-

Fototrend
Sziasztok, udvozlunk mindenkit Magyarorszag legnagyobb VMware forumjaban!



Új hozzászólás Aktív témák
-
válasz
 tasiadam
#5902
üzenetére
tasiadam
#5902
üzenetére
Szerintem engedd el, a Proxmox megváltás lesz. Ott legalább támogatott minden, arról nem is beszélve, hogy patchelni is tudod amikor csak kell a jövőben. A 6.5/6.7 idén novemberben end of tech support státuszba megy, és ha lesz megint valami security bug, akkor jövőre fogod a Proxmoxot telepíteni, az addigra már belakott rendszeren. Sokkal jobban fog fájni.
-
válasz
tasiadam
#5890
üzenetére
ESXi-Customizer nekem sose működött.
Megkerestem a leírást, ezzel mennie kellene (12.5-ös PowerCLI modulokkal ha jól emlékszem, ott még nem volt Python függőség). Értelemszrűen 6.7U3 iso kell neked, meg a Community driverek 6.7 verziója
-
#5719
 Jürgenmüller
kezdő
tasiadam
#5697
Jürgenmüller
kezdő
tasiadam
#5697
Jürgenmüller
kezdő
válasz
tasiadam
#5697
üzenetére
A VMware Tools nem erre való, és nem is erre tervezték. Erre megvannak a céleszközök. Vagy le tudod fejlesztetni, de ezért senki nem fog felelősséget vállalni, és nem is elvárható a VMware oldalról. Mi történik, ha a régi lesz a VMware tools, mert azt sok esetben egy ESXi szerver frissítés után utána kell húzni, valamint mi van akkor, ha a VMware tools megáll a VM-en? Ilyenbe nem szabad belemenni, bármennyire is low budget megoldásra van szükség.
Ugyan nem Hyper-V fórum, de konyítok hozzá, nálunk volt egy 110 node-os Hyper-V farm ezt sikerült lebontanom 50-esre, azóta az ESXi farmunk 400 host felett van.
A Hyper-V-t nem fejlesztik már, azaz kiadják az újabb verziókat, de nem sokat hoz a 2016-hoz képest.
Sokkal több munkát igényel a rendszergazdától, mint a VMware. A Vmware egy fabalta a Hyper-V-hez képest, nem tudásban, mert abban a Hyper-V nagyon el van maradva. Sehol nincs ahhoz képest, ezt én biztosan meggondolnám, hogy szükség van-e arra, hogy egy Live Migration (Ez a vMotion megfelelője) fejreállítja Hyper-V node-ot ha nem állítod be jól, ez a VMware-nél egy install minden be van állítva. És a Hyper-V esetében ez kb 30 beállítást jelent csak addig, hogy működjön normálisan.Ilyen sztorijaim nekem is vannak, tegyünk snapshotot az adatbázis, log szerverre, mert az a mentés. De amúgy tartsátok meg 2 hónapig, mert hát ki tudja.
Csináljunk file szerverre vSphere Replicationnel, mert az majd nagyon jó visszaállási pont lesz. A file szerver 12 TB volt.
Szintén Fault Tolerance, de kellene 12 vCpu és a gép 96 GB memóriával üzemel, ebből lenne 4 nem gond ugye? A hálozat 6 Gbit. A Clusterba 4 fizikai szerverrel, 2 Socket 6 Core.
Állítsunk be VADP mentést az adatbázis szerverekre, mert az jó.
stb.Hiába vannak ötletek, meg vannak olyan dolgok, amik nem oda valók, ahova elképzelik.
p { line-height: 115%; margin-bottom: 0.25cm; background: transparent }a:link { color: #000080; so-language: zxx; text-decoration: underline } -

A_ScHuLcZ
addikt
válasz
tasiadam
#5709
üzenetére
Nem ARM, épített x64-es gép. Kb 3 évvel ezelőtt végigteszteltem az összes NAS megoldást (köztük a TrueNAS-t is), nekem az OMV vált be legjobban. Eleinte direktben volt telepítve, majd később bevirtualizáltam, mert más VM-eket is szerettem volna futtatni mellette.
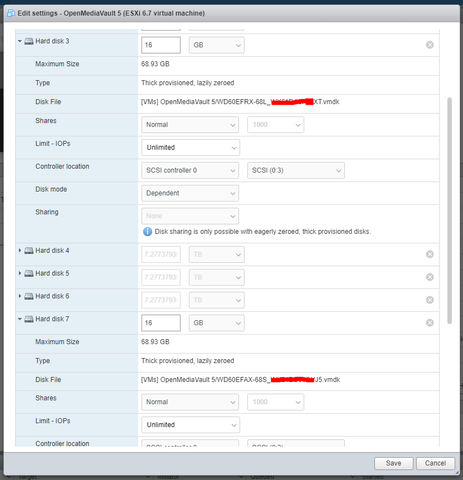
Igen, a VM-hez voltak/vannak addolva, nyilván ezért hisztizik. A kérdés az, hogy hogy tudom megmondani neki, hogy hagyja figyelmen kívül őket, vagy ne is próbálja map-elni?
Próbáltam törölni a VM alól, de azt sem engedte: Failed to reconfigure virtual machine OpenMediaVault 5. Unable to access file [VMs] OpenMediaVault 5/xxxx.vmdk
(az alábbi képeken disk3 és disk7 a két eltávolított lemez)

-

CsodaPOK
senior tag
válasz
tasiadam
#5697
üzenetére
"ha pl lehal a hálózat a VM-en, akkor indítsa újra"
Szvsz rossz az a megközelítés, hogy az infra oldja meg a VM-en belüli bajt.
Mit értesz azon normál esetben, hogy lehal a hálózat a VM-en?
- Ha infra oldali probléma miatt esik le a hálóról a VM, akkor az újraindításával semmit nem érsz el.
- Ha a VM-en belül van valami hálózati gubanc, akkor azt a VM-en belül detektáld és VM-en belül kezeld.
- Ha kívülről nézed a VM elérhetőségét valamilyen monitorozó rendszerrel, akkor pl az ott definiált riasztás automatikus válaszlépése lehet az, hogy meghív egy PS scriptet vagy API-n keresztül megszólítja a vCenter-t és reseteli a VM-et. (Vagy bármilyen automatizációs megoldás is megcsinálhatja ugyanezt.) Persze itt is valamilyen módon kell tudni ellenőrizni, hogy valóban a VM resetelése a megoldás-e vagy máshol van a baj. Nem fog jót tenni, ha 5 percenként kap a guest OS egy reset-et.A virtualizációs infrának az a feladata, hogy fussanak a VM-ek. Ne akard megerőszakolni és egy monitorozó, automatizáló izének használni. Arra megvannak a megfelelő eszközök.
-
-
válasz
tasiadam
#5675
üzenetére
"-Minden gépbe 2 kábel megy, iLO és network, amint a storage és a management is megy, ha ez lényeges (isolation esetében pl az)."
Ezt mondjuk javasolt lenne legalább még egy (ideális esetben még három) kábellel bővíteni, hogy legyen redundancia meg némi szétválasztása a storage és network forgalomnak.
-

[Newman]
tag
válasz
tasiadam
#5697
üzenetére
Igazából nem késéssel indítja, mert a HA működése percekben mérhető.
Amit akarsz, olyat a VMware nem tud. Mármint nincs mód arra - nyilván ha fejlesztesz magadnak ilyet, mert SDK van - hogy egy VM-ben a hálózat megáll, akkor csináljon valamit.
Szóval a VM monitoring segítségével nem fog ugrani arra, ha a VM által használt hálózatban/VLAN-ban mondjuk történik valami. Nem néz és nem tesztel hálózatot a VM-ből, csak azt nézi hogy pl a tools on keresztül él-e a VM van e bármi aktivitás benne.
VM Monitoring restarts individual virtual machines if their VMware Tools heartbeats are not received within a set time. Similarly, Application Monitoring can restart a virtual machine if the heartbeats for an application it is running are not received. You can enable these features and configure the sensitivity with which vSphere HA monitors non-responsiveness.
When you enable VM Monitoring, the VM Monitoring service (using VMware Tools) evaluates whether each virtual machine in the cluster is running by checking for regular heartbeats and I/O activity from the VMware Tools process running inside the guest. If no heartbeats or I/O activity are received, this is most likely because the guest operating system has failed or VMware Tools is not being allocated any time to complete tasks. In such a case, the VM Monitoring service determines that the virtual machine has failed and the virtual machine is rebooted to restore service. link -
[Newman]
tag
válasz
tasiadam
#5694
üzenetére
Nem éppen. A datastore heartbeat egy plusz dolog, ami abban az esetben segíthet, mikor a hosztok nem érik el egymást. Ekkor a datastore-on azért képesek jelezni mely gépek vannak bekapcsolva rajtuk, mely hosztok vannak életben.
Nyilvánvalóan egy IP alapú tárolónál körül kell járni a dolgot, mert ha például azonos fizikai interfészen, switch-eken történik a tároló forgalma, mint amúgy például a management vmkernel interfésze, akkor olyan nem nagyon fordulhat elő, hogy az egyik megy, a másik meg nem. Így van ez a VSAN-nál is, de nyilván az iSCSI tárolódnál is.
Isolation az egy tök másik dolog. Mikor van mondjuk három hosztod és - egyszerűsítve - az egyik leszakad, mert kihúztad a hálózati interfészeit. Akkor nyilván ő nem hallja a másik kettőt és a másik kettő nem hallja őt. Na ilyenkor megpingeli alapértelmezetten a default gw-t a management vmkernel-en és ha nem válaszol, akkor ő izolálódott. Ha négy hosztod van és kettő szakad le egyszerre és azok hallják egymást, akkor pedig partícionálódás van.
Nálad két hoszt van, szóval ha a másodikből kihúzod a kábelt, az abban a pillanatban el is veszti a storage-ot. Nem hallja a másikat és az isolation címet sem bírja pingelni és nyilván a datastore-on sem tud életjelet adni magáról. Szóval a "power off and restart VMs" lesz a vége. Az első hoszton, viszont nem azonnal. A HA nem két másodperc alatt lép.Mikor nem megy majd a HA? Millió oka lehet:
- sok a reservation VM vagy RP szinten. Ha pl az első hoszton futó VM-ek CPU/RAM erőforrásait rezerválod és a második hoszton futó VM-ekkel is ezt teszed, akkor az első hoszt csak annyit tud szolgáltatni, amennyi fizikailag benne van. Viszont két fizikai gépnyi erőforrást kéne előállítania, hiszen ami rezervált, az nem swap-polhatja ki, oda kell adni ténylegesen a fizikai RAM-ból.
- ha például bármely VM a második hoszton olyan port group-on van - standard switch esetén fordulhat elő - amely az első hoszton nincs felvéve. Tehát ha az Ubuntu VM-ed első interfésze mondjuk "VLAN10" nevű port group-ban van és az első hoszton az "VLAN 10"-ként van felvéve, akkor tuti nem lesz HA.
- Olyan ISO van becsatolva, ami a második hosztról elérhető, de az elsőről nem.
- Ha az FDM agent-nek van problémája, fel sem települt pl. Ha a host and clusters nézetben a HA agent státusz bármi más mint primary/secondary.Azért kértem a vmotion próbát, mert ha át lehet vmotion-özni a problémás gépet, akkor a fenti első három eshetőséget ki is zártuk. Igen tudom hogy a HA-hoz nem kell vMotion, de a fentiek a HA-nak is beakasztanak ha akár egy is közülük jelentkezik.
-
[Newman]
tag
válasz
tasiadam
#5682
üzenetére
Nem. Reservation alatt a reservation-re gondolok. VM-re állsz, majd mindegyiken megnézed ezt: [link]
Ha te magad vMotion-nel sem tudsz egyetlen gépet migrálni, azaz az Ubunti gépet sem, pedig az közös storage-on van, vmotion enabled a vmkernel-en mindkét hoszton, akkor írd már meg, hogy ott mikor a vmotion-t indítanád, ugyan milyen hibát ír már pontosan? Sokat segítene.
Admission controlt most teljesen felejtsük el. -
[Newman]
tag
válasz
tasiadam
#5680
üzenetére
A vmotion-t azért kérdeztem, mert érdekel, hogy amúgy kézzel te át tudád e tolni az összes VM-et a túlélő hosztra. A reservation-t pedig azért mert ha a klaszteredben több reservation van beállítva, mint a túlélő hoszton az összes bekapcsolt VM és azok amik e bedöntött hoszton futottak és most failover kéne rájuk, akkor tuti biztos hogy a HA nem fogja elindítani őket. Pont az ilyen esetek elkerülésére van az admission control, hogy ne tudj többet kiadni és biztosított legyen hogy X számú ESXi behalása esetén el tudja indítani a gépeket.
"Minden gépbe 2 kábel megy, iLO és network, amint a storage és a management is megy, ha ez lényeges (isolation esetében pl az)."
Mivel nálad iSCSI van és ráadásul azonos NIC-en a mgmt vmkernel-el, kb teljesen értelmetlen a datastore heartbeat beállítása, tekintve, hogy ha egymást nem hallja a két hoszt, akkor a datastore-on sem fogják egymás látni mert megszakadt a francba.Tehát kérlek nézd meg a reservation-öket, mennyi van beállítva összesen ha van, illetve próbáld meg kézzel az Ubuntu VM-edet át tudod-e tenni a másik hosztra. Ha már ez utóbbi sem megy - pedig amúgy CPU generációban stimmel, közös storage adott - akkor lehet például másképpen van elnevezve a vSwitch-en a network port group - gondolom nem vDS-t haszálsz.
-
[Newman]
tag
válasz
tasiadam
#5675
üzenetére
Igazából nem mindegy mennyi gép fut bármelyik hoszton, sőt elég komolyan számít mert hacsak nem állítod be, akkor minden gép HA védett és mindet át akarja tenni valamelyik - nálad egyetlen - lábon maradt hosztra.
Van reservation az Ubuntu VM-en? Egyáltalán bármely VM-en? Amúgy például vMotion-al át tudod tenni az az Ubuntu gépet a nagyobb hosztra?
Az admission control nem viccnek van, az egy fontos dolog. Ha percentage szarul van beállítva benne vagy slot policy van és van reservation, akkor jól alá lehet vágni mondjuk.













Új hozzászólás Aktív témák
- Elektromos autók - motorok
- One otthoni szolgáltatások (TV, internet, telefon)
- Samsung Galaxy Watch8 és Watch8 Classic – lelkes hiperaktivitás
- Milyen egeret válasszak?
- Linux Mint
- Eredeti játékok OFF topik
- Bemutatkozott a Poco F2 Pro (már megint)
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Autós topik
- exHWSW - Értünk mindenhez IS
- További aktív témák...
- Eladó Realme gt neo 2 5g Dobozában tokkal
- Bomba ár! HP EliteBook 2570P - i7-3GEN I 8GB I 128SSD I DVDRW I 12,5" HD I W10 I Garancia!
- AKCIÓ! LENOVO ThinkPad P15 Gen2 munkaállomás - i7 11800H 32GB DDR4 1TB SSD RTX A2000 4GB W
- ÁRGARANCIA!Épített KomPhone i5 14400F 32/64GB RAM RX 9060 XT 16GB GAMER PC termékbeszámítással
- MICROSOFT Surface Book 2,13.5", i5-7200U,8GB RAM,256GB SSD,WIN11
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest