Új hozzászólás Aktív témák
-
#27585
 Abu85
HÁZIGAZDA
Petykemano
#27583
Abu85
HÁZIGAZDA
Petykemano
#27583
Abu85
HÁZIGAZDA
válasz
 Petykemano
#27583
üzenetére
Petykemano
#27583
üzenetére
Mert a felhasználó a tuningolást a játékokban teszteli. De a VGA esetében nem csak olyan körülményben kell stabilnak lenni, amely a beépített részegységek zömét azonos időben nem is használja. Az xyz játékokban stabil nem jelenti azt, hogy egy w programban is az lesz. És ez egy fontos tényező az órajel beállításánál.
Nyilván, hogy ha saját magad tuningolsz, akkor te megteheted, hogy egy programra ráoptimalizálod az órajeleket. Mert úgy gondolod, hogy úgy stabil, de bőven lehet, sőt igen valószínű, hogy a világban van még egy olyan program, amellyel a tuningod már nem stabil. Ez saját órajelállításnál a te hibád, de ha az AMD csinálná, akkor az bizony gyártói hiba lenne, amiért leszednék a cég fejét.
-
Abu85
HÁZIGAZDA
válasz
 schawo
#27578
üzenetére
schawo
#27578
üzenetére
Ilyen a Polaris és ilyen lesz a Vega is. PID szabályozó, fuzzy vezérlővel, és táblázatos rásegítéssel, meghajtó oldali opcionális profilkonfigurálással. A táblázatra igazából azért van szükség, mert gyorsabb előre kiszámolt paramétereket kiolvasni és beállítani, mint real-time számolni, majd mire beállítanád a lehetőség a magasabb órajelre megszűnik. Mikromásodpercen belüli órajelváltás lehetőségével a reakcióidő kritikus.
-
Abu85
HÁZIGAZDA
Oké látom ez a skálázás nagyon nem világos. Megpróbálom leírni részletesen.
Szóval kezdjük azzal, hogy van egy termék skálázás nélkül. Ilyenkor az a helyzet, hogy a terméknek vannak megcélzott piacai, és ezeken a piacokon igen eltérő lehet a hőmérséklet és a páratartalom. Elég csak azt figyelembe venni, hogy Indiában azért vannak olyan hetek amikor 45°C van és a páratartalom is az egekbe szökik. De más egyenlítőhöz közel lévő területen is lehetnek hasonlók a körülmények. Ezzel szemben Európa mondjuk egész kellemes egy kontinensnek számít az itt uralkodó éghajlattal. Amikor tehát egy hardvert paramétereznek, akkor olyan órajelet és feszültséget kell beállítani, amivel Indiában is működni fog. Régen ez pusztán a hardvertervezés direktívái miatt nem volt probléma, mert igen kevés lépcsőre bontotta a futószalagokat egy GPU, tehát eleve alacsonyabb órajelre kényszerültek a gyártók, mint amennyit elméletben be lehetett volna állítani. Egyszerűen el kellett kerülni az órajel-csúszásokat. A pite onnan vált meleggé, amikor az órajel elkezdett felfelé kúszni. A gyártók elkezdték úgy tervezni az architektúrákat, hogy a futószalagokat több részre bontották, és ez a lépcsőzés lehetővé tette, hogy egy órajel alatt kevesebb munkát lehessen végrehajtani, tehát maga az órajelciklus is rövidebb lehetett, ami magasabb órajelet eredményezhetett. Ebből a szempontból az első igazán extrém megoldás a G80 volt, ami abból a szempontból nagyon érdekes volt, hogy nem csak többfokozatú lépcsőzést használt, hanem még a multiprocesszorokon belül is több fokozatra bontotta a feladatot. Ezért volt külön mag és külön shader órajel. Itt már volt egy alapvető skálázás a rendszerben, de turbó még nem, mert eléggé kezdetleges volt az egész. Viszont a G80 más feszültségen üzemelt például Európában és más feszültségen a trópusokon.
Az egész futószalagokat felbontó koncepció lehetővé tette az órajellel való játékot, mert már képesek voltak a gyártók elérni azt, hogy ostromolják az adott node határait. Ez hozta el a GPU-knál a komolyabb órajel- és feszültségskálázás szükségességét. Az első igazán életképes rendszereknek a Fermi (GeForce 400) és a Terascale 2 (Radeon HD 5000) volt tekinthető. Kezdetlegesek voltak ugyan, teljesen szoftver vezérelte őket, de működtek, és esetenként belenyúltak az órajelbe és a feszültségbe. Ehhez a meghajtóba volt építve egy táblázat, ami alapján a rendszer kiértékelte, hogy kell-e az órajelet csökkenteni vagy nem. Általában nem kellett, főleg az európai éghajlattal, de a lehetőség ott volt a rendszerben. Biztos emlékeztek még a Furmarkra, ami pont a Fermi és a Terascale 2 után vált használhatatlanná a VGA-k megsütése szempontjából, mert ezekben jött először egy életképes skálázó rendszer. Főleg a Terascale 2 volt védve, mert a szoftveres vezérlés mellett a túlterhelés ellen teljesen hardveres megoldása volt, tehát ha a szoftver nem tudott reagálni a körülményekre, akkor a hardver végső pajzsként megtette.
A DVFS valójában ezután csatlakozott be. Persze bizonyos értelemben a Fermi és a Terascale 2 lapkákat is nevezhetjük DVFS-nek, de a szó legszorosabb értelmében nem szokás, mert szoftverből volt szállítva a táblázat a működéshez, ugye ennek az volt a hátránya, hogy ha elrontottad a szoftvert meg is sültek a termékek, például a Fermi a Starcraft 2 alatt - [link].
A következő körben már igazi DVFS megoldások jöttek. Ezeknél az volt a lényeg, hogy az egyes külső körülményekhez már a lapkába került egy táblázat, ami alapján a rendszer maga is képes volt beállítani a megfelelő feszültséget és órajelet. Ezzel bejöttek a turbók is, mert reszponzívvá vált az egész, nem kellett a meghajtó jóváhagyására várni. Az AMD a HD 6900 sorozattal tért át erre a modellre, ami az első generációs PowerTune volt. Majd ezt követte a második generációs verzió a HD 7790-nel. Az AMD ezt azért fejlesztette két lépcsőben, mert teljesen át akartak térni hardveres vezérlésre. Ezt valójában a CPU-s mérnökök know-howja alapján rakták össze, de ez lényegtelen. Az NV az első igazi DVFS-t a Keplerben hozta. Ők még félig szoftveres szinten maradtak. Úgymond az órajel vezérlése hardveressé vált, de a védelmi rendszerek még szoftveres választi igényelnek, ahogy az órajelállapotok váltása is igényli a driver engedélyét. De ezektől a különbségektől eltekintve, nagyon lecsupaszítva az a lényeg, hogy a hardvert mindig a legrosszabb körülményre kell tervezni, tehát kvázi a trópusi igénybevételre, ugyanakkor Európában másképp is működhetne. Tehát az elérhető órajel más a trópusokon és más a mediterrán területeken. A DVFS táblázata ezt a különbséget hidalja át. Ezzel az elvi maximum órajelhez relatíve közel lehetett vinni a valós órajelet. Tehát ha mondjuk az elvi maximum ~1500 MHz lenne, akkor egy DVFS-sel valóban beállítható a gyakorlatban is egy ~1200 MHz-es maximum szint a táblázatba. Ha nem lenne DVFS, akkor az órajel pedig úgy ~900 MHz lenne, ami ugye eléggé messze van az elvi maximumtól.
Az AVFS pedig a következő lépcső ebben az órajelekért folytatott versenyben. Annyiban különbözik ez a rendszer a DVFS-től, hogy nincs egy előre beállított táblázat a lapkában, hanem az indítás során mért hőmérsékleti értékek alapján kalkulál egy saját táblázatott a chip. Ez azért jobb megoldás, mert ilyenkor a skálázást már nem egy legrosszabb körülményekre állított táblázatból valósul meg, hanem a hardver az adott körülményekhez számol egy sajátot. Ilyen formában mondjuk maradva az elvi ~1500 MHz-es maximumnál, a gyakorlatban beállítható maximum órajellel elérhető az ~1350 MHz is. Ennek az AVFS megoldásnak az a nehézsége, hogy jó táblázatott számoljon a hardver, és ez tényleg olyan nehézség, amely látszatra egyszerűnek tűnik, de a valóságban éves szintű tesztelések szükségesek, hogy egy implementációra rá lehessen mondani, hogy ez jó. Persze ismét vannak olyan GPU-s csoportok akiknek tálcán viszik a rendszert a CPU-s mérnökök, amiért az AMD RTG részlegének a dolga valljuk be baromira egyszerűvé válik. Tehát igazából az AMD és az NV megoldása között csak pár CPU-s mérnök áll, semmi más, mert amíg a CPU-s részleg nem vitt semmit a GPU-s részlegnek, addig az AMD és az NV nagyjából hasonló megoldásokat talált ki. Emiatt az NV mérnökei se dolgoznak rosszabbul, mint az AMD mérnökei, csak nekik senki sem vitt oda egy bő évtizedes know-howt a skálázási probléma kezeléséről. Emiatt lehet, hogy az NV egy másik irányt is válaszott az órajel meghatározása szempontjából, és jóval több futószalag fokozatot használnak az architektúrára. Ezzel a futószalagot több részre bontják, mint az AMD, ami magasabb órajel beállítását teszi lehetővé, de egy órajel alatt kevesebb munkát is tudnak elvégezni. A Vega esetében az AMD is növeli egyébként a futószalag fokozatok számát, hogy növelhessék az órajelet, de ezzel ugye nekik is kevesebb munka lesz elvégezhető egy órajel alatt. Az optimális futószalag fokozatok száma egyébként a GPU-knál is olyan kérdéses, mint a CPU-knál. Se a kevés nem jó, se a sok. Tipikusan van egy optimális szám, ami részben architketúrától is függ. Tehát annak kicsi a jelentősége, hogy az AMD kevesebb fokozattal dolgozik, mint az NV, mert ez egy architektúrára vonatkozó döntés is lehet.(#27576) s.bala31: Nem. Pont, hogy rosszabb. Például ezért nincsenek kiadva az ultragyáriagyontuningolt VGA-k az egyenlítő közelében, többek között Szingapúrban. De mondjuk Indiában is az van, hogy ezek simán nem működnek. A ~45°C-os nyári melegben le fognak fagyni, és azért pár nap van az évben, ami ilyen ezeken a területeken.
-
#27575
Abu85
HÁZIGAZDA
Petykemano
#27560
Abu85
HÁZIGAZDA
válasz
Petykemano
#27560
üzenetére
Egyáltalán nincsenek túlfeszelve a kártyák. Csak nem értik a felhasználók, hogy a földön uralkodó hőmérséklet és páratartalom nem egységes. Egy kiadott terméknek nem csak mediterrán éghajlatban kell működnie, hanem trópusi és szubtrópusi környezetben is. Az AVFS pedig arra szolgál, hogy a működési órajel ne 800-900 MHz legyen, hanem 1200-1300 MHz.
-
Abu85
HÁZIGAZDA
Mikroakadások elsődlegesen az API-tól és az alkalmazástól vannak, nem pedig a drivertől. Ha erre akarsz utalni, akkor jelen pillanatban az a helyzet, hogy az AMD driverei jelentik most a csúcsot. Most az ő fejlesztési konstrukciójuk a legjobb, és emiatt jó szinten tudják tartani a kódminőséget, nem jön gyorsan különböző kritikus hibákra hotfix, stb.
Mi az a BS? Black Screen vagy Blue Screen? Csak azért érdemes ezt értelmezni, mert ha bármilyen hiba van a gépben, akár VGA, akármi, akár szoftver, akkor mindenképpen fekete vagy kék képernyőt kapsz.

A pumpa és a hűtő igazából nem tipikusan olyan hiba, ami az AMD tervezéséből fakad, de nyilván ezek tényleges problémák, ki kell értékelni őket.
A 4 GB HBM memóriával tudtommal nem volt semmilyen stabilitási probléma, vagy bármi bug.
(#27458) Egon: Éppenséggel annyira nincs nagy különbség, hogy AMD vagy Intel proci mellé raksz AMD vagy NV VGA-t.
[link] - Itt meg lett nézve. A GTX 1060 és az RX 480 nagyon hasonlóan teljesít Intel és AMD CPU-val is. Egyedül a Rocket League esetében van az, hogy AMD CPU mellett lényegesen jobban fut Radeonon, de a Rocket League-ről köztudott, hogy egy AMD-re írt játék, az RX 480 is tartja a lépést a sokkal drágább GTX 1080-nal benne (99th percentile mérésben még jobb is az RX 480, nem is kevéssel). Valószínűleg vannak a programban különböző optimalizálási problémák, amelyek az NV driverét rosszul érintik, és emiatt általánosan esik a kártyáik elméleti teljesítménye, AMD CPU-val jobban. A fejlesztők pedig szarnak rá, nem éri meg nekik javítani.
-
Abu85
HÁZIGAZDA
válasz
 TTomax
#27447
üzenetére
TTomax
#27447
üzenetére
A semminél jóval többre mentek. Tulajdonképpen a kétszereplős piacon másodikként meghatározták, hogy milyenek legyenek az új API-k és az új programozási technikák. Olyanra még soha nem volt példa, hogy egy szabványalkotó a piacvezetőnek kedvezőtlen feltételeket teremtett volna. De most megtörtént. Látszik is, hogy mennyire más a Radeonok és a GeForce-ok DX11-es és DX12-es teljesítménye.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27442
üzenetére
Ez távolról sem annyira úttörő dolog. A memory paging rendszerek évtizedek óta léteznek. A HBCC tulajdonképpen egy ilyen rendszer, se több, se kevesebb. Az AMD-nek azért lesz hamarabb, mert az ATI-hoz beesett egy csomó CPU-s mérnök, akik már tizensokéve erre terveznek processzort. Az NV-nek ezek a mérnökök hiányoznak, tehát nekik fel kell szívniuk a saját tapasztalataikat, mert nem volt olyan szerencséjük, hogy hirtelen a GPU-t tervező részleg mellé került egy csúcsprocesszorokat tervező részleg egy rakás tapasztalt mérnökkel. Az AMD részéről ez az egész színtiszta mázli. Ha az ATI még mindig független lenne, akkor most nem beszélnénk a HBCC bevezetéséről, mert azt az utat kellene járniuk, amit az NV jár, és nem egy gigantikus felvásárlás utáni jól megrakott tálcán kínálják a know-howt a GPU-s mérnököknek.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27439
üzenetére
Alapvetően az NV-nek is van egy hasonló megoldása a GP100-ban, ami hardveresen próbálja menedzselni az allokációt, de az csak a CUDA-ra működik. A HBCC nem olyan dolog, hogy eldöntöm és csinálok egy ilyet, és hozom is. Az AMD-nél ennek az ötletét még az R600 megjelenésénél vettették fel. Szóval kb. egy évtizedes folyamat, amíg ez az első megbeszéléstől eljut egy lapkába. De abból, hogy a GP100-ban már van egy hasonló, csak még kezdetleges formában tulajdonképpen tudni lehet, hogy az NV is készül vele. Egyes pletykák szerint már a Volta tudja, de nem biztos, hogy mindegyik lapka.
Ez hasonló dolog a feszültség skálázáshoz. Nem azért használ szoftveresen vezérelt DVFS megoldást az NV, mert az olyan jó, hanem azért, mert a teljesen hardveres megoldások nagyon nehezen kivitelezhetők. Az NV mérnöki csapatába nem eset be az előző évtizedben egy rakás processzorokon megedződött mérnök, akik baromira sok know-howt tudtak vinni erről a problémáról. Az AMD-nek pedig beesett, de ha az ATI lenne az AMD még mindig, akkor marhára nem lenne nekik sem AVFS-ük. -
Abu85
HÁZIGAZDA
válasz
 #85552128
#27431
üzenetére
#85552128
#27431
üzenetére
Nem, a NAVI az inkább 2019-es fejlesztés. Az már új memóriarendszert használ, leszivárog az SSD a sima Radeonokra, így nem csak a Pro és az Instinct sorozat része lesz, mint a Vega esetében.
A következő nagy probléma a GPU-piacon az adatmennyiség kezelése. Egyszerűen a rendszermemória kapacitása kevés ahhoz, hogy fél terabájtnyi kódolatlan textúrát belezsúfoljanak a fejlesztők, a háttértár pedig túl messze van, és az összeköttetésre használt buszok lassúak. Ezek ellensúlyozására a megfelelő optimalizálást PC-n nem lehet elvégezni, mert túl sok mindent kezel az OS vagy a driver. Tehát még ha a VRAM menedzselése szempontjából a hardveres megoldás sok szemetelési problémát meg is old, akkor is kell a VRAM mellé egy gyors, legalább negyed terabájtos tároló, amibe bemásolható a kódolatlan textúra jelentős részlete. És ez még kódolt textúrával is eljátszható, mert vannak erre formátumok, így gyakorlatilag olyan játékterek építhetők, amelyek kódolatlan formában számolva terabájtos mértékű adatmennyiséggel dolgoznak. Tulajdonképpen megvalósul Carmack nagy álma a megatextúrázásról. A legtöbb mai motor ezt a formát amúgy is támogatja, sőt használja, csak az adatmennyiségnél nagyon finomra veszik a beállítást.
-
Abu85
HÁZIGAZDA
válasz
 Ren Hoek
#27392
üzenetére
Ren Hoek
#27392
üzenetére
Lehet viccesnek is felfogni, hogy ez mennyire az AMD-nek kedvez, de valójában a PC-nek ez eléggé nagy baj is. Nem a kedvezés, mert az API működésében vannak olyan részek, amelyek valamelyik architektúrának mindig kedveznek. Ez kivédhetetlen, amikor valami általános megoldással szeretnének előállni a szabványalkotók. Ugyanakkor ezek mind megbeszéléssel születtek meg, tehát az AMD, az Intel és az NV is elfogadott bizonyos kompromisszumokat. És összességében így "a gép kidobott egy DX12-t és egy Vulkánt", amivel nagyjából minden érintett elégedett most. És ez általános elégedettség, például a DX12-ben vannak pontok (root signature modell, fast pathok kizárása), amelyek az NV-t igen hátrányosan érintik, de a legrosszabb esetben is korrigálható pontokról van szó, csak nem sokan korrigálják azt, tehát végeredményben ugyanott vannak, de legalább nem dönti be a sebességet.
A wave intrinsics ennél sokkal durvább. Nem is igazán érthető, hogy miképp lesz ez elfogadva. Valószínűleg a Microsoft azt mondta az Intelnek és az NV-nek, hogy ez ilyen lesz és vagy támogatjátok vagy viszlát. Ez már önmagában egy hatalmas probléma, meg kellett volna beszélni, hogy az egyes hardverek mire képesek, és azok alapján kialakítani egy közös pontot a függvényeknek. Mert most hiába hozol global ordered append csoportot két függvénnyel, ha csak a GCN-ben van megfelelő belső memória a wave-ek sorrendfüggő feldolgozására. A többi hardver rá van kényszerítve, hogy a VRAM-ot használják, vagyis chipen kívülre kell viszi a munkát, és ez sosem egy sebességbajnok megoldás. Ezzel igazából a fejlesztők végül nem nyernek sokat, mert tök jó, hogy kaptak egy szabványos megoldást a konzoloknál elérhető fícsőrökre, de ugyanúgy kellenek majd alternatív shaderek az NV és az Intel GPU-kra, mint eddig. Csak annyit nyert a piac, hogy az alternatív shaderek az AMD GPU-kra már nem kellenek, de most tényleg erről szólna egy szabvány? -
Abu85
HÁZIGAZDA
válasz
#85552128
#27385
üzenetére
Azóta a SPIR-V előállt a saját megoldásával, és ez sokkal jobb a PC-nek. A wave intrinsics igazából csak az AMD GPU-ra tudja elhozni az egyszerű portolást. A GCN-nek biztos jó, hogy több függvény is rámeppelhető egy kibaszott utasításra, de ez egyáltalán nem előny általánosan a PC-nek.
Itt alapvető félreértés van a lehetőség és az igény között. Tök jó, hogy egységesítve lesz ez az egész a PC és a konzol között, és nyilván a gyártók kötelezve lesznek az emulációra is, de a fenébe is nem az a szabvány célja, hogy egy konzolt és egy hasonlító alaparchitektúrát kiszolgáljon a szabványalkotó, míg a többin majd le lesz emulálva. Nem erre van szükség! -
Abu85
HÁZIGAZDA
válasz
 Valdez
#27383
üzenetére
Valdez
#27383
üzenetére
Éppenséggel van miről beszélni. Itt nem arról van szó, hogy a hardverek lekövetik majd a wave intrinsics követelményeit, hanem arról, hogy a PC-nek nem ilyen szabványokra van szüksége. Persze nem kérdés, hogy két-három év múlva felkészül mindegyik architektúra, de erre nem lenne szükség, ha nem az Xbox megoldását másolnánk. Eleve minek egy szabványos, de gyártóhoz kötődő konstrukció, akinek ez kell majd használ AGS4.0-t. Szabványban olyan megoldás kell, amely figyel arra, hogy a meglévő hardverek között milyen különbségek vannak, és ezekre általános megoldást kínál. Érdekes a Khronosnak ez sikerül.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27378
üzenetére
Wave intrinsics kell nem shader modell 6.0. Remélhetőleg csak a Microsoft fogja használni, mert a SPIR-V sokkal általánosabb a hardverkezelés szempontjából. Ma viszont van AGS4.0, ami ugyan nem szabvány, de részben ugyanazokat kínálja, mint a szabványos wave intrinsics. Az AGS4.0 egyes függvényeit már kezeli a Battlefield 1, a Deus Ex: Mankind Divided, a Civilization 6, a Sniper Elite 4, a Resident Evil 7: Biohazard, a Doom, a Warhammer 40000: Dawn of War 3 és a Sniper Ghost Warrior 3. Remélem nem hagytam ki semmit.
(#27380) mcwolf79: A Microsoft wave intrinsics nem AMD-s csodák. Jelenlegi állapotát látva az Xbox One mono hozzáférésének intrinsics függvényéi PC-re másolva. Arra szolgálnak, hogy PC-re direkten átmásolhatók legyenek az Xbox optimalizálások. Az, hogy ez az AMD-nek addig jó, amig GCN-t használnak csak mázli. Viszont PC-re ilyen újításokat nem így kellene hozni, hanem úgy, ahogy a Khronos hozza. Semmi baja az AMD-nek például az 56 bites maszkkal visszatérő bollatt függvénnyel, de a Microsoft mégis 64 bites maszkkal dolgozót hoz, amivel az Intel és az NV hardverek sem igazán tudnak mit kezdeni, így hatásfokot veszítenek. Ez így hülyeség.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#27366
üzenetére
A konzolos uralom onnantól számít problémásnak a konkurenseknek, ha a szabványalkotók nem a piac érdekeit nézik, hanem a konzolét. Eddig szerencsére ez nem állt elő, de a wave intrinsics a shader modell 6.0-ban eléggé gázos lesz az Intelnek és az NV-nek.
Eddig csak az történt, hogy az AMD-re lehetett hozni opcionálisan konzolos optimalizálást. De ez nem volt szabványos. A Vulkan sokkal általánosabban fejlődik. Például a SPIR-V ballott nem csak GCN-re mappelhető hatékonyan, ellentétben a DXIL verzióval, ami 64 bites maszkkal tér vissza, és milyen véletlen, hogy a GCN 64 bites skalár regisztert használ. Ebből egy éven belül simán lesznek gondok. A Vulkan egyébként nagyon jó PC centrikus megoldásokkal próbál operálni, csak a Khronos lassan halad.
(#27367) Zsébernardo: Mindkettő fontos, de a termékek között is van kritikus fontosságú. Idén ez a Naples, illetve a Scorpio SoC. A többi nem kritikus.
(#27368) TTomax: A konzol az AMD-nek jelenleg évi ~1,5 milliard dollár közötti bevételt jelent. Ezért fontosak ezek a fix megrendelések. Eves szinten ezek tíz milliós fix eladások.
(#27371) imi123: A PS5 messze van. Lehet amúgy egy még gyorsabb PS4 verziót terveztetni az AMD-vel PS4 Pro Plus neven mondjuk. De ezek folyamatosan csúsztatják az új generáció érkezését, mert a fejlesztőknek ki kell termelni a generációra vonatkozó befektetést. A köztes hardver egyébként nem tűnik már rossz elgondolásnak, mert pont annyi időt dob ra az aktuális generációra, amivel elhúzható a valódi frissítés 2023-ig. Ezzel jó pár extra évet nyernek a partnerek, így nagyobb befektetésekkel operálhatnak.
-
Abu85
HÁZIGAZDA
válasz
 tom_tol
#27364
üzenetére
tom_tol
#27364
üzenetére
A következő negyedév az már a Q3. A Q2-re vonatkozik a 17%-os növekedés előrejelzése. Ebben a negyedévben startol egyébként a Naples és a Vega 10. Ezekre a fejlesztésekre számos termék épül majd. Egyszerűen arról van szó, hogy a befektetők 17%-os növekedésnél többre számítottak. Persze ez még simán több lehet, mert ez csak előrejelzés.
(#27361) Zsébernardo: Ez hülyeség. A befektetőknek a teljes évre vonatkozóan két AMD termék számít. Az Xbox Scorpio lapkája és a Naples. A többi az töltelék. Az Xbox Scorpio azért kell, mert megint lesz egy zsíros OEM szerződés, amivel 150 dollár körül rendel a Microsoft többmilliós tételben, ami felnyomja a bevételt. A Naples pedig azért lényeges, mert 300 dollár körül gyártható processzorról van szó, és eladják majd 3000-5000 dollárért. Ez a nyereséget szolgáltatja. A Ryzen, a Vega, a rakás tölteléket kb. leszarják a befektetők. Kb. arra jók, mint most az 500-as sorozat, hogy megdobja a notebookra vonatkozó eladásokat. Ugye ezek a termékek papíron még nem léteznek, de már szállítás alatt vannak az OEM-ek felé.
-
Abu85
HÁZIGAZDA
válasz
tom_tol
#27350
üzenetére
Semmi köze hozzá. A legtöbb esetben az ilyen nagy változásokat, főleg egy negyedéves beszámoló után a következő negyedévre vonatkozó előrejelzés határozza meg. Az AMD 17%-os növekedést jelzett előre szekvenciálisan, és ezt a befektetők kevésnek tartják. Emiatt esett a részvényár.
A Vega egyébként az AMD idei eredménye szempontjából pont annyira nem lényeges, mint a Ryzen. Ami számít az az Xbox Scorpio és a Naples. Ezek az idei húzótermékek. A többi az töltelék, vagy nagyon az év végén jön. A Scorpio azért lényeges, mert az termeli a bevételt a sok eladás miatt (és ha ez az év végén jön, akkor már nyáron el kell kezdeni szállítani), míg a Naples az egy szervertermék, tehát brutális szokás szerint a nyereség rajta. Illetve nem mellesleg bevezet olyan biztonsági újításokat, amelyekkel x86-os adatközpontokban még nem lehetett találkozni.
-
Abu85
HÁZIGAZDA
válasz
 Raggie
#27291
üzenetére
Raggie
#27291
üzenetére
Az nem bug. A motor támogatja a dinamikus napszakváltozást. Tehát, ha tovább állsz egy helyen, akkor a napból származó shadow casting fény már nem olyan szögben világít be. Ez okozza az eltéréseket. Ha pontosan ugyanabban az időben történne a felvétel, akkor ugyanolyan szögből érkezne a fény. A számításigény egyébként ettől nem változik meg, mert a shader úgyis lefut, csak más lesz az output az eltérő input miatt.
(#27285) FLATRONW: Tükröződik, csak valószínűleg egy pár percet állt az egyik gép a felvétel előtt, és ez elmozdította a shadow casting fényforrás helyét.
(#27286) Yutani: Mindkettőn jó, csak mozog a fényforrás. Persze az ennyire erős visszaverődés nyilván egy dizájnhiba, de ezt nem a kártyák rontják el, hanem ilyen a játék. Őszintén szólva az eddigi CI címekhez képest...

-
Abu85
HÁZIGAZDA
válasz
 FLATRONW
#27281
üzenetére
FLATRONW
#27281
üzenetére
Az se lett volna erősebb igazából, hiszen a nagy látótávolságú jeleneteknél 20 fps különbség is volt. Itt azért erős a Radeon, mert a CI Games frissítette a CryEngine-t, és az újabb verziók PC-re kétféle módon oldanak meg bizonyos problémákat. A szabványos kóddal szimplán sok atomi műveletet használ a motor a préseléshez, míg a másik mbcnt és ballot függvényt. Utóbbi sokkal gyorsabb már a kód szintjén, de csak GCN-en fut le, tehát a GeForce rá van kényszerítve a lassú kódra. Ennyi a titok. Majd ha az egész szabvány lesz a shader modell 6-ban, akkor ezek a függvények általános szinten is használhatók, és valamennyit gyorsítanak a GeForce-on is.
-
Abu85
HÁZIGAZDA
válasz
Raggie
#27268
üzenetére
Amelyik motort sok magra tervezték ott mindig volt haszna, ha négynél több magod volt.
Senkit sem zárnak ki a játékból. A legjobb az új API-kban a skálázhatóság. Alapvetően a szimulációt most sem tervezik többre, mint két mag, annyival pedig mindenki rendelkezik. Ergo azt nem kell skálázni igazán. A rajzolási parancsokkal viszont végre el lehet szállni. A látótávolság lehet igen extrém is, és egy rakás objektumot ki lehet rajzoltatni, és nem kell a LOD-dal levágni. Akinek négy magja vagy négy szála van, annak elég a world detailt low/medium-ra rakni, és rögtön tökélesen fut. Akinek pedig van hat magja mehet highra. Esetleg a 10-12 magos szörnyeknek lehet csinálni egy ultra beállítást.
A lényeg, hogy az új API-k lehetőségeivel a processzoroldali terhelés nagymértékben skálázhatóvá vált, újra, mint régen. Meghatározható, hogy mennyire messze jelenjenek meg az árnyékok az objektumokon, mi az a távolság, ameddig egyáltalán rajzoljon animált objektumot a rendszer. Erre ma is lehetőség van, de a legacy API-k fogják a rendszert, tehát nem tudják nagymértékben skálázni ezt a beállítást egy ideje. Pedig régen nagy különbségek voltak ebből a szempontból. Ez most végre visszatér. -
Abu85
HÁZIGAZDA
válasz
Raggie
#27264
üzenetére
Nem a Ryzen miatt adják ki, hanem azért, mert az új minimum a négy mag lesz, és egy négymagoson már kurtítani kell majd a látótávolságot, hogy fussanak a következő éra játékai, ezzel csökkentve a kiadott rajzolási parancsok számát.
Az ID tech 7 már duruzsol a Bethesdánál, és kiszedték belőle a régi API-k támogatását. Csak Vulkan API-ra építik, aminek az az előnye, hogy minden legacy eljárástól megfosztották, de cserébe nem a két mag a minimum, hanem a négy, és az ajánlott a hat-nyolc mag. A következő kör motorfejlesztései lényegében abban merülnek ki, hogy kiszedik belőlük a legacy API-k támogatását, így ezekhez már nem kell a motor szintjén igazodni, vagyis sokkal jobban lehet skálázni több magra. Ez nagyobb megengedhető látótávolságot, és több számítási lehetőséget jelent. A hat mag csupán ezért kell az Intelnek is, hogy tudjon az inteles felhasználó is hat magot venni ezekhez az igényekhez. Ha nem lenne Ryzen, akkor is kiadták volna, mert itt sokkal inkább a programokhoz kell hardvert kínálni. -
Abu85
HÁZIGAZDA
A "looks nice" igazából egy szabványszöveg. A helyzet az, hogy soha senki sem írhat mást hivatalosan. Így van ez az NV-nél, az AMD-nél, az Intelnél. Ezek a szövegek arra jók, hogy ha valaki kérdez egy érkező termékről, akkor egy ilyen szabványszöveggel lehet válaszolni, még akkor is ha agyonveri vagy kikap nagyon. Ezek központi utasítások az ilyen cégeknél. Aki ebből hírt ír nem nagyon érti, hogy hogyan működik a cégek közösségi médiájában az irányított kommunikáció. A "looks nice" azért jó szöveg, mert úgy érzi a kérdező, hogy válaszoltak neki, és eközben igazából nem történt konkrét utalás semmire.
-
#27254
Abu85
HÁZIGAZDA
huskydog17
#27252
Abu85
HÁZIGAZDA
válasz
 huskydog17
#27252
üzenetére
huskydog17
#27252
üzenetére
Az a baj, hogy egy külön UE4 branchbe került. Ugyanígy van Hairworks, VXAO, Flame, Turbulence, és egy rakás eltérő branch az UE4-re. Az Epic nem engedi meg, hogy bármilyen külső gyártótól származó DRM bekerüljön a main branchbe, és ezáltal a DRM-hez kötött effekteket sem tudják ott szállítani. Ugyanez lesz ennek is a sorsa, mint a fenti sok másik, UE4-be DRM-mel integrált effektnek. A fejlesztők többsége nem kockáztatja meg, hogy nem hivatalosan supportált branchre menjenek, inkább nem érdekli őket az effekt.
Ennek akkor lenne igazán áttörő hatása, ha szimplán egy MIT-szerű licenc mellett felkerülne az effekt a GitHUB-ra, tehát nem úgy, hogy ott a forrás, de bele nem nyúlhatsz, mert a DRM a módosítást nem engedi lefutni, hanem úgy, hogy vidd a forrást, nincs DRM sem és integrált a main branchbe, hogy minél többen használhassák. Ilyen formában sajnos halottnak a csók.
Egyébként az jó hír, hogy a DRM-tól megszabadulhat egy GameWorks effekt. A HBAO-t már megkapta az Epic DRM nélkül, és láss csodát be is építették a main branchbe, de persze közben jelentősen átírták, így sokkal gyorsabban is fut.
-
#27244
Abu85
HÁZIGAZDA
->Raizen<-
#27243
Abu85
HÁZIGAZDA
válasz
 ->Raizen<-
#27243
üzenetére
->Raizen<-
#27243
üzenetére
128 bites GDDR6-tal igazából kiváltasz egy 256 bites GDDR5-ös kiépítést. Nyilván sokkal jobb ezt 128 biten csinálni. A GDDR6-nak árhátránya csak az első fél évben lesz. Utána felfut a gyártás, normalizálódik a verseny, és onnantól már ez éri meg a GDDR5 helyett.
-
#27242
Abu85
HÁZIGAZDA
Petykemano
#27241
Abu85
HÁZIGAZDA
válasz
Petykemano
#27241
üzenetére
A GDDR6 simán jó a középkategóriába, ott nagy sikere lesz. Szerintem belépőszinten marad a GDDR5, míg a felsőházba a HBM2 kell. De középre a GDDR5 kevés, míg a HBM2 nem feltétlenül előnyös, ha nagyon drágán gyártja az adott GPU-t a bérgyártó. Ott a GDDR6 lesz az arany középút.
-
Abu85
HÁZIGAZDA
válasz
schawo
#27236
üzenetére
Elég régóta lehet tudni, hogy milyen újításokat vezet be. Ezek egy részét már az elmúlt évben tartott GDC-n beharangozta Matthaus, ezért maradt egy évig titok a publikum előtt a saját előadása, mert olyan dolgokat mondott el, amelyeket az AMD csak idén tárt fel, de a fejlesztőknek tudnia kellett róla korábban.
A legfontosabb nyilván a HW page menedzsment. Ez a GPU-k következő generációja, kb. akkora áttörés, mint anno a unified shader bevezetése volt. Az egyetlen probléma vele, hogy nehéz megcsinálni, de ha egyszer működik, akkor hatásfokban agyonveri a mostani VRAM menedzsmenteket. Muszáj erre rátérni, mert nem minden fejlesztő fog relatíve használható memóriamenedzsmentet írni a programba a DX12 és a Vulkan API-hoz, másrészt ha mondjuk a fejlesztők tényleg 8 GB-ot fognak igényelni a VRAM-ból, akkor optimálisan 32 GB kell a VGA-kra. Ez fél TB/s-os sávszél mellett már jó 80 wattos fogyasztás GDDR6-ból, és ezt a 32 GB-ot muszáj vinned a normális esetben 120 wattos TBP-jű VGA-kra is, ahol ugye 40 watt marad a memórián kívül minden másra. Ebből látható, hogy mekkora a probléma. -
Abu85
HÁZIGAZDA
válasz
schawo
#27231
üzenetére
Semmi köze a HBM2 fejlesztésének a Vega 10-hez. Régóta kész van a HBM2, régóta rendelhető, nagy mennyiségben. A Vega 10 egy később indított fejlesztés volt, mert azt már a következő generációs problémák megoldására tervezték. Emiatt tud egy rakás olyan dolgot, amilyet más hardver még nem.
De mondjuk az AMD-nek a memóriaválasztása eleve sokkal szabadabb lehet az NV-nél, mert sokkal olcsóbban gyárt nekik a GloFo, mint az NV-nek a TSMC. Nyilván az NV-nél számításba kell venni, hogy nagyon drágán veszik a wafert, ez korlátozza a választási lehetőségeiket. Amúgy mennének ők is a HBM2-re, mert nincs ellenérv rá. Viszont drágán gyártható GPU-k mellett már megfontolandó a GDDR6.
-
Abu85
HÁZIGAZDA
válasz
 Locutus
#27230
üzenetére
Locutus
#27230
üzenetére
A Fury X a HBM nélkül jó 20%-kal lassabb lett volna. A Vega 10 is lassabb lenne HBM2 nélkül. Azt még nem lehet tudni, hogy mennyivel, de nézd azt a tényezőt, hogy ha nem HBM2 lenne rajta, akkor a TBP-ből nem 4 wattot venne el a memória, hanem úgy 40-et, és emiatt a GPU működési órajele is -200-300 MHz lenne.
Nagyon tipikus probléma a VRAM-ra vonatkozó memória, hogy a hagyományosan épített konstrukciók iszonyatosan fogyasztanak már. Főleg a 256 bit feletti kiépítésben, mert ott már sok memórialapka kell, minimum 12 ugye, de lehet, hogy 24, és utóbbi már megint dupla fogyasztás, vagyis repülnek a mínuszok a GPU órajelére. És ugye ott az a szoftveres probléma, hogy kapacitásban minimum az igény négyszeresére érdemes építeni, mert a program által kontrollált rendszerben elveszhet 75%-nyi memória is. Erre mondjuk pont megoldás a HW page menedzsment, de ezt még csak a Vega tudja.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#27227
üzenetére
Yutani
#27227
üzenetére
Nagyon messze van a HBM2 fogyasztásától a GDDR6 is. Egy 1 TB/s-os 8 GB-os HBM2 stack csupán 4 watt. Egy szintén 1 TB/s-os 8 GB-os GDDR6 stack nagyjából 30 watt, beleszámolva a fogyasztáscsökkentést a GDDR5-höz képest. Ez azt jelenti, hogy GDDR6 mellett a TDP keretből 25 wattal kevesebb jut a GPU-nak. És azzal is számolni kell, hogy kell-e a 16 GB VRAM, aminél a HBM2 stack fogyasztása 6 wattra nő csak, de a GDDR6 stack esetében már 60 watt lesz az energiaigény, vagyis rögtön megint 30 wattal kevesebből gazdálkodhat a GPU. Akkora űr van a kettő között, hogy a GDDR6 a középkategória fölött használhatatlan. Persze az olyan trükkök segíthetnek, mint a HW page menedzsment, így mondjuk nem raknak a kártyára csak 4 GB-ot a 16 GB helyett, de még így is nyer a HBM2.
A GDDR6 elsődlegesen azért kell, mert a GDDR5X ára rendkívül magas. Rosszabb rá építeni, mint a HBM2-re, mert drágább lesz a VGA. Viszont a GDDR6 igazi, gyártók által széles körben támogatott szabvány lesz, tehát nem csak a Micron fogja gyártani, így ez végeredményben árversenyhez fog vezetni, és emiatt a GDDR6 végül olcsóbb lesz, mint a HBM2. Lehet, hogy nem az első pillanatban, de úgy fél éves távlatban simán bezuhan majd az ára, ahogy a tömeggyártás felfut.
-
Abu85
HÁZIGAZDA
válasz
 tailor74
#27196
üzenetére
tailor74
#27196
üzenetére
A mikrokódba kell belepiszkálni, de az annyira bonyolult, hogy nem lesz sose megoldva. Ugyanis, ha a mikrokódot sikerül is visszafejteni és visszaírni a változásokat, akkor tulajdonképpen egy 480-a marad a felhasználónak. Egyszerűbb a kártya nevét átírni editorral 580-ra, mert a hatása ebben kimerülne az új frissítésnek.
Sajnos a BIOS nem cseréli le a Polaris 10 GPU-t Polaris 20-ra a kártyán. Az egyébként megoldható lenne, ha valaki szerezne egy Polaris 20-at, leszedné a NYÁK-ról a Polaris 10-et, és így meglenne a hardvercsere, majd az új BIOS-t befrissítené. Ez viszont nagyon macerás. -
#27173
Abu85
HÁZIGAZDA
huskydog17
#27170
Abu85
HÁZIGAZDA
válasz
huskydog17
#27170
üzenetére
Új a memóriavezérlő, ettől lett egy új órajelállapot a memóriára, és új az UVD, olyan az egység, amiben vannak post-processhez dedikált fix-funkciós blokkok, így ezt a munkát már nem a shaderek csinálják. Ettől esik a fogyasztás. Az egész hardveres változás, mert az említett két blokkot kicserélték. Ezért nevezték el a lapkát Polaris 20-nak. Kapott még egy új AVFS módot is, amivel a gyári tuningos megoldások elmehetnek 1400 MHz körüli tempóra. Emiatt maga a TDP keret is megnőtt, hogy legyen mozgástér a gyári tuninghoz. Emellett ráoptimalizálták a lapkákat a Chillre. Röviden ennyi. Hosszabban majd a cikk első két oldalán.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#27135
üzenetére
Sehogy. Rá kell majd nézni a fogyasztásmérőre és ennyi. Ezekről nem lehet beszélni, de tényleg olyan dolgokban hoznak javítást az új lapkák, amelyekért egy csomó Radeon tulaj sír. Gyakorlatilag kisírták ezeket. Csak ugye ezek olyan dolgok, amelyekhez új lapkákat kell tervezni.
-
Abu85
HÁZIGAZDA
válasz
 füles_
#27132
üzenetére
füles_
#27132
üzenetére
Lehet, hogy pár 480-as tulaj is lecseréli, mert pont olyan dolgok változtak, amelyekre sokan vártak. Az igazság az, hogy a TPU hazudott az eredeti címben. Azóta ezt át ís írták, mert nem átnevezés, csak ők ezt nem tudják, mivel nem hívják már meg őket a briefingekre. Gondolom valaki elmondta nekik, hogy ne bénázzanak ennyire. Ezért is más már a cikk címe.
-
#27114
Abu85
HÁZIGAZDA
huskydog17
#27108
Abu85
HÁZIGAZDA
válasz
huskydog17
#27108
üzenetére
Azért fényesebb az új verzió, mert háromszor több pontfényforrás van benne, mint az eredetiben. Az UE3-ban korlátozott volt a motornak a tudása, emiatt hiába akartak valamit dizájnolni a fejlesztők, el kellett fogadni, hogy technológiailag az UE3-nak megvannak a korlátjai, és emiatt van egy maximum fényforrásszám, aminél többet nem tudnak használni. Az új verzió már az UE4-gyel készült, aminek sokkal hatékonyabb a leképezője, így el tudnak helyezni benne lényegesen több pontfényforrást, vagyis megkapták a lehetőséget a dizájnnál, hogy olyanra tervezzék a játékot, amilyenre megálmodták eredetileg, csak 2011-ben technikailag kivitelezhetetlen volt.
Miért csináljanak különdizájnolt PC-s verziót. Alig lesz olyan ember PC-n, aki megveszi, mert ezen a piacon már kijátszotta, aki akarta. Örüljünk annak, hogy egyáltalán leportolták a remastert PC-re, mert azt is mondhatták volna, hogy elég az PS4-re és X1-re is.
Egyébként egyáltalán nem történt butítás. A motorváltással történtek változások a leképezőben. Több pontfényforrást lehet használni, tehát a dizájncsapatot most már a motor képességei nem korlátozzák annyira. Emellett persze újra kellett tervezni a textúrák egy részét, mert 4K-hoz igazították a PC-s verziót, aminél nem elég az a felbontás, amit eredetileg alkalmaztak. Annak a duplája kellett bizonyos textúrákra. De a lényeg az, hogy szám szerint mindenben növekedés történt. Semmiféle butításnak a jele nem látszódik. A korábbi hsz-ben le is írtam az első pár jelenetre. Az, hogy neked jobban tetszik az előző, egy szubjektív dolog. A fejlesztők ezzel nem tudnak mit kezdeni, ők egyszerűen beleraktak mindenből többet.
A legtöbb stúdió nem házon belül csinálja a textúrákat. A People Can Fly sem. Egyszerűen vannak erre szakosodott cégek, akiknél leadod, hogy mire van szükséges, és csinálnak jó pénzért neked textúrákat.Adrian Chmielarzzal sem lenne ez más. Azt látni kell, hogy az UE3-ról olyan UE4 verzióra váltottak, hogy a textúraformátum, amit használtak eddig, kompatibilis legyen. Ez gondolom egy nagyon fontos kritérium volt, mert nem akartak minden textúrát újracsináltatni, csak azokat, amelyeknél a nagyobb felbontásra a 4K felbontás miatt feltétlenül szükség volt. Így viszont persze én sem értem, hogy mi kerül ebben 50 dollárba, de a Gearbox egy kapzsi kiadó.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27094
üzenetére
Az eredetihez hasonló vizet nem láttam még soha. Olyanhoz hasonlót viszont már láttam, ami a remasterben van. Lásd a trópusokon.
Ha a két jelenetet megmutatnák, és az lenne a kérdés, hogy milyen folyadék van rajta, akkor a másodikra azt mondanám víz. Az eredeti verzióra nem tudnék válaszolni, valami periódusos rendszerben nem létező elemekből összeálló izére tippelnék.Kérdés mennyire durván tőrnek elő a sugarak. Szerintem még a remaster is eltúlzott ebből a szempontból.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27092
üzenetére
Igen. Az első jelenetnél a víz egyértelműen szebb. Az ami van az eredeti verzióban egy nagyon régi shader, még 2007-es. Nem átlátszó, egyáltalán nem hasonlít a vízre. Az új shader sokkal jobb, szépen át lehet látni a vízfelszínen. Aztán rögtön az elején látható, hogy a fát mennyivel jobb modellre sikerült lecserélni. Nem töredezett, hanem sokkal simább. A lens flare is visszább van véve.
A második jelenetnél nagyon erősek a volumetrikus fények a napból, de csak azért, mert máshogy áll a shadow casting fényforrás, mint az új verzióban. A korábbi verzióban egész felhőkarcoló amin mentél olyan, mintha be lenne árnyékolva teljesen. Az új verzióban végre ezt sikerült korrigálni, viszont látható, hogy így az árnyékok is másképp állnak. Ez egy jó döntés a dizájner csapat részéről.
A harmadik jelenetben szintén a shadow casting fényforrás lett megváltoztatva. Valószínűleg azért, mert a faszi, akit lelőttek az eredeti verzióban világított, mint a karácsonyfaégő, csak nem lehetett tudni, hogy miért. Talán az aurája volt erős. De az új fénypozícióval ez sokkal jobban van kezelve.
A negyedik jelenetben láthatóan jobb az új verzió. Több a füst, jobb a robbanás. A több pontfényforrás is megtette a hatását.
Az ötödik jelenetben látható, hogy megint eltérő a shadow casting fényforrás pozíciója. Itt látható igazán, hogy mennyire más az új leképező, illetve látható az is, hogy új textúrákat kapott a játék.Nem kommentálom végig az egész videót jelenetenként. De úgy nagy átlagban az előnyére változott, főleg a durva grafikai dizájnhibák tekintetében.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27090
üzenetére
A textúrák mérete annyira lényegtelen a futtatáshoz. Akármilyen méretű textúrákkal is pontosan egy sugár lesz kilőve egy pixelből, és azok egységnyi szűrési feltételek mellett pontosan ugyanannyi texelből térnek vissza a mintával. Ezért látod azt, hogy a textúraméret növelésével vagy csökkentésével szinte alig változik az fps.
Elsősorban azért fut jobban a program, mert a szoftverfejlesztésnek van egy átlagfelhasználók előtt kevésbé ismert tapasztalati megfigyelése, miszerint egy "1.0-s" verzióban kiadott program teljesítménye másfél év alatt megduplázható ugyanazon a hardveren, csupán a kód optimalizálása által.A víz az egyébként lényegesen jobb lett. A régi víz az csupán az UE-vel kapott rendszer volt, míg most csináltak egy saját shadert hozzá. A fényeket sem butították le, sőt a leképező fejlesztése pont azt szorgalmazta, hogy több pontfényforrással dolgozhassanak, csak leszedték a túlerősített lens flare-t.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27088
üzenetére
Nem értem. Itt arról van szó, hogy hol a hiba. Nem tetszik a felhasználónak, mert megszokta a régit? Rossz munkát végzett a textúrákat elkészítő partnerstúdió? Nem volt teljesen összehangolt a munka a stúdiók között, így esetenként nem illik az adott tartalom az adott leképező működéséhez? ... kb. ez a három lehetőség merül fel, de biztos nem az, hogy kevesebbet számol az új verzió, mert jóval többet számol, elvégre a texelek szintjén jobb minőségűek az új tartalmak. Utóbbira nyilván szükség van a 4K-hoz, hiszen a régi tartalmat nem 4K-hoz tervezték, hanem Full HD-hez. Ezért rajzoltatták a textúrák zömét újra, mert a régi textúrákból nem kértek nagyobb felbontásút, mint amivel szállították.
-
#27087
Abu85
HÁZIGAZDA
huskydog17
#27086
Abu85
HÁZIGAZDA
válasz
huskydog17
#27086
üzenetére
Ahogy nézem ez a játék tényleg újra lett dizájnolva. Ha ez történik, akkor elég sok tartalom cserére kerül, tehát nehéz összehasonlítani az előzővel, mert már nem az eredeti tartalom köszön vissza mondjuk egy új leképezővel.
A textúrák közötti különbség is csak ebből adódhat, mert méretben a legtöbb textúra felbontása a kétszeresére nőtt. Kérdés, hogy az új textúrákat ki készítette. Lehet, hogy nem ugyanannak a partnernek adták ki a munkát. Viszont ez nem technikai szintű dolog, hanem pusztán az új partner nem végez olyan jó munkát a rajzolás terén. Ettől még pusztán a számok mezején, tisztán technikai értelemben az új verzió mindegyik korábbi portnál jobb minőséget prezentál, egyszerűen mindenből több van. Innentől kezdve az egész egy dizájnkérdés. -
-
Abu85
HÁZIGAZDA
válasz
 mlinus
#26976
üzenetére
mlinus
#26976
üzenetére
Nem. A PS4 libGNM-et használ, vagy libGNMX-et. Utóbbi a magasabb szintű elérés, ami valamennyire hasonlít a DirectX-hez, de nagyrészt inkább egy wrapper a libGNM-en. Ennél több API-ja a PS4-nek nincs. Szó volt a Vulkan API-ról egy időben, de nem prioritás. Egyszer persze lehet, hogy elkészül.
Egyébként az Xbox One-on is csak az egyik API a DirectX 12. Függetlenül attól, hogy a többi API-t is DirectX-nek hívják tulajdonképpen semmi közük a PC-ben található DirectX verziókhoz. Egyedül a 12-es verzió egyezik meg a PC-s API-val. A 11.x és a mono hozzáférést több helyen is eltér.
-
Abu85
HÁZIGAZDA
válasz
FLATRONW
#26918
üzenetére
A két termék között van ekkora különbség, ha a VRAM vagy a sávszél nem jelent korlátozást. A Fury X eléggé sávszéllimites VGA, míg az RX 480 jóval kevésbé az. Mivel a Unity egy mobil motor, így a sávszéllimit nem lényeges, mert eleve olyan a leképező, hogy spóroljon vele. Ezért tud elhúzni a Fury X, és feláll a valóban reális teljesítménykülönbség az RX 480 és a Fury X között.
De a GTX 1080 így is gyorsabb a Fury X-nél, ha egyszer lesz hozzá profil. Valószínűleg az NV-nek sokkal nagyobb prioritású feladatai vannak most, minthogy a Vikinghez profilt csináljanak. Az erőforrás pedig szűkös.A drivereknél van egy általános fejlesztés is, ami a háttérben zajlik. Ez is közrejátszhat. A GeForce driver GUI-ja nagyon elavult, sok erőforrást zabál és már igen lassú a reakcióideje, stb. Fél évtizede jó volt, de ma már nem az. Éppen ezért a háttérben zajlik a vezérlőpult GUI-jának reformja. Ez már egész jól halad. A gyártóktól annyit tudni, hogy a mostani vezérlőpult el fog tűnni és minden beállítás beköltözik a GeForce Experience-be, ami a driver univerzális GUI-ja lesz. Hasonlóan a Radeon Software Radeon Settings programhoz, ahol szintén egységes felületre kerül minden. A GeForce Experience 3.0 ezért kapott egy olyan alapvető frissítést nemrég, hogy kevesebb memóriát foglaljon és gyorsabban töltsön be. Ez az NV-nél szintén elvisz elég sok embert, miközben az AMD-nek már ezzel a problémával nem kell törődnie, csak a költözést kell befejezni.
Reálisan gondolva az NV valószínűleg arra jutott, hogy ez a vikinges izé nem olyan fontos játék, hogy szükség legyen day0 profilra. A 4K-t leszámítva eleve elég jól fut a program. Ezzel szemben az általános fejlesztéseket hozni kell. Követni kell a GUI átalakítását, az új trendeket, vagyis a teljes funkcionalitást egy közös felületről.
-
Abu85
HÁZIGAZDA
válasz
FLATRONW
#26916
üzenetére
Az AMD-nek amúgy is finomabban esik a teljesítménye a felbontás növelésével. Tehát ez általánosan látható jelenség. Amiért ez most durvának tűnik az az, hogy az NV-nek nincs normális profilja a játékra, míg az AMD driverében teljes profilja van rá, lecserélt shaderekkel. Ez tipikus driverprobléma. Nincs erőforrása az NV-nek mindenre reagálni, ha egy bugot háromszor kell javítani. Az AMD-nek ma sokkal kedvezőbb a helyzete a játékokra való optimalizálás során, mert csupán egy branch van.
-
Abu85
HÁZIGAZDA
válasz
 Vigilante
#26914
üzenetére
Vigilante
#26914
üzenetére
Itt sem erősebb, csak az NV túl lassan tudja hozza a profilokat az összes játékhoz. Egyre inkább az látszik, hogy a többcsapatos driverfejlesztés működésképtelen. Felesleges munkákat generál, ezek elveszik az időt és a humánerőforrást, korábban javított bugokat hoz vissza, és még megbízhatatlan is, amitől ömlenek a hotfixek. Ahogy korábban AMD is rájött erre, úgy az NV is rá fog jönni, hogy ez így hülyeség, csak az erőforrást pazarolják. Talán már rá is jöttek, csak marha nehéz visszaállni a régi modellre, mert szinte egy komplett strukturális reform kell hozzá. De megéri, mert így ez nem maradhat.
-
Abu85
HÁZIGAZDA
válasz
 Crytek
#26911
üzenetére
Crytek
#26911
üzenetére
Jól fog ez futni NV-n is. Az AMD-nek csak azért fut jól már most, mert nagyon jó a driverfejlesztési struktúrájuk, amit kialakítottak. Az az egy nagy csapat sok emberből áll, és nem csak az agyonreklámozott, hanem a fű alatt megjelenő játékokra is van bőven erőforrás, emiatt a Radeon Software-ben már van a játéknak profilja, ki vannak cserélve a shaderekben a tipikus operációk, meg a szokásos (ez bőven hoz úgy +15-20%-ot). Az NV-nek a csapata három részre van vágva, és ott a committeléssel keletkező bugok javítása is rengeteg erőforrást elvisz. Effektíve a feladatokra elérhető erőforrás tekintetében az NV-nek kevés az embere, mert rosszul van struktúrálva a fejlesztési folyamat. Ugyanaz a baj, amikor az AMD havi egy WHQL Catalystet hozott. Ezért ugyan az agyonreklámozott játékokhoz tudnak hozni profilt időre, de a csak simán megjelenőkhöz már nem. Lenne amúgy elég emberük rá, ha nem kellene egy bugot háromszor javítani sorban a három összevonás miatt, ez időben és emberi erőforrásban is háromszoros teher. Valószínűleg egy-két hét múlva kiadnak majd egy profilt a játékra, ami javít a teljesítményen.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26895
üzenetére
Nem mindegy, hogy miképpen váltanak motort. Ők eleve a CryEngine-t is nagyon durván átírták, amit tettek az annyi, hogy az eddig megírt kódot átvitték a Lumberyard alá, amit nem volt nehéz megtenni, mert a használt és az új motor struktúrája megegyezett. Tehát nem sok munkájuk volt ezzel, lévén a saját kódjukkal dolgoznak így is, csak mostantól az Amazontól kapnak technikai támogatást, és használhatják az AWS-t, alapvetően csak ezért váltottak.
Ha mondjuk nem a saját kódjukkal dolgoznának, akkor más lenne a helyzet, de nekik alapvetően nem a Lumberyard képessége kellett, hanem az Amazon Web Services.Eddig nagyrészt a Mantle kódot fejlesztették pusztán amiatt, mert ebben volt a legnagyobb időmennyiségük, illetve ez elfogadta a HLSL-t (ugye rengeteg effektet a játékba az AMD ír, tehát olyan API-n kell lenni, ahol ez tesztelhető). Ugyanakkor már be volt építve a DX12 és a Vulkan támogatás is, csak nem volt leoptimalizálva. Ez nem akkora gond, mert a három említett API alapvetően nagyon hasonlít egymásra, tehát az egyik API-ra írt struktúra helyből alkalmazható a másik kettőre. Vagyis a low-level leképező optimalizálása nem vesz el többet két hétnél. Annyit kell eldönteni, hogy a Mantle-ről merre lépnek tovább. Eredetileg a DX12-re akartak lépni, de inkább a Vulkan API-t választották. Ez összességében a terveket nem vetette hátrább, mert ugyanannyi idő és erőforrás kell az aktuálisan használt kiindulópontból mindkét API-ra optimalizálni. Talán Vulkánra még egy picikét könnyebb is, de ez csak a saját fejlesztési modelljük specifikus hatása.
Persze a shader fordításnál lesz egy kis extra meló, mire a HLSL-ből SPIR-V-t kapnak, de a nyílt forrású infrastruktúrák miatt ez ma már kivitelezhetővé vált. -
#26874
Abu85
HÁZIGAZDA
huskydog17
#26872
Abu85
HÁZIGAZDA
válasz
huskydog17
#26872
üzenetére
Nocsak. A DXIL köré húzott infrastruktúra kinyitja a kapukat? Végül is mind a DXIL, mind a SPIR-V nyílt forrású. A fordítók tehát szabadon felhasználhatók, így már csak egy DXIL->SPIR-V konverter kell. Nem elegáns, de tökéletesen működőképes. Gondolom a DX11-et is azért dobják el, hogy a D3BC-t kizárják a fejlesztésből.
-
Abu85
HÁZIGAZDA
A tesszellálást igen, de a végső megjelenítéshez használni kell a setupot és a rasztert is, ahol már gyorsabbak a Radeonok. Tehát összességében a Mass Effecthez hasonló nem túlzó, hanem inkább elbaszcsizott dizájnnal nem nyer senki.
Az NV egyébként nem véletlenül nem fejleszti már a GameWorks-ben a tesszellációs effektet. A Deus Ex MD-ben van az eddigi legdurvább háromszögszám jelenetenként, és ezért nyerik főleg a beépített benchmarkot a Radeonok. Hiába számolja ugyanis gyorsabban a nézőpontfüggő tesszellálast a GeForce, ha a raszternél jobban kikapnák.
Ez a fő oka, hogy olyan effektek készülnek a Gameworks-ben, ahol rejtett geometriákat lehet tesszellálni. Ez ugyanis nem terheli a rasztert, ami a Radeonok erőssége. A volumetrikus fényeffektjük pont ilyen. Az ott tesszellált geometria nem megy tovább a raszterre. Na persze az igazsághoz hozzátartozik, hogy egy ilyen effektnek semmi szüksége tesszellálásra, de ez már sokadrangú kérdés, hiszen benne van az érintett programokban low minőségben is, ami pici tesszellálást alkalmaz es a minősége szinte ugyanaz. De a lényeg, hogy a raszter miatt nem játszik már senki szándékosan krájsziszkettőset. Még az NV sem, mert többet vesztenek, mint nyernek. -
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26849
üzenetére
Nem is az új Frostbite-ra kellett volna lepni, hanem az egyel újabbra, amire elég könnyű lenne váltani, hiszen csak optimalizálást tartalmaz. A könnyűséget jelzi, hogy a Battlefront átváltott rá a legújabb DLC-vel.
A BF1-ben azért vannak átvezetők, hogy azok lejátszása alatt a pályabetöltés megkezdődjön. Akár real-time-ban is meg lehetne oldani, hiszen eleve egy Radeon Pro Duós gépen lettek rögzítve.
Mint írtam a legújabb motorverziót kivéve elég gyenge az animációs pipeline. Minden Frostbite játékot érint a probléma a BF1-en kívül. Ez van. Az új motorban már jobb rendszer van, tehát a jövő fényes.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26842
üzenetére
Ezt én másképp látom. A BF1-nél jobb a PBR. Különösen a fémes felületeké. Az égboltban egyetértek, de abban a Mass Effect megkapta a Frostbite kísérleti rendszerét. Ez a BF1-ből hiányzott. Ebben tényleg jobb a Mass Effect, de másban nem.
Az animáció és a mimika az egyes játékokban azért rossz, mert a régebbi Frostbite verzióknál nehéz volt bánni ezzel a modullal. A BF1-ben azért jó, mert kapott egy sokkal egyszerűbben kezelhető új pipeline-t, ami ráadásul sokkal jobb is. Sajnos ez nem igazán a munkamennyiség kérdése, illetve csak részben, sokkal inkább a felhasznált motorverzió animációs moduljának hiányossága.
Haj megjelenítése dettó ugyanilyen probléma. Öreg a motorverzió.
Ezeket sajnos nem nagyon tudják frissíteni, mert erre van meg a tartalom, így ezt a modult kell használni. Még a fejlesztés elején lehetett volna azt csinálni, hogy kooperációban dolgozik a Bioware a DICE-szal, és akkor esély lett volna a legújabb animációs modult használni. -
Abu85
HÁZIGAZDA
válasz
mlinus
#26843
üzenetére
Valójában az a motor sara. A legújabb Frosbite kapott egy jóval jobb animációs pipeline-t. Az egyik hibája volt annak a motorverziónak, amit az új ME használ, hogy elég régi alapra épült az animációs pipeline-ja, igy nehéz volt rajta jó eredményt elérni. Tekintve, hogy elég nagy fejlesztés egy RPG, így kevés erőforrás juthatott erre, ami a rossz alap mellett ennyire elég.
-
Abu85
HÁZIGAZDA
válasz
Valdez
#26841
üzenetére
Dehogynem. A mérések úgy készültek, hogy az AMD javítását kikapcsolták. Ezekhez az eredményekhez képest hardvertől függően 10-20%-kal jobb sebességet fognak kapni a felhasználók otthon, akiket a fair-play nem érdekli, csak nem akarják felesleges számításokkal csökkenteni a teljesítményt.
Nyilván egy tesztnél kérdéses, hogy miképp mérjenek. Aktiválják-e az AMD javítását, vagy várják a programfrissítést és addig a sík felületeket is tesszellálják a Radeonok is, mert az NV nem kínált erre meghajtó oldali javítást ... még. Valszeg, ha a Bioware nem lép, akkor a Metro Reduxokhoz hasonló profilt kap a Mass Effect is. Ott kikapcsolhatatlanul része a profilnak egy tesszellációs driveres korrigálás. -
Abu85
HÁZIGAZDA
Benne van driveres hírben, hogy az optimalizált beállítás kiszűri a sík vagy közel sík felületen történő tesszellálást. Kikapcsolni ezt nem érdemes, mert az rontja az igaz HOS-t. A speciális profil direkt azért van, hogy kezelje ezt a dizajnhibát. Ezt később úgyis javítja a Bioware, mert az NV már tuti veri az asztalt, hogy a GeForce-ok raszterizálójának hatékonyságát tesszellált sík felületek csökkentik, ami a képminőség javulása nélkül rontja a sebességet.
Ha offoljátok a tesszelálást, vagy 4x/8x-re korlátozzátok, akkor az látható képminősédromlást is eredményezhet, bár az eddigi beszámolók szerint a 8x beállítással ez nem vehető észre. Viszont így is a speciális profil a legjobb, mert az csak a dizajnhibákat javítja.
De a Bioware úgyis hoz patch-et erre, vagy ha nem, akkor az NV is meg tudja csinálni ugyanazt, amit az AMD, és ők is nyernek 8-10%-ot. A Metro Reduxokra úgyis megírták a szükséges modult. -
Abu85
HÁZIGAZDA
válasz
#35434496
#26837
üzenetére
4K-ban a BF1 single nagyobb részletesség mellett simán tud majdnem duplaannyit. Egyszerűen csak régi a motorverzió. A Mirror's Edge Catalysthez fejlesztett Frostbite verziót nem véletlenül nem használja a legtöbb EA projekt, ez a második játék, ami erre épül. Optimalizálatlan és bugos verzió az újabb verziókhoz képest. Van két újabb Frostbite. Az egyik a BF1-es, amire sajnos nem olyan könnyű átállni a fejlesztések végén, de a Fifa 17-es és a Battlefront frissített motorjára könnyű lépni. De a Mass Effect bugokat látva, valószínűleg nem ez volt a legnagyobb gondjuk a fejlesztőknek.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26825
üzenetére
A verzió az mindegy. Eleve a DX12 is fejlődik, hiszen most kap shader modell 6.0-t, és ettől az API-t még DX12-nek hívják. A Vulkan is fejlődik, bár az 1.1-es verzió valószínűleg csak az év második felére jön.
De maga a Vulkan lesz a jobban elterjedt hosszabb távon. Mint írtam csak is azért, mert a licenelésre felkínált motorok azt választották. A top stúdiók jelentős része valószínűleg marad a DirectX-nél. Már csak azért is, mert ez gyorsabban fog fejlődni, mint a Vulkan. Eleve tervben van már a shader lépcsők egyszerűsítése, illetve a memóriamenedzsment újragondolása. Azt nem tudom, hogy amikor ezekre megjönnek a frissítések, akkor a DX12 DX12 marad, vagy már DX13, esetleg DX12.5. Őszintén szólva lényegtelen.
Azt is figyelembe kell venni, hogy a DX12 egyik legnagyobb hibája a top stúdiók által az volt, hogy csak nagyon nehezen tudják kiegészíteni a gyártók. Emiatt az AMD, az Intel és az NV is külön szervizkönyvtárat ír hozzá. A DXIL-lel ez sokkal egyszerűbb lesz, mert magát az IR-t úgy építették fel, hogy nagyon egyszerűen rakhassanak bele a cégek vagy a stúdiók gyártóspecifikus kiterjesztést. -
Abu85
HÁZIGAZDA
-
#26822
Abu85
HÁZIGAZDA
huskydog17
#26813
Abu85
HÁZIGAZDA
válasz
huskydog17
#26813
üzenetére
Vulkan támogatást kínál a jövőben: Epic, Unity, Crytek, Amazon, Valve, id Software, Croteam, Egosoft, Oxide, Silicon Studio, Rebellion, Fish Labs, meg az openszószos motorok fejlesztői.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26819
üzenetére
A játékok mennyisége pusztán a Unity és UE Vulkan melletti kiállása miatt fog a Vulkan irányába eltolódni. Mindkét motorban van ugyan DX12 támogatás, de a Vulkan lesz az elsődleges, így a fejlesztőknek sem lesz értelme a DX12-re menniük, ha Unity és UE motort használnak. Ráadásul a Vulkan annak ellenére jobban áll mindkét motorban, hogy a DX12-höz képest jóval később kezdték a beépítését. Ennyit tesz az, hogy a befektetéseknél látják az értelmét az egyik API-ra költeni, míg a másikra nem. A CryEngine is inkább a Vulkan felé fog menni, ahogy a Lumberyard is, illetve az Open Source motorok is mind Vulkan API-ra mennek a DX11-ről. Aki licencelésből él, annak nincs értelme a DX12-t választania. Be fognak építeni egy alapvető DX12 támogatást, mert az pusztán a hibakeresés miatt megéri, de a megrendelők úgyis a Vulkan módot fogják engedélyezni, mert a jóval több befektetett munkaóra miatt az lesz a jobb.
Úgy gondolom, hogy a top stúdióknak megéri a DX12 mellett maradni, mert a Microsoft gyorsabban fogja fejleszteni, illetve a top stúdiók eleve arra álltak/állnak be, hogy GCN optimalizálásokat hozzanak át a konzolról PC-re, amihez valóban egy GCN-hez igazított API a legjobb alap. Májustól ezeknél az optimalizálásoknál nem is kell az AGS4-re építeni, hanem jön a szabványos shader modell 6.0. A nem csőlátásban konzolra fejlesztő rétegnek a Vulkan mindenképpen jobb API. Sokkal általánosabban kezeli a PC-s hardvereket, ezért a tradicionálisan PC-s fejlesztésekhez mindenképpen ez az ideális.
A PC-s felhasználó is jobban jár a Vulkan API-val, mert ha az általános felépítést nézzük, akkor sokkal függetlenebbül kezeli a hardvereket, mint a DX12. Persze nincs bindless, de nem muszáj ilyen kódot írni, bindless módban a DX12 is rendkívül részrehajló, sokkal jobban kezeli a GCN-t és a Gen9-et, mint bármi mást. A Vulkan inkább trükközve oldja meg ezt a problémát. Igazság szerint elég jól, nem mellesleg a jelenlegi modellje kiegészíthető bindlessé, ha szükség lesz rá.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#26810
üzenetére
Szerintem mindenképpen a Vulkan lesz az elterjedtebb, mintsem a DX12. Alapvetően nincs nagy különbség a két API között. Persze apró eltérések miatt fel lehet hozni mindkettő mellett a pró/kontra érveket, de nem tud sokkal többet a DX12. Ami igazi érv mellette az a multi-GPU és az executeindirect. A HLSL shaderek megléte nyilván ma fontos, de a SPIR-V nyílt rendszer, a DXIL is az lesz, tehát igen egyszerű lesz ezeket használva GLSL shadert küldeni DX12-re, vagy HLSL-t Vulkan API-ra. Az új platformok nyíltsága tulajdonképpen lehetővé teszi azt, hogy a magas szintű nyelv igazából ne számítson. Abban írja meg a fejlesztő a shadert, amiben akarja, aztán a nyílt rendszert kihasználva keres vagy ír egy fordítót, ami abból SPIR-V vagy DXIL kódot generál. Ez a jövőben egyáltalán nem lesz probléma. Ma még az a D3BC zártsága miatt, de ez az IR úgyis kuka lesz.
A Vulkan pedig kiegészíthető multi-GPU-val, multidraw indirecttel, akár bindless modellel, tehát végeredményben egyedül a platformfüggetlenség marad meg, mint előny. A többségnek ez sokkal jobban fog számítani, mint annak a kevés csúcstechnikával dolgozó stúdiónak/kiadónak, akiknek amúgy tényleg érnek is valamit a DX12 gyors és amúgy tényleg csúcs fejlesztései. Nem mellesleg nagyon nagy érv még a Vulkan mellett, hogy tényleg úgy építette fel a Khronos, hogy gyártófüggetlen legyen, míg a Microsoft a DX12-t láthatóan GCN-re csinálta az Xbox One miatt, és különböző fallback módok vannak a többi hardverre, ami ugyan nem követel eltérő kódot, de ezek implementációja jobban eszi a processzort, mint a GCN-é. Az Intel is egy brute force fejlesztéssel húzta be magát a legjobb szintekre, ami közel sem hatékony, de volt tranyóbudget bőven rá. Például más ilyet nem tud megjátszani. Ellenben a Vulkan jelenleg rendkívül igazságos az eltérő gyártók hardvereivel, ha lehet ilyet mondani.
-
Abu85
HÁZIGAZDA
válasz
 velizare
#26804
üzenetére
velizare
#26804
üzenetére
Gondolom megkapják. Végtére is a technika az AMD-é marad, és úgyis megjelenik a GPUOpenben. A Bethesda csak hamarabb kapja meg.
(#26805) Fred23: Mert kb. százezer sornyi HLSL shader van egy stúdiónál, amit nem olyan egyszerű hordozni. Majd ha elég jó lesz a HLSL->SPIR-V fordító, akkor több lesz a Vulkan port. A DX12 addig is elterjedtebb marad.
A shader nyelv problémáját a SPIR-V és a DXIL teljesen megoldja, mivel mindkét IR köré nyílt infrastruktúra épült. -
Abu85
HÁZIGAZDA
válasz
TTomax
#26799
üzenetére
Mert a Doomba nem igazán terveztek semmiféle innovatív eljárást vagy effektet. Tudott mindent, amit tudni kellett és azt gyorsan számolta. Nagyjából ennyi volt a cél. Ezt azért elég jól elérte.
Valószínűleg a Bethesda nem tart fenn olyan komoly technikai részleget, mint az EA. Ezért is pacsiztak le az AMD-vel, hogy az effektekre vonatkozó újításokat fejlesszék ők bele a játékaikba. Ez a Bethesdának tiszta haszon, mert ingyen kap csúcstechnikákat. -
Abu85
HÁZIGAZDA
válasz
Yutani
#26797
üzenetére
A motor az mindegy. A lényeg a deal, amit kötöttek a Bethesdával. Ha tényleg egy beszállító partner lesz az AMD, akkor a kódok jelentős részét ők adják és nem az adott stúdió fejleszti. Elképzelhető, hogy a Bethesdának így sokkal olcsóbb, mert megvágható a kutatási pénz. Az AMD, mint partner megcsinálja helyettük.
Másik API-t egyébként lehet rakni bármelyik motorba. Bár ha OpenGL lesz a QC, akkor egy rakás specifikus path lehetősége miatt nem biztos, hogy érdemes. Persze az kérdés, hogy az AMD csak effekteket szállít, vagy megírják a kívánt API támogatását is. Utóbbi esetben meg könnyebb a Bethesda dolga, hiszen megrendelhetik a támogatást.
-
Abu85
HÁZIGAZDA
válasz
Yutani
#26795
üzenetére
Na majd a Quake Champions.
![;]](//cdn.rios.hu/dl/s/v1.gif)
A PAX East videók alapján a kék színű hajú hősön TressFX 4 volt. Lehet ez lesz a debütáló cím, bár amit lehet hallani a Bethesda üzletről esélyes, hogy a Prey-be is belerakják. Eléggé furcsa dealt kötöttek, tulajdonképpen ag AMD a Bethesda kiszolgálója lesz. A stúdiók rendelnek effekteket az AMD pedig szállítja nekik. A Bethesda pedig megspórolja a kutatási költséget.
-
Abu85
HÁZIGAZDA
Abba gondoljatok bele, hogy ha az NV a G-Sync-kel hosszú távon számolna, akkor már rég csináltak volna egy olcsón gyártható ASIC-ot a mostani FPGA helyett. A helyzet viszont az, hogy ez nem éri meg. Át fognak állni a VESA szabványára, sőt, a notebookpiacon már at is álltak. Attól, hogy G-Sync a mobil piacon a név, a technológia már az Adaptive-Sync. Ugyanez lesz az asztalon is, csak elmennek a falig. A megcélzott felhasználóbázis pont úgy el fogja fogadni, mint a 3D Vision kivégzését. Vesznek új monitort, mint a 3D-nél. Nem véletlenül van prémiumként hirdetve, az a réteg, akinek ez szól kevésbé haragtartó, ha bejelentik, hogy vége. Jó persze sokan írogatnak majd a fórumukra, mint a 3D Visionnél, hogy köcsög NV, de ugyanúgy GeForce-ot fognak venni. Szóval anyagi kár ebből nem lesz.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#26732
üzenetére
A piac elárasztása termékekkel nagyon fontos, mert ma a többség nagyáruházakban vásárol. Ha bemész a Media Marktba, akkor mázli kell a G-Sync kijelző megvásárlásához, míg FreeSync-ből jellemzően 5 felé lesz raktáron. Ennek durvább esett volt, hogy egyszer teszteltettem a berlini áruházat a kinti ismerősömmel. Az eladó nem tudta, hogy mi az a G-Sync, amikor pedig elmagyarázta a spanom, akkor azt mondta neki, hogy az nem G-Sync, hanem FreeSync és vannak ilyen LG és Samsung kijelzőik. Remélem ebből látszik a probléma.
-
#26727
Abu85
HÁZIGAZDA
Petykemano
#26724
Abu85
HÁZIGAZDA
válasz
Petykemano
#26724
üzenetére
- a GloFo és a TSMC FinFET node-jának ára nem lényeges, mert az AMD fix wafer mennyiséget rendel. Ez egy előre fizetett szerződés, ami kötelezettséget von maga után. Például ha a GloFo nem tudja leszállítani a wafereket, akkor büntetést fizetnek, de ha az AMD kevesebbet akar rendelni a megbeszéltnél, akkor az szintén büntetést jelent. Ezt azért csinálja a Glofo, mert kell nekik egy fix megrendelő, mig az AMD azért megy bele, mert így a normál waferár felével meg lehet úszni. A TSMC ilyet nem csinál, mert ők versenyeztetik a megrendelőket. Aki többet fizet azé a gyártósor.
- a GDDR5X esetében nem az a baj, hogy csak az NV vásárolja, hanem az, hogy csak a Micron gyártja. Annyit kérnék a memóriáért amennyit akarnak, mert nem tud hova menni a megrendelő. -
Abu85
HÁZIGAZDA
válasz
 távcsőves
#26709
üzenetére
távcsőves
#26709
üzenetére
DX12-ben van, a Vulkánban pedig lesz, illetve már van, de még csak tesztelésre, hogy a jövőben egyszerű legyen beépíteni.
A hagyományos SLI és CF inkább nem lesz, mert túl bonyolult, ha egy meghajtó irányítja az egészet.
A DX12/Vulkan alatt a fejlesztőé a munka. A hagyományos CF/SLI-nél a driver vezérli az egészet, a fejlesztőnek arra kell figyelni, hogy a kódja kompatibilis legyen a driver igényeivel. Azért döglődik az egész, mert ezt egyre nehezebb összehozni. Ha nem sikerül, akkor mindenki csak néz ki a fejéből, hogy hol lehet a hiba, aztán a végén nem lesz CF/SLI a játékban. -
Abu85
HÁZIGAZDA
A shader nyelv leginkább azért jön, mert a konzolok shader nyelve fejlődött, mig a PC gyakorlatilag egy helyben toporgott. Ez leginkább azért gáz, mert a konvertáló, amit írnak PC-re sokkal lassabb kódokat generál. Az SM6 gyakorlatilag egy teljes modernizálás. A hardverek működéséhez igazítják az IR-t is, hiszen rég a SIMT a menő, amire egy SIMD-re fejlesztett IR nagyon nem jó. Szóval több probléma kerül megoldásra.
A Khronosnak ott van már a SPIR-V. Az nagyvonalakban DXIL képességű.
A wave intrinsics menni fog minden vason, csak nem mindegy, hogy például egy prefixsum egy utasítás, vagy több tucat. Itt igazából sebességkülönbségek lesznek.
-
#26639
Abu85
HÁZIGAZDA
huskydog17
#26629
Abu85
HÁZIGAZDA
válasz
huskydog17
#26629
üzenetére
Szóval az Ubi 12 éves engine struktúrája, amire felhúzták a jelenlegi motorjaikat nem működik DX12 alatt. Nahát?!
Érdekes az új alapokra épített Snowdrop alatt működik. Lehet, hogy az Anvil alappal van gond?
-
Abu85
HÁZIGAZDA
Ez maga a probléma. Egyre csak csökken a kihasználás hatásfoka.
(#26601) Locutus: A HBM-nél ez nem akkora gond, mert nagyon keveset fogyaszt maga a memória. A problémát a GDDR5/5X/6 jelenti. 32 GB-nyi ezekből a memóriákból már jó 70-100 wattot fogyaszt. Holott az optimális mennyiség a VRAM-ra leginkább 10-30 watt. Nem mindegy, hogy egy adott TDP keretből 20 wattot visz el a memória, vagy 80-at például. Ennyivel kevesebb jut ugyanis a GPU-nak. Ez igazából egy régen ismert probléma. Még az NV-től Dally és Marci a JEDEC-től csinált régebben egy tanulmányt, hogy a memória tipikus fejlődésével eljön az az idő, amikor az új VGA-k csak lassulni fognak. Erre a problémára reakció a wide IO vagy a hardveres memóriamenedzsment.
Itt a nagyon beszédes ábra a problémáról:
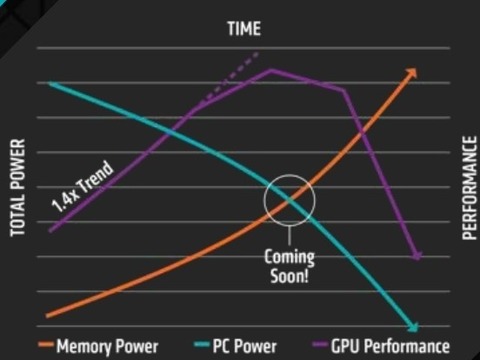
-
Abu85
HÁZIGAZDA
válasz
 core i7
#26595
üzenetére
core i7
#26595
üzenetére
Technikailag igaz, hogy a Volta ellen megy. Olyan technológiák lesznek benne, amelyeket az NV csak a Voltával hoz. Például az NV is átáll a hardveres memóriamenedzsmentre. A CUDA-val ez a GP100-ra korlátozva már működik, bár nem teljesen hardveres, de a következő lépés nyilván a HBCC szerű dizájn, amit a Volta hozhat legelőször az NV oldalán. A VEGA is ilyen radikális újításokat hoz, amelyek a rendszer rossz hatásfokkal működő komponenseit lecserélik. Nyilván a jövőben eléggé általánossá válik az a probléma, hogy ha tényleg akarsz 8 GB-nyi felhasználható VRAM-ot, akkor a kártyára 32 GB kell fizikailag. Tehát nem meglepő, hogy a Vega és a Volta elindult a hardveres menedzsment felé, hogy a 8 GB-nyi adat tárolására elég legyen 8 GB-nyi memória is.
-
Abu85
HÁZIGAZDA
válasz
 cyberkind
#26580
üzenetére
cyberkind
#26580
üzenetére
Elméletben nagyon sokáig elégnek kellene lennie. A probléma a gyakorlat. Egy nagyon jól optimalizált program VRAM kihasználása is 50%-nál rosszabb hatásfokú manapság. És akkor ott van az emberi tényező a DX12/Vulkan API-val, amiből nem ritkán látunk ma 20-30% közötti hatásfokot. Ez konkrétan azt jelenti, hogy ha van egy 8 GB-os kártyád, akkor a betöltött 8 GB-nyi adatból 2 GB a hasznos. A többi csak beszemetelt vagy már nem használt allokáció. A Sniper Elite 4-nek az Asura motorjának van valami félelmetesen jó menedzsmentje, mert ott a hatásfok eléri a 70%-ot is PC-n, amit nem is tudom, hogy miképp csinálnak. Ez már vetekszik a konzolos jellemzően 80% körüli hatásfokkal, de az ugye egyszerű, mert direkten célozható a hardver.
És akkor ott az a probléma, hogy a nagyobb felbontású textúrákkal a hatásfok is erősen csökkenni kezd, tehát nagyon nehéz leszállítani a legjobb minőségű tartalmat egy kész játékkal. Lehet, hogy lesz olyan kedves a fejlesztő és még egy évig optimalizál, hogy kiadhasson egy friss textúracsomagot, de ez nagyon ritka, mert az már nem hoz extra bevételt.Végeredményben azt lehet mondani, hogy ez programfüggő lesz. Láttunk több példát arra, hogy relatíve jó a hatásfok és láttunk legalább ennyit, ahol rossz. Valószínűleg ezért akar az AMD ebből kiszakadni, és áttenni a probléma kezelését hardverbe, mert sajnos a DX12/Vulkan esetében marhára árthat az emberi tényező, amellett persze, hogy sokan megcsinálják relatíve elfogadhatóra.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#26578
üzenetére
keIdor
#26578
üzenetére
Alapvetően egy komolyabb textúracsomag lesszállítása nem lenne speciálisan VEGA-hoz kötve. Amint jönnének 16-32 GB-os VRAM-mal szerelt hardverek azok is tudnák futtatni. Itt igazából csak arról van szó, hogy a fejlesztő adja ki az elkészített legjobb minőségű tartalmakat, mert tényleg nem ritka, hogy nem ezekkel szállítják az alkalmazásokat. Itt a legtöbb fejlesztő azért nem csinál ilyet, mert a program oldalon a textúraméret növelésével drámaian romlik a VRAM kihasználásának hatásfoka. Tehát tényleg sokat kellene várni, hogy legyen olyan hardver a piacon, amely tudná futtatni a legjobb minőségű tartalmakat. A Vega ezen annyit változtat, hogy a hatásfokról nem a fejlesztő által írt kód gondoskodik, hanem a hardver. Ez lehetővé tenné, hogy szimplán kiadják a már megvásárolt, elkészült tartalmakat, akár egy külön packként. De ez csak az elején VEGA only. Sőt, technikailag nem is lenne az, mert egy figyelmeztetés után bármikor felteheted a maximumra a textúrákat, maximum akadni fog. Nem is lenne értelme általánosan VEGA only cuccot csinálni, mert idővel úgyis lesznek jobb VGA-k nagyobb VRAM-mal.
-
Abu85
HÁZIGAZDA
válasz
schawo
#26550
üzenetére
Ez nem csoda. Egyszerűen az aktuális kód nagyon ramaty ahhoz képest, amilyen kódminőségét szállít az AMD. Ennek persze főleg az az oka, hogy az AMD a driver PAL rétegét majd két évvel hamarabb vetette be a gyakorlatban, mint az NV, ergo két évvel több a gyakorlati tapasztalat. Na most az elején lehet nagyokat ugrani a teljesítményben, tehát várható volt, hogy az NV is ráncba szedi a saját PAL rétegét. Ehhez természetesen idő kellett. Szóval semmi varázslat nincs itt. A rossz hatásfokról felugranak egy jobb szintre a tapasztalatokat felhasználva.
-
Abu85
HÁZIGAZDA
válasz
 daveoff
#26546
üzenetére
daveoff
#26546
üzenetére
Eléggé rászorulnak, mert roppant fos a DX12 driverük az AMD-hez képest. Vannak olyan szituációk, ahol a minimum fps csak úgy bezuhan és alacsony átlagot hoz igen sok másodpercen át, amíg a rendszer nem törli ki a beszemetelt memóriaallokációt. Ezen próbálnak javítani. Persze ezt nem úgy fogják eladni, hogy rossz az allokációs stratégia, hanem hogy javítottunk az aktuális helyzeten. Ez a javítás arra lesz elég, hogy a DX12 teljesítmény ne romoljon a DX11-hez képest, ahogy azt az AMD-n is lehet látni, hogy meg lehet csinálni. Valójában ez egy régóta húzódó bugfix.
-
Abu85
HÁZIGAZDA
válasz
 Fred23
#26419
üzenetére
Fred23
#26419
üzenetére
Mondjuk itt szerepet játszik, hogy a mai DX11-es driverek nagyon agresszívek, és alapvetően ez rontja helyenként a minimum fps-t. Két éve a DX11-es meghajtókat két-három szálhoz optimalizálták. A mai meghajtókat már nyolc-tíz szálhoz alakítják. Ez alapvetően javít a négymagosok kihasználásán is, igy valamelyest nő az átlag tempó, viszont csökkenti a minimum fps-t a sok aktív és passzív kernel driver server szál kezelése. Meg lehetne oldani azt, hogy a négy mag négy szál is jól mutasson a minimum fps-ben, de senki sem fizeti meg azt a munkaórát, ami ehhez kell, így inkább mennek a sok szálas optimalizálás felé, hiszen idővel mindenki cserél procit.
-
-
Abu85
HÁZIGAZDA
válasz
#85552128
#25990
üzenetére
Inkább árnyalatról beszélünk, mint színbeli eltérésről. Ez maximum a kapun látszik, de mindenhol jelen van, csak a más felület miatt nem látszik erősebben. A kapun is alig észrevehető, nézni kell legalább egy percet, hogy lásd a különbséget.
Ellenben a DX11-es árnyékok minősége kapásból kiveri az ember szemét, hogy a DX12-höz képest mennyit gyengültek.
 Lehet itt is mérni, de előbb mindenképpen ki kell kapcsolni a DX11-es különbségeket okozó effekteket, hogy egységes legyen DX11 alatt is a képminőség.
Lehet itt is mérni, de előbb mindenképpen ki kell kapcsolni a DX11-es különbségeket okozó effekteket, hogy egységes legyen DX11 alatt is a képminőség. -
Abu85
HÁZIGAZDA
válasz
#85552128
#25987
üzenetére
A szín teljesen mindegy, mert az szimplán lehet a capture programra vonatkozó eltérés is. A két kép a fontos részletekben megegyezik. Ezért mondtam, hogy DX12 alatt azonos a gyártók közötti minőség. Sajnos ez a DX11-es módra nagyon nem mondható el, az nagyon el lett baszarintva.
Valószínűleg a DX11-es mód eleve más effekteket is használ. Erre utal a jóval gyengébb minőségű AO is. Innen már lehet sebességet nyerni.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#25982
üzenetére
Akkor pontosan érted, hogy ez egy probléma. A Quantum Break még gyártói szinten sem végez ugyanolyan számítást ugyanazon a beállításokon. Ergo az egész DX11-es mód összehasonlíthatatlan, mert nem a felhasználó állítja be a grafikai részletességet, hanem a programon belül van valamiféle automatikus paraméterezés. Tehát vagy mindent DX12-ben mér az adott oldal a Quantum Break-nél, vagy mindent DX11-ben egy olyan beállításon, ahol kikapcsolták a képminőségbeli különbséget okozó effekteket. Ha viszont keverik a helyzetet, akkor elképesztően nagy lesz a szórás a képminőségben, és nyilván az egyes hardverek bizony többet fognak számolni. Jelen esetben a DX12-ben futók.
Van különbség az NV-n a DX11 és DX12 között. Nézd meg az árnyékokat a bejelölt részen. Olyan, mintha DX11 alatt teljesen más lenne az AO.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#25979
üzenetére
[link] - mindenki ellenőrizhette a problémákat a DX11-es verzióban. Hát nem működött jól és még ma sem működik. Csak a DX12-es verzió minősége egységes. Emiatt csak akkor érdemes két eltérő API-t összehasonlítani, ha a minőségi szint megegyezik. Sajnos a Quantum Breakre ez nem igaz. Vagy mindent DX12-ben mérnek, vagy megpróbálnak valahogy egységes beállítási alapot találni a DX11-re, ahol a hardverek előállított képminősége nagyjából megegyezik.
Persze manapság a média a sebességre van kihegyezve. Alapvetően semmilyen háttérmunkát nem végeznek, annak érdekében, hogy kiderítsék az elvégzendő teszt egyáltalán ugyanolyan minőségen születik-e meg.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#25976
üzenetére
A QB-ben a DX12 módban van kihasználva. De a DX11-es mód nem tartalmaz aszinkron compute-ot. Emellett a DX11 mód sokkal kevesebbet számol a problémás működése miatt. [link] - Ezért nem túl szerencsés az API-kat keverni, mert nem ugyanaz a minőség, amit előállítanak a hardverek. Sőt, a QB esetében csak a DX12-ben van egységes minőségi szint, a DX11-ben a beállításoktól függetlenül más lesz az egyes hardvereken a minőség. Ez egészen kellemetlen programmá teszi a DX11-es verziót.
-
#25967
Abu85
HÁZIGAZDA
huskydog17
#25962
Abu85
HÁZIGAZDA
válasz
huskydog17
#25962
üzenetére
Egyszerűen csak nincs kész. A LOD menedzsment és a memóriamenedzsment még mindig eléggé bugyuta, de ez az elmúlt években alig változott.
A LOD menedzsmentet egyébként minimum nem ártana rendbe hozni, mert arra nem lesz hardveres gyógyír a jövőben sem.Egyébként az ARK leképezője konzolon és PC-n lényegesen más. A konzolon klaszteres megoldás, amit a Microsofttól kaptak, míg a PC-n egy klasszikus régimódi deferred render van. Ez leginkább a kezdeti UE4-ből megmaradt leképező, de haszna az nem sok, mivel az Epic is kidobta már.
Azt fontosnak tartom, hogy vegyük figyelembe, hogy ez még mindig Early Access, leginkább egy pre-alpha. Leghamarabb 2018-ban lesz kész, de szerintem inkább 2019ben kerül ki az Early Access-ből. Addig nem tisztességes baszogatni őket, mert ki van írva a Steamre, hogy a játék nem végleges, és úgy vegyétek meg.
-
Abu85
HÁZIGAZDA
válasz
keIdor
#25823
üzenetére
A GoW 4 motorja már csak a nevében hasonlít az UE4-hez. Valójában kegyetlenül átírta már a Microsoft. A GoW 4-re egy teljesen új leképezőt írtak hozzá, vagyis az UE4-gyel érkező leképezőhöz köze nincs, amit a Microsoft stúdiói kapnak. Eredetileg arról volt szó, hogy a Microsoft visszaírja a saját leképezőjét az UE4-be, de ez eddig nem történt meg, illetve az Epic számára sem kritikus a gyors PC-s leképező. Az ARK egyébként élvezi a Microsoft támogatását, de a Microsoft leképezőjét csak az Xbox One-on használják csak. A PC-re egy 2015-ös verziót alkalmaznak, aminél már az UE4 aktuális leképezője is nagyságrendekkel gyorsabb, de nagyon drága lenne átállni arra a verzióra, miközben a konzolos leképező fejlesztése zajlik, és oda megy az erőforrás. A PC-s leképező majd akkor lesz leváltva az Xbox One-ra használt leképezővel, amikor a konzolon működni fog a rendszer. Utána majd kikerül a játék az Early Accessből, de ez még hónapokra van. A PC-s kód addig ugyanaz a másfél éve ráhagyott szarkupac lesz, és ehhez nem véletlenül nem nyúlnak, egyszerűen ki lesz dobva a fenébe, amint a konzolra portolás kész lesz. Azért várnak ezzel annyit, mert a Microsoft leképezője, amit az ARK tervez használni D3D12 only leképező, tehát amint leváltják a mostani motorverziót nem fog működni tovább a játék Windows 10-nél korábbi OS-eken. Ez persze annyira nem gond, mert a tényleges megjelenés jelenleg inkább 2018-ban valószínű, tehát akkorra már elfogadható lesz a Windows 10, mint minimum igény.
Az UE4-nek az új leképezőjét is használhatnák, de azzal meg az a baj, hogy már egyik opció sem támogatja a multi-GPU-t. Ezt a módot a 4.10-es verzió óta teljesen kivették. Egyedül a D3D12-es verzióban van egy olyan mód, amivel egy IGP és egy GPU összekapcsolható, de ezt is ki fogják venni a jövőben.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#25858
üzenetére
Nincs. A shadow cache-ből egyértelműen egy GCN2 tud profitálni a legtöbbet. Erre van a leginkább optimalizálva a konzolról áthozott kód.
Azok rendesen meg vannak tuningolva, a hibaarányuk is igen nagy a túl nagy húzás miatt. Elhiszem, hogy e-pénisz, de aligha érik meg a pénzüket.
Az a baj, hogy egy bonyolult dolgot próbálsz elképesztően egyszerűen értelmezni. A GPU-kban annyi teljesítmény van, amennyit kihoznak belőlük az optimalizálással.
-
Abu85
HÁZIGAZDA
Nincs gond egyik teszttel sem, csak a Guru3D referenciaórajelekkel teszttel, míg a PCGH agyontuningolt VGA-kkal. Ez óriási különbség.
Az RE7 esetében fontos tényező a shadow cache is, ami egy konzolról áthozott funkció, és ez jobban tetszik a GCN-nek. Emellett a GCN-ek sokkal gyorsabb shadereket futtatnak, mint az összes többi hardver. Az RE Engine a shader intrinsics-re nagyon épít az Xbox One-on, és ha már volt kész kód áthozták PC-re is. Egyelőre csak AMD-re, de később a shader model 6-tal támogatni tudnak más GPU-kat is. -
-
Abu85
HÁZIGAZDA
válasz
 Venyera7
#25796
üzenetére
Venyera7
#25796
üzenetére
A shader model 6-os szabványos megoldást kérdezed, vagy az AMD-féle zárt opciót? Előbbi valószínű, hogy lesz, illetve a SPIR-V is ki fog egészülni idén egyre több szabványos beépített függvénnyel. Nyilván hosszabb távon ezeket érdemes használni, tehát amint megérkeznek, áttérnek rá a fejlesztők. Már csak a szabványosság miatt is.
Az AMD-féle megoldás addig általános lesz, hiszen az Xbox One-hoz meg van írva a shader. Ahhoz minimális módosítás kell, hogy PC-n is működjön a GCN-en. Az érkező játékok közül a Resident Evil 7: Biohazard, a Sniper Elite 4, Styx: Shards of Darkness és a Mass Effect Andromeda használja. Utóbbi ugyanazt fogja bevetni belőle, amit a Battlefield 1, míg az előbbi három esetében kérdéses, hogy milyen függvényekhez nyúlnak.





























![;]](http://cdn.rios.hu/dl/s/v1.gif)








 Lehet itt is mérni, de előbb mindenképpen ki kell kapcsolni a DX11-es különbségeket okozó effekteket, hogy egységes legyen DX11 alatt is a képminőség.
Lehet itt is mérni, de előbb mindenképpen ki kell kapcsolni a DX11-es különbségeket okozó effekteket, hogy egységes legyen DX11 alatt is a képminőség.

Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Dell Latitude 7210 2-in-1 12" FHD touch, i7 10610U, 16GB RAM, 512GB SSD, jó akku, számla, 6 hó gar
- Apple iPhone 15 Pro 1TB,Újszerű,Adatkabel,12 hónap garanciával
- BESZÁMÍTÁS! Intel Core i7 4770K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Nvidia Quadro P400/ P620/ P1000/ T400/ T1000 - Low profile (LP) + RTX A2000 6/12Gb
- Magyarország piacvezető szoftver webáruháza
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest