, es nem hoz annyit, nem fizetik meg a vasarlok.
-
Fiery
veterán
válasz
Thrawn
#13972
üzenetére
Benne van minden a Kaveriban, ami a GDDR5 memoria tamogatasahoz kell, csak nem validaltak le, nincs hozza BIOS, stb. A Carrizonal pedig szerintem inkabb DDR4-re fog az AMD rarepulni, mintsem a GDDR5-re. A Carrizonal eleg sok jelentos valtoztatas lesz, pl. 20nm, AVX2, integralt FCH (SoC package), ujgeneracios iGPU, ujabb HSA fejlesztesek, stb. Eleg lesz ezeket osszehozni idore
-
Fiery
veterán
-
Fiery
veterán
válasz
 HeavyToys
#13933
üzenetére
HeavyToys
#13933
üzenetére
"Mantle alatt pedig sokkal jobb az AMD."
Marmint jobb lesz. Olyan jatekokrol van szo, amik nem keszultek el, es amik egy olyan API-t hasznalnak, ami szinten nem keszult el, es me'g egy nyamvadt benchmark score sincs rola. Ja es egy olyan APU-rol van szo, ami hivatalosan nem kaphato me'g, de kozben megis; es valojaban nincs az IGP-jehez video driver, tehat nem is tudsz jatszani rajta D3D alatt sem
![;]](//cdn.rios.hu/dl/s/v1.gif) De persze van driver, csak nem publikus, es valojaban tok gyors, csak varni kell kicsit, hogy kijojjon a publikus driver
De persze van driver, csak nem publikus, es valojaban tok gyors, csak varni kell kicsit, hogy kijojjon a publikus driver -
Fiery
veterán
válasz
stratova
#13915
üzenetére
Arra mondjuk kivancsi lennék, hogy egy jatek milyen alapon donti majd el, hogy mikepp ossza le a melot a rendelkezesre allo eroforrasok kozt. Pl. baromira nem mindegy, hogy egy eros dGPU (pl. R9 290X) van parositva egy gyenge iGPU-val (pl. A4-7300), vagy egy gyenge dGPU (pl. R7 240) egy eros iGPU-val (pl. A10-7850K). Ezt tovabb bonyolitja a mobil APU kerdese dGPU-val parositva (ha egyaltalan lesz ilyen Kaveri alapon), meg persze a CrossFire. Lehet persze mindenfele profilokat pakolni a Catalystba es/vagy a Mantle-os jatekokba, de a PC sokszinusege miatt erosen fuzzy logika lenne mindenre felkesziteni a jatekokat
A masik lehetoseg -- talan igy is lesz majd --, ha a Mantle-t tamogato jatekoknak lenne egy kalibracios modjuk, amivel felterkepezik az eroforrasokat, kiprobalnak nehany fele megoldast, ide-oda pakolgatva a feladatokat, es megnezik, hogy melyik megoldas szolgaltatja a legmagasabb FPS-t. Ami persze a PowerTune miatt megint nem feltetlenul fog korrektul mukodni
Izgalmas lesz ez. -
#13879
Fiery
veterán
BlueAthlon
#13877
Fiery
veterán
válasz
 BlueAthlon
#13877
üzenetére
BlueAthlon
#13877
üzenetére
Erdemes az AIDA64 Cache & Memory Benchmark Panel-rol beszurni egy shotot, azon latszodik a north bridge orajel is.
-
Fiery
veterán
válasz
 Valdez
#13676
üzenetére
Valdez
#13676
üzenetére
130-140W TDP mellett be tudna pakolni 16 db GCN2 CU-t is az AMD, de akkor aztan vegkepp nem lenne eleg ala a memoria savszelesseg. A jelenlegi keretek kozt a 8 CU-s APU a "sweet spot", aztan majd a Carrizo utan johet a 12 vagy 16 CU, ha lesz hozza izmos DDR4. Addig meg oruljunk (majd, januar kozepen) annak, hogy a 8 CU-s iGPU is eleg komoly elorelepes a Trinity/Richlandhez kepest, es siman hozza egy par generacioval ezelotti csucs dGPU szintjet, APU-bol

-
Fiery
veterán
válasz
leviske
#13667
üzenetére
Ha a nyers savszelessegrol beszelunk, akkor teljesen mindegy, hogy dGPU-rol vagy iGPU-rol van szo. A CPU is mindegy. Persze megint mas kerdes, ha abbol a szemszogbol nezzuk a dolgot, hogy mikepp tudod kihasznalni a GPU szamitasi erejet: ott a Mantle es a HSA sokat segithet (majd), es reszben ellensulyozhatja is a relative szukos savszelesseget.
-
Fiery
veterán
válasz
leviske
#13589
üzenetére
A slide aljan a csillagos megjegyzest is olvasd hozza a 20%-hoz
 Plusz vedd hozza, hogy jelen allas szerint kb. 10%-kal alacsonyabb orajelen startol a Kaveri, mint az A10-6800K (Richland csucsmodell). Ergo az x86 resz teljesitmenye jo esellyel nem lep elore szinte semmit, legalabbis kezdetben.
Plusz vedd hozza, hogy jelen allas szerint kb. 10%-kal alacsonyabb orajelen startol a Kaveri, mint az A10-6800K (Richland csucsmodell). Ergo az x86 resz teljesitmenye jo esellyel nem lep elore szinte semmit, legalabbis kezdetben. -
Fiery
veterán
válasz
Valdez
#13583
üzenetére
Igy igaz. De velhetoen a mobil termekeknel mindenkepp kell hogy legyen elorelepes a Richlandhez kepest. Maskepp nagyon le fognak maradni az ultrabook vonalon a Haswellhez kepest, legalabbis akkumulatoros idoben. A desktop vonalon mas a fokusz, ott nem a fogyasztasra figyel leginkabb az AMD, hanem inkabb a feature-okre es az iGPU teljesitmenyre. PCIe SSD-k kozvetlen csatlakoztatasa, HSA, 8 CU-s GCN2 iGPU, TrueAudio, stb, lasd a fenti slide-ok.
-
Fiery
veterán
válasz
 Oliverda
#13571
üzenetére
Oliverda
#13571
üzenetére
Valahol barmilyen GPU konkurencia az Intelnek, ugyhogy jol meg kell valogatnia, hogy mit gyart masoknak. De az nVIDIA-nak nemigen lesz mas eselye az AMD GCN2+Mantle kombo ellen, hacsak nem tudnak legyartani brute force alapon valami brutal nagy es sok shaderes GPU-t (amihez kellene egy 1x nm processz); vagy ha nem allitanak konkurenciat a Mantle-nak. Persze aztan az is lehet, hogy az nVIDIA idovel kivonul a GeForce dGPU piacrol, es a Teslakra, Quadrokra meg az SVM-es ARM+iGPU vonalra fokuszalnak inkabb.
-
Fiery
veterán
válasz
Oliverda
#13566
üzenetére
"Remélem legalább az NV tud gyártat majd velük valamit, mert akkor legalább valami konkrétabb viszonyítási alap lesz a TSMC-hez képest."
Egy 10-12 milliard tranzisztoros brutal Maxwell GPU-t az Intel-fele 14 nanon azert megnéznék
 A GCN2+Mantle parossal szemben lehet, hogy me'g az is keves lenne a jatekokban, de legalabb a GPGPU piacon tudna megint villantani egyet az nVIDIA.
A GCN2+Mantle parossal szemben lehet, hogy me'g az is keves lenne a jatekokban, de legalabb a GPGPU piacon tudna megint villantani egyet az nVIDIA. -
Fiery
veterán
válasz
leviske
#13567
üzenetére
Amig az AMD reszesedese a teljes x86 piacbol 2 szamjegyu, addig az Intel nem fog ra nem-konkurenskent nezni. Amit a VIA csinal, az mas teszta, ok nem tetel az Intelnek, nyilvan, de az AMD epp most izmozik, helyezkedik egy csomo fronton (konzolok, Mantle, HSA, Jaguar), pont most kell odafigyelni ra, nem "szem elol teveszteni"
-
Fiery
veterán
válasz
Oliverda
#13564
üzenetére
Meglepo, de valahol ertheto. Velhetoen az Intel gyarai nagyon rossz kihasznaltsaggal uzemelnek manapsag (a PC-piac zsugorodasa + a globalis gazdasagi valsag egyuttes hatasara), es me'g az FGPA bergyartassal sem sikerult kihasznalni a meglevo kapacitasokat. Logikus lepes, bar ezzel adott esetben a konkurenciat is erositheti az Intel. Mondjuk arrol nem szol a fama, hogy egy konkurens termek gyartasara pl. adhat irrealisan magas arajanlatot is az Intel, hogy ezzel riassza el a nem annyira kivanatos gyartokat -- de kozben meg ugy allithatja be magat, hogy mindenki szamara nyitottak a gyarai
De ez csak spekulacio meg gonoszkodas a reszemrol. Mindenesetre meg lennék lepodve (a mostaninal is jobban), ha (ARM vagy x86 alapu) CPU-kat gyartana az Intel masoknak, legyen szo AMD-rol, Apple-rol vagy barki masrol. Az nVIDIA dGPU-ban tobb raciot látnék, azzal adott esetben az Intel es az nVIDIA osszefogva alá tudna pörkölni kicsit az AMD-nek (ld. Mantle). -
Fiery
veterán
válasz
Thrawn
#13553
üzenetére
"Az Intel is szóba jöhetne, végülis gyártanak FPGA-t 14 nm-en más cégnek
"Poennak jo volt
 Az Intel csak a szamara nem konkurens termekeket gyart masoknak. Ha nagyot lazitananak is ezen a hozzaallason, akkor is max. az elkepzelheto, hogy mondjuk az nVIDIA-nak gyartsanak dGPU-kat 14 nanon, annal tobb semmikepp. De az is kizart egyebkent
Az Intel csak a szamara nem konkurens termekeket gyart masoknak. Ha nagyot lazitananak is ezen a hozzaallason, akkor is max. az elkepzelheto, hogy mondjuk az nVIDIA-nak gyartsanak dGPU-kat 14 nanon, annal tobb semmikepp. De az is kizart egyebkent -
Fiery
veterán
válasz
leviske
#13542
üzenetére
Magukat a HSA-ra optimalizalt szoftvereket ez nem igazan erinti. Fejlesztoi szempontbol a Kaverin is remekul lehet (majd) dolgozni. Nincs me'g teljesen kesz az SVM implementacioja a Kaverin, de azok a kisebb puzzle darabok, amik kimaradtak, a Carrizoval potlasra kerulnek. A "klasszikus" HSA evolucios slide-on jol latszik, hogy a 2014-re tervezett (Carrizo) feature-okkel egyutt lesz teljes a HSA -- de ezek mar nem olyan nagy dolgok, marmint a HSA-ra valo fejlesztest ezek nem hatraltatjak:
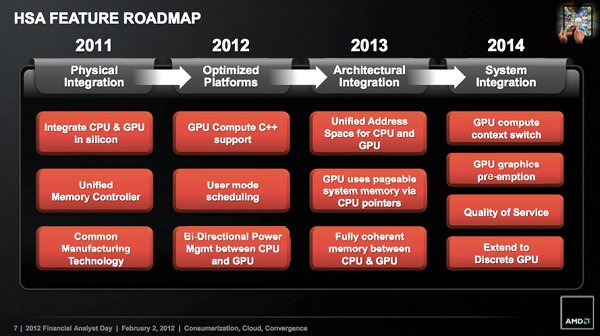
Meg persze az L2 cache kezeles nem teljesen optimalis a jelenlegi (Richland, Kaveri) felallasban, de az nem jelent problemat a HSA-nal.
-
Fiery
veterán
válasz
 zsolt320i
#13540
üzenetére
zsolt320i
#13540
üzenetére
Carrizo, FM2+ tokozas, belemegy a most mar kaphato FM2+ alaplapokba. Varhatoan 2 modul / 4 mag, 4 GHz koruli orajelek, AVX2 tamogatas, szelesebb vegrehajtoegysegek, full HSA, Mantle, TrueAudio, tovabbra is Bulldozer csalad, tovabbra is 28 nm. A GCN alapu iGPU-ja minden bizonnyal atlepi az 1 TFLOPS-os "alomhatart".
-
Fiery
veterán
válasz
Oliverda
#13526
üzenetére
No offense, de a kodnevet konnyebb leptetni, mint az IPC-t feljebb tornaszni
Az Intel Atom vonalon se volt tul sok valtozas a Bonnell es Saltwell kozott (leszamitva a processzt), aztan megis uj kodnevet adtak neki Itt meg legalabb maga a teljes APU SoC feljebb (pontosabban lejjebb) lep egy szintet TDP-ben, me'g ha nem is feltetlenul az architekturanak koszonheto a fejlodes. -
-
Fiery
veterán
Ez egyebkent remek magyarazat lenne arra, hogy funkcionalisan miert nem valtozott a Beema/Mullins a Kabini/Temash-hoz kepest. Mert en szemely szerint nem ertettem azt, hogy mi a kulonbseg az elozo generaciohoz kepest. Hiszen funkcionalitasban -- legalabbis az AMD dokumentacioi szerint -- lenyegeben nincs kulonbseg, SVM-et sem tamogat még az uj generacio, azonos processzen keszul, szinte azonos a tokozasa, azonos a magszam, latszolag nagyon hasonlo az iGPU-ja is, stb. De ha az egesz Beema/Mullins lenyege az, hogy a performance/Watt mutatot egy jo nagy lepcsovel feljebb nyomjak, akkor mar vilagos minden, igy varjuk szeretettel, a Bay Trail-t igy siman le tudjak nyomni majd, es nem csak iGPU-ban. Foleg arra leszek kivancsi, hogy clock-for-clock is lesz-e fejlodes a Kabini/Temash-hoz kepest, vagy "csupan" azonos orajelen fog kevesebb TDP-vel gazdalkodni a Beema/Mullins. Furcsa lenne, ha az architekturaba is melyen belenyultak volna, mikozben a funkcionalitast valtozatlanul hagytak, de vegul is nem lehet kizarni ezt a lehetoseget sem.
-
Fiery
veterán
válasz
 #24650752
#13497
üzenetére
#24650752
#13497
üzenetére
Kinek mi a jelentos. Ha azt nezzuk, hogy Richland = 844 MHz (iGPU), Kaveri = 720 MHz, az majdnem 15% difi negativ iranyban, nekem az jelentos. Aki tuningban er el a masik iranyban 15%-ot, azt is jelentosnek szokta titulalni
4000 MHz-rol 4600 MHz-re nem elhanyagolhato tuning peldaul.Teny, hogy ha az iGPU-t nezzuk, ott onmagaban a 33%-kal megnovelt CU-szam is tudja ellensulyozni az alacsonyabb orajelet (vs. Richland), ergo semmikepp sem lehet visszalepesrol beszelni. A problema nem is ott van, hanem inkabb az x86-reszben, de mivel sokan szeretnek leugatni engem, amikor barmi rosszat mondok barmilyen AMD termekrol, igy inkabb varjuk meg a januari release-t, majd leteszteli a media, es kiderul, hogy mire lesz jo az akkori Kaveri, az akkori orajelen, az akkor hasznalatos szoftverekben es benchmarkokban. Az fix, hogy az iGPU-val nem lesz gond, ez mindenkepp jo hir.
-
Fiery
veterán
válasz
#24650752
#13494
üzenetére
+10% es megvan, persze csak ha a memoria savszelesseg nem jelent problemat. De ez csak egy teszt, mas tesztekben kicsit maskepp viselkedhet a Kaveri. De mivel a Cape Verde es a Kaveri is GCN alapu, igy az arányok nagyjabol jol saccolhatoak. Jatekra mindenkepp cool lesz a Kaveri. Mantle-vel meg harapni fog

-
Fiery
veterán
Csak hogy ON is legyen es poztiv info, meg hogy elkezdjek vezekelni az elmult napokert
 Futtattunk Richland vs. Kaveri benchmarkot, iGPU-n, azonos CU (6) szam mellett, azonos iGPU orajelen, azonos CPU magorajelen, azonos memoria orajelen, CPB OFF, APM OFF allasban, OpenCL 1.x, semmi HSA varazslat, klasszikus GPGPU szamitasi feladat. Nem FLOPS, hanem egy konkret szamitasi feladat, ami valodi munkat vegez, nem csak porgeti a CU-kat. Single-precision floating-point tesztben tobb mint masfelszeres teljesitmenyt nyom a Kaveri a Richlandhez kepest, double-precision detto. Ennyivel hatekonyabban lehet etetni a GCN feldolgozokat a VLIW4-hez kepest. Nyilvan ez csak egyetlen (pontosabban 2) teszt, es nyilvan nem ennyire kedvezo a helyzet minden felhasznalasban, de az azert jol latszik, hogy a Kaveri iGPU-jaba tenyleg nehez lesz belekotni, legalabbis ha mas iGPU-kkal vetjuk ossze. A HSA egyebkent ezen a konkret teszten nem segitene, nem lenne tole gyorsabb, max. a kernel launch ideje lenne kicsit rovidebb.
Futtattunk Richland vs. Kaveri benchmarkot, iGPU-n, azonos CU (6) szam mellett, azonos iGPU orajelen, azonos CPU magorajelen, azonos memoria orajelen, CPB OFF, APM OFF allasban, OpenCL 1.x, semmi HSA varazslat, klasszikus GPGPU szamitasi feladat. Nem FLOPS, hanem egy konkret szamitasi feladat, ami valodi munkat vegez, nem csak porgeti a CU-kat. Single-precision floating-point tesztben tobb mint masfelszeres teljesitmenyt nyom a Kaveri a Richlandhez kepest, double-precision detto. Ennyivel hatekonyabban lehet etetni a GCN feldolgozokat a VLIW4-hez kepest. Nyilvan ez csak egyetlen (pontosabban 2) teszt, es nyilvan nem ennyire kedvezo a helyzet minden felhasznalasban, de az azert jol latszik, hogy a Kaveri iGPU-jaba tenyleg nehez lesz belekotni, legalabbis ha mas iGPU-kkal vetjuk ossze. A HSA egyebkent ezen a konkret teszten nem segitene, nem lenne tole gyorsabb, max. a kernel launch ideje lenne kicsit rovidebb. -
Fiery
veterán
"de szerintem mindenkinek úgy tűnik, hogy te kárörvendesz ezen."
Legfeljebb neked.
"Amit a kacsintól smiley is csak erősít."
Marmint szerinted. Kerj a forum fenntartoitol egy kulon "karorvendoen kacsinto" es egy "kacsintos, de nem karorvendo" smiley ikont, hogy egyertelmu legyen, hogy melyiket kell hasznalni. Hidd el, onnantol mindenki oda fog figyelni arra, nehogy Dezz felreertse a felhasznalt smiley tipusat. Addig meg kerlek ne taplald bele masokba a sajat velemenyedet es elkepzeleseidet, plane amikor nyilvanvalo rosszindulat vezerel.
-
Fiery
veterán
"Megtudhatnám, miért
van a hsz-ed végén helyett?"A kacsintos smiley annak szolt, amit elotte TESCO-Zsömle irt ("komoly egy roadmap"). Nem oromot fejezett ki. Engem teljesen hidegen hagy, hogy mikor jon a Carrizo. Pontosabban nem, hiszen sok szempontbol is fontos nekem az, hogy mikor jelenik meg, de nem leszek szomoru, ha kesobb jon, mint X idopont, es nem leszek boldog, ha hamarabb.
-
Fiery
veterán
A HSA terjedese szempontjabol nagyobb baj, hogy a Beema/Mullins sem tamogat HSA-t. A Kaveri HSA tamogatasa alapvetoen nem rossz, bar nem full HSA me'g mindig, de a fejlesztok szamara mar "eleg jo" ahhoz, hogy dolgozzanak vele. A Kaveri mint SVM-capable hardver, ha egy HSA fejleszto szemszogebol nezzuk, teljesen korrekt cucc, jol lehet vele dolgozni. Az orajelek meg nem szamitanak a fejlesztesnel tul sokat
Nagyobb baj, hogy nincs me'g beta allapotu HSA implementacio (szoftver stack) sem, hanem csak alpha, ami nem tartalmaz full funkcionalitast, lassu es bugos is nehol; no meg nem elerheto barki szamara. Nem veletlen, hogy az AMD nem demozta a HSA-t "eloben" az APU'13-on, gyakorlatilag nem volt mit demozni. Mukodik egyebkent az alpha HSA stack, marmint lehet vele HSA-compliant OpenCL 2.0 kernelt forditani es futtatni, csak epp joval lassabban, mint az OpenCL 1.x compile path segitsegevel, ugyanazon a vason. Ez annak koszonheto, hogy a regi, jol bevalt OpenCL --> AMD IL compilert kukaznia kellett az AMD-nek a HSA miatt, es helyette elkezdenie a nullarol fejlesztenie egy OpenCL --> HSAIL compilert. Ez utobbinak az allapota pedig erosen felkesz jelenleg, legalabbis ami a teljesitmenyt illeti.Az ARM-os szereplok munkajanak helyzeterol nem tudok semmit, de meg lennék lepodve, ha elorebb jarnanak, mint az AMD a sajat implementaciojaval. En a magam reszerol ugy gondolom, hogy az elkovetkezo 6 honap soran fog eloallni az AMD egy beta allapotu HSA implementacioval, ami mar publikus lesz, es barmelyik fejleszto (nem csak azok, akik a tuzhoz kozelebb ulnek, NDA alatt vagy maskepp) elkezdhet dolgozni vele. Az azutani 6 honap soran varom a stabil HSA implementacio megjeleneset, azaz mire a Carrizo megjon, addigra lesz ugymond kesz a HSA, szoftver es hardver oldalrol is. Az megint mas kerdes, hogy a szoftver fejlesztok mennyire harapnak ra a HSA-ra, mennyire sok HSA-optimalizalt szoftver jelenik meg jovore. Ha tippelnem kene, mondjuk 10-20 db szoftvert mondanek, legalabbis ha a beta allapotu implementaciokat is szamba vesszuk. Kerdeses persze, hogy ezek kozul a szoftverek kozul mennyi lesz majd altalanosan is felhasznalhato szoftver (pl. en a WinZip-re szamitok jovore), es mennyi lesz specifikus, szuk kor szamara keszulo szoftver (pl. CAD/CAM, kutatas, idojaras modellezes, stb), vagy epp HSA benchmark (pl. a CompuBench vagy az uj PCMark).
-
Fiery
veterán
Desktopra me'g johet a Carrizo jovore, arra van esely, de azert jo lenne latni egy friss desktop roadmapet. Ha nem keszul el 2014 vegere a Carrizo, akkor szinte biztos, hogy cca. 1 ev mulva bedob az AMD egy Richland-szeru koztes core-t ("Kaveri Refresh") a Broadwell-K elleneben.
-
#13474
Fiery
veterán
TESCO-Zsömle
#13473
Fiery
veterán
válasz
 TESCO-Zsömle
#13473
üzenetére
TESCO-Zsömle
#13473
üzenetére
Annyi legalabb kiderult rola, hogy a mobil Carrizo nem jon jovore, csak leghamarabb 2015-ben
-
-
Fiery
veterán
A K10 elott volt egy K9, ami kukazva lett, ott kezdodott a rossz szeria. Tehat K9, K10, Bulldozer, Komodo, ez nem csak egy atmeneti benazas meg 1-2 rossz ev, hanem folyamatos benazas. Lenyegeben az ATI felvasarlasa ota nincs teljesitmenyben is versenykepes x86 CPU-ja az AMD-nek. Pusztan veletlen egybeeses?
Az Intelre meg lehet mutogatni, de attol, hogy valaki nyomas alatt van, me'g lehet jo termeket tervezni, pl. az Opteronok a nehez idoszakban is eljutottak rengeteg gyarto gepebe. Aztan meg kikoptak megint, mert megint volt jobb valasztas. -
Fiery
veterán
Nem egy lufirol beszeltem, hanem tobb lufirol. K10, Bulldozer, Komodo, most meg a HSA. De ahogy fentebb is leirtam, ne legyen igazam a HSA-val kapcsolatban.
"az AMD segítsége nélkül zátonyra futott volna a projekt, az ATI pedig valószínű csődbe jutott volna."
Remelem, itt a penzugyi segitsegre gondolsz, es nem a mernokire
"Az AMD mérnökei segítettek kipofozni."
Persze, egyik naprol a masikra felvasarolsz egy GPU-gyartot, majd te segitesz nekik ugy a mernoki gardaddal, hogy elotte neked semmilyen GPU-fejlesztesi tapasztalatod nem volt. Abszolut eletszagu.
"A GCN-t pedig már együtt hozta létre a két cég mérnökeiből álló csoport."
Nyilvan egyutt hoztak letre, hiszen a Fusion projekt megkovetelte, hogy bizonyos szempontbol egymasnak rendeljek ala a fejleszteseket. De az azert megiscsak furcsa, hogy az AMD-s felvasarlas ota nem tudott az ATI reszleg rossz termeket produkalni, mig az AMD x86 magokkal kapcsolatban hat finoman szolva sem csak success story-k voltak az utobbi 5-6 evben.
"A megfogalmazásod is elég furcsa: ha van kivétel, akkor nem mondhatod, hogy csak a GPU-ik jók."
Egyetlen udito kivetel van, igy igaz. Eleg sovany vigasz.
-
Fiery
veterán
A lelkesedessel nincs baj. A tulzott lelkesedes nem celravezeto, plane ha csupan azon alapszik, hogy a gyarto felfuj egy szep nagy lufit
A tenyek viszont azt mutatjak, hogy amiota az AMD megvette az ATI-t, azota az ATI-nak van AMD-je, es nem forditva. Maskepp fogalmazva: csak azok a termekek utnek nagyot, ahol az ATI vonal a dominans, azaz ahol a GPU kore epul a termek. Kivetel ez alol a Jaguar, ott az AMD (CPU) resz is remek. -
Fiery
veterán
Engem nem zavar semmi, csak az szokott mosolyt csalni az arcomra, amikor egy adott marka fanjai a nyilvanvalo tenyeket is figyelmen kivul tudjak hagyni
Es a makacs tenyeket is konkret tamadasnak veszik az imadott marka ellen. Ja, meg az is mokas, amikor a jovorol jelen idoben kepesek beszelni, mint ha mar megnyertek volna egy me'g el sem kezdodott haborut Akinek nem inge, ne vegye magara persze. -
-
Fiery
veterán
válasz
Oliverda
#13424
üzenetére
"Finally, the performance values of L1 and L2 cache should reach those of Intel Ivy Bridge and Haswell."
Bulls***. Abszolut ertekben a Kaveri az Ivy Bridge sebesseget nem hogy nem eri el, de a legtobbszor meg sem kozeliti. A Haswellrol mar ne is beszeljunk, az fenyevekre van cache tekinteteben a Kaveritol.
Richland A10-6800K (read/write/copy/latency):
- L1 = 273868 / 49961 / 101432 / 0.9
- L2 = 179671 / 47835 / 87232 / 9.3Ivy Bridge 3770K (read/write/copy/latency):
- L1 = 472238 / 236482 / 471848 / 1.1
- L2 = 243322 / 153415 / 221859 / 3.3Haswell 4770 (read/write/copy/latency):
- L1 = 817131 / 346839 / 755005 / 1.1
- L2 = 356945 / 148899 / 221798 / 3.5A Turbo miatt kicsit nehez orajelciklusra atszamolni ezeket, de azert az arányok jol latszodnak igy is. Ha megis at akarod szamolni, akkor a Richland kb. 4.30 GHz-en, az IVB kb. 3.70 GHz-en, a HSW kb. 3.40 GHz-en futott a benchmark kozben. Persze le kell osztani core-okra is, stb, nem egyszeru az architektura kepessegeig leasni. De a nap vegen ugyis az szamit, hogy az adott orajelen, az adott magszam mellett mire is kepes a cucc osszessegeben.
-
Fiery
veterán
"A CUDA az olyan dolgot nem kínál, amit az OpenCL ne kínálna fel. Még csak gyorsabb programok sem írhatók benne. Az OpenCL-lel alapvetően ugyanúgy tudod használni bármelyik GPU-t, mert a lényeges dolgokban egyezik a CUDA és az OpenCL. Némileg persze más a körítés, de amit CUDA-ban megírsz azt legalább ugyanolyan jól meg tudod írni OpenCL-ben."
...
"A fejlesztői oldalon a CUDA-t azért cserélik manapság OpenCL-re, mert pont ugyanarra jó, így felesleges két fejlesztési irányt fenntartani. Ha csak az OpenCL-re koncentrálnak a fejlesztők, akkor összességében még jobb is lehet a sebesség, mintha írnának CUDA és OpenCL portot egyszerre. Ez egy előnyös dolog a piac minden résztvevőjének: kevesebb fejlesztéssel gyorsabb programok, melyek futnak minden gyártó újabb hardverein. Minden szempontból win-win szituáció."Kivetelesen 100%-ig egyetertek Abuval. Mi is gondolkoztunk azon, hogy az OpenCL GPGPU stressz tesztet vagy az OpenCL GPGPU benchmarkokat portoljuk-e CUDA-ra, de semmi ertelme. Ugyanazt a funkcionalitast, ugyanazt a teljesitmenyt kapod. Sot, ha jol tudom, a ForceWare az OpenCL kodot az elso forditasi fazis utan mar a CUDA feluleten keresztul forditja tovabb es futtatja le, ergo tok mindegy, melyiket hasznalja az ember. Amikor az OpenCL-ben me'g nem lehetett lekerdezni pl. az NVCC-t (Compute Capability), azaz detektalni a GPU generaciojat (pl. Fermi vs. Kepler, GK10x vs. GK110, stb), addig talan volt ertelme a CUDA-nak, mert jobban lehetett specifikusan optimalizalni. De most mar az OpenCL-en at is 100%-osan lehet detektalni az nVIDIA GPU tipusat, az NVCC-t es a PCI eszkozt is, ergo ez az elonye is elveszett a CUDA-nak.
A Mantle kapcsan egyebkent hamarosan beszamol az AMD reszletesen is az API-rol, en szemely szerint nagyon kivancsi leszek ra, mert ha eleg jol van kitalalva, akkor baromi sok mindent ki lehet majd belole hozni. Mondjuk en azert is orulok a Mantle-nak, mert vegre valami felbolygatja az allovizet. Ahogy az angol mondja: S*it hits the fan
-
#13405
Fiery
veterán
Ricsiii1992
#13404
Fiery
veterán
válasz
 Ricsiii1992
#13404
üzenetére
Ricsiii1992
#13404
üzenetére
Piledriver modulos FX most is van, Visheranak hivjak. Lesz majd valami frissites az FX platformra jovore (Warsaw kodnevu FX proci, tovabbra is AM3+ foglalatba), de velhetoen csak egy kis orajel emelesben, esetleg szofisztikaltabb CPB mukodesben ki fog merulni a frissites, hasonloan a Trinity --> Richland valtashoz
Az AMD mar egy jo ideje hallgat az FX vonalrol, legalabbis sem Steamrollerre, sem Excavatorra epulo FX-ekrol nincs szo az utitervukben.A TDP pedig egyeni dontes kerdese. Az FM1, FM2, FM2+ platformokat eleve max. 100 Wattra terveztek, ennel feljebb menni nincs sok ertelme. A sok magnak meg abbol a szempontbol nincs ertelme, hogy nem hozna ugysem annyit a konyhara teljesitmenyben, mint amennyivel dragabb es nehezkesebb lenne legyartani. Ez a mostani 2 modulos, eros iGPU-val tarsitott megoldas az AMD "sweet spot"-ja, amihez ugy tunik, ragaszkodni is fognak, hacsak valami alapvetoen nem valtozik meg a mostani mainstream desktop/mobil piacon. Amire leghamarabb 2015-ben lehet esely, a Skylake formajaban. De az is lehet, hogy az megint csak "business as usual" lesz, a Haswellnel kicsivel erosebb CPU-val, es 20-30%-kal erosebb iGPU-val -- az esetben pedig nem fogja a Skylake sem felforgatni a mostani piacot.
-
#13397
Fiery
veterán
tatararpad
#13395
Fiery
veterán
válasz
 tatararpad
#13395
üzenetére
tatararpad
#13395
üzenetére
Kaveribol letezik (ES verzioban) 65 Wattos, FM2+ foglalatos valtozat. Velhetoen ennel alacsonyabb TDP-vel is megjelenik majd idovel FM2+-ba.
-
-
Fiery
veterán
Oke, de ha innen nezzuk, akkor a Kaveri marad a bejelenteskori orajeleken, es majd a Carrizo fogja megint felnyomni az orajelet oda, ahol a Richland van most. Vagy a Carrizo csuszik fel-egy evet, es jon egy uj, koztes core (mint a Richland anno), ami egyenlo lesz a Kaverival, csak Richland orajeleken fog futni. Ertem en, tok logikus
De mindez semmit nem valtoztat azon a tenyen, hogy valami a Kaveri orajelei korul nem gombolyu. -
Fiery
veterán
"hogy viszonylag alacsonyabb órajelen vezeti be a termékeit, később pedig, ahogy tudja, folyamatosan növeli azt"
Ez a Trinitynel meg a Richlandnel is igy volt? Mert nekem baromira nem igy remlik. Hanem pont ugy, hogy az A10-5800K es a A10-6800K kijott a bejelenteskor, es utana nem jott utanuk magasabb SKU.
Teny, hogy az FX vonalon elofordult az ilyen faragas menet kozben, de most az APU-krol van szo, nem a hagyomanyos ertelemben vett CPU-krol. Megjegyzem, a Llanonal is csak +100 MHz-et sikerult kifacsarni menet kozben, ha jo remlik:
Ehhez kepest, most a Kaverinel nem 100 MHz-rol beszelunk (amennyivel alacsonyabb a CPU orajele, mint a 6800K-nak), hanem joval tobbrol. Remelem, be tudja hozni az AMD, mert amig nincs _kezzel foghato_ HSA, addig max. azoknak lesz tuti valasztas a Kaveri, akik mondjuk sokat jatszanak es nem akarnak dGPU-t venni.
-
Fiery
veterán
"Ők mind írják a szoftvereket."
Tehat megint jovo idorol van szo, oke, csak gondoltam tisztazzuk
Tehat a HSA ugy terjed, hogy egyre tobben foglalkoznak a dologgal, gondolkoznak rajta, esetleg mar fejlesztenek valamit HSA-ra. Ez is egyfajta terjedes, vegul is, de en inkabb akkor mondanam terjedesnek, amikor hetente egy-egy hir jon majd arrol, hogy epp milyen HSA-capable szoftver (vagy jatek) jelenik meg a piacon. No meg nem artana hozza egy stabil HSA SDK sem..."Most fejlődött a legtöbbet a belső north bridge-IMC"
Feature szinten igen. Csak nem teljesitmeny szinten.
-
Fiery
veterán
válasz
Oliverda
#13368
üzenetére
Annak mi koze barmihez is? No offense... Az legfeljebb abbol a szempontbol relevans, ha azt nezzuk, a Zambezi utan a Vishera milyen elorelepes. Az APU-knal nem is volt bdver1 alapu AMD termek. Az APU-knal a Llano --> Trinity --> Richland --> Kaveri vonalat erdemes vegigkovetni. Orajelben vegig jott az elorelepes, es az elso valtasnal architekturaban is jelentos volt a fejlodes (minusz a megosztott FPU, ugyebar). Ez most -- legalabbis ahogy en latom a dolgokat -- megbicsaklott, hiszen most a CPU resz eseteben nincs jelentos architekturalis fejlesztes (legalabbis ami teljesitmenyben hozhatna komolyabb elorelepest), az orajelek meg elindultak a visszafejlodes utjan.
Arrol nem is beszelve, hogy a Llano --> Trinity --> Richland vonalon peldaul az IMC is folyamatosan fejlodott, gyorsult, most meg mar az se fejlodott tovabb. Nincs DDR4, nincs GDDR5, nincs magasabb orajel a DDR3-hoz, nincs plusz mem.csatorna.
-
Fiery
veterán
"tekintve, hogy a vártnál sokkal gyorsabb a HSA terjedése"
Hol vannak a HSA implementaciok? Hol vannak a HSA-ra irt szoftverek? Vagy ugy erted, hogy az elozetes varakozas az volt, hogy az implementacio (mondjuk az AMD HSA SDK) 1 ev mulva keszul el, es akkorra lesznek kesz az elso HSA-t kihasznalo szoftverek; de kozben most meg ugy fest a dolog, hogy 6 honapra modosult mindket datum mostantol szamitva?
A karogast meg en nem csak a driverek kapcsan hallottam, olvastam, hanem a nyers CPU ero kapcsan foleg. Az emberek hozzaszoktak az olyan valtasokhoz, mint a P4 utan a Conroe, a Lynnfield utan a Sandy Bridge (stb), amikor no az orajel (me'g ha csak Turboval is), es no az IPC is. Most meg megallt -- latszolag -- az Intel is (ha az AVX2-t es az FMA-t nem szamoljuk), az AMD is, sot, elindultak visszafele (Kaveri, orajelben).
-
Fiery
veterán
válasz
Oliverda
#13366
üzenetére
A Llano --> Trinity (Stars --> Piledriver) valtas _sokkal_ tobb mindent hozott, mint Richland --> Kaveri (Piledriver --> Steamroller), legalabbis ha a CPU reszt nezzuk. De 1 het mulva kiderul minden
En szemely szerint nem lennék meglepodve, ha az AMD egyetlen benchmarkot se mutatna be az APU'13-on, amiben nincs valamilyen szerepe az iGPU-nak De majd a fuggetlen media bemutatja, hogy mit tud a Kaveri CPU-ban is, iGPU-ban is. -
Fiery
veterán
válasz
Oliverda
#13360
üzenetére
Megis mivel tudná kompenzalni?
Oke, kicsit faragnak az L1 data cache-en meg az L2 cache-en, de a CPU magok alapvetoen nem valtoznak, es nem kap mas vagy jobb memoriavezerlot sem az APU. Vagy ha mindent osszeadunk, optimistan vesszuk a dolgokat, akkor tegyuk fel, hogy CPU-ban ugyanott lesz, mint az A10-6800K. Az nem problema, hogy CPU-ban nincs semmi elorelepes cca. 1 ev utan es 1 processzel modernebb gyartassal? Bocs, hogy az Intelt rangatom ide, de amikor a Haswellnel nincs elorelepes az Ivy Bridge-hez kepest (CPU orajelben es -teljesitmenyben), viszont iGPU-ban eleg szepen lepked elore az Intel, akkor megy a karogas, hogy megallt a fejlodes, nem gyorsult a CPU, nincs magasabb orajel, stb. Az AMD-nek megbocsathato, mert ugyse eleg gyors a CPU, es majd jon a HSA, a "nagy piros messias"? Vagy hogy van ez? C2D vs. P4 eleg rossz parhuzam, hiszen ott alapveto architektura valtas volt, es a C2D teljesitmenyben siman lelepte a P4-et osszessegeben. Itt most egyikrol sincs szo a Richland --> Kaveri valtas kapcsan, hacsak nem a CPU-reszt teljesen zarojelbe nem tesszuk, es csak az iGPU-val foglalkozunk.
-
Fiery
veterán
Kisebb csikszelessegen nagyobb orajelt kellene tudniuk elerni, vagy azonos orajelen csokkennie kene a TDP-nek. Persze lehet, hogy az uj processz nincs me'g kidolgozva rendesen, inkabb rohannak, hogy piacra keruljon a Kaveri minel elobb, es majd kesobb adjak ki a magasabb orajelu verziokat, amikor a processzt bejarattak. Lehet ebben racio. De az orajelbeli visszalepes akkor is fura es kellemetlen.
-
Fiery
veterán
válasz
Oliverda
#13353
üzenetére
Nem csak az iGPU orajelerol beszeltem. Nyilvan, ha beraknak egy erosebb architekturat az iGPU-ba (GCN2), plusz 2 CU-t (ami darabra +33%), akkor nemileg alacsonyabb orajelen is gyorsabb lesz, mint a Richland iGPU-ja, de szamomra ez akkor is meglepo. A CPU-resz me'g nagyobb problema, hiszen ott az orajel csokkenest nem tudja ellensulyozni 33%-kal tobb CPU-mag (ami nincs, hiszen ugyanugy 2 modulos a Kaveri, mint a Richland), es a tobbi apro fejlesztes. Egyebkent sem ertem, miert kell alacsonyabbnak lennie a CPU-resz orajelenek, nem latom semmi ertelmet, semmi okat. Hacsak nem az van, hogy a Richland CPU orajeleivel nem ferne bele a Kaveri a 8 CU-s iGPU-val egyutt a 100 Watt TDP-be...
CPU teljesitmeny: Oke, hogy -- tegyuk fel, csak -- 3.5% a visszalepes, de akkor is visszalepes...
-
Fiery
veterán
Csopognek az infok kozben a hamarosan varhato Kaveri launch-rol. Ugy nez ki, vagy nem a leggyorsabb desktop SKU-t mutatjak be az APU'13 konferencian, vagy ha megis azt, akkor lesz siras-rivas. Amit bemutatnak, amirol a media is kapott embargos anyagot, az mind az x86/x64 CPU reszben, mind az iGPU reszben jelentosen _alacsonyabb_ orajelen fut, mint az elodje, az A10-6800K. Ergo, az az ES SKU, ami nalunk van, megsem ter el sokban a vegleges desktop Kaveritol (leszamitva a CU-k szamat).
Remelem, ez az egesz mostani "akcio" csak valami rossz vicc, vagy valami furcsa eltereles az AMD reszerol, es valojaban megis lesz az A10-6800K orajeleit elérő Kaveri SKU, csak nem most mutatjak be...
-
#13348
Fiery
veterán
Mahrenburg
#13347
Fiery
veterán
válasz
 Mahrenburg
#13347
üzenetére
Mahrenburg
#13347
üzenetére
AMD Bantry FM2+ referencia platform. Eleg hasonlo kialakitasu alaplap, mint az elod platformnal (AMD Annapurna FM2), semmi izgalmas, semmi egyedi igazandibol. De a celnak megfelel, nincsenek nagy igenyeink.
Valdez: Igen, neha felbukkan egy-egy a V***eran is, de annyira nem eletbevago, hogy tul sokat molyoljunk a dologgal
Nem kifejezetten a gyujtoszenvedely miatt vannak nekunk ilyen erdekes, ritka hardvereink, hanem a benchmark fejlesztes okan. Ahhoz viszont nem feltetlenul kell, hogy legyen a "flottaban" K6-2+ vagy K6-III+ is. Majd egyszer felenk hord a szel egy ilyet, es akkor bekerul a kollekcioba -
-
Fiery
veterán
válasz
Thrawn
#13326
üzenetére
Mi nem fetisizaljuk igy a hardvert, no offense
Csak egy haszontalan vasdarab az egesz alapvetoen. Hasznaljuk arra, amire kuldte az AMD, aztan berakjuk a sarokba, ahova valo. Plane miutan megjon a publikus, nem-ES verzio, amibol mindig veszunk utana egy konfigot, es onnantol azt hasznaljuk tovabb.[Mielott megint azzal vadolna valaki, hogy Intel-hivo vagyok, igen, az Intel-fele (es VIA-fele, stb) cuccokkal is ugyanigy teszunk. Ugyanugy megy a sarokba, amint a boltban is kaphatova valik, nem szeretunk gyartoi referencia alaplapot es ES procit kombinacioban hasznalni, az tul ES a szamunkra].
-
Fiery
veterán
válasz
Oliverda
#13325
üzenetére
Par 100 MHz csupan, nagyon messze az 1 GHz-tol. Azt viszont nem tudom megmondani egyelore, hogy a mostani Kaverink es az "A10-7800K" (a legdurvabb Kaveri SKU) mennyiben ter el orajelben. Bizom benne, hogy a kovetkezo, amit az AMD kuldott, mar megegyezik majd az "A10-7800K"-val. Legalabbis a multbeli tapasztalatok alapjan az mar az lesz, pl. igy kuldtek anno komplett PC-t olyan Richlanddel, ami me'g ES volt, es a CPUID name string-ben sem volt szo A10-rol vagy 6800K-rol, de parametereiben megegyezett a kesobb piacra kerulo A10-6800K-val.
-
Fiery
veterán
válasz
Oliverda
#13323
üzenetére
Nemtom, komplett gepet (desktop PC-t) kuldott az AMD, nem szedtuk ki a procit belole. Nem mondhatok el minden konkretumot, de ez a mostani Kaverink nem full SKU, csupan 6 CU, es az orajelei is elmaradnak a A10-6800K-etol, bar nem sokkal. KV-A1 stepping. De mar uton van felenk egy fullosabb SKU, az elvileg teljes, 8 CU-s lesz, es magasabb orajelen fog jarni, de azt nem tudom megmondani egyelore, hogy ujabb stepping lesz-e. Az AMD eddigi gyakorlatabol kiindulva az A1 stepping is be szokott valni a public release-hez.




 Aztan azt sem tudni pl., hogy a Turbo pontosan hogyan viselkedne a gyakorlatban, ha szokatlan modon az x86 CPU-magok es az iGPU is egyszerre le lenne terhelve maximalisan.
Aztan azt sem tudni pl., hogy a Turbo pontosan hogyan viselkedne a gyakorlatban, ha szokatlan modon az x86 CPU-magok es az iGPU is egyszerre le lenne terhelve maximalisan.











![;]](http://cdn.rios.hu/dl/s/v1.gif) De persze van driver, csak nem publikus, es valojaban tok gyors, csak varni kell kicsit, hogy kijojjon a publikus driver
De persze van driver, csak nem publikus, es valojaban tok gyors, csak varni kell kicsit, hogy kijojjon a publikus driver 





 A GCN2+Mantle parossal szemben lehet, hogy me'g az is keves lenne a jatekokban, de legalabb a GPGPU piacon tudna megint villantani egyet az nVIDIA.
A GCN2+Mantle parossal szemben lehet, hogy me'g az is keves lenne a jatekokban, de legalabb a GPGPU piacon tudna megint villantani egyet az nVIDIA. Az Intel csak a szamara nem konkurens termekeket gyart masoknak. Ha nagyot lazitananak is ezen a hozzaallason, akkor is max. az elkepzelheto, hogy mondjuk az nVIDIA-nak gyartsanak dGPU-kat 14 nanon, annal tobb semmikepp. De az is kizart egyebkent
Az Intel csak a szamara nem konkurens termekeket gyart masoknak. Ha nagyot lazitananak is ezen a hozzaallason, akkor is max. az elkepzelheto, hogy mondjuk az nVIDIA-nak gyartsanak dGPU-kat 14 nanon, annal tobb semmikepp. De az is kizart egyebkent 



 Futtattunk Richland vs. Kaveri benchmarkot, iGPU-n, azonos CU (6) szam mellett, azonos iGPU orajelen, azonos CPU magorajelen, azonos memoria orajelen, CPB OFF, APM OFF allasban, OpenCL 1.x, semmi HSA varazslat, klasszikus GPGPU szamitasi feladat. Nem FLOPS, hanem egy konkret szamitasi feladat, ami valodi munkat vegez, nem csak porgeti a CU-kat. Single-precision floating-point tesztben tobb mint masfelszeres teljesitmenyt nyom a Kaveri a Richlandhez kepest, double-precision detto. Ennyivel hatekonyabban lehet etetni a GCN feldolgozokat a VLIW4-hez kepest. Nyilvan ez csak egyetlen (pontosabban 2) teszt, es nyilvan nem ennyire kedvezo a helyzet minden felhasznalasban, de az azert jol latszik, hogy a Kaveri iGPU-jaba tenyleg nehez lesz belekotni, legalabbis ha mas iGPU-kkal vetjuk ossze. A HSA egyebkent ezen a konkret teszten nem segitene, nem lenne tole gyorsabb, max. a kernel launch ideje lenne kicsit rovidebb.
Futtattunk Richland vs. Kaveri benchmarkot, iGPU-n, azonos CU (6) szam mellett, azonos iGPU orajelen, azonos CPU magorajelen, azonos memoria orajelen, CPB OFF, APM OFF allasban, OpenCL 1.x, semmi HSA varazslat, klasszikus GPGPU szamitasi feladat. Nem FLOPS, hanem egy konkret szamitasi feladat, ami valodi munkat vegez, nem csak porgeti a CU-kat. Single-precision floating-point tesztben tobb mint masfelszeres teljesitmenyt nyom a Kaveri a Richlandhez kepest, double-precision detto. Ennyivel hatekonyabban lehet etetni a GCN feldolgozokat a VLIW4-hez kepest. Nyilvan ez csak egyetlen (pontosabban 2) teszt, es nyilvan nem ennyire kedvezo a helyzet minden felhasznalasban, de az azert jol latszik, hogy a Kaveri iGPU-jaba tenyleg nehez lesz belekotni, legalabbis ha mas iGPU-kkal vetjuk ossze. A HSA egyebkent ezen a konkret teszten nem segitene, nem lenne tole gyorsabb, max. a kernel launch ideje lenne kicsit rovidebb.






Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- iKing.hu Apple iPhone 12 Pro Max 128GB Gold használt, megkímélt 100% akku 6 hónap garancia
- Sata 240GB SSD // 100/100% // számla // garancia
- Telefon felvásárlás!! Honor Magic6 Lite, Honor Magic6 Pro, Honor Magic7 Lite, Honor Magic7 Pro
- BESZÁMÍTÁS! HP Elitedesk 800 G4 SFF számítógép - i5 8500 16GB DDR4 256GB SSD Intel UHD 630 250W W11
- LG 27GX700A-B - 27" OLED Tandem / QHD 2K / 280Hz 0.03ms / 1500 Nits / NVIDIA G-Sync / AMD FreeSync
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest