Új hozzászólás Aktív témák
-
-
#5004
 Petykemano
veterán
S_x96x_S
#5003
Petykemano
veterán
S_x96x_S
#5003
Petykemano
veterán
válasz
 S_x96x_S
#5003
üzenetére
S_x96x_S
#5003
üzenetére
Vajon az intelnél is van mobil - HPC különbség?
Vajon az AMD mindig HPC verziót fog használni és így megmarad a sűsűség hátránya?
A Samsung 5LPE valójában a 7nm továbbfejlesztése. Megtévesztő volt 5-nek választani. De ha 4nm-re nem virítanak Valamit,.akkor azért látszik, hogy bajban lesznek. -
#4965
Petykemano
veterán
S_x96x_S
#4964
Petykemano
veterán
válasz
S_x96x_S
#4964
üzenetére
A 6nm eléggé kis haszonnal jár. [link]
Mármint persze nézőpont kérdése. 18%-kal sűrűbb, alja a standalone apuk esetén kifejezetten jól jön és persze amikor szűk a kapacitás akkor pont ennyivel több lapka gurul le a gyártósorrol.
Viszont nem javít a fogyasztáson.És bennem az a kérdés vetődött fel, hogy mi van azzal az érvvel, hogy a chipletben az a jó, hogy ugyanazt gyártják nagy tételben különböző piacokra és válogatnak.
Jó, én értem, hogy a 7nm -es zen3-at továbbra is fogják gyártani és nyilván el fogják tudni passzolni, de így azért mégiscsak kétfélét gyártanak.
Vajon ugyanazt csinálják, mint a zen+ esetében? A chiplet külső méretei megegyeznek, csak a tranzisztorok kisebbik, több a dark silicon?
-

S_x96x_S
addikt
válasz
S_x96x_S
#4958
üzenetére
Ha abból indulok ki, hogy
a.) Augusztus ( után valamikor ) ---> új Threadripper
b. ) valamint nézegetve a legújabb Videocardz-os összefoglalót az AMD roadmap-ról. benne egy ilyen megjegyzéssel"The Zen3+ (unofficial name) based processors should launch later this year. We have heard some rumors that both next-gen Threadripper and Ryzen 5000 Refresh (or Ryzen 6000) might use this new node. It may explain the delay of the new Threadripper"
lassú felfogású vagyok ..
és most kezdek rádöbbeni, hogy az agusztusi Threadripper - akár már ZEN3+ ; 6nm -as is lehet ..
és talán akkor szeptemberben jön a hasonló Ryzen 6000-el és az új X570S-es alaplapokkal.( Párhuzamosan az Intel új procijaival. )

vagyis akkor a Zen3+ és 6nm a következő lépés.Persze a 6nm - valószínüleg csak a 7nm picit csiszolt verziója
( amolyan 7nm+ )
mindenesetre talán meglehet a bűvös 5GHz-es határ is.És remélem, hogy a ZEN4 procik első köre a következő év első felében (2022H1) piacra kerülnek ..
-

Cathulhu
addikt
-
#4956
Petykemano
veterán
S_x96x_S
#4945
Petykemano
veterán
válasz
S_x96x_S
#4945
üzenetére
A remrandtól ki van húzva az AM rész. Ezért lehet DDR5, de DIY nem lehet majd kapni.
Nekem az tűnt fel most - noha a navi2 már elég régóta szerepel a Raphael kódnévnél -, hogy az mégis miképp lesz RDNA2?
Tudtommal csak az RDNA3 lesz chipletes.
- Most akkor csinálnak egy chipletet külön RDNA2-ből?
- Vagy szakít az AMD a desktop-server közös chiplettel és a Raphael monolitikus lesz?
- vagy egy Rembrandt lapka lesz az IO lapka a Raphaelhez?
- vagy esetleg rá fognak.tudni hegeszteni egy navi 24-et? -

carl18
addikt
válasz
S_x96x_S
#4935
üzenetére
Azt a 30% százalékor meglátjuk év végén ha valóban úgy lesz-e!

Mert 30% a Zen 3 fölött már valóban nem semmi teljesítmény.
Azért én is vissza váltanák intel oldalra
A Régi címek amik nincsenek több szállra megírva nagyon fontos nekik az erős egy szállas teljesítmény.
GTA 4/StarCraft 2 nagyon sokat gyorsul az magas órajel/IPC mellet.
Az biztos végre az Alder Lake-S felborítja az álló vízet, mert végre elhagyják a 14 nanométert és az új Golden Cove magok is bevetésre kerülnek. Nagyon kíváncsi leszek a tesztekre.
Én az Am4 foglalat miatt még 2023-ig biztosan a piros oldalon maradok a garancia megléte és a fejleszthetőség végett még marad az AMD.Talán 2023-2025 körül tervezek egy új foglalatra ráutazni.
Hogy LGA 1700/vagy AM5 lesz az majd a jövő eldőnteni.
Ár-érték arány és teljesítmény alapján ki kinál többet.
Csak hát az a Golden magok ellen fele hívatalosan a Zen 4 lesz.
Az Am4 foglalat tulajoknak így is lesz elég széles választék fejleszhetőséget nézve. -
carl18
addikt
válasz
S_x96x_S
#4932
üzenetére
Kezdjük ott 2005-től egészen 2019 decemberéig kizárolag Intel processzorokat használtam. Aztán 2020-ban megtört a jég mert az AMD olcsott kinált jobban.
Hát tudod azért hogy az Intel még idén 30%-ot verjen a Zen 3-ra ez elég hihetetlen számomra, az intel az 5 generációs Broadwell óta használja a 14 nanométert.
7 cpu generáció jelent meg azon a 14 nanométeren.
Nem akarom az intel leszólni de az utobbi évek balépései miatt én nem hiszem hogy csak úgy a semmiből jön majd a csoda.
Hiszem ha látom, az AMD az utobbi években folytok bizonyított és megmutatta képes betartni az igéreteit.
A Golden Cove Alder Lake-S magjai igéretesnek tűnik, de a kérdés hogy fog élesben teljesíteni és hát az órajel mire lesz képes.
Persze szurkolok az intelnek is, csak hát valahogy nem tudok elhinni hogy még idén Zen 3 killert dob piacra. De szerintem mások se. -
carl18
addikt
válasz
S_x96x_S
#4930
üzenetére
Ősszel jön? Nincs az papírba vésve lehet abból még 2022 első negyedév is. Láthatjuk a Rocket Lake is csak most március végén startolt, szóval az Alder Lake se jön szerintem idén max december/januárba startol.
Zen 4 2022-ben jön, még a Zen 3-ból se tudnak eleget gyártani.
Szóval ameddig nem jutott mindenkinek Zen 3 fölösleges a Zen 4-et piacra dobni.
Én a sima X mentes Ryzen 5 5600-at várom, én nekem bőven elég volna. Ryzen 1600-ról váltanák szóval lenne előrelépés bőven! -
S_x96x_S
addikt
válasz
S_x96x_S
#4919
üzenetére
Benchmarking AMD Zen 3 With Predictive Store Forwarding Disabled
https://www.phoronix.com/scan.php?page=article&item=amd-zen3-psf&num=1
"So long story short, even though AMD isn't recommending their customers at large disable Predictive Store Forwarding, if you decide to disable it in the name of increased security it's not likely going to provide any meaningful performance difference. I'm still running some larger server workloads but with everything I've seen today and yesterday across multiple Zen 3 systems the PSF disabling isn't having any major impact... Will update if managing to find any configuration / large workloads there there is a meaningful difference from disabling PSF but at this stage looks to be of limited impact in toggling it at least for common test case scenarios. Thankfully nothing as scary as some of the past x86_64 speculative execution mitigations we have seen in recent years -- just a few days ago in fact looking at the Spectre mitigation costs still being carried by Intel's Rocket Lake, among many other examples and benchmarks over the past three years." -
#4914
 Balala2007
tag
S_x96x_S
#4910
Balala2007
tag
S_x96x_S
#4910
Balala2007
tag
válasz
S_x96x_S
#4910
üzenetére
Az "endianness" es "memory ordering" ket kulonbozo dolog.
Endianness: ABCD <-> DCBA
Memory ordering: koherencia fent (nem) tartasa, Load/Store reordering, barriers, atomi muveletek...
Endianness - Wikipedia
Memory ordering - Wikipedia -
-

hokuszpk
nagyúr
-

Yutani
nagyúr
válasz
S_x96x_S
#4895
üzenetére
Én a felhőszolgáltatók igényei alapján már X86 + ARM chipeket látok összetokozva.
és akkor rugalmasan - a kereslet alapján - bootoláskor vált X86 vagy ARM között.
Chipletes technológiával nem olyan nehéz megvalósítani.Az AMD-nél lehetne a SkyBridge elképzelésnek megfelelő CPU páros vagy vegyes felépítés, miszerint ha és amennyiben az I/O chip képes ARM chiplettel kommuikálni (nem valószínű), akkor jöhetne egy processzor foglalatba AMD vagy x64 chiples processzor, extrém esetben vegyes felépítéssel, ami te említettél. És akkor az EPYC platformokon ki lehetne építeni ARM támogatást is, vagy akár lejjebb is lehet hozni desktopra.
-
#4892
Petykemano
veterán
S_x96x_S
#4891
Petykemano
veterán
válasz
S_x96x_S
#4891
üzenetére
Én nem állítom, hogy tüzetesen átnyálaztam, itt-ott ért egy-egy impulzus az intel eseményéről, amely során legtöbbször az az impulzus ért, hogy Pat Gelsinger pózol az Intel legújabb fejlesztéseivel.
Mindenesetre nekem az jött át, hogy nem arról van szó, hogy az intel
- bárki számára felhasználhatóvá teszi az x86/AMD64 utasításkészletre vonatkozó szabadalmakat és akkor az volna a terv, hogy úgy maradhasson versenyképes az x86, hogy bárki tervezhet
és/vagy
- elfordul az x86-tól más utasításkészletek irányábaHanem a változás elsősorban a "hol gyártsuk" vagy pontosabban "mit hol gyártsunk" kérdéssel kapcsolatban merült föl.
Vagyis az én értelmezésemben a nyitás arra vonatkozik, hogy míg korábban a fő x86 magok IP blokkjait saját gyártáson belül tartották. Nyilván ha a TSMC-nél gyártanak, akkor az ottani szakembereknek meg kell kapniuk a terveket. Itt pl a féltve őrzött branch predictort emlegették és bár biztos szerződés köti a TSMC munkavállalóit, de szivárgás bármikor bárhol lehetséges. az AMD esetén is több alkalommal előfordult, utóbbi időben az intelnél is, hogy valaki felpakolt iratokkal távozott a cégtől. Többek között szerintem ennek volt köszönhető az, hogy az Nvidia az AMD terveinek ismeretében tűpontosan semlegesítette vagy megelőzte az AMD törekvéseit.
Az intel kész más gyártónál gyártani a fő x86 processzorait, Innentől kezdve ez a fizikai védettség megszűnik.A másik oldal pedig az, hogy mit kezdjenek a 14nm-es gyártósorokkal. Azt Daniel Nanni elmondta, hogy nem olyan könnyű egy - intel IP blokkokra optimalizált - gyártósort csak úgy megnyitni más számára is. A GF, a Samsung és a TSMC is nagyon sokat tesz azért, hogy Arm vagy más architektúrákat könnyen lehessen tervezni az ő gyártósoraira.
A kereslet most (is) nagyon nagy a nem leading edge gyártástechnológiák iránt és az intel bevételt tud szerezni a 14nm kínálatából. Hiszen azt azért el lehet mondani, hogy az Intel 14nm a nem leading edge gyártástechnológiák közül a legjobb.
A nyitás vonatkozhat erre, hogy (jobban) felkészítik a 14nm-t külső megrendelők igényeire. -
#4872
Petykemano
veterán
S_x96x_S
#4870
Petykemano
veterán
válasz
S_x96x_S
#4870
üzenetére
Akkor elvileg most kéne meglódulnia a piaci részesedésnek, nem?
Csak ez valójában nem 64 magos cuccokból fog kitevődni, hanem 8-24 magosokból.Vajon ez is tick-tock irányba fog igazodni?
Egyik gen fókusza a hyperscale irányába: magszám növelése, nagy magszámú sku-k teljesítményének növelése TDP kereten belül, ilyesmi,
Másik gen fókusza a kisebb szerverek irányába: ST teljesítmény növelése. -
-
-

poci76
aktív tag
válasz
S_x96x_S
#4824
üzenetére
Elég sokan vesznek 12 magosat is, és így annak elég lett volna 1 CCD is, ill. lehetett volna 10 magosat is csinálni. Szóval szerintem lett volna racionalitása. Ill. jöhetett volna 16, 20 és 24 magos, 2 CCD-s asztali proci, annak is lett volna közönsége. Ez nekem inkább úgy hangzik, hogy minek többet adni, mivel így sincs konkurencia.
-
#4799
Petykemano
veterán
S_x96x_S
#4797
Petykemano
veterán
válasz
S_x96x_S
#4797
üzenetére
Hmmm... nesze semmi, fogdmegjól.
Ez most akkor vajon azt jelenti, hogy idén érkezik a Warhol, ami zen3+ és még AM4, aztán jövőre a zen4 AM5-be,
vagy azt, hogy jövő év elején (vagyis a szokásos 15 hónapos release ciklussal) érkezik zen3+ és zen4 is új IOD-vel AM5-be és az a generáció vegyes lesz?mármint eddig is ezek voltak a lehetőségek, de én nem érzem magam közelebb a megoldáshoz.
-
-
válasz
S_x96x_S
#4788
üzenetére
Nem barkács az, de igen.
# ZenStates-Linux-master-1.5/zenstates.py --no-gui -l
CPUs: 1
CPUID: 00800F12
Package Type: 4
P0 - Enabled - FID = 26 - DID = 2 - VID = 20 - Ratio = 38.00 - vCore = 1.35000
P1 - Enabled - FID = 5A - DID = A - VID = 63 - Ratio = 18.00 - vCore = 0.93125
P2 - Enabled - FID = 60 - DID = 10 - VID = 69 - Ratio = 12.00 - vCore = 0.89375
P3 - Disabled
P4 - Disabled
P5 - Disabled
P6 - Disabled
P7 - Disabled
C6 State - Package - Disabled
C6 State - Core - DisabledÉs atomstabilan megy a 24 mag
mondjuk nálam SMT off, mert szerver környezetben inkább hátrány mint hasznos. -
válasz
S_x96x_S
#4782
üzenetére
Az a helyzet, hogy a Threadripper nálam elásta magát akkor amikor megjelent az első széria, azzal hogy max 60 PCIe lanes, max. 4ch DDR és az alaplapokon kevés PCIe slot.
Inkább maradok az EPYC-nél, az nekem bevált, meg az is megy magasabb frekvencián, csak szépen kell kérni.
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 1
NUMA node(s): 4
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD EPYC 7451 24-Core Processor
Stepping: 2
CPU MHz: 3802.226
CPU max MHz: 2300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4591.33
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 64K
L2 cache: 512K
L3 cache: 8192K
NUMA node0 CPU(s): 0-5
NUMA node1 CPU(s): 6-11
NUMA node2 CPU(s): 12-17
NUMA node3 CPU(s): 18-23Amúgy nézegettem én is ezeket a WRX80 WEPYC alaplapokat, amik már sokkal jobbak, de így is van rajta jópár olyan dolog ami nekem nem kell, és gyanítom, hogy az ára közelíteni fog a dual szerver alaplapokéhoz.
-
#4784
Petykemano
veterán
S_x96x_S
#4783
Petykemano
veterán
válasz
S_x96x_S
#4783
üzenetére
Tök jó lenne, ha már ilyesféle preventív ellencsapás-szerű trollkodásra is futná az AMD-től a Rocket Lake érkezésével kapcsolatban.
De sajnos a "bejelentés" nem az AMD-től van, hanem a Ryzen OC/UV tool készítőjétől. Tehát valószínűleg neki sikerült úgy konfigurálni (UV) egy zen3-at, hogy stabilan fusson 5Ghz-en.
-
#4773
Petykemano
veterán
S_x96x_S
#4772
Petykemano
veterán
válasz
S_x96x_S
#4772
üzenetére
Jól hangzanak a számok.
De azért a zen4 is évi 10-15%. Ez hosszútávon - már 5 év alatt - nagyon szép előrelépés. De nem kiugró. Ha hiszünk az M1 adatainak, akkor évi 10-15%kal nem fogják beérni. Kivéve persze ha a zen5 1 vagy 2 évvel, és nem hárommal, és valóban 40-50%-os IPC Piusszal fog jönni.A zen4 magasabb IPC növekedése nem volna irreális. Egyrészt már hozhat egy új IO die és a akár DDR5 is. Talán épp ezekből jön a zen3+ 4-7%-a is (pletyka)
Ahhoz képest ha a zen4 már csak 18-20%, ami egy új nodetól elvárható.Nem tartom irreálisnak azt, hogy a zen4 után találnak meg 15% IPC-t még 5nm-en.
Ha a zen5 az, ahol bevetnek valamilyen 3d tokozást és így növelik a cache méretét, esetleg a feldolgozók számát is, akkor a zen4+-hoz képest további 30-40% sem volna meglepő.
Ami meglepne az az, ha a zen5, valóban azzal az IPC növekménnyel (pl a 3d tokozásnak köszönhetően) már 2023-ban megjelenne.
-
#4768
 TESCO-Zsömle
titán
S_x96x_S
#4767
TESCO-Zsömle
titán
S_x96x_S
#4767
TESCO-Zsömle
titán
válasz
S_x96x_S
#4767
üzenetére
Amúgy játékra se ideális
 de azért a 64 magos EPYC -et lenyomja ..
de azért a 64 magos EPYC -et lenyomja ..Azt elolvastad, hogy a linkelt dián CPU-n renderelik a Crysis-t? Szóval nincs videókártya...
A hátrány meg szvsz abbó lszármazik, hogy a Crysis -emlékeim szerint- nem skálázódik túl sok magra, szóval nagyjából 4/8 szál fölött az órajel fog nyerni. -
S_x96x_S
addikt
válasz
S_x96x_S
#4747
üzenetére
> ABF substrate shortages
AMD Depends on TSMC, Who Depends on...TSMC manufactures the silicon itself and then packages it onto a substrate so the chip can be soldered or installed onto a motherboard of some type, though it isn't entirely clear which products TSMC packages for its customers or that use OSAT (outsourced assembly and test) firms for final assembly. This is called chip 'packaging,' and reports of chip packaging problems have been circulating for a few weeks.
Of course, it doesn't help that TSMC's capacity is already fully booked, but this news could shed new light on the reasons behind the supply issues. Previously, it was suspected that TSMC simply didn't have enough in-house lithographic capacity to make more chips, but it turns out that its reliance on external sources for either packaging supplies or final packaging services possibly contributes to the problem. TSMC's major ABF substrate suppliers, including Unimicron Technology, Kinsus Interconnect Technology, and Nan Ya PCB, are experiencing shortages.
Digitimes' sources indicate that AMD can currently only satisfy about 50 to 60 percent of Zen 2 demand for notebooks, and that ODM's (Original Design Manufacturers) expect to run into serious shortage issues when Zen 3-based notebooks enter the market in Q3. That's narrowed down to two possibilities (or perhaps both): Either TSMC or OSAT firms can't package enough chips, or AMD's chips for the PlayStation 5 are soaking up all of its production capacity.The situation isn't helped by the fact that demand is currently through the roof right now. AMD's CPUs, almost all GPUs, and the latest consoles are being bought up like pastries at a bakery — except there's only one bakery for an entire city.
Naturally, in such a situation, AMD is quite powerless as a fabless chipmaker because it relies on TSMC for its parts. One could argue that TSMC's suppliers should increase supply, but that would require increased capacity and investments from the substrate makers. No one can predict with any certainty that post-pandemic demand will remain at this level, potentially making that a poor investment for those firms, so that doesn't seem likely.
This means the current difficulties with finding Ryzen 5000, Radeon RX 6000, PS5, and Xbox Series X/S consoles are likely to continue. And the same goes for Nvidia's RTX 30-series GPUs.
https://www.tomshardware.com/news/amd-chip-shortage-packaging-issues -

-vitya-
őstag
válasz
S_x96x_S
#4717
üzenetére
Na most ez nagyon feküdne az aktuális hírek közé. Ha Intel befoglal TSMC 3nm-re, akkor máris veszthetnek kapacitást, ami nekik kellett volna. Úgy tudom, hogy az a jó, ha egy cég több lábon áll. Ez itt most az egyetlen lehetséges több lábon állás esete lenne a gyártásban.
szerintem. -
#4710
Petykemano
veterán
S_x96x_S
#4709
Petykemano
veterán
válasz
S_x96x_S
#4709
üzenetére
A 3nm mikorra várható? Idén év végén, vagy jövőre valamikor?
Tulajdonképp logikus az Intel részéről oda bevásárolnia magát. 1-2 éven belül a saját 10nm-es gyártásuk valószínűleg mainstreammé válik a portfólióban mellékágra küldve a 14nm-t és jó esetben éppenhogy elkezdhetik a 7nm felszerelését.
Így vagy úgy, de a TSMC szerintem nem tudná biztosítani az intelnek azt a kapacitást, ami kiszolgálná az összes keresletét. Szerintem nem.tudnak/fognak megválni a gyártósoraiktól, rá vannak utalva, hogy a kereslet derékhadát azzal szolgálják ki.
Azzal persze mindenképp az AMD alá vágnak, ha felvásárolják előlük a gyártókapacitást. Biztos vagyok benne, hogy az Intel mindent meg fog tenni, hogy helyettesítse a 14nm. Tehát lesz itt még 7nm és 5nm is. Akármit is gyártanak majd rajta. Most mutatták be a ponte vecchiot ami. Van vagy 20 chiplet. Ha csak cache lapkákat gyártatnak a tsmcnél - ami így kicsi és nagy kapacitású lehet, már azzal nyerhetnek.
Szerintem az Intel beszállása a tsmc/ss megrendelők közé azt is beárazza, hogy mennyi esély van arra, hogy az AMD piaci részesedést tudjon szerezni és nagyobb volumenben tudjon gyártani. Hiába tudna az AMD egyébként jobb terméket előállítani, nem lesz rendelkezésre álló kapacitás a bővülésre, folyton hiány és magas ár lenne tapasztalható.
-

Mumukuki
aktív tag
válasz
S_x96x_S
#4682
üzenetére
Nekem kezd olyan erzesem lenni, hogy a 2 chipletes modellekkel van valami gond. Van jo par reddites bejegyzes garis cseres 5900x/5950x rol, ahol allando WHEA bejegyzeseken csak a proci csere segitett. Olyan mintha az AMD direkt tartana alacsonyan ezeknek a szamat, amig a hibatlanokat teriti. Csere utan mar nem volt ilyen gond nekik.
-
#4674
Maelephant
senior tag
S_x96x_S
#4672
-
#4662
Petykemano
veterán
S_x96x_S
#4660
Petykemano
veterán
válasz
S_x96x_S
#4660
üzenetére
Ahogy Geralt mondaná: Hm
DIY piacon nem látom a kézzelfogható mindenki által vágyott előnyét az IGP-nek. Nem vitatom, hogy van előnye, mert mindig jól jön, amikor az ember gpu-t vált, de hangos többség véleménye mégis az, hogy kell a fenének az IGP, úgyse használom, legyen inkább annyival olcsóbb.
Ennek különösen úgy van létjogosultsága, hogy elvileg chipleten pakolnád mellé, nem pedig a compute chipben vagy az IO lapkában lenne integrálva.Notikba praktikus, hogy a dGPU-t ki lehet mellette kapcsolni.
Irodába jó az IGP-s cpu, de ott meg jellemzően nincs dGPU, eltekintve persze ha valaki kifejezetten arra fejleszt, vagy használja.Nem kristálytiszta számomra, hogy miképp valósulna meg a változás.
Mivel a DIY és az klassszikus OEM desktop megosztja a lapkákat a szerver piaccal, szerintem nem is kerül IGP a mainstream cpu-kba csak akkor ha és amennyiben és amikor az AMD úgy dönt, hogy
a) a mainstream CPU platformba tesz IGP chipletet is. De miért tenné?
b) az IO lapkába integrálja. De miért tenné?De ennek én csak akkor látnám létjogosultságát, ha az AMD valahogy tényleg kézzelfogható előnnyé tudja kovácsolni.
Leginkább valami olyasminek lenne értelme, hogy IO lapka kap egy hatalmas infinity cache-t, amit megoszt minden olyan chiplet, ami az IO lapkához csatlakozik. A csatlakozó lapka lehet egy RDNA lapka, egy cpu chiplet, vagy akár egy CDNA és akkor ebből lehet válogatni. Az infinity cache pedig minden "kliens chiplet" irányába megoldja, hogy a DDR4 vagy DDR5 sávszélessége ne legyen korlátozó.
Ez jól hangzik, de egyelőre nem látszik a horizonton, hogy valaki miért döntene egy ilyen vásárlása mellett. Később majd biztos megvillannak: AI gyorsítás, meg ilyenek, csak nem látszik az AMD víziója ezzel kapcsolatban. Legalábbis a mainstream piaci szegmensben.
-
válasz
S_x96x_S
#4660
üzenetére
Dual Graphicshoz:
Ph Kaveri tesztjében is néztek DG-t, 6 játék átlaga, nem hozott kb semmit a diszkrét R7 250-en az R7 250 + A10-7850K, ekkoriban már eléggé ejtve volt a téma. Kíváncsi lennék, Vulcan/DX12 éra ezen mennyiben változtathat.
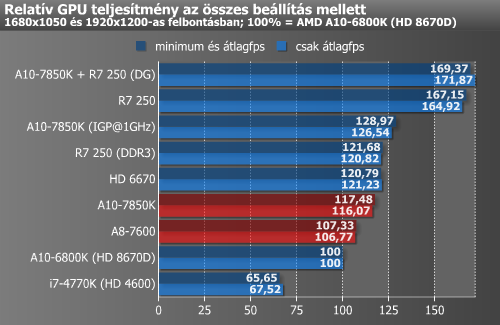
Llano idején még volt skálázódás (meg még tán Trinity/Richland esetében is), mindkét kártyával nézve javult a diszkréthez képest az együttes eredmény.
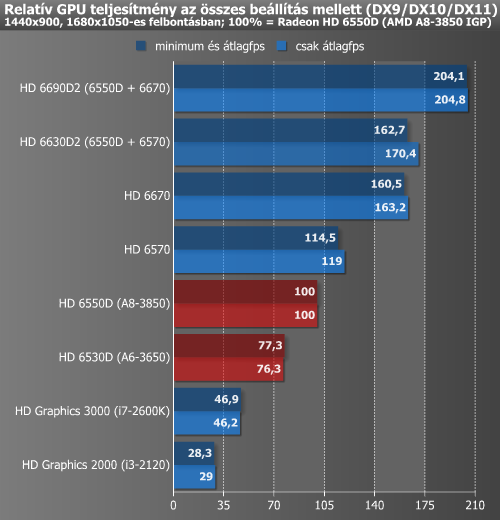
-
Cathulhu
addikt
válasz
S_x96x_S
#4654
üzenetére
Nade a nagy teljesitmenyu intel procik jellemzoen IGP-vel jonnek, a nagy teljesitmenyu AMD procik viszont nem. A desktop APUk (es itt nem a mobilrol beszelek, ott minden teljesitmeny szamit termeszetesen) altalaban csak irodai vagy netezos gepekbe mennek, pici peze. Ott meg szerintem tok mindegy, hogy Zen2 vagy Zen3, de meg azt is kimernem jelenteni, a Zen+ is elvan egy ideig.
-
#4649
Petykemano
veterán
S_x96x_S
#4648
Petykemano
veterán
válasz
S_x96x_S
#4648
üzenetére
Nem lep meg
Amilyen kis méretekben lehetett előállítani, SSD alternatívaként nem igazán jöhetett szóba szerintem. Vagy legalábbis voltak nevetséges méretek.Talán viszontlátjuk majd CXL kompatibilis bővítőkártyaként, amelynek célja kifejezetten a DIMM foglalat használata nélküli - nemvolatilis - memóriabővítés.
De akár olyan cuccként is lehet haszna, mint az AMD-nél az SSG - ami szintén memóriabővítés, csak integrált. Bár CXL-lel talán lehet majd így is, úgy is. -
Cathulhu
addikt
-
#4642
Petykemano
veterán
S_x96x_S
#4641
Petykemano
veterán
válasz
S_x96x_S
#4641
üzenetére
Nincs itt semmi szenzáció - ami korábban ne lett volna.
A 16 magos 5950X és a 24 magos TR 3960X is lenyomja a 64 magos epyc 7742-t.Így tűnik, a GB Multithread teszt vagy a pontozás nem lineárisan skálázódik a magok számával.
Lehet pl.hogy több különböző tesztet hajt végre: 4, 8, 16, 32, 64 stb magon és az eredményeket bizonyos súllyal átlagolja, mint ahogy a ... nemjuteszembe
Furcsák ezek a pontok, az oldalon 40000-60000 pontokat érnek el 64-128 magos rendszerek
-
Cathulhu
addikt
válasz
S_x96x_S
#4626
üzenetére
Hmm, érdekes, ezekszerint a Qualcomm annyira nem fél az nvidia arm összeborulástól hogy ennyi pénzt hajlandó az ARM piacba fektetni. Kíváncsi vagyok mi ér meg ennyi pénzt a nuviában szerintük, vagy csak előre menekülés lenne?
Az Intel CEO csere kicsit meglepő, bár utólag visszagondolva az elmúlt pár év teljesítményére, nem túl sokkoló.
-
#4625
Petykemano
veterán
S_x96x_S
#4624
Petykemano
veterán
válasz
S_x96x_S
#4624
üzenetére
Az szép. Az $1.4bn
Pedig még nem mutattak semmit, csak grafikonokat.
Jó, nyilván a a Qualcomm nem grafikonokra vette meg.Vajon az emberek kellettek, vagy az IP, vagy csak ellenséges kivásárlás? Mert mondjuk felvásárolhatta volna őket a MS is, akinek ugye a Qualcomm szállít.
-
Cathulhu
addikt
válasz
S_x96x_S
#4574
üzenetére
Szerintem szimplan hulyeseg amit mond, eleve nem is megoldhato. Viszont ami megoldhato lenne, mint a GPUknal vagy az Androidnal, hogy egy koztes nyelvre fordulna csak a kod es onnan pedig JIT oldana meg az optimalizaciot a futtato architekturata. Egy csapasra optimalizaltabb kodot kapnank es platform fuggetlenseget is. Tudna mukodni SIMD-vel is.
-

HSM
félisten
válasz
S_x96x_S
#4575
üzenetére
A C-Ray-nél az AVX optimalizációk is erősen számíthatnak. Látszik is, az -O3 kapcsoló ad sokat, nem az architektúra specifikus optimalizáció. A másik teszt viszont azért szépen hoz a konyhára zen2 vs zen3 finomhangolással az általános X86-hoz képest.

#4576 S_x96x_S : Ezekben a fogyasztási osztályokban nagyon nem mindegy a hűtés, és a konfigurált limitek, amik főleg a többszálú eredményekben látszanak. Amúgy szerintem jók az eredmények ennek ellenére, elfogadnám így is.
-

Ueda
senior tag
válasz
S_x96x_S
#4569
üzenetére
"és pár napot eredmény nélkül úgy el lehet tölteni, hogy még mindig nem tudod, hogy fog-e ez futni native módban."
Lehet nem ártana, ha maga a proci képes lenne programozási nyelvet futtatni. Hiszen az assembly használata úgyis hanyagolva van, csupán a fordításra korlátozódik.
-
#4564
Petykemano
veterán
S_x96x_S
#4562
Petykemano
veterán
válasz
S_x96x_S
#4562
üzenetére
Cezanne
"In Cinebench R20, the Ryzen 9 5900H scored 584 and 5264 points in single-core and multi-core tests respectively. A quick comparison to i7-10875H reveals that the AMD CPU is 17% in the single-core test and 22% faster in the multi-core according to Notebookcheck."
[link] -
#4560
Petykemano
veterán
S_x96x_S
#4555
Petykemano
veterán
válasz
S_x96x_S
#4555
üzenetére
Annak látod realitását, hogy az AMD az AVX512-t (az összes féle változatával együtt, ami ugye elég szerteágazó és ezért sokan kifejezték a csomaggal kapcsolatos ellenszenvüket) legalábbis kezdetben integrált FPGA-val oldja meg?
Nyilván szólnak érvek ellene.
Ha már ott vannak a 256bites FP végrehajtó egységek (4db), akkor arra "ugyanúgy" rá lehet építeni az AVX512-t, mint ahogy volt a 4db 128 bites és működött rajta a 256bites AVX2
Ugyanakkor nyilván már ennek is van tranzisztorköltsége. Nem is beszélve arról, ha bővítik a végrehajtóegységek szélességét 4db 512bitesre.
Ezt a megoldást - hacsak nem jön elő az AMD egy a SVE-hez hasonlatos rugalmasabb megoldással - persze nem vetném el, de az AVX512 penetrációja elég vékony és jelenleg azért rezeg a léc, ugye gyakran felmerül, hogy hát igazából ezeket a dolgokat hatékonyabb volna GPU-val végrehajtani.
Többféleképpen tudnám elképzelni a csomagolást:
- CCX-enként 1 FPGA
- magonként 1 FPGA
És azt is, hogy az AMD a megrendelőnek előre felkonfigurálva szállítja, vagy egy program futása előtt kell felkonfigurálni. Számomra kérdés (úgy értem, kétlem, hogy) utasításonként való felkonfigurálás elég gyors tudna lenni, tehát azt látom realitásnak, hogy ezzel az AMD különböző igényű cégeket tudna rugalmasan kiszolgálni anélkül, hogy egyedi terméket kellene gyártania. Egyik cégnek AVX512 kell, akkor ő olyan FPGA-t kap, a másiknak meg más.Feltehetnénk a kérdést, hogy de miért venne valaki ilyet, amikor már most is telepakolhatja a szervereit FPGA gyorsítókkal. A trükknek nyilván abban kell állnia, hogy a megrendelőnek egyáltalán ne kelljen a gyorsítóra progrmozni, hogy az FPGA-val megvalósított AVX512, vagy bármilyen új egyedi és virtuális x86 utasítás (?) úgy viselkedjen, mintha a cpu mag natívan tudná.
-
Cathulhu
addikt
válasz
S_x96x_S
#4555
üzenetére
Az a jo a kovetkezo konzolgeneracioig ez szepen ki fogja forrni magat es ez eleg lehet meg egy teljes generaciot behuzni. Megha az nV + ARM utol is erne oket addig, ez lehet a merlegben donto. Az intelnek lehetne hasonlo ajanlata, ha rakenyszerul addig custom gyartani, de nem hiszem hogy a GPU reszleguk versenykepes lesz akar meg ilyen tavlatban sem.
-






















![;]](http://cdn.rios.hu/dl/s/v1.gif)




 de azért a 64 magos EPYC -et lenyomja ..
de azért a 64 magos EPYC -et lenyomja ..







Új hozzászólás Aktív témák
- Xbox Series X, kitisztítva+újrapasztázva, 6 hó teljeskörű gar., Bp-i üzletből eladó!
- Nintendo Switch OLED Mario Edition 20.5, 512GB MicroSD + Android + Atmosphere, 3 hó garanciával
- Eladó alaplap + processzor + memória + hűtő
- Blackmagic Pocket Cinema Camera 4K + objektívek
- R5 5600X/32GB DDR4/6700 XT 12GB/1TB M2 P4+2TB M2 P3 SSD/Ss GX 750W/G213/Razer DA3+pad/FHD 170Hz 24"
- 176 - Lenovo Legion Pro 7 (16IAX10H) - Intel Core U9 275HX, RTX 5080
- ÁRGARANCIA!Épített KomPhone i9 14900KF 32/64GB DDR5 RAM RTX 5070 12GB GAMER PC termékbeszámítással
- GYÖNYÖRŰ iPhone 12 mini 128GB White -1 ÉV GARANCIA - Kártyafüggetlen, MS3856
- Azonnali készpénzes Intel i5 i7 i9 8xxx 9xxx processzor felvásárlás személyesen / csomagküldés
- Dupla Lencsés PTZ Biztonsági Kamera 2.4/5G Dual Band Wifi Kamera+128gb mermoria kártya
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: ATW Internet Kft.
Város: Budapest