-

Fototrend
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#35800
 Abu85
HÁZIGAZDA
huskydog17
#35799
Abu85
HÁZIGAZDA
huskydog17
#35799
Abu85
HÁZIGAZDA
válasz
 huskydog17
#35799
üzenetére
huskydog17
#35799
üzenetére
-
#35799
 huskydog17
addikt
#45185024
#35781
huskydog17
addikt
#45185024
#35781
huskydog17
addikt
válasz
 #45185024
#35781
üzenetére
#45185024
#35781
üzenetére
"Fallout 76 idTech 6 motorral ?"
Biztosan nem, nézz utána!
#35788: "Gamebryo a régi motor de a Starfield meg a ES6 már azt beszélik az újjal lesz"
Ki beszéli ezt és hol? Linket légyszi, köszi!#35797 Abu85: "A WCCFtech meg hasonlókkal ne foglalkozzatok. Iszonyat baromságokat írnak, az AMD konkrétan röhög a mai "exkluzív" cikkükön is."
Hm....ez a kijelentésed megmosolyogtató ennek fényében. Ahhoz képest, hogy iszonyat baromságokat írnak, elég sok cikket leközöltetek rájuk hivatkozva forrásként. Tehát akkor a PH is baromságokat ír?
-
#35798
 #45185024
törölt tag
szmörlock007
#35789
#45185024
törölt tag
szmörlock007
#35789
#45185024
törölt tag
válasz
 szmörlock007
#35789
üzenetére
szmörlock007
#35789
üzenetére
Nagy részével én ennek a cikknek egyetértek legyen is ez leírva ide magyarul:
Mégse Professzorova hardverova vagy Prohardware a lap neve nem igaz ?
● Az útiterv megváltozott. ✔
● Kiderült, hogy Lisa Su elsősorban az AMD processzor oldalának visszaállítására és egy erős, félig egyedi GPU rész létrehozására összpontosított ✔
● Az AMD Vega-t épített az Apple számára, és a Navi a Sony PS5-re épül ✔
Ezt már sokan sokféleképpen megfogalmazták itt de a lényeg hogy 2 már megtervezett kiadott GPU-t használnak fel tulajdonképpen ingyen Gamer terméknek. Amivel hát sikerült a piac 33%át megszerezni nem szenzációs ???
● ...ami várhatóan 2020-ban indul NO NO
2019 H1-ben kint lesz a Navi valamely formája. így a PS5 is 19-es.
● Ez azt jelentette, hogy a grafikai részlegnek közvetlenül az ütemtervhez kellett kötődnie, amelyet ezek a félig egyedi alkalmazások követtek ✔
Magyarázza a Vega indulását is...
● A Vega 7nm-en nem fog jönni a játékosok számára.✔
Lisa csak azt mondta hogy a Gamereknek lesz 7nm-es kártya Vegát meg sem említette.
Megjegyzem ha hozta volna a Vega a TI-t akkor többet hozna a gazdájának a konyhára és akkor lehet lenne 7nm-en.
Halkan hozzáteszem AMD Gamereket ez a "ki nyert" semmilyen módon nem érdekli minden kártyát az ár /teljesítmény értéke határoz meg. 140 ért vettem a ref Vegát megérte és 169 ezerért vettem a Custom 56ot szerintem az is megérte!
●A Navi lesz az első olyan architektúra is, amely a GCN-től (és vele együtt a 4096 SP / 64 CU-ra vonatkozó határértékkel, ami az uArch megvalósításában rejlik) távozik.✔
Bár a régi pletykák azt mondták Navi lesz az utolsó GCN én mégis azt gondolom ez IGAZ.
Sokkal ütőképesebb lesz a Navi ha nem kell a régi korlátaiba ütközni és még valami..
A Navi nem lesz egyedül Navis ehhez pedig sokkal jobban illeszkedne egy új arhitektúra.
ehhez pedig sokkal jobban illeszkedne egy új arhitektúra.
●Lisa választása esetleg elrabolta Radeon rajongóit az átállástól , de valószínűleg megmentette a társaságot.✔
Ezt aláírom Lisa is meg a miner árak is A CPU részleg megerősítése erősített a Cégen kb duplázta a részvényértékeket rövid időn belül. ha ezt idővel visszaforgatja a GPU részlegbe rendben van és egy erős NAVI családot kapunk széles választékkal !!!
● uArch formális kódneve KUMA volt amit megváltoztattak ... Hát ez a kis szines rovatba elmegy de ha vérszomjas giga titanhunternek nevezték volna attól se lenne gyorsabb
●Navi 20 is going to be the true high-end GPU built on the 7nm node and as things stand right now, you are tentatively looking at it landing sometime around 2021.
ja várj már le kéne fordítani Azt írja a Navi 20 lesz 21ben a csúcsszuper GPU, ez még a régi gondolkozás
Azt írja a Navi 20 lesz 21ben a csúcsszuper GPU, ez még a régi gondolkozás
Az új az moduláris és EPYC szerű, ha van egy navid klassz ha teszel hozzá még kettőt meg egy CPUt Az apuba az meg atomklassz akkor háromszor olyan erős, Nektek elég lenne egy Vega *3 erejű APU a gépetekbe ? ))))
))))
már írom is ki a piacra hogy Vega 56ot kis ráfizetéssel Navis Epycre cserélem)) -
#35797
Abu85
HÁZIGAZDA
Petykemano
#35796
Abu85
HÁZIGAZDA
válasz
 Petykemano
#35796
üzenetére
Petykemano
#35796
üzenetére
A semi-custom nem nem tud meghatározni semmit az RTG-nek. Hiszen nem része ennek a divíziónak az R&D részleg. Ha valakinek esetleg egyedi igénye van, például a Sony-nak volt a superstencil, akkor azt úgy biztosították, hogy beleadták a semi-custombe a mérnökeiket. De az AMD R&D részlegtől nem vontak el semmit. Persze a semi-custom licencelése eléggé specifikus lehet. Például az AMD licencelte a Sony superstenciljét. Ilyenkor jut az R&D szerephez, vagyis megszerezték a szabadalom használatára a jogot, és terveztek rá egy Sony-tól eltérő implementációt, mert a Sony-é nem került az AMD tulajdonába, annak ellenére sem, hogy a semi-custom részleg részt vett a tervezésében, és persze megvan az áramkör vázlata is. A licenc viszont ennek a felhasználását tiltja, tehát semmit sem ér, így az AMD-nek le kell terveznie a saját fizikai implementációját.
A semi-custom úgy nem tud meghatározni semmit, hogy a licencek tiltják a bevitt technológiák, egy az egyben történő felhasználását. Szép is lenne, ha a Sony ad egy IP-t az AMD-nek, amit az AMD rögtön tudna is biztosítani a Microsoftnak.A WCCFtech meg hasonlókkal ne foglalkozzatok. Iszonyat baromságokat írnak, az AMD konkrétan röhög a mai "exkluzív" cikkükön is.
-
#35796
 Petykemano
veterán
szmörlock007
#35789
Petykemano
veterán
szmörlock007
#35789
Petykemano
veterán
válasz
szmörlock007
#35789
üzenetére
A gaming olyan low-profit szegmens, hogy az nvidia másfélszer akkora bevételre tesz szert belőle jelenleg, mint az AMD TELJES bevétele és vidáman elteszi a felét profit gyanánt.
Egyébként Pepeeeee már hónapok óta ezt pofázza, hogy az AMD kártyák az Apple és a Sony&MS igényei alapján érkeznek a piacra. Talán lesz 1-2 jó év, amikor az intel megrendelései is piacra kerülnek....
Én előtte/közben csak finoman kritizáltam, hogy nem lenne baj, ha nem fűznék föl ennyire a megjelenő radeon kártyákat a konzolokra. Tehát hogy nem baj, ha van hasonlóság, van összefüggés - abu mindig azt mondja, hogy a semi-custom mindig csak a tavaly technológiát kapja meg - de ne a semi-custom határozza meg a technológiai fejlődést és főleg ne a konzol chip/design újrahasznosítása legyen a radeonként piacra dobott valami.
Márpedig most nagyjából ez van. .Halványan van már csak szó arról, hogy az AMD-nek lenne egy termékpalettája, amiből az IP-ket felhasználva a semi-custom 1-2 év alatt összedob valami egyedit. Sokkal inkább az van, hogy a saját IP-ket (nevezzük ötletnek) a Semicustommal készíttetik el, aztán abból a "rendes" grafikus csapat talán tud valamit hasznosítani.kár.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#35786
üzenetére
keIdor
#35786
üzenetére
Nem kell a Naviig várni a Vega 20 is ilyen. A GMI linkeket kell figyelni. Ha az van a GPU-ban, akkor alkalmas efféle összeköttetésre. Mondjuk a Vega 20 esetében ez szerintem az EPYC-hez van, ahol majd a CPU-val kapcsolják össze. De ennek előbb-utóbb lesz asztali verziója, ami dobja a PCI Express-t, és akkor egy 250 wattos tokozáson belül kapod a CPU-t és a pGPU-t, az összeköttetésük pedig memóriakoherens lesz.
-
#35792
 Televan74
nagyúr
szmörlock007
#35789
Televan74
nagyúr
szmörlock007
#35789
Televan74
nagyúr
válasz
szmörlock007
#35789
üzenetére
Ha ez így lesz egy darabig mindenki veheti a "drágább" Geforce kártyákat, ugyanis az Nvidia azt csinál a piaccal amit csak szeretne.
 - tudom "ha" -val nem kezdünk mondatot
- tudom "ha" -val nem kezdünk mondatot -
#35790
 keIdor
titán
szmörlock007
#35789
keIdor
titán
szmörlock007
#35789
keIdor
titán
válasz
szmörlock007
#35789
üzenetére
Sony PS5 2020 Navi-val, egyre jobb!
-
#35789
 szmörlock007
aktív tag
szmörlock007
aktív tag
szmörlock007
aktív tag
-
#45185024
törölt tag
válasz
keIdor
#35787
üzenetére
Tudom én papa ezek csak szerzodések
Viszont amit motrokba épitenek be az benne marad akkor is ha tovább frissitik
De ha Engine-t cserél akkor megy a kukába
Gamebryo a régi motor de a Starfield meg a ES6 már azt beszélik az újjal lesz
Ezért is szeretnénk ha valaki AMDtol nyilatkozna -
keIdor
titán
Még akár igaz is lehet, fél éves hír, de:
The AMD Vega chips might be the last big Radeon GPUs they ever makeVolt már a midrangeről eddig is szó:
AMD's next-gen Navi: GTX 1080 performance for $250?!A Navi-nál a lényeg az Infinity Fabric féle skálázhatóság lesz, Threadripper-hez hasonlóan.
Szerepel is, hogy "or GPU"
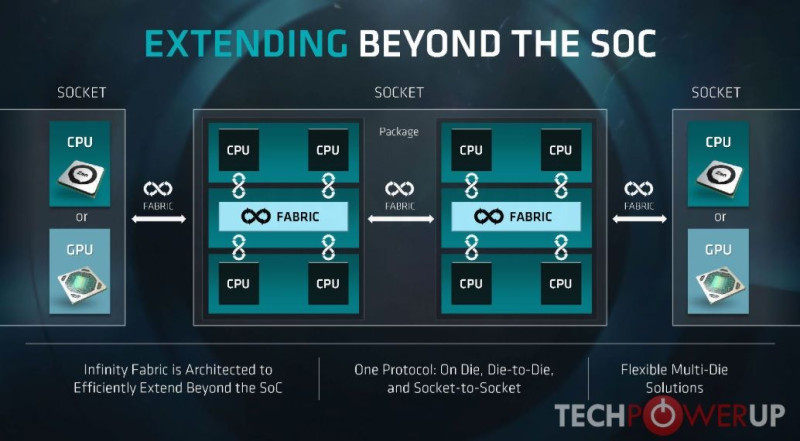
-
#35785
Petykemano
veterán
Z_A_P
#35782
Petykemano
veterán
Ha már beszélgetünk...
Teljesen világos, hogy a 4 Shader Engine, az ehhez tartozó 64 (4x16) CU és 64 ROP egy elég kemény limit a GCN számára. Nem lehet véletlen, hogy a Fiji óta ez a maximum.
A nagy kérdés, hogy a "Navi"-scalability arra vonatkozik-e, hogy ezeket a limiteket egy monolitikus chipben éptik le, vagy épphogy ragasztóznak.
Szerintem amikor épp most találták fel az infinity Glue-t, ÉS ezzel együtt világos, hogy nagy monolitikus chipek gyártása helyett jobban lehet majd a gyártói piacon boldogulni a kisebb lapkákkal, szerintem most már botorság lenne azon dolgozni, hogy egy chipen belül legyen 4 SE-nél, a vele járó ropokkal és geometry engine-ekkel együtt. A shaderek száma viszont ugye eddig se volt mindegy a compute teljesítmény terén. TEhát olyan skálázódást, amiről ABu beszélt, hogy innentől kezdve 16 helyett 25-30+ CU elférhet majd egy SE-ben ennek lenne értelme. Csak az nem mindegy, milyen piacon.
Ennélfogva én kevés értelmét nem látom ennek a mid-range - high-end navi megkülönböztetésnek. Pontosabban, ahogy mondtam, botorságnak tartanám, ha a midrange (4SE, 64CU, 64ROP) fölé egy ennél szélesebb monolitikus chipet készítenének.
Annak lenne értelme, ha a mid-range chip így néz ki:
4SE, 64CU (4096 shader), 64ROPMaximum annak lenne értelme ha ehhez képest van egy másik chip, ami ugyanúgy 4SE, ugyanúgy 64ROP, de 96, vagy 112 vagy 128 CU van benne. Tehát tulajdonképpen a chipnek csak a nyers számítási kapacitása skálázódik.
A többit meg megoldják ragasztóval. A második chip értelmét az adná, hogy compute célterületen nem duplikálják csak grafikához használt részeket és valószínűleg tervezés tekintetében csak kis változtatás. De a ha szilikonköltség nem számít, akkor még erre sem feltétlenül van szükség.
A történetet egy kicsit a GDDR6 tesz kérdésessé. Valahogy nem tudom elképzelni, hogy az összeragasztózott megoldást hogy tudná kiszolgálni a GDDR6. Tartok tőle, hogy a szükséges sávszélességhez túlságosan sok GDDR6 chip-re lenne szükség.
-
#45185024
törölt tag
válasz
keIdor
#35776
üzenetére
Megtaláltad a választ a saját kérdésedre
A konzol élettartam utolso fázisába érkezett
már hogy mikor lesz PS5 A last of US volt a konzolzáro cim PS3on
Most meg Last of US 2
Meglesz a NAVI már csak egy tubus ragaszto kell APUba záráshoz és meg is vagyunk
Kezdodik a TICKA másik téma ami mellett nem lehet elmenni az továbbra is az E3
és a RADEON forumhoz idomitva ugye az AMD partnership program
Milyen játékok tartoznak bele
máshol beszélgetnek errol itt nem sikerult beszélgetést kirobbantanom rola pedig adja a téma
DOOM Eternal VULCAN és még mi a Rage 2
és még mi a Rage 2
a Vulkán alatt hozza az 56 az 1080at a 64 meg a TI-t azért nagyon nem mindegy nekunk hogy milyen elterjedése lesz
Az uj Wolfenstein
Fallout 76 idTech 6 motorral ?
Vajon errol fognak beszélni a Heti E3 AMD bejelentkezésen
Aki azt gondolja ez nem fontos gondolja át hány ember retinájába égne be a világfájdalom egy Elder Scroll 6nál az AMD RYZEN RADEON logo miatt ezek kártyavásárlást formálo dolgok -
#35780
Petykemano
veterán
FollowTheORI
#35778
Petykemano
veterán
válasz
 FollowTheORI
#35778
üzenetére
FollowTheORI
#35778
üzenetére
Az nvidiának most már olyan kártyát kéne csinálnia, ami Abunak is tetszik. (mármint úgy igazán.)
-
válasz
 Oliverda
#35771
üzenetére
Oliverda
#35771
üzenetére
arra gondoltam, hogy ez a nevezéktan tradicionálisan a tranzisztor Lgate-jéhez van kötve. ez még valameddig valid is volt, és működött. mondjuk a 90es évek végéig.
most viszont már nem planár technológiát használunk, hanem 3d tranyókat, ergo nem a gate fog érdekelni, hanem a fin geometriai méretei.
csak egy példa, a 22ffl Lgateje megegyezik a 32nm Lgatejével. és igen ez marketing, mert az effektív csatornaszélesség nagyobb, mint az Lgate. de ebben a játékban az volt az egyedüli szabály, hogy a kisebb az jobb, akkor a nagyobb számot nem fogod tudni előrelépésnek eladni, hiába más a technológia. -
#35778
 FollowTheORI
nagyúr
keIdor
#35776
FollowTheORI
nagyúr
keIdor
#35776
-
keIdor
titán
-
Abu85
HÁZIGAZDA
válasz
Oliverda
#35774
üzenetére
Nem hiszem. Az Intelnél is volt ilyen, méghozzá a Sandy Bridge kapcsán. Az Intel ezt meg is magyarázta anno, hogy ez miért fordulhat elő. [link]
Az AMD mindig valósat ad meg, de egyébként megmondják a sematikusat is, ha megkérdezed őket. Mindkét érték helyes. A probléma az, hogy sok média ezt nem tudta, illetve kicsit kavarást okozott az Intel azzal, hogy egyszer a Sandy Bridge-re sematikust adott meg, de azóta valósat is közöltek mindig, de csak addig, amíg ezt a paramétert közölték is. Egy ideje viszont teljesen leálltak. Az AMD máig megadja a valósat, bár a sematikusat nem, azt külön kérdezni kell.
Szerintem az a problémájuk, hogy még ha a 10 nm-t csodával határos módon el is magyarázzák, hogy miért jobb a 7 nm-nél, a tranzisztorszámokat túl egyszerű összevetni, és abban már azonos "nanométer előtti számmal" is kikapnak, tehát ott úgy már nagyon kevés újságírót lehetne megvezetni. Sokkal egyszerűbb ezeknél a táblázatoknál maradni, és acélosan mutatni, hogy minden a legnagyobb rendben, így terveztük, szándékosan ilyen, stb. Kapaszkodni a végletekig abba a pár számba, amit még lehet mutogatni a médiának, és az erre vevő újságíróknak, és mereven eltitkolni a gyakorlati adatokat, hogy valós összevetés ezekből még csak véletlenül se születhessen.
-
Abu85
HÁZIGAZDA
válasz
Oliverda
#35771
üzenetére
És jegyezzük meg azt is, hogy az Intel volt az a gyártó, aki elkezdte titkolni a lapkáinak a tranzisztorszámát. Pedig milyen jól össze lehetne hasonlítani most a GloFo 14 nm-es node-járól a Summit vagy a Raven Ridge-et, az Intel Coffee Lake-kel és Skylake-X-szel. Ezt egyébként miért lépte meg az Intel? Régebben folyamatosan közölték ezeket az adatokat, hiszen jobban voltak, mint a konkurensek, most pedig a legutolsó CPU-s adat a Broadwell-EP LLC 3,2 milliárd/246 mm^2-es értékei. Pedig annyira jól mutat az Intel 14 nm-es csodatechnológiája a GloFo 14 nm-es iparági szarja mellett, amivel a Summit Ridge tud 4,8 milliárd/213 mm^2-t.
Vagy a gyakorlati lapkákkal nem szabad már foglalkozni, csak ami a papírra le van írva azt érdemes összevetni? A gyakorlat akkor nem is határozhatja meg, hogy egy node mire képes, hiszen a táblázatok alapján le is írtuk ezeket, és az a négy paraméter aztán perdöntő, másnak itt szerepe sincs? Az Intel a faszagyerek, csak éppen a lényeget nem árulják el, a gyakorlatban is elérhető lapkák adatait. Nem is értem miért... 
-

Oliverda
félisten
válasz
 velizare
#35761
üzenetére
velizare
#35761
üzenetére
Elsőként érdemes lenne tisztába tenni, hogy egyáltalán mi a fene az az ITRS:
The International Technology Roadmap for Semiconductors (ITRS) is a set of documents produced by a group of semiconductor industry experts. These experts are representative of the sponsoring organisations which include the Semiconductor Industry Associations of the United States, Europe, Japan, South Korea and Taiwan.
The documents produced carry this disclaimer: "The ITRS is devised and intended for technology assessment only and is without regard to any commercial considerations pertaining to individual products or equipment".
The documents represent best opinion on the directions of research and time-lines up to about 15 years into the future for the following areas of technology.
...
As of 2017, ITRS is no longer being updated. Its successor is the International Roadmap for Devices and Systems.
Egyszóval az ITRS-nek semmilyen kontrollja nincs a felett, hogy melyik gyártó minek nevezi el xy technológiáját. Sosem volt, és sosem lesz. Nem is tudna semmilyen alapon beleszólni ebbe az ITRS-sel foglalkozó csoport, mivel egyszerűen nincs hatásköre erre, illetve nem is szabályozó céllal hozták létre anno. Az úgynevezett "Logic Device Ground Rules" alatt pedig egyszerűen kiszámolták, hogy mely node-oknak milyen alapvető paramétereknek kellene megfelelniük a csíkszélességváltásoknál elvárható területskálázódáshoz. Ehhez aztán vagy megpróbálja valamelyik gyártó tartani magát, vagy nem. Utóbbinak semmilyen következménye nincs, legfeljebb röhög egyet xy fejlesztésen (pl. TSMC 16 nanométer) a szakma, és kész.
"pl. az intel nagyon agresszíven skálázta a gate hosszt. a finfet bevezetésével pedig már abszolút nem alkalmazható ez az ökölszabály az elnevezésre."
Nem világos, hogy itt pontosan mire gondolsz, de ebben az esetben érdemes egy pillanatra külön kezelni az Intelt és a bérgyártókat (TSMC, Samsung, GF). Az Intelnek jóformán csak a saját igényeinek kell megfelelni, miközben a bérgyártók a chiptervezők piacára dolgoznak, évről-évre meg kell győzni több tucat céget azért, hogy szerződjenek xy node-okra. Részben ezért kezdtek el magasról tojni az ITRS által lefektetett irányra és kvázi csalni a jelöléssel, illetve szinte nanométerekre lebontani a 14 nanométer alatti roadmapet.
A meglehetősen szabadon értelmezett jelölés miatt történhet meg, hogy az Intel 10 nanométere simán versenyben lehet majd a bérgyártók 7 nanométerével, már amennyiben sikerül egyszer elfogadható szintre felhúzni a kihozatalt.

Egyébként az Intel is bármikor átnevezhetné a 10 nanométerét 7-re, vagy 5-re, vagy amire csak akarná, de láthatóan a TMG-nek egyelőre nem érdeke marketingre gyúrni.
Ez az ábra elég jól mutatja, hogy nagyjából hogyan áll a három meghatározó szereplő egymáshoz viszonyítva: [link]
-

Jack@l
veterán
Elmagyaráznád akkor hogyan működik ez a cache?
Kezdjük onnan hogy fogsz egy random sugarat a szemből ami a monitor egyik rácspontján átmegy. Utána mi történik? A következő random sugárnál mi hogyan töltődik be? Jó lenne ezt időkkel, késleltetésekkel is alátámasztani. Ha jól emlékszem a pci express késleltetésekkel nagyon tisztában vagy. -
-
Jack@l
veterán
Akkor minek kell vram egyáltalán a gpu-ra professszionális szegmensben, ha (szerinted)háttértárról is majdnem olyan gyorsan renderel, mint tisztán vramból?
Elég csak a prof driver meg ssd és teljesen mindegy hogy 4 vagy 16gb van a kártyán, mert eltürpül a hbcc/ssg méretéhez képest. -
Abu85
HÁZIGAZDA
válasz
 Jack@l
#35764
üzenetére
Jack@l
#35764
üzenetére
Maga a VRAM nincs definiálva a Vega esetében. De ha mindenképpen akarod valahogy ezt definiálni, akkor gyakorlatilag a VRAM megegyezik a beállított caching szegmenssel. Na most ebbe a HBCC működése alapján, kifejezetten a professzionális driverben (mert a sima driver itt is különbözik) beletartozhat a GPU melletti memória, a rendszermemória, a helyi adattároló és a hálózati adattároló. Az egész egy csúszka a szoftverben, amit oda állítasz ahova akarsz, persze az elméleti limitekig bezárólag. Persze az igényelt adat a HBC-n belül lesz. Gyorsítótárazza. Ha nincs direkt támogatás a szoftverben, akkor pedig a HBC+rendszermemória lehet a HBCC szegmens.
-
Jack@l
veterán
Már megint nekem papolsz ,aki 10 éve követi pl a realtime ray meg path-tracing útját. Meséld már el légyszi, hogy hogyan fogod eltalálni annak a nézőpontból indított sugának az útjában levő háromszöget, ha nincs benne a vramban?
A dolgot fűszerezzük meg kicsit azzal hogy esetleg átlátszó vagy tükzöződő felületről van szó...@Kristof93: hiszek neked, bonyolult pár mp-es videót felvenni arról a blenderes ablakról
-
válasz
Oliverda
#35758
üzenetére
a technológia változott az idők folyamán. ezt az elnevezéstant még a 80/90es években találták ki, azóta meg történt egysmás a félvezetőiparban. pl. az intel nagyon agresszíven skálázta a gate hosszt. a finfet bevezetésével pedig már abszolút nem alkalmazható ez az ökölszabály az elnevezésre.
-
Abu85
HÁZIGAZDA
válasz
Oliverda
#35758
üzenetére
Nem végzik hanyagul a munkájukat, csak négy paraméternél sokkal többet vesznek számításba. Ezért létezik ez a szervezet, nélkülük mindenki azt írna az adott node-jára, amit csak akar. Nem lenne ellenőrzés, amivel ezek iparágilag igazolhatók. Ha nem tetszik a döntésük, akkor feléjük jelezd, hogy elégedetlen vagy azzal, ahogy ők ezeket a node-okat besorolják.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#35754
üzenetére
Yutani
#35754
üzenetére
Ezek tök jó cikkek, csak ha nem lenne annyi különbség ezek között, akkor az ITRS nem ismerné el őket más számú node-ként.
(#35755) Oliverda: Mire? Hogy az ITRS kategorizálja ezeket? Nem akarom elhinni, hogy ez neked újdonság. Ott az archívumotokban több Bizó Dani cikk, azokban van arról szó, hogy itt igazából semmi sem x nanométeres. Egyszerűen a gyártó specifikálja magának az adott node-ot, majd a specifikációt elküldi az ITRS-nek, hogy ők hitelesítsék azt. Addig mondhat a gyártó bármit rá, de csak akkor lesz x-y-z nm-es a node, ha az ITRS azt elismeri. Ami a leginkább számít az az M1 huzalok sűrűségének nagyjából a fele, de ez sem egyezik meg a nanométer elé írt számmal. Valójában semmi sem x-y-z nanométeres, ez csak egy osztályozás.
(#35757) cain69: Igen, bocs.
-

Yutani
nagyúr
At the leading edge, foundries are ramping up 10nm/7nm. Intel’s 14nm process is roughly equivalent to 10nm from other foundries. Intel’s 10nm is similar to 7nm from GlobalFoundries and TSMC, as well as 8nm from Samsung.
-
Abu85
HÁZIGAZDA
válasz
Yutani
#35752
üzenetére
Ha hasonló lenne, akkor 10 nm lenne ráírva és nem 7. Értsétek meg, hogy nem a gyártó dönti el, hogy milyen számot írhatnak a nanométer elé. Az ITRS végzi az osztályozást. A gyártó leadja a node igényelt paramétereit, ami egyébként több tucat adat, és az alapján az ITRS besorolja a node-ot egy osztályba. Ráadásul a 10 és a 7 nm között még van 8 nm is, tehát nem lehet azt mondani, hogy vagy 10 nm valami, vagy 7.
-

Cathulhu
addikt
válasz
#45185024
#35750
üzenetére
Ez nem erdekes, hanem hulye kerdes,a z intel nem external fabot hasznal, hanem sajatot. Epp ezert merult fel otlet szinten, hogyha ennyire elcsusztak a 10 nanoval, lehet ott is egeszsegesebb lenne szetvalasztani a kettot, mint ahogy az AMD is csinalta. Az AMD meg ne vegye vissza a glofot, mert az csak felesleges teher az egesz. Igy tudnak menni a TSMC-hez, Samsunghoz is, mindig ahhoz, aki a legjobbat kinalja es nem az van, ha bukik a glofo (mondjuk a 3 nanojaval) akkor bukik az egesz AMD is.
-
#45185024
törölt tag
Miután megnézte az ember a Bethesda konferenciát csak felmerul az emberben a kérdés
a Rage2 és a Fallout 76nál látunk e fekete AMD ryzen radeon Logot
Bárcsak lenne itt valaki aki meg tudná mondani
Egy érdekes kérdést boncolgatnak a redditen
Could anyone explain why doesn't intel use 7nm process nodes like AMD if both of them use external fabs ?
Egyszer volt hol nem volt volt az AMD-nek FAb-ja aztán megbotlott és már nincs
Szerintetek ha AMD-nek a ryzenekbol megszalad elképzelheto hogy felvásárolja a Glo Fo-t
Ugy tudom a teljes kapacitásukat lefoglalják most is folyamatosan -
#35749
Petykemano
veterán
#45185024
#35748
Petykemano
veterán
válasz
#45185024
#35748
üzenetére
Nos az a baj, hogy ez nyilvánvalóan nem safe space egy eltérő vallású technofan számára. Már amikor meglátja a topik nevét, akkor azt érzi: "I feel offended" - és akkor még bele se olvasott azokba az eretnek beszédekbe, amiket itt egyesek le merészelnek írni.
Még szerencse, hogy Jack nem Darth
-
#45185024
törölt tag
válasz
Yutani
#35747
üzenetére
Liberalizmus az amikor leszereljük a kereszteket a templomokról meg ne bántsuk a beáramló más vallású tömeget érzéseiben. Javasolnám hogy cseréljük le mi is a cégért "Nem NV találgatós Topic hanem a másik" táblára, és akkor a haterok egyből jobb érzéssel jönnének be ide. Szépen elmagyarázzuk nekik a triviálist hogy mi a vega, a hbcc , hogy a triangle a legkisebb poligon és hogy a pipeline-n hogy nyomjuk át az adatokat hogy a másik oldalán újra hálóvá álljon össze.
Ajánlom mindenkinek Nyisztor Károly Shaderprogramozás című alapművét.
Majd miután jól kitanítottuk őket, már tanult haterokkal vitázhatunk...Wait Bro ez nem is a VS szoba. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35743
üzenetére
Igen. Az a lényeg, hogy maga a Vega, ezen belül is a professzionális verzió 512 TB-ig be tud tölteni bármit. A gamer verzió csak 256 TB-ig, ez egy driveres limit. Na most igazából mindegy, hogy hol van az adat, a HBCC eléri, akár lehet a hálózaton egy NAS-ban is, a HBCC-nek nem számít. Az SSG amiatt gyorsabb, hogy a GPU melletti HBC mellett van még NAND a NYÁK-on, tehát oda tud gyorsítótárazni a rendszer, így a legtöbb adatot hamarabb éri el, és nem kell elnyúlni érte a rendszermemóriáig, a helyi adattárolóig, vagy akár a hálózati adattárolóig. Funkcionálisan viszont az SSG és az SSD nélküli professzionális Vega ugyanarra képes, csak utóbbi lassabban, sokszor jelentősen.
Maximum elkezdte leképezni, és a hiányzó ray-ek adatai nem látszanak a felvételen. De megközelítőleg sem volt kész. Ahhoz több másodperc kell. Ha egy 250 milliárd háromszöges modellt 1 másodpercen belül megoldaná egyetlen mai GPU, akkor az iparág a seggét csapkodná a földhöz örömében, és nem építene senki 100+ processzorból renderfarmokat. Az AMD sem építette volna meg a Project 47-et, hiszen minek is telepítsen bérelhető, petaflopsos szintű erőforrásokat Hollywood mellé, ha egy GPU-val simán megvan a feladat egy másodpercen belül. 7000 dollárt mindenki ki tud fizetni, az még a ZS kategória alatt is vállalható összeg. De sajnos nem, jóval több időbe kerül.
-
Jack@l
veterán
válasz
 Kristof93
#35741
üzenetére
Kristof93
#35741
üzenetére
Akkor most kérek egy 12 TB-osat is amiről a demóban szó volt(és nem 37 millió háromszöggel). Ugyanúgy másodperc alatti renderrel.
Vagy egy magyarázatot hogy lépik át a fizika korlátait mind átvitelben mind számítási kapacitásban.@Abu85: szóval azt mondod az ssg, alias SSD on board gyorsabban húzza át az adatot, mint az elméletileg 16gb/sec-es pci express 3 ramból?
Mert valahogy nem jön ki hogyan tudja átpörgetni a 12tb-ot egyik sem. A videóban meg 1mp-en bőven belül már renderelte a képet. -
#45185024
törölt tag
Este már nézhetitek az E3-at 9 kor!!! Viva Los Angeles.
E3 COLISEUM
AMD ott lesz -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35734
üzenetére
SSG nélkül inkább 5-6 másodpercen belül. Valószínűleg nincs sok tapasztalatod erről, de vizualizációnál beállítod a kamerát, és a rendszer abból a nézőpontból elkezdi a leképezést. Úgy nagyjából 1 másodperc múlva már látsz annyit a jelenetből, hogy kifejezetten az ilyen felvételeken az késznek tűnik, de ettől a hardver dolgozik tovább, és a teljes eredményig azért jó pár másodperc eltelik, csak ilyen távolról, ilyen minőségű videón ez nem látszik. Maga a rendezvény is professzionális közönségnek szólt, ezért nem rágták ezt szájba, mert feltételeztek annyit, hogy a közönségnek azért van egy minimális tapasztalata a tartalomvizualizációról, ergo tudják ezt. Ők sem a sebességet értékelték, mert ahhoz nem ilyen demót szoktak mutatni, ugyanis kérhetsz olyat is, hogy benyomod a jelenetet a programba, és leméred, hogy mennyi időt vesz igénybe egy képkocka elkészítése. De itt nem ezen van a hangsúly, hanem azon, hogy van egy bitang nagy, TB-os szintű adathalmazod, és azt nem kell 100-200-300 darabra bontani, mert a hardver egyben megoldja out of memory hibaüzenet nélkül. Vagy ha az anyagi részét fogjuk meg, akkor nem kell hozzá venni több tucat kétutas EPYC-et, hogy legyen 4 TB-nyi rendszermemóriád betölteni az adatokat. Ergo, ha nem akarsz hatalmas CPU-s renderfarmra költeni, vagy darabolni, akkor most már van alternatíva, igen olcsón is. Ezt akarták megmutatni ezzel. Ezért viccel egyébként a fószer a fehér képernyő láttán, hogy évek óta ezt látja. Persze, Bollywood sem olyan gazdag, hogy CPU-ból csinálják meg ezt, annak komoly fenntartási költségei vannak, így inkább vesznek GPU-s workstationt, szopnak a darabolással, és alapvetően sokkal olcsóbban megvan, csak közben marha sok extra meló is, mert ha nem jól daraboltad ki, akkor fehér képernyőt kapsz nincs több memória üzivel.
-
-
#35732
Oliverda
félisten
Petykemano
#35706
Oliverda
félisten
válasz
Petykemano
#35706
üzenetére
Elég világosan fogalmazott, szerintem ezt másképp nem lehet értelmezni.
Az AI vonat szerintem már elment, a gamingre viszont még vissza lehet kapaszkodni egy jó GPU-val.
-
#35731
#45185024
törölt tag
Petykemano
#35730
#45185024
törölt tag
válasz
Petykemano
#35730
üzenetére
Most 180-tól indulnak a Vegák.
volt már picit olcsóbb is de nem minden jön le sajna
64et csak néha lehet rendelni 200 alatt azt is csak külföldről... -
#35729
Yutani
nagyúr
Petykemano
#35728
Yutani
nagyúr
válasz
Petykemano
#35728
üzenetére
Elindultak lefelé a VGA árak?
-
#35728
Petykemano
veterán
Petykemano
veterán
Fpga mining
Emiatt kezdtek csökkenni az árak? -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35725
üzenetére
Milliárd.
Ez a kétrészes Baahubali filmhez készült tartalom. [link] a trailerben látható is, és a film egy jó része itt játszódik.
Egyébként ez nem az AMD tulajdona, csak megvan nekik, mert Rajanak az indiai cége részt vállalt a film elkészültében, és így birtokában van az adathalmaz. Azért jó ezzel demonstrálni a rendszer képességeit, mert a legtöbb vásárló a közelében sem lesz ennek a terhelésnek, de így megmutatják, hogy ezt is bírja.(#35726) Jack@l: Amíg 512 TB alatt van, addig a HBCC-nek nem jelent problémát a funkcionális kezelése. 512 TB fölött már jönni fog az out of memory. Itt még megjegyezném, hogy a gamingre szánt RX sorozatnál a meghajtóban van egy konfigurált limit, ami 256 TB, de a professzionális modellek a hardver elméleti határáig működnek.
(#35724) Z10N: A Vulkan is kb. ugyanazokkal a limitekkel küzd, mint a DX12. Alig van eltérés ma a két API képességei között, és ez behatárolja azt is, hogy mik a limitációk.
A GMI csak eszköz. Lehetne GenZ is. Ezeknél nem maga a protokoll számít, hanem a memóriakoherencia biztosítása. Van szabványos memóriakoherens interfész a PCI Express helyére, csak túl vízfejű az AMD, az NV és az Intel ahhoz, hogy ne a saját érdekeiket nézzék.
A konzoloknál az ára miatt természetesen eléggé reális opció. Mennyit lehet már spórolni vele ugye. És ahogy láttuk a PS4-nál, marhára számít ám, ha 399-en tud startolni a gép. -
Jack@l
veterán
Milió, vagy miliárd, ki hallja ki azt... Mutass olyat amit nem amd demózott textúra nélküli parasztvakítás, hanem húsvér project, rendes felhasználótól. Rendes ellenőrizhető méréssel.
Csak hozzávetőlegesen 2013-ban ez egy húvér project: [link] 300 millió háromszööggel, nem látom hogy az a várszerű izébe hogyan kerül 1000x több poligon....
De ha mégis bekerülne, hogy rendereli ki egy szutyok vega 1000x gyorsabban... -

Z10N
veterán
1) A Vulkan hogyan all ilyen teren?
2) Erre ott van a IF/GMI, nem?
3) Ezert becsultem a nextgen utanra.
4) A konzoloknal ez az irany es a vr, nem?Addigra az ilyen meretu hbm es nand lapkaknak az ara nagyon kedvezo lesz (remelhetoleg). Ameddig az nv-nek erre nincs valasza az amd nagyon el tudna huzni a koltsegcsokkentes teren. Raadasul az nvme-nel maradhatnanak korabbi node-n es meg tovabb lehetne az arakat faragni. Ezenkivul a meret is mardhat kompakt.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35722
üzenetére
Itt a Baahubali adathalmaz egyben, ami több TB, pontosan nem tudni, hogy mennyi, viszont annyi hivatalos, hogy ~250 milliárd háromszög. [link] - persze ez a W9100-on ment, az SSG-n gyorsabb lenne, viszont alapvetően mindkettőnek ugyanúgy 512 TB a hardlimitje, csak a sebességen segít az SSG.
-
válasz
#45185024
#35720
üzenetére
Nonetheless, in a small roundtable following AMD’s presentation, Wang confirmed that AMD would be bringing out a new graphics product every year, via a new architecture, process changes, or “maybe incremental architecture changes.”
a vastagon szedett részek között vagylagos kapcsolat van.
tehát minden évben lesz új grafikus termék. ami nem jelent új gpu-t. pl. a most bejelentett vega 56 nano az egy új termék. -
#45185024
törölt tag
válasz
velizare
#35718
üzenetére
that gamers will have something to look forward to every year. Link
A játékosoknak várni kell valamit minden évbenWang said AMD would shift their focus to an annual GPU release cycle to make the business "more fun" for consumers
Akkor ezt Te hogy értelmezed 4 GPU van a roadmapon 4 év alatt -
Abu85
HÁZIGAZDA
válasz
 Raymond
#35717
üzenetére
Raymond
#35717
üzenetére
Az nem fog változni, de a helyzet az, hogy a hardver előállítási költségével célszerű spórolni, mert az új node-okon a gyártás csak drágul, nem is kicsit ugye. Sokkal kedvezőbb csak annyi memóriát rakni a GPU mellé, amit tényleg jelenetenként aktívan használ, minthogy a fedélzeti tár 60%-a a programfuttatás 1-2%-ában legyen csak elérve. Az azért óriási gyártási pluszköltség csupán azért, mert szar a rendszert működtető szoftveres háttér. Végeredményben jóval olcsóbban kijössz, ha a memória egy része nem felejtő. Egyszerűen csak licencelsz egy vezérlőt a GPU-ba, és melléraksz két 32 GB-os V-NAND-ot RAID-ben, ahonnan gyorsítótárazod a szükséges adatokat a HBM2-be. Jelenetről-jelenetre ugorva a memóriaigényes változása igen csekély, alig pár MB-nyi extra adat lehet, amit simán be tudsz gyorsítótárazni, és megspórolod a memóriaköltség 70%-át is, amit mondjuk elkölthetsz nagyobb GPU-ra, azaz a memórián spórolt pénzt visszaforgatható ALU-kapacitásba.
-
Abu85
HÁZIGAZDA
Ez nagyon függ attól, hogy a fejlesztők mekkora világokat akarnak csinálni a játékokba. A jó hír, hogy az AI bevetése tényleg lehetőséget ad, hogy 10x-50x-100x nagyobb legyen minden egy játékban, és alig dobná meg a költségeket, viszont már a tízszeres növelés is jelentős módosítást igényelne nemcsak a hardverben, hanem magában az API-ban is. Ami nem baj, nyilván a Microsoft okkal csinálja a tiled_resources TIER4-et, csak ha erre elmegyünk, akkor igazából nem VGA-ként lenne jó az SSG, hanem Kaby Lake-G-hez hasonló pGPU-ként, csak éppen nem PCI Express kapcsolattal.
Szerintem a következő konzolgenerációig nem fog változni semmi. Addigra pedig az új tiled_resources is letisztul, mindenkinek lesz egy integrált rendszere hozzá, amire lehet építeni ugye. Valószínű addigra a Win32 is karóba lesz húzva, ha nem is lesz kivéve, akkor is az újítások tuti UWP-only megoldások lesznek már.
-
#45185024
törölt tag
A mai termés
Computex 2018: Level1 @ AMD!
Nagyon klassz Video osszefoglalo AMD Computexes jelenletrolSokadik David Wang interjut olvasom ha ezt az évente uj GPUt ad ki az AMD valoban ugy gondolják hogy a 480 után nem 580 jon hanem az /Inteltol átemelt / tick tock valoság lesz arra nagyon lelkesednék
Ez a Wang nekem nagyon becsuletesnek tunik és oszintének ha olyan ember aki évente kiveri a balhét ha nem kap értelmezheto pénzt az éves GPU-jára akkor barátok leszunk -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35707
üzenetére
A memória az előnye. Amíg a GV100-nál ez fixen 32 GB, tehát ebbe bele kell férni, ha törik, ha szakad, addig a Vega 10 esetében nincs ilyen limit. Illetve nyersen van, 512 TB, de ez aligha megközelíthető. Az a tapasztalat, hogy ~120 GB-os tartalomig bőven jó a sima Vega 10, míg efölött az SSG verzió az ajánlott, mert elkezd érezhetően gyorsabb lenni.
A scene mérete változó. A sima Vega 10 olyan 150 GB-nál kezd nagyon lassulni. Ott fogy el a HBCC tudása. Az SSG verzió 3,5 TB-ig tud hasonlóan működni. Efölött ugyan működik még a leképezés, de már durván visszalassul. Ugyanakkor sok esetében még így is megéri, mert többet nyernek a lassabb vizualizációval, mintha elkezdenének darabolni. Na meg ugye az is lényeges tényező már, hogy a 4 TB memóriát támogató szerverplatformok elég drágább, tehát persze ha kiépítesz egy csomót belőle, akkor előnyben leszel, de az nagyon durván növeli a költségeket. -
Cathulhu
addikt
-
Jack@l
veterán
Ez elég érdekes feltételezés, hogy grafikára rosszabb a tesla, mint a vega. Csak azért mert gtx1080 sebességre egy hangyányit rátesz. Meg 32 giga vramba is elég sokminden belefér... (szemben a mostani vega 16gb + kamu háttértárjával, amire nem mutattál még mindig konkrét mérős videót, mekkora scene, mennyi fps)
-
#35706
Petykemano
veterán
Oliverda
#35702
Petykemano
veterán
válasz
Oliverda
#35702
üzenetére
Ezt azért eddig is tudtuk... sőt mindig is így volt: az AMD a legjobb időkben is alig tudott mindsharet nyerni.
De te hogy értelmezed, ez annak beismerése, hogy a gaming háttérbeszorítása az AI-al szemben volt a hibás döntés, amiből az következik, hogy vissza kell térni a gaminghez, vagy az "all-purpose goodforall bestofnone" lapkák gyártásával kell felhagyni, mert ezzel soha nem fognak tudni virítani semmilyen kiemelkedőt , és örökké a futottak még de kit érdekel kategóriában maradnak?
-
Abu85
HÁZIGAZDA
válasz
 Cathulhu
#35703
üzenetére
Cathulhu
#35703
üzenetére
Pedig nem. Maximum tréningben közelít. Dedukcióban viszont sokkal jobb a Tesla V100. Ahol a Vega 10 nagyon erős az a professzionális grafika. Ott különösen az SSG verziónak nincs ellenfele. Tartalomvizualizáció szempontjából ég és föld a különbség, amit kínál, abban a környezetben az NV maximum "out of memory" hibaüzenetet tud adni.
Az se véletlen, hogy a Vega 10-zel nem igazán mennek rá az AI-ra. A Vega 20 arra sokkal jobb lesz. Dedukcióra a Linux driver szerint megjelenik a 4 és 8 elemű packed dot product. Előbbivel az 600 TOPS körüli teljesítmény másfél gigahertzes órajellel, ami amúgy a Vega 20-tól reális. Erre majd az NV is válaszol valószínűleg, mert a Tesla V100 ennek kb. a negyedét tudja, de nyilván a 4 elemű packed dot productot be lehet építeni, és rögtön ott lesz nekik is az NV-nek is 15 ops/clock.
-
Oliverda
félisten
válasz
Cathulhu
#35703
üzenetére
Igen, ezt már sokan mások is mondták. Az NV-nek bejött a saját zárt API-ra épülő szoftveres ökoszisztéma, amivel csak a saját hardvereiknek, illetve a saját ügyfelek igényeinek kell megfelelni. Ezért is vagyok szkeptikus, hogy a 7 nanométeres Vega bármin is változtatna majd.
-
Cathulhu
addikt
válasz
Oliverda
#35702
üzenetére
Ha a cegnel donteni kellene ilyen beszerzesrol en is a V100-at ajanlanam. De ez kizarolag a szoftveres kornyezet miatt van, amit emlitettem is. Nyers eroben a Vega nagyon ott lenne, softwareben kellene felnoniuk. Es ez nem azt jelenti, hogy egyetlen embert dedikalunk tensorflow portolasra...
-
Oliverda
félisten
válasz
Cathulhu
#35688
üzenetére
Mégis inkább a V100-at veszik, pedig utóbbiért többszörösét kéri az NV.
“I think the important thing was that Scott [Herkelman, senior vice president and GM of AMD Radeon Gaming] mentioned about having some sort of consistency, delivering something to our customers so that you keep stimulating the excitement,” Wang said. “I think that’s how you make this so business so exciting, so interesting. That’s how it makes the gamers so excited about [it], every year.”
Wang went on to say that he felt that “AMD had lost momentum” in terms of gaining mindshare in the consumer enthusiast space. “I think, you know, that we lost momentum in all of the media, spending all our energy in chasing AI.” Wang appeared to be referring to the Radeon Instinct, which is used for deep learning and artificial-intelligence applications.
A két szék közé csücsülés esete.






 ehhez pedig sokkal jobban illeszkedne egy új arhitektúra.
ehhez pedig sokkal jobban illeszkedne egy új arhitektúra. Azt írja a Navi 20 lesz 21ben a csúcsszuper GPU, ez még a régi gondolkozás
Azt írja a Navi 20 lesz 21ben a csúcsszuper GPU, ez még a régi gondolkozás ))))
))))



![;]](http://cdn.rios.hu/dl/s/v1.gif)


 - tudom "ha" -val nem kezdünk mondatot
- tudom "ha" -val nem kezdünk mondatot






 és még mi a Rage 2
és még mi a Rage 2 


































Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Béta iOS-t használók topikja
- Bittorrent topik
- Székesfehérvár és környéke adok-veszek-beszélgetek
- A fociról könnyedén, egy baráti társaságban
- Milyen egeret válasszak?
- Linux kezdőknek
- Debrecen és környéke adok-veszek-beszélgetek
- Bemutatkozik a slim billentyűzetekre való, ujjainkat vezető PFF kupakprofil
- Motorola Edge 50 Fusion - jó fogás
- Forradalomi előrelépésként jellemzi az NVIDIA a DLSS 5-öt
- További aktív témák...
- Akciós áron eladó HP Dragonfly G3 /I7-1265U/32 GB/512B SSD/13,5"/FHD+/400nit/Touch
- Beszámítás! Asus ROG Strix Scar Edition G533Z notebook-i7 12700H 16GB DDR5 1TB SSD RTX 3060 6GB W11
- Inno3D RTX 4070 Ti // ÚJSZERŰ // SZÁMLA // GARANCIA //
- BESZÁMÍTÁS! Intel Core i7 4770K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Ghost of Tsushima Director s Cut
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest