Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 #65755648
#18065
üzenetére
#65755648
#18065
üzenetére
Ez igaz, de az AMD a GPUOpennel eléggé beleköpött az állóvízbe. Nehéz megjósolni, hogy mik lesznek a GCN shader kiterjesztések hatásai, de a Doom és az új Deus Ex használja őket, szóval GCN nélkül ennél a két játéknál biztos nem lesz elérhető minden funkció. És akkor még jön olyan, hogy s_waitcnt/lgkmCnt/vmCnt, amik szintén nem kis fícsőrök, bár ezeket csak az Ubisoft kérte.
-
Abu85
HÁZIGAZDA
válasz
 FLATRONW
#18007
üzenetére
FLATRONW
#18007
üzenetére
Ezen amúgy az NV tudna sokat javítani. Emlékszel a Dirt Showdownra? Na azt driver hozta helyre. Egyszerűen a játékra kellett szabni egy regiszterallokációs optimalizálást, ami a Keplernél mindig is nagyon fontos volt, mert regiszterhiányos az architektúra az ALU-nkénti 1,33 kB-nyi regiszterrel. A feldolgozók elvesztése egy másik probléma. Egy multiprocesszorba négy warp ütemező került hat felfűzött tömbhöz, vagyis két tömböt mindig különálló utasításokkal kell ellátni. Ez is orvosolható driverből a shaderek cseréjével, ha a fejlesztő nem figyelt rá. A gond az, hogy nincs meg az akarat a Kepler teljesítményén javítani, mert ha meglenne, akkor aligha lennének olyan játékok ahol egy R9 280 elveri a 780-at.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#17931
üzenetére
keIdor
#17931
üzenetére
Én elfogult vagyok a PC-piaccal, és sosem tetszett, hogy ennek a piacnak a szépségét bizonyos gyártók semmibe veszik. Régen ezért szapultam az ATI-t, mert szándékosan értelmeztek félre egy nagyon fontos specifikációt, amivel rosszat tettet a PC-nek (R2VB erőltetése). Most sem tesz jobbat a PC-nek az NV úgy, hogy olyan eljárást választanak az egyes effektekbe, ahol ugyanazt az eredményt a geometry shader hatszor lassabban számolja ki, mint a vertex shader. Ez egyáltalán nem a piac érdeke.
Kettőnk között az a különbség, hogy én látom, hogy mikor vernek át, míg te nem akarod, vagy tudod megnézni.
[link] - és nem csak én látom ezt problémának.
-
Abu85
HÁZIGAZDA
Nem is vennék, ha nem tudnám elintézni a VGA-gyártókkal, hogy egy az egyben cseréljék az új VGA-kra a régi GeForce- és Radeonjaimat.

(#17929) Egon: Mert ők is hazudnak, de például az nem érdekel, hogy egy cég hazudik arról, hogy melyik VGA-val járok a legjobban, mert nyilván az az érdekük, hogy a legújabbat adják el. De az már érdekel, ha arról hazudnak, hogy az adott effekthez használt eljárások miért terhelik indokolatlanul meg az adott hardvert. Ennek nagyon prózai az oka, én nem hiszek a gépigény mesterséges növelésében, és nem tartom jónak, ha a PC-piacon ez az irány stratégiává válik.
-
Abu85
HÁZIGAZDA
válasz
 imi123
#17908
üzenetére
imi123
#17908
üzenetére
Nem, csak azok akik azt hiszik, hogy jót tesznek a piacnak.
Az AMD is hazudik. Ők annyiban jobbak, hogy nem ölik a piacot. Felvették azt a működési modellt, ami az NV-re volt jellemző a G80-as időkben.
A véleményem mindegy, mindenki láthatja, hogy milyen szuperül működnek a GameWorks reformok. Hogy is van ez a politikában? A reformok működnek? Ugyanaz történik, az alacsony IQ kihasználása a lényeg. Persze nem fogják beismerni, hogy a hülyékre utaznak, de ettől tény, hogy gazdaságilag ez a kifizetődő.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Annyit hozzátennék még, hogy lehet játszani a textúraszűréssel a driverekben. Ez az AMD-nél a mintázat szűrés minősége, míg az NV-nél angolul Texture Filtering néven szerepel (magyarul textúraszűrés néven lehet). Ne tévesszen meg senkit, hogy nagyjából ugyanazok a beállítások (teljesítmény vagy minőség), mindkét gyártónál más az értelmezés. Például az NV magas minőségű (high quality) módjának az AMD-nél a teljesítmény mód (performance) felel meg a képminőség tekintetében. És az AMD minőség módja egy nagyon agresszív szűrési rendszer, amit a konzolokon kívül nem szokás alkalmazni, és más nem is alkalmazza. Ezeket tetszőlegesen, akár játékokra leosztva lehet állítani, mert nincs univerzálisan jó beállítás manapság.
-
Abu85
HÁZIGAZDA
Akkor leírom hosszabban. Az efféle jelenség oka az ordered dithering, ami csak szimulálja az átlátszóságot. Ezt igen sok régebbi játéknál használták a fejlesztők, mert fel lehetett húzni a háromszögekre egy dithering textúrát, és ezzel nagyon olcsón megúszható az átlátszóság kezelése. A ordered dithering hátránya, hogy nem ad jó eredményt, mert bár piszkosul gyors, és bőven megúszható a rakás overlap, de az algoritmust egyrészt a hardverhez kell igazítani, másrészt mindig lesznek a képen apró pöttyöcskék, amik a dithering textúra mellékhatásai.
A képen is látható, hogy mindkét hardveren megvannak a pöttyöcskék, csak más mértékben, mert más algoritmussal működik az ordering. 4xMSAA ezen sokat segít, de ott is látható, hogy a korlátnál az NV-n is marad pár pötty. 8xMSAA lényegében jelentősen megritkítja a jelenséget.Közben megnéztem a játék whitepaperjét is, és az Advanced Blending beállítás bekapcsolása, már nem ordered ditheringet használ az átlátszóság kezelésére. Az Advanced Blending egyébként OIT-t használ.
-
Abu85
HÁZIGAZDA
A Dirt Rally alatt biztos, hogy el lehet tüntetni a grafikai beállítások maximumra állításával. A 8xMSAA radikálisan csökkenti a jelenséget. A Tomb Raider esetében ez beállítástól független.
(#17880) PuMbA: Felőlem vehetsz NV VGA-t, de ugyanazzal a grafikai beállítással nem fog ez a jelenség eltűnni, mert ez program oldalán keletkező dolog. Se driver, se hardver nem fog mást számolni, mint amit a program kér.
-
Abu85
HÁZIGAZDA
Soha, mivel ezt nem lehet driverből befolyásolni. Az alkalmazás fejlesztője tudja korrigálni, de ez egyébként terv szerint működik így, még ha ronda is.
Van még így működő játék. Például a Two Worlds 2 maximális minőségben. Arra itt panaszkodtak a userek. [link]Ezek egyébként a PS3/Xbox 360-on használt technikák portjai. Azért ilyenek, mert nem módosították a motor leképezőjét PC-re.
-
Abu85
HÁZIGAZDA
válasz
 rocket
#17854
üzenetére
rocket
#17854
üzenetére
Annyival magasabbra nem lőhették, mint tervezték, emellett a GDC alapján pontosan tudták, hogy mire számíthatnak, hiszen akkor az AMD már megmutatta, hogy miket hoz a GPUOpen-be és az NV-nél is tudják a mérnökök, hogy ezeknek a built-in függvényeknek a hatása eljárástól függően +20-70% közötti boost a végső teljesítményre. Elég csak azt figyelembe venni, hogy Tiago Sousa a PS4-en 3-5 ms-ot nyert a Doomban async és built-in függvényekkel. Szóval elég pontosan ki tudták számolni, hogy a legrosszabb eshetőség mellett is mekkora órajel kell ahhoz, hogy a specifikus kódokkal tarkított RX 480 előtt maradjon a GTX 1080.
-
Abu85
HÁZIGAZDA
válasz
rocket
#17851
üzenetére
Ők részben azért tértek át a GloFo-ra, mert a TSMC-nél csak a sorukra várnának, mert ők sem nagy megrendelők. A GloFo viszont kedvezőbb, mert egyrészt speciális szerződésük van kötelezettséggel, ami alacsonyabb waferárat is jelent, másrészt a legújabb dens libeket csak GloFóra fejlesztik, és ahhoz, hogy a TSMC-nél tudjanak FinFet GPU-t gyártani előbb át kell portolni a HPL-t. Na most ez borzalmasan költséges, mivel a TSMC-nél csak HDL-je van az AMD-nek, de azt már nem akarják GPU-khoz használni. Emiatt sokkal olcsóbb áthozni a gyártást a GloFóhoz, mint HPL-t portolni a TSMC-hez. Ez volt a fő szempont a váltás mögött. A többi járulékos előny csak adalék.
-
Abu85
HÁZIGAZDA
válasz
rocket
#17849
üzenetére
Azért annyira nem amatőrök. A 16 nm-es FinFet majdnem másfél éves alap, amit sokan gond nélkül használnak. Nem hiszem, hogy pont az NVIDIA tervezné annyira félre, hogy alacsony legyen a kihozatal. Ahhoz azért általában a bérgyártónak is bénáznia kell, ráadásul a TSMC biztos szólt volna, ha valami idióta dolgot csinálnak. Erre vannak a szakembereik.
Eddig minden lapkából csináltak B verziót, annak nem kell nagy jelentőséget tulajdonítani. A legtöbb esetben el sem jutott az üzletekbe a B-cucc.
-
Abu85
HÁZIGAZDA
válasz
 nubreed
#17845
üzenetére
nubreed
#17845
üzenetére
Az a Glofónál készül. Erős a valószínűsége, hogy az AMD azért mentek át, mert a TSMC-nél nehéz labdába rúgni a nagyobb megrendelőkkel szemben. Ráadásul nekik vannak oda is libjeik.
(#17846) =WiNTeR=: A memóriagyártók nem jelentenek gondot, mert lezárt specifikációjú gyártósorral nagyon gyorsan lehet reagálni. Maximum két hónap és annyi gyártósort építenek ki, amennyi kell. Már a HBM2 is tömeggyártásban van, szóval le van zárva a specifikáció.
-
Abu85
HÁZIGAZDA
válasz
rocket
#17841
üzenetére
Uh, ez így sokkal rosszabb helyzet, mert nem lehet megoldani két hónapon belül és nem fog javulni a GDDR5X gyártósorok kiépülésével. Még ha a Micron gyártani is fog elegendő mennyiségű GDDR5X-et, a TSMC-nél az NVIDIA csak a sokadik a sorban a sok SoC gyártó mögött. Ebből úgy jó fél évig hiány lesz.

-
Abu85
HÁZIGAZDA
válasz
#45185024
#17784
üzenetére
Semennyit. Az effektek számításához szükséges idő ugyanaz DX11 és DX12 alatt. Az aszinkron compute átfedése jelenthet előnyt, mert úgy pár compute effekt ingyenesség válik. A DX11 azért lassabb sokkal, mert nem arra optimalizálták a játékot. Túl költséges és időigényes lenne ennek a módnak a teljesítményét a DX12 közelébe vinni.
Ez egy stratégiai játék. Fölösleges a 60 fps. Nem igényli a játékmenet.(#17783) gbors: Majdnem 100%-os hatékonysággal lehet aszinkron compute-ot futtatni. Az MLAA esetében biztos, mert olyan fázisba van berakva, ahol az ALU-k eleve csak malmoznának. A GPU particles esetében pedig majd meglátjuk.
-
-
Abu85
HÁZIGAZDA
Van róla egy részletesebb leírás, hogy milyen effekt mennyi időbe kerül 4K-ban. Persze ez az aktuális verzióra igaz.
A Warhammer implementációja az éppen aktuális AMD MLAA verzió másolata. Az nem eszik annyit, mint a Jimenez-féle konstrukciók, amelyeket például a Crysis is használ.
Nem különbözik a DX11 és DX12 alatt az effekt elvégzéséhez szükséges idő, mert ugyanaz a shader. DX12 annyiban jobb, hogy átlapolja a számítást a következő képkocka kezdeti számításaival, ahol ugye ez lehetséges. Emiatt pár hardveren még -1-2 fps sem lesz belőle. -
Abu85
HÁZIGAZDA
válasz
 TTomax
#17768
üzenetére
TTomax
#17768
üzenetére
Természetesen nem reprezentálja. Ebben a tesztverzióban még nem fut aszinkron compute-ban a GPU particles, illetve még nincs kész az a speciális MSAA, amit beleraknak a végleges DX12 kódba. Ettől függetlenül az bullshit, amit Hilbert az MLAA-ról összehord, hogy az akkora "performance hog". Maximum 1 fps-t képes levenni a végső sebességből, és ez nagyon maximum.
-
Abu85
HÁZIGAZDA
válasz
 Valdez
#17765
üzenetére
Valdez
#17765
üzenetére
Ezt nem igazán lehet így leírni, mert számos MLAA algoritmus létezik. Az AMD algoritmusa az egyetlen, amely compute shaderben számol. Ebből van kevés a játékoknál, míg más MLAA konstrukció elterjedt, például az SMAA is egy MLAA algoritmus, de nagyon sok játékban az AA csak AA-nak van jelölve és zömében MLAA-k azok is.
Ami miatt az AMD MLAA-ja kedvezőbb DX12-re az az asszinkron compute, mert az AMD konstrukcióját szinte változtatás nélkül be lehet főzni dedikált compute parancslistára, míg más MLAA/FXAA/CMAA konstrukciók esetében át kell írni az egészet előtte. -
Abu85
HÁZIGAZDA
válasz
TTomax
#17758
üzenetére
Megnéztem az MLAA-t mennyit eszik. A kapott adatok alapján 4K-ben a 980 Ti-nek 0,61 ms, míg a Fury X-nek 0,94 ms. Tehát a GeForce-on fut jobban úgy ~30%-kal (ez kb. reális, egyébként nagyjából ennyivel fog jobban az FXAA a Radeonokon.). Ugyanakkor a Radeon aszinkron compute-ban futtatja, így náluk ez ingyenessé válik. Mindenesetre annyira kevés erőforrást igényel maga az effekt, hogy maximum -1 fps jöhet belőle hardvertől függően. Nem értem, hogy a Guru3D miről beszél, gondolom ezt is benézték, mint az FCAT-ot az AotS-ben.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
 joysefke
#17548
üzenetére
joysefke
#17548
üzenetére
Négy hónapig nem tudtak elég HBM-et gyártani a Fiji-hez sem. Mindig ugyanez a probléma az új rendszereknél. A kísérleti gyártásból kevés gyártósor megy át, mert direkt nem építik ki azokat, hátha rossz a kísérleti gyártósor. Utána viszont három-négy hónap mire a végleges specifikációnak megfelelően felhúznak annyi gyártósort, amennyi a megrendelések kielégítéséhez kell.
(#17547) Habugi: A vége az lesz, hogy HBM lesz mindenen, de a nulláról a teljes átmenet annyira nagy időtartam, hogy a köztes megoldásokat is figyelembe lehet venni. De hosszabb távon valamelyik újabb HBM generációé a jövő, mert az ahhoz hasonló specifikációjú alternatív konstrukciók sokkal többet fogyasztanak. Az alsóházba pedig jön a valamelyik Wide I/O szabvány. Utóbbi teljesítményben nem sokkal jobb a GDDR5(X)-nél, de fogyasztásban szétveri őket.
-
Abu85
HÁZIGAZDA
válasz
rocket
#17535
üzenetére
Teljesen mindegy, hogy mennyi a kereslet. A probléma ugyanaz, mint a Fiji-nél a HBM miatt. Nem fognak tudni annyi memóriát gyártani, hogy kielégítsék az igényeket. Ugyanaz fog lezajlani a megoldás szintjén is. Kell három-négy hónap átfutás, amíg a rendelésekhez igazodik a memóriagyártó.
Teljesen mindegy, hogy a kereslet egy termék esetében többször nagyobb vagy többször kisebb a vártnál. A reakcióidő a hiányra vonatkozó problémára ugyanannyi, mert párhuzamosan is lehet gyártósorokat építeni.
(#17539) vitko: Májusban kezdték meg a tömeggyártást. Ha márciusban megkezdték volna, semmi baj nem lenne, mivel három hónap kell egy gyártósor üzembe állításához.
-
Abu85
HÁZIGAZDA
válasz
rocket
#17532
üzenetére
Computex. Később bővítik.
Egyébként az okozza a félreértést, hogy a tömeggyártásnál mindenki a nagy mennyiségű gyártásra gondol. Valójában ez nem igaz. A tömeggyártás beindítása azt jelenti, hogy a kísérleti gyártáshoz használt gyártósorokat véglegesítik, és azokon elkezdődik az igazi termelés. Ugyanakkor a gyártósorok kapacitása ettől nem változik meg, csak lehetőség van arra, hogy új gyártósorokat építsenek a lezárt specifikációra. Ez azonban sok időt vesz igénybe.
A probléma annyi, hogy nem éri meg előre kiépíteni sok kísérleti gyártósort, mert ha azok rosszak, akkor mindet le kell bontani. Ezért csinálják úgy, hogy kevés gyártósor készül az elején és a véglegesítés után nő meg ezeknek a száma. -
Abu85
HÁZIGAZDA
A GTX 670 DX12 kódjához képest van előnye. Keplerre a Crystal Dynamics nem optimalizált már program oldali memória menedzsmentet. Csak Maxwell és GCN optimalizált menedzsment van az új Tomb Riaderben. Bár ez egyébként a sebességen nem fog meglátszani, inkább az akadások számában.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#17474
üzenetére
A következő évben is érkezik VEGA, csak nem ugyanaz a lapka. Azt hozzá kell tenni, hogy nem biztos, hogy az első VEGA HBM2-t kap. Ez csak találgatás.
 Ha erről kiderül valami biztos, akkor megírom.
Ha erről kiderül valami biztos, akkor megírom.Igazából a roadmapek alatt ki van írva, hogy változhat. Nyilván december óta megváltozhatott, így más lehetett a februári roadmap, amit a GDC-re vittek. Tényleg nagy kérdés, hogy a VEGA decemberben hol volt, mert Q4 elejét csak január óta lehet hallani, igaz a VEGA-t is.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#17469
üzenetére
Az investoros dia egy termékcsaládra vonatkozó dia. Azt jelzi, hogy az adott év melyik termékcsaládra lesz fókuszálva. Ezért jobb a másik dia, mert az nem fókuszálásra van kialakítva, hanem arra, hogy az adott termékcsalád első lapkája mikor jön.
Amióta bármit lehet tudni a VEGA első lapkájáról azóta Q4 eleje a célkitűzés. Ez január végét jelenti, mivel ekkor kerültek a tervek a fejlesztőpartnerek elé.
(#17470) Cifu: Mert mondjuk az új TR DX12 kódja lassabb, mint a DX11-es.

-
Abu85
HÁZIGAZDA
válasz
#85552128
#17467
üzenetére
A Vega az termékcsalád. Nem csak egy lapkából fog állni. De csak az egyik jön idén. Ezért van úgy jelezve a dián, hogy a négyzet nagy része 2016-ra van betolva.
Az investoros dia a 2015 decemberi bemutatóról származó dia másolata.Igazából már februárban lehetett hallani, hogy az első Vega Q4 elején jön. Ezt konkrétan a SEGA egyik stúdiójától hallottam.
-
Abu85
HÁZIGAZDA
válasz
 he7edik.
#17460
üzenetére
he7edik.
#17460
üzenetére
Kis segítség a grafikonon szereplő év elválasztásához.
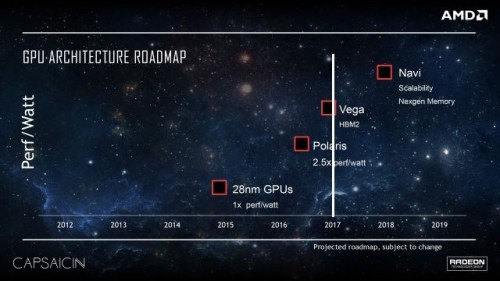
(#17464) sayinpety: Nem. Továbbra is október-november a target. Az történt, hogy pár média bekamuzta a 2017 elejét, aztán ezt a kamut úgy próbálják eladni, hogy az AMD előrehozta hirtelen (nyilván senki sem fogja azt mondani, hogy elbasztuk, szarok voltak az informátorok, vagy rossz volt a kristálygömb, stb. ... az is biztos, hogy az AMD nem fogja cáfolni ezeket, mert szabály náluk, hogy nem megjelent dolgokról nem beszélnek). Szóval az, amit neked mondtak pár hónapja továbbra is él.
-
Abu85
HÁZIGAZDA
Elég sok új játékban van lényeges előnye. Minden DX12-esben, vagy azokban, amik Mantle API-t használnak.
Bár azt hozzá kell tenni, hogy az előny nagy része annak köszönhető, hogy az NV már nem optimalizál a Keplerre regiszterallokációs rutinokat, illetve nem cserélik ki a shadereket Keplerhez való shaderekre, így elvesztik a magok 1/3-át. Ez például a Witcher 3-ban eléggé fáj. Sajnos ma egyedül az UE4 és a Frostbite használ Keplerre is optimalizált shadereket. A többiek szarnak rá. -
Abu85
HÁZIGAZDA
válasz
 Habugi
#17282
üzenetére
Habugi
#17282
üzenetére
Igazából ez csak egy alap, ami mutatja, hogy skálázódóvá teszi a játékot sok rajzolási paranccsal. Jelen formában csak azért adták oda a sajtónak, hogy megmutassák, hogy nem a játék működik rosszul, csak a DX11 nem bírja a terhelést. Később bekerül például az MSAA is, illetve a specifikus GCN optimalizálások.
-
Abu85
HÁZIGAZDA
válasz
joysefke
#17202
üzenetére
Egyrészt a Valve mondta, hogy a Vulkan itt csak teszt. Ráadásul egy wrapperen van rajta, vagyis egy magot használ csak, mint a Talos Principle. Ugyanakkor ki akarták próbálni élesben. Olyan kérdésekre keresik a választ, hogy mennyire megbízható több gyártóra levetítve a validátor, stb
Másrészt a Vulkan működése az aktuális motor alatt speciális, mert futtatási időben hoz létre számos szükséges adatot, amit a merevlemezen tárol majd a gépnek megfelelően. Ez azt jelenti, hogy kb. 15-20 percet kell játszani a játékkal, hogy minden meglegyen, és utána kerül tesztelhető állapotba a Vulkan kód. Ha hardvert cserélsz, akkor megint játszani kell ennyit a teszt előtt. Ez később nem lesz így, de az aktuális kód sajnos ilyen. Ha ezt nem teszed meg, akkor akadások és lassulások lehetnek Vulkan alatt. -
Abu85
HÁZIGAZDA
válasz
Valdez
#17142
üzenetére
Ha a validátor hibát jelez a kódra, akkor nem. A DX12-ben nincs kernel driver, hogy mindent ellenőrizzen futtatási időben. Ott az alkalmazásnak igen komoly jogosultságai vannak, ami egyrészt az egyszerűséget hozza el a programozónak, értsd sokkal hamarabb elérik a kívánt teljesítményt, de a jogosultságokkal lehet rosszat is tenni, és nem fogja ellenőrizni a driver, hogy amit a program ki akar törölni, az egyáltalán kitörölhető-e. Erre van az explicit API-khoz egy validátor, ami megmondja, ha a program hülyeséget csinál. Na most úgy nem szabad kiadni egy programot, amíg a validátor hibát jelez. Ezért nincs publikusan kiadva a DX12 benchmark, amit a sajtó egyébként már elér.
-
Abu85
HÁZIGAZDA
válasz
 velizare
#17131
üzenetére
velizare
#17131
üzenetére
Nem. Egyszerűen csak nincs kiadható állapotban.
(#17132) Szaby59: A játékok 99,9%-a félkész. A gond az, hogy nincs elég idő megírni az egészet, hogy teljesen optimalizált legyen. Alig egy-két stúdió figyel oda arra, hogy egy rakás energiát beleöljenek a DX12 mellett a DX11-es kódba, de ez valójában nem éri meg, mert amit gyorsan elérsz a DX12-vel sebességet, azt a DX11-gyel jó másfél éves extra munkával lehet hozni. Puszi a hasára mondjuk az Oxide-nak, hogy ők ezt felvállalják, és véglegekig szétoptimalizálják a motort, de a valóság az, hogy a kőkemény határidőket szabó kiadók többségének nem éri meg a megjelenést másfél évvel eltolni. Ilyen körülmények között a DX12 előny, mert sokkal gyorsabban eljuttat arra a sebességszintre, ami a cél volt. A DX11-et pedig vagy befoltozzák az elkövetkező évben, vagy ráhagyják.
-
Abu85
HÁZIGAZDA
válasz
velizare
#17128
üzenetére
A Polaris startjához érkezik a DX12 mód. De van már a sajtónak DX12 tesztprogramja előzetes kóddal. Cirka 60%-os extrát dob még erős procival is. Nekem úgy jó 90%-ot gyorsít. Valószínűleg a DX11-es kóddal már nem foglalkoztak annyit a fejlesztők, így abból nem hoztak ki mindent. Túl költséges lett volna.
(#17129) Locutus: Akit nem érdekel a DX12, az vehet CF XDMA rendszert vagy egynyákos multi GPU-t és az DX11-ben is skálázódik.
-
Abu85
HÁZIGAZDA
válasz
velizare
#17119
üzenetére
A CF-ből is csak az XDMA, illetve az egynyákos megoldás működik. A hidas SLI/CF konstrukciók negatívba skálázódnának. Ezért tiltva vannak driverből, persze lehet, hogy találnak valami megoldást később. Ugyanakkor lesz a DX12-es módnak multiadapter opciója, ami már ugye nem azokat a szerencsétlenül lassú hidakat használja. Na az skálázódni fog mindenhol.
-
Abu85
HÁZIGAZDA
válasz
 Laja333
#17086
üzenetére
Laja333
#17086
üzenetére
Rosszul. Az AMD elég régóta csak multiprecíziós ALU-kat tervez, tehát minden ALU támogat minden műveletet, de nyilván ezt le kell osztani az igényekre, mert például az interpoláció nem ingyenes, így az elviszi az ALU-k egy részét. Viszont számos DX12 funkció manuális interpolációt követel.
Az Intel is hasonló konstrukcióval dolgozik, csak nem mindegyik ALU-juk multiprecíziós. Manapság az ALU-ik fele az.
Az NV nem használ multiprecíziós ALU-kat, mert nehéz megtervezni őket. Helyette dedikált egységeket raknak be az egyes feladatokhoz. Egy CUDA magban van FP és integer ALU is, és egyik sem tud speciális utasítást végrehajtani, ahogy az interpolációt sem oldják meg. Így nem tudnak támogatni számos DX12 funkciót, de dedikálva lesz a munkára a részegység. -
#17085
Abu85
HÁZIGAZDA
#Morcosmedve
#17076
Abu85
HÁZIGAZDA
válasz
 #Morcosmedve
#17076
üzenetére
#Morcosmedve
#17076
üzenetére
Ezeket az újításokat mindenki komolyan veszi. Mint írtam minden gyártónál vannak erre vonatkozó kutatások, csak nem ugyanott tartanak. Az AMD gyakorlatban is beveti az explicit API-k problémáinak megoldásait. De mondom nekik könnyű volt, mert ők 2012-ben már mértek, míg a többiek olyan szoftverkonstrukciókhoz csak 2014-ben jutottak, amellyel valóban mérni lehetett.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#17075
üzenetére
Az ALU szám olyan értelmezésben, ahogy ti nézitek nagyon csalóka, mert a nem megfelelő magyarázatok miatt csak FP32 ALU-t számoltok. Ezenkívül azért vannak még más ALU-k is, vagy nincsenek. Például az interpolációnál az AMD manuális megoldást alkalmaz. Emiatt képes támogatni a rendszer a konzolos analitikai AA-kat, illetve a GS emuláció nélküli VP/RT tömbindexet a shader lépcsőkből a raszterizálóig. Ezekre az NVIDIA architektúrái nem képesek, így az ezeket kihasználó konzolos effektek nem futnak majd le. Ezeket a konzolos kódokat át kell írni az NV-nek a nem szabványos dedikált interpolációs és viewport struktúrájára (ha majd lesz kiterjesztés). Viszont az NV a dedikált interpolációt SFU-ból csinálja.
Szóval ez az ALU szám=ALU szám nagyon elméleti alapú.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#17063
üzenetére
Ezekről még nem lehet beszélni, de jön pár olyan dolog a Polarisban, amelyek évek óta kutatási alapnak számítanak minden gyártónál, de senkinek nem sikerült még a gyakorlatban implementálni. Ezeknek a dolgoknak a többsége a hatékonyság drasztikus növelését célozza. Később más is előáll majd hasonló konstrukciókkal, amint végigfutnak a kutatások, és ténylegesen bevethetők lesznek. Itt azért van egy olyan időbeli probléma, hogy az AMD már 2012-ban tesztelte, hogy mi kell az explicit API-ra, míg a többiek csak 2014-ben tudták meg, hogy hol vannak a GPU-kban a szűk keresztmetszetek ezekkel az új irányokkal. Nyilván az egyes problémákra csak akkor lehet reagálni, ha ki tudod azt mérni.
-
Abu85
HÁZIGAZDA
válasz
 mcwolf79
#17061
üzenetére
mcwolf79
#17061
üzenetére
Az OnlyAMDFeature nem igazán volt cél korábban. Legalábbis törekedtek arra, hogy amit csinálnak az lehetőség szerint legyen szabványos. Ez már csak azért is kell, mert nem elég nagy a PC-piac, hogy speciális dolgokkal foglalkozzanak a fejlesztők.
A GPUOpen hozza, illetve hozta ebben a törést, amikor az AMD már nem csak a PC-re dolgozik, hanem a PC+PS4+Xbox One kombinációra. És úgy már elég nagy a piac ahhoz, hogy a fejlesztők speciális dolgokkal foglalkozzanak. Jött is az OOO-raszter, illetve az mbcnt. Mindkettő csak a kezdet, de ezeket kérik a leginkább a konzolról portoló fejlesztők. Jön még a ds_swizzle és a writelane, illetve az ordered atomics. -
Abu85
HÁZIGAZDA
válasz
keIdor
#17055
üzenetére
A dadogás attól jön, hogy állandó a vertikális szinkron. Ez nem a gyártók hibája, hanem az alkalmazásé. Amint 60 fps-ről leesik akármennyire picit az fps akadni fog egyet. De az MS ezt már megoldotta. Go Windows update és leszedi a két új flipchain API-t, ami ezt kijavítja. A Forza 6 Apex erre tartalmaz már egy implementációt is, ha frissíted az alkalmazást. Probléma letudva.
Igen, mert az AMD-n ütközött a hapsi. Ez egy játékbeli bug, ami ütközésnél előjöhet. Szintén javítva lett egy javítással. Ezek a dolgok a DX12-vel nem kizárhatók, mert a meghajtó már nem játszik szerepet, így az alkalmazásfejlesztő elronthatja a menedzsmentet. Nyilván ennek az előnye, hogy olyan, hogy képi driverhiba nem létezik többet, de a hátránya, hogy az alkalmazás oldalán kell megírni hibátlanra.
-
Abu85
HÁZIGAZDA
válasz
keIdor
#17052
üzenetére
[link] - Forza 6 Apex DX12 390 vs 970.
Valójában az architektúra nem annyira fontos. A GCN1-2-3 között elég sok különbség van, de a lényeg az, hogy az alap, az ALU:Tex arány, a regisztertár, a gyorsítótárak kapacitása megegyezik mindhárom verzióban. Ez okozza azt, hogy a GCN1 is fejlődni tud még ma is, mert a multiprocesszor struktúrája nem változott meg. Az NV és az Intel is ilyen eltérésekkel dolgozik, de ott a főbb gond az, hogy a multiprocesszorok mindig változnak, mert nem találják az optimális arányokat, vagy az optimális arányra nincs elég tranzisztor, stb. Ez tesz be a programozóknak, és nem az, hogy az egyik Kepler, míg a másik Maxwell.
-
Abu85
HÁZIGAZDA
válasz
#35434496
#16774
üzenetére
Miért szerinted normális, hogy nekik van egy eredménysoruk, és rajtuk kívül senki, ismétlem senki sem mért még csak hasonlót sem? De elfogadható úgy, ha nem frissítik a programot, mert ez nálunk is probléma szokott lenni. Időnként annyi eredményt kell áthozni régebbről, hogy kimarad a frissítés, és akkor a mi eredményünk is eltér a többi eredménytől. Persze manapság igyekszünk állandó jelleggel frissíteni, de biztos, hogy az Anand dolga egyszerűbb volt négy méréssel, mint a Guru3D dolga két tucat méréssel. Előbbiért megéri frissíteni, míg utóbbiért nem.
(#16776) Szaby59: Nem. De a CPU limitet is nagyon félreértitek. A GPU-k belül nem olyan homogén rendszerek, mint amilyennek le vannak festve. Valójában ezek rendkívül rendkívül heterogén konstrukciók, amelyeknek a belső kihasználása úgy nő, ahogy nő a kiszámítandó pixelek száma. Már csak azért is, mert a geometria jellege a jelenet szintjén állandó, miközben a pixelek mérete nem, így a raszterizálás hatékonysága is állandóan nő a felbontás növelésével.
-
Abu85
HÁZIGAZDA
Másfelé nem lehet menni. Ez igazából az egész iparágban ismert. Azóta kezdődött el az erős váltás, amikor bejött a compute shader. Ennek a váltásnak a közepén tartunk.
Az ALU azért lényeges a skálázás szempontjából, mert jóval kevesebb limitbe lehet ütközni ezekkel a konstrukciókkal, mint a tradicionális grafikai megoldásokkal. Mivel mindenki ezt az irányt erősíti, nehéz kétségbe vonni, hogy az ALU powa a nyerő. Legalábbis nem látom senkin, hogy megoldást keresne a sávszélproblémára, vagy a quad raszter problémára. Az ALU sem hibátlan persze, hiszen az új API-k miatt jönnek majd a futószalagidőből adódó limitek, de talán lesz erre valamilyen megoldás a jövőben.
-
Abu85
HÁZIGAZDA
válasz
#35434496
#16767
üzenetére
Nézzétek terhelés mellett is. Ezeknek a VGA-knak a Full HD olyan, mint régen a 640x480 volt.
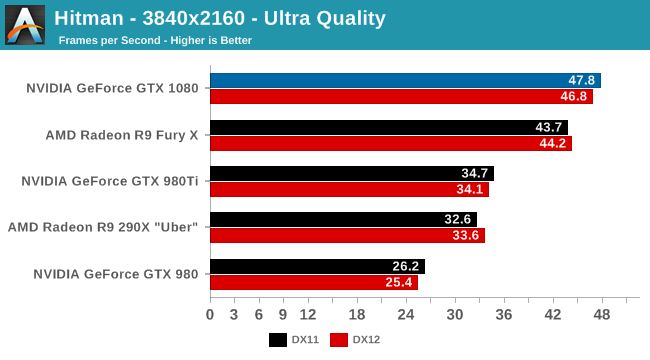
Egyébként a Guru3D eredményei manapság állandóan furcsák, valami van a tesztkonfigjukkal. Lassan pár hónapja össze-vissza mérnek. Persze az is lehet, hogy nem patch-elik a játékokat. Amilyen sok eredményt hordoznak simán elképzelhető, hogy nem fér bele mindent mindig újramérni. Emiatt viszont az eredmények sem elég frissek.
-
-
Abu85
HÁZIGAZDA
válasz
#85552128
#16763
üzenetére
Ne a Fury X gyorsulásához mérd ennek a gyorsulását. Közel sem tudnak annyit a Pascal GMU-k, mint amennyit a Fiji dedikált compute parancsmotorjai. Inkább a Tahiti GPU-hoz képest kellene megnézni, mert hardveresen kb. azon a szinten van a GP104 az aszinkron compute szempontjából.
-
Abu85
HÁZIGAZDA
válasz
 stratova
#16709
üzenetére
stratova
#16709
üzenetére
Meg. Ezek nem szándékos dolgok, csak az idő szűkössége miatt nem mindig lesznek jelentve. Ez visszavezethető teszthiányra is. Például arra, hogy az ID csak a legújabb architektúrákon nézte meg, és azzal jó volt, így gondolták minden jó lesz. A legfőbb indok az explicit elérés mellett lényegében ez, hogy a meghajtótól ne függjön annyi, így a fejlesztők rá lesznek kényszerítve, hogy alaposan teszteljenek.
-
-
#16574
Abu85
HÁZIGAZDA
gainwardgs
#16572
Abu85
HÁZIGAZDA
válasz
 gainwardgs
#16572
üzenetére
gainwardgs
#16572
üzenetére
Tudtommal egy rasterizationorder kiterjesztésről van szó, ami igazából a futtathatóságot nem befolyásolja, csak jelentősen növeli a tempót. Jó lenne látni a kiterjesztés specifikációját. Ezért írtam, hogy ez nagy kérdés, amit izgalmas lenne kideríteni, csak mindenki hallgat, mint a sír.
-
Abu85
HÁZIGAZDA
válasz
 Dyingsoul
#16566
üzenetére
Dyingsoul
#16566
üzenetére
vitko és Szaby: Szerintem januárban vagy még márciusban sem tudták a BF megjelenését. Ahhoz kell igazodni. Ez a lényeg igazából. Igazodni a DICE projektjéhez, hogy legyen hardver a Battlefield 1-hez!!!
Az igazán nagy kérdés egyébként az, hogy az a Vulkan kiterjesztés, amire a BF1 épít csak a Vega mellett érhető el, vagy a Polarissal is. Ezt azért fontos lenne megtudni. -
Abu85
HÁZIGAZDA
válasz
#85552128
#16563
üzenetére
[link] - ebben van a legfrissebb publikus. Amit beraktál nem tudom, hogy honnan veszed, hogy friss. A saját szememmel láttam a januári CES-es konferencia eladáson. Azóta a GDC-s roadmapot használja az AMD. De mondom van egy újabb, az elég részletes, de az nem publikus, így nem lehet kirakni. De lehet, hogy valaki kiszivárogtatja.
-
-
#16557
Abu85
HÁZIGAZDA
Malibutomi
#16555
Abu85
HÁZIGAZDA
válasz
 Malibutomi
#16555
üzenetére
Malibutomi
#16555
üzenetére
Maximum a dobozos termékeknél, de fontos tényező, hogy a 300+ dolláros szinten az eladott VGA-k 70%-a komplett gépben talál gazdára. Tehát fontos, hogy az OEM-eknek legyen valami marketingalapjuk az új komplett gépekhez.
-
#16553
Abu85
HÁZIGAZDA
Malibutomi
#16552
Abu85
HÁZIGAZDA
válasz
Malibutomi
#16552
üzenetére
Radeon Pro Duón ültek pár hónapig csak azért, hogy a VR eszközökhöz adják ki. Nem éri meg mindent akkor kiadni, amikor kész. Valamikor jóval nagyobb eladásokat lehet produkálni, ha valamihez hozzákapcsolják a terméket. Valami olyanhoz, amit a játékosok várnak. Ezek fontos stratégiai lépések. Kimutatható jelentőségük van a hatásuknak.
-
-
#16549
Abu85
HÁZIGAZDA
Malibutomi
#16548
Abu85
HÁZIGAZDA
válasz
Malibutomi
#16548
üzenetére
Mert 2016 végén jön az új Battlefield. Akkor Q4-et mondhatott az EA.
-
Abu85
HÁZIGAZDA
válasz
 sutyi^
#16532
üzenetére
sutyi^
#16532
üzenetére
Nem mindenféle, de a gyártók vihetnek cuccokat a computexre. Az AMD inkább a Carrizo utódjára fog koncentrálni, mert a GPU-knak az E3-on béreltek egy teljes épületet. Ott lesz publikus szinten engedélyezve minden.
A Vegát nem hozták előre. Minden csúcs-Radeonnál a DICE csúcsjátéka a target.(#16538) imi123: GPUOpennek nem pont a nyers PC-s optimalizálás az elsődleges célja. Hanem a konzolos kódok futtathatóvá tétele PC-n, így biztosítva a konzolos optimalizálás PC-re való áthozását. Ha azt kérnék, hogy optimalizálják a PC-s kódokat olyanra, amilyenre a konzolosokat, akkor az nem érdekelne senkit.
-
Abu85
HÁZIGAZDA
válasz
 daveoff
#16471
üzenetére
daveoff
#16471
üzenetére
Attól függ, hogy mennyi konzolfunkció hozható át NV-re. A GPUOpen nem olyan jó dolog, mint amilyennek tűnik. A fejlesztőnek nyilván az, hiszen hozza a konzol shadert egy az egyben PC-re, de ez nem kompatibilis az NV és az Intel hardvereivel, vagyis bizonyos függvények nem futnak majd le. Na most erre kellenek alternatív kiterjesztések, amelyekre írni kell alternatív shadreket, szóval bonyolult ügy lesz ez a PC most, hogy az AMD erőlteti ezt az "érd el a hardvert és használd ki" felfogást. A konzolra megírt kódok tömkelege miatt elég sokan vevők rá, mert csak egy copy-paste az egész.
Majd jövőre segít a shader modell 6.
-
#16461
Abu85
HÁZIGAZDA
Malibutomi
#16457
Abu85
HÁZIGAZDA
válasz
Malibutomi
#16457
üzenetére
Nem írtam semmi olyat, amit ne lehetett volna eddig is tudni.

Az lenne a gáz, ha leírnám, hogy lesz idén is PC Gaming Show az E3-on, és ott ... jaj, huh majdnem leírtam.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Abu85
HÁZIGAZDA
válasz
keIdor
#16453
üzenetére
Nyilván nem. Elsődlegesen azért, mert a partnerek már jelezték, hogy kifejezetten tetszik nekik, amit a Polaristól és a még be nem jelentett GPUOpen holmiktól láttak. Nem tűntek frusztráltnak. A Computexen ki lesz rakva számos modell.
A Polarisról ugyan senki sem beszél, de a GPUOpen tényleg érdekes irányt vesz azzal, hogy gyakorlatilag megengedi a fejlesztőknek a konzolos optimalizálás PC-re hozását. Bár ennek meglesz az az árnyoldala is, hogy a konzolos kód csak AGS-en működik.(#16456) Keldor papa: Csődbe mentek volna, mint a BFG. A váltással ezt kerülték el.
-
Abu85
HÁZIGAZDA
Nyilván. Ez szükséges ahhoz, hogy a már kiadott alkalmazások kompatibilisek maradjanak. Aztán egyébként patchekkel azt lehet csinálni, amit akarnak.
(#16427) oAcido: [link] - szokásos kooperáció. Az AMD-nél a DICE top projektje a csúcshardver targetje. Jelen esetben a Battlefield 1. Aztán persze csúszhat, de a cél elérni azt az alkalmazást.
-
Abu85
HÁZIGAZDA
Nehezen tudnak bele olyan architektúrát rakni, amelynél hiányzik a MIN/MAX/CMPSWAP utasítás az LDS atomics-re. Az rendben van, hogy van helyettük más, csak csak egy csomó program le van szállítva ezekre optimalizált binárisokkal. Ez nem PC, hogy shadert vagy IR-t szállítanak, itt lefordítják GCN ASIC ID120-ra esetleg még beletúrnak assembly szinten és kapod a binárist a lemezen. Ki lehet egészíteni egyébként a dizájnt, de meg kell őrizni a legacy utasításokat, hogy a legacy programok futtathatók maradjanak. Szóval biztos nem Polaris lesz benne, maximum egy GCN2-GCN4 hibrid. A konzolon az is számít, hogy egy utasításnak mennyi a büntetőciklusa, mert arra is optimalizálnak. A már leszállított programok ezért futnak majd alap módban, mert ott vissza lesz véve az órajel is PS4 szintre.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#16413
üzenetére
A fájlelérés egy szándékos limit. Igazából nem is a fájlelérés a probléma, hanem a módosítás, amit a kiadók nagyon nem szeretik a modolást. Az UWP eszerint az igény szerint készült.
A patchelés máshol is ilyen, ha volt olyan idióta a fejlesztő, hogy 20 GB-os állományt csomagolt egybe.
Azért van multiadapter az új API-kban, hogy működőképes lehessen a több GPU. Viszont annyira pici a piac, hogy nem sok céget érdekel. Inkább az IGP+dGPU konstrukciókat akarják kiszolgálni.
Leszarják tudatos a PC-s szokásokat. Nem az a céljuk, hogy a PC-s hardcore réteget kiszolgálják, hanem az, hogy a kiadók igényeinek megfelelő store-t csináljanak platformok közötti összeköthetőséggel és átjárással. -
Abu85
HÁZIGAZDA
válasz
#85552128
#16410
üzenetére
Nyilván, de utólag mindenki nagyon okos lesz.
(#16411) Loha: Az architektúra specifikációja akkor sem fog változni. Lásd PS4K, ahol nemhogy új tervezésű magok nem lesznek, de ugyanazokkal az erratákkal készül az egész. Csak több multiprocesszort kap. Egy konzolon ilyen szempontból mindig hatványozottan gyorsabb a problémákra reagálni, mert nincsenek meg a lassító tényezők.
Az UWP elsődlegesen a fejlesztők visszajelzései alapján készült, hogy a rendszer nagyon védje a szoftvereiket. Például a játékfejlesztők számára a Steam amellett, hogy a tömeg miatt támgatott, kifejezetten rossz biztonságot ad, mert relatíve gyorsan törhető minden, ami felkerül rá. -
Abu85
HÁZIGAZDA
válasz
#85552128
#16408
üzenetére
Valószínűleg kétlépcsős frissítés lesz. Az új swapchain API-k megjöhetnek ma, de a WDDM 2.0 javításai csak nyáron jönnek. Egyébként attól, hogy ezek az API-k jönnek még nem történik semmi, mert a program oldaláról támogatni kell az új lehetőségeket.
Az Xbox One egyetlen hardverspecifikáció. Kb. ezerszer gyorsabban lehet a problémáira reagálni, mert nem kell a gyártókkal leülni és kidolgozni a szabványos specifikációkat. -
Abu85
HÁZIGAZDA
válasz
stratova
#16301
üzenetére
Ők támogatni fogják, de még nem jelentették be, hogy mikortól. Igazából nekik csak az 1.2a aljzat hiányzik.
(#16302) gV: Nincs is igazán árverseny, de a monitorpiac az más.
Nyilván a licenc nélkül lényegesen olcsóbb lehet az A-Sync.(#16307) oAcido: A Best Buy friss adatai alapján 86% fölött van a Freesync. De ez azért nagyon csalóka, mert az új kijelzők többségében ez alapfunkció, tehát akkor is ilyet vesz a felhasználó, ha mondjuk nem kell a variálható frissítés. Egyszerűen default szolgáltatás lett.
Olyan összehasonlítás kellene, ami azt mutatja ki, hogy az eladások milyenek, ha célirányosan történt a variálható frissítés melletti vásárlás, de ilyen sajnos nincs.(#16311) Szaby59: Több API-t támogat. A SPIRV-Cross mellett már a shaderek szállítása sem gond.
-
Abu85
HÁZIGAZDA
A G-Sync akkor sem ment volna, ha jött volna szabványos támogatás. Itt a gyártók problémája ott kezdődik, hogy nagyon kicsi a kínálat, és az új kijelzőket az Acer és az ASUS 600-1200 dollár közé árazza, mert nem érdekeltek abban, hogy haszon nélkül adják el a monitorokat. Mivel csak két partner van, gyakorlatilag kizárt, hogy bármiféle árverseny kialakuljon, mert egymáshoz belövik magukat és kész. Ez önmagában hátrányos egy olyan területtel szemben, ahol tíznél is több gyártó küzd. Utóbbi sokkal kiszámíthatatlanabb, és a Samsung, illetve az LG is ott van közöttük, ami árversenyt is jelent.
A lényeg az alternatíva felkínálása, mert rengeteg felhasználó nem akar kockáztatni, és inkább menne a szabványra egyből anélkül, hogy Radeont kelljen hozzá venni. -
Abu85
HÁZIGAZDA
válasz
TTomax
#16293
üzenetére
Nem. De amikor a GDDR5 érkezett, akkor 4 GHz-es lapkákkal nyitottak, és azt az órajelet helyből hozták. Itt nem a lapkákkal van a baj, mert azok a Micronnál működnek, de annyira nehéz megoldani az árnyékolást, hogy egy korlátozott hosszúságú NYÁK-on nem lehet elérni a tervezett órajeleket. A Micron 47 cm-es NYÁK-on hozott 14 GHz-et, és ezt valószínűleg egy 45+ cm-es VGA is tudná.
-
Abu85
HÁZIGAZDA
Nem azt mondtam, hogy nem lesz, hanem azt, hogy az árnyékolás problémája miatt nagyon nehéz lesz a névleges órajeleket hozni. Ez így is lett, mert 14 GHz-re hitelesített lapkákból 10 GHz-et sikerült kinyerni. Ez teljesen általános probléma a GDDR5X esetében. Hiába az elméleti hitelesítés, azt szinte képtelenség elérni.
-
Abu85
HÁZIGAZDA
Nem. Arról volt szó, hogy a gyártók azt szeretnék, ha lenne a kártyákon DP 1.2a, vagy bármilyen a-s aljzat. Ugyanis a monitorgyártók között csak az Acer és az ASUS maradt a G-Sync mellett és ma már ők is úgy kezelik ezt, hogy nyereséggel adják el a monitoraikat, vagyis 600-1200 dollár közé árazzák az új kijelzőket. Emiatt mondták a partnerek, hogy ez nem olyan jó, mert tonnaszámra érkeznek az A-Sync kijelzők, amelyekből már 73 van, és idén azt várják, hogy őszre lesz belőlük 150+, vagyis pusztán mennyiségi fölénybe kerülnek az üzletekben. Ez a gyártóknak gáz, mert nehezebbé teszi a dolgukat. Az NV-nek nem az, mert ők a G-Sync-re prémium funkcióként tekintenek, és ezért igenis fizessenek érte a gyártók nekik 200 dollárt, azt meg leszarják, hogy a gyártók ezt a vásárlón hogyan hozzák be.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#16153
üzenetére
Rendet tudnak rakni. Ezért kap egy fixet az OS-ben a GPUMMU modul.
Az a baj, hogy mégis az NV-re mutogatnak, mert például a EuroGamer is azt emelte ki, hogy a fagyás Radeonon nem fordult elő utalva a driverbugra. A júzer pedig ennél tovább nem megy. Nem fog utánajárni, hogy ez nem driverbug, hanem egy alternatív lapmérettel dolgozó GPUMMU mód problémája. Ezért fontos a hibák behatárolása.
Egyébként nyilván logikus, hogy ha AMD-n megy és NV-n nem, akkor tutibiztos, hogy driver, de a gyakorlat ennél sokkal bonyolultabb.Nem adták fel. Minden VR játék a LiquidVR-rel a Mantle-t használja.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#16149
üzenetére
Azt látom, hogy őket nem érdekli, hogy miért nem jó. A júzerek többsége azt hiszi, hogy az NV DX12-es drivere a hibás. Valószínűleg azért, mert a EuroGamer is ezt mondta a Quantum Break PC-s videójában. De az NV is tehetetlen, mert a driver előtt az OS szintjén keletkezik a bug, amit hát a meghajtó továbbvisz, mert nem tud mit kezdeni vele.
-
Abu85
HÁZIGAZDA
válasz
 cyberkind
#16147
üzenetére
cyberkind
#16147
üzenetére
Csak arra akartam felhívni a figyelmed, hogy a DirectX 12-t hibáztatod egy olyan hibáért, amit nem a DirectX 12 okoz. Persze, hogy szar dolog ez, de nem az API a hibás érte, hanem egy másik modul, és ez is csak az alternatív működési módban hibás, vagyis az összes olyan hardver, amely a default működési módot használja hibamentes. Értem, hogy téged ez GeForce mellett nem boldogít, mert pont a hibás működési módot vagy kénytelen használni, de ettől a rendszer még működik, és GeForce-on is működni fog egy nyári Windows frissítéssel.
-
Abu85
HÁZIGAZDA
válasz
cyberkind
#16143
üzenetére
De nem a DX12 miatt ilyen. Ez nagyon fontos, mert az API működik, csak a GPUMMU specifikációjánál az MS ejtett egy hibát. Eleve az probléma, hogy kétféle lapkezelési rendszer van definiálva. Van az alap 4 kB-os az AMD GCN-nek és az Intel Gen8/9-nek, és van egy alternatív 64 kB-os az NVIDIA Fermi/Kepler/Maxwellnek, illetve az Intel Gen7.5-nek. Nyilván a 64 kB-os csak azért került hozzáadásra, hogy a GeForce-okon, illetve a régebbi Intel IGP-n is fussanak a DX12-es játékok, de újonnan már mindenki a 4 kB-os módot fogja támogatni.
Ez nem alkalmazásfüggő és még csak nem is driverfüggő. Az operációs rendszeren belül a GPUMMU modult kell frissítenie a Microsoftnak, hogy ne fagyjanak az alkalmazások 64 kB-os lapok mellett.
-
Abu85
HÁZIGAZDA
válasz
cyberkind
#16138
üzenetére
Ez nem az API hibája, hanem a WDDM 2.0-ban a GPUMMU-é. A 64 kB-os lapokkal dolgozó GPU-k bizonyos programok mellett összeomlanak egy adott idő után. De a 4 kB-os lapokkal dolgozó termékek rendben vannak, azokkal órákig is lehet játszani. Maga az API csak a memória magasabb szintű menedzselését biztosítja, de a lentebbi rétegekben keletkezik a hiba.
(#16139) Szaby59: A DICE Vulkan API-t akar magának. Azok a problémák, amelyekkel ők küzdenek a SPIR-V-vel oldhatók meg igazán, mert képesek lesznek használni az OpenCL-t a shader nyelvek helyett.
-
Abu85
HÁZIGAZDA
válasz
 wjbhbdux
#16133
üzenetére
wjbhbdux
#16133
üzenetére
Az nem driver crash, hanem hardverhiba. Le kell gariztatni a kártyát.
(#16132) Bratilla95: Simán vedd le a driverben a tesszellációs faktort x16-ra. Ugyanaz a minőség és rögtön nagyon jól fut a hajeffekt.
Az NV esetében írni kell egy petíciót, hogy a GeForce-on adja meg a cég a lehetőséget arra, hogy a felhasználóik korrigálhassák a mesterségesen magas gépigényű effektek működését. -
Abu85
HÁZIGAZDA
válasz
 schawo
#16111
üzenetére
schawo
#16111
üzenetére
Például ott a mosquito noise problémája, ami a tömörítésből ered. Egy külső post-process simán kiszűri. Ebben például messze a legjobb az AMD rendszere, és hiába kérik magát a kódot az alkalmazásfejlesztők, az AMD nem adja oda nekik. De persze lehetővé teszik, hogy az alkalmazás oldalán használhassák a driver post-processeit.
Régebben is észrevettem a cégeken, hogy multimédiában teljesen más a felfogás. Az Intel és az NV ezzel úgy van, hogy van egy rakás alkalmazás, ami megfelelő, míg az AMD szerint ezek valóban jók, de közel sem elég jók, így inkább jobb post-process rendszereket fejlesztenek a driverbe. Ez tisztán felfogásbeli különbség. Ha az Intel és az NV is így állna hozzá, akkor simán lemásolható lenne az AMD képminősége.
-
Abu85
HÁZIGAZDA
A stúdióban ilyeneket nem lehet csinálni. Egyébként minden kikapcsolható igény szerint. Ezek felfogásbeli különbségek.
Az AMD nagyrészt annak köszönheti azt, hogy még ma is a legjobb képminőségű alternatívának tartják, hogy nagyon sok pénzt tolnak abba, hogy a képminőség már default szinten erős legyen. Például egyedül az AMD drivere tartalmaz kijelzőprofilokat, vagyis az elterjedt panelekhez egyedi paraméterezést rendelnek. Az Intel és az NV ezt nem tartja fontosnak. Én sem igazából, de tény, hogy sokan nem jutnak el a beállításokig, és úgy már nyilván az AMD-nek a képminőségét tartják majd a legjobbnak, hiszen gyárilag előkezeléssel érkezik.
-
Abu85
HÁZIGAZDA
válasz
 deadwing
#16105
üzenetére
deadwing
#16105
üzenetére
Az AMD-nek rengeteg, igen komplex post-process minőségjavítója van a driverben, hogy a filmek jobban nézzenek ki. Hasonlót csinál az NV és az Intel is, de közel sem rendelkeznek olyan szoftverkonstrukciókkal erre, mint az AMD. Ezt a különbséget le lehetne dolgozni, de az AMD-n kívül más gyártó nem törekszik arra, hogy túl bonyolult post-processekkel javítsa a képminőséget. Egyszerűen nem költenek annyi pénzt és kutatást erre, mert úgy gondolják, hogy nem lényeges a nyerhető előny, miközben növeli a fogyasztást. Ezt a különbséget paraméterezéssel nem igazán lehet ledolgozni, legalábbis addig nem, amíg az NV és az Intel nem kezdi el szállítani azokat a komplex post-processeket a driverbe, amiket az AMD kínál.
-
Abu85
HÁZIGAZDA
A legnagyobb félreértéseket az szüli, hogy a PC-s játékpiacon itt a legtöbben AAA játékot értenek. Valójában a PC-s játékpiac legnagyobb része MMO, MOBA és eSport.
Igazából nem haldoklik semmi, mert a szabványok átdolgozása részben a szűkölő piacok életben tartását is szolgálja. Ha nem lenne DX12, akkor nem lenne Quantum Break és GoW: Ultimate Edition sem PC-re. Nyilván az tény, hogy ez a részpiac nem annyira erős, hogy érdemes legyen koncentrálni rá, de megváltozott a status quo is, mivel egyszerűsödött a portolás. Ergo olyan címek jöhetnek, amelyek a korábbi feltételek mellett nem jöhettek volna.
-
Abu85
HÁZIGAZDA
válasz
 Milka 78
#16044
üzenetére
Milka 78
#16044
üzenetére
Ne a homályosságot nézd, mert az a textúra beállítása miatt van. Amit nézni kell az az extra felületi ragyogás, ami egy post-process. A textúra lehet olyan részletes is, mint DX11-ben, csak az aktuális, nem túl jó frissítés miatt most kell hozzá egy 8 GB-os 390.
Attól nem gyorsul a játék, hogy a textúra beállításokat csökkented DX11-ben. Low és High mellett is ugyanaz a mintavételezés történik meg.
-
Abu85
HÁZIGAZDA
A megvilágításban az a helyes. Az, hogy rondább egyéni megítélés kérdése. Nyilván képzeld úgy, hogy a textúrák ugyanolyanok minden rendszeren, és akkor csak az a post-process effekt a különbség. Egyébként Surface Glare a motorban használt neve. Ez valamiért nem fut le DX11-ben. Egyfajta hamisan ragyogó hatást ad a nap által megsütött felületnek, ha oldalról nézed.
-
Abu85
HÁZIGAZDA
válasz
Laja333
#16033
üzenetére
Az előre megadott beállításoktól függ. A jelenlegi kódban mindegyik VGA-hoz hozzá van rendelve egy textúrabeállítás aszerint, hogy a streaming az adott hardverre mennyire hatékony. A 8 GB-os 390-eken a leghatékonyabb, így az kapja a High beállításokat. A Fijis és egyéb 4 GB-os Radeonok a Mediumot, míg az összes többi hardver a Low-ot (automatikus a nem definiált hardverekre). Aztán ezt felül lehet bírálni (nemigazán működik valamiért). Ez valószínűleg módosítva lesz pár napon belül.
-
#16032
Abu85
HÁZIGAZDA
huskydog17
#16026
Abu85
HÁZIGAZDA
válasz
huskydog17
#16026
üzenetére
A textúrák butításával nem lehet sebességet nyerni. Ugyanazt a mintavételezési munkát végzi el a GPU akármilyen textúrával. Itt az előkonfigurált textúrabeállításokat lehet látni. Ezen update-enként változtatnak, mert gondjuk van a streaminggel. A DX11-es megvilágítás azért néz ki másképp, mert a DX11-es kódban van egy bug, ami nem enged lefutni egy post-processt. DX12-ben ez lefut, és világosabb lesz a kép nappal. Ezt majd javítják. Megvilágítás szempontjából az a helyes, amit a DX12-es képeken látsz.





































![;]](http://cdn.rios.hu/dl/s/v1.gif)






Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Eladó ASUS GeForce RTX 3090 Ti 24GB GDDR6X OC (ROG-STRIX-LC-RTX3090TI-O24-GAMING) Videokártya
- Dell Alienware Nvidia Geforce RTX 2080 Super 8GB
- Nvidia geforce rtx 5070 ventus 3x 12gb(vram)
- PowerColor RX 6700 XT 12GB GDDR6 Hellhound Eladó!
- Gainward RTX 5060 Ti Python III 16GB GDDR7 128bit (NE7506T019T1-GB2061T) Videokártya
- Egérpadok, billentyűsapkák(keycapek), csuklótámaszok /ARCANE/DUCKY/GLORIOUS/
- Telefon felvásárlás!! Samsung Galaxy S25, Samsung Galaxy S25 Plus, Samsung Galaxy S25 Ultra
- Spigen Essential EF323MQ 3in1 Mágneses MagSafe Vezeték nélküli töltőállomás 25W Qi2.2 Fekete
- Xiaomi 15 12/256GB - Kártyafüggetlen, Zöld, ÚJSZERŰ - 1 Év Garanciával
- Dahua 22" FULL HD IPS LED monitor 100Hz
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest