-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#66847
 b.
félisten
huskydog17
#66846
b.
félisten
huskydog17
#66846
válasz
 huskydog17
#66846
üzenetére
huskydog17
#66846
üzenetére
Igen sajnos ez így van de itt nem csak szottveres gondok vannak. Ez amit pl az xGMI nyújt egy hatalmas hiba amit nem fognak tudni orvolsoni. ez azért kiüti szerintem a bizosítékot sok cégnél. papíron 0.5% ból!!! 2-4 szeres lemaradás.
EZt lehetne marketing hibának hívni de gyakorlatilag félrevezetés, nem csodálnám ha AMD belefutna valami kártérítésbe.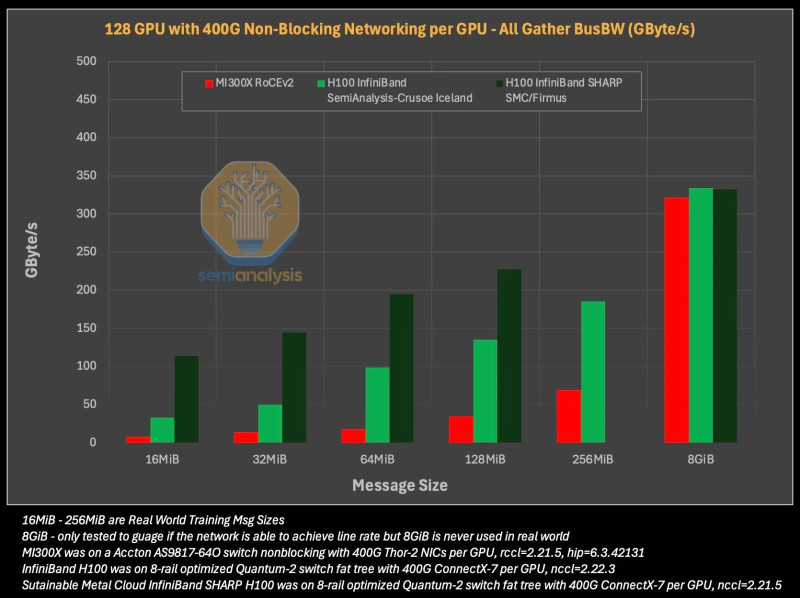
" H100-on és H200-on a méretezhető szövet neve NVLink, és GPU-nként 450 GByte/s sávszélességet biztosít, és 8 GPU-t köt össze. Az MI300X-en a méretnövelő szövetet xGMI-nek hívják, és papíron 8 GPU-t köt össze, így GPU-nként 448 GByte/s sávszélességet biztosít. A felszínen az MI300X méretezhető hálózata rendkívül hasonló és teljesítményében közel áll a H100/H200 hálózatához, mindössze 0,5%-kal kevesebb papír sávszélességet biztosít. Sajnos a helyzet valósága élesen eltér.
Először is, az MI300X xGMI-je pont-pont szövet, ami azt jelenti, hogy valójában nem biztosít 448 GByte/s sávszélességet a GPU-párok között. Ehelyett az egyes GPU-k csak 64 GByte/s sebességgel tudnak egymással beszélni. Egy GPU csak akkor érheti el a megadott 448 GByte/s sebességet, ha egy GPU egyszerre szólítja meg mind a 7 másik GPU-t. Ez azt jelenti, hogy a Tensor Parallelism TP=2 esetén a maximális sávszélesség 64 GByte/s, a TP=4 esetén pedig 189 GByte/s.
Ezzel szemben, mivel az Nvidia NVLink kapcsolt topográfiát használ, az egyik GPU a teljes 450 GByte/s sebességgel tud beszélni egy másik GPU-val. Ezenkívül a H100/H200 négy NVSwitche támogatja a hálózaton belüli csökkentést (a továbbiakban: NVLink SHARP (NVLS).



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- 10% tól elvihető BANKMENTES , KAMATMENTES , RÉSZLETFIZETÉS Legion Slim 5 16APH8 - Type 82Y9
- GYÖNYÖRŰ iPhone 13 mini 128GB Green -1 ÉV GARANCIA - Kártyafüggetlen, MS3837, 100% Akkumulátor
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7700X 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- Honor 200 Lite / 8/256GB / Kártyafüggetlen / 12HÓ Garancia
- ÚJ Lenovo ThinkPad X13 Gen 5 - 13.3" WUXGA IPS - Ultra 5 135U - 16GB - 512GB - Win11 - 2,5 év gari
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest