Új hozzászólás Aktív témák
-

prucam
tag
sziasztok,
hogyan lehet a sortörést (\n) törölni? Pl.:ez van egy doksiban "1a2b3c4d"
a betűk után beszúrok egy sortörést
cat abc | sed -e 's/^.*1a2b3c4d/1a\n2b\n3c\n4d/'ez lesz:
1a
2b
3c
4dMost, hogyan tudom visszacsinálni a "1a2b3c4d"-t?

Nektek biztos uncsi, de már órák óta keresem a neten, de nem találtam a megoldást.
üdv
-

ddekany
nagyúr
Jó, akkor: df .| jfilter usagePercentage gte 90. Mi van ezzel?
Parsolással meg nem tudom mi bajod, bár tán tesem... Igen, bele kell rakni egy hívás valami shared library funkcióra, ami az egész mechanizmust "meghívja". Soha nem látott komplexitás szoftverfejlesztés területén...
"meg mindig nem lattunk semmit ami igazolna hogy ez a vilagmegvalto ujitas valoban megsporolna szamottevo idot
 "
"Visszanézve a két példát, képes vagy ezt így kijelenteni. Valószínűleg direkt szórakozol... vagy van az a bizonyos határtalan dolog is elvégre, nem tudhatom.
-
A válasz: 42
-

doc
nagyúr
válasz
 ddekany
#1493
üzenetére
ddekany
#1493
üzenetére
akkor leirom meg egyszer: irj egy olyan parancsot/scriptet az altalad kitalalt szintakszis szerint, ami kilistazza a lefgeljebb 10% szabad helyet tartalmazo particiokat
Maga a parsolas hiaba rendszerfunkcio, attol meg bele kell rakni a programba. Nem mondhatod azt a librarynek hogy "itt a json input amit kaptam, csinalj belole helyettem olyat amilyet akarok" (ld: "visszavezetem bele amit én kikapartam szűrt meg így-úgy rendezett akármicsinált JSON eredményt, hogy na akkor ezt formázd, mintha csak te termelted volna belül magadnak")
alacsonabb rétegben befektetsz X emberévet, azzal megtakarítasz összességében sokszor X emberévet
meg mindig nem lattunk semmit ami igazolna hogy ez a vilagmegvalto ujitas valoban megsporolna szamottevo idot -
ddekany
nagyúr
"azzal, hogy nem valaszoltal"
De akkor mi akart lenni a kérdés? Remélem nem az, hogy hogyan nézem meg, hol nagyobb 90%-nál a foglaltság...
"az meg hogy minden egyes aprocska toolban legyen oda-vissza iranyu json parser es konverter"
Kurva egyszerű lenne pedig a tool író szempontjából, mivel ezek lényegében rendszer funkciók... kb. regisztrálsz két callbackot a toolban, egyik a formázás, másik maga a lényegi feladat elvégzése, és majd az OS(/shell) eldönti, hogy melyiket hívja mikor. Az meg nem tudom leesett-e, hogy ha egy alacsonabb rétegben befektetsz X emberévet, azzal megtakarítasz összességében sokszor X emberévet. Pl. sokkal kevesebb idő megy el tool írásra, mint tool használatra.
-
-
ddekany
nagyúr
Gondolom a felvetés itt az lenne, hogy de mi van, ha a JSON feldolgozások után mégis ki akarom írni a végeredményt a felhasználónak.
Először is, mi van jelenleg. Kitéphetek sorokat egy táblázatból, a fejléc meg ugye elmarad (fejléc nélküli táblázat meg azért elég necces). Aztán a táblázat oszlopok szélessége nem a megjelenített, hanem az összes (kiszűrt) cuccokhoz van igazítva, ez sem a legszebb.
Aztán mit lehetne a JSON (vagy ami) csodával... egy dictionary listából eleve lehet automatikusan táblázatot csinálni, aminek fejléce is van meg minden. Nyilván, ehhez az kell, hogy egy tool alapértelmezett kimeneti formátuma (JSON vagy plain text) jól dőljön el. Ezt megadhatnád kapcsolóban (--json VS --plain, mondjuk), vagy ha nem adod meg, akkor alapértelmezésben --plain lesz, kivéve ha egy speciális pipe szimbólumot adsz meg utána, mondjuk legyen .| vagy akármi, és akkor a --json lenne az alapértelmezés a bal oldalán. Aztán ha még csavarni akarsz azon, hogy hogy nézzen ki a táblázat, akkor erre is könnyű tool-okat írni, tehát pl. sokminden .| jtable egyikOszlopNeve=ígyformázva másikOszlopNeve=amúgyformázva ,és akkor ebbe belepipeolod amit akarsz. Sőt... egy másik érdekes lehetőség, hogy mivel a df ezen fiktív változata belül úgy is eleve JSON-ból (pontosabban annak AST-jéből, de most mindegy) formáztatja az embernek szánt kimenetet is, az is lehetne standard opció, hogy visszavezetem bele amit én kikapartam szűrt meg így-úgy rendezett akármicsinált JSON eredményt, hogy na akkor ezt formázd, mintha csak te termelted volna belül magadnak. Szóval elég sok hatékony dolgot lehet ezzel csinálni... Ha meg tényleg csak plain textet akarsz szűrni, azt is lehet, mert nem j-s kimenetet kérsz és kész...
-

bambano
titán
"Vagy, írj egy scriptet, ami csinál valamit (minegy mit), ha neki paraméterként átadott dev-ek bármelyikén 95% alá csökken az üres hely.":
#! /bin/bash
echo 'PÁÁÁÁNIIIK!!!!!!!!!'
ennyi.
persze ha figyelembe vesszük azt is, hogy nyilvánvalóan feltolták a vércukorszintjét és azért írt ökörséget, akkor ennél bonyolultabb scrtiptre is szükség lehet. Hint: 95% alá csökken az üres hely részmondatot szerintem nem így akarta megfogalmazni. -
doc
nagyúr
válasz
 dabadab
#1487
üzenetére
dabadab
#1487
üzenetére
persze, a scriptnek nyilvan robosztusnak kell lennie, ezert is irtam hogy kicsit tobb odafigyelessel, de megoldhato (ha mar mindenaron bash-ben gondolkodunk)
A df azert keszult hogy a user megtudja, mennyi a szabad hely. Persze a rendszer rugalmas felepitesenek es a szoveges kimenetnek koszonethoen akar masik script/program is feldolgozhatja amit a df kiad.
Egyebkent ha egy adott feladat annyira bonyolultta valik hogy pl. bash-ben megvalositani komoly problema, akkor valoszinuleg erdemes inkabb mas kornyezetben megoldani (ld. pl. a lenti df-es peldat Perlben).
A 'gepi feldolgozasra alkalmas kimenet' meg ahogy korabban mar irtam is, nem feltetlenul rossz otlet, de megprobalni rakenyszeriteni minden letezo parancssoros toolra mar az (marpedig ha egyikkel-masikkal mukodik, a tobbivel nem, akkor megette a fene az egeszet).
-
Az egy dolog, hogy te nem teszel bele, de lehet benne es ez pont olyasmi, amire shellscript iraskor tenyleg figyelni kell.
"a peldad meg santit, mert a df nyilvan alapvetoen arra van, hogy EN megnezzem mennyi a szabad hely"
Nem hiszem, hogy "alapvetoen" erre lenne, hiszen ha shellscriptbol meg akarod nezni, hogy mi a helyzet a szabad hellyel, akkor mast nem nagyon tudsz hasznalni. En egyebkent a magam reszerol orulnek, ha az ilyen fancy tooloknak lenne valami rendes, gepi feldolgozasra alkalmasabb kimenete is (ahol pl. nem vagja le a hosszabb nevu device-ok nevenek a veget, hogy mast ne mondjak, vagy nem localefuggo az, hogy mit ir ki).
-
ddekany
nagyúr
"biztos en vagyok a hulye, de en nem szoktam space-t rakni a filenevbe"
Legalábbis szerveren én sem... viszont nem is én állítom jellemzően elő a fájlokat, vagy nem olyan program amit én írtam, szóval a fölött nincs kontrollom (mint gondolom másnak sincs).
"a peldad meg santit, mert a df nyilvan alapvetoen arra van, hogy EN megnezzem mennyi a szabad hely"
Az van, hogy ott egy rakás tool a toolboxban, és nyilván azt lenne jó akkor használni scriptekben, szóval ezzel megint nincs mit kezdeni nagyon.
Ha meg a példák után is szerinted a JSON-s (vagy akármilyen gépi fogyasztásra strukturált) kimenettel a bonyolultabb minden, vagy nem érné meg globálisan egy ilyen irány, azzal már nem tudok mit kezdeni...
"ranezek a df outputjara, majd egyedul a "grep" parancsot hasznalva mar kesz is a megoldas"
És ha ránézel a shell scripte, amit nem tegnap írtál, vagy nem te írtad, akkor meg nem látod mit csinál... A forráskódokat általában többször olvassák mint írják.
"Alapvetoen nem rossz az otlet, hogy valamilyen szabvanyos feluleten kommunikaljanak egymassal a programok, de ezt rakenyszeriteni a felhasznaloi interakciora kitalalt programokra nagy butasag"
De hát 2x megírni a programokat, egyszer így, egyszer úgy, meg még nagyobb képtelenség. Hiszen a kétféle kimenet generálásnál a forráskód java része közös lenne.
De szóval mindegy... átadtam amire gondoltam ama másik topicban, aztán kész.
-
doc
nagyúr
válasz
ddekany
#1481
üzenetére
biztos en vagyok a hulye, de en nem szoktam space-t rakni a filenevbe (sem ekezetes karaktereket, sem hasonlo aljassagokat - szivtam ezzel eleget a windowsos rendszergazdasagom alatt...)
ha ez megis elofordult, akkor a problema valamivel bonyolultabb lesz, de kozel sem megoldhatatlan
a peldad meg santit, mert a df nyilvan alapvetoen arra van, hogy EN megnezzem mennyi a szabad hely
tehat ha jsonozni akarsz, akkor meg kell mondani neki hogy "fogalmazzon bonyolultan", majd meg kell keresnem hogy hogyan is hivja o a sajat kimeneteben a usage percentage-t. Mig most egyetlen ranezessel latszik, hogy eleg megkeresnem a "99%" format, addig a te megoldasodnal a json kimenetben turkalva kene megkeresnem a megfelelo nevet.szerintem a df --jsonoutput $dev | jget usagePercentage nem segit annyit a df $dev | grep -o '[0-9]\+%' | grep -o '[0-9]*' valtozathoz kepest, hogy az alapveto, brutalis munkat megkovetelo architekturalis valtozasokat indokolna (ranezek a df outputjara, majd egyedul a "grep" parancsot hasznalva mar kesz is a megoldas)
Alapvetoen nem rossz az otlet, hogy valamilyen szabvanyos feluleten kommunikaljanak egymassal a programok, de ezt rakenyszeriteni a felhasznaloi interakciora kitalalt programokra nagy butasag, es felesleges is (baromi sok pluszmelot igenyelne, es ha valaki eppen nem, vagy nem jol koveti az elvarast, akkor MINDEN borul)
Egyebkent nem talaltal ki semmi ujat, nezd meg pl. a DBUS-t - csak azt nem akarjak olyan helyeken is eroltetni, ahova nem valo. -
-
ddekany
nagyúr
Hát ez meg a másik... de ez meg itt OFF. Na de mindegy, akkor ide írom be, hogy ezért lenne jobb a JSON-al mert akkor csak simán:
df $dev | jget usagePercentage
Ránézel, és látod mit csinál, nem kell megnézni a kimenetet hány oszlop stb, leszedni a %-ot... Amúgy eredetileg df | jfilter device in @$-re is gondoltam, de mondjuk itt pont gány lenne, mert feleslegesen kérdezne le X device-t. (Csak az erdeti feladat valójában az volt, hogy melyik device-t NE nézze, azt adjuk át... de mindegy, innentől látod mire gondoltam a JSON-os kimenet feldolgozás kapcsán. Jó, ott sem elegáns a filter, de... mindegy, látszik mire jó.)
Ja, az ls meg úgy jeach file in `ls` kb. Ott nincs ez a kavar, mert a kimenet ["file név 1", "file név 2"].
-
ddekany
nagyúr
for i in `ls -1`; do echo $i ; done
Na, igen, aljas módon pont ezért kérdeztem... mert ez hibás. Az for szegény white-space-nél szeletel, nem csak sortörésnél, és ezért ha szóköz van egy fájlnévbe, akkor több fájlnak fogja nézni. Aljas egy csapda, és azért van, mert eléggé trükkös ahogy a dolgok több körben behelyettesítődnek meg értelmezve lesznek. Hát na, ilyenekre gondoltam ott a másik topicban...
-
doc
nagyúr
nem tul elegans megoldas (nincs parameterellenorzes sem), de mukodik
1 #!/bin/sh
2
3 while true; do
4 for dev in $@ ; do
5 if [ `df $dev | grep -o '[0-9]\+%' | grep -o '[0-9]*'` -gt 5 ]; then
6 echo Low space on $dev
7 fi
8 done
9 sleep 1
10 doneMOD: ehh, nem gondoltam volna hogy megeloznek
 mondjuk talaltam jo otletet dabadab scriptjeben, amivel tenyleg szebb lesz (pl. tr -d %)
mondjuk talaltam jo otletet dabadab scriptjeben, amivel tenyleg szebb lesz (pl. tr -d %) -
-
doc
nagyúr
egy masik topicbol, hogy ne azt kelljen szenne offolni
Akkor próbálj két dolgot megcsinálni, csak kapásból. Mondtad az ls-t. Akkor írt egy scriptet, ami az ls(!) kimenete alapján csinál valamit (mindegy mint... akár csak írja ki) az összes felsorolt fájl nevével.
ehhez nem kell script, nagyon egyszeruen megoldhatok par karakterbol:
for i in `ls -1`; do echo $i ; done
Vagy, írj egy scriptet, ami csinál valamit (minegy mit), ha neki paraméterként átadott dev-ek bármelyikén 95% alá csökken az üres hely.
ez mar egy hajszallal erdekesebb feladat, mindjart megirom es hozom, csak elotte eszek valamit -
#1476
 SteveBeard
senior tag
bambano
#1473
SteveBeard
senior tag
bambano
#1473
SteveBeard
senior tag
válasz
 bambano
#1473
üzenetére
bambano
#1473
üzenetére
Még egyszer köszönöm, jó lett.
Nem gondoltam, hogy ezt többször is lehet egymás után, mindig tanul az ember valamit.Íme a végeredmény, ami működik, csak azért így, hogy később ne kelljen a tűzfalban szerkesztgetni.
Egyszerűbb a txt fájlt módosítani.TIME_START=10:00
TIME_END=23:00
for LOCAL_IP in $(cat /etc/controlled_ip.txt | awk '{print $1}'); do
for URL_STRING in $(cat /etc/url_string.txt | awk '{print $1}') ; do
echo Blocking $URL_STRING from $LOCAL_IP at time interval $TIME_START - $TIME_END
iptables -I FORWARD -s $LOCAL_IP -m string --string $URL_STRING --algo bm -m time --weekdays Mon,Tue,Wed,Thu,Fri --timestart $TIME_START --timestop $TIME_END -j DROP
done
doneJól tudom, hogy linuxnál a txt kiterjesztést akár el is hagyhatom?
Nem túl rég használok linux rendszert... -
#1475
SteveBeard
senior tag
dabadab
#1472
SteveBeard
senior tag
válasz
dabadab
#1472
üzenetére
Bocsánat rosszul fogalmaztam

Azt gondolom így lett volna helyes a megfogalmazás:
a tiltást több helyi ip címre is alkalmazni tudjam?
De megpróbálom másként:
Az etc/url_string.txt file-ban sorolom fel amit tiltani akarok.
Majd itt adom meg melyik belső ip címre vonatkozzon a tiltás. -> LOCAL_IP=192.168.1.150
De szeretném ugyanezt a tiltást több belső ip címre is alkalmazni. Tehát ne csak a 192.168.1.150-re vonatkozzon, hanem mondjuk a 192.168.1.178-ra is, vagy akár többre is.
Ne haragudjatok a szakszerűtlen megfogalmazásért!
bambano
Köszönöm!
Kipróbálom.. -
#1473
bambano
titán
SteveBeard
#1471
bambano
titán
válasz
 SteveBeard
#1471
üzenetére
SteveBeard
#1471
üzenetére
ha a kérdés a forrás ip címre vonatkozik, akkor valahogy így:
a LOCAL_IP= sor helyett:
for LOCAL_IP in ip1 ip2 ip3; doa végére meg egy done.
a szépség kedvéért ilyenkor a TIME_ sorokat kiteheted a ciklus elé. -
#1472
 dabadab
titán
SteveBeard
#1471
dabadab
titán
SteveBeard
#1471
válasz
SteveBeard
#1471
üzenetére
Nem igazan ertem a kerdest. Ez mar most igy is tobb IP cimet is tud tiltani, csak fell kell oket sorolni az
etc/url_string.txt file-ban -
#1471
SteveBeard
senior tag
SteveBeard
senior tag
Sziasztok!
Ebben a scriptben, hogy tudnám megoldani azt, hogy a tiltást több ip címnél is alkalmazni tudjam?
Előre is köszi a segítséget!#Block URL on certain time for specified IP
LOCAL_IP=192.168.1.150
TIME_START=10:00
TIME_END=23:00
for URL_STRING in $(cat /etc/url_string.txt | awk '{print $1}') ; do
echo Blocking $URL_STRING from $LOCAL_IP at time interval $TIME_START - $TIME_END
iptables -I FORWARD -s $LOCAL_IP -m string --string $URL_STRING --algo bm -m time --weekdays Mon,Tue,Wed,Thu,Fri --timestart $TIME_START --timestop $TIME_END -j DROP
done -
prucam
tag
Sziasztok,
próbálgatom a scriptet. Van benne egy "if", aminek az lenne a célja, hogyha van a letöltött filek között olyan, aminek a nevében "index" szerepel, akkor azt (v. azokat) törölje.
Most volt egy olyan "futása" amiben majdnem 10 is volt, s ezt az üzit kaptam:
./7_down_links: line 19: [: too many arguments
Nem törölt semmit. Mit kellene módosítani?
...
c="index*"
....
if [ -e $c ]; then
rm $c
echo "Az index.html törölve"
else
echo "Nincs index.html nevű file"
fi
....üdv
-
-

PistiSan
addikt
Sziasztok!
Nem vagyok egy nagy shell író, remélem kapok segítséget.Probléma leírása: Adoot egy Raspberry Pi, ha áramszünet van, gyorsabban bootol be mint a router, ezért nem kap ip címet, ezért nem érem el hálózaton. Nincs rá se monitor, se billentyűzet kötve, a scriptnek annyit kellene tudnia, hogy ellenőrzi hogy kapott-e ip címet bekapcsolás után, ha nem, akkor próbáljon egy ip cím lekérést kérni. 5 perc múlva újra ellenőrízze, ha már jó az ip cím, akkor vége a ciklusnak, és kilép a script.
Valami ilyesmire gondltam, de nem akar össze jönni.
#!/bin/bash
ip_kell="inet 192.168.1.102 netmask 255.255.255.0 broadcast 192.168.1.255"
vizsgal=$(ifconfig | grep "inet 192.168")
ip_van=$vizsgal
if [ "$ip_kell" = "$ip_van" ]; then
echo "ip cim megfelelo, kilepek"
else
echo "it cim nem jo, ipcim lekeres"
#dhcpcd eth0
fiSajnos az "ip_van" változóban szerepel a megfelelő sor, csak előtte van egy rakás szóköz, amit nem tudom hogyan távolítsak el.
Igazából nekem elég lenne az is, ha csak az ip címet szűrném, tehát a "192.168.1.102"-t, de nem vagyok ennyire benne, hogy össze hozzam.Tudom még félkész sziten sincs a script, mivel nem szoktam scriptet írni, csak amatrőködöm, gondoltam hát ha segít valaki.
köszi. -
prucam
tag
válasz
bambano
#1463
üzenetére
grep '<title>' $d/$i | sed -e 's,^.*<title>[ ]*,,' -e 's,[ ]*-.*$,,' >> $d/title.txt
Ma próbáltam:
Bajok Harryvel
Az utolsó ítélet
Az utolsó kívánság
Bátorság próbaTökéletes! Ezt egyedül, nem találtam volna ki.
Azt elmondom, talán érdekel valakit mit is csinálok (ill. próbálok ?). Szeretnék egy olyan scriptet írni aminek lényege, hogy egy könyvtárba letölti a *html oldalakat, az infót kiszűri ami kell, másol, hozzáfűz stb. majd a végén *.rar-ba csomagol.
Sajnos, az egyszerűbb dolgokat még megoldom (v. utánézek a neten), de nem sok "lövésem" van a scriptekhez.
Amit egy hét alatt olvastam, az nem igazán elég, tudnátok-e továbbra is segíteni?üdv
-
bambano
titán
mondom, nem fork bombázunk
a sed másik jó tulajdonsága, hogy a keresés-csere parancsokban nem fixen bedrótozva / jel van, hanem az első karakter a delimiter az s után. ezt akkor érdemes használni, ha vagy a mintában, vagy a cserélendő stringben van (sok) /
tehát:
grep '<title>' |
sed -e 's,^.*<title>[ ]*,,' -e 's,[ ]*</title>.*$,,' >> $d/title.txt -
-

rt06
veterán
válasz
bambano
#1455
üzenetére
windoze-os editor osszehanyja egy sorba (legalabbis a mezei notepad) ha nem boldogul a crllf helyetti lf-fel
ez inkabb egy lf-et kezelni tudo editor, amiben be lett allitva, hogy jelenitse is meg a sortoresekettr amugy minden szokozt torolni fog, nem csak a sor vegen levot, nem?
-

snowdog
veterán
Az LF az a soremelés vezérlés. Ha kitörlöd, akkor mindent egybe fog írni. Normál szövegnézetben nem jelenik meg. Gondolom valamit bekapcsoltál hogy láthatóvá vált.
Amit alul írtál mintát, az pont ugyan az, ugyanis ott is szerepel az LF (Line Feed, soremelés), csak nem látod.
-
prucam
tag
válasz
 MacCaine
#1451
üzenetére
MacCaine
#1451
üzenetére
alakul!
grep '<title>' $d/$i | cut -d ">" -f2 | cut -d "-" -f1 >> $d/title.txt
már csak az kellene, hogy a cím utáni részt is törölni. (kép mellékelve)
Sajnos, azt még nem tudom, hogyan kell szóköz v. sorvéget törölni (cf meg lf v. micsoda)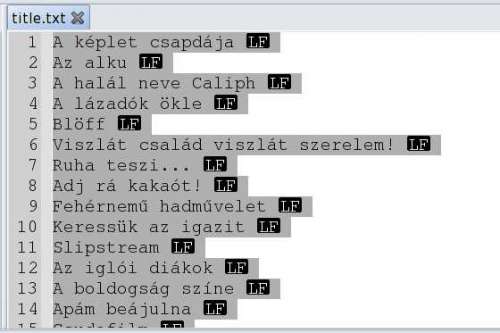
Ez legyen (egyelőre)
A képlet csapdája
Az alku
A halál neve Caliph
A lázadók ökle
Blöff
Viszlát család viszlát szerelem! -
prucam
tag
válasz
MacCaine
#1449
üzenetére
#!/bin/bash
d=/könyvtár útvonal
for i in `ls $d/`; do
grep '<title>' $d/$i >> $d/title.txt
done
exiteredmény:
<title>Gyilkos törvény - Fórum</title>
<title>Halálos érintés - Fórum</title>
<title>Motorlovagok - Fórum</title>
<title>Vízbe fojtott bűnök - Jindabyne - Fórum</title>
<title>Esküdt ellenség - Fórum</title>
<title>A bűncézár - Fórum</title>
.....Ez nekem eddig tetszik!

1, meg lehet-e adni úgy a keresést, hogy a "title.txt"-be csak a oldal címe legyen. Azaz:
Gyilkos törvény
Halálos érintés
Motorlovagok
Vízbe fojtott bűnök - Jindabyne
Esküdt ellenség
A bűncézár2, v. az elkészült "title.txt"-t kell tovább feldolgozni. Sed v. tr ??? Vagy hogyan?
-
prucam
tag
Sziasztok,
múlt héten kezdtem el foglalkozni a scriptekkel, azaz semmihez sem értek.

A fórumot azért elolvastam az elejétől!
Meg mást is olvasgatok néha.Szeretnék írni egy scriptet, ami a weblapok címét (nem URL), elmenti. Tehát az oldal html kódjában ez van:
<title>A nagy shell script topik - PROHARDVER! Hozzászólások</title>
Gondoltam:
w3m http://prohardver.hu/muvelet/hsz/uj.php?thrid=162198 | grep '<title>' >oldalcim
de ures a doksi. Sajnos nics elképzelésem, hogyan is kellene megoldani. Segítenétek?
köszi
-
cat-grep-while trióból érkező kimeneteket hogyan tudom egymás mellé kiiratni?
-
bambano
titán
idézet a man-ból:
An AWK program is a sequence of pattern {action} pairs and user function definitions.
Az END az end-pattern. Az action, amit utána írsz.
" BEGIN and END patterns require an action." tehát az END-nél nem maradhat le a kapcsos zárójel és közötte valami utasítás.
-

vanek
tag
válasz
bambano
#1438
üzenetére
Ezt sejtettem
csak arra lettem volna kíváncsi, hogy mit takar az action part...Mert ahogy látom Jester megoldásában sincs action part.. simán az END után kiírat..abban, hol az action..?
Gondolom az action part egy if, for...vagy valami ilyesmi?
Hasba akaszt? Ezt hogyan értsem ?
-
vanek
tag
válasz
 Jester01
#1433
üzenetére
Jester01
#1433
üzenetére
huhh...igazából valami enyhébb megoldásra gondoltam..
még csak tanulom a dolgot, egyik haverom pont most jár egyetemre, ezt veszik, megtetszett és gondoltam belekezdek..
úgyhogy valami ilyesmire gondoltam
#! /usr/bin/awk -f
BEGIN{osszmeret=0;}
END
{
{
osszmeret += $5
print ( $osszmeret)
}
}vagy azért ennyire egyszerűen nem megy? köszi
-

Jester01
veterán
válasz
 szoke12
#1430
üzenetére
szoke12
#1430
üzenetére
Ez egy négyzetes megoldás, ha már ciklust akarsz akkor miért nem egyszer mész végig a kimeneten?
Mi van ha időközben megváltozik a fájllista?
Directoryk méretét kell nézni?sum=0
for x in $(find . -maxdepth 1 -type f -printf '%s\n')
do
sum=$((sum + x))
done
echo $sum-vagy-
(find . -maxdepth 1 -type f -printf '%s+'; echo 0) | bc
ls használatával is lehet hasonlót, plusz nyilván a du még mindig erre való.
-

szoke12
őstag
Lehet, kicsit erőltetett módszer, de én csinálnék egy ciklust:
#! /bin/bash
SORSZAM=`ls -l | wc -l`
SORSZAM2=1
MERET=0
while [ $SORSZAM2 -ne $SORSZAM ]
do
FILEMERET=`ls -l | sed -n $SORSZAM2p | cut -f5`
MERET=`expr $MERET + $FILEMERET`
SORSZAM2=`expr SORSZAM2 + 1`
done
MERETMB=`expr $MERET / 1000`
echo "A fájlok mérete: $MERETMB MB."ott az "-ne" körül lehet játszani kell, de most nincs előttem, hogy kipróbáljam.
-
#1420
bambano
titán
puskas1993
#1419
bambano
titán
válasz
 puskas1993
#1419
üzenetére
puskas1993
#1419
üzenetére
TALALAT=$( grep -w "$1" szavak.txt | cut -d\| -f 2);
rt06: igen. de ha cifrázni akarod, akkor grep "$1|" szavak11111.txt, amennyiben a delimiter a pipe. vagy grep "^$1|"
-
-
#1417
bambano
titán
puskas1993
#1416
bambano
titán
válasz
puskas1993
#1416
üzenetére
cut -d\| -f 2
-
#1416
 puskas1993
tag
bambano
#1415
puskas1993
tag
bambano
#1415
puskas1993
tag
válasz
bambano
#1415
üzenetére
na sikerült is megcsinálni
 ezer köszönet mind kettőtöknek
ezer köszönet mind kettőtöknek már csak egyetlen kérdés... ugyebár megcsináltam pipével és hogyan tudnám csak a 2. oszlopát kiiratni??
pl.: data|adat és nekem csak az adat kell a kimenetrelehet a kóddal könnyeb lesz:
if [ -z "$1" ]
then
echo "Kérem legközelebb adja meg a szót, amelyet le kíván fordítani!"
else
TALALAT=$( grep -w "$1" szavak.txt );
if [ -z "${TALALAT}" ]
then
echo "Nincs találat!"
else
# echo A keresett $TALALAT' magyar megfejelője: $(cut -d\ -f 2)"
echo "A '$1' fordítása: $TALALAT"
fi
fi -
#1415
bambano
titán
puskas1993
#1414
bambano
titán
válasz
puskas1993
#1414
üzenetére
ha erre eredetileg is vigyáztál, akkor nem feltétlenül kell lecserélni a szóközt, de ha ez olyan házifeladat, amit tanár ellenőrizni fog, akkor a probléma kezelését valahol meg kell említeni.
egyébként meg szerintem a legegyszerűbb ez:
grep "$1" szavak11111.txt || echo nincs találat
a korábbi verzió szerint:
talalat=$(grep "$1" szavak111111.txt)
if [ $? -eq 0 ]; then
echo "A magyar fordítása: $talalat"
else
echo nincs találat
fi -
#1414
puskas1993
tag
rt06
#1413
-
#1413
rt06
veterán
puskas1993
#1412
rt06
veterán
válasz
puskas1993
#1412
üzenetére
az exit status-t bash-ben a $? valtozoban tallod
a szokozoket viszont kezzel kell, hogy kiscereld, mivel amire bambano celzott, azon nem segit, ha lecserels (pl sed-del) minden szokozt pipe-ra
pl van egy olyan kifejezesed a szotarban, hogy "eszem f*szom megall", se ennek a megfeleloje angolul az "un f*cking believable" - ez a sor az alabbi lesz a szotaradban:
eszem f*szom megall un f*cking believable
csere utan pedig igy fog kinezni
eszem|f*szom|megall|un|f*cking|believablea gond az, hogy a script egyik esetben sem fogja tudni, melyik szokoz vagy pipa az elvalaszto a magyar es az angol verzio kozott, s melyik resze a kifejezesnek
helyesen ugye igy nezne ki:
eszem f*szom megall|un f*cking believable -
#1412
puskas1993
tag
bambano
#1410
puskas1993
tag
válasz
bambano
#1410
üzenetére
sajnos fogalmam sincs hogyan tudnám megnézni mi tárolja a változókat
a fordított aposztrófot ki is cseréltem amire mondtad
a szóközöket 1 perc alatt kitudom cserélni, hogyha szerinted ugy jobb lenne
rt06:
de eleve ugy van, de akkor gyorsan meg is csinálom, hogy "|" /alt gr+w/ legyen a szóköz helyett ha már mind a ketten ezt javasoljátok
-
#1411
rt06
veterán
puskas1993
#1409
rt06
veterán
válasz
puskas1993
#1409
üzenetére
a grep kimenetet tedd valtozoba, es azt is vizsgald meg, hogy ures string-e
valtozoba tenni lp igy tudod:
TALALAT=$( grep -w "$1" szavak11111.txt )
ez ugyanaz, mint az alabbi
TALALAT=`grep -w "$1" szavak11111.txt`
viszont a backtick ( ` ) helyett illik a zarojeles megoldast hasznalniezutan egy ulyebb test-etl nezd meg, hogy a TALALAT valtozod ures-e (erre a korabbi != mellett hasznalhato a -z kapcsolo is), pl.:
if [ -z "${TALALAT}" ]
then
echo "nincs talalat"
else
...
fivalamint a megoldasod nem teljesen jo meg, mivel pl az "adat" szot megtalalhato a "data" szora es az "adat" szora keresve is (Felteve, hogy a szotaradban van olyan sor, hogy "data adat"
-
#1410
bambano
titán
puskas1993
#1409
bambano
titán
válasz
puskas1993
#1409
üzenetére
a bash manualjában megnézed, hogy melyik változó tárolja az előzőleg végrehajtott parancs exit státuszát, azt eltárolod, amikor a grep lefut. utána aszerint lehet választani, ha 0 az exit státusz, akkor talált a grep illeszkedést, ha nem nulla, akkor nem.
a fordított aposztróf deprecated (záros határidőn belül meg fogják szüntetni), mert nehéz egymásba ágyazni. helyette a $( ) javasolt.
a programodban egyébként ott fog borulni a bili, ha szóköz van a szavakban. én mezőelválasztónak |-t szoktam használni (pipeline, csővezeték, altgr+w)
-
#1409
puskas1993
tag
bambano
#1406
puskas1993
tag
válasz
bambano
#1406
üzenetére
na sikerült eljutnom odáig, hogy ha nem ír be semmit a felhasználó, akkor kíiírja, hogy adjon meg legközelebb valamit, ha pedig megadott, akkor keres.
#!/bin/bash
# Puskás Dénes / Internetes alkalmazásfejlesztő / 2013. június 22.
if [ "$1" != "" ]
then
#cat szavak11111.txt | grep -w $1
grep -w "$1" szavak11111.txt | echo "A keresett '$1' magyar megfelelője: `cut -d\ -f 2`"
else
echo "Kérem legközelebb adja meg a szót, amelyet le kíván fordítani!"
fimost azt hogyan kellene, hogyha nem találja a szót akkor valamit írjon ki... pl nincs találat ?
-
#1408
puskas1993
tag
puskas1993
tag
Bocsánat... Még egyszer leírtam ugyan azt amit már este.
-
#1406
bambano
titán
puskas1993
#1405
bambano
titán
válasz
puskas1993
#1405
üzenetére
azt ugye érzed, hogy felesleges forkot írni ide, abból balhé lesz?
["$1" == ""] ebbe emlékeim szerint kellenek a szóközök. tehát én ezt javaslom:
[ x"$1" == "x" ]
cat | grep helyett grep string filenév
oszlopokat kivagdosni legegyszerűbben a cut paranccsal lehet, pl. cut -d\ -f 1 vagy -f 2
a \ után legalább két szóköznek kell lennie! -
#1405
puskas1993
tag
bambano
#1404
puskas1993
tag
válasz
bambano
#1404
üzenetére
#!/bin/bash
if ["$1" == ""]
then
echo rossz
else
cat szavak11111.txt | grep -w $1
fiaz a baj, hogy megtalálja azt a sort amiben szerepel ki is írja, de még előtte kiirja ezt: szotar.sh: 8: szotar.sh: [data: not found
amugy azt, hogyan is tudnám megcsinálni, hogy csak az első vagy a második oszlopát írja ki annak amit eddig kiirt??
pl eddig így írta, hogy: data adat
de nekem csak az "adat" vagy csak a "data" kellene. -
#1404
bambano
titán
puskas1993
#1403
bambano
titán
válasz
puskas1993
#1403
üzenetére
másold ide be a kódrészletet, ami a hibát dobja.
egyébként a 2-es file descriptorra szokás hibaüzenetet írni.
-
#1403
puskas1993
tag
puskas1993
tag
Sziasztok!
Szótár programot/shell/ kellene írnok, mely ha rossz vagy semmilyen adatot nem kap a felhasználótól akkor hibaüzenetet írjon ki. Már kész van minden kivéve az, hogyan dobjon hibaüzenetet. Vagyis megvan az is, csak nem teljesen jó.
Valaki tudna nekem ebben segíteni?? Vagy csak átnézni a kódomat?? -








 "
"









 ):
):























 ezer köszönet mind kettőtöknek
ezer köszönet mind kettőtöknek Új hozzászólás Aktív témák
- Honor Magic V3 - mágikus realizmus
- Luck Dragon: Asszociációs játék. :)
- E-book olvasók
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Trollok komolyan
- Ötmillió példánynál jár a Crimson Desert
- Horgász topik
- Konzolokról KULTURÁLT módon
- Félő, hogy az okosszemüveg a szexuális zaklatók játékszere lesz
- OLED TV topic
- További aktív témák...
- Microsoft Office 2024 Home Business dobozos
- PC Szervizeket, Gépépítőket keresek B2B szoftver partnerségre (E-számlával)
- Számlás!Steam,EA,Epic és egyébb játékok Pc-re vagy XBox!
- Microsoft és egyéb dobozos retro szoftverek
- Windows, Office licencek kedvező áron, egyenesen a Microsoft-tól - Automata kézbesítés utalással is!
- HP EliteBook 840 G6, G5 14" i5, 8-16GB RAM, SSD, jó akku, számla, 6 hó gar
- Lenovo IdeaPad Slim 5 OLED i7-13620H 16 GB DDR5 512SSD FHD+ Garancia
- Samsung 870 QVO 8TB Sata 2.5 SSD
- Apple iPhone 13 Pro Max / 128GB / Kártyafüggetlen / 12Hó Garancia / Akku:86%
- Asus Tuf RTX 5070 // Felbontott, új // SZÁMLA // GARANCIA //
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest