Új hozzászólás Aktív témák
-

S_x96x_S
addikt
> Miért lenne más? Ha egy X86 utasítás-sor "tömörebb",
> akkor adott számú utasítást dekódolva órajelenként,
> azonos órajelen mégiscsak több hasznos "munka" lesz elvégezve,annyira szerintem nem sokkal tömörebb ,
mint amennyivel komplexebb.vagyis a komplexitáson többet veszít az X86-64-ISA - mint amennyit nyer a "tömörségével",
például extrém nehéz dekódolni és párhuzamosítani.-> high ILP (Instruction level-parallelism).
-> high MLP (memory level parallelism)
Anandtech: "Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4) that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions. On the ARM side of things, Samsung’s designs had been 6-wide from the M3 onwards, whilst Arm’s own Cortex cores had been steadily going wider with each generation, currently 4-wide in currently available silicon, and expected to see an increase to a 5-wide design in upcoming Cortex-X1 cores."
( Anandtech - M1 elemzés ) -
#4446
 Petykemano
veterán
HSM
#4438
Petykemano
veterán
HSM
#4438
Petykemano
veterán
köszi a mérést.
Azt mondod, hogy az AT tesztjében nem a backend fogyott el, hanem a TDP?
Ez azt jelentené, hogy bekapcsolt SMT-vel mondjuk 5-10%-kal alacsonyabb frekvencián megy, ha fullra van terhelve, mint kikapcsolt SMT-vel? Vagy megfordítva. a kikapcsolt SMT-t a TDP kereten belül kompenzálja valamivel magasabb frekvenciával.Egyébként félreértés ne essék: semmiképp sem kívántam azt sugallni, hogy a jelenlegi procikon ki kellene kapcsolni az SMT-t.
-
S_x96x_S
addikt
> A dekóderes rész nekem ott nagyon sántít, hogy nincs figyelembe véve,
> hogy az x86 komplex utasítás architektúra,
> azaz elviekben (!!!) kevesebb utasításból meg tudod csinálni ugyanazt,az csak a programkód méretére van kihatással,
de a végrehajtás már más.az X86-64-ISA és az ARM-ISA is mikrokódra fordítja át magát,
de míg az X86-os ISA kiterjesztés ( 8bit + 16bit + 32bit + 64 bit )
( szabadon keverheted )addig az ARM-nél át kell váltani az üzemmódot az
AArch32 és AArch64 között, vagyis az én értelmezésemben
2 optimalizált dekóder van, egy a 32bites és egy másik a 64bites utasításoknak.
emiatt az ARM dekódere sokkal egyszerűbb - és ez az egyszerűség tranzisztorban is megjelenik.Az X86-64-ISA annyira komplex, hogy már azt is nehéz megszámolni, hogy pontosan
hány regiszter vagy utasítás van benne.
https://blog.yossarian.net/2020/11/30/How-many-registers-does-an-x86-64-cpu-have
"All told, I think that there are roughly 557 registers on the average (relatively recent) x86-64 CPU core." ( és ebbe az AVX512 -es utasítások nincsenek beleszámítva )persze lehet vitatkozni, de szerintem az X86-64-ISA elég komplex az AArch64 -hez képest.
Ami még érdekes lesz az a
"Tachuym’s Prodigy Universal Processors " - által követett trend
ők nem tökölnek mindent (IS) akarnak futtatni
( x86, ARM and RISC-V binaries )"Prodigy is truly a universal processor. In addition to native Prodigy code, it also runs legacy x86, ARM and RISC-V binaries. And, with a single, highly efficient processor architecture, Prodigy delivers industry-leading performance across data center, AI, and HPC workloads. Prodigy, the company’s flagship Universal Processor, will enter volume production in 2021."
https://www.tachyum.com/pr-2020-08-11.shtmlKözben a RISC-V is megtette a tétet a héten
.. szerintük ők még az ARM-nél is jobb watt teljesítményt nyújtanak ( papiron )
64-bit RISC-V core claims 10x better CoreMarks/Watt compared to other 3-5GHz CPUs
http://linuxgizmos.com/64-bit-risc-v-core-claims-10x-better-coremarks-watt-compared-to-other-3-5ghz-cpus/
"Micro Magic unveiled an up to 64-bit RISC-V core showing a groundbreaking 110,000 CoreMarks/Watt, with a 3GHz chip consuming less than 70mW. The company claims 10 times better CoreMarks/Watt compared to other processors in the 3-5GHz range."
persze sok ígéretet már eleve kettővel kell osztani,
de ettől függetlenül a következő 10 év nem lesz könnyű az X86-64-ISA -nak ..
az ARM és a RISC-V jelentős piaci térnyerésével kell számolni az X86-64-ISA kárára
az ARM és a RISC-V -nél az új játékosok belépési küszöbe alacsony.
Sok új játékos lép a piacra és sokan elhullanak ..izgalmas évtized jön! És szerencsére az AMD-nek nem egy Ballmer típusú kormányosa van.
( A verseny jó )

-
S_x96x_S
addikt
> Ahogy az AT is megállapította, még úgy sem érdemes kikapcsolni az SMT-t,
> ha az 5950X-es egészen jól kompenzálja órajelből.link
AT: Investigating Performance of Multi-Threading on Zen 3 and AMD Ryzen 5000
( December 3, 2020 10:00 AM EST ) -
-

wwenigma
Jómunkásember
Álljunk meg. Arrol volt szo szerinted hogy egyik nem annyi W TDP mint amennyi rá van irva mig a masik pedig annyi. Még példát is hoztal hogy szigoruan 56 masodpercig alkalmazhatja turbóval ami meg van adva. Most meg kiderül hogyhát de ez az user miatt mégsem ennyi mert az OEM és az Intel nem alkalmazza azt a limitet amit feltuntet a datasheetben (frekvencia/TDP keret adott szalakra vonatkozo terheles mellett, etc), dobozán és hogy az user alkalmazhatja hogyha akarja...tehat akkor az se annyi.

Hagyjuk inkabb jo?
-

Yutani
nagyúr
Why Intel Processors Draw More Power Than Expected: TDP and Turbo Explained
AMD Ryzen TDP Explained: Deep-Dive on TDP Definitions & What Cooler Manufacturers Think
Mindkettőtöknek, szeretettel. Én nem olvastam el őket.

-
wwenigma
Jómunkásember
Gondolom a lap gyártója kesziti a biosokat amikben meg van adva az alapertelmezett beallitas. Ne nézz már madárnak....ugyanakkor pedig megnézném hogy mi is all kozelebb a valósághoz ha kikapcsolt limitekkel futnak. Alapertelmezetten.
A TDP pedig nincs kőbevésve és legfőképpen nem fogyasztást ad meg W-ban hanem a hűtésre vonatkozik. Ez az amit fentebb is írtak neked. Ennyi erővel AMD esetén add hozzá még az aktualis datumot is hogy csunyabbnak tűnjön. Mint a pincér a számlához, mert az idő pénz.
-
wwenigma
Jómunkásember
"ha a gyári specifikáció szerint van beállítva a BIOS"
Alapertelmezetten a lapok tobbsegen intelnél alapertelmezetten ki van kapcsolva a tiltas. Alapertelmezetten.
Ha pedig a fogyasztással kevered a TDP-t akkor szolok hogy a CPU core TDP az annyi amennyit mondanak. A SOC fogyasztását ne add hozzá.
-

BiP
nagyúr
Ami méginkább az AMD felé billenti a mérleget, mert az AMD számolása közelebb áll a valós, átlag felhasználáshoz.
#4284 sNk77 : +19% IPC-t mondanak, és erre még rájön pár % órajel emelkedés is. Szóval jóval gyorsabb lesz.
az 5000-es ryzenekkel szemben az intel egyetlen fegyvere már csak az ár maradt, a gaming is kiesett, mindenben alulmaradt.
Új versenyt majd a Rocket Lake hozhat 2021Q1 után (ha nem csúszik), aminél kétszámjegyű IPC növekedést jósol az intel, amivel közelebb kerülhet a Zen3-hoz. -
-
wwenigma
Jómunkásember
Igen, tolod a hulyesegedet arrol hogy MEKKORA feszultseg es hogy jajjmilesz. Ergo nem normalis mukodes, tul sok. Lehet szepen kipakolni az asztalra milyen papir alapjan mondasz ellent annak aki megtervezte a procit es a mukodeset.
Attol hogy te elbrennolsz vele es megkeresed a neked tetszo freki/feszko parost, rohadtul nem azt jelenti hogy barmilyen problema lenne az alap mukodesevel.
Unalmas mindenhol azt olvasni ahogy tolod a hulyeseget.
TESCO-Zsömle: nem kell keresni, mindegyikben bennevan hogy bőőőven TDP felett megy az első percben ami ugye az egesz teszt végső pontszámát is befolyásolja. Érdemes megnezni mi tortenik akkor ha a stock paramétereket engedélyezzük bios-ban, azaz a turbóra vonatkozó paramétereket, hány mag mekkora frekin mehet...
-
#4143
 TESCO-Zsömle
titán
HSM
#4118
TESCO-Zsömle
titán
HSM
#4118
TESCO-Zsömle
titán
Viszotn ugye fontos észben tartani, hogy nem fogyasztásról beszélünk, hanem TDP-ről, vagyis a hűtés profiljáról. Olyan helyeken, ahol a hűtés limitált, nem fog menni a 28mp PL2.
A másik poénja a dolognak ,hogy ha találsz benchmark-ot, ami lefut ennyi idő alatt, akkor számottevően jobb eredményt fog produkálni, mint ami valós felhasználás alatt elérhető. -
BiP
nagyúr
Nálam is autón nyaldossa az 1.4V-ot, manuálisan meg sokkal kisebb fesz-en is megy.
(#4125)snecy20: Mivel a Zen3-ban már 8magos egy CCX, így erre már nincs használva az IF (legalábbis egy 8magos prociban), max. a memória felé, de szerintem ott meg javultak annyit, hogy az 1800-1900 helyett már 2000-en is megy simán.
Ha AMD mondja, hogy DDR4-4000 a sweet spot,akkor elhiszem nekik. -
A cikkben lévő szöveg alapján végig PL2-n fogyaszt:
"A legfontosabb paraméter a Tau, vagyis a turbó időtartama, eddig tudja ugyanis maximum fenntartani az adott processzor a nagyobb, PL2-es fogyasztási értéket. Amennyiben ez az időtartam lejárt, az alapértelmezett működés tekintetében a rendszer visszavált a PL1-es fogyasztási szintre, ami a teljesítmény látványos csökkenésével is jár."
-
#4109
TESCO-Zsömle
titán
HSM
#4108
TESCO-Zsömle
titán
Pár hónapja volt táblázat az új Intel procukról, hogy hány másodpercig tudják tartani az abszolút maximum boost-ot és hogy mit eszik közben a proci. Röpködtek a 300w közeli értékek, csak néztem, hogy WUT?
sz: TDP meg alapvetően az OEM-eknek szól. A 125w-os hűtést is meg lehet ütni 200w-al, ha nem tart sokáig
-
S_x96x_S
addikt
> Ha le tudsz mondani pár extra PCIE4 portról,
adatokkal,adatbázisokkal foglalkozom - vagyis fontos az I/O;
úgyhogy min 2-4 nvme PCIE 4.0 diszk jövőbeli csatlakoztatása nélkül elég frusztrált és csalódott lennék ..Elméletileg a "B550 Aorus Master" - ban
( ami már szintén ~br.100e Ft körül van )
kivételesen 3db PCIe 4.0 x4 M.2 port van,
de ott valószínűelg a CPU-tól veszi el a PCIe 4.0 -sávokat ;
szóval az is kompromisszumos .."As spotted by BenchLife, the B550 Aorus Master seems to arrive with three PCIe 4.0 x4 M.2 ports. That's a pretty big deal since most B550 motherboards only bring PCIe 4.0 support on the primary PCIe x16 slot and M.2 slot. Therefore, the primary M.2 slot is likely linked to the Ryzen chip, while the other two M.2 slots share bandwidth with the PCIe x16 connection. There's a good possibility that the PCIe switches partition the PCIe x16 slot and secondary and tertiary M.2 slots to run at an x8, x4 and x4 configuration, respectively."
most az a stratégiám, hogy
a https://geizhals.de/?cat=mbam4&xf=317_X570 -on
beállítgatom az alap igényeimet ..
(X570; 4xDDR4; 2.5GB/s LAN; sok m.2/pcie/sata3 csati )
és dilemmázok ..Az én esetemben egy alap TRX40
egy ZEN2/ZEN3 -as Threadripper 16c/32t CPU-val ideális lenne ..
mindenféle későbbi bövítési lehetőségekkel ..
de jelenleg nincsen ...megvárom az október8-i ZEN3-as bejelentést ... aztán döntök ..
-
#3781
Petykemano
veterán
HSM
#3779
Petykemano
veterán
Pont emiatt érdekes elképzelés.
Azt gondoltam, hogy a zen3 nagy dobása az egységes L3$ lesz 8 magon. Játékok terén nagy dobás.Azért egy 5+5 bedobása a 10 magos intellel szemben elég nagy magabiztosságra vallana.
mondjuk a Rocket lake csak 8 magos lesz
Viszont lehetséges, hogy egy fullos 8 magos lapka drágább (ritkább, Milanhoz kellőbb), mint egy olyan, amin csak 5 mag jó.
4800X vagy akár 4900 is lehet belőle.
-

carl18
addikt
+1 Azért 8 mag egy CCX-en belül nagyon jól fog müködni játékok alatt. Elég csak a 3300X példáját megnézni, 7700K szintü processzor lett. Az biztos az IPC + a késleltetés kiküszölölése miatt ez a játékokban hatalmas előrelépést jelent majd.
Jön a háború akkor!

Pirates of the hardware (feat. AMD) -

Simid
senior tag
Pontosan! Ez a lényeg.
Folyamatosan ez a felvetés, hogy a monolitikus dizájnnal jobb lenne a késleltetés. De a rosszabb késleltetés a IF működéséből adódik. Az elektron ugyan olyan gyorsan fog haladni chipen kívül mint belül, a késleltetést az fabric controller fogja meghatározni, ami nagyon hasonló monolitikus felépítés esetén is. -
S_x96x_S
addikt
>Szerverekbe persze van/lehet értelme,
>de asztali CPU-knál szvsz a legtöbbször a 2 szál/mag sincs kihasználva.A Szerver / HPC / AI a jövő terjeszkedési lehetősége - itt van a nagy pénz, és a piac bővülő.
A Desktop / DIY piac másodlagos. pici és nem nagyon tud már hova nöni.
Még az INTEL-is a Desktop chipeket vágja meg, a szerverek és a notebook chipek javára.Közben az IBM a Power chipjével már az SMT8 -at akarja eladni az SMT4-el szemben.
-
#516
Petykemano
veterán
HSM
#514
Petykemano
veterán
Szerintem belefér AM4-be 2 chipletes 12 v 16 magos változat is. Méret, fogyasztás szempontjából mindenképp.
Ha az összekötő IO chipbe még EDramot is tesznek, azzal mindenképp megoldják a CCX-ek közötti kommunikációt és a 32MB/CcX és az edram együtt biztos jelentős mértékben tompíthatja a 2ch DDR terhelését.
Az ár még fontos. Frekvenciát még nem tudunk.. de ha a IF2, és az esetleges L4 kiküszöböli az eddigi CCx felépítésből adódó hátrányokat (latency) akkor már a 1x8 magos változattal is verhető a 9900K és a 2x6 és 2x8 változat is mehet a $400-700, ahol az ilyen magszámú TR1 jelenleg is vannak.Ha van L4, threadripperben biztos kisebb lesz az IO...
-
Hát, most azért, hogy néhol jó legyen, szerintem nem éri meg egy komplett lapkát odatenni a CPU mellé. E-pénisznek jó, de kb ennyi.
Az eDRAM elsődleges alkalmazása az SRAM cache kiváltása. Azaz ha valahol bazi nagy SRAM-ra lenne a szükség, akkor harmadakkora területen megoldható ugyanez eDRAM-mal.
-

TRitON
aktív tag
Egyáltalán nem jártál messze. Az egyes CCX-ek az SDF Plane-en keresztül férnek hozzá a memóriához és egymás cache-ében lévő adatokhoz is. Ezért olyan nagy a memória késleltetés.
Ha pedig chipek (IFOP), vagy tokok (IFIS) közti kommunikáció szükséges egy adat hozzáféréshez, ezt a késleltetést az interfész hossza és átviteli sebessége is befolyásolja.
A magyarázat szerint az egész SDF Plane a DRAM frekvencián megy, aminek nagy előnye, hogy nem kellenek bonyolult FIFO-k a CCX-ek és az SDF plane, valamint az SDF és az IFOP/IFIS interfészek közé. Volt, aki felvetette, hogy legyen az IF aszinkron és járjon valamivel magasabb frekvencián, azonban az aszinkron működés egyrészt bonyolítaná a kommunikációt a részegységek között, másrészt biztosan növelné a késleltetést. Jim Keller jó munkát végzett, ennél jobb megoldás szerintem nincsen.A Zen 1 és Zen+ IPC növekedését ugye a különböző késleltetések drasztikus csökkentése (tehát az IF reszelése) okozta. Én az Zen2-nél is hasonlóra számítok: magasabb lehetséges DDR4 sebesség (3600+4000MT/s+), csökkenő cache késleltetések, csökkenő interface latency és csak minimális változtatások a processzor magokban. (Meg persze több mag/CCX, de az a jelenlegi helyzetben IPC csökkentő hatású.)
-
#423
Petykemano
veterán
HSM
#422
Petykemano
veterán
Én is valami ilyesmire gondoltam. De ez azt jelenti, hogy lényegében a memórián keresztül kommunikálnak, nem közvetlenül.
Azt hallottuk abutól is, hogy az L3$ mérete négyszereződik (?) A zen2 (?) esetén, de az még mindig nem igazán segít a inter-CCX kommunikáció késleltetésén. Kivéve persze ha valamilyen writeback (amikor az írást nem várja meg) módon egy CCX L3$-e több más CCX victim L3$-e is egyben.
Akárhogy is, felvetődhet a kérdés, miért hagytak ki egy csak CCX-ek közötti megosztást célzó L4-et a lapkából? Vagy a zen2-nél ez miért nem pálya? -
#421
Petykemano
veterán
HSM
#420
Petykemano
veterán
Igen, az igaz, hogy 2 lapkás TR esetén is előfordulhat távoli elérés, de ez nyilván kevésbé égető probléma, mint memóriaelérés nélküli lapkáké.
Ami viszont érdekes, hogy ha jól emlékszem a L3$ késleltetésekre, akkor mintha az lett volna a sima Zeppelin esetén, hogy a másik CCX L3$-éből pont ugyanannyi késleltetéssel tud olvasni, mint memóriából.Ezeken az ábrákon gyönyörűen látszik, milyen késleltetéseket ad hozzá a blokkon kívüliség:

Mennyivel jobb jobb memóriával:

Összehasonlítás:

Én azt nem értem (és ennek megoldását várom), a következő zen verzióban, hogy a CCX-ek közötti és a lapkák közötti interconnect miért függ a memória frekvenciájától.
Azt sem értem, hogy hogy lehetséges az, hogy ha az lokális L3$ késleltetése 45-50ns, a memória elérésének késleltetése mondjuk 60-80ns, akkor hogy lehet, hogy a szomszédos L3$ elérése 120-150ns (memóriasebességtől függően) ? Kicsit olyan, mintha a két CCX a memórián keresztül kommunikálna. (Persze nyilván nem, mert akkor lapká belüli két CCX egymáshoz képesti elérésének késleltetése pont ugyanannyi lenne, mint két különböző lapka CCX-é a a TR-ben) Az világos, hogy a elméletileg A CCX-ek között és a memória felé is az IF a kapcsolódást megoldó alkatrész, csak nem világos, hogy miért a memóriaelérés késleltetése alacsonyabb a szomszédos L3$-nél?Nincs ezen mit trollkodni, ezek tények, ezen ha lehet javítani kell.
-
#419
Petykemano
veterán
HSM
#418
Petykemano
veterán
Ez a probléma csak a 4 lapkás Threadrippert érinti, nem? 24/32 mag. Ezt ajánlják HEDT gamer gépnek? Én azt hittem, az a 16 magnál megáll. a 2 lapkás Threadrippernek meg minden lapkára van memória elérése. Persze nyilván a memóriaelérés és késleltetések szempontjából még így is rosszabb, mint a 2700X, ami szintén rosszabb, mint az intel ring busa.
De azért azt valljuk be, hogy az intel HEDT procijainak teljesítményének kihasználását ugyanaz az ok akadályozta, ami azt is, hogy a 8 magos bulldozer származékok rendre lemaradtak a 4, 4/8 magos intelektől.
Láttam valamelik nap egy táblázatot, de nem találom.
De ez is elég jól mutatja: https://techreport.com/review/34192/intel-core-i9-9900k-cpu-reviewedHa az érték valamilyen "lokális elérés" késleltetése, akkor van hová fejlődni.
Ha azonban valamilyen átlagérték, ami a kellően jó késleltetésű lokális elérés mellett egybeméri a CCX-ek közötti kommunikációt, akkor ezen legjobb esetben is csak a CCX magszám emelése segíthet.Előbbi tűnik helyesnek, mert
itt és itt az 1db CCX-el rendelkező raven ridge is hasonló késleltetéssel éri el a memóriát.Ha nem függ össze a CPU frekvenciával, akkor szerintem ennek a késleltetésnek a javítása fontosabb lenne, mint a frekvencia növelése.
-
S_x96x_S
addikt
>Papíron jól néz ki a plusz két memória csatorna,
>de szerintem épp játékoknál nagyon nem ideális ez a jelenlegi numa modell,
>hiába próbálják megtákolnia régi játékoknak nem ideális. De az újakat már fel lehet rá készíteni és a Windowst is fel lehet rá készíteni.
Ha a játékfejlesztők alatt egyre inkább "Threadripper" lesz, akkor egyre kevesebb hasonló gond lesz.
És 1-2 év és már a játék enginek is támogatják majd.( remélhetőleg )De October 29 - után megtudjuk, mit ér valóságban.
Ideális -vagy - nem ideális - de akkor is jól jön az a pár százalék.
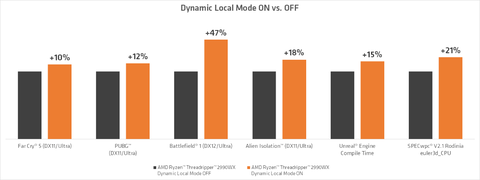
-
S_x96x_S
addikt
A következő év érdekes lesz, várhatóan az AMD teljes pályás letámadásba megy át.
a GF már elkezdte a mentegetődzést óóó nincs elég kapacitásunk ...
óóó nincs elég kapacitásunk ...-- "[AMD] will have more demand than we have capacity" for 7nm
ami még érdekes, hogy a GF döntése volt, hogy a TSMC-hez hasonló technikája legyen, ezzel is megkönnyítve a double sourcingot és az AMD helyzetét.
Viszont a vásárlók majd nézegethetik, hogy hol gyártották."Patton is quoted as stating that "[AMD] will have more demand than we have capacity" for 7nm, with EE Times reporting that GlobalFoundries has made their 7nm pitches and SRAM cells similar to TSMC to let AMD's design teams use both foundries.
What this means is that AMD could, in theory, make Zen 2/Ryzen 3rd Generation products using both TSMC and GlobalFoundries, creating a situation where one foundry could produce better CPUs than the other. One manufacturer could produce higher clocking chips than the other, adding another layer to the "silicon lottery" for buyers. "
https://www.overclock3d.net/news/cpu_mainboard/amd_will_have_more_demand_than_we_have_capacity_for_7nm_says_globalfoundries/1 -
#297
Petykemano
veterán
HSM
#296
Petykemano
veterán
Logikus, csak azt furcsállom, hogy a hardver képességei és a program igényei között nem az operációs rendszer közvetít, hanem kvázi ilyen "driveres hekkeléssel" kell kitrükközni, hogy a program ne kapjon szuboptimális erőforráskiosztást.
Vagy: ezt az egészet közvetlenül a program intézi saját hatáskörben? -

Devas
őstag
Ok, próbáltam értelmezni.
Tehát adtál neki 6 szálas terhelést, amiben mind a 12 szálat használhatta, de nyilván csak 6-ot tudott használni.
A 6 legerősebb szálat használhatta (ha ez így megfelelő kifejezés), tehát a HT-t kiiktatta, és csak a 6 mag dolgozott. Azaz nem volt "párhuzamosítás" a magokon belül.Ha a HT-it is használni szeretted volna, akkor gondolom kétszer ennyi Worker kellett volna. Nem ismerem a programot, csak találgatok.
De mivel te is tudod, hogy 70% körül volt a total CPU usage, ezért bebizonyítottad, hogy nem szabad komoly venni az MSI AB ezen részét.
Köszönöm, ezt elfogadom!
-
Devas
őstag
Na ácsi!
6 szálra engedted rá, nem pedig 6 magra! Nem ugyanaz! Ez pedig engem igazol.![;]](//cdn.rios.hu/dl/s/v1.gif)
11,9% usage magonként. A magonkénti HT még +4,76% usage. Tehát 16,66% x 3 = 50%
Ha a 6 magra engeded rá, és a HT-t nem használod az kb 71,4% usage.Ez minden HT-s procira igaz kábé, hogy a total CPU usage-ből 71,4% a magok miatt, 28,6% a HT miatt. Legalábbis MSI AB szerint.
Ezért hoz +40% teljesítmény növekedést a HT:
71,4% x 1,4 = 100%Ez az én elméletem. Gyenge lábakon áll, bevallom. Ott rúgod darabokra, ahol jólesik.

(#259) Ragnar_
Nyílván úgy tesztelik, ahogy akarják, csak ezzel most sokra nem megyünk. Persze látszik a tesztből pár dolog, amiket írtál is, de sok minden nem látszik a GPU limit miatt. De legalább remekül megmutatták a tesztben, hogy mire képes az a VGA a különféle procikkal az adott játékban. -
-
Devas
őstag
"Ha 20%-al gyorsabb HT-val minden mag, akkor ezt nem adhatod össze."
Ebben igazad van. Viszon a HT-ból a profit nem csak +20% FPS lehet, hanem mint az előző videoban láthattad akár +30%-is, és szerintem valahol +40%-on tetőzik."Igen jól írod, ha megy a HT, akkor 50%-nak fogja írni a 4 szálat..."
Pont ezt szajkózom, hogy nem 50%-nak fogja írni az MSI AB, hanem kb 72%-nak. De be is bizonyítom:
youtube Tomb Raidert kell nézni 2:10-nél.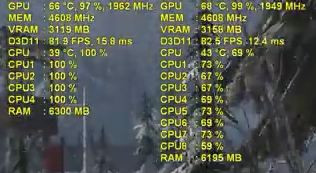
-
Devas
őstag
youtube
1:20-nál nézd. +30% a HT előnye úgy, hogy nem megy üveghangon az egész i3. Ha üveghangon menne, szerintem hozna +40%-ot is. Tehát +20% magonként. Ezért kérdeztem, hogy a 2c/4t 40%-al erősebb-e a 2c/2t-vel szemben? Vagy ez a különbség elérheti-e a +50%-ot?Tudom a HT működési elvét, hogy minden maghoz 2 szál tartozik. Én csak azt próbálom elmagyarázni neked, hogy az MS AB miként látja a Total CPU usage %-ot. Az előbb leírtam miként jön ki a total CPU %, ennél érthetőbben nem tudom, de megpróbálom.
Tehát ha van egy i7-ed és van egy játék ami kihasznál 4 teljes szálat és nem többet, nem kevesebbet, akkor:
Ha a HT disabled, akkor a Total CPU usage az 100%.
Ha a HT enabled, akkor a Total CPU usage az nem 50% lesz, hanem kb 72%. -
Devas
őstag
A Lighting-ok elvileg nem adnak plussz munkát a CPU-nak, vagy akár a felbontást is levehetjük, akkor az meg arányosan csökkenti a terhelést.
2c/2t vs 2c/4t esetén a teljesítmény többletre voltam kiváncsi (FPS). Elnézést, rosszul tettem fel a kérdést.
Egyébként meg a total CPU usage %-ot valahogy így kell számolni (saját elméletem következik, bele lehet kötni):
"Miből áll egy i7 proci? 4 magból és még 4 HT szálból. Egy HT szál teljesítménye nagyjából egy mag 40%-a.
Ebből kiszámolható, hogy egy mag a teljes CPU kihasználtság kb 18%-át fedi le, egy HT szál pedig kb a 7%-át.Tehát ebből következtethetünk arra, hogy ha a teljes CPU kihasználtság:
36% alatt van, akkor a játékhoz 2 magos / 2 szálas proci elég (Pentium).
36-50% a kihasználtság akkor 2 magos / 4 szálas (i3-as).
50-72%-os, akkor 4 magos / 4 szálas proci (i5-ös).
72%-99%, akkor 4 magos/ 8 szálas proci már profitál a sok szálból (i7-es)." -
Devas
őstag
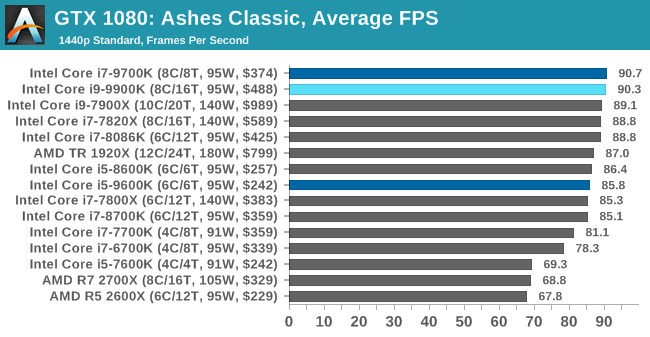
Így van, ez szembe tűnt nekem is. Nem értem miért kell egy proci összehasonlító tesztben Ultra grafikával GPU limitet csinálni. Asszem a Techspot tesztjeit is hanyagolni fogom a jövőben.
Remélem a PH! sem követi el ismét ezt a hibát majd a Zen procik tesztelésekor, hogy GPU limiten mér.
Én mindig ügyelek arra, hogy ne menjen a GPU LOAD 90% fölé, különben túrót nem ér a mérés.2c/2t vs 2c/4t esetében mennyi különséget mértél? 40%, vagy ment afölé is?
-

Ragnar_
addikt
Low Level API témában Doom amit láttam (AotS nem próbáltam) Vulkan alatt + 20% FPS, bár doomnál gyakorlatilag proci legyen a gépbe, még az is szinte mindegy, hogy i3, vagy i7.. [link] Azért ritka az ilyen konzolport inkább az a jellemző, mint Dishonored2/Deus Ex MD, hogy bármilyen PCn képes akadni. Jó mondjuk doomban nincsenek nagy nyílt belátható területek..
-
Ragnar_
addikt
Nade mi lenne ha 100% tudná hajtani a 6 magot ?
Sok ilyen sokmagos threades procitesztnél megfigyeltem, hogy 45 % átlagos procihasználat megy a tesztek nagyrésze alatt. Mondjuk, ha VGA limit van, akkor a CPU addig pihen, hiszen fölösleges a VGA-t több adattal ellátni, ha az 100%-on nem tud több framet megjeleníteni. Persze az se szerencsés, ha a 4 mag 100%-on teker, és az miatt van FPS cap..(Nem tudtam, hogy a prociterhelés mérő nem teljesen hiteles, és még elhiszem az eredményeket)
-
Devas
őstag
Korrekt teszt, koszi. Kicsit furcsa mennyire ugral a gpu load %. Az egyik kepen peldaul 100%.
Hogyan tudod, hogy a maghoz melyik logikai szalat kell meg letiltani?
En is akarok csinalni egy ilyen tesztet videokent majd 4 fele osztott kepernyovel: 6/12, 6/6, 4/8, 4/4. Bar ez biosbol is megoldhato elvileg.
De ha 4/8-as procit veszek, akkor: 4/8, 4/4, 2/4, 2/2.























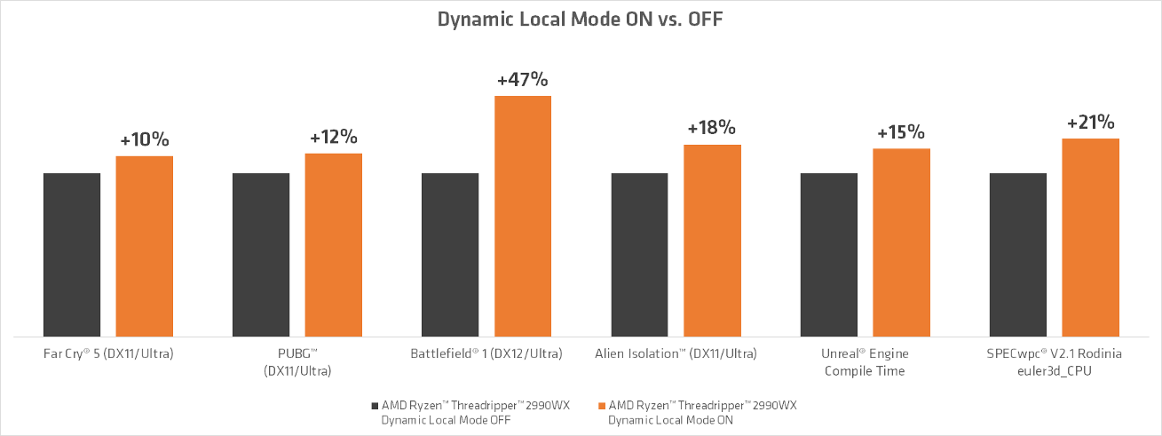
 óóó nincs elég kapacitásunk ...
óóó nincs elég kapacitásunk ...
![;]](http://cdn.rios.hu/dl/s/v1.gif)




Új hozzászólás Aktív témák
- Semmibe veszi a KRESZ-t a Tesla Mad Max módja
- Milyen házat vegyek?
- Xiaomi 15 - kicsi telefon nagy energiával
- Kerékpárosok, bringások ide!
- Samsung Galaxy S24 - nos, Exynos
- Androidos fejegységek
- AMD Navi Radeon™ RX 9xxx sorozat
- Építő/felújító topik
- Világ Ninjái és Kódfejtői, egyesüljetek!
- Futás, futópályák
- További aktív témák...
- DJI AVATA Dupla Fly More Combo drón szett - VADONATÚJ, aktiválatlan
- ÁRCSÖKKENTÉS MSI Z77 MPOWER Alaplap eladó
- DJI Air 3 Fly More Combo RC2 drón - NO LIMITS
- AMD Radeon RX 7900 XT 20GB XFX Speedster MERC310 Garanciás!
- Playstation 5 Slim Disc Edition 1TB, újra fémpasztázva, 6 hó garanciával, Bp-i üzletből eladó!
- DELL Universal Dock UD22
- HIBÁTLAN iPhone 15 Pro Max 256GB Natural Titanium -1 ÉV GARANCIA -Kártyafüggetlen, MS3591
- AKCIÓ! Apple Studio Display 27 5K Nanotexturált üveg monitor garanciával hibátlan működéssel
- Gamer PC- Számítógép! Csere-Beszámítás! I7 4790K / 16GB DDR3 / RX 5700XT 8GB / 512GB SSD
- GYÖNYÖRŰ iPhone 13 256GB Pink -1 ÉV GARANCIA - Kártyafüggetlen, MS3209, 94% Akkumulátor
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: NetGo.hu Kft.
Város: Gödöllő