- Fórumok
- Szoftverfejlesztés
- Programozás topic
- (kiemelt téma)
-
14900 - 14801
21056 - 20001 20000 - 18001 18000 - 16001 16000 - 15901 15900 - 15801 15800 - 15701 15700 - 15601 15600 - 15501 15500 - 15401 15400 - 15301 15300 - 15201 15200 - 15101 15100 - 15001 15000 - 14901 14900 - 14801 14800 - 14701 14700 - 14601 14600 - 14501 14500 - 14401 14400 - 14301 14300 - 14201 14200 - 14101 14100 - 14001 14000 - 13901 13900 - 13801 13800 - 13701 13700 - 13601 13600 - 13501 13500 - 13401 13400 - 13301 13300 - 13201 13200 - 13101 13100 - 13001 13000 - 12901 12900 - 12801 12800 - 12701 12700 - 12601 12600 - 12501 12500 - 12401 12400 - 12301 12300 - 12201 12200 - 12101 12100 - 12001 12000 - 10001 10000 - 8001 8000 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
-
 Fototrend
Frissítve: 2023-12-13 06:18 Téma összefoglaló
Fototrend
Fototrend
Frissítve: 2023-12-13 06:18 Téma összefoglaló
Fototrend


Új hozzászólás Aktív témák
-
 fatal`
titán
fatal`
titán
Én is két monitoron érzem jobban magam, virtuális asztalt nem használok, sosem tudtam megszokni.
Itthon és melóhelyen is 2 full hd monitor van.
-
 Silεncε
őstag
Silεncε
őstag
Sziasztok, remélem tudtok segíteni, tapasztalt, sok éve fejlesztők tanácsát kérném következő - meglehetősen banális (?) - szituhoz:
- infra tervezés
- linux, virtualizáció, konténerek
- node.JS, python
- frontend
- SQL
- hobbi fotózás és fotókidolgozásSzóval nagyjából sokmindenben kezdek elmélyedni már egy ideje.
Gyakorlati tanácsra lenne szükségem:
Van két monitorom és nem férek. Bal oldali egy 1680x1050-es öreg (de jó), jobb oldali 1920x1080-as, szintén jó. De nem elég, a desktop-ok közötti váltogatás meg olyan idegen tőlem kicsit + szeretném egyszerre is nézni őket, mikor hova pillantva.Mit ajánlanátok inkább: több fullhd monitor egymás mellett-felett (mondjuk olcsó fhd-sek, 3db moncsi 2 sorban), vagy egy hatalmas nagy lágyan ívelt szuperszéles böhöm ?
A színhűségnek a fotózás miatt legalább az egyik moncsin meg kell lennie (sRGB elég), ha többmonitoros verzió. A többire nem fontos.
Illetve az érdekelne még, hogy van-e értelme pl. az egyik jobbszélső monitort állóba forgatni kódhoz ? 1-2 helyen látok ilyet elvétve, de nem sokan élnek ezzel, ennek oka van, hogy nem sokan, vagy szimplán csak "weirdo" ?

Ui.: Debian, XFCE, RyzenVirtuális asztalokat én laptopon szoktam használni, ha éppen nincs külső monitor kéznél (Windowson). Sajnos ultrawide monitorom még nem volt, úgyhogy arról nem tudok nyilatkozni, de szerintem az inkább játékra meg videovagasra jó (havernak volt programozasra, o is inkabb eladta). Nekem otthon két 1080p van (21, 24 col, sajna nem egyforma nagyságúak), irodában előző munkahelyen két 24" 1080p volt, itt kipróbáltam az egyiket állítva, nekem nem volt jó, a tetejét már nem láttam rendesen (nem volt a legjobb a betekintési szöge meg messze is volt). Most HO miatt az otthoni monitoraimat használom munkára is, mivel laptopunk van, így van három kijelzőm is
-
 I02S3F
addikt
I02S3F
addikt
Én virtuális asztalból használok 6-7-et egy 27" 1440p monitoron.
Régebben volt 2 monitor, de valahogy jobban tudok fókuszálni, ha egy monitor van.
Ezt felezem meg két alkalmazás között és váltok virtuális asztalt ha kell.Kubuntu.
Azt hiszem ez egyéni preferencia lesz, mert nekem két monitor kényelmesebb, mint a virtuális asztalok között navigálni. Bár utóbbit is használtam!
-
 instantwater
addikt
instantwater
addikt
Sziasztok, remélem tudtok segíteni, tapasztalt, sok éve fejlesztők tanácsát kérném következő - meglehetősen banális (?) - szituhoz:
- infra tervezés
- linux, virtualizáció, konténerek
- node.JS, python
- frontend
- SQL
- hobbi fotózás és fotókidolgozásSzóval nagyjából sokmindenben kezdek elmélyedni már egy ideje.
Gyakorlati tanácsra lenne szükségem:
Van két monitorom és nem férek. Bal oldali egy 1680x1050-es öreg (de jó), jobb oldali 1920x1080-as, szintén jó. De nem elég, a desktop-ok közötti váltogatás meg olyan idegen tőlem kicsit + szeretném egyszerre is nézni őket, mikor hova pillantva.Mit ajánlanátok inkább: több fullhd monitor egymás mellett-felett (mondjuk olcsó fhd-sek, 3db moncsi 2 sorban), vagy egy hatalmas nagy lágyan ívelt szuperszéles böhöm ?
A színhűségnek a fotózás miatt legalább az egyik moncsin meg kell lennie (sRGB elég), ha többmonitoros verzió. A többire nem fontos.
Illetve az érdekelne még, hogy van-e értelme pl. az egyik jobbszélső monitort állóba forgatni kódhoz ? 1-2 helyen látok ilyet elvétve, de nem sokan élnek ezzel, ennek oka van, hogy nem sokan, vagy szimplán csak "weirdo" ?
Ui.: Debian, XFCE, RyzenÉn virtuális asztalból használok 6-7-et egy 27" 1440p monitoron.
Régebben volt 2 monitor, de valahogy jobban tudok fókuszálni, ha egy monitor van.
Ezt felezem meg két alkalmazás között és váltok virtuális asztalt ha kell.Kubuntu.
-
 Dißnäëß
nagyúr
Dißnäëß
nagyúr
Sziasztok, remélem tudtok segíteni, tapasztalt, sok éve fejlesztők tanácsát kérném következő - meglehetősen banális (?) - szituhoz:
- infra tervezés
- linux, virtualizáció, konténerek
- node.JS, python
- frontend
- SQL
- hobbi fotózás és fotókidolgozásSzóval nagyjából sokmindenben kezdek elmélyedni már egy ideje.
Gyakorlati tanácsra lenne szükségem:
Van két monitorom és nem férek. Bal oldali egy 1680x1050-es öreg (de jó), jobb oldali 1920x1080-as, szintén jó. De nem elég, a desktop-ok közötti váltogatás meg olyan idegen tőlem kicsit + szeretném egyszerre is nézni őket, mikor hova pillantva.Mit ajánlanátok inkább: több fullhd monitor egymás mellett-felett (mondjuk olcsó fhd-sek, 3db moncsi 2 sorban), vagy egy hatalmas nagy lágyan ívelt szuperszéles böhöm ?
A színhűségnek a fotózás miatt legalább az egyik moncsin meg kell lennie (sRGB elég), ha többmonitoros verzió. A többire nem fontos.
Illetve az érdekelne még, hogy van-e értelme pl. az egyik jobbszélső monitort állóba forgatni kódhoz ? 1-2 helyen látok ilyet elvétve, de nem sokan élnek ezzel, ennek oka van, hogy nem sokan, vagy szimplán csak "weirdo" ?
Ui.: Debian, XFCE, Ryzen -
 BProgrammer
csendes tag
BProgrammer
csendes tag
"Meg kellene nézni, hogy pont mire fordul le a kódod, de simán lehet, hogy a num++ nem egyetlen utasítás, hanem valami olyasmi, hogy a numot betölti egy regiszterbe, megnöveli a regisztert és azt írja vissza a memóriába:"
Ez stimmel:
mov eax, DWORD PTR num[rip]add eax, eaxmov DWORD PTR num[rip], eaxJa, igen nekem is ilyen a duplázás.
A növelés meg ehhez hasonlóan:
mov eax, DWORD PTR num[rip]add eax, 1mov DWORD PTR num[rip], eaxKöszi -
 emvy
félisten
emvy
félisten
Isten hozott a nematomi műveletek világában

Meg kellene nézni, hogy pont mire fordul le a kódod, de simán lehet, hogy a num++ nem egyetlen utasítás, hanem valami olyasmi, hogy a numot betölti egy regiszterbe, megnöveli a regisztert és azt írja vissza a memóriába: ha itt az első és a második vagy a második és a harmadik lépés között történik meg a duplázás, akkor a végén pont kétmilliót kapsz, mert a harmadik lépés felülírja a duplázás eredményét.
"Meg kellene nézni, hogy pont mire fordul le a kódod, de simán lehet, hogy a num++ nem egyetlen utasítás, hanem valami olyasmi, hogy a numot betölti egy regiszterbe, megnöveli a regisztert és azt írja vissza a memóriába:"
Ez stimmel:
mov eax, DWORD PTR num[rip]add eax, eaxmov DWORD PTR num[rip], eax -
emvy
félisten
Ennyire azert nem egyszeru a dolog, ez nem a klasszikus race condition. Ha az lenne, akkor a
std::cout<<"Double starting " << num << std::endl;
es astd::cout<<"Double ending " << num << std::endl;
sorok altal kiirt szam legalabb 2x-esere novekedne a ket sor kozott. De itt nem ez van.Mindjart gondolkozom rajta picit
-
BProgrammer
csendes tag
Isten hozott a nematomi műveletek világában
Meg kellene nézni, hogy pont mire fordul le a kódod, de simán lehet, hogy a num++ nem egyetlen utasítás, hanem valami olyasmi, hogy a numot betölti egy regiszterbe, megnöveli a regisztert és azt írja vissza a memóriába: ha itt az első és a második vagy a második és a harmadik lépés között történik meg a duplázás, akkor a végén pont kétmilliót kapsz, mert a harmadik lépés felülírja a duplázás eredményét.
Ja köszi, így már értem

-
BProgrammer
csendes tag
Azt értem, hogy véletlenszerű, igazából pont ezt akartam próbálgatni, hogy mindig más eredményt kapok emiatt, de nem értem, hogy mi lehet az a körülmény, ami miatt nem lesz nagyobb 2000000000-nál az eredmény. Mikor látom, hogy megtörténik a duplázás, illetve egyszer valamikor a végére az összes increment-nek is le kell futni, nem?
-
 dabadab
titán
dabadab
titán
Sziasztok!
Próbálgatom a párhuzamos programozást C++-ban és nem értem a következő működést:
Elindítok 2 szálat, az egyiken 2000000000-szor növelgetek egy globális változót, a másikat 2 másodperces sleep-pel indítom majd egyszer csak beduplázom ugyanazt a változót konkurensen, miközben az increment még nem ért véget. Közben kiírogatom a dolgokat, ellenőrzöm a 2 másodperc sleep után még valóban nem ér véget az increment sose az én gépemen. Látszik is, hogy kb. beduplázódik a szám, valamikor a futás közben. Szóval azt várnám, hogy a legvégén, mire mindkét szál lefut, valami 2000000000-nál határozottan nagyobb szám lesz az eredmény minden esetben. Valamikor tényleg ez is van, de nagyon sokszor van, hogy pontosan 2000000000 az eredmény. De ez hogy lehet, hiszen nem akkor fut le soha a duplázás, mikor az n még 0 (ellenőrzöm a kiiratással). Arra is gondoltam, hogy hátha valami optimalizáció van, hogy valójában nem fut le 2000000000-szor a ciklus, hanem az i helyett magát a num-ot nézi, hogy ha az nagyobb, akkor kilép a ciklusból, de akkor meg máskor mér lehet nagyobb? Meg hát -O0 kapcsolóval is ugyanaz a probléma.Meg amit végképp nem értek, hogy egyszer volt olyan is, hogy nem duplázta be a számot, és a duplázás előtti és utáni kiíratás csak pár incrementálásban különbözött. Szóval eléggé össze vagyok zavarodva. Van ötletetek?
Előre is köszi a válaszokat!

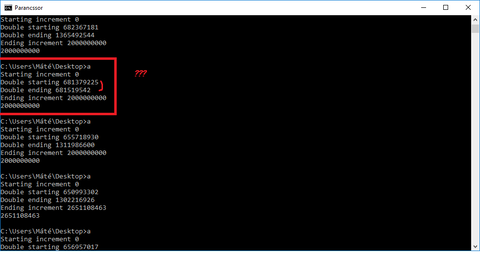
#include <iostream>#include <thread>#include <chrono>using namespace std::chrono_literals;unsigned int num = 0;void increment(){std::cout<<"Starting increment "<< num << std::endl;for(int i=0; i<2000000000; ++i){++num;}std::cout<<"Ending increment "<< num << std::endl;}void doubler(){std::this_thread::sleep_for(2s);std::cout<<"Double starting " << num << std::endl;num*=2;std::cout<<"Double ending " << num << std::endl;}int main() {std::thread t1(increment);std::thread t2(doubler);t1.join();t2.join();std::cout << num << std::endl;
}Isten hozott a nematomi műveletek világában
Meg kellene nézni, hogy pont mire fordul le a kódod, de simán lehet, hogy a num++ nem egyetlen utasítás, hanem valami olyasmi, hogy a numot betölti egy regiszterbe, megnöveli a regisztert és azt írja vissza a memóriába: ha itt az első és a második vagy a második és a harmadik lépés között történik meg a duplázás, akkor a végén pont kétmilliót kapsz, mert a harmadik lépés felülírja a duplázás eredményét.
-
Silεncε
őstag
Sziasztok!
Próbálgatom a párhuzamos programozást C++-ban és nem értem a következő működést:
Elindítok 2 szálat, az egyiken 2000000000-szor növelgetek egy globális változót, a másikat 2 másodperces sleep-pel indítom majd egyszer csak beduplázom ugyanazt a változót konkurensen, miközben az increment még nem ért véget. Közben kiírogatom a dolgokat, ellenőrzöm a 2 másodperc sleep után még valóban nem ér véget az increment sose az én gépemen. Látszik is, hogy kb. beduplázódik a szám, valamikor a futás közben. Szóval azt várnám, hogy a legvégén, mire mindkét szál lefut, valami 2000000000-nál határozottan nagyobb szám lesz az eredmény minden esetben. Valamikor tényleg ez is van, de nagyon sokszor van, hogy pontosan 2000000000 az eredmény. De ez hogy lehet, hiszen nem akkor fut le soha a duplázás, mikor az n még 0 (ellenőrzöm a kiiratással). Arra is gondoltam, hogy hátha valami optimalizáció van, hogy valójában nem fut le 2000000000-szor a ciklus, hanem az i helyett magát a num-ot nézi, hogy ha az nagyobb, akkor kilép a ciklusból, de akkor meg máskor mér lehet nagyobb? Meg hát -O0 kapcsolóval is ugyanaz a probléma.Meg amit végképp nem értek, hogy egyszer volt olyan is, hogy nem duplázta be a számot, és a duplázás előtti és utáni kiíratás csak pár incrementálásban különbözött. Szóval eléggé össze vagyok zavarodva. Van ötletetek?
Előre is köszi a válaszokat!
#include <iostream>#include <thread>#include <chrono>using namespace std::chrono_literals;unsigned int num = 0;void increment(){std::cout<<"Starting increment "<< num << std::endl;for(int i=0; i<2000000000; ++i){++num;}std::cout<<"Ending increment "<< num << std::endl;}void doubler(){std::this_thread::sleep_for(2s);std::cout<<"Double starting " << num << std::endl;num*=2;std::cout<<"Double ending " << num << std::endl;}int main() {std::thread t1(increment);std::thread t2(doubler);t1.join();t2.join();std::cout << num << std::endl;
}Race condition. A két szál teljesen véletlenszerű, mikor jut CPU-hoz, így a végkimenetele is véletlenszerű, hogy éppen mikor mi lesz az eredmény. Megoldás: mutex-szel le kell zárni a valtozót
-
BProgrammer
csendes tag
Sziasztok!
Próbálgatom a párhuzamos programozást C++-ban és nem értem a következő működést:
Elindítok 2 szálat, az egyiken 2000000000-szor növelgetek egy globális változót, a másikat 2 másodperces sleep-pel indítom majd egyszer csak beduplázom ugyanazt a változót konkurensen, miközben az increment még nem ért véget. Közben kiírogatom a dolgokat, ellenőrzöm a 2 másodperc sleep után még valóban nem ér véget az increment sose az én gépemen. Látszik is, hogy kb. beduplázódik a szám, valamikor a futás közben. Szóval azt várnám, hogy a legvégén, mire mindkét szál lefut, valami 2000000000-nál határozottan nagyobb szám lesz az eredmény minden esetben. Valamikor tényleg ez is van, de nagyon sokszor van, hogy pontosan 2000000000 az eredmény. De ez hogy lehet, hiszen nem akkor fut le soha a duplázás, mikor az n még 0 (ellenőrzöm a kiiratással). Arra is gondoltam, hogy hátha valami optimalizáció van, hogy valójában nem fut le 2000000000-szor a ciklus, hanem az i helyett magát a num-ot nézi, hogy ha az nagyobb, akkor kilép a ciklusból, de akkor meg máskor mér lehet nagyobb? Meg hát -O0 kapcsolóval is ugyanaz a probléma.Meg amit végképp nem értek, hogy egyszer volt olyan is, hogy nem duplázta be a számot, és a duplázás előtti és utáni kiíratás csak pár incrementálásban különbözött. Szóval eléggé össze vagyok zavarodva. Van ötletetek?
Előre is köszi a válaszokat!
#include <iostream>#include <thread>#include <chrono>using namespace std::chrono_literals;unsigned int num = 0;void increment(){std::cout<<"Starting increment "<< num << std::endl;for(int i=0; i<2000000000; ++i){++num;}std::cout<<"Ending increment "<< num << std::endl;}void doubler(){std::this_thread::sleep_for(2s);std::cout<<"Double starting " << num << std::endl;num*=2;std::cout<<"Double ending " << num << std::endl;}int main() {std::thread t1(increment);std::thread t2(doubler);t1.join();t2.join();std::cout << num << std::endl;
} -
instantwater
addikt
Ez egy őrültség.
Első dolgom volt a GitHub organisationben beállítani, hogy továbbra is master maradjon a neve új repoknál is.
Lesz ebből még fejfájás kezdőknek, hogy nem létezik a branch amit a StackOverflowon találtak a git parancsban.Ne borítsuk már fel a világot mert néhányan unatkoznak.

Amúgy sincs már rabszolgaság. Senki nem fog megsértődni egy master branchen. Főleg, hogy soha nem is volt slave branch.
-
 nevemfel
senior tag
nevemfel
senior tag
-
 martonx
veterán
martonx
veterán
-
 taf120
csendes tag
taf120
csendes tag
-
 Drizzt
nagyúr
Drizzt
nagyúr
-
taf120
csendes tag
Initialize the local directory as a Git repository.
$ git init -b main
Mit csinál ez a -b kapcsoló?
Nekem azt írja nincs is ilyen opció. -
y@g4n
tag
Miért van külön always blokkokba téve a számolás, a maxos-t meghatározó ciklus, ill. a maxos-ből a prediction_-t meghatározó case? Ezek egymásra épülnek, nem egymás után kellene végrehajtódniuk? Nem igazán értek hozzá, úgyhogy bocs, ha hülyeséget írok, de az always blokkok nem párhuzamosan hajtódnak végre? Mert akkor a végeredmény meglesz már mielőtt ki lenne számolva (mint a Tanú c. filmben az ítélet
). Nem kellene az egészet egy nagy always blokkba tenni?Jót írsz, párhuzamosak az alwaysok, lehetséges hogy egy darab always blokk lesz a megoldás de egy időre pihenőpályára teszem ezt a feladatot mert már elegem lett belőle, decemberig nem is sürgős, köszi a segítséget!
-
 kovisoft
őstag
kovisoft
őstag
Miért van külön always blokkokba téve a számolás, a maxos-t meghatározó ciklus, ill. a maxos-ből a prediction_-t meghatározó case? Ezek egymásra épülnek, nem egymás után kellene végrehajtódniuk? Nem igazán értek hozzá, úgyhogy bocs, ha hülyeséget írok, de az always blokkok nem párhuzamosan hajtódnak végre? Mert akkor a végeredmény meglesz már mielőtt ki lenne számolva (mint a Tanú c. filmben az ítélet
). Nem kellene az egészet egy nagy always blokkba tenni? -
y@g4n
tag
Megcsináltam, sajnos nem változtatott semmit.
-
kovisoft
őstag
Plusz az nem probléma, hogy az i változót két dologra is használod két különálló always blokkban? Az egyik blokkban lépteted 0-tól 6-ig a neuronháló szintjeinek végigszámolásához, a másik blokkban ciklusváltozónak használod. Nem kellene a második always-ben megvárni, amíg i==6 lesz?
-
kovisoft
őstag
Mit jelent, hogy változtathatóvá tetted az inputokat? A linkelt kódodban fix hardkódolt input van, tehát mindig ugyanazt az outputot kell generálja.
-
y@g4n
tag
A lenti kódrészben az i 25-től megy 34-ig, ezért a maxos 5-től 14-ig vehet fel értéket. A case-ben viszont 0-tól 9-ig vizsgálod. Ezt biztos, hogy így akartad? Nem maxos = (i - 25) kellene? És a max_ nem kap kezdőértéket, biztos, hogy alapból 0 az értéke és nem valami szemét van benne, ami miatt esetleg soha bele sem megy az if-be (és akkor a maxos-ba is valami szemét kerül)?
integer maxos;
always @(posedge clk)begin
for(i = 25; i < 35; i = i + 1)begin
if(neurons[i] > max_)
max_ = neurons[i];
maxos = (i - 20);
end
end
always @(posedge clk)
case(maxos)
0: prediction_ = 10'b1000000000;
1: prediction_ = 10'b0100000000;
2: prediction_ = 10'b0010000000;
3: prediction_ = 10'b0001000000;
4: prediction_ = 10'b0000100000;
5: prediction_ = 10'b0000010000;
6: prediction_ = 10'b0000001000;
7: prediction_ = 10'b0000000100;
8: prediction_ = 10'b0000000010;
9: prediction_ = 10'b0000000001;
endcaseA
maxos = (i - 25)-re felfigyeltem tegnap, a max_ kezdőértékre nem, (köszi) most mind a kettőt kijavítva ami egyedül változott az a 0. sorszámú led output buffer.
[link]
Meg változtathatóvá tettem az inputokat, arra vannak a switchek, de nem ez a lényegi baj. -
kovisoft
őstag
Sziasztok, Veriloggal (Vivado) kapcsolatban kérek segítséget. Generáltam egy hosszú verilog kódot;
egy Keras-Tensorflow segítségével trainelt neurális háló weights és bias értékeit extraktáltam pythonban, majd (hogy ne kézzel gépeljek ennyit) szintén pythonban egy szkripttel legeneráltam a sok regisztert meg localparamot verilogul.
Az input az 784 darab integer localparamként (egy kép az MNIST datasetből), az output pedig az FPGA 10 ledje közül lenne az egyik (amelyik számjegyet jelentette az input, azon led villan fel).
A köztes logika pedig a neurális háló weights * biases lenne layerenként.Szintézis, implementáció lefut, kihasználtsági szint cirka 0%, a schematicon összesen 10 db output buffer van, amik fix 0-ra állítja a ledeket.
Kérdésem hogy miért történik ez?
Ami segítséget eddig kaptam:
"Mivel a bemeneteidnek fix értéke van, így a kimenetnek is (10 db nulla az értéke az adott bemenet mellett), ezért a szintézer kb. mindent kidob, hiszen nincs szükség ténylegesen a szorzók, stb, implementálásására."
Ez még egy olyan kódra volt válasz mikor a legalján lévő switch case-ben volt default ág, már nincs.
De nem tudom mit akar ez jelenteni!
Miért ne lenne szükség pl. szorzók implementálására?Kód: [link]
Hosszú nagyon, az egész csak a RAW Paste Data résznél látszódik.
Schematic: [link]
A kártya amire implementálok: Digilent Nexys 4 Artix 7A lenti kódrészben az i 25-től megy 34-ig, ezért a maxos 5-től 14-ig vehet fel értéket. A case-ben viszont 0-tól 9-ig vizsgálod. Ezt biztos, hogy így akartad? Nem maxos = (i - 25) kellene? És a max_ nem kap kezdőértéket, biztos, hogy alapból 0 az értéke és nem valami szemét van benne, ami miatt esetleg soha bele sem megy az if-be (és akkor a maxos-ba is valami szemét kerül)?
integer maxos;
always @(posedge clk)begin
for(i = 25; i < 35; i = i + 1)begin
if(neurons[i] > max_)
max_ = neurons[i];
maxos = (i - 20);
end
end
always @(posedge clk)
case(maxos)
0: prediction_ = 10'b1000000000;
1: prediction_ = 10'b0100000000;
2: prediction_ = 10'b0010000000;
3: prediction_ = 10'b0001000000;
4: prediction_ = 10'b0000100000;
5: prediction_ = 10'b0000010000;
6: prediction_ = 10'b0000001000;
7: prediction_ = 10'b0000000100;
8: prediction_ = 10'b0000000010;
9: prediction_ = 10'b0000000001;
endcase -
y@g4n
tag
Sziasztok, Veriloggal (Vivado) kapcsolatban kérek segítséget. Generáltam egy hosszú verilog kódot;
egy Keras-Tensorflow segítségével trainelt neurális háló weights és bias értékeit extraktáltam pythonban, majd (hogy ne kézzel gépeljek ennyit) szintén pythonban egy szkripttel legeneráltam a sok regisztert meg localparamot verilogul.
Az input az 784 darab integer localparamként (egy kép az MNIST datasetből), az output pedig az FPGA 10 ledje közül lenne az egyik (amelyik számjegyet jelentette az input, azon led villan fel).
A köztes logika pedig a neurális háló weights * biases lenne layerenként.Szintézis, implementáció lefut, kihasználtsági szint cirka 0%, a schematicon összesen 10 db output buffer van, amik fix 0-ra állítja a ledeket.
Kérdésem hogy miért történik ez?
Ami segítséget eddig kaptam:
"Mivel a bemeneteidnek fix értéke van, így a kimenetnek is (10 db nulla az értéke az adott bemenet mellett), ezért a szintézer kb. mindent kidob, hiszen nincs szükség ténylegesen a szorzók, stb, implementálásására."
Ez még egy olyan kódra volt válasz mikor a legalján lévő switch case-ben volt default ág, már nincs.
De nem tudom mit akar ez jelenteni!
Miért ne lenne szükség pl. szorzók implementálására?Kód: [link]
Hosszú nagyon, az egész csak a RAW Paste Data résznél látszódik.
Schematic: [link]
A kártya amire implementálok: Digilent Nexys 4 Artix 7 -
 pomorski
őstag
pomorski
őstag
+kovisoft
Köszi mindkettőtöknek, majd ha időm engedi átírom kicsit az ominózus részt. Az "omp critical"-t szoktam használni, de most az sem segített.
-
kovisoft
őstag
Sziasztok,
egy kis okosságra/segítségre volna szükségem többszálas (openmp) programozás kapcsán. Adott egy fortran kód, amit mi írtunk, néhányezer soros egyszálas. Kimértük, hogy vannak olyan részek, amik végrehajtása nagyon-nagyon időigényes, ezért kézenfekvő volt az ötlet, hogy párhuzamosítani kellene openmp segítségével az időigényes blokkokat a lehető legtriviálisabb módon. Az egyik ilyen időigényes blokk az alábbi:
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres
do kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo
enddo
enddo
enddo
.
.
.
.
.
ezt az alábbi módon openmp-sítettem (a legbelső vastag betűvel szedett részt):
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres!$omp parallel &
!$omp private(kk,sl_tmp,sl_tmp1) &
!$omp reduction(+:jk)
!$omp dodo kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo!$omp end do
!$omp end parallelenddo
enddo
enddo
.
.
.
.
.
de sajnos hülyeséget számol a progi, ha őt -openmp kapcsolóval fordítom le. Ha nem rakom be eme kapcsolót, és a fordító egyszálas üzemmódban fordítja, akkor tökéletes eredményt számol a progi, -csak lassan ugyebár.“Ökölszabályként” tudom, hogy ami értéket kap az “private”, ami felösszegződik, annál használni kell a reduction-t. Illetve azt is, tudom, hogy időként szükség van a “shared”-re is. Sok mindent kipróbáltam, de a kód csak nem akar megfelelő lenni többszálas fordítás esetén. Ötlet?
szerk: Sajnos csak így sikerült beilleszteni a kódot, a formázás eltűnt, bocs.
Én sem igazán értek a fortranhoz, de szerintem ott lehet a gond, hogy a reduction-ben a jk-t összegzed, de ez csak a reduction végén történik meg, közben pedig minden szálnak saját private jk példánya van, nem az lesz, hogy a jk egyesével növekedne, mint ahogy az egyszálas futásnál történik. Ugyanakkor később a ciklus magjában kihasználod, hogy mi a jk értéke.
Igazából nem tudom, mi lenne a megoldás, talán a jk-t kivenni a reduction-ből és valami ordered-del rávenni, hogy márpedig jó sorrendben kapja az értékeket. De igazából passz.

-
Silεncε
őstag
Sziasztok,
egy kis okosságra/segítségre volna szükségem többszálas (openmp) programozás kapcsán. Adott egy fortran kód, amit mi írtunk, néhányezer soros egyszálas. Kimértük, hogy vannak olyan részek, amik végrehajtása nagyon-nagyon időigényes, ezért kézenfekvő volt az ötlet, hogy párhuzamosítani kellene openmp segítségével az időigényes blokkokat a lehető legtriviálisabb módon. Az egyik ilyen időigényes blokk az alábbi:
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres
do kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo
enddo
enddo
enddo
.
.
.
.
.
ezt az alábbi módon openmp-sítettem (a legbelső vastag betűvel szedett részt):
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres!$omp parallel &
!$omp private(kk,sl_tmp,sl_tmp1) &
!$omp reduction(+:jk)
!$omp dodo kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo!$omp end do
!$omp end parallelenddo
enddo
enddo
.
.
.
.
.
de sajnos hülyeséget számol a progi, ha őt -openmp kapcsolóval fordítom le. Ha nem rakom be eme kapcsolót, és a fordító egyszálas üzemmódban fordítja, akkor tökéletes eredményt számol a progi, -csak lassan ugyebár.“Ökölszabályként” tudom, hogy ami értéket kap az “private”, ami felösszegződik, annál használni kell a reduction-t. Illetve azt is, tudom, hogy időként szükség van a “shared”-re is. Sok mindent kipróbáltam, de a kód csak nem akar megfelelő lenni többszálas fordítás esetén. Ötlet?
szerk: Sajnos csak így sikerült beilleszteni a kódot, a formázás eltűnt, bocs.
Nagyon nem értek a fortranhoz, de ha tobbszálúsítás esetén az addig tökéletesen működő program hülyeségeket számol, nagy valószínűséggel az a baja, hogy race condition van.
Így hirtelen utánakeresve ezt találtam, nem tudom segít-e, ránézésre kéne neki: [link]
-
pomorski
őstag
Sziasztok,
egy kis okosságra/segítségre volna szükségem többszálas (openmp) programozás kapcsán. Adott egy fortran kód, amit mi írtunk, néhányezer soros egyszálas. Kimértük, hogy vannak olyan részek, amik végrehajtása nagyon-nagyon időigényes, ezért kézenfekvő volt az ötlet, hogy párhuzamosítani kellene openmp segítségével az időigényes blokkokat a lehető legtriviálisabb módon. Az egyik ilyen időigényes blokk az alábbi:
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres
do kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo
enddo
enddo
enddo
.
.
.
.
.
ezt az alábbi módon openmp-sítettem (a legbelső vastag betűvel szedett részt):
.
.
.
.
.
jb=0
do ib=1,elteres
do kb=1,mutato(ib)
jb=jb+1
jk=0
do ik=1,elteres!$omp parallel &
!$omp private(kk,sl_tmp,sl_tmp1) &
!$omp reduction(+:jk)
!$omp dodo kk=1,mutato(ik)
jk=jk+1
if (ib.eq.ik)then
sl_tmp=0._dp
if(kb.eq.kk)sl_tmp=egyedi_proton_spe(jb,jk,mm/2,n_of_sdet,s)
if(s(jb)%neutron.eq.s(jk)%neutron.and.kb.ge.kk)then
sl_tmp1=egyedi_proton_tbint(jb,jk,mm/2,n_of_sdet,s)
ujhmatp(ib)%hh(kk,kb)=sl_tmp+sl_tmp1
ujhmatp(ib)%hh(kb,kk)=sl_tmp+sl_tmp1
endif
endif
enddo!$omp end do
!$omp end parallelenddo
enddo
enddo
.
.
.
.
.
de sajnos hülyeséget számol a progi, ha őt -openmp kapcsolóval fordítom le. Ha nem rakom be eme kapcsolót, és a fordító egyszálas üzemmódban fordítja, akkor tökéletes eredményt számol a progi, -csak lassan ugyebár.“Ökölszabályként” tudom, hogy ami értéket kap az “private”, ami felösszegződik, annál használni kell a reduction-t. Illetve azt is, tudom, hogy időként szükség van a “shared”-re is. Sok mindent kipróbáltam, de a kód csak nem akar megfelelő lenni többszálas fordítás esetén. Ötlet?
szerk: Sajnos csak így sikerült beilleszteni a kódot, a formázás eltűnt, bocs.
-
y@g4n
tag
-
Drizzt
nagyúr
Köszi a tippeket.
PHP Laravel a környezet.
A Docker layerekkel és multi-step buildekkel tisztában vagyok, és a dependencyket külön layerbe rakom mindig pontosan a tárhely és újrahasznosíthatóság miatt, de jó tipp. Köszi.
Az alkalmazás környezeti változói jelenleg egy .env fájlban vannak minden szerveren. Ennek automatizálása is cél, és a k8s ebben is fog segíteni.
Esetleg arról is van infód, hogy nálatok milyen branching strategy vált be, és ha van automatizált telepítés, akkor mi triggereli az egyes környezetek frissítését?
Gondolkodtan egy olyan lehetőségen is, hogy masterbe mergelődnek a featurek, ami egyből telepítődik staging/UAT környezetbe és amikor kézzel tagelünk egy commitot egy verziószámmal akkor az kiküldi productionbe a kódot, de ezzel a korábban tárgyalt probléma van, hogy a fejlesztőn múlik, hogy ő patchnek vagy minor changenek itéli-e a PRját, vagy pedig a csapat senior tagjainak kell törni a fejét, hogy ez egy patch vagy minor verzió legyen mergelés után.
Jelenleg nincsenek verzió tagek. Simán a master branch van telepítve. Ezzel az a legnagyobb vaj, hogy csak a telepítésvezérlő környezetben látszik, hogy mikor mi lett telepítve, gitben erről nincs visszajelzés tagek formájában.
"Esetleg arról is van infód, hogy nálatok milyen branching strategy vált be, és ha van automatizált telepítés, akkor mi triggereli az egyes környezetek frissítését?"
Nevezzük módosított gitflownak. Azért módosított, mert muszáj egy adott alm, meg rlm rendszert használnunk, amit viszont más csapat birtokol, s nem igazán nyitott a változtatásokra, meg a rugalmasságra.
Automatizált deploy jelenleg nincs. DEV rendszerbe lehetne. UAT/feljebb nem mehet csak kézi kezdeményezésre, megfelelő jogosultságú emberek által, PROD-ra meg emberek még szűkebb csoportja által. Szerintem amúgy nincs ezzel különösebb gond. Minőségi garancia szinte semmi nincs jelenleg(még unit testek is általában a jobokban ki vannak kapcsolva, code review elvétve van; ha valaki önként jelzi, hogy szeretné, ha megnéznék a kódját), mégis meglepően stabilan mennek a dolgok. Ez szerintem csak azért mehet így, mert alapvetően masszív tapasztalatú emberekből áll a csapat(, legkisebb tapasztalatú ember valahol 5 év körül lehet, az átlag 15 körül).
Én amit legfontosabbnak tartok az az, hogy a build során elkészült alkalmazás része legyen mindenképpen valamilyen build metadata. Az sem árt, ha mondjuk induláskor is kiírja az ember a logba, hogy pontosan milyen verzió indult(legfontosabb a git sha-1). De azt is fontos lehet, ha meg tudja oldani az ember, hogy valahol a deployment verzió history is látsszon. De ezt a taget szintén a deployment pipeline is rárakhatja a commitra. Pl. jó ötletlet lehet rárakni a környezetet, meg a deployment timestamp-et. -
ssgk
aktív tag
Köszi mindenkinek !
-
 axioma
veterán
axioma
veterán
A korabbiakhoz pluszban: hackerearth, hackerrank (ezen szoktak interjut tartani, erdemes megismerni a hulyesegeit), codechef, esetleg topcoder vagy codeforces is hasonlo oldalak de azokon nem vagyok annyira kepben. Az easy-ket keresd, mert itt nem kodolastechnikailag hanem algoritmus ("technologia") nehezseg szerint vannak rangsorolva (foleg timeout szempontjabol). Bar az a tobbinel is igy van szerintem.
-
kovisoft
őstag
-
 tboy93
nagyúr
tboy93
nagyúr
-
 sztanozs
veterán
sztanozs
veterán
codewars-on vannak c challenge-ek is, illetve clash-of-codes
-
ssgk
aktív tag
Sziasztok !
Isemrtek olyan oldalt ahol C nyelvet lehet gyakorolni úgy, hogy adott feladatokat kér kódolni és ki is értékeli. Szolval, hogy nem a kódot látod és mit ír ki. És elég sokszínű kezdőtöl nehezebb problémákig ?
Köszi !
-
instantwater
addikt
Ez a tipikus gitflow master, develop plusz feature branchek.
Tehát verziószámok nélkül automatikusan megy a telepítés és sprint végén megy masterbe a merge? -
 K1nG HuNp
őstag
K1nG HuNp
őstag
A DevOps topik kihalt, úgyhogy bedobom ide.
Egy kis brainstormingot szeretnék indítani az alábbiakról.
Continuous Deployment környezetben ki melyik branching strategyt használja, és miért? Mi triggereli a promotiont stagingből productionbe?
Melyik azonosítót használnád a deploymentek jelölésére? Semver, git hash, vagy build id?
A semver igényel emberi közreműködést, mert default a patch számot növelné a rendszer, de a fejlesztő belátásán múlik, hogy a kód amit beküld az inkább egy minor bump legyen patch bump helyett.
Git hash egyértelmű, könnyen visszavezethető pontosan a forrás commitra. Viszont nincs benne szekvencia, nehéz megmondani 2 git hashról, hogy melyik a későbbi anélkül, hogy valaki megnézi a git historyt és megkeresi a commitokat ID alapján.
Build number szekvenciális, és nem igényel emberi beavatkozást, viszont nehéz visszavezetni commitra.
Viszont, ha nem kap verzió taget egy-egy commit, akkor mi triggereli a production deployt, ha stagingben megfelelt a kód?
Van erre valami best practice? Itt vissza térünk a kérdés elejére, hogy melyik branching strategy lenne a legideálisabb.
Jelenleg GitFlowot használunk, de macerás a dupla PR a hotfixekhez (master, develop), és a develop PRrel kerül a masterbe (és deployolásra) hetente 2x, amit szintén szeretnénk lecserélni napi többszöri deploymentre.
Az eszközökkel nincs baj, GitHub Actions, Docker, Terraform, Ansible tapasztalat megvan, inkább a mit mikor és hogyan lenne a kérdés.
A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket.
Ezt le akarom cserélni immutable image alapú deploymentre, ahol egyszer vannak telepítve a függőségek, majd ez az image van kitolva a szerverekre.
Ez lehet akár machine image buildeléssel aztán Terraformmal lecserélni a szervereket és újrakonfigurálni a routingot, de ezt lassúnak érzem. A másik opció Docker image buildelés lenne, mert az könnyen és gyorsan lehet kitolni a szerverekre.
Hosszabb távon a cél Kubernetesre költözés, de mivel egy monolit alkalmazásról van szó ezért úgy érzem az azonnali Kubernetesre váltás túl sok új komplikációt hozna, és jelenlegi archirektúra automatizálása egy jó köztes lépés lenne.
Vagy ahogy egy szakadékot sem lehet két ugrással átugrani, több értelme lenne egyből Kubernetesbe tolni az egészet, aztán lassan refaktorálni microservices architektúrára?
Kinek mi jött be, mi működött, nem működött?
master, canary, + mindenkinek a jelenleg porgetett issueja canarybol leagazva, ha kesz a sprint canaryba beont, canary kozben vegig stagingen fut ugyebar, ha az zsir akkor mehet a beontes masterbe, rinse, repeat
-
 Rula
tag
Rula
tag
Hát, az elég furcsa választás
Ez a könyv így belenézve elég használhatónak, ha rettenetes bőbeszédűnek is tűnik.
Ami meg nagyjából nélkülözhetetlen referenciaanyag, az a Ralf Brown-féle interrupt list
A hard mode meg a mindenféle miniatűr intrók kódjának tanulmányozása, ezt pl. 64 byte-tból hozta ki az alkotója: Gespensterwald, forrás is van hozzá: [link]
Egyetemen van assembly-s órám és valahogy szeretnék majd átmenni rajta
 Ott használjuk ezt.
Ott használjuk ezt. Köszi!
-
dabadab
titán
Hát, az elég furcsa választás
Ez a könyv így belenézve elég használhatónak, ha rettenetes bőbeszédűnek is tűnik.
Ami meg nagyjából nélkülözhetetlen referenciaanyag, az a Ralf Brown-féle interrupt list
A hard mode meg a mindenféle miniatűr intrók kódjának tanulmányozása, ezt pl. 64 byte-tból hozta ki az alkotója: Gespensterwald, forrás is van hozzá: [link]
-
instantwater
addikt
Library nalunk a semver. Ha breaking change van, akkor atirjuk manualisan a major verziot. Aki egy app-on frissiti a libet, igy tudja hogy oda kell figyelnie.
Sot, van olyan lib-unk ahol sajnos egyelore 2 verziot kell fenntartanni (py2-py3 migracio, hosszu sztori
 ), ott a 0.x es az 1.x-be is mennek frissitesek. Build id megoldasnal, ezt hogyan tudnad megcsinalni?
), ott a 0.x es az 1.x-be is mennek frissitesek. Build id megoldasnal, ezt hogyan tudnad megcsinalni?”Semmi pluszt nem ad” - de, annyit, hogy tudatosan oda figyelsz a breaking changere, plane ha olyan szerencsetlen helyzet van, hogy teszttel nincs lefedve az adott kod resz.
Deploymentet illetoen meg Docker + egy orchestrator, az nem is kerdeses. Mar csak az auto-skalazas miatt is.
Tehát ti külön branchet tartotok fell 0.x és 1.x verzióknak?
Tehát amolyan release branch stratégia, ahol az egyes releasek külön branchben vannak patchelve?Erről is szivesen fogadok infókat, mert nálunk is fennáll a helyzet, hogy a runtimet és a frameworkot is frissíteni kéne, viszont sok kód van ami csak a régi verzióval kompatibilis, és nem akarunk hetekig dolgozni egy feature branchen mire mindent kompatibiblissé teszünk az új verziókkal. Inkább szépen folyamatosan frissítenénk a kódbázis részeit, és szépen lassan irányítanánk át a feladatok feldolgozását az új verzióra.
-
instantwater
addikt
Egy tanács:
- Nem tudom ugyan, hogy milyen nyelven/frameworkon fejlesztetek, de ha Spring boot, akkor semmiképpen ne fat jarba package-eljetek docker image esetén, hanem a dependency-k, meg az alkalmazás források legyenek külön docker layerben. Ezzel az össz. helyfoglalás jóval kisebb lesz, illetve amíg nem változik a dependency-k összetétele, addig az a layer ott tud csücsülni azon a gépen, ahol a docker már találkozott vele, így nem kell letölteni se újra.
- Még érdekes kérdés, amit tisztázni kell, hogy hol tároljátok az alkalmazáshoz tartozó környezetfüggő konfigurációkat. Különös tekintettel a szenzitív adatokra(db cred, etc.).
- "A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket." Ez nagy baj, de docker használatával kapásból meg tudjátok oldani.Köszi a tippeket.
PHP Laravel a környezet.
A Docker layerekkel és multi-step buildekkel tisztában vagyok, és a dependencyket külön layerbe rakom mindig pontosan a tárhely és újrahasznosíthatóság miatt, de jó tipp. Köszi.
Az alkalmazás környezeti változói jelenleg egy .env fájlban vannak minden szerveren. Ennek automatizálása is cél, és a k8s ebben is fog segíteni.
Esetleg arról is van infód, hogy nálatok milyen branching strategy vált be, és ha van automatizált telepítés, akkor mi triggereli az egyes környezetek frissítését?
Gondolkodtan egy olyan lehetőségen is, hogy masterbe mergelődnek a featurek, ami egyből telepítődik staging/UAT környezetbe és amikor kézzel tagelünk egy commitot egy verziószámmal akkor az kiküldi productionbe a kódot, de ezzel a korábban tárgyalt probléma van, hogy a fejlesztőn múlik, hogy ő patchnek vagy minor changenek itéli-e a PRját, vagy pedig a csapat senior tagjainak kell törni a fejét, hogy ez egy patch vagy minor verzió legyen mergelés után.
Jelenleg nincsenek verzió tagek. Simán a master branch van telepítve. Ezzel az a legnagyobb vaj, hogy csak a telepítésvezérlő környezetben látszik, hogy mikor mi lett telepítve, gitben erről nincs visszajelzés tagek formájában.
-
 Froclee
őstag
Froclee
őstag
Ja, oke, igen.
> Ha nem semver, akkor a librarykat is build number alapján húzod be, vagy hogy?
Igen, nalunk az van, hogy <build-number>-<commit-hash> -bol tevodik ossze a lib verzio.
A semverrel a kovetkezo a bajom:
- a minor es a patch verzio kozott _elvileg_ a kliensnek nem kellene kulonbseget tennie; elviekben mindig kompatibilis az uj verzio, es be lehet huzni
- a gyakorlatban ugyis ujra kell tesztelni minden esetben
- major verziovaltas ugye elvileg megtori a visszafele-kompatibilitast, tehat ennyi erovel a libet is at lehetne nevezniMagyarul semver helyett lehet azt, hogy
- mylib1-bol hasznalsz verzio 1-et, es barmikor kijon egy uj verzio, akkor tesztelsz es upgradelsz
- kompatibilitas-tores eseten mylib1-bol lesz mylib2Es kesz. Semmi pluszt nem ad ehhez a semver.
Library nalunk a semver. Ha breaking change van, akkor atirjuk manualisan a major verziot. Aki egy app-on frissiti a libet, igy tudja hogy oda kell figyelnie.
Sot, van olyan lib-unk ahol sajnos egyelore 2 verziot kell fenntartanni (py2-py3 migracio, hosszu sztori
), ott a 0.x es az 1.x-be is mennek frissitesek. Build id megoldasnal, ezt hogyan tudnad megcsinalni?”Semmi pluszt nem ad” - de, annyit, hogy tudatosan oda figyelsz a breaking changere, plane ha olyan szerencsetlen helyzet van, hogy teszttel nincs lefedve az adott kod resz.
Deploymentet illetoen meg Docker + egy orchestrator, az nem is kerdeses. Mar csak az auto-skalazas miatt is.
-
Drizzt
nagyúr
A DevOps topik kihalt, úgyhogy bedobom ide.
Egy kis brainstormingot szeretnék indítani az alábbiakról.
Continuous Deployment környezetben ki melyik branching strategyt használja, és miért? Mi triggereli a promotiont stagingből productionbe?
Melyik azonosítót használnád a deploymentek jelölésére? Semver, git hash, vagy build id?
A semver igényel emberi közreműködést, mert default a patch számot növelné a rendszer, de a fejlesztő belátásán múlik, hogy a kód amit beküld az inkább egy minor bump legyen patch bump helyett.
Git hash egyértelmű, könnyen visszavezethető pontosan a forrás commitra. Viszont nincs benne szekvencia, nehéz megmondani 2 git hashról, hogy melyik a későbbi anélkül, hogy valaki megnézi a git historyt és megkeresi a commitokat ID alapján.
Build number szekvenciális, és nem igényel emberi beavatkozást, viszont nehéz visszavezetni commitra.
Viszont, ha nem kap verzió taget egy-egy commit, akkor mi triggereli a production deployt, ha stagingben megfelelt a kód?
Van erre valami best practice? Itt vissza térünk a kérdés elejére, hogy melyik branching strategy lenne a legideálisabb.
Jelenleg GitFlowot használunk, de macerás a dupla PR a hotfixekhez (master, develop), és a develop PRrel kerül a masterbe (és deployolásra) hetente 2x, amit szintén szeretnénk lecserélni napi többszöri deploymentre.
Az eszközökkel nincs baj, GitHub Actions, Docker, Terraform, Ansible tapasztalat megvan, inkább a mit mikor és hogyan lenne a kérdés.
A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket.
Ezt le akarom cserélni immutable image alapú deploymentre, ahol egyszer vannak telepítve a függőségek, majd ez az image van kitolva a szerverekre.
Ez lehet akár machine image buildeléssel aztán Terraformmal lecserélni a szervereket és újrakonfigurálni a routingot, de ezt lassúnak érzem. A másik opció Docker image buildelés lenne, mert az könnyen és gyorsan lehet kitolni a szerverekre.
Hosszabb távon a cél Kubernetesre költözés, de mivel egy monolit alkalmazásról van szó ezért úgy érzem az azonnali Kubernetesre váltás túl sok új komplikációt hozna, és jelenlegi archirektúra automatizálása egy jó köztes lépés lenne.
Vagy ahogy egy szakadékot sem lehet két ugrással átugrani, több értelme lenne egyből Kubernetesbe tolni az egészet, aztán lassan refaktorálni microservices architektúrára?
Kinek mi jött be, mi működött, nem működött?
Egy tanács:
- Nem tudom ugyan, hogy milyen nyelven/frameworkon fejlesztetek, de ha Spring boot, akkor semmiképpen ne fat jarba package-eljetek docker image esetén, hanem a dependency-k, meg az alkalmazás források legyenek külön docker layerben. Ezzel az össz. helyfoglalás jóval kisebb lesz, illetve amíg nem változik a dependency-k összetétele, addig az a layer ott tud csücsülni azon a gépen, ahol a docker már találkozott vele, így nem kell letölteni se újra.
- Még érdekes kérdés, amit tisztázni kell, hogy hol tároljátok az alkalmazáshoz tartozó környezetfüggő konfigurációkat. Különös tekintettel a szenzitív adatokra(db cred, etc.).
- "A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket." Ez nagy baj, de docker használatával kapásból meg tudjátok oldani. -
emvy
félisten
Trunk based developmentben is feature branchekben fejlesztenek, csak nincs külön develop és master branch, hanem a feature branchek a masterbe kerülnek mergelésre.
Ha nem semver, akkor a librarykat is build number alapján húzod be, vagy hogy? Elég sok publikus lib használ semvert a mai napig. Persze saját fejlesztésű belső használatra szánt libeknél nem feltétlen elvárás.
Ha clusterezhetőség alatt azt érted, hogy lehet-e futtatni több szerveren a nagyobb teljesítmény elérése érdekében, akkor igen, lehet. Jelenleg is így fut. Lényegében eventeket dolgoz fel egy queueból. Kubernetes Autoscalinggel egy rakás pénzt meg tudnánk spórolni, mert jelenleg egy csomó szerver azért fut éjjel-nappal, hogy napi néhány órát dolgozzon.
Ja, oke, igen.
> Ha nem semver, akkor a librarykat is build number alapján húzod be, vagy hogy?
Igen, nalunk az van, hogy <build-number>-<commit-hash> -bol tevodik ossze a lib verzio.
A semverrel a kovetkezo a bajom:
- a minor es a patch verzio kozott _elvileg_ a kliensnek nem kellene kulonbseget tennie; elviekben mindig kompatibilis az uj verzio, es be lehet huzni
- a gyakorlatban ugyis ujra kell tesztelni minden esetben
- major verziovaltas ugye elvileg megtori a visszafele-kompatibilitast, tehat ennyi erovel a libet is at lehetne nevezniMagyarul semver helyett lehet azt, hogy
- mylib1-bol hasznalsz verzio 1-et, es barmikor kijon egy uj verzio, akkor tesztelsz es upgradelsz
- kompatibilitas-tores eseten mylib1-bol lesz mylib2Es kesz. Semmi pluszt nem ad ehhez a semver.
-
instantwater
addikt
Trunk based developmentben is feature branchekben fejlesztenek, csak nincs külön develop és master branch, hanem a feature branchek a masterbe kerülnek mergelésre.
Ha nem semver, akkor a librarykat is build number alapján húzod be, vagy hogy? Elég sok publikus lib használ semvert a mai napig. Persze saját fejlesztésű belső használatra szánt libeknél nem feltétlen elvárás.
Ha clusterezhetőség alatt azt érted, hogy lehet-e futtatni több szerveren a nagyobb teljesítmény elérése érdekében, akkor igen, lehet. Jelenleg is így fut. Lényegében eventeket dolgoz fel egy queueból. Kubernetes Autoscalinggel egy rakás pénzt meg tudnánk spórolni, mert jelenleg egy csomó szerver azért fut éjjel-nappal, hogy napi néhány órát dolgozzon.
-
emvy
félisten
Tehát akkor trunk based developmentre váltottatok, ahol a masterból megy minden, és a tagek jelzik a production releaset.
Nem multirepos microservice. Monolit, ugyan szét van bontva több packagere, de a build eredménye egy monolit app.
Deployolt appnál mi a semver?
Semver formátumot használsz a taghez ami triggereli a deploymentet.Mostanában elindultunk a jelenlegi infrastruktúra javítása és automatizálása felé, de én ezt zsákutcának és extra munkának érzem, hiszen ahogy te is írtad, a k8s egy csomó mindent megold.
Szerencsére elég nagy beleszólásom van a dolgok folyásába. Konkrétan nekem kell kitalálni, hogy hogyan legyenek a dolgok jobbá téve.
> Tehát akkor trunk based developmentre váltottatok, ahol a masterból megy minden,
Nem, dehogy, feature branchek vannak.
A semvernek webappnal milyen értelme van? Szerintem semmi. Libraryk esetén is szinte semmi.
Clusterezheto az app? Ha nem, akkor a k8s tényleg overkill.
-
instantwater
addikt
- git flowt használtunk régen, mostmár siman tagek jelzik a verziókat; tehát amikor vki taggel egyet a master branchen, akkor az egy deployolhato egység (nyilván multirepos mikroszervizek esetén kell valami metarepo, mármint ha tényleg rendesen akartok tesztelni)
- semvernek nagyon ritkán van értelme, build hash nem inkrementalis, szoval autoincremented id, pl build number (deployolt webappnal mi a fenét jelent a semver?)
- immutable docker image kell, nyilván
Mi előbb mentünk k8s-re, aztán mikroszervizekre. A k8s elég sok mindent megold önmagában, uniform környezet élesben és tesztben, ingress, health checkek, jobok, perzisztens kötetek, logok gyűjtése.. és ugye megy akár egy laptopon is, ha a fejlesztőnek kell.
Mi Docker Swarm + privát szerverek kombóról kb. 4 hónap alatt átmentünk felhőbe, k8s-el, összesen talán 8 emberhonap ment bele, de ebben volt egy 3 TB-os Postgres migráció is, és kb 20 perc downtime lett végül összesen.
Tehát akkor trunk based developmentre váltottatok, ahol a masterból megy minden, és a tagek jelzik a production releaset.
Nem multirepos microservice. Monolit, ugyan szét van bontva több packagere, de a build eredménye egy monolit app.
Deployolt appnál mi a semver?
Semver formátumot használsz a taghez ami triggereli a deploymentet.Mostanában elindultunk a jelenlegi infrastruktúra javítása és automatizálása felé, de én ezt zsákutcának és extra munkának érzem, hiszen ahogy te is írtad, a k8s egy csomó mindent megold.
Szerencsére elég nagy beleszólásom van a dolgok folyásába. Konkrétan nekem kell kitalálni, hogy hogyan legyenek a dolgok jobbá téve.
-
Rula
tag
-
emvy
félisten
A DevOps topik kihalt, úgyhogy bedobom ide.
Egy kis brainstormingot szeretnék indítani az alábbiakról.
Continuous Deployment környezetben ki melyik branching strategyt használja, és miért? Mi triggereli a promotiont stagingből productionbe?
Melyik azonosítót használnád a deploymentek jelölésére? Semver, git hash, vagy build id?
A semver igényel emberi közreműködést, mert default a patch számot növelné a rendszer, de a fejlesztő belátásán múlik, hogy a kód amit beküld az inkább egy minor bump legyen patch bump helyett.
Git hash egyértelmű, könnyen visszavezethető pontosan a forrás commitra. Viszont nincs benne szekvencia, nehéz megmondani 2 git hashról, hogy melyik a későbbi anélkül, hogy valaki megnézi a git historyt és megkeresi a commitokat ID alapján.
Build number szekvenciális, és nem igényel emberi beavatkozást, viszont nehéz visszavezetni commitra.
Viszont, ha nem kap verzió taget egy-egy commit, akkor mi triggereli a production deployt, ha stagingben megfelelt a kód?
Van erre valami best practice? Itt vissza térünk a kérdés elejére, hogy melyik branching strategy lenne a legideálisabb.
Jelenleg GitFlowot használunk, de macerás a dupla PR a hotfixekhez (master, develop), és a develop PRrel kerül a masterbe (és deployolásra) hetente 2x, amit szintén szeretnénk lecserélni napi többszöri deploymentre.
Az eszközökkel nincs baj, GitHub Actions, Docker, Terraform, Ansible tapasztalat megvan, inkább a mit mikor és hogyan lenne a kérdés.
A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket.
Ezt le akarom cserélni immutable image alapú deploymentre, ahol egyszer vannak telepítve a függőségek, majd ez az image van kitolva a szerverekre.
Ez lehet akár machine image buildeléssel aztán Terraformmal lecserélni a szervereket és újrakonfigurálni a routingot, de ezt lassúnak érzem. A másik opció Docker image buildelés lenne, mert az könnyen és gyorsan lehet kitolni a szerverekre.
Hosszabb távon a cél Kubernetesre költözés, de mivel egy monolit alkalmazásról van szó ezért úgy érzem az azonnali Kubernetesre váltás túl sok új komplikációt hozna, és jelenlegi archirektúra automatizálása egy jó köztes lépés lenne.
Vagy ahogy egy szakadékot sem lehet két ugrással átugrani, több értelme lenne egyből Kubernetesbe tolni az egészet, aztán lassan refaktorálni microservices architektúrára?
Kinek mi jött be, mi működött, nem működött?
- git flowt használtunk régen, mostmár siman tagek jelzik a verziókat; tehát amikor vki taggel egyet a master branchen, akkor az egy deployolhato egység (nyilván multirepos mikroszervizek esetén kell valami metarepo, mármint ha tényleg rendesen akartok tesztelni)
- semvernek nagyon ritkán van értelme, build hash nem inkrementalis, szoval autoincremented id, pl build number (deployolt webappnal mi a fenét jelent a semver?)
- immutable docker image kell, nyilván
Mi előbb mentünk k8s-re, aztán mikroszervizekre. A k8s elég sok mindent megold önmagában, uniform környezet élesben és tesztben, ingress, health checkek, jobok, perzisztens kötetek, logok gyűjtése.. és ugye megy akár egy laptopon is, ha a fejlesztőnek kell.
Mi Docker Swarm + privát szerverek kombóról kb. 4 hónap alatt átmentünk felhőbe, k8s-el, összesen talán 8 emberhonap ment bele, de ebben volt egy 3 TB-os Postgres migráció is, és kb 20 perc downtime lett végül összesen.
-
I02S3F
addikt
A DevOps topik kihalt, úgyhogy bedobom ide.
Egy kis brainstormingot szeretnék indítani az alábbiakról.
Continuous Deployment környezetben ki melyik branching strategyt használja, és miért? Mi triggereli a promotiont stagingből productionbe?
Melyik azonosítót használnád a deploymentek jelölésére? Semver, git hash, vagy build id?
A semver igényel emberi közreműködést, mert default a patch számot növelné a rendszer, de a fejlesztő belátásán múlik, hogy a kód amit beküld az inkább egy minor bump legyen patch bump helyett.
Git hash egyértelmű, könnyen visszavezethető pontosan a forrás commitra. Viszont nincs benne szekvencia, nehéz megmondani 2 git hashról, hogy melyik a későbbi anélkül, hogy valaki megnézi a git historyt és megkeresi a commitokat ID alapján.
Build number szekvenciális, és nem igényel emberi beavatkozást, viszont nehéz visszavezetni commitra.
Viszont, ha nem kap verzió taget egy-egy commit, akkor mi triggereli a production deployt, ha stagingben megfelelt a kód?
Van erre valami best practice? Itt vissza térünk a kérdés elejére, hogy melyik branching strategy lenne a legideálisabb.
Jelenleg GitFlowot használunk, de macerás a dupla PR a hotfixekhez (master, develop), és a develop PRrel kerül a masterbe (és deployolásra) hetente 2x, amit szintén szeretnénk lecserélni napi többszöri deploymentre.
Az eszközökkel nincs baj, GitHub Actions, Docker, Terraform, Ansible tapasztalat megvan, inkább a mit mikor és hogyan lenne a kérdés.
A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket.
Ezt le akarom cserélni immutable image alapú deploymentre, ahol egyszer vannak telepítve a függőségek, majd ez az image van kitolva a szerverekre.
Ez lehet akár machine image buildeléssel aztán Terraformmal lecserélni a szervereket és újrakonfigurálni a routingot, de ezt lassúnak érzem. A másik opció Docker image buildelés lenne, mert az könnyen és gyorsan lehet kitolni a szerverekre.
Hosszabb távon a cél Kubernetesre költözés, de mivel egy monolit alkalmazásról van szó ezért úgy érzem az azonnali Kubernetesre váltás túl sok új komplikációt hozna, és jelenlegi archirektúra automatizálása egy jó köztes lépés lenne.
Vagy ahogy egy szakadékot sem lehet két ugrással átugrani, több értelme lenne egyből Kubernetesbe tolni az egészet, aztán lassan refaktorálni microservices architektúrára?
Kinek mi jött be, mi működött, nem működött?
Én nem konyítok hozzá(!) , de annyit tudok, hogy az utolsó előtti kérdésed megvalósítása óriási munka lenne.
-
Silεncε
őstag
-
instantwater
addikt
A DevOps topik kihalt, úgyhogy bedobom ide.
Egy kis brainstormingot szeretnék indítani az alábbiakról.
Continuous Deployment környezetben ki melyik branching strategyt használja, és miért? Mi triggereli a promotiont stagingből productionbe?
Melyik azonosítót használnád a deploymentek jelölésére? Semver, git hash, vagy build id?
A semver igényel emberi közreműködést, mert default a patch számot növelné a rendszer, de a fejlesztő belátásán múlik, hogy a kód amit beküld az inkább egy minor bump legyen patch bump helyett.
Git hash egyértelmű, könnyen visszavezethető pontosan a forrás commitra. Viszont nincs benne szekvencia, nehéz megmondani 2 git hashról, hogy melyik a későbbi anélkül, hogy valaki megnézi a git historyt és megkeresi a commitokat ID alapján.
Build number szekvenciális, és nem igényel emberi beavatkozást, viszont nehéz visszavezetni commitra.
Viszont, ha nem kap verzió taget egy-egy commit, akkor mi triggereli a production deployt, ha stagingben megfelelt a kód?
Van erre valami best practice? Itt vissza térünk a kérdés elejére, hogy melyik branching strategy lenne a legideálisabb.
Jelenleg GitFlowot használunk, de macerás a dupla PR a hotfixekhez (master, develop), és a develop PRrel kerül a masterbe (és deployolásra) hetente 2x, amit szintén szeretnénk lecserélni napi többszöri deploymentre.
Az eszközökkel nincs baj, GitHub Actions, Docker, Terraform, Ansible tapasztalat megvan, inkább a mit mikor és hogyan lenne a kérdés.
A deployment jelenleg egy több szerverre kitolt kódbázissal megy ahol a függőségek az összes szerveren helyben újra és újra telepítve vannak ami írtó sávszél pazarló, és fragile, mert boldog-boldogtalan root joggal bír a szervereken, és gyakran elb.rmolják az ownershipeket.
Ezt le akarom cserélni immutable image alapú deploymentre, ahol egyszer vannak telepítve a függőségek, majd ez az image van kitolva a szerverekre.
Ez lehet akár machine image buildeléssel aztán Terraformmal lecserélni a szervereket és újrakonfigurálni a routingot, de ezt lassúnak érzem. A másik opció Docker image buildelés lenne, mert az könnyen és gyorsan lehet kitolni a szerverekre.
Hosszabb távon a cél Kubernetesre költözés, de mivel egy monolit alkalmazásról van szó ezért úgy érzem az azonnali Kubernetesre váltás túl sok új komplikációt hozna, és jelenlegi archirektúra automatizálása egy jó köztes lépés lenne.
Vagy ahogy egy szakadékot sem lehet két ugrással átugrani, több értelme lenne egyből Kubernetesbe tolni az egészet, aztán lassan refaktorálni microservices architektúrára?
Kinek mi jött be, mi működött, nem működött?
-
Rula
tag
Sziasztok!
Assemblyhez tudnátok ajánlani valami jó kis könyvet?Angol nyelvű is tökéletes. (Még két szám összeadása is szenvedés jelenleg ) -
 fabri07
aktív tag
fabri07
aktív tag
-
Silεncε
őstag
Bocsi, de az első kb nem ennyi ?
class Program{static void Main(string[] args){Megszerkesztheto();}public static void Megszerkesztheto(){Console.WriteLine("a oldal:");int a = Convert.ToInt32(Console.ReadLine());Console.WriteLine("b oldal:");int b = Convert.ToInt32(Console.ReadLine());Console.WriteLine("c oldal:");int c = Convert.ToInt32(Console.ReadLine());int d = a + b;if (d > c){Console.WriteLine("megrajzolható");}else if(d < c){Console.WriteLine("nem megrajzolható");}}}}Olyankor mit ír ki, ha mondjuk a=100, b=5, c=9? Kiírja, hogy megrajzolhato, pedig mégse....
-
fabri07
aktív tag
-
 opr
nagyúr
opr
nagyúr
Bocsi, de az első kb nem ennyi ?
class Program{static void Main(string[] args){Megszerkesztheto();}public static void Megszerkesztheto(){Console.WriteLine("a oldal:");int a = Convert.ToInt32(Console.ReadLine());Console.WriteLine("b oldal:");int b = Convert.ToInt32(Console.ReadLine());Console.WriteLine("c oldal:");int c = Convert.ToInt32(Console.ReadLine());int d = a + b;if (d > c){Console.WriteLine("megrajzolható");}else if(d < c){Console.WriteLine("nem megrajzolható");}}}}Torghelle, szép lövés, bedobás.
De már nincs messze a teljes értékű megoldás. -
fabri07
aktív tag
Bocsi, de az első kb nem ennyi ?
class Program{static void Main(string[] args){Megszerkesztheto();}public static void Megszerkesztheto(){Console.WriteLine("a oldal:");int a = Convert.ToInt32(Console.ReadLine());Console.WriteLine("b oldal:");int b = Convert.ToInt32(Console.ReadLine());Console.WriteLine("c oldal:");int c = Convert.ToInt32(Console.ReadLine());int d = a + b;if (d > c){Console.WriteLine("megrajzolható");}else if(d < c){Console.WriteLine("nem megrajzolható");}}}} -
instantwater
addikt
-
 Ispy
nagyúr
Ispy
nagyúr
-
y@g4n
tag
-
Silεncε
őstag
-
 bandi0000
nagyúr
bandi0000
nagyúr
-
Drizzt
nagyúr
Az a szép benne, hogy csak az árszabályok mondják meg, hogy mit vesznek előre, gyakorlatilag egy sorrendet állít felm mégha nem is minden esetre
IGazából az, hogy honnan jön az ár nem is lényeg, ugyan sok fajta kedvezmény van, mondjuk 6-7 fajta, termékhez, termékcsoporthoz, ügyfélhez stb-hez kapcsolódnak, viszont a lényeg, hogy van egy listám, amiben jelenleg el vannak ezek tárolva, egymás után lekérdezve ugye
Egyik sem feltétlen olcsóbb vagy drágább mint a többi
Pl Egyedi ár 2000Ft, Márka kedvezményes ára: 1600Ft, Akciós ár: 1000Ft1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 2000 Ft lesz
2. Szabály: Legolcsóbb ár: Akkor is 1000Ft lesz
Pl Márka kedvezményes ára: 500Ft, Akciós ár: 650Ft, Termékcsoport kedvezményes ár: 300Ft
1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 300 Ft lesz
2. Szabály:Akciós ár vagy legolcsóbb: Akkor is 650Ft lesz
Igazából már létező rendszer, de ott jelenleg csak az egyedi ár, vagy legkedvezőbb ár szabály van, és pont ez a gond, mert jött másik ügyfél, aki mást akar, plusz ez ugye elméletileg bármikor kapcsolható, szóval így nem teljesen jól működik -
bandi0000
nagyúr
csinálsz egy táblát, amibe belerakod az adott termék/adott rendelés azonosítóit, egy azonosítót, hogy melyik árazási függvénnyel számoltak, és magát a kiszámolt árat.
ezek után x darab program, szubrutin, stb. bármi, lefut, és mindegyik beleönti ebbe a táblába a saját árát.
majd ebből a táblából kiválasztod termék/rendelés azonosító alapján, hogy a konkrét esetben melyik árat érvényesíted.Ötlennek nem lenne rossz, csak ezt real time-ban számolnuk mindig az aktuális friss adatokkal, ezért dordul elő, hogy ma van x fajta akcí/bármi de holnap már lehet nem lesz, meg hát ugye igazából kosárba rakás történik, szóval nem tudjuk előre mit vesznek
-
 bambano
titán
bambano
titán
Szinte igen bàr megpróbálom valós példákkal
Adottak a következő àr típusok: Egyedi ár, Akciós ár, Márka kedvezmény, Termék csoport kedvezmény
Van 3 Fajta àrazási szabàly : Egyedi àr vagy legolcsóbb, Akciós ár vagy legolcsóbb, Legolcsóbb
1. szabálynál, ha van egyedi ár akkor azt, ha nincs, akkor a maradékból a legolcsóbbat használja
2. Hasonló, csak akciós árral
3. Az összes közül a legolcsóbbat veszi ki
Persze lenne olyan is, hogy egyéni sorrend van köztük, de ez már lehet meg se valósul
Igazábó olyasmi dolgot szeretnék ami "legenerálja" anélkül, hogy tele raknám if-el, vagy return-el, illetve könnyű legyen újat hozzátenni
Olyasmire gondoltam, hogy lehetne az egyes àrakat súlyozni, és a legolcsóbb kategóriás árakat ugyan azzal a súllyal jellemezném, és ekkor választanán ki a legolcsóbbat
Persze ez lehet hülyeség
csinálsz egy táblát, amibe belerakod az adott termék/adott rendelés azonosítóit, egy azonosítót, hogy melyik árazási függvénnyel számoltak, és magát a kiszámolt árat.
ezek után x darab program, szubrutin, stb. bármi, lefut, és mindegyik beleönti ebbe a táblába a saját árát.
majd ebből a táblából kiválasztod termék/rendelés azonosító alapján, hogy a konkrét esetben melyik árat érvényesíted. -
bandi0000
nagyúr
Ebben az esetben dabadab kollegával értek egyet, ha már ennyi kész van, plusz ilyen ritkán kell változtatni, és ilyen kevés a variáció, akkor nem éri meg szopni egy teljesen generikus rendszerrel meg szétrefaktorálni az agyadat, vésd oda és kész, ha szépen csinálod meg dokumentálod (akár simán kommenteléssel), nincs azzal semmi gond, legalább triviális, de minimum egyszerű debuggolni.

Szerintem is, nem is jókedvemből akartam volna refaktorálni, csak jó lenne kicsit fejlődni, mert sajnos nem nagyon van senki aki "refaktoráljon", így az ilyeneken kicsit elszoktam agyalni, hogy jó-e így, nem-e lehetne szebben, persze nyilván azt meg tudjuk, hogy senki nem fizeti azt, hogy szebb lett
-
opr
nagyúr
Az a szép benne, hogy csak az árszabályok mondják meg, hogy mit vesznek előre, gyakorlatilag egy sorrendet állít felm mégha nem is minden esetre
IGazából az, hogy honnan jön az ár nem is lényeg, ugyan sok fajta kedvezmény van, mondjuk 6-7 fajta, termékhez, termékcsoporthoz, ügyfélhez stb-hez kapcsolódnak, viszont a lényeg, hogy van egy listám, amiben jelenleg el vannak ezek tárolva, egymás után lekérdezve ugye
Egyik sem feltétlen olcsóbb vagy drágább mint a többi
Pl Egyedi ár 2000Ft, Márka kedvezményes ára: 1600Ft, Akciós ár: 1000Ft1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 2000 Ft lesz
2. Szabály: Legolcsóbb ár: Akkor is 1000Ft lesz
Pl Márka kedvezményes ára: 500Ft, Akciós ár: 650Ft, Termékcsoport kedvezményes ár: 300Ft
1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 300 Ft lesz
2. Szabály:Akciós ár vagy legolcsóbb: Akkor is 650Ft lesz
Igazából már létező rendszer, de ott jelenleg csak az egyedi ár, vagy legkedvezőbb ár szabály van, és pont ez a gond, mert jött másik ügyfél, aki mást akar, plusz ez ugye elméletileg bármikor kapcsolható, szóval így nem teljesen jól működikEbben az esetben dabadab kollegával értek egyet, ha már ennyi kész van, plusz ilyen ritkán kell változtatni, és ilyen kevés a variáció, akkor nem éri meg szopni egy teljesen generikus rendszerrel meg szétrefaktorálni az agyadat, vésd oda és kész, ha szépen csinálod meg dokumentálod (akár simán kommenteléssel), nincs azzal semmi gond, legalább triviális, de minimum egyszerű debuggolni.
-
bandi0000
nagyúr
Egyedi ár mindig olcsóbb, mint a bármi más akciós ár?
Akciós ár mindig olcsóbb, mint a bármi más, kivéve egyedi ár?
Hogy kéne ezt elképzelni? Van egy meglevő terméklista, vagy ilyesmi, illetve vevők, és vevő kaphat egyedi árat, termék kaphat akciós árat? Hogy lehet egy terméknek több ára (ie: maradékból a legolcsóbb)?Valami valós példát be tudsz dobni légyszi, árakkal, ilyesmivel?
Illetve: létező rendszerbe akarunk extra funkciót (akció) vagy nulláról tervezett/írt rendszerről beszélünk, aminek ez lesz az egyik funkciója?
Az a szép benne, hogy csak az árszabályok mondják meg, hogy mit vesznek előre, gyakorlatilag egy sorrendet állít felm mégha nem is minden esetre
IGazából az, hogy honnan jön az ár nem is lényeg, ugyan sok fajta kedvezmény van, mondjuk 6-7 fajta, termékhez, termékcsoporthoz, ügyfélhez stb-hez kapcsolódnak, viszont a lényeg, hogy van egy listám, amiben jelenleg el vannak ezek tárolva, egymás után lekérdezve ugye
Egyik sem feltétlen olcsóbb vagy drágább mint a többi
Pl Egyedi ár 2000Ft, Márka kedvezményes ára: 1600Ft, Akciós ár: 1000Ft1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 2000 Ft lesz
2. Szabály: Legolcsóbb ár: Akkor is 1000Ft lesz
Pl Márka kedvezményes ára: 500Ft, Akciós ár: 650Ft, Termékcsoport kedvezményes ár: 300Ft
1. Szabály: Egyedi ár vagy legkedvezőbb esetben akkor az 300 Ft lesz
2. Szabály:Akciós ár vagy legolcsóbb: Akkor is 650Ft lesz
Igazából már létező rendszer, de ott jelenleg csak az egyedi ár, vagy legkedvezőbb ár szabály van, és pont ez a gond, mert jött másik ügyfél, aki mást akar, plusz ez ugye elméletileg bármikor kapcsolható, szóval így nem teljesen jól működik -
opr
nagyúr
Szinte igen bàr megpróbálom valós példákkal
Adottak a következő àr típusok: Egyedi ár, Akciós ár, Márka kedvezmény, Termék csoport kedvezmény
Van 3 Fajta àrazási szabàly : Egyedi àr vagy legolcsóbb, Akciós ár vagy legolcsóbb, Legolcsóbb
1. szabálynál, ha van egyedi ár akkor azt, ha nincs, akkor a maradékból a legolcsóbbat használja
2. Hasonló, csak akciós árral
3. Az összes közül a legolcsóbbat veszi ki
Persze lenne olyan is, hogy egyéni sorrend van köztük, de ez már lehet meg se valósul
Igazábó olyasmi dolgot szeretnék ami "legenerálja" anélkül, hogy tele raknám if-el, vagy return-el, illetve könnyű legyen újat hozzátenni
Olyasmire gondoltam, hogy lehetne az egyes àrakat súlyozni, és a legolcsóbb kategóriás árakat ugyan azzal a súllyal jellemezném, és ekkor választanán ki a legolcsóbbat
Persze ez lehet hülyeség
Egyedi ár mindig olcsóbb, mint a bármi más akciós ár?
Akciós ár mindig olcsóbb, mint a bármi más, kivéve egyedi ár?
Hogy kéne ezt elképzelni? Van egy meglevő terméklista, vagy ilyesmi, illetve vevők, és vevő kaphat egyedi árat, termék kaphat akciós árat? Hogy lehet egy terméknek több ára (ie: maradékból a legolcsóbb)?Valami valós példát be tudsz dobni légyszi, árakkal, ilyesmivel?
Illetve: létező rendszerbe akarunk extra funkciót (akció) vagy nulláról tervezett/írt rendszerről beszélünk, aminek ez lesz az egyik funkciója?
-
bandi0000
nagyúr
Addig, amíg tényleg három ilyen szabály van, szerintem a fixen bedrótozott kódnál jobb megoldás nincs.
Majd ha lesz sok, akkor lesz egyrészt értelme annak, hogy ezt az ember valamiféle általános módon kezelje meg akkor fog látszani, hogy hogyan is érdemes a követelményeket lemodellezni (mert ugye ilyenkor az szokott lenni, hogy a három példa alapján kitalálsz valami rendszert, lekódolod, örülsz, aztán másnap valaki kitalál egy negyediket, ami baromira nem illeszkedik abba, amit megcsináltál és vagy széthekkeled a rendszered vagy kezdheted majdnem előről).Akkor jól gondoltam, hogy nincs nagyon jobb megoldás rá, akkor reménykedek, hogy nem lesz több :Dx
-
dabadab
titán
Szinte igen bàr megpróbálom valós példákkal
Adottak a következő àr típusok: Egyedi ár, Akciós ár, Márka kedvezmény, Termék csoport kedvezmény
Van 3 Fajta àrazási szabàly : Egyedi àr vagy legolcsóbb, Akciós ár vagy legolcsóbb, Legolcsóbb
1. szabálynál, ha van egyedi ár akkor azt, ha nincs, akkor a maradékból a legolcsóbbat használja
2. Hasonló, csak akciós árral
3. Az összes közül a legolcsóbbat veszi ki
Persze lenne olyan is, hogy egyéni sorrend van köztük, de ez már lehet meg se valósul
Igazábó olyasmi dolgot szeretnék ami "legenerálja" anélkül, hogy tele raknám if-el, vagy return-el, illetve könnyű legyen újat hozzátenni
Olyasmire gondoltam, hogy lehetne az egyes àrakat súlyozni, és a legolcsóbb kategóriás árakat ugyan azzal a súllyal jellemezném, és ekkor választanán ki a legolcsóbbat
Persze ez lehet hülyeség
Addig, amíg tényleg három ilyen szabály van, szerintem a fixen bedrótozott kódnál jobb megoldás nincs.
Majd ha lesz sok, akkor lesz egyrészt értelme annak, hogy ezt az ember valamiféle általános módon kezelje meg akkor fog látszani, hogy hogyan is érdemes a követelményeket lemodellezni (mert ugye ilyenkor az szokott lenni, hogy a három példa alapján kitalálsz valami rendszert, lekódolod, örülsz, aztán másnap valaki kitalál egy negyediket, ami baromira nem illeszkedik abba, amit megcsináltál és vagy széthekkeled a rendszered vagy kezdheted majdnem előről). -
bandi0000
nagyúr
Csak hogy jól értem-e a feladatot:
Van n darab függvényed (mondjuk A1, A2, A3 stb) amik visszaadnak egy értéket.
Vannak szabályaid, amik azt mondják meg, hogy a fentiek közül melyik függvények értékei közül kell kiválasztani a (legkisebb? legnagyobb?) értéket, valami olyasmi, hogy min(A1, A3, A17).
És kellene írnod valamit, ami a szabályokat kezeli.
Jól értem?Szinte igen bàr megpróbálom valós példákkal
Adottak a következő àr típusok: Egyedi ár, Akciós ár, Márka kedvezmény, Termék csoport kedvezmény
Van 3 Fajta àrazási szabàly : Egyedi àr vagy legolcsóbb, Akciós ár vagy legolcsóbb, Legolcsóbb
1. szabálynál, ha van egyedi ár akkor azt, ha nincs, akkor a maradékból a legolcsóbbat használja
2. Hasonló, csak akciós árral
3. Az összes közül a legolcsóbbat veszi ki
Persze lenne olyan is, hogy egyéni sorrend van köztük, de ez már lehet meg se valósul
Igazábó olyasmi dolgot szeretnék ami "legenerálja" anélkül, hogy tele raknám if-el, vagy return-el, illetve könnyű legyen újat hozzátenni
Olyasmire gondoltam, hogy lehetne az egyes àrakat súlyozni, és a legolcsóbb kategóriás árakat ugyan azzal a súllyal jellemezném, és ekkor választanán ki a legolcsóbbat
Persze ez lehet hülyeség
-
dabadab
titán
Egy kis segítséget kérnék, hogy miképp lehetne szépen megoldani az alábbi feladatot
Adott egy árazó osztály, 3 fő árszabály van, vagy egyedi árat, vagy akciót, vagya többi fajtából a legkisebb árát vesszük figyelembe
Ezeknek különböző permutációját lehet beállítani, asszem most 3 fajta van
-Egyedi ár vagy legkedvezőbb ár a többi típusból
-Legkedvezőbb ár
-Akció vagy legkedvezőbb ár a többi típusbólEgyedi ár, akció és a többi fajtára mind van 1-1 fv az osztályon belül, ami visszaadja az árat
Nekem egyfajta megoldás jut eszembe hirtelen, 3 fő fv ami a szabályokat tartalmazza, és aszerint hívja meg a különböző fv-ket, nyilván ez annyira nem lenne szép
Van erre valami tervezési minta, amit ilyesmire lehetne alkalmazni?
Csak hogy jól értem-e a feladatot:
Van n darab függvényed (mondjuk A1, A2, A3 stb) amik visszaadnak egy értéket.
Vannak szabályaid, amik azt mondják meg, hogy a fentiek közül melyik függvények értékei közül kell kiválasztani a (legkisebb? legnagyobb?) értéket, valami olyasmi, hogy min(A1, A3, A17).
És kellene írnod valamit, ami a szabályokat kezeli.
Jól értem? -
bandi0000
nagyúr
-
opr
nagyúr
Egy kis segítséget kérnék, hogy miképp lehetne szépen megoldani az alábbi feladatot
Adott egy árazó osztály, 3 fő árszabály van, vagy egyedi árat, vagy akciót, vagya többi fajtából a legkisebb árát vesszük figyelembe
Ezeknek különböző permutációját lehet beállítani, asszem most 3 fajta van
-Egyedi ár vagy legkedvezőbb ár a többi típusból
-Legkedvezőbb ár
-Akció vagy legkedvezőbb ár a többi típusbólEgyedi ár, akció és a többi fajtára mind van 1-1 fv az osztályon belül, ami visszaadja az árat
Nekem egyfajta megoldás jut eszembe hirtelen, 3 fő fv ami a szabályokat tartalmazza, és aszerint hívja meg a különböző fv-ket, nyilván ez annyira nem lenne szép
Van erre valami tervezési minta, amit ilyesmire lehetne alkalmazni?
Ez nagyon úgy hangzik, mint egy bizonyos, főleg f1 területen mozgó londoni cég interjú házifeladata.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
bandi0000
nagyúr
Egy kis segítséget kérnék, hogy miképp lehetne szépen megoldani az alábbi feladatot
Adott egy árazó osztály, 3 fő árszabály van, vagy egyedi árat, vagy akciót, vagya többi fajtából a legkisebb árát vesszük figyelembe
Ezeknek különböző permutációját lehet beállítani, asszem most 3 fajta van
-Egyedi ár vagy legkedvezőbb ár a többi típusból
-Legkedvezőbb ár
-Akció vagy legkedvezőbb ár a többi típusbólEgyedi ár, akció és a többi fajtára mind van 1-1 fv az osztályon belül, ami visszaadja az árat
Nekem egyfajta megoldás jut eszembe hirtelen, 3 fő fv ami a szabályokat tartalmazza, és aszerint hívja meg a különböző fv-ket, nyilván ez annyira nem lenne szép
Van erre valami tervezési minta, amit ilyesmire lehetne alkalmazni?
-
emvy
félisten
Igen, ezt nyilvan figyelembe vesszuk a felvetelin.
-
Froclee
őstag
A “legyen mergelve” reszhez: tapasztalatom szerint 50-50 szazalek milyen karbantartokkal talalkozol. Volt PR-em 1 ora alatt mergelve, az egyik legnepszerubb Python csomagkezelonel pedig 1 eve van nyitva egy feature-om, amire 20+ thumb up erkezett kozben.
-
K1nG HuNp
őstag
egyszer 20 sor difire kaptam 4 review kommentet, ugy hogy az uj kod egybol 100% test coveragevel futott be
-
tboy93
nagyúr
-
emvy
félisten
-
Silεncε
őstag
-
 pelyib
tag
pelyib
tag
-
 skoda12
aktív tag
skoda12
aktív tag
Én mostanában épp ckeditor 5-ös plugineket javítgatok aktívan, így hogy havonta jönnek a breaking change-es új verziók. Én ebben az egészben azt nem értem, hogy ha már valaki vállalja, hogy csinál egy plugint, és kap emailt egy PR érkezéséről, mégis mi a f....ért nem képes belátható időn belül rányomni egy nyomorult merge gombra?
Régen én is küldtem kódot open source projektekhez, de folyton az volt, hogy a merge joggal rendelkező developerek alapvetően el voltak foglalva az új featureökkel és a critical/blocker bugokkal. Senkit nem érdekelt, hogy egy kevésbé súlyos bug engem érintett és amúgy megjavítottam, mert azt nekik idő átnézni, kipróbálni, visszaírni, hogy mi nem tetszik stb.
-
Silεncε
őstag
Nálunk egyetemen az egyik tantargyon ment ez csapatmunkában, csak nekünk az kimaradt, mert a tanár finoman szólva se volt a tanítás mestere...

-
martonx
veterán
Semmi komoly, 6 sor az egész, de ettől függetlenül is jó
Am ilyen nekem is volt. Cordova plugint az illető baszott karbantartani, szépen el is tört mint annak rendje, aztán lehetett valakinek a gh-n lévő megpatkolt forkját begányolni. Az open source egyik legnagyobb hátránya, hogy igazából senkié a cucc, aztán a karbantartó ráhagyja, akkor meg van baszva mindenki
Én mostanában épp ckeditor 5-ös plugineket javítgatok aktívan, így hogy havonta jönnek a breaking change-es új verziók. Én ebben az egészben azt nem értem, hogy ha már valaki vállalja, hogy csinál egy plugint, és kap emailt egy PR érkezéséről, mégis mi a f....ért nem képes belátható időn belül rányomni egy nyomorult merge gombra?
-
emvy
félisten
Nalunk a felveteli resze, h valassz ki egy open-source projektet (ami neked tetszik), fixalj meg valamit (ne legyen tobb melo, mint 3-4 ora), es lehetoseg szerint legyen mergelve.
-
Silεncε
őstag
Semmi komoly, 6 sor az egész, de ettől függetlenül is jó
Am ilyen nekem is volt. Cordova plugint az illető baszott karbantartani, szépen el is tört mint annak rendje, aztán lehetett valakinek a gh-n lévő megpatkolt forkját begányolni. Az open source egyik legnagyobb hátránya, hogy igazából senkié a cucc, aztán a karbantartó ráhagyja, akkor meg van baszva mindenki
-
martonx
veterán
Az attól függ. Amikor 1 soros javításokon is hónapokat kotlanak, az nem olyan jó érzés, és forkolhatod magadnak, aztán meg húzhatod be npm-ben a saját github forkodat.
Komolyabb PR-ek beküldése, viszont tagadhatatlanul jó érzés. Grat! -
Silεncε
őstag
Tök jó érzés, amikor életed első PR-je mergelésre kerül egy open source projektbe
-
opr
nagyúr
Persze, de ha jól értettem, Ő nem böngészgetni akarja, hanem rendesen időnként végigfésülni kb az egész fórumot. Még text only verzióban is jogosan jár érte a ban.
-
instantwater
addikt
Mobilappnál valóban nincs szükség TORos varázslásra.
Bár, ha nagyon sok user van egy szolgáltatói NAT mögül akkor IP ban befigyelhet extrém esetben.Illetve nagyon pazarlós megoldás letölteni az egész HTMLt és kliensoldalon parsolni ahelyett, hogy a szerver csak a lényeges adatot küldené le JSONban.
Nálam ez szakmai ártalom, hogy alapból mindent szerveroldalon csinálok. Sokkal kontrollálhatóbb mint a kliens.
-
 seredy
tag
seredy
tag
Btw, ha erre a fórumra kell, van unofficial PH app: [link] De nyilván sokkal nagyobb fun, ha magadnak csinálod, a topic összefoglalójában (amit linkeltem) megvan a régi verzió forráskódja [link]
De ha korábban nem programoztál még, akkor szerintem nem ezzel kéne kezdeni. Ha appokat akarsz csinálni, kezdj neki Javat vagy megjobb, ha Kotlint tanulni +Android fejlesztést
Köszönöm! Igen, sejtettem, hogy ez nem valami kezdő projekt, inkább az érdekelt, hogy lehetne-e ilyet csinálni, meg mik ennek a kulcsszavai
. Én egyelore html-t, CSS-t meg js-t nézegetek, bár annyira kevés idom van mostanában, hogy inkább csak blogokat olvasására jut Idő. Aztán felmerült bennem a fenti kérdés . -
Silεncε
őstag
Visszatöröltem már, de ezzel én is tisztában vagyok. Viszont én nem szerverben gondolkoztam, hanem hogy a mobilról küldesz requestet és azt a mobilon alakítod át, nincs központi szerver amin minden átfolyik. Valamiért úgy rémlik az unofficial PH app mögött sincsen backend









































 Ott használjuk ezt.
Ott használjuk ezt. 

 ), ott a 0.x es az 1.x-be is mennek frissitesek. Build id megoldasnal, ezt hogyan tudnad megcsinalni?
), ott a 0.x es az 1.x-be is mennek frissitesek. Build id megoldasnal, ezt hogyan tudnad megcsinalni?







![;]](http://cdn.rios.hu/dl/s/v1.gif)










Új hozzászólás Aktív témák
-
14900 - 14801
21056 - 20001 20000 - 18001 18000 - 16001 16000 - 15901 15900 - 15801 15800 - 15701 15700 - 15601 15600 - 15501 15500 - 15401 15400 - 15301 15300 - 15201 15200 - 15101 15100 - 15001 15000 - 14901 14900 - 14801 14800 - 14701 14700 - 14601 14600 - 14501 14500 - 14401 14400 - 14301 14300 - 14201 14200 - 14101 14100 - 14001 14000 - 13901 13900 - 13801 13800 - 13701 13700 - 13601 13600 - 13501 13500 - 13401 13400 - 13301 13300 - 13201 13200 - 13101 13100 - 13001 13000 - 12901 12900 - 12801 12800 - 12701 12700 - 12601 12600 - 12501 12500 - 12401 12400 - 12301 12300 - 12201 12200 - 12101 12100 - 12001 12000 - 10001 10000 - 8001 8000 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- Programozás topic
- (kiemelt téma)
● olvasd el a téma összefoglalót!
- Samsung Galaxy A54 - türelemjáték
- Youtube Android alkalmazás alternatívák reklámszűréssel / videók letöltése
- Miskolc és környéke adok-veszek-beszélgetek
- AMD Navi Radeon™ RX 9xxx sorozat
- Játékosok asztalára: MSI MPG 271QR X50 monitor tesztje
- exHWSW - Értünk mindenhez IS
- ASUS ROG Ally
- Milyen billentyűzetet vegyek?
- A Linux megnégyszerezte magát a Steamen — a Microsoft ismét ígérget
- AMD vs. INTEL vs. NVIDIA
- További aktív témák...
- HP Omen 16" FHD+ IPS Ryzen 9 8940HX RTX 5070 32GB 1TB NVMe gar
- GoPro HERO11 Black Creator Edition KOMPLETT, eredeti doboz, alig használt
- Bomba ár! Lenovo TP Yoga 370 - i5-7G I 8GB I 512SSD I 13,3" FHD Touch I Cam I W11 I Gari
- Bomba ár! Lenovo ThinkPad X390 - i7-8G I 16GB I 256SSD I 13,3" FHD I HDMI I Cam I W11 I Gari!
- playseat evolution black actifit
- PlayStation 5 SLIM DIGITAL 1 TB + kontroller 6 hónap garanciával, számlával!
- Ducky One 3 Pure White/PBT/DE/Cherry RGB Silent Red switch (Space nem működik)
- 14" Dell Latitude laptopok: 5400, 5480, 5490, 7480, 7420, E6410, E6440, E5450 / SZÁMLA + GARANCIA
- HP ProBook 455 G7 15,6" Ryzen 3 4300U, 8-16GB RAM, SSD, jó akku, számla, 6 hó gar
- ASUS Vivobook X1704VA Intel Core 5 120U 16GB RAM 512GB SSD ÚJ! GARANCIA 2029-IG!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest