Új hozzászólás Aktív témák
-

wwenigma
Jómunkásember
válasz
 S_x96x_S
#3354
üzenetére
S_x96x_S
#3354
üzenetére
AMD responds to motherboards misreporting power telemetry
"We want to be clear with our customers: AMD Ryzen processors contain a diverse array of internal safeguards that operate independently of external data sources. These safeguards enforce the safety and reliability of the processor during stock operation. Based on our initial assessment, we do not believe that altering external telemetry in the manner described by those public reports would have a material impact on the longevity or safety of a user's processor."
TL,DR a belső védelmi vonalak miatt nem okoz problémát a dolog mert az megfogja, de ezt amúgy leírták közben mások is ahogy linkelted.
-

S_x96x_S
addikt
válasz
S_x96x_S
#3387
üzenetére
Jim Keller ..
https://www.youtube.com/watch?v=n3wdcLFjNj4
"Now that Jim Keller is on the final leg of his time at Intel, I wonder where exactly someone of his ability will go next. People have peppered me with suggestions: AMD! Nuvia! Apple! I'll explain why I think he will or won't be at these various places."( TechTechPotato by Dr. Ian Cutress )
0:00 Start
0:13 Keller Leaves Intel
1:30 AMD
2:50 Nuvia
4:20 Apple
5:45 Sovereign Designs
6:54 Retire?
7:10 An AI Startup -
#3382
 Petykemano
veterán
S_x96x_S
#3381
Petykemano
veterán
S_x96x_S
#3381
Petykemano
veterán
válasz
S_x96x_S
#3381
üzenetére
Később olvastam a híreket.
Pl a fél év tanácsadást.Találgatnak mindenfélét. Persze ott van, hogy personal reasons, meg hogy szeretne többet lenni a családjával, de hát Raja Koduri is kábé ugyanezeket mondta pár hónappal azelőtt, hogy átnyergelt az intelhez.
Az, hogy 4 emberrel helyettesítik jelentheti azt is, hogy tényleg hírtelen kellett távoznia.
Ami nekem fura, az az, hogy 4 indiainak hangzó nevet soroltak fel. Egészen durva agyelszívás.
Vagy... lehet, Raja építi a birodalmát is kifúrta kellert 😃 -
S_x96x_S
addikt
válasz
S_x96x_S
#3378
üzenetére
Ian Cutress(Anandtech)
"FWIW, Jim isn't likely going to be going to AMD next. As he's consulting for Intel for six more months for the transition, I suspect he won't be able to work anywhere else. If it's his health, then he needs to rest up.
Jim likes challenges. AMD has a strong roadmap."
https://twitter.com/IanCutress/status/1271181698647154688"Keller normally sticks around for three plus years, so the fact he's gone in two is a little odd. He is still listed as the Hot Chips keynote speaker. He remains as a consultant for six months, which indicates it's likely a health issue (as stated). "
https://twitter.com/IanCutress/status/1271179761780510729 -
válasz
S_x96x_S
#3354
üzenetére
Nem tudom, ez megvolt-e: https://www.tomshardware.com/news/ryzen-burnout-amd-board-power-cheats-may-shorten-cpu-lifespan
-

Cathulhu
addikt
-
#3353
Petykemano
veterán
S_x96x_S
#3352
Petykemano
veterán
válasz
S_x96x_S
#3352
üzenetére
Ez a diasor megerősíti azt erősíti , hogy a zen3 és RDNA2, valamint a CDNA1 7nm-en, még idén és nem feltétlenül az utolsó napokon fognak érkezni.
Ugyanakkor azok a pletykák is ott vannak a porondon, hogy az 5nm-es kínálatot tényleg az AMD szívta fel és következő év elején kezdődik a tömeggyártás (ramp up)
Tényleg érdekelne, hogy ha ennyire kapkodnak (most a szó jó értelmében), mi fog ott készülni -
Cathulhu
addikt
válasz
S_x96x_S
#3340
üzenetére
erdekes
Ertem, hogy a srac az alienwaretol jott, igy valoszinuleg jo kapcsolatot apol a delllel, de az meg pont az intel leghusegesebb szolgaja. Igy probalnanak ezen valtoztatni? Ketelu kard ez, a tobbi gyartonak ez biztos nem esik jol, nem tudom megeri-e az AMD-nek az, hogy a tobbieknek rossz szajize legyen. -
#3333
Petykemano
veterán
S_x96x_S
#3332
Petykemano
veterán
válasz
S_x96x_S
#3332
üzenetére
Írja a cikk végén, hogy ugyanabban a méretben Arm alapon magokat, X86 alapon pedig hardver szálakat kapsz.
Árazás:
I was just interested in what the raw prices were, not any kind of analysis. I looked it up myself here https://aws.amazon.com/ec2/pricing/on-demand/:
Arm m6g.8xlarge $1.232
EPYC c5a.8xlarge $1.232
EPYC m5a.8xlarge $1.376
Xeon m5.8xlarge $1.536
Arm m6g.16xlarge $2.464
EPYC c5a.16xlarge $2.464
EPYC m5a.16xlarge $2.752
Xeon m5.16xlarge $3.072
Szerintem sincs idő lazsálni. Kell a Milan.
Ezzel együtt azt gondolom egyébként, hogy az, hogy a Naples után most már Rome is került az Amazonhoz arra utal, hogy megindultak ezen az úton. Vagyis lesz szerintem Milan is a kínálatban és valószínűleg majd Genoa is. -

awexco
őstag
válasz
S_x96x_S
#3326
üzenetére
Gyanús , hogy azonos típusnál ha 3 féle memórai menyiséggel vásárolható meg az akkor 3 tipust jelent nem pedig egyet . Annak fényében elég kevés . Lehet sok komponensel variálni .
Azér a gyártókat láthaton több kategóriába lehet sorolni aktivitásuk szerint .
Az éllovasok : Acer,Asus
Középmezőny : Hp, Lenovo (bár ők lennének érdekesek igazán mert üzleti modellekbe a legnagyobb menyiséget tudnák vásárolni, eladni )
És legvégül (intel pártiak ) Dell ( Bezzeg az első TR procit be tudták húzni maguknak kizárólagosra . ) -
#3316
Petykemano
veterán
S_x96x_S
#3315
Petykemano
veterán
válasz
S_x96x_S
#3315
üzenetére
Hogy érzed a "hegymenetben" a Renoir tapadása jobb, mint a korábbi mobil megoldásoké?
Nagyobb lesz a kínálat, az elérhetőség, több AMD lesz a polcokon és nem kell majd lesajnálni, hogy "igen-igen, van AMD megoldás is, de annak azért gyengébb az akkuja is, de amúgy is rövidebb ideig bírná és igaz, hogy az IGP erősebb, de a beletett RX 460M mellett az meg mondjuk teljesen mindegy." ? -
#3297
Petykemano
veterán
S_x96x_S
#3292
Petykemano
veterán
válasz
S_x96x_S
#3292
üzenetére
Szerintem nem irreális (nem.nevezném álmodozásnak.)
A skylakeről azért nem.mozdult el az Intel,.mert ipct növelni az új nodeokon a 1-5-2x tranzisztorsűrűséggel kényelmes. Azt gondolom, hogy az Intel is arra számított, hogy hamarabb lesz használható a 10nm.
A sunny cove már benne van az icelakeben, csak épp nem használható mobilon kívül.
A willow cove idén érkezik a tiger lake.formájában. de ez is még csak mobil. 15-28W
Kicsit később érkezik a 35-45W,.de szerintem asztali ebből.se lesz, mert az a rocket lake.A zen3 ezzel fog versenyezni.
Igazából az látszik szerintem, hogy mivel az Intel ügyesen megoldotta, hogy a 10nm-en is meg tudja közelíteni az 5GHz-et, és valahogy összerakja 14nm-en is a cove magot, ezért 15% IPC növekedés a zen3-at legjobb esetben is épp csak szinten tartaná.
Ennél.több kell.
Vagy hamarabb,.mint az Intel termékeMivel jön a tiger lake U, ezért nem meglepő, ha a Cézanne-nal iparkodnak.
Alder lake (golden cove) vs zen4
Azt gondolom még ekkor is problémát.fog jelenteni az intelnél az, hogy megfelelő mennyiségben tudjon gyártani 10nm-en.
Az 5nm 1.84x tratnzisztorsűrűséget ad. Azzal azért már lehet gazdálkodni. Ráadásul bejön a DDR5 is, ami duplázza a sávszélességet. Bár ez lehet, hogy csak multithread teljesítményben fog látszani.Ocean.cove vs zen5
A nagy kérdés itt szerintem az, hogy a az Intel boldogul -e a 7nm ével.Igazából.ugye nem tudunk semmit a zen3-on túl, amiből bármire is Lehetne következtetni, hogy milyen IPC növekesésre lehet számítani.
Illetve azt sem tudjuk, hogy vajon a Warhol féle "optimalizációs" lépcsővel vajon változik-e a product release cadence. Mondjuk sűrűsödhet, miközben a zen gemerációk fejlesztése hosszabbodik.
-
-
#3284
Petykemano
veterán
S_x96x_S
#3280
Petykemano
veterán
válasz
S_x96x_S
#3280
üzenetére
Azon gondolkodtam el, hogy lehet-e a matisse 2 elnevezés forrása egy 7nm-es IO lapka?
Korábban volt róla szó, hogy sok esetben azért sem tud tovább skálázódni a zen2, mert valójában a fabric frekvenciát nem lehet tovább emelni.
Namost egy 7nm-es io lapka ezen esetleg pont segíthet. És mivel pont lehet külön fejleszteni, hiszen pont ezt hoztuk fel mindig a chiplet design élőnyének, ezért kézzelfogható magyarázata lenne.
Nem csak a matisse2-nek, de a Vermeer után jövő szintén zen3@7nm Warholnak is.
És esetleg még a 15 hónapos zen ciklusnak sem kell emiatt borulnia, sőt, épphogy rövidülhet.Ha a vermeer idén év vége felé jön, jövő ilyenkor vidáman kidobhatják ugyanazt a ccdt ddr5-os IO lapkával warhol néven. Ez persze csak egy példa.
-
#3269
Petykemano
veterán
S_x96x_S
#3257
Petykemano
veterán
válasz
S_x96x_S
#3257
üzenetére
Ha az AMD early adopter 5nm-en, akkor 2 helyen látnám indokoltnak/szükségesnek:
a mobil piacon. De ha a Van Gogh (9W) az első 5nm.-es mondjuk zen3-as apu, ami mondjuk 2021Q1-Q2-ben jelenne meg, akkor az azért eléggé zárójelbe teszi az elvileg év végén érkező Cézanne-t, ami szintén zen3 apu, csak 7nm-en.
Talán mondhatjuk, hogy technikai értelemben az AMD a ROme-mal és a Milan-nal előnyben van, itt nincs ok kapkodásra
Ahol viszont kézzelfogható előnyt jelentene, az az Arcturus/CDNA gyorsító az nvidiával szemben.¯\_(ツ)_/¯
-
-
awexco
őstag
válasz
S_x96x_S
#3249
üzenetére
"We measured the system drawing 320W with Windows Server 2019 in idle and peaking at 537W with all 128 cores under maximum load."
Amenyi vezérlő meg ram meg eszköz van benne nem csoda a 320 as idle fogyasztás. De a 2 proci 217 wattal eszik többet csúcson mint idlében az nem sok . Az lehet hogy pár eszközt lehetne használat mentes időszakban alacsony energia takarékos üzemben futatni.
De a cikk írója szerintem részre hajló kékszemüveges lehetett.
De már kezd valami line upp kialakulni dell fronton is :
[link]
Hp fronton se etek túlzásokba :
[link]
Arra kíváncsi lennék ithon akart e valaki ilyeneket venni és tudot is ? -
#3231
Petykemano
veterán
S_x96x_S
#3228
-
#3230
Petykemano
veterán
S_x96x_S
#3227
Petykemano
veterán
válasz
S_x96x_S
#3227
üzenetére
Y-series
Jó, de annak van piaca? Jó Végülis raven ridge 2 is van. És kerül ryzen apu rpi alternatívába is.SP5
Én elképzelhetőnek tartom a DDR5-t is."SK Hynix has estimated that 25% of all memory market sales will be represented by DDR5 in 2020 and by 2021 they expect over 40% respectively. "
[link]
bár nem gondolom, hogy az AM szérián kívül bárminek a nevében lenne összefüggés a memóriával.Ha az armos összehasonlítást nézed, akkor az AMD számára elég fontos a memóriasávszélesség a sokmagos procik esetén.
-
#3226
Petykemano
veterán
S_x96x_S
#3224
Petykemano
veterán
válasz
S_x96x_S
#3224
üzenetére
Azt mondják, az X1 nem Neoverse N1 utód, vagyis nem szerverchip.
Ha ez igaz, akkor az lehet, amit mondtam, hogy az A78 megmarad azon az egyensúly szintén és a nextgen socok 2xX1 + 4xA78 + 4xA55 felépítésben v 1-2-4 vagy hasonlóban fognak.jönni. nyilván a tdptől függően lehet több mag.De nyilván lesz átfedés. Ebből a szempontból tök érdekes, hogy az arm vastagság szempontjából különbözőképpen tervezi a cpukat. Az intelnél is lesz ilyen' egyedül az AMD tartja magát. Bár a l3$-sel ők is játszanak.
Nem tudom, én egyelőre nem látom az amdt érdekeltnek arm proci fejlesztésében. Bármi, amit az arm dob ki az más számára is licencelhető. Tehát akkor tudna armra építeni, ha 1-2 generációval az arm előtt tudna járni, és a magok integrálására lenne valami jó megoldása. Lásd qualcomm.
Ma még mennyivél jobb egy qualcomm chip egy kirintől vagy mediatektől?
A Samsung is feladta a aaját mongoose magok fejlesztését. -
#3206
Petykemano
veterán
S_x96x_S
#3205
-
-
#3188
Petykemano
veterán
S_x96x_S
#3187
-
#3181
Petykemano
veterán
S_x96x_S
#3177
Petykemano
veterán
válasz
S_x96x_S
#3177
üzenetére
"de amúgy felturbózott ARM-el tervezik letarolni a szerverpiacot .."
Azt értem, de úgy érzékelem, hogy nagyobb hype övezi őket, mint olyan cégeket, amelyek már ma is kínálnak designt (Ampere) vagy megoldást (graviton2)
Igaz, persze a nuvia azt ígéri, éteri színtre emeli az egyszálas teljesítményt is.
De azt olvastam a az AT egy fórumán, hogy azért az Apple jól meghatározott célra és jól körülhatárolható eszközökkel érte el a felturbózást
Az A13 esetén a két erős mag 128-128kb L1d és L1i cache-sel és és 8MB (2x4?) L2$-sel rendelkezik. Ezzel etetik az elvileg 6 feldolgozó szálat. Ehhez képest a zen2 32kb/32kb L1 és 512kb L2$ és 1 mag osztozik. Persze nem állítom, hogy a cache mindent megold és az is mérnöki teljesítmény, hogy ilyen Nagy cache esetén is jó a késleltetés.Azt gondolom, hogy egy Apple soc működése ilyen szempontból más. Gondolom, ott nem pattogtatja a szálakat a lightning és thunder magok között.ehhez képest ahol a zen magok kerülnek felhasználásra, ott egyik magról pattoghat másikra.
Nekem tök szimpi lenne egy olyan big.LITTLE megoldás, hogy egy designban van egy 1-2 magos szupererős, szupercachekitömött mag és több általános. Biztos össze Lehetne rendezni egy ccx -et is. Csak ez nem biztos hogy jó lenne szerveres környezetben. Meg arra akkor szoftver is kell, ami nem pattogtatja feleslegesen a szálakat a két külön ccx között. Mondjuk ez most is fontos.Mindenesetre ebből nem látunk még semmit.
Miért nem mondjuk az amazontól várjuk, hogy elhozza az Apple a13 ipct 3-4GHz-cel 128 maggal, stb? Szóval a nevek miatt, akik odamentek? -
#3179
Petykemano
veterán
S_x96x_S
#3176
Petykemano
veterán
válasz
S_x96x_S
#3176
üzenetére
Ez elég érdekes.
Mármint ez már a második pletyka a matisse2/zen2 refresh témában.Mivel a 3300X 4.3GHz-es turbó órajele meghaladja a 3500X és 3600 turbó órajeleit is, ezért végső soron indokolt Lehetne a vérfrissítés.
Ugyanakkor ez az XT elnevezés elég furi.
Nagy a vita arról, hogy ez most minek köszönhető.
- pusztán csak finomodott a gyártástechnilógia
- kipörgetik a mainstream piacra a jó lapkákat, ami eddig rome-ba ment.
- vagy csupán arról van szó, hogy jön a B550 és a renoiron kívül nincs más, Amivel kínálni lehetneÉn nem várok nagy durranást, szerintem csak felviszik a 8 magosok turbóját is 4.7GHz-re, a 6 magosét meg 4.6-ra.
Mindenképpen szokatlan lépés a zen3-hoz ennyire közel még akkor is, ha gyakorlatilag nem kerül semmibe
-

joysefke
veterán
válasz
S_x96x_S
#3156
üzenetére
Szerintem az Intel jön ki elébb a PCIe5.0 / DDR5 -val
Meglátjuk a presztizsen kívül ennek mennyi értelme lesz:
Kezdetben a DDR5 nagyon drága lesz és csak adatközpontokban lesz gyakorlati haszna. Desktopon a magas ár gátolná a rá épülő platform terjedését (a nem-csúcs kategóriában) tehát nem érdemes azonnal meglépni a DDR4-DDR5 váltást, adatközpontban pedig az önmagában nem hívószó, hogy "DDR5-ös rendszer", hanem megfelelő teljesítményt/hatékonyságot is kell mellé tenni processzor oldalról. -
#3083
Petykemano
veterán
S_x96x_S
#3079
Petykemano
veterán
válasz
S_x96x_S
#3079
üzenetére
Hát azért ez elég vicces
A ryzen 1k csak két chipset évadot élt meg
A ryzen 2k 2.5-öt
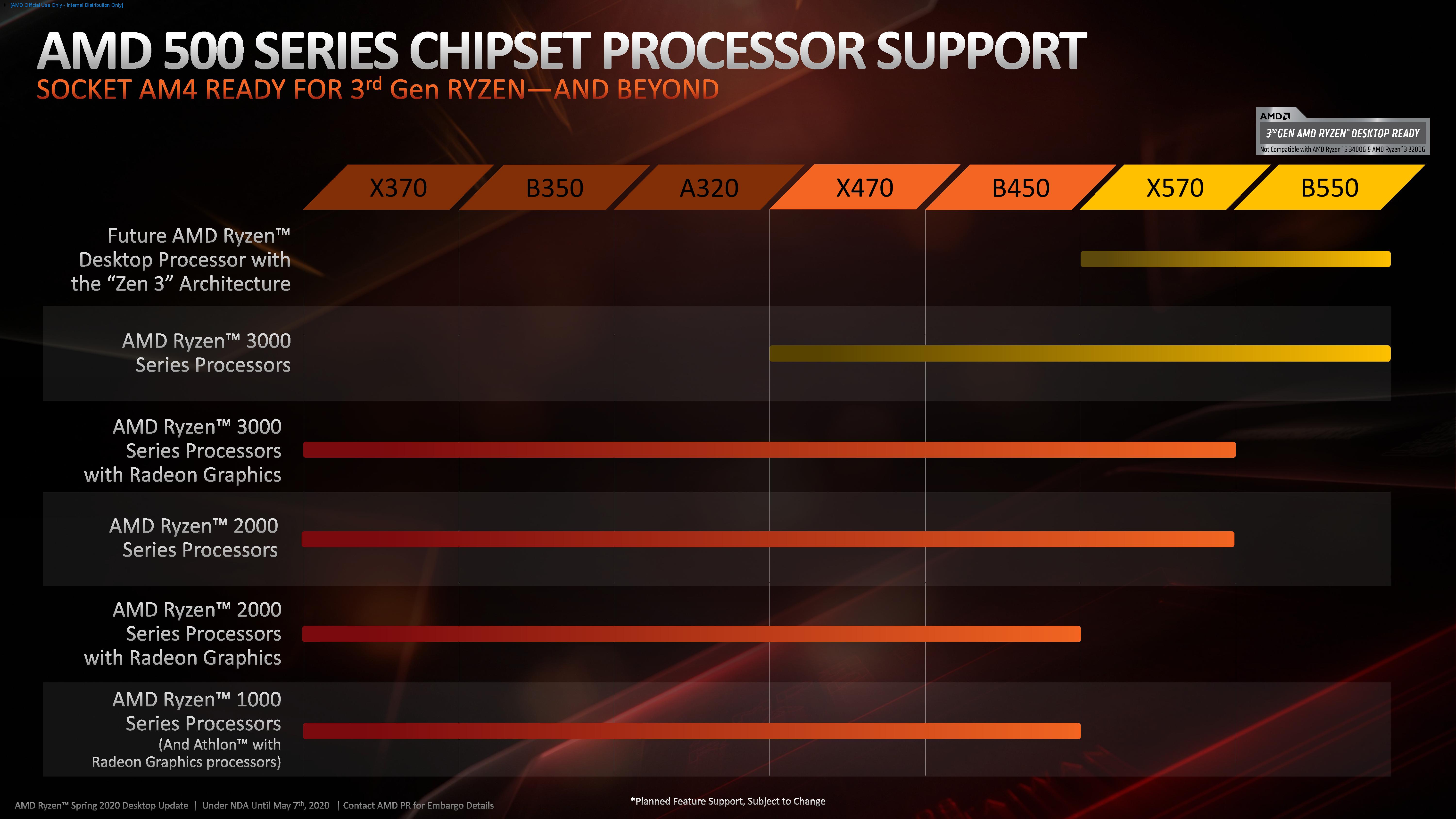
Ha lesz még 6X0 chipset, ami AM4 (ez nem.biztos sztém ) Valószínűleg abba már a zen2 se megy majd bele.Szóval tök jó, hogy a foglalat PIN kiosztása ugyamazaradt, de ez csak arra elég, hogy ha egy szériát akarsz előre váltani. Én a B350es lapomba már nem tudok majd zen3-at betolni. Elvileg zen2-t kéne, bár ez alapján az ábra alapján nem.
Amúgy valaki mondja már el nekem, hogy Mit tud a B550 chipset, ami olyan többletet jelent a X470 vagy B450-hez képest, ami miatt megérte ennyit kotlani rajta?
-
#3066
Petykemano
veterán
S_x96x_S
#3065
-

olymind1
senior tag
válasz
S_x96x_S
#3048
üzenetére
Németeknél most 166 € az R5 3600 BOX verzió, ha úgy nézzük hogy az a 150 US$ áfa nélküli, míg az €-s már áfás ár, jelenlegi árfolyammal számolva: a 150$ -os ár az 48600 huf + 27% áfa, = 61722 huf, míg az 166 eurós 58598 huf. Jelenleg itthon is van 1 bolt ami kb annyiért árulja, egyébként 60-63e körüli áron nem olyan sokkal drágább a német vagy épp az amcsi áraktól, tehát már be is esett 150$ alá

De remélhetőleg a Zen3-mal még olcsóbbak lesznek majd a Zen2-k, és megint pakolnak mellé 1-2 értelmesebb játékot és egyből jobban megéri majd megvenni.

-

DraXoN
addikt
válasz
S_x96x_S
#3046
üzenetére
esélyes az árcsökkentés.. ez talán már nagy különbség. bár tippre a 3600 megy be 157(+/-5)$ a 3600X a mostani 179(+/-5)$ körülire.. hacsak nem sikerült kicsit javítani az intel IPC-jén, de ez nem valószínű, hogy jelentősen hozzányúltak (az elvileg a következő generáció lesz, ez csak 2+mag és némi optimalizáció.. de utóbbi nehéz már egy több generáció óta csiszolt technikán, azzal tempót találni nem sok esély van, max új utasításokkal, vagy nagyobb órajellel lehetséges).
-
válasz
S_x96x_S
#3037
üzenetére
Úgy fest az Epyc volumen még mindig nem túl nagy, érdemi forgalomcsökkenés és veszteség az üzletágban.

Enterprise, Embedded and Semi-Custom segment revenue was $348 million, down 21 percent year-over-year and 25 percent sequentially primarily due to lower semi-custom sales, partially offset by higher EPYC processor sales.
◦ Operating loss was $26 million compared to operating income of $68 million a year ago, which included a $60 million licensing gain. The decline from operating income of $45 million in the prior quarter was primarily due to lower revenue and higher operating expenses. -
#3034
Petykemano
veterán
S_x96x_S
#3032
Petykemano
veterán
válasz
S_x96x_S
#3032
üzenetére
Felmerült bennem a kérdés, hogy tulajdonképpen mi választja el manapság az SSD-t az optane/3dXpoint-től?
Mármint régen mondjuk a 100k IOPS egy elég hard limitnek tűnt az SSD-k esetén. De ma már a M.2 foglalatos PCI3/4-es ma még talán prémiumnak számító SSD-k is (mérettől függően akár) 500k is IOPS-t tudnak.
A kérdést nem oda akarom kifuttatni, hogy mi értelme az optane/3dXpoint-nak, de az előnyeit látni kell. A kérdés önmagában csak azért vetődik fel, mert az intel által piacra dobott termékek eddig nem igazán váltották be azokat a számokat, amivel a kezdetekben reklámozták. Ezek a kezdei 64GB-os alaplapi összeköttetéssel bíró példányok nem, vagy alig adtak többletet egy hagyományos SSD-hez képest, miközben drága is volt és kicsi is. Háttértárnak.
Kiderült, hogy a Sony terve a seamless load, a játékok adatainak streamelése SSD meghajtóról. 5-7GB/s És ehhez terveztek is egy IO chipet, ami DSP formában tartalmazza a kraken decompressort.
Felröppent a hír, hogy az RDNA3 256GB fedélzeti memóriával fog érkezni. (Ezt persze ne vegyük
készpénznekérintésmentes másodlagos számlaazonosítóra történő azonnali átutalásnak) De a lényeg, hogy megint felröppent a hír, hogy esetleg a GPU-ra integrálva lehetne használni memóriabővítésként SSD-t.Több ötletem / kérdésem is van.
1) Lehetséges-e vajon, hogy az SSD - legalábbis amiket eddig a profi SSG-kben használtak - nem kellően gyorsak RAM helyettesítésére. De az optane / 3dXpoint igen, különben nem lenne DDR foglalat helyére beilleszthető modul. Méretet késleltetésért, persze, de a jobb körökben úgy használják, hogy a foglalatokban levő valódi DRAM gyorsítótárként funkcionál.
Tehát ha már az optane/3dXpoint úgyis alkalmas DRAM helyettesítőként DRAM gyorsítótárral kevés késleltetés árán nagy méretnövekedéssel, akkor lehet-e ez a megoldás?2) Általában persze az SSD-k úgy működnek, hogy van valami vezérlőchip rajtuk, és azok is szintén - jobbára - használnak DRAM-ot gyorsítótárként. az SSG is valószínűleg úgy működött, hogy kellett azért a GPU-ba egy olyan IO vezérlő, ami az SSD-ket kezelte. (kivéve persze, ha ez magán az SSD-n volt)
Amikor a Vega HBCC-vel működött, ott is volt HBCC, ami történetesen PCIe-n keresztül használta a rendszermemóriát úgy, hogy a fedélzeti HBM csak cache volt.Mindenesetre az nyilvánvaló, hogy valami vezérlő kell
Lehet-e az a DDR és a GDDR jövője, hogy kvázi a mai DDR és GDDR chipekre 3d stackiing ráépítik a már ramhelyettesítésre is elég gyors 3dXpoint-ot ennek lekezeléséhez szükséges vezérlőkkel együtt. (Nyilván a gondolat annyiből nem új, hogy maguk a DRAM chipek és SRAM cache-sel működnek már most is)
-
S_x96x_S
addikt
válasz
S_x96x_S
#3028
üzenetére

Köszönöm a visszajelzéseket Micron HSE - ügyében ..
valószínüleg ez még nem a full Optane RAM -os helyettesítő ..
csak szoftveres optimalizáció a filerendszer overheadjének kiküszöbölésére."This HSE storage engine depends upon an mpool object storage media pool that is implemented as a Linux kernel module. Mpool interfaces with SSDs or other persistent memory storage directly, bypassing file-systems and other overhead while also supporting replication across classes of memory and other storage features"
https://www.phoronix.com/scan.php?page=news_item&px=Micron-HSE-Projectmindenesetre én nagyon ki vagyok éhezve az ilyen hírekre (is) ..
A szűk keresztmetszet ( nálam - legtöbbször ) már az I/O ...
Remélem idén lesz valami előrelépés .. -
#3029
Petykemano
veterán
S_x96x_S
#3028
Petykemano
veterán
-
S_x96x_S
addikt
válasz
S_x96x_S
#3023
üzenetére
csak összehasonlításként
- Az Intel is frissitett
https://www.lenovo.com/de/de/laptops/ideapad/s-series/IdeaPad-5-15IIL05/p/81YKCTO1WWDEDE1/customize?Alap:
Intel Core i5-1035G1 Prozessor (4 Kerne, 8 Threads, bis zu 3,60 GHz, 6 MB Cache)+ 160,00 €
Intel Core i7-1065G7 Prozessor (4 Kerne, 8 Threads, bis zu 3,90 GHz, 8 MB Cache)Az Intel mellett (ami már 10nm) az
AVX-512 ; (Intel® DL Boost) és az Optane szól ;
de sajnos nincs belőle 6 és 8 magos verzió.valamint nVidia is van
Alap: NVIDIA GeForce MX330, 2 GB GDDR5, 64 Bit
+ 30,00 € : NVIDIA GeForce MX350, 2 GB GDDR5, 64 Bitmindenesetre szerintem 1-2 hét és lesznek tesztek is és meglátjuk hogy az AMD hogy szerepel ...
ARK-os összehasonlítás:
https://ark.intel.com/content/www/us/en/ark/compare.html?productIds=196603,196597
Ami érdekes, hogy az ajánlott ár különbsége
( $426.00 - $297.00 = 129$ )
az OEM nél már 160 EUR lesz ; persze az árfolyamok és a VAT ... -
Cathulhu
addikt
válasz
S_x96x_S
#2992
üzenetére
De ez is csak ilyen onallo, komplett gep, amit bele tudok dugni PCIe-be, de minek dolog? sajat rammal, vrm-mel mindennel? mert annak oszinten streamelos gepeken kivul (amit mar egy 8+ magos CPU is egyben kiszolgal) semmi ertelmet nem latom.
Amit el tudnek kepzelni, hogy a foglalatokon keresztul, de nem pci-on keresztul, hanem valami fabricon at (ami memoria koherens es gyorsabb mint a RAM) tetszoleges szamu CPU-t es GPU-t dughassunk, amik aztan egyutt dolgoznak es nem kulon-kulon egysegenkent. Jelenleg ez meg GPU-k eseteben se mukodik tul jol, prociknal is csak trobb socketes lapoknal lattam, szoval ettol meg asztali konfiguracioknal szerintem kicsit messze vagyunk :/ -

#82819712
törölt tag
válasz
S_x96x_S
#2992
üzenetére
Az iparág azért mozdul el mert jön az AI AGE. és az EPH-k vele a többszörös felhasználású chipek.
És ehhez szimultán bedobják az Arcturus-t ami CPU is GPU is memóriai is ,"mindenreisjó", kesselhetsz a HBM-el.
A CPUknál hiába csak a licenszek fogják meg a mag számot és a chippek szépen kommunikálnak a hálózati topológiákon, a GPUknál ez nem így van. Az OS nem fejlődik eléggé a hardverrel. (nem jött a Directx 13 aminél a chipletes gpuk memóriakoherens elérést és külön puffert kapnak)
...és ha már van 32 GB HBM-ed +Cpu-d Gpu-d ráteszed egy pcbre ami neked pénzt spórol akkor már ott a szabványos vagy nem szabványos PCI E! -
#2977
Petykemano
veterán
S_x96x_S
#2976
Petykemano
veterán
válasz
S_x96x_S
#2976
üzenetére
Szerintem desktopon a 3700X-et megközelítő "4700G" nem akkora durranás. Illetve PRO szegmensben igen. Ott fegyvertény, hogy lehet szállítani 6-8 magos IGP-s 45-65W munkaállomásokat is.
A G-s chipekhez persze ha árban is olyanok, ideálisak lennének a B550 alaplapok megjelenése mellé. Inkább, mint a vermeer.
Amúgy adoredtv podcastban írták vmi Matisse2-ről. Alvilág június. Persze lehet, hogy nettó találgatás, de arról van szó, hogy esetleg lesz zen2 refresh?
A másik dolog. Ugye adoredtv azt mondta, a forrása szerint A0 steppingben nem működik az SMT. Valakiben felmerült, hogy azért, mert titkolni kell az SMT4-et. Ez persze nettó találgatás, semmi bizonyíték nincs rá. Csak egy érdekes felvetés.
-
#2971
Petykemano
veterán
S_x96x_S
#2970
Petykemano
veterán
válasz
S_x96x_S
#2970
üzenetére
Én nem ismerem az egyes típusokat, sorozatokat.
És bevallom, ezen kívül csak a hwunboxed videóját láttam. A srác ott azért inkább visszafogott volt, az összegzésben sem áradozott,.hanem inkább Azokat sorolta, mik azok az esetek, amelyek esetén vagy miatt még mindig inkább intelt érdemes venni.Azért dobtam be, mert én mondtam, hogy széles körben le fogják húzni és azt fogják sugallni, hogy ha találsz legalább egy okot, amiért az intelt érdemeseb venni, akkor inkább fókuszálj arra az egy okra és vegyél intelt, semminthogy elmerülj a részletekben.
De linus nem. Ez persze nem az AMD brand érdeke, hanem a terméké.
-
#2967
Petykemano
veterán
S_x96x_S
#2966
Petykemano
veterán
válasz
S_x96x_S
#2966
üzenetére
Linus videóját szerintem érdemes megnézni ab zephyrusról. Mármint azt sejtem, hogy ő populárisabb videókat készít, nem ilyen mélyelemzéseket, de számomra meglepő volt a Renoir pozitív fogadtatása.
Apropó, tudjátok hogy fogják hívni a 2020-ben megjelent 4900H-t 2 generációval később?
Senoir.
(Ez szar volt) -
joysefke
veterán
válasz
S_x96x_S
#2961
üzenetére
inkább az OEM-től függ ez aki beszállít nektek.
és beszállítókat néha sokéves szerződés köti ,
meg lehet, hogy az Intel nagyobb jutalékot csurgat vissza, mégha a többfeltfelárat az ügyfél fizeti meg .Majd mennek szépen a levesbe, persze ez az AMD jelenlegi helyzetén itt-és-most nem sokat javít
Aki annyira kevés hozzáadott értéket ad a végtermékhez, hogy a beszállítója el tudja tiltani a jobb alternatíváktól, annak szerintem 2020-ban már nincs vissza 10 jó éve.Aztán ha az AMD megint padlót fog, akkor minden visszaáll a régi kerékvágásba és nem kell ilyeneken agyalnunk...
-
DraXoN
addikt
válasz
S_x96x_S
#2924
üzenetére
Architektúrálisan változik valami az i9-9980HK-ban találhatókhoz képest?
Mert az LTT tesztben eléggé leszerepelt a 4900HS ellen.. [link]
Ha csak kicsit magasabb lesz az órajel nem segít, maximum az általánosan jobb órajel segíthet, de arról nem szól semmi.Lehet jön belőle 10magos ide is?
Kíváncsi leszek mi lesz.. -
#2925
Petykemano
veterán
S_x96x_S
#2924
Petykemano
veterán
válasz
S_x96x_S
#2924
üzenetére
Ja, hát afelől semmi kétség, hogy egy év alatt javíthattak Annyit a 14nm-en tovább, hogy párszáz plusz megahertz rövidebb ideig beleférjen.
Szóval elképzelhető, hogy a slide nem lódít nagyot.
Amit kétlek azért, hogy ehhez nem kell majd Nagy árat fizetni üzemidőben.Meg hát vajon ez mennyire lesz fenntartható? A nagyobb ipct hozó architektúrához 10nm kell, ott meg valószínűleg kell pár év, mire újra elérik az 5.3GHz-et
-
DraXoN
addikt
válasz
S_x96x_S
#2916
üzenetére
ez már a vég?
még minimum 2 év amíg valami (talán) versenyképes lekerülhet az asztali platformra inteltől (és lehet akkor még "pozitív" a hozzáállásom).
Kb. 4 év alatt megfordult a piac náluk bevételt tekintve...persze.. a COVID még összekuszálhatja itt a dolgokat és termék elkészülési időket (ha kiesik egy-két kulcsfontosságú mérnök, vagy akár egész csapat).
-
#2904
Petykemano
veterán
S_x96x_S
#2902
-
wwenigma
Jómunkásember
válasz
S_x96x_S
#2348
üzenetére
4900H és a többi is kintvan.
AMD launches Ryzen 4000 Mobile Renoir processors with 7nm Vega iGPU
Hardware Unboxed: OEM can only get the „HS“ series APU if they follow strict design guidelines from AMD and use it together with high end components.

































![;]](http://cdn.rios.hu/dl/s/v1.gif)
Új hozzászólás Aktív témák
- Steam, GOG, Epic Store, Humble Store, Xbox PC Game Pass, Origin Access, uPlay+, Apple Arcade felhasználók barátságos izgulós topikja
- OpenMediaVault
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Parkside szerszám kibeszélő
- Gaming notebook topik
- BGA-zók, ReWork-ösök szakmai topic-ja
- Konteó topic
- Könyvajánló
- Sorozatok
- Vélemény: nem úgy tűnik, de Lip-Bu Tan most menti meg az Intelt
- További aktív témák...
- Dell Latitude 7410 Strapabíró Ütésálló Profi Ultrabook Laptop 14" -80% i7-10610U 16/512 FHD IPS MATT
- Eladó Lian Li O11D MINI-X gépház
- Lenovo ThinkPad P17 Tervező Vágó Laptop -50% 17,3" i7-10750H 32/512 QUADRO T1000 4GB
- FSP DAGGER PRO ATX3.0(PCIe5.0) 850W Sfx tápegység
- Eladó PNY GeForce RTX 4070 Ti SUPER 16GB OC XLR8
- Új! HP 230 Vezetéknélküli USB-s Billentyűzet
- Apple iPhone 13 Pro 128GB, Kártyafüggetlen, 1 Év Garanciával
- ÁRGARANCIA!Épített KomPhone i5 14600KF 32/64GB DDR5 RAM RX 9070 16GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! Apple MacBook Pro 16 M4 Pro 24GB RAM 512GB SSD - garanciával hibátlan működéssel
- Bomba ár! HP EliteBook Folio 1040 G2 - i5-G5 I 8GB I 256GB SSD I 14" HD+ I Cam I W10 I Garancia!
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest