Új hozzászólás Aktív témák
-
válasz
 galaxy55
#4293
üzenetére
galaxy55
#4293
üzenetére
Itt a kod:
try:ssh.connect('192.168.56.145', username = username, password = password)except paramiko.ssh_exception.AuthenticationException:print('\t[ LOADER ]: Wrong credentials, exiting...\n')ssh.close()sys.exit(5)except FileNotFoundError as err:print('\t[ LOADER ]: Wrong path, exiting...\n')ssh.close()sys.exit(6)Itt pedig a traceback:
Traceback (most recent call last):File "/home/sh4d0w/projects/pyloader/./loader.py", line 124, in <module>main()File "/home/sh4d0w/projects/pyloader/./loader.py", line 120, in mainreadDBConfig()File "/home/sh4d0w/projects/pyloader/./loader.py", line 104, in readDBConfigdbConfigFile = sftp.open('/etc/mongod.conf')^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/home/sh4d0w/projects/pyloader/venv/lib/python3.11/site-packages/paramiko/sftp_client.py", line 372, in opent, msg = self._request(CMD_OPEN, filename, imode, attrblock)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/home/sh4d0w/projects/pyloader/venv/lib/python3.11/site-packages/paramiko/sftp_client.py", line 857, in _requestreturn self._read_response(num)^^^^^^^^^^^^^^^^^^^^^^^^File "/home/sh4d0w/projects/pyloader/venv/lib/python3.11/site-packages/paramiko/sftp_client.py", line 909, in _read_responseself._convert_status(msg)File "/home/sh4d0w/projects/pyloader/venv/lib/python3.11/site-packages/paramiko/sftp_client.py", line 938, in _convert_statusraise IOError(errno.ENOENT, text)FileNotFoundError: [Errno 2] No such file
Ha a FileNotFoundError helyett OSError-t vagy IOError-t irok, pont ugyanez a vegeredmeny. -

jerry311
nagyúr
válasz
galaxy55
#4293
üzenetére
Nem ugy nez ki mint ha nagyon elvarazsolt lenne az exception a Paramiko sftp_client.py-ban:
def _convert_status(self, msg):"""Raises EOFError or IOError on error status; otherwise does nothing."""code = msg.get_int()text = msg.get_text()if code == SFTP_OK:returnelif code == SFTP_EOF:raise EOFError(text)elif code == SFTP_NO_SUCH_FILE:# clever idea from john a. meinel: map the error codes to errnoraise IOError(errno.ENOENT, text)elif code == SFTP_PERMISSION_DENIED:raise IOError(errno.EACCES, text)else:raise IOError(text) -
Csunyan elakadtam egy ostoba hibaval es nem jovok ra a megoldasra: a program paramiko-n keresztul kapcsolodik egy masik rendszerhez es sftp-vel beolvas onnan egy file-t. Olvasas elott ellenoriznem, hogy a file tenyleg ott van-e, de valamiert a "FileNotFoundError: [Errno 2] No such file" hibat nem tudom elkapni. Probaltam ezt, probaltam az IOError-t, probaltam altalanossagban minden exceptiont elkapni, de ez konokul visszajon, ez az utolso harom sor:
File "/home/sh4d0w/projects/pyloader/venv/lib/python3.11/site-packages/paramiko/sftp_client.py", line 938, in _convert_statusraise IOError(errno.ENOENT, text)FileNotFoundError: [Errno 2] No such fileVan vkinek otlete?
-
#4289
 Atomantiii
addikt
Atomantiii
#4288
Atomantiii
addikt
Atomantiii
#4288
Atomantiii
addikt
válasz
 Atomantiii
#4288
üzenetére
Atomantiii
#4288
üzenetére
Közben megvan a megoldás.
-
#4288
Atomantiii
addikt
Atomantiii
#4287
Atomantiii
addikt
válasz
Atomantiii
#4287
üzenetére
Mégsem teljesen jó ötlet a letöltésvezérlő, mert minden fájlnak ugyanaz a neve csak a más link. Vagyis letöltés közben át is kellene nevezni mondjuk sorszám alapján.
-
#4287
Atomantiii
addikt
Atomantiii
#4286
Atomantiii
addikt
válasz
Atomantiii
#4286
üzenetére
Bár lehet egyszerűbb kimásolnom a linkeket és megetetni egy letöltő progival.
-
#4286
Atomantiii
addikt
Atomantiii
addikt
Tudna valaki segíteni (akár privát üzenetben is) egy letöltő srcipt készítésében, ahol van egy ilyen szerkezetű fájl, amiben a letöltendő oldalak vannak meghatározva melyik oldalnak mi a pontos elérése. A pdf-eket szeretném, hogy letöltse, már ha lehet olyat.
{"editionGUID": "602de21a-dd42-4413-bd98-dc89232280fe","pagesDomain": "https://valami.com","pageGroups": [{"pages": [{"pdf": "https://valami.com/page1.pdf","pageNum": 1,"type": "page"}]},{"pages": [{"pdf": "https://valami.com//page2.pdf","pageNum": 2,"type": "page"}]},{"pages": [{"pdf": "https://valami.com/page3.pdf","pageNum": 3,"type": "page"stb...} ] } ] } -

sztikac
őstag
Sziasztok, a Learn Python 3 The Hard Way könyvből tanulom a Python-t és van ez a feladat:
from sys import argvfrom os.path import exists
script, from_file, to_file = argv
print(f"Copying from {from_file} to {to_file}")
# we could do these two on one line, how?
in_file = open(from_file)
indata = in_file.read()
print(f"The input file is {len(indata)} bytes long")
print(f"Does the output file exist? {exists(to_file)}")
print("Ready, hit RETURN to continue, CTRL-C to abort.")
input()
out_file = open(to_file, 'w')
out_file.write(indata)
print("Alright, all done.")out_file.close()
in_file.close()Ezt teljesen világos is, hogy mit-miért csinál.
Aztán van ugye a feladatok között egy ilyen:See how short you can make the script. I could make this one line long.
Ezzel eddig jutottam (még elég messze vagyok az 1 sortól
 ):
):from sys import argvscript, from_file, to_file = argvin_data = open(from_file).read()open(to_file, 'w').write(in_data)Ez így lefut, rendben le is másolja a megadott fájlt, csak ugye ebben az esetben nincs file descriptorom így nem tudom min meghívni a close()-t. Úgy tudom a program lefutása után az OS úgyis bezárja a nyitott fájlokat, de szabályos ez így?
-
válasz
 jerry311
#4278
üzenetére
jerry311
#4278
üzenetére
Nem, ez egy list, 7 dict entryvel:
[{k.strip():v.strip() for k,v in [line.split(':', maxsplit=1)]} for line in szoveg.splitlines() if line.strip()]
[
{'AMRunningMode': 'Normal'},
{'AntispywareSignatureLastUpdated': '29/04/2024 05:36:35'},
{'AntispywareSignatureVersion': '1.409.590.0'},
{'AntivirusSignatureLastUpdated': '29/04/2024 05:36:33'},
{'AntivirusSignatureVersion': '1.409.590.0'},
{'NISSignatureLastUpdated': '29/04/2024 05:36:33'},
{'NISSignatureVersion': '1.409.590.0'}
]
a dict igy nez ki:{k.strip():v.strip() for k,v in [line.split(':', maxsplit=1) for line in szoveg.splitlines() if line.strip()]}
{
'AMRunningMode': 'Normal',
'AntispywareSignatureLastUpdated': '29/04/2024 05:36:35',
'AntispywareSignatureVersion': '1.409.590.0',
'AntivirusSignatureLastUpdated': '29/04/2024 05:36:33',
'AntivirusSignatureVersion': '1.409.590.0',
'NISSignatureLastUpdated': '29/04/2024 05:36:33',
'NISSignatureVersion': '1.409.590.0'
} -
jerry311
nagyúr
-
válasz
jerry311
#4273
üzenetére
miert kell 7 dict es nem egy dict 7 elemmel?
szoveg='''AMRunningMode : Normal
AntispywareSignatureLastUpdated : 29/04/2024 05:36:35
AntispywareSignatureVersion : 1.409.590.0
AntivirusSignatureLastUpdated : 29/04/2024 05:36:33
AntivirusSignatureVersion : 1.409.590.0
NISSignatureLastUpdated : 29/04/2024 05:36:33
NISSignatureVersion : 1.409.590.0'''
cleanlines = [{k.strip():v.strip() for k,v in [line.split(':', maxsplit=1)]} for line in szoveg.splitlines() if line.strip()] -

axioma
veterán
válasz
jerry311
#4275
üzenetére
Ah, jogos, a szokozok segitettek. De amugy az nem kizarhato, hogy az ertekben olyan is legyen, igy arra szerintem kevesbe jo altalanosan epiteni. Az elso : az mondjuk hihetobb hogy bejon (bal oldal jellemzoen valami azonosito, abban nem lehet).
Nem mondanam hatekonyabbnak ha idoigenyre gondolsz, nincs erdemi kulonbseg, csak olvashatobb-karbantarthatobb. -
jerry311
nagyúr
Hatékonyabb, rövidebb kód volt a cél, mert én Pythonban jelenleg kb. olyan messze vagyok a hatékony programozástól, mint hentes a sebésztől. Ha le kell vágni valamit, akkor az megy, csak nem lesz szép.

Köszönöm!

Ilyesmire gondoltam, mert ugyan a kódom megoldotta a feladatot, de nem tűnt helyesnek, ahogy elértem a megoldást. Lásd pl.resdictionary/tömb.A : résszel nem volt gond (szerintem), mert a delimiterben előtte és utána is van space. Ilyen csak középen fordul elő.
-
axioma
veterán
válasz
jerry311
#4273
üzenetére
Nem egeszen egyertelmu, hogy ekvivalens kodra vagy-e kivancsi, de mondjuk.
A te logikaddal csak "more pythonic way":def parseupdates(dictentry):
cleanlines = [line for line in dictentry.splitlines() if line.strip()]
d = " : "
workarray = {}
for line in cleanlines:
arr = line.split(d)
workarray[arr[0].strip()] = arr[1].strip()Sot, ha biztos hogy mindig pontosan egy : van benne:
def parseupdates(dictentry):
d = " : "
workarray = {}
for line in dictentry.splitlines():
if line.strip():
a,b = line.split(d)
workarray[a.strip()] = b.strip()Azert a
linenevet nem jo indexnek hasznalni, foleg hogy a for ciklus pont ki tudja venni a konkret elemet is, nem kell az indexeket kovetni. Ami me'g nagyon idegen, hogy aresdictionary-nak van inicializalva, kozben tombkent hasznaltad.Hm varj most nezem nem csak egy : -od van a peldaban. Es azokat te se rakod utana ossze... tehat az sztem eleve hozott volna "36":"35" , "36":"33" parokat, es mazlid hogy mind paratlan darab :, amugy me'g jobban keresztbe sikerult volna (nem futtattam, csak gyanitom)
Szoval az eredeti feladatra talan inkabb:
def parseupdates(dictentry):
d = " : "
workarray = {}
for line in dictentry.splitlines():
idx = line.find(d)
if idx != -1:
workarray[line[:idx].strip()] = line[idx+1:].strip() -
jerry311
nagyúr
Hi,
Lehete ezt szebben, jobban parositani?
Kiindulo szoveg:
AMRunningMode : NormalAntispywareSignatureLastUpdated : 29/04/2024 05:36:35AntispywareSignatureVersion : 1.409.590.0AntivirusSignatureLastUpdated : 29/04/2024 05:36:33AntivirusSignatureVersion : 1.409.590.0NISSignatureLastUpdated : 29/04/2024 05:36:33NISSignatureVersion : 1.409.590.0Kivant eredmeny:
7 dictionary elem:
{'AMRunningMode': 'Normal'}
{'AntispywareSignatureLastUpdated': '29/04/2024 05:36:35'}
{'AntispywareSignatureVersion': '1.409.590.0'}
{'AntivirusSignatureLastUpdated': '29/04/2024 05:36:33'}
{'AntivirusSignatureVersion': '1.409.590.0'}
{'NISSignatureLastUpdated': '29/04/2024 05:36:33'}
{'NISSignatureVersion': '1.409.590.0'}def parseupdates(dictentry):# initialize variablesres = {}cleanlines = []lines = dictentry.splitlines()for line in range(len(lines)):if lines[line].strip(): # remove blank linescleanlines.append(lines[line])for line in range(len(cleanlines)): # split lines at the middle colond = " : "temp = cleanlines[line].split(d)for idx, element in enumerate(temp): # assign valuesres[idx] = element.strip()for i in range(0, len(res) - 1, 2): # reassemble key value pairsj = i + 1workarray[res[i]] = res[j] -
#4272
 J0shu4M1ll3r
senior tag
sztanozs
#4269
J0shu4M1ll3r
senior tag
sztanozs
#4269
J0shu4M1ll3r
senior tag
válasz
 sztanozs
#4269
üzenetére
sztanozs
#4269
üzenetére
Köszi, valami ilyesmire gondoltam én is, de lehet a == is elmaradt, megnézem.
@ kovisoft:
igen, mert gondolom több megoldás is, lehet, pedig sudokuzni szeretek, de ezen csak pislogtam
Nem is kérném, hogy más csinálja meg, pont, hogy meg akarom érteni, hogy mi miért van, de lehet nem fog olyan gyorsan menni, mint gondoltam.
A fix számok kellenek, mert azok adottak, és ezek ismeretében kell kiszámolni a maradék helyekre a lehetséges számokat, így legalább nem lesz 800 megoldás -
válasz
sztanozs
#4269
üzenetére
ja, haromszogeket szamoltam, nem oldalakat, azert nem adott ki eredmenyt
from itertools import permutations
def szabaly(doboz):
a, d, f, k = 1, 4, 7, 2
b, c, e, g, h, i, j, l = doboz
return 26 == a + b + d + e == c + d + f + g == e +f + h + i == g + h + j + k == i + j + l + a
def print_doboz(doboz):
a, d, f, k = 1, 4, 7, 2
b, c, e, g, h, i, j, l = doboz
print(f" {a:>2}\n"
f"{k:>2} {l:>2} {b:>2} {c:>2}\n"
f" {j:>2} {d:>2}\n"
f"{i:>2} {h:>2} {f:>2} {e:>2}\n"
f" {g:>2}\n")
dobozok = permutations([3, 5, 6, 8, 9, 10, 11, 12])
eredmeny = filter(szabaly, dobozok)
for doboz in eredmeny:
print_doboz(doboz)
print() -
#4270
 kovisoft
őstag
J0shu4M1ll3r
#4268
kovisoft
őstag
J0shu4M1ll3r
#4268
kovisoft
őstag
válasz
 J0shu4M1ll3r
#4268
üzenetére
J0shu4M1ll3r
#4268
üzenetére
Permutációval roppant egyszerű a dolog. Egy ciklusban végigmész a permutations([...]) által visszaadott listán, aminek mindegy eleme egy mondjuk x tömb lesz az aktuális permutációval. Az x tömb a nyolc ismeretlen számot jelöli (x[0]-tól x[7]-ig). Ezekre beteszel 6 darab if-et (olyasmit, mint amit te is felírtál, csak nem egyedi változókkal, hanem a tömb elemeivel), amiben ellenőrzöd az egyes vonalak mentén az összegeket. Ha bármelyik nem 26, akkor continue. A legvégén pedig kiiratod az x-et.
Házi feladatokat nem igazán oldunk meg más helyett, de ha van bármi kód kezdeményed, és elakadsz, akkor szívesen segítünk.
Szerk: Csak egy megjegyzés, hogy ne zavarjunk még jobban össze: én a fix számokat nem vettem bele a permutációba, mint sztanozs. Én csak a 8 ismeretlent permutálnám.
-
#4269
 sztanozs
veterán
J0shu4M1ll3r
#4265
sztanozs
veterán
J0shu4M1ll3r
#4265
válasz
J0shu4M1ll3r
#4265
üzenetére
1. szamozd be a cellakat 0-11-ig:
2. csinalj egy teljes permutaciot:
3. meccseld a permutaciot a szabalyra:
doboz[0] == 1
doboz[3] == 4
doboz[5] == 7
doboz[10] == 2
es az z osszegre vonatkozo logika:
doboz[0] + doboz[1] + doboz[11] == 26
doboz[1] + doboz[2] + doboz[3] == 26
doboz[3] + doboz[4] + doboz[5] == 26
doboz[5] + doboz[6] + doboz[7] == 26
doboz[7] + doboz[8] + doboz[9] == 26
doboz[9] + doboz[11] + doboz[11] == 26 -
#4268
J0shu4M1ll3r
senior tag
J0shu4M1ll3r
senior tag
Próbálom értelmezni, de nem megy
Látnom kéne a teljes kódot, hogy ki tudjam sakkozni, hogy mi miért történik, de azt sem tudom, hogyan fogjak hozzá.
-
#4267
kovisoft
őstag
J0shu4M1ll3r
#4265
kovisoft
őstag
válasz
J0shu4M1ll3r
#4265
üzenetére
Ha valamilyen backtrack-szerű algoritmust akarsz használni, akkor a számokat ne egyedi változókban tárold, hanem pl. tömbben, és akkor egységesen tudod tölteni őket. A feltételeidet ugyanúgy fel tudod írni pl. 2+X[0]+X[1]+X[2]+X[3]==26 formában,
De talán az axioma által is említett permutáció generálás a legegyszerűbb: az itertools modul permutations([3,5,6,8,9,10,11,12]) függvényével le tudod generálni a maradék nyolc szám összes permutációját, ezek közül kell azokat kiválogatni, ahol minden vonalra teljesül, hogy a számok összege 26.
-
#4266
axioma
veterán
J0shu4M1ll3r
#4265
axioma
veterán
válasz
J0shu4M1ll3r
#4265
üzenetére
Szerintem itt brute force [vagy max elagazas-korlatozassal megoldasra ha mar advanced] gondoltak. A 8! nem olyan nagy szam... plane hogy a pythonhoz lib van ami legeneralja a permutaciokat ;-) de gondolom az inkabb a feladat lenyege lenne.
-
#4265
J0shu4M1ll3r
senior tag
J0shu4M1ll3r
senior tag
Sziasztok!
Az alábbi csodálatos háziban kérnék segítséget: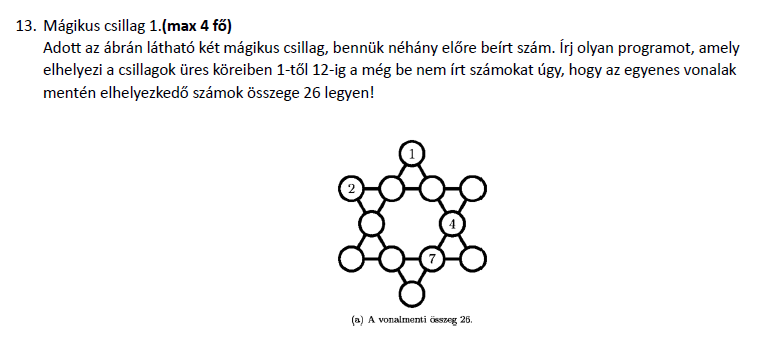
Próbáltam felírni a sorokat, átlókat egyenletként, de bele is zavarodtam, és chatgpt se nagyon segít, vagy nálam vacakol a VS, mert semmi megoldást nem ad vissza.
Mi a jó megközelítése?
Jelenleg itt tartok:
Elneveztem a pontokat betűkkel és beírtam a fix számokat:
1. 1+C+F+H=26
2. 1+D+G+K=26
3. 2+C+D+E=26
4. H+I+7+K=26
5. 2+F+I+L=26
6. E+4+7+L=26
Ezekből kijött pár betűnek a meghatározása, mintha egy nagy egyenletrendszer lenne, de itt elakadtam.
Köszi! -

Hege1234
addikt
válasz
sztanozs
#4263
üzenetére
nem én írtam egy sorba, és fura is volt így ömlesztve látni
viszont nem gondoltam, hogy problémát okozhatna mert
kb. minden powershell-es line-ba amit találtam a PATH-hoz az elválasztás az ez volt hozzá;$env:Path -split ';'( ha új sorba van írva akkor nem si kerül a végére a
;) -
Hege1234
addikt
-
válasz
 Hege1234
#4259
üzenetére
Hege1234
#4259
üzenetére
Ez az elsot felveszi es belerakja a path-ba:
@ECHO off
setlocal EnableDelayedExpansion
WHERE /q python.exe
IF ERRORLEVEL 1 (
WHERE /q /R %LOCALAPPDATA% python.exe
IF ERRORLEVEL 1 (
ECHO Nincs installalt python a APPDATA LOCAL-ban!
EXIT /b -1
) ELSE (
ECHO Van installalt python a APPDATA LOCAL-ban!
)
CALL :sub
set "scripts_dir=!py_path!Scripts\"
set "python_dir=!py_path!"
for /f "usebackq tokens=2,*" %%A in (`reg query HKCU\Environment /v PATH`) do set userPATH=%%B
ECHO "!userPATH!;!scripts_dir!;!python_dir!"
setx PATH "%userPATH%;%scripts_dir%;%python_dir%"
)
GOTO :eof
:sub
FOR /f "tokens=*" %%A IN ('WHERE /R %LOCALAPPDATA% python.exe') do (
REM ECHO %%A
SET "py_path=%%~dpA"
EXIT /b
)
GOTO :eof -
válasz
Hege1234
#4254
üzenetére
setx + kozvetlen registry mokolas:
@echo off
WHERE /q python.exe
IF ERRORLEVEL 1 (
set /p spec_python_ver=add python dir: (eg.: Python39) write here:
set "scripts_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\Scripts\"
set "python_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\"
for /f "usebackq tokens=2,*" %A in (`reg query HKCU\Environment /v PATH`) do set
userPATH=%B
setx PATH "%userPATH%;%scripts_dir%;%python_dir%"
) -
Hege1234
addikt
válasz
sztanozs
#4253
üzenetére
Ha nincs python a path-on, akkor hogy futtatod ezt a python fajlt?
hát erre valóban nem gondoltam, így hogy nálam az már hozzá van adva a path-hoz

és akkor egy cmd-vel vagy inkább egy .bat fájlt használva megoldható lenne?
@echo off
set /p spec_python_ver=add python dir: (eg.: Python39) write here:
set "scripts_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\Scripts\"
set "python_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\"
echo scripts_dir: %scripts_dir%
echo python_dir: %python_dir%így az útvonalat megkapom, de batch-el mivel tudom hozzáadni közvetlenül a PATH-hoz?
-
válasz
Hege1234
#4251
üzenetére
Kornyezeti valtozokat dictionary-kent kell kezelni Python alatt, tehat az ertek, amit be akarsz allitani, string kell, hogy legyen.
Viszont amihez admin jog kell - eleg rohejes lenne, ha egy ilyen egyszeru scripttel meg tudnad kerulni - azt vagy adminkent inditod, vagy UAC promptot kapsz.
-
Hege1234
addikt
sziasztok!
szeretném megoldani, hogy ha nem lett bejelölve a python win installálásnál az add to path
akkor futtatva a script-et, hozzáadja a PATH-hoz, és akkor nem kell újrainstallálni vagy manuálisan szórakozni vele..mivel minden ilyen módosításhoz admin jog kell, lehetséges lenne ezt python alól megoldani?
ilyesmivel próbálkozok, de mivel nem ad ki írási hibát így gondolom még csak meg se próbálja hozzáadni
import os
spec_python_ver = input('add python dir: (eg.: Python39) write here: ')
scripts_dir = os.path.join(os.environ['LOCALAPPDATA'], f'Programs\\Python\\{spec_python_ver}\\Scripts\\')
python_dir = os.path.join(os.environ['LOCALAPPDATA'], f'Programs\\Python\\{spec_python_ver}\\')
dirs_to_add = [scripts_dir, python_dir]
for directory in dirs_to_add:
if directory not in os.environ['PATH']:
os.environ['PATH'] += os.pathsep + directory
print(f"'{directory}' added to PATH")
else:
print(f"'{directory}' already in PATH")
print("\nUpdated PATH:")
print(os.environ['PATH']) -
-

Blasius
tag
Sziasztok,
Egy egyszerű kódot szeretnék futtatni microPythonban egy openWRT routeren:
import socket
soc = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
soc.bind(('', 2215))De már a harmadik sorban elakadtam, és ezt a hibaüzenetet kapom:
TypeError: object with buffer protocol requiredUgyanaz a hibaüzenet a routeren is és egy linuxos gépen is. Rendes pythonban jól megy.
Mi lehet a probléma a microPythonban? -

cigam
titán
A két ciklus közé kellett ez a pár sor, és most úgy működik, ahogy szeretném.# Ha a ch1 piros, kikapcsolja a ch1 zöldetif 14 in powered_pins and 16 in powered_pins:powered_pins.remove(16)# Ha a ch2 piros, kikapcsolja a ch2 zöldetif 4 in powered_pins and 26 in powered_pins:powered_pins.remove(26)# Ha a ch3 piros, kikapcsolja a ch3 zöldetif 3 in powered_pins and 20 in powered_pins:powered_pins.remove(20)# Ha a ch4 piros, kikapcsolja a ch4 zöldetif 2 in powered_pins and 21 in powered_pins:powered_pins.remove(21)Köszönöm a segítséget, útba igazítást!
-
kovisoft
őstag
Az if-ben dupla == az egyenlőségvizsgálat.
A json konfig mintában azt látom, hogy csak deviceId-k és azon belül pinNumber-ök vannak definiálva, ezzel a konfiggal leginkább csak hardkódolni tudod. De ha kiegészítheted a konfigot, akkor felvehetsz plusz attribútumokat, amikkel megadhatod, hogy az adott device vagy az adott device adott pin-je milyen másik device milyen pin-jével nem működhet együtt. Pl. a "pinNumber" mellé felvehetsz egy "conflictingDeviceId" és egy "conflictingPinNumber" mezőt. Ide beírod, hogy mivel nem tud együtt működni. A kódban pedig gpo["conflictingPinNumber"]-ként tudsz rá hivatkozni.
-
cigam
titán
A példa kedvéért tegyül fel, hogy az 1,3,5,7 lábak vezérlik a piros lámpákat, a 2,4,6,8 pedig a zöldeket. Az első csatornához tartozik a 1,2, a második csatornához a 3,4,...
# Ha az első piros lámpa bekapcsolódikif pinNUmber = 1:# Kikapcsolja a hozzá tartozó zöldetpowered_pins.remove(2)powered_pins.append(gpo["pinNumber"])
Ha a piros lámpát bekapcsolja, a hozzá tartozó zöld lámpa sorszámát kiveszi a powered_pins listából, így a következő ciklusban kikapcsolja a hozzá tartozó zöldet. (Nem fut hibára, ha egy nem létező elemet vennék ki?) Viszont semmi nem garantálja, hogy a piros lámpa után, a rákövetkező ciklusban nem a csatornához tartozó zöld lámpát olvassa be, ami visszakapcsolhatja.
Ezért az ellenörzést, kikapcsolást, inkább a két ciklus közé kellene tenni, amikor már minden bekapcsolt relét tartalmazó lista elkészült.# Ha a az első piros lámpa bekapcsolódikif 1 in powered_pins:# Kikapcsolja a hozzá tartozó zöldetpowered_pins.remove(4)
Vagy be lehet passzítani valahogy az első listába, amikor a powered_pins készül?Megoldható, hogy ne legyen beégetve a IO láb sorszáma, hanem a .json fájlból beolvasott értékekkel hivatkozzak rá?
-
axioma
veterán
válasz
 kovisoft
#4242
üzenetére
kovisoft
#4242
üzenetére
Hm, jogos, latszik h csak a logikai vegeredmenyt neztem
 nem vagyok hardverhez szokva...
nem vagyok hardverhez szokva...
Akkor is megoldhato kettoben: elsore nem kapcsol csak gyujti, masodikban meg kapcsol mind2 iranyban, csak a zold kivant allapotat update-eli a set-beli allapothoz kepest a muvelet elott. -
kovisoft
őstag
Ez villogást (vagy ha nem lámpáról lenne szó, akkor egyéb mellékhatást) okozhatna, valószínűleg az sem véletlen, hogy nem azt csinálja a program, hogy először mindent kikapcsol, aztán bekapcsolja azokat, amiket be kell. De persze, ha ez nem zavaró, akkor úgy is lehet csinálni, ahogy írod.
-
axioma
veterán
-
kovisoft
őstag
Én sem vágom, hogy itt ki kinek mikor mit küld, mit hív, stb. De szerintem az első cikus végzi a device_state-ben megkapott device-ok megadott pin-jeinek a bekapcsolását. És a powered_pins-ben összegyűjti azokat a pin-eket, amiket bekapcsolt. Utána a második ciklus pedig azt csinálhatja, hogy végigmegy az összes device összes pin-jén, és azokat kikapcsolja, amiket az első ciklus nem kapcsolt be. Azaz a végére pontosan azok lesznek bekapcsolva, amiknek bekapcsolva kell lenniük, az összes többi pedig ki lesz kapcsolva.
Tehát ha jól gondolom, akkor az első ciklusba tudnál betenni valami feltételvizsgálatot, hogy ha be tudod azonosítani azt az eszközt és a pin-eket, amik a zöld és piros lámpákat jelentik, akkor a zöldet ne kapcsolja be, ha a pirosat be kellene kapcsolni.
Nem tudom, meg lehet-e oldani mondjuk, hogy a konfigban hamarabb szerepeljen a piros lámpa pin-je, mert akkor mire a zöldre kerül a ciklus, addigra már lehetne látni, hogy a pirost be kell-e kapcsolni.
Ha ez nem járható út, akkor esetleg csinálhatsz az egész elé egy harmadik ciklust, ami kb. ugyanazt csinálja, mint a mostani első ciklus, de ténylegesen nem kapcsol pin-t, csak megjegyzi egy változóban, hogy a pirosat be kellene-e kapcsolni. És ha ez a változó be van állítva, akkor a bekapcsoló ciklusban kihagyja a zöldet.
Persze ehhez tudni kellene, hogy tényleg a processTallyData az a függvény, ami a kapcsolgatást végzi. Ezt mondjuk ki tudod próbálni, ha kikommentezed benne a bekapcsolást, és attól elmúlik a lámpák bekapcsolása.
-
cigam
titán
válasz
kovisoft
#4238
üzenetére
Aha... Köszi!
A projekt "fő" programja, a tallyarbiter. Ez kommunikál a képkeverővel, figyeli a megadott csatornák állapotát. Egy csatonának 2 "állapotjelzője" van:
-preview csatonára kapcsolva
-program csatornára kapcsolva
A képkeverő csatornáinak az állapotát küldi el a "kliens" programkonak. Ez lehet egy mikrovezérlő(vel egybeépített színes LED), vagy egy relé modul,...
Esetemben a Pi-re kötött relé modul pedig a kapott adatoknak megfelelően kapcsolgatja ki/be a zöld/piros lámpákat attól függően, hogy a képkeverőn hogyan kapcsolták preview vagy program csatornára a kamerákat.A valóságban egyszerübb mint itt elmesélni, leírni a működését
Nézegetem ezt a processTallyData() fügvényt, de mint az a bizonyos borjú az új kapura ... Valahogy nem megy a kód értelmezése (a Python (szemantika) ismeretének hiánya is nehezíti, hogy most éppen mire gondolt a költő: powered_pins.append(gpo["pinNumber"])
Miért van eltárolva a "bekcsolt" lábak listája?
Miért van két külön ciklus a be ill. a kikapcsolásra?
Hová kéne berakni a plussz ellenörzést, és hogyan? Hiszen a ciklus végimegyaz összes előre definiált IO porton. Hogyan ellenörzöm, hogy az adott pi "program"kimenetnek van kapcsolva, vagyis a hozzá tartozó "preview" kimenetet ki kell kapcsolni?Erre még aludni kell párat ...
-
kovisoft
őstag
Szerintem nem a setStates függvény az, amit keresel. Ha megnézed, a setStates és a GPO_off gyakorlatilag pont ugyanazt csinálja: kikapcsolja az összes bekonfigurált pint. És a setStates csak induláskor van egyszer meghívva, miután a konfig be lett olvasva.
Nem értem, hogy pontosan hogyan működik maga a program, hogyan lehet neki utasításokat adni, de szerintem a GPIO.output hívásokat kellene végignézned, hogy melyik lehet az, amelyik neked a lámpákat vezérli, és oda lehetne betenni egy olyan feltételt, hogy a zöldet ne kapcsolja, ha egyúttal a pirosat is kellene kapcsolnia. Ez valószínűleg a processTallyData lehet, mert az on_flash ránézésre egyetlen pint villogtat.
-
cigam
titán
Adott egy Python program. Raspberry-n fut, és az IO lábakon keresztül vezérel 2 relésort (4db "zöld", és 4db "piros"). A parancsokat egy másik program adja neki hálózaton. Szépen rendben teszi is a dolgát, és kapcsolgatja a reléket. A relék kimenete egy "utasító"ra van kötve, amin keresztül kommunikálni lehet az operatőrökkel. Ez az eszköz képes a kamerákhoz tartozó piros/zöld lámpák vezérlésére.
Sajnos a gyárban valamit nagyon elkeféltek, mert ha azt a parancsot kapja, hogy a kamerán egyszerre világítson a zöld és a piros lámpa, akkor az zöld marad, holott a pirosnak kellene prioritást kapni, hiszen azzal jelzik neki, hogy ne igazgassa ide oda kamerát, mert "adásban van". Remélem érthető bevezője volt ennek a kódnak.
Arra tippelek, hogy a 156. sornál kezdődő résznél lehet a megoldás kulcsa.def setStates():GPIO.setmode(GPIO.BCM)GPIO.setwarnings(False)for gpo_group in config_object["gpo_groups"]:for gpo in gpo_group["gpos"]:GPIO.setup(gpo["pinNumber"], GPIO.OUT)GPIO.output(gpo["pinNumber"], getOutputValue(False))gpo["lastState"] = FalseSzerintem ide kellene egy ellenörzést beiktatni, hogy abban az esetben ha "gpo_groups"-on belül mindekkető be van kapcsolva (a zöld "preview", és piros "program" is), akkor a zöldet kapcsolja ki, és csak a piros legyen bekapcsolva. Jó irányba kapisgálok?
-
#4235
sztanozs
veterán
Atomantiii
#4234
válasz
Atomantiii
#4234
üzenetére
nope
de ranezek majd este otthonrol, ha el nem felejtem... -
#4233
sztanozs
veterán
Atomantiii
#4232
válasz
Atomantiii
#4232
üzenetére
sajna google drive (se onedrive, se pastebin) sem jatszik... -
#4232
Atomantiii
addikt
sztanozs
#4231
Atomantiii
addikt
válasz
sztanozs
#4231
üzenetére
Működik Hege javaslata is, persze biztos meg lehet csinálni máshogy is. Itt a forrás fájl.
import xml.etree.ElementTree as ET
import re
xml_content = ET.parse('forras.xml')
root = xml_content.getroot()
not_needed = ["credits", "category", "country", "date", "episode-num", "icon", "length", "previously-shown", "rating", "star-rating", "url"]
for programme in root.findall(".//programme"):
for element_name in not_needed:
elements = programme.findall(f".//{element_name}")
for element in elements:
if element in programme:
programme.remove(element)
edited_tv_programs = ET.tostring(root, encoding='unicode')
# kiszedi a clumpidx="0/1"-et
edited_tv_programs = re.sub(r' clumpidx=.*\"', r'', edited_tv_programs)
# kiszedi a (0.)-át
edited_tv_programs = re.sub(r'<desc lang="hu">(\(.*\.\) )', r'<desc lang="hu">', edited_tv_programs)
# kiszedi a ...-ot
edited_tv_programs = re.sub(r'<desc lang="hu">(\.\.\. )', r'<desc lang="hu">', edited_tv_programs)
with open('edited.xml', 'w', encoding='utf-8') as file:
file.write(edited_tv_programs) -
#4231
sztanozs
veterán
Atomantiii
#4215
válasz
Atomantiii
#4215
üzenetére
Szerintem mashogyan kellene megkozeliteni... vsz csak azt kellene kivalogatni, ami neked kell.
Fel tudod rakni valahova mashova a fajlt? Melohelyrol nem erem el... -
#4230
Atomantiii
addikt
Hege1234
#4229
Atomantiii
addikt
válasz
Hege1234
#4229
üzenetére
Köszi, jó lett.
edited_tv_programs = re.sub(r'<desc lang="hu">(\(.*\.\) )', r'<desc lang="hu">', edited_tv_programs)Elvileg elég lenne a desc lang hu-s rész nélkül is, de így is jó. Már itt kínlódtam vele egy jó ideje, sehol sem találtam meg, hogy hivatkozzak a zárójelre, a 0-ra és a .-ra egyszerre.
Így az eredeti 85 MB-os fájlból lett 33 MB.
-
#4229
Hege1234
addikt
Atomantiii
#4228
Hege1234
addikt
válasz
Atomantiii
#4228
üzenetére
sztem az valahogy így nézne ki:
edited_tv_programs = re.sub(r'<desc.*hu.*(\(.*\.\) )', r'<desc lang="hu">', edited_tv_programs)ha csak tényleg a (0.) ami nem kell akkor így
edited_tv_programs = re.sub(r'<desc.*hu.*(\(0.\) )', r'<desc lang="hu">', edited_tv_programs) -
#4228
Atomantiii
addikt
Hege1234
#4226
Atomantiii
addikt
válasz
Hege1234
#4226
üzenetére
Közben találtam még egy olyat, hogy egyes sorokban van feleslegben egy ilyen a <desc lang="hu"> után, hogy zárójel nulla pont zárójel szóköz, ami felesleges. Ezt próbáltam kitörölni, de sehogy sem sikerül.
<desc lang="hu">(0.) Get ready as we bring you all of the greatest hits from singing sensation Ariana Grande!</desc>
edited_tv_programs = re.sub(r'<desc lang="hu">(0.) ', r'<desc lang="hu">', edited_tv_programs)Akárhogy csináltam mindig csak a kezdő zárójel tűnt el de a 0 és a többi maradt.
-
#4226
Hege1234
addikt
Atomantiii
#4225
Hege1234
addikt
válasz
Atomantiii
#4225
üzenetére
az elejére akkor ezt add még hozzá:
import reedited_tv_programs = ... alatt pedig ez legyen:
edited_tv_programs = re.sub(r'( clumpidx=.*\")', r'', edited_tv_programs) -
#4225
Atomantiii
addikt
Atomantiii
addikt
Ez így nagyon szuper, de esetleg lehetne neki mondani valahogy egy olyat, hogy törölje még ezt ki az xml-ből? " clumpidx="0/1" és helyette csak egy ilyet rakjon be: "
Notepad++-ban egy sima keresés és cserével megoldható, de jó lett volna valahogy automatizálni.
-
#4224
Atomantiii
addikt
Atomantiii
#4223
Atomantiii
addikt
válasz
Atomantiii
#4223
üzenetére
Közben rájöttem, most már jó.
-
#4223
Atomantiii
addikt
Hege1234
#4221
Atomantiii
addikt
válasz
Hege1234
#4221
üzenetére
Abban tudnál még segíteni, hogy ezt hogy tudom átírni, hogy ne a tárhelyről, hanem a saját gépemről töltse be a forrás xml-t és oda is mentse le?
Próbáltam, de nem igazán akar összejönni, mindig hibát ír erre a sorra:
edited_tv_programs = ET.tostring(root, encoding='unicode')Traceback (most recent call last):
File "d:\EPG\xmlremove.py", line 24, in <module>
edited_tv_programs = ET.tostring(root, encoding='unicode')
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\xml\etree\ElementTree.py", line 1083, in tostring
ElementTree(element).write(stream, encoding,
File "C:\Python312\Lib\xml\etree\ElementTree.py", line 728, in write
serialize(write, self._root, qnames, namespaces,
File "C:\Python312\Lib\xml\etree\ElementTree.py", line 851, in _serialize_xml
tag = elem.tag
^^^^^^^^
AttributeError: 'ElementTree' object has no attribute 'tag' -
#4221
Hege1234
addikt
Atomantiii
#4220
Hege1234
addikt
válasz
Atomantiii
#4220
üzenetére
esetleg fontold meg a "credits" kiszedését is
akkor úgy kb. 40 MB lesz összesennot_needed = ["url", "previously-shown", "rating", "credits"] -
#4219
Hege1234
addikt
Atomantiii
#4218
Hege1234
addikt
válasz
Atomantiii
#4218
üzenetére
valami ilyesmi (biztos van jobb megoldás is rá)
(sokkal amúgy nem lett kisebb a fájl..)import requests
import xml.etree.ElementTree as ET
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}
xml_content = requests.get('ide írd a linket', headers=headers).content
root = ET.fromstring(xml_content)
not_needed = ["url", "previously-shown", "rating"]
for programme in root.findall(".//programme"):
for element_name in not_needed:
elements = programme.findall(f".//{element_name}")
for element in elements:
if element in programme:
programme.remove(element)
edited_tv_programs = ET.tostring(root, encoding='unicode')
with open('edited_tv_programs.xml', 'w', encoding='utf-8') as file:
file.write(edited_tv_programs) -
#4218
Atomantiii
addikt
Hege1234
#4217
Atomantiii
addikt
válasz
Hege1234
#4217
üzenetére
Ez a teljes fájl. Ebből szeretnék kitakarítani felesleges dolgokat.
Pl az url-eket, ikonokat esetleg még másokat is, de ha már az egyik összejönne az is sokat jelentene méretben, mert több ezer van benne.
<url system="port.hu">http://port.hu/adatlap/szemely/peter-breitmayer/person-293341</url>
<icon src="https://port.hu/img/agelimit/raster/12_age_icon_black.png" /> -
#4217
Hege1234
addikt
Atomantiii
#4215
Hege1234
addikt
válasz
Atomantiii
#4215
üzenetére
ezt nem probléma megcsinálni ezzel a modullal:
xml.etree.ElementTree
azthiszem alapból benne van a python 3-baa példád csak egy programra mutat
hogyan néz ki amikor van pl. 2 vagy 3 benne? -
#4215
Atomantiii
addikt
Atomantiii
addikt
Újabb xml fájlos kérdésem lenne, hátha valakinek lenne ötlete hogyan induljak el.
Ilyen tartalom van az xml fájomban, hogy pl:
<programme start="20240226052500 +0100" channel="5.port.hu" stop="20240226060000 +0100" clumpidx="0/1">
<title>Fókusz</title>
<sub-title lang="hu">(magazinműsor, 2024)</sub-title>
<desc lang="hu">Hétköznaponként jelentkező riportmagazin a legfrissebb hírekkel, aktuális információkkal, eseményekkel, emberi sorsokkal, érdekes történetekkel és helyszínekkel a világ minden részéről az RTL Gold-on is. Az RTL Klub mai adása felvételről.</desc>
<date>2024</date>
<category lang="en">Magazines/Reports/Documentary</category>
<category lang="hu">Magazinok/Riportok/Dokumentumfilm</category>
<category lang="en">tvshow</category>
<url system="port.hu">https://port.hu/adatlap/film/tv/fokusz/event-tv-1416159575-5/movie-3806</url>
<previously-shown/>
<rating>
<value>12</value>
<icon src="https://port.hu/img/agelimit/raster/12_age_icon_black.png"/>
</rating>
</programme>Hogy tudnék egy olyan xml-t csinálni belőle, amivel törölném a felesleges sorokat belőle?
Pl ne legyenek benne ezek a sorok:
<url system="port.hu">https://port.hu/adatlap/film/tv/fokusz/event-tv-1416159575-5/movie-3806</url>
<value>12</value>
<icon src="https://port.hu/img/agelimit/raster/12_age_icon_black.png"/>
<category lang="en">Magazines/Reports/Documentary</category>Valakinek ötlete akár arra is, hogy neten hol keresgéljek?
-
#4213
 creative123
újonc
creative123
újonc
creative123
újonc
Sziasztok,
Most ismerkednék a python-nal, és lenne egy olyan kérdésem amire nem találtam még sehol leírást. Minden oktatóvideóban szépen sorba vesznek mindent, adatok, függvények..stb. Majd egyszercsak megírnak belőle egy programot Import kezdetű bevezetéssel.
De erről én nem találtam semmit, hogy hogyan, honnan tudod, mikor mit kell használni?
Igen tudom, hogy a programokban használatos dolgokhoz szükséges, de erről nem találok sehol infót, hogy mégis mi alapján tudod, hogy mihez mi kell?
Köszi a választ előre is. -
-
válasz
 don_peter
#4203
üzenetére
don_peter
#4203
üzenetére
Kerdes lehet meg, hogy BE, vagy LE a byte rendezes...
Tudod, hogy milyen ertekeket kell felvegyen a rekord alapjan a struct?namedtuple megy egyebkent igy is:
s = namedtuple('struct',('header','id','time'))
vagy vesszovel elvalasztva:s = namedtuple('struct', 'header,id,time') -

don_peter
senior tag
Sziasztok. Nem vagyok python-os, de sajna muszáj vele foglalkoznom. Egy feladat megoldásával kínlódok, de nem jövök rá a megoldásra. Segítségeteket kérem. Köszi előre is.
Probléma:
Van egy adathalmazom, amely byte-os sorozat és ezt szeretném struktúrába rendezni:record = b'\x08\x32\x12\x33\x10\xEE\x0a\xff\x01\xAA\x22\x55\x99\x0f\x02\x06\x66\x76'print('\n\r',len(record))s= namedtuple('struct','header' # Uint8 [6]'id' # Uint32'time' # Uint64)s = s._make(unpack('6bHq', record))
A lényeg, hogy az egyes elemekbe a megfelelő számú byte kerüljön. Ha meg lehet oldani tömbösítve az is érdekes lehet, de nem szükséges. Köszi.













 ):
):
























Új hozzászólás Aktív témák
- Lenovo ThinkPad L13 Gen 3 13,3" - i3 1215U, 8GB RAM, SSD, jó akku, Thunderbolt 4 - számla, 6 hó gar
- Hibás Lenovo ThinkPad P17 Gen1 20sq, 17,3" workstation notebook
- HP ProDesk 400, 600 G2,G3 Mini és 600 G2 MT , félkonfig, bővítési opció, mini PC/NAS/HTPC alap
- OnePlus Nord CE5 128GB, Kártyafüggetlen, 1 Év Garanciával
- Apple iPhone 16 Plus 128GB Ultramarine használt, karcmentes 96% akku (266 ciklus) 6 hónap gar
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest