-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
válasz
 Cathulhu
#43800
üzenetére
Cathulhu
#43800
üzenetére
Lehet hülye elképzelés és nem vagyok tisztában a fejlesztés horribilis költségeivel,de AMD nek, ha jól megy lehet megérné anyagilag támogatnia GloFot a 7 nm vagy az alatti átállás befejezésére.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

Abu85
HÁZIGAZDA
Már nem. Ez nem olyan, hogy csak befejezed és kész. A GloFo annyit tehetne, amit a 14 nm-nél, hogy licenceli a Samsungtól. Mivel a Common Platformnak még mindig a része a két cég, így ez egyébként lehetséges lenne, de még így sem biztos, hogy az AMD-t érdekelné, és ha az AMD-t nem érdekli, akkor nincs értelme licencelni sem a GloFo-nak.
Ugye a GloFo alapvetően nem azért állíthatta le a 7 nm-t, mert nem működik az, amit az IBM-től megszereztek. Inkább az lehetett az indok, hogy az AMD megmondta nekik, hogy a 7 nm-nél tipliznek a TSMC-hez. Így meg a GloFo számára nem volt túl nagy értelme befejezni a 7 nm-jüket. Ez nem pénzkérdés, az ATIC tele van lóvéval, hiszen ott van mögötte az arab olajpénz. De ha az AMD-t nem érdekli a GloFo 7 nm-es node-ja, akkor nincs értelme kifejleszteni. Ugye alapvetően kinek kellene? Mindenki a TSMC-hez akar menni, mert messze ők a legjobbak. Akiknek pedig nem jut hely, azok jó eséllyel inkább a Samsungot választják. Nem a legjobb, de szódával elmegy, mármint az élvonalbeli node-okat tekintve. A GloFo nem nagyon tud ám ajánlani semmit, ami nincs a Samsungnál, a TSMC-vel pedig ugyanúgy versenyképtelenek. A specializált gyártástechnológia más kérdést, ott a GloFo lehet alternatíva, de leginkább azért, mert a Samsungot és a TSMC-t annyira nem érdeklik ezek a niche piacok.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Cathulhu
addikt
Nem birna azt az AMD finanszirozni, igy is allandoan a nyeresegesseg hataran egyensulyoznak. Az egyik legjobb dontes volt megszabadulni toluk. A TSMC-nel csak addig kell kibirni, amig a nagyhalak kisebb node-okra nem ugranak es maradni kicsit a 7esen, szep lassan emelgetve az orajeleket, ahogy javul a minoseg. Ezen az EUV is segiteni fog, raadasul azon mar Q4-ben indul a tomeggyartas. En ezt a strategiat valasztanam, sot szerintem most is boven eleg lett volna a tavalyi 10-es, nem kellett volna rogton a state-of-the art. Intelt igy is bucira verik fogyasztasban, nVidiahoz meg a 7 is keves. Bar lehet igy konnyebb lesz a Zen3-at illetve a tobbi RDNA-as Radeont 7+ EUV-ra vinni.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#43805
 Petykemano
veterán
Cathulhu
#43804
Petykemano
veterán
Cathulhu
#43804
Petykemano
veterán
válasz
Cathulhu
#43804
üzenetére
"A TSMC-nel csak addig kell kibirni, amig a nagyhalak kisebb node-okra nem ugranak es maradni kicsit a 7esen, szep lassan emelgetve az orajeleket, ahogy javul a minoseg"
Az a baj, hogy úgy tűnik, hogy míg eddig a nodeváltással az volt a cél, hogy nagyobb órajeleket érjenek el, úgy tűnik, hogy most át/vissza fognak állni arra, hogy a tranzisztorokat IPC növekedésre vagy más okosításra költsék. Erre utal Jim Keller Willow Cove-ra tett utalása, amely szerint az jóval nagyobb lesz, mint elődje (Sunny Cove)
Azt, hogy nagyobb legyen nyilvánvalóan a nagyobb sűrűség és az alacsonyabb fogyasztás teszi lehetővé. Ha ez nincs, akkor úgy tűnik, semmi sincs. Mármint persze 2-300Mhz-et lehet reszelni, mint a 12nm esetén is tették, de mondjuk ez elég távol van attól, hogy duplázzák a tranzisztorszámot, növelik az IPC-t 20%-kal és még így is nevetve jobb fogyasztást produkálnak. (lásd: zen2 vs zen, sunny cove vs skylake - utóbbinál a csökkenő frekvenciától tekintsünk el)
Tegyükhozzá: azonos node-on valami jobbat alkotni sajnos nem az AMD területe
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#43807
Petykemano
veterán
Petykemano
veterán
Added AMD Radeon RX 5500.
Added preliminary support of AMD Arcturus.
HWInfo Upcoming changesTalálgatunk, aztán majd úgyis kiderül..
-
válasz
Cathulhu
#43804
üzenetére
Pont ez a bajom amúgy, hogy az AMD a 7nm-en sem tud látványos előnyt bemutatni az nVidia féle 12nm-el szemben. Most vagy az nVidia talált el nagyon valamit (nem lenne csoda, sokszoros R&D pénzzel), vagy az AMD szúrt el nagyon valamit. Esetleg mindkettő.
Abu azt mondja, hogy a Radeon VII meg a Zen2 hatalmas előny a 7nm-es gyártástechnológia miatt, mert sok tapasztalathoz jutottak hozzá. Ez lehet, hogy így van, de az RX 5700 mégse alázza le a 12nm-es Turingot teljesítmény/fogyasztás terén. Még akkor sem, ha tényleg tudnak mondjuk 10%-ot gyorsulni, ha kiforrnak driverek. Ez alapján az RDNA vagy valami meg nem értett zseni, ami majd egyszer ( ki tudja mikor... ) hirtelen berobban, és hülyére ver mindenkit a piacon, vagy az AMD tévútra futott vele...
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
persze ezzel tisztában voltam, hogy nem így működik.
"Akiknek pedig nem jut hely, azok jó eséllyel inkább a Samsungot választják. Nem a legjobb, de szódával elmegy, mármint az élvonalbeli node-okat tekintve."
hát pedig sok szempontból előrébb tart mint a TSMC 7 nm a másik meg hogy úgy néz ki nem a csíkszél a kulcs egy architektúra minőségére.
Mondjuk 1 éven belül is annyi forgatókönyv volt.. tavasszal TSMC azt nyilatkozta mégis van bőven kapacitás nem lesz gond. Most meg ezt hogy gáz van nincs kapacitás.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#43810
Abu85
HÁZIGAZDA
Petykemano
#43806
Abu85
HÁZIGAZDA
válasz
 Petykemano
#43806
üzenetére
Petykemano
#43806
üzenetére
Az Apple és a Huawei legújabb chipje készül EUV-s 7 nm-en. Minden más még a nem EUV-s verzión készül. Nem biztos, hogy mindenkinek megéri váltani, vagy ugyanabban az időben lépni.
Egyébként ez a két node külön üzemekben van, tehát egymástól nem veszik el a kapacitást.(#43808) Cifu: Mert a gyártástechnológia ugyanolyan lapka mellett tud javítani, de ha kigyúrod a 7 nm-en a dizájnt sokkal modernebbre, például ahogy a Navit kigyúrták IPC/munkaelemre, akkor annak hátrányai is vannak, hiszen például négyszer gyorsabb lett az egy lane-re levetített teljesítmény. És ez bizony fogyasztásba kerül, mert az ehhez szükséges áramköröket be kell építeni. Ugyanígy, ha az NV-nek is jön ez a váltás, mert wave programozással megéri váltani, akkor természetesen ez hátrányos a fogyasztásra nézve, viszont sokkal előnyös lesz az egy lane-re levetített teljesítményt tekintve.
Hasonló tényező ez a Pollack-szabályhoz, és valamilyen mértékben ez érvényesül is a GPU-knál, még akkor is, ha a CPU-kra találta ki. Viszont eddig minden GPU-t throughputra terveztek, mert a shader nyelv nem tette lehetővé a lane-ekre vonatkozó párhuzamosítást, de az új shader nyelvek lehetővé teszik, így viszont megnőtt arra az igény, hogy egy munkaelemre levetítve is legyen nagyobb az IPC. Viszont, ahogy a CPU-knál is a nagyobb magonkénti IPC fogyasztáshátránnyal jár, így ez is ugyanilyen gondot jelent a GPU-knál. Viszont cserébe, amíg a CPU-knál a magas szálankénti IPC előnyt is jelent, úgy ugyanez igaz a GPU-kra is, ha kapnak egy divergens kódot, és ott már szétalázható minden throughputra optimalizált dizájnt, mert egy munkaelemre levetítve négyszer nagyobb a teljesítmény.
A pipe-cleaner akkor segít, ha a tranzisztorstruktúra a végét járja. Megfigyelhető volt, hogy 28 nm-en jött pipe cleaner, mert akkor a bulk struktúra kezdett kifulladni, és úgy előny volt hozni egy korai 28 nm-es lapkát. Viszont 10-20 nm között ez értelmetlen volt, mert a FinFET ereje teljében volt. 7 nm-en azonban kezdenek már mutatkozni a FinFET limitjei, így a pipe-cleaner újra jó ötletté vált a tapasztalatszerzés érdekében. Majd amikor megyünk a GAAFET-re, akkor megint nem lesz, mert új a tranzisztorstruktúra, és sok dolog just works jellegű lesz újra.
(#43809) b. : A TSMC-nek óriási előnye a tapasztalat, mert rengetegen ott gyártatnak. A papír valóban sok dolgot elbír, de végeredményben a cégeknek is az számít, hogy a gyakorlatban mit kapnak a gyártópartnerüktől, és nem véletlen, hogy a TSMC-hez akarnak menni.
Nézd a bérgyártónak van egy terve arra, hogy mennyi kapacitása lesz, és a partnerei leadnak nekik bizonyos igényeket, amelyeket ugye összevetnek a terveikkel, és mondják, hogy jó-e vagy sem. Tavasszal még elképzelhető volt, hogy más igényekkel számoltak a partnereik is, de nekik is változik a piac, többet kell rendelni ebből-abból, és akkor rögtön borul minden. Ez van. Akik most partnerek, azoknak ez nem akkora gond, mert tudják, hogy milyen kihozatallal tudnak gyártani, tehát leadják jó előre a rendeléseket, mert pontosan ki tudják számolni, hogy milyen igényekhez, mekkora rendelési tétel kell. Azoknak baj most a TSMC-nek ez a korai rendelésre vonatkozó szabálya, akik még nem gyártanak ott, mert nem tudják ezt elég pontosan kiszámolni a kihozatalra vonatkozó számok hiányában. Ha meg sokat rendelnek, akkor baj lesz a raktáraránnyal. Az tehát igaz, hogy a TSMC ezzel az új partnerek dolgát alaposan megnehezítette, de a maguk részéről ez az igény számukra kedvező. Ez jelzi, hogy megéri új gyárakat építeni, amelyek épülnek is, és ezzel meglesz a tőke a további gyártástechnológiai lépcsőkre is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Jack@l
veterán
Nagyon nem töri össze magát az amd a fejlesztéssel, 2020 decemberig ellébecolnak kis kártyákkal:
https://www.vice.com/en_us/article/a3544z/the-playstation-5-will-launch-in-time-for-the-2020-holidays[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
A Keplerrel az NVIDIA megfordította a teljesítmény / fogyasztás szituációt, és azóta minden generációval nyílik az olló a párhuzamos architektúrák között. Ez mostanra akkorára nyílt, hogy a gyártástechnológiból fakadó előny éppencsak kompenzálja.
Ráadás, hogy úgy tűnik, a nem agyonhajszolt Navi chipek kb. úgy fogyasztanak hasonló chipméret mellett, mint az agyonhajszolt Polaris...Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
A Kepler ugyan tényleg sokat hozott, de inkább úgy fogalmaznék, hogy utolérte a GCN-t (GK104 vs Tahiti), nagy különbség nem volt. A Maxwell csinált csodát. Ez az amit csak a Polaris-szal tudtak hozni. Most meg a Navival hozzák a Pascal / Turing szintjét. Maga az olló nem nyílik, habár komoly lemaradásban vannak, ez tény.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#43814
Cathulhu
addikt
Petykemano
#43805
Cathulhu
addikt
válasz
Petykemano
#43805
üzenetére
Szerintem bőszen van még a Zen architektúrában annyi suboptimális megoldás, hogy azonos tranzisztor büdzséből jelentős IPC ugrást lehessen elérni. Zen2 ereje se a 7 nanoban van, ugyanezt az IPC ugrást 12 nanon is sikerült volna, és ehez olyan nagyon komolyan hozzá se kellett nyúlni a Zenhez. Ráadásul egy kiforrott gyártósorról lepotyogó 4.7 all core, 5 GHz turbo chipek önmagukban is elég éves ugrást hoznának.
Vega detto, ott az alap architektúra gyenge, a Navi alapok valamivel időt állóbbnak tűnnek, de az is gyenge elsőre, reszelgetésben is sok van még ott
[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
válasz
 lezso6
#43813
üzenetére
lezso6
#43813
üzenetére
Nem volt nagy különbség, de határozottan volt, és a Kepler javára - a 680 az indulásakor rendelkezett 5-6% előnnyel, és 10%-kal kevesebbet fogyasztott. Vesd össze ezt az 5870 VS GTX 480 szituációval...
Az ollót én úgy nézem, hogy azonos processzen hasonló chipméret mellett hogy viszonyul a perf / watt. Ehhez persze még kell a 7nm-es NVIDIA, de őszintén szólva annyira underwhelming a Navi ezen a téren, hogy meg merem előlegezni, hogy tovább nyílik.Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
A vásárlókat nem az érdekli, hogy milyen technikai húzást mutat be az AMD, hanem azt, hogy adott pénzért milyen FPS-t kap. Természetesen némi túlzásba estem, mert ár/értékben többé-kevésbé egy szinten vannak a pirosak és a zöldek, mivel ha nagyon kilógna valamelyik, akkor azt értelemszerűen nem lehetne eladni.
Megértettem elsőre is a wave programozási módszer előnyeit, de majd akkor hiszem el, hogy emiatt lesz majd egyszer ütős az RDNA, ha gyakorlati szinten is bizonyítja életképességét. Jó ideje ha az AMD előjött valami látványosnak ígért csodával, kiderült, hogy a nagy betűs életben kevés hasznát látjuk. A Mantle/Vulkan lehet talán az egyetlen kivétel, de aligha nevezhetjük elterjedt megoldásnak. A fejlesztők pedig nagy részt élnek az nVidia támogatásával, ha rendelkezésre áll (és az nVidia ilyen téren rendelkezésre áll), így a játékokban azt látjuk, hogy az nVidia kártyái jól szerepelnek...
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
#43817
Petykemano
veterán
Cathulhu
#43814
Petykemano
veterán
válasz
Cathulhu
#43814
üzenetére
"Zen2 ereje se a 7 nanoban van, ugyanezt az IPC ugrást 12 nanon is sikerült volna"
Ez Igaz, a 7nm az alacsonyabb fogyasztást tette lehetővé, ami pedig azt tette lehetővé, hogy ~kétszer annyi magot pakoljanak ugyanakkora TDP-be.
Ha ugyanezeket a változtatásokat 12nm-en hajtották volna végre, akkor abból minimum fogyasztáscsökkenés nem lett volna, de a duplázott L3$ miatt talán még nőtt is volna valamicskét.
Akkor is az látszik, hogy több előnnyel vagy komforttal jár - a végtermék működése szempontjából - átmenni a sűrűbb és alacsonyabb fogysztású nodera, mint azonos nodeon optimalizálni.
Nem állítom, hogy a 7nm lehetőségei maradéktalanul kiaknázottak, csak azt, hogy szerintem nagy a nyomás
Ugye vannak tradeoffok, ha a lapka új nodeon van, akkor kicsi és "olcsó", keveset fogyaszt. Feltekerheted a fríkvenciát, akkor bukod a fogyasztást, vagy ha ügyes vagy, feltekerheted a tranzisztorszámot a több telhesítményért, Amivel fogyasztást nyerhetsz, de elengeded a lapka méretét és árát (Apple, nvidia)
Az Apple és az arm minduntalan 30%-os IPC növekedést hoz. Persze a bejelentés mindig 1 évvel hamarabbi, mint a piacra kerülés. Ezt úgy érik el, hogy mindig a legfrissebb nodeon készül.
Ha ezzel lépést akarnak tartani, akkor vagy friss node kell, vagy a lapkaméret nő, ha bénák, akkor a fogyasztás is.Találgatunk, aztán majd úgyis kiderül..
-

Mumee
őstag
Ez csak azért tűnik így, mert (gondolom) a rossz kihozatal miatt közel sem optimális keretek között lett kiadva a kártya.
1,2V GPU, 1,2V SoC , de még sima nonXT 5700-nál is közel 1V GPU, 1,2V SoC.
XT esetén a gyári órajelet a kártyák 95%+ bírja 1,1V körül, 1V pedig 1900-1950mhz-hez kell nem 1750mhz.
SoC pedig AIB-ok is mind 1,05V-on jöttek.
Ezzel a 2 fesz-el pedig undorító módon együtt mozog a fogyasztás.
Az a 0,1V a GPU-n kb. 50W és a SoC-on a 0,15V is kb. 10W.1,1V GPU körül kéri be a 200W-ot, ami az alapórajelhez elég.
A sima 5700 normális fesz-el 150W-ból megvan peak-el együtt, alapórajelen. -
Abu85
HÁZIGAZDA
Ezeket az architektúrákat évekre tervezik. Legalább 5-6 évre. Tehát ha most tervezel valamit, akkor az az optimális, ha a wave programozásra tervezed, hiszen ma már ott van a subgroup, illetve a wave intrinsics a Vulkan és DirectX 12 API-kban. 2010 környékén, amikor az RDNA-n kívüli architektúrák alapjai megszülettek, még nem volt meg ez a wave programozásra vonatkozó lehetőség az API-kban, így felesleges volt így tervezni a hardvereket. Viszont elég jelentős maga az előrelépés programozási szempontból. Itt a shader modell 6-ra a Microsoft leírása:
"Up until now, the HLSL programming model has exposed only a single thread of execution. As of v6.0, new wave-level operations are provided to explicitly take advantage of the fact that on current GPUs, many threads can be executing in lockstep on the same core simultaneously. For example, these intrinsics enable the elimination of barrier constructs when the scope of synchronization is within the width of the SIMD processor. These can also work in the case of some other grouping of threads that are known to be atomic relative to each other.
Potential use cases include performance improvements to: stream compaction, reductions, block transpose, bitonic sort or FFT, binning, stream de-duplication, etc."És ugye ez folyamatosan egészül ki, az SM6 például nemrég a variálható wave-hosszal, amit szintén támogat az RDNA, de csak ez a dizájn, az öregebbek nem, mivel azok alapjai 2010 környékiek, és komolyabb áttervezés a wave execution résznél egyiknél sem volt. Viszont ezek a képességek komplexebbé teszik a hardvert.
A Vulkan nem azért gyorsabb az AMD-n, mert a hardver jobb. De tényleg. Több szempontból a Vulkan hardverre vonatkozó igényei finomabbak a DirectX 12-höz képest. Persze ettől egy picit bonyolultabb a memóriamenedzsment, de alapvetően a két API ugyanúgy működik, tehát az a pár extra probléma nem túl lényeges, amire a Vulkan esetében még figyelni kell. Valószínűleg hosszabb lesz a leképező kódja Vulkánban, de a menedzsmentje rendkívül hasonló. Az ok, amiért a Vulkan játékok az első pár hónapban jobbak, hogy amíg a DirectX 12-re a Microsoftnak ott a PIX, és az tényleg egy bitang jó fejlesztőeszköz, széles hardvertámogatással, addig a Khronos a validációs rétegén kívül nem kínál sokkal többet. Az egyetlen igazán jó fejlesztőeszköz a Renderdoc+RGP, de ennek a PIX-szel szemben az a hátránya, hogy kizárólag Radeonokon működő kombináció. Tehát a fejlesztésnél a DirectX 12-re tudsz minden gyártónál ellenőrizni, de a Vulkan esetében a Renderdoc+RGP Radeonra korlátozza az egész munkát, és majd a végén érdemes az NV és az Intel hardvereihez igazítani. Na most utóbbi esetében az szokott lenni, hogy a felsőbb vezetés már sikít, hogy meg kéne jelenni, szóval valamennyire összecsapják a kódot, hogy legalább működjön, de jellemzően a sebesség az NV és az Intel hardvereken, 2-3 hónap múlva érkezik meg, amikor az NV és az Intel tud javasolni annyi változást a kódba, hogy a kiadáskori rossz hatásfokra vonatkozó hátrányt le tudják küzdeni. Viszont önmagában a hardver maga jó az NV és az Intel oldalán is, hiszen láthatod a World War Z-t, hogy kiadáskor köhögött mindkettőn, de 3 hónap múlva kapott egy patch-et, és sokkal jobban megy. A No Mans Sky esetében is ez van. Köhög nagyon NV-n és Intelen, de ugyanazért, amiért a World War Z köhögött. Nincs normális fejlesztőeszköz ezekre a hardverekre, így amikor bizonyos döntéseket kell hozni a kód szempontjából, akkor az történik, hogy a Radeonoknak optimális döntéseket hoznak, mert arra tudnak mérni. A többi hardvernél feltételezik, hogy ugyanúgy működik, de közben nem ugyanúgy megy, csak nincs semmi a fejlesztők kezében, hogy ezt meg tudják cáfolni. Szóval menni kell a hardver gyártójához, és kérdezni, hogy ezzel a kódrésszel mi legyen, jó-e, stb. A gyártó meg tudja mondani, csak jellemzően ezt már a kiadás után teszi meg, és kell 2-3 hónap, hogy az erre vonatkozó programkódbeli hátrányokat leküzdjék. Szóval ez a Vulkan esetében a probléma, és nem az AMD hardvere a jobb az API-hoz.
Nyilván egyébként a fentiek azt is eredményezték, hogy a Vulkanra portolók csak Radeont használnak, mert PIX-szintű fejlesztőeszköz nélkül a többi hardver szart sem ér a fejlesztés szempontjából. Nagyon ritka az, amikor egy stúdiónak van saját fejlesztőeszköze, például az id-nek, de ez sok stúdiónak nem éri meg, mert a Renderdoc működik, interoperabilitást ad az RGP-vel, minek ölnének egy rakás pénzt és erőforrást egy saját megoldásra? Olcsóbb Radeonra cserélni a gépparkot. Ezt csinálta az Epic is, pedig nekik lennének erőforrásaik saját eszközökre.
Ebből a szempontból egyébként a DirectX 12 sokkal jobb. A Microsoft nagyon jól felismerte, hogy a PIX egy kritikus komponens, és nagyon lényeges, hogy mindegyik gyártót maximálisan támogassák, amibe komoly erőforrást ölnek. A Renderdoc mögött viszont nincs egy mamutcég a kifogyhatatlan pénztárcájával. Sokkal limitáltabbak a lehetőségeik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

GeryFlash
veterán
válasz
Cathulhu
#43800
üzenetére
+1 végre valaki leírta ezt helyettem is
 Sokan abban élnek hogy hülye AMD elfelejtett időben szólni a TSMC-nek hogy jajj srácok akarunk kis NAVI-kat novemberben.
Sokan abban élnek hogy hülye AMD elfelejtett időben szólni a TSMC-nek hogy jajj srácok akarunk kis NAVI-kat novemberben.Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Ez jó, de nem jelenti automatikusan azt, hogy később javítanak a gyári paramétereken - a Polaris esetében sem tették. Várjunk pár hónapot, addig úgysem lesz 7nm-es NVIDIA kártya, aztán értékeljünk újra.
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
Sziasztok!
Lehet, hogy hülye kérdés de.
A next gen konzolok mindkét gyártó szerint támogatni fogják a ray tracing-et és az AMD RDNA-ra fonak építeni. Na már most ha ez így van akkor elképzelhető-e, hogy a pc-s RDNA-s radeonok RT támogatást kapnak majd valamikor a jövőben mondjuk egy driver + OS frissítéssel?
Vagy a konzolokba szánt verzió pont abban fog különbözni a jelenlegi RDNA-tól, hogy azokban van külön egység amit az RT-ért felel?(Már rég voltam a vörös oldalon és az 5700 vonz. Egy GTX1070-et váltana)

[ Szerkesztve ]
Addig gyorsítottuk a világot míg mi magunk maradtunk le...
-
Mumee
őstag
Biztos vagyok benne, hogy nem fogják, de ettől függetlenül ez legalább nem a Navi architektúra hibája, csak nem optimális órajel/feszültség -en adták ki, gondolom megint azért hogy 2060-2070-nél biztosan gyorsabb legyen a két 5700 és minél kevesebb selejtel.
Érdekesség képpen :
1,3V-on Hwinfo 300W, Igor-nál [1,25V] normális méréssel 250W volt, így nagyjából reális a 300W, még ha nem is teljesen pontos, hisz víz alatt volt mind2.
A 30k graphics pont pedig 2080 Super szint, ami 350W gyárilag Furmark alatt. [link]Persze itt optimalizálva van már az 5700 és víz alatt, léggel lenne ez is 350-380W.
A lényeg, hogy felfelé is korrektül skálázódik a Navi, arányosan a feszültséggel és hűtéssel és nincs elborulva az Nvidia-tól teljesítmény/fogyasztásban csak optimalizálatlanul van gyárilag és 7nm.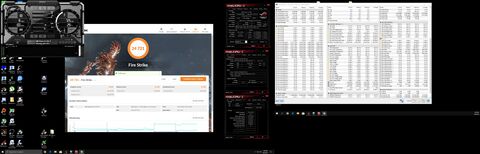
-
Abu85
HÁZIGAZDA
válasz
 adamssss
#43822
üzenetére
adamssss
#43822
üzenetére
Drivert a mostani hardverekhez is lehet írni. Egyébként a 19.30-as batchben ott van a bejárási rutin, csak nincs bekötve a gyári implementációba. A Radeon drivereknek van egy úgynevezett developer módjuk, amikor bizonyos képességek előhozhatók, de ehhez egy külön fájl kell, ami ellenőrzi, hogy az adott gép regisztrált-e az AMD adatbázisában, és jogosult-e xy fícsőr használatára. Én is használom a gyári Radeon developer módját az RGP-re, de ott ugye nincs előfeltétel, azt bármelyik nem regisztrált gépre kilakatolja a devpanel fájl, hiszen csak egy háttérfolyamatot indít el, amivel összekapcsolja a drivert. Amikor ez a kapcsolat megszűnik, nem működik tovább a fícsőr, és újra normál módba kerül a cucc. A nem publikus funkciókat nem lehet így kilakatolni, oda hitelesítés kell.
De egyébként mindegy, hogy megkapja-e lassú lesz, illetve nem is így fog kinézni egyik konzolon sem a raytracing. A Sony konzolján például nagyon más lesz az egész grafikai futószalag. A PC-s verzió hasonlítani fog az új Xbox rendszeréhez, de azért lesznek eltérések. PC-n gondot jelent, hogy sok régi megkötéssel kompatibilisnek kell maradni. A konzolon ez nem gond, ott bátran nyomhatsz egy resetet, ha sebességben lényeges az előny. A Sony ezt csinálta a PS5-nél. Annak csak a legacy API-jaiban lesz elérhető a PC-hez hasonlító futószalag, az új API-ban nyoma sem lesz a vertex-geometry-domain shadereknek. Az új Xboxon lesz egy original futószalag és egy upgrade. Utóbbiból lesznek kivágva a legacy shader lépcsők.
Konzolhoz idomuló hardvert egyébként most nem kapsz. Az RDNA ugyan képes a motorháztető alatt átfordítani a vertex-geometry-domain shadereket az új pipeline-ra, de a jó ég tudja, hogy miben egyezik meg a Microsoft a gyártókkal, és lehet, hogy a valódi pipeline változást már nem fogja támogatni. Viszont PC-n ennek a valódi pipeline változásnak meg értelme nincs, mert motoronként 200-300 ezer sornyi kódot kellene átírni, hogy kompatibilis legyen, és a kompatibilitás azt is jelenti, hogy a régi hardverekkel az új kódok meg nem lesznek kompatibilisek, tehát meg kell őrizni a régi kódokat is.
Nem egy fejlesztőcsalogató változás ez így.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#43825
Cathulhu
addikt
Petykemano
#43817
Cathulhu
addikt
válasz
Petykemano
#43817
üzenetére
"Ez Igaz, a 7nm az alacsonyabb fogyasztást tette lehetővé, ami pedig azt tette lehetővé, hogy ~kétszer annyi magot pakoljanak ugyanakkora TDP-be."
Ez szep es jo, de fokent igaz. Ugyanakkor egyik piacon se volt ra igeny. Intel jelenleg nem tud semmilyen konkurenciat allitani a Zen2-nek, gamer piacon semmi szukseg jelenleg 8 magnal tobbre, cserebe 2-300 MHz plussz egy 3800X-nel az verne minden intel konkurenst. HEDT-n es szerveren is eleg lenne a 32 mag egyelore, mivel szervereknel mar 1 szalon is veri az intelt, es az a 32 magosra se tud konkurenciat felmutatni. Egyedul mobilnal lenne ertelme a minel kisebb nodenak, de ott meg pont nem hasznalja ki az AMD.Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
De szeretem ezeket az Abu-s válaszokat mert ilyenkor legalább 3-szor el kell olvasnom a hszt, hogy tudjam, hogy mit kell megnéznem a google-ban, hogy utána még 3-szor elolvasva nagyjából felogjam, hogy a kérdésemre mi is a válasz.
Szóval ami nekem lejött, hogy a jelenlegi RDNA-s kártyákon Win10 alatt nem lesz RT, ergo ha ilyent veszek akkor a ray-tracinget felejtsem el.
Addig gyorsítottuk a világot míg mi magunk maradtunk le...
-
Abu85
HÁZIGAZDA
válasz
adamssss
#43826
üzenetére
Ha lesz is, akkor sem lesz sebessége. A mai hardvereken ezt tényleg felejtsd el. Majd a következő DXR verziónál, amikor a vertex formátum már nem csak 32 bites lebegőpontos lehet, hanem snorm is, ami sokkal hatékonyabb, illetve nincs hardveresen kötve a bejárás. Viszont ezekhez új hardverek kellenek, amelyek még nincsenek piacon, majd valamikor jövő ilyenkorra, vagy talán jövő nyáron.
Ma alig látható dolgokért fizetsz iszonyatos sebességet, amit sok szoftveres és hardveres limit szűkít le. Emiatt van az, hogy nem igazán látsz gyakorlati különbséget például a BF5-ben: [link] vagy a ME-ben: [link]
De mondjuk, ha nem kellene erősen visszafogni a paraméterezést, mert lenne hozzá egy elég jó szoftveres és hardveres háttér, akkor viszont lényegi különbséget is lehetne mutatni, nem kellene hozzá állóképeket elemezni, hogy ezeket meglásd.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
GeryFlash
veterán
A Microsoft mikor szándékozik véglegesíteni az új PC-s DXR-t? 2021 Q1ig meglesz vagy csak az új konzol jövetelekor esetleg még utána?
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Abu85
HÁZIGAZDA
válasz
 GeryFlash
#43828
üzenetére
GeryFlash
#43828
üzenetére
Szerintem elég fontos nekik, hogy a konzol és a PC annyira közös alapokra építkezzen szoftveres szinten, amennyire csak lehet, így valószínűleg csak az új konzoljukkal párhuzamosan oldják ezt meg.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#43830
Petykemano
veterán
Cathulhu
#43825
Petykemano
veterán
válasz
Cathulhu
#43825
üzenetére
"Ugyanakkor egyik piacon se volt ra igeny. "
Szerintem a Rome-nak épphogy az az egyik legnagyobb vonzereje, hogy ugyanakkora TDP-ben (ugyanannyi socketba) kétszer annyi magot, kétszer annyi teljesítményt tudnak belecsomagolni.A gamer piacon meg arra a termékpalettára lenne szükség, amit még AdoredTV mutogatott: hogy a 6 mag a belépőszint (<$200) és a 8 mag a mocskosul olcsó mainstream ($200-$250)
Hogy terjedjen a 8+ mag, hogy mihamarabb szükséges legyen a 8 mag a gamerek körében. Ámbátor a mindfactory számokból látható, hogy DIY piacon így is sikert arat.Találgatunk, aztán majd úgyis kiderül..
-
GeryFlash
veterán
Tehát akkor jó eséllyel az új Nvidia széria (Ampere?) se fogja tudni az új DXR-t? Vagy azért a partnerek közti tárgyalásokban addigra azért véglegesítve lesz? Csak mert ha jól értem, akkor előállhat az a dolog, hogy a 1. generációs NAVI (ideértve a jövő év elején érkező csúcs NAVI-t) se régi DXR-t se az újat nem fogja tudni, míg az Nvidia mindkettőt le fogja fedni 2 szériával.
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Abu85
HÁZIGAZDA
válasz
GeryFlash
#43832
üzenetére
Azért ezek a gyártó tudják, hogy mik lesznek a változások, tehát természetesen a hardvereket tudják ahhoz igazítani. Az már kis túlzással mindegy, hogy ehhez a szoftveres szint mikor lesz végleges. Nem egy olyan funkció van ma is, amelyre a hardver sokkal hamarabb megvolt, és a funkció csak most jött vagy jön.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Z10N
veterán
Pedzegethetnenk az RX5500 8 pinjet es a 2300-s max orajelet. Milyen fesz kellhet neki? Remelem nem 1300mV. Illetve, hogy miert kapott egy also kategorias lapka 32 ROP-t.
Ha a gyartokon mulik akkor lesz visszafojtott 6 pines keves vrm-mel es agyon tuningolt is.
[ Szerkesztve ]
# sshnuke 10.2.2.2 -rootpw="Z10N0101"
-
GeryFlash
veterán
És szerinted van esély rá hogy az AMD NAVI-ja már most tudja a még nem releaselt DXR-t?
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Prohardveren (teljes rendszer fogyasztása terén) a 680 perf/watt 10%-kal volt jobb 7970-nél, a TPU teszt szerint (csak GPU-t mérve) csak 5%-kal. Mondjuk ez eléggé ellentmondó.
A 480 vs 5870 esetén az utóbbi 17%-kal jobb PH teszten, míg TPU-nál meg 60%-kal, ami azért bőven odabasz-kategória. Szóval fordult a dolog, de arányaiban nagyon más, csak erről van szó.A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#43840
Abu85
HÁZIGAZDA
Petykemano
#43838
Abu85
HÁZIGAZDA
válasz
Petykemano
#43838
üzenetére
Nincs különösebb összetevője. Azt kell megérteni, hogy van egy fixfunkciós hardver. Az kap bemenetet és ad kimenetet. De korlátozott a bementi adatokra a támogatása, tehát nem mindegy, hogy azt milyen formátumban adod oda neki. Mivel több formátum jön, így ezt a fixfunkciós hardvert annyiban kell módosítani, hogy elfogadja az új formátumokat is, és azokkal is tudjon dolgozni. A mostani hardverek erre nem lesznek képesek, mert a fixfunkciós blokk nem programozható, tehát nem tudod megetetni vele az új formátumokat. Lövése sincs arról, hogy mit csináljon vele, nem erre tervezték. De ettől maga az API működni fog, mert a Microsoft úgy építette fel, hogy a fixfunkciós blokk a hardveren belül rejtve legyen, vagyis annyi lesz a változás a mostani hardvereken, hogy a régi formátumú adatok mehetnek a fixfunkciós blokkra, míg az új formátum mellett a shaderek lesznek használva.
Ez igazából a kezdeni rendszerek problémái. Nincs letisztulva az egész, sok a fejlődési lehetőség, így eleinte venni kell a hardvereket. Lásd a shader modell korai szakaszát. Aztán a shader modell 3.0-nál letisztult az egész, mert kialakult egy optimális specifikáció.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#43841
Petykemano
veterán
Abu85
#43840
Petykemano
veterán
Eddig azt mondtad, hogy az RT core nem kifejezetten core, nem számító egység, csupán egy speciális cache.
Vagy félreértettem?Tulajdonképpen néhány játék már hozott is olyan Raytracing implementációt, amihez nem volt szükséges az ún RT core, elfutott hagyományos CU(DA)-kon is.
Ha nem az(/egy) arcturus a RayTracing co-processsor, akkor az Mit keresett a kiszivárgott xbox képernyőn?
Találgatunk, aztán majd úgyis kiderül..
-
#43842
Abu85
HÁZIGAZDA
Petykemano
#43841
Abu85
HÁZIGAZDA
válasz
Petykemano
#43841
üzenetére
Egy fixfunkciós motor. Persze a jellege miatt nagyrészt egy speciális cache, de kap egy bemenetet és abból lesz egy kimenet. Minden fixfunkciós hardver ilyen, függetlenül a felépítésétől.
Ma még az iparág keresi az irányt. Ez nem baj, de egy-két éven belül úgyis lesz egy ultimate megoldás. Valószínűleg nem a mostaniak, de egy olyan, amire lesz a két elterjedt API-ban támogatás, és lesznek hozzá hardverek. Meg persze jó eséllyel azért a konzolokban található megoldásokhoz való igazodás is fontos. Azok pontos másolása talán nem, az inkább hátrányos lenne, hiszen figyelembe kell venni a fejleszthetőséget.
A coprocesszor nem igazán alkalmas RT-re. Ezt be kell építeni. Túl véletlenszerű az adatelérés, hogy egy külön lapka hatékony legyen. Esetleg egy koherenciamotorral, de azért a sugarakat nem könnyű ám csoportosítani, jó eséllyel ez egy nagy hardver lenne, és nem biztos, hogy ez most megéri, hiszen többet érne ebbe a tranyóbüdzsébe ALU-kat rakni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
lezso6
#43839
üzenetére
A teljes gép fogyasztását ne nézzük már ilyen mutatókban
A TPU tesztben valamiért nagyon kitűnően fogyasztott a 7970, minden más oldalon sokkal többet evett.
Persze, nem azt írtam, hogy annyival lett jobb a Kepler, mint amennyivel a Cypress volt - de egy brutális hátrányból lett szemmel azért látható előny.Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-

.Ishi.
aktív tag
Uh, ne is mondd. Nekem ez a okt. 7-i "bejelentés" eléggé lagymatagra sikerült. Se TDP, se ár, a "gyártókra van bízva," nincs hír az XT variánsról - ez mindennek tűnik, csak sziklaszilárd stratégiának nem.
Ha már eltelt szinte három és fél év az RX480 óta, és volt egy 7nm-re való váltás, akkor egy RX590 +5% teljesítményű kártyára nem kéne elég lennie a 6 pinnek?

-
#43846
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
-
#43847
 Cifu
nagyúr
Petykemano
#43846
Cifu
nagyúr
Petykemano
#43846
válasz
Petykemano
#43846
üzenetére
Page Not Found
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
#43849
Abu85
HÁZIGAZDA
Petykemano
#43843
Abu85
HÁZIGAZDA
válasz
Petykemano
#43843
üzenetére
Én azt nem tudom. Nem is biztos, hogy köze van hozzá.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Jack@l
veterán
Hagyjuk a ködösítést, valószínű ez lesz az rt rész neve amd-n.
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.





















 Sokan abban élnek hogy hülye AMD elfelejtett időben szólni a TSMC-nek hogy jajj srácok akarunk kis NAVI-kat novemberben.
Sokan abban élnek hogy hülye AMD elfelejtett időben szólni a TSMC-nek hogy jajj srácok akarunk kis NAVI-kat novemberben.












Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.