Új hozzászólás Aktív témák
-
#20250
 Abu85
HÁZIGAZDA
turbokappa
#20248
Abu85
HÁZIGAZDA
turbokappa
#20248
Abu85
HÁZIGAZDA
válasz
 turbokappa
#20248
üzenetére
turbokappa
#20248
üzenetére
Bár kevés adatot adtál meg, de azért azt leírhatom, hogy nagy esély van rá, hogy a problémád a Windows 10, ugyanis a HD 6970 idén lesz 6 éves, vagyis lejárt róla az 5 éves mainline terméktámogatás. Emiatt Windows 10-hez leginkább a Win Update meghajtó érhető el, és ezt csomagolja az AMD is. Ez például nem tartalmazza azokat a rutinokat, amelyek a hibásan megírt játékok javításához kellenek, például hiányzó BeginScene()-EndScene(). Érdemes lenne Win 8.1-re visszaváltani, vagy hardvert cserélni. Ma már a 20K-s VGA-k is erősebbek a 6970-nél.
-
#20245
Abu85
HÁZIGAZDA
turbokappa
#20244
Abu85
HÁZIGAZDA
válasz
turbokappa
#20244
üzenetére
Ez sem segít. Konkrétumok kellenek. Egy nagyon részletes leírás a problémáidról, mert így kb. olyan helyzet van, mintha megkérdeznéd az orvost, hogy miért hasogat az arcod pár másodpercre naponta. Fogalma sem lesz róla vizsgálatok nélkül.
-
#20243
Abu85
HÁZIGAZDA
turbokappa
#20241
Abu85
HÁZIGAZDA
válasz
turbokappa
#20241
üzenetére
De ez nem segít. A játék címe is kell, illetve az, hogy mi a konkrét hibaüzenet, illetve a teljes gép konfigurációja, illetve nem ártana a Windows verzió sem. Nem a 10-es, hanem a konkrét verziószám, mert a régi VGA-knál az előtelepített meghajtó ettől függ.
-
#20239
Abu85
HÁZIGAZDA
turbokappa
#20238
Abu85
HÁZIGAZDA
válasz
turbokappa
#20238
üzenetére
A VGA típusától és a játéktól függ. Nyilván nagyon régi, 5+ éves VGA-val már nem minden új játék fut. Ezért lenne jó ezt konkrétabban kezelni (teljes konfig és maga a játék), mert általánosan erre senki sem tud választ adni.
-
Abu85
HÁZIGAZDA
Nem lehet lemérni. A compute queue nem tiltható az ID tech 6-ban, és általánosan a Vulkan úgy épül fel, hogy ha a meghajtó jelzi a compute queue-t, akkor használja. Ugyanígy a shader intrinsics. Ha ott vannak a kiterjesztések az indítás melletti beolvasásnál, akkor használja. Az egyetlen lehetőség az lenne, ha létezne olyan meghajtó, amit az AMD compute queue és kiterjesztések nélkül adna ki, de ilyen nincs. Régi meghajtóval pedig baszik elindulni a Doom.

-
Abu85
HÁZIGAZDA
válasz
 #00137984
#20176
üzenetére
#00137984
#20176
üzenetére
Mivel a shader intrinsics minden GCN verzión ugyanaz ISA szinten, így pontosan ugyanannyit kínál mindegyik architektúra iteráción.
A GCN4-nek ettől még lesz előnye, hiszen van benne speciális háromszögkivágás, ami elég sokat jelent a rosszul optimalizált játékoknál, illetve van benne utasítás-előbetöltés, ami szintén sokat segít, ha kevés wavefront futhat a CU-n.
-
#20158
Abu85
HÁZIGAZDA
FollowTheORI
#20156
Abu85
HÁZIGAZDA
válasz
 FollowTheORI
#20156
üzenetére
FollowTheORI
#20156
üzenetére
Ahol le van tiltva ott VendorID-re van letiltva. Szóval bármid van, ami NV azon nem fut az async.
Egyébként az async az nem egy általános valami. Annak lehetnek használati formái. Abban a formában ahogy, mondjuk a felsorolt játékok használják nem segít a Pascalon se, maximum nem csökken a teljesítmény attól sem, ha aktiválják. A Maxwellre elsődlegesen ezért tiltották le, mert negatívba megy a teljesítmény. És itt nem 2-3%-ról van szó, hanem 10-15%-ról. -2-3% elfogadható, ahogy az AotS is elfogadja, és aktív is.Tomb Raider ugyanez. Ott sem gyorsul a Pascal csak a GCN. De nem megy negatívba a Pascal teljesítménye!
Egyedül a 3DMarkban hoz az async extrát az NV-nek, de ott nem is úgy implementálták ezt, ahogy egy játékban szokás.
-
Abu85
HÁZIGAZDA
válasz
 lezso6
#20152
üzenetére
lezso6
#20152
üzenetére
A regiszterszegénység sosem lesz általános probléma, mert a meghajtóba írható más allokációs rutin, amit akár játékokra is rá lehet szabni. Emellett a shaderek is cserélhetők.
Az async compute pedig már probléma. Nem azért tiltják le például ezt a Warhammerben, GOW-ban, a QB-ben, a Hitmanben, a Doomban, stb. mert szívatni akarják az NV-t, hanem azért, mert nem működik jól. Ennél nagyobb problémát ez nem fog okozni. [link] -
Abu85
HÁZIGAZDA
válasz
 mcwolf79
#20138
üzenetére
mcwolf79
#20138
üzenetére
Természetesen nem fogod érezni a hátrányát annak, hogy az AMD specifikus, míg az NV szabványos shadert futtat. Pusztán azért nem, mert kétféle shader kód van szállítva. Egy gyors és egy szabványos. Ennek igazából nincs hátránya csak előnye. Az AMD-re gyors kódot írnak a fejlesztők és ennyi. Például az 1060-ra vonatkozóan annak önmagában nincs hátránya, hogy a speciális gyors kód mellett az RX 480 20-30%-kal gyorsabb a Doomban.
-
Abu85
HÁZIGAZDA
válasz
 schawo
#20136
üzenetére
schawo
#20136
üzenetére
Az első Xbox az halott volt. Szopatta a Microsoftot az Intel és az eladások is a padlón voltak. A második Xbox már a piacon volt 10 évig. Az nem számít, hogy 8 év után követte az új Xbox, a lényeg, hogy utána is jöttek még rá játékok.
A PS2 is piacon volt 10 évig. Nem számít, hogy jött egy PS3, új program jött még rá. -
Abu85
HÁZIGAZDA
válasz
 keIdor
#20130
üzenetére
keIdor
#20130
üzenetére
A konzol időtállósága garantáltan 8-10 év. Mindegy, hogy milyen hardver van benne, maga a piac berendezkedése miatt szükséges az, hogy egy konzolgeneráció 8-10 évig a piacon maradjon. Ennyi idő kell ahhoz, hogy egy adott generációra fejlesztett motorba injektált befektetés megfelelő nyereséggel térüljön meg. Szóval minden konzolnál az időtállóság azt jelenti, hogy amíg a konzol gyártója le nem lövi a forgalmazást. Az Xbox One, az Xbox One S és az új Scorpio is pont ugyanaddig lesz a piacon. Ennek az oka az, hogy mindegyik hardver ugyanazt a befektetést igényli, vagyis a szoftveres R&D-ből mindegyik ugyanúgy profitál. Egy idő után azonban jön egy igazi új generáció, megváltoztatott ISA-val, és mindent elölről kell kezdeni.
-
Abu85
HÁZIGAZDA
válasz
keIdor
#20123
üzenetére
Az AMD letervezett volna nekik egy szörnyeteget, ha az lett volna az igénye az MS-nek. Simán tudják azt mondani, hogy oké legyen háromszor erősebb, de akkor 400 dollár/SoC.
 Végül az úgy 1400 dolláros Xbox One-t eredményezett volna. Szerinted megvették volna 25 millióan?
Végül az úgy 1400 dolláros Xbox One-t eredményezett volna. Szerinted megvették volna 25 millióan? -
Abu85
HÁZIGAZDA
válasz
 Zeratul
#20122
üzenetére
Zeratul
#20122
üzenetére
Az azért fontos, hogy az AMD-GloFo és az NV-TSMC kapcsolat teljesen más. A TSMC nem kínál olyan megrendelési modellt senkinek, amit a GloFo biztosít az AMD-nek. Egyszerűen a TSMC nincs rákényszerülve arra, hogy legyen egy stabil megrendelő, aki elvisz egy rakás gyártósort. A TSMC üzleti modellje szimplán a profitmaximalizálásra épül, semmit a gyárak kihasználására. Utóbbi egyszerűen automatikusan megtörténik a sok megrendelő miatt. A GloFo számára a gyárak kihasználása a cél, és utána jöhet csak szóba a profit. Nyilván ez jóval alacsonyabb waferárakat eredményez.
-
Abu85
HÁZIGAZDA
válasz
 Puma K
#20092
üzenetére
Puma K
#20092
üzenetére
Az Xbox One minden idők legjobban fogyó Xboxja, míg a PlayStation 4 minden idők legjobban fogyó PlayStationje. Egyedül az MS lehett egy kicsit pipa, hogy nem sikerült annyit eladniuk, amennyit a Sony-nak.
Valahol mérlegelhető az az üzlet, hogy ha ebben a fejlesztési modellben ennyire veszik a hardvert, akkor megéri újakat kiadni. Végtére is most a konzolokon nincs veszteség, igaz nagy nyereség sem, mert az AMD-nek sokat kell fizetni, de az már jó az MS és a Sony számára, ha nincs mínuszban a gyártás. Most tipikusan sikerült eltalálni egy win-win-win szituációs üzleti modellt. Az kérdéses, hogy ez meddig tartható fent, de ahogy látom úgy van ezzel mindenki, hogy amíg ez a modell működik, addig kiszívnak belőle minden pénzt.
-
Abu85
HÁZIGAZDA
válasz
schawo
#20085
üzenetére
Már abban sem vagyok annyira biztos. Maga a két irány abszolút megél egymás mellett, csak mondjuk úgy, hogy eltérő fejlesztői igényeket céloznak meg. Például egy DICE, egy ID, vagy egy Eidos Montreal, vagy más multiplatform fejlesztő számára az az ideális, ha össze tudják vonni a konzolos és a PC-s R&D-t. Emiatt ezek a kiadók és stúdiók főleg az AMD partnerségét keresik majd. Ellenben egy indie stúdió, amely készíti a következő survivor gyűjtögetős játékot nem fog abból profitálni, hogy az AMD konstrukciójában egységesen van kezelve a konzol és a PC. Számukra ez mindegy, mert úgysincs komoly R&D-jük ezen a területen, nagyjából addig jutnak, amit a licencelt motor (UE, Unity, CryEngine, akármi) megenged. Emiatt ezek a fejlesztők főleg az NVIDIA partnerségét fogják keresni.
-
#20089
Abu85
HÁZIGAZDA
#Morcosmedve
#20086
Abu85
HÁZIGAZDA
válasz
 #Morcosmedve
#20086
üzenetére
#Morcosmedve
#20086
üzenetére
Ebből az következik, hogy nem értitek az AMD miért ment el ebben az irányba. A GPUOpen lényege, hogy amit konzolra lenyomnak R&D-t az egy az egyben hasznosítható legyen PC-n is. Ezzel a konstrukcióval sokkal fontosabbá válik a PC+X1+PS4 részesedés, mert ezt a három platformot végre egyként lehet kezelni. Emiatt jött egy csomó exkluzív funkció a GCN-re a Doomban, és ugyanezért kap ilyen exkluzív eljárásokat a GCN az új Deus Ex és Battlefield alatt. Ez egyébként nem jelenti azt, hogy az NV-re nem is dolgoznak, csak ebben az új szemléletben a GCN lett a piacvezető, ezért az van fókuszban.
Emiatt törekszik arra az NV, hogy a PC-t és a konzolt válasszák külön, mert a piacvezetői szerep attól függ, hogy miképp fejleszt a stúdió.Szerk.: Időközben szerkesztetted a hsz-t.
-
Abu85
HÁZIGAZDA
válasz
Puma K
#20080
üzenetére
Nyilván az NV-nek a legkevésbé sem tetszik, hogy az AMD elvitte a Microsoft és a Sony konzolokat, nyitja meg PC-n a GPU-t, mindent dokumentálnak, mindenből van nyílt forráskód, illetve emellett még igény is van arra, hogy az AMD a PC-t és a konzolt egy szoftveres háttér alatt kezelje. Ez nekik azért kellemetlen, mert amelyik stúdió multiplatform játékot tervez sokkal jobban jár az AMD-vel, mert csökkenthetők a fejlesztési kiadásaik. Ennek a kiteljesülése a Doom, ami GCN exkluzív eljárásokat is hozott PC-re csak azért, mert a játék célpiacán GCN a piacvezető
Az NV sokkal inkább azt akarja, hogy a PC és a konzol fejlesztése teljesen váljon külön, még akkor is, ha mondjuk többet nem jön PC-re az új Call of Duty, vagy más főleg konzolon sikeres játék. Ellenben lesz több PC exkluzív cím. -
Abu85
HÁZIGAZDA
válasz
#35434496
#19871
üzenetére
A teszt típusától függ. Amire a 3DMark esetében figyelni kell, hogy olyan async kód legyen minden hardveren, ami egyik terméken sem okoz lassulást. Emiatt a lehetőségek rendkívül korlátozottak, mert ha olyat alkalmaznak, amilyenek a játékokban vannak, akkor az nem növeli, hanem csökkenti a sebességet a GeForce-on. Viszont tesztről lévén szó nem lehet alternatív kódutat írni az egyes gyártóknak, hogy a lecsökkentett teljesítményt visszanyerjék. Emiatt érdemes olyan megoldást keresni, aminek nem sok köze van a játékokhoz, de legalább nem csökkenti sehol sem a sebességet.
(#19874) Petykemano: Az, hogy a köznyelv mit ért rajta, és hogy mit enged a szabvány két különböző dolog.
Mert két futószalag fut párhuzamosan. Azt senki sem írja elő a szabványban, hogy csak grafikai és compute futószalag dolgozhat párhuzamosan. Annak az oka, hogy ilyen konstrukciót alkalmaznak a játékok csupán az, hogy itt lehet messze a legtöbbet nyerni ezzel a technikával, mert bizonyos jellegű, sokszor alkalmazott grafikai futószalagok mellett a shaderek csak malmoznak.
Hívhatják akárhogy, de az "asynchronus compute" sem egy valós elnevezés, hanem egy marketing. A valódi neve a technikának "multi-engine and synchronization". Még van asynchronus shader is, amit az AMD használ. Szimplán definiálták, hogy ez mi, mivel ezt csak a Radeonok támogatják, és exkluzív funkcióként utalnak rá.
-
Abu85
HÁZIGAZDA
válasz
 guftabi96
#19912
üzenetére
guftabi96
#19912
üzenetére
Naná, hogy volt róla hivatalos bejelentés, csak még májusban, illetve a Computexen, amikor Raja mondta, hogy a Doom Vulkan kódja Polaris exkluzív funkciókat fog tartalmazni. Ez persze csak egy kis szelete az igazságnak, mert valójában ezek a gyors kódok minden GCN-en futtathatók, de gondolom a marketing miatt a Polarist kell tolni, ugyanakkor amikor mi erről írtunk, akkor mindig kiemeltük, hogy minden GCN-nel működnek. Majd a hónap végén hivatalosan leírható, hogy milyen játékokban lesz még GCN exkluzív gyors kód. Az egyik hekkelős-lopakodós-összeesküvős lesz, a másik pedig csatateres-egyes.

-
Abu85
HÁZIGAZDA
válasz
#35434496
#19863
üzenetére
Nem. Írtunk már róla, hogy a 3DMark nem úgy használja az aszinkron compute-ot, ahogy a játékok. Ezt a FutureMark is elismerte. Az Async nem egy univerzális technika, számos felhasználási módja van, ami befolyásolhatja a teljesítményt. Ez leginkább fejlesztői döntés kérdése. A játékfejlesztők ma leginkább a grafikai futószalagokat futtatják párhuzamosan a compute futószalagokkal. A 3DMark leginkább compute-ot lapol át compute-tal. Ez egy tesztprogram esetében kedvezőbb, mert nem alkalmazhatnak gyártóspecifikus kódokat.
-
-
#19796
Abu85
HÁZIGAZDA
huskydog17
#19795
Abu85
HÁZIGAZDA
válasz
huskydog17
#19795
üzenetére
Az ID-t ne keverjük ide. Ott teljesen más az erre szánt erőforrás. Nekik nyilván a Vulkan a jó megoldás.
A Windows 7/8.1-et teljesen elfogadom indoknak, de a Linuxot már nem. Az jelenleg egy kerekítési hiba a játékosok tekintetében. Maximum jópofizni akar a cég, ha portol rá játékot, de alig van benne pénz. Ezért sincs Doom Linuxra.
A Vulkan sem enged egyébként minden réteget játszani. Az Intelnek csak Skylake-hez lesz drivere hozzá, tehát a Broadwell és a Haswell IGP-vel játszó réteg kiesik, míg DX12-vel ők megmaradnak.És a struktúrát átírták már? Vagy még mindig egy magra van kényszerítve a parancskreálás egy wrapperen? Igazából ez lenne a lényege a dolognak, nem a kódban lévő kisebb hibák foltozgatása. Az is fontos, de az igazi fejlesztést a motorstruktúra átdolgozása jelentené.
Nincs kétségem afelől, hogy annyit lehet nyerni, de azt már kétlem, hogy az ahhoz szükséges új motorstruktúrát visszaírják a Talosba. De lepjenek meg vele.
-
#19794
Abu85
HÁZIGAZDA
huskydog17
#19792
Abu85
HÁZIGAZDA
válasz
huskydog17
#19792
üzenetére
Én nem láttam, hogy frissítették volna a Vulkan leképezőt a megjelenése óta. Lehet mondani dolgokat, de a Talos nem kritikus annyira, hogy arra visszaportolják a fejlesztést. Ahhoz, hogy a Vulkan nekik jól működjön át kell írni a motor struktúráját. Ha azt visszaírják a Talosba, akkor elég komoly meló újratesztelni a játékot. Tekintve, hogy ez így is jól működik, felesleges pénz égetni erre, mert extra zsét ez már nem hoz.
A Serious Sam VR-et a LiquidVR miatt támogatják. Az egy másik csoport. Azt egyébként muszáj támogatniuk, mert a LiquidVR DX11-et és DX12-t támogat, tehát csak akkor tud LiquidVR+Vulkan konstrukciót fejleszteni a Croteam, ha az AMD odaadja nekik a nem publikus verziót.
Én örülök a Croteam döntésének. Ettől függetlenül a DX12 egy olyan stúdiónak, mint ők egyszerűen kedvezőbb. De persze hajrá szeretem, ha egy stúdió kihívást keres.
-
Abu85
HÁZIGAZDA
válasz
 Venyera7
#19791
üzenetére
Venyera7
#19791
üzenetére
Ahol használják, ott nagyjából olyan lesz a felállás, amilyen a Doomban, ahol pedig nem használják, ott olyan lesz, mint a többi DX12 játékban.
Egy kakukktojásos helyzet van, ami a manuális interpolációt előnyeit használja ki, és ezt a konzolban a fejlesztők előszeretettel alkalmazzák a geometry shaderek pixel shaderre cserélésére. Ilyenkor a tempóelőny nagyon erős lehet, mert a GCN-nek nem kell a geometry shader lépcső használnia. -
Abu85
HÁZIGAZDA
válasz
 imi123
#19789
üzenetére
imi123
#19789
üzenetére
Hosszabb távon ezeket az API-kba kellene beépíteni szabványos formában. A Vulkan már támogatja a Ballot és a RL/RFL függvényeket ARB szinten. A többit sajnos még nem, de a SPIR-V-nek hamarosan érkezik a frissítése, és abban állítólag újabb pár intrinsics lesz szabványosítva (pletyik szerint az mbcnt és a swizzle).
A Microsoft esetében ezt nem tudni. Ők inkább az új shader modellen dolgoznak, így kevés koncentrációt fordítanak az intrinsics-re. Megelégednek azzal, hogy Xbox One-ra elérhetők és kész. Persze az új shader nyelv ideális terep arra, hogy egyben jöjjenek új függvények is.
-
-
Abu85
HÁZIGAZDA
válasz
 Ren Hoek
#19761
üzenetére
Ren Hoek
#19761
üzenetére
Sok függvény egy konkrét utasítás az ISA szintjén. Persze tranyóba kerül.
OpenCL alatt használható egy részük, szabványosan. CUDA alatt is. Csak a grafikus API-k ilyen túrók ezen a téren.
DX11-re készült NVAPI-ba és AGS-be kiterjesztés, de a kutya se nyúlt azokhoz.
Szerk.: A GCN-nél ebből puskázhattok, ha nem akartok 300+ oldalas dokumentumokat túrni. [link]
-
Abu85
HÁZIGAZDA
válasz
keIdor
#19746
üzenetére
Ne keverjük az API-val a beépített függvényeket. Az API a hatékonyságot biztosítja a rendszer felé, míg a beépített függvények a nyers sebességet.
(#19747) TTomax: Ennek semmi köze a preempcióhoz, illetve tulajdonképpen magához a hardverhez sem. Az NV GPU-iban is vannak hasonló beépített függvények. A probléma pont az, hogy az API nem engedi elérni őket. Az változott most, hogy az AMD megnyitotta a GPU-t, és elérést ad ezekhez a funkciókhoz. Az NV is megtehetné ugyanezt, ahogy az Intel is.
A függvények beépítésével nem éri hátrány a többi hardvergyártót. Pont az a lényeg, hogy a GCN-en ne a szabványos, hanem egy alternatív, úgynevezett gyors kód fusson, amit a konzolból hoznak át. A Doomban sem éri ettől semmi hátrány az NV tulajokat. -
Abu85
HÁZIGAZDA
válasz
 TTomax
#19743
üzenetére
TTomax
#19743
üzenetére
Aki vár leginkább a DX12 és a Vulkan miatt teszi, hiszen ezekben az API-kban a Radeon általánosan gyorsabb. Nem beszélve arról, hogy Radeonon van shader intrinsics, ami már bizonyított a Doomban (~20% extra tempó), illetve jön az új Deus Ex-be és az új Battlefieldbe. Azért ezek a függvények nem kicsi extra boostot adnak, és akkor még nem láttuk az ordered countot, ami a Battlefieldhez jön.
A többiek nem akarnak felkészülni ezekre a játékokra, így maradnak az 1060-nál. Azon is futni fog, csak nem kapcsolható be minden, illetve nem a gyors kód fog futni. Nagyjából ezeket mérlegelheti egy hozzáértő vásárló.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#19724
üzenetére
Ha kis stúdió vagy Vulkan után érdeklődve, akkor nehéz. Egyedül az AMD-nek van ebben az API-ban, illetve az elődjében komoly tapasztalata, így az ő segítségük szükséges ahhoz, hogy rövid legyen a tanulási folyamat, de ők annyira sok nagyobb stúdióval dolgoznak, hogy egy Croteam nyilván nem fér bele.
DX12-vel kedvezőbb egyébként a helyzet. Ott már az Intel és az NV is rendelkezik tapasztalattal, tehát képesek relatíve hatékonyan segíteni.Motort semmiképpen sem érdemes venni, mert az elérhető árú rendszerek nem fókuszálnak PC-re. Nem véletlen, hogy a Croteam is inkább fejleszt. Nem egyszerű, de jó úton járnak. Jó ötlet volt kiadni egy Vulkan frissítést. Nézd úgy, hogy egy csomóan megnézték, és visszajelzést írtak a tapasztalatokról. Ez nagy segítség.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#19722
üzenetére
Egyszerű az oka. Nulláról nekiállni egy fő projektnek nagyon kellemetlen, mert a tapasztalathiány visszaüthet. Arról nem beszélve, hogy a Croteam nem akkora stúdió, hogy ha odamennek az AMD-hez, akkor olyan komoly segítséget kapnak a fejlesztésükhöz, mint mondjuk az EA, vagy a Firaxis, vagy az Ubisoft, stb. Az NV-hez és az Intelhez pedig hiába mennek, technikai felkészültségben ők is ugyanúgy nulla projektnél tartanak. Maximum szakembert adhatnak, de átfogó tapasztalatot nem. Emiatt célszerű egy pilot projekt, amit akár érdemes is kiadni, és ez nem lesz jó minőségű cucc, de pusztán az érdeklődés miatt ráomlik a stúdióra egy rakás visszajelzés, ami nagymértékben megkönnyítheti a tényleges projekt fejlesztését.
-
Abu85
HÁZIGAZDA
válasz
 stratova
#19710
üzenetére
stratova
#19710
üzenetére
Ezen már nem dolgoznak. Eleve mondták, hogy a Talos Principle Vulkan kódja igazából egy wrapperen fut, vagyis nem natív. Nem olyan még a motor struktúrája, hogy támogassa a natív Vulkan leképezőt.
(#19715) gbors: Jó, de azért nem úgy gondolták az egyszerűsítést, hogy csak egy réteget írjanak az aktuális leképező alá, ami ráadásul force-oltan single thread. Persze próbának jó, aminek ők is szánták, de a következő körben nyilván natív módot kap a motor.
(#19718) stratova: A gyors kódnak semmi köze a Vulkan API-hoz, az az AMD-nek egy kiterjesztésekkel elérhető rendszere, amire szimplán gyors shadereket lehet írni. De ezek nem szabványos shaderek.
(#19714) olymind1: Természetesen ezeket maga a Frostbite kapja meg, az a verzió, ami a BF1-et futtatja, és onnantól minden játék profitál belőle, amelyik ezt az ominózus Frostbite verziót használja. Azt most meg nem mondom, hogy az új Mass Effect melyik verzióval készül.
-
Abu85
HÁZIGAZDA
válasz
 daveoff
#19652
üzenetére
daveoff
#19652
üzenetére
A BF1-nek szüksége van bindless bekötésre. Ezen belül is sokat profitál a pure bindless bekötésből. Innen a Vulkan kedvezőtlenebb, mert annak a bekötési modellje nem bindless, vagyis még a GCN-es Radeonokon is processzoridőbe kerül minden bekötés, míg DX12 alatt a GCN nem terheli ezzel a processzort. Emiatt döntöttek a DX12 mellett. A Dishonored 2 motorja kevésbé igényel sok szabad processzoridőt, így elég, ha csak relatíve olcsó a bekötés.
Általában az mondható el, hogy ha nincs valami különleges igény, amit csak a DX12 ad meg, akkor érdemes Vulkánra menni, mert 1) nincs Windows 10-hez kötve, 2) kevésbé GCN-centrikus az API. -
-
Abu85
HÁZIGAZDA
válasz
Venyera7
#19642
üzenetére
Gondolom a shader intrinsics-re gondolsz, mert az hozhat +40%-ot is, de ezt ne keverjük bele a DX12-be. Egyrészt ez egy AGS 4.0-s funkció, ami elérhető DX11 alatt is, bár ezt valószínűleg nem fogják kihasználni. Másrészt a DX12 alapvetően egy szabvány, míg az AGS 4.0 egyáltalán nem az. Csak azért van ennek hatása jelenleg, mert sokkal egyszerűbb a konzol shaderét másolni, mint írni egy hasonlóan gyorsat PC-re a szabvány korlátjai mellett.
Ugyanezt a hibát követik el a felhasználók a Doomnál. Nem a Vulkan miatt gyors az AMD, hanem azért, mert a GCN gyors kódot futtathat. A szabványnak ezekhez a gyors kódokhoz semmi köze, csak egyszerű a kódot másolni a konzolról.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#19628
üzenetére
Yutani
#19628
üzenetére
Nyilván, ha 8 GB-nál húzzák meg a határt, akkor abban nem lesz benne.
(#19629) mlinus: Válasz lásd egy sorral fentebb.
(#19633) darky@: Nyilván el kell dönteni, hogy megéri-e a kompromisszum. Valakinek meg. Szerintem sincs óriási különbség.
A Doom szerencsére nem probléma. Az megatextúrázik. Ott csak a nightmare mód igényel 5 GB+ VRAM-ot Vulkan alatt. -
-
Abu85
HÁZIGAZDA
válasz
stratova
#19587
üzenetére
A COD: BO3 sosem volt NV cím. Az Activision régen valóban foglalkozott a gyártókkal, de ma már nem. Túl sok kiadást jelentett a PC-s port optimalizálása, a gyártókkal való egyeztetés, és hasonlók. A legutóbbi két résznél már ezt a lépcsőt kihagyták, és szimplán a konzolon GCN-re optimalizált shadereket hozták PC-re. Emiatt az utolsó két COD-ban nagyon erős lett az AMD, illetve nyilván mindegyik új COD-ban megmarad ez az előny, mert ha továbbra is csak a konzolos kódokat hozzák át, akkor a többi architektúrának az nem jó.
(#19588) Egon: Értem, de igazából ez nem meglepő. Ha csőlátásban GCN-re optimalizálnak, akkor aligha lehet más az eredmény. Ez van sajnos. Az Activision eldöntötte, hogy a legnagyobb piaci részesedésű architektúrát veszi figyelembe, és a többit le se szarja.
Szerintem ez hibás döntés, de hát a pénz az fontos tényező. -
Abu85
HÁZIGAZDA
A COD csak az utolsó két rész óta megy ilyen jól AMD-n. Onnan a váltás, hogy az Activision megszüntette a kapcsolatot a gyártókkal, így lecsípik a kiadásnál a PC-s optimalizálást. Innentől kezdve csak GCN-re fejleszt a csapat, ami nyilván egyáltalán nem jó a többi architektúrának.
-
Abu85
HÁZIGAZDA
válasz
 wjbhbdux
#19570
üzenetére
wjbhbdux
#19570
üzenetére
Az AotS költségvetésen nem volt nagy. Azt igazából csak egy tesztnek csinálta a Stardock, mert ők valójában a Nitrous motort finanszírozták, és nem a játékot. Az Oxide-ot csak a motorért hozták létre mert a Stardock nem tudta megoldani ezt a problémát. [link] - itt van az Oxide első bejelentője, hogy létrehoznak egy új rendszer szerint működő motort, ami megold egy rakás iparági problémát. Ezt segítette az AMD, az Intel és az NVIDIA. Jelen pillanatban eléggé megérte a Stardocknak, mert már 5 saját játékot írnak a Nitrousra, és nekik ez számított, nem pedig az AotS, bár nyilván utóbbi elég jó Supreme Commander utód.
-
Abu85
HÁZIGAZDA
válasz
#35434496
#19548
üzenetére
A BF1 már azzal a Frostbite motorral jön, ami erősen gyúr a GCN shader intrinsics-re. A hogyan ebben a prezentációban benne van 31-44-es, 50-56-os és 68-71-es diáig. Ezeknek a függvényeknek van AGS 4.0-s megfelelője, kivéve az ordered countot, ami ősszel jön.
(#19559) gollo91: Az új Deus Ex az új GeometryFX-et használja, tehát azon keresztül kap shader intrinsics-et (Readlane, Ballot, MBCnt).
-
Abu85
HÁZIGAZDA
A Doomot érdemes lenne úgy értelmezni, hogy először használja a GPUOpen shader intrinsics függvényeket. Ezt nagyon fontos kiemelni, mert van egy gyors kódút és egy szabványos, és a GCN a gyorsat futtatja, míg a többi hardver a szabványosat. Természetesen a gyors kódút neve azért gyors, mert gyorsan fut. Nyilván ez minden olyan motorban előjöhet, amely shader intrinsicet használ, mint az új Frostbite, vagy a Dawn, de nem lesz általános a jelenség.
-
Abu85
HÁZIGAZDA
válasz
mcwolf79
#19529
üzenetére
Amikor a böngészős gyorsításról beszélünk, akkor az eléggé általános dolog. Igazából nem ajánlott kikapcsolni, mert például az Edge gyorsítása teljesen szabványos, így működik minden hardverrel. Ugyanakkor vannak olyan böngészők, amelyek nem követik teljesen a szabványt ebből a szempontból (Chrome, Firefox) és ilyenkor nyilván a szabvány szerint felépített driverek nem igazán tudnak ezzel mit kezdeni, amíg nem frissítik a böngészőre vonatkozó rutinokat. Emiatt gyártófüggetlen ez a gond.
A DDU egyáltalán nem ajánlott!!! Ennek használata okozza a problémák zömét. [link] - ez az ajánlott törlési metódus. Teljes törlésnél pedig ez: [link]A ZeroCore a bug állítólagos ideje alatt évekig működött a tesztjeinkben.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#19458
üzenetére
Custom modellt az AMD nem küldhet tesztre. Azt csak az adott modell gyártója teheti meg. Mivel az RX 480-ra NDA már nincs, ezt megtehetik a gyártók akár ma is.
Lehet, hogy mellbevágó lesz, de a VGA-eladások ~70%-a OEM. Hogy megéri-e a háromszor nagyobb eladással kecsegtető szegmenst választani? Naná. Ha van elég lapka, akkor érdemes azonnal letámadni az OEM-eket.
-
Abu85
HÁZIGAZDA
A Fury X-ból szállítottak sokat az OEM-eknek. A Fury viszont csak AIB kártya volt.
Nincs Dual Fury. Radeon Pro Duo van. Azt a professzionális piac elég szépen viszi, hiszen más VGA erre a területre nincs, miközben VR filmeket és tartalmat csinálni kell.
A drága VGA-k nem szólnak bele igazán a részesedés növekedésébe, mert ezek az eladás tekintetében a 10%-át sem teszik ki az összes VGA-eladásnak.Megszokhatnád, hogy a PH nem üzleti lap, ide pénzügyi jelentést évek óta nem rakunk ki. Egyszerűen senkit sem érdekelt. Állandóan a sereghajtóak voltak a pénzügyi hírek a lekattintás tekintetében.
-
Abu85
HÁZIGAZDA
válasz
mcwolf79
#19439
üzenetére
Mint mondta ki lehet listázni a custom modelleket a webáruházakba, de ellátás nem lesz. Ugyanaz lenne a helyzet, mint a GeForce-nál. Rendelés után kapnád a levelet, hogy mire tudják a rendelésed változtatni.
Nyilván egyébként az AMD-nek és az NV-nek más gondjai vannak. Az NV-nek a TSMC a gondja, míg az AMD-nek az OEM-ek kiszolgálása, de az eredmény ugyanaz. Ha bejelentenek custom modelleket, ha nem, ellátni már nem tudják a piacot ezekkel. Még legalább kell hozzá egy hónap, hogy normalizálódjon a helyzet. -
Abu85
HÁZIGAZDA
válasz
#45185024
#19435
üzenetére
Nem teljesen. A custom kártya az nehéz ügy, mert kell egy lapkamennyiség, hogy a gyártónak ne legyen rajta vesztesége. Ha ez nincs meg, akkor onnantól kezdve a gyártósor nem hozza, hanem viszi a pénzt. Nem véletlenül jöttek az ASUS Turbo modellek is az 1070/1080-ból ebben a hónapban. Egyszerűen nincs elég lapka, hogy a gyártósor egy partnernél nyereségesen üzemeljen. Emiatt működtetni sem érdemes. Egyre több ilyen custom VGA van GeForce-ból, amelyeket nem a gyártók gyártanak le maguknak, hanem egy gyárból kerülnek ki, és csak blower hűtőt raknak rájuk.
-
Abu85
HÁZIGAZDA
válasz
stratova
#19434
üzenetére
400 lapka/hét/custom verzió alatt nem éri meg beindítani a tömeggyártást. Az NV-nél 100 lapka/hét/custom verzió alatt beindították, és elég nagy veszteségeik vannak a gyártóknak, mert a kiépített gyártósor a hét 5 napjából négyet pihen. Az EVGA ugye már bejelentett termékeket is törölt, mert csak állna a gyártósorban a pénz. Az elején egy indok van arra, hogy kevés különböző termék legyen, mégpedig az, hogy a kiépített gyártósorok 100%-os kapacitással üzemeljenek. Most az AMD-nél ez még a Polaris 10-zel sem biztos, hogy megoldható, még akkor sem, ha 4x-5x több lapkát gyártanak, mert azoknak a többsége megy az OEM-ekhez. Persze egyébként mondhatnák azt az AMD-nél is, hogy csináljátok a gyártósort tuti lesz elég lapka, csak ha nincs elég lapka, akkor a partner fogja megszívni, mert addig veszteségesen gyárt, amíg tényleg nem lesz elég lapka.
-
Abu85
HÁZIGAZDA
Az RX 480-ból a nyáron biztos lesznek custom verziók, de inkább augusztus felé. Az AMD startja más volt, mint az NV-é, mert amíg az NV csak AIB-re dolgozott, addig az AMD a Polaris 10-et bedobta az OEM-eknek is. A lapkák 60%-a ide megy, és a dobozos termékek esetén meg kell várni, míg az AMD garantálni tud a gyártóknak minimum heti 400 lapkát custom megoldásonként. Ezalatt úgy sem indítják a tömeggyártást, mert az például felesleges, hogy úgy járjanak, mint az EVGA, hogy bejelentés után vonják vissza egy termék gyártását lapkahiány miatt.
-
Abu85
HÁZIGAZDA
válasz
mcwolf79
#19401
üzenetére
A BF1 egyáltalán nem azt a kódot futtatja GCN-en, amit a többi más hardveren. Ott az új motort úgy tervezték, hogy az Xbox One D3D12 mono, míg a PS4 libGNM API-t használ, míg a PC-n lesz egy GCN-es mód, ami a DX12+AGS4.0 API-t használja, és lesz a normál DX12 szabványos kód a többi architektúrára, illetve egy DX11 fallback, ha nincs Windows 10. Azt is elmondták már, hogy a gyors shaderek az új kivágási rendszert érintik. A szabványos kód nem futtat Ballot, RFL, barycentric, M3 és ordered count funkciókkal tarkított kódot. Egyébként a szabványos kód ettől nem fog szarul futni, csak a gyors kód gyorsabb lesz a'la Doom.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#19321
üzenetére
Ha pedig beírsz a Guruba, hogy ajánljanak játékgépet, akkor GeForce-ot ajánlanak. Ellenben minden ajánlás csak ajánlás. Azt meg lehet fogadni, vagy sem. Nem kötelez rá senki. És egyik ajánláshoz sem írja oda senki, hogy az a legjobb választás. A végszót úgyis a vásárló mondja ki.
Nyilván a vásárló lehet csőlátású, és megy minden ajánlás után, vagy lehet megfontolt és utánanéz mindennek a vásárlás előtt, természetesen figyelembe véve az ajánlásokat. És ezt tök általánosan írom az ajánlásokra.Magát az ajánlót is sarokba lehet szorítani, ha nem írod le, hogy mire kell, mert akkor nagyon általánosan kell ajánlania.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#19316
üzenetére
Igen. Szerintem addig biztosan várni kell, amíg nem lesz GCN4-es FirePro.
Itt a SolidWorks ajánlója AMD-re és NVIDIA-ra.
A SolidWorks megrendeléseket teljesít, amikor a NV kéri meg őket, hogy adjanak ki anyagot, akkor az NV-t említik. Amikor az AMD kéri ugyanezt, akkor az AMD-t. Ez egy üzlet. Általánosan pedig ott a fenti két oldal, ami ugye nem megrendelés, hanem információbiztosítás.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#19312
üzenetére
A Solidworks optimalizál mindenre. Csupán a FirePro és a Quadro előnyt élvez. Ez amiatt kell, hogy nekik van hitelesítési rendszerük, ami ellenőrzi az AMD és az NV FirePro és Quadro VGA-it, hogy megfelelnek-e sebességben és működésben. Ez garantálja, hogy ha ezek közül vásárolsz, akkor a hitelesített meghajtókkal biztosan működni fog a program. Sajnos a Radeon és GeForce VGA-kat nem hitelesítik, mert azokra egyik gyártó sem fizeti be a díjat, de nyilván egyébként a lejelentett problémákat a Solidworks javítja, csak az nem prioritás.
Nem lehet helyrehozni az OpenGL-t driverben. A problémát az adja, hogy minden egyes eljárásnak egy tucat alternatívája van. Ezek az egyes hardvereken eltérő teljesítménnyel működnek. A Solidworks azt csinálja, hogy minden egyes GPU-ra külön OpenGL optimalizálást ír, annak érdekében, hogy kezeljék az API töredezettségét. Az egyetlen megoldás áttérni DirectX-re vagy Vulkanra. Ezek az API-k nem engedik meg, hogy ugyanarra a problémára több megoldás legyen definiálva.
-
Abu85
HÁZIGAZDA
válasz
Locutus
#19309
üzenetére
Túl új a hardver, így nincs hozzá még a programban optimalizálás. A Solidworks esetében az OpenGL a probléma, ugyanis az egy olyan töredezett API, hogy minden hardverre specifikusan végig kell menni egy optimalizálással, és csak utána lesz jó. Hiába tekintik az OpenGL-t szabványnak, a gyakorlatban nem az. Magában az API-ban minden egyes problémára létezik legalább egy tucat eltérő sebességű megoldás, és minden hardveren más megoldás jelenti a fast path-ot. Ugye a Vulkan fő fejlesztési alapja ezért például az volt, hogy minden problémára csak EGY megoldás legyen, és az legyen gyors.
-
Abu85
HÁZIGAZDA
válasz
 Habugi
#19306
üzenetére
Habugi
#19306
üzenetére
Az OpenGL az mindegy, mert minden gyártóra külön specifikus OpenGL kód van az ID-nél. Olyan kód, amivel a legjobban megy. Emiatt számos gyártóspecifikus kiterjesztés is fel van használva.
A Vulkan esetében már van egy alapként szolgáló szabványos kód, illetve egy gyors kód. Utóbbi lényegtelen, mert csak az AMD éri el, és a Vulkan 1.0.17 azért kell hozzá, mert ebben van benne az a SPIR-V implementáció, ami megengedi a rendszernek, hogy a gyors shadereket fordítsa a hardver virtuális ISA-jára.
A többiek csak szabványos SPIR-V-ket fordítanak, tehát oda elég az 1.0.8. Egyébként nyilván elfogadja azt is, ha a driverben újabb Vulkan implementáció van, de nem szükséges. -
Abu85
HÁZIGAZDA
válasz
 cyberkind
#19259
üzenetére
cyberkind
#19259
üzenetére
DX11 standard és DX12 + GPUOpen shader intrinsics. A Vulkan opció, de nem biztos, hogy meglesz a megjelenésre. A DX11-ből csak alap kódot készítenek, de még nincs eldöntve, hogy belerakják-e a véglegesbe. Lehet, hogy tartják a WDDM 2.0-s minimum igényre vonatkozó tervet, és akkor csak DX12 jön.
-
Abu85
HÁZIGAZDA
válasz
imi123
#19201
üzenetére
Eléggé sokáig baszogatták őket a fejlesztők, mire beadták a derekukat. Ugyanezt megtehették volna 2012-ben is, hiszen ugyanazok a lehetőségeik voltak a hardverben, és akkor is volt AGS DirectX 11-re. A probléma az, hogy egy ilyen modell alapvető problémákat is felvet az API fejlesztésénél. Főleg úgy, hogy az AMD két nagy konzolban is ott van. Nem feltétlenül csak az üzleti szempontokat kell látni, hanem azt is, hogy mennyire káros, ha az API-ba beleraksz egy olyan képességet, ami a konzolban elérhető, és csak azért ezt használja PC-n is a fejlesztő, mert a konzolra megy el az R&D büdzsé 99%-a. Ennek vannak negatív hatásai is.
(#19203) imi123: Használ, de máshogy.
-
Abu85
HÁZIGAZDA
válasz
Habugi
#19197
üzenetére
Szabványos kódon kaphatnak async compute-ot. Pascal tuti, míg a Maxwell ha kap is, az hardveresen nem előnyös rendszer. Ugyanakkor a nem GCN-es hardvereknek az a hátrányuk állandóan meglesz, hogy nem tudják futtatni a gyors shadereket. Nem mindegy, hogy egy préselés szálcsoport szinten 32-64 atomi utasítást, vagy pár egyszerűbb built-in meghívását vonja maga után.
Az okosság az természetesen jó, de a GCN-nél is látszik, hogy csak akkor ér valamit, ha hozzá is nyúlnak a fejlesztők a hardverben rejlő lehetőségekhez. Most hozzányúltak, elsősorban azért, mert megkapták rá a lehetőséget az AMD-től. Az NV és az Intel is elgondolkodhat ezen, de évekig tart az ennek megfelelő terep előkészítése, dokumentációk publikálása, a kiterjesztések elkészítése, és megnyerni legalább egy konzoldizájnt.
-
Abu85
HÁZIGAZDA
válasz
Habugi
#19191
üzenetére
Nem az aszinkron compute jelenti itt az AMD-nek ezt az extrém gyorsulást, hanem ez: [link] Persze TSSAA-val az async is számít, de nem annyit, mint a gyors shaderek futtatásának lehetősége. Nem véletlenül nevezik ezeket a nem szabványos shadereket gyors kódoknak. Ennek azon egyszerű oka van, hogy sokkal gyorsabban futnak, mint a szabványos kódok.
-
#19153
Abu85
HÁZIGAZDA
Harley quinn
#19150
Abu85
HÁZIGAZDA
válasz
 Harley quinn
#19150
üzenetére
Harley quinn
#19150
üzenetére
Minden architektúrában van ennyi, csak a szabványok nem adnak lehetőséget a kihasználásra. Itt sem szabványos kód fut RX 480-on, hanem úgynevezett gyors kód.
-
Abu85
HÁZIGAZDA
A Doom esetében az OpenGL nem annyira limites, amennyire más játéknál. Eléggé modern kiterjesztéseket használnak mindkét gyártónál, szóval nem igazán a szabványos OpenGL lehetőségek működnek benne. Emiatt erősebb CPU mellett szinte mindig GPU-limit van. A Vulkan általánosan csupán pár százalékot jelent erős CPU-val. Gyengével persze sokat.
Ami hozza a sebességet az az aszinkron compute, de ez GCN1/GCN2/GCN3-on üzemel csak, míg GCN4-re egyelőre nincs engedélyezve, mert ez a rendszer egy másik konstrukciót kap. Emellett a nagy sebességet a GPUOpen intrinsics hozza, ennek GPU-limit mellett 10-20%-ot lehet köszönni. Az RX 480 csak ettől gyorsul annyit amennyit. -
Abu85
HÁZIGAZDA
válasz
nubreed
#18819
üzenetére
Általában ezeket a megjelenés előtt felrakják, hiszen az adott gyártó az OEM-ekre vonatkozóan már végez limitált szintű előzetes terméktámogatást a kiszállított mintákra, de az nyilván nettó hanyagság, hogy ezeket nem rejtik el a publikum elől.
(#18820) schawo: Default beállítással nem lesz teljesítményveszteség. Ugyanakkor lesz egy TDP-t csökkentő speciális beállítás is, ami egy előre konfigurált power limitet állít be, azzal pár százalék tempócsökkentés lesz. Viszont ez alapértelmezetten ki van kapcsolva.
-
Abu85
HÁZIGAZDA
Ehhez még annyit hozzáfűznék, hogy jellemzően gyakorlati a meghajtók fejlesztése, noha tény, hogy erősen elméleti alapokra van építve. A legnagyobb ismeretlen az RX 480-nál az utasítás-előbetöltés, és ennek a kiismerése hozhatja a legtöbb extrát, mert korábban minden esetben arra törekedtek a rendszerprogramozók, hogy megfelelően át legyenek lapolva a rendszerben futó szálak. Ez számos kellemetlen döntést is vont maga után minden GPU-n, de érdemes volt a kisebbik rosszt választani. Az RX 480 itt teljesen megkavarja a kártyákat, és érdemes kísérletezni azzal, hogy nem az átlapolásra, hanem az utasítás-előbetöltés épül a meghajtó optimalizálásának egy része, ugyanis lehet, hogy a többi hardver miatt csupán egy kényszerből bevezetett rutinok a GCN4-re egyáltalán nem szükségesek, így mehet az optimális konstrukcióval is a feldolgozás.
-
Abu85
HÁZIGAZDA
válasz
nubreed
#18814
üzenetére
Valószínűleg csak az RX 480-on. A többi VGA-n nagyon nehéz ilyen hirtelen ennyi teljesítményt találni, mert ezek már nagyon régóta elérhetők, és nagyon régóta fejlesztik rájuk a szoftveres hátteret. Az RX 480 csak a szokásos fejlődést követi. Jellemző, hogy mindegyik új architektúrát használó VGA gyorsul 7-10%-ot a megjelenéstől számítva fél éven belül. Ez azért van, mert az új dolgok megfelelő működését a szoftveres csapatnak ki kell tapasztalni, és annyira bonyolult ez a buli, hogy ez hónapokig tartó tanulási folyamatot von maga után. Az RX 480 ráadásul olyan dolgokat vezetett be, amelyeket soha egyetlen GPU sem tartalmazott, tehát nagyon sok az ismeretlen tényező. Emiatt nőhet a vártnál picit gyorsabban a sebesség az elején is egy-egy driverrel, mert teljesen ismeretlen vizeken járnak a rendszerprogramozók.
-
Abu85
HÁZIGAZDA
válasz
 nonsen5e
#18737
üzenetére
nonsen5e
#18737
üzenetére
Dehogyis nincs. Csak van egy funkció, amit a DX12-es kódnál a Warhammer hardveresen old meg, és nincs szoftveres backend. Ilyenek a jövőben is lehetnek, ahogy fejlődik a rendszer. Emiatt mondtam mindig, hogy törekedni kell a legújabb architektúrára, mert azok többet támogatnak.
Ez a táblázat egyébként segíthet eligazodni:
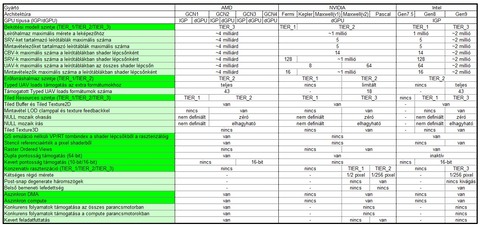
-
Abu85
HÁZIGAZDA
válasz
oAcido
#18734
üzenetére
Mennyit akartok még profitálni a HD 7970-ből? A GTX 680-nal volt egy szinten a startkor és most a GTX 780 és 780 Ti között van jelentősen lenyomva a GTX 680-at. A 290X a GTX 780 Ti-vel volt egy szinten és most a GTX 970-980 között van jelentősen lenyomva a 780 Ti-t. Plusz kaptak a vásárlók aszinkron compute-ot, ami szintén hozza a boostokat, úgy hogy a megjelenéskor nem DX12-re vették ezeket a VGA-kat. Plusz a 290X-szel futtatható a Warhammer DX12-es módja, míg a GTX 780 Ti-vel már nem. Nem ez lesz az utolsó példa erre idén.
Idővel minden felett eljár az idő. Természetes, hogy az AMD nem tudja beépíteni a Polaris újításait a kiadott hardverekbe. Ebbe bele kell törődni.
-
Abu85
HÁZIGAZDA
válasz
 FLATRONW
#18730
üzenetére
FLATRONW
#18730
üzenetére
Az hátulról nem állapítható meg. Sok NYÁK-on van több bekötési pont, de aztán végül nem lesznek felhasználva. Az biztos, hogy maga a tápcsatlakozó nem a NYÁK-on lesz, hanem valahol kivezetve. Talán hátrébb. Kvázi hosszabbítóval lehet bekötni, amit gondolom bele is építenek.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#18720
üzenetére
Custom kellett volna oda. De annyira nehéz azt a hülye grafikont javítani, hogy úgy maradt.
(#18721) oAcido: Itt nem gondolnak az időre a mérnökök. Egyszerűen a Mantle tesztelésénél látták, hogy az eddigi limitek leküzdésével milyen limitek keletkeznek a rendszerben. Ezek eddig is ott voltak, csak korábban beleütköztél egy erősebb limitbe, így minden mögötte lévő limit érdektelen volt. Nyilván a skálázhatóság múlik azon, hogy a felszínre került új limiteket kezeljék, emiatt került be az utasítás előbetöltés. Ennek igazából minden játékra van már hatása, csak lehet csekély és sok, és az egész beállításfüggő. Viszont a hardveresen kezelt probléma a fejlesztők életét egyszerűbbé teszi, mivel persze észreveszik, hogy hol keletkezik a rendszerben a limit, csak nem kritikus fontosságú tenni ellene, mert a Polaris hardveresen kezeli. Sokkal egyszerűbb egy cégnek azt közölni, hogy vegyél Polarist, mint azt, hogy beküldök pár mérnököt egy szobába, és egy év múlva jön a patch.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
#85552128
#18711
üzenetére
Mi nem küldjük a méréseket a netre, nincs bekötve a tesztgép.
 (elővigyázatosság, hogy ne frissüljön az alkalmazás). Persze lehet, hogy egyet-egyet a neten futtatunk, de amikor élesben megy, akkor sosem. Ezt nem tudom, hogy kinek van kedve a mi nevünkkel nyomulni, lehet, hogy nem mi vagyunk azok, mert nem PH-s nevet szoktunk használni. Persze az AotS-re van több accountunk. Az az app legalább háromszor megvan.
(elővigyázatosság, hogy ne frissüljön az alkalmazás). Persze lehet, hogy egyet-egyet a neten futtatunk, de amikor élesben megy, akkor sosem. Ezt nem tudom, hogy kinek van kedve a mi nevünkkel nyomulni, lehet, hogy nem mi vagyunk azok, mert nem PH-s nevet szoktunk használni. Persze az AotS-re van több accountunk. Az az app legalább háromszor megvan. -
Abu85
HÁZIGAZDA
válasz
#85552128
#18707
üzenetére
Az extreme preset csak a kiindulás volt. Azon még változtattunk. Közel van hozzá a minőség, de ahogy írtam megnöveltük a mintavételezést. Ezt azért tettük, hogy ráküldjük a hardvereket a futószalagozás határára. Ezt az összes előre konfigurált preset próbálja elkerülni, de mi pont arra voltuk kíváncsiak, hogy melyik hardver skálázódik, ha belefutnak a belső limitekbe. Egyelőre csak a Polaris.
A skálázás azért lényeges, mert nem mindenki fog hónapokat szöszölni a megfelelő preset konfiguráción, ahogy azt teszi az Oxide. Puszi a hasukra a lelkiismeretes munkájukért, de a valóság inkább az lesz, hogy ha egy stúdió belefut a limitekbe, akkor azt elkönyvelik hardveres gondnak. -
Abu85
HÁZIGAZDA
válasz
#85552128
#18695
üzenetére
Mi úgy állítottuk be az AotS-t, hogy sok legyen a mintavétel, ami növeli a rajzolási parancsok számát. Az RX 480 azért olyan erős itt, mert ez az első GPU, ami támogat utasítás előbetöltést, és nem ütközik bele a futószalag mélységének limitjeibe, ami a régebbi GPU-kra jellemző. Amint tízezer rajzolás fölé megy a jelenet komplexitása, azonnal hatékonyságot vesztenek a korábbi hardverek, mert 1 mikromásodpercük van egy rajzolásra, és az túl alacsony érték ahhoz, hogy a memóriaelérést átlapolja a többi szál. A Polaris esetében a határérték 100 nanomásodperc, vagyis 100-szor kisebb a futószalag mélysége, így addig biztosan skálázódik a hardver, ameddig az API. Talán tovább is, de értelemszerűen ezt a gyakorlatban nem lehet még megnézni.
-
Abu85
HÁZIGAZDA
válasz
 Valdez
#18674
üzenetére
Valdez
#18674
üzenetére
Mindig szükséges egy pilot projekt, hogy lássák jól működik-e. Az ID software vállalta most magára ezt a szerepet. A játék kiadása miatt itt az időpont nem lényeges már, mert az a céljuk vele, hogy lássák mennyire működik, ha a konzolon használt optimalizálásokat áttelepítik PC-re. Nyilván az AMD ebből csinálhat marketinget, de számukra is egy teszt az egész, mert eddig soha senki nem hozott át konzolról optimalizálásokat. Még a Mantle-re sem, mert az sem tartalmazta a szükséges függvényeket. Szóval a Doom önmagában senkinek nem lényeges. A lényeg az a kérdés, hogy ezt az egészet jól lehet-e alkalmazni PC-n, hogy innentől minden ID tech 6-os játéknál számoljanak vele. Illetve az AMD kérdése az, hogy milyen felkészültséget igényel az implementálás, hiszen aszerint viszik majd a többi fejlesztőhöz.
-
Abu85
HÁZIGAZDA
válasz
wjbhbdux
#18673
üzenetére
Az AMD-nél nem újdonság, hogy rendkívül szorossá fűzik a fejlesztői kapcsolatokat. Amióta kijöttek a konzolok azóta ezen munkálkodnak. Az NV fordítottan dolgozik. Ők egyre inkább kizárnák a fejlesztőket a fejlesztésekből, ami viccesen hangzik, de ez a fő cél. Volt is erről egy nagyon jó fejlesztői blog, ami mérgelődött ezen: [link]
Ezek stratégiai döntések. A piac jelen helyzetében nagyon is megéri az AMD-nek betelepedni a fejlesztők mellé, míg az NV-nek nagyon nem éri meg. Az az alapprobléma, hogy a konzolok miatt a fejlesztők mindent tudnak a GCN-ről, emiatt a GCN-es ismeretek szerint optimalizálnak. Az NV ezzel szemben azt akarja elérni, hogy ne optimalizáljanak. A PC megvan nélküle. -
#18672
Abu85
HÁZIGAZDA
Petykemano
#18667
Abu85
HÁZIGAZDA
válasz
 Petykemano
#18667
üzenetére
Petykemano
#18667
üzenetére
Nézd meg a Radeonok teljesítményét DX12-ben. Ezért éri meg nekik. Például a legújabb esetet vizsgálva a végleges Warhammer patch-ben az AMD gyorsul, míg az NV lassul, ez elsődlegesen annak köszönhető, hogy az AMD-nél ott a knowhow arra, hogy miképp kell gyorsulni.
Azt sem tartom kizártnak, hogy a knowhow nem jár ingyen, bár ez már erősen üzleti alapú. Annyi biztos, hogy az AMD tapasztalata kell a fejlesztőknek, tehát nagyon előnyös a tárgyalási pozíció arra, hogy a fejlesztők beépítsenek exkluzív dolgokat is, ahogy például a Doom fejlesztői is Radeon-exkluzív eljárásokat raknak a Vulkan leképezőjükbe. Lehet, hogy megtennék maguktól, de az is lehet, hogy csak azért foglalkoznak vele, mert az AMD odaígérte nekik a tudást, és ezt kérték cserébe. -
Abu85
HÁZIGAZDA
válasz
TTomax
#18663
üzenetére
Elbeszélünk egymás mellett. Pár éve a Mantle volt a téma. Azt jóval egyszerűbb beépíteni. Nem azért, mert nagyon eltérő az API, hanem azért, mert aki azt kérte biztosan rendelkezett egy olyan motorral, amely strukturálisan megfelel a célnak, vagy ha nem, akkor rövid időn belül átalakítható. A DX12 és a Vulkan a vezető stúdiók számára hasonló, de az API-k gyártófüggetlen mivolta miatt nem csak a top stúdiók érdeklődnek, és olyan motorok is előkerülnek, amelyek strukturálisan nagyon messze vannak attól, amit ezek az API-k igényelnek.
Mondjuk, hogy egy Nitroust DX12-re felkészíteni egészen más jellegű munka, mint például a Crystal Engine-be belerakni a támogatást. Az előbbivel járó munka nem több pár hétnél, míg az utóbbihoz jópár hónap kell, de nem ahhoz, hogy a DX12-t belerakd, hanem ahhoz, hogy a motor struktúráját annyira átírd, hogy működjön. És akkor ez még mindig csak a működés, lásd Rise of the Tomb Raider. A sebesség ezután jöhet csak. Persze a stúdiók jelentős részénél ez is egy tekintélyes előny a DX11-es szopásokhoz viszonyítva. Még ha nem is hozza a DX11 sebességét, lényegesen kevesebb idő alatt érték el a megcélzott teljesítményt. Ez egy új motor fejlesztésénél nagyon fontos, mert 4-5 éve fejlesztett motoroknál már a DX11 leképező nagyon optimalizált. Tehát innen vizsgálva a DX12/Vulkan API-val egy új motornál hamarabb hozható a célzott teljesítmény.Itt egyébként az AMD már publikusan is árasztja el az ipart a tapasztalataival, és két hónapja elmondták, hogy milyen struktúra az ideális. [link] - na most egy "Stage 3"-ként jelölt struktúrához azért igen durva módosítás szükséges a legtöbb motorban. Ezek azok a tudások, amelyek hiányoznak, mert az AMD ezekről eddig nem beszélt nyíltan, és ugye a többi cégnek nincs három év tapasztalata egy explicit API-val, hogy ezeket tudják. És a beszámoló is csak a felszín, maga a kiindulási alap, onnan még rengeteg limitet kell leküzdeni, mire ebből gyors program lesz. Az iparág problémája innen részben az, hogy a leküzdéshez szükséges tudást is csak az AMD birtokolja. Nyilván három év múlva másnak is lesz ennyi tapasztalata, de a jelenben nincs sok választás.
(#18664) Gertrius: A Valve legfrissebb technológiája nem tartja a lépést a nagyokkal, így számukra annyira nem fontos, hogy kiemelt szerepet élvezzenek egy gyártónál. Tartják a kapcsolatot mindenkivel és fejlesztgetnek. A Valve "amikor kész lesz" fejlesztési modellje egészen más lehetőségeket jelent számukra. Nincs mögöttük egy kiadó, amely esetleg elzárja a pénzcsapot, ha sokszor mondod, hogy csúsznia kell a projektnek. A legtöbb stúdiónál az a probléma, hogy a kitűzött időpont az életben maradást szolgálja.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#18661
üzenetére
Azt nem tudom, hogy teljesen lemondtak-e róla, de borzalmasan messze van az aktuális állapot attól, amit el szeretnének érni. A kiadók általában nem szeretnek a játék megjelenése után olyan projekteket finanszírozni, amelyektől igazából lényeges extra bevétel nem várható. A DX12 leképezőt is a megjelenés után kezdték el fejleszteni, és ugye a játék használna ROVs-ot és konzervatív raszterizációt (TIER3-ast), de mindkettő hihetetlenül lassú. A konzervatív raszterizáció úgy felezi az fps-t, hogy annak elvileg gyorsítani kellene, így nyilván nem kell az Intelnek a Skylake-re. A ROVs meg egy teljesítménygyilkos. Intelen harmadolja, míg NV-n századrészre csökkenti a sebességet. Ez részben fejlesztői hiba is lehet, teljesen elmérték, hogy mire képesek a mai hardverek. A Microsoft sem kínál igazából tanulmányokat erről, ami szintén problémás, hiszen nincs kiindulópont. Csupán annyi van, hogy 4-5 éves távon fognak ezek a funkciók valamit érni, de ez a Microsoft hibája, mert miattuk nem történik itt előrelépés, hiszen úgy vannak vele, hogy 4-5 év múlva ráérnek foglalkozni a DX12 extra funkcióival, és kínálni hozzájuk működő példákat, fejlesztőeszközöket.
-
Abu85
HÁZIGAZDA
válasz
#25237004
#18600
üzenetére
Azért a DX12 beépítését segíteni nem olyan egyszerű, mint azt sokan gondolják. Általában egy fejlesztő, ha partnert választ több tényezőt veszi figyelembe. Az első a knowledge. Az AMD eddig 10 megjelent, explicit API-t használó projektet vezényelt le. Abból kilencet sikerrel, míg egy volt bevallottan a pilot. Az NV eddig 1 explicit API-s projekten van túl, ami szintén a pilot volt. Világos, hogy tudást hol találnak. A második a fejlesztőeszközök. Ezek az API-tól eléggé függetlenül fejlődnek, és két tényezőt vesznek figyelembe a fejlesztők. Az egyik a forráskódra vonatkozó licenc, míg a másik a kiforrottság. Az AMD MIT licenc mellett nyílt forráskóddal kínál DX12-es fejlesztőeszközöket. Az NV-nek viszont még ma sincsenek stabil DX12-es fejlesztőeszközei. A harmadik tényező a reklám, de ez igazából megegyezés kérdése, tehát bármit ki lehet hozni belőle, többek között itt lehet meggyőzni a céget arról, hogy még ha minden ellened szól is, akkor is téged válasszon. Ez leginkább a kis stúdióknál válik be.
Mindegyik cég dolgozik egyébként DX12-es játékokon. Elsősorban azért is, mert az AMD pokoli túlterhelt. A kapacitásaik végét járják, hiszen ők a partnerei a Deus Ex: Mankind Divided, a Star Citizen, a Watch Dogs 2, a Battlefield 1, a Dishonored 2 játékoknak, és már az Ark: Survival Evolved fejlesztőit is felvették, plusz van egy rakás be nem jelentett projekt is, na meg ott a Vulkan, amit használni fog a Doom. Az NV is hoz majd DX12-es játékokat, például a King of Wushu és a Squad című játékoknál segédkeznek. Az Intel tervez a DX12-vel, bár az F1 2015 és a Just Cause 3 frissítést lelőtték, mert a DX11-hez képest csökkent a teljesítmény.
-
Abu85
HÁZIGAZDA
-
#18398
Abu85
HÁZIGAZDA
FollowTheORI
#18397
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#18397
üzenetére
A Division csak bizonyos beállításokkal. A Polaris ezzel a fejlesztéssel menetesül a GameWorks egyes negatív hatásaitól is, amivel az összes többi hardvernek (még a GeForce-oknak is) meg kell küzdenie. A Divisionben a HBAO+ eléggé optimalizálatlan, így ezt bekapcsolva a Polarisnak kedvez a rendszer, míg a többi GPU bele van kényszerítve egy rakás NOP-ba (üres ciklus).
Mi ezért nem kapcsoljuk be ezeket az effekteket, mert nagyon mesterségesen ferdítik a valóságot. Ma főleg a Polarisnak kedvezve. -
#18394
Abu85
HÁZIGAZDA
FollowTheORI
#18385
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#18385
üzenetére
A Black Ops 3-ban azért ilyen, mert viszonylag optimalizálatlan játékról van szó, amiben sok a pipeline stall. Ezeket a helyzeteket a Polaris hardverből kezeli, míg a többi hardver a viszonylag optimalizálatlan kóddal nem tud mit kezdeni. Erre is a harmadik oldal ad majd választ.
Bár a fő fejlesztési indok az AMD-nél nem ez volt, de amolyan melléktermékként a Polaris iszonyatosan jól bánik az optimalizálatlan shaderekkel. Ennek a legnagyobb előnye az lesz, hogy már day0 jól mehetnek vele a játékok, és nem kell a shaderek cseréjére várni.
-
Abu85
HÁZIGAZDA
válasz
 rocket
#18363
üzenetére
rocket
#18363
üzenetére
Az SM6.0 önmagában nem egy Polaris exkluzív valami. Az csak egy új shader nyelv. Annak vannak olyan dolgai, amelyeket bármelyik DX12-es hardver képes teljesíteni, és vannak kiterjesztései, amelyekhez speciális hardverek kellenek. Ezeknek a kiterjesztéseknek egy része lehetővé teszi, hogy áthozzák a fejlesztők a konzolos kódot. Például a barycentric, de ez egyébként ma is megtehető a GPUOpen kiterjesztésekkel, csak az ID például mondta, hogy amit erre írnak Vulkan kódot a Doomhoz és innentől minden játékukhoz, az nem lesz szabványos, tehát akkor sem fog futni nem AMD hardveren, ha a hardver esetleg tudja a magát az eljárást. Ezért jön szabványos formában. Emellett lesznek még további kiegészítések, amelyek még a GPUOpennek sem a részei. Például ordered atomics. Bár erre annyira nagy az igény, hogy hoz rá kiterjesztés az AMD még az SM6.0 előtt, de ez sem lesz szabványos.
Az SM6.0 tehát önmagában nem clickbait, csak az teszi azzá, hogy nincs elég tudásotok felfogni, hogy mi van mögötte, így csak rövidítéseket tudtok rugózni.
-
#18311
Abu85
HÁZIGAZDA
Malibutomi
#18308
Abu85
HÁZIGAZDA
válasz
 Malibutomi
#18308
üzenetére
Malibutomi
#18308
üzenetére
Mondtam, hogy béna ehhez a clickbait műfajhoz. Ez nem az ő terepe.
Nem akarok nagy szavakat használni, de erre születni kell.
-
#18307
Abu85
HÁZIGAZDA
Malibutomi
#18306
Abu85
HÁZIGAZDA
válasz
Malibutomi
#18306
üzenetére
Nem. Kyle, Fuad és Charlie ugyanaz, csak Fuad és Charlie ért hozzá, míg Kyle egyszerűen béna ehhez a műfajhoz.
-
Abu85
HÁZIGAZDA
válasz
 füles_
#18264
üzenetére
füles_
#18264
üzenetére
Nincs különösebb gond a gyártással. A TSMC-nél nincs elég wafer biztosítva az NV-nek, mert gyártat az Apple, a Qualcomm, a MediaTek és a Xilinx. Ők a nagyobb rendelési tétel miatt az NV előtt vannak a, vagyis hiába épül folyamatosan a gyártósor abból az NV nem érez semmit. A kihozatal persze nem tökéletes, de egyáltalán nem katasztrófa. Mondhatni teljesen normális egy új node-nál. Egyszerűen csak annyi a baj, hogy a TSMC alul termel, és ezt a a legkisebb, jelen esetben az NV szívja meg a legjobban.
A GPU-gyártóknak általánosan el kell azon gondolkodni, hogy olyan bérgyártókhoz menjenek, ahol egy node-ra kevésbé nagy az igény a partnerek részéről. A TSMC mostantól káros az ellátásra, mert egy GPU-gyártó nem tud akkora mennyiséget gyártatni, amekkorát a fenti négy cég igénye.












 Végül az úgy 1400 dolláros Xbox One-t eredményezett volna. Szerinted megvették volna 25 millióan?
Végül az úgy 1400 dolláros Xbox One-t eredményezett volna. Szerinted megvették volna 25 millióan?
















 Ez engem zavar, pedig már fél éve szóltam.
Ez engem zavar, pedig már fél éve szóltam.









 (elővigyázatosság, hogy ne frissüljön az alkalmazás). Persze lehet, hogy egyet-egyet a neten futtatunk, de amikor élesben megy, akkor sosem. Ezt nem tudom, hogy kinek van kedve a mi nevünkkel nyomulni, lehet, hogy nem mi vagyunk azok, mert nem PH-s nevet szoktunk használni. Persze az AotS-re van több accountunk. Az az app legalább háromszor megvan.
(elővigyázatosság, hogy ne frissüljön az alkalmazás). Persze lehet, hogy egyet-egyet a neten futtatunk, de amikor élesben megy, akkor sosem. Ezt nem tudom, hogy kinek van kedve a mi nevünkkel nyomulni, lehet, hogy nem mi vagyunk azok, mert nem PH-s nevet szoktunk használni. Persze az AotS-re van több accountunk. Az az app legalább háromszor megvan. 




Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Motorolaj, hajtóműolaj, hűtőfolyadék, adalékok és szűrők topikja
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Milyen egeret válasszak?
- exHWSW - Értünk mindenhez IS
- Anglia - élmények, tapasztalatok
- Wise (ex-TransferWise)
- Revolut
- Hegesztés topic
- AMD vs. INTEL vs. NVIDIA
- További aktív témák...
- Xbox Series S 512 GB + kontroller 6 hó garancia, számlával!
- Tablet felvásárlás!! Samsung Galaxy Tab A8, Samsung Galaxy Tab A9, Samsung Galaxy Tab S6 Lite
- Újszerű Apple Macbook Pro 13 - Touch B - M2 - 8/256GB - 18 Ciklus - 100% akku - MAGYAR -asztroszürke
- Eladó Dell Latitude 5340 i5-1345U 16 GB DDR5 Törésgarancia
- REFURBISHED és ÚJ - HP USB-C Dock G5 (5TW10AA) - 3x4K felbontás
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest