-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 Busterftw
#68071
üzenetére
Busterftw
#68071
üzenetére
Akkor kifejtem, hogy mi a gond. A DirectX 12 bevezette a leírókat, amelyek egy csöppet bonyik. És persze a shader modell 6.6 ezt kiegészítette az erőforrások dinamikus bekötésével, de ehhez olyan driveres implementáció is kell, ami ezt támogatja, és hát olyan nem sok van jelenleg. Nem azért, mert a modern hardverek nem alkalmasak rá, hanem mert a régi hardverek nem azok, és azokat is támogatni kell vagy akarják a cégek.
Na most a gond alapvetően a leírók esetében az, hogy a jelenlegi specifikációk az elrendezésre vonatkozóan bonyolultak. De csak azért, mert amikor a DirectX 12 jelent, akkor a fő működési konstrukciót tekintve a legbutább bindless hardverhez igazodott, ami akkoriban a Kepler volt.
Na most a fő célja például a Mantle-nek az volt, hogy megszüntesse az úgynevezett buffer zoo-nak csúfolt jelenséget. Ne legyen sok puffer, csak annyi, amennyi feltétlenül kell, és ezzel a módszerrel használható egy hatalmas leírókészlet, amelyben minden erőforrás óriási tömbbe van rendezve, aztán lehet indexeket adni a shadernek, és rém egyszerű az egész. Nincsenek drága leírókészlet-cserék, nem kell több pipeline, stb. Egyszerű, gyors, hardverközeli. Már csak ránézésre is mennyivel barátibb:
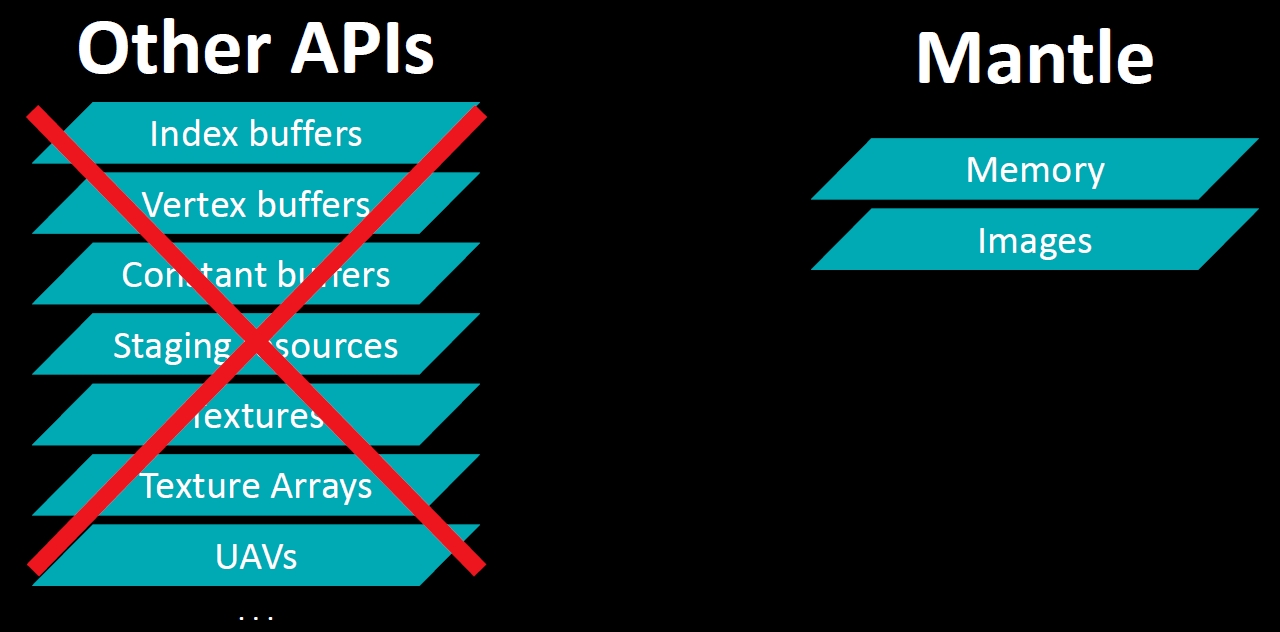
Na most a Mantle koncepcióját ugyan átmentette a többi API, így a DirectX 12 és a Vulkan, de ezt az egyszerűséget nem, mert nem lehetett több hardvert támogatni ezzel a pure bindless modellel. És itt most értsd ezt úgy, hogy most 2012-ről beszélünk, az akkori hardverekről, nem a mostaniakról. Ha most jönnének a szabványos explicit API-k, akkor sokkal inkább hasonlítanának a Mantle-re a bekötés szempontjából, mert ma már vannak ilyen hardverek általánosan, amire ez az egyszerűség megoldható. Például a shader modell 6.6-ban az erőforrások dinamikus bekötése a Mantle irányába megy. Még mindig buffer zoo, de működésben már inkább másolja a Mantle-t.
Na most az alapvető gond az, hogy még egy gyártón belül is rendkívül eltérő az, hogy az egyes még támogatott dizájnok milyen módon érik el az egyes puffereket. Erre többféle hardveres lehetőség van, és akkor sorban menjünk a legrosszabbtól a legjobb felé:
- fixfunkciós elérés: A klasszikus fos módszer, ahol az erőforrások fix hardveres helyekhez vannak kötve. Ez egyfajta bekötési táblás megoldás, amikor van egy fix helyed a táblában, és lényegében ez a tábla kezeli a bekötéseket. A nagyon régi hardverek így működtek, például a TeraScale Radeonok, a Fermi GeForce-ok, stb. Nem is igazán voltak ezek jók az exklicit API-kkal, sok ilyen dizájnhoz nem is készült D3D12 implementáció. Minek ugye, úgyis szar lenne.
- leíróhalmazos/-pufferes elérés: Ez már igazodik a D3D12 alapvető bekötéséhez, és alapvetően arról van szó, hogy a leírók honnan kerülnek bekötésre. A halmazos módszernél egy globális táblában vannak, míg a pufferesnél konkrétan pufferben lesznek tárolva. Igazából az API-hoz mindkettő jó, de a működéshez jobban illik a pufferes módszer, kisebb a többletterhelése.
- közvetlen elérés: Ez a legjobb megoldás, ilyenkor a shader nem használ semmilyen extra erőforrást, közvetlenül át tudja adni a leírót az erőforráshoz való hozzáférést kezelő utasításnak. És itt tök mindegy, hogy a leíró honnan származik, a hozzáférés mindig közvetlen. Ugye erre épül a shader modell 6.6-ban a erőforrások dinamikus bekötése, a szó is arra utal, hogy a shader megkap mindent és a hardver tudja is kezelni. Ezzel a módszerrel a bekötés konkrétan nem kerül semmibe a processzor oldalán, a GPU elvégzi a szükséges címfordítást is.
Na most az egyes hardverek az eltérő pufferkere máshogy működhetnek. Ugye többféle erőforrás van, texture, image, sampler, UBO, SSBO, TB...
Az AMD-nek azért olyan kicsi többletterhelésű a drivere, mert mindegy, hogy milyen pufferről van szó, az elérés mindenképpen közvetlen, vagyis soha egyetlen egy órajelciklust nem köt le az ezzel járó munka a CPU oldalán.
Az Intel és az NV esetében az egyes elérések vagy leíróhalmazosan vagy leírópufferesek. És itt jönnek a dizájndöntések. Például a Maxwell és Pascal esetében mindegyik erőforrás elérése leíróhalmazos módon történik, vagyis a legnagyobb a terhelés a proci oldalán, ráadásul ezen ront az, hogy eléggé fix hardveres limitek is vannak, amiket az NV megkerül egyfajta emulációval, hogy ne kelljen korlátozni az erőforrások számát. Tehát emulálják a közvetlen elérést, mert hasznos a limit nélküli módszer, de nem tudják ezt megoldani a korai hardverek, tehát a CPU csinálja a munka egy részét. Megoldható persze, csak jelentős többletterhelést von maga után.
A Turing és az Ada bizonyos erőforrásokat halmazosan, másokat pufferesen ér el. Míg az Ada és a Blackwell bizonyos erőforrásokra már támogatja a direkt elérést hardveresen is. Nem mindre, de például az SSBO-ra igen. Csak ugye ezt nem tudod használni, mert emulálva van implementálva a driverben.
Szóval itt arról van szó, hogy ha az NV kidobja a Mawellt és a Pascalt, akkor már előrelépnek, mert a pufferes elérés elég jó ahhoz, hogy az natív legyen, ne kelljen hozzá emuláció. És így az Ada és a Blackwell is mehed direkt elérésre az SSBO-knál például, és akkor nulla CPU-t fognak használni. De a legjobb, ha eldobják a Maxwell, Pascal, Turing és Ampere supportot, mert akkor dobható maga az emuláció, és mehet a pufferes és direkt elérés, mert ezek a dizájnok már nem is alkalmaznak halmazos elérést. Ez a mostani CPU többletterhelést konkrétan a töredékére csökkentené. Még mindig lenne egy pici, valószínűleg, több, mint az AMD-nek, mert még mindig nem direkt elérésű minden erőforrás, de annyira nem lenne már jelentősége, mert a különbség kevés lenne.
Az Intel is átment az Arc generációval a pufferes bekötésre, és az Arc C átviszi ezt részben direktre. Tehát egy-két generáció még és mindegyik hardver közvetlen elérésű lesz ilyen szempontból. Az Intelnél egyébként az UBO és az SSBO már most is direkt.



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Macska topik
- Milyen billentyűzetet vegyek?
- EA Sports WRC '23
- A fociról könnyedén, egy baráti társaságban
- Politika
- exHWSW - Értünk mindenhez IS
- Mellényzsebbe csúsztatható retrokonzol közeledik az Anbernic színeiben
- Samsung Galaxy Watch (Tizen és Wear OS) ingyenes számlapok, kupon kódok
- Xbox Series X|S
- AMD Radeon™ RX 470 / 480 és RX 570 / 580 / 590
- További aktív témák...
- LG 65BX - 65" OLED - 4K 120Hz 1ms - NVIDIA G-Sync - FreeSync Premium - HDMI 2.1 - PS5 és Xbox Ready!
- Telefon Felvásárlás!! iPhone 14/iPhone 14 Plus/iPhone 14 Pro/iPhone 14 Pro Max
- Gyors, Precíz, Megbízható TELEFONSZERVIZ, amire számíthatsz! Akár 1 órán belül
- DELL Thunderbolt Dock - WD19TB modul 02HV8N (ELKELT)
- ÁRGARANCIA! Beszámítás, 27% áfa, összesen 5db RTX 5060 Ti 16GB 3 ventilátoros készletről BOMBA ÁRON!
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest