Új hozzászólás Aktív témák
-
-

dezz
nagyúr
Ja, elfelejtettem beleírni, hogy szerencsére az Intel piaci fölényének hatása inkább csak a 3DNow! & utódai vs. SSE2 & utódai harcának kimenetelében mutatkozott meg.
Persze alakulhatott volna rosszabbul is a dolog, emlékezzünk csak arra, amikor az Intel elkezdett a keresztlicenc-szerződés hatálya alá nem eső proci-foglalatokat és -slotokat bevezetni, lehetetlenné téve a közös platform és chipset használatát, minek hatására az AMD kénytelen volt ezekből sajátot/3rd partyt alkalmazni. Szerencsére a chipset gyártók őket is támogatták, nem csak az Intelt, különben igencsak nehéz (ill. még nehezebb) helyzetbe kerültek volna... Azonban ennek volt egy pozitív következménye is: ha már úgyis saját foglalat és saját/3rd party chipset kell, megnyílt az út az AMD számára az említett innovációk előtt...

zsolt320i: Előfordul.

-
dezz
nagyúr
válasz
 zsolt320i
#52
üzenetére
zsolt320i
#52
üzenetére
Szerencsére az x86-64-et (x64, AMD64) sikerült forgalomba hozni, mert ott a MS döntésén múlt a dolog, nem a két procigyártó piaci befolyásán. A 3DNow! vs. SSE(2) meccs nem volt ilyen nagy jelentőségű, így ott nem szólt bele a MS (mindkettőt támogatta).
Egyébként Dávid és Góliát, utóbbi az óriás.x86 vonalon az AMD vezette be a floating-point SIMD-et, ez volt a 3DNow! (*), a prociba integrált memóriavezérlőt, p2p rendszerű, közvetlen kapcsolatot a procik és proci-chipset között (HT) (ezek évekig komoly előnyt jelentettek szerver vonalon, az Opteronoknál), a 64 bitet, a virtualizáció HW-es támogatását, a natív dual-core-t (és eleve a dual-core-t is, hiszen jóval előbb kezdték a munkát, az Intel magától nem csinálta volna, csak mert kényszerítve volt, hamar összedobták a MCM [2/több külön lapka egy tokban] rendszerű Pentium-D-t), a natív 4-core-t, stb. (Az Intel csak most tér át az integrált memóriavezérlőre, a p2p rendszerű buszra (amit szinte egy-az-egyben a HT-ről másolt, de azért sem licencelte inkább az eredetit), és a natív 4-core-ra.)
szerk: Oliverda beelőzőtt.
(* Itt az SSE volt előbb, azonban az csak integer utasításokat tartalmazott, ezt bővítette ki a 3DNow! lebegőpontos utasításokkal; ezt az Intel nem akarta átvenni, helyette jött az SSE2.)
(#53) Bici: A Stream SDK támogatni fogja az OpenCL-t is, így segíthet. Nem hiszem, hogy rá lehetne venni a fejlesztőit, hogy kimondottan az Intelt támogassák, hiszen elkötelezettek a platform-függetlenség mellett, az az alapja az egésznek. Különben is, ez egy nyitott API, minden cég felhasználhatja, és magának kell implementálnia (a specnek megfelelően megvalósítania) a saját rendszerében.
-

Oliverda
félisten
válasz
zsolt320i
#52
üzenetére
Szerintem a vásárók elenyésző részét érdekli hogy ki fejlesztette ki a CPU-ban található utasításkészleteket.
"mert ha az AMD ki is talál bármilyen innovatív dolgot, egyáltalán nem biztos hogy sikerül a gyakorlatba is átültetnie"
IMC, natív 4 mag, Direct Connect Architecture, x64... Ezek mind az AMD (innovatív) fejlesztései amit ma már az Intel szépen átvett és sikeresen alkalmazott. Nem sok embert érdekel hogy ezeket ki találta ki és ki alkalmazta először. Ugyanez fordítva is igaz tehát ezen kár sírni. Majd ha az AMD-nek háromszor akkora lesz a piaci részesedése akkor majd lesz esélyük teljesen saját utasításkészlet beveztésére addig pedig sokkal jobban járnak ha az egységességre törekednek. Talán az Intel-en kívül ezzel mindenki jobban jár.
-
Köszi a részletes leírást!

Viszont nem látom pontosan, hogy az OpenCL is segíthet-e ezen a problémán.
Ha úgy nézem, hogy a programozóknak csak egy félével kell foglalkozniuk, és a chip gyártókon múlik csak, hogy mennyire teszik OpenCL-baráttá a saját termékeiket, akkor jól fest az ábra.
Viszont, ha azt nézem, hogy magát az OpenCL-t fejlesztő csapatot biztosan lehet majd az intel megoldásai felé terelni némi pénz segítségével, akkor máris csúnyább a kép. Remélem, hogy csak én vagyok túl rosszhiszemű.
-

zsolt320i
senior tag
igaz!
Ha jobban belegondol bárki, az csak jó ha egy processzor minél több "programozási szabvány"t és "utasításkészletet" támogat, sőt kompatibilis a konkurencia megoldásaival, mert ebből csak nyerhet az adott termék.
Ebben az esetben az AMD ha majd ismeri, és hatékonyan kezeli az Intel féle utasításkészleteket + még lesznek saját megoldások is amit csak az AMD proci fog tudni az kitűnő lesz!
Ami egy kicsit nekem is piszkálja a csőrömet hogy általában nem a legjobb programozási megoldás, illetve leghatékonyabb utasításkészletek kerülnek "forgalomba" mert van egy óriás és egy góliát, és sajnos mindent az óriás diktál .
.
Ebből következően, amit bici írt sztem megalapozott mert ha az AMD ki is talál bármilyen innovatív dolgot, egyáltalán nem biztos hogy sikerül a gyakorlatba is átültetnie -
dezz
nagyúr
Sokat javít a helyzeten (a piaci dominanciát és fordító-függőséget illetően) a következő. Itt nem csak olyan utasításokról van már szó, amiket CPU-orientált felhasználói programok használhatnak (közvetlenül), mely programokat a szokásos fordítókkal fordítanak. Hanem itt kezd elmosódni a határ CPU és GPU között... Hiszen ezen új utasítások egy része eddig főleg a GPU-k shader egységeiben volt megtalálható. Így ezek az új CPU-k át tudják majd venni a GPU-k feladatainak egy részét (ahol nem a nagyon sokszoros párhuzamosítás, hanem az összetettebb feladatok hatékony elvégzése dominál).
És itt jön az érdekesség:
1. A grafikai shaderprogramokat nem a szokásos fordítókkal fordítják, hanem ezekre minden PC-s GPU/IGP gyártónak van saját fordítója, benne a VGA driverben: a DirectX-es HLSL-ről, az OpenGL-es GLSL-ről ki-ki a saját HW-ére fordít. (Említeném még az Nvidia Cg-jét is, amihez úgy tudom, csak neki van fordítója, és talán csak saját HW-hez, de utóbbi nem biztos.)2. A (eddigi) GPGPU alkalmazások (amikor a GPU nyers erejét általánosabb feladatokra veszik igénybe) fejlesztése is új irányt vehet, legalábbis bejön egy új irányzat, lehetőség is. Eddig itt Nvidia oldalon volt a CUDA, AMD oldalon meg a Stream SDK. Mindkét környezet magában foglal 1-1 GPGPU-orientált C nyelv változatot, és hozzá való fordítót. (Persze ezeknek a fordítóknak nem erősségük a teljesen általános kód.)
Sőt, mivel itt a GPU-s (shaderes) számítási megoldások ereje és a CPU rugalmassága egyesül, vélhetően az eddig összetettségüknél fogva kimondottan a CPU-ra bízott számításoknak legalábbis egy részét is érdemes lesz adott esetben ezen környezetekben (újra)implementálni... Bár itt már bejön az, hogy az olyan jelentős és eddig platformfüggetlen alkalmazások esetén, mint pl. a 3D rendererek, ezen túl is meg akarják majd tartani ezt a platformfüggetlenséget, és olyan fordítót használnak hozzájuk, ami ezt többé-kevésbé, de biztosítja. (Persze itt a platformfüggőséget relatívan kell [sajnos] értelmezni, szóval pl. mindenképp Windows, néha még Linux, de pl. általában csak x86, stb.)
De amiatt is hasznos lehet a viszonylagos kompatibilitás, mert a 2. pontban említett alkalmazások ütemesebb terjedése esetén valamely külső cég is kedvet kaphat egy közös (AMD-t és Intelt is támogató) környezet létrehozására.
-
(#46) dezz, (#48) P.H.: Köszi az infókat!
Nem túl jó jel ez a jövőre nézve. Így az AMD folyton követni kényszerül az intelt, és ha van egy jó ötletük, ami nem esik egybe az intel által diktált iránnyal, akkor vagy kukázniuk kell, vagy senki sem használja ki.
Attól tartok, hogy ha pár év múlva VGA/GPU fronton is az AMD és az intel lesz a két nagy kutya (ha az nV tényleg kiszáll), akkor megintcsak így alakulnak majd a dolgok.
Najó, Abu szerint a kettőt nem jó keverni, és remélem is, hogy alaptalan az aggodalmam. -
dezz
nagyúr
válasz
zsolt320i
#47
üzenetére
Nyilván megtették volna már, ha módjukban állna... Nem könnyű olyan szakembergárdát összehozni, ami nagyon jól optimizáló fordítót tud írni, és nem is olcsó. Aztán ha meglenne, még rá kellene venni az ipart, hogy inkább ezt használják, nem az Intel-félét. (Mindkettőt egyszerre meg körülményes.)
De szerencsére ez a dolog elsősorban integer kódnál jön ki (nagyjából 5% sebességkülönbséget okoz), lebegőpontos és vektorkódnál nem annyira, a (jelenleg) hasonló implementációk miatt.
P.H.: Már hiányoltalak.
-

P.H.
senior tag
Is-is, de az előbbi nem túl költség- és időhatékony. Ebben az is benne van, hogy a különbség jelenleg nem jelentős (párszor 5% maximum), és az elterjedtség is (ezt Abu elég jól körül szokta írni a komolyabb VGA-s topikokban
).A kérdésed megelőzi a korát: majd a következő generációk és utasításkészletek megjelenésével fog ez igazán érdekessé válni.
Viszont ez az egész vector-dolog még elég képlékeny mindkét cégnél jelenleg, úgy tűnik, teljesen még senki nem fedte fel a kártyáit. De majd kb. ősszel fog eljönni az igazán találgatós időszak: akkora fog a megjelenő Core i5 is után a következő generáció fókuszba kerülni, az AMD-nél is időszerű lesz akkorra a Bulldozer végleges karakterének kialakulása (addig érdemes lehet ezt a blogot figyelemmel követni, bár patent-ekből levont következtetésekkel is lehet bőven nagyot tévedni).
-
dezz
nagyúr
Inkább az utóbbi, de ma már nem nagyon programoznak (x86 platformon) assemblyben, hanem mindez a C fordítóra van bízva. Itt jön képbe az Intel fordítója, ami nagyon jól optimizál (ezért főleg ezt használják pl. a 3D rendererek fejlesztésére), de csak a saját procijaikat veszik figyelembe (sőt volt idő, amikor alaposan meg is nehezítették pl. az SSEx használatát AMD procikon), aztán ez vagy fekszik az AMD prociknak is, vagy nem. Ott van még a MS Visual C-je, ami mindkét procira tud külön optimizálni, de nem akkora hatékonysággal. A GCC sem valami nagy szám ebben.
zsolt320i: Az AMD viszont találékonyabb.
-
Biztos hülye kérdés, de mondjuk egy 3dsMAX render engine esetén a programozók megírják a kódot intel és AMD procikra is, és futás elött a főprogi azt hívja meg, ami a procinak kell, vagy csak intelre írják meg, és amit abból az AMD proci tud, azt használja, amin nem, azt meg nem? Vagy hogy műxik?
-
dezz
nagyúr
válasz
zsolt320i
#39
üzenetére
1. A 3DNow!-t is előbb készítette el az AMD, mint az Intel az SSE-t, és még jobb is volt, mégis mindenki az utóbbit és utódait használta... Az Intel egy kicsivel nagyobb súlyú cég. (A 64 bit egy kicsit más téma.)
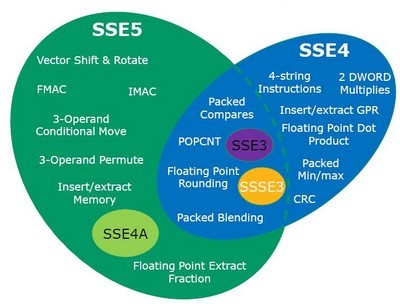
2. Az SSE5-öt eredetileg 128 bitesnek tervezték (mert most 2009-ben, amikorra eredetileg tervezték a bevezetést, még ez lett volna időszerű), az AVX viszont már támogatja a 256 bites műveleteket is.
3. Csak részben alkalmazkodnak, mert az SSE5 többmindent tartalmaz, mint az AVX, és ezeket nem dobják el. Csak az egészet (vagy legalábbis az átfedő részt) az AVX keretrendszeréhez igazítják, az ugyanolyan funkcionalitású utasításoknak azonos kódjuk lesz, stb.
4. Az Intel saját C-fordítója az egyik legelterjedtebb (ezt sokszor nem túl etikusan használja ki), és nyilván nem támogatná külön az SSE5-öt.Egyébként mikor alkottak még nem valami nagyot?
-

Devid_81
félisten
"A kiterjesztés az eddig megjelent adatok alapján főleg három-, illetve pár négyoperandusos, 128 és 256 bites utasításokat kezelő rendszer, ami jól kidolgozott permutáló instrukciókkal és FMA (fused multiply-add) támogatással rendelkezik."
Nos talán ennél a résznél nálam is kimentek a bisztik

-
dezz
nagyúr
Esetleg így? "Fontos megemlíteni, hogy az FMA4 [előző mondatban ott van, mi ez] valódi négyoperandusos művelet, míg az Intel jövőbeli FMA megvalósítása (a jelenlegi terveik szerint) csak virtuálisan négyoperandusos, mivel az eredményt az egyik operandus által használt regiszterbe kerül."
(Aztán nem tudom, érdemes-e még hozzátenni, hogy később valószínűleg mindkét cég támogatni fogja a másik megoldást is.)
-
dezz
nagyúr
Szóval, ez...
"Fontos azonban megemlíteni, hogy az AMD SSE5-ben bemutatkozó fused multiply-add utasítás csak virtuálisan négyoperandusos, mivel az eredményt az egyik operandus által használt regiszterben kell elhelyezni. Az Intel jövőbeli FMA megvalósítása már valós négyoperandusos művelet."
...az új felállásban pont fordíva lesz!
Talán az Intel arra számított, hogy az AMD is az FMA(3)-at preferálja (hiszen az eredeti SSE5 tervezetben ez volt), de közben az AMD már ráállt a jobb FMA4-re. De az is lehet, hogy az AMD úgy is tett, mintha így tenne, de közben mégsem, szal kicselezte az Intelt...
Talán nem véletlen, hogy csak most jelentik be az FMA4 használatát. -
dezz
nagyúr
válasz
 divrapier
#12
üzenetére
divrapier
#12
üzenetére
Nem egészen, de a hír sem pontos. Több lépésben történtek a dolgok:
1. Az eredeti SSE5-ben 3 operand + 1 operand+destination FMA lett volna.
2. Kijött az AVX tervezet 4 operand + 1 destination FMA-val.
3. Az AMD úgy döntött, hasznos adaptálnia az AVX-et. El is kezdték a munkát.
4. Erre tavaly decemberben az Intel módosított az AVX-en, a 4+1-es FMA helyett bevezetve a kevésbé hatékony, de könnyeb megvalósítású 3+1-es FMA-t.
5. Az AMD úgy látta, nem tudják tartani az ütemtervet, ha követik ezt a változást. Így a Bulldozerben az eredeti AVX tervezet 4+1-es FMA-ja lesz (átkeresztelve FMA4-re), és később veszik át a 3+1-es FMA-t.Így tehát a Bulldozerben a hatékonyabb FMA4-lesz, miközben az Intel az FMA-t fogja használni. Bár valószínű, hogy később az Intel is bevezeti az FMA4-et.
-

Abu85
HÁZIGAZDA
A tesszellátort itt nem érdemes felhozni példának. Teljesen más ez a téma.
Itt csak zavaró, ha más piacok alakulása alapján akarunk jósolni.Itt alapvetően egyetértés hiánya fedezhető fel az Intel és az AMD között. Egyelőre az a biztos, hogy az Bulldozer támogatni fogja az FMA4 kiterjesztést, hogy ezek után, hogy alakul a helyzet, az tényleg a jövő zenéje.
CYBERIA: Az SSE5 támogatja az SSE4.1 és 4.2 utasításainak egy kis részét.
-

TK36
aktív tag
-
De akkor ez így nem túl jó, mert hiába jön hamarabb, úgy járnak majd, mint a tesselator esetében. Nem?
Vagy a programozók hajlandóak egy olyan eljárással foglalkozni, amivel sem a jelenlegi, sem a jövőbeli intel procik sem kompatibilisek?Más téma, de mintha úgy hallottam volna, hogy az MMX, és az SSE korábbi változatai sem kompatibilisek teljesen a két cég procijai között. Ez igaz? Ha igen, akkor emiatt is lehet az AMD procik lemaradása, nem?
-
Abu85
HÁZIGAZDA
A VGA piacon elért eredményekkel kifejezetten elégedett az AMD. A 100 dollár feletti diszkrét rendszereken akartak sokat nyerni és az eladási adatok alapján nyertek is. Az 50 dollár körüli NV uralomra és az IGP területekre még csak most kezdenek koncentrálni.
Az Intelt meg nemsokára helyrerakja némi szaftos bírsággal az EU, aztán Dánia, majd az USA.
-
Abu85
HÁZIGAZDA
Nem ... itt az SSE5 és az AVX kódolási sémája különbözött. Nyilván ez teljes inkompatibilitást jelentett volna. Most az AMD bejelentette, hogy átdolgozzák/átdolgozták a rendszert, hogy kompatibilis legyen az AVX-szel.
Az FMA kiterjesztés, az továbbra sem kompatibilis az Intel féle FMA-val, de az AMD hamarabb prezentálja a saját megoldását. -

bsh
addikt
gondolom a 2007-es sse5 specifikációban ilyen "virtuális 4 opos" volt ez az utasítás, azonban az intel megcsinálja valódi 4opra. ezért aggódtak a fejlesztők, hogy akkor így nem lesz kompatibilis a két procin a kódjuk. erre jelentette be most az amd, hogy akkor ők is az intel-féle tervekkel kompatibilisen csinálják majd meg. (gondolom én)
-

DraXoN
addikt
"AMD SSE5-ben bemutatkozó fused multiply-add utasítás csak virtuálisan négyoperandusos, mivel az eredményt az egyik operandus által használt regiszterben kell elhelyezni. Az Intel jövőbeli FMA megvalósítása már valós négyoperandusos művelet."
Ez nem hangzik nekem jól... tehát ha jól értem itt a Bulldozer nem lesz túl erős ezen utasításokban, inkább csak kompatibilis, de lassabb lehet mint az Intel következő processzora?
Vagy lehet, hogy mégsem, mert sokkal gyorsabb lesz az AMD prociban a végrehajtás és ez ellensúlyozza a virtuális működési elvet?...Nektek mi erről a véleményetek?
Jobblesz? rosszabblesz? nem meghatározható? vagy teljesen hülyeséget írtam ?
? -
Oliverda
félisten
Akit még részletesebben érdekel a dolog az olvasgathat:
AMD Developer Blogs - Striking a Balance
AMD to support Intel AVX instructions
AMD embraces AVX making a new superset with SSE5(256bit support)
















 .
.







 Ez tetszett..
Ez tetszett.. ![;]](http://cdn.rios.hu/dl/s/v1.gif)




























Új hozzászólás Aktív témák
- Ducky One 3 FULL/TKL/SF/MINI billentyűzetek többféle színben és kapcsolókkal, plusz csuklótámaszok
- Gamer PC-Számítógép! Csere-Beszámítás! I3 14100F / RTX 3070 8GB / 16GB DDR4 / 512 Nvme SSD
- Új HP 15 Victus FHD IPS 144Hz i5-12500H 12mag 16GB 512GB SSD Nvidia RTX 4050 6GB Win11 Garancia
- GYÖNYÖRŰ iPhone 14 Pro Max 128GB Deep Purple - 1 ÉV GARANCIA -Kártyafüggetlen, MS3702
- ÚJ Bontatlan Honor X7d 6/128GB fekete/ 12 hónap jótállással!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest