-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#55900
 Busterftw
nagyúr
Petykemano
#55899
Busterftw
nagyúr
Petykemano
#55899
Busterftw
nagyúr
válasz
 Petykemano
#55899
üzenetére
Petykemano
#55899
üzenetére
Jo lenne ha kinn lenne a negyedeves jelentes gaming bevetel vagy market share-rol.
"Nyilván minden kereslet-kínálat függvénye és hát gamerek lassan háromnegyed éve várnak"Szerintem is sokan vartak/varnak, viszont igy is rengetegen vettek kartyat a 9 honap alatt aprankent, mert minden elfogy. Tehat az igenynek valamennyire csokkennie kellett mar.
Tehat tegyuk fel atlag 100 helyett 300 volt az igeny (vegre jo ugras a szeria), 9 honap alatt aprankent 150 biztos vett kartyat, nem pedig 80 es 220-an meg varnak.Aztan kitudja.
-
#55899
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Több érdekes infó is van MLiD videójában: [link]
- az Nvidia "az RDNA2 láttán ijedtében véletlenül" alulárazta / felülspecifikálta a 3060-at. Valójában nem akartak 12GB-os modellt, mert azért amit elkérnek érte, túl drága
- ezzel együtt a 6600XT megjelenésével együtt javulni fog a 3060/ti elérhetősége is. (Itt elvileg az volna a magyarázat, hogy az nvidia készleteket halmozott fel (tartott vissza) amire nem nagyon van értelmes magyarázat mint az, hogy az árak magasan tartása lehetett a cél.)
- GDDR6: $10/GB
- a $270-os használt 3060 árak kínában értendők és nagy tételben
- senki ne számítson gyors árzuhanásokra (állítólag egyesek szerint hamarosan msrp alatt lehet majd kapni a dolgokat, de én mondjuk nem találkoztam ilyen véleménnyel, a magam részéről szintén azt gondolom, hogy innen a 1.5x árról nagyon lassan fognak már belesimulni az msrp-be az árak. Nyilván minden kereslet-kínálat függvénye és hát gamerek lassan háromnegyed éve várnak)
- az NVidia és az AMD lényegében meg akarja szüntetni a $400 alatti termékkategóriákat. (2024-ig)Másik hír:
5600G és 5700G msrp ár felett kerül piacra. [link]
(Ez mondjuk új termékek lévén annyira nem meglepő, általában így szokott lenni és mondjuk fél-1 év elteltével esik be msrp alá akár hivatalos árcsökkentés nélkül is.) -
#55894
 Z10N
veterán
Petykemano
#55882
Z10N
veterán
Petykemano
#55882
Z10N
veterán
válasz
Petykemano
#55882
üzenetére
AMD Radeon RX 6600 non-XT not to launch sooner than September
Ahogy mondtam bejelentik nyaron es eltokolnek vele oszig (tavasszal ezt prediktaltam). Az 5500
XTutodjat pedig bejelentik keso osszel es ev vegre talan kaphato lesz. A budget Rx6300 szeriat 64bit-tel es tovabbi rohejes csonkitasokkal majd jovo ev elejen sunyiban kiadjak az OEM-eknek. Amugy ugy nez ki, mint a $100-150-os Rx560/570. Az ar ahogy mondtam meg $379 lesz vagy az altalad emlitett wunder driver miatt arcoskodnak es $399 lesz. Szanalmas. -
#55893
Z10N
veterán
Petykemano
#55890
Z10N
veterán
válasz
Petykemano
#55890
üzenetére
"Tudtommal például az XSX például 56 CU-val kerül forgalomba, de valójában 60 van benne."
56 es 52 CU. -
#55892
 Televan74
nagyúr
Petykemano
#55886
Televan74
nagyúr
Petykemano
#55886
Televan74
nagyúr
válasz
Petykemano
#55886
üzenetére
4700S -be nincs iGPU.
Compatible Graphics Required
List of Compatible Graphics Cards:
AMD Radeon™ 550 Graphics
AMD Radeon™ RX 550 Graphics
AMD Radeon™ RX 560 Graphics
AMD Radeon™ RX 570 Graphics
AMD Radeon™ RX 580 Graphics
AMD Radeon™ RX 590 Graphics
NVIDIA GeForce GT 1030
NVIDIA GeForce GTX 1050
NVIDIA GeForce GTX 1050 Ti
NVIDIA GeForce GTX 1060Egyik oldal PS5 selejtnek hívja, a másik meg Xbox -nak. Kinek hova húz a szíve!
![;]](//cdn.rios.hu/dl/s/v1.gif)
A 4700S egy selejt iGPU nélkül. Nem mondom hogy rossz, főleg az alaplapra forrasztott 16GB GDDR6 memóriával. Csak a kompatibilis GPU lista igen karcsú, de gondolom ezt egy bios frissítéssel lehet orvosolni. Jó áron árusítanák, akkor sok embernek elég lenne 1080p -re egy RX580/590 -el. -
-
#55890
Petykemano
veterán
Devid_81
#55889
Petykemano
veterán
válasz
 Devid_81
#55889
üzenetére
Devid_81
#55889
üzenetére
"Nagyon jo dontes lenne kiadni barmilyen vagott formaban mukodo iGPU-val"
Tudomásom szerint pár CU-val (4) mindig direkt túltervezik a lapkát, hogy még a selejt is jó legyen. Tudtommal például az XSX például 56 CU-val kerül forgalomba, de valójában 60 van benne. Nem azt mondom, hogy nem fordulhat elő, hogy egynél több hiba keletkezik, de engem meglep, hogy ennyire sok ilyen fordul elő, hogy abból terméket lehet kiadni. (Ráadásul több sku-t is)Egyébként persze, a fenghuang raven-se véletlen vártuk.
-
#55889
 Devid_81
félisten
Petykemano
#55886
Devid_81
félisten
Petykemano
#55886
Devid_81
félisten
válasz
Petykemano
#55886
üzenetére
Nagyon jo dontes lenne kiadni barmilyen vagott formaban mukodo iGPU-val

Nagy sok fajta jatekra alkalmas HTPC szulethetne belole, plusz jelenleg ahogy irtak is az RDNA 2.0 ritka mint a feher hollo, nem artana piaci reszesedes.
Bar ha nagyon kellene nekik a piac akkor pl a 6700XT-t sem kellett volna olyan aron ami...
-
#55888
 Alogonomus
őstag
Petykemano
#55886
Alogonomus
őstag
Petykemano
#55886
Alogonomus
őstag
válasz
Petykemano
#55886
üzenetére
Vagy az AMD rájött, hogy még a részben selejtesre sikerült, ezért csak csökkentett teljesítmény mellett stabil termékeket is érdemes piacra dobnia, mert a súlyos keresleti nyomás miatt mindent el lehet adni.
Ráadásul a Ryzen 5700G sem lett elég erős a legtöbb játékhoz. Csak az IGP-k között ért el új rekordot, de még egy "non Ti" GTX 1050 is erősebb nála. Ez a "selejt PS5" processzor viszont már tényleg elég erős lehet egy 1080p szituációhoz.
Az AMD legnagyobb gondja jelenleg az, hogy mivel a 7 nm-es TSMC kontingensének nagy részét nem a dVGA szektorba kellett csatornáznia, hanem a konzolokra és a processzorokba, így még most is gyenge a RDNA2 piaci penetrációja. Eközben az Nvidia szinte a teljes 8 nm-es Samsung kontingenséből Ampere kártyákkal áraszthatta el a piacot, amit el is kapkodtak a vásárlók, mert RDNA2 kártya alig került a polcokra. -
#55887
 FollowTheORI
nagyúr
Petykemano
#55886
FollowTheORI
nagyúr
Petykemano
#55886
válasz
Petykemano
#55886
üzenetére
Vagy mindkettő.

-
#55886
Petykemano
veterán
Petykemano
veterán
"AMD posted a new patch series bringing up a new graphics processor, Cyan Skillfish.
As usual, this is a Linux-focused codename for a yet-to-be-launched product with their naming convention of an X11 color name paired with a fish species.
While yet to be launched, Cyan Skillfish isn't as exciting as some of the recent RDNA2 or CDNA GPUs. Cyan Skillfish is the support for a Navi (1x) graphics processor in a forthcoming APU.
There are 29 patches published today bringing up this Cyan Skillfish support. Given that it's reusing existing Navi 10 codepaths, it amounts to just over two thousand lines of code and mostly mundane additions for bringing it up."
Phoronixrogame szerint:
"My guess is this 0x13FE is salvage PS5 APU like 4700S but with an active cut-down GPU."
[link]Újrahasznosított PS5 chip, vágott, de működőképes IGP-vel.
(Ha ez igaz, akkor most vagy brutálisan túltermeltek PS5-ből, vagy brutálisan szar lett a design, hogy ennyi a selejt.)
-
#55885
Petykemano
veterán
Petykemano
veterán
6600 Non-XT September/October
Navi24 end of this year -
#55884
Petykemano
veterán
olymind1
#55883
Petykemano
veterán
válasz
 olymind1
#55883
üzenetére
olymind1
#55883
üzenetére
Csak AIB modellek lesznek.
Tehát a 6600XT biztos sok esetben kap.majd komolyabb hütést. Mondjuk valamit átraknak a régi polaris 20 kártyákról. És akkor remélhetőleg az lesz $399.Aztán lehet, hogy lesznek gyengébb modellek is. $359-379-ért
$349-ért 8G halk 6600
$299-ért pedig remélhetőleg meg lehet már majd kapni a 4GB memóriával szerelt 1 ventis kártyát (ami régen $100-150 volt) -
#55883
 olymind1
senior tag
Petykemano
#55882
olymind1
senior tag
Petykemano
#55882
olymind1
senior tag
válasz
Petykemano
#55882
üzenetére
Ránézésre egy olcsó kategóriás 100-150 dolláros kártyának tűnik. Jelenlegi RX 460-omon van ilyen szintű hűtés.

-
#55882
Petykemano
veterán
Z10N
#55880
Petykemano
veterán
~ 3060Ti ($399)
Amennyiben a teljesítmény végleges, akkor Abu árazási függvényével (-$30 azonos teljestmény esetén, vagy azonos ár +10% teljesítmény mellett) ez $379 lesz, legjobb esetben $349.
Persze iylenkor szokta abu mondani, hogy háháhá, az a driver még nem a végleges és még 15-20% jön (valóságban 8-10%) viszont ott már az árazási függvény "azonos ár + 10% teljesítmény esetén" oldala érvényesül.
-
Z10N
veterán
AMD Radeon RX 6600 XT and RX 6600 to launch on August 11th
Unfortunately, Fudzilla does not have an update on RX 6600 series MSRP, however, both cards should cost less than 400 USD.
Last bets, s'il vous plaît.
-
#55878
Petykemano
veterán
Yutani
#55876
Petykemano
veterán
válasz
 Yutani
#55876
üzenetére
Yutani
#55876
üzenetére
"In particular, versus their current N5 process, TSMC's N3 promises to increase performance by 10% – 15% (at the same power and complexity) or reduce power consumption by 25% – 30% (at the same performance and complexity). All the while the new node will also improve transistor density by 1.1 ~ 1.7 times depending on the structures (1.1X for analog, 1.2X for SRAM, 1.7X for logic)."
[link]
A 6nm-ről kifejezetten jókat mondanak. Többek között azt, hogy mivel EUV, ezért olcsóbb lesz, rajta a gyártás mint a 7nm, mert egy csomó gyártási lépcső, meg maszk izé megspórolható.
Máskülönben meg hát ugye half-node, ahogy mondod, tehát egyszerű a 7nm-es cumókat áttervezni rá.az IO lapkákra az az 1.1-1.2 vonatkozik.
De ha megnézed mondjuk a zen magokat, azok is nagyrészt már SRAM cache-ből állnak és azok skálázódása is lelassul. Mármint hogy hiába váltasz kisebb csíkszélességre, a fizikai kiterjedés nem fog jelentősen csökkenni.
Úgyhogy szerintem azt fogjuk majd látni például a zen4 esetén is már talán, hogy a mag beépített L3$ része nem nő, viszont régebbi gyártástechnológián gyártanak majd cache lapkákat, amit - most már tudjuk - 3D stacking módon rápakolnak.És szerintem hasonlót fogunk látni a GPU-k esetén is. A CU-k L2$-sel együtt mennek 5nm-re, az oo$ pedig marad 6nm-en. Ehhez persze valószínűleg vagy LSI-t kell használni, vagy szintén 3D stackinget, hogy meglegyen a kellő sávszélesség.
-

Yutani
nagyúr
Igen, a chipletes GPU-kra nagyon kíváncsi vagyok (mindkét gyártótól), de az 5 és 6 nm vegyes alkalmazás is érdekes. Mindkettő TSMC, de miért mixelik? Azt megértem, hogy ha mondjuk a 6nm az a jól ismert 7nm half node-ja és a Zen3+ CPU-t azon gyártják, mert hát a Zen3 7nm volt, de az RDNA3-ban miért keverik? Az egyik egység (ami a Zennél i/o die) 6nm lesz, a multiprocesszorok meg 5nm? Egy dolgot tudok elképzelni: költség optimalizálás.
-
válasz
 #32839680
#55869
üzenetére
#32839680
#55869
üzenetére
Az általános számítási teljesítmény esik vissza, nem a fogyasztás nő( erre utaltam ) .. Pascalokon kb 20-30 % is lehet a tensorok hiányában, RTX kártyákon kb 10 %. azonos erősségű GPU-k esetén. ( 1080 Ti vs 2070, saját mérés. )
ez egy elég jó teszt lett, [link] bár azóta van újabb verzió, ami javított az RTX kártyák terhelésén, kb 10 % a max amit mertem, de általában olyan 7-8.Amúgy én sem látom sok értelmét ennek a speciális hardvernek gaming szegmensben , egyetértek Abuval, bár a Voice hasznos és jól működik az Ampereben már optimalizálhatnák az elfekvő 10 TFLOPS számítási teljesítményre és nehezen elérhető kapacításra a működését legalább a saját szoftvereikben.
-
#55866
 b.
félisten
Alogonomus
#55865
b.
félisten
Alogonomus
#55865
válasz
 Alogonomus
#55865
üzenetére
Alogonomus
#55865
üzenetére
Arra írtam választ és igazolást de azzal nehéz mit kezdeni, hogy a saját magad által leírt dolgokkal nem vagy tisztában, mit jelent hogy "elszállt" , "magas" , "vad" és hasonló kifejezések. Még legénybúcsú nélkül sem.
tensormagokkal telepakolt 3080 10 % kal van a 6800 XT fölött és a 3070 pedig kevesebbet eszik perf/ wattban mint a 6700XT. sok tensormaggal.
ez az "elszállt" GPu fogyasztás amire hivatkozol. A tensor magok használatban vannak lásd RTX Voice vagy DLSS különböző verziói. Nincs itt igazán különbség a kártya család között, ne aggódj ha ez magas, az RDNA fogyasztása is az, főleg hogy 2. generáció 7 nm gyártás van szemben egy 10 nm halfnode első genes gyártásával. -
#55865
Alogonomus
őstag
b.
#55863
Alogonomus
őstag
Ha vitatkozni próbálsz, legalább téged igazoló tesztről linkeljél mérést. A Tom's Hardware tesztje szerint is az alap RX 6800 XT 302/307 Wattot, míg az alap RTX 3080 332/334 Wattot fogyasztott.
De akár vessél akkor erre egy pillantást.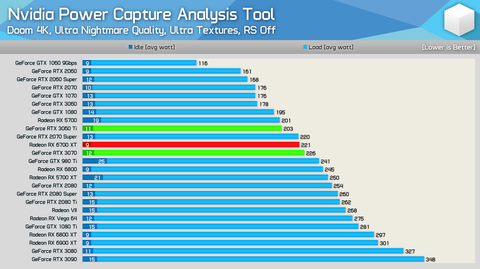
Az ugyanolyan kialakítású AIB kártyák ventilátorsebessége is a HWU és az általad linkelt értékeket igazolja. Még a Tom's Hardware listája alapján is erősebb az RX 6800 XT, mint a valójában 30 Wattal "éhesebb" RTX 3080.
Józanodj ki a legénybúcsú után. Vagy a fentieket már elvileg kijózanodás után írtad?

-
#55864
 Abu85
HÁZIGAZDA
Petykemano
#55861
Abu85
HÁZIGAZDA
Petykemano
#55861
Abu85
HÁZIGAZDA
válasz
Petykemano
#55861
üzenetére
A chiplet. De ez nem csak úgy lesz, hanem meg is kell oldani hardveresen, és az nem egyszerű.
-
#55863
b.
félisten
Alogonomus
#55857
válasz
Alogonomus
#55857
üzenetére
te ezeket zsigerből tolod?
egyszer nézd meg és értelmezd már ezeket a chartokat . Úgy kéthavonta egyszer :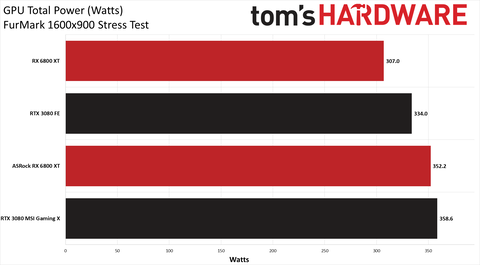
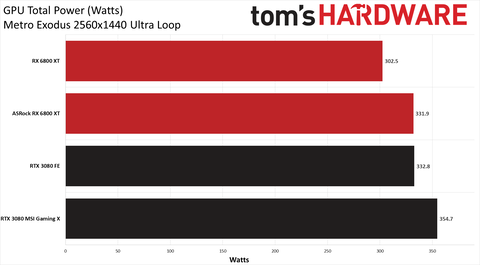

-
#55860
 Jack@l
veterán
Alogonomus
#55857
Jack@l
veterán
Alogonomus
#55857
Jack@l
veterán
válasz
Alogonomus
#55857
üzenetére
Többet nem válaszolok neked, felesleges...
-
#55859
Abu85
HÁZIGAZDA
Petykemano
#55855
Abu85
HÁZIGAZDA
válasz
Petykemano
#55855
üzenetére
A GCN-ben nem volt klasszikus értelemben dísz-ALU, ez akkor van, ha nem tudsz rá feladatot rakni. Kétféle limitbe ütközhet egy GPU, kihasználtság és függőség. Az architektúra dönti el, hogy melyik limit él.
Kihasználtságlimit az, amikor nem tudsz elég wave-et futtatni egy multiprocesszoron ahhoz, hogy átlapold a memóriaelérést. Ez a SIMT dizájnok sajátossága, és mindegyik GPU lehet kihasználtságlimites, viszont ezt nagyrészt az határozza meg, hogy van-e elég regiszter az ALU-k mellett. A probléma a mai GPU-kkal az, hogy az erőforrás-allokációjuk rém egyszerű. Egyszerűen statikus az egész, vagyis ha betöltesz egy shader programot, akkor előre lefoglal minden erőforrást, amire elméletben szüksége lehet. Ha nem nyúl hozzájuk, akkor is elveszi a helyet a regiszterekben és compute shader esetén az LDS-ben. Ennél sokkal jobb módszer lenne az, amit a CPU-k alkalmaznak, azok ugyanis dinamikus erőforrás-allokációval dolgoznak, vagyis csak olyan dolog kerül a regiszterbe, amivel dolgozni is fognak. De ez komoly ütemezőt is igényel, így egyelőre a GPU-knál ezzel nem foglalkoznak.
A fentiek mellett függőséglimit egy speciális korlát, ami a SIMD architektúrák sajátja. Klasszikus értelemben az AMD Terascale volt ilyen dizájn, azóta az alapfeldolgozást tekintve már mindenki SIMT-re váltott, tehát a mai GPU-architektúrák egységesen kihasználtságlimitesek. Technikailag az Intel dizájnja is, de annak egy sajátossága, hogy a regiszterek oldaláról ez a limit nem állhat be, viszont az LDS tekintetében ugyanúgy korlátozva lehet a feldolgozás. Ezért van az, hogy az Intel dizájnok az egzotikus, például geometry shader kódokban rohadt gyorsak, de a gyakorlatban ez egyáltalán nem mutatkozik meg, mert a fejlesztők compute shaderrel váltják ki a geometry shadert, amiben viszont eléggé vérzik az Intel hardvere.
A SIMT architektúrák esetében van egy speciális irány, amikor maga a dizájn SIMT, de egy ütemezőre több SIMD van felfűzve. Ilyenkor az architektúra egyszerre kihasználtság- és függőséglimites. Ide tartoznak az Intel dizájnjai, illetve az Ampere. Ezeknél látható, hogy papíron kurva nagy TFLOPS-ot tudnak, de ennek a gyakorlati felhasználás 95%-ában úgy kb. a 60%-a kihasználható.
Ezt azért csinálják a gyártók, mert maga az ALU olcsó a dedikált ütemezés és a dedikált regiszter nélkül. Illetve minden architektúrának vannak belső limitjei a működés tekintetében. Tehát dupla ALU-t nem olyan egyszerű ám beépíteni, mert lehet, hogy annyi multiprocesszort már nem tud kiszolgálni a tervezett memóriamodell. Azért ne felejtsük el, hogy a mai GPU-k memóriamodellje eléggé koros. Az AMD-é 2012-es, az NV-é 2010-es, az Intelé pedig 2009-es. Azóta a cégek ehhez nem nyúltak, csak viszik tovább az új dizájnokba. És egy ideje már a limiten vannak, azért próbálják ilyen-olyan egzotikus trükkökkel blokkokba rendezni a multiprocesszort, stb. És ha ez is kifújt, akkor jön elő az extra ALU tömb, de saját ütemező nélkül, mert ez a memóriamodell limitjeinek nem jelent extra terhelést, egyedül az a probléma vele, hogy a fejlesztőnek muszáj úgy programoznia, hogy a futtatott wave-ek között ne legyen függőség, mert ha az van, akkor az ütemező nélküli ALU tömb csak dísz. Nem tudja rárakni a hardver a következő wave-et, mert az éppen futtatott wave még számolja hozzá az szükséges adatokat. De mire ezt kiszámolja, addigra az elsődleges feldolgozótömb is felszabadul, tehát mehet arra a wave, ami a következő wave-hez számolja az adatokat, így azt sem lehet a másodlagos ALU-kra rárakni, és így tovább. Ezen úgy lehet segíteni, ha egy multiprocesszor két shadert is futtat, viszont ahhoz le kell particionálni a regiszterterületet, és abból nincs sok már egy shadernek sem, vagyis végeredményben, ha abból elveszünk, akkor kihasználtságlimitbe toljuk a multiprocesszort a túl nagy regiszternyomással. Ennek az eredménye ugyanúgy az, hogy az ALU nem dolgozik, csak nem a függőség miatt, hanem azért, mert nincs elég konkurens wave, így várni kell a memóriaelérésre. -
#55857
Alogonomus
őstag
Jack@l
#55856
Alogonomus
őstag
válasz
 Jack@l
#55856
üzenetére
Jack@l
#55856
üzenetére
A tensor magok használata nélkül is magas már az Ampere kártyák fogyasztása. Munkára fogott tensor magokkal vagy még vadabb fogyasztási értékek jelentkeznének, ami 2,5 kilós 4 slotos kártyákat eredményezne, vagy a tensor magok "felzabálnák" a fogyasztási keretet a hatékonyabb feldolgozók elől, ami meg simán teljesítményveszteséget okozna csak.
-
#55856
Jack@l
veterán
Petykemano
#55855
Jack@l
veterán
válasz
Petykemano
#55855
üzenetére
Féloff: ha esetleg neurális hálóval akarna nv sokkal jobb felskálázást csinálni (amit nem kell előre betanítani), lazán megtehetné. Van egy csomó tensor mag, ami játék közben nem csinál semmit.
-
#55855
Petykemano
veterán
Abu85
#55854
Petykemano
veterán
980Ti: 6tflops
Fury x: 8.6tflops (+~40%)GTX 1080: 8.9tflops
Vega 64: 12.6tflops (+40%)RTX 3090: 35,6 TFLOPS (+~55%)
RX 6900 XT: 23 TFLOPSDe persze, amit az AMD csinált, az kiváló volt, mert sosem épített co-issue-ra és veszettül ki volt tömve regiszterrel. Ott aztán nem egy darab dísz-ALU se volt. Az eredmények magukért beszéltek!
De mindegy, nem ez volt az eredeti téma, hanem az FSR algoritmus esetleges továbbfejlesztése és amennyiben a algoritmus erőforrásigényesebbé válna, akkor annak dedikált gyorsítóval való kiszolgálása. Ezt megbeszéltük.
-
#55854
Abu85
HÁZIGAZDA
Petykemano
#55853
Abu85
HÁZIGAZDA
válasz
Petykemano
#55853
üzenetére
A GCN sosem épített co-issue-ra. Ráadásul regiszterrel is veszettül ki volt tömve. Ezt az utat az NV kezdte el járni a Turinggal, az Ampere-be pedig beletervezték a co-issue-t. Ha a kódot ennek megfelelően írod, akkor van haszna, de ha nem, akkor az ALU-k fele csak dísz.
-
#55852
Abu85
HÁZIGAZDA
Petykemano
#55845
Abu85
HÁZIGAZDA
válasz
Petykemano
#55845
üzenetére
Mármint, hogy az Apple pár beépített szolgáltatása használja, és semmi más. Kb. ugyanez Androidon. Ennek nem sok haszna van.
Ki lehet tömni a hardvert ALU-kkal, de ha nem rendelsz hozzá kellő regisztert, esetleg dedikáltat, akkor a gyakorlatban az elméleti számítási teljesítmény csak a papírra jó. Nem hiszed? A GeForce RTX 3090 számítási teljesítménye 35,6 TFLOPS, a Radeon RX 6900 XT-é 23 TFLOPS. Eközben a két hardver gyakorlati teljesítménye nagyon hasonló, hol az egyik, hol a másik gyorsabb. Nyilván az AMD is megtehetné, hogy megduplázza az ALU-kat, és akkor co-issue megy majd két vektor, de amit nyersz, az a papíron a több TFLOPS, a gyakorlatban sok kihasználatlan feldolgozód lesz.
Ha a DLSS-re tervezték, akkor nagyon rossz hardverelemet terveztek hozzá, mert a tensor abszolút nem arra való, amit a DLSS csinál. De egyébként ezt a HPC-piacra tervezték, ott nincs meg az a probléma, hogy egyszerre mennek a tensorok és a fő ALU-k, így csak az egyik regiszternyomásával kell számolni. Szemben egy játékkal, ahol azért marha nagy probléma, hogy a tensor ugyanazokat a regisztereket használja, amelyekeből a statikus erőforrás-menedzsment miatt eleve kevés van a fő ALU-knak.
#55850 hokuszpk : Ehhez képest számos cégnél jelen van az overengineering. Ágyúval akarnak verébre lőni.
#55851 b. : Természetesen az NVIDIA bármikor csinálhat egy FSR másolatot, viszont nem valószínű, hogy megéri nekik, mert akkor ugyanarra a problémára lesz két megoldásuk, és a fejlesztő nyilván az egyszerűbbet fogja választani, ami nem a DLSS lesz, mert annak számos követelménye van a leképezőre, míg egy FSR-szerű eljárásnak lényegében semmi, azon kívül, hogy élsimított képet kér. Ennyi erővel kidobhatják a kukába a DLSS-t, mert nincs értelme egy fejlesztőnek azt választania egy NVIDIA-féle FSR elérhetősége mellett.
Arról nem is beszélve, hogy mi értelme volna az NV-nek egy saját FSR, amikor maga az eredeti FSR nyílt forráskódú. A CAS-ra sem reagáltak, pedig az is egyszerűen másolható, csak nem túl nagy ötlet olyanra költeni az erőforrást, amire már van megoldás. -
ettől függetlenül ugye ez egy lebutított , kisebb felbontású kép textúra javítása és élesítése különböző sharpen szűrő eljárásokkal Minkét gyártónak van ilyenje. úgy nagyjából azt látom ebben, hogy Nvidia kiad egy HRS-t ( bármivel helyettesíthető) amit majd a saját filterével élesít és megtartja még mondjuk egy darabig a DLSS-t a saját támogatású játékaira. Már csak azért is
-

hokuszpk
nagyúr
"A másik dolog, hogy az AMD régóta tart FidelityFX-es preziket, és sokszor elmondták már, hogy az elmúlt évtizedben arra jöttek rá, hogy sokszor a legegyszerűbb megoldások a legjobb válaszok egy problémára"
ha meghivtak volna egy meetingre, kapasbol bebofogom, ugyanis ezt a valaszt mar ugy 40 eve megtanultam, es akkorsem en talaltam fel, hanem a tanero igensokszor elmondta. Es megcsak nem is egyetemi vagy mernokkepzorol volt szo.
* szerintem mindenki ismeri a peldat a milliardokbol fejlesztett Amerika urtollrol ; az "Oroszok ceruzat hasznaltak" csattanoval.
-
-
-
#55847
Yutani
nagyúr
Petykemano
#55845
Yutani
nagyúr
válasz
Petykemano
#55845
üzenetére
A Tensor magok nem a DLSS miatt kerültek bele az NV hardverekbe:
NVIDIA Tensor Core technology has brought dramatic speedups to AI, reducing training time from weeks to hours and providing massive acceleration to inference. The NVIDIA Ampere architecture provides a huge performance boost and delivers new precisions to cover the full spectrum required by researchers— TF32, FP64, FP16, INT8, and INT4—accelerating and simplifying AI adoption and extending the power of NVIDIA Tensor Cores to HPC.
Forrás: NVIDIA
-
#55846
Jack@l
veterán
Petykemano
#55843
Jack@l
veterán
válasz
Petykemano
#55843
üzenetére
A linken amit beírtam, már találgatják kommentekben, hogy lehet a laczosnál jobb minőségű felskálázásokat beépíteni reshade-be.
Majd fsr2-ben meglépik 1 év mulva, mint csodatétel. -
#55845
Petykemano
veterán
Abu85
#55844
Petykemano
veterán
köszi.
Csak két megjegyzés:
"Értem, hogy sokan hisznek ebben a gyorsítás dologban, de ez a valóságban elég nagy kockázat."
Ennek valószínűleg az lehet az oka, hogy több - talán főképp mobilos, elsősorban Apple - példán keresztül úgy tűnik, hogy jelenleg az a nyerő irány, hogy a SoC-odba több különböző dedikált fixfunkciós hardverelemet építesz.
Persze értem én, hogy az Apple azért más tészta, mert ott a szoftver is az ő irányításuk alatt áll. A fixfunkciós dedikált egység és az általános programozhatóság megközelítése nyilván mindig küzdeni fog egymással.
Nagyjából ez a megközelítés látszik az nvidiánál is az RT, tensor és hagyományos magok megkülönböztetésével. És legalábbis eddig ez nyerőnek tűnt. Számok alapján mindenképpen, hiszen az AMD CDNA-ja még mindig nem közelíti meg azokat a számokat, amit a tensor magos nvidia gpu-k tudnak."A DLSS-en borzasztóan látszik, hogy mennyire nem jól működik, a kezdeti kód óta folyamatosan kerül át a normál ALU-kra a feldolgozás, mert hiába jó papíron a tensor valamire, ha nem olyan dologra használod, amire le van tervezve a hardver."
Ezzel ugye nem azt akarod mondani, hogy a tensor magokat az Nvidia nem az DLSS felskzálázó megoldáshoz tervezte, hanem alapvetően professzionális/AI célokra, és csak megpróbálta valamiképp hasznosítani, ha már benne van a hardverben és úgy adta el(ő), mintha ez mindig is a gamereknek készült volna? -
#55844
Abu85
HÁZIGAZDA
Petykemano
#55840
Abu85
HÁZIGAZDA
válasz
Petykemano
#55840
üzenetére
Ez a kód eléggé ALU-intenzívre van szabva, szóban akkor fog gyorsabban futni, ha több ALU kerül a hardverbe. De dedikált maggal nem.
A dedikált magnak mindig az a gondja, hogy sok követelmény van a kód felé, és ez behatárolja a fejleszthetőséget. Ez látható a DLSS-nél. Az kezdetben a tensor magokon működött, majd az 1.9-cel lekerült róla, ekkor jött egy nagy minőségbeli ugrás. Majd a 2.0-2.1-gyel részben visszakerült, de a 2.2-vel megint lekerültek feladatok a tensorról. Egyszerűen maga a tensor mag egyáltalán nem hatékony abban a feladatban, amit a DLSS mostani verziója csinál, így jobb lesz az eljárás, ha a munka jó részét nem is a tensor csinálja meg.
És innen trükkös a helyzet, mert építesz a hardverbe egy rakás olyan feldolgozót, amire próbálsz valamilyen munkát rakni, de közben rossz lesz a hatékonyság. A DLSS-nél ez úgy működne jól, ha a tensor magoknak lenne dedikált regiszterterületük, de akkor meg a lapka fele a tensor lenne, amit használhatsz 100-akárhány játékkal, a többi cím alatt pedig minden drámaian lelassul, mert az ALU-nak szánt tranyókat elvitte a tensor regiszterterülete.
Értem, hogy sokan hisznek ebben a gyorsítás dologban, de ez a valóságban elég nagy kockázat. A DLSS-en borzasztóan látszik, hogy mennyire nem jól működik, a kezdeti kód óta folyamatosan kerül át a normál ALU-kra a feldolgozás, mert hiába jó papíron a tensor valamire, ha nem olyan dologra használod, amire le van tervezve a hardver. Ha pedig úgy használod, akkor meg szar lesz a minőség, lásd DLSS 1.0. Pont ugyanez lenne a baja egy FSR-nek is, ha elkezdenél dedikált hardvert építeni rá, és még a fejleszthetőséget is behatárolja.
Olyan lehet, hogy a feladat egy kis részét gyorsítod egy külön hardverrel, de eleve egy olyan eljárás az FSR, ami egy elég gyönge GPU-n is 1 ms alatt megvan. Most ha annak egy részfeladatát felgyorsítod, akkor meglesz egy hasonló képességű modern GPU-n az eljárás 0,8 ms-ból, és akkor megveregetheted a vállad, mert az kb. 1-2 fps plusz a végleges képkockára. Cserébe ellőttél egy csomó pénzt a hardverre, a hozzáigazított szoftverre, és a tranyók egy része az FSR-t nem támogató játékokban nem is aktív. Badarság ilyet csinálni jelenleg.
#55841 Busterftw : A tensor már a DLSS új verzióival is nagyon rossza hatékonyságú, felesleges az NV-nek az FSR átalakításába pénzt ölnie, mert a dedikált hardverek használatától csak lassulnának.
#55842 Alogonomus : Annyira nem memóriaintenzív ez az eljárás, hogy az IF nagymértékben számítson. Valamennyit mindenképpen számít, de ez még +1 fps-t sem ad ki.
-
#55843
Petykemano
veterán
Busterftw
#55841
Petykemano
veterán
válasz
 Busterftw
#55841
üzenetére
Busterftw
#55841
üzenetére
Én is azt feltételeztem, hogy az FSR footprintje nagyon minimális és ezt végülis Abu megerősítette azzal, hogy azt mondta, hogy 1ms.
Ha ez igaz, akkor - a jelenlegi algoritmuson - nincs igazán mit gyorsítani.Az én kérdésem az, hogy vajon lehet-e úgy bonyolítani az algoritmust, hogy jobb minőséget adjon, cserébe erőforrás-igényesebb legyen, amit viszont már érdemes dedikált hardverelemmel gyorsítani.
Abu szavaiból azt veszem, ki, hogy nem.
De persze Abuból általában az AMD marketing osztály beszél és ha lenne ilyen nem publikus tervük, akkor azt Abu sem mondaná.Ha lehetséges az algoritmust így módosítani, akkor végülis az Nvidia beküldhet olyan PR-t, ami opcionális és tensor által gyorsított. Nem mondom, hogy lehetséges, de az út az Nvidia előtt nyitva van.
-
#55842
Alogonomus
őstag
Petykemano
#55840
Alogonomus
őstag
válasz
Petykemano
#55840
üzenetére
Több helyen olvastam olyan fejtegetést, hogy az Infinity Cache az óriási adatátviteli sebességének és elhanyagolható késleltetésének, meg a kisebb felbontásból származó nagyobb találati aránynak köszönhetően bizonyos szempontból már tekinthető az FSR "hardveres gyorsítójának" is.
-
#55841
Busterftw
nagyúr
Petykemano
#55840
Busterftw
nagyúr
válasz
Petykemano
#55840
üzenetére
Megforditva, elofordulhat az, hogy Nvidia tensor core-okon gyorsabban fusson, ha az Nvidia arra optimalizal?
-
#55840
Petykemano
veterán
Abu85
#55837
Petykemano
veterán
Akkor tehát a válasz az, hogy az FSR-re nem várható és nem is elképzelhető dedikált hardveres gyorsítás.
Tehát nincs olyan masterplan, hogy az AMD elterjeszti az egyszerű, bármin futó FSR-t, amihez aztán beépít a saját hardverébe valamilyen olyan elemet, ami aztán lényegesen gyorsít, vagy javít a minőségen és már nem lesz érdemes a konkurenciát vásárolni.Mondjuk az is igaz, hogy ha az algoritmus open-source, akkor talán bárki más is készíthetne hozzá dedikált hardverelemet. Nem?
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55834
üzenetére
A probléma az eredeti algoritmussal az volt, hogy nem mindig végez elég jó munkát, illetve nem is gyors.
A "nem is gyorsra" az volt a válasz, hogy megkeresték azokat a részeit az számításoknak, amelyek marhára lassan futnának egy GPU-n. Ilyenek a különböző szögfüggvénye, a négyzetgyök, stb. Ezek azért futnak lassan, mert a fő ALU-kban, nincs rá utasítás egyik GPU-ban sem. Helyettük a multiprocesszorok tartalmaznak pár SFU-t, amelyek el tudják végezni a feladatokat, de úgy 32-, 256- rosszabb esetben 512-szer lassabban. Ez ugye elég nagy szopás ahhoz, hogy valós időben az alapalgoritmus ne legyen alkalmazható. Egyrészt az SFU-k száma nem sok egy teljes GPU-n belül, másrészt az egyes speciális operációk is 8-16 órajel alatt valósulnak meg.
Ezt a problémát kezeli a kódban egy 0x5F3759DF WTF-szerű ötlet, amely a lassan futó operációkat kicseréli alapműveletekre, amelyek több nagyságrenddel gyorsabban futnak, és ezért csak kevés pontosságot áldozol. Emiatt az alapalgoritmus teljesítménye az egyes GPU-kon akár a százezerszeresére is tud nőni, vagyis eljutottál ahhoz a tartományhoz, hogy valós időben alkalmazható legyen.A másik probléma a "nem elég jó munka". Ehhez az alapalgoritmusnak külön kezelték a képi hibákat adó részeit. Ezeket kompletten átírták, illetve a képi hibák lehetőségét mellőzni lehessen. Ugye ennek is az volt a kulcsa, hogy az alapalgoritmust átlagosan a sok tízezerszeresére gyorsították egy GPU-n, tehát most már van miből költeni a jobb minőségre. Ebből jön az élek rekonstrukciója, ami az eljárás alapja.
A további modulnak számító RCAS már csak egy adalék, ami extra helyreállítási munkát végez.
#55835 Petykemano : A Xilinxet nem ezért veszi meg az AMD.
A FidelityFX Super Resolution eleve egy rohadt gyors eljárás. Amellett, hogy ez adja az ismert eljárások közül a legjobb rekonstrukciós minőséget, még ez is fut a leggyorsabban a GPU-kon. Tehető ennél gyorsabbá is, de egy középkategóriás VGA-n sem számol 1 ms-nél tovább, ha azt leviszed 0,9-re, ami egyébként még talán realitás is, akkor sem nyersz vele sok sebességet, mert a képszámítási teljes idejének a töredékrészén optimalizáltál 10%-ot, vagyis a teljes képszámítás időigényén ez jó ha 1%-ot dob.
Jobb minőség sem várható, mert eleve képes arra az algoritmus, hogy a natívval nagyon megegyező minőséget csináljon. Elméletben a natív minőség a referencia. Papíron ennél jobbat nem lehet csinálni. Az más kérdés, hogy a FidelityFX Super Resolution esetében is van olyan, hogy az UQ beállítás szebbnek tűnik, de ugye papíron ez nem lehet szebb, csak szubjektív benyomás szintjén.
Az alacsonyabb felbontásról való rekonstrukción lehet javítani. De ez egy balansz kérdés. Minél alacsonyabb felbontásról skálázol fel valamit, annál nagyobb számítási teljesítmény kell magához a skálázáshoz, hogy jó eredményt érj el. Az AMD nem véletlenül ajánl előre skálázási paramétereket. Azok ugyanis a sweet spotok.
A másik dolog, hogy az AMD régóta tart FidelityFX-es preziket, és sokszor elmondták már, hogy az elmúlt évtizedben arra jöttek rá, hogy sokszor a legegyszerűbb megoldások a legjobb válaszok egy problémára. Semmiféle overengineeringet nem szabad felvállalni. A FidelityFX fejlesztése úgy működik, hogy feltárnak egy problémát, arra átbeszélnek pár megoldást, és abból mindig a legegyszerűbbet választják, mert az esetek 99,99%-ában az a legcélszerűbb. Amikor egy algoritmust bonyolítasz, akkor előjönnek vele a problémák, nehezebben kezelhető lesz, több limitációt kell figyelembe venni, arra nem is biztos, hogy mindegyik fejlesztő hajlandó. Magát a FidelityFX CAS-t is az egyszerűsége adta el. Ugyanezt az elvet követi az FSR is.
#55836 FLATRONW : Mire gondolsz NGU alatt? Hirtelen nem tudom dekódolni.
-
#55835
Petykemano
veterán
Abu85
#55833
Petykemano
veterán
(Xilinx) FPGA-val, vagy más dedikált ASIC akár integrált, akár chipletes összeragasztáss tehető az FSR futása
- gyorsabbá?
És/vagy
- jobb minőségűvé?Korábban ez a gondolat felmerült a pletykákban, de ha jól értem, a jelenlegi algoritmus a lehető leggyorsabbra van átalakítva, így gondolom a skálázás footprintje nagyon elhanyagolható. A minőséget illetve a gyorsulást pedig döntően az befolyásolja, hogy mekkora a forrás és cél felbontás közötti különbség.
Tehát a kérdés az, hogy egy esetleges FSR2 esetén - új, bonyolultabb, de valamilyen dedikált hardverelemmel gyorsított algoritmussal, javulhat-e az eredménye?
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55832
üzenetére
Mert jóval több is. A Lanczos évtizedek óta a legjobb megoldás skálázásra, nem véletlen, hogy a MadVR is arra épít, de rengeteg olyan operációt alkalmaz, amelyben a GPU-k veszettül lassúak. Az AMD implementációja pont ezen módosít jelentősen, illetve az egész algoritmus problémáit kicseréli olyan eljárásokra, amelyek nem okoznak képi hibákat.
És figyeld meg, hogy mennyien be fogják építeni. Pont az a lényege, hogy semmiféle overengineering nincs benne. Egyszerű megoldás egy egyszerű problémára, ami akármilyen futószalagon belül működik, ráadásul 14 évre visszamenőleg fut a hardvereken.
-
#55828
olymind1
senior tag
Petykemano
#55825
olymind1
senior tag
válasz
Petykemano
#55825
üzenetére
Mondjuk nem csoda, ha mindent egyre drágábban adnak, akkor kevesebbet is vesznek belőle, mert szűkül a réteg is aki megveszi, vagy aki hajlandó annyi pénzt kiadni érte. De az is biztos hogy magyar piacra terveznek ezek a cégek.
Játékfejlesztőknek egyébként előbb-utóbb nem fog feltűnni, hogy kevesebbet vesznek a játékaikból, mert nem tudják futtatni őket?
-
Televan74
nagyúr
válasz
 solfilo
#55826
üzenetére
solfilo
#55826
üzenetére
Azért hajol le hogy felvegye, vagy azért hogy le..opjon.? Esetleg tegyem be neki hátulról?
De a témánál maradva. Feltételezzük hogy kb. 80 millió új felhasználó vett gépet a covidnak köszönhetően. És ők nem a csóresz gamer tábort alkotják. Velük hamar meglehet a kívánt bevétel, sőt ha egy kicsit normalizálódnak az árak, azok is vesznek akik eddig kivártak. -
#55826
 solfilo
veterán
Petykemano
#55825
solfilo
veterán
Petykemano
#55825
válasz
Petykemano
#55825
üzenetére
Az mindenesetre szépen látszik, hogy az AMD-nek is megéri lehajolnia ezért a 2021-re 30+ mrd USD-osra becsült piacért.
-
#55825
Petykemano
veterán
Busterftw
#55824
Petykemano
veterán
válasz
Busterftw
#55824
üzenetére
Nem ment át, amit mondani akartam.
Arról volt szó az elmúlt 4-5 évben, hogy szűkül a piac, a GPU piac az nagyon kicsi.
És mivel kicsi, ezért mindenki mostohája és mivel kis volumen, ezért drágul is.(Ebből már bullshit generátort lehetne készíteni)
Az eközben meg arra vonatkozik, hogy épp most nő kétszeresére a TAM.
jójójó, persze ezt 2018-ban senki nem láthatta előre, tehát akkor lehet, hogy tényleg szűkült.És hát ugye az is igaz, hogy ez nem volumen, hanem összeg, amibe nyilván beleszámít, hogy a $400 az új $250. A volumen meg lehet, hogy továbbra is picit csökkenőben van.
-
#55824
Busterftw
nagyúr
Petykemano
#55823
Busterftw
nagyúr
válasz
Petykemano
#55823
üzenetére
Ez mondjuk latszik, mert hiaba novekszik, nem novekszik olyan utemben mint pl 2020-2021-ben.
-
#55823
Petykemano
veterán
Petykemano
veterán
"Szűkül a piac, egyre kevesebben vásárolnak játékra PC-t, mainstreamből geekség lett."
Eközben:
[link] JPR előrejelzés
-
#55822
Abu85
HÁZIGAZDA
Hellwhatever
#55811
Abu85
HÁZIGAZDA
válasz
 Hellwhatever
#55811
üzenetére
Hellwhatever
#55811
üzenetére
Ha nem skálázódna, akkor sorakoznának egymás mögött azok a kártyák, amelyek teljesítménykülönbsége amúgy kétszeres. Ez az AMD-nél nem következik be, csak az NV-nél lassabb procival.
-
#55821
Jack@l
veterán
Computer4U
#55818
Jack@l
veterán
válasz
 Computer4U
#55818
üzenetére
Computer4U
#55818
üzenetére
A legelső hsz-ben le van irva.
-
#55818
 Computer4U
kezdő
Computer4U
kezdő
Computer4U
kezdő
Sziasztok!
Egy olyan kérdésem lenne, hogy ha játék alatt afterburnerrel szeretném kiiratni az infókat rivatunerren keresztül miért van az, hogy csak kb 5 féle adat látszik.
Szeretném látni az 1% és 0,1% fps stb, de semmi. Hiába pipálom be, hogy monitorozza és írja ki OSD-n.
Köszi -

GeryFlash
veterán
válasz
 Callisto
#55813
üzenetére
Callisto
#55813
üzenetére
b. bevallottan Nvidia szimpatizáns, drukkol nekik és örül a sikereiknek, de az AMD-vel rendre objektív csak krvára idegesíti a kettős mérce (csak 1 példa az ezer közül: VEGA korszakban az 1440p volt a fontos, 4 évvel később az hogy mennyivel gyorsabb kikapcsolt RT-vel 1080p mediumon a 6600XT a 3060TI-nál). Abu ezzel szemben nem bevallottan AMD szimpatizáns, de valahogy mindig úgy csűri-csavarja... Komolyan ez hogy hetekig sejtelmesen fel lett szopva a 6600XT, aztán kiderül hogy egy 3060TI-nál 7%kal gyorsabb VGA viszont RT-ben szintekkel rosszabb és kevesebb VRAM mindezt drágábban
Kiadták az 5700XT-t RT támogatással kisebb fogyasztással 400 dollárért. Ez volt a világmegváltó cucc. Ehhez képest a 3060/3060TI/6700XT kiemelkedően jó ár/érték arány.
De héh, 128 biten hozza az 5 éves 1080TI-t 1080p-n 🤡 -
#55812
b.
félisten
Obliterátor
#55759
válasz
 Obliterátor
#55759
üzenetére
Obliterátor
#55759
üzenetére
"hónapok óta követni azt a fika hadjáratot , amit az AMD ellen folytatsz."
Mutatnál példát a hónapokból a fika hadjáratra AMD ellen? Véleményt olvastál, nem AMD re vonatkoztatva. Abu= AMD ? oh wait..Sejtem kinek az alteregója vagy.
-
-

paprobert
őstag
válasz
Busterftw
#55770
üzenetére
DX11-ben konstans NV előny volt.: "-Az átlag konzumer úgysem 1080p-ben játszik, tehát mindegy, és sosem jönne ki a különbség, csak VR-ban." "-Válts 1440p-re vagy 4K-ra, és akkor egy FX is elég lesz, az AMD driver overhead-del ne foglalkozz."
DX12-ben masszív AMD előny van.: - Azonnal fontos a 1080p high refresh gaming.
Én is érzékelem a fordulatot.
Bár annyiban igazat lehet adni, hogyha a konzolban található Zen2@3.5GHz lesz a 30fps-re elég CPU erő, akkor az NV driver 15-30%-os overhead-je tud számítani középtávon bármilyen felbontáson.Még nem láttunk CPU-gyilkos next-gen játékot, de már nem lehetnek túl messze.
-
#55808
Abu85
HÁZIGAZDA
Hellwhatever
#55807
Abu85
HÁZIGAZDA
válasz
Hellwhatever
#55807
üzenetére
Mint ugye többször írtam, és nem győzöm hangsúlyozni, hogy a Radeon esetében ez a javulás nem figyelhető meg. Egyszerűen azok skálázódnak Zen 2-vel és Zen 3-mal is. A Radeon 6800 XT esetében a Zen 3-ra váltás előnye csak 3-4%. A GeForce driver mellett eredményez a játék akkora többletterhelést, hogy valamiért nem tud jól működni a játék a régebbi, kevésbé tempós procikkal.
És a probléma még mindig jelen van 1080p-ben a GeForce-on, hiába a Zen 3, a Radeon most is jobban skálázódik, de már nem extrém a különbség. -
#55807
 Hellwhatever
aktív tag
Abu85
#55805
Hellwhatever
aktív tag
Abu85
#55805
Hellwhatever
aktív tag
Szerintem ez inkább a Zen 2 -> "normális" procira váltás eredménye. Kíváncsi lennék ha valami (ne adj isten OC-s) i9-re váltotok akkor mik a számok. (Gyanítom hogy hasonló ugrást látnánk.)
A Zen 2 játékok alatt sok esetben mérhetően lassabb volt a konkurenciához képest, az AMD csak a Zen 3-mal tudott egyértelműen fordítani.
Volt 3800X-em és még az is (asszem 3700X-etek volt javítsatok ki ha tévedek) határozottan lassabbnak érződött már Windows alatt is mint az elődje a 4.8-ra húzott 9600K.
Szvsz egyik Zen 2 se való top VGA mellé (tesztelésre meg főleg), de ez csak az én véleményem.
-
#55805
Abu85
HÁZIGAZDA
Petykemano
#55804
Abu85
HÁZIGAZDA
válasz
Petykemano
#55804
üzenetére
Sajnos elég sokat fogsz még úgy is belőle észrevenni. A medium részletesség csak segít a kimutatásban, de ez már max részlegességen is érződik. Láthatod a TPU tesztben, hogy ott a 3080 még 4,8 GHz-re húzott Zen 3-mal is CPU-limites pár játékban 1080p-ben, néhol 1440p-ben is.
Max részletességre értettem. Egyszerűen a Valhallában a Zen 2-Zen 3-ra váltás ennyit ért egy top GeForce-on, 1080p-ben. Ez már nem csak a medium részletességet érinti, ha csak azt érintené, akkor lehetett volna használni a Valhallát Zen 2-vel is, de egymás mögött sorakoztak a GeForce-ok 1080p maxon, miközben a Radeonok szépen skálázódtak.
Ott van a TPU mérésekben 1080p-ben a CPU-limit a GeForce 3080-on, és bivaly tuningolt procival, elég ha megnézed.
-
#55804
Petykemano
veterán
Abu85
#55767
Petykemano
veterán
Ez beszédesebb mint amiket Te linkeltél: [link]
És látszik is, hogy a 3070 teljesítménye alacsony felbontáson és alacsony minőségben sokkal inkább függ attól, hogy milyen procit raksz alá, mint pl a 5600XT vagy 5700XT esetén.
Tehát ne érts félre, a driver overhead tényleg létezik, csak azzal kötözködök, hogy ebből milyen ÁLTALÁNOS megfogalmazásokat (marketing szövegeket) vonsz le.
A valóság az, hogy ha az általánosan elfogadott feltételek mellett (tehát az elérhető legjobb procival) mérsz (Megjegyzés: a jelenségnek vajmi kevés köze van a magszámhoz, tehát nem attól pörög jól a review-kban az nvidia kártya, hogy brutáldrága 5950X-et raknak alá. Ugyanúgy érvényes ez az 5600X-re.), akkor nem, vagy alig fogsz észrevenni bármit is ebből a driver overhead-ből.
Az általad - általános sebességkülönbség színben feltüntetett - 20-30%-os különbséget csak akkor tapasztalhatod, ha
- gyenge minőségben (1080p medium)
és
- valami topa cpu-val mérszÉn a helyedben ezeket az apróságokat a helyedben kiemeltebben kezelném, mert pont az ilyen csúsztatások miatt szoktak kapni cégek és újságok egyaránt.










![;]](http://cdn.rios.hu/dl/s/v1.gif)











































Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Xiaomi Watch 2 Pro - oké, Google, itt vagyunk mi is
- exHWSW - Értünk mindenhez IS
- Célegyenesben a Yettel TV
- Facebook és Messenger
- Kuponkunyeráló
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Politika
- LEGO klub
- Folyószámla, bankszámla, bankváltás, külföldi kártyahasználat
- Xiaomi 13 - felnőni nehéz
- További aktív témák...
- Apple iPhone 12 Pro 128GB, Kártyafüggetlen, 1 Év Garanciával
- Beszámítás! Lenovo Thinkpad P15 Gen1 15 FHD notebook - i7 10850H 16GB RAM 1TB SSD Quadro T1000 W11
- ÁRGARANCIA!Épített KomPhone Ryzen 5 4500 16/32/64GB RAM RTX 3050 6GB GAMER PC termékbeszámítással
- Xiaomi Redmi Note 10 Pro 128GB Kártyafüggetlen, 1Év Garanciával
- LG 27GP95RP - 27" Nano IPS - UHD 4K - 160Hz 1ms - NVIDIA G-Sync - FreeSync Premium PRO - HDR 600
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest